
Data Imputation Based on Retrieval-Augmented Generation


Abstract
1. Introduction
- Semantic Indexing Framework: We propose a unified and optimized semantic indexing framework for large-scale data lakes, significantly improving data retrieval efficiency and accuracy.
- Retrieval-Enhanced Inference: We designe a retrieval-enhanced method combining high recall scores and precise ranking, greatly enhancing the accuracy of data imputation inference.
- Reduce Costs while Ensuring Inference Quality: We propose a code generation framework based on LLMs for data imputation on large-scale datasets, significantly reducing costs while ensuring the quality of data imputation.
2. Related Work
2.1. Data Imputation
2.2. Retrieval-Augmented Generation (RAG)
3. Methods
3.1. Framework
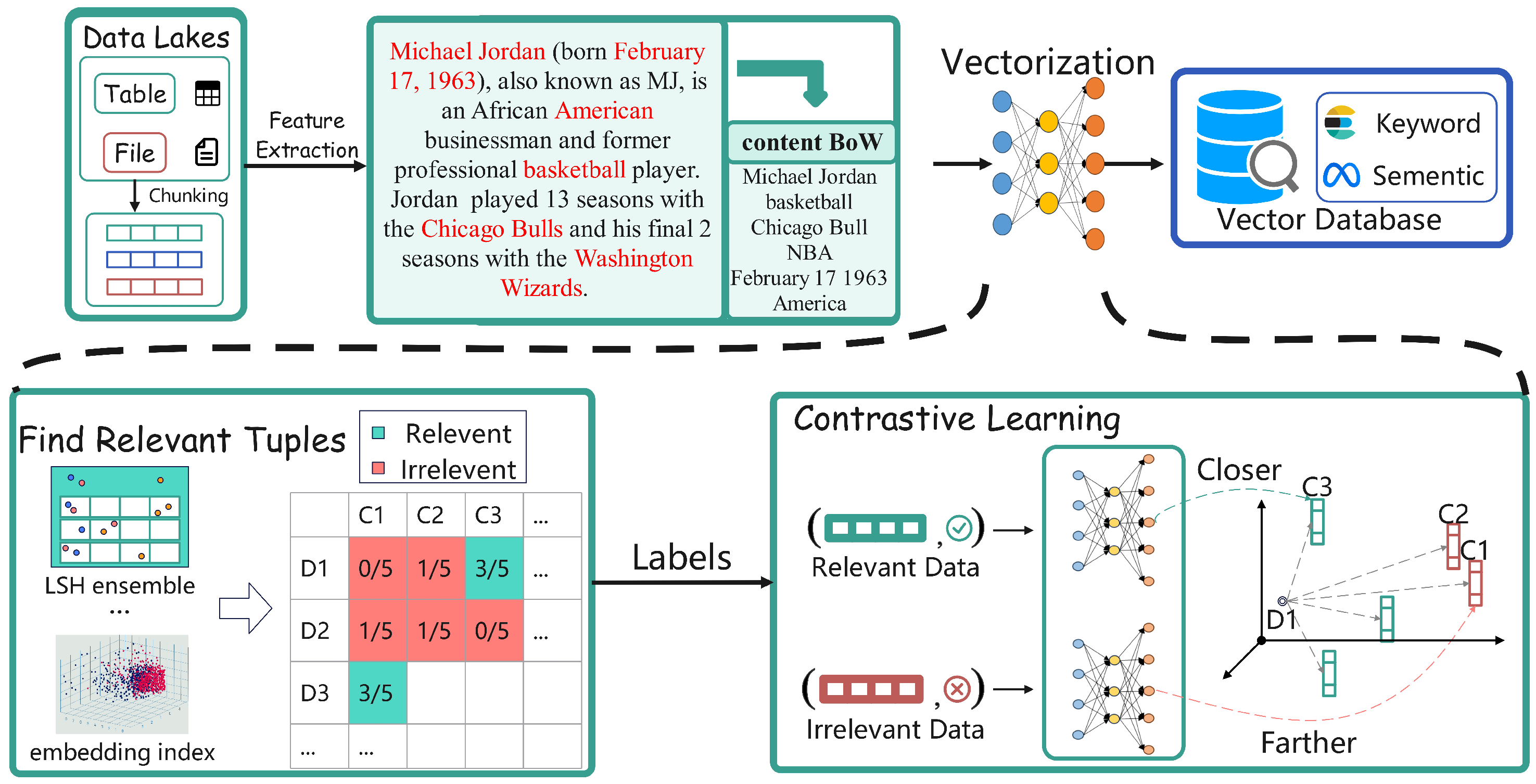
3.2. Semantic Data Lake Indexing Technology
3.3. Recall and Re-Ranking Retrieval-Augmented Technology
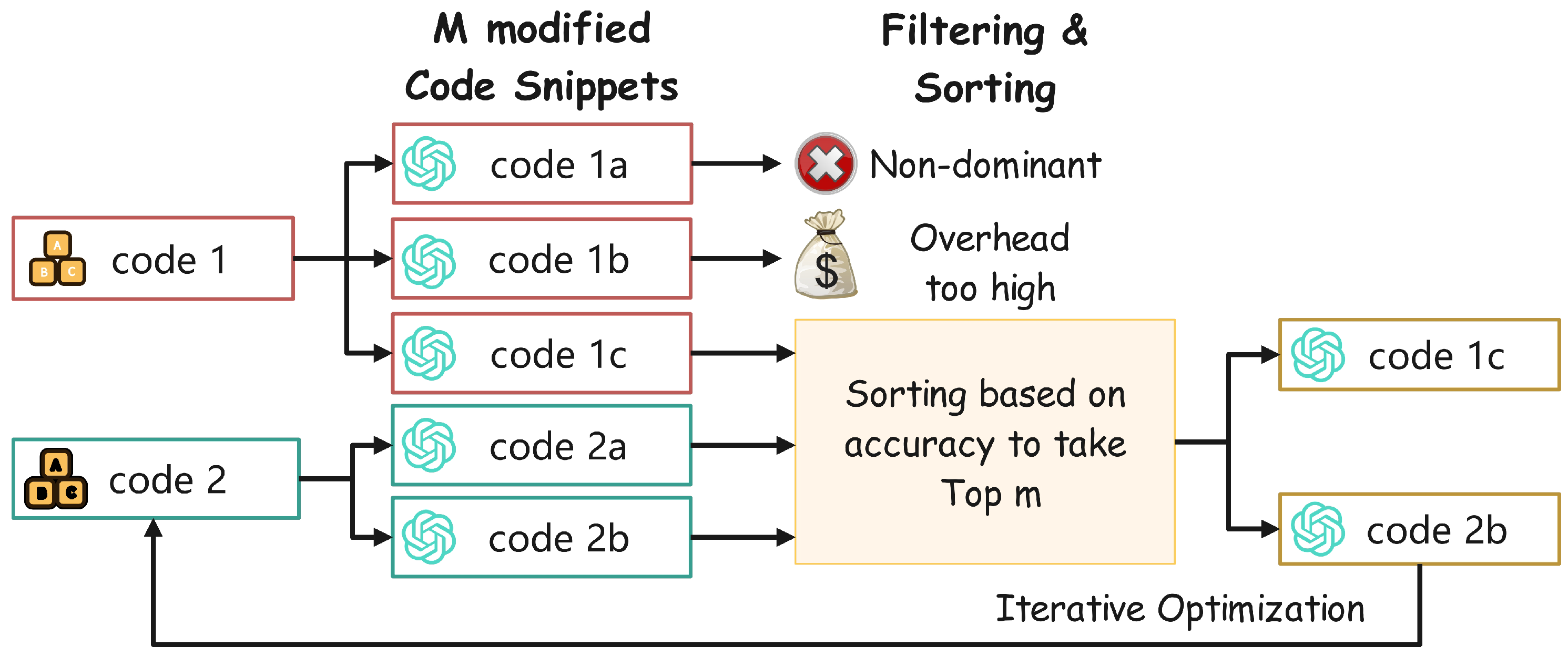
3.4. Inference Optimization Methods Under Cost Constraints
- Task Decomposition: An LLM (acting as an advisor) first decomposes the task into smaller, manageable components. Each component is then translated into a specific code generation objective.
- Code Generation and Verification: A code generator produces the corresponding code snippets, which are iteratively refined using automated test cases and debugging tools.
- Error Handling and Refinement: A verifier identifies logical or semantic errors in the generated code, feeding this information back to the advisor for further refinement until all errors are resolved.
- Validated code generation: This method integrates code generation and debugging into a unified process. By leveraging the reasoning capabilities of LLMs, the system iteratively refines code snippets until all test cases are satisfied. This approach minimizes user input and enhances code quality.
- Evolutionary code integration: This technique generates multiple code snippets with complementary strengths, combining them iteratively to handle complex tasks. By optimizing the integration of these snippets, the framework ensures robustness and scalability.
4. Experimental Verification
4.1. Evaluation of the Overall Experimental Effect of Data Imputation
4.1.1. Dataset Preparation
- Dataset Collection: Our goal is to showcase datasets with specific features: (1) they should originate from real-world scenarios, and (2) they should cover a variety of data domains. Guided by these criteria and existing work on missing value imputation, we collected the three datasets from real-world data sources:
