
VDMS: An Improved Vision Transformer-Based Model for PM2.5 Concentration Prediction

Abstract
1. Introduction
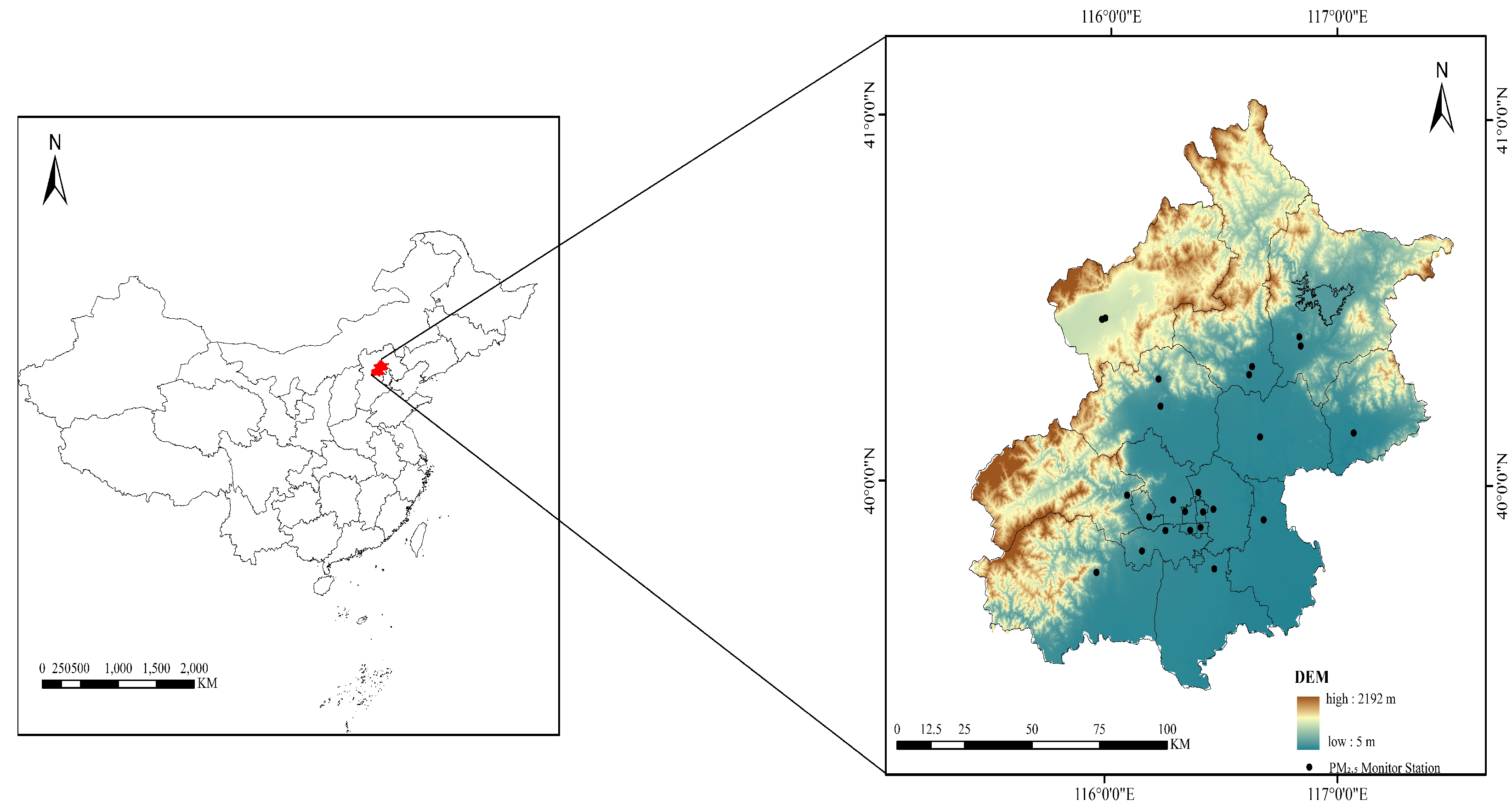
2. Data
2.1. Ground-Level PM2.5 Data
2.2. AOD Data
2.3. Auxiliary Data
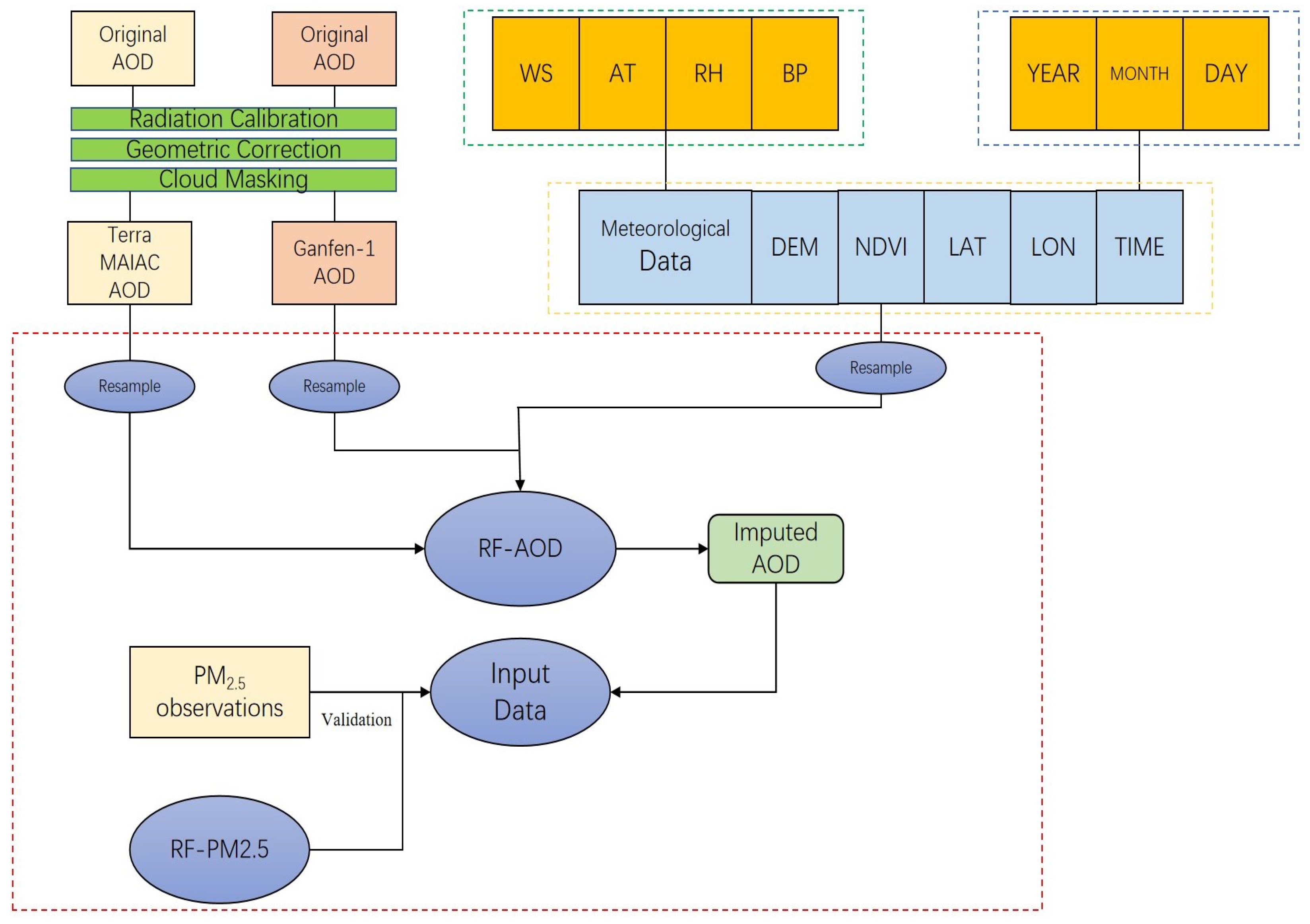
2.4. Data Preprocessing
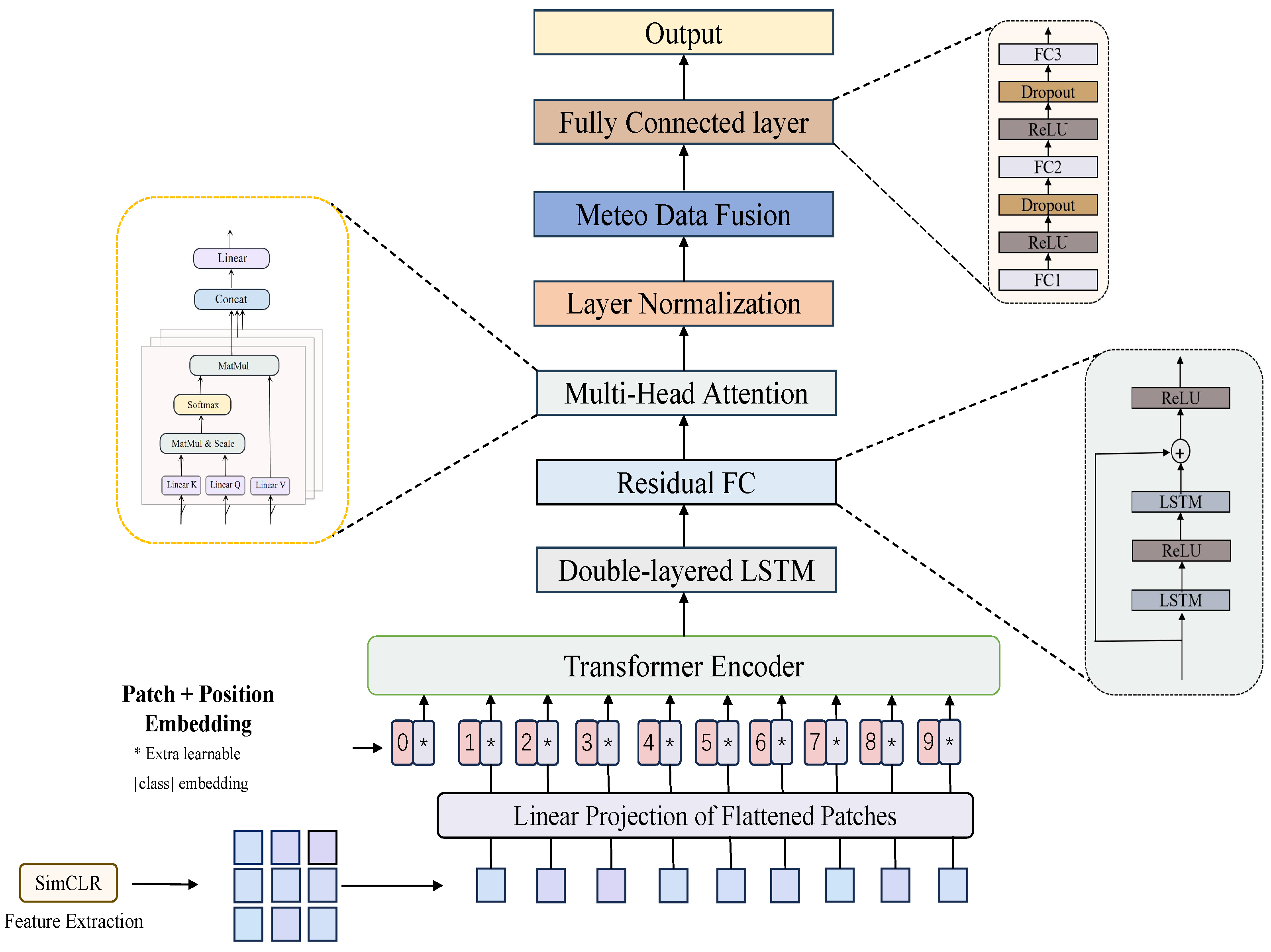
3. Methods
4. Results
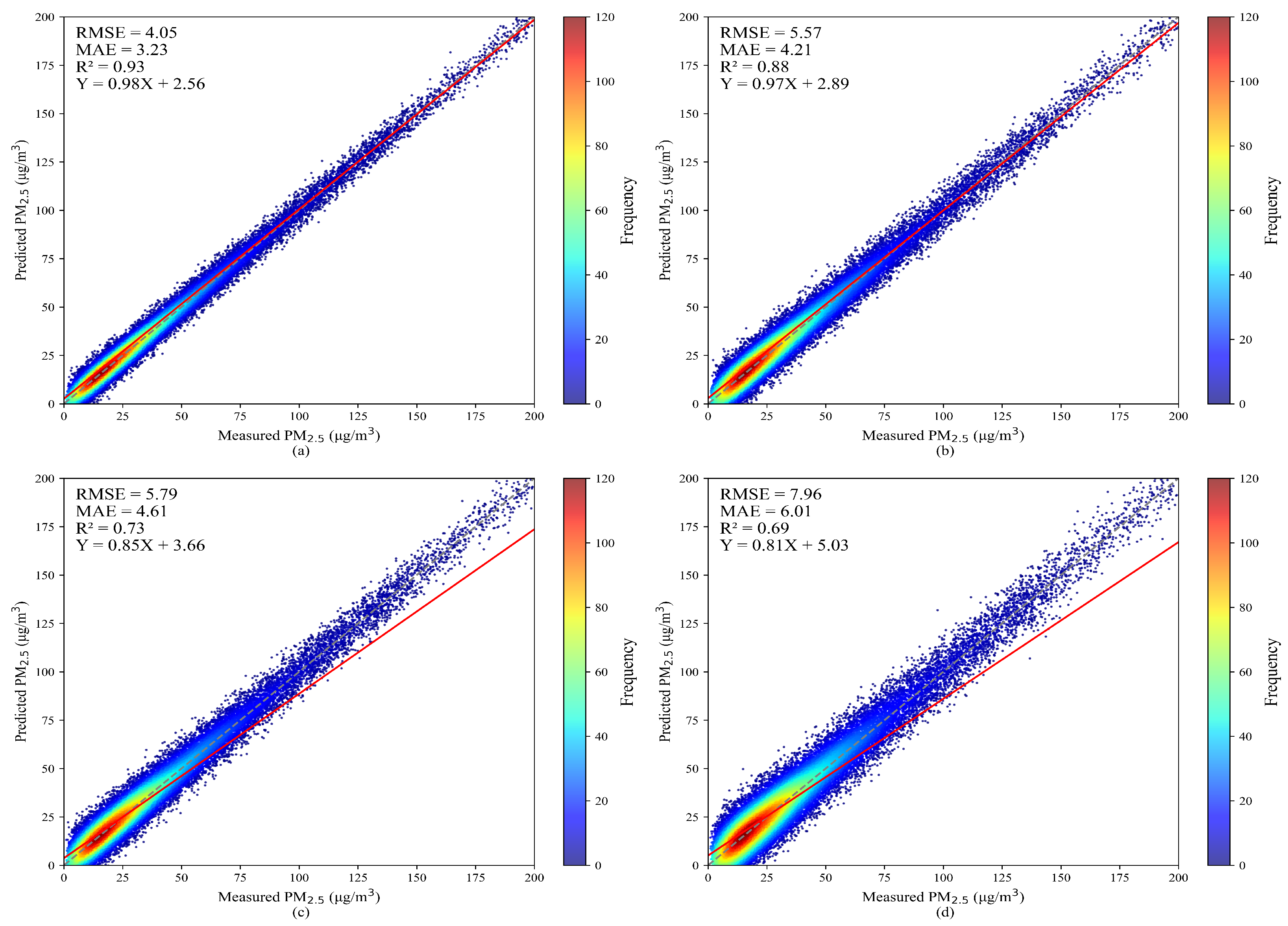
4.1. Model Validation and Comparison
4.2. Model Estimation
5. Discussion
5.1. Analysis in Model Performance
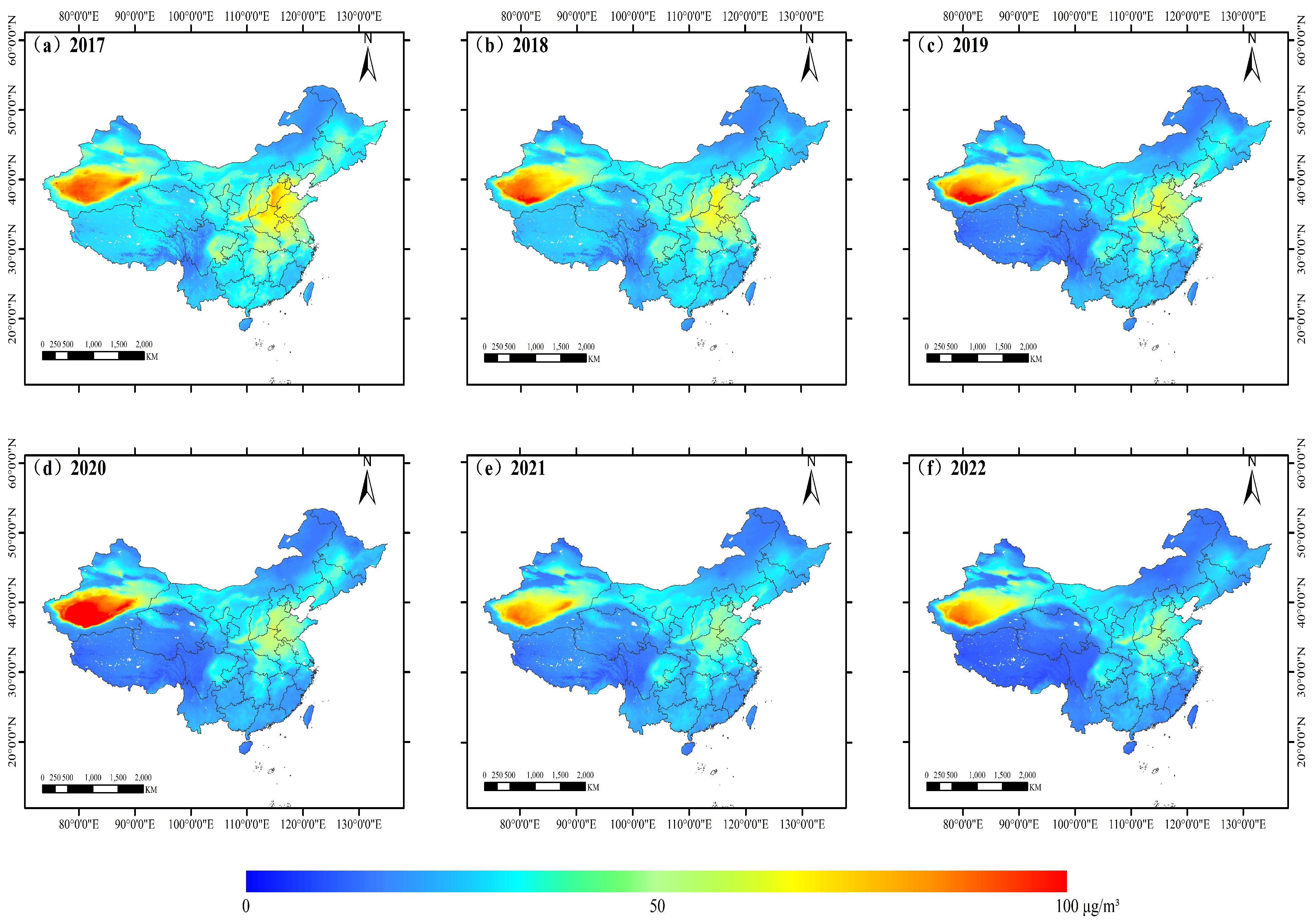
5.2. Analysis in Time and Space
5.3. Limitations and Improvements of the Model
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, N.; Shi, X. Study on public habituation to haze based on factor analysis and entropy method. J. Arid. Land Resour. Environ. 2020, 34, 15–21. [Google Scholar] [CrossRef]
- Gu, S. Study on the Assessment of Indirect Economic Losses from Haze Pollution. Master’s Thesis, Nanjing University of Information Science and Technology, Nanjing, China, 2016. [Google Scholar]
- Jiang, W.; Chen, D. Analysis of air quality status and meteorological conditions in Chongqing main urban area in 2015. Sichuan Environ. 2016, 35, 90–93. [Google Scholar] [CrossRef]
- Maji, K.J.; Arora, M.; Dikshit, A.K. Premature mortality attributable to PM2.5 exposure and future policy roadmap for ‘airpocalypse’affected Asian megacities. Process Saf. Environ. Prot. 2018, 118, 371–383. [Google Scholar] [CrossRef]
- Yao, L.; Sun, S.; Wang, Y.; Song, C.; Xu, Y. New insight into the urban PM2.5 pollution island effect enabled by the Gaussian surface fitting model: A case study in a mega urban agglomeration region of China. Int. J. Appl. Earth Obs. Geoinf. 2022, 113, 102982. [Google Scholar] [CrossRef]
