

Deep Learning-Based Layout Analysis Method for Complex Layout Image Elements
 , and
, and
Abstract
Featured Application
Abstract
1. Introduction
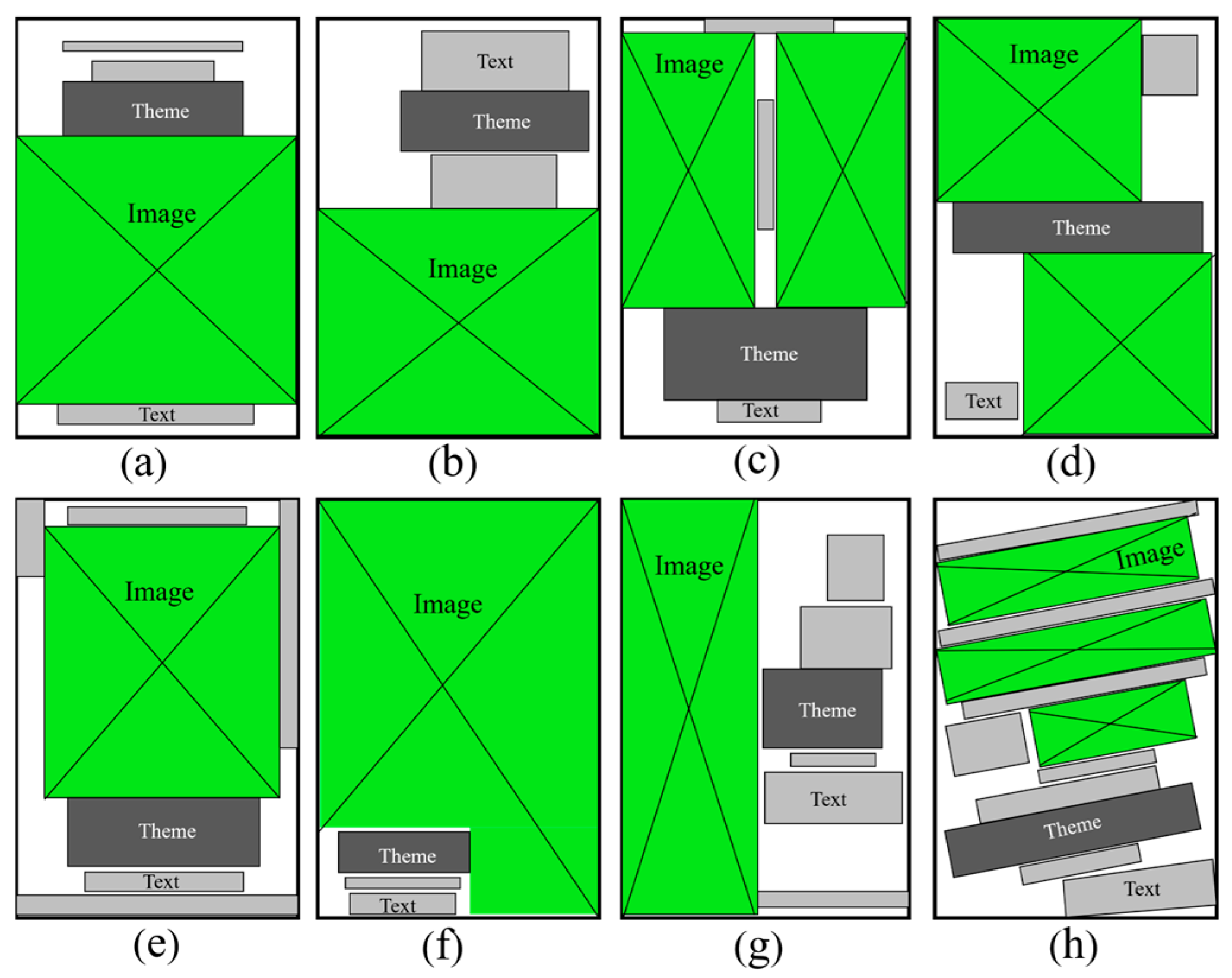
2. Film Poster Composition Layout Method
3. Film Poster Layout Segmentation Method Based on Improved DeepLabv3+
3.1. Relevant Model Theory
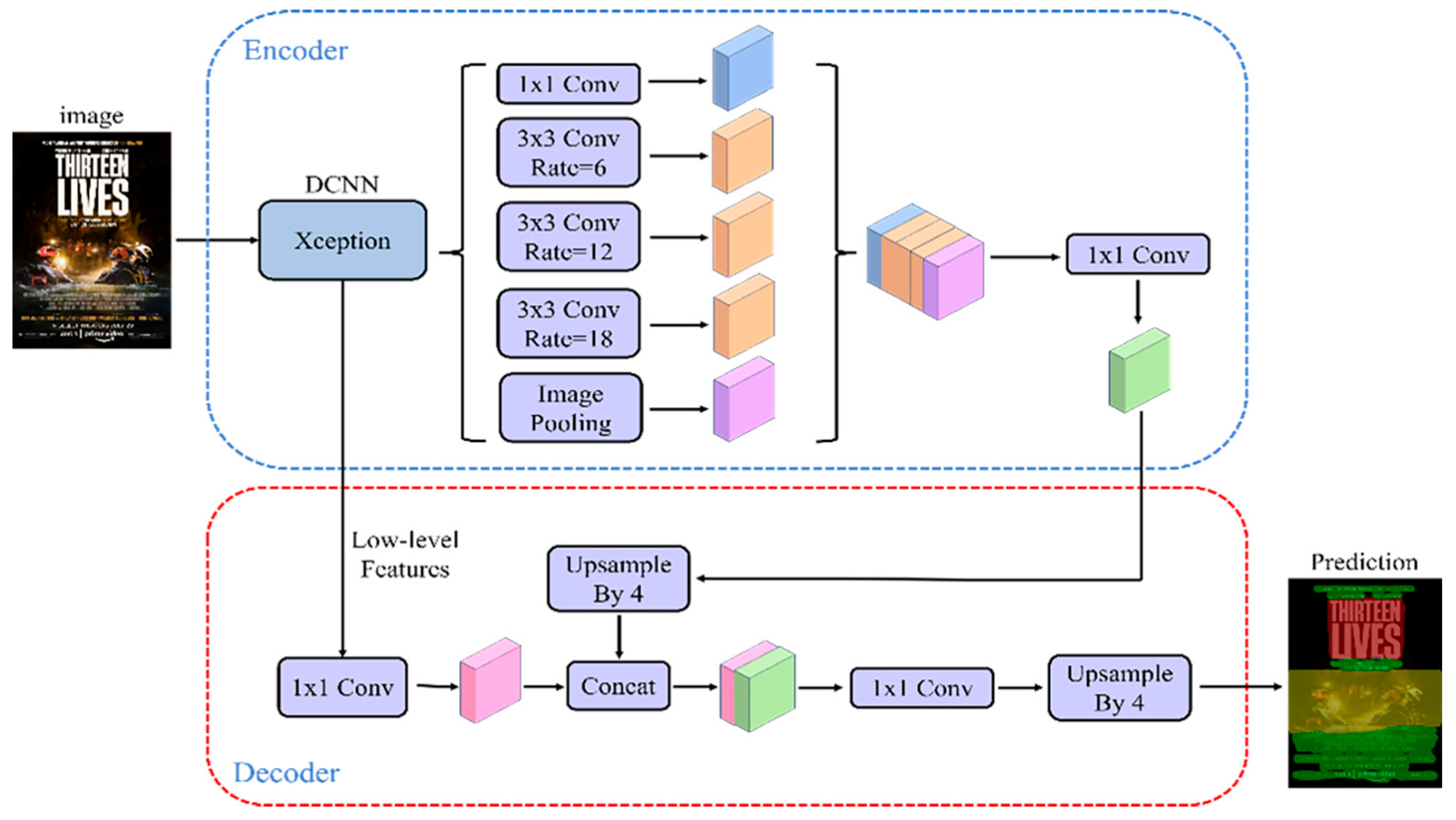
3.1.1. DeepLabv3+ Base Model
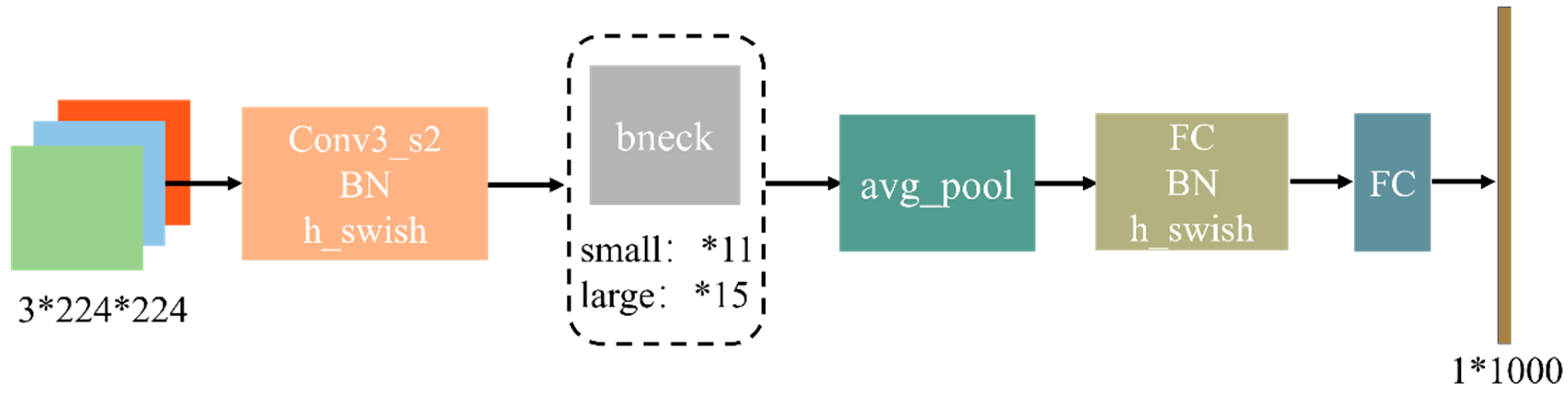
3.1.2. Mobilenetv3 Network
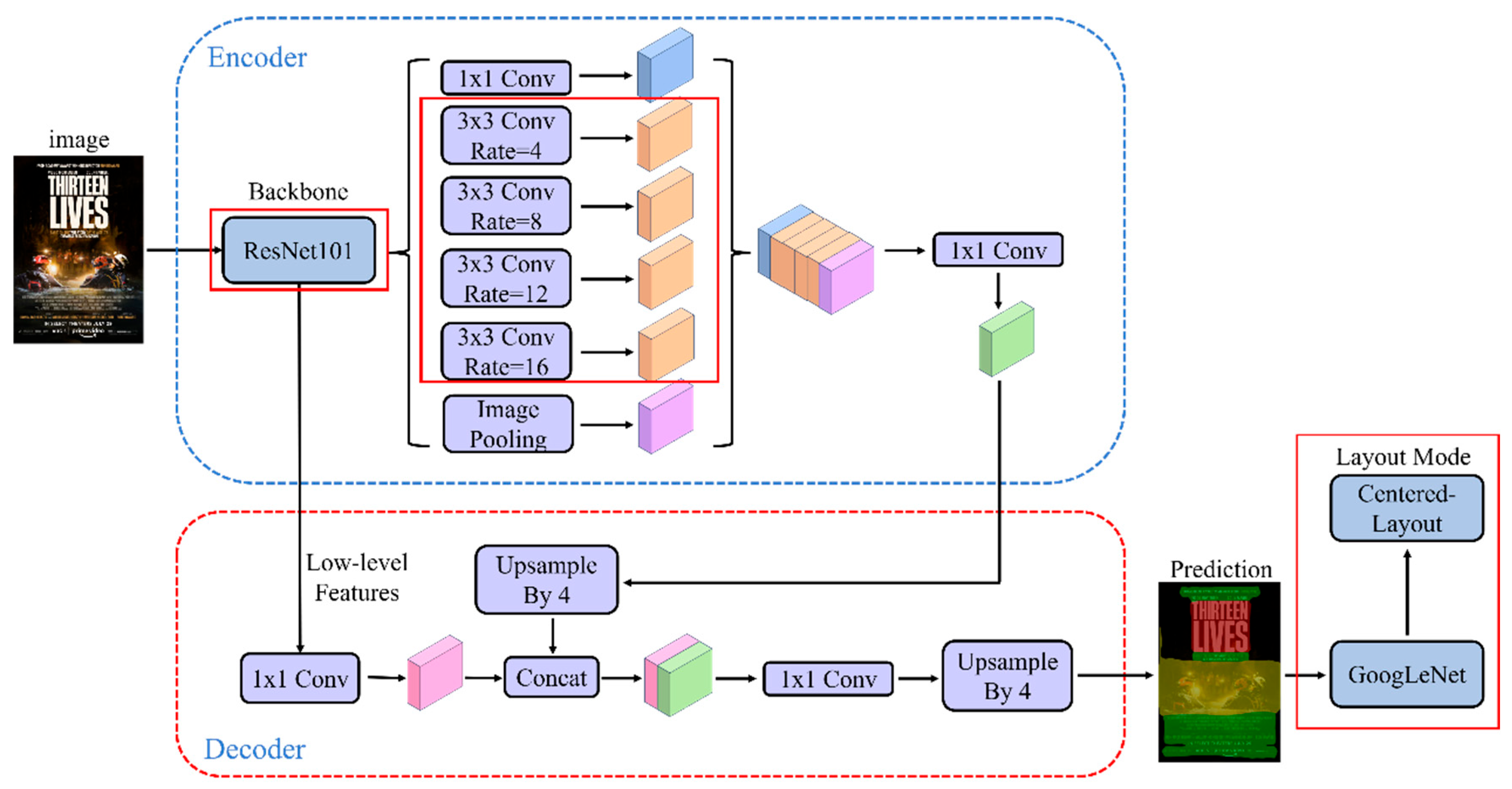
3.1.3. GoogLeNet Network
3.2. Improved DeepLabv3+ Network Models
4. Dataset and Model Training
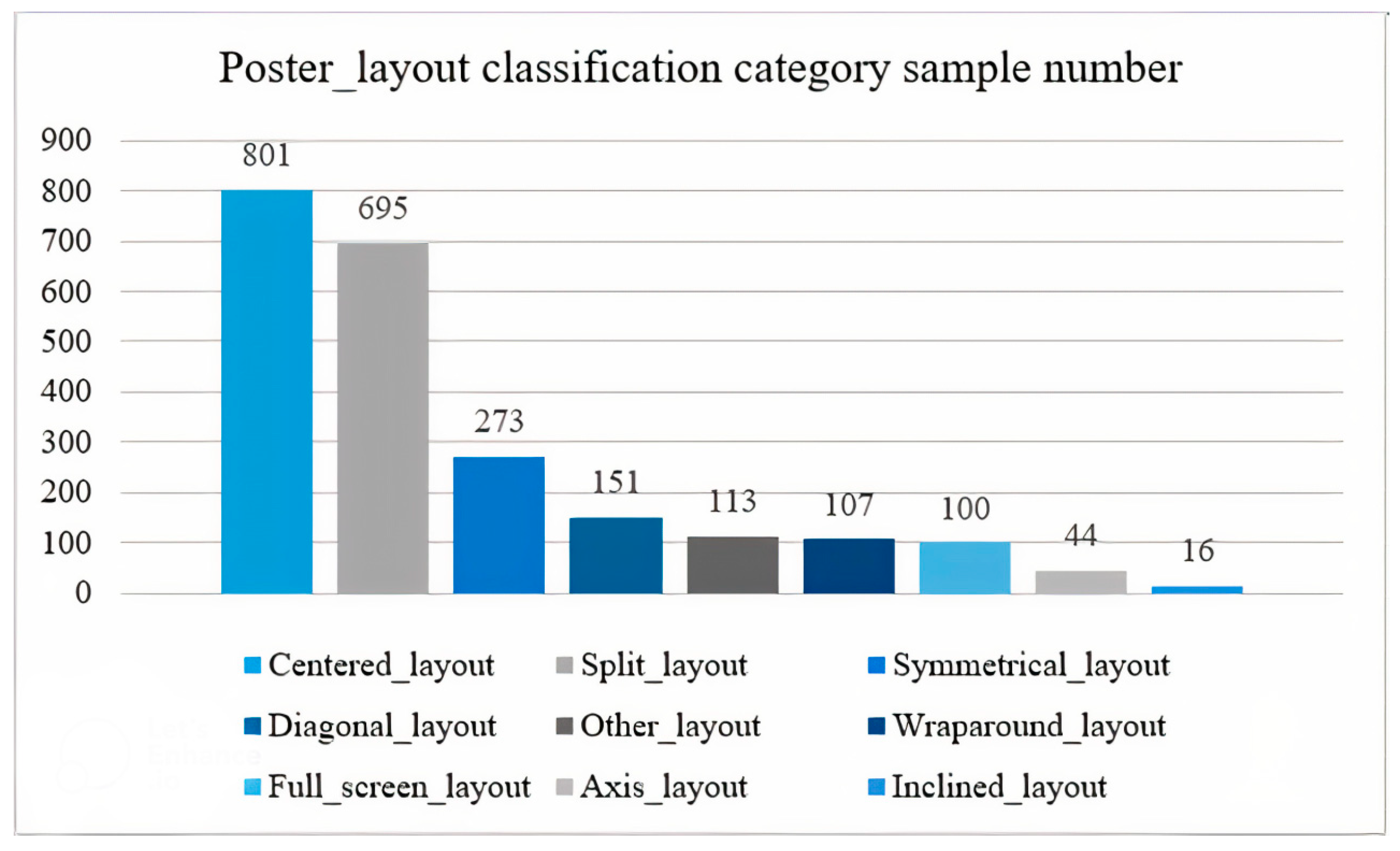
4.1. Dataset Production
4.2. Model Training
5. Experimental Results and Analysis
