
IECI: A Pipeline Framework for Iterative Event Causal Identification with Dynamic Inference Chains



Abstract
1. Introduction
- (1)
- We propose a pipeline-based event causality identification framework, IECI, in which the SRCIG module performs causal inference by incorporating semantic role guidance, dynamic threshold control, and iterative optimization mechanisms.
- (2)
- We introduce the PRED module, which leverages prompts to supervise the downstream causal inference task of the IECI framework.
- (3)
- The performance of IECI is systematically evaluated using both the EventStoryLine and MAVEN-ERE datasets. Experimental results show that IECI significantly outperforms state-of-the-art methods across several key metrics, demonstrating the accuracy and robustness of the proposed model.
2. Related Work
2.1. Event Causality Identification
2.2. Event Detection
3. Methodology
3.1. Prompt-Based Event Detection
3.1.1. Semantic-Based Context Embedding
3.1.2. Prompt-Based Type-Aware Embedding
3.1.3. Attention-Based Feature Fusion
- All slots across event type templates are free to attend to each other, enabling shared semantic modeling.
- Each slot and the event type it belongs to can follow each other.
3.1.4. Event Prediction
3.2. Semantic-Role Guided Causal Inference Graph
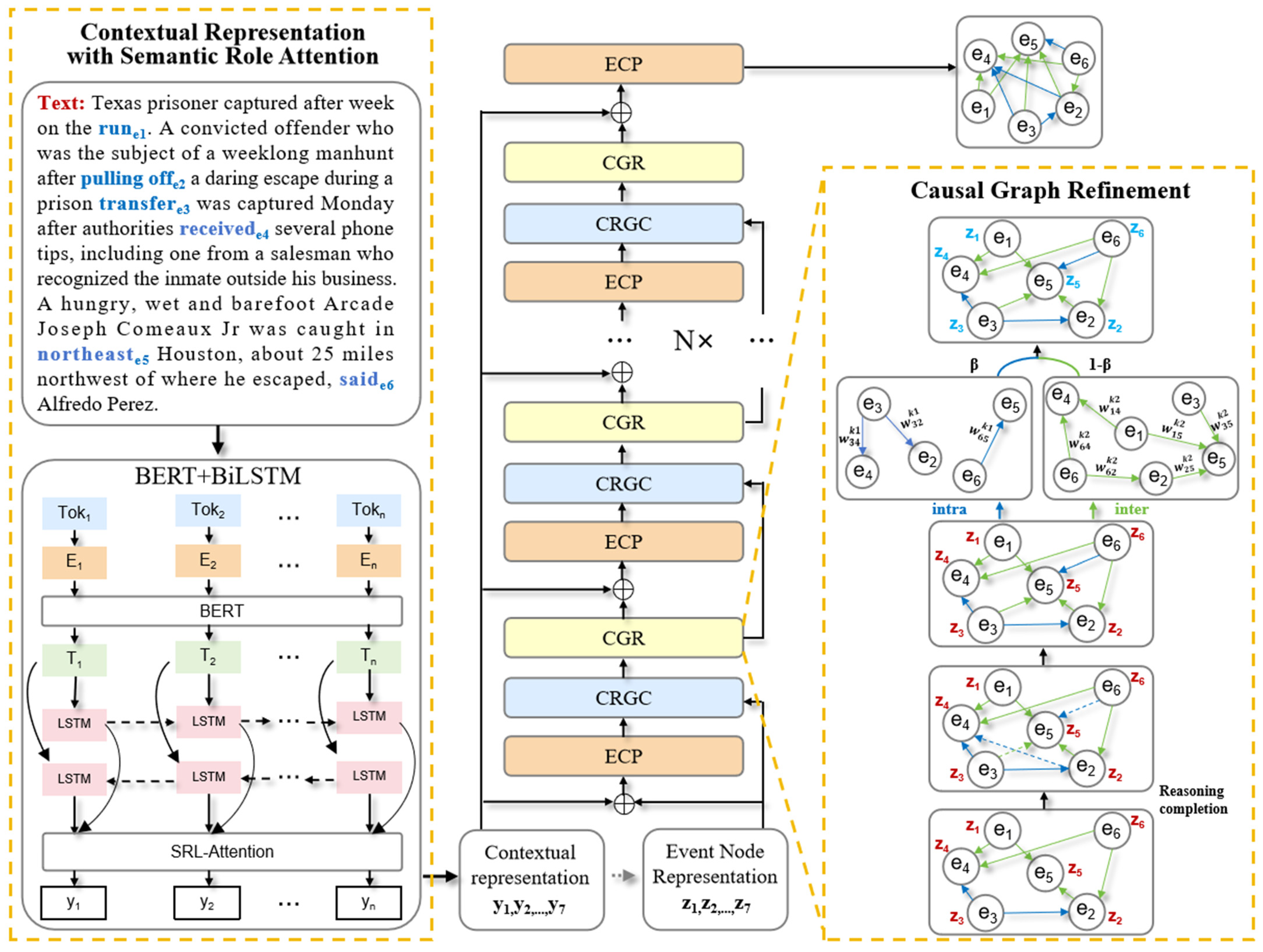
3.2.1. Contextual Representation with Semantic Role Attention
3.2.2. Event Causal Predictor
3.2.3. Causal Relation Graph Construction
3.2.4. Causal Graph Refinement
4. Experiments
4.1. Datasets and Evaluation Metrics
4.2. Parameter Settings
4.3. Experimental Results and Discussion
4.3.1. Experiments for PRED
4.3.2. Experiments for IECI
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Moreira, F.; Velez-Bedoya, J.I.; Arango-López, J. Integration of Causal Models and Deep Neural Networks for Recommendation Systems in Dynamic Environments: A Case Study in StarCraft II. Appl. Sci. 2025, 15, 4263. [Google Scholar] [CrossRef]
- Lu, F.; Li, Y.; Bao, Y. Deep Knowledge Tracing Integrating Temporal Causal Inference and PINN. Appl. Sci. 2025, 15, 1504. [Google Scholar] [CrossRef]
- Razouk, H.; Benischke, L.; Gärber, D.; Kern, R. Increasing the Accessibility of Causal Domain Knowledge via Causal Information Extraction Methods: A Case Study in the Semiconductor Manufacturing Industry. Appl. Sci. 2025, 15, 2573. [Google Scholar] [CrossRef]
- Zhao, K.; Ji, D.; He, F.; Liu, Y.; Ren, Y. Document-Level Event Causality Identification via Graph Inference Mechanism. Inf. Sci. 2021, 561, 115–129. [Google Scholar] [CrossRef]
- Chan, C.; Cheng, J.; Wang, W.; Jiang, Y.; Fang, T.; Liu, X.; Song, Y. ChatGPT Evaluation on Sentence Level Relations: A Focus on Temporal, Causal, and Discourse Relations. arXiv 2024, arXiv:2304.14827. [Google Scholar]
