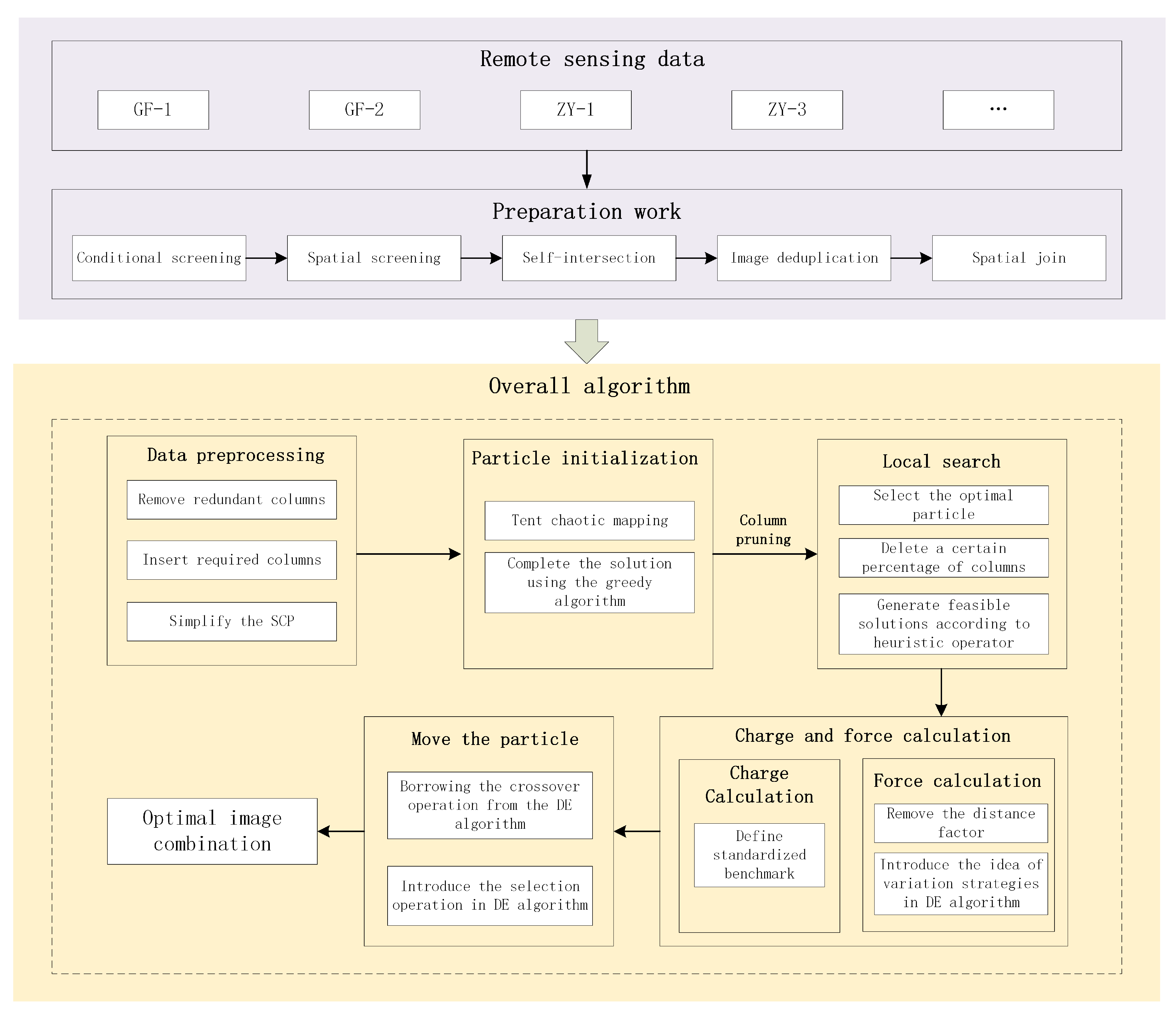
3.3. Experimental Design
In order to verify whether the improved algorithm outperforms the original algorithm in terms of optimization seeking performance, we have conducted a systematic experimental design aiming at evaluating the performance of the improved algorithm in terms of processing speed, optimal solution, and robustness, etc., and the following is a detailed description of the experiments. To present the differences among various experimental groups in key aspects more clearly,
Table 2 is specifically created.
Experiment A: Greedy algorithm. A locally optimal solution is obtained based on the rule that column covers the maximum number of rows.
