
Uncertainty Detection: A Multi-View Decision Boundary Approach Against Healthcare Unknown Intents


Abstract
1. Introduction
2. Literature Review and Design Theories
2.1. Challenges in Healthcare E-Services
2.2. Unknown Intent Detection Technologies and Decision Boundary Learning
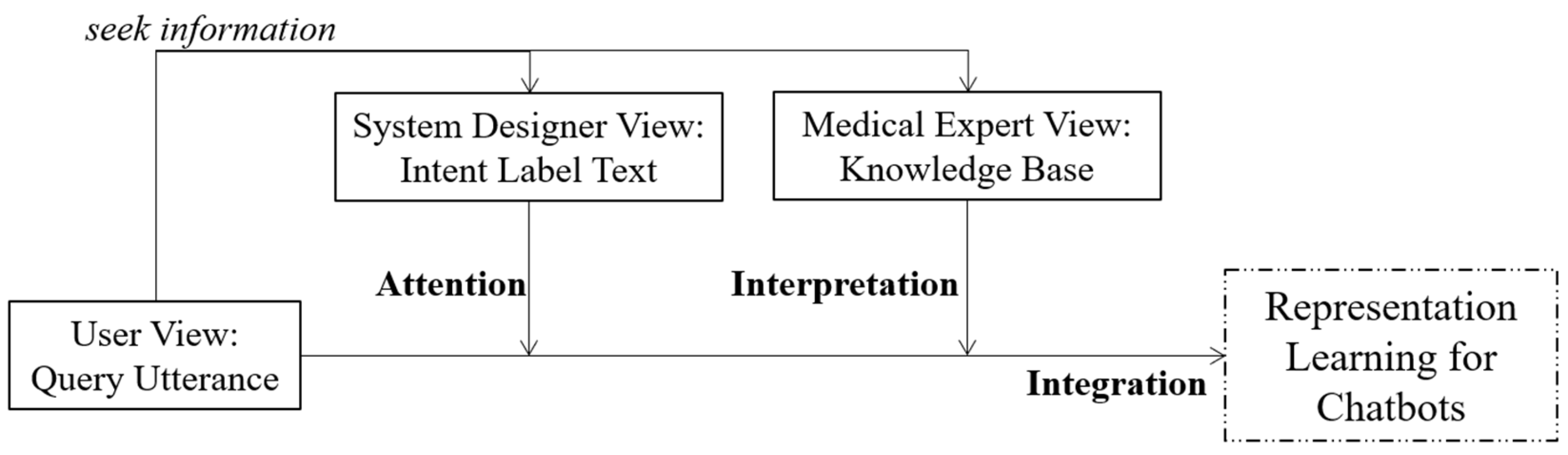
2.3. Design Theories and Multi-View Representation Learning
3. A Multi-View Decision Boundary Learning Approach for Unknown Intent Detection
3.1. Problem Setup
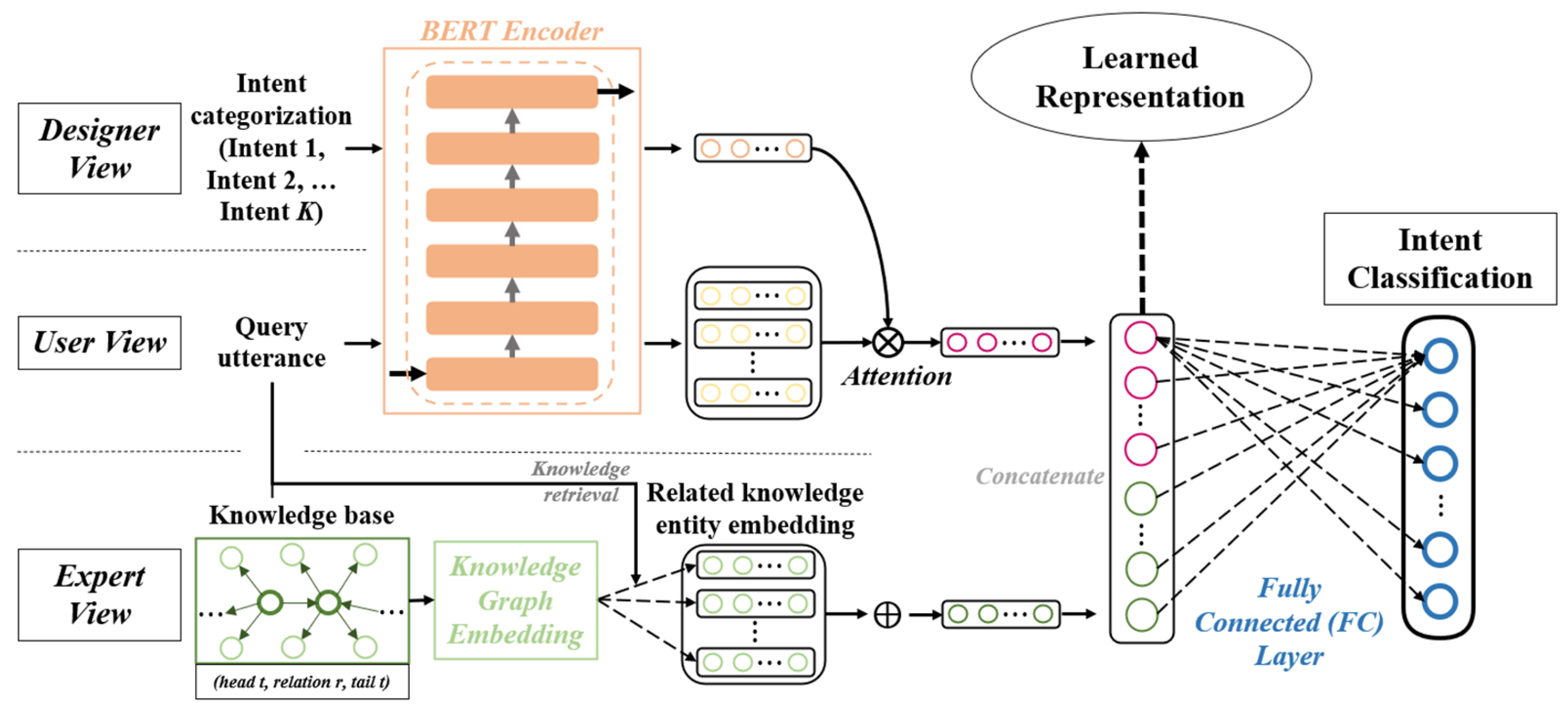
3.2. First-Stage Training for Query Representation
3.3. Second-Stage Training for Unknown Intent Detection
4. Context and Materials
4.1. Query Data
4.2. Knowledge Base Data
5. Performance Evaluation and Result Analysis
5.1. Baseline Models
5.2. Comparative Experiment
5.3. Ablation Study
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| NLP | Natural Language Processing |
| UV | User View |
| SDV | System Developer View |
| MEV | Medical Expert View |
References
- Parviainen, J.; Rantala, J. Chatbot Breakthrough in the 2020s? An Ethical Reflection on the Trend of Automated Consultations in Health Care. Med. Health Care Philos. 2022, 25, 61–71. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.X.; Lau, R.Y.K.; Xu, J.D.; Rao, Y.H.; Li, Y.F. Business Chatbots with Deep Learning Technologies: State-of-the-Art, Taxonomies, and Future Research Directions. Artif. Intell. Rev. 2024, 57, 113. [Google Scholar] [CrossRef]
- Javaid, M.; Haleem, A.; Singh, R.P. ChatGPT for Healthcare Services: An Emerging Stage for an Innovative Perspective. BenchCouncil Trans. Benchmarks Stand. Eval. 2023, 3, 100105. [Google Scholar] [CrossRef]
- Laranjo, L.; Dunn, A.G.; Tong, H.L.; Kocaballi, A.B.; Chen, J.; Bashir, R.; Surian, D.; Gallego, B.; Magrabi, F.; Lau, A.Y.S.; et al. Conversational Agents in Healthcare: A Systematic Review. J. Am. Med. Inform. Assoc. 2018, 25, 1248–1258. [Google Scholar] [CrossRef]
- King, M.R. The Future of AI in Medicine: A Perspective from a Chatbot. Ann. Biomed. Eng. 2023, 51, 291–295. [Google Scholar] [CrossRef]
- Aggarwal, A.; Tam, C.C.; Wu, D.Z.; Li, X.M.; Qiao, S. Artificial Intelligence-Based Chatbots for Promoting Health Behavioral Changes: Systematic Review. J. Med. Internet Res. 2023, 25, e40789. [Google Scholar] [CrossRef]
- Fjelland, R. Why general artificial intelligence will not be realized. Humanit. Soc. Sci. Commun. 2020, 7. [Google Scholar] [CrossRef]
