This section presents detailed experimental results obtained from evaluating both baseline models (ResNet-50, VGGNet, and DenseNet) and the proposed hybrid model (SE-ResNet50) on the CIFAKE dataset. Results are analyzed and compared across critical performance metrics, including accuracy, precision, recall, F1-score, ROC-AUC scores, confusion matrices, and training efficiency.
4.1. Performance Evaluation of Baseline Models
To establish a strong comparative foundation for evaluating the proposed hybrid architecture, three well-established deep learning models—ResNet-50, VGGNet, and DenseNet—were re-implemented and evaluated using the CIFAKE dataset. This dataset, comprising a balanced set of real and AI-generated images, served as a reliable benchmark to assess each model’s capability in accurately distinguishing between synthetic and authentic visual content.
Each model was trained under identical experimental conditions using 80% of the dataset for training and 20% for testing. This uniform configuration ensured a fair and consistent evaluation across all architectures.
The SE-ResNet50 model emerged as the best-performing architecture among all evaluated models, achieving a test accuracy of 96.12%, precision of 97.04%, recall of 88.94%, F1-score of 92.82%, and a ROC-AUC score of 0.9862. This superior performance underscores the impact of integrating Squeeze-and-Excitation (SE) blocks into the ResNet-50 backbone. By recalibrating feature channels dynamically, the SE mechanism allows the network to focus more effectively on subtle and discriminative cues typically introduced by generative models, such as minor texture inconsistencies or unnatural patterns, thereby enhancing the model’s ability to distinguish between real and synthetic images with greater precision.
VGGNet, although architecturally simpler with its fixed-size () convolutional layers, achieved a test accuracy of 94.06%. Its deep and sequential design contributes to strong generalization but comes at the cost of higher computational demand and slower training. DenseNet, with its densely connected layers that promote efficient gradient flow and feature reuse, slightly outperformed VGGNet with a test accuracy of 95.98%. However, it lagged behind SE-ResNet50 in precision, recall, and F1-score, highlighting its relative weakness in maintaining classification balance between real and fake image categories.
Overall, while both VGGNet and DenseNet performed competitively, SE-ResNet50 clearly outperformed them across most key metrics, demonstrating not only high classification accuracy but also strong generalization, low false-positive rates, and improved focus on semantically relevant features. These characteristics make it especially suitable for high-stakes applications such as digital content authentication, where both performance and interpretability are critical.
Table 2 summarizes the performance metrics of baseline models evaluated on the CIFAKE dataset.
Results indicate that the ResNet-50 model, enhanced with Squeeze-and-Excitation (SE) attention blocks, achieved the best performance among all the evaluated models. With an accuracy of 96.12%, precision of 97.04%, recall of 88.94%, and an F1-score of 92.82%, SE-ResNet50 outperformed both DenseNet and VGGNet across all major classification metrics. Its high ROC-AUC score of 0.9862 further confirms its strong discriminative capability between real and AI-generated images.
This superior performance can be attributed to the SE blocks, which dynamically recalibrate the importance of feature channels. By emphasizing informative features and suppressing less useful ones, the model becomes more sensitive to subtle visual discrepancies, such as texture artifacts or unnatural transitions, commonly found in synthetic images.
VGGNet, while architecturally simpler and effective in generating deep representations through stacked convolutional layers, achieved a lower accuracy of 94.06%. Despite its good precision, the model’s large parameter count and lack of efficient connectivity resulted in slower training and higher memory usage. DenseNet showed marginally better results than VGGNet with an accuracy of 95.98%, benefiting from its densely connected layers that encourage feature reuse. However, it still lagged behind SE-ResNet50 in precision, F1-score, and computational efficiency.
To further analyze classification behavior, a confusion matrix for the ResNet-50 model is presented in
Table 3. It provides insights into the distribution of true positives, false positives, true negatives, and false negatives.
The model correctly classified 9729 real images and 8894 synthetic images, with relatively low rates of misclassification—271 false positives and 1106 false negatives. These results demonstrate the model’s balanced classification capability and reliability in distinguishing between visually similar image classes. Compared with VGGNet and DenseNet, SE-ResNet-50 shows clear improvements not only in numerical performance but also in reducing both types of classification errors.
