
RISC-Based 10K+ Core Finite Difference Method Accelerator for CFD

Abstract
1. Introduction
- Application-Specific Microprocessor Architecture (FCore) and Instruction Set Design. The characteristics of the finite difference method were studied. Based on these characteristics, the FCore microprocessor architecture and its corresponding instruction set architecture (F-RISC) were designed.
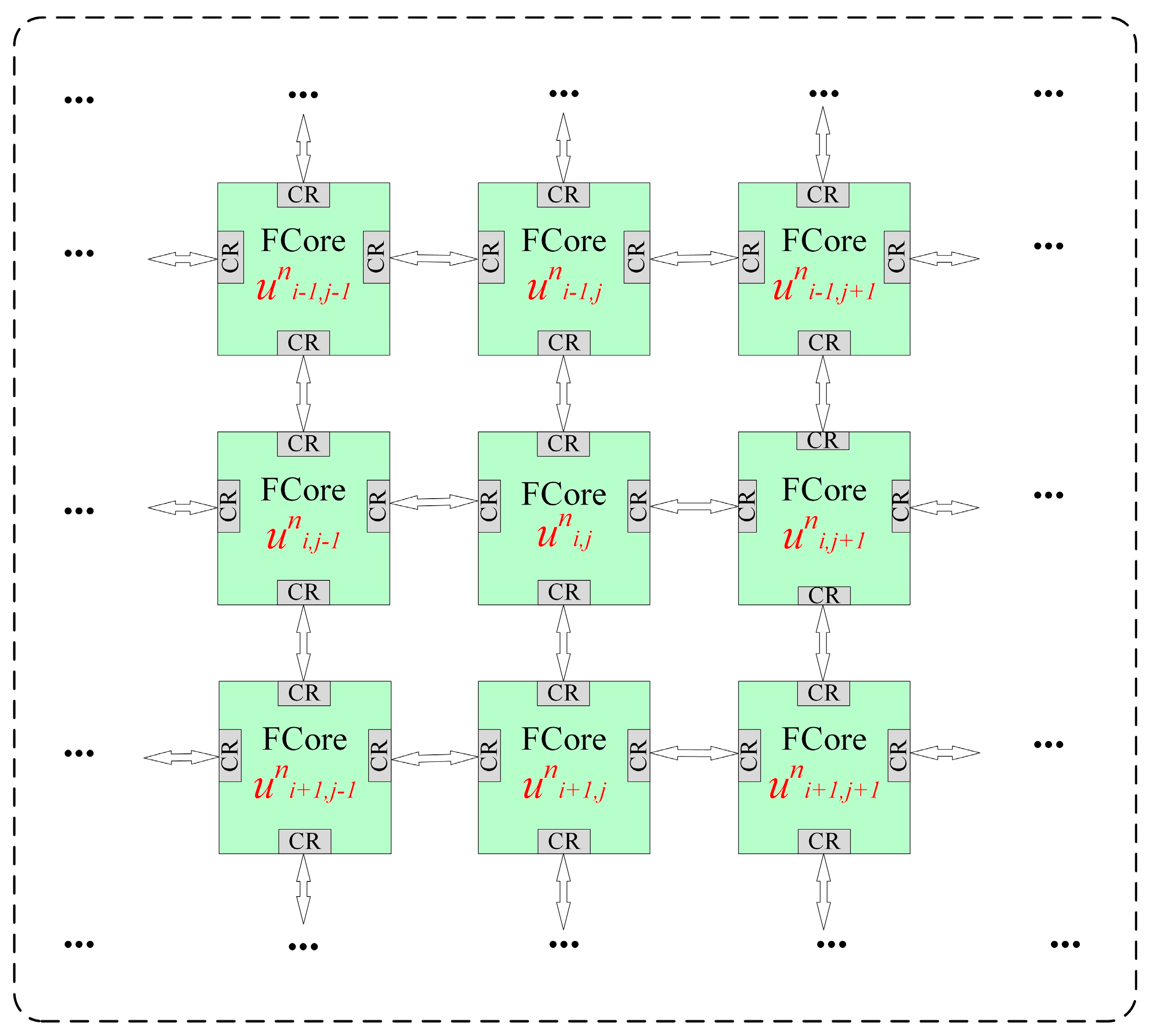
- Dedicated Network Structure (FMesh). The FMesh network structure was developed. By equipping each FCore with a dedicated router (FRouter), Fmesh enables the transmission of initial data, boundary condition data, and instruction programs to the FCores, thereby enhancing network programmability.
