Abstract
Large Language Models (LLMs) are driving a revolution in the way we access information, yet there remains a lack of exploration to capture people’s information interaction preferences in LLM environments. In this study, we designed a comprehensive analysis framework to evaluate students’ prompt texts during a professional academic writing task. The framework includes a dimensionality reduction and classification method, three topic modeling approaches, namely BERTopic, BoW-LDA, and TF-IDF-NMF, and a set of evaluation criteria. These criteria assess both the semantic quality of topic content and the structural quality of clustering. Using this framework, we analyzed 288 prompt texts to identify key topics that reflect students’ information interaction behaviors. The results showed that students with low academic performance tend to focus on structural clarity and task execution, including task inquiry, format specifications, and methodological search, indicating that their interaction mode is instruction-oriented. In contrast, students with high academic performance interact with LLM not only in basic task completion but also in knowledge integration and the pursuit of novel ideas. This is reflected in more complex topic levels and diverse, innovative keywords. It shows that they have stronger self-planning and self-regulation abilities. This study provides a new approach to studying the interaction between students and LLM in engineering education by using natural language processing to process prompts, contributing to the exploration of the performance of students with different performance levels in professional academic writing using LLM.
1. Introduction
The rapid development of large language models (LLMs) has injected new vitality into higher education, but also brought opportunities and challenges [1,2]. LLM tools like ChatGPT 4o have been widely applied to support students’ independent and active learning [3,4,5]. The learning through LLM is essentially a process of information interaction [6,7]. Students explore and learn by engaging in conversational question-and-answer sessions with LLMs to achieve information interaction, which is free from the constraints of time and space [8]. Users are able to express their ideas or questions anytime and anywhere, and LLM acts as a huge intelligent assistant that can help users summarize and organize large amounts of information and knowledge [9]. It can provide personal tutoring, summarize complex texts into an easy-to-understand format, act as a text and grammar editing tool to improve written performance, and can also provide detailed explanations and discussions for some complex issues to promote learning and stimulate creative thinking [10].
LLMs have shown great potential in STEM education. Guo et al. developed a framework for LLMs to support science and engineering practices and experimentally demonstrated that LLMs can improve students’ scientific knowledge, problem-solving skills, and engagement [11]. Tsai et al. explored the application of large language models (LLMs) in chemical engineering education and used Chat-GPT to build core course question models to enhance students’ core chemical engineering knowledge and cultivate critical thinking skills [12]. One important application area of LLM-assisted learning is professional academic writing (PAW) in STEM (science, technology, engineering, and mathematics) education. Students at the beginning of LLM development have already used LLM tools to complete academic assignments or paperwork in their STEM subjects [13] and then applied the LLM to a variety of engineering education applications, practices, and project writing [14]. Bernabei’s research also confirmed that students can use LLM to complete industrial design experimental tasks and academic writing well [15].
Although LLM has many advantages in assisting PAW in STEM, including improving their grammar and spelling skills, assisting in information integration and structure construction [16,17] and helping formula interpretation and algorithm optimization [18,19], there are huge challenges in using LLMs to assist academic writing in STEM, majority faces significant challenges, both ethical and technical. Ethical issues include over-reliance on LLM [20], which may lead to plagiarism and other behaviors [21]. The technical problem is that the performance of using LLM for STEM reasoning and solving is unstable, so relevant experts have been working to improve the reasoning and calculation capabilities of LLMs [22,23,24].
Therefore, to avoid the difficulties that LLMs bring to STEM learning, it is crucial to understanding how students interact with information, preferences and topics in an LLM-supported environment, which can provide important help for teachers and STEM experts to design corresponding interventions and support, as well as optimize the STEM reasoning and teaching capabilities of LLMs [25,26,27]. Many previous studies on students’ LLM-assisted learning process and behavior are based on the self-regulated learning (SRL) theory [27,28,29], and it refers to the learner’s ability to control and plan their cognitive, motivational and behavioral processes during the learning process, involving learning goal setting, strategic planning, self-monitoring, etc., enabling learners to effectively manage their own learning activities [30]. Although SRL provides a valuable perspective for understanding students’ decision-making processes or planning priorities in LLM-assisted settings, it often relies on ex post facto methods such as self-report data or questionnaires, which may not capture the original data of students’ real-time interactions with their LLM, such as prompts. This modality of data relies on natural language processing technology, and natural language processing technology is also widely used in fields such as educational technology. Wang et al. used the BERTopic algorithm to identify interdisciplinary topics and their evolution process [31], and Yu et al. used the LDA algorithm to process the sentiment trends of students in personalized learning [32]. It has also made meaningful contributions to text exploration in other fields, including social sciences [33], diet [34], and medicine [35].
This study proposes a topic modeling framework based on natural language processing. It includes a clustering-based dimension reduction module for group processing and three topic modeling models, and examines the differences in component performance and out-of-group performance of these models on various topics. This study designed an experiment of exploratory learning of data science based on the LLM environment and used this framework to explore the information interaction preferences of STEM students in prompts.
2. Related Work
2.1. Students’ Information Interaction Preferences
The process by which students seek and explore new information essentially constitutes the learning process [36]. Due to their limited cognitive processing capacity, learners selectively process information [37]. Cognitive Dissonance Theory posits that when new information conflicts with existing cognitions, this triggers information filtering behaviors, which in turn generate observed information preferences [38]. Especially during the interaction, these preferences will be further amplified. Perifanou’s research confirmed that most student teams used LLM tools in multiple collaboration modes under a project-based learning model, with a focus on specific collaboration modes [39]. These focuses highlight the differences among students in many aspects. But there are some rules in this difference. When using LLM for assisted learning, some common information search strategies and information interaction behaviors used by students are highly similar, and significant preferences only emerged in the context of higher-level strategies and approaches involving self-regulation [40,41]. In LLM-supported tasks, students with self-regulated learning are more likely to exhibit behaviors such as developing conscious cues, refining queries to optimize the relevance and depth of the output, and monitoring their own progress during interaction. Those behaviors are also more likely to be observed in some learning analytics experiments and modeled as learners learning scientifically [42].
It is partly due to endogenous factors [43] such as variations in cognitive abilities and self-efficacy, which shape their understanding and utilization of LLM tools. For example, Qi et al.’s research shows that critical thinking and autonomous learning significantly affect the quality of information they obtain when using LLM [44]. Hu’s research revealed that students in the high-motivation group showed higher interest and curiosity in LLM artistic creations [45]. LLM can provide a variety of functions, including generating code, organizing formats, summarizing text, generating new ideas, etc., and students tend to focus on specific functionalities within their comprehension range, forming observable preferences. Additionally, exogenous interventions, such as the design of cognitive scaffolding, cultivate and reinforce students’ understanding and application of LLM tool features. The LLM scaffolding provided by Kim et al. enables students to obtain more detailed and coherent ideas and construct stronger arguments in academic writing [46].
2.2. LLM-Assisted Academic Writing
Academic writing is a complex and multi-dimensional learning activity that requires the integration of multiple cognitive abilities and cognitive resources to effectively organize the academic writing process, including goal setting, process planning, strategy management, and coordination. How to use LLM to support students’ academic writing has always been a cross-disciplinary hot topic. LLM in academic writing may offer opportunities to improve the quality of student writing, benefiting students in the writing process, writing performance, and emotional domains [47]. It provides students with detailed and ongoing support throughout the academic writing process, including essay structure, editing, grammar checking, etc., [48,49]. LLM can correct students ‘academic writing manuscripts for grammatical errors [50], improve the overall clarity and coherence of manuscripts, provide critical suggestions, and prompt students to perform metacognitive monitoring and reflection [51].
Most of the research on academic writing assisted by LLM is centered around the fields of language or social sciences. For example, Altınmakas et al. discussed the impact of LLM on academic writing for literary students [52]. Kim et al. studied academic writing related to digital education among higher education students [53]. This also leads to the fact that most research on LLM-assisted academic writing is limited to improving writing itself, lacking exploration of professional fields that require writing. It must be acknowledged that a large part of the demand for academic writing also comes from the STEM field [54]. LLM can not only assist students in writing in terms of language and wording, but also provide students with feasible algorithms or formulas for some engineering problems. This includes providing innovative guidance on experiments and methodologies in specialized fields [55], helping analyze and deconstruct complex data and structures [56], and assisting in the coherent organization of raw materials and documents [57].