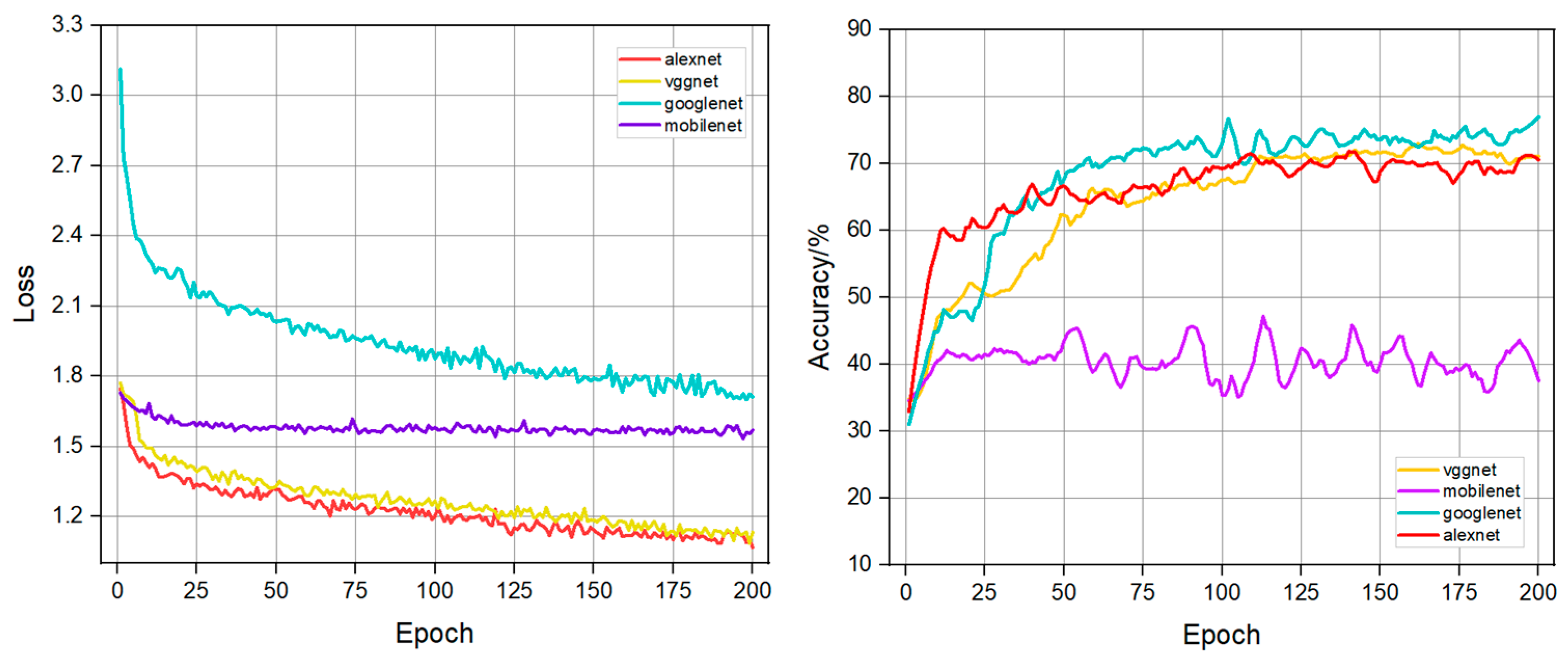
5.1. Loss Functions and Evaluation Indicators
5.2. Segmentation Comparison Experiment Analysis
5.2.1. Impact of Different Backbone Feature Extraction Networks on Model Performance
5.2.2. Comparative Experimental Analysis of Different Models
5.3. Analysis of Layout Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, H. Visual communication design of digital media in digital advertising. J. Contemp. Educ. Res. 2021, 5, 36–39. [Google Scholar] [CrossRef]
- Jin, X.; Zhou, B.; Zou, D.; Li, X.; Sun, H.; Wu, L. Image aesthetic quality assessment: A survey. Sci. Technol. Rev. 2018, 36, 36–45. Available online: http://www.kjdb.org/CN/10.3981/j.issn.1000-7857.2018.09.005 (accessed on 1 March 2025).