Therefore, the proposed SE-ResNet-50 hybrid model sets a new benchmark for detecting AI-generated images in this context, combining strong predictive accuracy with efficient computation and enhanced feature sensitivity.
4.4. Performance of Proposed Hybrid Model (SE-ResNet-50)
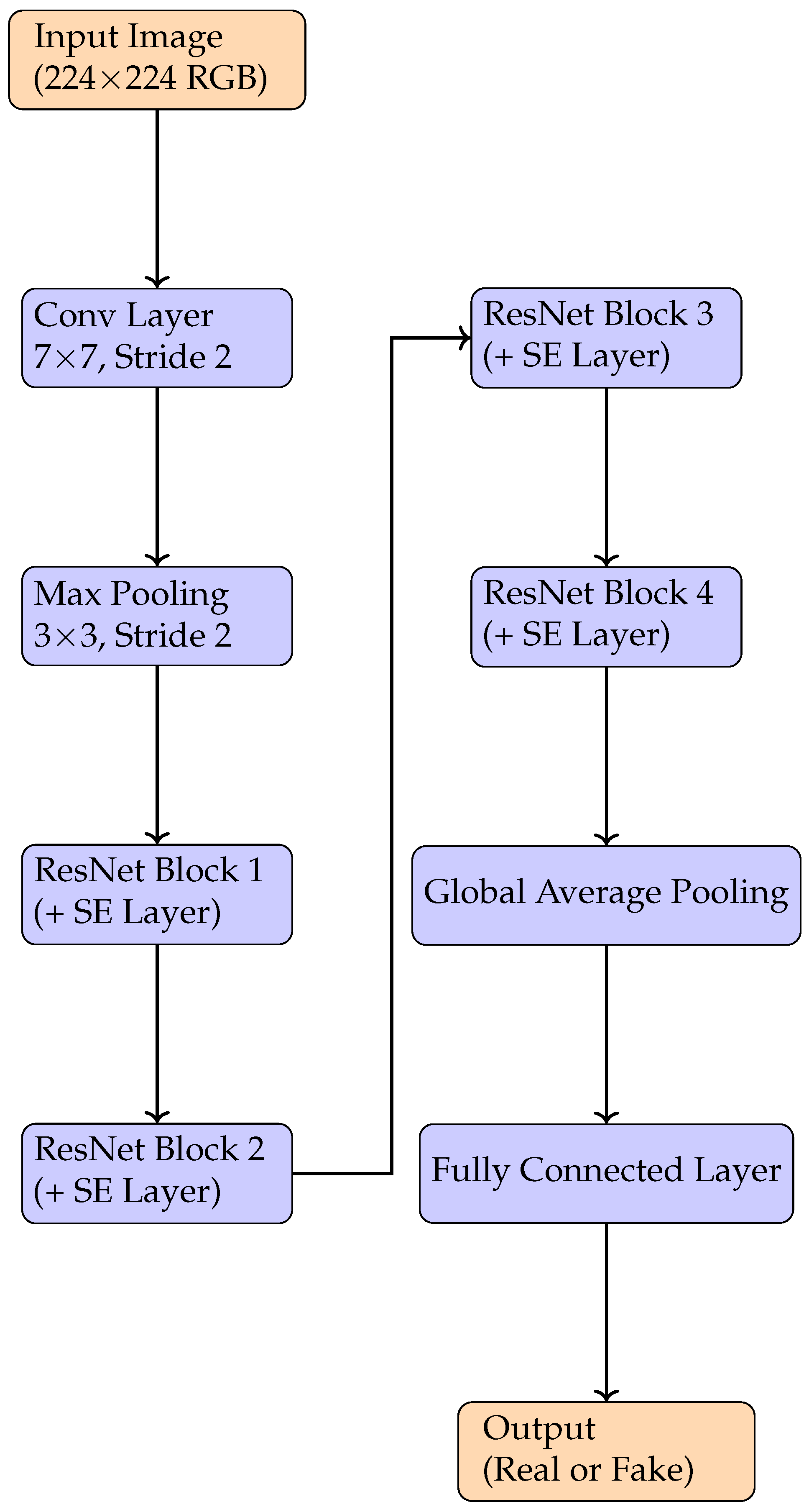
To overcome the limitations identified in the baseline models, particularly in handling nuanced visual cues and computational trade-offs, a hybrid model—SE-ResNet50—has been proposed and rigorously evaluated on the same CIFAKE dataset. This architecture augments the traditional ResNet-50 framework with Squeeze-and-Excitation (SE) blocks, a channel-wise attention mechanism designed to dynamically recalibrate the importance of feature maps. The goal was to enable the network to focus more selectively on image regions that contain subtle generative artifacts often missed by traditional convolutional networks.
