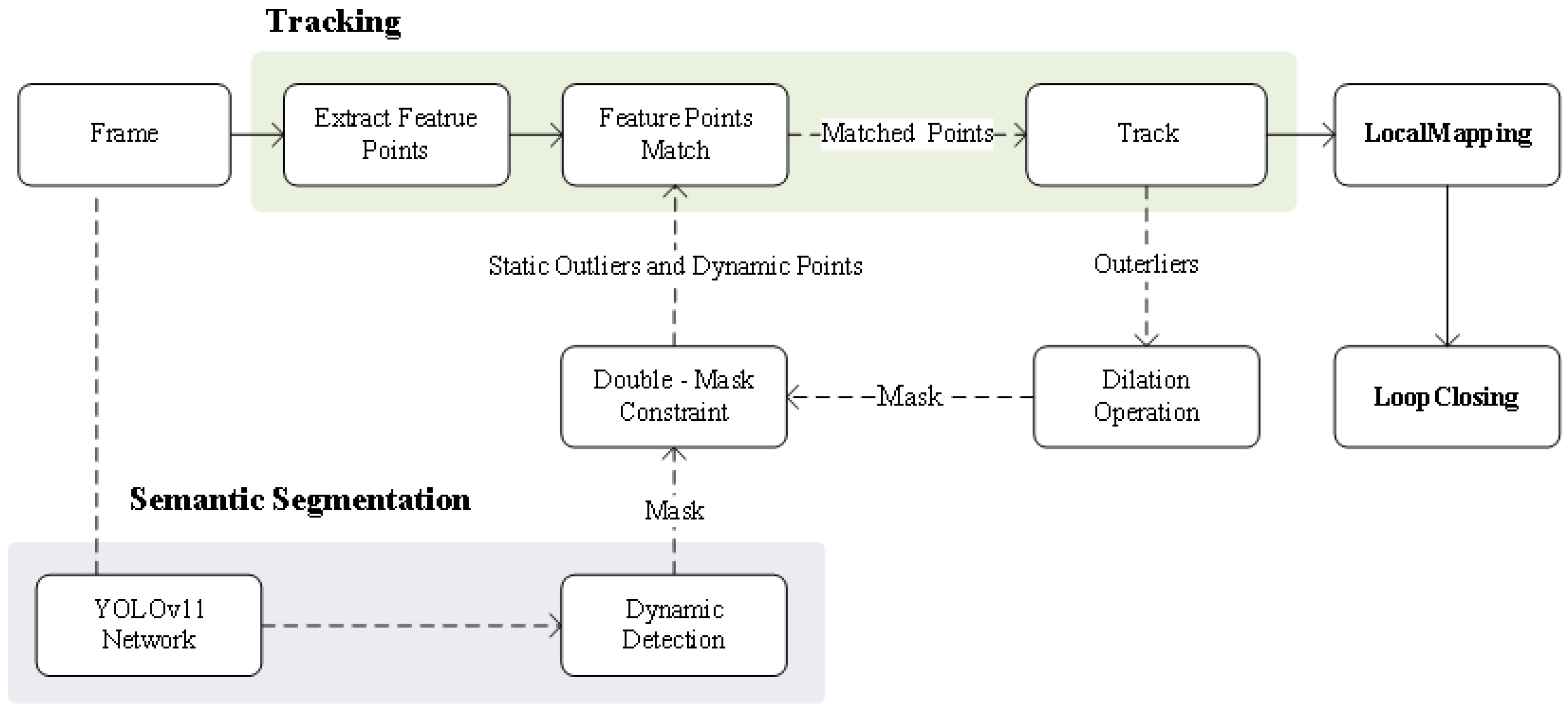
We conducted experimental validation of the proposed system using the public datasets KITTI and TUM. In our experiments, the proposed method was compared and evaluated against the mainstream ORB-SLAM3 system, with the Absolute Trajectory Error (ATE) and Relative Pose Error (RPE) selected as performance metrics. The ATE reflects the overall deviation between the system’s estimated trajectory and the actual trajectory, intuitively demonstrating the cumulative error caused by mismatches in dynamic features. The RPE measures the accuracy of relative pose estimation between adjacent frames but is more susceptible to instantaneous dynamic disturbances; as a result, it is primarily used to assess a system’s local stability. For error quantification, the ATE is assessed using the Root Mean Square Error (RMSE) to reflect the degree of overall trajectory deviation, while the RPE is measured using the mean in order to reflect the system’s stability performance in inter-frame pose estimation. The above evaluation methods enable a comprehensive verification of the system’s accuracy and robustness in different dynamic environments.
