1. Introduction
Over the past decade, there has been a dynamic rise in interest in applying computational methods to combustion science and engineering. Technological advancements, growing environmental demands, and the push for higher energy efficiency have led researchers and engineers to turn to advanced computational techniques—particularly artificial intelligence (AI), machine learning (ML), and genetic algorithms (GAs). While traditional approaches based on laboratory experiments and deterministic physico-chemical models remain important, they are often insufficient when faced with the complexity and variability of combustion processes over time and space [
1,
2].
The application of machine learning in the field of fuel combustion enables, among other things, automatic classification of combustion types, prediction of pollutant emissions, optimization of engine operating parameters, and the development of simplified surrogate models that significantly reduce computation time. Genetic algorithms, on the other hand, are used for multi-objective optimization of process parameters and for designing fuel mixtures. Hybrid methods are also of particular importance—combining classical Computational Fluid Dynamics (CFD) models with AI systems—which makes it possible to more accurately replicate real-world operating conditions and improve the precision of predictions [
3,
4]. However, it is worth noting that the scope and effectiveness of these applications can vary significantly depending on the type of fuel and the characteristics of the combustion system. For example, in the case of solid fuels such as biomass or coal, the classification of combustion types requires the analysis of additional variables related to the physical structure of the material (e.g., porosity, moisture), which can make it difficult to standardize the inputs for ML models. On the other hand, for gaseous fuels, such as hydrogen or natural gas, parameters related to mixing and ignition kinetics become important, which require a different approach to the construction of the predictive model. Therefore, the universal use of ML models requires taking into account the specifics of the energy medium and adapting both the input data and the model architecture to the analyzed context.
An important area of development is the application of these methods to a wide range of fuels—both conventional (coal, gasoline, diesel) and alternative (biodiesel, biomass, hydrogen, natural gas). The diverse physico-chemical properties of these fuels require adaptive and flexible modelling approaches, which are difficult to achieve using classical methods alone. This is precisely why AI and genetic algorithms are gaining increasing recognition in processes such as high-pressure combustion, gasification, pyrolysis, and co-combustion [
5,
6]. Despite the growing number of scientific publications on the use of computational methods in combustion engineering, existing literature reviews often have a limited scope. They tend to focus on specific fuel types, individual methods (e.g., only neural networks or only CFD), or particular industrial applications (such as solely HCCI engines or power plant boilers). However, what is lacking is a comprehensive analysis that considers both the diversity of fuels and the range of computational approaches, as well as their practical integration [
7].
This review addresses the existing gap by presenting a comprehensive analysis of the applications of machine learning and genetic algorithms in combustion science and engineering from 2015 to 2024. It is based on a systematic search of the Scopus database and includes 97 original scientific publications. The articles were classified according to fuel type (biodiesel, biomass, coal, gasoline, hydrogen, natural gas) and analytical method (CFD, ANN, SVM, regression, PCA, decision trees, GA, etc.). This structure allows readers to fully grasp current trends and effectively compare the approaches used across various sectors of combustion technology. The scope of the analysis covers:
Modelling and simulation of combustion processes,
Applications in engines and energy systems,
Design and optimization of alternative fuels,
Emission control,
Large-scale industrial combustion systems.
Additionally, this article includes a geographical analysis identifying leading research centers worldwide. Significant contributions have been noted from countries such as Canada, China, India, Iran, Japan, Germany, Malaysia, Saudi Arabia, the United Kingdom, and the United States.
What sets this review apart from previous publications is its breadth, methodological rigor, and unique thematic and algorithmic classification. It is the first systematic review of the past decade to encompass both physico-chemical modeling and artificial intelligence applications in the context of diverse fuels and combustion technologies. Importantly, it also considers model validation methodologies, challenges related to limited availability of experimental data, and issues concerning computational costs and model interpretability in ML.
Another essential aspect of real-world deployment is the integration of sustainability-related performance indicators. These include not only improvements in fuel economy and a reduction in CO2 emissions but also the ability to balance trade-offs between thermal efficiency and pollutant formation. ML and GA-based models can be instrumental in achieving such multi-objective optimization, enabling dynamic control of combustion systems under varying operating conditions while meeting environmental and economic targets. Future studies should more explicitly evaluate the environmental impact of applied algorithms to better align combustion research with sustainability goals.
In light of the growing importance of efficient energy management, emission reduction, and the advancement of low-emission technologies, there is a pressing need for such a broad and integrated review. This article serves as a valuable reference point for further research and practical implementations in the field of digital optimization of combustion processes both at the laboratory scale and at the industrial scale.
The goal of this review is to provide a comprehensive and structured synthesis of the application of machine learning and genetic algorithms in combustion research across a wide spectrum of fuel types. This paper seeks to identify which computational techniques are most frequently used in combustion modeling, clarify how their applications vary depending on the specific characteristics of different fuels, and highlight the most pressing methodological challenges and research gaps. By addressing these issues, the review aims to support future advancements in the development of more efficient, robust, and interpretable AI-driven solutions for sustainable combustion systems.
2. Materials and Methods
This article presents a systematic review of scientific literature focused on the application of machine learning (ML) and genetic algorithms (GAs) in the analysis, modeling, and optimization of combustion processes, gasification, and the operation of engines and energy systems. The primary aim of the study is to provide a comprehensive overview of technological advancements between 2015 and 2024 in integrating numerical methods and artificial intelligence with various combustion processes—from conventional diesel engines to modern biomass and hydrogen gasification systems. Special attention is given to the effectiveness and flexibility of AI/GAs in reducing emissions, improving efficiency, and designing new fuels.
In the context of the growing importance of low-emission energy technologies, this review addresses five key research questions:
To what extent have machine learning methods and genetic algorithms been integrated into combustion process modeling in engineering practice?
Which method configurations (e.g., CFD + AI, ANN + GAs) have demonstrated the highest effectiveness in optimizing operating parameters and reducing emissions in the analyzed fuel systems?
What are the key limitations, research gaps, and challenges related to validating and generalizing ML/GA-based models under real-world industrial conditions?
Is there a statistically significant relationship between the type of fuel and the choice of computational methods (AI/GAs)?
Does the choice of research approach (experiment, literature analysis, conceptual modeling) depend on the type of fuel being studied?
2.1. Search and Select Documents
A literature search was carried out in the Scopus database using a systematic approach inspired by the PRISMA protocol. The inquiry was aimed at selecting publications on the applications of ML, AI, and GAs in combustion, gasification, engines, and fuels. The following query was used:
“TITLE-ABS-KEY(combustion AND “Machine Learning” OR “Genetic Algorithms”) AND PUBYEAR > 2014 AND PUBYEAR < 2025 AND (LIMIT-TO (PUBSTAGE,“final”)) AND (EXCLUDE (SUBJAREA,“DECI”) OR EXCLUDE (SUBJAREA,“MEDI”) OR EXCLUDE (SUBJAREA,“NEUR”) OR EXCLUDE (SUBJAREA,“BUSI”) OR EXCLUDE (SUBJAREA,“BIOC”) OR EXCLUDE (SUBJAREA,“SOCI”) OR EXCLUDE (SUBJAREA,“EART”) OR EXCLUDE (SUBJAREA,“MATE”) OR EXCLUDE (SUBJAREA,“PHYS”) OR EXCLUDE (SUBJAREA,“MATH”) OR EXCLUDE (SUBJAREA,“ENVI”) OR EXCLUDE (SUBJAREA,“MULT”)) AND (EXCLUDE (DOCTYPE,“cr”)) AND (LIMIT-TO (LANGUAGE,“English”))
AND (LIMIT-TO (EXACTKEYWORD,“Gasoline”) OR LIMIT-TO (EXACTKEYWORD,“Biodiesel”) OR LIMIT-TO (EXACTKEYWORD,“Hydrogen”) OR LIMIT-TO (EXACTKEYWORD,“Coal”) OR LIMIT-TO (EXACTKEYWORD,“Biomass”) OR LIMIT-TO (EXACTKEYWORD,“Natural Gas”))”
The results were limited to publications in English from 2015 to 2024, at the stage of final publication. Articles from fields not related to engineering (e.g., medicine, organic chemistry, agriculture) were excluded. A total of 165 publications were identified, of which 97 papers were qualified for further analysis after full-text selection. Most publications came from China, India, the USA, Iran, Japan, Germany, and Malaysia. The selection process is shown in
Figure 1.
2.2. Classification Criteria
All publications included in this review were classified according to five main analytical axes: the type of method applied, the type of fuel analyzed, the technical application area, the type of research, and the main function performed by machine learning (ML) methods and genetic algorithms (GAs). The classification was based on the analysis of titles, abstracts, keywords, and—when necessary—full texts. Due to the frequent occurrence of complex approaches involving more than one technique, the categorization was non-unique and multi-variant.
The first criterion was the identification of the computational methods used. The most frequently applied was Computational Fluid Dynamics (CFD), which enables detailed modeling of flow, mixing, heat transfer, and chemical reactions in combustion systems. The second important area involved artificial neural networks (ANNs), used for emission prediction, engine parameter optimization, fuel property modeling, and replacing time-consuming simulations. Support vector machines (SVMs) were also popular, mainly used for ignition state classification, cyclic combustion stability, and emission pattern recognition. Many studies also applied decision trees (DTs) and random forests (RFs), which offer interpretability and effective analysis of multidimensional data. Genetic algorithms (GAs) played a key role in optimization tasks, such as piston geometry design, fuel composition optimization, and combustion condition adjustment. Principal component analysis (PCA) was also applied to analyze parameter relationships, enabling dimensionality reduction and identification of dominant factors. Regression analysis (RA) was used for building regression models, and mean square error (MSE) was applied to evaluate prediction accuracy. Many publications featured hybrid approaches, combining classical methods (e.g., SVM, RF) with deep learning (e.g., ANN) and CFD simulations.
The second classification criterion was the type of fuel analyzed in the given study. Both conventional fuels, such as diesel and gasoline, and alternative fuels, such as biodiesel, bioethanol, biobutanol, waste biomass, hydrogen (H2), natural gas (NG), methanol, and various synthetic mixtures, including dual-fuel and ternary configurations, were considered. The fuels analyzed were often combined to achieve a compromise between efficiency and low emission of harmful substances.
The third aspect of the classification concerned technical applications. The largest number of publications addressed combustion in piston engines, both conventional (e.g., compression ignition and spark ignition) and modern concepts such as HCCI (Homogeneous Charge Compression Ignition), GCI (Gasoline Compression Ignition), and RCCI (Reactivity Controlled Compression Ignition). The second important area involved biomass or coal gasification systems aimed, among others, at hydrogen production. Other studies focused on combustion in pulverized coal boilers, fluidized bed boilers, blast furnace systems, and industrial energy furnaces. In many cases, ML and GAs also supported the design of new fuel compositions, combustion condition optimization, and additive selection (e.g., nanoparticles). The fourth classification axis concerned the type of research. Four categories were included:
- (1)
Simulation studies—mainly based on CFD, supplemented with ANN or SVM models;
- (2)
Laboratory and industrial experiments—involving real engines, thermogravimetric analysis (TGA), and emission and performance measurements;
- (3)
Conceptual and theoretical analyses—developing new models, correlations, or control strategies;
- (4)
Literature reviews—presenting the current state of knowledge and identifying areas requiring further research.