- Cai, R.; Yu, S.; Zhang, J.; Chen, W.; Xu, B.; Zhang, K. Dr.ECI: Infusing Large Language Models with Causal Knowledge for Decomposed Reasoning in Event Causality Identification. In Proceedings of the 31st International Conference on Computational Linguistics, Abu Dhabi, United Arab Emirates, 19–24 January 2025; Rambow, O., Wanner, L., Apidianaki, M., Al-Khalifa, H., Eugenio, B.D., Schockaert, S., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2025; pp. 9346–9375. [Google Scholar]
- Yan, Y.; Liu, Z.; Gao, F.; Gu, J. Type Hierarchy Enhanced Event Detection without Triggers. Appl. Sci. 2023, 13, 2296. [Google Scholar] [CrossRef]
- Chen, J.; Chen, P.; Wu, X. Generating Chinese Event Extraction Method Based on ChatGPT and Prompt Learning. Appl. Sci. 2023, 13, 9500. [Google Scholar] [CrossRef]
- Zhang, S.; Ji, T.; Ji, W.; Wang, X. Zero-Shot Event Detection Based on Ordered Contrastive Learning and Prompt-Based Prediction. In Proceedings of the Findings of the Association for Computational Linguistics: NAACL 2022, Seattle, WA, USA, 10–15 July 2022; Carpuat, M., de Marneffe, M.-C., Meza Ruiz, I.V., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2022; pp. 2572–2580. [Google Scholar]
- Hashimoto, C. Weakly Supervised Multilingual Causality Extraction from Wikipedia. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Inui, K., Jiang, J., Ng, V., Wan, X., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 2988–2999. [Google Scholar]
- Liu, J.; Chen, Y.; Zhao, J. Knowledge Enhanced Event Causality Identification with Mention Masking Generalizations. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, Yokohama, Japan, 7–15 January 2021. [Google Scholar]
- Zuo, X.; Cao, P.; Chen, Y.; Liu, K.; Zhao, J.; Peng, W.; Chen, Y. Improving Event Causality Identification via Self-Supervised Representation Learning on External Causal Statement. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Online, 2–4 August 2021; Zong, C., Xia, F., Li, W., Navigli, R., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 2162–2172. [Google Scholar]
- Hu, Z.; Li, Z.; Jin, X.; Bai, L.; Guan, S.; Guo, J.; Cheng, X. Semantic Structure Enhanced Event Causality Identification. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Toronto, ON, Canada, 9–14 July 2023; Rogers, A., Boyd-Graber, J., Okazaki, N., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2023; pp. 10901–10913. [Google Scholar]
- Liu, J.; Zhang, Z.; Guo, Z.; Jin, L.; Li, X.; Wei, K.; Sun, X. KEPT: Knowledge Enhanced Prompt Tuning for Event Causality Identification. Knowl.-Based Syst. 2023, 259, 110064. [Google Scholar] [CrossRef]
- Wang, X.; Luo, W.; Yang, X. An Event Causality Identification Framework Using Ensemble Learning. Information 2025, 16, 32. [Google Scholar] [CrossRef]
- Gao, L.; Choubey, P.K.; Huang, R. Modeling Document-Level Causal Structures for Event Causal Relation Identification. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; Burstein, J., Doran, C., Solorio, T., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 1808–1817. [Google Scholar]
