1. Introduction
Advances in Deep Learning for Sound Source Localization: Challenges and Opportunities. As a core technology for environmental sensing, sound source localization (SSL) provides indispensable capabilities across public security, marine exploration [
1,
2], smart home interaction [
3], and airspace surveillance [
4]. In security systems, precise SSL enables rapid localization of emergency events. For marine monitoring, its accuracy in underwater target detection directly impacts national security and ecological studies. In smart homes, SSL-based voice interfaces must overcome complex reverberation to enhance user experience. However, traditional methods—including beamforming [
5], time-delay estimation [
6], and MUSIC algorithm [
7]—rely on manually designed physical models and idealized assumptions, proving inadequate for dynamic real-world scenarios. Specific challenges include spatiotemporal heterogeneity of sound speed profiles in marine environments, high reverberation with a low signal-to-noise ratio (SNR) in indoor spaces, and non-stationary UAV noise characteristics [
8,
9], which significantly degrade traditional localization accuracy or cause complete failure.
Recent breakthroughs in deep learning have revolutionized SSL through three key advantages: end-to-end feature adaptability, data-driven modeling scalability, and cross-scenario generalization. In marine applications, complex-valued convolutional networks achieve centimeter-level precision under a low SNR via phase information fusion. For indoor reverberant environments, attention mechanisms combined with multimodal architectures suppress multi-source interference through adaptive acoustic feature weighting. UAV monitoring systems integrate lightweight models with spatio-temporal Transformers to attain sub-meter accuracy at −10 dB SNR while addressing edge computing constraints. Nevertheless, three critical challenges persist: the insufficient integration of environmental physics limiting model generalization [
10]; the prohibitive costs of data annotation hindering unsupervised/few-shot learning [
11]; unresolved trade-offs between real-time processing and accuracy in edge deployments [
12].
The German Aerospace Center (DLR) exemplifies cutting-edge applications through two initiatives:
Marine Systems: The DLR Institute for the Protection of Maritime Infrastructures developed Autonomous Underwater Vehicles (AUVs) equipped with dual-frequency side-scan sonars for seabed mapping and multibeam echosounders for bathymetry. Integrated with terrestrial and aerial surveillance networks, these systems enable the near-real-time detection of mobile underwater targets.
Aerial Systems: At the National Experimental Test Center for Unmanned Aircraft Systems in Cochstedt, the DLR tests UAV platforms for medical supply delivery to remote areas, disaster relief, agricultural monitoring, and industrial logistics. These applications underscore the urgent need for robust UAV detection and localization technologies (see
Figure 1).
This comprehensive review structures its analysis as follows:
Section 2 categorizes technical challenges and deep learning solutions across three domains: marine [
13,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23,
24,
25,
26,
27] (e.g., phase-sensitive networks), indoor [
26,
28,
29,
30,
31,
32,
33,
34,
35] (e.g., attention-based fusion), and UAV [
36,
37,
38,
39,
40,
41,
42,
43,
44] (e.g., spatiotemporal Transformers).
Section 3 elucidates fundamental SSL principles, detailing feature extraction (time–frequency transforms, phase-difference fusion) and model architectures (CNN, LSTM, GFGRU, U-Net, GAN) with mathematical formulations and schematic diagrams.
Section 4 critically evaluates method trade-offs in computational efficiency, generalization capacity, and data dependency through comparative analysis.
Section 5 outlines future directions, proposing physics-informed modeling, multimodal edge intelligence, and ethical compliance frameworks to advance SSL toward high-precision, robust, and energy-efficient intelligent systems.
2. Classification of Sound Source Localization
2.1. Marine Sound Source Localization
Marine sound source localization (SSL) is crucial in various fields. Traditional methods like MFP [
45,
46,
47] depend on precise models but face challenges from environmental uncertainties, especially mismatch issues due to ocean parameter variations. Improved methods like environment-focused MFP [
48,
49,
50] and Bayesian MFP [
51,
52] address this but raise computational load problems for real-time processing.
In the domain of marine sound source localization, deep learning approaches have remarkably improved localization performance in complex environments through data-driven modeling. Van Komen et al. proposed a CNN-based algorithm for simultaneous seabed type identification and long-range deep-sea localization, achieving a distance prediction error of <0.5 km within a 5 km range [
13]. Subsequently, Liu et al. integrated a CNN with beamforming, reducing localization errors by 32% in shallow-water scenarios (see
Figure 2) in the South China Sea [
14]. Qian et al. employed a U-Net-based multi-task learning framework to compress features, enabling multi-source localization accuracy approaching that of SBL in deep-sea environments with internal waves [
15]. Qu et al. fused CNN and Transformer architectures, decreasing underwater ranging errors by 35% compared to traditional methods [
16]. Ashok et al. proposed Audio Perspective Regional CNN using depthwise separable convolution, focusing on key underwater acoustic signal features via regional extraction [
17].
Nie et al. adopted a two-stage “beam network” combined with data augmentation, reducing the angular root mean square error (RMSE) to 0.5° for direction-of-arrival (DOA) estimation in marine environments [
18]. Liu et al. enhanced deep-sea localization robustness via unsupervised domain adaptation, maintaining errors < 200 m under 20° array tilt [
19]. Wang et al. leveraged adversarial transfer learning with generative adversarial networks for horizontal line array localization, improving transfer accuracy by 18% to 92.7% [
20]. Additionally, Liu et al. optimized shallow-water geoacoustic inversion using CNN-based processing of multi-range vertical array data [
21], while Niu et al. employed a 50-layer residual network (ResNet50) with a two-stage training strategy, achieving localization errors < 1 km in the Yellow Sea [
22]. Qu et al. demonstrated 90.5% accuracy with a 3D residual CNN under 29% sound speed mismatch [
23], and Zhai et al. combined computational mechanics and deep learning for precise shallow-water source localization [
24]. Wang et al. fused multi-spectral transformation with CNN, reducing deep-sea depth estimation errors to 0.8 m [
25], while Long et al. outperformed traditional matched-field processing via unsupervised domain adaptation in few-shot scenarios [
26]. Yang et al. further improved deep-sea low-SNR localization by leveraging phase information through complex-valued convolutional networks [
27]. Liu et al. proposed a CNN-based method for processing multi-range vertical array data to estimate shallow water geoacoustic parameters [
21].
Collectively, these studies address marine challenges such as sound speed mismatch and multipath interference through CNN variants, transfer learning, and multimodal fusion, achieving 15–60% reductions in localization errors compared to traditional methods (see
Table 1).
2.2. Indoor Sound Source Localization
Traditional sound source localization methods, such as TODA [
53,
54] and beamforming [
55], rely on multi-channel microphone arrays and wave equation propagation models. TDOA estimates source coordinates via time delay differences from generalized cross-correlation, while beamforming forms spatial spectral peaks through covariance matrix optimization. These methods excel in ideal conditions but suffer from reduced accuracy in high-reverberation or low-SNR environments due to signal distortion and high computational complexity. Their reliance on precise array geometry and environmental models also limits adaptability in dynamic scenarios (see
Table 2).
