
Improving Multi-Class Classification for Recognition of the Prioritized Classes Using the Analytic Hierarchy Process



Abstract
1. Introduction
- Its novelty is using adaptive incremental learning, which allows ML models to learn new information continuously by analyzing changing data from a data stream, to design an improved ML model for the more accurate recognition of the prioritized cyber-attack classes.
- When multi-class classification is used, performance metrics for machine learning models are calculated for each class individually, and it is quite common when a single characteristic increases for one class and decreases for the other class. In such cases, it is difficult to decide if the model changes are acceptable. To mitigate these shortcomings of the composite scores, we propose the use of the Analytical Hierarchy Process (AHP) to make the right decision based on the model performance evaluation according to prioritized classes.
2. Related Work
- One of the biggest shortcomings is the situation in which one or more classes, known as minority classes, are significantly less frequent than other classes, known as majority classes. This will result in a distortion of the decision border, hence increasing the classification error for high-value attack data.
- The classification approaches proposed by the other authors are not oriented to correctly classify prioritized classes; instead, all multi-class classes are combined in two classes (normal and abnormal), and binary classification approaches are used to differentiate between normal and abnormal behavior,
- A new method needs to be proposed if we ar3 to create an ML model that is oriented towards better recognition of the important classes that have been prioritized.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Problem | Solution | Dataset | Details |
|---|---|---|---|---|
| Taylor et al. [18] | A challenge in creating an ML-based detection system that uses heterogeneous network data samples. | Employing a multilayer perception (MLP) model, a type of feedforward artificial neural network. | NF-ToN-IoT 10 classes 19.6% benign 80.4% various attacks | Binary classification. |
| Maseno et al. [19] | Capacity of deep learning algorithms in the selection of optimal feature subset in the field of IDS. | Used CNN’s potential for selecting the best feature subsets to enhance intrusion detection. | TON_IoT SMOTEtomek applied to solve the issue of class imbalance | Binary classification. |
| Bhuiyan et al. [20] | A key research gap is the reliance on outdated datasets for training and evaluation. | An innovative DNN model introduced for efficient detection of stealthy and polymorphic variants of network intrusions. Conducts an ablation study to dissect the components of the DNN model. | NF-ToN-loT NF-UNSW-NB15-v2 4 classes 2,390,275 flows, with 3.98% attacks | Binary classification. |
| Khan et al. [21] | Effective anomaly recognition and explanation are critical for ensuring quality services in IIOT. | The phenomenon of sliding windows is utilized for the processing of time-series data. | Industrial Control System (ICS) dataset 8 classes 214,580 normal 60,048 anomalous | Binary classification. |
| Kumar et al. [22] | Anomaly-based IDS in IoT network. | The gain ratio is used for feature selection and BiLSTM is used for classification. | BoT-IoT ToN-IoT 300,000 normal 162,043 attacks | Binary classification ToN-IoT |
| Park et al. [23] | The problem of data imbalance, in which AI models cannot sufficiently learn malicious behavior and thus fail to detect network threats accurately. | Focused on the reconstruction error and Wasserstein distance-based generative adversarial networks, and autoencoder-driven deep learning models. | NSL-KDD 4 classes 77,052 normal 71,464 attacks UNSW-NB15 10 classes 93,000 normal 164,673 attacks | Binary classification and Multi-classification Generated synthetic data for each class via the generative model |
| Oliveira et al. [24] | Addressed the CIDDS-001 dataset using the AttackType label to train machine learning methods. | Single-flow (%) recall 71.4–95.68 Multi-flow (%) recall 85.65–89.71 | CIDDS-001 | Multi-class |
| Kollu et al. [25] | Cloud-based smart contract analysis in Fintech. | Integrated federated learning in intrusion detection | KDDCUP99, ISCX, and NSL-KDD | Two-class and four-class categories |
| Alamsyah et al. [26] | Innovative credit risk assessment. | Integrated social media analytics within credit scoring systems. | Data collected from LinkedIn | Binary classification |
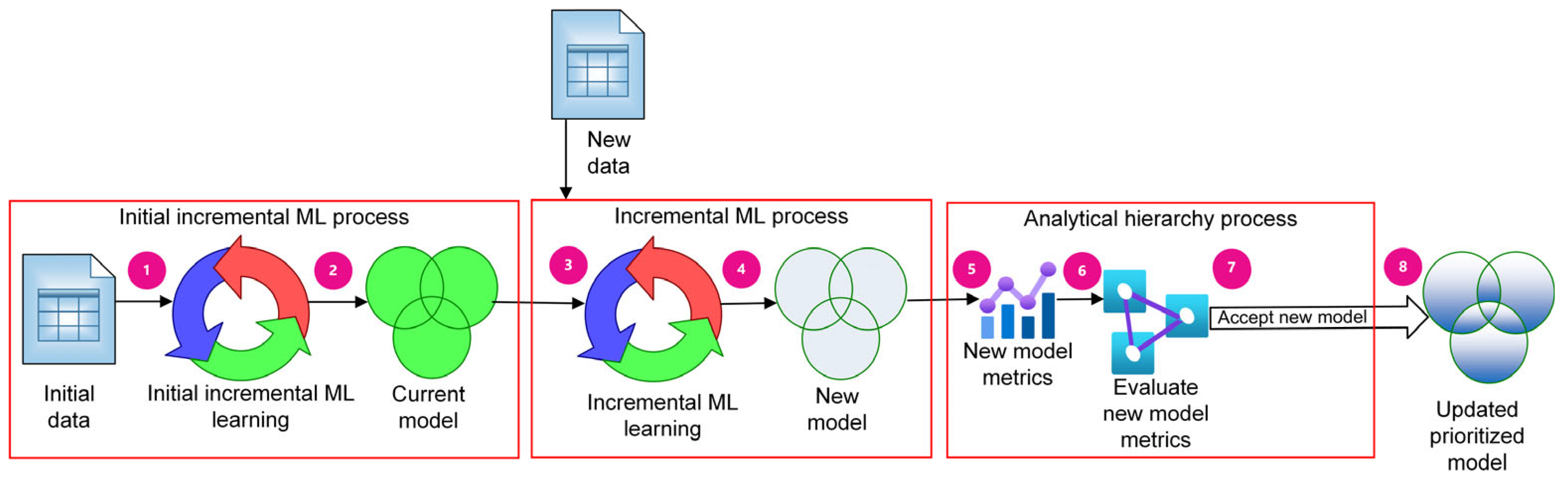
3. Improving Multi-Class Classification for Recognition of the Prioritized Classes Using the AHP
- Use the initial available data and train the incremental ML model.
