Abstract
This study proposes a federated learning-based real-time surface roughness prediction framework for WEDM to address issues of empirical parameter tuning and data privacy. By sharing only the model parameters, cross-machine training was enabled without exposing raw data. A custom data acquisition system collected discharge current and spindle current signals, which were solely used as input features to train the deep learning model. Data balancing techniques improved prediction accuracy, achieving performance comparable to centralized models. After optimizing the training dataset through balancing and augmentation, the federated model achieved a Root Mean Square Error (RMSE) of 0.076, which closely approaches the 0.074 RMSE obtained by the centralized model. The results show that federated learning enhances both data security and model generalization, offering an effective solution for smart manufacturing.
1. Introduction
Federated learning, as an emerging decentralized machine learning technique, has gained significant attention in recent years, particularly in the industrial sector. It demonstrates notable advantages in data privacy protection and decentralized data management. Li et al. [1] systematically reviewed the applications of federated learning in the industrial, healthcare, and Internet of Things (IoT) domains, highlighting its outstanding performance in handling sensitive data while maintaining privacy. Liu et al. [2] proposed a federated learning solution based on an edge computing framework for the Industrial IoT (IIoT), effectively enhancing production efficiency and data security. Xianhui et al. [3] further applied federated learning to industrial artificial intelligence by integrating threshold secret sharing and homomorphic encryption to strengthen data security. However, their approach requires more communication rounds, which may reduce training efficiency. Additionally, Tianhao et al. [4] introduced the Federated Shapley Value method to evaluate the contribution of data in federated learning. This method supports fair distribution and can effectively improve overall training efficiency while identifying low-quality participants. Yiqiang et al. [5] combined federated learning with transfer learning through the FedHealth framework to address cross-domain data integration issues in wearable devices. By encrypting model parameter transmissions and applying transfer learning to user models, they successfully improved model accuracy by 5.3%, demonstrating a strong balance between privacy protection and performance. However, federated learning still faces numerous challenges in real-world applications, particularly the issue of non-independent and identically distributed (non-IID) data. Mahdi et al. [6] proposed a data augmentation method based on Stable Diffusion, named Gen-FedSD, which effectively alleviates the problem of non-IID data distribution in federated learning. This approach significantly enhanced the model’s generalization ability and achieved outstanding performance on the CIFAR-10 and CIFAR-100 datasets. Jie et al. [7] conducted an in-depth discussion on federated learning in terms of privacy protection, communication efficiency, and data heterogeneity, offering suggestions and future research directions. Peter et al. [8] also provided a comprehensive review of federated learning from multiple perspectives, including efficiency improvement, privacy preservation, fairness, and systemic challenges. They thoroughly examined critical unresolved issues such as non-IID data handling, communication constraints, and attack defenses. In addition, Weiting et al. [9] proposed a three-tier collaborative federated learning architecture, which utilizes multi-agent reinforcement learning to optimize device selection and resource allocation, effectively reducing communication costs and improving learning accuracy. Wei et al. [10] developed a decentralized federated learning framework that achieves an ideal balance between communication and computation costs, offering valuable insights for practical applications. In specific research on surface roughness prediction in wire electrical discharge machining (WEDM), traditional approaches have mainly focused on the application of artificial neural networks and optimization techniques. Conde et al. [11] proposed the use of an Elman-type recurrent neural network (LRNN) to predict geometric errors combined with simulated annealing (SA) to optimize cutting paths, effectively compensating for profile deviations caused by wire deformation. Mustafa et al. [12] compared four machine learning algorithms (ELM, W-ELM, SVR, and Q-SVR) in predicting surface roughness in aluminum alloy WEDM, confirming the superior performance of the W-ELM model (R2 = 0.9720), which demonstrates the strong potential of artificial intelligence techniques for surface quality prediction in non-traditional machining. Jiang and Yen [13] integrated a Markov Transition Field (MTF) with a Convolutional Long Short-Term Memory network (LSTM), proposing an MTF-LSTM model that considers both static machining parameters and dynamic process conditions and effectively improving prediction accuracy. In addition, Zeng et al. [14] presented a hybrid prediction framework that integrated physical modeling with deep learning, employing a physics-guided loss function and data augmentation strategies to significantly improve model generalization and predictive performance. Concurrently, Chen et al. [15] utilized a backpropagation neural network (BPNN) to construct their prediction model and conducted variance analyses to examine the effects of machining parameters. Kanlayasiri et al. [16] and Dodun et al. [17] investigated surface roughness prediction in WEDM by utilizing pulse current, pulse duration, and workpiece thickness as model inputs. However, their methodologies rely on pre-established parameters, including fixed machine settings and workpiece characteristics, limiting their real-time prediction capabilities. Addressing this constraint, we referred to the study by Khan et al. [18], which demonstrated that surface roughness could be accurately predicted using only electrical signals such as current and voltage. Building upon these insights, our research extends the minimal-input approach by validating its efficacy on two distinct WEDM machines, highlighting its robustness and cross-machine applicability for real-time surface roughness prediction. Furthermore, federated learning technology has demonstrated broad potential in industrial applications. Rieke et al. [19] explored the use of federated learning in the field of digital health, emphasizing its ability to protect patient privacy while enabling personalized healthcare through decentralized machine learning techniques. Mohammad et al. [20] systematically reviewed the strategies and future prospects of federated learning aggregation algorithms, while Subrato et al. [21] provided a comprehensive overview of the application domains, challenges, and technological development directions of federated learning. Sanchez et al. [22] proposed a deep learning architecture that combines convolutional neural networks with gated recurrent units (CGRUs), which can effectively utilize voltage signals in wire electrical discharge machining (WEDM) to predict unexpected events during the machining process. Taken together, these studies highlight that by leveraging federated learning for real-time prediction of surface roughness in WEDM, it is possible to not only protect data privacy but also significantly enhance real-time monitoring and quality control efficiency in manufacturing. This presents a meaningful step toward the realization of Industry 4.0.