- WikiTuples [99]: This dataset is composed of 207,912 tables from various fields within the data lake, such as sports, politics, and arts. It contains 10,003 tuples, with missing values present in 807 tables. These missing values span multiple attributes, including Party, Director, Team, Album, etc. On average, each tuple with missing values corresponds to 4.38 target tuples, reflecting the complexity of locating target tuples among 2,674,164 tuples in the data lake. Although WikiTuples and the retriever’s training data come from the same source, the latter did not undergo the same rigorous annotation process. Furthermore, only 41,000 tables were used during the pre-training phase, which is significantly smaller than the size of the data lake.
- Education [100]: This dataset includes information about elementary and high schools in Chicago, containing 654 tuples, with missing values in the Address, Zip Code, and Phone Number columns. It comprises 11,132 tuples, with each tuple missing values corresponding to four target tuples.
- Cricket Players [101]: The Cricket Players dataset also originates from RetClean and focuses on the sports domain. It contains 213 incomplete tuples, with the data lake containing 94,164 tuples. On average, each tuple with missing values corresponds to 1.38 target tuples. The missing information pertains to players’ nationality and bowling style attributes.
- Candidate Tuple Construction: For tuples with missing values (i.e., incomplete tuples), we first create a candidate set by selecting tuples that may assist in imputing the missing values. Given the large number of tuples in the data lake, we utilize explicit information, such as matching the same subject ID or linking to the same entity in the original data. This helps us establish effective filtering rules to identify potential candidates for incomplete tuples.
- Expert Annotation: The final step is managing the target tuples for each incomplete tuple. For each tuple with missing values, we obtain the corresponding candidate set from the previous step. We present each tuple, along with its candidate tuples, to experts, who evaluate whether any of the candidates can fill at least one missing value in the tuple, thereby being identified as target tuples. This manual process is very time-consuming and requires specific domain knowledge, making attempts to automate it quite challenging. To reduce annotation costs, we primarily focus on cases where the candidate set contains 10 or fewer tuples.
4.1.2. Baseline Model
- Reasoner Baseline: We use the following baselines for end-to-end data imputation:
- GPT-3.5/GPT-4.0: We directly use GPT-3.5 and GPT-4.0 as the reasoners for data imputation without the retrieval module. Additionally, to guide the model in recognizing the format of missing values, we add an extra complete tuple to the table that requires imputation.
- BM25-based GPT-3.5/GPT-4.0: To study the impact of different retrieval methods in our retrieval-enhanced imputation framework, we use BM25 [102] as the retriever module. This setup allows us to evaluate the influence of various retrieval strategies on the accuracy of data imputation.