- As a result of the first training, the initial model is produced, and initial performance characteristics are calculated. The initial model is marked as the current model.
- After the new batch of training data is available, train the current version of the ML model using the new data.
- As a result of step 3, the new ML model is produced, and performance characteristics are obtained.
- Present the performance metrics of both the existing model and the new model for the AHP decision-making process.
- Load the application-specific AHP judgment matrix with the results of the pairwise comparison of the metrics receiving prioritization;
- Use the AHP process and make decisions to include (or not to include) the new data in the prioritized model. If the decision is to not include the new data, then the new ML model is discarded. Otherwise, the new ML model is marked as the current model.
- Repeat the process starting, from step 3, until no new data is available. The current ML model becomes the final updated prioritized model after processing all batches of data.
- The AHP provides the ability to check the consistency of the evaluations provided by decision makers;
- The AHP allows the use of heterogeneous measurement scales for different criteria;
- The AHP eases multi-objective decision-making by using exclusively pairwise comparisons of the alternatives, which provides increased reliability of the results;
- The most controversial step of manual weight assignment to different criteria is avoided.
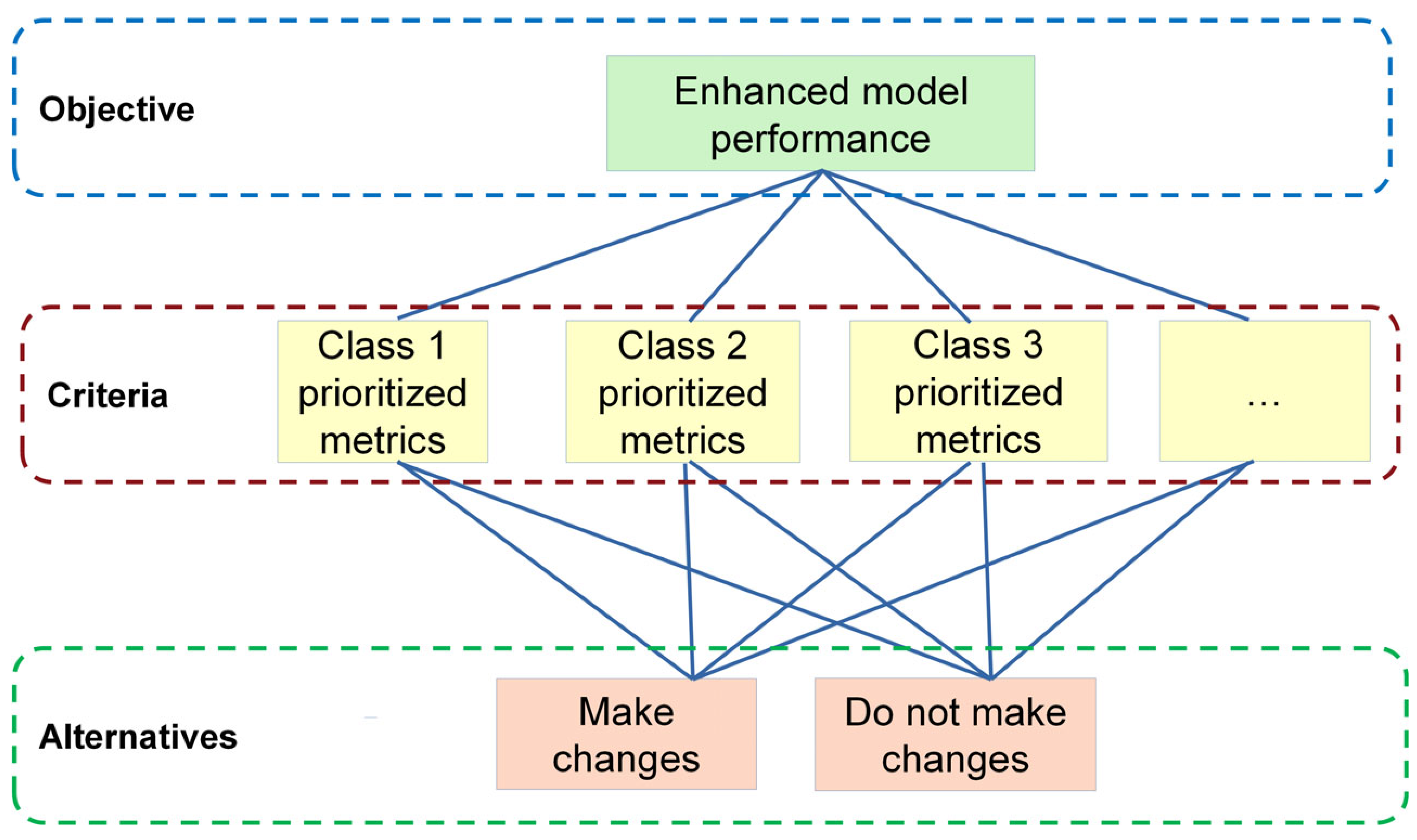
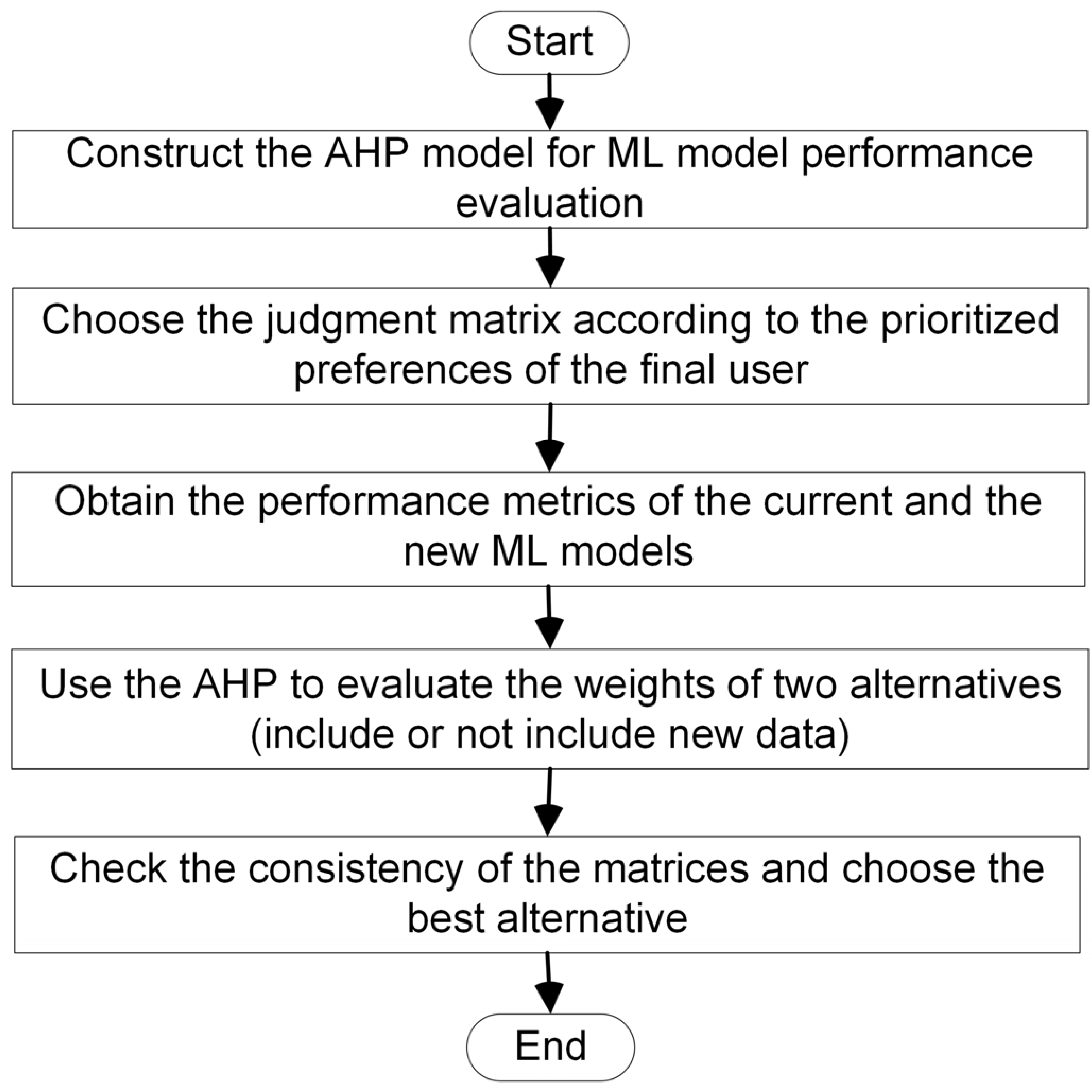
- Construct an AHP framework according to the structure provided in Figure 2 and include all the criteria suitable for the concrete dataset and application area.
- Load the judgment matrix representing the priorities of the concrete organization with the results of pairwise comparisons of all criteria.
- Obtain the performance characteristics of the current and the new machine learning models.
- For each criterion, repeat the following:
- Construct the weight coefficient matrix using both alternatives (i.e., metrics of the current and the new ML model). The elements of the matrix are calculated using a comparison function, which compares performance metrics of the current and the new model and converts them into real numbers from the interval (0, 9].
- Provide all the created matrices with the standard AHP decision-making method to obtain the estimated weights of both alternatives.
- Check the consistency of the matrices using AHP consistency indicators. Choose the best alternative as the final decision.