- Zhou, L.; Zhou, C.; Yang, F.; Che, L.; Wang, B.; Sun, D. Spatio-temporal evolution and the influencing factors of PM2.5 in China between 2000 and 2015. J. Geogr. Sci. 2019, 29, 253–270. [Google Scholar] [CrossRef]
- Liu, Y.; Zhao, N.; Vanos, J.K.; Cao, G. Revisiting the estimations of PM2.5-attributable mortality with advancements in PM2.5 mapping and mortality statistics. Sci. Total Environ. 2019, 666, 499–507. [Google Scholar] [CrossRef] [PubMed]
- Pun, V.C.; Kazemiparkouhi, F.; Manjourides, J.; Suh, H.H. Long-term PM2.5 exposure and respiratory, cancer, and cardiovascular mortality in older US adults. Am. J. Epidemiol. 2017, 186, 961–969. [Google Scholar] [CrossRef]
- Xie, Y.; Dai, H.; Hanaoka, T.; Masui, T. Health and economic impacts of PM2.5 pollution in Beijing-Tianjin-Hebei Area. China Popul. Resour. Environ. 2016, 26, 19–27. [Google Scholar]
- Ahmad, N.A.; Ismail, N.W.; Sidique, S.F.A.; Mazlan, N.S. Air pollution, governance quality, and health outcomes: Evidence from developing countries. Environ. Sci. Pollut. Res. 2023, 30, 41060–41072. [Google Scholar] [CrossRef]
- Li-juan, K.; Hai-ye, Y.; Mei-chen, C.; Zhao-jia, P.; Shuang, L.; Jing-min, D.; Lei, Z.; Yuan-yuan, S. Analyze on the Response Characteristics of Leaf vegetables to Particle Matters Based on Hyperspectral. Spectrosc. Spectr. Anal. 2021, 41, 236–242. [Google Scholar]
- Zhang, Q.; Zheng, Y.; Tong, D.; Shao, M.; Wang, S.; Zhang, Y.; Xu, X.; Wang, J.; He, H.; Liu, W.; et al. Drivers of improved PM2.5 air quality in China from 2013 to 2017. Proc. Natl. Acad. Sci. USA 2019, 116, 24463–24469. [Google Scholar] [CrossRef] [PubMed]