Deep learning has revolutionized SSL by enabling data-driven feature learning. Architectures like deep neural networks [
56], convolutional neural networks [
28,
57], and recurrent neural networks [
29] enable end-to-end acoustic feature extraction, outperforming traditional methods in noisy/reverberant conditions. For example, Zhang et al. integrated CNN with TDOA for regional localization [
28], while Liu et al. used DNN with room-specific reverberation modeling to enhance robustness [
30]. Tan et al. combined CNN with regression for phase difference-based SSL (see
Figure 3) [
31], and Wu et al. improved accuracy via deep learning-assisted sound intensity estimation [
32]. Recent breakthroughs focus on reverberation suppression and unsupervised domain adaptation, such as Wu et al.’s SSLIDE method [
33], Long et al.’s unsupervised range estimation [
26], and Yan et al.’s 3D localization [
34]. The SoS dataset introduced by Nguyen-Vu and Lee [
35] serves as a benchmark for indoor SSL research.
2.3. Unmanned Aerial Vehicle Localization
UAV technology has seen wide application, but illegal uses pose security risks. Traditional monitoring methods like RF [
58], radar [
59], and vision [
60] have limitations in addressing these risks, while acoustic localization using UAV noise offers all-weather, anti-interference advantages for low-SNR monitoring. In the domain of unmanned aerial vehicle (UAV) acoustic localization, deep learning methods have particularly addressed critical challenges posed by non-stationary noise and real-time processing constraints (see
Table 3). Wu et al. integrated the MUSIC algorithm with deep prediction to achieve localization errors ≤ 20 m at −8 dB SNR, outperforming traditional signal processing in low-SNR environments [
36]. Manikandan combined mel-frequency cepstral coefficients (MFCC) with 1D CNN for UAV sound recognition, achieving 96.57% precision and 92.53% recall in outdoor detection scenarios [
37]. Dong et al. proposed a feature-level fusion model using Log-Mel spectrograms and MFCC, achieving 94.5% detection accuracy within 50 m by leveraging evidential theory to integrate dual-channel CNN outputs [
38].
Li et al. developed a multi-scale convolutional network with global–local attention, directly processing raw audio signals to enhance UAV monitoring accuracy to 98.11% in complex environments [
39]. Aydın et al. designed a lightweight CNN (LWCNN) for high-noise environments, combining mel-spectral features with SVM to achieve a 95.61% classification accuracy while reducing computational load [
40]. Sun et al. improved UAV sound event detection by integrating beamforming with CNN, expanding the effective range to 135 m despite background noise [
42]. Al-Emadi et al. utilized GANs to augment UAV audio datasets, improving novel UAV detection accuracy to 96.38% when combined with CNN-RNN hybrid models [
41].
Yan et al. proposed a linear shrinkage–subspace projection (LSP) method to reconstruct covariance matrices (see
Figure 4), suppressing interference and enhancing localization accuracy by 15.12% [
43]. Seo et al. achieved 98.87% accuracy using STFT-based CNN features for outdoor UAV detection, demonstrating robust spectral-temporal feature extraction [
44]. Collectively, these approaches leverage lightweight architectures, spatiotemporal Transformer fusion, and data augmentation to address UAV noise non-stationarity, enabling real-time edge deployment with detection errors reduced by 20–45% compared to traditional acoustic methods.
3. General Principles of Deep Learning-Based Sound Source Localization
3.1. Feature Extraction
Multi-channel input signals recorded by a microphone array are processed through a feature extraction module to generate input features. These features are then fed into various neural networks for direction-of-arrival DOA estimation. Signals are typically converted into time–frequency representations via generalized cross-correlation or short-time Fourier transform STFT, or by extracting features such as phase differences and cepstral differences.
X(
t,f) denotes the STFT result, representing the signal intensity at time t, and frequency.
X(
n) is the discrete time-domain signal, defined as a complex exponential function which converts the time-domain signal to the frequency domain.
is a window function. The core idea of STFT is to divide the signal into short segments, apply the Fourier transform to each segment, and thereby capture local time–frequency characteristics, commonly serving as input features for deep learning models.
quantifies the cross-correlation between signals xi(t) and xj(t) at time delay τ. and are their frequency-domain representations, with as the complex conjugate. The phase term models the time delay effect in the frequency domain. . sums over discrete frequency bins to ensure accurate correlation estimation, where is the sampling rate and is the FFT length.
3.2. Model Architectures
The neural network architectures for SSL integrate deep learning-based feature extraction with physical models from traditional signal processing, forming core frameworks such as CNN, CRNN, Transformer, GFGRU (Gated Feedback Gated Recurrent Unit), and multi-task networks. These architectures demonstrate significant advantages in complex scenarios including indoor environments, UAV monitoring, and underwater applications.
