
Debris Flow Susceptibility Prediction Using Transfer Learning: A Case Study in Western Sichuan, China


Abstract
1. Introduction
2. Study Area
3. Data and Methods
3.1. Debris Flow Inventory
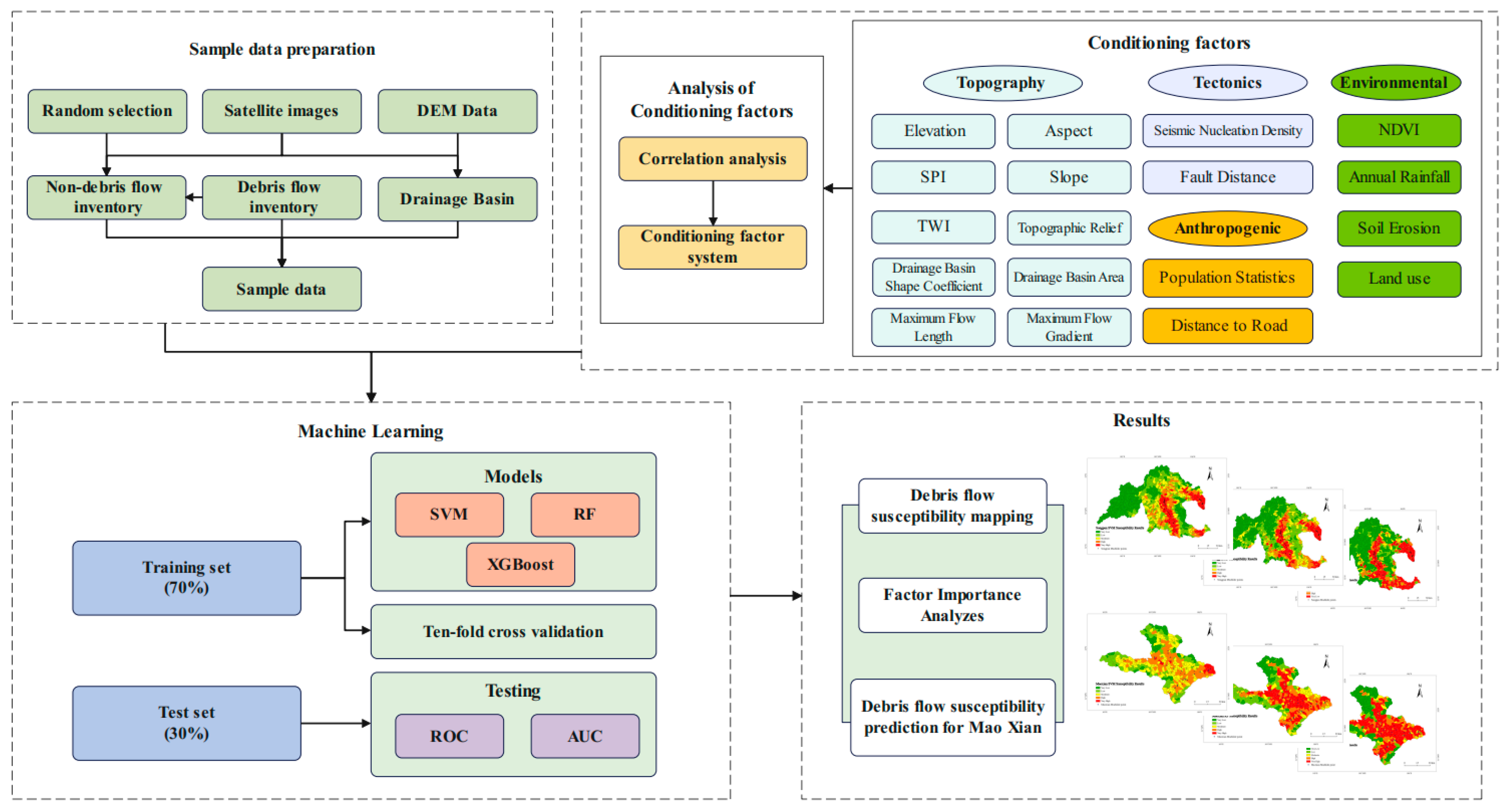
3.2. Susceptibility Assessment Process
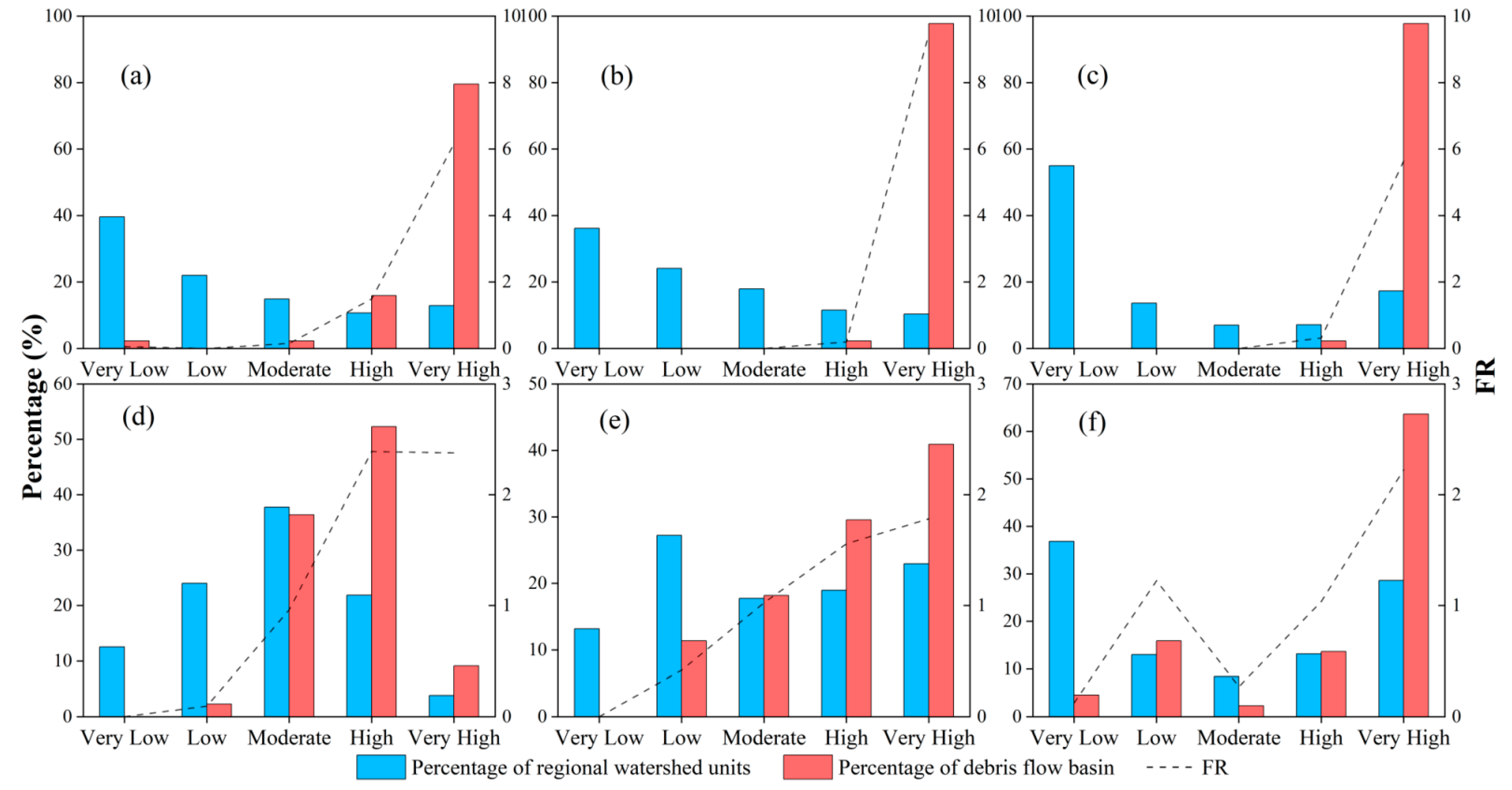
3.3. Sample Data Preparation
3.4. Conditioning Factors
- (1)
- Topography: This includes elevation, slope, aspect, topographic wetness index, stream power index, topographic relief, drainage basin shape coefficient, drainage basin area, maximum flow length, and maximum flow gradient. Elevation influences geomorphological and geological evolution, shaping the natural disaster background and indirectly regulating the spatial distribution of human activities. Slope is highly related to the formation and development of debris flows, with suitable slopes facilitating their initiation. Aspect affects microclimatic conditions, which in turn influence vegetation and rock weathering, controlling material availability. The topographic wetness index describes how terrain controls runoff generation and saturation source areas. The stream power index reflects the erosive force of flowing water. Topographic relief indicates the degree of surface erosion and tectonic activity. The drainage basin shape coefficient, drainage basin area, maximum flow length, and maximum flow gradient are the basic parameters for calculating flow paths and velocities, determining debris flow probability and scale.
- (2)
- Geology. This includes seismic nucleation density and fault distance. Earthquakes and tectonic faults weaken rock and soil strength, producing loose material that serves as debris flow sources.
- (3)
- Environmental factors. These include the normalized difference vegetation index, soil erosion, land use, and annual rainfall. The normalized difference vegetation index reflects vegetation cover, which promotes soil and water conservation and reduces debris flow sources. Soil erosion indicates surface susceptibility to erosion. Land use alters runoff and infiltration processes, potentially triggering debris flows. Annual rainfall is one of the primary triggers for debris flow events.
- (4)
- Human activities. These include distance to road and population statistics. Road construction along riverbanks can induce slope instability and accelerate loose material accumulation, raising debris flow risk. Population statistics reflect human activity intensity but are often highest in flatter areas, where geological conditions tend to inhibit debris flow development.
3.5. Overview of Machine Learning Models
3.5.1. Random Forest
3.5.2. Support Vector Machine
3.5.3. Extreme Gradient Boosting
3.5.4. Model Accuracy Verification
4. Results
4.1. Hyperparameter Optimization
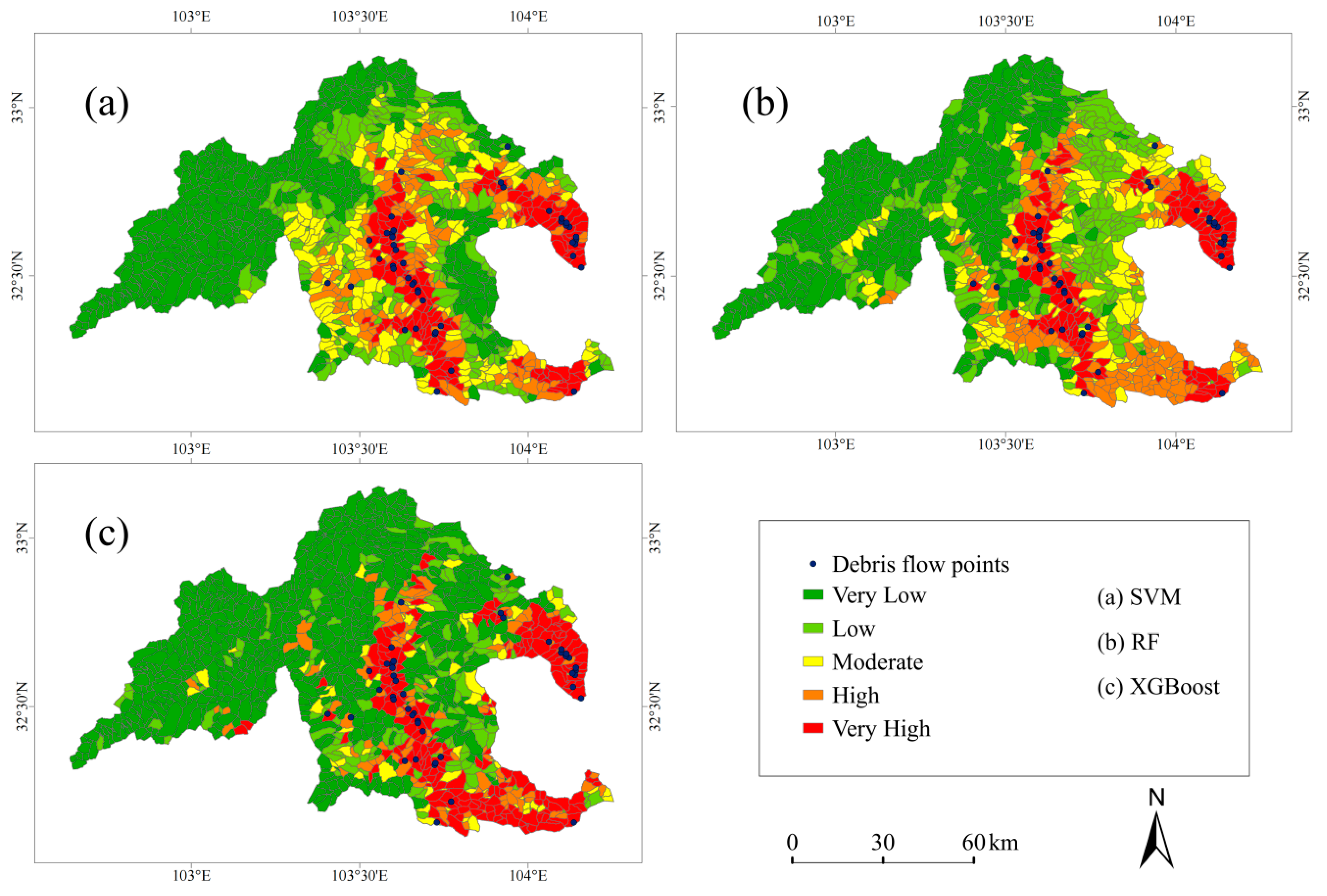
4.2. Debris Flow Susceptibility Mapping in Songpan
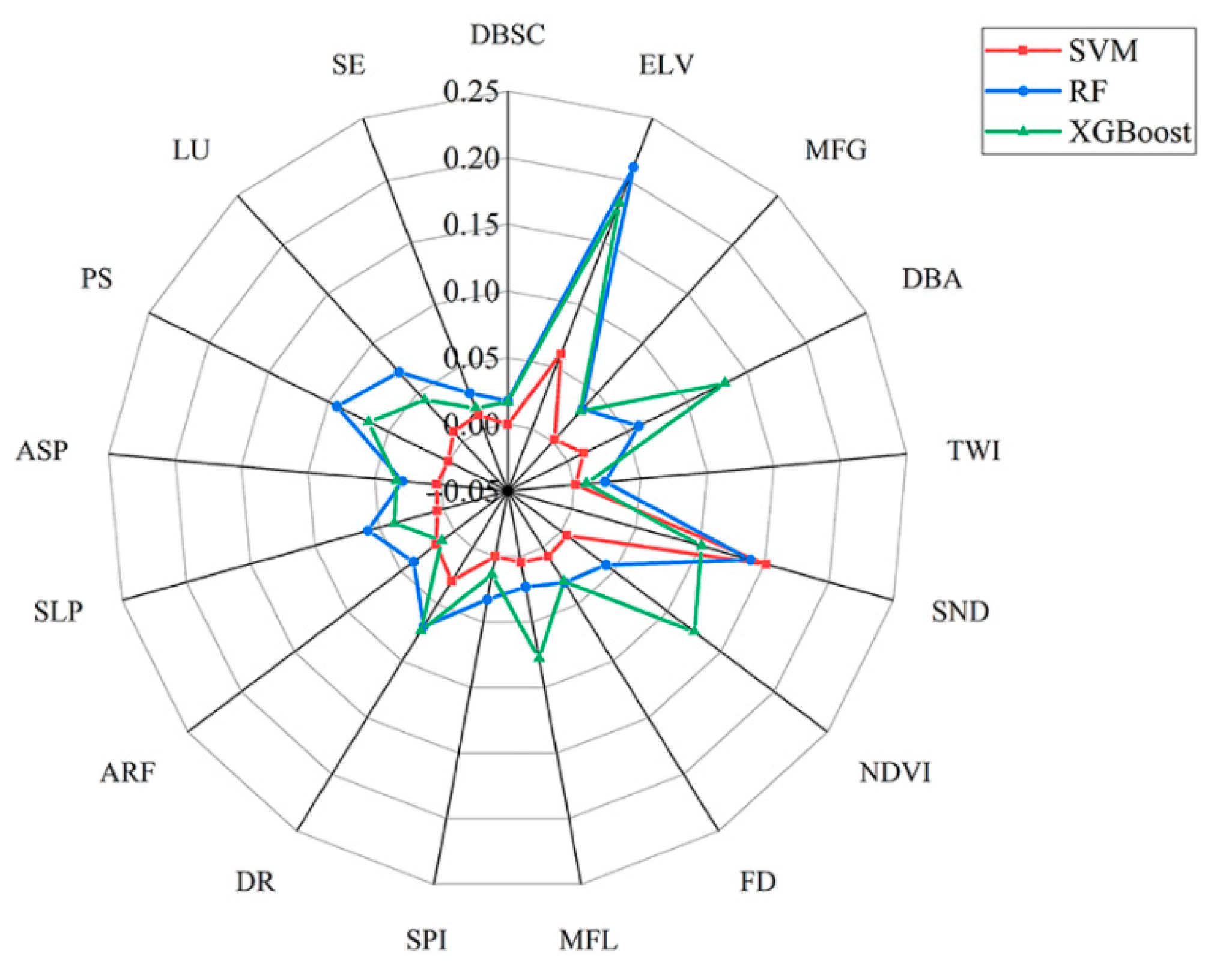
4.3. Factor Importance
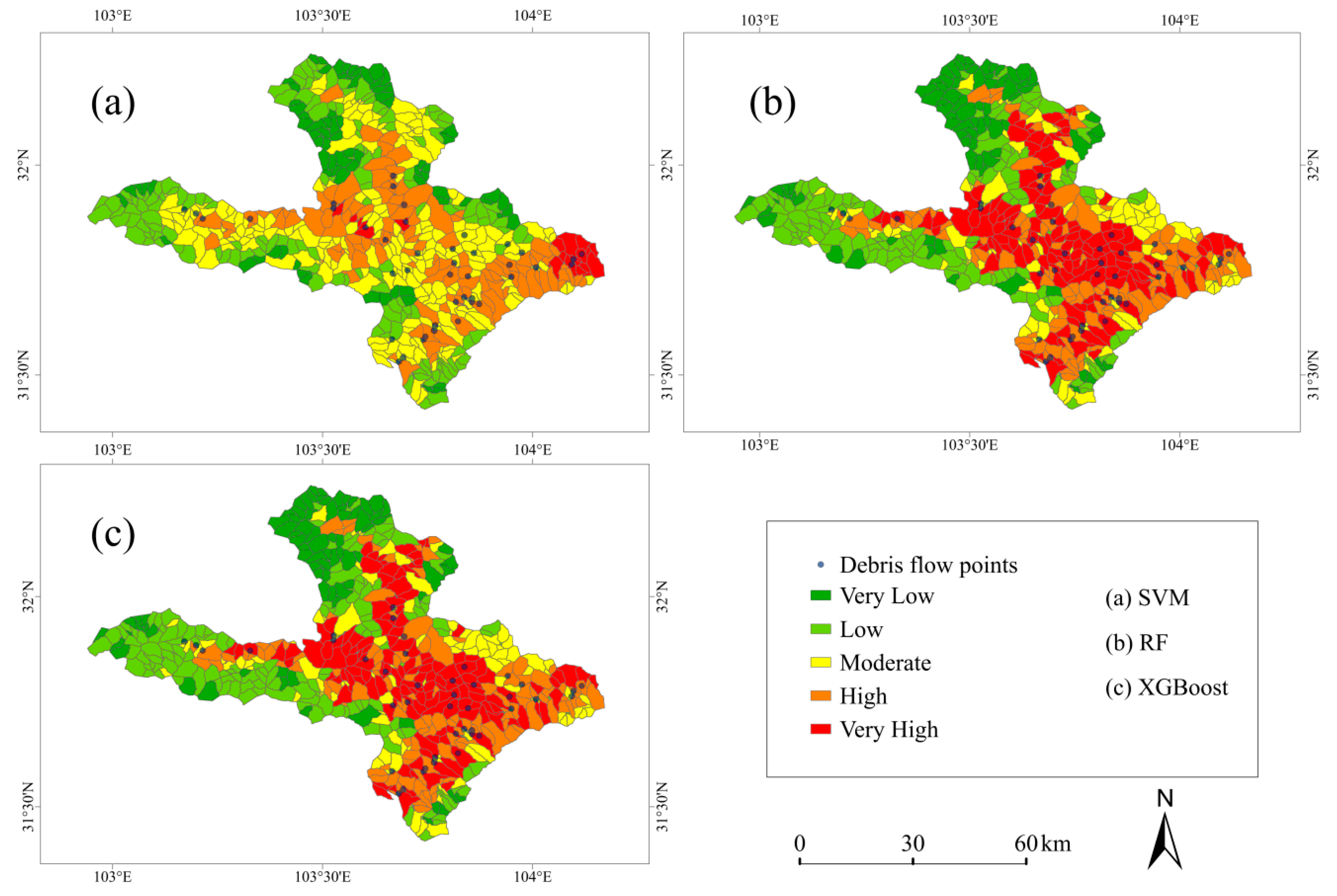
4.4. Debris Flow Susceptibility Mapping in Mao County
5. Discussion
5.1. Factor Importance Analysis
5.2. Best Model
5.3. Regional Adaptability Challenges in Transfer Learning
5.4. Limitations and Future Work
6. Conclusions
- (1)
- In the Songpan region, high landslide susceptibility areas are primarily located in the central, southern, and northeast–southeast transition zones of the study area, while low-susceptibility areas are concentrated in the northwest plateau region. In the Mao County region, high-susceptibility areas are concentrated in the central fault basin, southern deeply cut river valleys, and along the eastern fault zone in a strip-like distribution. Low-susceptibility areas are mainly found in the western plateau and northern folded mountains. This spatial distribution pattern highly matches the spatial distribution characteristics of landslide disaster points, thus validating the scientific and reliable evaluation method used in this study.