Similarly, students’ PAW in LLM-assisted learning not only involves text processing and writing but also includes the exploration and learning of knowledge and methodologies in their professional fields. The PAW in STEM fields process is divided into two parts: the exploration of prior domain knowledge and the exploration of academic writing itself, which brings unique challenges, such as how to manage and allocate the cognitive load of information search related to complex concepts and formulas and the details of academic writing [58,59], Our research focuses on the niche area of academic writing in STEM fields.
2.3. Topic Modeling for Natural Language Processing
Topic modeling is an unsupervised machine learning method for automatically identifying hidden topic structures from text documents [60]. The idea of topic modeling is to split the text representation in a set of documents into probability distributions of several topics in natural language processing, and each topic is the probability distribution of words in the vocabulary, so as to classify the content of the text [61]. It consists of three parts: text representation, algorithm modeling, and algorithm evaluation.
2.3.1. Text Representation
Text representation is the form in which the text can be understood and quantified, which is called a vectorized form. The most classic form of text processing in the early stage is the bag-of-words (BoW) model [62]. It directly uses the frequency of each word as the input feature of the classifier. However, the disadvantage of the BoW model is that it only counts word frequency or existence, but ignores word order and grammar, which makes the vector representation it generates unstable [63]. The TF-IDF algorithm [64] is optimized based on BoW and takes into account both word frequency and inverse document frequency as indicators for calculating text relevance. As shown in Formulas (1)–(3) is the number of times t appears in document d. represents the total number of documents, and represents the number of documents containing term t.
Compared to BoW, TF-IDF solves the problem of the BoW model, which is overly sensitive to high-frequency words and ignores word differentiation by weighting word frequency and inverse document frequency. This approach can better distinguish different categories and extract keywords. However, as an upgraded version of the BoW model, it still does not have the limitation of relying on a predefined corpus to capture word order or semantics. With the development of deep learning, BERT (Bidirectional Encoder Representations from Transformers), as a context-aware pre-trained language model, has been widely used to improve the text vector representation problem in topic modeling tasks. The structure of the BERT model is shown in Figure 1. It consists of three parts: word embedding, sentence embedding, and position embedding, which form a new comprehensive embedding. The word embedding maps each word into a high-dimensional vector. The sentence embedding enables BERT to distinguish and process a single text or text pair. The position embedding provides sequential information and marks the position of a word in a sentence. Such an encoding structure can contain semantic information about words and sentences while retaining position information.
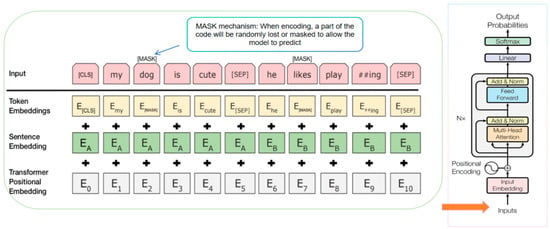
Figure 1.
The structure of the encoding and probability representation of the BERT model.
2.3.2. Algorithm Modeling
After the text data is vectorized, some modeling algorithms need to be selected to implement topic modeling. LDA is a word probability distribution model based on the Bayesian framework. It assumes that each document is generated by a mixture of multiple potential topics, each topic is a probability distribution on the vocabulary, and the sparsity of the document-topic () and topic-word () distribution is controlled by the Dirichlet Prior. The generation process will sample each document or sentence, that is, sample a topic distribution from the Dirichlet distribution. The same is true for each word in the document: sample a topic from ; sample a word from the word distribution () corresponding to the topic.
Formula (4) expresses the probability distribution of all words w appearing in a document set under given hyperparameters α, β:
NMF (Non-Negative Matrix Factorization) is another method to convert vectorization into a topic distribution. It decomposes the word matrix generated by the TF-IDF algorithm into the product of two low-dimensional non-negative matrices and , where is the document-topic matrix, each row represents the topic weight of the document. is the matrix of topic-word combination, each row represents the word distribution of a topic and finds the distribution by minimizing the reconstruction error, as shown in Formula (5). After generating the center, we manually selected the 10 words with the highest weight in each topic.
In addition, the deep learning method does not rely on certain theoretical assumptions. After BERT text vectorization, it will pass through a multi-layer Transformer encoder, which contains multi-head self-attention and feedforward networks. The deep network is used to calculate the distribution probability and wait for further downstream tasks.
2.3.3. Topic Modeling Evaluation
In topic modeling, evaluation criteria are used to measure the quality and practicality of generated topics. This paper introduces three classic criteria for measuring the quality of classification: Topic Coherence, Topic Diversity, and Semantic Consistency. This is also the symbol used in the framework analysis of this article. The first two are evaluations of content quality, and the latter is also an additional evaluation criterion for clustering structure.
Topic Coherence uses word co-occurrence statistics and word context similarity to calculate the degree of coherence between keywords in a topic, which is shown in Formula (6). The higher the index, the more relevant the keywords within each topic are, and the clearer the semantics are. represents the total number of words. NPMI is the “normalized point mutual information”, which is used to measure the co-occurrence degree between the first few keywords of each topic.
Topic Diversity measures the uniqueness of keywords used in different topics, which is shown in Formula (7). The larger the value the Topic Diversity is, the less overlap of keywords used between topics, and the more independent the topics are. is the set of first keywords of the -th topic, is the total number of duplicate keywords before N in all topics.
This paper uses the CH Score to evaluate Semantic Consistency. CH Score is an indicator commonly used to measure the clustering effect of samples in clustering space, which is shown in Formula (8). The higher the CH Score, the clearer the clustering of the document distribution in the topic vector space. is the total number of samples, k is the number of clusters, is the trace of the inter-class scatter matrix, and is the trace of the intra-class scatter matrix.
3. Methodology
3.1. Study Design
This study designed an academic writing task based on the field of data science, requiring students to use the self-developed intelligent LLM assistant to learn and analyze data science. Specifically, we provided students with an educational dataset and asked them to analyze the provided educational database and write an academic paper based on their findings. After the experiment was completed, we collected all the prompt texts of students interacting with the LLM.
Before the experiment began, we sent an informed consent form to all students, informing them that all data collection and processing complied with the Declaration of Helsinki. We distributed a pre-test questionnaire based on a Likert scale to students, including the frequency of students’ use of LLM, the use and scope of advanced functions, to measure students’ experience with LLM. Afterwards, a one-hour preparatory workshop was conducted to teach the most basic data science thinking and LLM usage tutorials, and confirm that they met the basic threshold for participating in the experiment. After that, students were issued paper requirements containing detailed task specification instructions, as follows,
“Educational data mining is a very important area in learning analytics. By analyzing various characteristics of students, such as demographic characteristics, learning habits, educators, and institutions, we can better understand learners and formulate targeted strategies to provide more efficient learning support. The following is a relevant data set containing key variables. Please learn data science-related knowledge by asking questions to LLM, discover hidden insights in the dataset, and complete an academic writing paper of 2000 words. Please pay attention to the format of the article, including the integrity of the structure, logical coherence, and reference insertion.”
Then we introduced the LLM platform we provide to students and a brief introduction to the generated dataset used for this experiment, which is shown in Figure 2. The dataset was adapted from www.kaggle.com/datasets/markmedhat/student-scores (accessed on 20 February 2025). Students logged in to the platform on their computer devices to start the experiment. They could use non-LLM tools, such as web search engines or data processing software, for auxiliary activities, provided that these tools did not involve additional guidance for PAW tasks. Students were required to submit tasks within a controllable time of 30 min to 4 h. After completing the task, students submitted a final academic paper to be evaluated by a data science instructor and an educational technology lecturer. The evaluation adopted the human-computer collaborative writing evaluation criteria [57], which as shown in Appendix A.
Figure 2.
Examples of LLM tools and demonstration datasets used in data analysis experiments.
We categorized students into high- and low-performing groups to better understand how students of different academic writing performance interacted with LLM in the PAW mintask. Previous research has shown that students with different performance differences tend to differ in their learning strategies, cognitive engagement, and use of tools [65,66]. By categorizing students in this way, we aimed to explore and compare how students of different performance levels crafted prompts, conversed with LLM, and incorporated AI-generated prompts and materials into PAW. This comparative approach allowed for a more nuanced analysis of the effectiveness and challenges of LLM-assisted PAW across different groups of learners, providing insights into how educational interventions can be tailored to meet the needs of different students.