- Xu, Z.; Jain, S.; Kankanhalli, M. Hallucination is Inevitable: An Innate Limitation of Large Language Models. arXiv 2024. [Google Scholar] [CrossRef]
- Miles, O.; West, R.; Nadarzynski, T. Health Chatbots Acceptability Moderated by Perceived Stigma and Severity: A Cross-sectional Survey. Digit. Health 2021, 7, 20552076211063012. [Google Scholar] [CrossRef]
- Fenza, G.; Orciuoli, F.; Peduto, A.; Postiglione, A. Healthcare Conversational Agents: Chatbot for Improving Patient-Reported Outcomes. In Advanced Information Networking and Applications; Springer International Publishing: Cham, Switzerland, 2023; pp. 137–148. [Google Scholar] [CrossRef]
- Lin, T.E.; Xu, H. A Post-Processing Method for Detecting Unknown Intent of Dialogue System via Pre-Trained Deep Neural Network Classifier. Knowl.-Based Syst. 2019, 186, 104979. [Google Scholar] [CrossRef]
- Zhang, H.L.; Xu, H.; Lin, T.E. Deep Open Intent Classification with Adaptive Decision Boundary. In Proceedings of the 35th AAAI Conference on Artificial Intelligence/33rd Conference on Innovative Applications of Artificial Intelligence/11th Symposium on Educational Advances in Artificial Intelligence, Virtual Conference, 2–9 February 2021; pp. 14374–14382. [Google Scholar]
- Zhang, H.L.; Xu, H.; Zhao, S.J.; Zhou, Q.R. Learning Discriminative Representations and Decision Boundaries for Open Intent Detection. IEEE/ACM Trans. Audio Speech Lang. Process. 2023, 31, 1611–1623. [Google Scholar] [CrossRef]
- Lei, S.; Hu, X.; Bing, L. DOC: Deep Open Classification of Text Documents. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2017. [Google Scholar]
- Chen, G.Y.; Peng, P.X.; Wang, X.Q.; Tian, Y.H. Adversarial Reciprocal Points Learning for Open Set Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 8065–8081. [Google Scholar] [CrossRef] [PubMed]
- Zhang, N.; Chen, M.; Bi, Z.; Liang, X.; Li, L.; Shang, X.; Yin, K.; Tan, C.; Xu, J.; Huang, F.; et al. CBLUE: A Chinese Biomedical Language Understanding Evaluation Benchmark. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland, 22–27 May 2022; pp. 7888–7915. [Google Scholar]
- Hermes, S.; Riasanow, T.; Clemons, E.K.; Böhm, M.; Krcmar, H. The Digital Transformation of the Healthcare Industry: Exploring the Rise of Emerging Platform Ecosystems and their Influence on the Role of Patients. Bus. Res. 2020, 13, 1033–1069. [Google Scholar] [CrossRef]
- Anisha, S.A.; Sen, A.; Bain, C. Evaluating the Potential and Pitfalls of AI-Powered ConversationalAgents as Humanlike Virtual Health Carers in the RemoteManagement of Noncommunicable Diseases:Scoping Review. J. Med. Internet Res. 2024, 26, e56114. [Google Scholar] [CrossRef]