- (2)
- The study results highlight the significant influences of factors such as elevation, seismic nucleation density, population density, and distance to roads on landslide susceptibility, further revealing the main controlling factors of landslide disasters in the region.
- (3)
- Compared to the Support Vector Machine model and Extreme Gradient Boosting model, the Random Forest model demonstrated better applicability in both the Songpan and Mao County regions. It exhibited greater advantages in landslide susceptibility prediction tasks and is a more suitable choice for landslide susceptibility analysis in the complex geological environment of western Sichuan. This provides a cross-regional adaptive technical framework and quantitative evaluation paradigm for risk prevention and control in typical geological disaster-prone areas, such as active regions influenced by monsoon climates.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dias, H.C.; Hölbling, D.; Grohmann, C.H. Landslide Susceptibility Mapping in Brazil: A Review. Geosciences 2021, 11, 425. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, J.; Sun, X.; Li, Y.; Zhang, Y.; Xu, W.; Yan, J.; Ji, Y.; Wang, Q. A progressive framework combining unsupervised and optimized supervised learning for debris flow susceptibility assessment. CATENA 2024, 234, 107560. [Google Scholar] [CrossRef]
- Li, Y.-m.; Su, L.-j.; Zou, Q.; Wei, X.-l. Risk assessment of glacial debris flow on alpine highway under climate change: A case study of Aierkuran Gully along Karakoram Highway. J. Mt. Sci. 2021, 18, 1458–1475. [Google Scholar] [CrossRef]
- Hossain, M.N.; Mumu, U.H. Flood susceptibility modelling of the Teesta River Basin through the AHP-MCDA process using GIS and remote sensing. Nat. Hazards 2024, 120, 12137–12161. [Google Scholar] [CrossRef]
- Zhang, G.; Cai, Y.; Zheng, Z.; Zhen, J.; Liu, Y.; Huang, K. Integration of the Statistical Index Method and the Analytic Hierarchy Process technique for the assessment of landslide susceptibility in Huizhou, China. CATENA 2016, 142, 233–244. [Google Scholar] [CrossRef]
- Dash, R.K.; Falae, P.O.; Kanungo, D.P. Debris flow susceptibility zonation using statistical models in parts of Northwest Indian Himalayas—Implementation, validation, and comparative evaluation. Nat. Hazards 2022, 111, 2011–2058. [Google Scholar] [CrossRef]
- Tayyab, M.; Hussain, M.; Zhang, J.; Ullah, S.; Tong, Z.; Rahman, Z.U.; Al-Aizari, A.R.; Al-Shaibah, B. Leveraging GIS-based AHP, remote sensing, and machine learning for susceptibility assessment of different flood types in peshawar, Pakistan. J. Environ. Manag. 2024, 371, 123094. [Google Scholar] [CrossRef]
- Chen, W.; Panahi, M.; Tsangaratos, P.; Shahabi, H.; Ilia, I.; Panahi, S.; Li, S.; Jaafari, A.; Ahmad, B.B. Applying population-based evolutionary algorithms and a neuro-fuzzy system for modeling landslide susceptibility. CATENA 2019, 172, 212–231. [Google Scholar] [CrossRef]
- Youssef, A.M.; Pourghasemi, H.R.; El-Haddad, B.A.; Dhahry, B.K. Landslide susceptibility maps using different probabilistic and bivariate statistical models and comparison of their performance at Wadi Itwad Basin, Asir Region, Saudi Arabia. Bull. Eng. Geol. Environ. 2016, 75, 63–87. [Google Scholar] [CrossRef]
- Huang, F.; Yan, J.; Fan, X.; Yao, C.; Huang, J.; Chen, W.; Hong, H. Uncertainty pattern in landslide susceptibility prediction modelling: Effects of different landslide boundaries and spatial shape expressions. Geosci. Front. 2022, 13, 101317. [Google Scholar] [CrossRef]