The SE-ResNet-50 model demonstrated the best classification performance among all tested models, achieving an accuracy of 96.12%, a precision of 97.04%, a recall of 88.94%, and an F1-score of 92.82%. Additionally, the model attained a high ROC-AUC score of 0.9862, indicating excellent discrimination capability between real and synthetic images across classification thresholds. These results confirm SE-ResNet50 as the most balanced and effective model for the detection task.
Table 6 presents a detailed comparison of core evaluation metrics.
The superior performance of the SE-ResNet50 model—achieving 96.12% accuracy and a ROC-AUC score of 0.9862—is primarily attributed to the incorporation of SE blocks into the ResNet-50 architecture. These blocks perform dynamic, channel-wise recalibration of feature maps by leveraging global context through the squeeze operation and reweighting informative features via excitation. As a result, the model is able to highlight fine-grained patterns and subtle visual anomalies—such as edge inconsistencies or low-level artifacts—that are often overlooked by conventional convolutional layers. This architectural enhancement improves class separability and reduces misclassification, particularly in challenging or visually ambiguous cases, contributing directly to the model’s high classification fidelity.
The precision score of 97.04% reflects the model’s ability to reduce false positives, while the recall score of 88.94% demonstrates its effectiveness in detecting AI-generated images. The F1-score of 92.82% highlights its overall robustness in balancing sensitivity and specificity. With the highest test performance across all evaluated models, SE-ResNet-50 emerges as the optimal choice for real-world applications requiring both accuracy and efficiency.
4.4.1. Impact of SE Attention Mechanism
The significant performance boost can be directly attributed to the integration of SE blocks, which apply channel-wise attention to modulate feature responses based on their relative importance. Unlike traditional convolutional layers that treat all feature channels equally, SE blocks allow the network to attend to channels that encode critical visual cues—such as edge inconsistencies, textural anomalies, and spatial distortions—often introduced by generative models like GANs or diffusion networks [
2,
3].
Through global average pooling, each SE block captures a compact summary of the global context of each feature map, followed by excitation through a pair of fully connected layers. This mechanism enables the model to suppress uninformative or noisy channels while amplifying those that carry meaningful signals indicative of synthetic content.
4.4.2. Comparative Analysis and Discussion
To visualize comparative performance, ROC curves and confusion matrices for the baseline models and the proposed SE-ResNet50 are analyzed.
