1. Introduction
With the steady advancement of deep learning, object detection powered by this technology has made significant progress across various circumstances. This momentum has also extended to the specialized field of ship target detection [
1]. Ship detection is central to intelligent shipping systems [
2] and remains a core safeguard for canal operations and navigational safety. In real-world low-illumination scenes or during nighttime [
3], ship images often suffer from poor visibility and blurred details. Taking a bird’s-eye view of recent research, it can be vividly seen that directly applying generic detectors to low-illumination ship images typically leads to a decline in accuracy because vessels appear faint [
4]. These disadvantages mean that plenty of essential visual clues are missing. Therefore, achieving stable and high precision in ship detection under low-illumination conditions remains a significant challenge for various research communities [
5].
To cope with the recognition demands in low-illumination scenes, researchers are more willing to combine image enhancement techniques with network optimizations to improve detection performance. Wang Y.T. [
6] incorporated RetinexFormer into the same backbone, to estimate illumination and reflectance maps, thereby improving brightness and contrast. Zhang Y.H. [
7] combined Retime enhancement with receptive-field modules in YOLOv4, achieving effective detection of maritime targets in foggy conditions. Building on Retinex and saliency theory, Pengcheng Hao [
8] devised a low-light enhancement framework that fused predicted salient regions with the enhanced image, boosting detection under dim lighting. Zhang et al. [
9] proposed a lightweight CNN equipped with a CA-Ghost module and hybrid training, which strengthens shallow features and raises accuracy in foggy and nighttime scenes. Hong et al. [
10] streamlined YOLOv4 by introducing residual blocks, easing network degradation and markedly improving detection in low-illumination scenes. Finally, Sen Li [
11] used contrastive-learning pre-training to mitigate nighttime feature degradation without adding significant complexity. References [
6,
7,
8] highlight target cues through enhanced or fused strategies. However, they have limited capacity for global modeling and fail to rank feature importance, leading to missed detections. The missing detection of the vessel could lead to potential hazards. In response to these negative factors, many effective measures are taken, for instance, incorporating non-local attention mechanisms to enhance long-range dependency modeling, employing dual-path channel-spatial attention for dynamic feature map reweighting, and constructing multi-scale feature pyramid networks to mitigate cross-level semantic conflicts. References [
9,
10,
11] optimize network features for low-illumination scenes, yet semantic conflicts across levels remain unsolved. In low-illumination scenes, the misalignment between abstract representations and contour clues prevents existing models from sensibly balancing multi-scale perception. In some complex situations, these core methods do adaptively weight textures and outlines to cope with their specific contexts. Nevertheless, the prior distributions and overall traits of multi-scale cognition there differ significantly from ours, so those schemes lose their edge in our setting. In monocular scenes, extracting high-level clues with deep models can conflict with low-level perceptions such as ship outlines. Clearly, this hampers ship detection in low-illumination scenes.
As smart maritime systems and intelligent shipping technologies continue to advance, object detection algorithms are increasingly required to demonstrate high adaptability in complex real-world environments—particularly regarding multi-scale feature representation and fine-grained perception of vessel targets. In nighttime or low-illumination scenarios, vessel imagery often suffers from insufficient luminance, degraded contrast, ambiguous boundaries, and loss of structural details, which collectively undermine the capability of conventional detection algorithms to effectively delineate object contours and morphology. Representative application domains include canal port surveillance, nighttime maritime security patrols, and maritime supervision under adverse weather conditions. The targets encompass heterogeneous vessel types—such as cargo ships, fishing vessels, and passenger ferries—which frequently exhibit visual challenges including large scale variation, partial occlusion, low-texture surfaces, and significant background–boundary fusion. These characteristics commonly result in performance degradation of existing detection models, manifesting as false negatives and misclassifications.
Although the YOLO series exhibits strong real-time performance and overall effectiveness, its capacity to extract and represent low-level features is significantly constrained under low-light conditions. These limitations often induce semantic inconsistencies and multi-scale feature imbalance during the fusion process, consequently impairing detection responsiveness and degrading boundary localization accuracy for maritime targets. To tackle these challenges, this paper proposes YOLO-SAR, a specialized low-light ship detection framework that integrates an expanded receptive field with an adaptive spatial feature fusion mechanism. Built upon YOLO11, the proposed architecture incorporates a SCINet module to improve input image quality and employs a cross-level perception structure coupled with a dynamic weighting fusion strategy, thereby enhancing detection precision and robustness under conditions involving low illumination, multiple targets, and scale variance. The major contributions of this study are as follows:
(1) A method for constructing a low-light ship dataset is proposed, and its effectiveness is validated through comparative experiments based on gray value and HSV color space analysis. This approach partially addresses the limitations of existing open-source datasets.
(2) To address the challenges of low-light ship detection, a dedicated framework named YOLO-SAR is proposed for inland river scenarios. This framework alleviates semantic conflicts and enhances multi-scale feature learning by integrating a Self-Calibrated Illumination Network, which recovers multi-scale feature details of ships in low-light images. Additionally, it introduces attentional convolution with expanded receptive fields to improve global context modeling and incorporates an adaptive spatial feature fusion strategy to overcome feature insufficiency. Together, these components significantly improve detection accuracy in such challenging environments.
(3) Extensive experiments conducted on the self-constructed Lowship dataset and a real-world low-light vessel dataset demonstrate that YOLO-SAR achieves superior detection accuracy compared to existing methods, including YOLOv11. This framework lays a solid foundation for robust vessel recognition and tracking in canal scenarios and contributes to the advancement of intelligent shipping systems.
The remainder of this paper is organized as follows:
Section 2 reviews related work, focusing on advanced object-detection methods applied to ship detection and the baseline YOLO11.
Section 3 details the proposed YOLO-SAR framework.
Section 4 represents extensive experiments validating its effectiveness, and
Section 5 concludes this study and discusses future research directions.