3.2. Analysis Method
To identify students’ information interaction preferences when interacting with LLM when completing PAW tasks, we adopted a comparative topic modeling framework. As shown in Figure 3, the framework adopts a model that includes three types of topic modeling in our setting. The first and second are BoW-LDA, the second is TD-IDF-NMF, and the third is BERTopic. The three models represent three different approaches to topic modeling, which can provide a more comprehensive assessment of the accuracy of topic modeling.
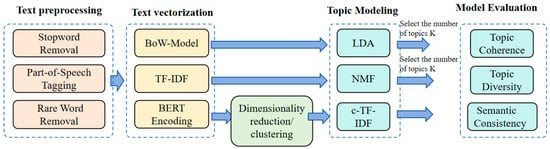
Figure 3.
Topic Modeling analysis framework.
At the beginning of the framework, we first systematically preprocessed the text data to remove noise and improve the classification performance of the model, including stop word removal, word segmentation, and rare word removal. We then vectorize this article using the BoW model and the TF-IDF model. The results are then fed into the LDA and NMF models, respectively. We used Python’s Gensim 4.3.3 package to calculate LDA and the sklearn package to calculate NMF.
For the third method, we directly selected BERTopic to complete the preset process. BERTopic [67] is a text topic extraction technology based on BERT [33] and topic modeling [68]. It automatically identifies meaningful topics and keywords from text data through the powerful semantic understanding ability of pre-trained language models. Figure 4 reveals the process of the BERTopic method: We first used the BERT model to convert the text into a high-dimensional vector, then applied the UMAP (Uniform Manifold Approximation and Projection) algorithm to reduce the dimension of the embedding vector to decrease noise, and finally employed the HDBSCAN (Hierarchical Density-Based Spatial Clustering of Applications with Noise) algorithm for clustering, which could automatically discover topic clusters in the data and support the identification of unrelated texts. Finally, Class-TF-IDF is automatically employed to calculate the keyword weight of each topic and generate the corresponding tags. In parameter tuning, we chose the lightweight and efficient all-MiniLM-L6-v2 BERT derivative model as the training model. Meanwhile, we adjusted the HDBSCAN parameters, reducing the minimum cluster size to capture more fine-grained topics and allowing relatively loose clustering to accommodate semantically similar but scattered documents.

Figure 4.
Flowchart of the BERTopic algorithm.
For topic consistency, we used the CoherenceModel provided by the Gensim package to calculate Topic Coherence and Topic Diversity and apply the calinski_harabasz_score in sklearn.metrics to calculate semantic consistency. We also controlled the random seeds in NMF and BERTopic, which can be explicitly adjusted to ensure reproducible results.
3.3. Clustering Algorithm
To distinguish students more accurately with different academic performances, this study also implemented a clustering algorithm that combines K-means and Principal Component Analysis (PCA). The algorithm first projects high-dimensional data into a two-dimensional subspace through PCA and maximizes the variance on the principal component axis, and then applies K-means clustering in the feature space after dimensionality reduction. At the same time, we use an intuitive method, the elbow method, to determine the optimal number of clusters, and determine the inflection point as the optimal number of clusters by using the trend of the error sum of squares changing with the number of clusters. This combined dimensionality reduction-clustering method is mature in data mining [69]. Compared with basic classification methods such as simple interval division, this joint algorithm extracts the core features of the data through principal component dimensionality reduction, provides a visual explanation of the classification results in low-dimensional space [70], and alleviates the impact of high-dimensional noise on clustering, while taking into account the problem of class imbalance [71].
4. Results
4.1. Classify Students with Different Academic Performances
We recruited freshmen to juniors from a university in [anonymous] for the experiment and collected a total of 288 prompt engineering texts (M = 12.00, SD = 4.55) from 24 students. 54.17% of students are male (N = 13), and the rest are female. 57.14% of students are from the Faculty of Science and Technology; 29.17% are from the Faculty of Business Management. The remaining students are from the Faculty of Social Sciences.
As shown in Figure 5a, an evident elbow point emerged at K = 2. This led us to select it for our unsupervised clustering, effectively categorizing students into low-performance and high-performance groups. The clustering results showed that 11 students (Total 138 prompt texts, M = 12.55, SD = 5.50) were grouped into the low-performance cluster, and 13 students (150 prompt texts, M = 11.54, SD = 3.48) were assigned to the high-performance cluster. Subsequently, we applied PCA to distinguish between these two groups of students with different academic performances (PC1: 71.8%, PC2: 11.6%). As illustrated in Figure 5b, these two principal components collectively explained 83.4% of the total variance in the data. Finally, we used the Mann-Whitney U test to measure the difference in academic performance between the two types of students, whose data may not satisfy the normal distribution. The results showed that the difference in academic performance between the two types of students was significant (U = 0.57, p = 0.00), proving that our method can distinguish students’ performance well. The Mann-Whitney U test was also conducted on the pre-test questionnaires of students with different performances, and it was found that there was no significant difference in students’ AI experience (U = 74.5, p = 0.81).
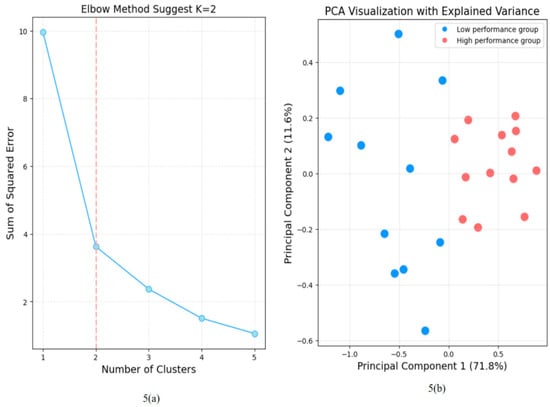
Figure 5.
The clustering-dimensionality reduction algorithm is used to classify students based on their performance. 5 (a) shows the shortcomings of the elbow method for classifying students into the best category, and 5 (b) shows the distribution of students under two-dimensional PCA.
4.2. Optimal K Value Selection
Generally speaking, the number of topics in topic modeling needs to be manually specified based on technical indicators, theoretical conditions, and practical problems. The BERTopic algorithm has a built-in HDBSCAN clustering algorithm that can automatically determine the number of topics based on density. However, BoW-LDA and TF-IDF-NMF need to be determined manually. We set the range of K and find the inflection point of the Topic Coherence score under different numbers of topics to determine the optimal number of topics. As shown in Figure 6, the results showed that the optimal number of topics for BoW-LDA is 7, while the optimal number of topics for TF-IDF-NMF is 5. The optimal number of topics for the BERTopic model is confirmed to be 4
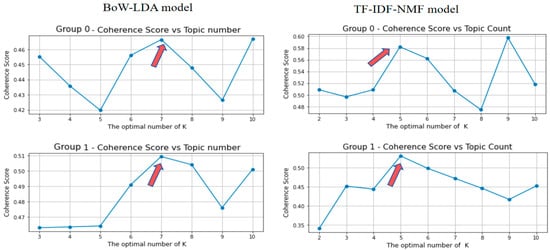
Figure 6.
Optimal cluster K selection for BoW-LDA and TF-IDF-NMF algorithms in different groups.
4.3. Topic Modeling Evaluation
To ensure reproducibility, we provide the hyperparameter configurations for each topic modeling algorithm. For BoW-LDA, we used the default CountVectorizer (max_df = 0.9, min_df = 2, stop_words = ‘english’, max_features = 1000), and set n_components = 7, max_iter = 1000, learning_method = ‘batch’, random_state = 40. For TF-IDF-NMF, the vectorizer was TfidfVectorizer, with the same vectorizer configuration as used in BoW-LDA, and the model was initialized with init = ‘nndsvd’, n_components = 5, max_iter = 1000, and random_state = 40. For BERTopic, we used the “all-MiniLM-L6-v2” embedding model from Sentence Transformers. The dimensionality reduction was performed using UMAP (n_neighbors = 15, n_components = 5, min_dist = 0.0, metric = ‘cosine’, random_state = 40), followed by clustering with HDBSCAN (min_cluster_size = 8, min_samples = 3, and cluster_selection_epsilon = 0.4). The vectorization was handled with a default CountVectorizer, and we enabled calculate_probabilities = True for topic assignment probabilities.