3.2.1. LSTM
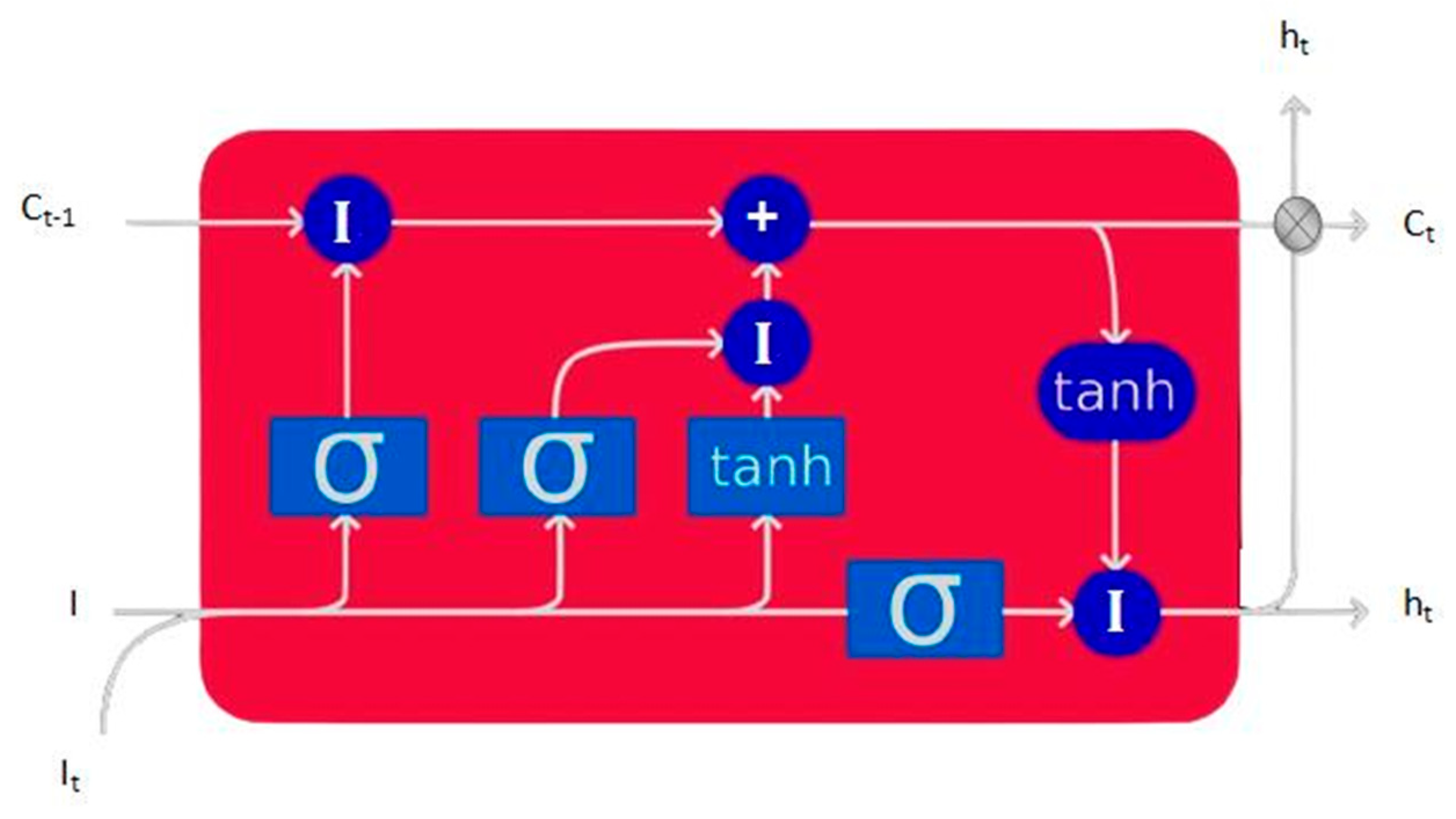
Long short-term memory (LSTM) networks, a specialized type of recurrent neural network, address the gradient vanishing problem in traditional RNNs through gating mechanisms and enable efficient modeling of long-term temporal dependencies. Following the implementation in [
17], the LSTM core comprises memory cells and three gating modules, operating as follows (see
Figure 5):
The LSTM dynamically controls information flow through the following gates:
Forget Gate: Determines which information to discard from the cell state by outputting weights in the range [0, 1] via a Sigmoid function.
Input Gate: Regulates the degree to which current input updates the cell state, jointly governed by Sigmoid and Tanh functions.
Output Gate: Generates the current hidden state output based on the updated cell state.
The mathematical expressions for each gate are defined as:
σ(⋅) denotes the Sigmoid function, ⊙ represents element-wise multiplication, W is the weight matrix, and b is the bias term.
In [
17], LSTM is integrated into a denoising autoencoder DAE framework to form an LSTM-DAE network. This network employs unsupervised learning to encode and decode ship-radiated noise, effectively extracting deep temporal features from acoustic signals. The encoder progressively compresses input dimensions through stacked LSTM layers while reconstructing model parameters; the decoder leverages LSTM’s temporal modeling capability to recover key signal features and suppress noise interference. Specifically, LSTM encodes and decodes acoustic signals through unsupervised temporal feature extraction, enhancing robustness against complex acoustic variations and providing high-quality feature representations for subsequent classification and localization tasks. By capturing long-term dependencies through memory gate mechanisms, LSTM helps distinguish temporal patterns of different sound sources, indirectly aiding localization. Although primarily used for temporal feature extraction and classification, LSTM’s ability to model temporal dynamics, suppress noise, and enhance feature discriminability provides critical support for downstream SSL algorithms.
Furthermore, LSTM’s long-term dependency modeling capability is combined with DLMN to form a collaborative training architecture. Through reinforcement learning strategies, features extracted by LSTM-DAE are further optimized for target classification tasks. Experiments confirm that this synergistic mechanism significantly improves the robustness of underwater acoustic target recognition, particularly excelling in low-SNR environments.
3.2.2. CNN
The convolutional neural network (CNN), as a canonical feedforward deep neural network, excels in hierarchical feature extraction and parameter sharing mechanisms. As referenced [
61] in the literature and illustrated in the figure, a CNN primarily consists of an input layer, multiple feature extraction layers, fully connected layers, and an output layer. The feature extraction phase achieves progressive spatial abstraction through cascaded convolution-pooling operations, culminating in feature integration and classification by the fully connected layers. CNN’s weight-sharing property significantly reduces model complexity and parameter count. Unlike traditional neural networks, convolutional kernels slide over local receptive fields of input data, extracting translation-invariant features through shared weight parameters. This mechanism not only mimics the local receptive characteristics of biological vision systems but also endows the model with strong robustness against geometric distortions such as translation, scaling, and tilting.
Convolutional Layer: Performs local feature extraction via trainable kernels, mathematically expressed as
denotes the feature map selection set, represents convolutional kernel weights, is the bias term, and employs the ReLU activation function to enhance nonlinear expressiveness.
Pooling Layer: Compresses feature dimensions through downsampling, serving to enhance feature spatial compactness, reduce model parameters (n × n pooling decreases parameters by n
2 times), and improve noise immunity.
Fully Connected Layer: Compresses high-dimensional features into 1D vectors and implements classification via Softmax cross-entropy loss.