3. Methods
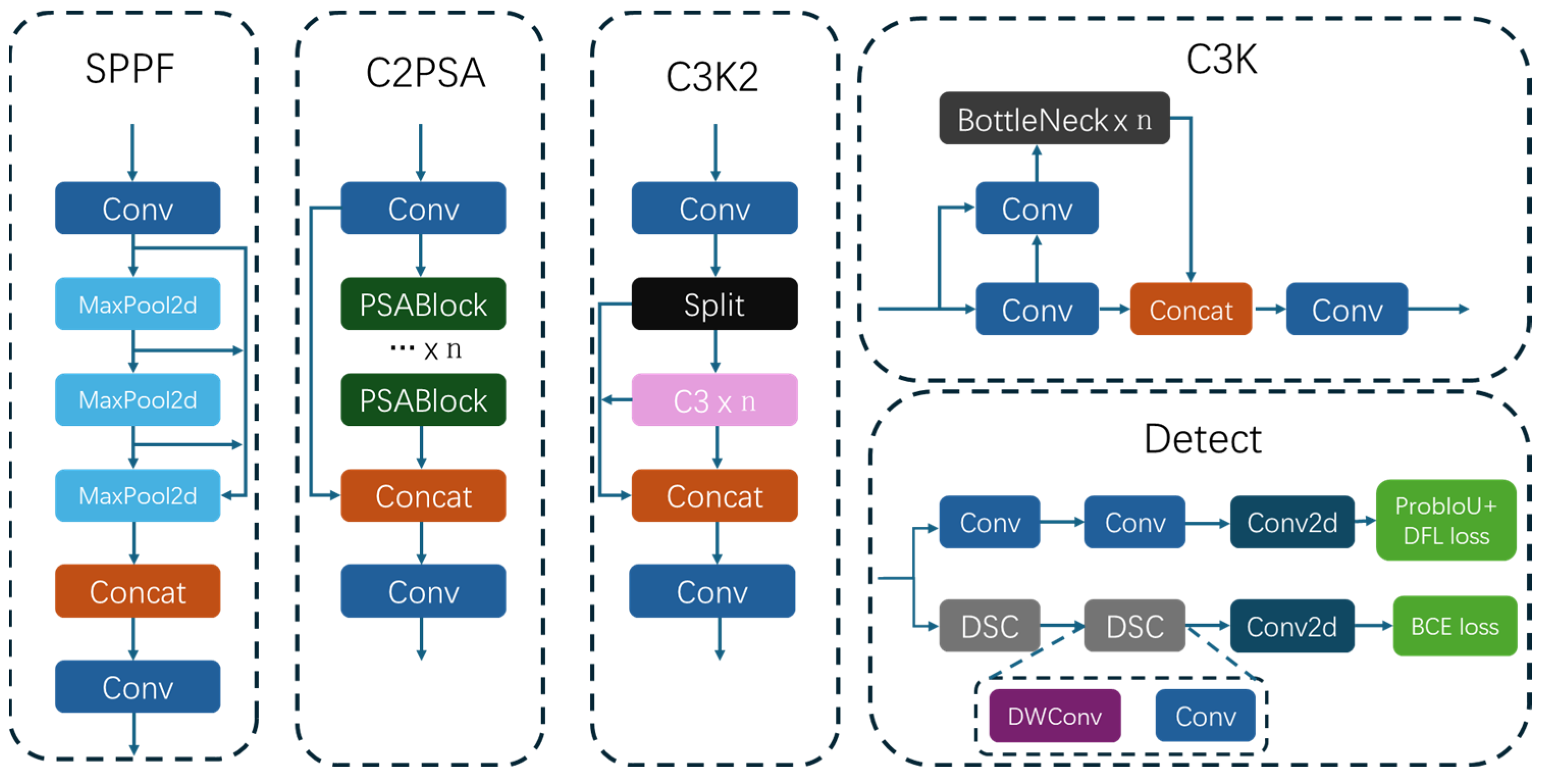
Based on the YOLO11 architecture, YOLO-SAR addresses key limitations of the baseline model by enhancing its backbone, neck, and detection head components. The backbone integrates an illumination enhancement module, multiple convolutional layers, and a Spatial Pyramid Pooling Fast (SPPF) module. SCINet employs a cascaded illumination learning process and a weight-sharing mechanism to improve visual clarity in low-light images, thereby recovering fine-grained, multi-scale ship features. Furthermore, the standard convolutions are replaced with the receptive-field attention convolution (RFAConv) module, which dynamically recalibrates intra-receptive-field feature weights to enhance global context modeling and compensate for limitations in capturing long-range dependencies. The SPPF module consolidates multi-scale features into a unified resolution, improving the detection of ships of varying sizes. In the neck section, the model adopts a hybrid of feature pyramid network (FPN) and Path Aggregation Network (PANet) to enable hierarchical feature fusion. The backbone outputs are first channel-aligned and then refined through the RFAConv module, which enhances salient feature representations using a dynamic receptive-field attention mechanism. Top-down and bottom-up fusion through upsampling and downsampling operations further integrates multi-scale features into robust fused representations, enhancing detection across different scales. The detection head adopts the Adaptively Spatial Feature Fusion (ASFF) module, which dynamically assigns spatial attention weights to resolve semantic conflicts during cross-scale feature aggregation. ASFF adaptively modulates contributions from different layers, mitigating contour ambiguity and feature degradation in low-light conditions. Additionally, a decoupled anchor-based head separately optimizes bounding box regression and object classification, thereby improving both precision and robustness in challenging environments. Collectively, these architectural enhancements significantly strengthen the model’s capability for reliable vessel detection under complex low-illumination scenarios.
In low-illumination ship-detection tasks, the SCINet module utilizes pixel clues from low-light environments through abstract node interactions. By constructing abstract node comprehensions and feature representations, it effectively extracts low-light characteristics and enables the detector to capture ship features more accurately. The receptive field is introduced to restore the missing global context subsequently, thereby reducing the likelihood of missed detections of small ships. They are supposed to focus on the frame edge representations. Furthermore, the Adaptively Spatial Feature Fusion (ASFF) in the head adaptively fuses cross-scale cues, facilitating multi-scale learning and ensuring precise ship recognition. In conclusion, our improved YOLO11 framework consists of SCINet, RFAConv, and ASFF modules. SCINet emphasizes low-contrast and low-saturation ship patterns. ASFF dynamically readjusts their weights within the cascade, feature tuning in time and blemish filtering, which ensures robust detection. Its complete architecture is illustrated in
Figure 2 and guarantees robust ship detection.