4. Experimental Settings and Results
4.1. Dataset
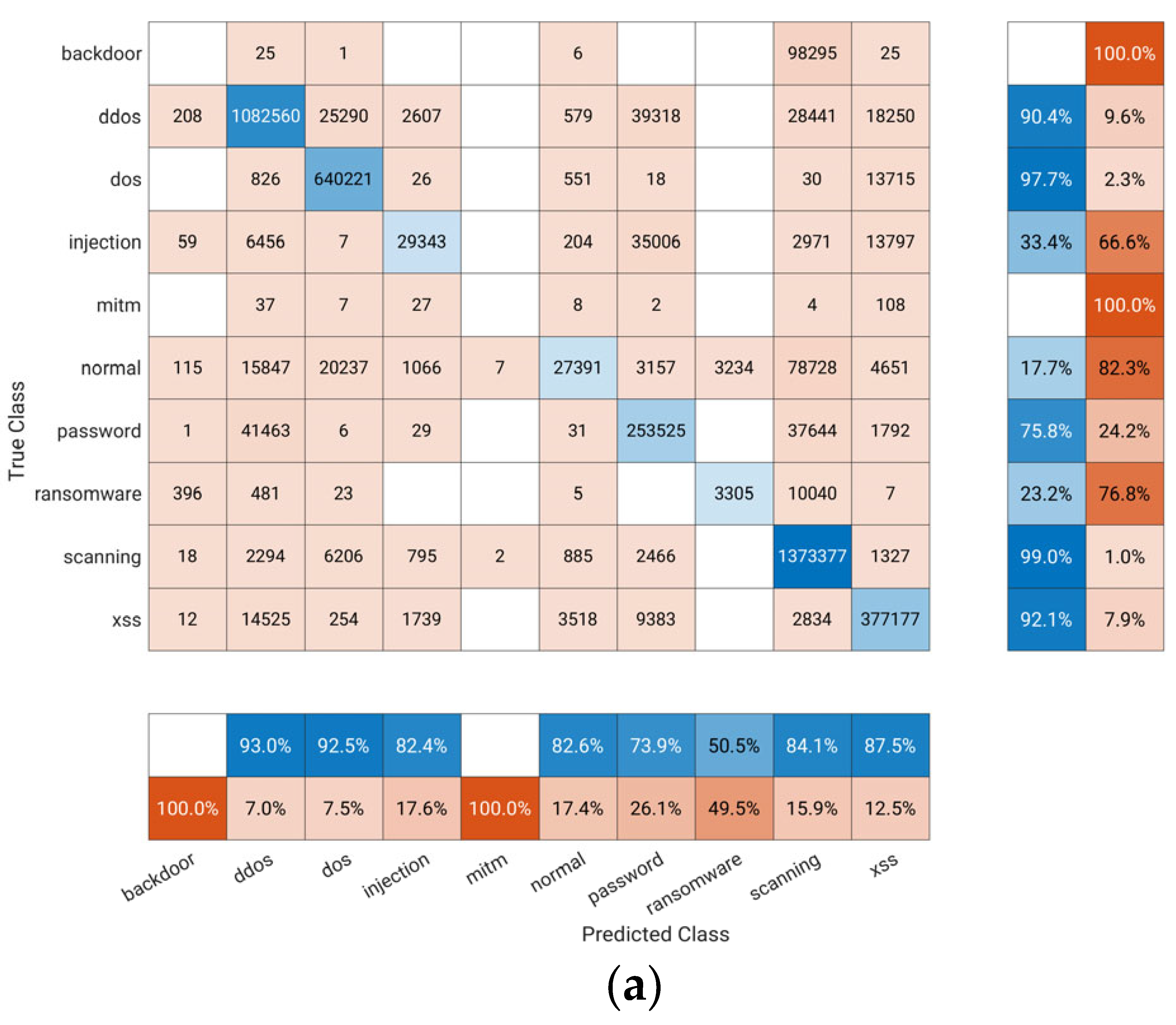
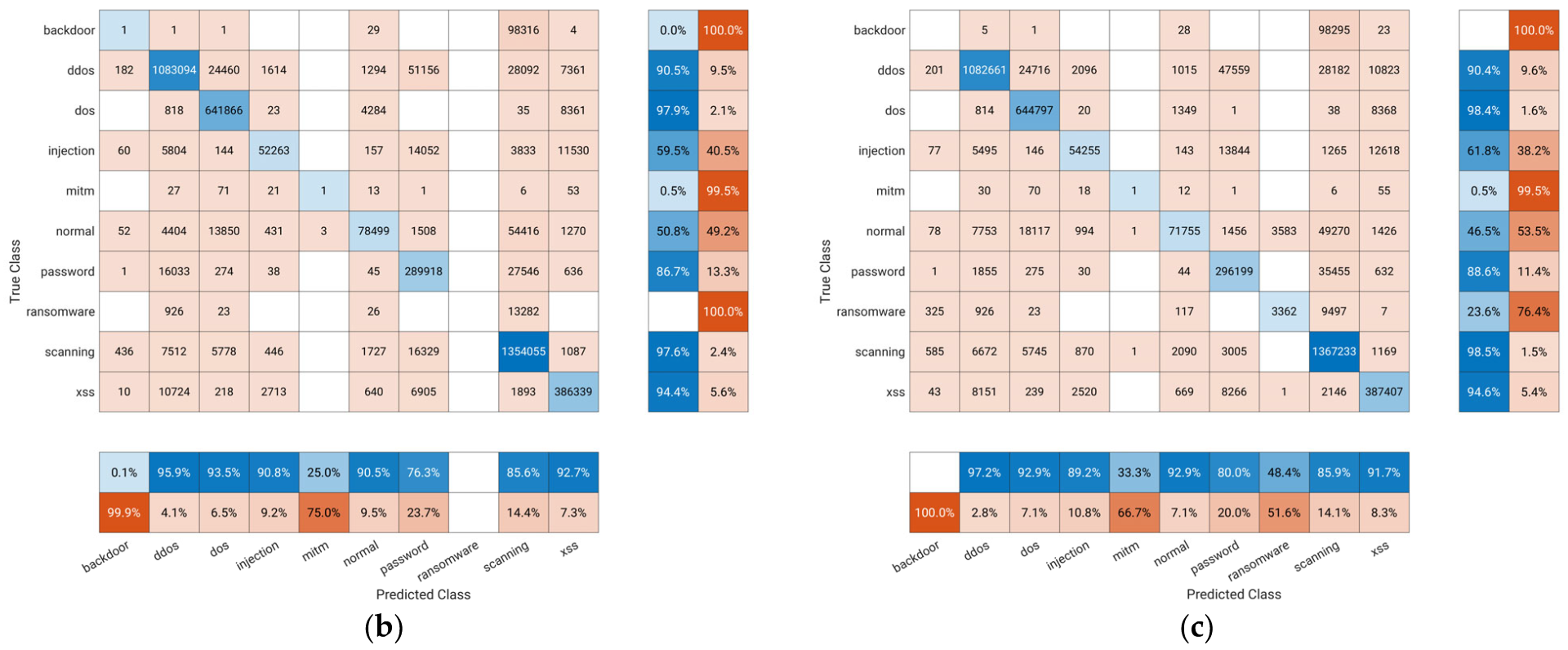
4.2. Experimantal Evaluation of the Proposed Method
5. Discussion
- The proposed approach employs incremental learning, AHP, and ECOC to improve ML model performance for the important classes that have been prioritized.
