
Two-Dimensional Human Pose Estimation with Deep Learning: A Review


Abstract
1. Introduction
1.1. Background
1.2. Research Status
1.3. Purpose and Structure of the Paper
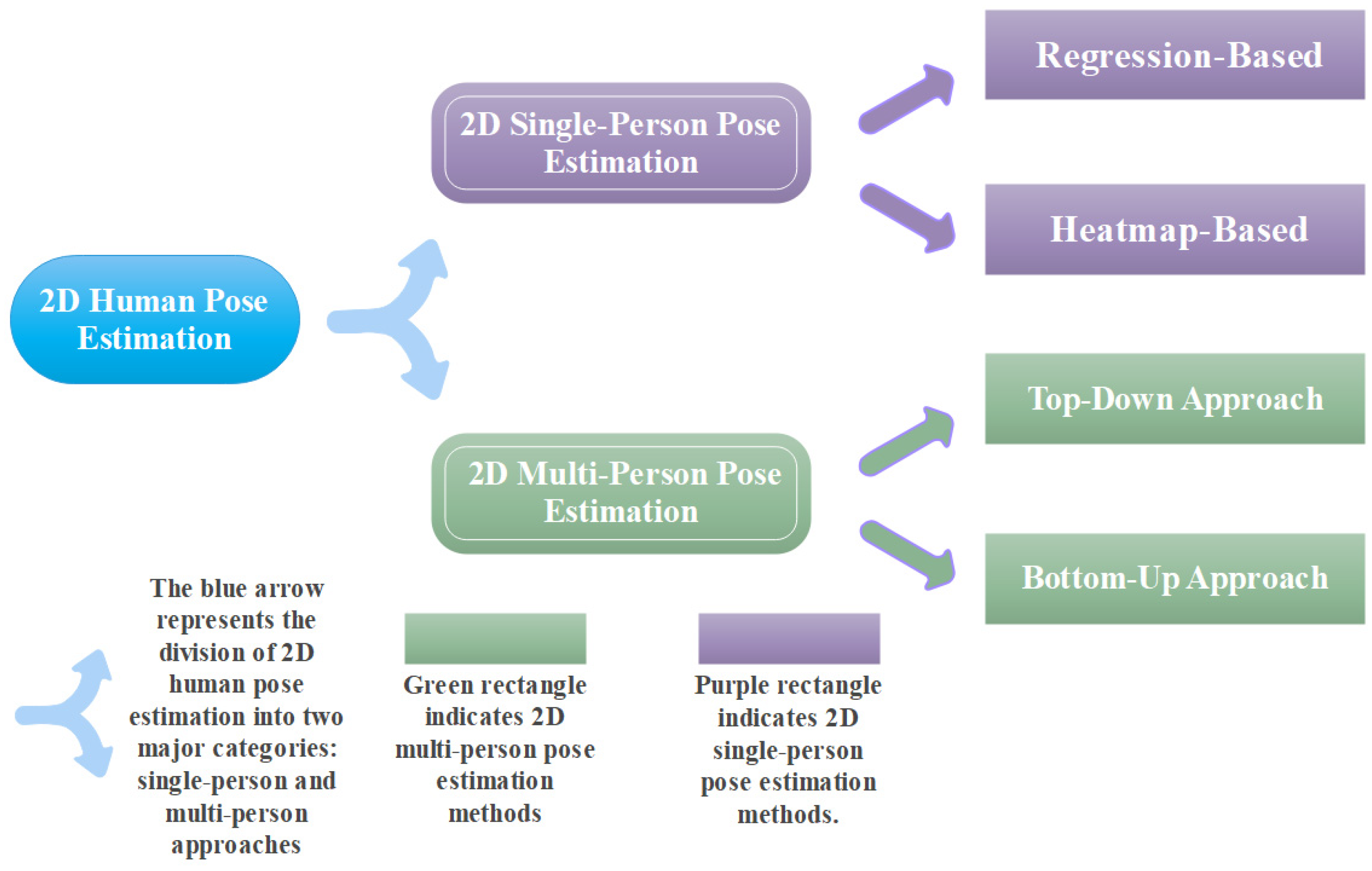
2. Two-Dimensional Human Pose Estimation
2.1. Two-Dimensional Single-Person Pose Estimation
2.1.1. Regression-Based Pose Estimation
2.1.2. Heatmap-Based Pose Estimation
2.2. Two-Dimensional Multi-Person Pose Estimation
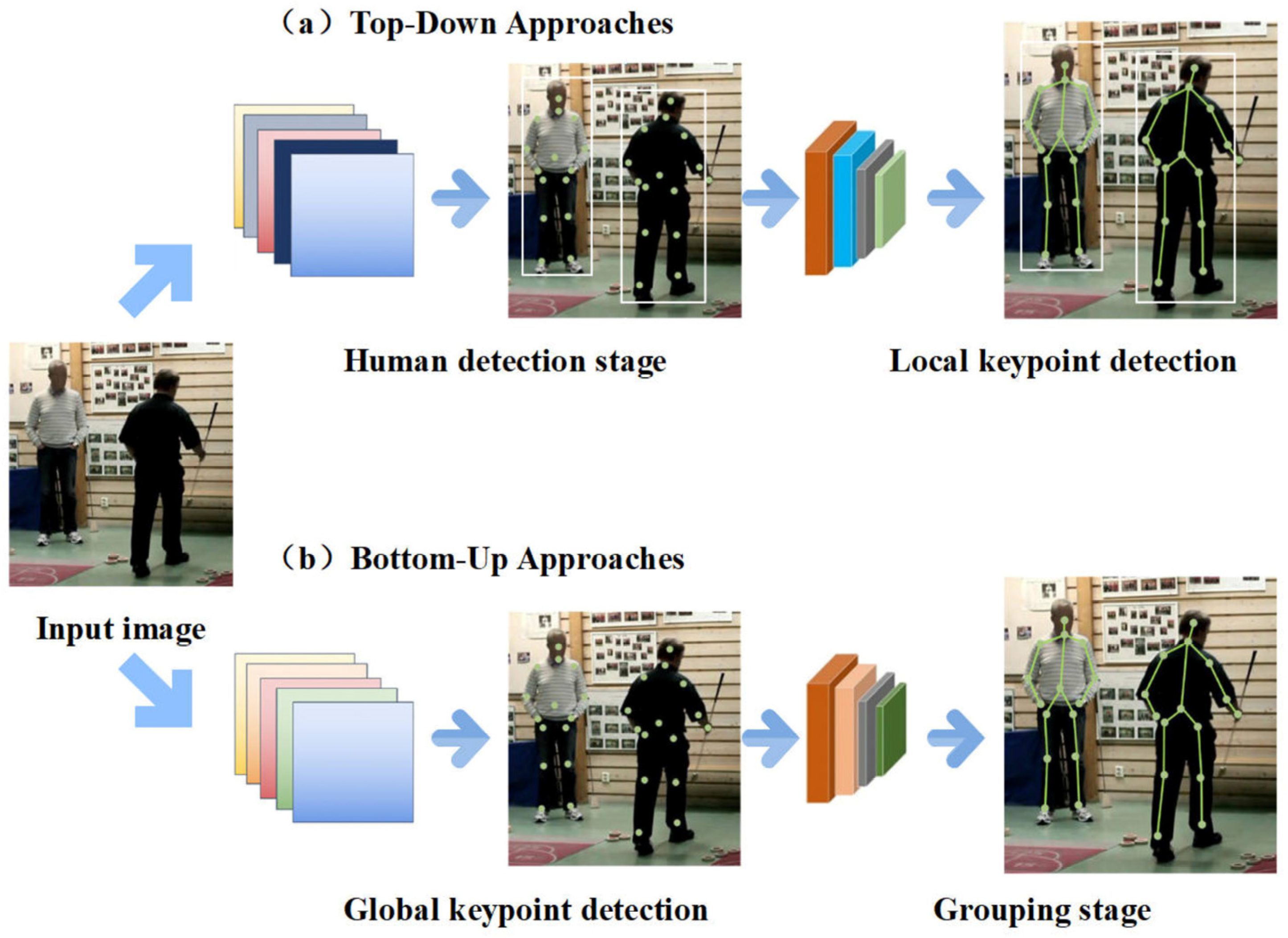
2.2.1. Top-Down Approach of 2D Multi-Person Pose Estimation
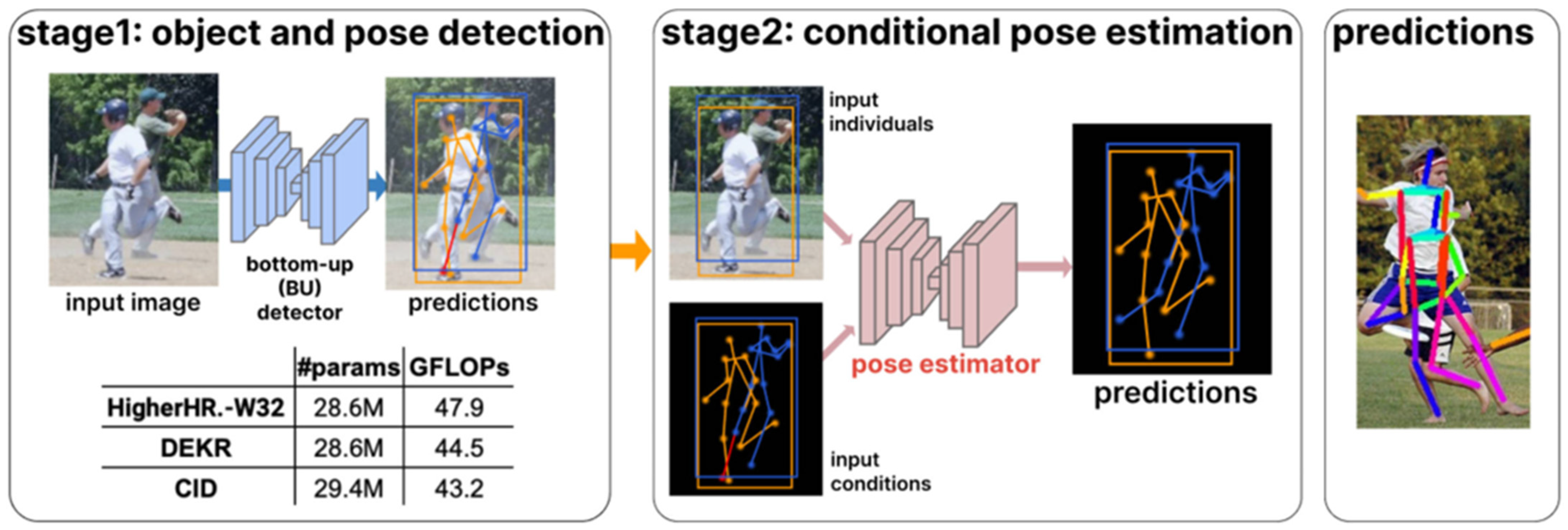
2.2.2. Bottom-Up Approach of 2D Multi-Person Pose Estimation
3. Evaluation Metrics and Benchmark Datasets
3.1. Evaluation Metrics
3.2. Benchmark Datasets
3.2.1. Max Planck Institute for Informatics (MPII)
3.2.2. Common Objects in Context (COCO)
3.2.3. Leeds Sports Pose (LSP) and LSP Extended (LSPE)
3.2.4. Occluded Human Dataset (OCHuman)
3.2.5. CrowdPose Dataset
4. Top-Performing Models on Benchmark Datasets
4.1. Top-Performing Models on the MPII Dataset
4.2. Top-Performing Models on the COCO Test-Dev Dataset
4.3. Top-Performing Models on the LSP Dataset
4.4. Top-Performing Models on the OCHuman Dataset