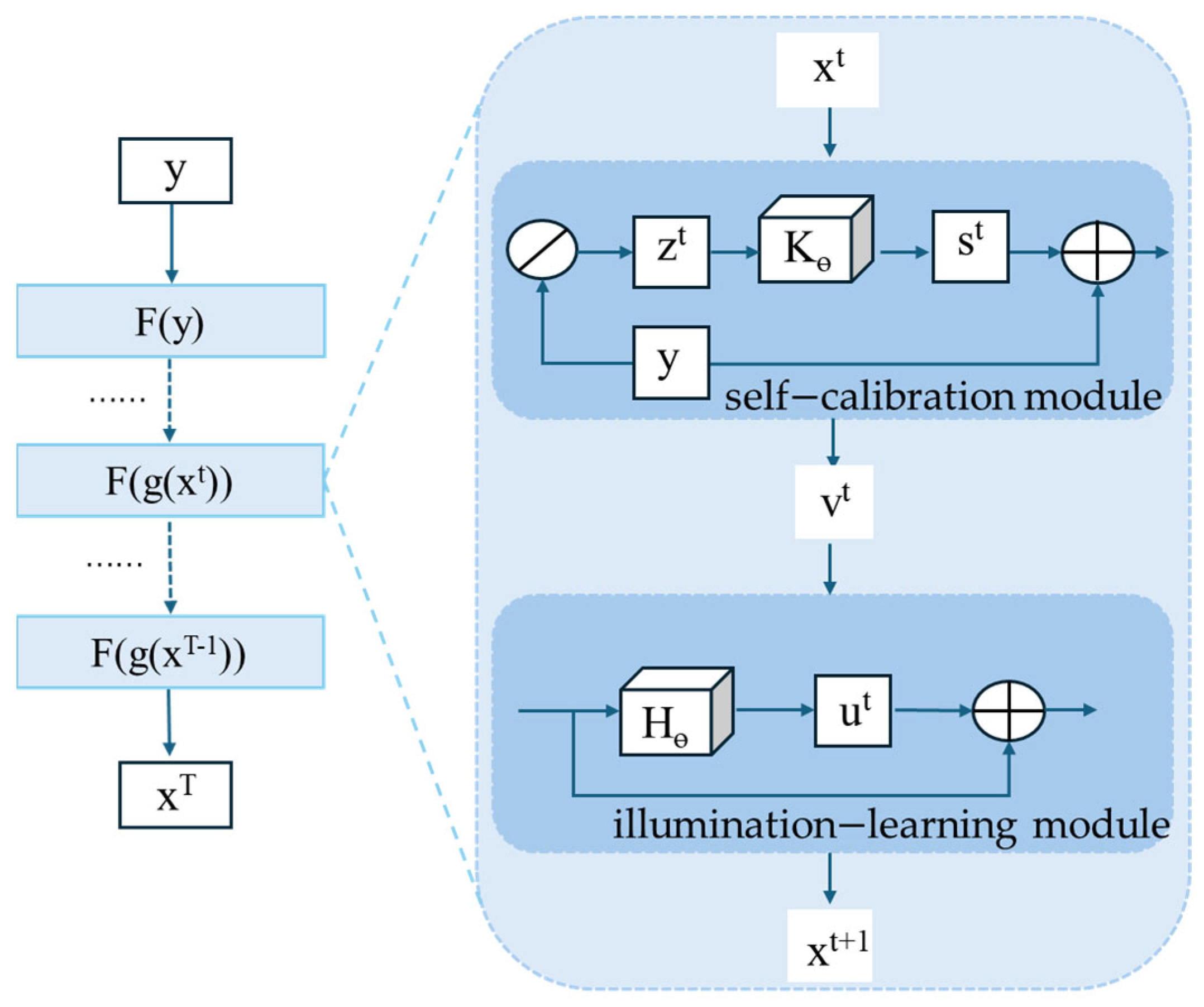
3.1. SCINet Module
To address the challenges of poor discriminability of multi-scale features and significant spatio-temporal fragmentation in low-illumination scenarios, this framework introduces a Self-Calibrated Illumination Network (SCINet). SCINet is a deep learning model that integrates spatial and channel representations; it adaptively enhances multi-scale feature perception in low-illumination scenes marked by low saturation, low contrast, and weak discriminability. Built from several convolutional and deconvolutional layers, SCINet consists of two main components: an illumination learning module and a self-calibration module, which are described in detail below in
Figure 3.
The illumination learning module gradually refines illumination estimation via residual learning, capturing the residual between illumination and the low-illumination image, and in doing so, this approach reduces computational costs while stabilizing model performance. Employing the Retinex formulation, a low-illumination observation is modeled as the element-wise product of a clean image and its illumination map. Learnable mapping is then introduced to track illumination variations progressively, forming a bidirectional mapping that adapts dynamically to changing lighting and achieves precise image enhancement. In Equation (1),
and
denote the residual term and the illumination at stage
, respectively.
represents the learnable mapping function.
As for low-illumination observations, the self-calibration module constrains each stage’s output by defining an unsupervised training loss. It also reduces the model’s computational cost and endows it with adaptability to diverse scenarios. This can be found in Equation (2).
In Equation (2),
denotes the calibrated input to the next stage, and
represents a learnable parametric operator. On this basis, the input to the illumination-learning process becomes this calibrated output, and the basic unit of the illumination-optimization process can be expressed as Equation (3).
