FF-YOLO: An Improved YOLO11-Based Fatigue Detection Algorithm for Air Traffic Controllers

Abstract
1. Introduction
- A dataset of facial images of ATCOs under radar control scenarios was established, including facial image data of 10 ATCOs during work. Fatigue states were annotated based on subjective fatigue scale scores and PERCLOS indicators, and the positive and negative sample quantities in the dataset were balanced;
- The CA-C3K2 feature extraction module was proposed, which introduces a dual-branch channel attention mechanism based on the C3K2 module to enhance cross-channel feature extraction capabilities for extracting fine-grained facial fatigue features such as facial muscle relaxation and lower eyelid swelling in ATCOs. The CA-C3K2 module was adopted in the backbone and neck of the FF-YOLO model to replace the original C3K2 module to improve the fatigue feature extraction capability under complex lighting conditions;
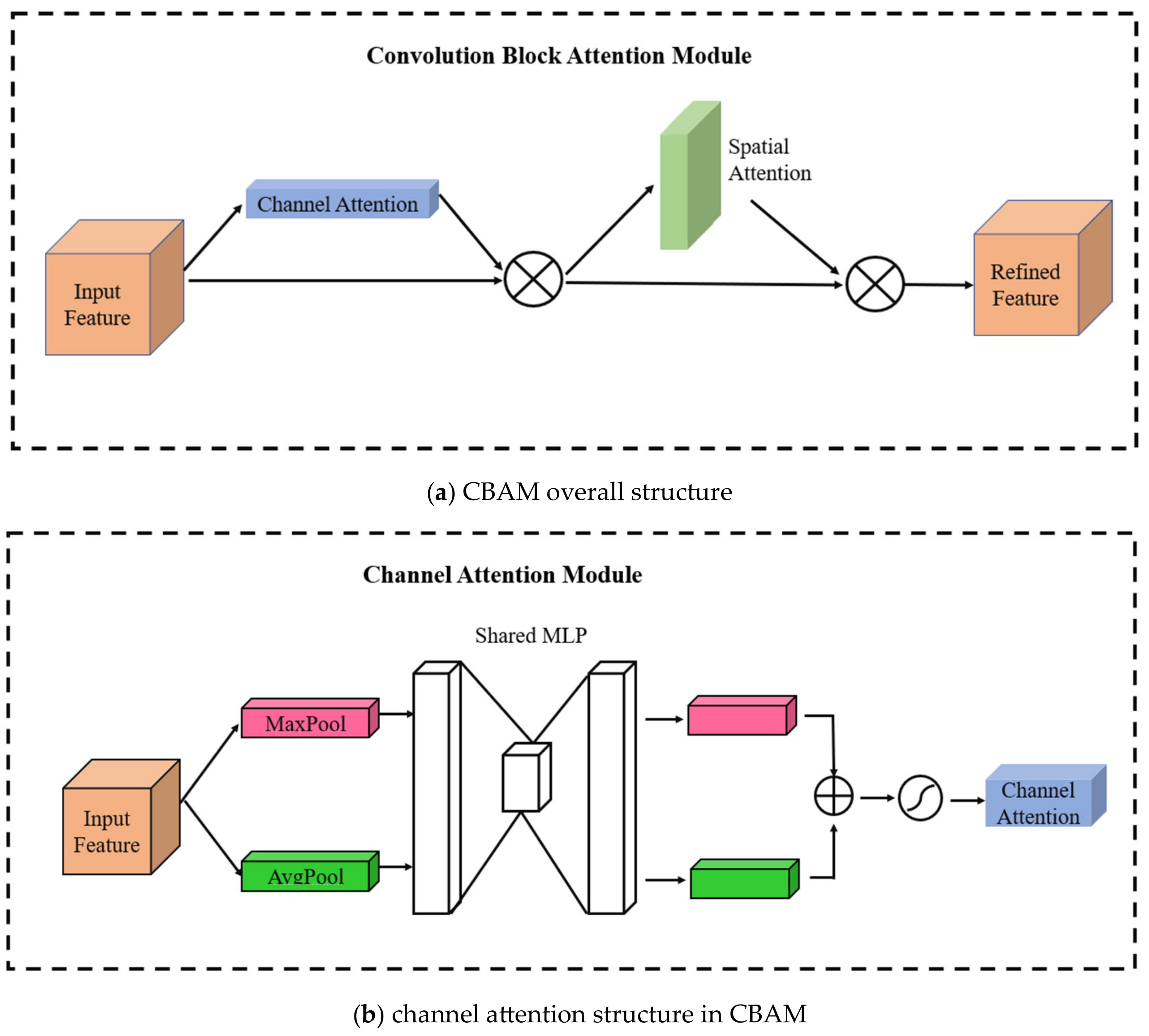
- The CBAM module was introduced in the detection head to learn the spatial and channel characteristics of fatigue features, thereby improving the accuracy of fatigue detection in the presence of occlusion and head deflection interference;
- The model’s loss function was replaced with MPDIoU to accelerate model convergence and enhance the accuracy of fatigue detection in facial images of different sizes.