- Unlike data-driven methods, the proposed approach does not involve any modifications to the dataset; rather, we use the original multi-class dataset in its current form.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AdaGrad | Adaptive Gradient Algorithm |
| AHP | Analytical Hierarchy Process |
| AI | Artificial Intelligence |
| CNN | Convolutional Neural Network |
| CTI | Cyber Threat Intelligence |
| ECOC | Error-Correcting Output Codes |
| Fintech | Financial Technology |
| IDS | Intrusion Detection Systems |
| KNN | K-Nearest Neighbor Algorithm |
| LightGBM | Light Gradient-Boosting Machine |
| LSTM | Long Short-Term Memory |
| ML | Machine learning |
| MLP | Multilayer Perceptrons |
| RF | Random Forest |
| RMSprop | Root Mean Square Propagation |
| SGD | Stochastic Gradient Descent |
| SMOTE | Synthetic Minority Oversampling Technique |
| SVM | Support Vector Machine |
| XGBoost | eXtreme Gradient Boosting |
References
- Jafri, J.A.; Amin, S.I.M.; Rahman, A.A.; Nor, S.M. A systematic literature review of the role of trust and security on Fintech adoption in banking. Heliyon 2024, 10, 1. [Google Scholar] [CrossRef] [PubMed]
- Ndichu, S.; Ban, T.; Takahashi, T.; Inoue, D. AI-Assisted Security Alert Data Analysis with Imbalanced Learning Methods. Appl. Sci. 2023, 13, 1977. [Google Scholar] [CrossRef]
- Javaheri, D.; Fahmideh, M.; Chizari, H.; Lalbakhsh, P.; Hur, J. Cybersecurity threats in FinTech: A systematic review. Expert Syst. Appl. 2024, 241, 122697. [Google Scholar] [CrossRef]
- Chao, X.; Ran, Q.; Chen, J.; Li, T.; Qian, Q.; Ergu, D. Regulatory technology (Reg-Tech) in financial stability supervision: Taxonomy, key methods, applications and future directions. Int. Rev. Financ. Anal. 2022, 80, 102023. [Google Scholar] [CrossRef]
- Aaron, W.C.; Irekponor, O.; Aleke, N.T.; Yeboah, L.; Joseph, J.E. Machine learning techniques for enhancing security in financial technology systems. Int. J. Sci. Res. Arch. 2025, 15, 2. [Google Scholar] [CrossRef]
- Angela, O.; Atoyebi, I.; Soyele, A.; Ogunwobi, E. Enhancing fraud detection and prevention in fintech: Big data and machine learning approaches. World J. Adv. Res. Rev. 2024, 24, 2. [Google Scholar] [CrossRef]
- Cao, Z.; Zhao, Z.; Shang, W.; Ai, S.; Shen, S. Using the ToN-IoT dataset to develop a new intrusion detection system for industrial IoT devices. Multimed. Tools Appl. 2025, 84, 16425–16453. [Google Scholar] [CrossRef]
- Ding, H.; Chen, L.; Dong, L.; Fu, Z.; Cui, X. Imbalanced data classification: A KNN and generative adversarial networks-based hybrid approach for intrusion detection. Future Gener. Comput. Syst. 2022, 131, 240–254. [Google Scholar] [CrossRef]
- Li, J.; Othman, M.S.; Chen, H.; Yusuf, L.M. Cybersecurity Insights: Analyzing IoT Data Through Statistical and Visualization Techniques. In Proceedings of the 2024 International Symposium on Parallel Computing and Distributed Systems (PCDS), Singapore, 21–22 September 2024; pp. 1–10. [Google Scholar] [CrossRef]
- Yildirim, O.; Bakhshi, S.; Can, F. Prioritized Binary Transformation Method for Efficient Multi-label Classification of Data Streams with Many Labels. In Proceedings of the 33rd ACM International Conference on Information and Knowledge Management (CIKM’24). Association for Computing Machinery, New York, NY, USA, 21–25 October 2024; pp. 4218–4222. [Google Scholar] [CrossRef]
- Bulavas, V.; Marcinkevičius, V.; Rumiński, J. Study of Multi-Class Classification Algorithms’ Performance on Highly Imbalanced Network Intrusion Datasets. Informatica 2021, 3, 441–475. [Google Scholar] [CrossRef]
- Mortier, T.; Wydmuch, M.; Dembczyński, K.; Hüllermeier, E.; Waegeman, W. Efficient set-valued prediction in multi-class classification. Data Min. Knowl. Disc. 2021, 35, 1435–1469. [Google Scholar] [CrossRef]