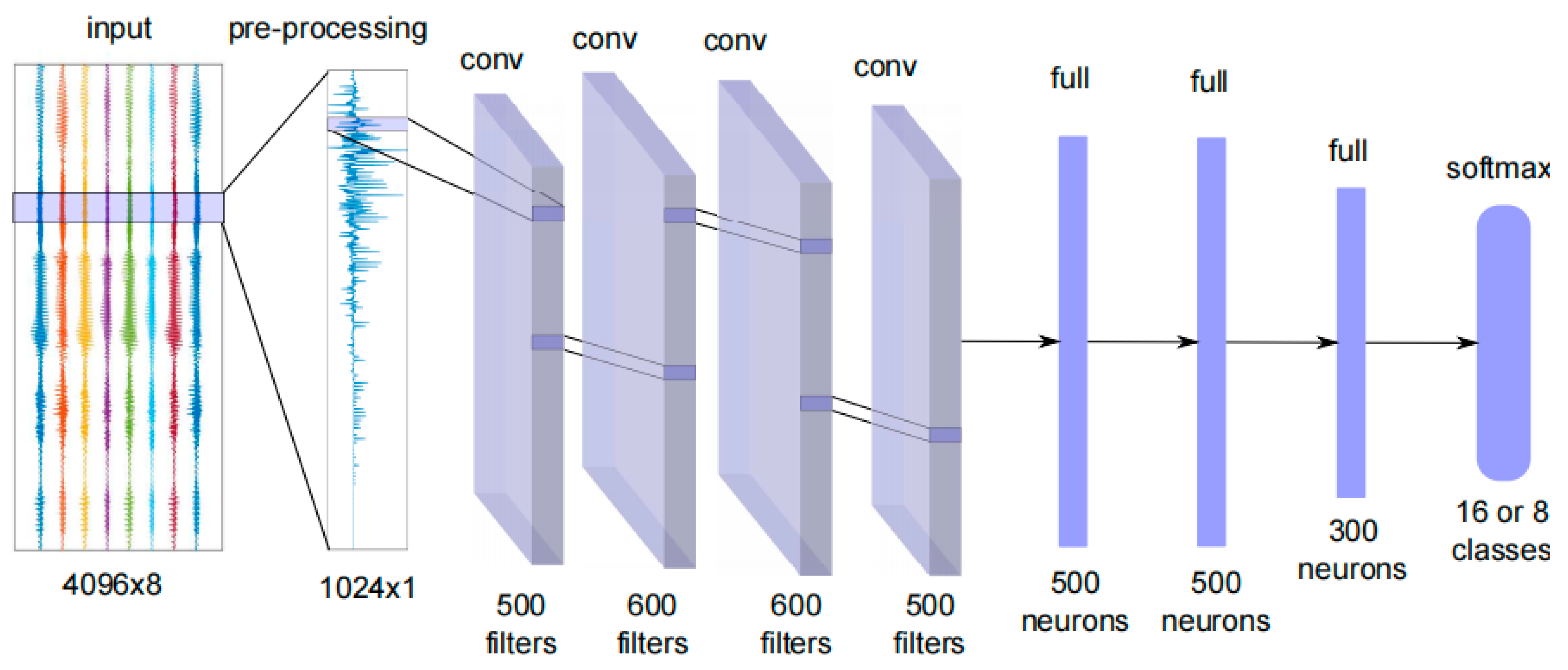
Traditional sound source localization methods rely on manually designed features and algorithms, such as DOA estimation based on time differences or phase analysis. However, these approaches often require extensive manual tuning and optimization in complex environments. In contrast, CNNs automatically learn and extract features, eliminating laborious manual feature engineering. As demonstrated in the literature, a CNN-compatible input format is constructed by converting audio signals from an 8-microphone virtual array into spectrograms via a short-time Fourier transform (STFT). These spectrograms are then concatenated across frequency bands into a 1024-dimensional input vector preserving spatial information (see
Figure 6). The first four convolutional layers extract spatial features from audio spectra through local connectivity and weight sharing, while the subsequent three fully connected layers map these features to a classification space. This transforms direction estimation into a multi-class classification problem, assigning probabilities to distinct azimuthal angles for source focusing.
3.2.3. GFGRU
The computational flow of GFGRU units is defined by the following equations, simulating SBL’s iterative optimization through gating mechanisms:
Update Gate and Reset Gate:
: Control the retention ratio of historical states and the intensity of information resetting, respectively.
: The concatenation of historical states from all stacked layers.
Candidate State and Final State Update:
Element-wise multiplication achieves selective information fusion. The hidden states are concatenated through horizontal unrolling steps:
, generating the final ambiguity surface:
GFGRU comprises multiple stacked GRU layers [
14], with identical input features at each timestep to simulate SBL’s iterative optimization. By regulating hidden state flow via gating mechanisms and global reset gates for inter-layer interactions, GFGRU effectively suppresses sidelobes and enhances localization accuracy (see
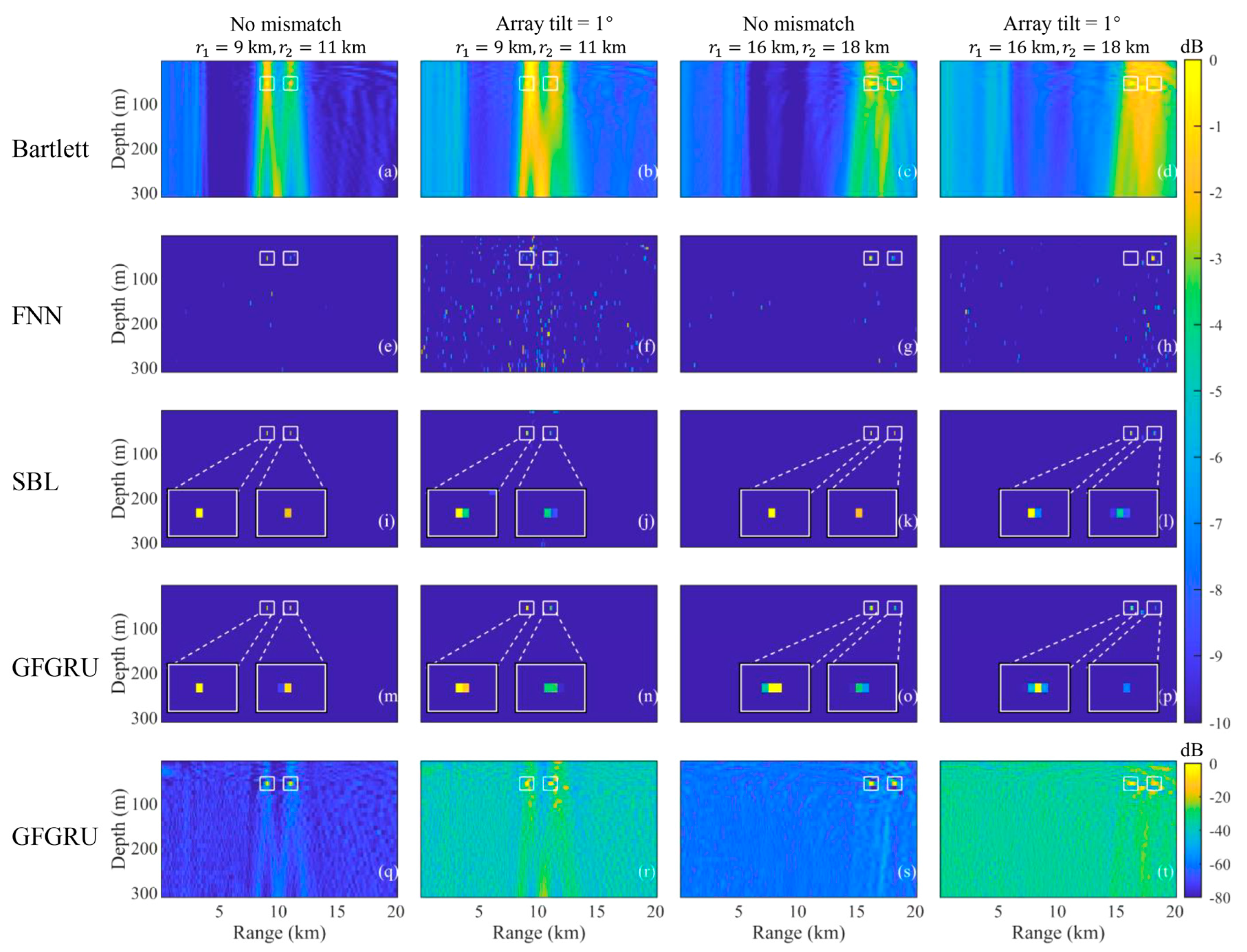
Figure 7). As demonstrated in the literature, GFGRU takes frequency-domain signals obtained from vertical array acoustic pressure measurements via short-time Fourier transform (STFT) as input. The localization problem is formulated as a sparse estimation task, where input signals are preprocessed by computing normalized covariance matrices or applying singular value decomposition (SVD). The real and imaginary upper-triangular parts of the spatial covariance matrix (SCM) are flattened into vectors as input features, which are then concatenated across frequencies. The resulting ambiguity surface outputs probability values for candidate locations through a Softmax layer, forming a probability distribution. In summary, GFGRU integrates gating mechanisms with feedback connections to mimic sparse estimation algorithms’ iterative optimization, effectively addressing deep-sea multi-source localization challenges.