- Tran Phu, M.; Nguyen, T.H. Graph Convolutional Networks for Event Causality Identification with Rich Document-Level Structures. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; Toutanova, K., Rumshisky, A., Zettlemoyer, L., Hakkani-Tur, D., Beltagy, I., Bethard, S., Cotterell, R., Chakraborty, T., Zhou, Y., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 3480–3490. [Google Scholar]
- Chen, M.; Cao, Y.; Deng, K.; Li, M.; Wang, K.; Shao, J.; Zhang, Y. ERGO: Event Relational Graph Transformer for Document-Level Event Causality Identification. In Proceedings of the 29th International Conference on Computational Linguistics, Gyeongju, Republic of Korea, 12–17 October 2022; Calzolari, N., Huang, C.-R., Kim, H., Pustejovsky, J., Wanner, L., Choi, K.-S., Ryu, P.-M., Chen, H.-H., Donatelli, L., Ji, H., et al., Eds.; International Committee on Computational Linguistics: Stroudsburg, PA, USA, 2022; pp. 2118–2128. [Google Scholar]
- Liu, Z.; Hu, B.; Xu, Z.; Zhang, M. PPAT: Progressive Graph Pairwise Attention Network for Event Causality Identification. In Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence, Macao, China, 19–25 August 2023. [Google Scholar]
- Chen, M.; Cao, Y.; Zhang, Y.; Liu, Z. CHEER: Centrality-Aware High-Order Event Reasoning Network for Document-Level Event Causality Identification. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Toronto, ON, Canada, 9–14 July 2023; Rogers, A., Boyd-Graber, J., Okazaki, N., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2023; pp. 10804–10816. [Google Scholar]
- Yuan, C.; Huang, H.; Cao, Y.; Wen, Y. Discriminative Reasoning with Sparse Event Representation for Document-Level Event-Event Relation Extraction. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Toronto, Canada, 9–14 July 2023; Rogers, A., Boyd-Graber, J., Okazaki, N., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2023; pp. 16222–16234. [Google Scholar]
- Zeng, X.; Bai, Z.; Qin, K.; Luo, G. EiGC: An Event-Induced Graph with Constraints for Event Causality Identification. Electronics 2024, 13, 4608. [Google Scholar] [CrossRef]
- Li, X.; Nguyen, T.H.; Cao, K.; Grishman, R. Improving Event Detection with Abstract Meaning Representation. In Proceedings of the First Workshop on Computing News Storylines, Beijing, China, 26–31 July 2015; Caselli, T., van Erp, M., Minard, A.-L., Finlayson, M., Miller, B., Atserias, J., Balahur, A., Vossen, P., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2015; pp. 11–15. [Google Scholar]
- Liu, S.; Liu, K.; He, S.; Zhao, J. A Probabilistic Soft Logic Based Approach to Exploiting Latent and Global Information in Event Classification. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; AAAI Press: Washington, DC, USA, 2016; pp. 2993–2999. [Google Scholar]
- Nguyen, T.H.; Cho, K.; Grishman, R. Joint Event Extraction via Recurrent Neural Networks. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; Knight, K., Nenkova, A., Rambow, O., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; pp. 300–309. [Google Scholar]