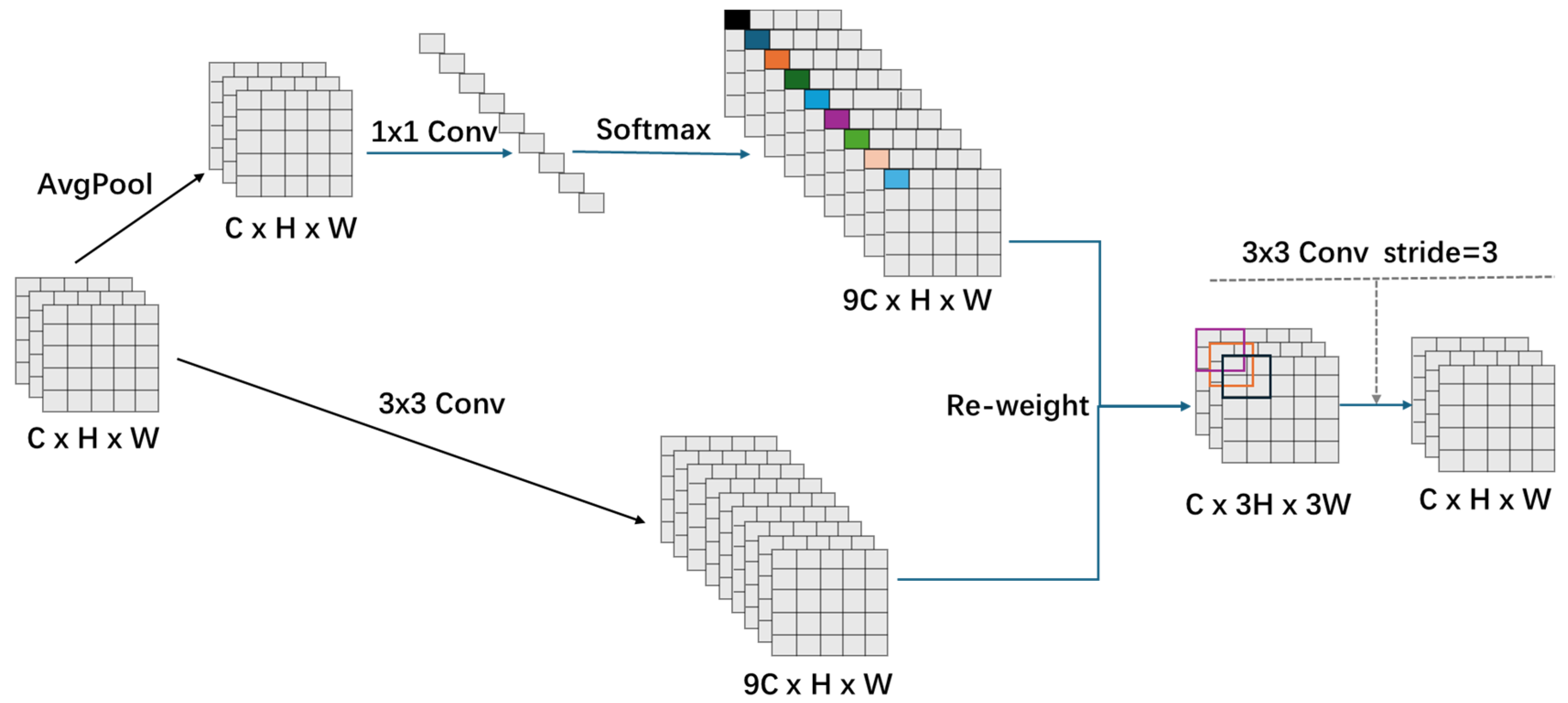
3.2. RFAConv Module
Standard convolutions are introduced here to utilize fixed kernels, which overlook both spatial heterogeneity and variations in feature importance indeed. They do more harm than good to suboptimal feature extraction and are not able to bring more robust ship detections. To address these limitations, we introduce receptive-field attention convolution (RFAConv). Unlike standard convolutions, RFAConv emphasizes spatial differences within each receptive field. They are adopted here to effectively mitigate the shortcomings of conventional convolution in capturing long-range dependencies. In addition, it adaptively adjusts weights across scales to enhance the extraction of key features. Furthermore, RFAConv leverages dynamic interactions between receptive field features and kernels, thereby significantly improving the model’s overall detection accuracy on time. The architecture of the RFAConv module can be illustrated in
Figure 4.
RFAConv segments the input feature map into non-overlapping patches, each corresponding to a receptive field, thus transforming spatial features into receptive-field representations. Each patch undergoes average pooling to aggregate receptive-field features and capture global context. A 1 × 1 convolution then enables feature interaction across receptive fields, strengthening feature correlation and global expressiveness. The softmax function is used to generate attention weights. These weights reflect the importance of features within each receptive field. By multiplying weights with receptive-field features element-wise, salient clues are emphasized, thereby improving extraction effectiveness. A convolution aligns feature mapping matching mechanisms to the attention map. Applying the attention weights and resizing then yields the final RFAConv output.
RFAConv effectively addresses the limitations of standard convolutions in convolutional neural networks, which benefits weight readjustment and spatial insensitivity. They are adopted here and account for the significance of features within each receptive field. Based on dynamic generation of distinct attention weights for each receptive field, RFAConv introduces a non-shared weight convolutional operation that substantially energizes feature extraction precision. Furthermore, the integration of convolutional operations at the backbone, neck, and head levels enables the capture of multi-scale ship features. They are more willing to work together and allow the YOLO SAR framework to efficiently detect vessels across varying scales. Following this, RFAConv improves the framework’s ship recognition, detail comprehension, and perception capabilities without introducing lots of computational overhead or parameters.
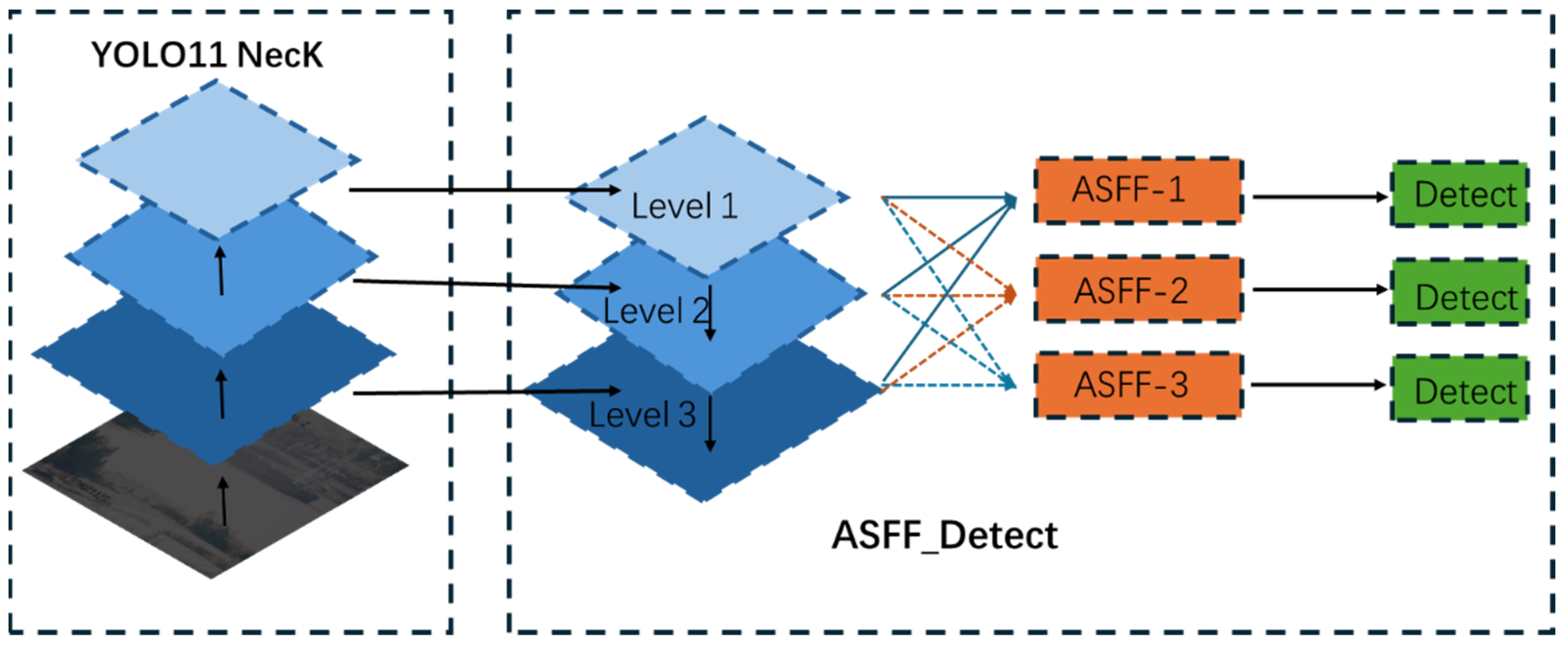
3.3. ASFF Module
In the YOLO11 network, conventional multi-scale feature fusion can result in conflicts across feature levels. When a target is labeled positive in one layer, the same region may be treated as the background in other layers. These negative factors may lead to significant semantic gaps between scales. In the context of ship detection under low-illumination conditions, poor lighting and occlusion frequently blur contours, exacerbate scale differences, and obscure critical features. To address these challenges, we incorporate an Adaptively Spatial Feature Fusion (ASFF) strategy within the detection head. ASFF adjusts spatially adaptive weights to mitigate inter-level semantic conflicts and filters out noise that destabilizes backpropagation, thereby resolving scale inconsistencies. Subsequently, it reshapes features from all scales to a common size, allowing each level to leverage its strengths effectively. The architecture of the ASFF module is illustrated in
Figure 5.