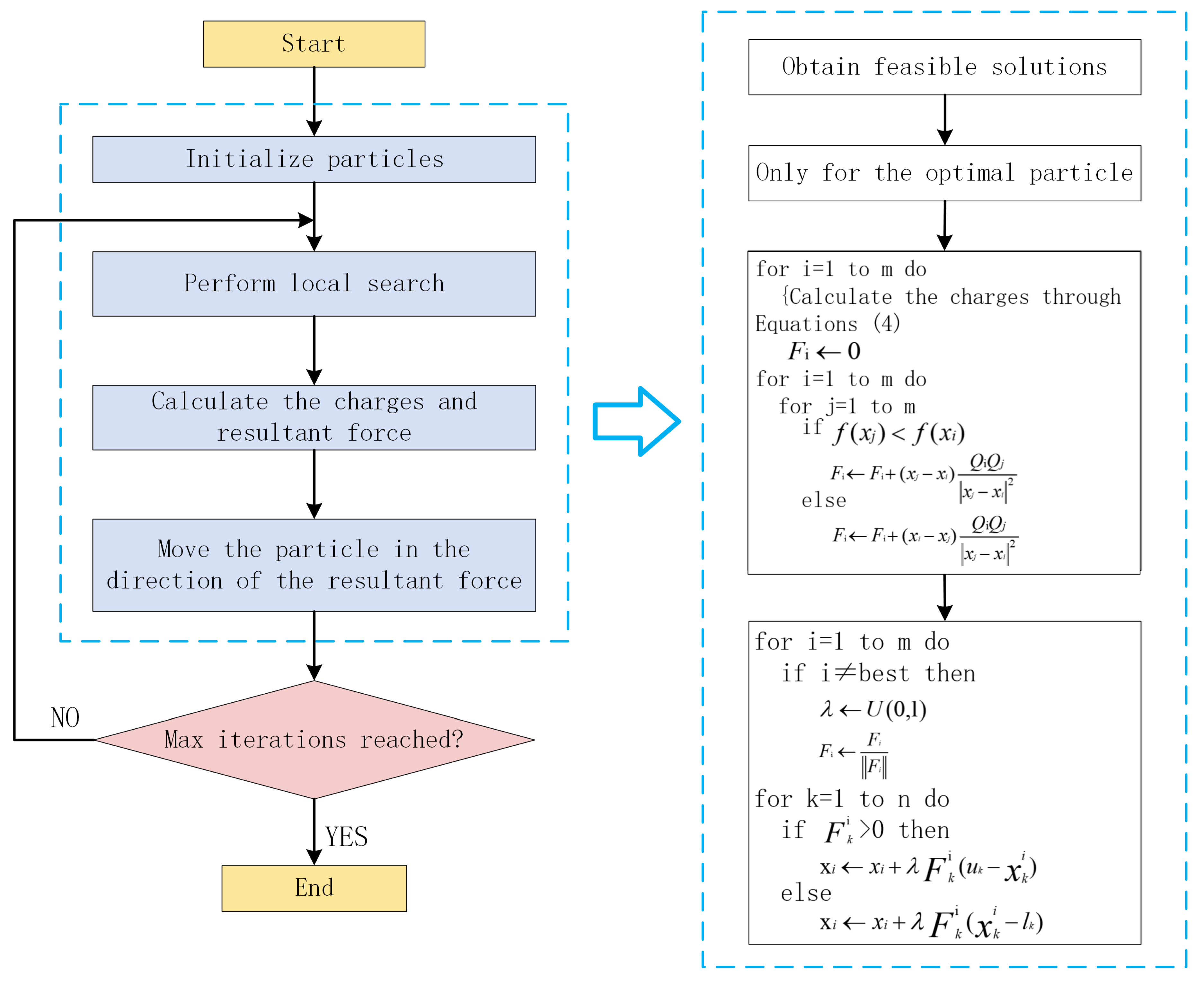
Experiment B: EM algorithm experiment. We use the greedy algorithm to obtain a locally optimal solution and then repeat the local search process m times to generate the initial population. This local search process uses the local search strategy mentioned in
Section 2.3.3 of this paper. At this point, after generating a new solution, there may be some redundant columns, so a column pruning process is added. The specific process is to traverse all the columns, if the solution obtained after deleting the column can still cover all the rows, the column is considered to be redundant and the column is deleted.
Experiment C: Tent chaotic map to construct initial population experiment. The method can both fully utilize the traversal advantages of chaos and produce more uniform particles.