- Park, S.; Lee, J.; Im, J.; Song, C.K.; Choi, M.; Kim, J.; Lee, S.; Park, R.; Kim, S.M.; Yoon, J.; et al. Estimation of spatially continuous daytime particulate matter concentrations under all sky conditions through the synergistic use of satellite-based AOD and numerical models. Sci. Total Environ. 2020, 713, 136516. [Google Scholar] [CrossRef] [PubMed]
- Ma, Z.; Dey, S.; Christopher, S.; Liu, R.; Bi, J.; Balyan, P.; Liu, Y. A review of statistical methods used for developing large-scale and long-term PM2.5 models from satellite data. Remote Sens. Environ. 2022, 269, 112827. [Google Scholar] [CrossRef]
- Guo, J.P.; Zhang, X.Y.; Che, H.Z.; Gong, S.L.; An, X.; Cao, C.X.; Guang, J.; Zhang, H.; Wang, Y.Q.; Zhang, X.C.; et al. Correlation between PM concentrations and aerosol optical depth in eastern China. Atmos. Environ. 2009, 43, 5876–5886. [Google Scholar] [CrossRef]
- Yang, Q.; Yuan, Q.; Yue, L.; Li, T.; Shen, H.; Zhang, L. The relationships between PM2.5 and aerosol optical depth (AOD) in mainland China: About and behind the spatio-temporal variations. Environ. Pollut. 2019, 248, 526–535. [Google Scholar] [CrossRef]
- Li, S.; Zou, B.; Fang, X.; Lin, Y. Time series modeling of PM2.5 concentrations with residual variance constraint in eastern mainland China during 2013–2017. Sci. Total Environ. 2020, 710, 135755. [Google Scholar] [CrossRef]
- Li, Z.; Zhang, Y.; Shao, J.; Li, B.; Hong, J.; Liu, D.; Li, D.; Wei, P.; Li, W.; Li, L.; et al. Remote sensing of atmospheric particulate mass of dry PM2.5 near the ground: Method validation using ground-based measurements. Remote Sens. Environ. 2016, 173, 59–68. [Google Scholar] [CrossRef]