The ASFF module contains Level 1, Level 2, and Level 3 representations. They are adopted here to represent three distinct fusion strategies at different layers and scales. Level 1 emphasizes the finest scale and utilizes high-resolution feature mapping processes to capture the intricate details of small objects. Level 2 operates at medium resolution to identify medium-sized targets while maintaining a low computational cost. Level 3 concentrates more on the coarsest scale, employing the lowest-resolution feature mapping processes to delineate entire large objects. Within the ASFF framework, fusion weights adaptively adjust to reflect each level’s contribution and comprehend the spatial relationships among multi-scale features indeed. ASFF incorporates a spatial filtering mechanism that eliminates mismatched responses, thereby enhancing the effectiveness of feature fusion. The final fusion multiplies each feature map by three learnable weights,
,
, and
, reflecting its importance at each scale. The computation is provided in Equation (4).
denotes the new feature map produced by the ASFF module.
represents the feature vector at position (
,
) that is mapped from level 1 to level
.
,
,
∈ [0, 1] are the spatial weights.
are assigned to position (
,
) on level
. These representations are shown in Equation (5).
The adaptive spatial feature fusion head mentioned above effectively resolves the feature loss that often arises during cross-scale fusion, and this mechanism not only enriches the core representations on various network features but also markedly boosts the model’s robustness across diverse detection scenarios.
4. Results
4.1. Dataset Preprocessing
Due to the limited availability of low-light ship datasets, this study incorporates images independently captured in the Yujiang River Basin, Guilin, Guangxi. The imaging device used was the Hikvision DS-2DC7423IW-AE surveillance camera. All images were recorded in 1920 × 1080 resolution and H.264 format, with a fixed shutter speed of 1/1000 s and ISO set to auto. To enrich data diversity, additional samples were selected from the publicly available SeaShips dataset. The collected and selected images primarily depict open inland waterways, featuring vessels with varying viewing angles, scales, and background complexities. The vessels are categorized into five types: bulk carriers, container ships, fishing vessels, ore carriers, and passenger ships. As these images were all captured under normal lighting conditions, with several examples presented in
Figure 6, a low-light simulation method was proposed to transform them into corresponding low-illumination scenarios. The construction pipeline of the resulting low-light dataset is elaborated in the following sections.
To simulate the underexposure characteristics of sensors in low-illumination scenarios, each pixel is multiplied by a randomly sampled exposure coefficient exposure ∈ [0.1, 0.4], allowing the image to retain visible details in low-light environments. Gaussian sensor noise is then added to the exposure-adjusted image to the additional quality degradation caused by hardware limits. We employ a Gaussian-noise model with intensity sensor = 0.03, meaning that noise accounts for 3% of the 0~255 gray-level range.
Following these modifications, gamma correction is applied to refine the luminance distribution curve. This correction comprehends the nonlinear response of sensors in low-illumination environments, with the gamma value
being randomly drawn from [1.0, 1.5]. The exact computation is given in Equation (6).
and
denote the pixel values before and after correction, respectively. The image contrast is then slightly adjusted to emulate the compressed dynamic range typical of low-illumination scenes; the contrast coefficient must be kept within a reasonable range to avoid unnaturally strong or weak contrast [
36]. In the end, to enhance nighttime realism, a mild tone adjustment is applied, particularly by amplifying the blue channel to replicate the cool tint commonly observed in nocturnal images [
37]. This effect is achieved by decreasing the intensity of the red channel while increasing that of the blue channel.
After the multi-stage processing described above, images captured under normal lighting now exhibit the hallmarks of low-illumination scenes—reduced brightness, heightened noise levels, weaker contrast, and a slight color cast. These operations faithfully mimic a sensor’s response to external light in low-illumination scenes, bringing the images closer to real-world capture conditions.
The same procedure is used to create a low-illumination ship dataset called Lowship, which contains 12,606 images belonging to a single class. The dataset is randomly divided by a ratio of 8:2, resulting in 10,084 training images and 2522 validation images. Several samples from the dataset are presented in
Figure 7.