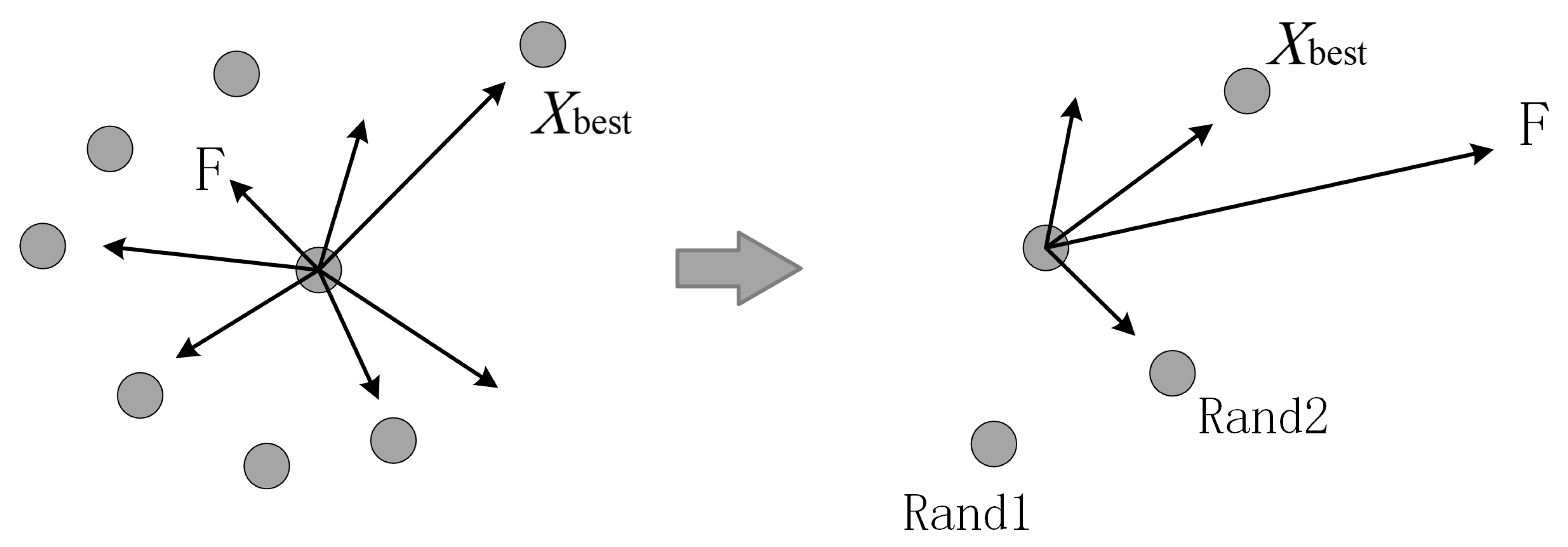
Experiment D: Improved EM algorithm experiment. Based on experiment C, in order to optimize the experimental results and ensure that the particles in the population move towards the optimal solution every time, we introduced the idea of DE algorithm in the process of moving particles.
Experiment E: Comparative Reference Experiment. We respectively use the ant colony optimization algorithm (ACO), the genetic algorithm (GA), and the particle swarm optimization algorithm (PSO) to conduct the optimal screening of remote sensing data for the United States, Hebei 1, Hebei 2, and Inner Mongolia regions, so as to further evaluate the performance and effect of the algorithms in this study.
In experiment BCD, we set the iteration number to 50 and the initial population number to 15 to remain unchanged, and the value range for different deletion column proportion parameters is 0.1–0.5 (0.1, 0.2, 0.3, 0.4, and 0.5). The control parameter pop of different threshold ranges from 0.7 to 0.95 (0.7, 0.8, 0.85, 0.9, and 0.95).
3.4. Result and Discussion
Based on the U.S. regional datasets, we set the cost of each view image to be the same (i.e., ), resulting in a cost of 1786 for the pre-screening data.
The optimal solution cost of Experiment A is 340, and the result is the same every time. When Experiment C also uses the same column pruning process as Experiment B, the minimum cost is 299, which takes 3497.77 s. From
Table 3, the column pruning process of Experiment C consumes about 80.89% of the time. After we completely deleted this process, the minimum cost is 315, which takes 1647.24 s. If we only perform column pruning after constructing the initial population, we obtain the minimum cost of 307, which takes 2007.69 s, where the column pruning process consumes 15.38% of the time. From the above experimental results, we can see that column pruning operation is crucial to the optimization of the algorithm. However, considering the influence of time, we choose to carry out the column pruning operation only after generating the initial population, at which time the experimental optimal result is 307, which is reduced by 8–22 compared to Experiment B, and the time consumed is significantly reduced, which is exactly what was adopted for Experiment C recorded in
Table 4.