- Sha, L.; Qian, F.; Chang, B.; Sui, Z. Jointly Extracting Event Triggers and Arguments by Dependency-Bridge RNN and Tensor-Based Argument Interaction. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence and Thirtieth Innovative Applications of Artificial Intelligence Conference and Eighth AAAI Symposium on Educational Advances in Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; AAAI Press: Washington, DC, USA, 2018. [Google Scholar]
- Orr, W.; Tadepalli, P.; Fern, X. Event Detection with Neural Networks: A Rigorous Empirical Evaluation. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; Riloff, E., Chiang, D., Hockenmaier, J., Tsujii, J., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 999–1004. [Google Scholar]
- Yan, H.; Jin, X.; Meng, X.; Guo, J.; Cheng, X. Event Detection with Multi-Order Graph Convolution and Aggregated Attention. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Inui, K., Jiang, J., Ng, V., Wan, X., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 5766–5770. [Google Scholar]
- Huang, L.; Ji, H. Semi-Supervised New Event Type Induction and Event Detection. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; Webber, B., Cohn, T., He, Y., Liu, Y., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 718–724. [Google Scholar]
- Chen, J.; Lin, H.; Han, X.; Sun, L. Honey or Poison? Solving the Trigger Curse in Few-Shot Event Detection via Causal Intervention. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Online and Punta Cana, Dominican Republic, 7–11 November 2021; Moens, M.-F., Huang, X., Specia, L., Yih, S.W., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 8078–8088. [Google Scholar]
- Sheng, J.; Sun, R.; Guo, S.; Cui, S.; Cao, J.; Wang, L.; Liu, T.; Xu, H. CorED: Incorporating Type-Level and Instance-Level Correlations for Fine-Grained Event Detection. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, 11–15 July 2022; Association for Computing Machinery: New York, NY, USA, 2022; pp. 1122–1132. [Google Scholar]
- Wu, G.; Lu, Z.; Zhuo, X.; Bao, X.; Wu, X. Semantic Fusion Enhanced Event Detection via Multi-Graph Attention Network with Skip Connection. IEEE Trans. Emerg. Top. Comput. Intell. 2023, 7, 931–941. [Google Scholar] [CrossRef]
- Fu, R.; Wang, H.; Zhang, X.; Zhou, J.; Yan, Y. SynED: A Syntax-Based Low-Resource Event Detection Method for New Event Types. Int. J. Innov. Comput. Inf. Control 2023, 19, 47–60. [Google Scholar]
- Liu, B.; Rao, G.; Wang, X.; Zhang, L.; Cong, Q. DE3TC: Detecting Events with Effective Event Type Information and Context. Neural Process. Lett. 2024, 56, 89. [Google Scholar] [CrossRef]
- Hershowitz, B.; Hodkiewicz, M.; Bikaun, T.; Stewart, M.; Liu, W. Causal Knowledge Extraction from Long Text Maintenance Documents. Comput. Ind. 2024, 161, 104110. [Google Scholar] [CrossRef]
- Caselli, T.; Vossen, P. The Event StoryLine Corpus: A New Benchmark for Causal and Temporal Relation Extraction. In Proceedings of the Events and Stories in the News Workshop, Vancouver, BC, Canada, 4 August 2017; Caselli, T., Miller, B., van Erp, M., Vossen, P., Palmer, M., Hovy, E., Mitamura, T., Caswell, D., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2017; pp. 77–86. [Google Scholar]