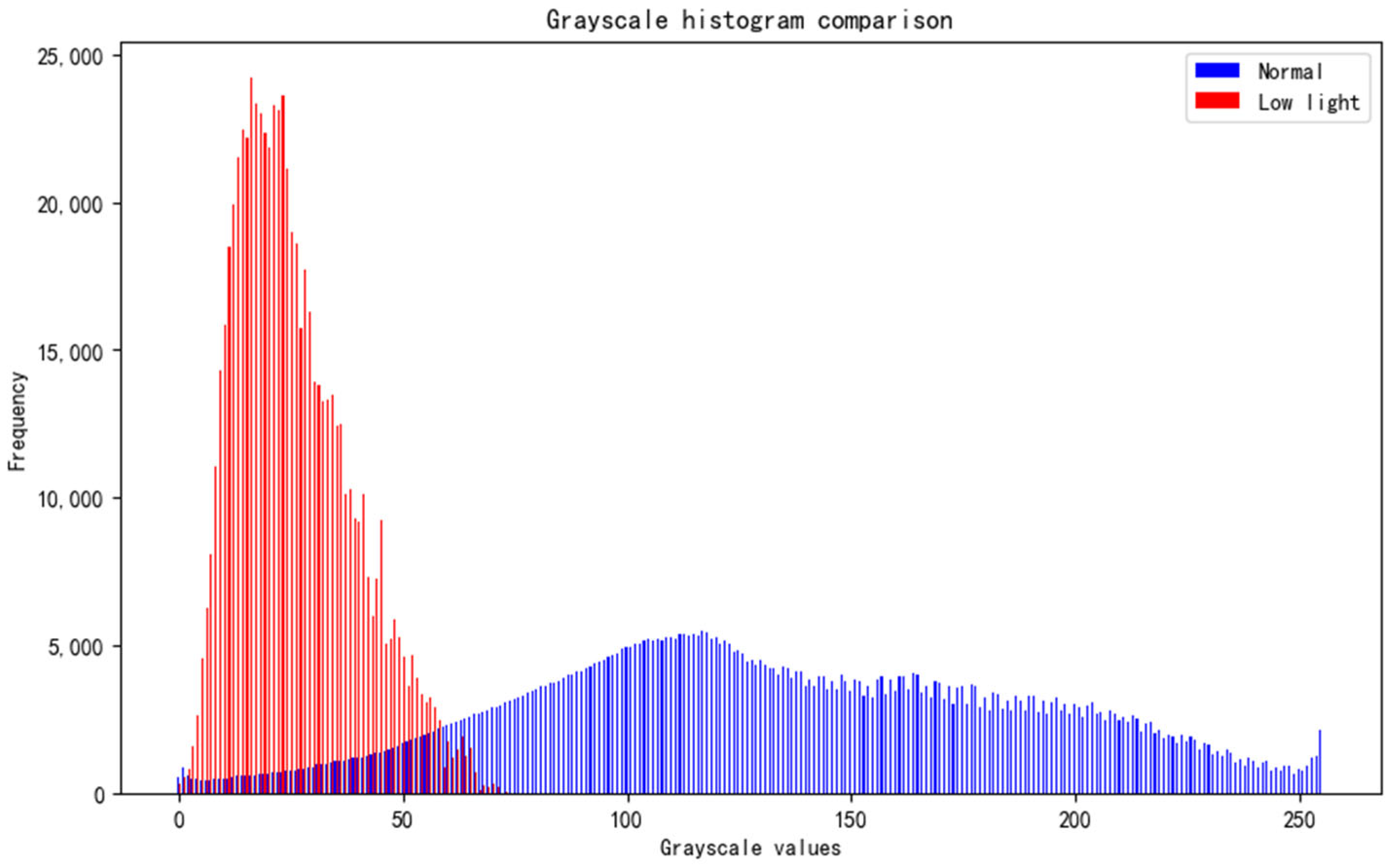
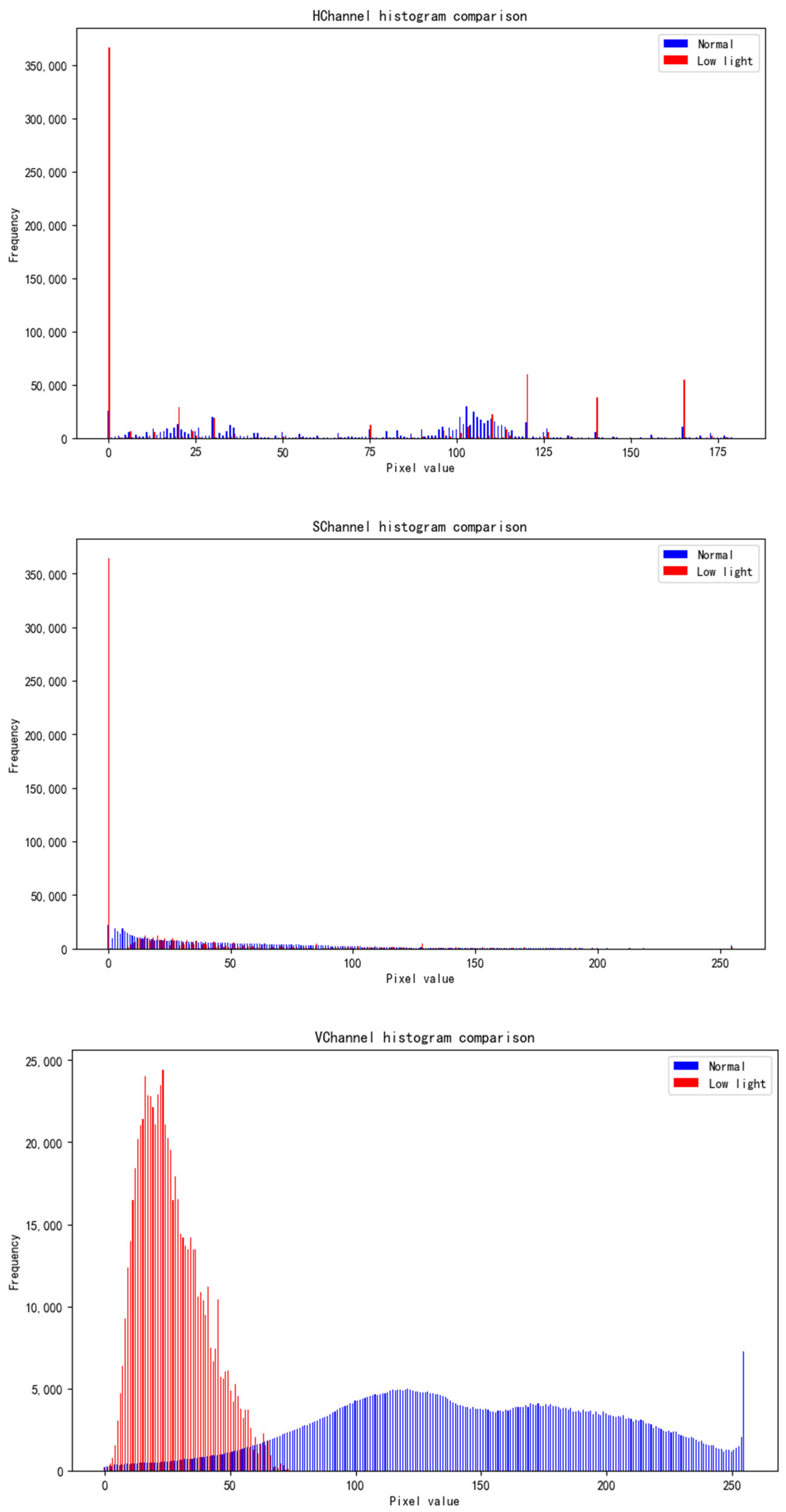
To evaluate the effectiveness of the proposed dataset-preprocessing strategy, comparative experiments are conducted in grayscale and HSV color spaces on both the original dataset and the low-illumination ship dataset generated through this method. In the experiments, grayscale values and the three HSV channels—hue (H), saturation (S), and value (V)—are extracted from ship images in both datasets and represented as histograms.