The running results of Experiment BCD are shown in
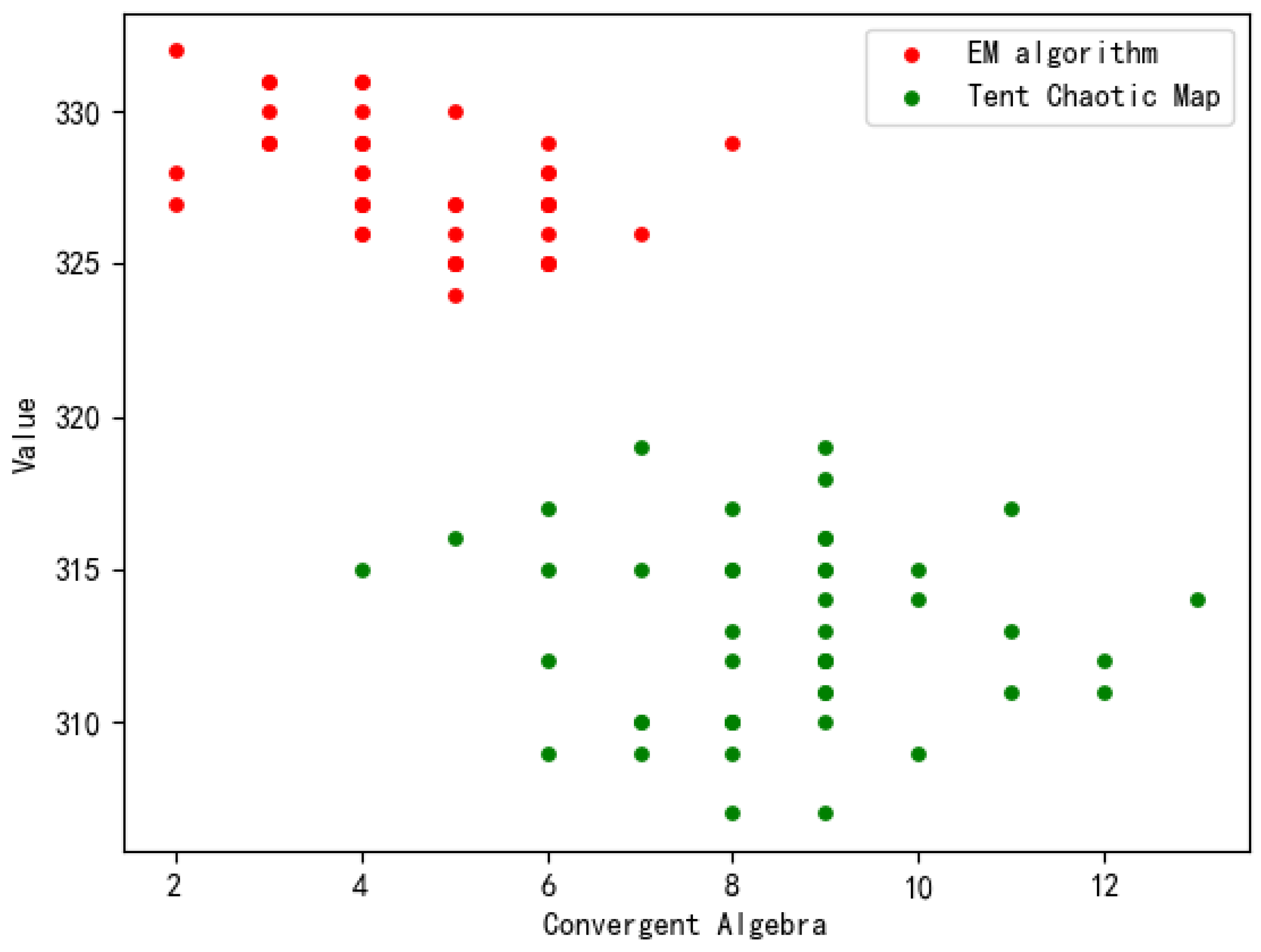
Table 4. We choose the convergence algebra and optimal solution cost in Experiment B and Experiment C to plot the scatter plot. As shown in
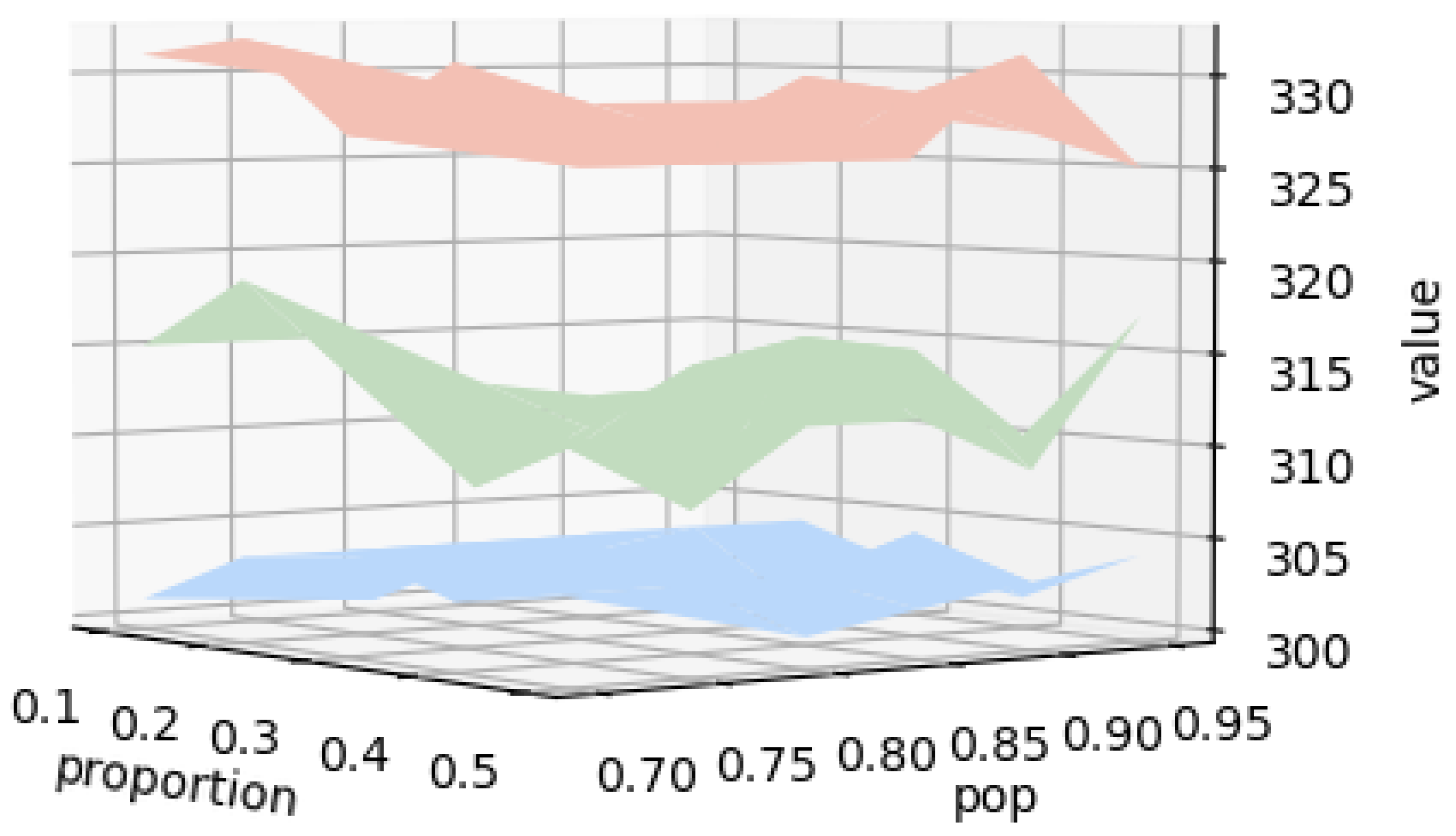
Figure 5, the initial population constructed by the tent chaotic map has a richer diversity and more uniform distribution, i.e., it is easier to escape from the local optimum, and at the same time, it has a better optimization performance. In Experiment D, we obtain a minimum cost of 300, which takes 1821.54 s. We plotted a 3D surface map based on the different parameter settings of Experiment BCD, with each parameter combination corresponding to a surface, as shown in
Figure 6. It can be seen that the experimental results of the improved algorithm are better.