2. Related Works
3. Materials and Methods
3.1. Dataset Construction
3.1.1. Data Collection
- Pairwise comparison: The six dimensions were combined in pairs, resulting in 15 combinations, such as comparing Mental Demand with Physical Demand or Mental Demand with Temporal Demand.
- Selection of the more important dimension: For each pair, participants were asked to select which dimension had a greater impact on workload. For example, in the comparison between Mental Demand and Physical Demand, if the participant deemed Mental Demand to be more important, a count of 1 was added to the tally for Mental Demand.
- Weight calculation: The number of times each dimension was selected served as its weight. The range of weights was from 0 to 5, as each dimension could be selected a maximum of 5 times.
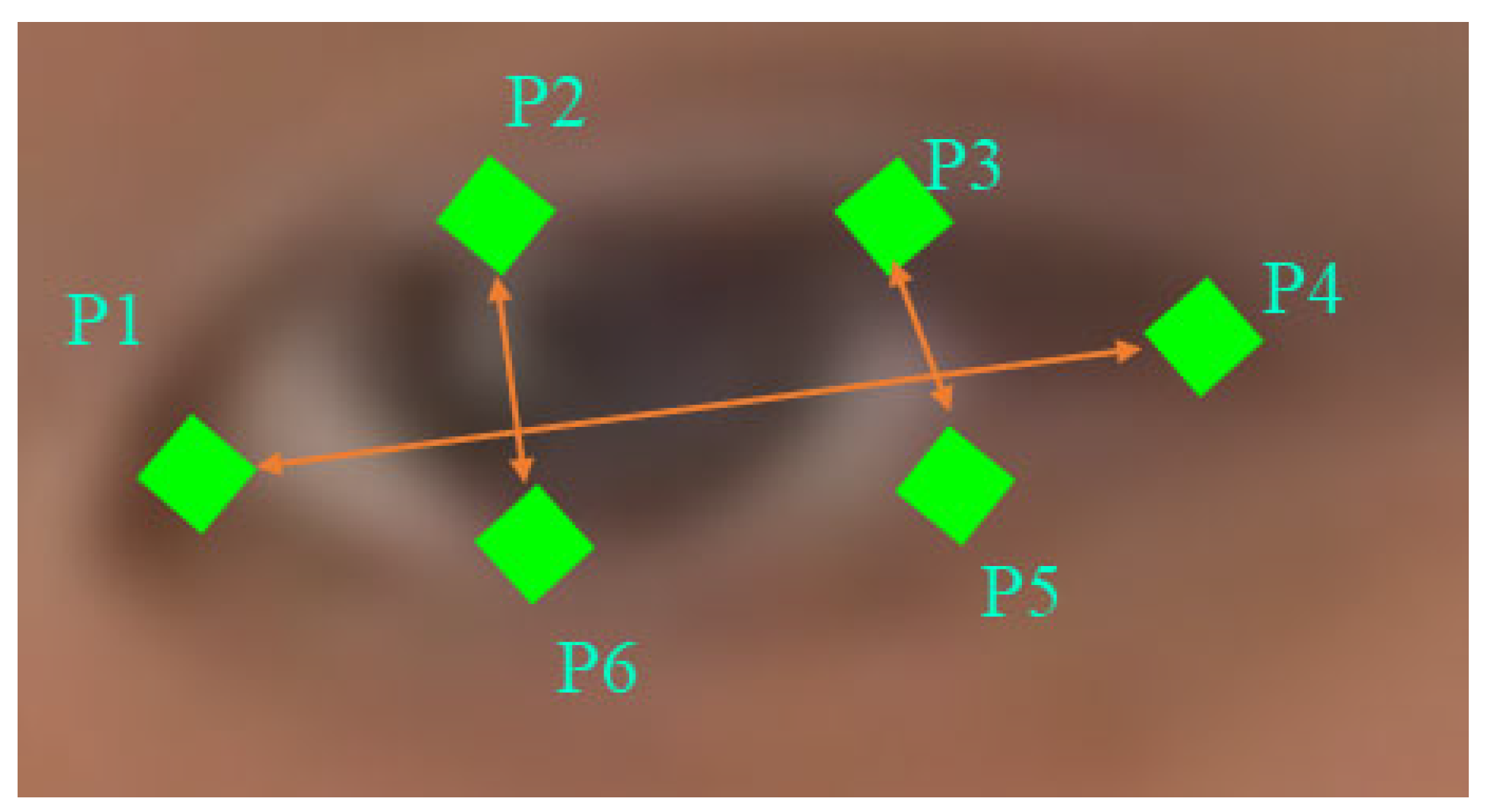
3.1.2. Dataset Labeling
3.2. CA-C3K2 Module
3.3. FF-YOLO Network
3.3.1. Backbone and Neck Network
3.3.2. Head Network with Spatial–Channel Attention Mechanism
3.3.3. MPDIoU Loss Function
3.4. Experimental Environment and Parameter Settings
3.5. Evaluation Metrics
4. Results
4.1. FF-YOLO Network Performance
4.2. Ablation Experiment
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ATC | Air traffic control |
| ATCO | Air traffic controller |
| FF-YOLO | Facial-Features-YOLO |
| CFS | Chalder Fatigue Scale |
| NASA-TLX | NASA-Task Load Index |
| CAAC | Civil Aviation Administration of China |
| EAR | Eye Aspect Ratio |
| MAR | Mouth Aspect Ratio |
| CA-C3K2 | Channel-Attention-C3K2 |
| SE | Squeeze-and-Excitation |
| CBAM | Convolutional Block Attention Module |
| CAM | Channel Attention Module |
| SAM | Spatial Attention Module |
| P-R Curve | Precision–Recall Curve |
References
- Schuver-van Blanken, M.; Huisman, H.; Roerdink, M. The ATC Cognitive Process & Operational Situation Model. In Proceedings of the European Association for Aviation Psychology Conference, Budapest, Hungary, 20 September 2010. [Google Scholar]
- Zhang, J.; Chen, Z.; Liu, W.; Ding, P.; Wu, Q. A field study of work type influence on air traffic controllers’ fatigue based on data-driven PERCLOS detection. Int. J. Environ. Res. Public Health 2021, 18, 11937. [Google Scholar] [CrossRef] [PubMed]
- Li, W.C.; Kearney, P.; Zhang, J.; Hsu, Y.L.; Braithwaite, G. The analysis of occurrences associated with air traffic volume and air traffic controllers’ alertness for fatigue risk management. Risk Anal. 2021, 41, 1004–1018. [Google Scholar] [CrossRef] [PubMed]
- Pan, H.; Hu, Y.; Wang, Y.; Duong, V. Fatigue Detection in Air Traffic Controllers: A Comprehensive Review; IEEE Access: Piscataway, NJ, USA, 2024. [Google Scholar]