4.1.3. Evaluation Metrics
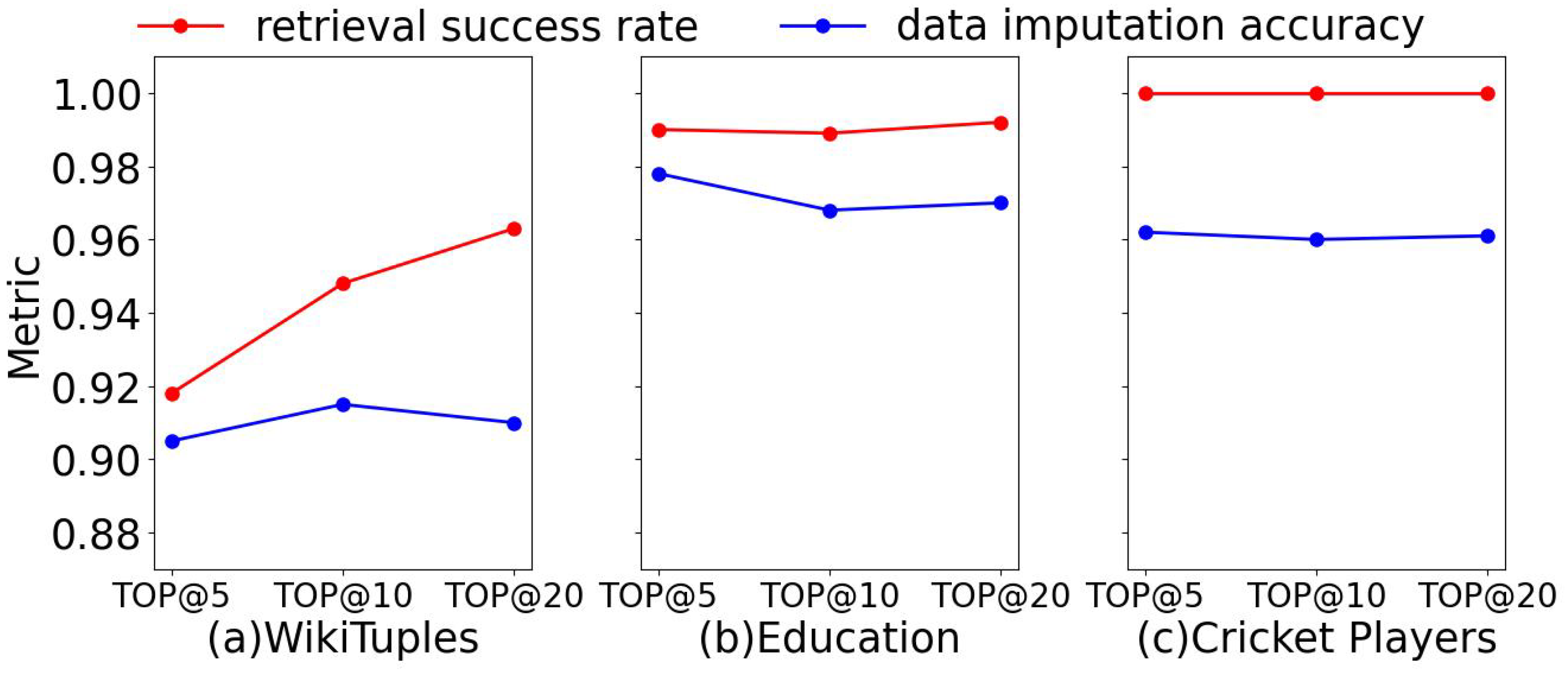
4.1.4. Experimental Results and Analysis
4.2. Evaluation of Retriever Effectiveness
4.2.1. Dataset Preparation
4.2.2. Baseline Model
- Retriever Baseline: We compare our retriever with several baselines. The first two methods have zero-shot capabilities and are, thus, applied directly. For the third method, we retrain it using the same training data for a fair comparison. The baselines are introduced as follows:
- BM25: BM25 is the most commonly used sparse retrieval method and demonstrates very robust performance.
- Contriever: Contriever is an unsupervised retriever that performs well in few-shot and zero-shot settings for paragraph retrieval.
- BERT [103] with Language Modeling (LM) Task: Previous work on table data representation has adopted pre-training tasks centered around language modeling and tabular data structures. For example, TabReformer and TURL utilize masked language modeling tasks, with the latter adding masked entity recovery. To demonstrate that contrastive learning methods are crucial for the success of tuple embeddings in retrieval, we trained a tuple encoder using the BERT-base model. This model shares the same basic structure as our encoder but was trained using a language modeling task.Specifically, for a given tuple (t), we randomly mask one cell, then input t into the encoder, asking it to predict the value of the masked cell. Additionally, we apply two enhancement operators—shuffle and delete—to tuple t to enrich our training data. Due to the structural nature of tables and their inherent permutation invariance, these operators are commonly used for tabular data.
4.2.3. Evaluation Metrics
4.2.4. Experimental Results and Analysis
4.3. Evaluation of Re-Ranker Effectiveness
4.3.1. Dataset Preparation
4.3.2. Baseline Model
- monoBERT [104]: This is a model designed for query-based paragraph re-ranking, utilizing the BERT model. This process involves concatenating the query with the paragraph text, then using the [CLS] vector to compute the re-ranking score. To compare monoBERT with our re-ranker, we use the provided parameters to initialize it and fine-tune it on our training data.
- RoBERTa-LCE: This introduces a new loss called Local Contrastive Estimation (LCE) to train a more robust re-ranker. We fine-tune the RoBERTa-base model using the LCE loss on our training data for a fair comparison.
- GPT-3.5 with List: Recent studies have highlighted the exceptional performance of LLMs in relevance re-ranking tasks. Thus, we use GPT-3.5 as a re-ranker employing the list method. Specifically, GPT-3.5 is fed a set of retrieved tuples and an incomplete tuple, instructing the model to generate a re-ranked list based on relevance to the incomplete tuple. To manage input limitations, we adopt a sliding window strategy with a window size of 30 and a step size of 14.