- Esper Angillieri, M.Y. Debris flow susceptibility mapping using frequency ratio and seed cells, in a portion of a mountain international route, Dry Central Andes of Argentina. CATENA 2020, 189, 104504. [Google Scholar] [CrossRef]
- Ahmed, B.; Dewan, A. Application of Bivariate and Multivariate Statistical Techniques in Landslide Susceptibility Modeling in Chittagong City Corporation, Bangladesh. Remote Sens. 2017, 9, 304. [Google Scholar] [CrossRef]
- Li, J.; Chen, Y.; Jiao, J.; Chen, Y.; Chen, T.; Zhao, C.; Zhao, W.; Shang, T.; Xu, Q.; Wang, H.; et al. Gully erosion susceptibility maps and influence factor analysis in the Lhasa River Basin on the Tibetan Plateau, based on machine learning algorithms. CATENA 2024, 235, 107695. [Google Scholar] [CrossRef]
- Li, Y.; Chen, J.; Tan, C.; Li, Y.; Gu, F.; Zhang, Y.; Mehmood, Q. Application of the borderline-SMOTE method in susceptibility assessments of debris flows in Pinggu District, Beijing, China. Nat. Hazards 2021, 105, 2499–2522. [Google Scholar] [CrossRef]
- Pourghasemi, H.R.; Rahmati, O. Prediction of the landslide susceptibility: Which algorithm, which precision? CATENA 2018, 162, 177–192. [Google Scholar] [CrossRef]
- Youssef, A.M.; Pourghasemi, H.R. Landslide susceptibility mapping using machine learning algorithms and comparison of their performance at Abha Basin, Asir Region, Saudi Arabia. Geosci. Front. 2021, 12, 639–655. [Google Scholar] [CrossRef]
- Chou, T.-Y.; Hoang, T.-V.; Fang, Y.-M.; Nguyen, Q.-H.; Lai, T.A.; Pham, V.-M.; Vu, V.-M.; Bui, Q.-T. Swarm-based optimizer for convolutional neural network: An application for flood susceptibility mapping. Trans. GIS 2021, 25, 1009–1026. [Google Scholar] [CrossRef]
- Yi, Y.; Zhang, Z.; Zhang, W.; Jia, H.; Zhang, J. Landslide susceptibility mapping using multiscale sampling strategy and convolutional neural network: A case study in Jiuzhaigou region. CATENA 2020, 195, 104851. [Google Scholar] [CrossRef]
- Sharma, N.; Saharia, M.; Ramana, G.V. High resolution landslide susceptibility mapping using ensemble machine learning and geospatial big data. CATENA 2024, 235, 107653. [Google Scholar] [CrossRef]
- Gao, R.; Wang, C.; Wu, D.; Liu, H.; Liu, X. Comprehensive application of transfer learning, unsupervised learning and supervised learning in debris flow susceptibility mapping. Appl. Soft Comput. 2025, 170, 112612. [Google Scholar] [CrossRef]
- Achour, Y.; Pourghasemi, H.R. How do machine learning techniques help in increasing accuracy of landslide susceptibility maps? Geosci. Front. 2020, 11, 871–883. [Google Scholar] [CrossRef]
- Gao, R.-y.; Wang, C.-m.; Liang, Z. Comparison of different sampling strategies for debris flow susceptibility mapping: A case study using the centroids of the scarp area, flowing area and accumulation area of debris flow watersheds. J. Mt. Sci. 2021, 18, 1476–1488. [Google Scholar] [CrossRef]
- Rabby, Y.W.; Hossain, M.B.; Abedin, J. Landslide susceptibility mapping in three Upazilas of Rangamati hill district Bangladesh: Application and comparison of GIS-based machine learning methods. Geocarto Int. 2022, 37, 3371–3396. [Google Scholar] [CrossRef]
- Shi, X.; Chen, D.; Wang, J.; Wang, P.; Wu, Y.; Zhang, S.; Zhang, Y.; Yang, C.; Wang, L. Refined landslide inventory and susceptibility of Weining County, China, inferred from machine learning and Sentinel-1 InSAR analysis. Trans. GIS 2024, 28, 1594–1616. [Google Scholar] [CrossRef]
- Zhu, X.; Guo, H.; Huang, J.J. Urban flood susceptibility mapping using remote sensing, social sensing and an ensemble machine learning model. Sustain. Cities Soc. 2024, 108, 105508. [Google Scholar] [CrossRef]
- Zhang, Y.; Ge, T.; Tian, W.; Liou, Y.-A. Debris Flow Susceptibility Mapping Using Machine-Learning Techniques in Shigatse Area, China. Remote Sens. 2019, 11, 2801. [Google Scholar] [CrossRef]