- Du, J.; Zhou, Y.; Liu, P.; Vong, C.; Wang, T. Parameter-Free Loss for Class-Imbalanced Deep Learning in Image Classification. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 3234–3240. [Google Scholar] [CrossRef] [PubMed]
- Xie, S.; He, Z.; Pan, L.; Liu, K.; Su, S. An adaptive error-correcting output codes algorithm based on gene expression programming and similarity measurement matrix. Pattern. Recognit. 2024, 145, 109957. [Google Scholar] [CrossRef]
- Ruchay, A.; Feldman, E.; Cherbadzhi, D.; Sokolov, A. The Imbalanced Classification of Fraudulent Bank Transactions Using Machine Learning. Mathematics 2023, 11, 2862. [Google Scholar] [CrossRef]
- Chen, W.; Yang, K.; Yu, Z.; Shi, Y.; Chen, C.L.P. A survey on imbalanced learning: Latest research, applications and future directions. Artif. Intell. 2024, 57, 137. [Google Scholar] [CrossRef]
- Khan, A.A.; Chaudhari, O.; Chandra, R. A review of ensemble learning and data augmentation models for class imbalanced problems: Combination, implementation and evaluation. Expert Syst. Appl. 2024, 244, 122778. [Google Scholar] [CrossRef]
- Taylor, G.; Johnson, D.; Roy, K. Threat Detection Using MLP for IoT Network. In Proceedings of the 2024 Internet Computing and IoT and Embedded Systems, Cyber-physical Systems, and Applications (CSCE 2024), Las Vegas, USA, 22–25 July 2024; Springer: Berlin/Heidelberg, Germany; Volume 2260, pp. 108–115. [Google Scholar] [CrossRef]
- Maseno, E.M.; Wang, Z.; Sun, Y. Performance Evaluation of Intrusion Detection Systems on the TON_IoT Datasets Using a Feature Selection Method. In Proceedings of the 8th International Conference on Computer Science and Artificial Intelligence (CSAI’24). Association for Computing Machinery, New York, NY, USA, 6–8 December 2024; pp. 607–613. [Google Scholar] [CrossRef]
- Bhuiyan, M.H.; Alam, K.; Shahin, K.I.; Farid, D.M. A Deep Learning Approach for Network Intrusion Classification. In Proceedings of the IEEE Region 10 Symposium (TENSYMP), New Delhi, India, 27–29 September 2024. [Google Scholar] [CrossRef]
- Khan, I.A.; Moustafa, N.; Pi, D.; Sallam, K.M.; Zomaya, A.Y.; Li, B. A New Explainable Deep Learning Framework for Cyber Threat Discovery in Industrial IoT Networks. IEEE Internet Things 2022, 9, 11604–11613. [Google Scholar] [CrossRef]
- Kumar, P.J.; Neduncheliyan, S.; Adnan, M.M.; Sudhakar, K.; Sudhakar, A.V.V. Anomaly-Based Intrusion Detection System Using Bidirectional Long Short-Term Memory for Internet of Things. In Proceedings of the Third International Conference on Distributed Computing and Electrical Circuits and Electronics (ICDCECE), Ballari, India, 26–27 April 2024; pp. 1–4. [Google Scholar] [CrossRef]
- Park, C.; Lee, J.; Kim, Y.; Park, J. -G.; Kim, H.; Hong, D. An Enhanced AI-Based Network Intrusion Detection System Using Generative Adversarial Networks. IEEE Internet Things 2023, 10, 2330–2345. [Google Scholar] [CrossRef]
- Oliveira, N.; Praça, I.; Maia, E.; Sousa, O. Intelligent Cyber Attack Detection and Classification for Network-Based Intrusion Detection Systems. Appl. Sci. 2021, 11, 1674. [Google Scholar] [CrossRef]
- Kollu, V.N.; Janarthanan, V.; Karupusamy, M.; Ramachandran, M. Cloud-Based Smart Contract Analysis in FinTech Using IoT-Integrated Federated Learning in Intrusion Detection. Data 2023, 8, 83. [Google Scholar] [CrossRef]
- Alamsyah, A.; Hafidh, A.A.; Mulya, A.D. Innovative Credit Risk Assessment: Leveraging Social Media Data for Inclusive Credit Scoring in Indonesia’s Fintech Sector. Risk Financ. Manag. 2025, 18, 74. [Google Scholar] [CrossRef]
- Venčkauskas, A.; Toldinas, J.; Morkevičius, N.; Serkovas, E.; Krištaponis, M. Enhancing the Resilience of a Federated Learning Global Model Using Client Model Benchmark Validation. Electronics 2025, 14, 1215. [Google Scholar] [CrossRef]
- Incremental Learning: Adaptive and Real-Time Machine Learning. Available online: https://blogs.mathworks.com/deep-learning/2024/03/04/incremental-learning-adaptive-and-real-time-machine-learning/ (accessed on 22 April 2025).