- Mélan, C.; Cascino, N. Contrasting effects of work schedule changes and air traffic intensity on ATCOs’ fatigue, stress and quality of life. In Proceedings of the 33rd Conference of the European Association of Aviation Psychology, Dubrovnik, Croatia, 24–28 September 2018. [Google Scholar]
- Yen, J.R.; Hsu, C.C.; Ho, H.; Lin, F.F.; Yu, S.H. Identifying flight fatigue factors: An econometric modeling approach. J. Air Transp. Manag. 2005, 11, 408–416. [Google Scholar] [CrossRef]
- Pettersson, M.; Westgren, O. Staff Scheduling in ACC at ATCC Stockholm. Master’s Thesis, Linköping University Electronic Press, Linköping, Sweden, 2013; pp. 12–14. [Google Scholar]
- Chalder, T.; Berelowitz, G.; Pawlikowska, T.; Watts, L.; Wessely, S.; Wright, D.; Wallace, E.P. Development of a fatigue scale. J. Psychosom. Res. 1993, 37, 147–153. [Google Scholar] [CrossRef]
- Mohanavelu, K.; Lamshe, R.; Poonguzhali, S.; Adalarasu, K.; Jagannath, M. Assessment of human fatigue during physical performance using physiological signals: A review. Biomed. Pharmacol. J. 2017, 10, 1887–1896. [Google Scholar] [CrossRef]
- Liang, Q.; Xu, L.; Bao, N.; Qi, L.; Shi, J.; Yang, Y.; Yao, Y. Research on non-contact monitoring system for human physiological signal and body movement. Biosensors 2019, 9, 58. [Google Scholar] [CrossRef]
- Hooda, R.; Joshi, V.; Shah, M. A comprehensive review of approaches to detect fatigue using machine learning techniques. Chronic Dis. Transl. Med. 2022, 8, 26–35. [Google Scholar] [CrossRef]
- Hart, S.G.; Staveland, L.E. Development of NASA-TLX (Task Load Index): Results of empirical and theoretical research. In Advances in Psychology; North-Holland: Amsterdam, The Netherlands, 1988; Volume 52, pp. 139–183. [Google Scholar]
- Triyanti, V.; Azis, H.A.; Iridiastadi, H. Workload and fatigue assessment on air traffic controller. In Proceedings of the 12th ISIEM (International Seminar on Industrial Engineering & Management): “Industrial Intelligence System on Engineering, Information, and Management”, Batu, Malang, East Java, Indonesia, 17–19 March 2020; Volume 847, No. 1. p. 012087. [Google Scholar]
- Hu, F.; Zhang, L.; Yang, X.; Zhang, W.A. EEG-Based driver Fatigue Detection using Spatio-Temporal Fusion network with brain region partitioning strategy. IEEE Trans. Intell. Transp. Syst. 2024, 25, 9618–9630. [Google Scholar] [CrossRef]
- Zhao, Y.; Xie, K.; Zou, Z.; He, J.B. Intelligent recognition of fatigue and sleepiness based on inceptionV3-LSTM via multi-feature fusion. Ieee Access 2020, 8, 144205–144217. [Google Scholar] [CrossRef]
- Mu, S.; Liao, S.; Tao, K.; Shen, Y. Intelligent fatigue detection based on hierarchical multi-scale ECG representations and HRV measures. Biomed. Signal Process. Control 2024, 92, 106127. [Google Scholar] [CrossRef]