Table 1 shows the evaluation results of the three models, and each model has its own advantages. In terms of topic coherence, TF-IDF-NMF was better than the other two models, with the highest Topic Coherence in both groups (Group 0: 0.582, Group 1: 0.531). BoW-LDA was second (Group 0: 0.420, Group 1: 0.464). BERTopic was the lowest (Group 0: 0.417, Group 1: 0.489), indicating that it was relatively weak in the semantic aggregation of keywords. One possible reason is that although BERTopic can extract more dimensions, such as position, sentence meaning, etc., the conceptual distance of keywords in the topic may be farther than other models that simply consider similarity and are not concentrated enough.

Table 1.
Results of model evaluation.
In terms of topic diversity, BERTopic performed best in both groups (Group 0: 0.925, Group 1: 0.967), indicating that the generated topics were quite different and had good diversity. TF-IDF-NMF also performed well (0.960 and 0.920); however, BoW-LDA performed worse (0.640 and 0.660), indicating that there was a lot of keyword overlap between different topics. BoW-LDA is based on the BoW model and is not context-aware. The topics it generates are likely to share high-frequency words, which are often reused by multiple topics, resulting in a high degree of overlap in keyword sets for different topics, thereby reducing Topic Diversity.
In the comparison of semantic consistency indicators, BoW-LDA performed best (Group 0: 1977.158, Group 1: 1746.345), showing that its internal keyword aggregation was high, and its semantic consistency is strong. BERTopic is second (Group 0: 108.551, Group 1: 132.909), while TF-IDF-NMF performed the weakest (Group 0: 2.310, Group 1: 2.207), indicating that its topic clustering structure is the loosest among the three, and the keyword semantic distribution is the most dispersed. Compared with the generative or semantic embedding methods of LDA and BERTopic, NMF can only handle linear structures and cannot model complex semantic boundaries or topic overlaps. This leads to discrete semantic distributions.
In our framework, Topic Coherence and Diversity jointly evaluate the semantic quality of topics, focusing on keyword selection and uniqueness. In contrast, Semantic Consistency, measured by CH Score, evaluates the document-level clustering quality, which is crucial for ensuring that topic boundaries are meaningful and interpretable in vector space.
Averaged over both clusters, TF-IDF-NMF achieves the highest Topic Coherence (0.5565), while BERTopic’s coherence score is only 18.6% lower (0.453) and its Topic Diversity is only slightly higher by 0.64% (0.946 vs. 0.940). These results indicate that BERTopic is within 10% of TF-IDF-NMF in terms of model content quality, making it the second-best performing model. However, the difference becomes significant when semantic consistency is considered. BERTopic’s CH score (120.73) is more than 50 times higher than TF-IDF-NMF (2.26), indicating that its clustering quality and interpretability far exceed TF-IDF-NMF. Moreover, a too small CH score also means that its structure is close to a non-clustered structure and is not interpretable. Since our study needs to maintain reliable topic assignment based on a certain, performance for subsequent analysis of students’ LLM interaction behaviors, we give priority to, models with stronger structural clustering performance, BERTopic achieves the best combination between semantic clarity and, structural completeness, making it the most suitable model for our framework.
4.4. Topic Modeling of Prompt Text
When performing topic modeling and text mining using BERTopic, the results can be affected by random seed initialization, leading to instability in the outcomes. To address this, we selected the most frequently occurring topic classification within a specified range (i = 10) as the final topic modeling result.
For the low-performance student group, the 4-topic classification appeared most frequently (60% of cases), while for the high-performance group, the 4-topic classification was also most common (50% of cases). Consequently, we adopted these two topic classification scenarios as representative results for further analysis.
In the low-performance group, the topic clusters were distributed as Topic -1 (N = 7, noise cluster), Topic 0 (N = 49), Topic 1 (N = 37), Topic 2 (N = 34), and Topic 3 (N = 11). We applied the UMAP dimensionality reduction algorithm to project the BERTopic word embeddings into a 3D space, with the resulting clustering visualization presented in Figure 7. Each point represents a prompt text sample. The distance between points reflects their “semantic similarity” in the original semantic space. The farther away, the greater the semantic difference between these texts. The high-performance group exhibited the following topic clusters: Topic -1 (N = 6, noise cluster), Topic 0 (N = 63), Topic 1 (N = 42), Topic 2 (N = 29), and Topic 3 (N = 10). The corresponding 3D UMAP visualization is shown in Figure 8. For low-performing students, the cluster of Topic 3 has higher score values in the three dimensions, and the number of its cluster points is the sparsest. For high-performing students, the number of cluster points in Topic 3 is the sparsest. However, there is no most prominent cluster in terms of the values of different dimensions.
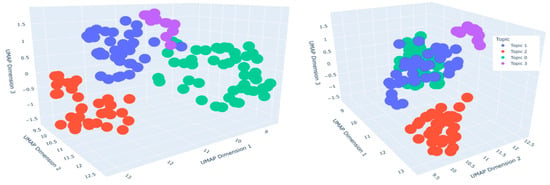
Figure 7.
Topic distribution diagram of low-performing students after clustering the prompt text. The distance between points reflects the semantic similarity of the text in the original semantic space.
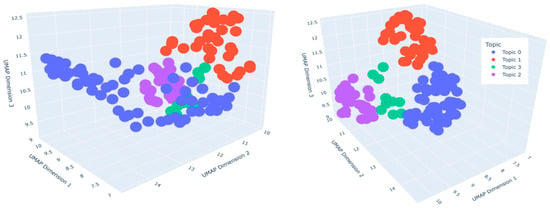
Figure 8.
Topic distribution diagram of high-performing students after clustering the prompt text.
The topic modeling quality was assessed using two metrics: Probability consistency, which measures topic assignment similarity with cosine similarity (Low performers: 0.948, High performers: 0.927), and semantic consistency, which measures embedding similarity after PCA to 2 dimensions (Low performers: 0.526, High performers: 0.568). Both metrics confirmed robust topic discrimination (>0.5), with high-performing students showing slightly stronger semantic coherence in reduced dimensions.
4.5. RQ1: Focus of Preferences
Figure 9 displays the keyword cloud diagrams for the topics of the low-performance group and the high-performance group, arranged from top to bottom as Topic 0, Topic 1, up to Topic 4. Figure 10 presents the scores of the topic keywords. Together, these figures provided insights into students’ preferences for exploratory learning topics supported by LLM. The topic word score graph shows the connotation and characteristics of each topic. This visualization is based on the class-based TF-IDF technology, which compares the frequency difference between each topic and other topics to identify the most discriminative keywords in the topic.

Figure 9.
Cloud chart of topic keywords of students with different academic performances.
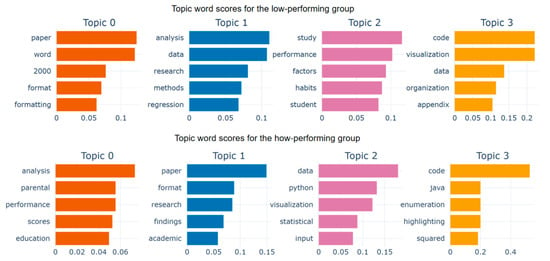
Figure 10.
Scores of keywords in each topic for students with different academic performance. The keyword score is calculated based on c-TF-IDF.
For the low-performance group, the top five keywords in Topic 0 were paper, word, 2000, format, and formatting. These keywords originated from the task instructions and requirements provided to students at the beginning of the LLM-assisted learning phase. This clustering indicated that students input the task instructions and requirements as supplementary background information into the LLM for analysis.
In Topic 1, the top five keywords were analysis, data, research, methods, and regression. This topic demonstrated that students used LLM for knowledge discovery and in-depth thinking centered around data analysis and methodological approaches. The top five keywords in Topic 2 were study, performance, factors, habits, and student. These keywords are also derived partly from the task instructions and dataset content. Unlike Topic 0, this topic primarily involved students using LLM to search for information and discover knowledge related to task requirements and student characteristics. Topic 3 reflected students’ integration of code analysis and presentation in data science tasks, with the top five keywords being code, visualization, data, organization, and student.