As shown in
Figure 8, the grayscale distribution reveals that while images captured under normal lighting exhibit values evenly distributed across the higher range, the low-illumination images demonstrate a shift towards lower values, indicating a reduction in brightness following preprocessing.
Figure 9 illustrates a comparison of histograms for pixel distributions across the HSV channels under normal lighting and low-illumination scenes. In the H channel (hue), the hue values of low-illumination images cluster in the lower range, with most frequencies approaching zero. By contrast, the hue distribution in the original dataset under normal lighting is more uniform. The histogram of the S channel (saturation) shows that low-illumination images possess lower saturation compared to images captured under normal lighting. In the V channel (value), it is evident that the brightness values of low-illumination images predominantly fall within the lower range, further confirming the decrease in luminance.
The analysis mentioned above demonstrates that the processed dataset exhibits notable differences in brightness, hue, saturation, and grayscale characteristics compared to the original dataset, thereby validating the effectiveness of preprocessing strategies in simulating low-illumination environments.
4.2. Evaluation Metrics
To objectively evaluate the detection framework’s performance, we use precision (P), recall (R), mean average precision (mAP), giga floating-point operations (GFLOPs), frames per second (FPS), and parameters as evaluation metrics.
Precision (P) is defined as the ratio of correctly detected objects to the total number of detections. In the context of ship detection tasks, it is calculated as the number of accurately identified ships divided by the total number of predicted bounding boxes. Recall (R) measures the ratio of detected objects to the actual number of objects, calculated as the number of correctly detected ships divided by the ground-truth ship count. A higher precision indicates more accurate detections, while a higher recall indicates fewer missed targets. The exact computations are provided in Equations (7) and (8).
Mean average precision (mAP) represents the area under the precision–recall curve. It combines precision and recall into a single metric and is the most widely used measure in object detection. A higher mAP indicates better detection accuracy. mAP@50 denotes the average precision over all classes at an IoU threshold of 0.5. mAP@50:95 represents the average precision at IoU thresholds from 0.5 to 0.95 in increments of 0.05. These two metrics evaluate performance at different strictness levels, with higher values indicating superior detection capabilities. Detailed formulations of these metrics can be found in Equations (9) and (10).
4.3. Comparative Experiments
All comparisons in this paper refer to absolute changes measured in percentage points. The experiments were run on a 64-bit Windows 11 system with Python 3.9, PyTorch 2.5.0, CUDA 12.1, and an RTX 3070 GPU with 8 GB of VRAM. The model was trained from zero with an early-stopping strategy: training was halted when validation performance ceased to improve, effectively reducing overfitting.
To empirically demonstrate the performance superiority of our proposed YOLO-SAR low-illumination ship-detection framework, we performed a benchmark comparison on the Lowship dataset against other YOLO variants and several representative object-detection models. The experimental results for all key metrics are presented in
Table 1.
Based on the experimental results, the proposed YOLO-SAR framework demonstrates superior performance across multiple evaluation metrics, showcasing enhanced robustness and accuracy in low-light object detection. Traditional detection algorithms, such as Faster R-CNN and SSD, show limited effectiveness under low-illumination conditions due to their dependence on shallow convolutional backbones, which are insufficient in capturing weak textures and low-contrast features. These methods are highly sensitive to illumination degradation and edge information, often resulting in false negatives and false positives under challenging conditions such as image blur or poor lighting, rendering them inadequate for ship detection in low-light scenarios. Although YOLOv3-tiny achieves extremely high inference speed, its lightweight architecture compromises its feature representation capability and lacks an effective multi-scale feature perception mechanism, leading to degraded detection performance on small or low-texture targets. Specifically, compared to YOLOv3-tiny, YOLO-SAR achieves improvements of 11.1% in precision, 10.2% in recall, and 9.3% in mAP@0.5, highlighting its ability to maintain high detection performance under complex low-light conditions.
Although recent mainstream YOLO series models—such as YOLOv5, YOLOv8n, YOLOv9t, and YOLOv10n—achieve a good trade-off between accuracy and speed under general lighting conditions, their network architectures are not specifically optimized for the characteristics of low-light imagery. In particular, they exhibit clear limitations in shallow-level edge representation and cross-scale semantic alignment. Most of these models adopt static feature aggregation schemes, which lack the ability to dynamically adjust multi-scale feature weights based on image content. As a result, they struggle to resolve scale-level semantic inconsistencies prevalent in low-light environments. Experimental results show that under identical testing conditions, YOLO-SAR outperforms the aforementioned models by 3.2%, 2.6%, 4.7%, and 3.5% in terms of mAP@0.5, respectively, demonstrating its superior overall performance in low-light object detection scenarios. Despite the introduction of multiple modules that introduce a certain computational overhead, YOLO-SAR maintains an inference speed of 51.7 FPS. This indicates that the overall real-time performance remains within acceptable limits and is sufficient to meet the requirements of most practical applications.
To further evaluate the generalization capability and practical applicability of the proposed YOLO-SAR framework under varying low-light conditions, a real-world ship image dataset was collected at dusk from the Yujiang River Basin in Guilin, Guangxi. This dataset consists of 8529 images captured in representative inland open-water scenarios. The ship targets exhibit varied viewpoints, object scales, and complex backgrounds, and include representative vessel classes such as cargo ships and ore carriers. The images were acquired under dusk lighting conditions, closely simulating real nighttime application environments. The data acquisition setup and parameter configurations are consistent with those used in the Lowship dataset. Example images are provided in
Figure 10.
In terms of experimental setup, the same hardware platform and hyperparameter configurations as the main experiment were adopted. The real-world dataset was partitioned using an 8:2 split into a training set (6823 images) and a validation set (1706 images). All baseline models were trained from zero, with consistent evaluation and testing procedures.
The experimental results on the real-world dataset are summarized in
Table 2. YOLO-SAR achieves substantial improvements across all key detection metrics, notably achieving an accuracy of 96.4%, recall of 93.6%, and mAP@0.5 of 94.5%, outperforming state-of-the-art detectors such as YOLOv5, YOLOv8n, and YOLOv10n. These results underscore its robustness and generalization capability in real-world low-light conditions. Benefiting from the synergistic integration of an image enhancement module, receptive-field attention mechanism, and multi-scale feature fusion strategy, YOLO-SAR demonstrates superior perception of low-texture targets, along with enhanced fine-grained detection and adaptability to complex environments, making it well-suited for nighttime maritime surveillance tasks in challenging inland waterway scenarios.