- Li, Q.; Ng, K.K.; Simon, C.M.; Yiu, C.Y.; Li, F.; Chan, F.T. Using EEG and eye-tracking as indicators to investigate situation awareness variation during flight monitoring in air traffic control system. J. Navig. 2025, 77, 485–506. [Google Scholar] [CrossRef]
- Fu, S.; Yang, Z.; Ma, Y.; Li, Z.; Xu, L.; Zhou, H. Advancements in the intelligent detection of driver fatigue and distraction: A comprehensive review. Appl. Sci. 2024, 14, 3016. [Google Scholar] [CrossRef]
- Zhao, G.; He, Y.; Yang, H.; Tao, Y. Research on fatigue detection based on visual features. IET Image Process. 2022, 16, 1044–1053. [Google Scholar] [CrossRef]
- Chen, Z.; Zhang, X.; Li, J.; Ni, J.; Chen, G.; Wang, S.; Fan, F.; Wang, C.C.; Li, X. Machine vision detection to daily facial fatigue with a nonlocal 3D attention network. arXiv 2021, arXiv:2104.10420. [Google Scholar]
- Khan, S.A.; Hussain, S.; Xiaoming, S.; Yang, S. An effective framework for driver fatigue recognition based on intelligent facial expressions analysis. IEEE Access 2018, 6, 67459–67468. [Google Scholar] [CrossRef]
- Li, X.; Li, X.; Shen, Z.; Qian, G. Driver fatigue detection based on improved YOLOv7. J. Real-Time Image Process. 2024, 21, 75. [Google Scholar] [CrossRef]
- Zhao, S.; Peng, Y.; Wang, Y.; Li, G.; Al-Mahbashi, M. Lightweight YOLOM-Net for Automatic Identification and Real-Time Detection of Fatigue Driving. Comput. Mater. Contin. 2025, 82, 4995–5017. [Google Scholar] [CrossRef]
- Yu, N.; Yin, X.; Li, B.; Zhang, X.; Meng, J. Fatigue Driving Recognition Method Based on Improved GD-YOLO. In Proceedings of the 2024 8th Asian Conference on Artificial Intelligence Technology (ACAIT), Fuzhou, China, 8–10 November 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 828–834. [Google Scholar]
- Arsintescu, L.; Chachad, R.; Gregory, K.B.; Mulligan, J.B.; Flynn-Evans, E.E. The relationship between workload, performance and fatigue in a short-haul airline. Chronobiol. Int. 2020, 37, 1492–1494. [Google Scholar] [CrossRef]
- Grier, R.A. How high is high? A meta-analysis of NASA-TLX global workload scores. In Proceedings of the Human Factors and Ergonomics Society Annual Meeting; Sage Publications: Los Angeles, CA, USA, 2015; Volume 59, No. 1. pp. 1727–1731. [Google Scholar]
- Wierwille, W.; Tijerina, L.; Glecker, M.; Duane, S.; Johnston, S.; Goodman, M. PERCLOS: A Valid Psychophysiological Measure of Alertness As Assessed by Psychomotor Vigilance; United States Federal Motor Carrier Safety Administration: Washingtone, DC, USA, 1998. [Google Scholar]
- King, D.E. Dlib-ml: A machine learning toolkit. J. Mach. Learn. Res. 2009, 10, 1755–1758. [Google Scholar]
- Soukupova, T.; Cech, J. Eye blink detection using facial landmarks. In Proceedings of the 21st Computer Vision Winter Workshop, Rimske Toplice, Slovenia, 3–5 February 2016; Volume 2, p. 4. [Google Scholar]