To provide a comprehensive overview of the proposed methodology, Figure 1 illustrates the overall workflow of this study. The process begins with the high-resolution acquisition of machining data, including discharge current, spindle current, wire tension, and cutting speed, using a custom-built sensing system. Surface roughness measurements are conducted using a precision roughness tester to obtain accurate ground truth labels. The collected data undergo preprocessing steps such as denoising, normalization, and feature fusion to form a structured time-series input. This input is then fed into a modified Mini-GPT model for surface roughness prediction. Two training paradigms are evaluated: centralized training and federated learning. In the federated approach, local models are trained on separate nodes and periodically aggregated on a central server, ensuring data privacy. Furthermore, data balancing techniques are applied to mitigate the effects of non-uniform distributions across devices. This end-to-end workflow reflects the practical deployment scenario of real-time surface quality monitoring in wire EDM and serves as the foundation for the experimental design discussed in the following sections.
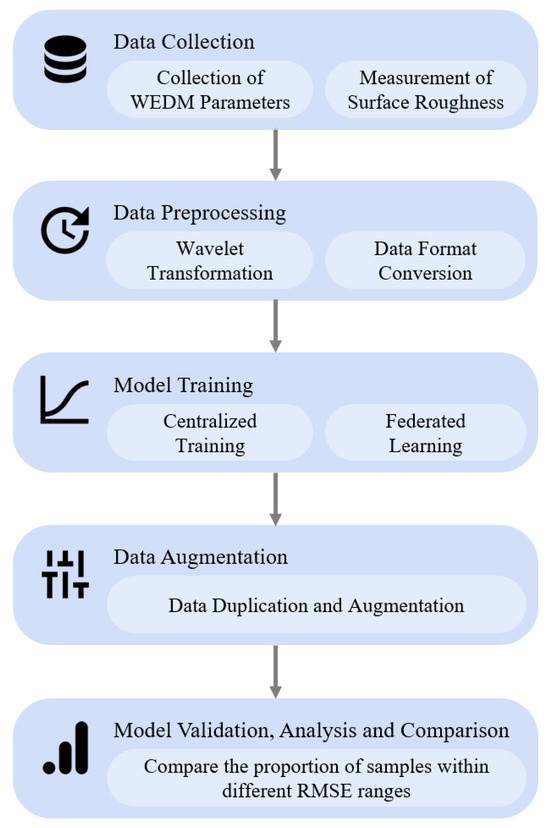
Figure 1.
Overall workflow of the federated learning-based WEDM surface roughness prediction process.
2. Related Technologies
2.1. Federated Learning
Federated learning [23] is a distributed machine learning technique that enables the collaborative training of a shared model across multiple devices or nodes without centralizing data. Instead of sharing raw data, only model gradients are exchanged to ensure data privacy and security. In the federated learning framework, each node independently trains the model using its local data and uploads the computed gradients or model updates to a central server. The server then aggregates these updates and distributes the updated global model back to the nodes for the next round of training. While federated learning effectively preserves data privacy, it faces practical challenges such as non-identically distributed data and model update aggregation. Techniques like Federated Averaging are commonly used to address these issues by performing weighted averaging of model updates, ensuring that data heterogeneity among devices does not compromise the model’s generalization capability. In this study, the experimental setup involves two industrial PCs (IPCs) functioning as agent nodes. Each IPC computes model gradients based on its local data and uploads the results to a central server for model weight updates. The updated model is then sent back to the IPCs to continue the subsequent training process.
2.2. Mini-GPT with Time-Series Data
The model architecture in this study is a modified version of Mini-GPT [24] tailored for real-time surface roughness prediction in wire electrical discharge machining (WEDM). The original Mini-GPT was designed primarily for text generation and natural language processing tasks, incorporating an embedded layer for vectorizing textual data. However, considering the nature of industrial data—specifically, time-series numerical data—this study replaced the embedded layer with a fully connected (dense) layer. This adjustment allows the model to directly process continuous numerical inputs, enhancing both computational efficiency and prediction accuracy.
The input data are structured as a three-dimensional time-series matrix defined as input = [a, b, c], with time measured in seconds. The three dimensions represent the following:
- a (measured value dimension): actual sensor readings, such as current, voltage, or vibration intensity;
- b (data type dimension): distinguishes data from different sources or sensor types;
- c (sampling frequency dimension): reflects the number of samples taken per second by the sensors.
This structure ensures the model effectively captures temporal patterns and multi-variate relationships critical for accurate surface roughness prediction.