- Dou, J.; Yunus, A.P.; Bui, D.T.; Merghadi, A.; Sahana, M.; Zhu, Z.; Chen, C.-W.; Han, Z.; Pham, B.T. Improved landslide assessment using support vector machine with bagging, boosting, and stacking ensemble machine learning framework in a mountainous watershed, Japan. Landslides 2020, 17, 641–658. [Google Scholar] [CrossRef]
- Shirzadi, A.; Shahabi, H.; Chapi, K.; Bui, D.T.; Pham, B.T.; Shahedi, K.; Ahmad, B.B. A comparative study between popular statistical and machine learning methods for simulating volume of landslides. CATENA 2017, 157, 213–226. [Google Scholar] [CrossRef]
- Lin, Y.; Jin, Y.; Lin, M.; Wen, L.; Lai, Q.; Zhang, F.; Ge, Y.; Li, B. Exploring the spatial and temporal evolution of landscape ecological risks under tourism disturbance: A case study of the Min River Basin, China. Ecol. Indic. 2024, 166, 112412. [Google Scholar] [CrossRef]
- Lin, Y.; Hu, X.; Zheng, X.; Hou, X.; Zhang, Z.; Zhou, X.; Qiu, R.; Lin, J. Spatial variations in the relationships between road network and landscape ecological risks in the highest forest coverage region of China. Ecol. Indic. 2019, 96, 392–403. [Google Scholar] [CrossRef]
- Liu, J.; Wang, J.; Wang, S.; Wang, J.; Deng, G. Analysis and simulation of the spatiotemporal evolution pattern of tourism lands at the Natural World Heritage Site Jiuzhaigou, China. Habitat Int. 2018, 79, 74–88. [Google Scholar] [CrossRef]
- Zhang, Y.-Q.; Wang, Y.-L.; Li, H.; Li, X.-M. Risk assessment of mountain tourism on the Western Sichuan Plateau, China. J. Mt. Sci. 2023, 20, 3360–3375. [Google Scholar] [CrossRef]
- Liu, Y.; Peng, J.; Zhang, T.; Zhao, M. Assessing landscape eco-risk associated with hilly construction land exploitation in the southwest of China: Trade-off and adaptation. Ecol. Indic. 2016, 62, 289–297. [Google Scholar] [CrossRef]
- Cao, J.; Zhang, Z.; Du, J.; Zhang, L.; Song, Y.; Sun, G. Multi-geohazards susceptibility mapping based on machine learning—A case study in Jiuzhaigou, China. Nat. Hazards 2020, 102, 851–871. [Google Scholar] [CrossRef]
- Li, Y.; Xu, L.; Shang, Y.; Chen, S. Debris Flow Susceptibility Evaluation in Meizoseismal Region: A Case Study in Jiuzhaigou, China. J. Earth Sci. 2024, 35, 263–279. [Google Scholar] [CrossRef]
- Chen, X.; Chen, H.; You, Y.; Chen, X.; Liu, J. Weights-of-evidence method based on GIS for assessing susceptibility to debris flows in Kangding County, Sichuan Province, China. Environ. Earth Sci. 2015, 75, 70. [Google Scholar] [CrossRef]
- Xu, W.; Yu, W.; Jing, S.; Zhang, G.; Huang, J. Debris flow susceptibility assessment by GIS and information value model in a large-scale region, Sichuan Province (China). Nat. Hazards 2013, 65, 1379–1392. [Google Scholar] [CrossRef]
- Di, B.; Zhang, H.; Liu, Y.; Li, J.; Chen, N.; Stamatopoulos, C.A.; Luo, Y.; Zhan, Y. Assessing Susceptibility of Debris Flow in Southwest China Using Gradient Boosting Machine. Sci. Rep. 2019, 9, 12532. [Google Scholar] [CrossRef]
- Xiong, K.; Adhikari, B.R.; Stamatopoulos, C.A.; Zhan, Y.; Wu, S.; Dong, Z.; Di, B. Comparison of Different Machine Learning Methods for Debris Flow Susceptibility Mapping: A Case Study in the Sichuan Province, China. Remote Sens. 2020, 12, 295. [Google Scholar] [CrossRef]
- Hu, X.; Wang, J.; Hu, J.; Hu, K.; Zhou, L.; Liu, W. Probabilistic identification of debris flow source areas in the Wenchuan earthquake-affected region of China based on Bayesian geomorphology. Environ. Earth Sci. 2024, 83, 528. [Google Scholar] [CrossRef]
- Zêzere, J.L.; Pereira, S.; Melo, R.; Oliveira, S.C.; Garcia, R.A.C. Mapping landslide susceptibility using data-driven methods. Sci. Total Environ. 2017, 589, 250–267. [Google Scholar] [CrossRef]