- Van Donkelaar, A.; Martin, R.V.; Park, R.J. Estimating ground-level PM2.5 using aerosol optical depth determined from satellite remote sensing. J. Geophys. Res. Atmos. 2006, 111. [Google Scholar] [CrossRef]
- Zhang, Z.; Wu, W.; Fan, M.; Wei, J.; Tan, Y.; Wang, Q. Evaluation of MAIAC aerosol retrievals over China. Atmos. Environ. 2019, 202, 8–16. [Google Scholar] [CrossRef]
- Xie, Y.; Wang, Y.; Bilal, M.; Dong, W. Mapping daily PM2.5 at 500 m resolution over Beijing with improved hazy day performance. Sci. Total Environ. 2019, 659, 410–418. [Google Scholar] [CrossRef]
- Zhang, T.; Zhu, Z.; Gong, W.; Zhu, Z.; Sun, K.; Wang, L.; Huang, Y.; Mao, F.; Shen, H.; Li, Z.; et al. Estimation of ultrahigh resolution PM2.5 concentrations in urban areas using 160 m Gaofen-1 AOD retrievals. Remote Sens. Environ. 2018, 216, 91–104. [Google Scholar] [CrossRef]
- Xiao, Q.; Wang, Y.; Chang, H.H.; Meng, X.; Geng, G.; Lyapustin, A.; Liu, Y. Full-coverage high-resolution daily PM2.5 estimation using MAIAC AOD in the Yangtze River Delta of China. Remote Sens. Environ. 2017, 199, 437–446. [Google Scholar] [CrossRef]
- Lee, H.J. Benefits of high resolution PM2.5 prediction using satellite MAIAC AOD and land use regression for exposure assessment: California examples. Environ. Sci. Technol. 2019, 53, 12774–12783. [Google Scholar] [CrossRef]
- Ma, Z.; Liu, Y.; Zhao, Q.; Liu, M.; Zhou, Y.; Bi, J. Satellite-derived high resolution PM2.5 concentrations in Yangtze River Delta Region of China using improved linear mixed effects model. Atmos. Environ. 2016, 133, 156–164. [Google Scholar] [CrossRef]