4.5. Top-Performing Models on CrowdPose Dataset
4.6. Discussion
5. Conclusions and Future Perspectives
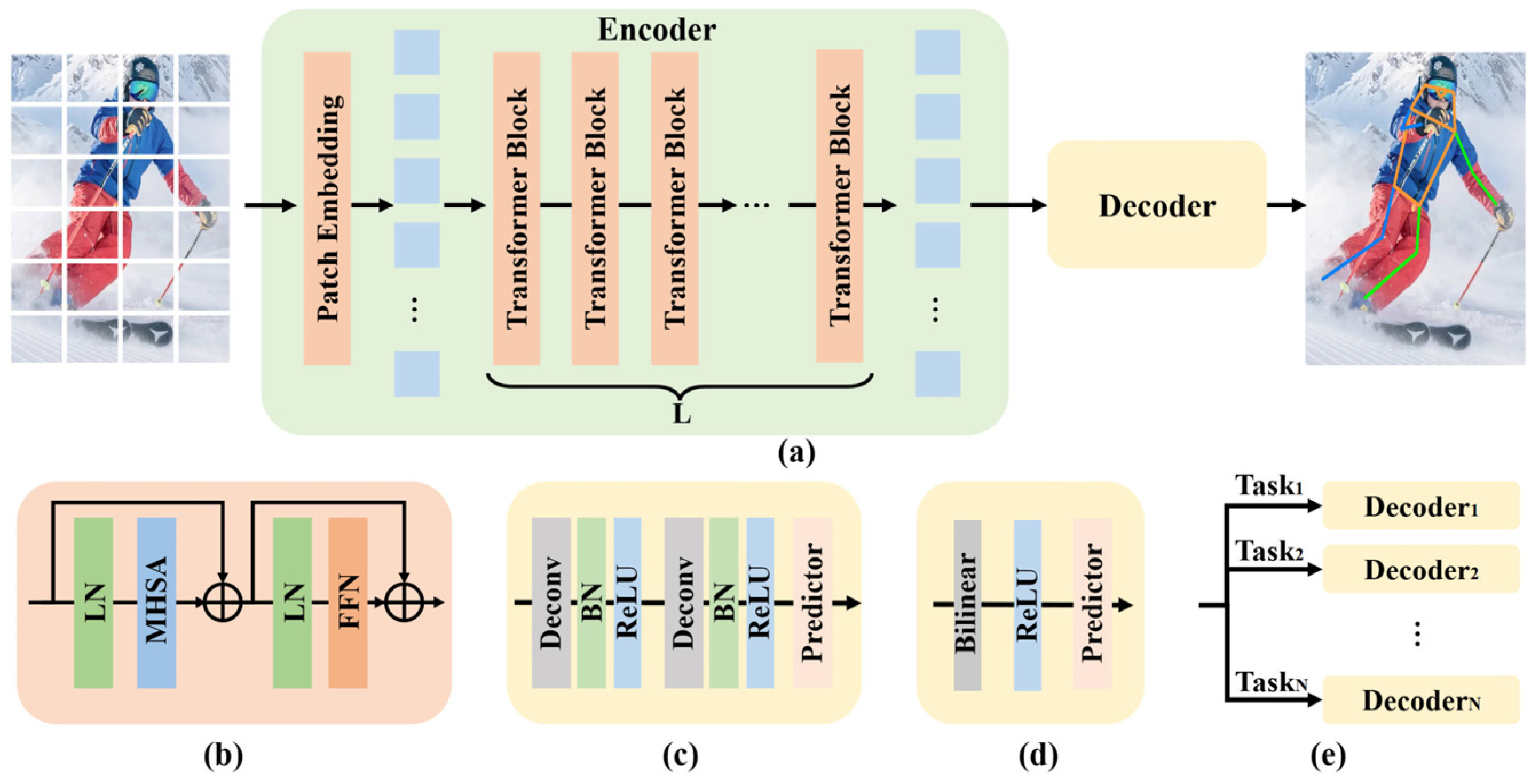
- To enhance overall efficiency and inter-module synergy, future research should prioritize the development of end-to-end frameworks that integrate object detection, keypoint estimation, and post-processing. Most existing methods rely on multi-stage pipelines, which despite their modularity, are susceptible to error accumulation and exhibit low inference efficiency. A unified architecture that jointly optimizes detection and pose estimation could streamline the training process and improve system consistency. Transformer-based architectures, due to their strong capacity to model global dependencies, have demonstrated promising performance in pose estimation, as evidenced by TokenPose [16] and ViTPose [35]. Building on this foundation, future work may explore query-based architectures inspired by DETR [70], which employ learnable queries to directly predict human instances along with their keypoints. Furthermore, integrating structural priors—such as skeletal graphs or symmetry constraints—may enhance the anatomical plausibility and robustness of predicted poses.
- Incorporating unsupervised and self-supervised pretraining strategies can reduce dependence on large-scale annotated datasets. These approaches also improve the robustness of keypoint estimation under occlusion. In recent years, masked image modeling techniques (e.g., MAE [71], SimMIM [72]) and contrastive learning methods (e.g., MoCo [73], DINO [74]) have been widely adopted for visual representation learning. Masked image modeling (MIM) approaches, such as MAE and SimMIM, reconstruct masked regions in the input image. This process encourages the model to learn structural and contextual features. This mechanism naturally facilitates the recovery of occluded keypoints. In contrast, contrastive learning frameworks such as MoCo and DINO enhance robustness to viewpoint changes and articulated pose variations. They achieve this by enforcing feature consistency across diverse augmentations. In addition, multimodal self-supervised methods (e.g., CLIP [75]) and cross-task pretraining frameworks (e.g., DINOv2 [76]) have been incorporated into pose estimation pipelines to produce more generalizable visual backbones.