4.3.3. Evaluation Metrics
4.3.4. Experimental Results and Analysis
4.4. Evaluation of Code Generator Effectiveness
4.4.1. Dataset Preparation
4.4.2. Baseline Model
4.4.3. Evaluation Metrics
4.4.4. Experimental Results and Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Blazquez, D.; Domenech, J. Big Data sources and methods for social and economic analyses. Technol. Forecast. Soc. Chang. 2018, 130, 99–113. [Google Scholar] [CrossRef]
- Can, U.; Alatas, B. Big social network data and sustainable economic development. Sustainability 2017, 9, 2027. [Google Scholar] [CrossRef]
- Arora, A.; Vats, P.; Tomer, N.; Kaur, R.; Saini, A.K.; Shekhawat, S.S.; Roopak, M. Data-Driven Decision Support Systems in E-Governance: Leveraging AI for Policymaking. In Proceedings of the International Conference on Artificial Intelligence on Textile and Apparel; Springer: Berlin/Heidelberg, Germany, 2023; pp. 229–243. [Google Scholar]
- Linkov, I.; Trump, B.D.; Poinsatte-Jones, K.; Florin, M.V. Governance strategies for a sustainable digital world. Sustainability 2018, 10, 440. [Google Scholar] [CrossRef]
- van Veenstra, A.F.; Kotterink, B. Data-driven policy making: The policy lab approach. In Proceedings of the Electronic Participation: 9th IFIP WG 8.5 International Conference, ePart 2017, St. Petersburg, Russia, 4–7 September 2017; Proceedings 9. Springer: Berlin/Heidelberg, Germany, 2017; pp. 100–111. [Google Scholar]
- Rendle, S. Factorization machines. In Proceedings of the 2010 IEEE International Conference on Data Mining, Sydney, Australia, 13–17 December 2010; pp. 995–1000. [Google Scholar]
- He, X.; Chua, T.S. Neural factorization machines for sparse predictive analytics. In Proceedings of the 40th International ACM SIGIR conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 355–364. [Google Scholar]
- Jiang, P.; Xiao, C.; Cross, A.; Sun, J. Graphcare: Enhancing healthcare predictions with personalized knowledge graphs. arXiv 2023, arXiv:2305.12788. [Google Scholar]
- Wang, L.; Liu, Q.; Zhang, M.; Hu, Y.; Wu, S.; Wang, L. Stage-aware hierarchical attentive relational network for diagnosis prediction. IEEE Trans. Knowl. Data Eng. 2023, 36, 1773–1784. [Google Scholar] [CrossRef]
- Ye, M.; Cui, S.; Wang, Y.; Luo, J.; Xiao, C.; Ma, F. Medpath: Augmenting health risk prediction via medical knowledge paths. In Proceedings of the Web Conference, Ljubljana, Slovenia, 19–23 April 2021; pp. 1397–1409. [Google Scholar]
- Yang, K.; Xu, Y.; Zou, P.; Ding, H.; Zhao, J.; Wang, Y.; Xie, B. KerPrint: Local-global knowledge graph enhanced diagnosis prediction for retrospective and prospective interpretations. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 5357–5365. [Google Scholar]
- Cui, C.; Wang, W.; Zhang, M.; Chen, G.; Luo, Z.; Ooi, B.C. Alphaevolve: A learning framework to discover novel alphas in quantitative investment. In Proceedings of the 2021 International Conference on Management of Data, Xi’an, China, 20–25 June 2021; pp. 2208–2216. [Google Scholar]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; Volume 35, pp. 11106–11115. [Google Scholar]
- Ren, Y.; Chen, Y.; Liu, S.; Wang, B.; Yu, H.; Cui, Z. TPLLM: A traffic prediction framework based on pretrained large language models. arXiv 2024, arXiv:2403.02221. [Google Scholar]
- Adhikari, D.; Jiang, W.; Zhan, J.; He, Z.; Rawat, D.B.; Aickelin, U.; Khorshidi, H.A. A comprehensive survey on imputation of missing data in internet of things. ACM Comput. Surv. 2022, 55, 1–38. [Google Scholar] [CrossRef]
- Little, R.J.; Rubin, D.B. Statistical Analysis with Missing Data; John Wiley & Sons: Hoboken, NJ, USA, 2019; Volume 793. [Google Scholar]
- Farhangfar, A.; Kurgan, L.A.; Pedrycz, W. A novel framework for imputation of missing values in databases. IEEE Trans. Syst. Man Cybern.-Part A Syst. Humans 2007, 37, 692–709. [Google Scholar] [CrossRef]
- Altman, N.S. An introduction to kernel and nearest-neighbor nonparametric regression. Am. Stat. 1992, 46, 175–185. [Google Scholar] [CrossRef]
- Jerez, J.M.; Molina, I.; García-Laencina, P.J.; Alba, E.; Ribelles, N.; Martín, M.; Franco, L. Missing data imputation using statistical and machine learning methods in a real breast cancer problem. Artif. Intell. Med. 2010, 50, 105–115. [Google Scholar] [CrossRef]
- Twala, B.; Cartwright, M.; Shepperd, M. Comparison of various methods for handling incomplete data in software engineering databases. In Proceedings of the IEEE 2005 International Symposium on Empirical Software Engineering, Noosa Heads, Australia, 17–18 November 2005; p. 10. [Google Scholar]
- Gondara, L.; Wang, K. Multiple imputation using deep denoising autoencoders. arXiv 2017, arXiv:1705.02737. [Google Scholar]
- Mattei, P.A.; Frellsen, J. MIWAE: Deep generative modelling and imputation of incomplete data sets. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 4413–4423. [Google Scholar]
- Zheng, Y. Methodologies for cross-domain data fusion: An overview. IEEE Trans. Big Data 2015, 1, 16–34. [Google Scholar] [CrossRef]