- Wang, X.; Chen, Y.; Ding, N.; Peng, H.; Wang, Z.; Lin, Y.; Han, X.; Hou, L.; Li, J.; Liu, Z.; et al. MAVEN-ERE: A Unified Large-Scale Dataset for Event Coreference, Temporal, Causal, and Subevent Relation Extraction. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 7–11 December 2022; Goldberg, Y., Kozareva, Z., Zhang, Y., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2022; pp. 926–941. [Google Scholar]
- Lai, P.; Ye, F.; Zhang, L.; Chen, Z.; Fu, Y.; Wu, Y.; Wang, Y. PCBERT: Parent and Child BERT for Chinese Few-Shot NER. In Proceedings of the 29th International Conference on Computational Linguistics, Gyeongju, Republic of Korea, 12–17 October 2022; Calzolari, N., Huang, C.-R., Kim, H., Pustejovsky, J., Wanner, L., Choi, K.-S., Ryu, P.-M., Chen, H.-H., Donatelli, L., Ji, H., et al., Eds.; International Committee on Computational Linguistics: New York, NY, USA, 2022; pp. 2199–2209. [Google Scholar]
- Hu, S.; Zhang, H.; Hu, X.; Du, J. Chinese Named Entity Recognition Based on BERT-CRF Model. In Proceedings of the 2022 IEEE/ACIS 22nd International Conference on Computer and Information Science (ICIS), Zhuhai, China, 26–28 June 2022; pp. 105–108. [Google Scholar]
- He, W.; Xu, Y.; Yu, Q. BERT-BiLSTM-CRF Chinese Resume Named Entity Recognition Combining Attention Mechanisms. In Proceedings of the 4th International Conference on Artificial Intelligence and Computer Engineering, Dalian, China, 17–19 November 2023; Association for Computing Machinery: New York, NY, USA, 2024; pp. 542–547. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; Burstein, J., Doran, C., Solorio, T., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 4171–4186. [Google Scholar]
- Man, H.; Nguyen, C.V.; Ngo, N.T.; Ngo, L.; Dernoncourt, F.; Nguyen, T.H. Hierarchical Selection of Important Context for Generative Event Causality Identification with Optimal Transports. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), Torino, Italy, 20–25 May 2024; Calzolari, N., Kan, M.-Y., Hoste, V., Lenci, A., Sakti, S., Xue, N., Eds.; ELRA and ICCL: Paris, France, 2024; pp. 8122–8132. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
| Methods | Event Detection (%) | Runtime (min) | ||
|---|---|---|---|---|
| P | R | F1 | ||
| BERT-NER [38] | 86.4 | 84.9 | 85.6 | 31.5 |
| BERT-CRF-NER [39] | 89.1 | 87.7 | 88.2 | 38.6 |
| BERT-BiLSTM-NER [40] | 90.1 | 89.9 | 91.7 | 50.2 |
| PRED (Ours) | 95.9 | 95.2 | 95.4 | 73.1 |
| Methods | Event Detection (%) | Runtime (min) | ||
|---|---|---|---|---|
| P | R | F1 | ||
| BERT-NER [38] | 86.1 | 83.0 | 86.1 | 24.2 |
| BERT-CRF-NER [39] | 89.7 | 86.1 | 89.3 | 30.0 |
| BERT-BiLSTM-NER [40] | 91.4 | 89.5 | 92.2 | 36.3 |
| PRED (Ours) | 96.5 | 96.2 | 96.4 | 56.0 |
| Methods | Intra-Sentence (%) | Inter-Sentence (%) | Intra + Inter (%) | Runtime (min/fold) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | ||
| LIP [28] | 38.8 | 52.4 | 44.6 | 35.1 | 48.2 | 40.6 | 36.2 | 49.5 | 41.9 | 100.4 |