- Addressing the computational challenges and deployment constraints of pose estimation methods in real-time environments is essential. Although many methods achieve high accuracy on standard GPUs, real-world applications—such as those on mobile devices, wearables, and embedded platforms—face limitations associated with computational resources, latency sensitivity, and power efficiency. Therefore, models must strike a balance between accuracy and efficiency during deployment. Future research should emphasize low-latency inference, computational efficiency, and model compression. It is recommended that studies consistently report key deployment metrics—such as FLOPs, parameter count, model size, and inference latency—along with testing conditions (e.g., hardware platform and input resolution). These standardized reports enable fair comparisons and support practical deployment. In addition, techniques such as model pruning, quantization, knowledge distillation, and neural architecture search (NAS) can be employed to develop lightweight architectures that are suitable for edge devices. These efforts are critical to bridging the gap between academic performance and real-world system integration.
- Constructing more diverse and densely annotated datasets is essential to advancing human pose estimation. Existing mainstream datasets offer limited diversity in gender, body shape, clothing, occlusion, and motion patterns. This lack of variation restricts model generalization in complex real-world scenarios. To enhance model adaptability in real-world applications, future datasets should focus on both diversity and annotation granularity. Specifically, datasets should include varied camera viewpoints, cultural contexts, and motion types. They should also improve annotation precision and semantic depth. For example, structured information such as 3D occlusion relationships, skeletal topology constraints, and temporal alignment can offer richer priors and more informative training signals. These enhancements are critical to developing more robust and generalizable pose estimation models.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sun, R.; Lin, Z.; Leng, S.; Wang, A.; Zhao, L. An In-Depth Analysis of 2D and 3D Pose Estimation Techniques in Deep Learning: Methodologies and Advances. Electronics 2025, 14, 1307. [Google Scholar] [CrossRef]
- Rawat, W.; Wang, Z. Deep convolutional neural networks for image classification: A comprehensive review. Neural Comput. 2017, 29, 2352–2449. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Tian, L.; Wang, P.; Liang, G.; Shen, C. An adversarial human pose estimation network injected with graph structure. Pattern Recognit. 2021, 115, 107863. [Google Scholar] [CrossRef]
- Felzenszwalb, P.F.; Huttenlocher, D.P. Pictorial structures for object recognition. Int. J. Comput. Vis. 2005, 61, 55–79. [Google Scholar] [CrossRef]
- Felzenszwalb, P.; McAllester, D.; Ramanan, D. A discriminatively trained, multiscale, deformable part model. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 1–8. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime multi-person 2D pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7291–7299. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Xiao, B.; Wu, H.; Wei, Y. Simple baselines for human pose estimation and tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 466–481. [Google Scholar]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Xiao, B. Deep high-resolution representation learning for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3349–3364. [Google Scholar] [CrossRef]
- Newell, A.; Huang, Z.; Deng, J. Associative embedding: End-to-end learning for joint detection and grouping. Adv. Neural Inf. Process. Syst. 2017, 30, 2277–2287. [Google Scholar]
- Cheng, B.; Xiao, B.; Wang, J.; Shi, H.; Huang, T.S.; Zhang, L. Higherhrnet: Scale-aware representation learning for bottom-up human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5386–5395. [Google Scholar]
- Ma, X.; Su, J.; Wang, C.; Ci, H.; Wang, Y. Context modeling in 3d human pose estimation: A unified perspective. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6238–6247. [Google Scholar]
- Li, Y.; Zhang, S.; Wang, Z.; Yang, S.; Yang, W.; Xia, S.T.; Zhou, E. Tokenpose: Learning keypoint tokens for human pose estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 11313–11322. [Google Scholar]
- Yuan, Y.; Fu, R.; Huang, L.; Lin, W.; Zhang, C.; Chen, X.; Wang, J. Hrformer: High-resolution transformer for dense prediction. arXiv 2021, arXiv:2110.09408. [Google Scholar]
- Yu, C.; Xiao, B.; Gao, C.; Yuan, L.; Zhang, L.; Sang, N.; Wang, J. Lite-hrnet: A lightweight high-resolution network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10440–10450. [Google Scholar]
- Hou, T.; Ahmadyan, A.; Zhang, L.; Wei, J.; Grundmann, M. MobilePose: Real-time pose estimation for unseen objects with weak shape supervision. arXiv 2020, arXiv:2003.03522. [Google Scholar]
- Toshev, A.; Szegedy, C. Deeppose: Human pose estimation via deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1653–1660. [Google Scholar]
- Carreira, J.; Agrawal, P.; Fragkiadaki, K.; Malik, J. Human pose estimation with iterative error feedback. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4733–4742. [Google Scholar]