- Petrillo, A.; Salomon, V.A.P.; Tramarico, C.L. State-of-the-Art Review on the Analytic Hierarchy Process with Benefits, Op-portunities, Costs, and Risks. J. Risk Financ. Manag. 2023, 16, 372. [Google Scholar] [CrossRef]
- Saaty, T.L.; Vargas, L.G. The Seven Pillars of the Analytic Hierarchy Process. In Models, Methods, Concepts & Applications of the Analytic Hierarchy Process; Springer: Boston, MA, USA, 2001; pp. 27–46. ISBN 978-1-4615-1665-1. [Google Scholar]
- Zhang, Y.; Jiang, R.; Wang, L. A Novel Network Attack Evaluation Scheme Based on AHP Grey Clustering Model. In Proceedings of the 8th International Conference on Computing, Control and Industrial Engineering (CCIE2024); Shmaliy, Y.S., Ed.; Springer Nature Singapore: Singapore, 2024; pp. 375–383. [Google Scholar]
- Akshitha, K.; M, B.A.; Kodipalli, A.; Rao, T.; R, R.B.; N, G. An Approach for Ranking Cyber Crime Using Fuzzy AHP and Fuzzy TOPSIS. In Proceedings of the 2023 International Conference on Recent Advances in Science and Engineering Technology (ICRASET), Dharwad, India, 11 August 2023; pp. 1–7. [Google Scholar]
- Khaira, A.; Dwivedi, R.K. A State of the Art Review of Analytical Hierarchy Process. Mater. Today Proc. 2018, 5, 4029–4035. [Google Scholar] [CrossRef]
- Moustafa, N. A new distributed architecture for evaluating AI-based security systems at the edge: Network TON_IoT datasets. Sustain. Cities Soc. 2021, 72, 102994. [Google Scholar] [CrossRef]
- TON_IoT Datasets. Available online: https://unsw-my.sharepoint.com/personal/z5025758_ad_unsw_edu_au/_layouts/15/onedrive.aspx?id=%2Fpersonal%2Fz5025758%5Fad%5Funsw%5Fedu%5Fau%2FDocuments%2FTON%5FIoT%20datasets&ga=1 (accessed on 22 April 2025).
- Majidian, Z.; TaghipourEivazi, S.; Arasteh, B.; Babaie, S. An intrusion detection method to detect denial of service attacks using error-correcting output codes and adaptive neuro-fuzzy inference. Comput. Electr. Eng. 2023, 106, 108600. [Google Scholar] [CrossRef]
- Oreski, D.; Oreski, S.; Klicek, B. Effects of dataset characteristics on the performance of feature selection techniques. Appl. Soft Comput. 2017, 52, 109–119. [Google Scholar] [CrossRef]
- Thabtah, F.; Hammoud, S.; Kamalov, F.; Gonsalves, A. Data imbalance in classification: Experimental evaluation. Inf. Sci. 2020, 513, 429–441. [Google Scholar] [CrossRef]
- Wang, P.; Wang, X.; Song, Y.; Huang, J.; Ding, P.; Yang, Z. TransIDS: A Transformer-based approach for intrusion detection in Internet of Things using Label Smoothing. In Proceedings of the 4th International Conference on Computer Engineering and Application (ICCEA), Hangzhou, China, 7–9 April 2023; pp. 216–222. [Google Scholar] [CrossRef]
- Eren, K.K.; Küçük, K. Improving Intrusion Detection Systems for IoT Devices using Automated Feature Generation based on ToN_IoT dataset. In Proceedings of the 8th International Conference on Computer Science and Engineering (UBMK), Burdur, Turkiye, 13–15 September 2023; pp. 276–281. [Google Scholar] [CrossRef]
- Alotaibi, Y.; Ilyas, M. Enhancing IoT Attack Detection Through Ensemble-Based Multiclass Attacks Classification. In Proceedings of the 20th International Conference on Smart Communities: Improving Quality of Life using AI, Robotics and IoT (HONET), Boca Raton, FL, USA, 4–6 December 2023; pp. 1–6. [Google Scholar] [CrossRef]
| Full | Training | Testing | ||||
|---|---|---|---|---|---|---|
| Class | Count | % | Count | % | Count | % |
| backdoor | 508,116 | 2.275 | 409,764 | 2.276 | 98,352 | 2.267 |
| ddos | 6,165,008 | 27.597 | 4,967,755 | 27.599 | 1,197,253 | 27.593 |
| dos | 3,375,328 | 15.110 | 2,719,941 | 15.111 | 655,387 | 15.104 |
| injection | 452,659 | 2.026 | 364,816 | 2.027 | 87,843 | 2.024 |
| mitm | 1052 | 0.005 | 859 | 0.005 | 193 | 0.004 |
| password | 1,718,568 | 7.693 | 1,384,077 | 7.689 | 334,491 | 7.709 |
| ransomware | 72,805 | 0.326 | 58,548 | 0.325 | 14,257 | 0.329 |
| scanning | 7,140,161 | 31.963 | 5,752,791 | 31.960 | 1,387,370 | 31.974 |
| xss | 2,108,944 | 9.441 | 1,699,502 | 9.442 | 409,442 | 9.436 |
| normal | 796,380 | 3.565 | 641,947 | 3.566 | 154,433 | 3.559 |
| Total | 22,339,021 | 18,000,000 | 4,339,021 | |||
| Step | The Important Attack Classes That Have Been Prioritized | AHP Score | Include the New Data | Training Time (s) | AHP Evaluation Time (ms) | ||
|---|---|---|---|---|---|---|---|
| Injection | Password | Ransomware | |||||