| BERT [41] | 47.8 | 57.2 | 52.1 | 36.8 | 29.2 | 32.6 | 41.3 | 38.3 | 39.7 | 117.8 |
| RichGCN [29] | 49.2 | 63.0 | 55.2 | 39.2 | 45.7 | 42.2 | 42.6 | 51.3 | 46.6 | 141.8 |
| ERGO [30] | 49.7 | 72.6 | 59.0 | 43.2 | 48.8 | 45.8 | 46.3 | 50.1 | 48.1 | 139.5 |
| PPAT [31] | 62.1 | 68.8 | 65.3 | 54.0 | 50.2 | 52.0 | 56.8 | 56.0 | 56.4 | 156.6 |
| HOTECI [42] | 66.1 | 72.3 | 69.1 | 81.4 | 40.6 | 55.1 | 63.1 | 51.2 | 56.5 | 167.0 |
| IECI (Ours) | 76.5 | 67.5 | 70.8 | 54.8 | 65.4 | 58.5 | 59.5 | 64.0 | 60.7 | 175.8 |
| Methods | Intra-Sentence(%) | Inter-Sentence(%) | Intra + Inter (%) | Runtime (min/fold) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | ||
| BERT [41] | 43.7 | 5.9 | 10.5 | 29.4 | 12.3 | 17.4 | 30.8 | 10.7 | 15.9 | 217.5 |
| ERGO [30] | 63.1 | 65.3 | 64.2 | 48.7 | 62.0 | 54.6 | 49.6 | 62.3 | 55.2 | 256.1 |
| PPAT [31] | 37.9 | 66.7 | 47.7 | 28.2 | 40.8 | 33.6 | 31.3 | 45.1 | 37.0 | 289.7 |
| IECI (Ours) | 71.7 | 50.2 | 64.9 | 63.7 | 48.3 | 56.5 | 66.0 | 48.1 | 56.2 | 326.6 |
| Methods | Intra-Sentence (%) | Inter-Sentence (%) | Intra + Inter (%) | Runtime | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | (min/fold) | |
| IECI (Ours) | 76.5 | 67.5 | 70.8 | 54.8 | 65.4 | 58.5 | 59.5 | 64.0 | 60.7 | 175.8 |
| w/o SRL | 74.7 | 62.3 | 69.2 | 49.7 | 62.1 | 54.9 | 55.6 | 60.2 | 57.1 | 170.6 |
| w/o Dynamic Threshold | 75.4 | 65.6 | 70.1 | 53.5 | 62.9 | 56.1 | 57.3 | 61.4 | 58.0 | 171.2 |
| w/o SimFilter | 74.4 | 63.7 | 68.6 | 50.1 | 64.5 | 56.7 | 56.3 | 60.5 | 57.9 | 167.8 |
| Methods | Intra-Sentence (%) | Inter-Sentence (%) | Intra + Inter (%) | Runtime | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | (min/fold) | |
| IECI (Ours) | 71.7 | 50.2 | 64.9 | 63.7 | 48.3 | 56.5 | 66.0 | 48.1 | 56.2 | 326.6 |
| w/o SRL | 69.5 | 44.9 | 62.8 | 57.4 | 43.8 | 52.3 | 61.8 | 42.9 | 53.4 | 310.7 |
| w/o Dynamic Threshold | 70.2 | 48.7 | 63.4 | 62.4 | 45.1 | 53.6 | 63.9 | 46.3 | 54.3 | 319.5 |
| w/o SimFilter | 68.8 | 47.1 | 63.6 | 59.1 | 47.2 | 55.1 | 61.9 | 43.8 | 54.5 | 304.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, H.; Cai, Y.; Song, Z.; Zhang, Y.; Zhang, H. IECI: A Pipeline Framework for Iterative Event Causal Identification with Dynamic Inference Chains. Appl. Sci. 2025, 15, 7348. https://doi.org/10.3390/app15137348
Chen H, Cai Y, Song Z, Zhang Y, Zhang H. IECI: A Pipeline Framework for Iterative Event Causal Identification with Dynamic Inference Chains. Applied Sciences. 2025; 15(13):7348. https://doi.org/10.3390/app15137348
Chicago/Turabian StyleChen, Hefei, Yuanyuan Cai, Zexi Song, Yiyao Zhang, and Hongbo Zhang. 2025. "IECI: A Pipeline Framework for Iterative Event Causal Identification with Dynamic Inference Chains" Applied Sciences 15, no. 13: 7348. https://doi.org/10.3390/app15137348
APA StyleChen, H., Cai, Y., Song, Z., Zhang, Y., & Zhang, H. (2025). IECI: A Pipeline Framework for Iterative Event Causal Identification with Dynamic Inference Chains. Applied Sciences, 15(13), 7348. https://doi.org/10.3390/app15137348