- Deng, Y.; Loy, C.C.; Tang, X. Image aesthetic assessment: An experimental survey. IEEE Signal Process. Mag. 2017, 34, 80–106. [Google Scholar] [CrossRef]
- She, D.; Lai, Y.-K.; Yi, G.; Xu, K. Hierarchical layout-aware graph convolutional network for unified aesthetics assessment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR, Online, 19–25 June 2021; pp. 8475–8484. [Google Scholar] [CrossRef]
- Riyanto, B. Analysis of Design Elements on Secret Magic Control Agency Movie Poster. TAMA J. Vis. Arts 2023, 1, 29–37. [Google Scholar] [CrossRef]
- Chen, S.; Liu, D.; Pu, Y.; Zhong, Y. Advances in deep learning-based image recognition of product packaging. Image Vis. Comput. 2022, 128, 104571. [Google Scholar] [CrossRef]
- George, N.; Sharad, C.S. Hierarchical image representation with application to optically scanned documents. In Proceedings of the 7th International Conference on Pattern Recognition (ICPR), Montreal, QC, Canada, 30 July–2 August 1984; pp. 347–349. Available online: http://digitalcommons.unl.edu/cseconfwork (accessed on 15 March 2025).
- Mao, S.; Rosenfeld, A.; Kanungo, T.; Smith, E.H.B.; Hu, J.; Kantor, P.B. Document structure analysis algorithms: A literature survey. Doc. Recognit. Retr. X 2003, 5010, 197–207. [Google Scholar] [CrossRef]
- Ha, J.; Haralick, R.M.; Phillips, I.T. Document page decomposition by the bounding-box project. In Proceedings of the IEEE 