- Kurniawan, M.H.; Handiyani, H.; Nuraini, T.; Hariyati, R.T.S.; Sutrisno, S. A Systematic Review of Artificial Intelligence-Powered (AI-powered) Chatbot Intervention for Managing Chronic Illness. Ann. Med. 2024, 56, 2302980. [Google Scholar] [CrossRef]
- Boucher, E.M.; Harake, N.R.; Ward, H.E.; Stoeckl, S.E.; Vargas, J.; Minkel, J.; Parks, A.C.; Zilca, R. Artificially Intelligent Chatbots in Digital Mental Health Interventions: A Review. Expert Rev. Med. Dev. 2021, 18, 37–49. [Google Scholar] [CrossRef]
- Alosaim, S.S.A.; Al-Qathmi, N.N.M.; Mamail, A.H.O.; Alotiby, A.A.F.; Mueeni, F.M.J.; Almutairi, A.H.H.; Alqahtani, H.F.; Alzaid, S.A.; Alotaibi, H.F.M.; Alqahtani, N.A.; et al. Leveraging Health Informatics to Enhance the Efficiency and Accuracy of Medical Secretaries in Healthcare Administration. Egypt. J. Chem. 2024, 67, 1597–1601. [Google Scholar] [CrossRef]
- Meeks, D.W.; Takian, A.; Sittig, D.F.; Singh, H.; Barber, N. Exploring the Sociotechnical Intersection of Patient Safety and Electronic Health Record Implementation. J. Am. Med. Inform. Assoc. 2014, 21, E28–E34. [Google Scholar] [CrossRef]
- Sittig, D.F.; Wright, A.; Coiera, E.; Magrabi, F.; Ratwani, R.; Bates, D.W.; Singh, H. Current Challenges in Health Information Technology-Related Patient Safety. Health Inform. J. 2020, 26, 181–189. [Google Scholar] [CrossRef]
- Singh, H.; Sittig, D.F. Measuring and Improving Patient Safety Through Health Information Technology: The Health IT Safety Framework. BMJ Qual. Saf. 2016, 25, 226–232. [Google Scholar] [CrossRef]
- van Velsen, L.; Ludden, G.; Grünloh, C. The Limitations of User-and Human-Centered Design in an eHealth Context and How to Move Beyond Them. J. Med. Internet Res. 2022, 24, e37341. [Google Scholar] [CrossRef] [PubMed]
- Duffy, A.; Christie, G.J.; Moreno, S. The Challenges Toward Real-World Implementation of Digital Health Design Approaches: Narrative Review. JMIR Hum. Factors 2022, 9, e35693. [Google Scholar] [CrossRef] [PubMed]
- Cornet, V.P.; Toscos, T.; Bolchini, D.; Ghahari, R.R.; Ahmed, R.; Daley, C.; Mirro, M.J.; Holden, R.J. Untold Stories in User-Centered Design of Mobile Health: Practical Challenges and Strategies Learned From the Design and Evaluation of an App for Older Adults With Heart Failure. JMIR mHealth uHealth 2020, 8, e17703. [Google Scholar] [CrossRef]