- Zhang, R.; Di, B.; Luo, Y.; Deng, X.; Grieneisen, M.L.; Wang, Z.; Yao, G.; Zhan, Y. A nonparametric approach to filling gaps in satellite-retrieved aerosol optical depth for estimating ambient PM2.5 levels. Environ. Pollut. 2018, 243, 998–1007. [Google Scholar] [CrossRef]
- Shtein, A.; Kloog, I.; Schwartz, J.; Silibello, C.; Michelozzi, P.; Gariazzo, C.; Viegi, G.; Forastiere, F.; Karnieli, A.; Just, A.C.; et al. Estimating daily PM2.5 and PM10 over Italy using an ensemble model. Environ. Sci. Technol. 2019, 54, 120–128. [Google Scholar] [CrossRef] [PubMed]
- Ashish, V. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Fu, Y.; Ye, Z.; Deng, J.; Zheng, X.; Huang, Y.; Yang, W.; Wang, Y.; Wang, K. Finer resolution mapping of marine aquaculture areas using worldView-2 imagery and a hierarchical cascade convolutional neural network. Remote Sens. 2019, 11, 1678. [Google Scholar] [CrossRef]
- Ye, Z.; Fu, Y.; Gan, M.; Deng, J.; Comber, A.; Wang, K. Building extraction from very high resolution aerial imagery using joint attention deep neural network. Remote Sens. 2019, 11, 2970. [Google Scholar] [CrossRef]
- Shen, H.; Li, T.; Yuan, Q.; Zhang, L. Estimating regional ground-level PM2.5 directly from satellite top-of-atmosphere reflectance using deep belief networks. J. Geophys. Res. Atmos. 2018, 123, 13–875. [Google Scholar] [CrossRef]
- Kaufman, Y.J.; Sendra, C. Algorithm for automatic atmospheric corrections to visible and near-IR satellite imagery. Int. J. Remote Sens. 1988, 9, 1357–1381. [Google Scholar] [CrossRef]
