2. Literature Review
2.1. Evolution from Industry 4.0 to Industry 5.0: Cognitive Burden and Human–AI Collaboration
The industrial environment has undergone significant transformation due to the digitalization and automation associated with Industry 4.0. This revolution is marked by the integration of cyber-physical systems, the IoT, and advanced data analytics, which have enhanced productivity, operational efficiency, and connectivity across sectors, as per Arcelay et al. [
29,
30]. However, these advancements have introduced challenges for human operators, including heightened cognitive burdens and mental stress caused by complex human–machine interfaces and continuous monitoring requirements [
31,
32]. Research indicates that while collaborative robots (cobots) are designed to assist human workers, their unpredictable behaviors and lack of contextual awareness can increase the cognitive workload and stress for operators [
31,
32].
The term Operator 4.0 refers to the modern worker who is required to manage, troubleshoot, and adapt to increasingly complex systems, generating skill demands that can adversely affect mental health [
30]. Conversely, Industry 5.0 emerges as a corrective approach that emphasizes human-centricity, sustainability, and resilience, highlighting the essential role of human workers in production processes [
33]. This new paradigm proposes a future where technology not only enhances human creativity and critical thinking but also fosters complex problem-solving skills rather than supplanting them [
2].
Central to Industry 5.0 is the idea of Operator 5.0, where humans and machines collaborate synergistically, leveraging AI’s precision alongside human traits such as judgment and adaptability [
33]. This shift underscores the importance of integrating advanced human–machine interfaces (HMIs), digital twins, and AI-driven co-creation tools, all aimed at enhancing and supporting human capabilities in real time [
34]. Furthermore, Industry 5.0 promotes the development of personalized, sustainable, and resilient industrial ecosystems, prioritizing inclusivity, workers’ well-being, and ongoing innovation [
35].
2.2. Limitations of Traditional Proficiency Assessment Models
Traditional models for assessing human proficiency face substantial challenges when applied to the dynamic contexts of Industry 5.0. These models often rely on static and retrospective methodologies that can limit their effectiveness in the rapidly changing industrial environments characterized by increased collaboration between humans and machines. For instance, the NASA-TLX serves as a conventional assessment tool that provides evaluations of workload and performance post-task completion. However, this approach does not adequately reflect the temporal dynamics of human performance related to fluctuating factors, such as learning, fatigue, and stress [
36].
Moreover, existing methodologies such as the NASA-TLX encounter methodological limitations, such as involving forced-pairwise rankings, which some authors argue may limit the reliability of workload assessments in fast-paced industrial settings [
6,
37]. Unimodal approaches, whether they focus on physiological, behavioral, or subjective metrics, fail to capture the complex, context-dependent nature of real-world operator performance, leaving significant gaps in understanding human proficiency [
17].
The lack of temporal and contextual resolution in these traditional models is a critical impediment to achieving the adaptive and collaborative aspirations of Industry 5.0. Real-time assessments of proficiency must evolve to account for myriad factors, including task complexity and individual operator characteristics [
12]. Thus, assessment systems must develop capabilities for the real-time monitoring and interpretation of these variables, providing timely insights that facilitate adaptive behaviors and effective human–AI collaboration [
17].
2.3. The Multifaceted Nature of Human Proficiency
The multifaceted nature of human proficiency underscores the intricate interplay between cognitive, physiological, and behavioral factors affecting an individual’s ability to perform tasks effectively and adapt to varying demands. Traditional assessments often fall short of capturing this complexity, necessitating a nuanced understanding of various dimensions of human performance.
Cognitive factors, including attention, perception, memory, and decision making, play a significant role in proficiency. Research indicates that cognitive performance can be impacted by physical activity, showing improved post-exercise capabilities, which highlights the dynamic nature of cognition and its susceptibility to various influencing factors, according to Chang et al. [
38]. Furthermore, cognitive functions influenced by fatigue and stress directly correlate with performance outcomes; this connection emphasizes the need for the continuous monitoring of these factors [
6].
Physiological factors can also be informative, with indicators such as HRV and electrodermal activity serving as objective metrics of stress and cognitive load [
39]. Studies illustrate that the integration of these physiological signals can enhance our understanding of overall readiness and performance capabilities, affirming that physiological responses provide valuable insights into cognitive stress and the behavior of the autonomic nervous system [
39].
Behavioral factors, which manifest as observable metrics—such as TCT, accuracy, and performance consistency—reflect underlying cognitive and physiological states [
13]. For instance, an operator may exhibit stable behavioral performance while experiencing elevated cognitive loads; such discrepancies between subjective and objective metrics could lead to misclassifications of proficiency if assessed by unimodal methods alone [
15].
2.4. Rationale for Multimodal Assessment
The rationale for multimodal assessment stems from the limitations of unimodal approaches; research consistently shows that integrating various data sources yields superior accuracy and reliability in evaluating human proficiency. Multimodal assessments have demonstrated performance improvements, reflecting a more comprehensive view of human proficiency in dynamic environments [
3]. The synthesis of physiological indicators, behavioral data, and subjective evaluations fosters a rich understanding of performance, which is critical for the adaptive and collaborative goals inherent in Industry 5.0 [
17].
A comprehensive assessment of human proficiency must consider cognitive, physiological, and behavioral dimensions concurrently. Recognizing the interdependence of these factors and adopting a multimodal approach will provide a more accurate and actionable understanding of operator performance in complex, dynamic settings.
2.5. Three-Level Proficiency Classification Framework
The Three-Level Proficiency Classification Framework (Novice, Intermediate, and Expert) aligns with the established cognitive science literature, particularly models of skill acquisition, such as the Dreyfus Model and Cognitive Load Theory. This framework emphasizes the developmental stages of expertise as follows:
Novice: Individuals at this level demonstrate rule-based behavior that requires explicit instruction and guidance. They frequently experience substantial cognitive load during task execution. Research indicates that Cognitive Load Theory significantly influences learning outcomes, particularly in problem-solving contexts [
40]. For example, studies suggest that appropriate cognitive load management can improve problem-solving skills by creating conducive learning environments for novices [
40].
Intermediate: At this proficiency level, individuals can perform tasks independently in familiar contexts, having developed procedural skills. However, they may still struggle with new or complex situations. Evidence suggests that intermediate learners exhibit varying levels of cognitive workload that affect their efficiency in managing routine tasks. Monitoring cognitive workload via physiological metrics, such as HRV has been examined in settings where cognitive task demands vary, indicating that these fluctuations can lead to performance inconsistencies in unfamiliar scenarios [
21,
41].
Expert: Experts demonstrate highly flexible and effective performance, marked by a comprehensive understanding of their tasks and systems. They can foresee potential issues and make informed decisions, relying on a reduced perceived cognitive load for the routine components of tasks [
42]. Research suggests that the assessment of cognitive workload is crucial for understanding expert performance, indicating that experts can maintain high performance despite dynamic cognitive demands [
41,
42]. Moreover, effective feedback is critical during the skill acquisition process for experts, enhancing their learning outcomes [
43].
2.6. Rationale for Selected Proficiency Indicators: HRV, TCT, and NASA-TLX
The rationale for selecting HRV, TCT, and the NASA-TLX as primary indicators of proficiency is supported by empirical literature that highlights the relevance of these metrics for capturing the complexity of human performance in dynamic settings.
HRV is a well-established physiological metric that reflects the autonomic nervous system’s activity, making it an important indicator of an individual’s mental workload, stress, and overall arousal levels. Research indicates that HRV can be effectively used to assess cognitive load and emotional states, as it demonstrates sensitivity to variations in psychological stress and cognitive effort [
21]. Studies have shown that HRV is associated with attentional control and emotional regulation, which are crucial for maintaining performance under pressure [
44]. Time-domain and frequency-domain metrics, such as Standard Deviation of Normal-to-Normal intervals (SDNN) and Root Mean Square of Successive Differences (RMSSD) for time-domain analysis, and Low-Frequency (LF) and High-Frequency (HF) power for frequency-domain analysis, provide insights into autonomic balance and are relevant for understanding how HRV responds to cognitive demands [
44].
TCT serves as a direct and objective metric of performance efficiency. It is commonly utilized in studies related to skill acquisition. Research indicates that reductions in TCT over successive trials typically signify improvements in proficiency and learning, while increases or variability in TCT can indicate challenges, such as task difficulty or operator fatigue [
23]. Studies in simulation environments confirm TCT’s effectiveness as an objective tool for measuring skills and strategies, reinforcing its relevance to assessing proficiency in real-time systems [
23].
NASA-TLX is a validated measure of perceived mental workload, providing insights into the subjective experience of task demands through its multi-dimensional framework. Although it is not designed for continuous real-time monitoring, its inclusion in a multimodal assessment framework enhances the understanding of how operators perceive and manage workloads. Research illustrates that perceived workload can diverge from objective performance indicators, highlighting the importance of subjective assessments in human-centered evaluation approaches [
45]. Moreover, empirical evidence shows that higher NASA-TLX scores are significantly associated with lower self-reported job satisfaction, indicating that the instrument can also serve as an indirect proxy for job-satisfaction levels when task demands are high [
46].
The combination of HRV, TCT, and NASA-TLX creates a balanced framework for assessing proficiency. HRV provides physiological insights into an operator’s internal state, TCT offers a measure of task performance that is likely to link to higher-level productivity metrics, and NASA-TLX captures subjective perceptions of workload. This triad enables a comprehensive understanding of human proficiency, ensuring that critical aspects of performance are not overlooked, which is often the case in unimodal assessments [
23,
44,
47].
Although HRV, TCT, and NASA-TLX were selected because they are widely validated and practical across many domains, the framework is deliberately metric-agnostic: any appropriate trio of physiological (e.g., HRV, EEG, fNIRS), behavioral (e.g., TCT, error-rate, eye-movement latency), and subjective (e.g., NASA-TLX, SURG-TLX) indicators can be substituted to suit the constraints of a specific application, provided that all three information channels remain represented [
48,
49].