To further explore the effect of population size on the experimental results, we increased the initial population number to 30, and chose the set of parameter configurations that contained the largest number of optimal solutions, i.e., we chose a pop value of 0.85 for the experiment. As shown in
Table 5, when the initial population size is doubled, the minimum cost of 298 is obtained, which takes 4091.61 s. The cost of the optimal solution shows a decreasing trend in general, but the decrease is not significant, while at the same time, the corresponding running time increases significantly. Similarly, in order to determine the effect of the number of iterations on the experimental results, the number of iterations was increased to 100 for the experiments, and it was found that its minimum cost did not fluctuate significantly with the increase in the number of iterations, and its convergence algebra was almost the same as that of 50 iterations in
Table 4. After the validation of several repetitions of the experiment, we found that the experiment was able to achieve the optimal balance between efficiency and solution quality when the iteration number is set to 50 and the initial population is set to 15.
Based on the analysis of the above experimental results, we find that the improved EM algorithm proposed in this paper exhibits low sensitivity to these parameter adjustments, which highlights its robustness in the face of parameter changes. In other words, even if the parameters fluctuate within a certain range, the algorithm can still maintain a stable performance. In addition, the implementation of the algorithmic improvement strategy at each step of the process improves the performance of the algorithm, resulting in a more efficient final result compared to the previous one.
In order to verify the feasibility and effectiveness of the improved EM algorithm proposed in this paper to solve the optimization screening problem of remote sensing data, we use the datasets of Hebei and Inner Mongolia for screening. We summarize the results obtained by using other meta-heuristic algorithms for data screening in Experiment E in
Table 6, and through comparative analysis, we find that there are differences in the data screening effects of different algorithms for different regions, which may be related to the characteristics of regional data and the design of the algorithms. In each region, the improved EM algorithm screened the least number of scenes, followed by PSO and greedy algorithm, and the GA and ACO had poor screening results.
Because the greedy algorithm is representative in the field of remote sensing image screening, we use the greedy algorithm as a benchmark method, and we find that the improved EM algorithm improves its optimal solution by about 9.78% on average compared to the greedy algorithm. In order to verify that the improvement was not caused by randomization, we conducted a paired sample t-test and confidence intervals. The original hypothesis (H0) was that there is no significant difference between the screening results of the two methods (mean difference is 0), and the alternative hypothesis (H1) is that there is a significant difference between the screening results of the two methods (mean difference is not 0). The result p-value = 0.0287 < 0.05 was obtained, then, the original hypothesis was rejected and the two methods were considered to show a significant difference in the screening results. Specifically, the mean difference between the two methods is 46, indicating that the greedy screening method is 46 units higher than the improved EM algorithm screening method in terms of screening effectiveness. In addition, the 95% confidence interval ranges from 9.07 to 82.93, which means that we can assume with 95% certainty that the actual mean difference falls within this interval.
These experimental results show that using the improved EM algorithm proposed in this paper to solve the problem can effectively eliminate most of the duplicate coverage data existing in the remote sensing datasets, and obtain the smallest possible dataset that satisfies the conditions, and the optimal solution of the improved EM algorithm is improved by about 9.78% on average compared with the greedy algorithm. Regarding the computational cost, the greedy screening method takes much less time than the improved EM algorithm. Although the improved EM algorithm performs well in screening results, its higher computational cost may limit its application on large-scale datasets. In the future, we will explore optimization strategies to reduce the computational complexity through algorithm optimization and hardware acceleration (e.g., GPU parallel computing). The experimental data in this study are mainly from four regions, and there may be a dependence on region-specific data, which may be affected by the uniformity of regional data distribution. In order to improve the generalization ability of the algorithm, we plan to introduce more diverse datasets in future studies.
The solution of the SCP is not only of theoretical significance, but also has a wide range of applications in real life. For example, by solving the SCP, we can apply its methodology to the fire station location problem [
6]. In fire station layout, we need to determine the location of the minimum number of fire stations that can respond quickly to fire and emergency rescue needs throughout the city. This corresponds directly to the goal in the set coverage problem: to select the fewest sets (or regions) such that the concatenation of these sets covers the entire fire risk area of the city. Therefore, the solution of the SCP is not only a theoretical algorithmic optimization, but also an effective tool for solving important problems in real life. As future work, we plan to explore more intelligent optimization algorithms. Additionally, we will actively expand cross-disciplinary applications by integrating deep learning, and apply the results to fields such as urban planning and disaster warning.


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}