- Sun, X.; Xiao, B.; Wei, F.; Liang, S.; Wei, Y. Integral human pose regression. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 529–545. [Google Scholar]
- Moon, G.; Chang, J.Y.; Lee, K.M. Posefix: Model-agnostic general human pose refinement network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7773–7781. [Google Scholar]
- Tompson, J.J.; Jain, A.; LeCun, Y.; Bregler, C. Joint training of a convolutional network and a graphical model for human pose estimation. Adv. Neural Inf. Process. Syst. 2014, 27, 1799–1807. [Google Scholar]
- Wei, S.E.; Ramakrishna, V.; Kanade, T.; Sheikh, Y. Convolutional pose machines. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4724–4732. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked hourglass networks for human pose estimation. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer International Publishing: Berlin/Heidelberg, Germany, 2016. Part VIII. pp. 483–499. [Google Scholar]
- Yang, W.; Li, S.; Ouyang, W.; Li, H.; Wang, X. Learning feature pyramids for human pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1281–1290. [Google Scholar]
- Chu, X.; Yang, W.; Ouyang, W.; Ma, C.; Yuille, A.L.; Wang, X. Multi-context attention for human pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1831–1840. [Google Scholar]
- Zhang, F.; Zhu, X.; Dai, H.; Ye, M.; Zhu, C. Distribution-aware coordinate representation for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7093–7102. [Google Scholar]
- Huang, J.; Zhu, Z.; Guo, F.; Huang, G. The devil is in the details: Delving into unbiased data processing for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5700–5709. [Google Scholar]
- Li, K.; Wang, S.; Zhang, X.; Xu, Y.; Xu, W.; Tu, Z. Pose recognition with cascade transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1944–1953. [Google Scholar]
- Wang, J.; Long, X.; Gao, Y.; Ding, E.; Wen, S. Graph-pcnn: Two stage human pose estimation with graph pose refinement. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer International Publishing: Berlin/Heidelberg, Germany, 2020. Part XI. pp. 492–508. [Google Scholar]
- Kocabas, M.; Karagoz, S.; Akbas, E. Multiposenet: Fast multi-person pose estimation using pose residual network. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 417–433. [Google Scholar]
- Khirodkar, R.; Chari, V.; Agrawal, A.; Tyagi, A. Multi-instance pose networks: Rethinking top-down pose estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; pp. 3122–3131. [Google Scholar]
- Xu, Y.; Zhang, J.; Zhang, Q.; Tao, D. Vitpose: Simple vision transformer baselines for human pose estimation. Adv. Neural Inf. Process. Syst. 2022, 35, 38571–38584. [Google Scholar]
- Cao, Z.; Hidalgo, G.; Simon, T.; Wei, S.E.; Sheikh, Y. Openpose: Realtime multi-person 2d pose estimation using part affinity fields. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 172–186. [Google Scholar] [CrossRef]
- Papandreou, G.; Zhu, T.; Chen, L.C.; Gidaris, S.; Tompson, J.; Murphy, K. Personlab: Person pose estimation and instance segmentation with a bottom-up, part-based, geometric embedding model. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 269–286. [Google Scholar]
- Li, M.; Zhou, Z.; Li, J.; Liu, X. Bottom-up pose estimation of multiple person with bounding box constraint. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; IEEE: Piscataway, NJ, USA, 2008; pp. 115–120. [Google Scholar]
- Jin, S.; Ma, X.; Han, Z.; Wu, Y.; Yang, W.; Liu, W.; Qian, C.; Ouyang, W. Towards multi-person pose tracking: Bottom-up and top-down methods. ICCV Posetrack Workshop 2017, 2, 7. [Google Scholar]
- Li, J.; Su, W.; Wang, Z. Simple pose: Rethinking and improving a bottom-up approach for multi-person pose estimation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11354–11361. [Google Scholar]
- Geng, Z.; Sun, K.; Xiao, B.; Zhang, Z.; Wang, J. Bottom-up human pose estimation via disentangled keypoint regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14676–14686. [Google Scholar]
- Shi, D.; Wei, X.; Li, L.; Ren, Y.; Tan, W. End-to-end multi-person pose estimation with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11069–11078. [Google Scholar]
- Barron, J.L.; Fleet, D.J.; Beauchemin, S.S. Performance of optical flow techniques. Int. J. Comput. Vis. 1994, 12, 43–77. [Google Scholar] [CrossRef]
- Ferrari, V.; Marin-Jimenez, M.; Zisserman, A. Progressive search space reduction for human pose estimation. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, Alaska, 23–28 June 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 1–8. [Google Scholar]
- Yang, Y.; Ramanan, D. Articulated human detection with flexible mixtures of parts. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 2878. [Google Scholar] [CrossRef] [PubMed]
- Andriluka, M.; Pishchulin, L.; Gehler, P.; Schiele, B. 2D human pose estimation: New benchmark and state of the art analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3686–3693. [Google Scholar]