As a practical example, this study collects data using current sensors installed on three axes (X, Y, and Z). Each time the sensors perform a measurement, three types of current data are obtained: average current (avgCurrent), maximum current (maxCurrent), and minimum current (minCurrent). Therefore, the resulting data matrix, with a dimensionality of b, can be explicitly represented as a set of current measurements across the three axes, as illustrated in Figure 2.
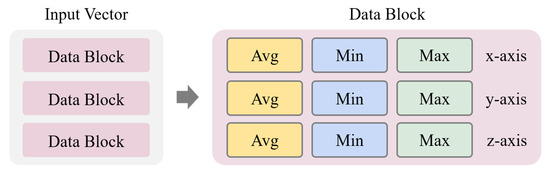
Figure 2.
Input vector structure for current data.
The data sampling frequency dimension c is adjusted based on the actual configuration of the sensors. For instance, the current sensors used in this study operate at a sampling rate of approximately 20 data points per second, meaning that 20 (a,b) matrices are generated every second. However, this frequency can be dynamically modified according to practical needs, depending on the machining task or sensing scenario. With the above improvements, the proposed model is capable of effectively handling high-frequency, multi-dimensional machining data and capturing subtle variations in current across each axis that influence surface roughness during machine operation. In addition, by removing the original embedding layer of Mini-GPT and directly using a dense layer to receive continuous numerical inputs, the model avoids unnecessary data transformation and computation, thereby reducing model size, increasing training speed, and saving both energy and computational resources.
3. Methods
3.1. Experimental Setup
This study employed two AccuteX AP6040 (Accutex Technologies Co., Ltd., Taichung, Taiwan) wire electrical discharge machining (WEDM) systems for surface roughness experimentation. Each machine supports a maximum workpiece size of 800 × 500 × 245 mm, with a peak discharge voltage of 140 V, maximum pulse duration of 1200 ns, and a maximum off-time of 50 μs. The selection of machining parameters, including pulse duration (8, 10, 12 μs), off-time (8, 10, 12 μs), wire tension (10, 12, 14 kg·m/s2), and spark gap (0.733, 0.772, 0.811 μm), was based on prior studies that demonstrated their critical influence on machining outcomes such as surface roughness, dimensional accuracy, and hardness [16,17]. These parameter ranges were chosen to ensure experimental coverage across practical operating conditions reported the in literature. As shown in Figure 3, each workpiece measured 150 × 150 mm and was divided into two parameter zones, with three repeated square cuts per zone, yielding six processed areas per workpiece. All machining operations were simultaneously conducted on both machines to simulate a heterogeneous equipment environment and assess the model’s generalization and adaptability under a federated learning framework. Surface roughness was measured using a PORA FBT-650 roughness tester (JIN-MAO Science Technology Instrument Enterprise CO., LTD., Kaohsiung, Taiwan), featuring a repeatability of 0.005 μm and a measurement range of 0.02–160 μm, ensuring reliable ground truth data for model training. This well-controlled and reproducible experimental setup forms the foundation for subsequent federated model development and performance evaluation.
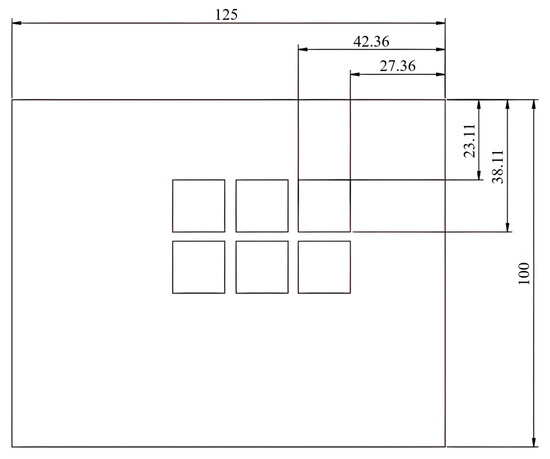
Figure 3.
Engineering drawing of the WEDM workpiece and cutting layout.
3.2. WEDM Data Collection
In this study, to overcome the limitation of conventional Delta power meters—which can only provide one data point per second and thus fail to capture current fluctuations during high-frequency machining processes—we designed and implemented a custom current data acquisition system based on a Raspberry Pi and an ADS1115, as illustrated in Figure 4. The system uses a Raspberry Pi as the central controller and employs the ADS1115 for 16-bit resolution analog-to-digital conversion via the I2C protocol. It is integrated with SCT013-25A (Dechang Electronic, Beijing, China) and SCT013-10A (Dechang Electronic, Beijing, China) current sensor coils, which are used to monitor the discharge circuit and spindle circuit currents, respectively. This architecture enables a stable data acquisition rate of 20 samples per second, offering a 20-fold improvement in temporal resolution compared to traditional power meters. As a result, the system effectively captures fine-grained current variations during the machining process. The raw current signals undergo real-time preprocessing on the Raspberry Pi, including denoising, timestamp synchronization, and data formatting. The processed data are then stored on an industrial data platform, ensuring the availability of high-quality input for subsequent model training and analysis.