For the high-performance group, Topic 0 corresponded to their process of dataset analysis and knowledge discovery during exploratory learning. The keyword cloud for this topic included terms such as parental, lunch, and education, which were related to student features. Topic 1 of the high-performance group was similar to Topic 0 of the low-performance group. The top five keywords here were paper, format, research, finding, and academic, suggesting that students engaged in interactions centered around task descriptions and formatting. Topic 2 highlighted discussions on advanced data functionalities and presentations, as evidenced by keywords such as visualization, charts, and presentation in the cloud diagram. Meanwhile, Topic 3 appeared to involve in-depth discussions on specific code development, with code scoring significantly higher than other terms. Additionally, the presence of terms like Java and enumeration hinted at the concrete implementation of code.
4.6. RQ2: Focus of Discrepancies
Table 2 summarizes the clustering of Topics among students with different performance levels. Students with varying performance exhibit distinct preferences in exploratory and learning behaviors when using LLM-assisted learning. Low-performing students tend to input task requirements verbatim into LLM, performing simple and direct information queries. Additionally, they interact with LLM to clarify research questions, outline structures, and refine methodologies. Subsequently, they proceed to analyze code and data, presenting results after adjustments guided by LLM. As seen in the hierarchical clustering of Figure 11, the low-performing group’s LLM-assisted learning process converges into two distinct phases: Data and format information-seeking and knowledge discovery through concrete analysis of data and code. In contrast, high-performing students demonstrate greater complexity in their approach. Rather than copying task requirements directly, they strategically refine their prmpts by incorporating structured instructions and personal insights. This indicates that high-performing students have already developed a planned approach to LLM-assisted learning, demonstrating strong agency.
Table 2.
Summary of topic word clustering.
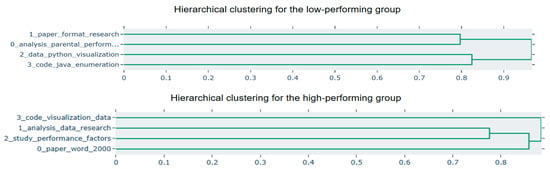
Figure 11.
Hierarchical clustering of different groups of students, merging topics based on semantic similarity.
The hierarchical graph can identify the hierarchical structure between topics. The graph can organize and aggregate topics into the same node according to their semantic similarity to identify potential hierarchical patterns in text data, reflecting the relationship between topics and subtopics. Similarity represents the distance between clusters. Figure 11 shows the hierarchical clustering of LLM prompt topics for students with different performances. For low-performing students, Topic 0 is similar to Topic 1 and similar to Topic 2.3, so they are aggregated to the upper node. Therefore, it can be roughly judged that low-performing students divide engineering tasks into two main directions when conducting LLM-assisted engineering learning.
The hierarchical clustering of high-performing students is more complex, where Topic 1 and Topic 2 are merged and then merged with Topic 0, and finally merged with Topic 3 at the highest level, reflecting that high-performing students are more independent in the LLM cue word topics than low-performing students, which to some extent reflects their diversity in self-regulation: Students are able to conduct effective self-monitoring and learning management. In the process of interacting with LLM, they tend to actively adjust their prompting strategies according to task goals, feedback effects, and information value [72]. This strategy adjustment ability is an important manifestation of SRL [73]. High-performing students tend to generate more targeted prompts around different task requirements, thus forming a topic structure with obvious differences.
5. Discussion
5.1. Student Preferences in Information Interaction
The research results reveal the discrepancies in the information interaction preferences of students in different performance groups in LLM-assisted PAW tasks. Students with different performances place different weights on “innovation” and “structure” in the prompts for using LLM for PAW. From the results, low-performing students prefer to sort out the task structure when using LLM to complete information retrieval and interaction. This can be seen from the text clusters and the topic clusters in the hierarchical diagram. It is not difficult to find that low-performing students tend to apply LLM as an intelligent assistant to perform tasks that require detailed inspections, including format specifications and methodology retrieval, and data listing in the learning process. This preference has been confirmed in multiple studies [74,75]. Meanwhile, Low-performing students are more concerned about the breadth and comprehensiveness of LLM-assisted learning tasks but lack concern for the depth of technology or details because prompts related to innovation have not formed a stable text cluster, and the number of topic clusters related to the development of advanced functions such as visualization is also very scarce. In the low-performance group, the keywords are concentrated on “paper”, “word”, “format”, “methods”, “visualization”, etc., indicating that their prompts are mainly centered around low-level tasks such as task description, format requirements, and code output, showing operational behaviors oriented towards completing task instructions, reflecting the surface and separated processing characteristics of task cognition. This situation is also reflected in the clear cluster separation of Methodology Search (Topic 1) and Data Analysis (Topic 2) formed in the mid-term stage, which verifies that they have not yet established a systematic knowledge integration ability in LLM-assisted learning.
The situation is different for High-performing students. The keyword scores in Figure 10 show that the average keyword score of students is lower, which means that prompts of high-performing students are more divergent and less repetitive. The multi-level clustering structure shown in Figure 11 shows that high-performing students not only focus on task execution when interacting with LLM, but also conduct multi-dimensional exploration around task goals. These indicated students can actively construct problem situations, integrate existing knowledge, and expand the use of LLM functions to support the completion of complex tasks, which actually shows a higher level of self-regulatory strategy.
In particular, in Topic 3, in the high-performance group, the keywords expanded to “parental”, “education”, “enumeration”, “presentation”, etc., showing a higher level of processing. This advanced processing or positive attempt should be regarded as a prototype of innovation. High-performing students prefer to actively guide LLM to complete their ideas and creativity, showing higher task value and goal orientation. Within the theoretical framework of SRL, this active pursuit of innovation can be viewed as a process that integrates creativity into motivation and goal setting, thereby stimulating the intrinsic driving force for learning [76].
5.2. No Superiority or Inferiority in Information Interaction Preferences
It should be emphasized that preferences for information interaction or cognitive differences often have no absolute advantages or disadvantages. The performance criteria were based on five indicators: Content, Analysis, Organization and Structure, Quality of Writing, and Word Limit and Referencing. However, these metrics cannot fully capture the quality of students’ information interaction or SRL processes. In the low-performing prompt texts, although words related to relevant concepts had relatively low keyword scores, some students still attempted to engage in innovative interactions with the LLM, such as using it for data visualization. However, certain confounding factors may have contributed to their lower performance scores, which do not accurately reflect the effective self-regulation strategies these students demonstrated in their use of LLM prompts.
High-performing students are not without shortcomings in the process of self-regulation and supervision. High-performing students are more active in thinking and have greater self-awareness when using LLM to conduct PAW, but this situation should be regarded as a double-edged sword. On the one hand, self-awareness can avoid falling into the wrong information caused by AI hallucination [77]. Strong self-awareness can effectively identify and avoid the information illusion that may be produced by LLM, and this active thinking path helps to break through the conventional cognitive framework, such as obtaining unexpected discoveries [78]. However, this active thinking process may have the risk of cognitive bias, such as being more likely to produce unexpected associations or misunderstandings [79], or divergent thinking may cause the core problem to lose focus. In addition, there will be the risk of wasting excessive cognitive resources when thinking, and it will be difficult to adjust the thinking direction in time [80].
We suggest that in the educational practice of LLM-assisted learning, educators should redesign the cognitive scaffolding within the learning environment from the perspective of niche construction. This approach can help guide different students toward a path of sustainable cognitive development. For example, the design for low-performing students should be more inclined to cognitive and thinking development, while for high-performing students, they should provide supplementary content that may be left over from jumping thinking. It is necessary to protect the divergence of innovative thinking and optimize the efficiency and accuracy of the thinking process of different students in LLM-assisted learning through metacognitive training.
6. Conclusions
In the era of LLM-assisted learning, understanding the information interaction preferences of students with different characteristics is an important channel to promote students’ personalized development and teach students according to their aptitude. This study designed a PAW experiment with LLM-assisted learning, aiming to analyze the preferences of students with different performance in using LLM for information interaction. Through the analysis of 288 prompts, it was found that among low-performing students, they tend to regard LLM as an intelligent assistant and prefer to deal with tedious details such as article format, and we also reveal LLM reliance among low-performing students. In comparison, high-performing students show a higher level of self-regulated learning. In information interaction, they prefer to apply LLM for cognitive challenges to achieve more advanced functions. We also discuss potential issues and risks arising from these divergent interaction preferences. There are also some limitations in this study during the experiment. The study only focuses on the single mode of prompt text and does not capture behavioral data of other modes, which may lead to data loss at the information interaction level. Third, it is difficult to fully simulate the real complex environment in which students use LLMs in practice, which may make it difficult to eliminate the influence of students’ self-efficacy or laziness. In future work, we will make a more fine-grained division of the formation of this preference and explore the performance of students in the process of preference formation through more modal processing.