- Lv, F.; Liang, T.; Chen, X.; Lin, G. Cross-domain semantic segmentation via domain-invariant interactive relation transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 4334–4343. [Google Scholar]
- Manjunath, G.; Murty, M.N.; Sitaram, D. Combining heterogeneous classifiers for relational databases. Pattern Recognit. 2013, 46, 317–324. [Google Scholar] [CrossRef]
- Sayyadian, M.; LeKhac, H.; Doan, A.; Gravano, L. Efficient keyword search across heterogeneous relational databases. In Proceedings of the 2007 IEEE 23rd International Conference on Data Engineering, Istanbul, Turkey, 15–20 April 2006; pp. 346–355. [Google Scholar]
- Drutsa, A.; Fedorova, V.; Ustalov, D.; Megorskaya, O.; Zerminova, E.; Baidakova, D. Crowdsourcing practice for efficient data labeling: Aggregation, incremental relabeling, and pricing. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data, Portland, OR, USA, 14–19 June 2020; pp. 2623–2627. [Google Scholar]
- Zhang, C.; Zhong, H.; Zhang, K.; Chai, C.; Wang, R.; Zhuang, X.; Bai, T.; Qiu, J.; Cao, L.; Fan, J.; et al. Harnessing Diversity for Important Data Selection in Pretraining Large Language Models. arXiv 2024, arXiv:2409.16986. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Narayan, A.; Chami, I.; Orr, L.; Arora, S.; Ré, C. Can foundation models wrangle your data? arXiv 2022, arXiv:2205.09911. [Google Scholar] [CrossRef]
- Wei, J.; Bosma, M.; Zhao, V.Y.; Guu, K.; Yu, A.W.; Lester, B.; Du, N.; Dai, A.M.; Le, Q.V. Finetuned language models are zero-shot learners. arXiv 2021, arXiv:2109.01652. [Google Scholar]
- Xu, D.D.; Mukherjee, S.; Liu, X.; Dey, D.; Wang, W.; Zhang, X.; Awadallah, A.; Gao, J. Few-shot task-agnostic neural architecture search for distilling large language models. Adv. Neural Inf. Process. Syst. 2022, 35, 28644–28656. [Google Scholar]
- Tian, P.; Li, W.; Gao, Y. Consistent meta-regularization for better meta-knowledge in few-shot learning. IEEE Trans. Neural Networks Learn. Syst. 2021, 33, 7277–7288. [Google Scholar] [CrossRef]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Ichter, B.; Xia, F.; Chi, E.; Le, Q.V.; Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. Adv. Neural Inf. Process. Syst. 2022, 35, 24824–24837. [Google Scholar]
- Yao, S.; Yu, D.; Zhao, J.; Shafran, I.; Griffiths, T.; Cao, Y.; Narasimhan, K. Tree of thoughts: Deliberate problem solving with large language models. Adv. Neural Inf. Process. Syst. 2023, 36, 11809–11822. [Google Scholar]
- Qahtan, A.A.; Elmagarmid, A.; Castro Fernandez, R.; Ouzzani, M.; Tang, N. FAHES: A robust disguised missing values detector. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 2100–2109. [Google Scholar]
- Soliman, M.A.; Ilyas, I.F.; Ben-David, S. Supporting ranking queries on uncertain and incomplete data. VLDB J. 2010, 19, 477–501. [Google Scholar] [CrossRef]
- Berti-Équille, L.; Harmouch, H.; Naumann, F.; Novelli, N.; Thirumuruganathan, S. Discovery of genuine functional dependencies from relational data with missing values. Proc. VLDB Endow. 2018, 11, 880–892. [Google Scholar] [CrossRef]
- Tian, Y.; Zhang, K.; Li, J.; Lin, X.; Yang, B. LSTM-based traffic flow prediction with missing data. Neurocomputing 2018, 318, 297–305. [Google Scholar] [CrossRef]
- Song, H.; Szafir, D.A. Where’s my data? evaluating visualizations with missing data. IEEE Trans. Vis. Comput. Graph. 2018, 25, 914–924. [Google Scholar] [CrossRef]
- Wei, Z.; Link, S. Embedded functional dependencies and data-completeness tailored database design. Proc. VLDB Endow. 2019, 12, 1458–1470. [Google Scholar] [CrossRef]
- Režnáková, M.; Tencer, L.; Plamondon, R.; Cheriet, M. Forgetting of unused classes in missing data environment using automatically generated data: Application to on-line handwritten gesture command recognition. Pattern Recognit. 2017, 72, 355–367. [Google Scholar] [CrossRef]
- Zhao, B.; Wu, B.; Wu, T.; Wang, Y. Zero-shot learning posed as a missing data problem. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 2616–2622. [Google Scholar]
- Li, Z.; Qin, L.; Cheng, H.; Zhang, X.; Zhou, X. TRIP: An interactive retrieving-inferring data imputation approach. IEEE Trans. Knowl. Data Eng. 2015, 27, 2550–2563. [Google Scholar] [CrossRef]
- Song, S.; Sun, Y.; Zhang, A.; Chen, L.; Wang, J. Enriching data imputation under similarity rule constraints. IEEE Trans. Knowl. Data Eng. 2018, 32, 275–287. [Google Scholar] [CrossRef]
- Lakshminarayan, K.; Harp, S.A.; Samad, T. Imputation of missing data in industrial databases. Appl. Intell. 1999, 11, 259–275. [Google Scholar] [CrossRef]
- Wahl, S.; Boulesteix, A.L.; Zierer, A.; Thorand, B.; van de Wiel, M.A. Assessment of predictive performance in incomplete data by combining internal validation and multiple imputation. BMC Med Res. Methodol. 2016, 16, 144. [Google Scholar] [CrossRef]
- Edwards, J.K.; Cole, S.R.; Troester, M.A.; Richardson, D.B. Accounting for misclassified outcomes in binary regression models using multiple imputation with internal validation data. Am. J. Epidemiol. 2013, 177, 904–912. [Google Scholar] [CrossRef] [PubMed]