- Sun, X.; Shang, J.; Liang, S.; Wei, Y. Compositional human pose regression. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2602–2611. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision—ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Springer International Publishing: Berlin/Heidelberg, Germany, 2014. Part V. pp. 740–755. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes VOC challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Johnson, S.; Everingham, M. Clustered pose and nonlinear appearance models for human pose estimation. Bmvc 2010, 2, 5. [Google Scholar]
- Zhang, S.H.; Li, R.; Dong, X.; Rosin, P.; Cai, Z.; Han, X.; Yang, D.; Huang, H.; Hu, S.M. Pose2seg: Detection free human instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 889–898. [Google Scholar]
- Li, J.; Wang, C.; Zhu, H.; Mao, Y.; Fang, H.S.; Lu, C. Crowdpose: Efficient crowded scenes pose estimation and a new benchmark. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10863–10872. [Google Scholar]
- Geng, Y.; Xu, W.; Ma, B.; Ma, Q.; Lin, D. Supplementary material for Human pose as compositional tokens [Supplemental material]. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2023), Vancouver, BC, Canada, 18–22 June 2023. [Google Scholar]
- Geng, Z.; Wang, C.; Wei, Y.; Liu, Z.; Li, H.; Hu, H. Human pose as compositional tokens. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 660–671. [Google Scholar]
- Cai, Y.; Wang, Z.; Luo, Z.; Yin, B.; Du, A.; Wang, H.; Zhang, X.; Zhou, X.; Zhou, E.; Sun, J. Learning delicate local representations for multi-person pose estimation. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer International Publishing: Cham, Switzerland, 2020; pp. 455–472. [Google Scholar]
- Artacho, B.; Savakis, A. Unipose: Unified human pose estimation in single images and videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7035–7044. [Google Scholar]
- Li, W.; Wang, Z.; Yin, B.; Peng, Q.; Du, Y.; Xiao, T.; Yu, G.; Lu, H.; Wei, Y.; Sun, J. Rethinking on multi-stage networks for human pose estimation. arXiv 2019, arXiv:1901.00148. [Google Scholar]
- Zhang, H.; Ouyang, H.; Liu, S.; Qi, X.; Shen, X.; Yang, R.; Jia, J. Human pose estimation with spatial contextual information. arXiv 2019, arXiv:1901.01760. [Google Scholar]
- Liu, H.; Liu, F.; Fan, X.; Huang, D. Polarized self-attention: Towards high-quality pixel-wise regression. arXiv 2021, arXiv:2107.00782. [Google Scholar]
- Zhang, J.; Chen, Z.; Tao, D. Towards high performance human keypoint detection. Int. J. Comput. Vis. 2021, 129, 2639–2662. [Google Scholar] [CrossRef]
- Artacho, B.; Savakis, A. Omnipose: A multi-scale framework for multi-person pose estimation. arXiv 2021, arXiv:2103.10180. [Google Scholar]
- Bulat, A.; Kossaifi, J.; Tzimiropoulos, G.; Pantic, M. Toward fast and accurate human pose estimation via soft-gated skip connections. In Proceedings of the 2020 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020), Buenos Aires, Argentina, 16–20 November 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 8–15. [Google Scholar]
- Peng, X.; Tang, Z.; Yang, F.; Feris, R.S.; Metaxas, D. Jointly optimize data augmentation and network training: Adversarial data augmentation in human pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 2226–2234. [Google Scholar]
- Chou, C.J.; Chien, J.T.; Chen, H.T. Self adversarial training for human pose estimation. In Proceedings of the 2018 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Honolulu, HI, USA, 12–15 November 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 17–30. [Google Scholar]
- Zhou, M.; Stoffl, L.; Mathis, M.W.; Mathis, A. Rethinking pose estimation in crowds: Overcoming the detection information bottleneck and ambiguity. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Vancouver, BC, Canada, 17–24 June 2023; pp. 14689–14699. [Google Scholar]
- Jin, S.; Li, S.; Li, T.; Liu, W.; Qian, C.; Luo, P. You only learn one query: Learning unified human query for single-stage multi-person multi-task human-centric perception. In Proceedings of the Computer Vision—ECCV 2024: 18th European Conference, Milan, Italy, 29 September–4 October 2024; Springer Nature: Cham, Switzerland, 2024; pp. 126–146. [Google Scholar]
- Wang, D.; Zhang, S. Contextual instance decoupling for robust multi-person pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11060–11068. [Google Scholar]
- Xie, Z.; Geng, Z.; Hu, J.; Zhang, Z.; Hu, H.; Cao, Y. Revealing the dark secrets of masked image modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 14475–14485. [Google Scholar]
- Kreiss, S.; Bertoni, L.; Alahi, A. Openpifpaf: Composite fields for semantic keypoint detection and spatio-temporal association. IEEE Trans. Intell. Transp. Syst. 2021, 23, 13498–13511. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer International Publishing: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16000–16009. [Google Scholar]
- Xie, Z.; Zhang, Z.; Cao, Y.; Lin, Y.; Bao, J.; Yao, Z.; Dai, Q.; Hu, H. Simmim: A simple framework for masked image modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 9653–9663. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9729–9738. [Google Scholar]
- Caron, M.; Touvron, H.; Misra, I.; Jégou, H.; Mairal, J.; Bojanowski, P.; Joulin, A. Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; pp. 9650–9660. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J. Learning transferable visual models from natural language supervision. In International Conference on Machine Learning; PmLR: Edmonton, AB, Canada, 2021; pp. 8748–8763. [Google Scholar]