- Chan, C.V.; Kaufman, D.R. A Framework for Characterizing eHealth Literacy Demands and Barriers. J. Med. Internet Res. 2011, 13, e94. [Google Scholar] [CrossRef]
- Rudd, R.E.; Anderson, J.E.; Oppenheimer, S.; Nath, C. Health Literacy: An Update of Medical and Public Health Literature. In Review of Adult Learning and Literacy; Routledge: Oxfordshire, UK, 2023; Volume 7, pp. 175–204. [Google Scholar]
- Malamas, N.; Papangelou, K.; Symeonidis, A.L. Upon Improving the Performance of Localized Healthcare Virtual Assistants. Healthcare 2022, 10, 99. [Google Scholar] [CrossRef]
- Babu, A.; Boddu, S.B. BERT-Based Medical Chatbot: Enhancing Healthcare Communication through Natural Language Understanding. Explor. Res. Clin. Soc. Pharm. 2024, 13, 100419. [Google Scholar] [CrossRef]
- Yan, G.F.; Fan, L.; Li, Q.M.; Liu, H.; Zhang, X.T.; Wu, X.M.; Lam, A.Y.S. Unknown Intent Detection Using Gaussian Mixture Model with an Application to Zero-shot Intent Classification. In Proceedings of the 58th Annual Meeting of the Association-for-Computational-Linguistics (ACL), Virtual Conference, 5–10 July 2020; pp. 1050–1060. [Google Scholar]
- Coghlan, S.; Leins, K.; Sheldrick, S.; Cheong, M.; Gooding, P.; D’Alfonso, S. To Chat or Bot to Chat: Ethical Issues with Using Chatbots in Mental Health. Digit. Health 2023, 9, 20552076231183542. [Google Scholar] [CrossRef]
- Ratwani, R.M.; Reider, J.; Singh, H. A Decade of Health Information Technology Usability Challenges and the Path Forward. JAMA 2019, 321, 743–744. [Google Scholar] [CrossRef]
- Cheng, Z.F.; Jiang, Z.W.; Yin, Y.F.; Wang, C.; Gu, Q. Learning to Classify Open Intent via Soft Labeling and Manifold Mixup. IEEE/ACM Trans. Audio Speech Lang. Process. 2022, 30, 635–645. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Podolskiy, A.; Lipin, D.; Bout, A.; Artemova, E.; Piontkovskaya, I. Revisiting Mahalanobis Distance for Transformer-Based Out-of-Domain Detection. In Proceedings of the 35th AAAI Conference on Artificial Intelligence/33rd Conference on Innovative Applications of Artificial Intelligence/11th Symposium on Educational Advances in Artificial Intelligence, Virtual Conference, 2–9 February 2021; pp. 13675–13682. [Google Scholar]
- Zeng, Z.Y.; He, K.Q.; Yan, Y.M.; Liu, Z.J.; Wu, Y.A.; Xu, H.; Jiang, H.X.; Xu, W.R. Modeling Discriminative Representations for Out-of-Domain Detection with Supervised Contrastive Learning. In Proceedings of the Joint Conference of 59th Annual Meeting of the Association-for-Computational-Linguistics (ACL)/11th International Joint Conference on Natural Language Processing (IJCNLP)/6th Workshop on Representation Learning for NLP (RepL4NLP), Virtual Conference, 1–6 August 2021; pp. 870–878. [Google Scholar]