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–18 August 1995; Volume 2, pp. 1119–1122. [Google Scholar] [CrossRef]
- Pu, Y.; Liu, D.; Chen, S.; Zhong, Y. Research Progress on the Aesthetic Quality Assessment of Complex Layout Images Based on Deep Learning. Appl. Sci. 2023, 13, 9763. [Google Scholar] [CrossRef]
- Wu, X.; Zheng, Y.; Ma, T.; Ye, H.; He, L. Document image layout analysis via explicit edge embedding network. Inf. Sci. 2021, 577, 436–448. [Google Scholar] [CrossRef]
- Guo, S.; Jin, Z.; Sun, F.; Li, J.; Li, Z.; Shi, Y.; Cao, N. Vinci: An intelligent graphic design system for generating advertising posters. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, New Orleans, LA, USA, 8–13 May 2021; pp. 1–17. [Google Scholar] [CrossRef]
- Huo, H.; Wang, F. A Study of Artificial Intelligence-Based Poster Layout Design in Visual Communication. Sci. Program. 2022, 2022, 1191073. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar] [CrossRef]
- Howard, A.; Sandler, M.; Chen, B.; Wang, W.; Chen, L.-C.; Tan, M.; Chu, G.; Vasudevan, V.; Zhu, Y.; Pang, R.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A.; Liu, W.; et al. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Everingham, M.; Eslami, S.M.A.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the MICCAI 2015, Munich, Germany, 5–9 October 2015; pp. 234–241. Available online: https://arxiv.org/abs/1505.04597 (accessed on 20 April 2025).