2.7. Sensor Types for Multimodal Data Acquisition
In the emerging Industry 5.0 paradigm, the ability to fuse physiological, behavioral, and subjective data into a multimodal proficiency-assessment pipeline is increasingly viewed as a foundational pillar of truly human-centric production ecosystems [
3].
Table 1 summarizes key sensor modalities, types, and devices for capturing HRV, TCT, and NASA-TLX, enhancing reliability over unimodal methods [
50].
HRV, a sensitive indicator of cognitive workload, is measured using high-fidelity ECG sensors (e.g., Polar H10) or wearable PPG sensors (e.g., Apple Watch, Oura Ring) [
3]. TCT is captured via software event logs, motion sensors (e.g., accelerometers), or RFID tools, providing precise behavioral data [
51]. NASA-TLX, the standard for subjective workload, uses digital or paper questionnaires, with mobile apps enabling real-time collection [
50].
2.8. Modeling Approaches: A Comparative Analysis of Temporal Models
To develop a robust comparative analysis of the MHMM against other prominent temporal modeling techniques, it is essential to draw on existing literature that covers the strengths and weaknesses of each model, as well as their applicability to dynamic assessment scenarios. Below is a summarized comparative analysis with references that support the characteristics of each modeling approach discussed.
Long Short-Term Memory (LSTM) Networks: LSTM networks are advanced neural networks capable of capturing long-range dependencies in sequential data, making them highly effective for various tasks, including language modeling and time-series prediction. They achieve superior accuracy, but at the cost of interpretability. The complexity of LSTMs can lead to a “black-box” effect, where understanding the rationale behind predictions is challenging [
52]. Recent studies have shown that LSTMs outperform traditional models in various contexts due to their flexibility and power [
53].
Conditional Random Fields (CRFs): CRFs serve as a powerful discriminative model that incorporates the entire context of sequences for prediction. They effectively avoid the independence assumptions typical of generative models, thereby improving the accuracy of predictions. However, training CRFs can be computationally intensive, and they might fall short of capturing very long-range dependencies compared to LSTMs [
54,
55]. Their integration into applications such as image labeling and natural language processing showcases their versatility [
56].
Markov chain: Markov chains are well-studied and highly interpretable because they assume the system’s state is fully observable at every time-step, so the transition matrix can be inspected directly [
57]. This transparency is valuable when clear state-to-state dynamics must be reported. However, a plain Markov chain has two key limitations for multimodal proficiency assessment:
- o
It cannot represent hidden or latent proficiency states, because there are no observation model mapping unobserved states to measured signals; problems that involve unobservable constructs therefore require more expressive models such as Hidden Markov Models [
57].
- o
When multiple data streams (e.g., physiological, behavioral, subjective) are concatenated into a composite state, the number of distinct states grows exponentially, producing the classic curse of dimensionality and making the approach impractical for rich multimodal data [
58].
Unimodal Hidden Markov Model (HMM): Unimodal HMMs are proficient at modeling temporal sequences and are well documented for their effectiveness in applications such as speech recognition and time series analysis. Their strength lies in their ability to capture temporal dependencies clearly, according to Liao et al. [
59]. However, they are inherently limited by their inability to incorporate multiple data streams, leading to a potentially incomplete assessment of human proficiency [
57].
Table 2 shows a comparison of Temporal Modeling.
The choice of modeling approach hinges on the trade-off between predictive accuracy and interpretability. Advanced models, such as LSTMs, tend to deliver high accuracy but may lack interpretability. In contrast, models such as CRFs and HMMs, while providing more interpretability, may not always reach the same level of predictive performance, especially in dynamic and multimodal scenarios. The generative framework of the MHMM offers a clearer and more interpretable structure that can directly connect to real-world performance concepts, which is essential for applications focused on enhancing human operator understanding and support.
2.9. The Need for Temporal Models and the Markov Chain Foundation
Human proficiency is best understood as a dynamic process rather than a static trait, necessitating a model that can interpret and process temporal data. Operators experience fluctuations in skill levels due to factors such as learning, fatigue, and task complexity. Static models that capture a single point in time do not align with this understanding, emphasizing the need for temporal models that accommodate changing states over time.
Markov chains provide a foundational framework for these temporal models. A Markov Chain is a statistical model in which the probability of transitioning to the next state relies solely on the current state, allowing the assessment of transitions between proficiency states, such as from Novice to Intermediate. This transition probability can yield insights into learning rates and the stability of proficiency levels [
18,
59]. However, traditional Markov Chain models assume that these states are directly observable, while true proficiency is inherently latent and inferred from observable behavior rather than measured directly [
57].
The limitation of observing only behavior emphasizes the necessity of advanced models that can infer latent constructs. As pointed out in the literature, combining objective metrics with hidden states can enrich the understanding of underlying proficiency mechanisms [
19]. Therefore, leveraging temporal models, such as the Markov Chain, while addressing their inherent limitations regarding latently measured states can enhance our ability to understand human proficiency dynamics in real-time settings.
2.10. The HMM as the Superior Choice
The HMM is particularly suited for this research due to its ability to address the limitations inherent in standard Markov Chains. Unlike a conventional Markov Chain, which only considers observable states, the HMM incorporates a layer of hidden states—such as Novice, Intermediate, and Expert—which evolve over time according to defined transition probabilities. These states are not directly measurable but are inferred from observable data streams that represent an individual’s proficiency.
Probabilistic Linking: The HMM probabilistically connects these hidden proficiency states to observable data, such as physiological metrics (e.g., HRV), behavioral metrics (e.g., TCT), and subjective feedback (e.g., responses on the NASA-TLX). This linkage allows a comprehensive understanding of proficiency that is informed by real-world indicators [
59].
Latent Proficiency Assessment: The structure of the HMM aligns with the challenge of proficiency assessment by acknowledging that true proficiency is a latent construct that cannot be measured directly. Instead, it infers proficiency through related, observable behaviors and states, thus enriching the assessment process. This capability to capture temporal learning rates and state transitions can be instrumental for understanding dynamic human performance [
19].
Temporal Dynamics: HMM retains the ability to model temporal dynamics and state changes effectively, providing valuable insights into how an operator’s skills develop over time. For instance, using established algorithms such as the Viterbi Algorithm, an HMM can analyze sequences of multimodal observations and discern the likeliest underlying sequence of proficiency states, making it a promising approach for this type of analysis [
60].
Real-World Applications: HMMs have been successfully applied in diverse fields, such as speech recognition, bioinformatics, and human–computer interaction, demonstrating their versatility in modeling sequences where hidden states play a crucial role [
60]. The adaptability and robustness of HMMs makes them particularly advantageous for capturing the fluctuating nature of human proficiency as influenced by various factors be they learning, fatigue, or task complexity.
The HMM framework not only effectively models the transitions between observable behaviors and unobservable proficiency states, but also potentially provides the interpretability needed for practical applications. By capturing hidden states and facilitating a nuanced understanding of operator performance, HMMs offers prospects of empowering researchers and practitioners to assess and support human operators more effectively.
2.11. Comparative Review of HMM Implementations
Although the benefits of MHMMs seem promising, it is important to situate this methodology within the framework of current empirical studies. HMMs and associated temporal modeling methodologies have been utilized in diverse fields to evaluate human conditions such as awareness, cognitive load, and task effort.
This comparative review (
Table 3) combines essential works employing HMMs and other related models for human state evaluation, assessing each according to their data modalities, principal contributions, and distinct limits, underscoring the necessity of a more comprehensive framework.
2.12. Synthesis and Rationale for the Proposed MHMM Framework
This section synthesizes the literature review’s findings, identifying critical gaps in existing proficiency assessment models and providing a rationale for the proposed Multimodal Hidden Markov Model (MHMM) as a dynamic, multimodal solution for Industry 5.0.
The examination of existing empirical work on human proficiency assessment reveals a consistent pattern: No current model successfully integrates physiological, behavioral, and subjective data within a dynamic temporal framework specifically designed for the real-time classification of human proficiency. To address this gap, we propose the Multimodal Hidden Markov Model (MHMM) as a framework with distinct advantages uniquely suited to address this challenge:
Superior Temporal Modeling: Unlike static classifiers, such as Artificial Neural Networks (ANNs) and k-Nearest Neighbors (KNN), which consider each data point independently, the MHMM is built to model sequences of proficiency states through its transition matrix. This allows it to track the evolution of proficiency, capturing learning curves and fatigue onset. Research on vigilance and driving fatigue underscores the importance of such capabilities for accurate assessments of human performance, showing that dynamic modeling is key in tracking changes in performance over time rather than relying on static assessments [
27].
Increased Robustness: By relying on multiple data streams, the MHMM provides state estimation that is more resilient to noise or artifacts in any single channel. For example, if HRV data are temporarily unreliable, the model can still utilize TCT and subjective data from validated measures, such as the NASA-TLX, to maintain stable and accurate proficiency assessments. This resilience to data quality fluctuations is supported by literature that recognizes the importance of integrating multimodal data to enhance the robustness of assessments in complex environments.
Predictive and Diagnostic Power: Beyond classification, the transition probabilities inherent in the MHMM enable the prediction of proficiency changes. If an operator’s transition probability shifts from Intermediate to Novice under stress, this may trigger proactive support within the operational system. Such predictive capabilities allow targeted training interventions that are often absent in static models.
The transition to Industry 5.0 demands a paradigm shift from static, unimodal assessments toward dynamic, human-centric models of human proficiency. The literature confirms that proficiency is a multidimensional construct best understood through the integration of physiological, behavioral, and subjective data. While various modeling techniques have been explored, significant limitations persist due to the reliance on single data modalities or a focus on constructs unrelated to proficiency.
3. Methodology
This section presents the theoretical foundations of HMMs and introduces the proposed MHMM for real-time human proficiency assessment. The rationale behind selecting HMMs to model latent proficiency states is discussed along with a detailed design of the MHMM, focusing on its assumptions and the statistical distributions appropriate for multimodal observation streams.