Author Contributions
Y.T.L. proposed the idea to conceive and design this study. Y.T.L., and K.I.C. analyzed the data. Y.T.L. completed the manuscript with the assistance of T.L., and Z.W. P.C.-I.P. supervised students and oversaw this work. All authors discussed the results and contributed to the final manuscript. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Macao Polytechnic University research grant (project code: RP/FCA-10/2022).
Institutional Review Board Statement
This study complies with the Declaration of Helsinki and has been approved by the Ethics Committee of Macao Polytechnic University (Ethics Approval No.: HEA006-FCA-2025). All procedures will adhere to informed consent, data anonymization, and minimal risk principles.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data used and/or analyzed during the current study are available from the corresponding author on reasonable request.
Conflicts of Interest
The authors declare no competing interests.
Appendix A
| Assessed Areas | Excellent (4) | Good (3) | Fair (2) | Poor (1) |
| Content | The selected topic is well-suited to the characteristics of the dataset, with clear and concise perspectives that effectively extract and analyze the features of the original dataset, leading to an outstanding understanding. | The selected topic is reasonably aligned with the characteristics of the dataset, presenting clear viewpoints that appropriately correspond to the features of the original dataset, facilitating relevant extraction and analysis, and resulting in a good understanding. | The selected topic shows a moderate alignment with the characteristics of the dataset, offering relatively clear viewpoints that somewhat correspond to the features of the original dataset, enabling adequate extraction and analysis, and yielding a satisfactory understanding. | The selected topic is not entirely consistent with the characteristics of the dataset, with subpar viewpoints that fail to adequately correspond to the features of the original dataset, thereby hindering effective extraction and analysis and resulting in a limited understanding. |
| Analysis | A comprehensive range of quantitative data analysis methods was employed, complemented by various graphical representations to effectively support the arguments presented. | A selection of quantitative data analysis methods was utilized, along with graphical representations, to provide support for the arguments. | Quantitative data analysis methods were used, supplemented by figures or tables, to offer a degree of support for the arguments. | No quantitative data analysis methods were employed, nor were any graphical representations used to display the data analysis results, resulting in a lack of support for the arguments. |
| Organization and Structure | Presents a well-structured essay with a clear introduction, body, and conclusion. Transitions are used effectively to connect ideas and paragraphs. | Presents a well-structured essay with a clear introduction, body, and conclusion. Transitions are used somewhat effectively to connect ideas and paragraphs. | Presents a fairly structured essay with a clear introduction, body, and conclusion. Transitions are used somewhat effectively to connect ideas and paragraphs. | Poorly structured essay. Transitions are not used effectively to connect ideas and paragraphs. |
| Quality of writing | Good writing, with only a few minor errors. Sentences are well-constructed, with correct grammar and punctuation. Suitable for a professional audience. | Fair writing quality or good writing, but a few incorrect grammar and/or punctuation. Style is not suitable for a professional audience. | Fair writing quality, but has many errors. | Poor writing quality with a significant number of errors. |
| Word limit and Referencing | Writing is within the word limit. Able to insert references correctly. | Writing may be slightly outside of the word limit. Able to insert references relatively correctly. | Writing may be slightly outside of the word limit. Some attempts at referencing, but with some noticeable errors. References can be inserted, but the format does not conform to the specification. | Writing is significantly over or under the word limit. Missing references. |
References
- Luo, Y.; Wang, Z. Feature mining algorithm for student academic prediction based on interpretable deep neural network. In Proceedings of the 2024 12th International Conference on Information and Education Technology (ICIET), Yamaguchi, Japan, 18–20 March 2024; pp. 1–5. [Google Scholar]
- Ma, T. Systematically Visualizing Chatgpt Used in Higher Education: Publication Trend, Disciplinary Domains, Research Themes, Adoption and Acceptance. Comput. Educ. Artif. Intell. 2024, 8, 100336. [Google Scholar] [CrossRef]
- Fan, Y.; Tang, L.; Le, H.; Shen, K.; Tan, S.; Zhao, Y.; Shen, Y.; Li, X.; Gašević, D. Beware of metacognitive laziness: Effects of generative artificial intelligence on learning motivation, processes, and performance. Br. J. Educ. Technol. 2025, 56, 489–530. [Google Scholar] [CrossRef]
- Rasul, T.; Nair, S.; Kalendra, D.; Robin, M.; de Oliveira Santini, F.; Ladeira, W.J.; Sun, M.; Day, I.; Rather, R.A.; Heathcote, L. The role of ChatGPT in higher education: Benefits, challenges, and future research directions. J. Appl. Learn. Teach. 2023, 6, 41–56. [Google Scholar]
- Hartley, K.; Hayak, M.; Ko, U.H. Artificial intelligence supporting independent student learning: An evaluative case study of ChatGPT and learning to code. Educ. Sci. 2024, 14, 120. [Google Scholar] [CrossRef]
- Shah, C.; White, R.W. Panmodal information interaction. arXiv 2024, arXiv:2405.12923. [Google Scholar]
- Rebholz, T.R.; Koop, A.; Hütter, M. Conversational user interfaces: Explanations and interactivity positively influence advice taking from generative artificial intelligence. Technol. Mind Behav. 2024, 5, 1–11. [Google Scholar] [CrossRef]
- Chan, C.K.Y.; Lee, K.K. The AI generation gap: Are Gen Z students more interested in adopting generative AI such as ChatGPT in teaching and learning than their Gen X and millennial generation teachers? Smart Learn. Environ. 2023, 10, 60. [Google Scholar] [CrossRef]
- Luo, Y.; Pang, P.C.-I.; Chang, S. Enhancing Exploratory Learning through Exploratory Search with the Emergence of Large Language Models. In Proceedings of the 58th Hawaii International Conference on System Sciences (HICSS 2025), Hilton Waikoloa Village, Big Island, 7–10 January 2025; pp. 44–53. [Google Scholar] [CrossRef]
- Belkina, M.; Daniel, S.; Nikolic, S.; Haque, R.; Lyden, S.; Neal, P.; Grundy, S.; Hassan, G.M. Implementing generative AI (GenAI) in higher education: A systematic review of case studies. Comput. Educ. Artif. Intell. 2025, 8, 100407. [Google Scholar] [CrossRef]
- Guo, Q.; Zhen, J.; Wu, F.; He, Y.; Qiao, C. Can Students Make STEM Progress With the Large Language Models (LLMs)? An Empirical Study of LLMs Integration Within Middle School Science and Engineering Practice. J. Educ. Comput. Res. 2025, 63, 372–405. [Google Scholar] [CrossRef]
- Tsai, M.-L.; Ong, C.W.; Chen, C.-L. Exploring the use of large language models (LLMs) in chemical engineering education: Building core course problem models with Chat-GPT. Educ. Chem. Eng. 2023, 44, 71–95. [Google Scholar] [CrossRef]
- Misanchuk, M.; Hyzyk, J. ChatGPT in STEM Teaching: An Introduction to Using LLM-Based Tools in Higher Ed. 2024. Available online: https://openlibrary-repo.ecampusontario.ca/jspui/handle/123456789/2121 (accessed on 25 February 2025).