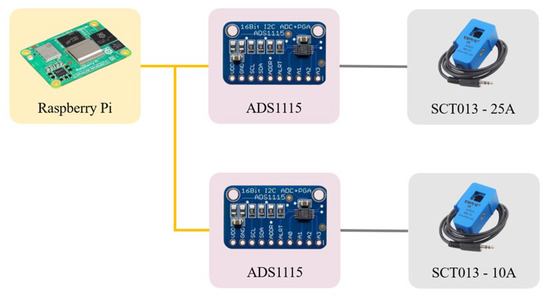
Figure 4.
Voltage and Current Acquisition Architecture.
3.3. Measurement of Surface Roughness
In this study, a PORA FBT-650 surface roughness tester was employed to perform high-precision measurements of the workpiece surface quality. As illustrated in Figure 5, three measurement points were evenly distributed on each of the four side faces of the workpiece, resulting in a total of twelve measurement locations. At each point, three independent measurements were conducted, and the median value was taken as the representative result to minimize the influence of random errors. This measurement configuration ensured comprehensive coverage of the workpiece surface features, thereby enhancing the representativeness and stability of the acquired data. All measurement results were transmitted in real time to the central control system for preliminary processing and structured organization and subsequently stored in the local industrial PC of the machine. This data management strategy is intended to not only enhance data security and privacy protection but also lay the groundwork for implementing federated learning without transferring raw data. It enables collaborative model training across machines and supports the integration of intelligent manufacturing applications.
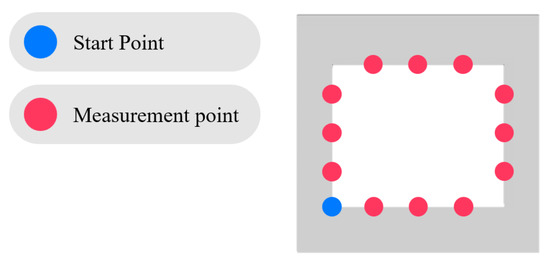
Figure 5.
Measurement points for WEDM workpieces.
3.4. Data Preprocessing
As shown in Figure 6, the model architecture adopted in this study is based on a simplified GPT decoder design, featuring the capability to handle time-series characteristics and multi-source sensor data. On the input side, the model integrates three key types of features: discharge current, spindle current, and cutting parameters (cutting speed and wire tension). The discharge and spindle current data are first processed using wavelet transform and standardization, preserving the original, high-frequency, and low-frequency components. These are then expanded into multi-channel matrices. In contrast, cutting speed and wire tension, due to their lower sampling frequency, are adjusted using linear normalization and aligned in dimensionality with the other features. All of these features are ultimately combined into a sequential input representing 5 s of historical data, effectively retaining both temporal dependencies and feature density. On the output side, the model predicts surface roughness indicators in accordance with the ISO 25178 standard [25]. The prediction results are normalized to a fixed range and output as a single numerical value. The overall architecture estimates surface roughness through time-series encoding combined with non-linear mapping via fully connected layers. A unified data preprocessing pipeline ensures consistent alignment among input features, contributing to the stability and reliability of the model’s predictions.
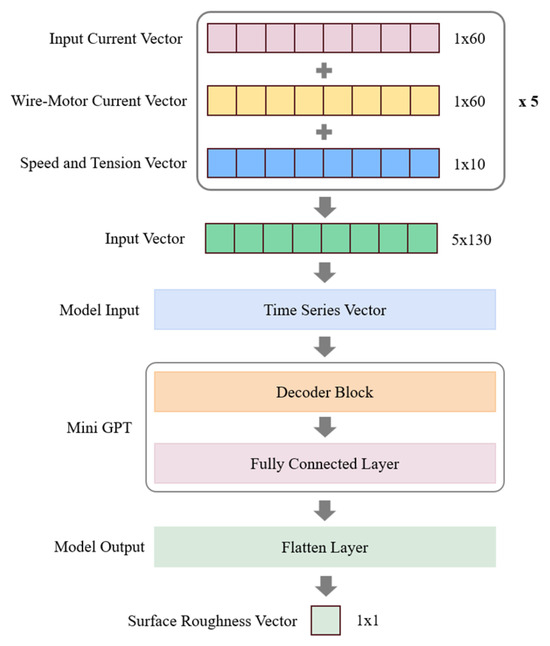
Figure 6.
Schematic of the Mini-GPT model input and output using WEDM data.
3.5. Federated Learning Framework
The federated learning architecture employed in this study is illustrated in Figure 7. During the federated training process, each edge computing device (Local IPC) at the machining site computes gradients locally from the collected training data without transmitting raw data externally. After local computations, the gradients are securely uploaded to a central server, which aggregates them using the Federated Averaging (FedAvg) algorithm. FedAvg was specifically chosen for its simplicity and effectiveness given the consistent precision and similar data volume from sensors installed on both machining setups, eliminating the need to assign differentiated weights to individual agents. Once aggregation is completed, the central global model is updated accordingly and redistributed to each local IPC. This iterative training mechanism allows for efficient and privacy-preserving collaborative learning, enhancing the generalization performance of the global model across diverse machine environments and rapidly accommodating newly integrated machines.
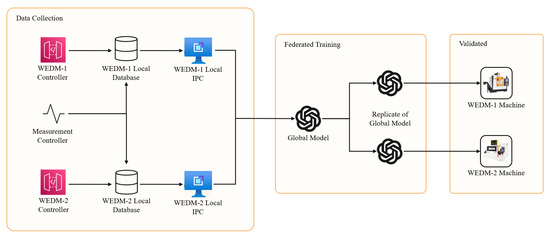
Figure 7.