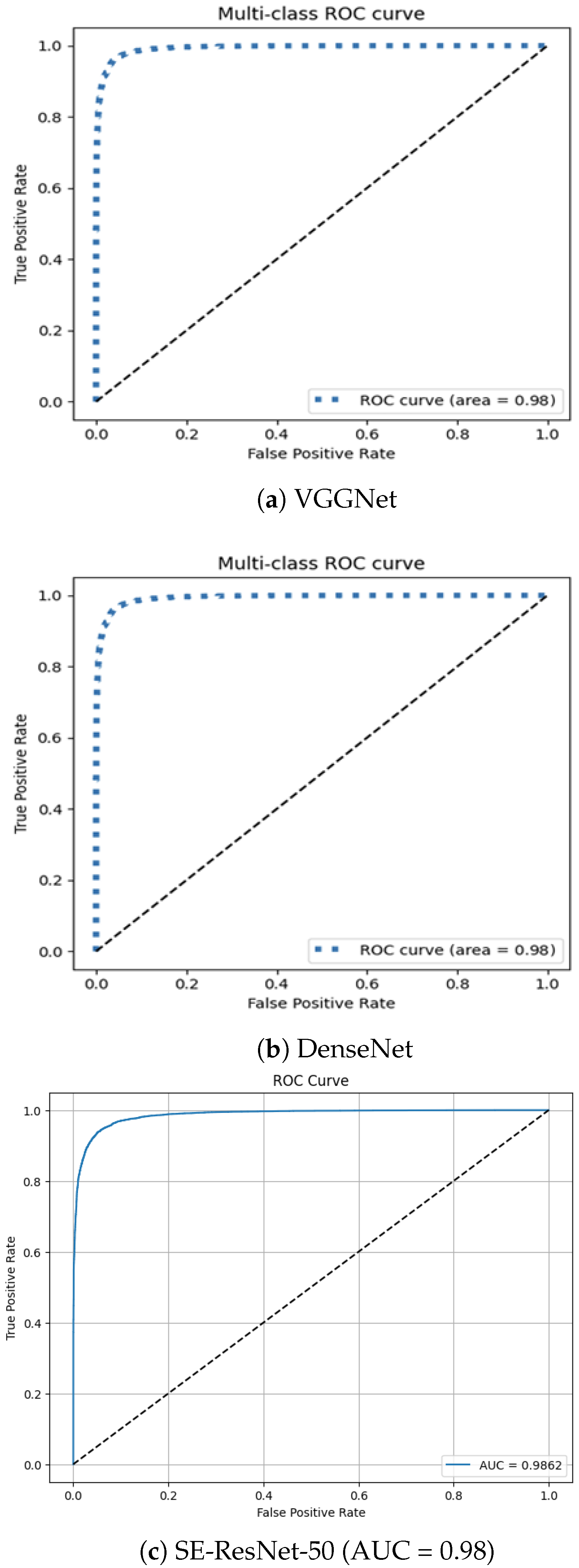
Figure 3 illustrates the comparative ROC curves of the hybrid and baseline models. The SE-ResNet50 model achieves an area under the curve (AUC) of 0.98, demonstrating superior classification performance compared with VGGNet and DenseNet. Its ROC curve remains consistently above those of the baselines, particularly in the low false-positive rate region, reaffirming its heightened sensitivity and specificity in detecting AI-generated images.
To provide a comparative diagnostic analysis of classification behavior,
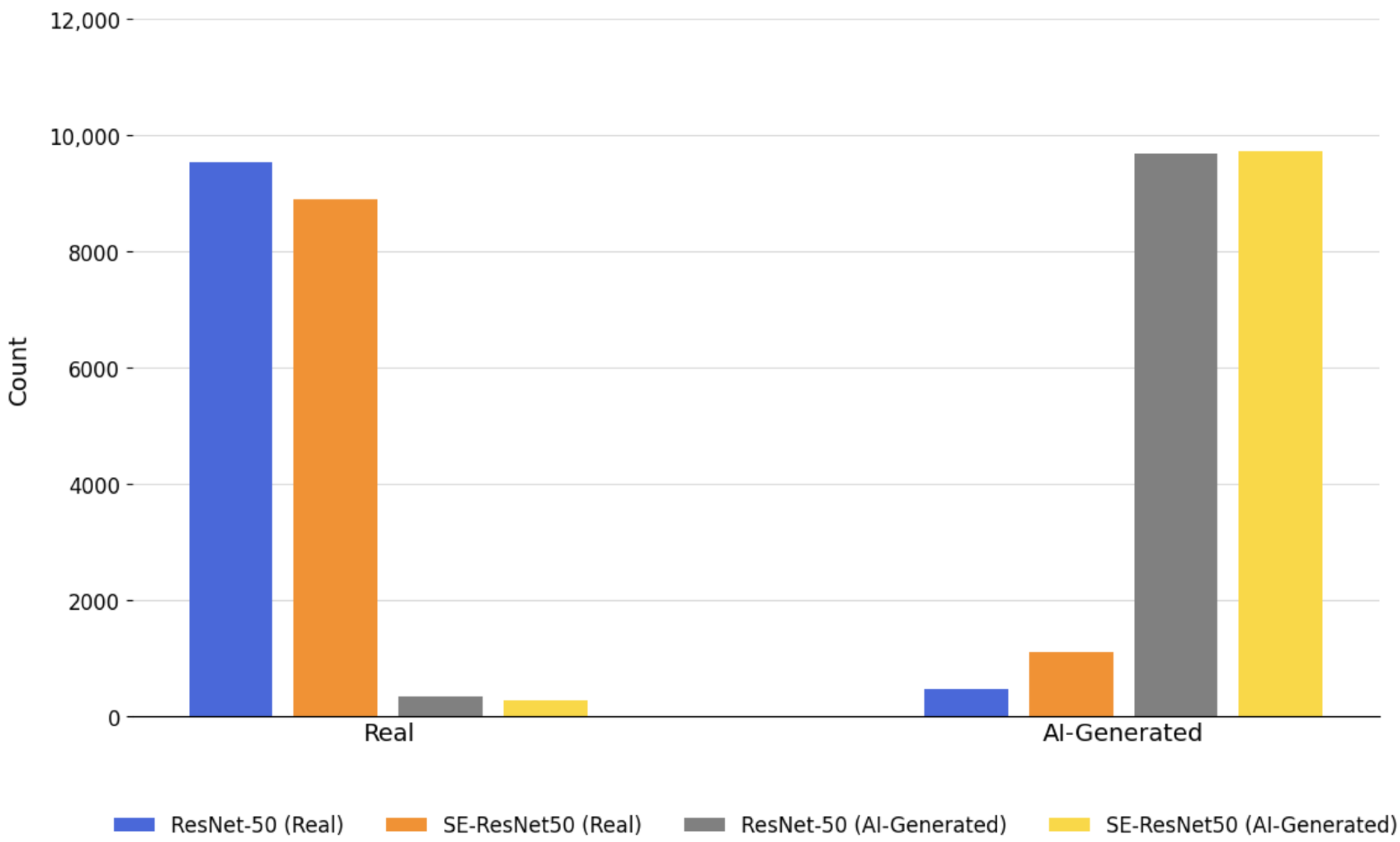
Table 7 presents a side-by-side confusion matrix comparison between ResNet-50 and the proposed SE-ResNet50 model. The SE-ResNet50 model exhibits a notable reduction in both false positives and false negatives, further evidencing its enhanced discriminatory capability and robustness in practical deployment scenarios.
Furthermore,
Figure 4 presents the graphical representation of confusion matrices for both ResNet-50 and SE-ResNet50. The hybrid model demonstrates significantly fewer misclassifications, especially in detecting synthetic (AI-generated) images. This improvement is particularly vital for high-stakes applications in digital forensics, media integrity verification, and identity protection.
The remarkable improvement observed in SE-ResNet50 can be attributed to the integration of Squeeze-and-Excitation (SE) blocks. These attention mechanisms dynamically recalibrate feature maps across channels, enabling the network to better capture subtle, class-discriminative features commonly embedded in AI-generated imagery.
4.4.3. Training Stability and Computational Efficiency
The model also demonstrates training stability, achieving convergence within 20 epochs using a batch size of 32 and an initial learning rate of
. The integration of SE blocks introduces only a modest increase in computational overhead compared with plain ResNet-50, while being significantly faster than DenseNet. As detailed in
Table 8, SE-ResNet-50 provides an efficient trade-off between accuracy and training time.
SE-ResNet-50 maintains efficient computational performance (318 s/epoch), significantly faster than DenseNet (646 s/epoch), despite similar accuracy levels. While slightly slower than basic ResNet-50, the substantial accuracy improvements justify the moderate increase in computational demand. This efficiency makes the proposed model more suitable for deployment in real-world applications, including mobile edge devices and cloud-based platforms, where computational resources may be constrained.
To quantify its efficiency, the model’s training time and GPU utilization were recorded and are shown in
Table 9. The average training time per epoch was 318 s, and GPU utilization was moderate at 48 units, reflecting a good balance between performance and resource consumption. Additionally, the model maintained accuracy stability with a standard deviation of ±0.25%, indicating robust and consistent learning behavior across training runs.