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. BiSeNet: Bilateral Segmentation Network for Real-time Semantic Segmentation. In Proceedings of the ECCV 2018, Munich, Germany, 8–14 September 2018; pp. 334–349. Available online: https://arxiv.org/abs/1808.00897 (accessed on 20 April 2025).
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–14 December 2021; Available online: https://arxiv.org/abs/2105.15203 (accessed on 20 April 2025).
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar] [CrossRef]
- Cabini, R.F.; Tettamanti, H.; Zanella, M. Understanding the Impact of Evaluation Metrics in Kinetic Models for Consensus-Based Segmentation. Entropy 2025, 27, 149. [Google Scholar] [CrossRef] [PubMed]
- Cabini, R.F.; Pichiecchio, A.; Lascialfari, A.; Figini, S.; Zanella, M. A Kinetic Approach to Consensus-Based Segmentation of Biomedical Images. Kinet. Relat. Models 2025, 18, 286–311. [Google Scholar] [CrossRef]
- Ye, M.; Zhang, J.; Liu, J.; Liu, C.; Yin, B.; Liu, C.; Tao, D. Hi-SAM: Marrying Segment Anything Model for Hierarchical Text Segmentation. arXiv 2024, arXiv:2401.17904. [Google Scholar] [CrossRef] [PubMed]
- Ding, L.; Liu, Y.; Zhao, Q.; Liu, Y. Text Font Correction and Alignment Method for Scene Text Recognition. Sensors 2024, 24, 7917. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Train | Val | Test |
|---|---|---|---|
| Poster Segmentation | 1610 | 460 | 230 |
| Poster_layout classification | 2080 | 220 | — |
| Backbone | MIoU/% | Time/h |
|---|---|---|
| Xception | 71.09 | 25.10 |
| ResNet101 | 72.89 | 26.20 |
| Mobilenetv2 | 70.05 | 16.20 |
| Mobilenetv3-small | 75.60 | 15.09 |
| Model | Backbone | MIoU/% | Time/h |
|---|---|---|---|
| FCN | ResNet101 | 73.00 | 15.54 |
| PSPNet | ResNet101 | 73.60 | 16.27 |
| DeepLabv3 | ResNet101 | 74.80 | 17.54 |
| DeepLabv3+ Textual model | Mobilenetv2 Mobilenetv3-small | 69.50 75.60 | 16.01 15.09 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhong, Y.; Pu, Y.; Li, X.; Zhou, W.; He, H.; Chen, Y.; Zhong, L.; Liu, D. Deep Learning-Based Layout Analysis Method for Complex Layout Image Elements. Appl. Sci. 2025, 15, 7797. https://doi.org/10.3390/app15147797
Zhong Y, Pu Y, Li X, Zhou W, He H, Chen Y, Zhong L, Liu D. Deep Learning-Based Layout Analysis Method for Complex Layout Image Elements. Applied Sciences. 2025; 15(14):7797. https://doi.org/10.3390/app15147797
Chicago/Turabian StyleZhong, Yunfei, Yumei Pu, Xiaoxuan Li, Wenxuan Zhou, Hongjian He, Yuyang Chen, Lang Zhong, and Danfei Liu. 2025. "Deep Learning-Based Layout Analysis Method for Complex Layout Image Elements" Applied Sciences 15, no. 14: 7797. https://doi.org/10.3390/app15147797
APA StyleZhong, Y., Pu, Y., Li, X., Zhou, W., He, H., Chen, Y., Zhong, L., & Liu, D. (2025). Deep Learning-Based Layout Analysis Method for Complex Layout Image Elements. Applied Sciences, 15(14), 7797. https://doi.org/10.3390/app15147797