- Thiesmeier, R.; Bottai, M.; Orsini, N. Imputing missing values with external data. arXiv 2024, arXiv:2410.02982. [Google Scholar]
- Edwards, J.K.; Cole, S.R.; Fox, M.P. Flexibly accounting for exposure misclassification with external validation data. Am. J. Epidemiol. 2020, 189, 850–860. [Google Scholar] [CrossRef]
- Salgado, C.M.; Azevedo, C.; Proença, H.; Vieira, S.M. Missing data. In Secondary Analysis of Electronic Health Records; Springer: Berlin/Heidelberg, Germany, 2016; pp. 143–162. [Google Scholar]
- Muzellec, B.; Josse, J.; Boyer, C.; Cuturi, M. Missing data imputation using optimal transport. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 7130–7140. [Google Scholar]
- García-Laencina, P.J.; Sancho-Gómez, J.L.; Figueiras-Vidal, A.R. Pattern classification with missing data: A review. Neural Comput. Appl. 2010, 19, 263–282. [Google Scholar] [CrossRef]
- Stekhoven, D.J.; Bühlmann, P. MissForest—non-parametric missing value imputation for mixed-type data. Bioinformatics 2012, 28, 112–118. [Google Scholar] [CrossRef]
- Zhang, A.; Song, S.; Sun, Y.; Wang, J. Learning individual models for imputation. In Proceedings of the 2019 IEEE 35th International Conference on Data Engineering (ICDE), Macao, China, 8–11 April 2019; pp. 160–171. [Google Scholar]
- McCoy, J.T.; Kroon, S.; Auret, L. Variational autoencoders for missing data imputation with application to a simulated milling circuit. IFAC-PapersOnLine 2018, 51, 141–146. [Google Scholar] [CrossRef]
- Nazabal, A.; Olmos, P.M.; Ghahramani, Z.; Valera, I. Handling incomplete heterogeneous data using vaes. Pattern Recognit. 2020, 107, 107501. [Google Scholar] [CrossRef]
- Spinelli, I.; Scardapane, S.; Uncini, A. Missing data imputation with adversarially-trained graph convolutional networks. Neural Netw. 2020, 129, 249–260. [Google Scholar] [CrossRef]
- Yoon, J.; Jordon, J.; Schaar, M. Gain: Missing data imputation using generative adversarial nets. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 5689–5698. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Royston, P.; White, I.R. Multiple imputation by chained equations (MICE): Implementation in Stata. J. Stat. Softw. 2011, 45, 1–20. [Google Scholar] [CrossRef]
- Mazumder, R.; Hastie, T.; Tibshirani, R. Spectral regularization algorithms for learning large incomplete matrices. J. Mach. Learn. Res. 2010, 11, 2287–2322. [Google Scholar]
- Lee, D.; Seung, H.S. Algorithms for non-negative matrix factorization. Adv. Neural Inf. Process. Syst. 2000, 13. [Google Scholar]
- Josse, J.; Pagès, J.; Husson, F. Multiple imputation in principal component analysis. Adv. Data Anal. Classif. 2011, 5, 231–246. [Google Scholar] [CrossRef]
- Doersch, C. Tutorial on variational autoencoders. arXiv 2016, arXiv:1606.05908. [Google Scholar]
- Germain, M.; Gregor, K.; Murray, I.; Larochelle, H. Made: Masked autoencoder for distribution estimation. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 881–889. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 214–223. [Google Scholar]
- Chen, J.; Wu, Y.; Jia, C.; Zheng, H.; Huang, G. Customizable text generation via conditional text generative adversarial network. Neurocomputing 2020, 416, 125–135. [Google Scholar] [CrossRef]
- Mei, Y.; Song, S.; Fang, C.; Yang, H.; Fang, J.; Long, J. Capturing semantics for imputation with pre-trained language models. In Proceedings of the 2021 IEEE 37th International Conference on Data Engineering (ICDE), Chania, Greece, 19–22 April 2021; pp. 61–72. [Google Scholar]
- Chen, Y.; Wang, X.; Xu, G. Gatgpt: A pre-trained large language model with graph attention network for spatiotemporal imputation. arXiv 2023, arXiv:2311.14332. [Google Scholar]
- Ding, Z.; Tian, J.; Wang, Z.; Zhao, J.; Li, S. Data imputation using large language model to accelerate recommendation system. arXiv 2024, arXiv:2407.10078. [Google Scholar]
- Radford, A. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://www.mikecaptain.com/resources/pdf/GPT-1.pdf (accessed on 10 June 2025).
- Ruder, S.; Peters, M.E.; Swayamdipta, S.; Wolf, T. Transfer learning in natural language processing. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Tutorials, Minneapolis, MN, USA, 2–7 June 2019; pp. 15–18. [Google Scholar]
- Luo, G.; Han, Y.T.; Mou, L.; Firdaus, M. Prompt-based editing for text style transfer. arXiv 2023, arXiv:2301.11997. [Google Scholar]
- Izacard, G.; Lewis, P.; Lomeli, M.; Hosseini, L.; Petroni, F.; Schick, T.; Dwivedi-Yu, J.; Joulin, A.; Riedel, S.; Grave, E. Atlas: Few-shot learning with retrieval augmented language models. J. Mach. Learn. Res. 2023, 24, 1–43. [Google Scholar]
- Wang, Z.; Sun, J. Transtab: Learning transferable tabular transformers across tables. Adv. Neural Inf. Process. Syst. 2022, 35, 2902–2915. [Google Scholar]
- Yang, C.; Luo, Y.; Cui, C.; Fan, J.; Chai, C.; Tang, N. Retrieval Augmented Imputation Using Data Lake Tables. Available online: https://openreview.net/forum?id=EyW92b6DyY (accessed on 10 June 2025).