- Zhan, L.M.; Liang, H.W.; Liu, B.; Fan, L.; Wu, X.M.; Lam, A.Y.S. Out-of-Scope Intent Detection with Self-Supervision and Discriminative Training. In Proceedings of the Joint Conference of 59th Annual Meeting of the Association-for-Computational-Linguistics (ACL)/11th International Joint Conference on Natural Language Processing (IJCNLP)/6th Workshop on Representation Learning for NLP (RepL4NLP), Virtual Conference, 1–6 August; pp. 3521–3532.
- Wu, Y.A.; He, K.Q.; Yan, Y.M.; Gao, Q.X.; Zeng, Z.Y.; Zheng, F.J.; Zhao, L.L.; Jiang, H.X.; Wu, W.; Xu, W.R.; et al. Revisit Overconfidence for OOD Detection: Reassigned Contrastive Learning with Adaptive Class-dependent Threshold. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Seattle, WA, USA, 10–15 July 2022; pp. 4165–4179. [Google Scholar]
- Breunig, M.M.; Kriegel, H.P.; Ng, R.T.; Sander, J. LOF: Identifying Density-Based Local Outliers. ACM SIGMOD Rec. 2000, 29, 93–104. [Google Scholar] [CrossRef]
- Hendrycks, D.; Gimpel, K. A Baseline for Detecting Misclassified and Out-of-Distribution Examples in Neural Networks. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Brashers, D.E. Communication and Uncertainty Management. J. Commun. 2001, 51, 477–497. [Google Scholar] [CrossRef]
- Salancik, G.R.; Pfeffer, J. An Examination of Need-Satisfaction Models of Job Attitudes. Adm. Sci. Q. 1977, 22, 427–456. [Google Scholar] [CrossRef]
- Salancik, G.R.; Pfeffer, J. A Social Information Processing Approach to Job Attitudes and Task Design. Adm. Sci. Q. 1978, 23, 224–253. [Google Scholar] [CrossRef] [PubMed]
- Simon, H.A. Motivational and Emotional Controls of Cognition. Psychol. Rev. 1967, 74, 29–39. [Google Scholar] [CrossRef] [PubMed]
- Zalesny, M.D.; Ford, J.K. Extending the Social Information Processing Perspective: New Links to Attitudes, Behaviors, and Perceptions. Organ. Behav. Human Decis. Process. 1990, 47, 205–246. [Google Scholar] [CrossRef]
- Dodge, K.A. A Social Information Processing Model of Social Competence in Children. In Cognitive Perspectives on Children’s Social and Behavioral Development; Psychology Press: London, UK, 1986; pp. 77–125. [Google Scholar]
- Dodge, K.A.; Crick, N.R. Social Information-Processing Bases of Aggressive Behavior in Children. Personal. Soc. Psychol. Bull. 1990, 16, 8–22. [Google Scholar] [CrossRef]