- Martinello, C.; Chiara, C.; Christian, C.; Valerio, A.; Rotigliano, E. Optimal slope units partitioning in landslide susceptibility mapping. J. Maps 2021, 17, 152–162. [Google Scholar] [CrossRef]
- Ma, S.; Shao, X.; Xu, C. Potential Controlling Factors and Landslide Susceptibility Features of the 2022 Ms 6.8 Luding Earthquake. Remote Sens. 2024, 16, 2861. [Google Scholar] [CrossRef]
- Bregoli, F.; Medina, V.; Chevalier, G.; Hürlimann, M.; Bateman, A. Debris-flow susceptibility assessment at regional scale: Validation on an alpine environment. Landslides 2015, 12, 437–454. [Google Scholar] [CrossRef]
- Zhao, Z.; Liu, Z.y.; Xu, C. Slope Unit-Based Landslide Susceptibility Mapping Using Certainty Factor, Support Vector Machine, Random Forest, CF-SVM and CF-RF Models. Front. Earth Sci. 2021, 9, 589630. [Google Scholar] [CrossRef]
- Zeng, T.; Wu, L.; Hayakawa, Y.S.; Yin, K.; Gui, L.; Jin, B.; Guo, Z.; Peduto, D. Advanced integration of ensemble learning and MT-InSAR for enhanced slow-moving landslide susceptibility zoning. Eng. Geol. 2024, 331, 107436. [Google Scholar] [CrossRef]
- Liu, Q.; Tang, A.; Huang, D. Exploring the uncertainty of landslide susceptibility assessment caused by the number of non–landslides. CATENA 2023, 227, 107109. [Google Scholar] [CrossRef]
- Hong, H.; Miao, Y.; Liu, J.; Zhu, A.X. Exploring the effects of the design and quantity of absence data on the performance of random forest-based landslide susceptibility mapping. CATENA 2019, 176, 45–64. [Google Scholar] [CrossRef]
- Dou, H.-q.; Huang, S.-y.; Jian, W.-b.; Wang, H. Landslide susceptibility mapping of mountain roads based on machine learning combined model. J. Mt. Sci. 2023, 20, 1232–1248. [Google Scholar] [CrossRef]
- Woodard, J.B.; Mirus, B.B. Overcoming the data limitations in landslide susceptibility modeling. Sci. Adv. 2025, 11, eadt1541. [Google Scholar] [CrossRef]
- Lloyd, S. Least squares quantization in PCM. IEEE Trans. Inf. Theory 1982, 28, 129–137. [Google Scholar] [CrossRef]
- Brenning, A. Spatial cross-validation and bootstrap for the assessment of prediction rules in remote sensing: The R package sperrorest. In Proceedings of the 2012 IEEE International Geoscience and Remote Sensing Symposium, Munich, Germany, 22–27 July 2012; pp. 5372–5375. [Google Scholar]
- Lee, R.; White, C.J.; Adnan, M.S.G.; Douglas, J.; Mahecha, M.D.; O’Loughlin, F.E.; Patelli, E.; Ramos, A.M.; Roberts, M.J.; Martius, O.; et al. Reclassifying historical disasters: From single to multi-hazards. Sci. Total Environ. 2024, 912, 169120. [Google Scholar] [CrossRef]
- Javidan, N.; Kavian, A.; Pourghasemi, H.R.; Conoscenti, C.; Jafarian, Z.; Rodrigo-Comino, J. Evaluation of multi-hazard map produced using MaxEnt machine learning technique. Sci. Rep. 2021, 11, 6496. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, H.D.; Dang, D.-K.; Bui, Q.-T.; Petrisor, A.-I. Multi-hazard assessment using machine learning and remote sensing in the North Central region of Vietnam. Trans. GIS 2023, 27, 1614–1640. [Google Scholar] [CrossRef]
- Lin, Q.; Steger, S.; Pittore, M.; Zhang, J.; Wang, L.; Jiang, T.; Wang, Y. Evaluation of potential changes in landslide susceptibility and landslide occurrence frequency in China under climate change. Sci. Total Environ. 2022, 850, 158049. [Google Scholar] [CrossRef] [PubMed]
- Duan, Y.; Xiong, J.; Cheng, W.; Wang, N.; Li, Y.; He, Y.; Liu, J.; He, W.; Yang, G. Flood vulnerability assessment using the triangular fuzzy number-based analytic hierarchy process and support vector machine model for the Belt and Road region. Nat. Hazards 2022, 110, 269–294. [Google Scholar] [CrossRef]
- Thi Thuy Linh, N.; Pandey, M.; Janizadeh, S.; Sankar Bhunia, G.; Norouzi, A.; Ali, S.; Bao Pham, Q.; Tran Anh, D.; Ahmadi, K. Flood susceptibility modeling based on new hybrid intelligence model: Optimization of XGboost model using GA metaheuristic algorithm. Adv. Space Res. 2022, 69, 3301–3318. [Google Scholar] [CrossRef]