Federated learning architecture for WEDM surface roughness prediction.
4. Results
4.1. Model Results for Surface Roughness Prediction in a Centralized Learning Environment
To evaluate the performance of the neural network model in predicting surface roughness during wire-cut electrical discharge machining (WEDM), we conducted a detailed analysis using Absolute Error. The model’s predictive capability was quantified by calculating the distribution of absolute prediction errors over the test dataset and analyzing the proportion of samples falling within different error ranges. Furthermore, we compared the effectiveness of federated learning (FL) and traditional centralized training (CT) to explore the impact of distributed learning approaches on model performance under heterogeneous machine environments. This comparison aimed to assess the practical feasibility and advantages of FL in real-world manufacturing scenarios. During model training, we partitioned the dataset from a single machine (729 samples) into 80% for training (583 samples) and 20% for testing (146 samples). For centralized training, the training data from two machines were combined, resulting in a total of 1166 training samples and 292 testing samples. Figure 8 presents a comparison between the model’s predictions and the ground truth labels on the test dataset. The results show that while the model successfully captured the overall trend of surface roughness, there was a certain degree of prediction dispersion—particularly at the extreme ends of the roughness scale, where the prediction error tended to increase. In addition, the RMSE calculated on the same test dataset was 0.074, indicating a generally reliable prediction performance.
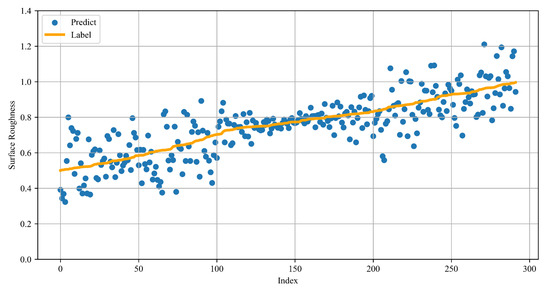
Figure 8.
Performance of centralized model for surface roughness prediction.
The distribution of model performance across various error ranges is summarized in Table 1, and the proportion of samples within different Absolute Error intervals is illustrated in Figure 9.

Table 1.
Centralized training results of surface roughness prediction model.
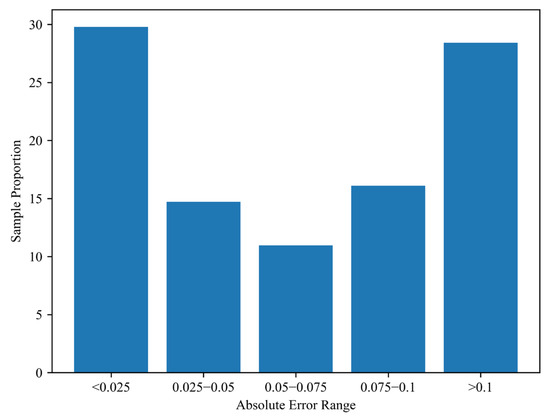
Figure 9.
Centralized training results of surface roughness prediction model.
It is worth noting that 28.42% of the samples exhibited a prediction error greater than 0.1, indicating that the model still faces limitations in understanding data features under certain conditions. This may be attributed to fluctuations during the data collection process or inconsistencies in timestamps during data preprocessing. Overall, the model achieved a high-accuracy sample proportion of 71.56% (Absolute Error < 0.1), demonstrating strong learning and predictive capabilities in most cases. However, further improvements are necessary for handling high-error samples. Future work will focus on optimizing the neural network architecture and applying data augmentation strategies, such as enhancing training data quality or employing more effective feature engineering techniques to improve the model’s generalization performance.
4.2. Model Results for Surface Roughness Prediction in a Federated Learning Environment
In the preliminary experiments of federated learning, we directly utilized the existing distributed datasets for training without performing any data augmentation or expansion. Based on the raw Absolute Error results shown in Table 1, the application of federated learning led to an approximate 10% reduction in the overall Absolute Error, indicating potential benefits. However, there remains significant room for improvement. Figure 10 illustrates the comparison between the predicted values and actual labels on the test dataset using the federated learning model without any data balancing strategies. From the figure, it can be observed that although the model was capable of capturing the overall trend of surface roughness, the prediction errors increased noticeably in certain data intervals. This is particularly evident in regions with relatively high or low roughness values, where the predictions appear more dispersed and less accurate. This issue mainly stems from the uneven data distribution across clients in the federated learning setup. Some clients have limited data volume, or the data within specific roughness ranges are underrepresented. As a result, the global model’s learning performance in those regions is constrained. To address this, future experiments will focus on adjusting data distribution strategies to improve model robustness. The detailed Absolute Error distribution of the federated learning model is summarized in Table 2, and the distribution of sample proportions across different Absolute Error intervals is shown in Figure 11. Additionally, the RMSE during this phase increased to 0.109, indicating reduced prediction accuracy in the initial federated setup.