- Crick, N.R.; Dodge, K.A. Social Information-Processing Mechanisms in Reactive and Proactive Aggression. Child Dev. 1996, 67, 993–1002. [Google Scholar] [CrossRef]
- Xiu, X.L.; Qian, Q.; Wu, S.Z. Construction of a Digestive System Tumor Knowledge Graph Based on Chinese Electronic Medical Records: Development and Usability Study. JMIR Med. Inf. 2020, 8, e18287. [Google Scholar] [CrossRef]
- Yan, H.M.; Jiang, Y.T.; Zheng, J.; Fu, B.M.; Xiao, S.Z.; Peng, C.L. The Internet-Based Knowledge Acquisition and Management Method to Construct Large-Scale Distributed Medical Expert Systems. Comput. Meth. Prog. Biomed. 2004, 74, 1–10. [Google Scholar] [CrossRef]
- Booth, A.; Carroll, C. How to Build Up the Actionable Knowledge Base: The Role of ‘Best Fit’ Framework Synthesis for Studies of Improvement in Healthcare. BMJ Qual. Saf. 2015, 24, 700–708. [Google Scholar] [CrossRef]
- Sun, Z.; Deng, Z.-H.; Nie, J.-Y.; Tang, J. RotatE: Knowledge Graph Embedding by Relational Rotation in Complex Space. In Proceedings of the 7th International International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- He, H.; Choi, J.D. The Stem Cell Hypothesis: Dilemma Behind Multi-Task Learning with Transformer Encoders. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Online and Punta Cana, Dominican Republic, 7–11 November 2021; pp. 5555–5577. [Google Scholar]
- Peng, C.; Zhang, J.; Xu, Y.; Yang, J. DiseaseKG: Knowledge Graph of Common Disease Information Based on cnSchma. Available online: http://data.openkg.cn/dataset/disease-information (accessed on 22 June 2025).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Intent Label | Query Sample No. | ||
|---|---|---|---|
| Training Set | Validation Set | Test Set | |
| “病情诊断” (“diagnosis”) | 877 | 144 | 144 |
| “病因分析” (“cause”) | 153 | 15 | 14 |
| “疾病表述” (“disease_express”) | 594 | 79 | 79 |
| “注意事项” (“attention”) | 650 | 60 | 60 |
| “治疗方案” (“method”) | 1750 | 338 | 338 |
| “指标解读” (“metric_explain”) | 137 | 16 | 16 |
| “就医建议” (“advice”) | 371 | 67 | 67 |
| “后果表述” (“result”) | 235 | 22 | 23 |
| “医疗费用” (“price”) | 177 | 25 | 25 |
| “功效作用” (“effect”) | 370 | 14 | 14 |
| Data Field | Example |
|---|---|
| Query | “最近早上起来浑身无力是怎么回事?” (“Why do I always feel so weak after I wake up in the morning?”) |
| Intent Label | “病情诊断” (“diagnosis”) |
| Method | Accuracy | F1 | F1-Known | F1-Unknown |
|---|---|---|---|---|
| LOF | 0.6866 † | 0.5416 † | 0.6042 † | 0.0417 † |
| DOC | 0.7165 † | 0.5871 † | 0.6263 † | 0.2740 † |