- High-Performance CFD Accelerator. The proposed FAcc accelerator achieves a significantly higher speedup ratio. It represents the first instruction set architecture-based accelerator specifically designed for CFD.
2. Computational Characteristics of CFD
- Minimal Arithmetic Complexity. Computational operations are limited to basic arithmetic (addition, subtraction, and multiplication).
- High Parallelizability. The absence of control dependencies and structural hazards between spatial nodes enables fully parallel execution. Structural dependencies are resolved by allocating dedicated computational resources to each spatial node.
- Strong Data Locality. Data dependencies are localized to adjacent spatial nodes, with minimal requirements for long-range data exchange across multiple grid points.
- Stable Data Production–Consumption Pattern. Data generated at step n are exclusively consumed at step n + 1, eliminating the need for high-capacity data storage and reducing memory access frequency.
3. Design and Implementation of Multi-Core Accelerator Architecture
3.1. The FCore Implementation
3.1.1. Special ISA Designed
- Register-type (R-type). Both operands sourced from registers. Processor Usage: Operands are retrieved exclusively from the register file. The instruction’s opcode triggers ALU computation using two register-addressed values, with results written back to a destination register.
- Immediate-type (I-type). Both operands are immediate values. Processor Usage: Embeds operands directly within the instruction word. During decode, immediate values are sign-/zero-extended and propagated to the ALU or memory interface, bypassing register fetch.
- Hybrid-type (H-type). One operand is sourced from a register, while the other is an immediate value. Processor Usage: Combines one register-sourced operand with an instruction-embedded immediate. The register operand accesses the register file, while the immediate is concurrently expanded and routed to the execution unit.
3.1.2. FCore, Four-Stage Pipeline Microprocessor
- Instruction Fetch (IF) Stage: This stage incorporates a 128-depth instruction memory (IM) and addressing logic. It fetches the current instruction based on the value of the instruction address controller and determines the next instruction address for the subsequent clock cycle, supporting both sequential execution and branch/jump operations.
- Instruction Decode (ID) Stage: Equipped with a 60-entry general-purpose register (GPR) file, this stage decodes the instruction retrieved from the IF stage by interpreting its opcode and operand fields.
- Execute (EX) Stage: The arithmetic logic unit (ALU) performs operations such as fixed/floating-point addition, subtraction, multiplication, comparison, and branch target address calculation.
- Write Back (WB) Stage: This final stage updates the GPR file with computational results generated in the EX-stage.
3.2. FMesh, the Bridge of FAcc Communicatio
3.2.1. The FRouter Implementation
3.2.2. Package and Flits Design Scheme
- Type 1 followed by one or more Type 5 flits.
- Type 2 followed by one or more Type 5 flits.
- Type 3 followed by one or more Type 5 flits.
- Type 4 followed by one or more Type 5 flits.
- MSBs = 00, unicast to a specific FCore at coordinates (X_destination, Y_destination).
- MSBs = 01, region-based broadcast to all FCores with X ≤ X_destination_max and Y ≤ Y_destination_max.
- MSB = 1, direct transmission of data or instructions to targeted FCores.
3.3. FAcc Working Modes
3.3.1. Loading Mode
- Unidirectional Propagation: Data injected into FMesh flows away from the input port, ensuring each FRouter receives valid data from only one port per cycle. This eliminates overhead arbitration caused by concurrent valid data arrivals at a single FRouter, thereby significantly simplifying FRouter design.
- Local Routing Logic: As illustrated in Figure 9, upon receiving a data packet, the local FRouter’s routing computation unit (rc_unit) parses and forwards it to downstream FRouters. A tag decoder determines whether the packet targets the local FCore, subsequently routing it to either the IM or GPR.
- Hybrid Transmission Strategies: To minimize packet size and optimize transmission efficiency, FMesh supports broadcast and point-to-point modes. Identical instruction programs are broadcast to all FCores, while initial/boundary conditions employ hybrid transmission: broadcast for shared data (dark green FCores in Figure 10) and point-to-point for unique data (light green FCores in Figure 10).