3.1. HMM Foundations for Proficiency Assessment
HMMs are extensively utilized for inferring latent states from observable data sequences [
57]. In contexts where human proficiency is evaluated, it serves as an unobservable metric derived indirectly through performance indicators, such as task completion time and physiological metrics [
19]. The HMM framework is particularly adept at analyzing time-series data, capturing the dynamics of these latent constructs, and revealing insights into proficiency trajectories.
3.1.1. The Hidden Markov Model: A Framework for Latent Proficiency States
An HMM consists of several integral components: a set of hidden states representing unobservable conditions, an observation space of measurable signals, and various probability distributions detailing transitions and emissions. For instance, in our study, the hidden states may reflect proficiency levels such as Novice, Intermediate, and Expert. The observable outputs include multimodal data consisting of TCT, HRV, and the NASA-TLX. Each of these data types has unique statistical properties that influence their representation in the HMM.
An HMM is formally defined by the following components:
Set of Hidden States : These represent distinct, unobservable conditions of the underlying system. In the present study, these states correspond to discrete levels of proficiency, such as Novice, Intermediate, and Expert.” The state at time is denoted as .
Set of Observation Space : These are the distinct, measurable outputs or signals that can be observed at each time step. In our research, observations are vectors comprising multimodal data: TCT, HRV, and NASA-TLX scores. The observation at time is denoted . For continuous observations, represents the space from which observations are drawn, and probability density functions are used instead of discrete probabilities.
Initial State Distribution
: The initial probability of hidden states at
.
For example, in Equation (1) represents the probability that an individual will begin in the novice proficiency state.
State Transition Probability Matrix
: This
matrix defines the probability of transitioning from hidden state
to
:
For example, in Equation (2) denotes the probability of transitioning from Novice to Intermediate.
Emission Probability Distribution
The probability of observing
when in hidden state
:
For example, in Equation (3) represent the likelihood of observing this specific combination of performance metrics if the individual is currently in the Novice proficiency state.
The definition of “time” t within the HMM is a critical design parameter. It can represent discrete task trials, segments within a continuous task, or fixed time windows. This choice significantly influences the interpretation of transition probabilities A; for instance, short time steps might reveal rapid intra-task fluctuations, while longer steps or trial-based steps might reflect slower learning curves or inter-task proficiency shifts.
The practical application of HMMs often relies on two key assumptions to maintain mathematical tractability and computational feasibility:
First-Order Markov Assumption: The current hidden state
depends only on the previous state
:
Output Independence Assumption: The current observation
is conditionally independent of all other observations and past hidden states, given the current hidden state
:
3.1.2. Algorithmic Solutions for HMM Problems in Proficiency Modeling
HMMs provide a framework for addressing three fundamental problems, each of which has direct relevance to proficiency assessments:
Likelihood Evaluation: Given an HMM defined by
(Equations (1)–(3)) and a sequence of observations, determine the probability of observing this sequence:
. This is crucial for comparing how well different proficiency models (e.g., an HMM trained on expert data versus one trained on novice data) explain a new operator’s observed performance sequence. The Forward Algorithm, a dynamic programming approach, efficiently solves this problem [
59].
Decoding: Given an HMM,
(Equations (1)–(3)), and a sequence of observations
, find the likeliest sequence of hidden states that could have generated these observations. This is arguably the key problem for real-time proficiency assessment, as it allows the inference of an operator’s proficiency trajectory (e.g., Novice → Novice → Intermediate) over the duration of a task or series of tasks. The Viterbi Algorithm is the well-studied method for finding this optimal state sequence (In everyday terms, the Viterbi Algorithm acts like a GPS for hidden states: it traces the single most likely “route” an operator’s proficiency could have taken, step-by-step, to produce the observations you recorded). Importantly, the output of the Viterbi Algorithm is an inference of the most probable state sequence, not an absolute ground truth; its accuracy is contingent upon the quality and validity of the learned HMM parameters [
60].
Learning (or Training): Given a sequence of observations
(and potentially the number of hidden states
), estimate the HMM parameters
that maximize the probability of the observed data
. This is how the proficiency models are constructed from the training data. The Baum-Welch Algorithm (In everyday terms, Baum-Welch is like tuning a radio: you keep nudging the dial until the signal comes in clearest, iteratively adjusting the model’s probabilities so they best explain the data you hear), a specific instance of the Expectation-Maximization (EM) Algorithm, is commonly used for this unsupervised learning task. The nature and quality of the training data used with the Baum-Welch Algorithm are paramount [
64]. The quality of training data is important; distinct proficiency models (e.g., Novice, Expert) require observation sequences from clearly categorized individuals to ensure model validity [
65].
3.2. The Proposed Multimodal Hidden Markov Model (MHMM)
Building on the foundational principles of HMMs, this research proposes an MHMM specifically designed for the dynamic assessment of human proficiency.
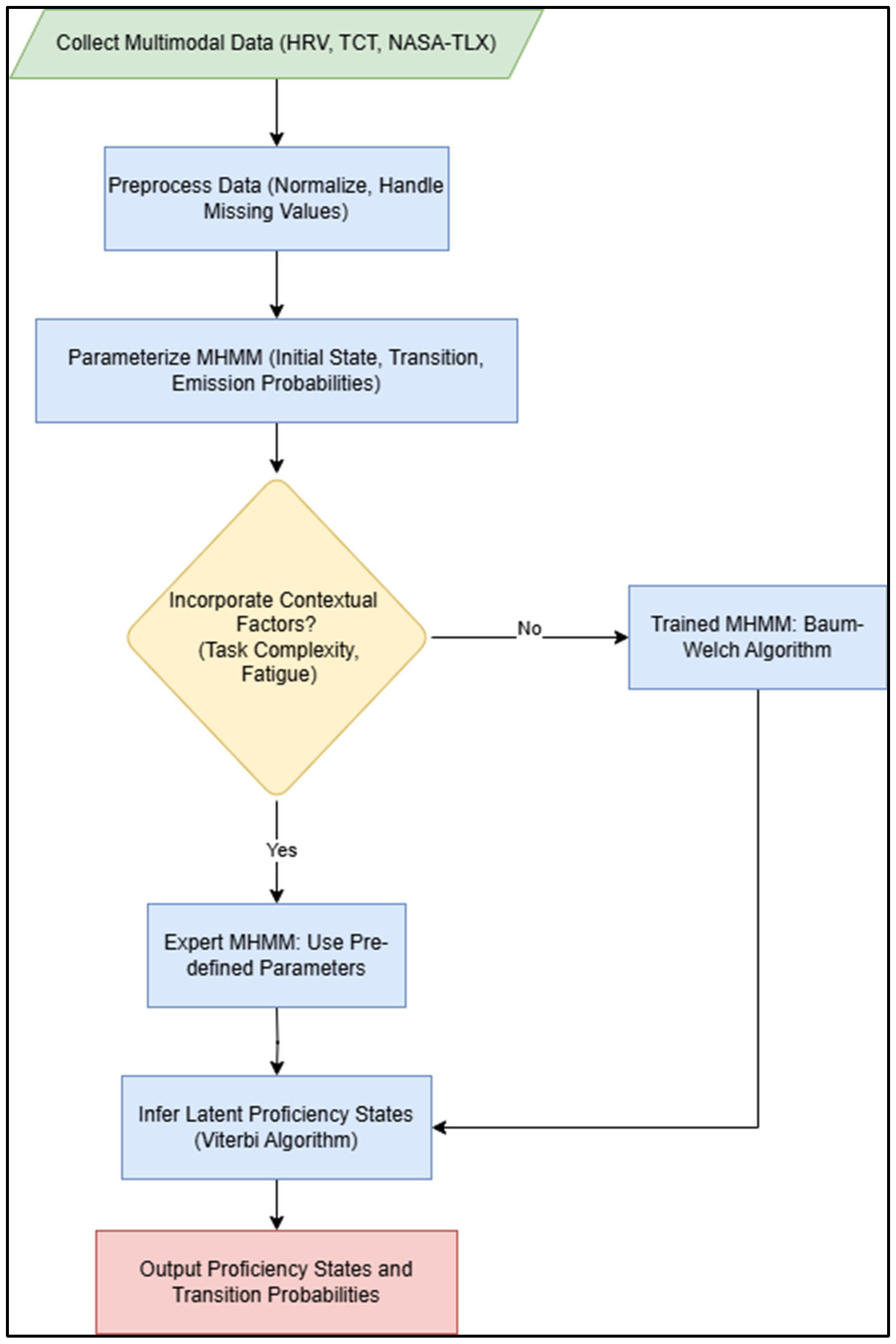
The conceptual architecture of the proposed MHMM is illustrated in
Figure 1. The model’s key innovation is its two-layer structure.
The model is structured into two layers. The Hidden Layer contains the unobservable proficiency states (Novice, Intermediate, and Expert), which must be inferred. The Observation Layer consists of directly measurable data streams: Heart Rate Variability (HRV), Task Completion Time (TCT), and NASA Task Load Index (NASA-TLX). Arrows within the hidden layer represent Transition Probabilities (A) (Equation (2)), modeling how proficiency evolves. Dashed arrows from the hidden to the observation layer represent Emission Probabilities (B) (Equation (3)), linking proficiency states to the data they are likely to produce.
Figure 2, this flowchart visually outlines the MHMM framework for real-time human proficiency assessment. It details the steps from initial multimodal data collection (HRV, TCT, NASA-TLX), and preprocessing (normalization, handling missing values), through the parameterization of the MHMM (initial state, transition, and emission probabilities). It highlights the crucial decision point of incorporating contextual factors (task complexity, fatigue) to either utilize an expert-driven model or a trained model, ultimately leading to the inference of latent proficiency states using the Viterbi Algorithm and the output of valuable transition probabilities. This systematic approach underpins the dynamic and comprehensive understanding of operator proficiency, crucial for human-centric systems in Industry 5.0.