3.2.4. U-Net
The MTL-UNET-CBAM model described in [
15] extends the classical U-Net architecture by integrating feature compression mechanisms and a multi-task learning framework for joint estimation of distance and depth in shallow-water underwater source localization. The network structure adopts a symmetrical encoder–decoder design, as depicted in the accompanying figure (see
Figure 8).
Encoder (Entry Flow): Each stage of the encoder employs cascaded feature compression modules with three key components:
Dual Convolutional Layers: Utilize 3 × 3 convolutional kernels for local feature extraction, augmented by batch normalization and parametric activation functions to strengthen nonlinear mapping capabilities.
Attention Mechanism: Incorporates the Convolutional Block Attention Module (CBAM), which dynamically reweights critical feature channels and spatial regions through channel-wise and spatial attention mechanisms.
Downsampling Layer: Reduces feature map spatial dimensions using 2 × 2 max-pooling with stride 2. This operation is mathematically expressed as
This design reduces input dimensions from 2F × L × L to 1 × F × L2, addressing the dimensional imbalance in traditional MTL-CNN.
The U-Net framework leverages its signature encoder–decoder structure with skip connections, enhanced through multi-task learning and transfer learning strategies to achieve precise and efficient localization in challenging marine environments. Following the methodology in [
15], input signals are first transformed via Fast Fourier Transform (FFT) to compute normalized covariance matrices. These matrices undergo progressive spatial reduction through two convolutional layers and 2 × 2 max-pooling operations, preserving essential abstract features. The decoder branch subsequently processes distance and depth estimation tasks independently, with final predictions generated through fully connected layers. A key innovation lies in the integration of CBAM attention mechanisms and multi-task learning: CBAM selectively amplifies discriminative features through adaptive channel and spatial attention. Multi-task learning employs trainable weight parameters to harmonize optimization objectives across tasks.
where
and
are adaptive task weights learned via backpropagation, balancing scale differences between km-level range and m-level depth estimations.
3.2.5. GAN
Reference [
26] proposes an unsupervised adversarial domain adaptation (UDA) algorithm that addresses the distribution shift between simulated and measured data through a modified generative adversarial network (GAN) framework. Unlike conventional GANs focused on data synthesis, this methodology eliminates domain discrepancy by aligning latent space representations across domains. The architecture employs a feature generator (G) and domain discriminator (D) in an adversarial learning paradigm (see
Figure 9).
The generator, implemented as a deep neural network, maps both simulated and measured acoustic pressure signals into a shared latent space through multi-band normalized covariance matrix inputs. To enhance frequency-specific feature extraction, the generator incorporates a modified ResNet architecture with grouped convolutional layers that independently process distinct frequency bands of acoustic field data. Simultaneously, the discriminator learns to classify feature origins (source vs. target domain) using binary cross-entropy loss. A gradient reversal layer inverts discriminator gradients during backpropagation, enforcing adversarial optimization where the generator minimizes domain discriminability while the discriminator maximizes classification accuracy. The optimization objective combines source domain classification error minimization with domain discrepancy reduction, measured as follows:
where
and
denote target/source domain errors, respectively. The adversarial training dynamically estimates and optimizes the distributional distance
. For practical implementation, continuous source distance estimation is discretized into 93 equidistant intervals, transforming the regression task into a multi-class classification problem. The final classifier produces a 93-dimensional probability vector, with the maximum probability interval selected as the predicted distance. This domain-invariant feature learning enables robust cross-domain generalization, allowing the classifier trained on labeled simulated data to achieve accurate source localization in unlabeled measured environments without explicit target domain annotations.
4. Strengths and Limitations of Deep Learning Methods
CNNs have demonstrated remarkable efficacy in indoor single-source localization and drone-based acoustic detection due to their localized feature extraction capabilities and computational efficiency. For instance, multi-scale convolutional kernels enable high-precision azimuth estimation in low-reverberation environments by capturing spectral features. However, CNNs exhibit limitations in modeling multi-source overlapping signals and long-term temporal dependencies, rendering them less adaptable to dynamic noise scenarios. In contrast, U-Net’s encoder–decoder architecture supports multi-task outputs, such as joint estimation of distance and depth in marine environments. Despite its ability to process complex acoustic field data, U-Net’s substantial parameter count and computational overhead restrict real-time performance, making it more suitable for offline applications. To address non-stationary interference in drone noise and indoor reverberant environments, GFGRU leverage temporal feature fusion through gating mechanisms and cross-layer feedback. Yet, their reliance on high-quality annotated data and convergence instability hinder practical deployment efficiency.
Lightweight CNNs, employing depthwise separable convolutions and parameter compression techniques, enable low-power real-time monitoring on edge devices like oceanic buoys and drones. However, these models suffer from significant accuracy degradation, particularly under low signal-to-noise ratio (SNR) conditions. Conversely, complex-valued convolutional networks achieve a 20–30% reduction in localization errors in deep-sea low-SNR environments by integrating acoustic phase information through complex-domain operations. Nevertheless, their heightened hardware requirements and model complexity necessitate high-performance computing platforms, limiting their edge deployment. Transformers, while exhibiting strong robustness in complex noise environments via global self-attention mechanisms, face challenges in small-scale labeled scenarios due to prohibitive computational complexity and data demands.
Current methodologies are constrained by three core limitations: Inadequate integration of physical principles: Traditional CNNs lack explicit modeling of acoustic wave propagation equations, restricting generalization in dynamic marine environments. Data dependency trade-offs: Although GANs alleviate annotation scarcity through domain adaptation, their performance is hindered by adversarial training instability and synthetic data quality issues. Real-time-precision imbalance: Architectures like residual CNNs, despite enabling deep acoustic field modeling, struggle with edge deployment due to excessive parameter counts and computational loads.