- Li, Y.; Lei, Y.; Chen, B.; Chen, J. Evaluation of geological hazard susceptibility based on the multi-kernel density information method. Sci. Rep. 2025, 15, 7892. [Google Scholar] [CrossRef]
- Alqadhi, S.; Mallick, J.; Hang, H.T.; Al Asmari, A.F.S.; Kumari, R. Evaluating the influence of road construction on landslide susceptibility in Saudi Arabia’s mountainous terrain: A Bayesian-optimised deep learning approach with attention mechanism and sensitivity analysis. Environ. Sci. Pollut. Res. 2024, 31, 3169–3194. [Google Scholar] [CrossRef]
- Pokharel, B.; Althuwaynee, O.F.; Aydda, A.; Kim, S.-W.; Lim, S.; Park, H.-J. Spatial clustering and modelling for landslide susceptibility mapping in the north of the Kathmandu Valley, Nepal. Landslides 2021, 18, 1403–1419. [Google Scholar] [CrossRef]
- Crozier, M.J. Deciphering the effect of climate change on landslide activity: A review. Geomorphology 2010, 124, 260–267. [Google Scholar] [CrossRef]
- Achu, A.L.; Aju, C.D.; Di Napoli, M.; Prakash, P.; Gopinath, G.; Shaji, E.; Chandra, V. Machine-learning based landslide susceptibility modelling with emphasis on uncertainty analysis. Geosci. Front. 2023, 14, 101657. [Google Scholar] [CrossRef]
- Zeng, T.; Jin, B.; Glade, T.; Xie, Y.; Li, Y.; Zhu, Y.; Yin, K. Assessing the imperative of conditioning factor grading in machine learning-based landslide susceptibility modeling: A critical inquiry. CATENA 2024, 236, 107732. [Google Scholar] [CrossRef]
- Agboola, G.; Beni, L.H.; Elbayoumi, T.; Thompson, G. Optimizing landslide susceptibility mapping using machine learning and geospatial techniques. Ecol. Inform. 2024, 81, 102583. [Google Scholar] [CrossRef]
- Chang, Z.; Catani, F.; Huang, F.; Liu, G.; Meena, S.R.; Huang, J.; Zhou, C. Landslide susceptibility prediction using slope unit-based machine learning models considering the heterogeneity of conditioning factors. J. Rock Mech. Geotech. Eng. 2023, 15, 1127–1143. [Google Scholar] [CrossRef]
- Yang, C.; Liu, L.-L.; Huang, F.; Huang, L.; Wang, X.-M. Machine learning-based landslide susceptibility assessment with optimized ratio of landslide to non-landslide samples. Gondwana Res. 2023, 123, 198–216. [Google Scholar] [CrossRef]
- Hussain, M.A.; Chen, Z.; Zheng, Y.; Zhou, Y.; Daud, H. Deep Learning and Machine Learning Models for Landslide Susceptibility Mapping with Remote Sensing Data. Remote Sens. 2023, 15, 4703. [Google Scholar] [CrossRef]
- Lyu, H.-M.; Yin, Z.-Y. Flood susceptibility prediction using tree-based machine learning models in the GBA. Sustain. Cities Soc. 2023, 97, 104744. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Jones, S.; Shabani, F. Identifying the essential flood conditioning factors for flood prone area mapping using machine learning techniques. CATENA 2019, 175, 174–192. [Google Scholar] [CrossRef]
- Kumar, A.; Sarkar, R. Debris Flow Susceptibility Evaluation—A Review. Iranian Journal of Science and Technology. Trans. Civ. Eng. 2023, 47, 1277–1292. [Google Scholar] [CrossRef]
- Kazemi, F.; Asgarkhani, N.; Jankowski, R. Optimization-Based Stacked Machine-Learning Method for Seismic Probability and Risk Assessment of Reinforced Concrete Shear Walls. Expert Syst. Appl. 2024, 255, 124897. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Micheletti, N.; Foresti, L.; Robert, S.; Leuenberger, M.; Pedrazzini, A.; Jaboyedoff, M.; Kanevski, M. Machine Learning Feature Selection Methods for Landslide Susceptibility Mapping. Math. Geosci. 2014, 46, 33–57. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Gorsevski, P.V.; Brown, M.K.; Panter, K.; Onasch, C.M.; Simic, A.; Snyder, J. Landslide detection and susceptibility mapping using LiDAR and an artificial neural network approach: A case study in the Cuyahoga Valley National Park, Ohio. Landslides 2016, 13, 467–484. [Google Scholar] [CrossRef]