3.2.1. The Conditional Independence Assumption in MHMM
A key simplifying assumption in the proposed MHMM, common to many multimodal HMM applications, is the conditional independence of the observation streams, given the hidden proficiency state. Formally, the joint probability of observing a particular set of HRV, TCT, and NASA-TLX values at time
, given the system is in proficiency state
, is factored as shown in Equation (4):
This assumption means that, for any given level of proficiency, the HRV value is considered independent from the TCT and NASA-TLX score at that moment. The main reason for using this assumption is to make the model simpler and easier to work with. It reduces the number of parameters the model needs, which makes training faster and running the model more efficient.
Of course, in real life, elements such as HRV, TCT, and perceived effort often change together, even when someone’s skill level stays the same. For example, frustration might raise HRV, decelerate task time, and increase the sense of effort simultaneously. However, HMMs are generally quite good at handling small violations of this independence assumption. In practice, the different types of data (physiological, behavioral, and subjective) often show clear enough patterns for each skill level-Novice, Intermediate, Expert-that the model can still tell the difference between them, even if some overlap exists. In this approach, each type of data acts somewhat similar to an independent “signal” about the person’s skill level. As long as these signals are mostly reliable and distinct for each level, the model can be expected to work reasonably well.
3.2.2. Statistical Modeling of Emission Probabilities
A critical design choice in an MHMM for continuous data is the selection of appropriate probability distributions for the emission probabilities
. For this exposition we use surgery proficiency as the use-case and use statistical properties and benchmarks from surgical literature, particularly the work of Shrivastava et al. (2025) [
24], the following distributions were chosen:
Task Completion Time (TCT)–Lognormal Distribution: TCT data are positive, skewed right, and bounded at zero, with a long tail due to errors or hesitation. The lognormal distribution is suitable for such data [
66].
Heart Rate Variability (HRV)–Normal (Gaussian) Distribution: HRV, as a physiological measure, clusters symmetrically around a mean for a given cognitive state, making the normal distribution appropriate [
67].
NASA Task Load Index (TLX)–Normal (Gaussian) Distribution: Subjective TLX scores are assumed to follow a normal distribution around a mean characteristic of a proficiency level [
37].
The use of these specific distributions ensures that the MHMM accurately captures the statistical properties of each data stream, thereby improving the fidelity of the emission probability calculations and the overall accuracy of proficiency state inference, creating distinct multimodal signatures for each proficiency state for the surgery use-case. More generally, the specific distributions and their parameters will depend on the application in terms of the tasks, multi-modal measurements, and of course the human operators and associated proficiency levels.
4. Dataset Generation and Simulation Environment
This section details the simulation-based approach employed to rigorously validate the MHMM. Our methodology emphasizes grounding a high-fidelity synthetic dataset in empirical literature, ensuring it mirrors real-world human proficiency dynamics. This controlled environment provides an unambiguous ground truth, enabling precise and quantitative evaluation of the proposed MHMM approach’s ability to recover latent proficiency states from multimodal data streams under various conditions. Furthermore, this section outlines a sensitivity analysis to assess the robustness of the MHMM’s parameter settings and describes an expanded comparative framework including advanced neural models and methodological transparency.
4.1. Rationale for a Simulation-Based Approach
While real-world field data are the ultimate benchmark, a simulation-based approach offers several indispensable advantages for the initial, rigorous validation of a complex framework such as the MHMM:
Establishing an Unambiguous Ground Truth: The core task of the MHMM is to infer latent (hidden) proficiency states (Novice, Intermediate, Expert). In real-world settings, an operator’s true, moment-to-moment proficiency level is unobservable and cannot be labeled with perfect accuracy. Our simulation provides an unambiguous ground truth where the underlying state sequence is known by design, allowing for precise, quantitative evaluation of model performance that is impossible with field data alone.
Enabling Controlled, Systematic Stress Testing: Real-world data are often noisy and incomplete. A simulation allows for controlled experimentation where specific challenges can be isolated and systematically tested. As detailed in later, we can create scenarios to evaluate a model’s robustness to sensor noise, its resilience to missing data, and its performance on imbalanced class distributions. This targeted stress testing is important for understanding a model’s limitations before real-world deployment.
Feasibility and Scalability: Collecting large-scale, longitudinal multimodal data in high-stakes environments (e.g., operating rooms, industrial settings) is logistically complex, prohibitively expensive, and fraught with ethical and privacy challenges. Simulation provides a practical method for generating the rich datasets required to train and validate sophisticated temporal models.
Ensuring Reproducibility: By generating data from a defined parameterized model, this study is fully reproducible. Other researchers can use the same generative process to benchmark their models against this study’s results, fostering transparency and advancing the field.
Therefore, this illustrative study uses simulation not as a substitute for real-world validation, but as a necessary first step to rigorously demonstrate the MHMM’s methodological soundness and comparative advantages under a range of controlled conditions.
4.2. Simulation Design and Ground-Truth Generation
The evaluation’s foundation is a synthetic dataset generated by the MHMM class configured in “Expert Mode,” acting as a ground-truth generator. This dataset comprises longitudinal data for 100 simulated participants, each performing 200 distinct procedural tasks, totaling 20,000 individual data points. Each data point represents multimodal observations HRV, TCT, and NASA-TLX intrinsically linked to a known underlying proficiency state (Novice, Intermediate, or Expert).
To ensure ecological validity, the MHMM’s generative parameters were meticulously initialized using empirical benchmarks from the surgical training literature (Shrivastava et al., 2025 [
24]). The initial state distribution for participants was set to favor Novice states (
). The base transition probability matrix (A_base) (Equation (2)) was designed to reflect typical learning curves, with high self-transition probabilities and smaller probabilities for progression (e.g., Novice to Intermediate) or regression (e.g., Intermediate to Novice). For emission parameters, the means and standard deviations for each modality (TCT as Lognormal, HRV and NASA-TLX as Normal distributions) were directly matched to empirical findings from Shrivastava et al. (2025) [
24], creating distinct multimodal signatures for each proficiency state.
A key innovation of this simulation is its ability to model how contextual factors dynamically influence proficiency transitions. The compute_dynamic_transition_matrix_expert function modulates the base transition probabilities at each procedural step based on simulated workplace challenges. These include task complexity (impeding skill acquisition), skill decay and forgetting (increasing regression probabilities based on time gaps between procedures), cumulative fatigue and stress (increasing regression probabilities based on physiological strain and perceived workload), and collaboration intensity (adjusting learning and regression based on interaction with AI). The data generation process is an iterative, step-by-step procedure in Python 3.11.13, where at each step, the next hidden state is probabilistically sampled based on dynamic transitions, and corresponding multimodal observations are generated from their defined emission distributions, with all contextual metadata recorded. This ensures a rich, longitudinal dataset with known ground-truth trajectories for rigorous model evaluation.
4.3. Comparative Benchmarking Framework
To objectively assess the MHMM’s performance, its two variants (Expert System and Trained) were benchmarked against a suite of established temporal models, chosen to represent different classes of sequence modeling approaches. This comprehensive comparison evaluates the benefits of multimodal fusion and the MHMM’s interpretability against state-of-the-art black-box and discriminative models.
MHMM (Expert System): This variant of our Multimodal Hidden Markov Model uses pre-defined, expert-informed parameters. It represents an ideal scenario where domain knowledge is perfectly integrated, and it uniquely leverages contextual metadata (task complexity, fatigue events) to dynamically adjust its predictions, showcasing the full potential of a context-aware system.
MHMM (Trained): This is a standard MHMM that learns its parameters (initial state probabilities, transition probabilities, and emission distributions) directly from the training data using the Baum-Welch algorithm. Its inclusion evaluates the MHMM’s ability to discover proficiency dynamics from raw observation sequences without prior expert knowledge, providing a more realistic benchmark for data-driven applications.
Unimodal HMMs (TCT, HRV, or TLX): Three separate Hidden Markov Models were implemented, each trained exclusively on a single data modality (Task Completion Time, Heart Rate Variability, or NASA Task Load Index). These serve as crucial baselines to empirically demonstrate the advantage of multimodal data fusion over relying on any single physiological, behavioral, or subjective indicator.
Long Short-Term Memory (LSTM) Network: As a type of recurrent neural network, LSTM models are state-of-the-art in sequence learning, capable of capturing complex long-range dependencies in data. They serve as a powerful “black-box” performance benchmark, often achieving high accuracy but lacking the inherent interpretability of probabilistic models like HMMs.
Transformer Model: This advanced neural architecture, known for its use of self-attention mechanisms, excels in capturing global dependencies within sequences, making it highly effective for sequence-to-sequence tasks. Its inclusion provides a contemporary benchmark from the deep learning domain to assess how advanced neural architectures perform in modeling temporal proficiency dynamics.
Hybrid HMM-LSTM Model: This model combines the strengths of both HMMs and LSTMs. It uses the MHMM’s emission probabilities (representing the likelihood of observations given each hidden state) as additional features for an LSTM network. This hybrid approach explores whether integrating probabilistic insights from HMMs can enhance the predictive power of neural sequence processing.
Conditional Random Field (CRF): Unlike generative models such as HMMs, CRFs are discriminative models that focus on directly modeling the conditional probability of a sequence of labels given a sequence of observations. They are powerful for sequence labeling tasks and avoid some of the strong independence assumptions of HMMs, offering an alternative probabilistic modeling approach for comparison.
4.4. Experimental Procedure and Stress-Testing Scenarios
All models were evaluated using a standardized procedure with a participant-level 70/30 train-test split to ensure generalizability. Model performance was assessed not only on clean data but also across four stress-test scenarios designed to simulate realistic data challenges: a Baseline Scenario (unaltered data), a Noise Robustness Scenario (15% of data points corrupted by a multiplicative noise factor), a Missing Data Scenario (15% of data points randomly set to NaN), and an Imbalanced Data Scenario (highly skewed proficiency distribution, e.g., 80% Novice). Performance was quantified using Accuracy and Weighted F1-Score, with the find_state_mapping function ensuring correct alignment of unsupervised model labels with true proficiency states.