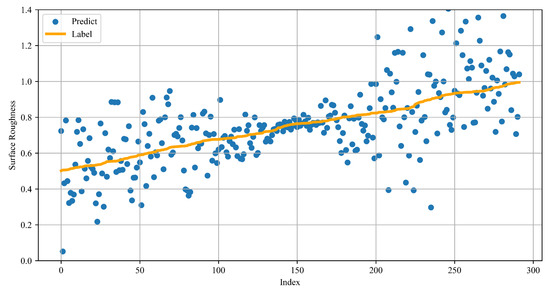
Figure 10.
Prediction performance of federated model for imbalanced surface roughness data.
Table 2.
Federated training results of surface roughness prediction model.
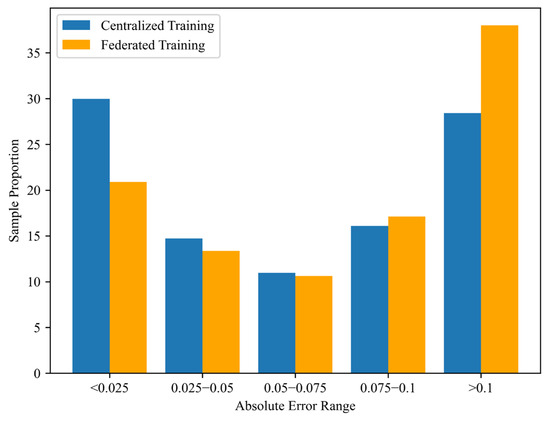
Figure 11.
Comparison of centralized and federated training results.
As shown in Table 2, the proportion of samples falling within the high-accuracy range (Absolute Error < 0.1) was 62%, indicating that federated learning can effectively enhance the model’s learning capability for certain portions of the data. However, 38.21% of the samples exhibited prediction errors exceeding 0.1, highlighting that data imbalance can significantly impact the model’s stability and generalization performance. To further address this issue, the study will conduct an in-depth analysis of the underlying causes and propose effective data processing strategies in subsequent phases, with the goal of improving the overall predictive performance of the model.
4.3. Federated Learning Prediction Before and After Data Balancing
The results indicate that the balance of data distribution plays a critical role in the stability and predictive performance of the model. Figure 12 illustrates the uneven distribution of labels (surface roughness values) in the original training dataset across different value intervals. Using the range of 0.2 to 0.8 μm as the baseline and dividing it into intervals of 0.1 μm, the analysis reveals that data points with roughness below 0.4 μm accounted for only 2.1% of the entire dataset. Such severe data imbalance can lead to model overfitting or underfitting in certain ranges, thereby degrading overall model performance. To address this issue, we used the class with the highest data count as a reference and calculated the ratio of data points in each class relative to this reference. These ratios were then used as scaling factors for data augmentation. Based on the computed factors, we replicated the original training samples within each class and introduced random noise to the duplicated data to expand the dataset. This approach helped balance the number of samples across all classes, resulting in a more uniform training data distribution, as shown in Figure 13. Through this augmentation strategy, we effectively mitigated the original imbalance problem, enabling the federated learning model to learn from each surface roughness range more evenly. Consequently, the model’s predictive ability in sparse regions improved, enhancing the overall generalization performance.
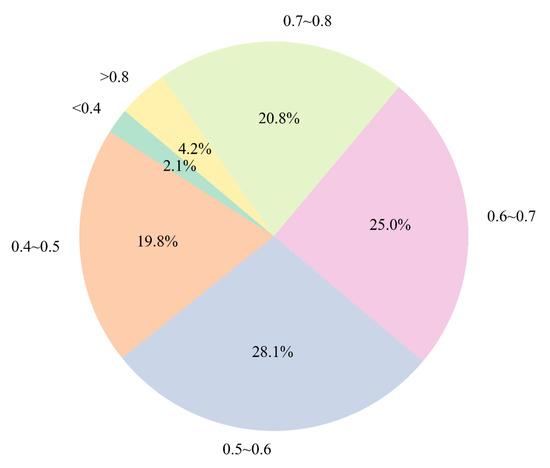
Figure 12.
Output value distribution of imbalanced data.
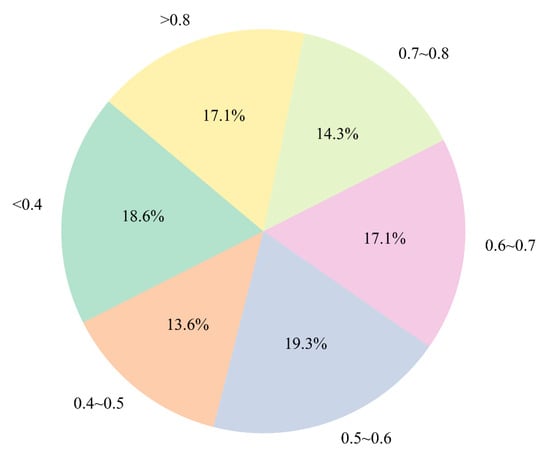
Figure 13.
Output value distribution after data balancing.
After applying data balancing and augmentation, we retrained the federated learning model. Through data resampling and augmentation techniques, we mitigated the issue of uneven data distribution across different clients, allowing the model to learn from a more diverse range of data scenarios. Figure 14 illustrates the comparison between the predicted values and actual labels on the test dataset after the data balancing process. The corresponding Absolute Error statistics are summarized in Table 3, while the distribution of sample proportions across different Absolute Error ranges is shown in Figure 15. In addition, the RMSE after data balancing decreased to 0.076, indicating an improvement in the model’s overall predictive accuracy.