- Merghadi, A.; Yunus, A.P.; Dou, J.; Whiteley, J.; ThaiPham, B.; Bui, D.T.; Avtar, R.; Abderrahmane, B. Machine learning methods for landslide susceptibility studies: A comparative overview of algorithm performance. Earth-Sci. Rev. 2020, 207, 103225. [Google Scholar] [CrossRef]
- Liu, Q.; Huang, D.; Tang, A.; Han, X. Model performance analysis for landslide susceptibility in cold regions using accuracy rate and fluctuation characteristics. Nat. Hazards 2021, 108, 1047–1067. [Google Scholar] [CrossRef]
- Soma, A.S.; Kubota, T.; Mizuno, H. Optimization of causative factors using logistic regression and artificial neural network models for landslide susceptibility assessment in Ujung Loe Watershed, South Sulawesi Indonesia. J. Mt. Sci. 2019, 16, 383–401. [Google Scholar] [CrossRef]
- Tian, C.; Liu, X.; Wang, J. Susceptibility assessment of geological hazards in Guangdong Province based on CF and Logistic regression models. Hydrogeol. Eng. Geol. 2016, 43, 154–161+170, (In Chinese with English abstract). [Google Scholar] [CrossRef]
- Duarte, E.; Wainer, J. Empirical comparison of cross-validation and internal metrics for tuning SVM hyperparameters. Pattern Recognit. Lett. 2017, 88, 6–11. [Google Scholar] [CrossRef]
- Schratz, P.; Muenchow, J.; Iturritxa, E.; Richter, J.; Brenning, A. Hyperparameter tuning and performance assessment of statistical and machine-learning algorithms using spatial data. Ecol. Model. 2019, 406, 109–120. [Google Scholar] [CrossRef]
- Cao, J.; Zhang, Z.; Wang, C.; Liu, J.; Zhang, L. Susceptibility assessment of landslides triggered by earthquakes in the Western Sichuan Plateau. CATENA 2019, 175, 63–76. [Google Scholar] [CrossRef]
- He, Y.; Ding, M.; Duan, Y.; Zheng, H.; He, W.; Liu, J. Debris flows dynamic risk assessment and interpretable Shapley method-based driving mechanisms exploring—A case study of the upper reach of the Min River. Ecol. Indic. 2025, 173, 113400. [Google Scholar] [CrossRef]
- Liu, R.; Han, J.; Gou, J.; Cao, K.; Pan, X.; Wang, D. Indispensable factors in landslide susceptibility modeling: The critical role of slope unit quantity-sensitivity. Earth Sci. Inform. 2025, 18, 248. [Google Scholar] [CrossRef]
- Zhou, C.; Ye, M.; Xia, Z.; Wang, W.; Luo, C.; Muller, J.-P. An interpretable attention-based deep learning method for landslide prediction based on multi-temporal InSAR time series: A case study of Xinpu landslide in the TGRA. Remote Sens. Environ. 2025, 318, 114580. [Google Scholar] [CrossRef]
- Zhu, A.X.; Miao, Y.; Wang, R.; Zhu, T.; Deng, Y.; Liu, J.; Yang, L.; Qin, C.-Z.; Hong, H. A comparative study of an expert knowledge-based model and two data-driven models for landslide susceptibility mapping. CATENA 2018, 166, 317–327. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Type | Source of Information | Spatial Resolution |
|---|---|---|
| Debris Flow Hazard Spatial Dataset | The Resources and Environmental Sciences Data Center of the Chinese Academy of Sciences | Vector data |
| Digital Elevation Model (DEM) | 12.5 m | |
| Road Network Vector Data | Vector data | |
| Land Use Raster Data | 30 m | |
| Geological Fault Line Vectors | Vector data | |
| Seismic Hazard Point Distributions | Vector data | |
| Annual Precipitation Raster Data | 1 km | |
| Soil Erosion Type and Intensity Classification Rasters | 1 km | |
| Normalized Difference Vegetation Index (NDVI) Raster Data | 250 m | |
| Population Spatial Distribution | 1 km |
| Conditioning Factors | Very Low | Low | Moderate | High | Very High |
|---|---|---|---|---|---|