To reduce interference from external factors, each test sequence was subjected to ten repeated experiments, with the median taken as the final experimental outcome. All experiments were conducted on a desktop computer equipped with an Intel i5-14600KF processor, NVIDIA GeForce RTX 4070S graphics card, and 32GB of memory.
4.1. Evaluation on the KITTI Dataset
The KITTI dataset provides real vehicular scenes containing both dynamic and static objects, and is widely used to evaluate the effectiveness of visual SLAM systems in separating moving and stationary objects in dynamic environments. In this experiment, the performance of the SLAM system proposed in this paper was compared and analyzed against ORB-SLAM3 under a monocular setting across eleven image sequences, with a focus on the impact of the dynamic object elimination strategy on the system’s localization accuracy and robustness. The performance of different systems in each sequence is summarized in
Table 1 and
Table 2, where bold font indicates the best result for that metric.
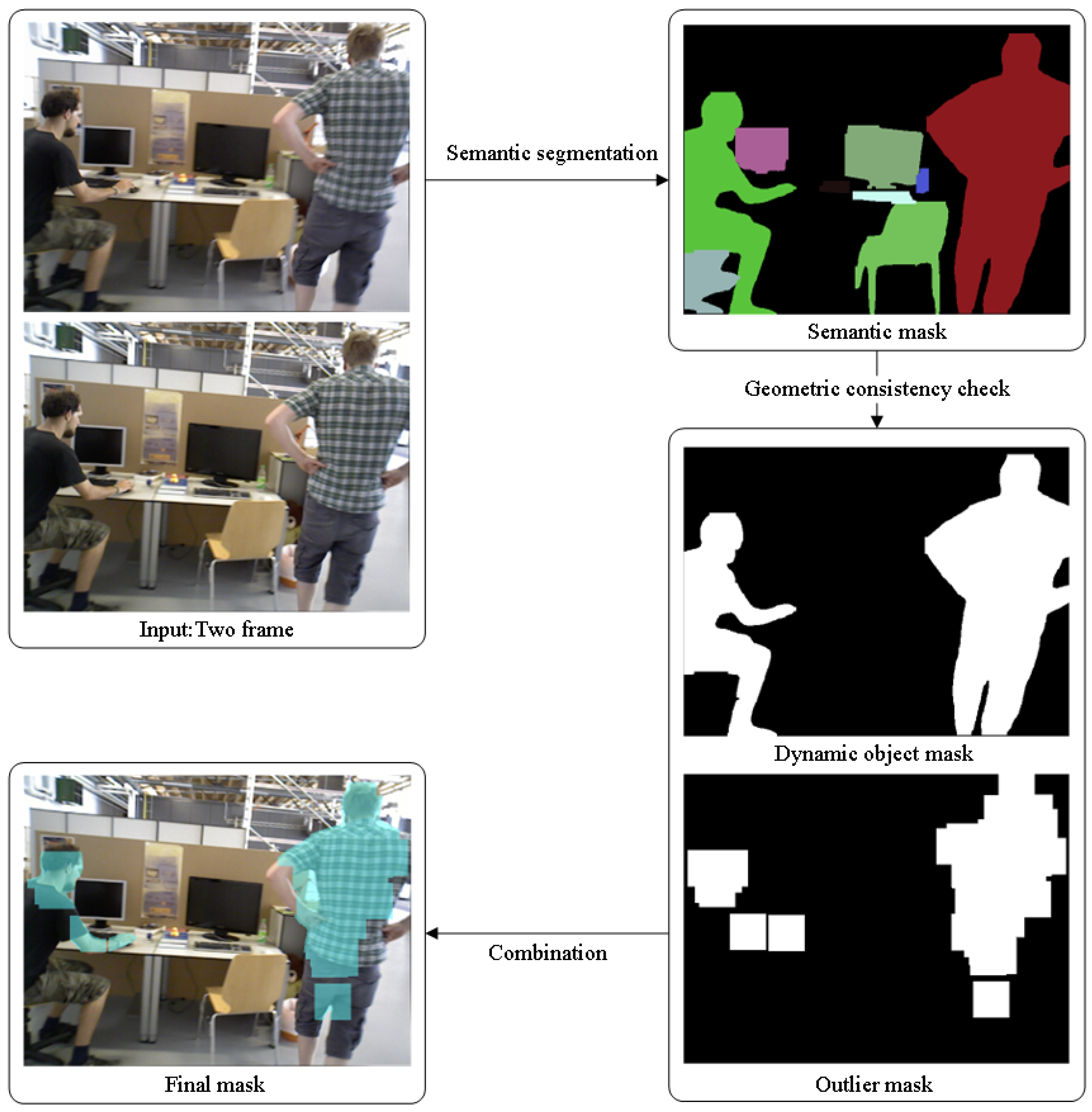
In
Table 1 and
Table 2, both System(D) and System(D+O) represent the dynamic SLAM systems proposed in this paper; System(D) refers to the system that uses a dynamic mask to directly eliminate the entire dynamic object, while System(D+O) refers to the system that uses a combination of dynamic mask and outlier mask in a dual-mask method to precisely exclude dynamic points. In the absolute trajectory evaluation on the KITTI dataset, System(D+O) is the most accurate in most sequences; in relative pose estimation, System(D) and System(D+O) are similar, with both performing better than the ORB-SLAM3 system.