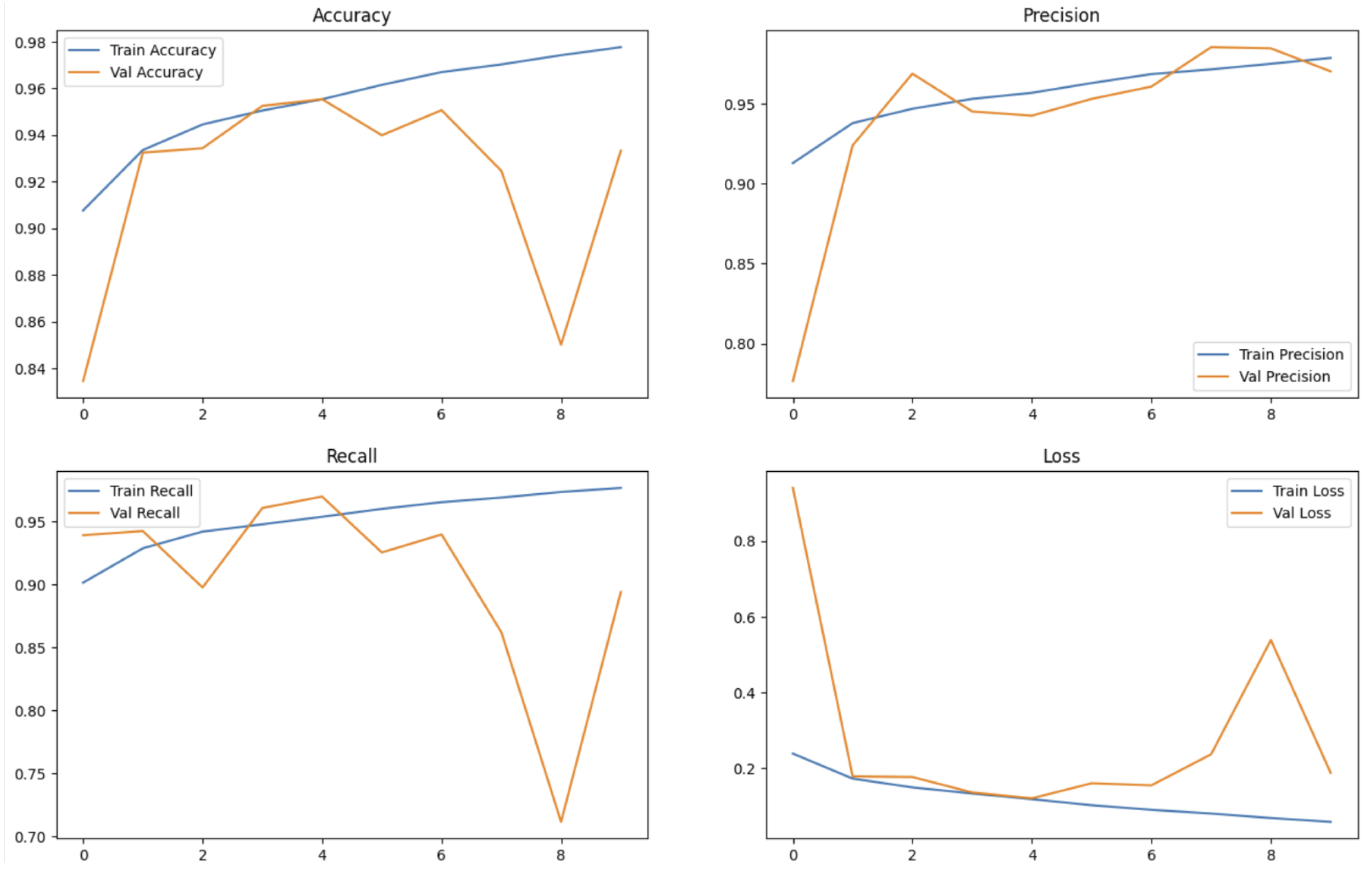
Figure 5 illustrates the training dynamics of the SE-ResNet-50 model. The training curves show consistent improvement across epochs with minimal overfitting, though a slight divergence is observed in recall and validation loss after epoch 6, possibly due to increased sensitivity to subtle generative features. The stability in training loss and precision confirms robust convergence. This data supports the feasibility of deploying the model in both cloud-based and resource-constrained edge environments. Compared with DenseNet—which, while slightly more accurate, incurs nearly double the training cost—the SE-ResNet-50 model achieves an optimal balance of speed, accuracy, and hardware efficiency.