The final classification criterion referred to the main function that ML or GA methods performed in the given study. The following main objectives were distinguished: emission prediction (NOx, CO, particulate matter), combustion parameter optimization (temperature, ignition timing, injection), combustion chamber or piston geometry design, fuel property modeling (e.g., octane number, viscosity, elemental composition), and identification and classification of ignition stability or cyclic variability. Many publications addressed more than one of these objectives.
A summary of thematic categories and interrelationships between methods and fuel types is presented in
Figure 2. This classification allows for multi-faceted analysis and comparison of scientific output, while also indicating dominant directions and underrepresented areas that may serve as a starting point for future research.
At the same time, it is worth noting that some of the categories presented in
Figure 2 may functionally overlap. In practice, many ML/GA models perform more than one task: for example, the same algorithms can be used both for the classification of combustion phenomena and for emission prediction, as well as for the optimization of equipment operating parameters. Such multi-purpose applications mean that some research papers could be assigned to several categories at the same time. This phenomenon was deliberately accepted as part of the review, with clarity of classification and taking into account the context in which the tool was used.
2.3. Data Processing and Analysis
The collected bibliographic data, including publication title, authors, year of publication, institutional affiliations, DOI identifier, and keywords, were imported into a relational PostgreSQL database. This structure enabled systematic organization of the information and allowed for the execution of complex SQL queries to aggregate, filter, and segment the data.
For further analysis, the Python 3.12.2 programming environment was used along with the following libraries: pandas 2.2.2 (for processing tabular data), matplotlib 3.8.4, and seaborn 0.13.2 (for generating charts and visualizations). Publications were assigned to previously defined classification categories, such as the type of computational technique used (e.g., CFD, ANN, SVM), type of fuel analyzed (e.g., biomass, hydrogen, diesel), application area (e.g., engines, gasification systems), and nature of the study (e.g., experimental, simulation-based, conceptual).
A geographical analysis based on author affiliations was also conducted, allowing for the identification of active research centers and a comparison of research intensity across different countries. In addition, a temporal analysis covering the years 2015–2024 was developed to capture development trends in the application of machine learning methods and genetic algorithms in combustion engineering.
2.4. Review Protocol and Publication Quality
In order to ensure transparency and reproducibility, the review was conducted in accordance with a structured protocol inspired by the PRISMA (Preferred Reporting Items for Systematic Reviews and Meta-Analyses) guidelines. The literature selection process consisted of four key steps: identification, pre-selection, eligibility assessment, and final inclusion. A diagram showing this process is shown in
Figure 3.
During the identification phase, a total of 165 documents were retrieved from the Scopus database using the query TITLE (Combustion AND Machine Learning OR Genetic Algorithms). The search was limited to publications from the years 2015–2024 written in English and at the final stage of publication. In the initial screening, duplicates were removed, and titles and abstracts were analyzed for thematic relevance. Studies that did not directly involve the application of machine learning or genetic algorithms in the context of combustion, fuel design, or energy systems were excluded. During the eligibility assessment phase, a full-text analysis was conducted. Publications were included in the next stage if they met the following criteria:
Addressed practical or conceptual applications of ML or GAs in the analysis of combustion, gasification, or fuel design processes,
Provided an adequate description of the methodology,
Were peer-reviewed journal articles or conference proceedings,
Originated from one of the 15 selected countries active in this research area (including China, India, Germany, Iran, Japan, Malaysia, Poland, Saudi Arabia, the USA, and the UK).
The final selection resulted in 97 publications being included in the detailed analysis. Publications from non-technical fields (e.g., psychology, social sciences, arts) and papers without specific applications or combustion process modeling were excluded. However, conceptual or review papers were included if they offered relevant methodological contributions or identified research gaps in the studied area.
The quality assessment of the publications was based on citation count, source type (journal or conference), and journal ranking (e.g., Q1–Q2). Priority was given to studies with a solid experimental foundation and clearly described methodology, even if the citation count was still low due to recent publication. Each publication was independently evaluated by two authors in terms of thematic relevance, completeness, and clarity of methods. In cases of disagreement, consensus was reached through discussion.
3. Analysis of the State of the Art
The publications reviewed can be divided into two groups: methodological papers based on literature reviews, which identify key research gaps and directions for the development of combustion technologies, and conceptual studies, which propose new analytical approaches that require future practical or experimental validation. Each type makes a significant contribution to the advancement of combustion knowledge, although their limitations stem from the lack of direct experimental data and the need for further validation of the results.
3.1. Methods and Algorithms
Research on combustion, gasification and design of propulsion systems has made extensive use of advanced numerical methods, artificial intelligence, and hybrid approaches combining multiple computational techniques. CFD and machine learning methods played a central role here, often supported by genetic algorithms, decision trees, neural networks, and support vector machines (SVMs).
3.1.1. Combustion Optimization Using CFD and AI
The use of CFD as a tool for precise modelling of heat flow, reaction, and transport has been the basis for many works. Ref. [
2] used CFD simulations supported by a genetic algorithm to optimize the combustion chamber in a diesel engine powered by a mixture of gasoline and diesel. In this study, optimization was based on a two-step approach: First, CFD simulations were used to generate data on temperature and emission distribution in different combustor configurations. Then, based on this data, the genetic algorithm optimized the geometry and performance of the engine, aiming to maximize efficiency while reducing NO
x and particulate emissions. This approach was sequential—CFD provided input data that was then analyzed by the GA. Iterative configurations are also found in the literature, where the results of optimization are re-entered into CFD simulations to further refine the model. In the analyzed case, however, the process was not cyclical, which should be clearly noted to avoid misunderstandings about the method of integration of computational tools. This approach increased efficiency and reduced soot emissions by as much as 90%, with a slight increase in NO
x. Similarly, in Ref. [
3], where the homogeneity of heating in a gas furnace was studied, CFD was used to analyze the temperature field, and then simplified models (surrogate models) were developed using neural networks and genetic algorithms. This significantly reduces temperature differences and optimizes heating control. In Ref. [
8], CFD was used to optimize combustion conditions in the dual-fuel system (diesel–natural gas). Although they found configurations that provide both low emissions and high efficiency, they indicated that the effectiveness of optimization is strongly dependent on the initial conditions. In Ref. [
9], CFD was combined with a genetic algorithm to optimize injection parameters in the HPDI engine (high-pressure diesel + natural gas), which simultaneously allowed for a reduction in NO
x and soot emissions and an improvement in overall efficiency. Also in Ref. [
10], a hybrid approach combining CFD, a chemical model, and the NSGA-II algorithm with a Kriging function was used to optimize piston geometry in a gas engine with microdose diesel. The description of the piston crown was based on Bézier curves, which allowed for precise shaping of the combustion chamber. The optimization reduced HC emissions by 56% and CO emissions by 34%, without compromising efficiency or NO
x emissions. Similar approaches were used in Refs. [
11,
12], where combustion in dual-fuel and three-fuel engines using methane, hydrogen, and diesel was analyzed. In both cases, the combination of CFD with genetic algorithms enabled simultaneous emission reductions and efficiency improvements, particularly through dynamic ignition control and variable fuel content. In Ref. [
13], ANN and SVM models were developed for predicting laminar flame velocity (LFS) for low-carbon fuels (ammonia, hydrogen, methanol), while maintaining high accuracy and low computational cost. Ref. [
14] presents a comprehensive review of the use of ML methods (mainly ANN) in biodiesel research, indicating their advantage in modeling, optimization, and control of biodiesel production.
However, it should be noted that the effectiveness of neural networks in industrial environments is limited by several important factors. These models are often sensitive to input data interference, and their performance can significantly decrease in conditions that differ from those in which they were trained. In addition, industrial environments have variable operating conditions that can cause difficulties in adapting the model. Issues such as overfitting, limited generalization, and lack of immunity to measurement noise should be taken into account when implementing them. Therefore, despite their high effectiveness in controlled laboratory conditions, the use of neural networks in industry requires careful validation and resistance tests to operational variables.
In Ref. [
15], an ANN was used to predict pyrolysis and incineration of dairy waste. The model accurately reproduced the experimental data of TGA, enabling the prediction of thermal process kinetics. In Ref. [
16], an ANN made it possible to accurately predict hydrogen production from the reaction of aluminum and NaOH, with a correlation coefficient of 0.998. In Ref. [
17], ANN + PCA were used to predict the distribution of solid nanoparticles (PMs) from the GDI engine. The results were highly consistent with the experimental data. It should also be noted that Ref. [
18] developed a method to optimize the biomass gasification process by combining Monte Carlo simulations, a kinetic model, and a random forest (RF) algorithm. Randomly generated process data predicted which parameters (e.g., water content, reaction temperature) had the greatest impact on syngas yield. A high agreement of the predictions with the experimental results was obtained.
3.1.2. Neural Networks and Hybrid AI Models
In Ref. [
6], the HFRD-MMLP method was proposed, combining data from flamelets and artificial neural networks for rapid prediction of chemical reactions in turbulent DME combustion. An ANN was able to predict thermochemical states as much as 16 times faster than classical methods, maintaining high agreement with accurate models. Ref. [
19] developed a hybrid GA-ANN model to predict the laminar combustion rate of isooctane-alternative fuel blends. Using a genetic algorithm to optimize the network achieved an accuracy of R
2 = 0.991. In Ref. [
20], an ANN was used to forecast the emission of a gasoline engine at a dynamically changing load. Although the model was effective, its versatility was limited to a specific engine. Similarly, in Ref. [
21], an ANN predicted the diffusion coefficient of the liquid phase between gasoline and engine oil. In Ref. [
22], a BPNN neural network and a genetic algorithm were used to optimize coal mixing in boilers with furnace mixing, obtaining better power plant operating parameters. In Ref. [
23], neural networks predicted the parameters of the biomass gasification process and hydrogen production, reaching R
2 = 0.99. Models with Bayesian regularization and gradient allowed for high precision even under complex operating conditions. In Ref. [
24], ANNs were used to predict the physicochemical properties of fuels containing oxygen groups (alcohols, esters, ketones). The models showed R
2 = 0.99 for density and 0.98 for viscosity. In Ref. [
25], neural networks with backpropagation were used, the parameters of which were optimized by a genetic algorithm, obtaining a clear improvement in accuracy in predicting the octane number of the fuel. In Ref. [
26], a lightweight artificial neural network for forecasting the turbulent velocity of the hydrogen flame was developed, intended for integration with CFD solvers in the context of explosions in nuclear power plants. The model was trained based on experimental data and showed good agreement with literature correlations, with much shorter calculation time. Ref. [
27] used three ML algorithms (logistic regression, CART, and ANN) to predict the initiation of detonation from hot spots in hydrogen mixtures. These models enabled efficient prediction of the reaction propagation mode without the need for costly CFD simulations, significantly improving accuracy compared to classical approaches based on Zeldovich’s theory. Refs. [
28,
29,
30] point to the growing role of ML and ANN methods in the design and combustion of fuels as a complement to classic models. In Ref. [
31], an ANN and PCA were used to model the co-pyrolysis of coal sludge and waste from the coffee industry, demonstrating a synergy effect and effective prediction of mass losses based on process parameters. In Ref. [
32], an ANN was used to predict octane number based on NMR spectra and functional group composition, achieving R
2 = 0.99 and an average error of 1.2. In Ref. [
33], soft calculation models (SVM, ANN, ANFIS) were compared to predict the viscosity of biodiesels, indicating ANFIS and ANN + GA as the most accurate (R
2 = 0.9964). In Ref. [
34], a predictive model based on the composition of biodiesel was developed, using artificial neural networks to predict engine characteristics and a genetic algorithm to optimize fuel composition. Optimal proportions of saturated and unsaturated methyl esters reduced NO
x emissions and improved fuel economy in biodiesel engines.