- Oquab, M.; Darcet, T.; Moutakanni, T.; Vo, H.; Szafraniec, M.; Khalidov, V.; Bojanowski, P. Dinov2: Learning robust visual features without supervision. arXiv 2023, arXiv:2304.07193. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metric Name | Full Name | Normalized | Structure Considered | Confidence Considered | Applicable Datasets |
|---|---|---|---|---|---|
| PCP [44] | Percentage of Correct Parts | √ | √ | × | LSP, LSP-Extended |
| PCK [45] | Percentage of Correct Keypoints | √ | × | × | MPII, LSP, AI Challenger |
| PCKh [46] | PCK with Head-normalized | √ | × | × | MPII |
| AUC [47] | Area Under Curve | √ | × | × | AI Challenger |
| OKS [48] | Object Keypoint Similarity | √ | √ | √ | COCO, PoseTrack |
| AP@OKS [48] | Average Precision based on OKS | √ | √ | √ | COCO, CrowdPose |
| AR@OKS [48] | Average Recall based on OKS | √ | √ | √ | COCO, CrowdPose |
| mAP@OKS [48] | Mean Average Precision based on OKS | √ | √ | √ | COCO, PoseTrack, OCHuman |
| IoU [49] | Intersection over Union | √ | × | × | COCO |
| Metric Name | Computation Principle | Advantages | Limitations |
|---|---|---|---|
| PCP [44] | A body part is considered correct if both predicted endpoints fall within a tolerance distance of the ground truth endpoints. | Captures structural correctness; accounts for limb connectivity. | Sensitive to limb length; ineffective for small parts; rarely used in modern benchmarks. |
| PCK [45] | A keypoint prediction is correct if it lies within α × reference length of the ground truth point. | Simple and intuitive; widely adopted in early pose estimation research. | Threshold-dependent; not scale-invariant; ignores keypoint visibility. |
| PCKh [46] | Similar to PCK but uses head segment length as the normalization factor | Better normalization for human scale; standard for the MPII dataset. | Depends on accurate head annotation; not suitable for multi-person scenarios. |
| AUC [47] | Computes the area under the PCK curve across varying thresholds. | Aggregates performance across multiple thresholds; reduces threshold sensitivity. | Less interpretable; inherits limitations of PCK. |
| OKS [48] | Measures keypoint similarity using a Gaussian penalty based on Euclidean distance, normalized by object scale and keypoint-specific constants. | Scale-invariant; considers keypoint visibility and relative importance. | Sensitive to hyperparameters (e.g., σ); requires manual calibration; complex to compute. |
| AP@OKS [48] | Computes average precision across multiple OKS thresholds (0.50–0.95) using confidence-ranked predictions. | Official COCO benchmark; evaluates both localization and detection confidence. | High computational cost; strongly dependent on confidence ranking; penalizes slight deviations. |
| AR@OKS [48] | Computes average recall across a fixed OKS threshold under varying detection limits (e.g., maxDets = 20). | Measures detection completeness; useful in dense or occluded scenes. | Does not reflect precision; prone to false positives; affected by maxDets setting. |
| mAP@OKS [48] | Mean of AP@OKS scores across 10 OKS thresholds (0.50–0.95, step size 0.05). | Standard benchmark for multi-person pose estimation; balances precision and recall across scales and occlusion. | Sensitive to confidence calibration; penalizes invisible or slightly off keypoints; computationally intensive. |
| IoU [49] | Ratio of overlap area to union area between predicted and ground truth bounding boxes. | Intuitive geometric measure; standard in object detection. | Inapplicable to keypoint evaluation; insensitive to pose structure or semantics. |
| Model | Year | Backbone | PCKh@0.5 | Input Size | GFLOPs | Params | Characteristic |
|---|---|---|---|---|---|---|---|
| PCT [54] | 2023 | swin-base | 93.8% | 256 × 256 | 15.2 | ~88 M | PCT enhances dependency modeling and occlusion-robust inference by decomposing human poses into structured, discrete symbolic subcomponents. |
| 4 × RSN-50 [55] | 2020 | ResNet-50 | 93.0% | 256 × 192 | 29.3 | 111.8 M | 4 × RSN-50 enhances keypoint localization accuracy and efficiency by stacking Residual Steps Blocks (RSBs) to integrate fine-grained local features. |
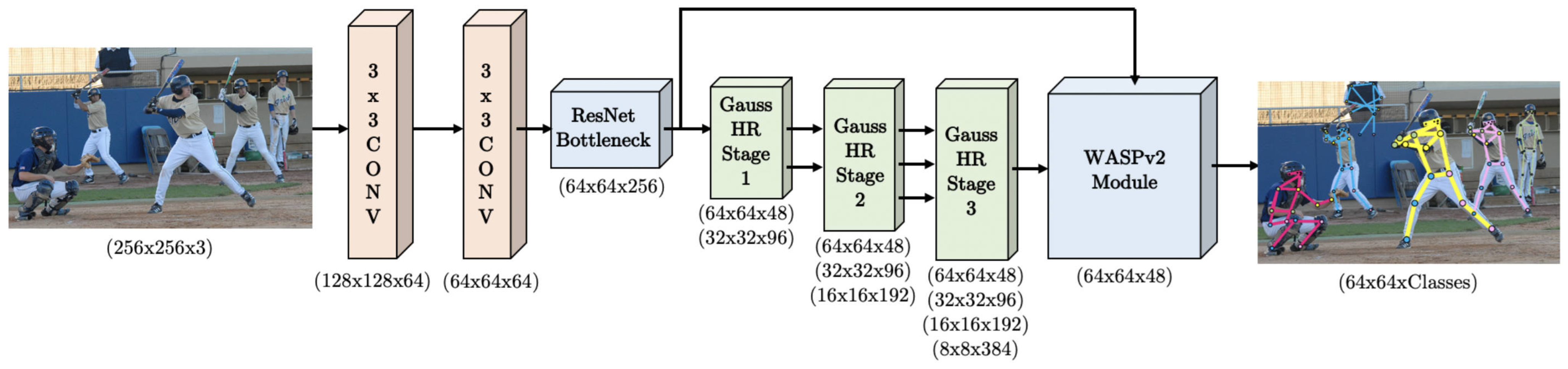
| UniPose [56] | 2020 | ResNet-101 | 92.7% | 1280 × 720 | 29.5 | 48.3 M | By integrating the ResNet architecture with the WASP multi-scale module, the model achieves efficient and accurate single-stage pose estimation and bounding box detection. |
| MSPN [57] | 2019 | ResNet-50 | 92.6% | 384 × 288 | ~45 | 100 M | MSPN improves both accuracy and efficiency by optimizing single-stage modules, feature aggregation mechanisms, and supervision strategies. |
| Spatial Context [58] | 2019 | ResNet-50 | 92.5% | 256 × 256 | 41.4 | 23.9 M | The Spatial Context model integrates multi-stage prediction with joint graph structures to accurately capture spatial relationships between human joints. |
| Model | Year | Backbone | AP | Input Size | GFLOPs | Params | Characteristic |
|---|---|---|---|---|---|---|---|
| ViTPose [35] | 2022 | ViTAE-G | 80.9 | 576 × 432 | >200 | 1 B | ViTPose is built on a streamlined ViT architecture, offering a compelling combination of high performance, scalability, and strong transferability. |