4.5. Robustness to Noisy and Missing Sensor Data
The simulation study evaluates the MHMM’s performance under realistic data challenges, including noisy and missing sensor data, as outlined in the stress-testing scenarios. In real-world industrial settings, such as smart factories or surgical training, sensor data like HRV, TCT, and NASA-TLX are often subject to noise from environmental interference or missing due to sensor failures, such as wearable device dropouts. The MHMM is designed to handle these challenges robustly, ensuring reliable proficiency assessment in Industry 5.0’s human-centric, technology-augmented environments. This subsection outlines the MHMM’s mechanisms for managing noisy and missing data, as tested in the simulation, enabling continuous operator support without workflow disruption.
For missing data, the MHMM employs a native approach in its _emission_log_probability function, which conditionally includes only non-missing modalities when computing the log probability of an observation vector for a given proficiency state (Novice, Intermediate, Expert). For instance, if HRV data is unavailable (NaN), the calculation omits HRV’s contribution while incorporating TCT and NASA-TLX, ensuring partial observations remain usable without requiring imputation. This approach was tested in the Missing Data scenario, simulating intermittent sensor failures common in industrial training systems.
For noisy data, the MHMM leverages continuous probability distributions parameterized by empirically grounded means and standard deviations from Shrivastava et al. (2025) [
24]. These distributions, detailed above, capture the expected variability in each modality, allowing the model to absorb moderate noise perturbations as part of the natural spread of the data rather than interpreting them as significant changes. Numerical stability is ensured through log-space computations and probability clipping in the Baum-Welch and Viterbi algorithms, preventing underflow or overflow issues when processing noisy data. The Trained MHMM’s parameter initialization, using K-Means clustering, promotes robust convergence on noisy training data by identifying stable initial emission parameters, as evaluated in the Noise Robustness scenario.
4.6. Parameter Sensitivity Analysis
To further assess the robustness of the MHMM’s trained parameters, a sensitivity analysis was conducted. This involved systematically perturbing key emission parameters (means and standard deviations of HRV, TCT, and NASA-TLX for specific states) by ±10% or ±15%. For each perturbation, the MHMM (Expert System) was re-evaluated on the test dataset, and its performance (accuracy and macro-averaged F1-Score) was compared against the original model. This analysis quantifies the model’s stability under variations in empirical estimates, providing critical insight into its reliability in practical applications where precise parameter values may vary.
5. Results and Discussion
This section presents and analyzes the findings from the simulation study. The results validate the MHMM’s superior performance in accuracy, robustness, and temporal tracking compared to other state-of-the-art models. Furthermore, the discussion highlights the MHMM’s unique interpretability, exploring its implications for developing human-centric AI systems in Industry 5.0.
5.1. Data Distribution and Model Grounding
The fidelity of the simulation is critical for the validity of the evaluation.
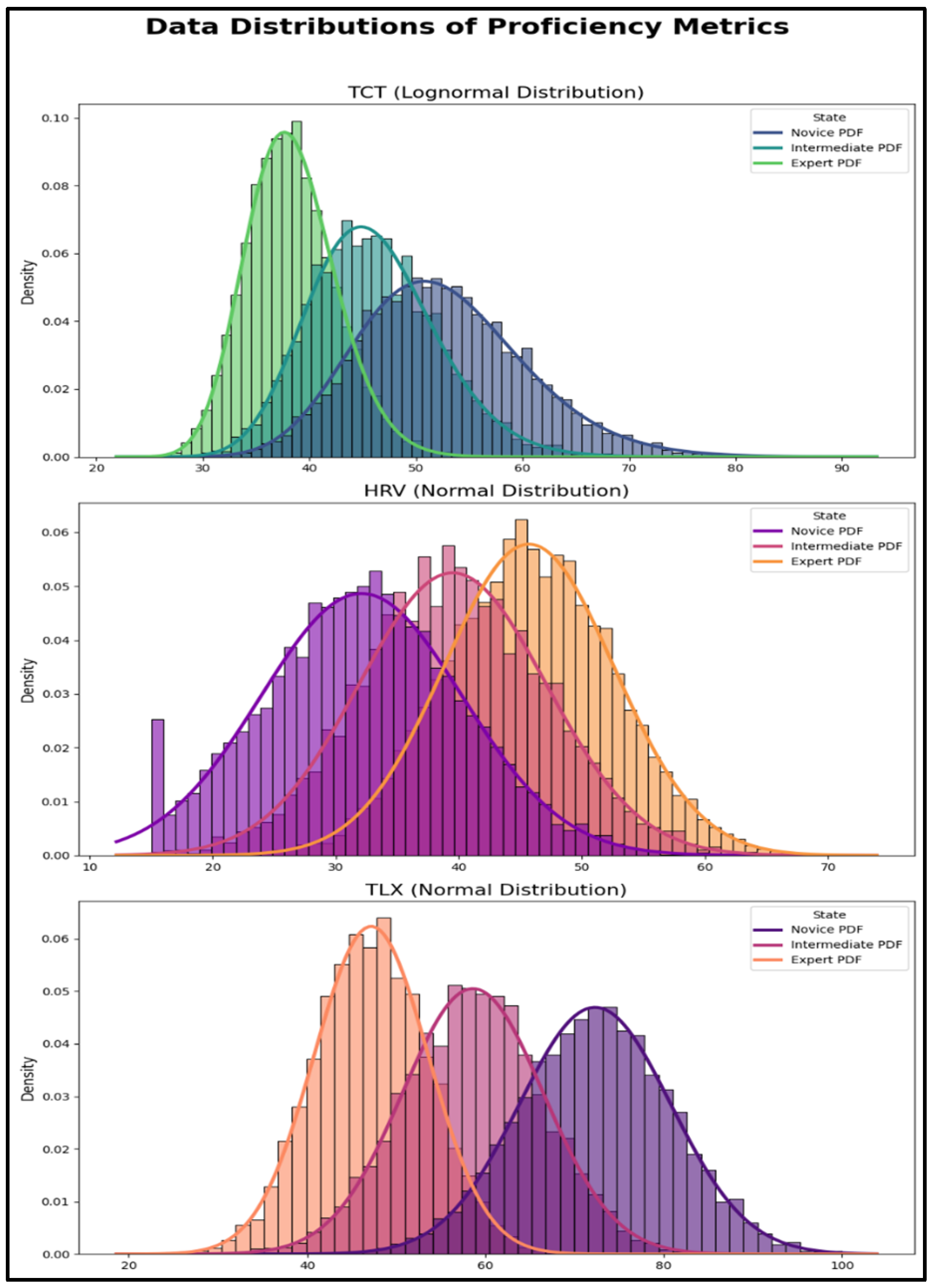
Figure 3 illustrates the distributions of the generated multimodal data (TCT, HRV, and TLX) for each proficiency state. The distinct overlapping distributions for Novice, Intermediate, and Expert closely mirror the empirical benchmarks established in the surgical literature (Shrivastava et al., 2025) [
24]. For instance, TCT shows a clear rightward shift and increased variance for novices, while HRV shifts rightward (indicating lower stress) with increased expertise. This demonstrates that the synthetic data successfully capture the nuanced statistical signatures of real-world proficiency, providing a valid foundation for benchmarking the models.
To further elaborate on the characteristics of the multimodal data,
Figure 4 provides a detailed view of the density distribution of each physiological (HRV), behavioral (TCT), and subjective (NASA-TLX) metric within each proficiency state (Novice, Intermediate, Expert). These violin plots, unlike simple box plots, illustrate the full shape of the data distribution, including peaks and spread. This allows for a more nuanced understanding of how these multimodal inputs differentiate (or exhibit overlap between) proficiency levels, thereby confirming the statistical properties and distinctiveness of the generated data for each state.
5.2. Comparative Model Performance Across Scenarios
The performance of all models is evaluated across four scenarios designed to test their accuracy and robustness.
Table 4 summarizes the key performance metrics (Accuracy and Weighted F1-Score) for each model across these scenarios.
Several key findings emerge from these results:
Superiority of MHMM: In all four scenarios, the MHMM (Expert System) and MHMM (Trained) variants consistently outperformed all other models in both accuracy and F1-scores. The F1-score measures how well a model balances precision (how many predicted labels are correct) and recall (how many actual cases it finds). It is calculated as:
This makes it useful for evaluating performance when some classes are less frequent than others. This demonstrates the inherent strength of the HMM framework for this task, especially when it can leverage either expert knowledge or learn directly from multimodal data.
Clear Advantage of Multimodal Fusion: Unimodal HMMs performed significantly worse than all multimodal approaches, with accuracies hovering between 61% and 65% in the baseline scenario. This provides strong evidence for the central hypothesis of this study: Fusing physiological, behavioral, and subjective data streams provides a far more robust and reliable assessment of proficiency than any single indicator alone.
Robustness to Noise and Missing Data: The MHMM variants showed remarkable resilience in the stress test scenarios. In the Missing Data scenario, the MHMM’s performance barely degraded, highlighting the advantage of its native ability to handle missing observations without relying on imputation. In contrast, CRF’s performance dropped from 0.885 to 0.801 accuracy, indicating its vulnerability to incomplete data.
5.3. Parameter Sensitivity Analysis of the Trained MHMM
To further evaluate the robustness and reliability of the trained MHMM, a sensitivity analysis was performed on its key emission parameters. This analysis involved systematically perturbing the learned mean and standard deviation values for HRV, TCT, and NASA-TLX distributions across the different proficiency states (0: Novice, 1: Intermediate, 2: Expert). The impact of these perturbations on the model’s overall classification accuracy and F1-Macro score was then observed.
As presented in
Table 5, the results demonstrate the trained MHMM’s resilience to variations in its emission parameters. Even with significant perturbations, such as a ±10% change in the mean of HRV for Novice (state 0) or Intermediate (state 1), the model’s accuracy and F1-Macro scores remained remarkably close to the baseline performance (0.925 accuracy, 0.912 F1-Macro). Similar minimal performance degradation was observed when the standard deviation of TCT for Novice (state 0) was varied by ±15%, or when the mean and standard deviation of TLX for Intermediate (state 1) and Expert (state 2) were perturbed by ±10%. Only the most impactful results are included in the table for brevity and clarity, as the remaining perturbations yielded changes in less than 0.002, statistically negligible and visually uninformative. This consistent performance across perturbed parameters underscores the inherent stability of the MHMM, suggesting that its ability to infer proficiency states is robust even when faced with minor inaccuracies or natural variability in the underlying data distributions. This finding is crucial for practical applications where precise parameter estimation might be challenging.