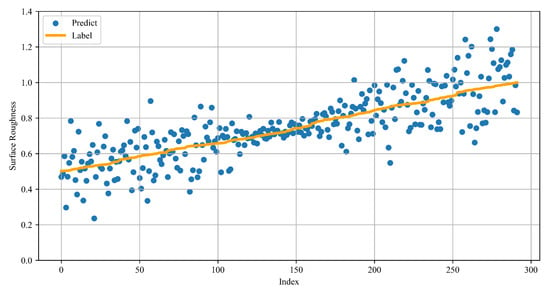
Figure 14.
Prediction performance of federated models after data balancing.
Table 3.
Federated training results based on balanced data.
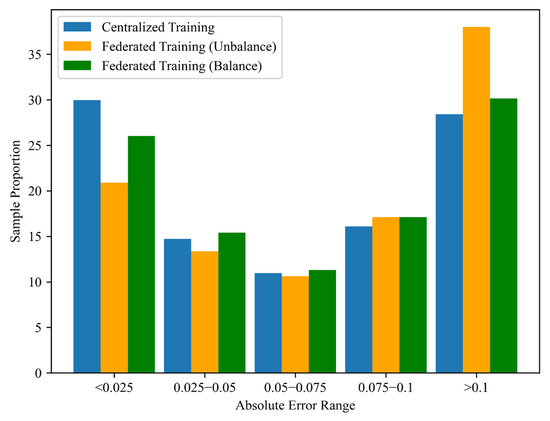
Figure 15.
Comparison of balanced, imbalanced, and original training results.
As shown in Table 3, after applying data balancing, the proportion of samples falling within the high-accuracy range (Absolute Error < 0.1) increased to 70%, which is significantly higher compared to the results obtained from the unbalanced dataset described earlier. Conversely, the proportion of samples with high prediction errors (Absolute Error > 0.1) decreased to 30%, indicating a notable improvement in the model’s ability to generalize to sparse data regions. Further analysis of the weight distributions between the centralized training model and the federated learning model reveals differences in their learning behaviors. The weight distribution in the centralized model is narrower, suggesting more consistent and less variable weight updates. This is attributed to the fact that the model was trained on the entire dataset globally, allowing for more stable convergence. In contrast, the federated learning model exhibits a more dispersed weight distribution, reflecting the influence of heterogeneous client data on the learning process and resulting in less consistent weight updates. This phenomenon was more pronounced when the training data were imbalanced. Although data balancing helped stabilize the weight distribution in federated learning to some extent, its variability remained higher than that observed in centralized training.
5. Conclusions
This study aimed to address the challenge of real-time surface roughness prediction in wire electrical discharge machining (WEDM) by proposing a predictive framework that integrates an enhanced Mini-GPT model with federated learning. The system enables local model training across machines while preserving data privacy. The experimental results demonstrate that the centralized model achieved high prediction accuracy (Absolute Error < 0.1) for 71.56% of samples, with a low RMSE of 0.074. The federated model, after data balancing and augmentation, reached comparable performance with 70% accuracy and an RMSE of 0.076, confirming its practical viability for distributed industrial settings.
A key observation was that prediction accuracy is closely tied to sensor resolution and synchronization. Deviations were often associated with non-linear current patterns and millisecond-level timing offsets between sensor data streams. These findings suggest that incorporating high-precision time synchronization mechanisms could further improve model reliability and accuracy.
The primary contribution of this work lies in offering manufacturers a non-intrusive, scalable solution for real-time defect detection that only requires external current sensors. The federated learning architecture also supports rapid adaptation to new machines, promoting broader industrial deployment. Future research will explore the integration of multimodal sensors and federated transfer learning to enhance the robustness and generalization of the proposed system across different manufacturing platforms.
Author Contributions
Conceptualization, K.-L.C., Y.-H.T., W.-R.J., S.-C.C. and Z.-W.Z.; Methodology, K.-L.C., Y.-H.T., W.-R.J., S.-C.C. and Z.-W.Z.; Software, K.-L.C.; Validation, K.-L.C., Y.-H.T., W.-R.J. and S.-C.C.; Writing—original draft, K.-L.C.; Writing—review & editing, Y.-H.T. and Z.-W.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors on request.