Meanwhile, in the evaluation of ATE, the average standard deviations of ORB-SLAM3, System(D), and System(D+O) are 19.01, 16.90, and 17.64, respectively. Compared to ORB-SLAM3, System(D) achieves a reduction of approximately 11.1%, while System(D+O) achieves a reduction of about 7.2%. In the evaluation of RPE, the average standard deviations are 0.373, 0.282, and 0.325 for ORB-SLAM3, System(D), and System(D+O), respectively, with System(D) and System(D+O) reducing the standard deviation by 24.4% and 12.9%, respectively. These results indicate that System(D), which directly removes dynamic objects using a dynamic mask strategy, achieves the lowest average standard deviations in both ATE and RPE evaluations. This suggests significantly reduced error fluctuations compared to ORB-SLAM3 and verifies the effectiveness of the proposed strategy in suppressing error dispersion and enhancing the stability of the SLAM system, with particularly notable advantages in relative pose estimation.
To further investigate the specific impact of potential dynamic objects on SLAM system performance,
Table 3 lists the distribution of potential dynamic objects in each sequence along with an analysis of their impact on localization accuracy. For brevity, in this paper we denote System(D) as “D”, System(D+O) as “DO”, and ORB-SLAM3 as “3”.
The analysis shows that the distribution of dynamic and static objects significantly affects system performance. In the KITTI dataset sequences, ORB-SLAM3 only outperforms the dynamic SLAM system in sequences with fewer dynamic objects, such as sequences 03 and 06. This suggests that the dynamic SLAM system may erroneously eliminate static objects, resulting in reduced trajectory estimation accuracy.
Conversely, in scenarios with many dynamic objects, such as sequences 01, 04, and 07, the dynamic SLAM system significantly outperforms ORB-SLAM3 in terms of both ATE and RPE, further validating the effectiveness of the dynamic object elimination mechanism in complex dynamic environments. To quantify the degree of system performance improvement, this paper uses the following improvement rate (enhancement rate) calculation equation:
where
o represents the error value of ORB-SLAM3,
r represents the error value of the proposed method in this paper, and
is the percentage of improvement.
As shown in
Table 4, based on this evaluation, System(D) achieves an average improvement of 6.69% in absolute trajectory accuracy and 8.69% in relative pose estimation accuracy compared to ORB-SLAM3, while System(D+O) achieves an average improvement of 3.43% and 11.42%, respectively. These results demonstrate the comprehensive advantage of the proposed systems in dynamic environments.
Further comparison between System(D) and System(D+O) reveals that because the KITTI dataset primarily consists of vehicular scenes, with potential dynamic objects mostly being vehicles, System(D) employs a strategy of globally removing dynamic objects, which requires high accuracy in dynamic object recognition. Any misclassification can lead to a significant performance degradation in the system. In scenes with a higher presence of static vehicles and pedestrians and with fewer dynamic vehicles (such as sequences 00, 08, 09, and 10), System(D+O) outperforms System(D) in both trajectory and relative pose accuracy. This indicates that its fine-grained dual-mask method effectively prevents performance fluctuations caused by the misremoval of static objects, demonstrating stronger stability.