- Borisov, V.; Leemann, T.; Seßler, K.; Haug, J.; Pawelczyk, M.; Kasneci, G. Deep neural networks and tabular data: A survey. IEEE Trans. Neural Netw. Learn. Syst. 2022, 35, 7499–7519. [Google Scholar] [CrossRef]
- Carballo, K.V.; Na, L.; Ma, Y.; Boussioux, L.; Zeng, C.; Soenksen, L.R.; Bertsimas, D. TabText: A Flexible and Contextual Approach to Tabular Data Representation. arXiv 2022, arXiv:2206.10381. [Google Scholar]
- Ren, W.; Zhao, T.; Huang, Y.; Honavar, V. Deep Learning within Tabular Data: Foundations, Challenges, Advances and Future Directions. arXiv 2025, arXiv:2501.03540. [Google Scholar]
- Yi, Z.; Ouyang, J.; Liu, Y.; Liao, T.; Xu, Z.; Shen, Y. A Survey on Recent Advances in LLM-Based Multi-turn Dialogue Systems. arXiv 2024, arXiv:2402.18013. [Google Scholar]
- Bai, G.; Liu, J.; Bu, X.; He, Y.; Liu, J.; Zhou, Z.; Lin, Z.; Su, W.; Ge, T.; Zheng, B.; et al. Mt-bench-101: A fine-grained benchmark for evaluating large language models in multi-turn dialogues. arXiv 2024, arXiv:2402.14762. [Google Scholar]
- Gao, Y.; Xiong, Y.; Gao, X.; Jia, K.; Pan, J.; Bi, Y.; Dai, Y.; Sun, J.; Wang, H. Retrieval-augmented generation for large language models: A survey. arXiv 2023, arXiv:2312.10997. [Google Scholar]
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.t.; Rocktäschel, T.; et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Adv. Neural Inf. Process. Syst. 2020, 33, 9459–9474. [Google Scholar]
- Wu, Y.; Zhao, Y.; Hu, B.; Minervini, P.; Stenetorp, P.; Riedel, S. An efficient memory-augmented transformer for knowledge-intensive nlp tasks. arXiv 2022, arXiv:2210.16773. [Google Scholar]
- Jiang, Z.; Xu, F.F.; Gao, L.; Sun, Z.; Liu, Q.; Dwivedi-Yu, J.; Yang, Y.; Callan, J.; Neubig, G. Active retrieval augmented generation. arXiv 2023, arXiv:2305.06983. [Google Scholar]
- Guu, K.; Lee, K.; Tung, Z.; Pasupat, P.; Chang, M. Retrieval augmented language model pre-training. In Proceedings of the International Conference on Machine Learning, Virtual Event, 13–18 July 2020; pp. 3929–3938. [Google Scholar]
- Zhuang, X.; Peng, J.; Ma, R.; Wang, Y.; Bai, T.; Wei, X.; Qiu, J.; Zhang, C.; Qian, Y.; He, C. Meta-rater: A Multi-dimensional Data Selection Method for Pre-training Language Models. arXiv 2025, arXiv:2310.09263. [Google Scholar]
- Ram, O.; Levine, Y.; Dalmedigos, I.; Muhlgay, D.; Shashua, A.; Leyton-Brown, K.; Shoham, Y. In-context retrieval-augmented language models. Trans. Assoc. Comput. Linguist. 2023, 11, 1316–1331. [Google Scholar] [CrossRef]
- Li, P.; He, Y.; Yashar, D.; Cui, W.; Ge, S.; Zhang, H.; Fainman, D.R.; Zhang, D.; Chaudhuri, S. Table-gpt: Table-tuned gpt for diverse table tasks. arXiv 2023, arXiv:2310.09263. [Google Scholar] [CrossRef]
- Li, P.; He, Y.; Yashar, D.; Cui, W.; Ge, S.; Zhang, H.; Rifinski Fainman, D.; Zhang, D.; Chaudhuri, S. Table-GPT: Table Fine-tuned GPT for Diverse Table Tasks. Proc. ACM Manag. Data 2024, 2, 1–28. [Google Scholar] [CrossRef]
- Zhang, D.; Yin, C.; Zeng, J.; Yuan, X.; Zhang, P. Combining structured and unstructured data for predictive models: A deep learning approach. BMC Med. Inform. Decis. Mak. 2020, 20, 280. [Google Scholar] [CrossRef]
- Alessandro, M.D.; Calabrés, E.; Elkano, M. A Modular End-to-End Multimodal Learning Method for Structured and Unstructured Data. arXiv 2024, arXiv:2403.04866. [Google Scholar]
- Bai, T.; Yang, L.; Wong, Z.H.; Peng, J.; Zhuang, X.; Zhang, C.; Wu, L.; Qiu, J.; Zhang, W.; Yuan, B.; et al. Multi-Agent Collaborative Data Selection for Efficient LLM Pretraining. arXiv 2024, arXiv:2410.08102. [Google Scholar]
- Ebrahimi, S.; Arik, S.O.; Dong, Y.; Pfister, T. Lanistr: Multimodal learning from structured and unstructured data. arXiv 2023, arXiv:2305.16556. [Google Scholar]
- Yang, S.; Zhang, R.; Erfani, S.M.; Lau, J.H. UniMF: A Unified Framework to Incorporate Multimodal Knowledge Bases intoEnd-to-End Task-Oriented Dialogue Systems. In Proceedings of the IJCAI, Montreal, QC, Canada, 19–27 August 2021; pp. 3978–3984. [Google Scholar]
- Santos, M.S.; Abreu, P.H.; Fernández, A.; Luengo, J.; Santos, J. The impact of heterogeneous distance functions on missing data imputation and classification performance. Eng. Appl. Artif. Intell. 2022, 111, 104791. [Google Scholar] [CrossRef]
- Guțu, B.M.; Popescu, N. Exploring Data Analysis Methods in Generative Models: From Fine-Tuning to RAG Implementation. Computers 2024, 13, 327. [Google Scholar] [CrossRef]
- Naeem, Z.A.; Ahmad, M.S.; Eltabakh, M.; Ouzzani, M.; Tang, N. RetClean: Retrieval-Based Data Cleaning Using Foundation Models and Data Lakes. arXiv 2024, arXiv:2303.16909. [Google Scholar]
- Deng, X.; Sun, H.; Lees, A.; Wu, Y.; Yu, C. TURL: Table Understanding through Representation Learning. arXiv 2020, arXiv:2006.14806. [Google Scholar] [CrossRef]
- City of Chicago. Chicago Data Portal. 2023. Available online: https://data.cityofchicago.org/Public-Safety/Crimes-2023/xguy-4ndq/about_data (accessed on 30 June 2023).