| UDP- Pose-PSA [59] | 2021 | HRNet-W48 | 79.5 | 384 × 288 | 35.4 | 70.1 M | UDP-Pose-PSA integrates HRNet-W48 with polarized self-attention to enhance long-range dependency modeling, thereby improving the accuracy and fine-grained performance of keypoint detection. |
| 4 × RSN-50 (ensemble) [55] | 2020 | ResNet-50 | 79.2 | 256 × 192 | 29.3 | 111.8 M | 4 × RSN-50 (ensemble) integrates four multi-branch Residual Steps Networks to effectively fuse intra-layer features. |
| CCM+ [60] | 2020 | HRNet-w48 | 78.9 | 384 × 288 | 36.3 | 63.7 M | CCM+ significantly improves keypoint detection accuracy through cascaded contextual fusion, sub-pixel localization, and an efficient training strategy. |
| UDP-Pose-PSA [59] | 2021 | HRNet-W48 | 78.9 | 256 × 192 | 15.7 | 70.1 M | UDP-Pose-PSA achieves an AP of 78.9 at an input resolution of 256 × 192, which is slightly lower than the 79.5 obtained at 384 × 288. |
| Model | Year | Backbone | PCK | Input Size | GFLOPs | Params | Characteristic |
|---|---|---|---|---|---|---|---|
| Soft-gated Skip Connections [62] | 2020 | Hourglass and U-Net | 94.8% | 256 × 256 | 9.9 | 8.5 M | A channel scaling factor is introduced to optimize feature fusion, enhancing both model accuracy and computational efficiency. |
| UniPose [56] | 2020 | ResNet-101 | 94.5% | 1280 × 720 | ~150 | ~48 M | UniPose integrates a ResNet backbone with the WASP module to enable efficient end-to-end pose estimation and bounding box detection. |
| Residual Hourglass + ASR + AHO [63] | 2018 | Stacked Hourglass | 94.5% | 256 × 256 | ~200 | 38 M | Residual Hourglass combines residual structures with adversarial enhancement to improve multi-scale feature modeling and the accuracy of keypoint localization. |
| SAHPE-Network [64] | 2017 | Stacked Hourglass Network | 94% | 256 × 256 | ~50 | ~30 M | This approach introduces a discriminator to learn structural constraints, thereby enhancing the accuracy and plausibility of pose estimation. |
| PRMs [27] | 2017 | Stacked Hourglass Network | 93.9% | 256 × 256 | 45.9 | 26.9 M | PRMs employs multi-branch convolutions to extract multi-scale features, enhancing the adaptability and accuracy of pose estimation under varying scales. |
| Model | Year | Backbone | Test AP | Input Size | GFLOPs | Params | Characteristic |
|---|---|---|---|---|---|---|---|
| BUCTD [65] | 2023 | CID-W32 | 47.2 | 256 × 192 | ~10 | ~35 M | BUCTD leverages bottom-up pose estimation as a conditional input to enhance accuracy and robustness in crowded and occluded scenarios. |
| HQNet [66] | 2024 | ViT-L | 45.6 | 512 × 512 | ~80 | ~304 M | HQNet enables unified modeling of multi-task human understanding by sharing a transformer decoder and a human query mechanism. |
| CID [34] | 2022 | HRNet-W48 | 45.0 | 512 × 512 | 43.14 | 29.4 M | CID introduces a context-instance decoupling mechanism that employs spatial and channel attention to extract instance-aware features for keypoint estimation. |
| MIPNet [64] | 2021 | HRNet-W48 | 42.5 | 256 × 256 | ~19 | 28.6 M | MIPNet introduces a Multi-Instance Modulation Block (MIMB) that enables efficient prediction of multiple pose instances within a single detection box. |
| HQNet [66] | 2024 | ResNet-50 | 40.0 | 512 × 512 | ~25 | ~53 M | Built on a ResNet-50 backbone, the model offers strong spatial locality modeling, high computational efficiency, and a lightweight structure. |
| Model | Year | Backbone | AP | Input Size | GFLOPs | Params | Characteristic |
|---|---|---|---|---|---|---|---|
| BUCTD [65] | 2023 | HRNet-W48 | 76.7 | 384 × 288 | ~40 | ~65 M | The BUCTD model integrates conditional inputs inspired by the PETR framework. |
| SwinV2-L 1K-MIM [68] | 2022 | Swin Transformer | 75.5 | 384 × 384 | ~115 | 197 M | By employing self-supervised Masked Image Modeling (MIM) pretraining on the ImageNet-1K dataset, the model is able to learn rich and generalizable representations. |
| SwinV2-B 1K-MIM [68] | 2022 | Swin Transformer | 74.9 | 224 × 224 | ~20 | ~87 M | Self-supervised pretraining with Masked Image Modeling (MIM) significantly enhances the model’s performance on geometric and motion-related tasks. |
| BUCTD [65] | 2023 | ResNet-50 | 72.9 | 384 × 288 | ~15 | ~28 M | The BUCTD model uses the CoAM-W48 configuration without employing any sampling strategy. |
| OpenPifPaf [69] | 2021 | ResNet-50 | 70.5 | 641 × 641 | ~30 | ~28 M | OpenPifPaf is a real-time, single-stage composite field method that simultaneously performs semantic keypoint detection and spatiotemporal association. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Shin, S.-Y. Two-Dimensional Human Pose Estimation with Deep Learning: A Review. Appl. Sci. 2025, 15, 7344. https://doi.org/10.3390/app15137344
Zhang Z, Shin S-Y. Two-Dimensional Human Pose Estimation with Deep Learning: A Review. Applied Sciences. 2025; 15(13):7344. https://doi.org/10.3390/app15137344
Chicago/Turabian StyleZhang, Zheyu, and Seong-Yoon Shin. 2025. "Two-Dimensional Human Pose Estimation with Deep Learning: A Review" Applied Sciences 15, no. 13: 7344. https://doi.org/10.3390/app15137344
APA StyleZhang, Z., & Shin, S.-Y. (2025). Two-Dimensional Human Pose Estimation with Deep Learning: A Review. Applied Sciences, 15(13), 7344. https://doi.org/10.3390/app15137344