4.4. Ablation Experiments
Ablation experiments were conducted on the Lowship dataset using the YOLO11n model as the baseline to assess each module’s effectiveness in ship detection tasks. All ablation experiments employed consistent hyperparameter settings, and the results are summarized in
Table 3.
As shown in
Table 3, each standalone modification to the detection framework effectively boosts its accuracy. Compared to the baseline YOLO11n, the integration of the Self-Calibrated Illumination Network (SCINet) increases the mAP@0.5 by 0.8 percentage points. This addition effectively addresses multi-scale perception deficits and uneven feature contrast through cascaded low-illumination enhancement. Introducing receptive-field attention convolution (RFAConv) further increases mAP@0.5 by 0.6 percentage points, indicating that the model not only captures global context more effectively but also adaptively reweights multi-scale features. Additionally, incorporating the Adaptively Spatial Feature Fusion (ASFF) module in the head results in a 1.1 percentage point increase in mAP@0.5, demonstrating the great capacity to adaptively flexible multi-scale features and automatically balance information across different levels through learnable weights. While all three modifications contribute to improved detection performance, they do incur a corresponding increase in parameter count and computational overhead.
The combined-methods experiments show that merging SCINet and RFAConv modules improve the mAP@0.5 by 1.5% and the mAP@0.5:0.95 by 1.6%, further enhancing detection performance compared to single-module upgrades. Additionally, the combination of SCINet module with ASFF module results in an increase of 2.0 percentage points in mAP@0.5. Finally, the integration of all three enhancements yields significant improvements in precision, recall, mAP@0.5, and mAP@0.5:0.95, with increases of 2.6, 3.8, 2.7, and 2.4 percentage points, respectively. These findings validate that our core YOLO SAR framework achieves a noteworthy enhancement in detection accuracy.
4.5. Data Visualization Analysis
To visually assess YOLO-SAR’s detection performance, representative images from the Lowship dataset have been selected for analysis. YOLO-SAR has been benchmarked against YOLOv3-tiny, YOLOv5, YOLOv9t, YOLOv10n, and YOLO11n. The detection comparison is shown in
Figure 11. Heatmaps are also used to highlight the feature-map regions to which each algorithm attended. A blue-to-red gradient heatmap indicates attention levels: deep red denotes highest attention, while deep blue denotes lowest. The heatmap results are presented in
Figure 12.
From the detection results in
Figure 11, the improved YOLO-SAR framework successfully identifies all ship targets within the images. The YOLO-SAR framework reduces missed detections by enhancing long-range relationship modeling and achieves precise recognition of occluded ships through the adaptive weighting of ship feature sets. YOLOv9t and YOLOv10n fail to detect small ships in the second image, mainly due to the loss of target features under low-illumination conditions. In the third image with occluded ships, all algorithms except for YOLO-SAR exhibit poor performance when suffering with occlusions. This phenomenon is evidenced by redundant detection boxes and missed targets. This deficiency is primarily due to multi-level feature conflicts that arise during occlusion. These findings underscore that the enhanced YOLO-SAR framework demonstrates exceptional detection performance in complex environments. The heatmaps in
Figure 12 more clearly illustrate YOLO-SAR’s advantages over other algorithms. With a wider receptive field, the YOLO-SAR framework can accurately locate ship targets and reduce missed detections. Furthermore, its adaptive spatial feature fusion mechanism effectively facilitates interaction between high-level semantics and low-level contours, thereby significantly improving overall detection accuracy.
5. Conclusions and Future Directions
To address the challenges of ship detection in low-light environments—such as degraded target features and limited image contrast, which significantly hinder the deployment of existing detection algorithms—this paper proposes an enhanced detection framework for low-light ship imagery, named YOLO-SAR. Extensive empirical evaluations on both a custom-built dataset and a real-world dataset demonstrate its effectiveness and practical potential under challenging illumination conditions.
To address the limited availability of low-light ship imagery, this paper presents a preprocessing approach based on image degradation modeling and introduces the Lowship dataset. The proposed method simulates realistic nighttime conditions by applying exposure suppression, noise injection, gamma correction, and tone adjustment. Its effectiveness is quantitatively validated through comparative experiments using grayscale intensity and HSV color space metrics. In terms of architecture, the YOLO-SAR framework integrates the SCINet module to enhance perceptual image quality. It incorporates receptive-field attention convolution (RFAConv) to strengthen global contextual representation and adopts an adaptive spatial feature fusion (ASFF) mechanism in the detection head to address semantic inconsistencies across feature hierarchies.
Comparative experiments on the Lowship dataset demonstrate that YOLO-SAR achieves significant improvements in detection performance. It surpasses YOLOv5, YOLOv8n, YOLOv9t, and YOLOv10n by 3.2%, 2.6%, 4.7%, and 3.5%, respectively, in terms of mAP@0.5. Ablation studies further validate the individual contributions of each module and highlight the cumulative benefits of the overall architecture in improving detection accuracy. To assess the model’s real-world applicability and cross-domain generalization, a low-light ship image dataset was collected from the Yujiang River Basin in Guilin, Guangxi. Experimental results show that YOLO-SAR continues to deliver state-of-the-art performance on this real-world dataset, demonstrating strong generalization capabilities and promising potential for practical deployment.
Although YOLO-SAR demonstrates notable performance gains in low-light object detection, it still presents several critical limitations in real-world applications that require further improvement. First, under conditions of extreme darkness, complex occlusion, or severe noise, the model tends to generate both false negatives and false positives, compromising detection robustness. Second, the current model incurs high computational costs, including substantial parameters and inference latency, which restrict its deployment on resource-constrained embedded or edge platforms. Additionally, while the proposed low-light preprocessing method enables the generation of synthetic datasets and has undergone initial validation using grayscale and HSV domain comparisons, it lacks a systematic analysis of parameter configurations and a comprehensive quantitative evaluation of its effectiveness.
To address these limitations, future work will focus on the following directions: (i) exploring structural pruning, lightweight attention mechanisms, and knowledge distillation to improve inference efficiency while maintaining accuracy; (ii) designing a multi-scale fusion architecture with scalability and pruning flexibility to enhance real-time performance and deployment adaptability on embedded platforms; (iii) systematically evaluating the impact of image degradation parameters on both image quality and detection accuracy, and establishing a quantitative correlation framework between preprocessing strategies and detection outcomes, thereby enabling automated preprocessing selection and scenario-specific optimization.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}