| DeepUnk | 0.7048 † | 0.5392 † | 0.5919 † | 0.1179 † |
| ADB | 0.7735 † | 0.7418 † | 0.7870 | 0.3799 |
| Ours | 0.7896 | 0.7565 | 0.8000 | 0.4082 |
| Method | Accuracy | F1 | F1-Known | F1-Unknown |
|---|---|---|---|---|
| LOF | 0.4535 † | 0.4259 † | 0.4942 † | 0.0850 † |
| DOC | 0.5320 † | 0.4940 † | 0.5284 † | 0.3227 † |
| DeepUnk | 0.4871 † | 0.4597 † | 0.5137 † | 0.1903 † |
| ADB | 0.7346 | 0.7161 | 0.7242 | 0.6757 |
| Ours | 0.7457 | 0.7279 | 0.7362 | 0.6864 |
| Method | Accuracy | F1 | F1-Known | F1-Unknown |
|---|---|---|---|---|
| LOF | 0.2047 † | 0.2285 † | 0.2514 † | 0.1828 † |
| DOC | 0.2243 † | 0.2305 † | 0.2370 † | 0.2177 † |
| DeepUnk | 0.1752 † | 0.2105 † | 0.2426 † | 0.1466 † |
| ADB | 0.5058 | 0.4224 | 0.3424 | 0.5823 |
| Ours | 0.5213 | 0.4477 | 0.3742 | 0.5948 |
| View Assembly | Accuracy | F1 | F1-Known | F1-Unknown |
|---|---|---|---|---|
| UV | 0.7735 | 0.7418 | 0.7870 | 0.3799 |
| UV + SDV | 0.7823 | 0.7474 | 0.7920 | 0.3909 |
| UV + MEV | 0.7794 | 0.7542 | 0.7987 | 0.3977 |
| UV + SDV + MEV | 0.7896 | 0.7565 | 0.8000 | 0.4082 |
| View Assembly | Accuracy | F1 | F1-Known | F1-Unknown |
|---|---|---|---|---|
| UV | 0.7346 | 0.7161 | 0.7242 | 0.6757 |
| UV + SDV | 0.7506 | 0.7266 | 0.7334 | 0.6931 |
| UV + MEV | 0.7353 | 0.7140 | 0.7208 | 0.6797 |
| UV + SDV + MEV | 0.7457 | 0.7279 | 0.7362 | 0.6864 |
| View Assembly | Accuracy | F1 | F1-Known | F1-Unknown |
|---|---|---|---|---|
| UV | 0.5058 | 0.4224 | 0.3424 | 0.5823 |
| UV + SDV | 0.5165 | 0.4482 | 0.3777 | 0.5893 |
| UV + MEV | 0.5181 | 0.4230 | 0.3406 | 0.5878 |
| UV + SDV + MEV | 0.5213 | 0.4477 | 0.3742 | 0.5948 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Lau, R.Y.K. Uncertainty Detection: A Multi-View Decision Boundary Approach Against Healthcare Unknown Intents. Appl. Sci. 2025, 15, 7114. https://doi.org/10.3390/app15137114
Zhang Y, Lau RYK. Uncertainty Detection: A Multi-View Decision Boundary Approach Against Healthcare Unknown Intents. Applied Sciences. 2025; 15(13):7114. https://doi.org/10.3390/app15137114
Chicago/Turabian StyleZhang, Yongxiang, and Raymond Y. K. Lau. 2025. "Uncertainty Detection: A Multi-View Decision Boundary Approach Against Healthcare Unknown Intents" Applied Sciences 15, no. 13: 7114. https://doi.org/10.3390/app15137114
APA StyleZhang, Y., & Lau, R. Y. K. (2025). Uncertainty Detection: A Multi-View Decision Boundary Approach Against Healthcare Unknown Intents. Applied Sciences, 15(13), 7114. https://doi.org/10.3390/app15137114