3.1.3. Decision Trees, Random Forest, and Classification Analysis
Decision trees have proven to be effective in classifying and analyzing combustion phenomena. In Ref. [
35], a method for predicting the temperature in the rotary kiln was developed using random forest models optimized by a genetic algorithm, which significantly reduced the prediction error and shortened the simulation time from weeks to a few seconds. The method based on CFD data and industrial experiments can be used as a soft sensor in metallurgical process control systems. In Ref. [
36], the random forest algorithm was used to model the coal flotation process, enabling the identification of the most important operational variables affecting yield and ash content. It is worth noting that many publications lack a systematic comparison of the discussed tree algorithms with classic statistical methods, such as logistic regression or discriminant analysis. Including such control analyses would allow for a better estimate of whether the accuracy improvements achieved by ML methods are due to the model’s actual ability to capture complex nonlinear relationships, or merely to fitting into a specific dataset. For example, in the classification of ignition status or the evaluation of combustion cyclic variability, a comparison of RF results with logistic regression could indicate to what extent the interpretability and simplicity of classical methods can be maintained without significant loss of effectiveness. From the point of view of industrial implementations, such a combination of models is also important because classical methods are often better known and easier to validate in environments with limited computing power or stringent certification requirements. In Ref. [
37], random forests were used to predict the cyclic variability of combustion (CCV) based on LES simulations in a gasoline engine. Accurate peak pressure predictions were obtained, although further tuning for other engine configurations was necessary. In Ref. [
38], random forests were found to be more effective than SVM in predicting spontaneous combustion of coal under mining conditions. Their interpretative clarity and ability to capture complex relationships proved to be crucial, although the authors pointed to the need for further validation. In Ref. [
39], a stacking model combining decision trees, SVMs and other algorithms was developed to predict octane losses in the refining process. The combination of the models significantly reduced the prediction error (MSE) and identified the most important features affecting RON. Ref. [
40] compared several ML models (RF, RDT, GLM, BBD) in the sensitivity and uncertainty analysis of textile sludge co-incineration with incense sticks, indicating that random forests had the best predictive outcomes. The analysis showed that temperature and component ratio were key factors influencing the results of thermochemical processes (RM, DSC, DTG). In Ref. [
41], a novel RF-WOA-LSSVM predictive model was developed for estimating the iodine number of biodiesel based on the FAME composition, achieving a coefficient of determination R
2 = 0.9989 and very low prediction errors.
3.1.4. Support Vector Machines (SVMs)
In Ref. [
7], SVM, in addition to FNN and GPR, were compared in terms of predicting the rate of chemical reactions of alkenes with the OH radical. While FNN scored the best, SVM also achieved good accuracy. In Ref. [
20], a comparison with random forests showed their limited effectiveness in specific conditions. In the study [
22], SVM was used to classify the oxidation state of carbon based on terahertz data, and an accuracy of 87.5% was achieved, which confirmed the usefulness of this method in detecting spontaneous ignition hazards. Ref. [
42] compared five ML models for predicting combustion phases in hydrogen-powered Wankel engines; the GPR model achieved the best generalization, and SVM and EnTR obtained high accuracy for key combustion phase stages. In the case of SVM applications for the classification of combustion states, it is important to choose the kernel function, which determines how the data is transformed into a feature space and the model’s ability to separate nonlinear relationships. In the analyzed works, RBF (radial basis function) functions are mainly used, which work well in conditions of a large number of features and non-linear relationships between process parameters (e.g., temperature, pressure, component concentrations). In the context of combustion data, which is often characterized by a high correlation of variables and the presence of measurement noise, SVM offers a good balance between prediction accuracy and robustness to learning. However, these models require careful selection of parameters—such as the regularization factor C and the gamma parameter for the RBF function—which in practice is often carried out using a search grid or optimization algorithms. For example, in the classification of cyclic combustion variability in ZI engines, SVM with a properly selected nucleus allows for precise detection of limit states, which is directly important for ignition and emission control. The results highlight the importance of algorithm selection for the precision of alternative fuel engine control. In Ref. [
43], an adaptive PSO-SVM model was used to predict the behavior of the S-CO
2 CFB boiler in the scaling process, effectively replacing costly CFD simulations. In Ref. [
44], an optimized model for the prediction of cycle variability was developed for Wankel engines powered by gasoline and n-butanol with the addition of hydrogen, combining SVM with a genetic algorithm. On the other hand, Ref. [
45] proposes the use of a neural network (BP-ANN) improved by a genetic algorithm (GA) to optimize combustion parameters in a coal boiler, enabling precise tuning of the fuel and air ratio to improve efficiency and reduce emissions.
3.1.5. Genetic Algorithms as a Universal Optimization Tool
Genetic algorithms appear as a key component of many optimization systems. In Ref. [
46], they were used to adjust the kinetic parameters of combustion of large biomass samples. In Ref. [
9], as well as in Refs. [
10,
11,
12,
47,
48], GA supported the optimization of injection systems, piston geometry, and GCI engine operation. In Ref. [
49], GA was used to simplify the kinetic mechanism of methane reforming, achieving a reduction in computation time without compromising accuracy. Although it is often assumed in the literature that genetic algorithms are able to effectively explore the multidimensional space of fuel combinations, there is a lack of clear analyses confirming the effectiveness of these methods in the context of different types of fuels and combustion conditions. In many cases, it is not clearly defined how the algorithm’s ability to find global optimums in complex parametric spaces was evaluated. For example, work on the optimization of biofuel and synthetic fuel blends rarely indicates how the algorithm coped with the traps of local minima or how the stability of solutions was tested when input conditions (e.g., pressure, temperature, air–fuel ratio) were tested. To increase the reliability of the study, the authors should consider introducing comparative tests on established benchmarks (e.g., sets of known fuel configurations with assessed combustion efficiency), as well as using techniques such as cross-validation, sensitivity analysis, and testing the algorithm on simulated data with known properties. A lack of such validation can lead to overinterpretation of the results and the adoption of false assumptions about the universality and effectiveness of the algorithm, especially in industrial applications where operating parameters are constantly changing. In Ref. [
50], a genetic algorithm enabled the design of an industrial burner with reduced NO
x emissions. Refs. [
51,
52] prove its usefulness also in the design of fuel composition: in the first one, the operating parameters of the dual-fuel engine were optimized, and in the second, the composition of mixtures with the required octane number was utilized, while minimizing the costs of the components. In Ref. [
53], the genetic algorithm and the KIVA-3V code were used to optimize the injection and geometry of the combustion chamber in a diesel/natural gas dual-fuel engine. In Ref. [
54], the NSGA-II genetic algorithm was used for multi-criteria optimization of the geometry of the cyclone used in the combustion of pulverized coal, which allowed for an increase in combustion efficiency of 47% and a reduction in NO
x emissions of 19%. Response area-based optimization took into account parameters such as cyclone diameter, number, and angle of flow control vanes. In Ref. [
55], the NSGA-III algorithm was used for multi-criteria optimization of the DI-NG engine, obtaining compromise operating configurations that meet EURO V emission standards at different combustion modes. In Ref. [
56], GPR and NSGA-II were used to model and optimize engine performance on COEE8 biodiesel, effectively predicting emissions and fuel consumption with little data. In Ref. [
57], CFD was combined with NSGA to optimize the performance of RCCI engines with gasoline/diesel and methanol/diesel mixtures, taking into account the influence of fuel properties and initial conditions. On the other hand, in Ref. [
58], genetic algorithms were used for automatic calibration of combustion diagnostic parameters in a spark engine fueled by natural gas, in order to better understand cyclic variability.
3.2. Research Methodology
This review follows a structured approach to literature analysis. Peer-reviewed publications were retrieved from the Scopus database using keyword combinations such as “machine learning,” “genetic algorithm,” “combustion,” “engine,” and various fuel types (e.g., “biomass,” “hydrogen,” “biodiesel”). The search was limited to English-language articles published between January 2015 and March 2024. Abstracts were screened manually to exclude unrelated works, duplicates, or purely theoretical studies lacking combustion context. Only studies with a clear application of ML or GA methods to combustion-related problems were retained. A total of 165 papers were analyzed and subsequently categorized by fuel type, algorithmic approach, and target application (e.g., prediction, classification, optimization). This thematic classification forms the foundation for the structured analysis presented in the subsequent sections.
A variety of research strategies were used in the analyzed work, combining numerical simulations, laboratory experiments, industrial tests, and processing of large datasets. In many cases, the experimental data was used to train ML models or validate numerical results.
3.2.1. Laboratory and Industrial Experiments
Experimental studies played a key role in the analysis of combustion processes and emissions. In Ref. [
46], a specialized Macro TGA device was used to test the combustion of centimeter samples of charred biomass (pine) under conditions simulating industrial furnaces. This work aimed to map the behavior of large particles in real combustion systems and demonstrated consistency with the results of the zero-dimensional model. Ref. [
59], on the other hand, focused on experiments with a ternary fuel (biodiesel karanja, biobutanol and diesel) with the addition of cerium oxide nanoparticles (CeO
2) in the CRDI engine. Based on the experimental results, an MLP model was built to optimize operating parameters, reducing fuel consumption and emissions. In Ref. [
60], the combustion of poultry manure was analyzed by thermogravimetry (TGA), determining the ignition and burnout parameters. This data was compared with the results of isoconversion and ML models, which allowed for optimization of the waste biofuel combustion process. An experimental approach was also used in a study [
61] that analyzed the effect of CNG (10–40%) in a fuel mixture with microalgae biodiesel in a diesel engine. Real-world NO
x emissions, smoke emissions, and efficiency were measured and used to train ML models. The aim was to extend the range of stable operation of this type of engine. Emissions and efficiency measurements were taken at different fuel ratios and used to train the ANN model. In Ref. [
62], ML was used to analyze CFD data to optimize injector design in GDI systems, reducing the need for costly simulations. In Ref. [
63], a random forest was used to analyze the effect of flame topology and pre-ignition flow metrics on cycle variability (CCV) in an SI gasoline engine. The model predicted peak cylinder pressure based on data from 123 LES cycles.