- Zhao, C.; Wang, Q.; Ban, J.; Liu, Z.; Zhang, Y.; Ma, R.; Li, S.; Li, T. Estimating the daily PM2.5 concentration in the Beijing-Tianjin-Hebei region using a random forest model with a 0.01× 0.01 spatial resolution. Environ. Int. 2020, 134, 105297. [Google Scholar] [CrossRef] [PubMed]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Graves, A.; Mohamed, A.r.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 6645–6649. [Google Scholar]
- Keskar, N.S.; Mudigere, D.; Nocedal, J.; Smelyanskiy, M.; Tang, P.T.P. On large-batch training for deep learning: Generalization gap and sharp minima. arXiv 2016, arXiv:1609.04836. [Google Scholar]
- Poujois, A.; Woimant, F. Wilson’s disease: A 2017 update. Clin. Res. Hepatol. Gastroenterol. 2018, 42, 512–520. [Google Scholar] [CrossRef]
- Smith, S.L.; Le, Q.V. A bayesian perspective on generalization and stochastic gradient descent. arXiv 2017, arXiv:1710.06451. [Google Scholar]
- Lindemann, B.; Müller, T.; Vietz, H.; Jazdi, N.; Weyrich, M. A survey on long short-term memory networks for time series prediction. Procedia CIRP 2021, 99, 650–655. [Google Scholar] [CrossRef]
- Greff, K.; Srivastava, R.K.; Koutník, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A search space odyssey. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 2222–2232. [Google Scholar] [CrossRef] [PubMed]
- Ye, Y.; Cao, Y.; Dong, Y.; Yan, H. A Graph Neural Network and Transformer-based model for PM2.5 prediction through spatiotemporal correlation. Environ. Model. Softw. 2025, 106501. [Google Scholar] [CrossRef]
- Bello, I.; Zoph, B.; Vaswani, A.; Shlens, J.; Le, Q.V. Attention augmented convolutional networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3286–3295. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, PmLR, Vienna, Austria, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Maschinot, A.; Liu, C.; Krishnan, D. Supervised contrastive learning. Adv. Neural Inf. Process. Syst. 2020, 33, 18661–18673. [Google Scholar]