- Robertson, S.; Zaragoza, H. The probabilistic relevance framework: BM25 and beyond. Found. Trends® Inf. Retr. 2009, 3, 333–389. [Google Scholar] [CrossRef]
- Devlin, J. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Nogueira, R.; Yang, W.; Cho, K.; Lin, J. Multi-stage document ranking with BERT. arXiv 2019, arXiv:1910.14424. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reasoner | Retrieval Modules | WikiTuples | Education | Cricket Players |
|---|---|---|---|---|
| GPT-3.5 | w/o | 0.715 ± 0.008 | 0.017 ± 0.002 | 0.896 ± 0.005 |
| w/tuples (BM25) | 0.577 ± 0.007 | 0.892 ± 0.004 | 0.889 ± 0.006 | |
| w/tuples (ours) | 0.886 ± 0.005 | 0.976 ± 0.003 | 0.964 ± 0.004 | |
| GPT-4.0 | w/o | 0.752 ± 0.009 | 0.597 ± 0.006 | 0.863 ± 0.005 |
| w/tuples (BM25) | 0.800 ± 0.006 | 0.925 ± 0.004 | 0.909 ± 0.004 | |
| w/tuples (ours) | 0.902 ± 0.004 | 0.979 ± 0.002 | 0.972 ± 0.003 |
| Retriever | WikiTuples | Education | Cricket Players | |||
|---|---|---|---|---|---|---|
| S@1 | S@5 | S@1 | S@5 | S@1 | S@5 | |
| Initial Retrieval | 0.327 ± 0.006 | 0.279 ± 0.005 | 0.743 ± 0.004 | 0.901 ± 0.003 | 0.902 ± 0.002 | 0.043 ± 0.001 |
| Contriever | 0.485 ± 0.007 | 0.456 ± 0.006 | 0.758 ± 0.005 | 0.825 ± 0.004 | 0.074 ± 0.002 | 0.043 ± 0.001 |
| BERT w/LM Task | 0.275 ± 0.005 | 0.201 ± 0.004 | 0 ± 0 | 0 ± 0 | 0 ± 0 | 0 ± 0 |
| Re-ranker (ours) | 0.951 ± 0.003 | 0.791 ± 0.003 | 0.992 ± 0.002 | 0.923 ± 0.002 | 1.000 ± 0.000 | 0.989 ± 0.001 |
| Re-Ranker | WikiTuples | Education | Cricket Players | |||
|---|---|---|---|---|---|---|
| S@1 | S@5 | S@1 | S@5 | S@1 | S@5 | |
| Initial Retrieval | 0.531 ± 0.006 | 0.803 ± 0.004 | 0.577 ± 0.005 | 0.923 ± 0.003 | 0.830 ± 0.003 | 0.989 ± 0.001 |
| monoBERT | 0.501 ± 0.007 | 0.799 ± 0.005 | 0.973 ± 0.003 | 0.984 ± 0.002 | 0.622 ± 0.004 | 0.931 ± 0.002 |
| RoBERTa-LCE | 0.615 ± 0.006 | 0.837 ± 0.004 | 0.970 ± 0.002 | 0.984 ± 0.002 | 0.902 ± 0.003 | 0.974 ± 0.002 |
| Re-ranker (ours) | 0.713 ± 0.005 | 0.927 ± 0.003 | 0.976 ± 0.002 | 0.986 ± 0.001 | 0.941 ± 0.002 | 1.000 ± 0.000 |
| Re-ranker | WikiTuples | Education | Cricket Players | |||
|---|---|---|---|---|---|---|
| S@1 | S@5 | S@1 | S@5 | S@1 | S@5 | |
| Initial Retrieval | 0.231 ± 0.005 | 0.733 ± 0.004 | 0.577 ± 0.004 | 0.923 ± 0.003 | 0.830 ± 0.003 | 0.989 ± 0.001 |
| GPT-3.5/Pairwise | 0.470 ± 0.006 | 0.756 ± 0.004 | 0.260 ± 0.005 | 0.960 ± 0.002 | 0.932 ± 0.002 | 0.989 ± 0.001 |
| GPT-3.5/Listwise | 0.210 ± 0.007 | 0.676 ± 0.005 | 0.255 ± 0.006 | 0.825 ± 0.003 | 0.750 ± 0.003 | 0.841 ± 0.002 |
| Re-ranker (ours) | 0.630 ± 0.005 | 0.915 ± 0.003 | 0.976 ± 0.002 | 0.986 ± 0.001 | 0.941 ± 0.002 | 1.000 ± 0.000 |
| Method | Buy | Restaurant | ||
|---|---|---|---|---|
| acc | LLMs Ratio | acc | LLMs Ratio | |
| HoloClean | 0.162 ± 0.003 | N/A | 0.331 ± 0.004 | N/A |
| IMP | 0.965 ± 0.004 | N/A | 0.772 ± 0.005 | N/A |
| FMs | 0.963 ± 0.003 | 1.000 ± 0.000 | 0.875 ± 0.004 | 1.000 ± 0.000 |
| Our method (LLMs only) | 0.976 ± 0.002 | 1.000 ± 0.000 | 0.890 ± 0.003 | 1.000 ± 0.000 |
| Our method | 0.961 ± 0.004 | 0.439 ± 0.012 | 0.821 ± 0.005 | 0.000 ± 0.000 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, X.; Wang, J.; Chung, G.J.; Julian, D.; Qiao, L. Data Imputation Based on Retrieval-Augmented Generation. Appl. Sci. 2025, 15, 7371. https://doi.org/10.3390/app15137371
Shi X, Wang J, Chung GJ, Julian D, Qiao L. Data Imputation Based on Retrieval-Augmented Generation. Applied Sciences. 2025; 15(13):7371. https://doi.org/10.3390/app15137371
Chicago/Turabian StyleShi, Xiaojun, Jiacheng Wang, Gregorius Justin Chung, Derick Julian, and Lianpeng Qiao. 2025. "Data Imputation Based on Retrieval-Augmented Generation" Applied Sciences 15, no. 13: 7371. https://doi.org/10.3390/app15137371
APA StyleShi, X., Wang, J., Chung, G. J., Julian, D., & Qiao, L. (2025). Data Imputation Based on Retrieval-Augmented Generation. Applied Sciences, 15(13), 7371. https://doi.org/10.3390/app15137371