3.2.2. CFD Simulations and Numerical Methods
Numerical simulations were the core of the research methodology of many works. In Ref. [
3], CFD simulations were used to analyze the flow and temperature distribution in the furnace, and then supplemented with simplified models built with the use of an ANN and GAs. It was indicated that the synergistic adjustment of the fuel composition and operating conditions allowed for low NO
x and soot emissions to be obtained over a wide range of loads. In Refs. [
10,
64,
65,
66], CFD played a key role in the analysis of injection, fuel blending, and combustion in engines powered by different blends (diesel, natural gas, hydrogen, methanol). In each case, the actual operating conditions were taken into account, and the models were verified in terms of combustion, emissions, and efficiency. In Ref. [
67], data from the RANS simulation was used to train ML models predicting the hydrogen mixing efficiency in a scramjet engine. In Ref. [
68], a simplified CFD model was integrated with a neural network for predicting phenomena in blast furnaces. Although the approach significantly reduced the calculation time, it was pointed out that the model needed to be adapted when boundary conditions changed. In Ref. [
69], the order reduction of the CFD model by orthogonal decomposition (POD) was used, and then combustion parameters (temperature and oxygen distribution) were predicted using SVM. The slagging index was assessed using the fuzzy comprehensive assessment (FCE) method, and optimization was carried out with both classic GA and its simulated annealing (SAGA) version, resulting in a significant reduction in slagging levels. In Refs. [
50,
70], CFD was applied to the modeling of combustion in a coal-fired boiler, where optimization was carried out using a GA. The authors emphasized that the results must be confirmed in real industrial conditions. Ref. [
71] combined CFD and machine learning to optimize the geometry and injection parameters of the GCI engine, achieving up to a 10.7% reduction in fuel consumption under partial-load conditions. In Ref. [
72], a simple linear regression model was developed to predict the three-dimensional structure of fuel spray under Spray G conditions of the ECN network, using experimental data and tomography. The model showed very good compliance with real measurements and exceeded the accuracy of classic CFD simulations with less computational effort. Ref. [
73] presents the current state of development of CFD simulations of high-fidelity combustion of pulverized coal, with particular emphasis on DNS, LES, and combinations of the two. The authors pointed out that further advances require more efficient algorithms, model calibration, and greater use of machine learning to improve prediction accuracy and reduce computational costs. In Ref. [
74], a micro-genetic optimization algorithm and CFD were used to improve efficiency and reduce emissions in a dual-fuel heavy fuel engine running on natural gas and diesel.
3.2.3. Creation and Use of Datasets
In many works, the starting point for building ML models was literature data, measurement data, or data generated from simulations. In Ref. [
19], 2234 data points from the literature were used to train the GA-ANN model for combustion velocity. In Ref. [
75], SVM models were trained on data from 147 tests with seven types of biofuels. Another study [
76] collected CFD data (576 cases) to train ANNs to optimize fuel injection strategies with varying reactivity in the DDFS engine. In Ref. [
77], the gas engine test data was used to train an ML model to predict IMEP. In Ref. [
78], operational data from a coal-fired power plant was used to train an ANN model for optimizing combustion while maintaining environmental requirements (reduction in NO
x emissions and ammonia consumption). Also, in Ref. [
79], data from the industrial LIBS spectroscopy system was automatically analyzed and processed by synergistic regression (SR) algorithms to assess coal quality. In Ref. [
80], an ANN model was developed that predicts as many as eight parameters of the operation of a natural gas-powered engine. Inputs such as ignition angle, lambda, and rotational speed were used for training. Ref. [
70] used data from mahua wood gasification and trained RF and AdaBoost models to predict hydrogen yield and lower calorific value. In Ref. [
81], physicochemical data of gasoline components was used to build a random forest model for predicting the octane number. A similar approach was used in Refs. [
31,
82], where experimental or simulation data supported the development of models for the prediction of combustion parameters and emissions. Ref. [
83] concerns the multi-criteria optimization of the operating parameters of a Wankel engine with the addition of hydrogen using SVM and a genetic algorithm. The regression model predicted emissions, efficiency, and combustion with an error of <1%. In Ref. [
84], CFD simulations were performed for the GCI engine, analyzing the effects of gasoline–ethanol and butanol mixtures on soot emissions and combustion phasing. It was found that soot emissions depend on both the chemical and the physical properties of the fuel, especially with earlier injection times.
3.2.4. Validation, Accuracy Analysis, and Constraints
In all the works, great importance was attached to model validation—most often by comparing prediction results with experiments or accurate simulations. In Refs. [
85,
86], the ANN method was verified on a series of Sandia flames, and in Refs. [
23,
87,
88], the agreement of the results was confirmed with experimental data for gasification gases and thermophysical properties of biodiesel. Ref. [
89] used mean square error (MSE) to select the most accurate model for predicting fuel spraying, with the authors stressing that a low MSE does not always guarantee correctness outside the training range. Similarly, in Ref. [
90], where an ANN was used to predict the heat transfer coefficient of aviation fuels, attention was paid to the trade-off between error and the risk of overlearning. In Refs. [
91,
92], MSE was used as a criterion for estimating the composition of carbon, obtaining the best results for the RF model. In Refs. [
86,
93,
94], the use of PCA as a feature selection method contributed to the improvement of the performance of neural networks, especially in the analysis of biomass co-firing. Ref. [
95] is an overview of ML applications in thermochemical biomass conversion—it includes combustion, gasification, pyrolysis, and torrefaction. The role of artificial neural networks and hybrid models in the prediction and optimization of complex processes is particularly emphasized. A novelty of recent years is the use of the ability of acoustic waves to extinguish and control flames from various sources and fuels [
96,
97,
98,
99,
100,
101], as well as infrasound techniques in power engineering [
102,
103]. In practice, the data obtained can be useful for practical model training.
3.3. Challenges Related to Data Availability, Quality, and Generalization
Based on the analysis of the publications discussed in
Section 3.1 and
Section 3.2, one of the key challenges can be identified, which is the quality and consistency of data used in AI and GA models (for example, Refs. [
6,
19,
23]) and hybrid configurations (e.g., CFD + GA in Refs. [
3,
10,
11]), which require large datasets with high accuracy and representativeness. However, this data is often obtained from different sources—experiments, simulations, or previous publications, leading to inconsistencies. The lack of uniform measurement protocols, differences in operating conditions, and a limited number of experimental cases make these models often difficult to generalize.
In Ref. [
19], literature data with over 2200 points was used to train the GA-ANN model, but despite its high efficiency (R
2 = 0.991), the model was limited to the conditions of isooctane and alternative fuel blends. In Ref. [
76], data from CFD simulations (576 cases) were used to train ANN to optimize fuel injection. The authors noted that changing the geometry of the combustion chamber or other boundary parameters significantly affects the performance of the model. In Ref. [
78], operational data from a coal-fired power plant made it possible to create a predictive model for NO
x emissions and ammonia consumption, but its effectiveness was limited to a specific system, which again emphasizes the problem of model transferability.
An additional challenge is the lack of sufficient data from real industrial systems, which is due to both technological limitations (lack of real-time measurement systems) and legal barriers (trade secrets). In Ref. [
70], despite the use of advanced RF and AdaBoost algorithms, the authors emphasized the limitations associated with the small number of observations and indicated the need to develop more comprehensive datasets.
It is also worth noting that many models perform well solely within the parameters on which they were trained. Beyond this range—especially with variable fuel ratios, different combustion conditions, or modified geometries—their predictive accuracy decreases significantly. Therefore, there is a need to use techniques such as active learning, transfer learning, feature analysis using PCA, and automatic anomaly detection. Unfortunately, as the analysis of Refs. [
10,
21,
104] shows, these techniques are still rarely implemented, which limits the practical application of AI/GA models on an industrial scale.
3.4. Interpretability and Practical Validation of Models in an Industrial Context
The second important challenge, often emphasized in the literature (e.g., Refs. [
38,
39,
69,
78,
89]), is the interpretability of ML models and their practical validation in real conditions. Models such as deep neural networks (ANNs), ensemble algorithms (e.g., stacking, random forest), and hybrid CFD + GA combinations offer high prediction accuracy, but their structural complexity makes it difficult for engineers to understand how and why a given model makes specific decisions.
In Ref. [
39], the stacking model allowed for high-accuracy prediction of octane losses in the fuel refining process, but its structure was so complicated that only advanced interpretative tools (such as feature analysis) made it possible to identify the main input variables. In Ref. [
38], which compared the effectiveness of RF and SVM for the prediction of carbon spontaneous ignition, better transparency of random forests was indicated, but at the same time it was stipulated that both methods require further validation and standardization. In Refs. [
23,
25], on the other hand, ANNs obtained very high R
2 values, but their “black box” limited the usefulness of the models in the decision-making process of operators.
Insufficient validation in operational environments is also a significant problem. For example, in Ref. [
50], the optimization of a coal-fired boiler using CFD and GA yielded very good results in simulations, but the authors clearly indicated the need for tests in real industrial conditions. Similarly, in Ref. [
69], the combination of SVM with the reduction in the CFD model showed efficacy in predicting slagging, but the limitations of applying the model to a particular furnace remain a significant practical barrier.
In the light of the above examples, the use of tools such as SHAP (SHapley Additive exPlanations), sensitivity analysis, principal component analysis (PCA), or interpretable regression models is increasingly suggested. They are designed to improve the transparency of models and enable better collaboration between AI systems and users. However, their implementation in production environments (e.g., SCADA, PLC) remains technically difficult and cost-prohibitive.
Further progress in this area will depend on (1) the development of explainable AI (XAI); (2) the creation of open, well-described industrial benchmarks; and (3) the integration of ML systems with real combustion systems. Only then will it be possible to fully exploit the potential of AI and GA models in the real transformation of the energy sector. To allow the reader to better compare the effectiveness of different approaches, it is worth supplementing the analysis with a synthetic summary of the accuracy of models used in typical predictive tasks.
Table 1 shows examples of performance indicators (R
2, RMSE, MAE) for different ML/GA methods in the context of NO
x emission prediction, flame laminar velocity (LFS) estimation, and peak pressure prediction in engines. Such a comparison not only allows for the identification of the most effective algorithms but also draws attention to potential differences resulting from the characteristics of the input data and the type of modeled phenomenon.
In light of the literature analysis, it can be clearly stated that machine learning methods and genetic algorithms are increasingly being integrated with modeling and optimization of combustion processes. Question 1 concerned the scope of this integration in engineering practice. The conclusions of the review of 97 publications published between 2015 and 2024 show that ML and GA techniques have been used both in numerical modeling (e.g., using CFDs) and in experimental research. This applies to many types of fuel systems—from classic gasoline and diesel engines to biomass gasification and the use of hydrogen. AI-based models were used to predict emissions, identify combustion parameters, assess process stability, and automatically optimize operating conditions.
Question 2 referred to the effectiveness of specific method configurations, such as CFD combinations with AI or ANNs with optimization algorithms. The analyzed publications confirm that the most effective were hybrid configurations, combining neural networks with genetic algorithms (ANN + GA) and CFD methods supported by artificial intelligence algorithms. Such systems achieved high predictive accuracy (coefficients of determination R2 often above 0.98) and enabled simultaneous optimization of several variables—e.g., minimizing emissions and maximizing efficiency. The best results were observed for hydrogen, natural gas, and gasoline, where the complexity of the process required flexible and well-tuned models. Also important was the resilience of these methods to the variability of operating conditions and the ability of models to adapt to new data.
Question 3 addressed the key limitations and challenges of validating and generalizing ML/GA models in real industrial settings. The reviewed publications indicate that the limited availability of high-quality input data remains a major problem, making it difficult to train models correctly and then apply them in dynamic environments. Many ML-based models work well in laboratory or simulation settings, but their effectiveness is significantly reduced in industrial practice due to interference, measurement noise, and changing operating conditions. An additional challenge is the lack of uniform validation procedures and the difficulty in interpreting the performance of more complex models, such as deep neural networks. Therefore, further research is needed on the resilience of models to distorted data, their ability to generalize, and the development of tools to improve interpretability and transparency of predictions.