- Zhang, L.; An, J.; Liu, M.; Li, Z.; Liu, Y.; Tao, L.; Liu, X.; Zhang, F.; Zheng, D.; Gao, Q.; et al. Spatiotemporal variations and influencing factors of PM2.5 concentrations in Beijing, China. Environ. Pollut. 2020, 262, 114276. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.; Xue, W.; Lei, Y.; Zhao, Y.; Cheng, S.; Ren, Z.; Huang, Q. Impact of meteorological conditions on PM2.5 pollution in China during winter. Atmosphere 2018, 9, 429. [Google Scholar] [CrossRef]
- Liang, F.; Xiao, Q.; Wang, Y.; Lyapustin, A.; Li, G.; Gu, D.; Pan, X.; Liu, Y. MAIAC-based long-term spatiotemporal trends of PM2.5 in Beijing, China. Sci. Total Environ. 2018, 616, 1589–1598. [Google Scholar] [CrossRef] [PubMed]
- Hao, J.; Wang, L. Improving urban air quality in China: Beijing case study. J. Air Waste Manag. Assoc. 2005, 55, 1298–1305. [Google Scholar] [CrossRef] [PubMed]
- Wu, J.; Su, Y.; Chen, X.; Liu, L.; Sun, C.; Zhang, H.; Li, Y.; Ye, Y.; Zhou, X.; Yang, J.; et al. Redistribution characteristics of atmospheric precipitation in different spatial levels of Guangzhou urban typical forests in southern China. Atmos. Pollut. Res. 2019, 10, 1404–1411. [Google Scholar] [CrossRef]
- Liu, H.; Liu, J.; Li, M.; Gou, P.; Cheng, Y. Assessing the evolution of PM2.5 and related health impacts resulting from air quality policies in China. Environ. Impact Assess. Rev. 2022, 93, 106727. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Sam-CV | Sta-CV | ||||
|---|---|---|---|---|---|---|
| RMSE | MAE | RMSE | MAE | |||