3.3.2. Calculating Mode
3.3.3. Recycle Mode
3.4. Physical Design Implementation
4. Performance and Discussion
4.1. In the Calculating Mode
4.2. In the Loading and Recycle Mode
4.3. Overall Performance
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Koziel, S.; Tesfahunegn, Y.; Leifsson, L. Variable-Fidelity CFD Models and Co-Kriging for Expedited Multi-Objective Aerodynamic Design Optimization. Eng. Comput. 2016, 33, 2320–2338. [Google Scholar] [CrossRef]
- Posch, S.; Gößnitzer, C.; Lang, M.; Novella, R.; Steiner, H.; Wimmer, A. Turbulent Combustion Modeling for Internal Combustion Engine CFD: A Review. Prog. Energy Combust. Sci. 2025, 106, 101200. [Google Scholar] [CrossRef]
- Viviani, A.; Aprovitola, A.; Pezzella, G.; Rainone, C. CFD Design Capabilities for next Generation High-Speed Aircraft. Acta Astronaut. 2021, 178, 143–158. [Google Scholar] [CrossRef]
- Zhang, L.; Deng, X.; He, L.; Li, M.; He, X. The Opportunity and Grand Challenges in Computational Fluid Dynamics by Exascale Computing. Acta Aerodyn. Sin. 2016, 34, 405–417. [Google Scholar]
- Liu, W.; Lombardi, F.; Shulte, M. A Retrospective and Prospective View of Approximate Computing. Proc. IEEE 2020, 108, 394–399. [Google Scholar] [CrossRef]
- Borges, R.B.D.R.; Da Silva, N.D.P.; Gomes, F.A.A.; Shu, C.-W. High-Resolution Viscous Terms Discretization and ILW Solid Wall Boundary Treatment for the Navier–Stokes Equations. Arch. Comput. Methods Eng. 2022, 29, 2383–2395. [Google Scholar] [CrossRef]
- Knobloch, M.; Mohr, B. Tools for GPU Computing—Debugging and Performance Analysis of Heterogenous HPC Applications. Supercomput. Front. Innov. 2020, 7, 91–111. [Google Scholar]
- Jacobsen, D.A.; Thibault, J.C.; Senocak, I. An MPI-CUDA Implementation for Massively Parallel Incompressible Flow Computations on Multi-GPU Clusters. In Proceedings of the 48th AIAA Aerospace Sciences Meeting Including the New Horizons Forum and Aerospace Exposition, Orlando, FL, USA, 4–7 January 2010. [Google Scholar]
- Jacobsen, D.; Senocak, I. Scalability of Incompressible Flow Computations on Multi-GPU Clusters Using Dual-Level and Tri-Level Parallelism. In Proceedings of the AIAA Aerospace Sciences Meeting Including the New Horizons Forum & Aerospace Exposition, Orlando, FL, USA, 4–7 January 2011. [Google Scholar]
- Jacobsen, D.A.; Senocak, I. Multi-Level Parallelism for Incompressible Flow Computations on GPU Clusters. Parallel Comput. 2013, 39, 1–20. [Google Scholar] [CrossRef]
- Ntoukas, G.; Rubio, G.; Marino, O.; Liosi, A.; Bottone, F.; Hoessler, J.; Ferrer, E. A Comparative Study of Explicit and Implicit Large Eddy Simulations Using a High-Order Discontinuous Galerkin Solver: Application to a Formula 1 Front Wing. Results Eng. 2025, 25, 104425. [Google Scholar] [CrossRef]
- Aissa, M.; Verstraete, T.; Vuik, C. Toward a GPU-Aware Comparison of Explicit and Implicit CFD Simulations on Structured Meshes. Comput. Math. Appl. 2017, 74, 201–217. [Google Scholar] [CrossRef]
- Tsoutsanis, P.; Antoniadis, A.F.; Jenkins, K.W. Improvement of the Computational Performance of a Parallel Unstructured WENO Finite Volume CFD Code for Implicit Large Eddy Simulation. Comput. Fluids 2018, 173, 157–170. [Google Scholar] [CrossRef]
- Perén, J.I.; Van Hooff, T.; Leite, B.C.C.; Blocken, B. CFD Simulation of Wind-Driven Upward Cross Ventilation and Its Enhancement in Long Buildings: Impact of Single-Span versus Double-Span Leeward Sawtooth Roof and Opening Ratio. Build. Environ. 2016, 96, 142–156. [Google Scholar] [CrossRef]
- Kampolis, I.C.; Trompoukis, X.S.; Asouti, V.G.; Giannakoglou, K.C. CFD-Based Analysis and Two-Level Aerodynamic Optimization on Graphics Processing Units. Comput. Methods Appl. Mech. Eng. 2010, 199, 712–722. [Google Scholar] [CrossRef]