In connection with the above information, further research is necessary on the resistance of models to distorted data, their ability to generalize, and the development of tools to improve the interpretability and transparency of predictions. Against the background of the available literature, this review is distinguished by a comprehensive approach to the topic, including not only an overview of artificial intelligence methods used in the context of combustion and gasification processes but also their comparison with specific types of fuels, research methodology, and statistical results. The combination of qualitative and quantitative analysis allowed us to identify both dominant technology trends and gaps and limitations in existing research. An important element of this study is also the integration of statistical conclusions (based on chi-square tests), which were omitted in most previous reviews. As a result, the presented results not only synthesize the current state of knowledge but also provide a starting point for further, more targeted research in the field of low-carbon energy technologies supported by artificial intelligence.
4. Statistical Overview
In order to complement the overview of the state of the art presented in the previous sections, an analysis of the distribution of publications by type of document, type of fuel, calculation methods used, and research approaches was performed. The quantitative analysis was carried out separately for two periods: 2015–2019 and 2020–2024.
In the first stage, publications were compiled by type of document. As shown in
Figure 4, the number of journal articles increased from 15 in the first period to 72 in 2020–2024, an increase of 380% and indicating a rapid development of this topic in peer-reviewed literature. At the same time, the number of conference papers increased from three to six (i.e., by 100%). The “Other” category is marginal, with only one such case recorded in a more recent period.
Another aspect was the analysis of the type of fuel taken into account in the research (
Figure 5). The largest increase was recorded for hydrogen, which was not analyzed at all in 2015–2019, and in the following years it appeared in as many as 17 publications (17.5% of the total). The subject of gasoline developed equally dynamically—an increase from 6 to 24 publications (an increase of 300%). In the case of biomass and biodiesel, a jump from 0 to 10 and from 2 to 9, respectively, was observed—indicating an increase in interest in renewable fuels. However, it should be noted that petrol, coal, natural gas, and hydrogen still dominated as the most frequently studied fuels.
With regard to the computational methods and algorithms used (
Figure 6), neural networks were the most frequently used, with an increase from 6 to 36 publications, which means an increase of as much as 500% and a share of 37% in the total number of analyzed papers (42 out of 97). In second place were genetic algorithms, used in 39 publications (an increase from 14 to 25). The vast majority of techniques, such as SVM, PCA, random forest, or regression, showed an increase in occurrence in the analyzed time period. The expansion of SVM (from 2 to 16—an increase of 700%) and regression (from 0 to 13) was particularly noticeable. Such dynamic growth confirms the growing role of artificial intelligence methods in advanced analysis of combustion processes.
From the point of view of research methodology (
Figure 7), the most commonly used approach was experiments, the number of which increased from 17 to 72 (a total of 89 publications, i.e., 91.8% of the total). The second most common category was conceptual work, with an increase from 15 to 55, for a total of 70 publications. Literature analyses appeared less frequently (4 in the first period, 24 in the second), constituting a total of 28 cases. This data shows that while the importance of reviews and theoretical concepts is increasing, empirical research remains the foundation for the verification of AI and GA models.
In order to assess the relationship between the type of fuel and the method used, a chi-square test was performed. For the “Methods and Algorithms” category, a value of p = 0.06 was obtained, which is close to the conventional significance level (α = 0.05), but does not allow for unambiguous confirmation of the statistical relationship. For the “Research Methodology” category, p = 0.95 was obtained, which indicates a lack of significant differences—in other words, the choice of research methodology did not depend significantly on the type of fuel analyzed.
To sum up, the presented quantitative data confirms the dynamic development of AI/GAs in fuel combustion. The number of publications, especially scientific articles, is clearly increasing, and methods such as ANNs and GAs are becoming the dominant tools in the analysis, optimization, and prediction of combustion phenomena. At the same time, despite differences in the type of fuels, experiments supported by simulations and numerical modeling remain the predominant form of research.
The overall numerical distribution by fuel type and type of calculation method and research methodology is presented in
Table 2. The list shows that gasoline was the most frequently tested fuel (30 papers), followed by hydrogen (17), coal, and natural gas (16 each). The fewest cases analyzed were for biomass (10) and biodiesel (11).
In terms of methods, neural networks were used in 42 papers (43%) and genetic algorithms in 39 (40%). They were especially dominant in the case of gasoline, natural gas, and hydrogen. Methods such as SVM (18 papers) and regression (13) played an important, albeit ancillary, role. Less frequently used were random forest (8), PCA (6), and MSE (12).
In terms of the type of research, experiments accounted for 89 out of 97 publications (92%), which confirms the high dependence of AI/GA applications on empirical data. Conceptual work (70 cases) was often an extension of experimental results, while literature analyses (28) were used to develop theoretical models or comparisons between different approaches.
It is worth noting that the statistical analysis showed no significant relationship between the type of fuel and the choice of research methodology (p = 0.95), while for the selection of calculation methods, a trend close to significance was observed (p = 0.06), which may indicate an ambiguous preference for specific algorithms depending on the fuel.
Another aspect analyzed in the literature review was the geographical distribution of the publication, which allows for the identification of leading research centers dealing with the application of artificial intelligence and genetic algorithms in combustion engineering.
Figure 8 shows the number of publications per selected country in two time periods: 2015–2019 and 2020–2024. This data has also been aggregated in
Table 2, which additionally presents the percentage share of individual countries in the 97 total analyzed publications.
Based on the list, it is clear that China was the dominant leader in this area—in 2020–2024, as many as 36 papers were published there, for a total of 43 publications in the entire analyzed period. This is 44.33% of all publications, i.e., almost every second work came from Chinese institutions. This is a five-fold increase compared to the previous period (7 publications in 2015–2019).The next places were taken by:
United States—13 publications (13.4%), of which 10 were in the last five years,
India—increased from 1 to 11 publications, with 12 in total (12.37%),
Saudi Arabia—increased from 1 to 10 (11.34%),
Germany—total increase from 0 to 9 publications (9.28%).
There was also a noticeable increase in activity in countries such as Iran, the United Kingdom, Pakistan, Canada, and Malaysia, although their percentage share in the total number of publications did not exceed 5%. Other categories covering other countries accounted for 12 works (12.37%). The number of publications by country by year and the percentage share is presented in
Table 3.
The data also shows that 81% of all publications (79 out of 97) were from the last five years, which confirms the rapid development of the research area and its timeliness. According to the data from the chi-square test, the value of the statistic was χ2 = 11.6 with 12 degrees of freedom, which translates to a value of p = 0.48. This means that no statistically significant relationship was observed between national affiliation and the period of publication. In other words, the increase in the number of publications was general and not limited to a specific geographical region.
The summary of data from
Table 3 and its visualization in
Figure 9 and
Figure 10 allows for the assessment of the relationship between the type of analyzed fuel and the calculation methods and research approach used. In the 97 publications analyzed, gasoline was the most frequently studied fuel (30 cases), followed by hydrogen (17), natural gas, and coal (16 each), and the least attention was paid to biomass (10) and biodiesel (11).
When it comes to the methods and algorithms used, neural networks and genetic algorithms stand out in particular. The former appeared in as many as 42 papers, most often in the context of hydrogen (11 publications), gasoline (11), biodiesel (7), and natural gas (5). Genetic algorithms, present in 39 papers, were most commonly used for gasoline (14), natural gas (12), coal (7), and hydrogen (4). This confirms their wide application, both for the optimization of combustion parameters and for the construction of predictive models.
The SVM (support vector machine) method was also relatively popular—18 publications, with a dominant share in research on hydrogen (7), gasoline (5), and carbon (4). In the case of the CFD (Computational Fluid Dynamics) method, a concentration on gasoline (12 cases), coal (4), and natural gas (4) was noticed. PCA, random forests, and regression played a minor role but have been used in supporting analyses such as feature selection and assessment of the impact of input variables. It is also worth noting the low presence of some methods for specific fuels—for example, PCA was not used at all for biodiesel or hydrogen, and random forests did not appear in the work on hydrogen and natural gas. A numerical summary of these relations is shown in
Figure 9.
The data indicates that gasoline and hydrogen are the fuels for which the widest range of modeling tools were tested. In the case of hydrogen, AI methods (ANN, SVM) dominated, while for gasoline, almost all techniques appeared, from classical (regression, PCA) to optimization (GA) and classification (RF, SVM, decision trees).
With regard to research approaches, the vast majority of publications—89 out of 97, i.e., as much as 91.8%—were experimental. The largest number of such studies concerned gasoline (28), hydrogen (16), natural gas (16), and coal (14), reflecting their industrial importance and the availability of research equipment. Concept work was the second most represented category—70 cases, with the largest share in research on gasoline (25), natural gas (14), and coal (10). Literature reviews appeared mainly in the context of hydrogen (6), biomass (5), and gasoline (6). This data is summarized in
Figure 10, which illustrates the frequency of use of each type of approach for the fuel tested.
The information in
Figure 9 and
Figure 10 is derived from the aggregate data presented in
Table 4, which lists in detail the number of publications using specific methods for each fuel type and the methodological breakdown.
According to the chi-square test, the value of χ2 = 54.69 at 40 degrees of freedom was obtained for the “Methods and Algorithms” group, which translates to p = 0.06. This result is close to the conventional significance threshold (α = 0.05), which may suggest the existence of a relationship between the choice of method and the type of fuel. In particular, it can be noted that ANNs and SVM dominated with hydrogen, while GAs and CFD dominated with gasoline and natural gas. For the “Research Methodology” group, the value of p = 0.95 at 10 degrees of freedom indicates a lack of statistically significant relationships regardless of the type of fuel.
These conclusions indicate that although calculation methods are often chosen depending on the specificity of the fuel, the type of testing itself does not depend on this factor and is universal in nature. Particular attention is drawn to the high number of experiments and the growing popularity of neural networks and genetic algorithms as the dominant methods in the analysis of fuel combustion.
Summing up the results of the quantitative analysis, a statistical assessment of the relationship between the type of fuel and two research aspects was carried out: the selection of calculation methods (ML/GAs) and the choice of methodological approach. The results obtained allow for unambiguous answers to the formulated statistical questions.
The fourth question concerned the potential relationship between the type of fuel and the calculation method used. The chi-square test performed for this group (χ2 = 54.69; df = 40) yielded a value of p = 0.06, which is just below the conventional significance threshold (α = 0.05). Although this does not allow for full confirmation of a statistically significant relationship, this result indicates a clear thematic trend, with a preference for specific methods observed in the analysis of specific fuels. For example, SVM and ANN algorithms were more commonly used in hydrogen research, while CFD and genetic algorithms dominated in gasoline and natural gas combustion analyses. This suggests that the choice of calculation method largely depends on the characteristics of the fuel and the specifics of the problem being analyzed.
The fifth question concerned the relationship between the type of fuel and the choice of research approach (experiment, concept, literature analysis). The result of the chi-square test (χ2 = 3.86; df = 10; p = 0.95) clearly showed no statistically significant relationship between these variables. Regardless of the type of fuel studied, experimental studies were by far the dominant approach, present in over 90% of publications. Other approaches, such as literature analyses and conceptual work, were evenly distributed across all fuel groups, demonstrating their universal nature.