| CNN | 0.75 | 7.77 | 6.42 | 0.70 | 9.29 | 7.40 |
| ViT | 0.53 | 8.05 | 6.51 | 0.48 | 9.57 | 7.49 |
| SimCLR | 0.86 | 7.43 | 5.78 | 0.81 | 8.95 | 6.76 |
| VDMS | 0.93 | 4.05 | 3.23 | 0.88 | 5.57 | 4.21 |
| Model | Sam-CV | Sta-CV | ||||
|---|---|---|---|---|---|---|
| RMSE | MAE | RMSE | MAE | |||
| ViT-LSTM | 0.58 | 7.64 | 5.23 | 0.53 | 9.16 | 6.21 |
| ViT-DLSTM | 0.73 | 6.14 | 4.77 | 0.68 | 7.66 | 5.75 |
| VDM | 0.85 | 4.54 | 3.31 | 0.81 | 6.06 | 4.29 |
| VDMS | 0.93 | 4.05 | 3.23 | 0.88 | 5.57 | 4.21 |
| Season\Year | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 |
|---|---|---|---|---|---|---|
| Spring | 59.87 | 69.79 | 46.50 | 34.07 | 49.09 | 32.96 |
| Summer | 44.31 | 43.12 | 31.76 | 33.06 | 17.71 | 20.52 |
| Autumn | 51.98 | 45.23 | 39.97 | 33.54 | 29.74 | 29.17 |
| Winter | 76.40 | 43.29 | 48.30 | 49.44 | 43.18 | 39.21 |
| Annual | 58.14 | 50.36 | 41.63 | 37.53 | 34.93 | 30.47 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, T.; Qu, M. VDMS: An Improved Vision Transformer-Based Model for PM2.5 Concentration Prediction. Appl. Sci. 2025, 15, 7346. https://doi.org/10.3390/app15137346
Zhao T, Qu M. VDMS: An Improved Vision Transformer-Based Model for PM2.5 Concentration Prediction. Applied Sciences. 2025; 15(13):7346. https://doi.org/10.3390/app15137346
Chicago/Turabian StyleZhao, Tong, and Meixia Qu. 2025. "VDMS: An Improved Vision Transformer-Based Model for PM2.5 Concentration Prediction" Applied Sciences 15, no. 13: 7346. https://doi.org/10.3390/app15137346
APA StyleZhao, T., & Qu, M. (2025). VDMS: An Improved Vision Transformer-Based Model for PM2.5 Concentration Prediction. Applied Sciences, 15(13), 7346. https://doi.org/10.3390/app15137346