Future research should prioritize physics-informed architectures that embed domain-specific knowledge (e.g., differentiable wave equation solvers), unsupervised domain adaptation techniques to bridge simulation-to-reality gaps, and hardware–algorithm co-design for resource-constrained platforms. For instance, integrating neural architecture search with model compression could optimize edge-device efficiency, while hybrid approaches combining CNNs with spectral graph theory may enhance multi-source separation. These advancements will drive acoustic localization technologies toward intelligent systems characterized by high precision, robustness, and energy efficiency, enabling transformative applications in underwater exploration, autonomous drones, and adaptive smart environments (see
Table 4).
5. Conclusions
The rapid advancement of deep learning has catalyzed a paradigm shift in acoustic source localization, offering transformative solutions through end-to-end adaptive feature learning, data-driven modeling, and cross-domain generalization. In marine environments, convolutional neural networks (CNNs) and U-Net architectures address multipath interference and environmental mismatch by adaptively extracting spectral–temporal features from acoustic signals. Complex-valued CNNs further enhance precision in low-SNR deep-sea conditions by explicitly encoding acoustic phase information, achieving centimeter-level localization accuracy. While adversarial domain adaptation techniques improve robustness to dynamic sound speed profiles, challenges persist in acquiring large-scale annotated datasets and ensuring real-time inference in fluctuating underwater environments. Future advancements may integrate physics-informed neural architectures that embed differentiable wave propagation equations, coupled with hybrid frameworks combining GAN and simulation-to-reality data co-optimization to mitigate domain gaps.
Indoor localization systems face unique challenges in high-reverberation and multi-source overlapping scenarios. Attention mechanisms dynamically prioritize critical acoustic features to suppress reverberation artifacts, while lightweight CNN with depthwise separable convolutions enable edge deployment on smart devices. However, performance degradation in complex multi-source environments remains unresolved. Emerging solutions explore acoustic–visual–infrared multimodal fusion to exploit complementary sensory data, alongside spatiotemporal Transformer networks that model long-range dependencies for robust source separation. Hardware-accelerated architectures leveraging FPGA or ASIC platforms show promise for achieving millisecond-level inference speeds, essential for real-time applications in dynamic indoor settings.
Drone-based acoustic monitoring benefits from spatiotemporal Transformers and GNN, which capture non-stationary noise characteristics through spectral–temporal analysis. Distributed micro-microphone arrays paired with lightweight models facilitate low-power edge deployment, yet background noise interference and sensor layout generalization limit practical efficacy. Meta-learning frameworks aim to bridge simulation-to-reality knowledge transfer, while differential privacy techniques anonymize sensitive frequency bands to address ethical concerns in surveillance applications.
Despite the fact that current research on UAV acoustic localization has achieved sub-meter accuracy at a −10 dB signal-to-noise ratio by means of lightweight CNN and spatio-temporal Transformer models, it still faces three core challenges: the mid-high frequency tonal components are susceptible to environmental noise interference, and the time-varying characteristics of noise spectra lead to insufficient model generalization; single-modal acoustic methods have difficulty in distinguishing co-frequency interference sources, and there is ambiguity in out-of-sight localization; the inference delay and computational power consumption of high-performance models on edge devices fail to meet the real-time tracking requirements. Multi-source data fusion represents a significant trend in UAVs. will comprehensively utilize multi-sensor data from satellite navigation, inertial navigation, vision, lidar, and acoustics. Through the mutual complementation and validation of multi-source data, the accuracy, stability, and anti-jamming capabilities of localization will be enhanced to adapt to more complex and diverse environments. For example, in areas with disturbed satellite signals such as indoor spaces or urban canyons, the combination of visual positioning and inertial navigation ensures stable UAV flight; in forest monitoring, fusing lidar data to construct 3D terrain models assists satellite navigation in achieving precise positioning.
Underpinning these domain-specific advancements are three systemic challenges: the insufficient integration of wave physics in data-driven models, the reliance on costly annotated datasets, and unresolved trade-offs between algorithmic complexity and edge-device efficiency. To address these limitations, interdisciplinary efforts are converging on physics-guided architectures that couple neural operators with computational acoustic models, self-supervised learning paradigms utilizing contrastive learning and synthetic data augmentation, and hardware–algorithm co-design strategies incorporating NAS and adaptive model compression. The development of standardized datasets, open-source frameworks, and privacy-preserving protocols will be critical for fostering an ethical ecosystem to support scalable deployments in marine exploration, autonomous drones, and smart cities. By synergizing multimodal sensor fusion, computational physics, and energy-efficient edge computing, next-generation systems could achieve sub-centimeter precision with millisecond latency, ultimately advancing toward intelligent, sustainable, and socially responsible acoustic localization technologies.
Author Contributions
Conceptualization, Z.Z. and K.X.; investigation, K.X.; resources, D.L.; data curation, Z.Z.; writing—original draft preparation, Z.Z.; writing—review and editing, K.X.; visualization, D.L.; supervision, R.W.; project administration, L.Y.; funding acquisition, K.X., R.W. and L.Y. All authors have read and agreed to the published version of the manuscript.
Funding
China’s National Natural Science Foundation Youth Fund (Project ID: 12002150); Ministry of Education of China’s Youth Fund for Humanities and Social Sciences (Project ID: 24YJAZH188); Open Project of the Key Laboratory of Aerodynamic Noise Control (ANCL20230302).