| 1 | 0.317 | 0.757 | 0.000 | Yes | 4.45 | ||
| 2 | 0.459 | 0.885 | 0.000 | 0.62 | Yes | 4.38 | 1.05 |
| 3 | 0.469 | 0.768 | 0.233 | 0.56 | Yes | 4.32 | 0.42 |
| 4 | 0.435 | 0.765 | 0.000 | 0.34 | No | 4.32 | 0.42 |
| 5 | 0.568 | 0.768 | 0.234 | 0.57 | Yes | 4.39 | 0.42 |
| 6 | 0.618 | 0.866 | 0.235 | 0.65 | Yes | 4.36 | 0.50 |
| 7 | 0.598 | 0.885 | 0.000 | 0.43 | No | 4.37 | 0.36 |
| 8 | 0.442 | 0.767 | 0.000 | 0.31 | No | 4.36 | 0.36 |
| 9 | 0.596 | 0.885 | 0.234 | 0.51 | Yes | 4.35 | 0.35 |
| 10 | 0.600 | 0.885 | 0.000 | 0.48 | No | 4.33 | 0.35 |
| 11 | 0.450 | 0.767 | 0.234 | 0.40 | No | 4.33 | 0.35 |
| 12 | 0.613 | 0.835 | 0.000 | 0.42 | No | 4.32 | 0.38 |
| 13 | 0.590 | 0.885 | 0.235 | 0.48 | No | 4.31 | 0.38 |
| 14 | 0.618 | 0.885 | 0.234 | 0.57 | Yes | 4.32 | 0.36 |
| 15 | 0.586 | 0.885 | 0.235 | 0.51 | Yes | 4.35 | 0.35 |
| 16 | 0.601 | 0.885 | 0.000 | 0.46 | No | 4.30 | 0.35 |
| 17 | 0.600 | 0.885 | 0.000 | 0.47 | No | 4.35 | 0.36 |
| 18 | 0.559 | 0.771 | 0.236 | 0.39 | No | 4.37 | 0.35 |
| 19 | 0.594 | 0.886 | 0.000 | 0.46 | No | 4.33 | 0.35 |
| 20 | 0.611 | 0.886 | 0.236 | 0.56 | Yes | 4.29 | 0.35 |
| 21 | 0.606 | 0.886 | 0.000 | 0.37 | No | 4.32 | 0.35 |
| 22 | 0.416 | 0.805 | 0.000 | 0.28 | No | 4.26 | 0.38 |
| 23 | 0.587 | 0.885 | 0.236 | 0.45 | No | 4.31 | 0.35 |
| 24 | 0.560 | 0.842 | 0.000 | 0.32 | No | 4.36 | 0.35 |
| 25 | 0.572 | 0.863 | 0.000 | 0.32 | No | 4.40 | 0.35 |
| 26 | 0.595 | 0.886 | 0.236 | 0.45 | No | 4.35 | 0.36 |
| 27 | 0.598 | 0.885 | 0.000 | 0.36 | No | 4.36 | 0.35 |
| 28 | 0.614 | 0.886 | 0.000 | 0.45 | No | 4.34 | 0.35 |
| 29 | 0.606 | 0.876 | 0.236 | 0.41 | No | 4.43 | 0.37 |
| 30 | 0.565 | 0.885 | 0.222 | 0.36 | No | 4.39 | 0.35 |
| 31 | 0.549 | 0.788 | 0.084 | 0.31 | No | 4.37 | 0.35 |
| 32 | 0.618 | 0.886 | 0.236 | 0.53 | Yes | 4.36 | 0.37 |
| 33 | 0.516 | 0.814 | 0.097 | 0.31 | No | 4.39 | 0.35 |
| 34 | 0.599 | 0.885 | 0.093 | 0.39 | No | 4.43 | 0.35 |
| 35 | 0.602 | 0.875 | 0.309 | 0.47 | No | 4.37 | 0.36 |
| 36 | 0.596 | 0.872 | 0.000 | 0.32 | No | 4.37 | 0.35 |
| 37 | 0.618 | 0.886 | 0.236 | ||||
| The Important Attack Classes That Have Been Prioritized | Step | Recall | Precision | F1-Score |
|---|---|---|---|---|
| Injection | 1 | 0.317 | 0.830 | 0.459 |
| 37 | 0.618 | 0.892 | 0.730 | |
| Password | 1 | 0.757 | 0.734 | 0.745 |
| 37 | 0.886 | 0.800 | 0.840 | |
| Ransomware | 1 | 0.000 | 0.000 | 0.000 |
| 37 | 0.236 | 0.484 | 0.317 |
| Research | Dataset | Proposed Approach | Dataset Balance Method | Feature Ranking | Improve Performance for Prioritized Classes |
|---|---|---|---|---|---|
| Wang et al. [39] | TON_IoT | Transformer-based IoT intrusion detection method | Label smoothing regularization to add fuzzy noise to the training sample labels | The deep global feature extraction capability of a stacked encoder | No |
| Eren et al. [40] | TON_IoT | RF-based intrusion detection | SMOTE and cluster-based undersampling | Feature elimination using multi-collinearity-based generation of complex features | No |
| Alotaibi et al. [41] | TON_IoT | Merging five multi-class supervised ML models: RF, DT, ET, XgBoost and K-Nearest Neighbor | SMOTE | Mutual Information, Pearson Correlation Coefficient, and K-Best | No |
| Proposed | TON_IoT | Incremental learning, AHP ECOC | Original dataset was used | The original dataset was used | Yes |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Venčkauskas, A.; Toldinas, J.; Morkevičius, N. Improving Multi-Class Classification for Recognition of the Prioritized Classes Using the Analytic Hierarchy Process. Appl. Sci. 2025, 15, 7071. https://doi.org/10.3390/app15137071
Venčkauskas A, Toldinas J, Morkevičius N. Improving Multi-Class Classification for Recognition of the Prioritized Classes Using the Analytic Hierarchy Process. Applied Sciences. 2025; 15(13):7071. https://doi.org/10.3390/app15137071
Chicago/Turabian StyleVenčkauskas, Algimantas, Jevgenijus Toldinas, and Nerijus Morkevičius. 2025. "Improving Multi-Class Classification for Recognition of the Prioritized Classes Using the Analytic Hierarchy Process" Applied Sciences 15, no. 13: 7071. https://doi.org/10.3390/app15137071
APA StyleVenčkauskas, A., Toldinas, J., & Morkevičius, N. (2025). Improving Multi-Class Classification for Recognition of the Prioritized Classes Using the Analytic Hierarchy Process. Applied Sciences, 15(13), 7071. https://doi.org/10.3390/app15137071