5.4. Real-World Applicability and Implementation Scenarios
The two MHMM variants evaluated in this study-Expert MHMM and Trained MHMM-demonstrate the framework’s adaptability to diverse real-world needs in Industry 5.0, where human-centric and resilient systems are foundational. The choice between a pre-defined or trainable model depends on the application context, data availability, and the balance between standardized assessment and context-specific adaptation, with both ensuring secure handling of sensitive multimodal data (e.g., HRV, TCT, NASA-TLX).
Expert MHMM: This model is suited for standardized, high-stakes settings with established proficiency benchmarks, such as surgical training programs. Its pre-defined parameters, derived from empirical literature (e.g., Shrivastava et al., 2025) [
24], enable a computationally efficient “plug-and-play” system, ideal when large, context-specific datasets are unavailable. For example, in surgical simulation, the Expert MHMM could use securely collected HRV data to assess trainee proficiency, ensuring data privacy through encrypted transmission. Its interpretable transition probabilities (e.g., 15% Novice-to-Intermediate transition) support trusted decision-making in safety-critical applications. In our simulation, the Expert MHMM achieved 92.7% accuracy (
Table 4), highlighting its potential for standardized assessments.
Trained MHMM: This variant is ideal for dynamic environments where local factors influence performance, such as smart factories with unique workflows. By learning parameters via the Baum-Welch Algorithm [
68], it adapts to context-specific variations, enhancing accuracy within particular settings. For instance, a manufacturing facility could train the MHMM on encrypted TCT data to monitor human proficiency with cobots, ensuring data security. The Trained MHMM’s 92.5% accuracy (
Table 4) demonstrates its robustness in data-driven scenarios. This adaptability supports Industry 5.0’s vision of personalized operator support [
68].
The flexibility of the MHMM framework to accommodate both standardized and customized applications underscores its value for human–AI collaboration in Industry 5.0. While simulation results validate its efficacy, future empirical validation in real-world settings (e.g., manufacturing or healthcare) is needed to confirm its practical impact.
5.5. Analysis of Proficiency Trajectory Tracking
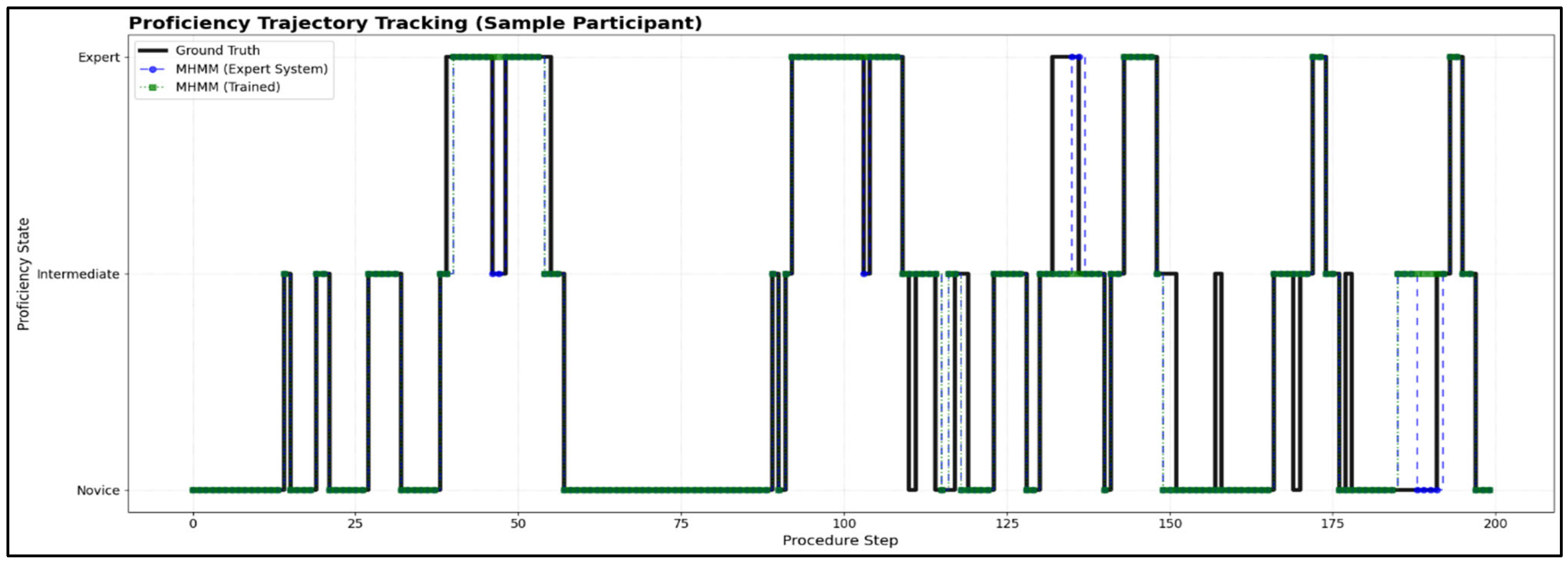
As shown in
Figure 5, both MHMMs track the ground truth with exceptional accuracy. They successfully capture not only the stable periods within a single proficiency state but also the precise moments of transition, such as learning progressions (Novice → Intermediate) and temporary regressions. This ability to accurately model the temporal dynamics of skill acquisition and decay is a key advantage of the MHMM framework.
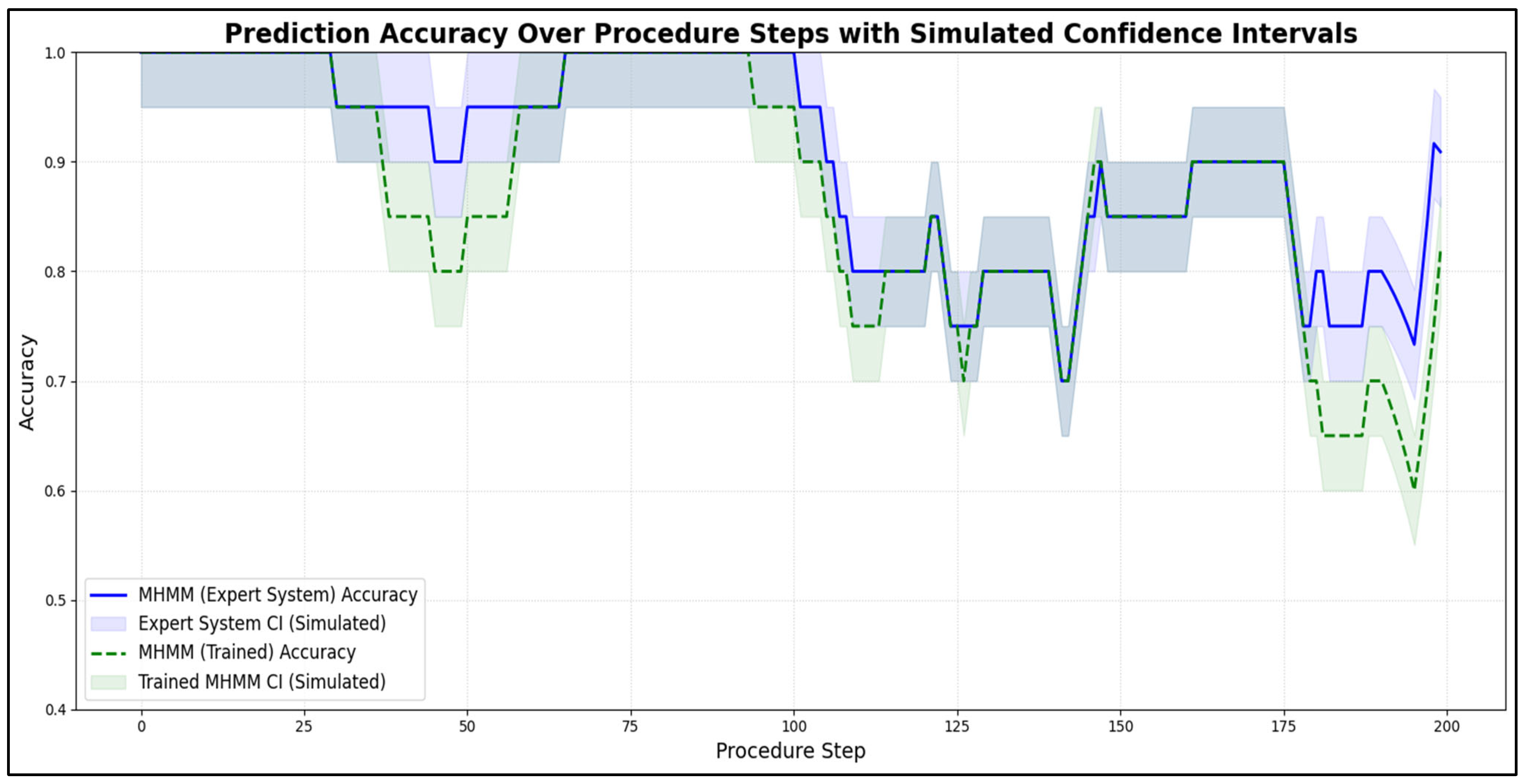
Furthermore,
Figure 6 displays the step-wise prediction accuracy of both MHMM variants (Expert System and Trained) over the duration of the procedure for a sample participant. The shaded regions around each accuracy line represent simulated confidence intervals, providing an indication of the reliability and variability of the predictions at each point in time. This offers a statistical perspective on the models’ consistent performance and prediction uncertainty throughout the task.
5.6. Interpretability: Unpacking Proficiency Dynamics
A core advantage of the MHMM over black-box models such as LSTMs is its interpretability. The model’s learned parameters are not abstract weights but tangible probabilities that offer direct insights into proficiency dynamics.