- Filippi, S.; Motyl, B. Large language models (LLMs) in engineering education: A systematic review and suggestions for practical adoption. Information 2024, 15, 345. [Google Scholar] [CrossRef]
- Bernabei, M.; Colabianchi, S.; Falegnami, A.; Costantino, F. Students’ use of large language models in engineering education: A case study on technology acceptance, perceptions, efficacy, and detection chances. Comput. Educ. Artif. Intell. 2023, 5, 100172. [Google Scholar] [CrossRef]
- Malik, A.R.; Pratiwi, Y.; Andajani, K.; Numertayasa, I.W.; Suharti, S.; Darwis, A. Exploring artificial intelligence in academic essay: Higher education student’s perspective. Int. J. Educ. Res. Open 2023, 5, 100296. [Google Scholar] [CrossRef]
- Kim, J.; Yu, S.; Lee, S.-S.; Detrick, R. Students’ prompt patterns and its effects in AI-assisted academic writing: Focusing on students’ level of AI literacy. J. Res. Technol. Educ. 2025, 57, 1–18. [Google Scholar] [CrossRef]
- Gao, C.; Jiang, H.; Cai, D.; Shi, S.; Lam, W. Strategyllm: Large language models as strategy generators, executors, optimizers, and evaluators for problem solving. Adv. Neural Inf. Process. Syst. 2024, 37, 96797–96846. [Google Scholar]
- Velez, X. Understanding Algorithmic Problem Solving using LLMs. In Proceedings of the 2024 on ACM Virtual Global Computing Education Conference V. 2, Virtual Event, NC, USA, 5–8 December 2024; pp. 327–328. [Google Scholar]
- Zhai, C.; Wibowo, S.; Li, L.D. The effects of over-reliance on AI dialogue systems on students’ cognitive abilities: A systematic review. Smart Learn. Environ. 2024, 11, 28. [Google Scholar] [CrossRef]
- Akkaş, Ö.M.; Tosun, C.; Gökçearslan, Ş. Artificial intelligence (AI) and cheating: The concept of generative artificial intelligence (GenAI). In Transforming Education With Generative AI: Prompt Engineering and Synthetic Content Creation; IGI Global Scientific Publishing: Hershey, PA, USA, 2024; pp. 182–199. [Google Scholar]
- Ahmed, T.; Choudhury, S. LM4OPT: Unveiling the potential of Large Language Models in formulating mathematical optimization problems. INFOR: Inf. Syst. Oper. Res. 2024, 62, 559–572. [Google Scholar] [CrossRef]
- Matzakos, N.; Doukakis, S.; Moundridou, M. Learning mathematics with large language models: A comparative study with computer algebra systems and other tools. Int. J. Emerg. Technol. Learn. (Ijet) 2023, 18, 51–71. [Google Scholar] [CrossRef]
- Lee, U.; Kim, Y.; Lee, S.; Park, J.; Mun, J.; Lee, E.; Kim, H.; Lim, C.; Yoo, Y.J. Can we use GPT-4 as a mathematics evaluator in education?: Exploring the efficacy and limitation of LLM-based automatic assessment system for open-ended mathematics question. Int. J. Artif. Intell. Educ. 2024, 35, 1–37. [Google Scholar] [CrossRef]
- Barkoczi, N. The Reinforcement of Teachers’ Design Thinking in STEM Education by Integrating AI tools-A Literature Review. Bul. Științific–Ser. A–Fasc. Pedagogie. Psihologie. Metod. 2024, 24, 5–17. [Google Scholar] [CrossRef]
- Subramaniam, R.C.; Morphew, J.W.; Rebello, C.M.; Rebello, N.S. Presenting STEM ways of a thinking framework for engineering design-based physics problems. Phys. Rev. Phys. Educ. Res. 2025, 21, 010122. [Google Scholar] [CrossRef]
- Kim, N.J.; Belland, B.R.; Walker, A.E. Effectiveness of computer-based scaffolding in the context of problem-based learning for STEM education: Bayesian meta-analysis. Educ. Psychol. Rev. 2018, 30, 397–429. [Google Scholar] [CrossRef]
- Jin, F.; Lin, C.-H.; Lai, C. Modeling AI-assisted writing: How self-regulated learning influences writing outcomes. Comput. Hum. Behav. 2025, 165, 108538. [Google Scholar] [CrossRef]
- Karaoglan Yilmaz, F.G.; Yilmaz, R. Exploring the role of self-regulated learnings skills, cognitive flexibility, and metacognitive awareness on generative artificial intelligence attitude. Innov. Educ. Teach. Int. 2025, 62, 1–14. [Google Scholar] [CrossRef]
- Gambo, Y.; Shakir, M.Z. Review on self-regulated learning in smart learning environment. Smart Learn. Environ. 2021, 8, 12. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, J.; Chen, J.; Chen, H. Identifying interdisciplinary topics and their evolution based on BERTopic. Scientometrics 2024, 129, 7359–7384. [Google Scholar] [CrossRef]
- Yu, J.H.; Chauhan, D. Trends in NLP for personalized learning: LDA and sentiment analysis insights. Educ. Inf. Technol. 2025, 30, 4307–4348. [Google Scholar] [CrossRef]
- Jiang, K.; Yang, H.; Wang, Y.; Chen, Q.; Luo, Y. Ensemble BERT: A student social network text sentiment classification model based on ensemble learning and BERT architecture. In Proceedings of the 2024 IEEE 2nd International Conference on Sensors, Electronics and Computer Engineering (ICSECE), Jinzhou, China, 29–31 August 2024; pp. 359–362. [Google Scholar]
- Choi, I.; Kim, J.; Kim, W.C. An Explainable Prediction for Dietary-Related Diseases via Language Models. Nutrients 2024, 16, 686. [Google Scholar] [CrossRef]
- Li, J.; Yang, Y.; Mao, C.; Pang, P.C.-I.; Zhu, Q.; Xu, D.; Wang, Y. Revealing patient dissatisfaction with health care resource allocation in multiple dimensions using large language models and the international classification of diseases 11th revision: Aspect-based sentiment analysis. J. Med. Internet Res. 2025, 27, e66344. [Google Scholar] [CrossRef]
- Eskola, E. University students’ information seeking behaviour in a changing learning environment. How are students’ information needs, seeking and use affected by new teaching methods. Inf. Res. 1998, 4, 2. [Google Scholar]
- Majovski, L.V.; Jacques, S. Cognitive information processing and learning mechanisms of the brain. Neurosurgery 1982, 10, 663–677. [Google Scholar] [CrossRef] [PubMed]
- Harmon-Jones, E.; Mills, J. An introduction to cognitive dissonance theory and an overview of current perspectives on the theory. In Cognitive Dissonance: Reexamining a Pivotal Theory in Psychology; American Psychological Association: Washington, DC, USA, 2019. [Google Scholar]
- Perifanou, M.; Economides, A.A. Collaborative uses of GenAI tools in project-based learning. Educ. Sci. 2025, 15, 354. [Google Scholar] [CrossRef]
- Cai, Y.; Tian, S. Student translators’ web-based vs. GenAI-based information-seeking behavior in translation process: A comparative study. Educ. Inf. Technol. 2025, 30, 1–29. [Google Scholar] [CrossRef]
- Lin, H.; Chen, Z.; Wei, W.; Lu, H. GenAI Tools in Academic Reading: A Study on AI-Assisted Metacognitive Strategies and Emotional Reactions. In Asia Education Technology Symposium; Springer: Berlin/Heidelberg, Germany, 2024; pp. 98–112. [Google Scholar]
- Winne, P.H. Modeling self-regulated learning as learners doing learning science: How trace data and learning analytics help develop skills for self-regulated learning. Metacognition Learn. 2022, 17, 773–791. [Google Scholar] [CrossRef]
- Liew, S.X.; Embrey, J.R.; Newell, B.R. The non-unitary nature of information preference. Psychon. Bull. Rev. 2023, 30, 1966–1974. [Google Scholar] [CrossRef]
- Qi, J.; Liu, J.a.; Xu, Y. The Role of Individual Capabilities in Maximizing the Benefits for Students Using GenAI Tools in Higher Education. Behav. Sci. 2025, 15, 328. [Google Scholar] [CrossRef]
- Chu, H.-C.; Lu, Y.-C.; Tu, Y.-F. How GenAI-supported multi-modal presentations benefit students with different motivation levels. Educ. Technol. Soc. 2025, 28, 250–269. [Google Scholar]