| Elevation (m) | 1009.10–2416.90 | 2416.90–3120.80 | 3120.80–3578.33 | 3578.33–3983.07 | 3983.08–5496.46 |
| Slope (°) | 0–14 | 14–24 | 24–32 | 32–43 | 43–86 |
| Topographic Wetness Index | 0–4 | 4–6 | 6–9 | 9–14 | 14–33 |
| Stream Power Index | 0–4.0 × 103 | 4.0 × 103–1.0 × 104 | 1.0 × 104–5.0 × 104 | 5.0 × 104–1.0 × 106 | 1.0 × 106–8.66 × 107 |
| Drainage Basin Shape Coefficient | 0–0.25 | 0.25–0.5 | 0.5–0.75 | 0.75–1 | 1–478 |
| Drainage Basin Area (km2) | 0–2.47 | 2.47–5.61 | 5.61–9.59 | 9.59–16.09 | 16.09–45.96 |
| Maximum Flow Length (km) | 0–2.50 | 2.50–4.26 | 4.26–6.05 | 6.05–8.85 | 8.85–17.53 |
| Maximum Flow Gradient | 0–0.127 | 0.127–0.204 | 0.204–0.293 | 0.29–0.401 | 0.401–0.732 |
| Seismic Nucleation Density | 4.4 × 10−5–4.8 × 10−5 | 4.9 × 10−5–5.1 × 10−5 | 5.2 × 10−5–5.4 × 10−5 | 5.4 × 10−5–5.6 × 10−5 | 5.6 × 10−5–5.7 × 10−5 |
| Fault Distance (km) | 0–4 | 4–10 | 10–16 | 16–22 | 22–30 |
| Normalized Difference Vegetation Index | 0.082–0.410 | 0.411–0.596 | 0.597–0.729 | 0.730–0.808 | 0.809–0.912 |
| Soil Erosion (kg/m2/a) | 0.015–12.94 | 12.94–42.02 | 42.02–87.26 | 87.26–166.42 | 166.42–411.99 |
| Annual Rainfall (mm) | 685.31–734.83 | 734.83–758.33 | 758.33–790.23 | 790.23–826.32 | 826.32–899.34 |
| Population Statistics (person/km2) | 0–2 | 2–10 | 10–30 | 30–70 | 70–214 |
| Distance to Road (km) | 0–3 | 3–8 | 8–13 | 13–22 | 22–39 |
| Model | Hyperparameter | Definition | Optimum |
|---|---|---|---|
| SVM | C | Regularization parameter that controls the trade-off between achieving a low error and keeping the model simple. Higher values reduce bias but may increase variance. | 10 |
| gamma | Defines how far the influence of a single training example reaches. A lower value means a larger influence region. | scale | |
| kernel | Specifies the kernel type to be used in the algorithm, affecting decision boundaries. | RBF | |
| RF | n_estimators | The number of trees in the forest. More trees generally improve performance but increase computation time. | 200 |
| max_depth | The maximum depth of each decision tree. If none, nodes are expanded until all leaves are pure. | 10 | |
| min_samples_split | The minimum number of samples required to split an internal node. Higher values prevent overfitting. | 2 | |
| min_samples_leaf | The minimum number of samples required to be at a leaf node. Higher values make the model more robust. | 1 | |
| XGBoost | n_estimators | The number of boosting rounds. More rounds can improve performance but may lead to overfitting. | 100 |
| max_depth | Maximum depth of a tree. Larger values capture more patterns but increase complexity. | 6 | |
| learning_rate | Controls the step size in updating weights. Lower values lead to slower but more stable convergence. | 0.2 | |
| subsample | Fraction of training samples used in each boosting iteration to prevent overfitting. | 1.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, T.; Huang, Q.; Chen, Q. Debris Flow Susceptibility Prediction Using Transfer Learning: A Case Study in Western Sichuan, China. Appl. Sci. 2025, 15, 7462. https://doi.org/10.3390/app15137462
Li T, Huang Q, Chen Q. Debris Flow Susceptibility Prediction Using Transfer Learning: A Case Study in Western Sichuan, China. Applied Sciences. 2025; 15(13):7462. https://doi.org/10.3390/app15137462
Chicago/Turabian StyleLi, Tiezhu, Qidi Huang, and Qigang Chen. 2025. "Debris Flow Susceptibility Prediction Using Transfer Learning: A Case Study in Western Sichuan, China" Applied Sciences 15, no. 13: 7462. https://doi.org/10.3390/app15137462
APA StyleLi, T., Huang, Q., & Chen, Q. (2025). Debris Flow Susceptibility Prediction Using Transfer Learning: A Case Study in Western Sichuan, China. Applied Sciences, 15(13), 7462. https://doi.org/10.3390/app15137462