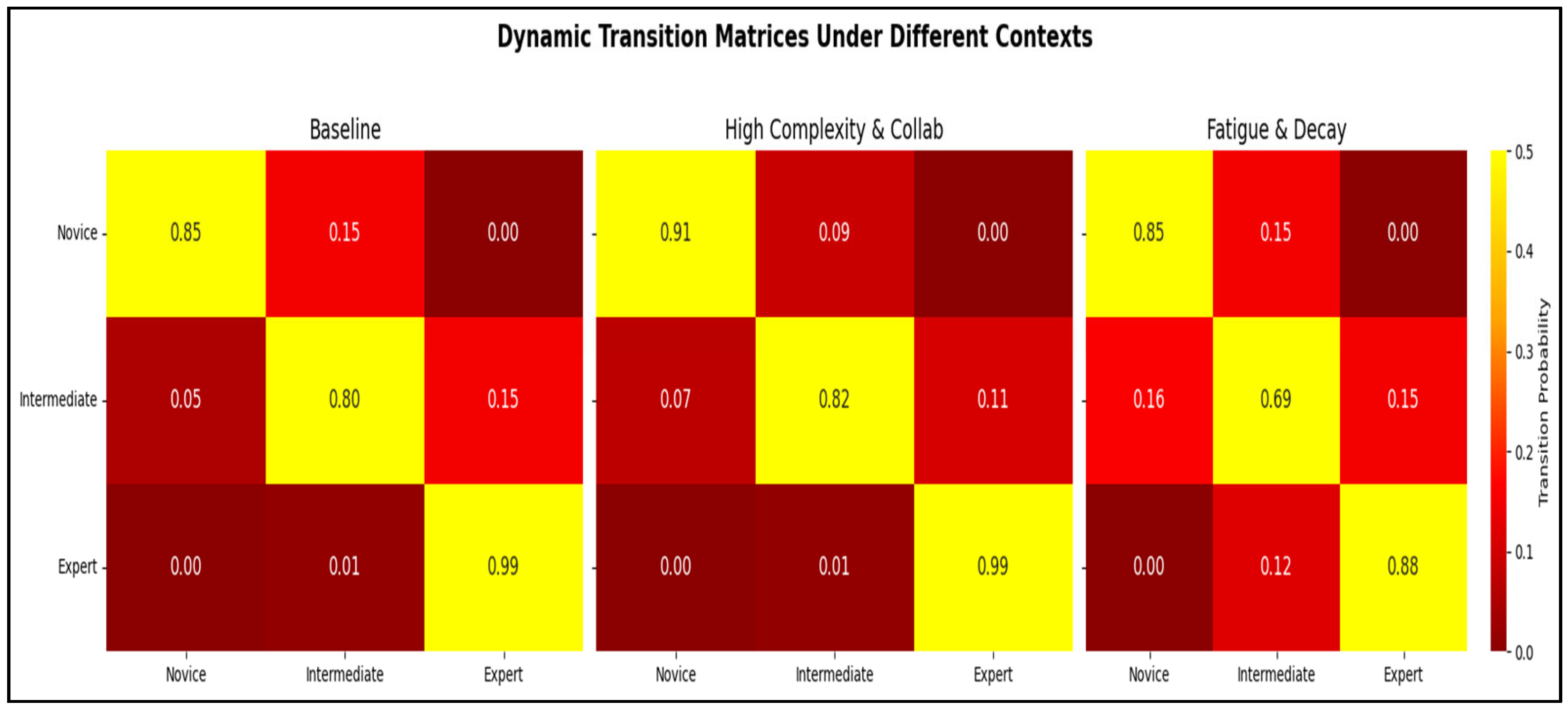
Figure 7 visualizes the dynamic transition matrices under different simulated contexts.
The heatmaps show how the probabilities of transitioning between proficiency states change from the Baseline condition in response to high complexity and collaboration intensity (Collab) and fatigue and decay.
These matrices provide quantifiable, actionable metrics:
Baseline Learning Rates: Under standard conditions, the probability of a Novice transitioning to Intermediate, as defined by the transition matrix in Equation (2), is 15%, implying an expected dwell time of approximately six to seven procedures in that state.
Contextual Adjustments: The model quantifies how context impacts proficiency. High task complexity reduces the Novice-to-Intermediate transition probability from 15% to 9%. The onset of fatigue and skill decay increases the probability of an Expert regressing to Intermediate from a mere 1% to 12%.
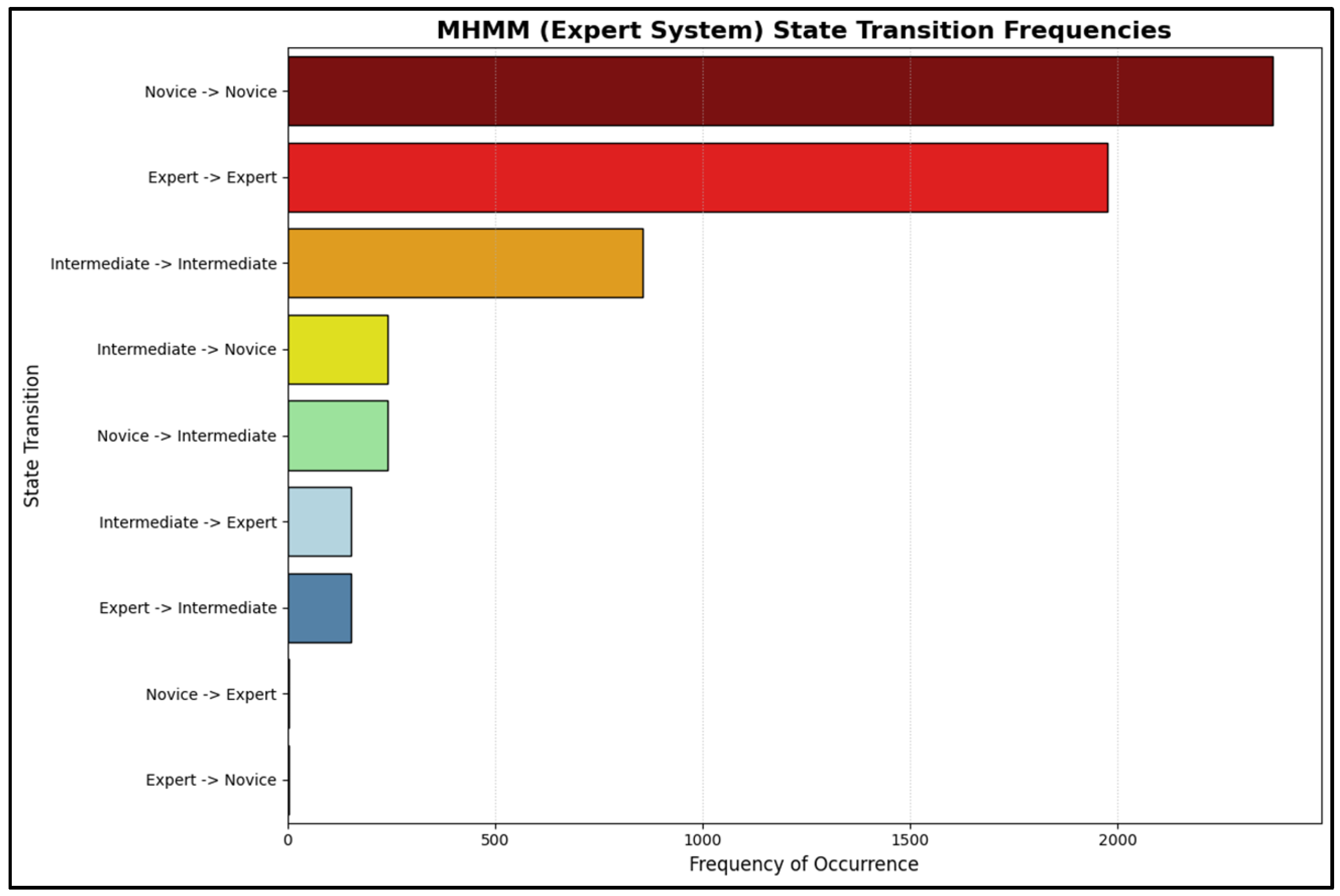
Additionally, in
Figure 8, visually represents the most commonly observed state-to-state transitions for a sample participant. This bar chart effectively highlights the most frequent pathways of proficiency change (e.g., “Novice → Novice” or “Intermediate → Expert”), offering an intuitive overview of the predominant flow of proficiency states within the simulated trajectory.
This level of transparency allows trainers and system designers to understand why a model makes a certain prediction. It enables data-driven interventions (e.g., scheduling rest breaks when the regression risk is high) and fosters trust in the AI system, a critical factor for adoption in high-stakes environments.
5.7. Recent Temporal Modeling Approaches (2020–2025)
To further contextualize the performance of the proposed MHMM, a detailed comparative summary of recent temporal modeling approaches applied to human state evaluation is presented in
Table 6. This table highlights their data modalities, methodologies, reported accuracies, and main limitations, providing a broader perspective on the current landscape of research.
While recent temporal modeling approaches demonstrate promising results across diverse domains (from gaming and driving to pilot monitoring) they often rely on unimodal data, lack longitudinal proficiency tracking, or omit subjective context. As summarized in
Table 6, many models either prioritize short-term states (e.g., fatigue, vigilance) or are validated on narrow, domain-specific tasks. In contrast, the proposed MHMM integrates physiological, behavioral, and subjective modalities within a three-state interpretable framework, achieving high accuracy (92.5%) and aligning with cognitive science theories. Despite the current limitation of relying on simulation-based validation, the MHMM offers strong potential for real-time, generalizable proficiency tracking in complex industrial environments. Its modular design and multimodal integration position it as a promising foundation for future adaptive and human-centered AI systems in Industry 5.0.
5.8. Discussion and Implications for Industry 5.0
The results of this study position the MHMM as a powerful and practical tool for realizing the human-centric vision of Industry 5.0. Its high accuracy, robustness to imperfect data, and unique interpretability make it highly suitable for real-world deployment. By providing a continuous, context-aware understanding of human proficiency, the MHMM can power a new generation of adaptive systems:
Personalized Training: The system can tailor training curricula in real time, providing more support to a Novice and offering more challenging scenarios to an Expert.