Acknowledgments
The authors extend their sincere gratitude to the Key Laboratory of Aerodynamic Noise Control (ANCL20230302) for providing experimental support and technical guidance. We also appreciate the financial support from China’s National Natural Science Foundation Youth Fund (Project ID: 12002150) and the Ministry of Education of China’s Youth Fund for Humanities and Social Sciences (Project ID: 24YJAZH188), which enabled the completion of this research. Additionally, we thank the reviewers for their constructive comments that significantly improved the clarity and depth of this review. Finally, we acknowledge the professors of all colleagues at Shanghai Maritime University and Northwestern Polytechnical University for their fruitful discussions and assistance throughout the study.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Nsalo Kong, D.F.; Shen, C.; Tian, C.; Zhang, K. A New Low-Cost Acoustic Beamforming Architecture for Real-Time Marine Sensing: Evaluation and Design. J. Mar. Sci. Eng. 2021, 9, 868. [Google Scholar] [CrossRef]
- Hożyń, S. A Review of Underwater Mine Detection and Classification in Sonar Imagery. Electronics 2021, 10, 2943. [Google Scholar] [CrossRef]
- Li, X.; Girin, L.; Badeig, F.; Horaud, R. Reverberant sound localization with a robot head based on direct-path relative transfer function. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Republic of Korea, 9–14 October 2016; pp. 2819–2826. [Google Scholar]
- Jekateryńczuk, G.; Piotrowski, Z. A Survey of Sound Source Localization and Detection Methods and Their Applications. Sensors 2024, 24, 68. [Google Scholar] [CrossRef]
- Chiariotti, P. Acoustic Beamforming for Noise Source Localization—Reviews, Methodology and Applications. Mech. Syst. Signal Process. 2019, 120, 422–448. [Google Scholar] [CrossRef]
- Knapp, C. The Generalized Correlation Method for Estimation of Time Delay. IEEE Trans. Acoust. Speech Signal Process. 1976, 24, 320–327. [Google Scholar] [CrossRef]
- Schmidt, R. Multiple emitter location and signal parameter estimation. IEEE Trans. Antennas Propag. 1986, 34, 276–280. [Google Scholar] [CrossRef]
- Blandin, C.; Ozerov, A.; Vincent, E. Multi-source TDOA estimation in reverberant audio using angular spectra and clustering. Signal Process. 2012, 92, 1950–1960. [Google Scholar] [CrossRef]
- Evers, C.; Löllmann, H.W.; Mellmann, H.; Schmidt, A.; Barfuss, H.; Naylor, P.A.; Kellermann, W. The LOCATA challenge: Acoustic source localization and tracking. IEEE Trans. Acoust. Speech Signal Process. 2020, 28, 1620–1643. [Google Scholar] [CrossRef]
- Karniadakis, G.E.; Kevrekidis, I.G.; Lu, L.; Perdikaris, P.; Wang, S.; Yang, L. Physics-informed machine learning. Nature 2021, 3, 422–440. [Google Scholar] [CrossRef]
- Northcutt, C. Pervasive Label Errors in Test Sets Destabilize Machine Learning Benchmarks. arXiv 2021, arXiv:2103.14749. [Google Scholar]
- Warden, P. Speech commands: A dataset for limited-vocabulary speech recognition. arXiv 2018, arXiv:1804.03209. [Google Scholar]
- Van Komen, D.F.; Neilsen, T.B.; Howarth, K.; Knobles, D.P.; Dahl, P.H. Seabed and range estimation of impulsive time series using a convolutional neural network. J. Acoust. Soc. Am. 2020, 147, 403–408. [Google Scholar] [CrossRef]
- Liu, Y.; Niu, H.; Yang, S.; Li, Z. Multiple source localization using learning-based sparse estimation in deep ocean. J. Acoust. Soc. Am. 2021, 150, 3773–3786. [Google Scholar] [CrossRef]
- Qian, P.; Gan, W.; Niu, H.; Ji, G.; Li, Z.; Li, G. A feature-compressed multi-task learning U-Net for shallow-water source localization in the presence of internal waves. Appl. Acoust. 2023, 211, 109530. [Google Scholar] [CrossRef]
- Qu, Y.; Huang, Y. Underwater Sound Source Range Estimation Based on Deep Learning. In Proceedings of the OCEANS 2024—Singapore, Singapore, 15–18 April 2024; IEEE: Piscataway, NJ, USA, 2024. [Google Scholar]
- Ashok, P.; Latha, B. Feature Extraction of Underwater Acoustic Signal Target Using Machine Learning Technique. Trait. Du Signal 2024, 41, 1303–1314. [Google Scholar] [CrossRef]
- Nie, W.; Zhang, X. Adaptive Direction-of-Arrival Estimation Using Deep Neural Network in Marine Acoustic Environment. IEEE Sens. J. 2023, 23, 211–222. [Google Scholar] [CrossRef]
- Liu, Y.; Niu, H.; Li, Z.; Zhai, D. Unsupervised Domain Adaptation for Source Localization Using Ships of Opportunity With a Deep Vertical Line Array. IEEE J. Ocean. Eng. 2024, 49, 456–467. [Google Scholar] [CrossRef]
- Wang, J.; Liu, F.; Pan, X.; Li, A.; Jiao, J. Adversarial Transfer Learning for Underwater Sound Source Localization Based on Horizontal Line Array. In Proceedings of the 2024 OES China Ocean Acoustics (COA), Harbin, China, 29–31 May 2024; IEEE: Piscataway, NJ, USA, 2024. [Google Scholar]
- Liu, M.; Niu, H.; Li, Z.; Liu, Y.; Zhang, Q. Deep-learning geoacoustic inversion using multi-range vertical array data in shallow water. J. Acoust. Soc. Am. 2022, 151, 2101–2116. [Google Scholar] [CrossRef]
- Niu, H.; Gong, Z.; Ozanich, E.; Gerstoft, P.; Wang, H.; Li, Z. Deep-learning source localization using multi-frequency magnitude-only data. J. Acoust. Soc. Am. 2019, 146, 211–222. [Google Scholar] [CrossRef] [PubMed]
- Qu, Y.; Sun, J.; Yu, J.; Tian, Y.; Dong, H. Deep-Learning-Based Source Localization Using a Local 3-D Acoustic Intensity Field in a Sound-Speed Mismatched Deep-Ocean Environment. IEEE Sens. J. 2024, 24, 7890–7901. [Google Scholar] [CrossRef]
- Zhai, J.; Fu, N.; Shang, L. Random acoustic radiation prediction and source localization for shell structures in shallow sea based on ConvNeXt network. Eng. Anal. Bound. Elem. 2024, 166, 105826. [Google Scholar] [CrossRef]
- Wang, W.; Wang, Z.; Su, L.; Hu, T.; Ren, Q.; Gerstoft, P.; Ma, L. Source depth estimation using spectral transformations and convolutional neural network in a deep-sea environment. J. Acoust. Soc. Am. 2020, 148, 3633–3644. [Google Scholar] [CrossRef]
- Long, R.; Zhou, J. Deep unsupervised adversarial domain adaptation for underwater source range estimation. J. Acoust. Soc. Am. 2023, 154, 3125–3144. [Google Scholar] [CrossRef]
- Yang, Z.; Shen, T. Source localization in deep ocean based on complex convolutional neural network. J. Phys. Conf. Ser. 2024, 2718, 012096. [Google Scholar] [CrossRef]
- Zhang, X.; Sun, H.; Wang, S. A New Regional Localization Method for Indoor Sound Source Based on Convolutional Neural Networks. IEEE Access 2018, 6, 74380–74390. [Google Scholar]
- Liu, Y.; Tong, F.; Zhong, S.; Hong, Q.; Li, L. Reverberation aware deep learning for environment tolerant microphone array DOA estimation. Appl. Acoust. 2021, 184, 108337. [Google Scholar] [CrossRef]