- Kim, M.K.; Kim, N.J.; Heidari, A. Learner experience in artificial intelligence-scaffolded argumentation. Assess. Eval. High. Educ. 2022, 47, 1301–1316. [Google Scholar] [CrossRef]
- Kim, J.; Yu, S.; Detrick, R.; Li, N. Exploring students’ perspectives on generative AI-assisted academic writing. Educ. Inf. Technol. 2025, 30, 1265–1300. [Google Scholar] [CrossRef]
- Rowland, D.R. Two frameworks to guide discussions around levels of acceptable use of generative AI in student academic research and writing. J. Acad. Lang. Learn. 2023, 17, T31–T69. [Google Scholar]
- Chanpradit, T. Generative artificial intelligence in academic writing in higher education: A systematic review. Edelweiss Appl. Sci. Technol. 2025, 9, 889–906. [Google Scholar] [CrossRef]
- Nelson, A.S.; Santamaría, P.V.; Javens, J.S.; Ricaurte, M. Students’ Perceptions of Generative Artificial Intelligence (GenAI) Use in Academic Writing in English as a Foreign Language. Educ. Sci. 2025, 15, 611. [Google Scholar] [CrossRef]
- Hanafi, A.M.; Al-mansi, M.M.; Al-Sharif, O.A. Generative AI in Academia: A Comprehensive Review of Applications and Implications for the Research Process. Int. J. Eng. Appl. Sci.-Oct. 6 Univ. 2025, 2, 91–110. [Google Scholar] [CrossRef]
- Altınmakas, D.; Bayyurt, Y. An exploratory study on factors influencing undergraduate students’ academic writing practices in Turkey. J. Engl. Acad. Purp. 2019, 37, 88–103. [Google Scholar] [CrossRef]
- Kim, J.; Lee, S.-S.; Detrick, R.; Wang, J.; Li, N. Students-Generative AI interaction patterns and its impact on academic writing. J. Comput. High. Educ. 2025, 37, 1–22. [Google Scholar] [CrossRef]
- Reddy, M.R.; Walter, N.G.; Sevryugina, Y.V. Implementation and Evaluation of a ChatGPT-Assisted Special Topics Writing Assignment in Biochemistry. J. Chem. Educ. 2024, 101, 2740–2748. [Google Scholar] [CrossRef]
- Doron, G.; Genway, S.; Roberts, M.; Jasti, S. Generative AI: Driving productivity and scientific breakthroughs in pharmaceutical R&D. Drug Discov. Today 2024, 30, 104272. [Google Scholar]
- Xu, W.; Wang, Y.; Zhang, D.; Yang, Z.; Yuan, Z.; Lin, Y.; Yan, H.; Zhou, X.; Yang, C. Transparent AI-assisted chemical engineering process: Machine learning modeling and multi-objective optimization for integrating process data and molecular-level reaction mechanisms. J. Clean. Prod. 2024, 448, 141412. [Google Scholar] [CrossRef]
- Nguyen, A.; Hong, Y.; Dang, B.; Huang, X. Human-AI collaboration patterns in AI-assisted academic writing. Stud. High. Educ. 2024, 49, 847–864. [Google Scholar] [CrossRef]
- Hazzan, O.; Erez, Y. Rethinking Computer Science Education in the Age of GenAI. ACM Trans. Comput. Educ. 2025, 25, 1–9. [Google Scholar] [CrossRef]
- Wang, K.D.; Wu, Z.; Tufts II, L.N.; Wieman, C.; Salehi, S.; Haber, N. Scaffold or Crutch? Examining College Students’ Use and Views of Generative AI Tools for STEM Education. arXiv 2024, arXiv:2412.02653. [Google Scholar]
- Alami, N.; Meknassi, M.; En-nahnahi, N.; El Adlouni, Y.; Ammor, O. Unsupervised neural networks for automatic Arabic text summarization using document clustering and topic modeling. Expert Syst. Appl. 2021, 172, 114652. [Google Scholar] [CrossRef]
- Vulić, I.; De Smet, W.; Tang, J.; Moens, M.-F. Probabilistic topic modeling in multilingual settings: An overview of its methodology and applications. Inf. Process. Manag. 2015, 51, 111–147. [Google Scholar] [CrossRef]
- Zhang, Y.; Jin, R.; Zhou, Z.-H. Understanding bag-of-words model: A statistical framework. Int. J. Mach. Learn. Cybern. 2010, 1, 43–52. [Google Scholar] [CrossRef]
- Abubakar, H.D.; Umar, M.; Bakale, M.A. Sentiment classification: Review of text vectorization methods: Bag of words, Tf-Idf, Word2vec and Doc2vec. SLU J. Sci. Technol. 2022, 4, 27–33. [Google Scholar] [CrossRef]
- Ramos, J. Using tf-idf to determine word relevance in document queries. In Proceedings of the First Instructional Conference on Machine Learning, Los Angeles, CA, USA, 23–24 June 2003; Volume 242, pp. 29–48. [Google Scholar]
- Qiao, S.; Yeung, S.S.s.; Zainuddin, Z.; Ng, D.T.K.; Chu, S.K.W. Examining the effects of mixed and non-digital gamification on students’ learning performance, cognitive engagement and course satisfaction. Br. J. Educ. Technol. 2023, 54, 394–413. [Google Scholar] [CrossRef]
- Liu, K.; Yao, J.; Tao, D.; Yang, T. Influence of individual-technology-task-environment fit on university student online learning performance: The mediating role of behavioral, emotional, and cognitive engagement. Educ. Inf. Technol. 2023, 28, 15949–15968. [Google Scholar] [CrossRef] [PubMed]
- Grootendorst, M. BERTopic: Neural topic modeling with a class-based TF-IDF procedure. arXiv 2022, arXiv:2203.05794. [Google Scholar]
- Vayansky, I.; Kumar, S.A. A review of topic modeling methods. Inf. Syst. 2020, 94, 101582. [Google Scholar] [CrossRef]
- Markos, A.; Moschidis, O.; Chadjipantelis, T. Sequential dimension reduction and clustering of mixed-type data. Int. J. Data Anal. Tech. Strateg. 2020, 12, 228–246. [Google Scholar] [CrossRef]
- Vlachos, M.; Domeniconi, C.; Gunopulos, D.; Kollios, G.; Koudas, N. Non-linear dimensionality reduction techniques for classification and visualization. In Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Edmonton, AB, Canada, 23–26 July 2002; pp. 645–651. [Google Scholar]
- Ding, C.; He, X. K-means clustering via principal component analysis. In Proceedings of the Twenty-First International Conference on Machine Learning, Banff, AB, Canada, 4–8 July 2004; p. 29. [Google Scholar]
- Sun, D.; Xu, P.; Zhang, J.; Liu, R.; Zhang, J. How Self-Regulated Learning Is Affected by Feedback Based on Large Language Models: Data-Driven Sustainable Development in Computer Programming Learning. Electronics 2025, 14, 194. [Google Scholar] [CrossRef]
- Liu, Z.-M.; Hwang, G.-J.; Chen, C.-Q.; Chen, X.-D.; Ye, X.-D. Integrating large language models into EFL writing instruction: Effects on performance, self-regulated learning strategies, and motivation. Comput. Assist. Lang. Learn. 2024, 37, 1–25. [Google Scholar] [CrossRef]
- Pallant, J.L.; Blijlevens, J.; Campbell, A.; Jopp, R. Mastering knowledge: The impact of generative AI on student learning outcomes. Stud. High. Educ. 2025, 50, 1–22. [Google Scholar] [CrossRef]
- Yang, M.; Jiang, S.; Li, B.; Herman, K.; Luo, T.; Moots, S.C.; Lovett, N. Analysing nontraditional students’ ChatGPT interaction, engagement, self-efficacy and performance: A mixed-methods approach. Br. J. Educ. Technol. 2025, 56, 1–27. [Google Scholar] [CrossRef]
- Voskamp, A.; Kuiper, E.; Volman, M. Teaching practices for self-directed and self-regulated learning: Case studies in Dutch innovative secondary schools. Educ. Stud. 2022, 48, 772–789. [Google Scholar] [CrossRef]
- Liang, Y.; Song, Z.; Wang, H.; Zhang, J. Learning to trust your feelings: Leveraging self-awareness in llms for hallucination mitigation. arXiv 2024, arXiv:2401.15449. [Google Scholar]
- Tan, T. Future Human: Consciousness, Cognition and the Role of Human Insight in an AI Future; World Scientific: Singapore, 2024. [Google Scholar]
- Mumford, M.D.; Blair, C.; Dailey, L.; Leritz, L.E.; Osburn, H.K. Errors in creative thought? Cognitive biases in a complex processing activity. J. Creat. Behav. 2006, 40, 75–109. [Google Scholar] [CrossRef]
- Sparrow, P. Strategy and cognition: Understanding the role of management knowledge structures, organizational memory and information overload. Creat. Innov. Manag. 1999, 8, 140–148. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).