Adaptive Human–AI Collaboration: A cobot could adjust its level of assistance based on the operator’s inferred state, offering more explicit guidance during moments of fatigue or simplifying tasks when the operator is struggling.
Proactive Well-being Management: By detecting early signs of fatigue-induced skill regression, the system can prompt interventions to prevent burnout and ensure workforce sustainability.
The model’s strong performance, grounded in realistic, empirically derived data, underscores its potential to bridge the gap between human operators and intelligent systems, creating safer, more efficient, and more supportive work environments.
5.9. Limitations and Future Directions
Despite its robust design and significant performance, the MHMM framework acknowledges limitations guiding future research:
Simulation-Based Validation: The current reliance on synthetic data is essential for controlled methodological validation but limits claims regarding real-world performance. Operational field validation remains a crucial next step.
Future Empirical Validation: Empirical validation studies are planned within real-world settings, such as advanced manufacturing environments and surgical training centers. These studies will involve operators performing authentic tasks while monitored through wearable physiological devices, detailed behavioral data, and continuous subjective assessments via adaptive interfaces. Expert-validated proficiency evaluations will be employed to benchmark the MHMM’s predictions, ensuring robust real-world applicability and facilitating the refinement of parameters.
Conditional Independence Assumption: While the conditional independence assumption greatly simplifies computational modeling, real-world data may show interdependencies across physiological, behavioral, and subjective metrics. Future studies could explore more sophisticated coupled HMMs or Bayesian network models to explicitly capture these inter-modal correlations, potentially enhancing accuracy.
Ethical and Practical Constraints: Multimodal monitoring introduces privacy concerns and necessitates transparent data-handling protocols aligned with regulatory compliance (e.g., General Data Protection Regulation (GDPR)or Health Insurance Portability and Accountability Act (HIPAA)). Ensuring equitable access across diverse industries and populations also remains essential. Future research must prioritize ethical considerations, consent processes, and non-intrusive sensor technologies.
Moreover, extending the MHMM framework to incorporate bidirectional interactions between operators and AI systems, particularly cognitive feedback loops adjusting assistance levels based on real-time inferred workload, would further advance its alignment with the collaborative ethos of Industry 5.0.
6. Conclusions
The transition to Industry 5.0 demands dynamic, human-centric tools that transcend the limitations of static, unimodal proficiency assessments. This paper introduced the Multimodal Hidden Markov Model (MHMM), a novel framework that integrates physiological (HRV), behavioral (TCT), and subjective (NASA-TLX) data to infer latent proficiency states in real time. Through a comprehensive simulation study, the MHMM (trained) achieved a remarkable 92.5% accuracy, outperforming unimodal HMMs and rivaling advanced models, such as LSTMs and CRFs. Its ability to model temporal dynamics and adapt to contextual factors—such as task complexity, fatigue, and skill decay—ensures robust and context-aware proficiency tracking.
Although we operationalized the MHMM with three hidden states, (the framework is state-agnostic. In domains where proficiency unfolds in finer, task-specific increments (e.g., surgery, aviation maintenance, or advanced pilot training), researchers have successfully deployed HMM variants with five or more states to reflect detailed sub-phases of expertise [
26,
69]. Accordingly, the number of latent states in our MHMM can be scaled up or down to match the granularity required by a given application without altering the underlying probabilistic machinery.
The MHMM’s interpretable transition probabilities provide granular insights into learning and forgetting rates, enabling targeted interventions and adaptive human–AI collaboration. By aligning with Industry 5.0’s pillars of human-centricity, resilience, and sustainability, the MHMM supports safer, more efficient, and equitable industrial ecosystems. While challenges such as real-world validation and ethical data collection remain, the framework’s empirical foundation and generalizable methodology position it as a transformative tool for high-stakes domains. The MHMM not only advances proficiency assessments but also paves the way for empathetic, collaborative AI systems that empower human potential in Industry 5.0 and beyond.
7. Potential Applications and Broader Impact
By integrating physiological, behavioral, and subjective data streams, the MHMM framework enables real-time, context-sensitive human proficiency assessment. This approach is intrinsically aligned with the human-centric, resilient, and sustainable vision of Industry 5.0, where AI is designed to augment, rather than replace, human capabilities. The goal is to foster highly synergistic human–machine collaboration and adaptive decision making, particularly in high-stakes, safety-critical domains [
70,
71]. The potential applications and broader impacts of this framework are extensive and transformative.
7.1. Domain-Specific Applications
Healthcare and Surgical Training: In healthcare, MHMMs offer significant promises for revolutionizing surgical training and intraoperative support. By continuously monitoring metrics such as HRV, TCT, and subjective workload indices from trainees, the system can provide adaptive feedback and personalized training curricula [
72]. Wearable devices enable real-time physiological data collection, supporting the development of data-driven training systems [
72]. For instance, the real-time detection of cognitive overload or excessive fatigue can trigger automated assistance from a robotic surgical system, thereby reducing error rates and enhancing patient safety [
41]. Recent work has demonstrated the value of using physiological and kinematic data to assess surgical skills, underscoring the relevance of multimodal models for creating data-driven, objective, and personalized medical education [
73].
Aviation and Aerospace: In aviation, MHMMs can be embedded within next-generation flight simulators and operational cockpit systems to personalize pilot training and augment in-flight safety. By classifying mental states, such as high workload, distraction, or fatigue, the system can dynamically adjust scenarios’ complexity or modify cockpit interfaces to mitigate the risks associated with cognitive overload, especially during critical flight phases or long-haul operations [
74]. The aerospace industry is increasingly focused on leveraging AI-driven workload assessment to address persistent challenges in pilot performance and safety, with MHMMs offering scalable solutions for both adaptive training and real-time risk mitigation [
75].
Smart Manufacturing and Industry 5.0: Within smart factories, the MHMM framework empowers cobots to adapt their behaviors based on a human operator’s real-time proficiency and cognitive state. This aligns directly with the Operator 5.0 paradigm, where technology acts as a supportive partner [
71]. For example, a novice operator exhibiting signs of high cognitive load might receive more detailed, stepwise guidance and proactive physical assistance from a cobot. Conversely, an expert would be entrusted with more strategic, supervisory tasks, optimizing workflow efficiency and team resilience [
76]. This dynamic, human-aware adaptation is a cornerstone of the Industry 5.0 vision, enhancing productivity, safety, and the overall well-being of the workforce [
70,
71].
Education and Adaptive Learning: Beyond industrial settings, MHMMs can enhance educational platforms by monitoring student engagement, proficiency, and affective states (e.g., frustration, and confusion) using wearable sensors and behavioral analytics. The real-time classification of mental workloads enables personalized learning pathways, where content difficulty, resource recommendations, and task assignments are dynamically adjusted to the individual learner’s needs. This fosters more inclusive, engaging, and effective learning environments, particularly in complex domains such as STEM education [
77].
7.2. Broader Societal and Economic Impact
The widespread adoption of MHMM-based systems promises significant societal and economic benefits. By enabling early detection of fatigue, distraction, and skill degradation, MHMMs can support timely interventions that reduce burnout and work-related stress. Notably, research highlights the prevalence of mental health challenges faced by healthcare professionals, exacerbated by factors such as excessive workloads and the COVID-19 pandemic [
78,
79]. The findings presented by [
78]; illustrate the critical need for support mechanisms for mental health professionals, indicating that actionable measures like MHMM could mitigate issues such as compassion fatigue. Likewise, Frías et al. (2025) discuss strategies to bolster the mental health of healthcare workers, underscoring the urgency of protecting this workforce [
78,
79].
Furthermore, the proactive risk mitigation capabilities of MHMM (particularly in medical settings, aviation, and industrial operations) can prevent costly errors and improve overall safety and operational efficiency. Reports on the impact of MHMM implementations in high-stakes environments support claims about operational improvements, with potential cost savings aligning with findings from studies advocating for enhanced protocols in sectors such as healthcare [
79,
80].
Beyond traditional applications, MHMM’s scope extends into fields like renewable energy and autonomous logistics.
These adaptations are crucial as organizations strive toward Industry 5.0’s human-centric vision, which prioritizes workers’ well-being amidst technological advancements. Studies highlight the necessity of scalable AI solutions like MHMM in ensuring resilience within these emerging applications, underscoring this approach’s relevance in addressing the increasing complexity of today’s operational environments [
81].
The transparent nature of the MHMM framework supports trust and accountability in human–AI interactions, addressing ethical imperatives crucial for responsible AI deployment.
Moreover, the importance of human–AI synergy for workforce resilience, particularly in the context of Industry 5.0, highlights the potential societal benefits of MHMM implementation. Studies suggest that engaging with AI positively impacts employee mental health and promotes a supportive work environment, essential for sustaining a healthy workforce [
79,
81].
The potential benefits of MHMM-based systems encapsulate a wider societal and economic impact that includes enhanced mental health support for workers, improved operational safety across sectors, and a commitment to ethical AI deployment. As industries adopt these systems, the integrated approach of MHMM could facilitate transformative changes that foster resilience within the workforce while addressing the challenges presented by modern work environments.
7.3. Methodological Innovation and Implementation Challenges
The MHMM framework serves as a catalyst for interdisciplinary research, merging cognitive science, human factor engineering, and machine learning. Its application advances the frontiers of human–computer interaction, wearable technology, and affective computing.
Despite its promise, the practical deployment of MHMMs must overcome significant challenges. Ethical considerations are paramount, requiring robust frameworks for data governance, users’ privacy, and informed consent in compliance with regulations such as GDPR and HIPAA [
68]. The development of unobtrusive sensing technologies that can capture high-fidelity data without disrupting natural workflows is a critical engineering challenge. Finally, ensuring the fairness and equity of these systems requires rigorous validation across diverse demographic groups to identify and mitigate potential biases in the underlying models [
82]. Future work must focus on addressing these challenges to unlock the full transformative potential of this technology.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}