- Wierwille, W.W.; Ellsworth, L.A. Evaluation of driver drowsiness by trained raters. Accid. Anal. Prev. 1994, 26, 571–581. [Google Scholar] [CrossRef]
- Kumar, P.; Bhatnagar, R.; Gaur, K.; Bhatnagar, A. Classification of imbalanced data: Review of methods and applications. IOP Conf. Ser. Mater. Sci. Eng 2021, 1099, 012077. [Google Scholar] [CrossRef]
- Chen, Y.; Liu, W.; Zhang, L.; Yan, M.; Zeng, Y. Hybrid facial image feature extraction and recognition for non-invasive chronic fatigue syndrome diagnosis. Comput. Biol. Med. 2015, 64, 30–39. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Khanam, R.; Hussain, M. Yolov11: An overview of the key architectural enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, No. 7. pp. 12993–13000. [Google Scholar]
- Du, S.; Zhang, B.; Zhang, P.; Xiang, P. An improved bounding box regression loss function based on CIOU loss for multi-scale object detection. In Proceedings of the 2021 IEEE 2nd International Conference on Pattern Recognition and Machine Learning (PRML), Chengdu, China, 16–18 July 2021; pp. 92–98. [Google Scholar]
- Ma, S.; Xu, Y. Mpdiou: A loss for efficient and accurate bounding box regression. arXiv 2023, arXiv:2307.07662. [Google Scholar]
- Brown, P.F.; Cocke, J.; Della Pietra, S.A.; Della Pietra, V.J.; Jelinek, F.; Lafferty, J.; Mercer, R.L.; Roossin, P.S. A statistical approach to machine translation. Comput. Linguist. 1990, 16, 79–85. [Google Scholar]
- Schütze, H.; Manning, C.D.; Raghavan, P. Introduction to Information Retrieval; Cambridge University Press: Cambridge, UK, 2008; Volume 39, pp. 234–265. [Google Scholar]
- Davis, J.; Goadrich, M. The relationship between Precision-Recall and ROC curves. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 233–240. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Zitnick, C.L. Microsoft coco: Common objects in context, European Conf. In Computer Vision; Springer: Cham, Germany, 2014; pp. 740–755. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Shifts | Time Periods |
|---|---|
| Morning | 8:30~11:30 |
| Afternoon | 14:30~17:30 |
| Evening | 19:30~21:00 |
| Dimensions | Descriptions | Weights |
|---|---|---|
| Mental Demand | The amount of mental and perceptual effort required, such as thinking, deciding, calculating, remembering, observing, and searching. Was the task straightforward or challenging, simple or complex? | 0.26 |
| Physical Demand | The level of physical effort needed, including activities like pushing, pulling, turning, and controlling. Was the task physically easy or hard, slow or fast, relaxed or strenuous? | 0.07 |