- Vermeire, B.C.; Witherden, F.D.; Vincent, P.E. On the Utility of GPU Accelerated High-Order Methods for Unsteady Flow Simulations: A Comparison with Industry-Standard Tools. J. Comput. Phys. 2017, 334, 497–521. [Google Scholar] [CrossRef]
- Karantasis, K.I.; Polychronopoulos, E.D.; Ekaterinaris, J.A. High Order Accurate Simulation of Compressible Flows on GPU Clusters over Software Distributed Shared Memory. Comput. Fluids 2014, 93, 18–29. [Google Scholar] [CrossRef]
- Darian, H.M.; Esfahanian, V. Assessment of WENO Schemes for Multi-dimensional Euler Equations Using GPU. Int. J. Numer. Methods Fluids 2015, 76, 961–981. [Google Scholar] [CrossRef]
- Esfahanian, V.; Baghapour, B.; Torabzadeh, M.; Chizari, H. An Efficient GPU Implementation of Cyclic Reduction Solver for High-Order Compressible Viscous Flow Simulations. Comput. Fluids 2014, 92, 160–171. [Google Scholar] [CrossRef]
- Franco, E.E.; Barrera, H.M.; Laín, S. 2D Lid-Driven Cavity Flow Simulation Using GPU-CUDA with a High-Order Finite Difference Scheme. J. Braz. Soc. Mech. Sci. Eng. 2015, 37, 1329–1338. [Google Scholar] [CrossRef]
- Parna, P.; Meyer, K.; Falconer, R. GPU Driven Finite Difference WENO Scheme for Real Time Solution of the Shallow Water Equations. Comput. Fluids 2018, 161, 107–120. [Google Scholar] [CrossRef]
- Tutkun, B.; Edis, F.O. A GPU Application for High-Order Compact Finite Difference Scheme. Comput. Fluids 2012, 55, 29–35. [Google Scholar] [CrossRef]
- Lei, J.; Li, D.L.; Zhou, Y.L.; Liu, W. Optimization and Acceleration of Flow Simulations for CFD on CPU/GPU Architecture. J. Braz. Soc. Mech. Sci. Eng. 2019, 41, 290. [Google Scholar] [CrossRef]
- Elsen, E.; Legresley, P.; Darve, E. Large Calculation of the Flow over a Hypersonic Vehicle Using a GPU. J. Comput. Phys. 2008, 227, 10148–10161. [Google Scholar] [CrossRef]
- Klöckner, A.; Warburton, T.; Bridge, J.; Hesthaven, J.S. Nodal Discontinuous Galerkin Methods on Graphics Processors. J. Comput. Phys. 2009, 228, 7863–7882. [Google Scholar] [CrossRef]
- Corrigan, A.; Camelli, F.F.; Löhner, R.; Wallin, J. Running Unstructured Grid-Based CFD Solvers on Modern Graphics Hardware. Int. J. Numer. Methods Fluids 2011, 66, 221–229. [Google Scholar] [CrossRef]
- Wan, Y.; Zhao, Z.; Liu, J.; Zhang, L.; Zhang, Y.; Chen, J. Large-scale Homo- and Heterogeneous Parallel Paradigm Design Based on CFD Application PHengLEI. Concurr. Comput. Pract. Exp. 2024, 36, e7933. [Google Scholar] [CrossRef]
- Xia, Y.; Lou, J.; Luo, H.; Edwards, J.; Mueller, F. OpenACC Acceleration of an Unstructured CFD Solver Based on a Reconstructed Discontinuous Galerkin Method for Compressible Flows. Int. J. Numer. Methods Fluids 2015, 78, 123–139. [Google Scholar] [CrossRef]
- Slotnick, J.; Khodadoust, A.; Alonso, J.; Darmofal, D.; Gropp, W.; Lurie, E.; Mavriplis, D. CFD Vision 2030 Study: A Path to Revolutionary Computational Aerosciences. In Mchenry County Natural Hazards Mitigation Plan; NASA: Hampton, VA, USA, 2014. [Google Scholar]
- Baroughi, A.S.; Huemer, S.; Shahhoseini, H.S.; TaheriNejad, N. AxE: An Approximate-Exact Multi-Processor System-on-Chip Platform. In Proceedings of the 2022 25th Euromicro Conference on Digital System Design (DSD), Maspalomas, Spain, 1 April–25 May 2022; pp. 60–66. [Google Scholar]
- Esposito, D.; Di Meo, G.; De Caro, D.; Strollo, A.G.M.; Napoli, E. Quality-Scalable Approximate LMS Filter. In Proceedings of the 2018 25th IEEE International Conference on Electronics, Circuits and Systems (ICECS), Bordeaux, France, 9–12 December 2018; pp. 849–852. [Google Scholar]