These conclusions confirm that while the selection of calculation methods may depend to some extent on the type of fuel, the research methodology remains independent of this factor and is mainly based on experiments, regardless of the fuel area analyzed.
While the analysis confirms a growing interest in the application of machine learning and genetic algorithms in combustion research, many studies show recurring methodological weaknesses. Limited data availability often results in narrow model training, which raises concerns about robustness and generalization. Furthermore, performance metrics are frequently reported without benchmarking against traditional methods, obscuring whether AI-based approaches offer real improvement. The lack of open data, source code, and detailed reporting also limits reproducibility and transparency. These critical gaps should be addressed in future work to ensure that AI tools can be reliably integrated into combustion system design and control in real-world scenarios.
5. Discussion
The results of the literature review are widely confirmed by the analyzed publications and allow us to capture both the dominant directions of research and their evolution over time. Numerous papers [
3,
4,
8,
20,
39] indicate the effectiveness of hybrid methods, especially CFD combinations with genetic algorithms and neural networks in precise modeling of combustion processes and emission reduction. These observations were also confirmed in this list, where configurations such as ANN + GA or CFD + SVM were characterized by the highest accuracy and predictive versatility.
In Refs. [
9,
21,
38,
67], attention was paid to the use of neural networks for forecasting NO
x and CO emissions, as well as for the assessment of the moment of spontaneous ignition and the maximum temperature in the combustion chamber. These models showed high efficiency, especially in conditions of variable fuel parameters and engine geometry. On the other hand, the authors of Refs. [
10,
65,
78,
105] drew attention to the important role of optimization algorithms, both genetic and random forest-based, in the selection of input parameters in complex biomass gasification and synthetic fuel combustion systems. These conclusions correspond to the observed trend of more frequent use of evolutionary and population methods in the case of alternative fuels.
In the literature analysis, there were also critical voices regarding the limitations of these methods. Refs. [
23,
49,
51,
77] highlighted problems related to the interpretability of ML models, their tendency to overlearn, and dependence on the quality of input data. The same limitations have also been identified in the current review—especially in the context of deep learning models, whose effectiveness decreased under disturbed conditions or with too narrow a range of training data. On the other hand, the authors of Refs. [
52,
70,
79,
80] pointed to the need to standardize validation procedures and the need to assess the resistance of models to operational variability, and these postulates are also reflected in this study.
A unique feature of this review, which distinguishes it from previous studies (e.g., Refs. [
6,
25,
50,
75,
81]), is the use of statistical analysis, which allowed for an objective assessment of the relationship between the type of fuel, the calculation method, and the research approach. Previous work has mostly been based on qualitative analysis, while the use of chi-square tests has made it possible to identify statistical correlations, such as preference for specific methods in hydrogen analysis or the dominance of experimental research regardless of the type of fuel.
Finally, it is also important that this review took into account both classic items cited many times in the literature and the latest research from 2022–2024 [
61,
86,
88,
91,
104], which allowed for current trends in AI and GA applications in the energy sector to be captured. This approach creates a more complete picture of the changes taking place in the approach to the design and control of combustion processes, and better indicates research gaps and potential directions for further development.
The results of the statistical analysis provide an additional layer of interpretation that complements the qualitative conclusions of the literature review. For example, the chi-square test performed for the “Methods and Algorithms” group showed a value of χ
2 = 54.69 with 40 degrees of freedom and a significance level of
p = 0.06. Although this result did not exceed the conventional significance threshold (
p < 0.05), it was very close, which suggests the existence of clear trends in the selection of methods in relation to the type of fuel. This means that although the relationship is not fully statistically confirmed, the observed differences are not accidental. Similar conclusions were also formulated in Refs. [
8,
21,
78], where the authors noted that hydrogen and natural gas were more often analyzed using neural networks and SVMs, while in the case of fossil fuels, regression and classification methods were more often used.
On the other hand, statistical analysis within methodological approaches (experiment, literature analysis, conceptual) did not show any significant differences between the types of fuels—the value of χ
2 = 3.86 at 10 degrees of freedom and
p = 0.95 clearly indicates the lack of dependence. This interpretation suggests that regardless of the energy carrier studied, the experimental approach dominates in all cases. This result confirms earlier observations from the literature [
49,
50,
77] in which it was emphasized that research based on measurement data is of greater application importance, which translates into its more frequent presence in works on combustion and gasification.
Equally important was the statistical analysis of the geographical distribution of publications over time (
Table 2). The results indicate that the largest increases in the number of publications occurred in China, India, and Saudi Arabia in the period 2020–2024. China currently accounts for more than 44% of all analyzed papers, which is also confirmed by previous reviews [
52,
67,
75] The result of the chi-square test (χ
2 = 11.6, df = 12,
p = 0.48) for this group did not show significant differences in the distribution of the number of publications between countries and time periods, but the relative values and dynamics of publication growth in selected regions are clear and may indicate a shift in the geographical center of AI/GA research in the energy sector. Such a conclusion reinforces the theses formulated in Refs. [
68,
80,
86], which indicate that in recent years it has been Asia, not Europe or the USA, that is setting the tone for research on the optimization of combustion processes and low-emission technologies.
Thanks to the introduction of elements of statistical analysis, this study not only describes the state of knowledge but also reveals structures and dependencies that have so far been often omitted in the literature on the subject. This approach allows for a more reliable assessment of dominant trends and provides the basis for formulating research hypotheses in future work. Compared to previous reviews, which were purely qualitative, the quantitative approach discussed here makes the analysis more transparent, replicable, and embedded in hard data, which is its significant added value.
In the light of the conducted analyses, there are clear prospects for further development of research on the application of artificial intelligence methods and optimization algorithms in thermal energy. One of the main directions of development is the further integration of ML models with CFD simulations in real time, which will allow for dynamic control of combustion processes based on real operational data. The need to develop automated predictive systems for industrial power installations that would be able to respond to disturbances and changing operating conditions in an autonomous and adaptive manner is increasingly raised in the literature [
52,
86,
95].
Many studies [
51,
80,
88] have noted that although deep neural networks offer high accuracy, they are difficult for engineers to verify and validate without specialized IT knowledge. Therefore, the development of explainable AI (XAI) is an important area of future research, especially in the context of industrial applications, where model decisions must be justified and comply with safety procedures. There are also initiatives combining classical physical models with physics-informed neural networks (PINNs), which may be a future-oriented compromise between the accuracy and transparency of the model.
Another area requiring further research is the development of data quality standards and validation procedures. As this review shows, many analyses are based on experimental or simulation data, which is not always comparable in terms of boundary conditions, equipment, or measurement characteristics. The development of common test protocols and reference databases could help improve the reliability and replication of results. Such actions are particularly needed in the context of the development of combustion systems with variable fuel composition (e.g., hydrogen–biogas), which require flexible and resilient predictive models.
Another important direction for future research is improving the reproducibility and transparency of ML/GA models used in combustion studies. The increasing complexity of hybrid modeling frameworks and the variability in training data sources make it difficult to replicate results and benchmark models across different systems. To address this, greater emphasis should be placed on the publication of open-source code, standardized datasets, and clear documentation of model architecture and hyperparameters. Additionally, the incorporation of explainable AI (XAI) techniques—such as SHAP values or sensitivity analysis—can enhance the interpretability of predictions and increase confidence in the deployment of AI systems in industrial combustion processes. Encouraging open science practices in combustion modeling will foster collaboration, facilitate validation, and accelerate the translation of research into practice.
Finally, the development of AI and GA in the context of energy should also take into account environmental and regulatory aspects. The growing importance of the “zero-emission” strategy and the pressure to reduce the carbon footprint mean that optimization models must take into account not only technical parameters but also the total environmental cost, plant lifetime, and recyclability. The first studies integrating ML with life cycle analysis (LCA) and external cost analysis are already being developed [
81,
84], which opens up a new field for interdisciplinary applications of intelligent methods in environmental engineering.
While this review presents a broad and detailed overview of ML and GA applications in combustion science, it also reveals critical challenges that must be addressed. The lack of standardized validation frameworks and benchmark datasets limits the comparability of findings across studies. Moreover, the dominance of data-driven approaches with little integration of domain-specific physics raises concerns about model robustness and interpretability. To enhance the scientific value and practical impact of future work, researchers should prioritize transparent reporting, reproducibility, and the integration of explainable AI and hybrid models that incorporate physical laws. These steps will be essential for transitioning ML/GA solutions from academic studies to reliable industrial applications.
6. Conclusions
This literature review was not only justified but also necessary in the context of the extremely dynamic development of research on the applications of artificial intelligence methods and genetic algorithms in combustion and gasification processes. An analysis of 97 publications revealed that more than 80% of the papers analyzed had been published in the last five years, clearly indicating a sharp increase in interest in the subject and its growing importance in research on low-carbon energy technologies. This review fills a clear gap in the existing literature, which has so far focused mainly on qualitative analyses, often omitting the quantitative approach and statistical summaries.
The analysis answered three key research questions. In the context of the former, it has been shown that ML and GA methods are increasingly being implemented in engineering practice, covering the full spectrum of fuels—from traditional to alternative fuels such as hydrogen or biomass. The second question allowed us to identify the most effective method configurations—hybrid combinations dominate here, in particular ANN + GA and CFD + ML, which allow not only for accurate prediction but also for optimization of combustion and emission parameters. The third question identified key barriers such as limited data availability, low transparency of deep models, and difficulties in validating results in industrial settings.
The use of a statistical approach, including chi-square tests, additionally allowed for an objective assessment of the distribution of methods and fuels and demonstrated the existence of strong thematic trends in research, especially in the field of AI applications for hydrogen, natural gas, and biomass gasification. The fact that most of the publications analyzed come from Asia (mainly China and India) indicates a shift in the geographical center of innovation towards regions with high dynamics of development of the energy sector.
In light of the presented findings, it can be clearly stated that this review not only synthesizes the current state of knowledge but also shows the key directions of further work and the need for in-depth quantitative research. Its value lies not only in the clean-up of existing achievements but also in the identification of gaps and inconsistencies that may become the subject of further research projects.
In the next stages, it is planned to expand the analysis with data from other renowned scientific databases, such as Google Scholar, Web of Science, or IEEE Xplore. This will allow us to verify the results obtained in an even broader perspective and capture the global dynamics of development of this key field. The aim of future work will also be to analyze industrial implementation cases and develop integrated, transparent predictive models to support the energy transition towards climate neutrality.
In addition to technical performance, future work should also address the broader societal and environmental implications of integrating ML and GAs into combustion systems. While these methods hold the potential to significantly reduce pollutant emissions and improve fuel efficiency, they also require careful consideration of their computational energy cost, model transparency, and operational safety. In industrial settings, the use of opaque “black box” algorithms may raise questions about accountability and regulatory compliance. Therefore, efforts toward explainable AI, energy-efficient training strategies, and ethical deployment practices should be integral to the advancement of data-driven combustion technologies.