| Temporal Demand | The sense of time pressure due to the task’s pace. Did you feel the task was leisurely or rushed, slow or fast-paced? | 0.2 |
| Performance | Your perceived success in achieving the task objectives. How well did you think you performed in meeting the goals of the task? | 0.07 |
| Effort | The amount of mental and physical effort you had to exert to achieve your performance level. How hard did you have to work to accomplish the task? | 0.33 |
| Frustration Level | The degree of stress, irritation, and annoyance you felt during the task. Did you feel secure, satisfied, content, relaxed, or did you feel insecure, discouraged, irritated, stressed, and annoyed? | 0.07 |
| Subsets | Drowsy | Non-Drowsy |
|---|---|---|
| Training | 7546 | 7546 |
| Validation | 2515 | 2516 |
| Test | 2516 | 2515 |
| Environment Configuration | Parameter |
|---|---|
| Operating system | Windows 11 |
| CPU | Intel(R) Core(TM) i5-8300H @2.30 GHz (Intel, Santa Clara, CA, USA) |
| GPU | NVIDIA GeForce GTX 1060 (NVIDIA, Santa Clara, CA, USA) |
| Memory | 16,384 MB RAM |
| Frame | Pytorch 2.3.1 |
| Operating platform | CUDA 12.1 |
| Programming language | Python 3.12.4 |
| Hyperparameter | Parameter |
|---|---|
| Epochs | 100 |
| Warmup-epochs | 3 |
| Batch size | 2 |
| Optimizer | SGD |
| Input image size | 928 |
| Initial learning rate | 0.01 |
| Momentum | 0.937 |
| Model | CA-C3K2 | CBAM | MPDIoU | mAP@50 (%) | mAP@50-95 (%) | P (%) | R (%) | Parameters | FLOPs (G) |
|---|---|---|---|---|---|---|---|---|---|
| YOLO11n | × | × | × | 80.5 | 63.1 | 83.2 | 67.9 | 2,582,347 | 6.3 |
| YOLO-CA | √ | × | × | 90.9 | 74.4 | 84.3 | 74.1 | 3,220,129 | 7.6 |
| YOLO—C | × | √ | × | 92.4 | 71.6 | 84.6 | 71.8 | 2,582,542 | 6.3 |
| YOLO—M | × | × | √ | 82.7 | 63.7 | 82.7 | 68.3 | 2,582,347 | 6.3 |
| FF-YOLO (ours) | √ | √ | √ | 94.2 | 74.7 | 83.8 | 73.8 | 3,220,324 | 7.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tan, S.; Pan, W.; Deng, L.; Zuo, Q.; Zheng, Y. FF-YOLO: An Improved YOLO11-Based Fatigue Detection Algorithm for Air Traffic Controllers. Appl. Sci. 2025, 15, 7503. https://doi.org/10.3390/app15137503
Tan S, Pan W, Deng L, Zuo Q, Zheng Y. FF-YOLO: An Improved YOLO11-Based Fatigue Detection Algorithm for Air Traffic Controllers. Applied Sciences. 2025; 15(13):7503. https://doi.org/10.3390/app15137503
Chicago/Turabian StyleTan, Shijie, Weijun Pan, Leilei Deng, Qinghai Zuo, and Yao Zheng. 2025. "FF-YOLO: An Improved YOLO11-Based Fatigue Detection Algorithm for Air Traffic Controllers" Applied Sciences 15, no. 13: 7503. https://doi.org/10.3390/app15137503
APA StyleTan, S., Pan, W., Deng, L., Zuo, Q., & Zheng, Y. (2025). FF-YOLO: An Improved YOLO11-Based Fatigue Detection Algorithm for Air Traffic Controllers. Applied Sciences, 15(13), 7503. https://doi.org/10.3390/app15137503