- Zhang, S.; Li, Q.; Zhang, L.; Zhang, H. The History of CFD in China. Acta Aerodyn. Sin. 2016, 34, 157–174. [Google Scholar]
- Mattiussi, C. The Finite Volume, Finite Element, and Finite Difference Methods as Numerical Methods for Physical Field Problems. Adv. Imaging Electron Phys. 2000, 113, 1–146. [Google Scholar]
- Dimov, I.; Faragó, I.; Vulkov, L. Finite Difference Methods, Theory and Applications; Springer International Publishing: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Chalk, B.S. Reduced Instruction Set Computers. In Computer Organisation and Architecture; Palgrave: London, UK, 1996. [Google Scholar]
- Cui, E.; Li, T.; Wei, Q. RISC-V Instruction Set Architecture Extensions: A Survey. IEEE Access 2023, 11, 24696–24711. [Google Scholar] [CrossRef]
- Hepola, K.; Multanen, J.; Jääskeläinen, P. Energy-Efficient Exposed Datapath Architecture With a RISC-V Instruction Set Mode. IEEE Trans. Comput. 2024, 73, 560–573. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Instruction | Description |
|---|---|---|
| Control instruction | NOP | No Operation |
| HALT | Stop Execution | |
| JUMPI | Jump with Fixed-Point Immediate | |
| BEQZ | Conditional Branch | |
| BNEZ | ||
| BEQN | ||
| BNEN | ||
| Calculating instruction | ADDI | Add Fixed-Point Immediate |
| SUBI | Subtract Fixed-Point Immediate | |
| CMP | Compare Fixed-Point | |
| ADDF | Floating-Point Add Register | |
| SUBF | Floating-Point Subtract Register | |
| MULF | Floating-Point Multiply Register | |
| Data migration | MOV | Data Move |
| Type | Label Code | Description | Flit Component |
|---|---|---|---|
| 1 | 000 | Data transmission of point-to-point | Head–Body |
| 2 | 001 | Instruction transmission of point-to-point | Head–Body |
| 3 | 010 | Data broadcast | Head–Body |
| 4 | 011 | Instruction broadcast | Head–Body |
| 5 | 1 | Data or Instruction | Body |
| Governing Equations | Network Scale | Difference Scheme | Time Steps | Number of Instructions Program | Number of Running Instructions | Number of GPRs |
|---|---|---|---|---|---|---|
| 1-D linear convection equation | first order | 25 | 18 | 383 | 7 | |
| 1-D nonlinear convection equation | first order | 20 | 21 | 368 | 7 | |
| 1-D diffusion equation | second order | 20 | 22 | 429 | 10 | |
| 2-D linear convection equation | first order | 100 | 22 | 1908 | 11 | |
| 2-D Poisson equation | second order | 100 | 23 | 1909 | 15 | |
| 2-D momentum equation | second order | 100 | 111 | 88,608 | 41 |
| N-S Equations | Network Scale | Flit Numbers | Loading Time | Recycle Time |
|---|---|---|---|---|
| 1-D linear convection equation | 20 | 55 | 41 | |
| 1-D nonlinear convection equation | 16 | 49 | 41 | |
| 1-D diffusion equation | 28 | 63 | 41 | |
| 2-D linear convection equation | 23 | 136 | 121 | |
| 2-D Poisson equation | 32 | 91 | 75 | |
| 2-D momentum equation | 335 | 349 | 61 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gong, Y.; Liu, B.; Huang, D.; Lai, W.; Wei, X. RISC-Based 10K+ Core Finite Difference Method Accelerator for CFD. Appl. Sci. 2025, 15, 7283. https://doi.org/10.3390/app15137283
Gong Y, Liu B, Huang D, Lai W, Wei X. RISC-Based 10K+ Core Finite Difference Method Accelerator for CFD. Applied Sciences. 2025; 15(13):7283. https://doi.org/10.3390/app15137283
Chicago/Turabian StyleGong, Yanqiong, Biwei Liu, Dongchang Huang, Wen Lai, and Xuhui Wei. 2025. "RISC-Based 10K+ Core Finite Difference Method Accelerator for CFD" Applied Sciences 15, no. 13: 7283. https://doi.org/10.3390/app15137283
APA StyleGong, Y., Liu, B., Huang, D., Lai, W., & Wei, X. (2025). RISC-Based 10K+ Core Finite Difference Method Accelerator for CFD. Applied Sciences, 15(13), 7283. https://doi.org/10.3390/app15137283