In scenarios with a high density of dynamic objects but a lack of static ones (such as sequences 01 and 04), System(D) exhibits superior performance due to the absence of misjudged static object interference, as its coarse-grained elimination strategy is more advantageous in such contexts.
In summary, the experimental results demonstrate that the dual-mask dynamic object elimination method proposed in this paper can effectively reduce pose estimation errors in dynamic scenes. The proposed system achieves accuracy surpassing that of ORB-SLAM3 in most KITTI sequences, exhibiting robustness and versatility. Even in complex boundary scenarios with many static objects and fewer dynamic ones, the performance of our system remains stable, further validating the key role of the proposed dual-mask strategy in enhancing accuracy and stability in dynamic SLAM systems.
4.2. TUM RGB-D Dataset Evaluation
The TUM RGB-D dataset includes real indoor scenes with human activity and static objects, and is designed to assess system accuracy and stability in high-dynamic indoor environments. In this experiment, we conducted a comparative analysis of the impact of dynamic contexts on the performance of the proposed SLAM system versus ORB-SLAM3 in a monocular setting across six image sequences from the TUM RGB-D dataset. The performance of the different systems across the sequences is summarized in
Table 5,
Table 6 and
Table 7, where bold font indicates the best results in each metric.
As presented in
Table 7, compared to ORB-SLAM3, the proposed System(D) achieves an average reduction of 28% in ATE and 4.27% in RPE. The enhanced System(D+O) achieves an average reduction of 24% in ATE and 8.27% in RPE. These quantitative results verify that our methods effectively mitigate cumulative errors induced by dynamic feature mismatches. Furthermore, the experimental data in
Table 5 and
Table 6 reveal that both System(D) and System(D+O) exhibit lower standard deviation (Std) values, demonstrating the high adaptability and stability of our proposed approaches in dynamic environments. Similarly,
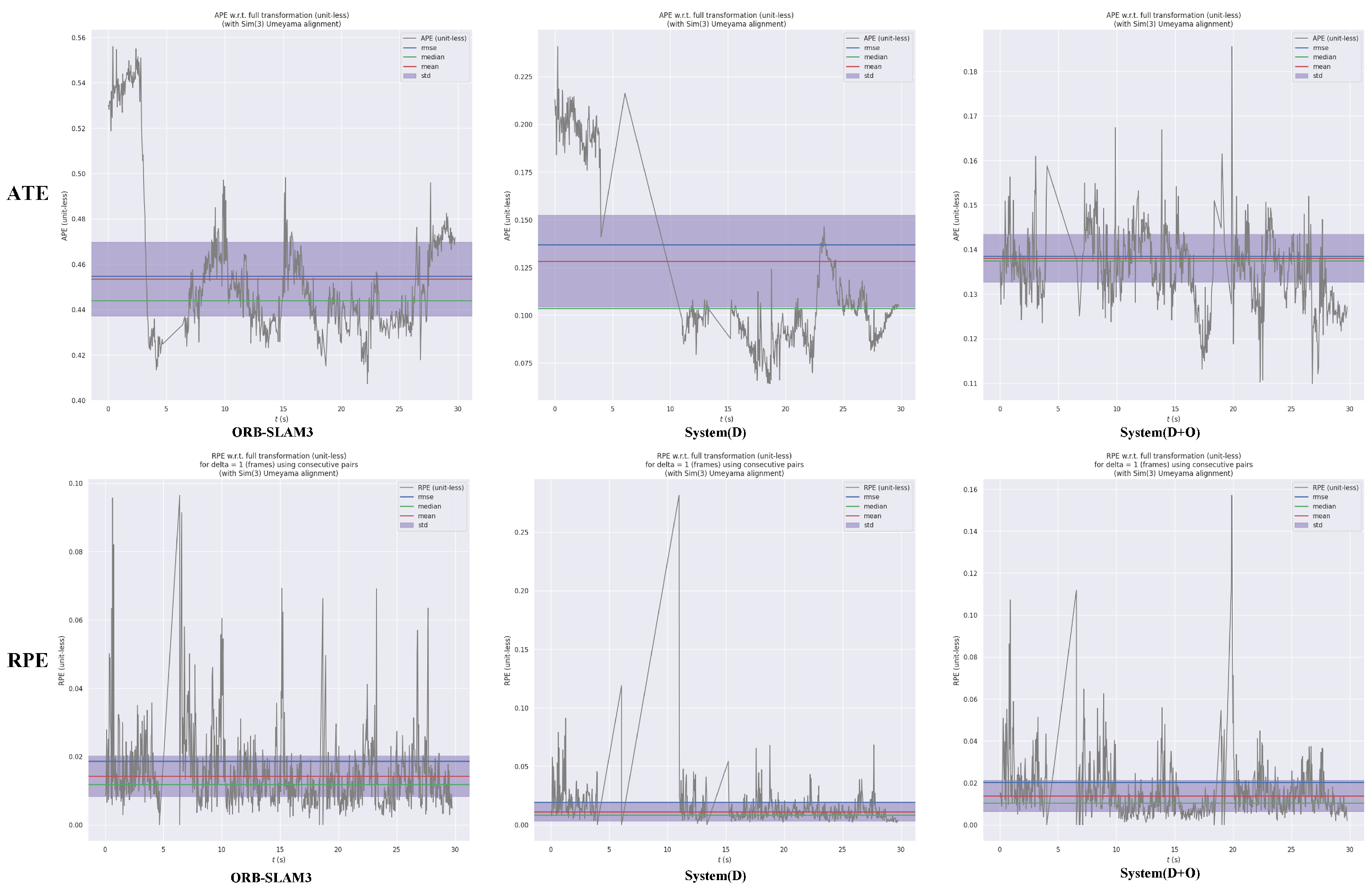
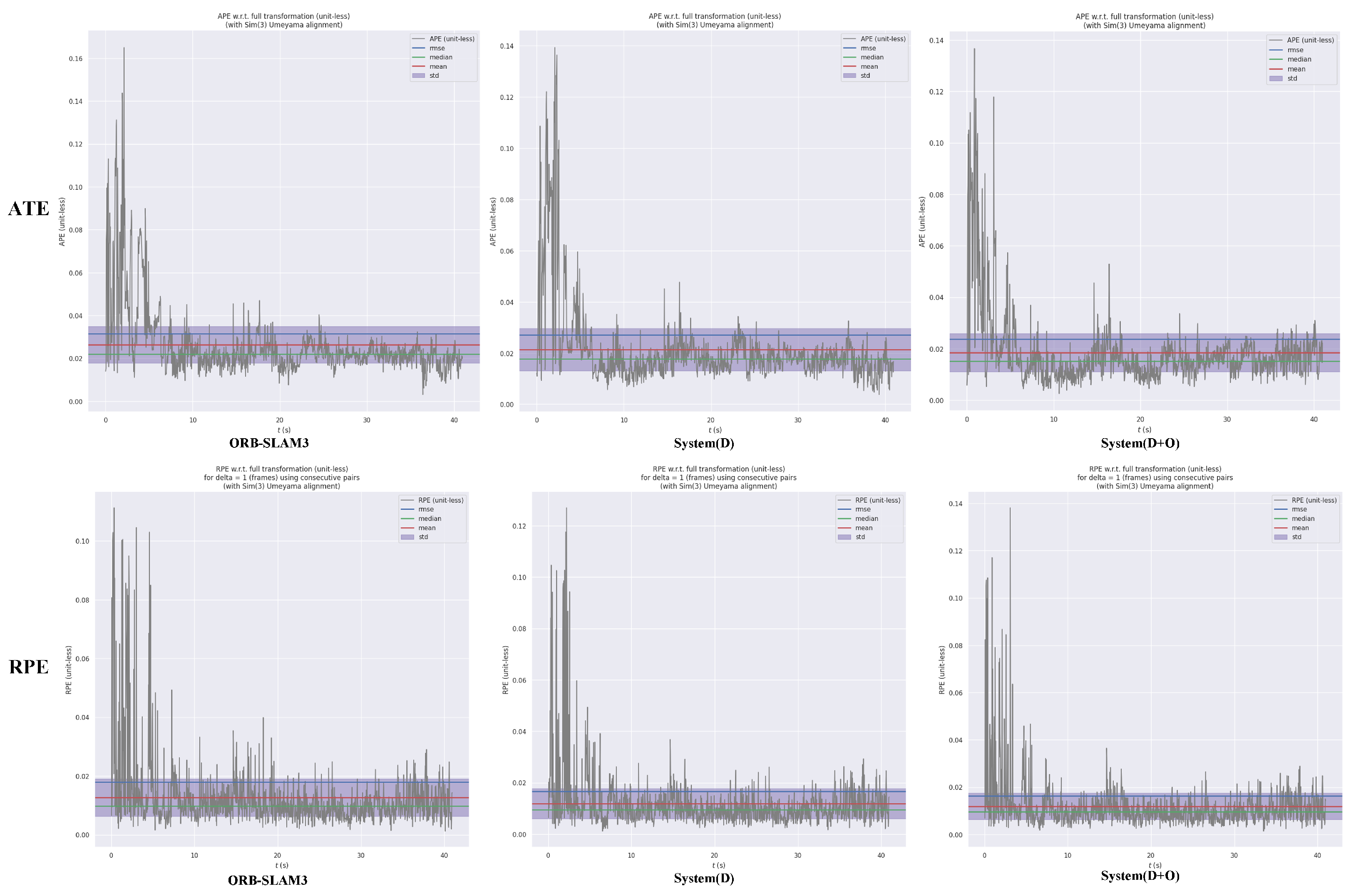
Figure 3 and Figure 5 visually demonstrate that both System(D) and System(D+O) exhibit narrower standard deviation ranges compared to ORB-SLAM3, indicating more stable performance.
From a specific scenario analysis, walking sequences such as w_halfsphere, w_rpy, and w_static contain significant overall motion by individuals, causing notable dynamic interference. Traditional methods are prone to feature matching failures and drift estimation due to the presence of dynamic points. In contrast, the proposed approaches exhibit greater accuracy improvements in these highly dynamic sequences, indicating that our dynamic point elimination mechanism has good suppression capabilities for widespread disturbances.
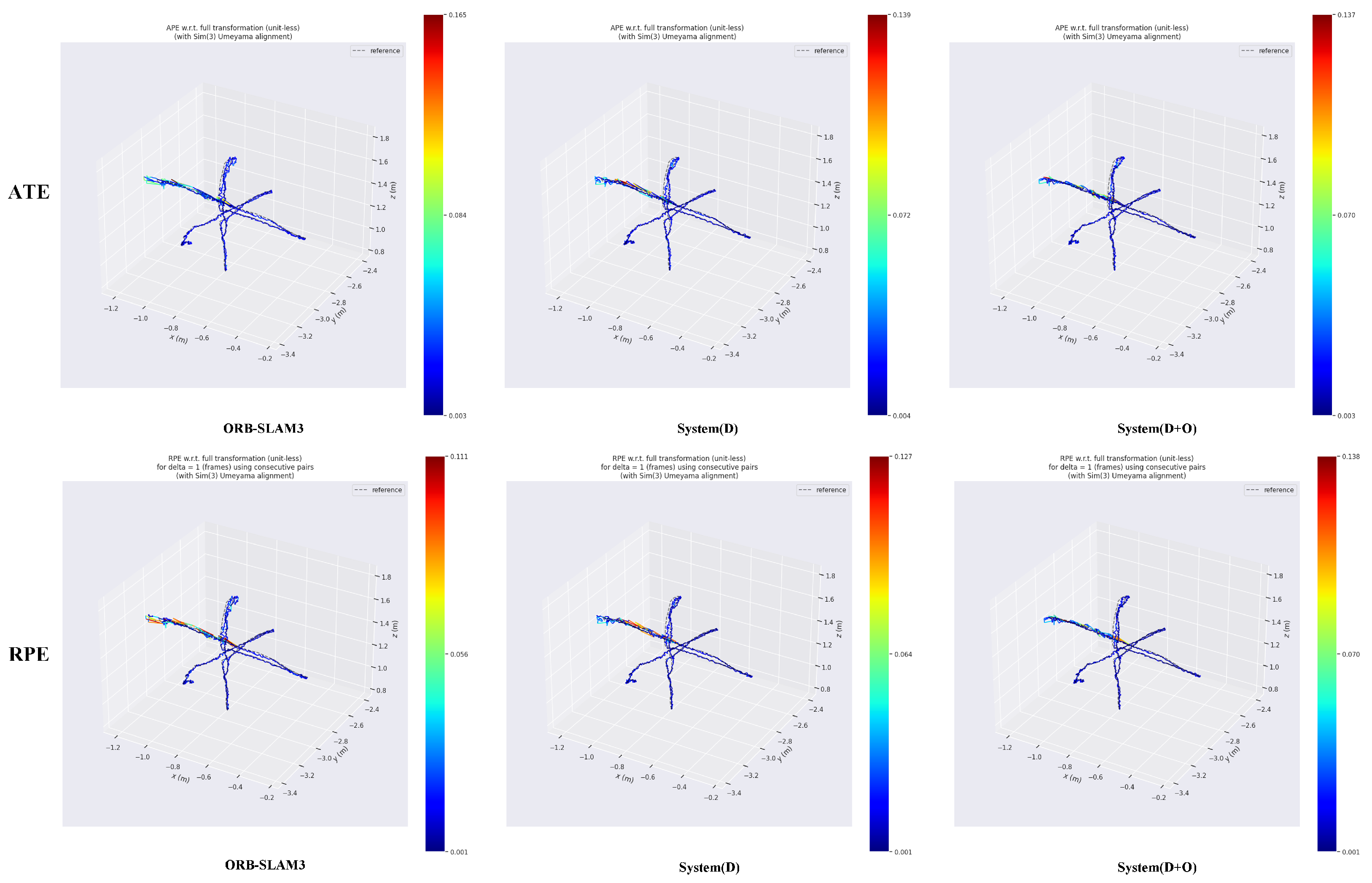
In the experimental results for the fre3_walking_rpy(w_rpy) sequence,
Figure 3 shows that the trajectory error of ORB-SLAM is in the range of 0.019–0.035, the trajectory error of System(D) is in the error range is 0.018–0.03, and the trajectory error of System(D+O) is in the range of 0.017–0.043. The accuracy of System(D+O) is almost the same as that of System(D).