 ,
, 

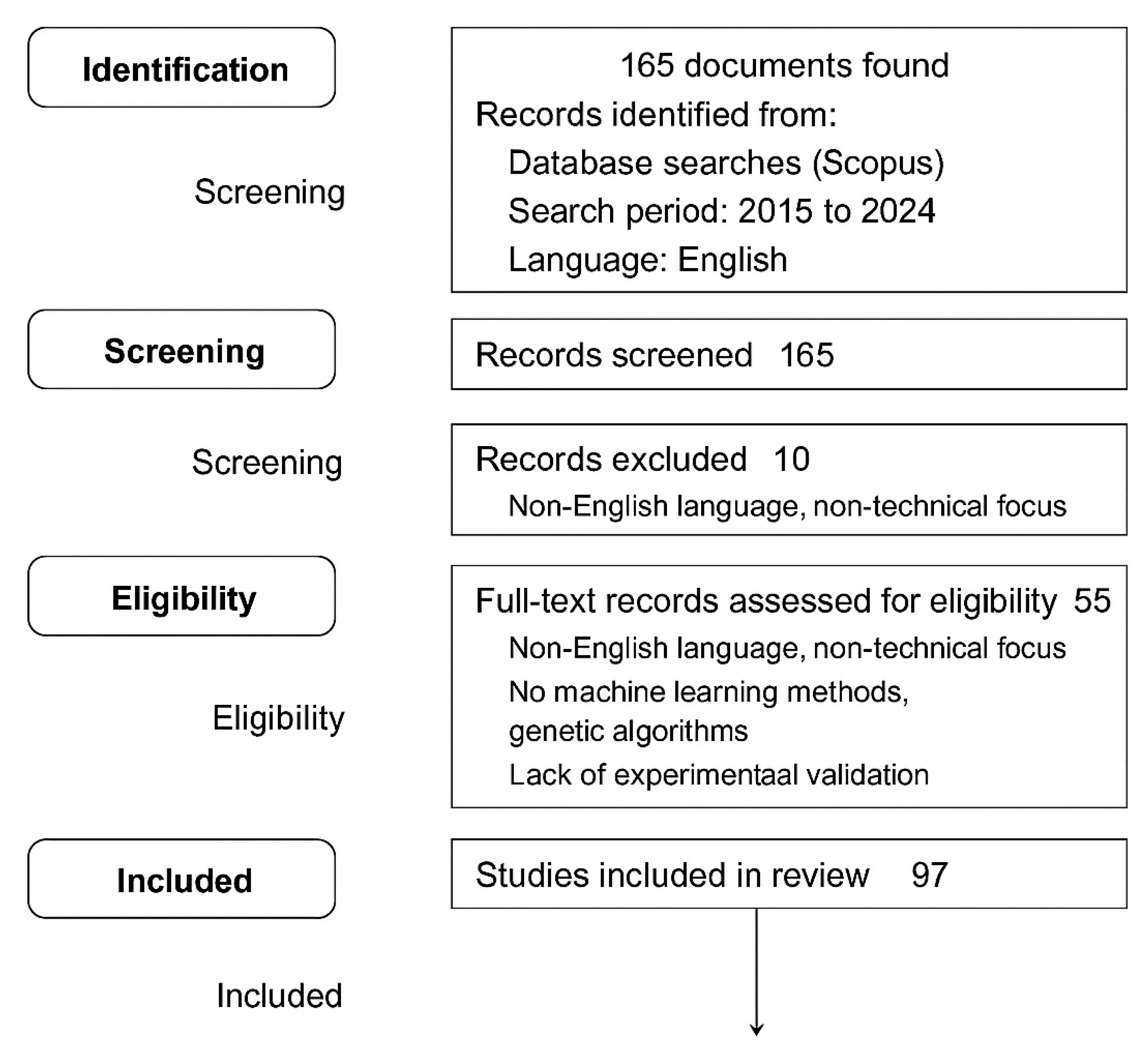

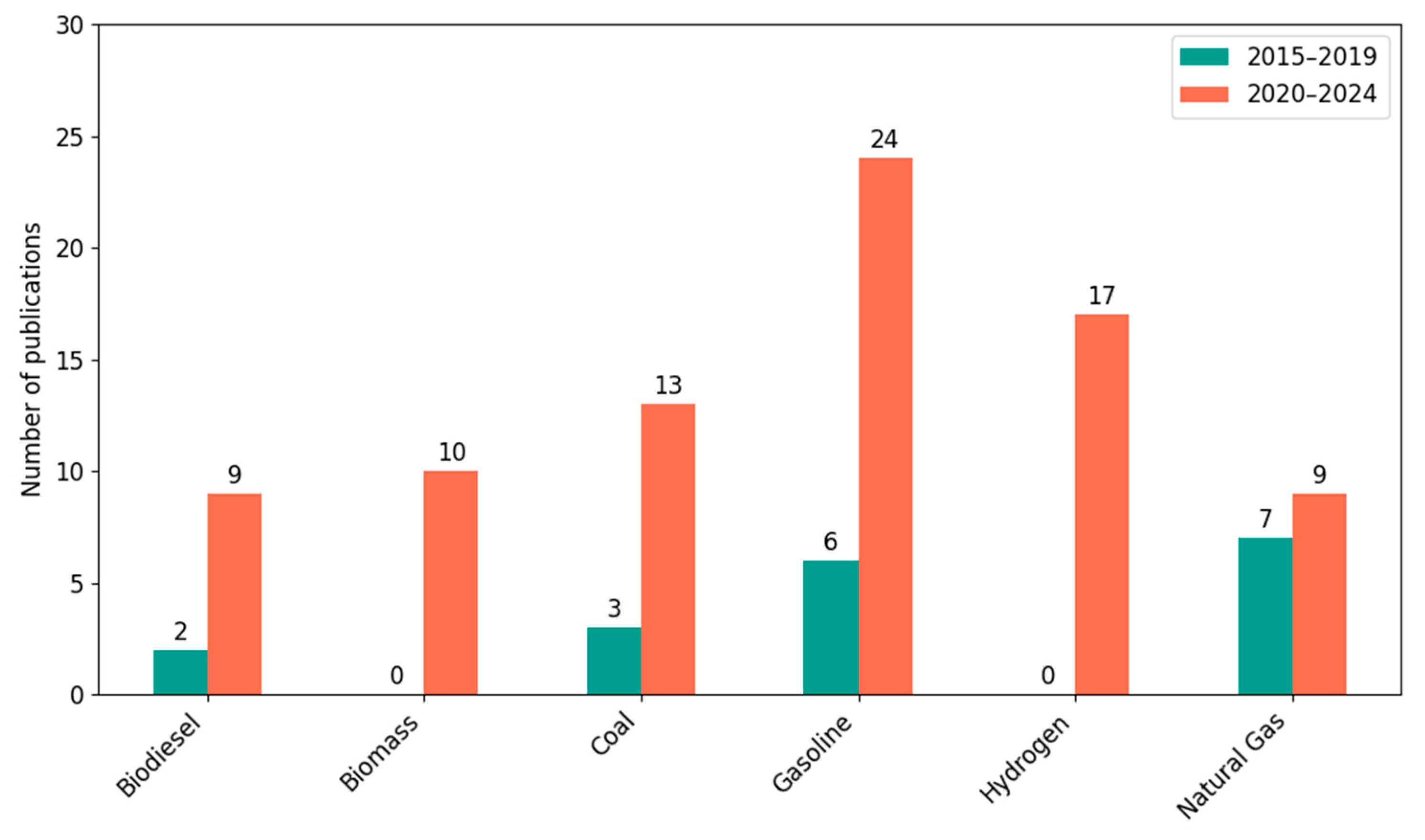
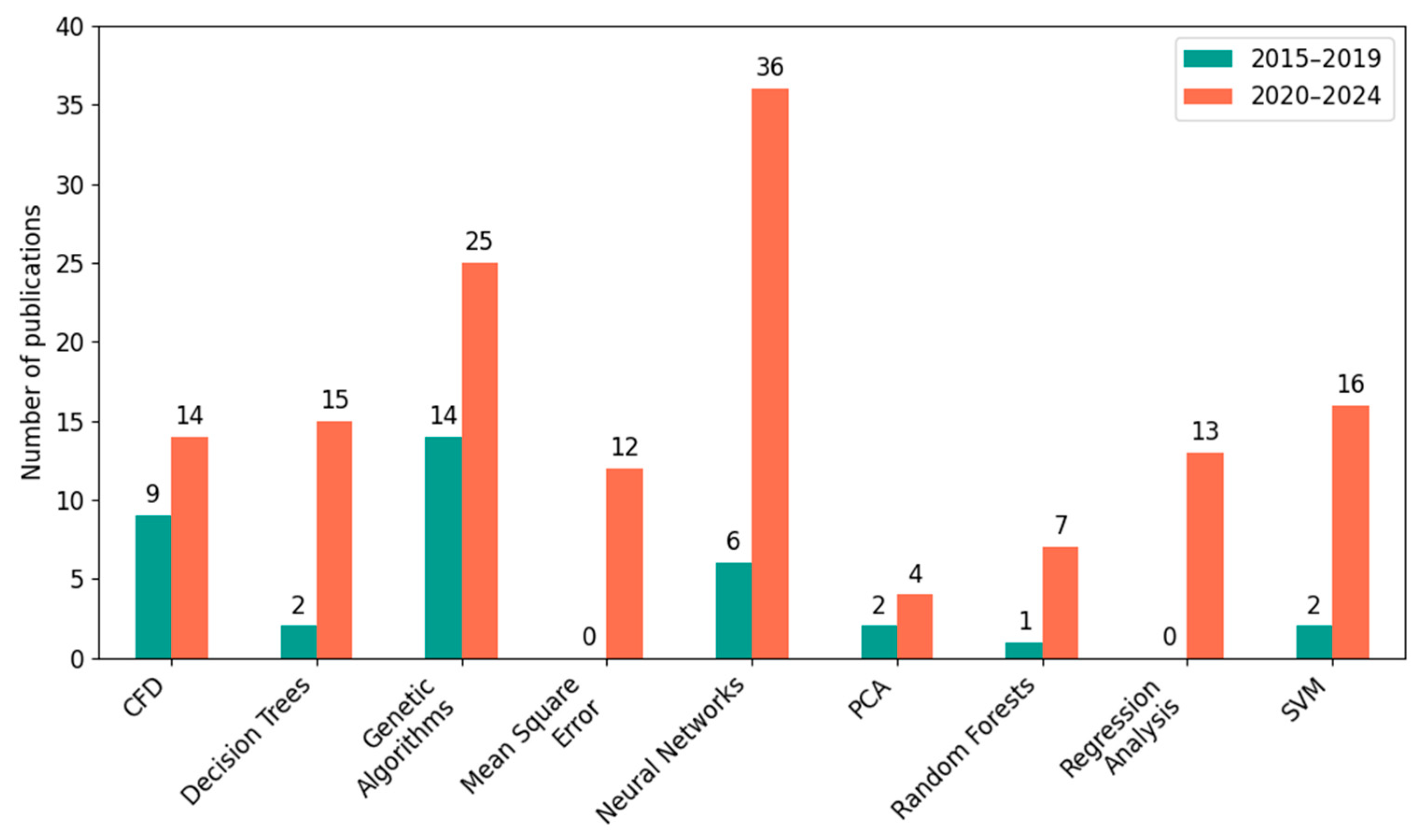
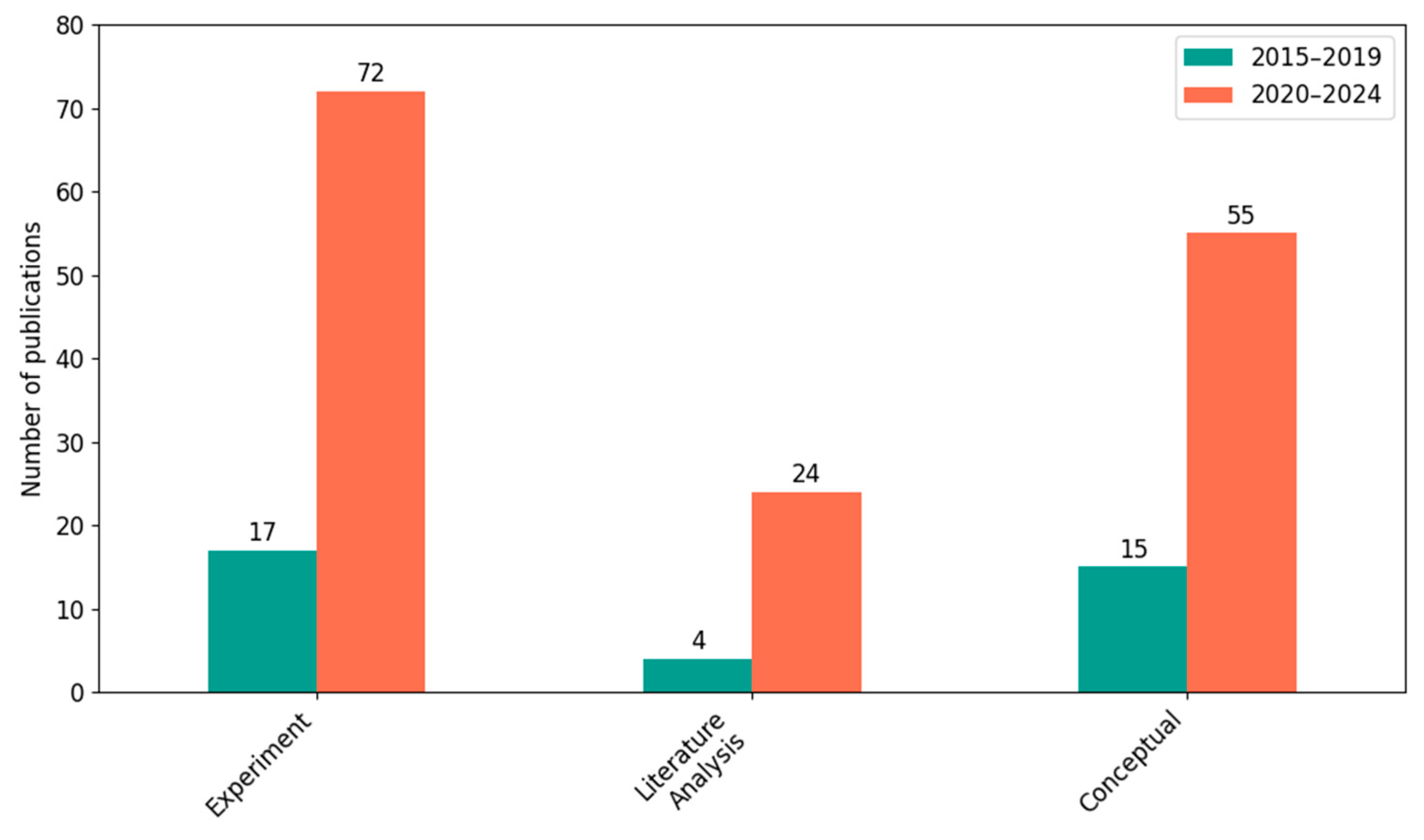