- Tan, T.-H.; Lin, Y.-T.; Chang, Y.-L.; Alkhaleefah, M. Sound Source Localization Using a Convolutional Neural Network and Regression Model. Sensors 2021, 21, 8031. [Google Scholar] [CrossRef]
- Liu, N.; Chen, H.; Songgong, K.; Li, Y. Deep learning assisted sound source localization using two orthogonal first-order differential microphone arrays. J. Acoust. Soc. Am. 2021, 149, 1069–1084. [Google Scholar] [CrossRef]
- Sun, Y.; Chen, J.; Yuen, C.; Rahardja, S. Indoor Sound Source Localization with Probabilistic Neural Network. IEEE Trans. Ind. Electron. 2018, 65, 3478–3487. [Google Scholar] [CrossRef]
- Wu, Y.; Ayyalasomayajula, R.; Bianco, M.J.; Bharadia, D.; Gerstoft, P. SSLIDE: Sound source localization for indoors based on deep learning. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; Volume 69, pp. 1–15. [Google Scholar]
- Yan, J.; Zhao, W.; Wu, Y.I.; Zhou, Y. Indoor sound source localization under reverberation by extracting the features of sample covariance. Appl. Acoust. 2023, 65, 3478–3487. [Google Scholar] [CrossRef]
- Nguyen-Vu, L.; Lee, J. CHAWA: Overcoming Phase Anomalies in Sound Localization. IEEE Access 2024, 12, 148653–148665. [Google Scholar] [CrossRef]
- Wu, S.; Zheng, Y.; Ye, K.; Cao, H.; Zhang, X.; Sun, H. Sound Source Localization for Unmanned Aerial Vehicles in Low Signal-to-Noise Ratio Environments. Remote Sens. 2024, 16, 1847. [Google Scholar] [CrossRef]
- Ganapathi, U.; Sabarimalai Manikandan, M. Convolutional Neural Network Based Sound Recognition Methods for Detecting Presence of Amateur Drones in Unauthorized Zones. J. Signal Process. Syst. 2020, 92, 1023–1035. [Google Scholar]
- Dong, Q.; Liu, Y.; Liu, X. Drone sound detection system based on feature result-level fusion using deep learning. Multimed. Tools Appl. 2023, 81, 12345–12360. [Google Scholar] [CrossRef]
- Li, J.; Zhao, J.; Ren, J.; Gao, X.; Li, Z. A multi-scale integrated learning model with attention mechanisms for UAV audio signal detection. Signal Image Video Process. 2025, 37, 6789–6805. [Google Scholar] [CrossRef]
- Aydın, I.; Kızılay, E. Development of a new Light-Weight Convolutional Neural Network for acoustic-based amateur drone detection. Appl. Acoust. 2022, 193, 108773. [Google Scholar] [CrossRef]
- Al-Emadi, S.; Al-Ali, A.; Al-Ali, A. Audio-based drone detection and identification using deep learning techniques with dataset enhancement through generative adversarial networks. Sensors 2021, 21, 4953. [Google Scholar] [CrossRef]
- Sun, Y.; Li, J.; Wang, L.; Xv, J.; Liu, Y. Deep Learning-based drone acoustic event detection system for microphone arrays. Multimed. Tools Appl. 2024, 42, 4567–4580. [Google Scholar] [CrossRef]
- Sun, Y.; Liu, Y.; Wang, L.; Li, J.; Wang, J.; Zhang, A.; Wang, S. Improved method for drone sound event detection system aiming at the impact of background noise and angle deviation. Sens. Actuators A Phys. 2024, 207, 117924. [Google Scholar] [CrossRef]
- Seo, Y.; Jang, B.; Im, S. Drone Detection Using Convolutional Neural Networks with Acoustic STFT features. In Proceedings of the 2018 15th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Auckland, New Zealand, 27–30 November 2018. [Google Scholar]
- Westwood, E.K. Broadband matched-field source localization. J. Acoust. Soc. Am. 1992, 91, 2777–2789. [Google Scholar] [CrossRef]
- Michalopoulou, Z.-H.; Porter, M. Matched-field processing for broadband source localization. IEEE J. Ocean. Eng. 1996, 21, 384–392. [Google Scholar] [CrossRef]
- Baggeroer, A.B.; Kuperman, W.A. An overview of matched field methods in ocean acoustics. IEEE J. Ocean. Eng. 1993, 18, 401–424. [Google Scholar] [CrossRef]
- Collins, M.D.; Kuperman, W.A. Focalization: Environmental focusing and source localization. Acoust. Soc. Am. 1991, 90, 1410–1422. [Google Scholar] [CrossRef]
- Gerstoft, P. Inversion of seismo acoustic data using genetic algorithms and a posteriori probability distributions. Acoust. Soc. Am. 1994, 95, 770–782. [Google Scholar] [CrossRef]
- Gingras, D.F. Inversion for geometric and geoacoustic parameters in shallow water: Experimental results. Acoust. Soc. Am. 1995, 97, 3589–3598. [Google Scholar] [CrossRef]
- Dosso, S.E. Uncertainty estimation in simultaneous Bayesian tracking and environmental inversion. Acoust. Soc. Am. 2008, 124, 82–97. [Google Scholar] [CrossRef]
- Dosso, S.E. Comparison of focalization and marginalization for Bayesian tracking in an uncertain ocean environment. J. Acoust. Soc. Am. 2009, 125, 717–722. [Google Scholar] [CrossRef]
- Scheuing, J.; Yang, B. Disambiguation of TDOA estimation for multiple sources in reverberant environments. IEEE Trans. Audio Speech Lang. Process. 2008, 16, 1479–1489. [Google Scholar] [CrossRef]
- Zohourian, M.; Enzner, G.; Martin, R. Binaural speaker localization integrated into an adaptive beamformer for hearing aids. IEEE ACM Trans. Audio Speech Lang. Process. 2017, 26, 515–528. [Google Scholar] [CrossRef]
- Chakrabarty, S.; Habets, E.A. Multi-speaker DOA estimation using deep convolutional networks trained with noise signals. IEEE J. Sel. Top. Signal Process. 2019, 13, 8–21. [Google Scholar] [CrossRef]
- Hu, Y.; Samarasinghe, P.N.; Gannot, S.; Abhayapala, T.D. Semi-supervised multiple source localization using relative harmonic coefficients under noisy and reverberant environments. IEEE ACM Trans. Audio Speech Lang. Process. 2020, 28, 3108–3123. [Google Scholar] [CrossRef]
- Pang, C.; Liu, H.; Li, X. Multitask learning of time-frequency CNN for sound source localization. IEEE Access 2019, 7, 40725–40737. [Google Scholar] [CrossRef]
- Nie, W.; Han, Z.-C.; Zhou, M.; Xie, L.-B.; Jiang, Q. UAV detection and identification based on WiFi signal and RF fingerprint. IEEE Sens. 2021, 21, 13540–13550. [Google Scholar] [CrossRef]
- Wellig, P.; Speirs, P.; Schuepbach, C.; Oechslin, R.; Renker, M.; Boeniger, U.; Pratisto, H. Radar systems and challenges for CUAV. In Proceedings of the 2018 19th International Radar Symposium (IRS), Bonn, Germany, 20–22 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–8. [Google Scholar]
- Li, J.; Ye, D.H.; Kolsch, M.; Wachs, J.P.; Bouman, C.A. Fast and robust UAV to UAV detection and tracking from video. IEEE Trans. Emerg. Top. Comput. 2021, 10, 1519–1531. [Google Scholar] [CrossRef]
- Hirvonen, T. Classification of Spatial Audio Location and Content Using Convolutional Neural Networks. In Proceedings of the Audio Engineering Society Convention 138, Warsaw, Poland, 7–10 May 2015. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}