4.5. Qualitative Analysis of Classification Behavior
False Positives (FP): real images with compression noise or poor lighting were occasionally misclassified as fake, likely due to superficial texture anomalies.
False Negatives (FN): some AI-generated images with high photorealism and clean edge consistency evaded detection, leading to misclassification.
True Positives (TP): synthetic images with repetitive patterns, artifacts, or blurred textures were consistently flagged as fake.
True Negatives (TN): natural scenes with complex lighting and realistic depth cues were correctly classified as authentic.
This qualitative analysis supports the numerical metrics and reveals edge cases where generative quality or real-world noise affects prediction reliability.
4.5.1. Interpretability and Transparency
Beyond numerical performance, the model also enhances interpretability, a critical factor in deep learning-based security applications. The learned attention weights from SE blocks provide insight into the model’s decision-making, allowing practitioners to visualize and understand which parts of the image contributed most to its classification. This capability not only supports debugging and refinement but also enhances trustworthiness, especially in forensic and legal scenarios.
4.5.2. Discussion of Implications and Limitations
The experimental results obtained from the proposed SE-ResNet-50 model not only highlight its superior performance but also underline several broader implications and practical considerations for the real-world deployment of AI-generated image detection systems. Future investigations could address these limitations through enhanced optimization strategies, more robust data augmentation methods, or by exploring other lightweight attention mechanisms.
Real-World Applicability and Societal Impact
The increasing prevalence of AI-generated images in digital art, journalism, advertising, and social media introduces significant ethical and operational challenges, including misinformation, identity fraud, and digital forgery [
1,
3]. The high accuracy (96.12%) and precision (97.04%) of the proposed hybrid model suggest it can serve as a reliable automated tool for detecting such synthetic content across various industries, particularly in content moderation, digital forensics, law enforcement, and media authentication.
Importantly, the model demonstrates not just statistical excellence but operational robustness. Its ability to operate with moderate computational demands while retaining state-of-the-art accuracy positions it well for real-time or embedded applications, such as browser plugins, mobile applications, or edge AI devices. Moreover, its enhanced interpretability via attention weights allows stakeholders to better trust, audit, and explain decisions made by the system—an essential requirement in regulated environments like legal and governmental contexts.
Ethical Considerations and Explainability
As the arms race between generative AI and detection systems accelerates, explainability becomes paramount. The integration of SE blocks introduces a level of transparency uncommon in traditional CNNs. By providing insight into which feature channels the model emphasizes, developers and analysts gain the ability to interpret, debug, and validate model predictions—bridging the gap between black-box AI and human interpretability [
15].
This attention-guided insight can also support efforts toward ethical AI governance, where transparency and accountability in decision-making processes are increasingly required by both institutions and emerging legislation worldwide.
Limitations and Areas for Caution
Despite its high performance, the SE-ResNet-50 model presents certain limitations that warrant further research and engineering optimization:
Computational overhead: Although more efficient than DenseNet, the hybrid model still introduces additional parameters due to the SE blocks. This could be a constraint for ultra-low-power devices or latency-sensitive real-time systems.
Data sensitivity: The model’s performance is closely tied to the quality and diversity of training data. Biases or limitations within the CIFAKE dataset could influence its generalization ability across unseen generative models or content types.
Overfitting to visual artifacts: There is a risk that the model may be overfit to the generative patterns present in the current dataset (e.g., GAN fingerprints or compression artifacts), reducing its adaptability to emerging or more advanced synthetic generation techniques that minimize such artifacts [
29,
31].
Adversarial vulnerability: Like most deep learning models, SE-ResNet-50 may remain vulnerable to adversarial attacks, where carefully crafted perturbations can manipulate outputs. Adversarial robustness was not the focus of this study and remains a critical direction for future investigation [
17].
Limited architecture comparison: While our study compares with traditional CNN architectures, a comprehensive comparison with newer transformer-based models was not fully explored. Although our current results show competitive performance against selected transformer architectures, a more extensive evaluation across the full spectrum of vision transformers and diffusion-aware models would provide additional insights into relative strengths and weaknesses.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}