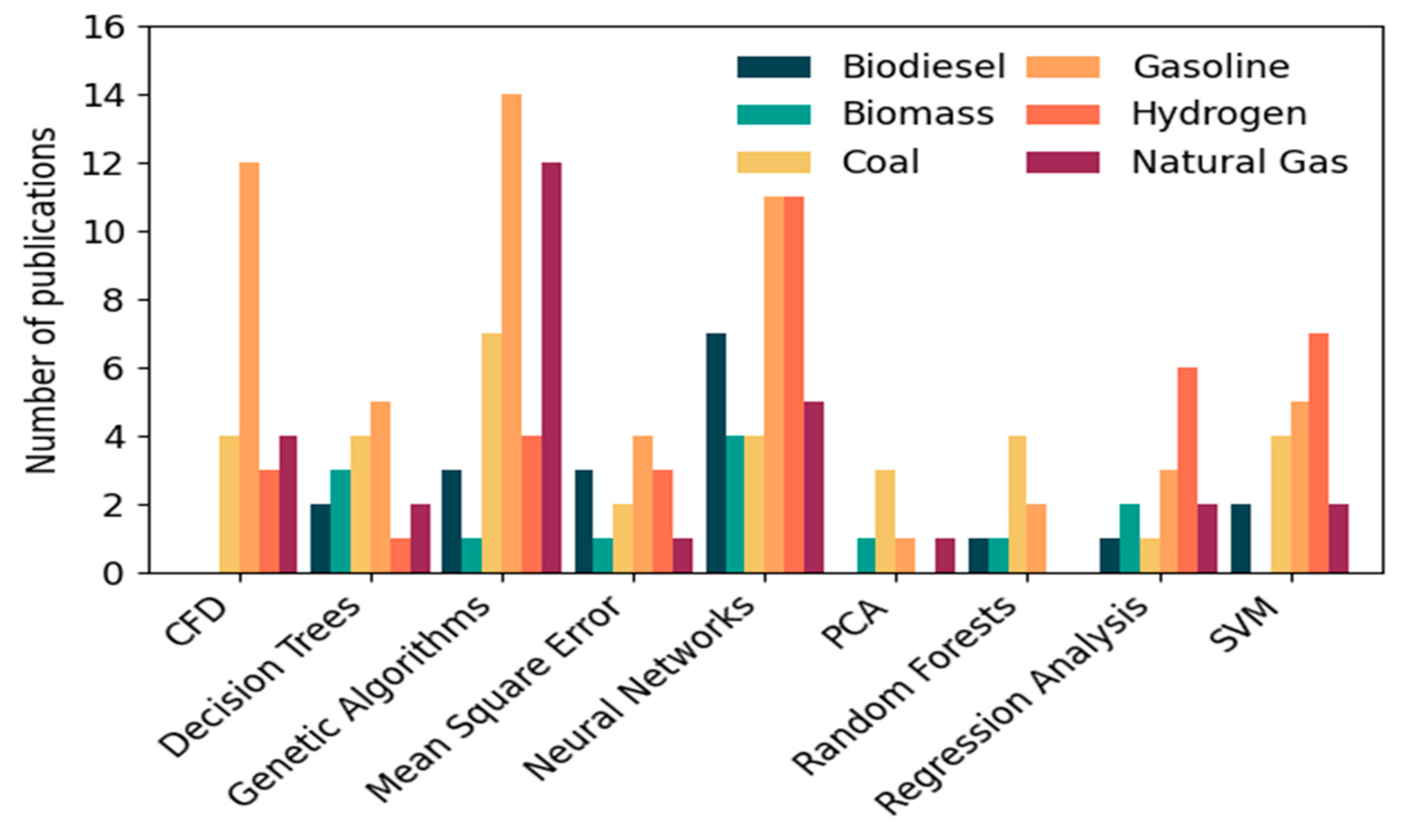
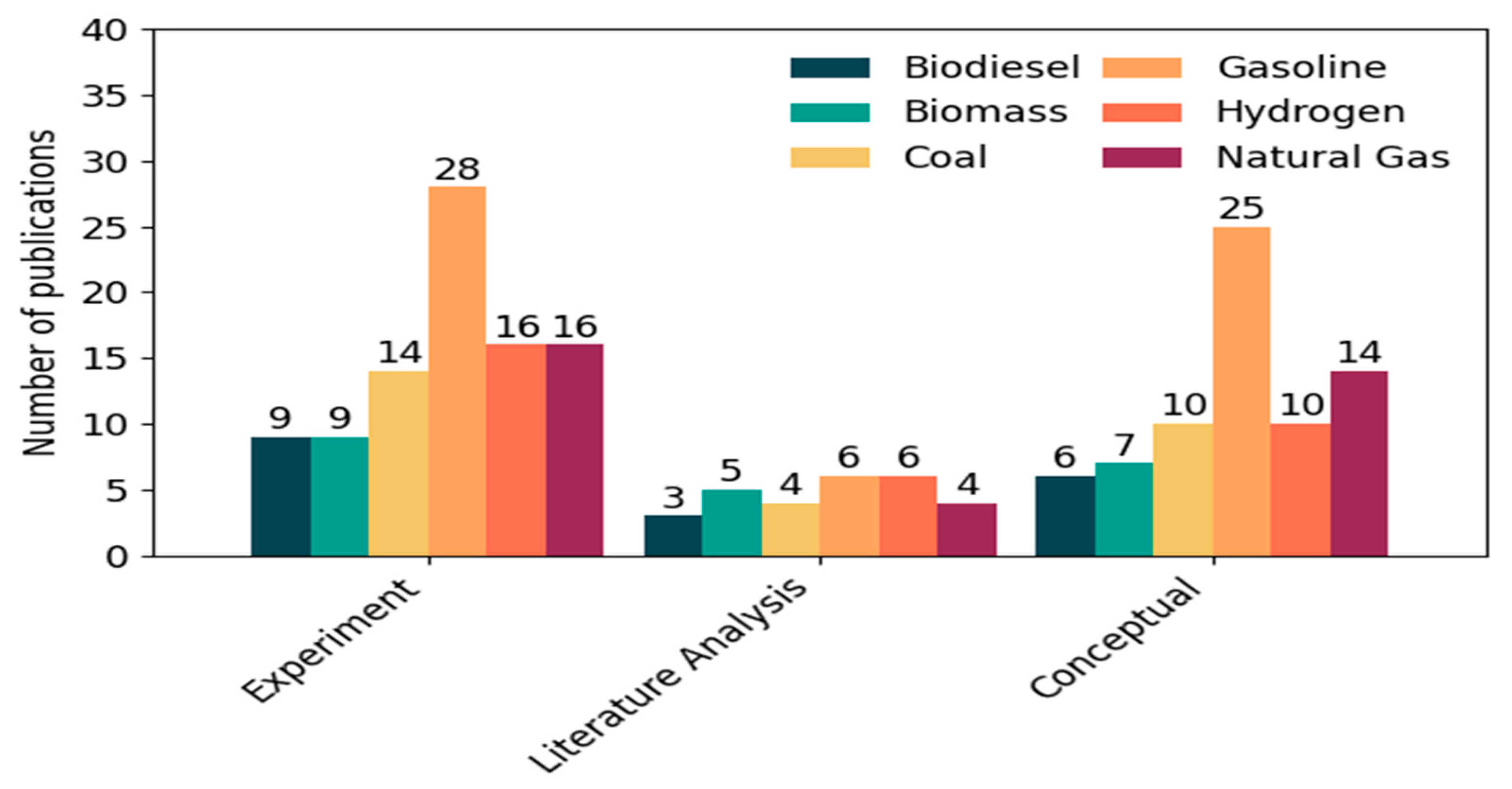

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}