Figure 4 presents the trajectory deviation map in comparison to ground truth, showing that ORB-SLAM3 experiences significant drift, while System(D) offers the most accurate trajectory estimation. In these results, System(D+O) exhibits marginally lower performance compared to System(D).
Conversely, sitting sequences such as s_halfsphere, s_rpy, and s_static are less dynamic, with only minor movements of the hands and head. In such scenarios, systems are more likely to misjudge local dynamics as global dynamics, leading to loss of static information. Therefore, the fine-grained dynamic discrimination strategy introduced in this paper is particularly crucial.
In the experimental results for the fre3_sitting_xyz(s_xyz) sequence, the constrained local movements in this sitting scenario are primarily limited to head and hand motions, resulting in negligible dynamic interference.
Figure 5 shows that the trajectory error of ORB-SLAM is in the range of 0.019–0.035 and that the trajectory error is relatively small, while the trajectory error of System(D) is in the error range is 0.018–0.03 and the trajectory error of System(D+O) is in the range of 0.017–0.043. As evidenced in
Figure 6, the trajectory deviation map demonstrates no visually discernible differences between the compared systems. Thus, both System(D) and System(D+O) continue to exhibit enhancements in the ATE and RPE metrics compared with the ORB-SLAM3 system.
When comparing the performance of System(D+O) and System(D), the former demonstrates superior ATE performance in the sitting sequences, indicating that its fine-grained dynamic point removal strategy can more effectively distinguish between local microdynamics and globally static regions, resulting in improved overall localization accuracy. System(D+O) also demonstrates measurable improvements over System(D), with enhancements of 3.18% in ATE and 8.15% in RPE. In contrast, the coarse-grained removal mechanism employed by System(D) is more prone to incorrectly eliminating static objects in such fine-grained scenarios, resulting in decreased accuracy. Conversely, in the highly dynamic walking sequences, the global removal strategy of System(D) exhibits greater advantages, as it can rapidly eliminate interfering features within large-scale moving regions. As a result, System(D) shows slightly better ATE performance in certain sequences compared to System(D+O).
In conclusion, the dual-mask dynamic point filtering method proposed in this paper demonstrates exceptional performance in complex indoor dynamic scenarios. In particular, it shows a distinct advantage in the ATE metric. System(D+O) is suitable for refined scenarios with a mix of dynamic areas and static backgrounds, while System(D) is more appropriate for handling environments with extensive highly dynamic disturbances. Regardless of the level of dynamism, the method presented in this paper significantly enhances the precision of pose estimation and the overall robustness of the system, demonstrating good versatility and potential for practical application.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}