Conflicts of Interest
Author Yu-Hung Ting was employed by the company Moldintel Co., Ltd. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Li, L.; Yuxi, F.; Mike, T.; Kuo-Yi, L. A review of applications in federated learning. Sci. Comput. Ind. Eng. 2020, 149, 106854. [Google Scholar] [CrossRef]
- Xianhui, L.; Xianghu, D.; Ning, J.; Weidong, Z. Federated Learning-Oriented Edge Computing Framework for the IioT. Sensors 2024, 24, 5–6. [Google Scholar]
- Meng, H.; Hongwei, L.; Xizhao, L.; Guowen, X.; Haomiao, Y.; Sen, L. Efficient and Privacy-enhanced Federated Learning for Industrial Artificial Intelligence. IEEE Trans. Ind. Inform. 2020, 16, 6532–6542. [Google Scholar]
- Tianhao, W.; Johannes, R.; Ce, Z.; Ruoxi, J.; Dawn, S. A Principled Approach to Data Valuation for Federated Learning. arXiv 2020, arXiv:2009.06192. [Google Scholar]
- Yiqiang, C.; Jindong, W.; Chaohui, Y.; Wen, G.; Xin, Q. A Federated Transfer Learning Framework for Wearable Healthcare. arXiv 2021, arXiv:1907.09173. [Google Scholar]
- Mahdi, M.; Matthias, R.; Bill, L.; Christos, L. Stable Diffusion-based Data Augmentation for Federated Learning with Non-IID Data. arXiv 2024, arXiv:2405.07925. [Google Scholar]
- Jie, W.; Zhixia, Z.; Yang, L.; Zhihua, C.; Jianghui, C.; Wensheng, Z. A survey on federated learning: Challenges and applications. Int. J. Mach. Learn. Cybern. 2023, 14, 516–523. [Google Scholar]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawitz, K.; Charles, Z.; Cormode, G.; Cummings, R.; et al. Advances and Open Problems in Federated Learning. Found. Trends® Mach. Learn. 2021, 14, 1–210. [Google Scholar] [CrossRef]
- Weiting, Z.; Dong, Y.; Wen, W.; Haixia, P.; Ning, Z.; Hongke, Z. Optimizing Federated Learning in Distributed Industrial IoT: A Multi-Agent Approach. IEEE J. Sel. Areas Commun. 2021, 39, 3688–3703. [Google Scholar]
- Wei, L.; Li, C.; Wenyi, Z. Decentralized Federated Learning: Balancing Communication and Computing Costs. arXiv 2022, arXiv:2107.12048. [Google Scholar]
- Conde, A.; Arriandiaga, A.; Sanchez, J.A.; Portillo, E.; Plaza, S.; Cabanes, I. High-accuracy wire electrical discharge machining using artificial neural networks and optimization techniques. Robot. Comput.-Integr. Manuf. 2018, 49, 24–38. [Google Scholar] [CrossRef]
- Mustafa, U.; Osman, A.; Turan, G.; Cihan, O. Surface roughness prediction of machined aluminum alloy with wire electrical discharge machining by different machine learning algorithms. J. Mater. Res. Technol. 2020, 9, 12519. [Google Scholar]
- Jehn-Ruey, J.; Cheng-Tai, Y. Product Quality Prediction for Wire Electrical Discharge Machining with Markov Transition Fields and Convolutional Long Short-Term Memory Neural Networks. Appl. Sci. 2021, 11, 5922. [Google Scholar]
- Shi, Z.; Dechang, P. Milling Surface Roughness Prediction Based on Physics-Informed Machine Learning. Sensors 2023, 23, 4969. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.H.; Jeng, S.Y.; Lin, C.J. Prediction and Analysis of the Surface Roughness in CNC End Milling Using Neural Networks. Appl. Sci. 2022, 12, 393. [Google Scholar] [CrossRef]
- Kanlayasiri, K.; Boonmung, S. An investigation on effects of wire-EDM machining parameters on surface roughness of newly developed DC53 die steel. J. Mater. Process. Technol. 2007, 187–188, 27–28. [Google Scholar] [CrossRef]
- Dodun, O.; Slătineanu, L.; Coteaţă, M.; Merticaru, V.; Nagîţ, G. Surface Roughness at Wire Electrical Discharge Machining. Appl. Mech. Mater. 2015, 760, 551–556. [Google Scholar] [CrossRef]
- Ahsan, A.K.; Munira, B.M.A.; Norhashimah, B.M.S. Relationship of Surface Roughness with Current and Voltage During Wire EDM. J. Appl. Sci. 2006, 6, 2317–2320. [Google Scholar]
- Rieke, N.; Hancox, J.; Li, W.; Milletari, F.; Roth, H.R.; Albarqouni, S.; Bakas, S.; Galtier, M.N.; Landman, B.A.; Maier-Hein, K.; et al. The future of digital health with federated learning. Digit. Med. 2020, 119, 5–6. [Google Scholar] [CrossRef]
- Mohammad, M.; Mehdi, A.; Abdenour, B.; Hussin, L.; Ali, R. Reviewing Federated Learning Aggregation Algorithms; Strategies, Contributions, Limitations and Future Perspectives. Electronics 2023, 12, 2287. [Google Scholar] [CrossRef]
- Bharati, S.; Mondal, M.R.H.; Podder, P.; Prasath, V.B.S. Federated learning: Applications, challenges and future directions. arXiv 2022, arXiv:2205.09513. [Google Scholar] [CrossRef]
- Sanchez, J.A.; Conde, A.; Arriandiaga, A.; Wang, J.; Plaza, S. Unexpected Event Prediction in Wire Electrical Discharge Machining Using Deep Learning Techniques. Materials 2018, 11, 1100. [Google Scholar] [CrossRef] [PubMed]
- Hard, A.; Rao, K.; Mathews, R.; Ramaswamy, S.; Beaufays, F.; Augenstein, S.; Eichner, H.; Kiddon, C.; Ramage, D. Federated Learning for Mobile Keyboard Prediction. arXiv 2018, arXiv:1811.03604. [Google Scholar]
- Zhu, D.; Chen, J.; Shen, X.; Li, X.; Elhoseiny, M. MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models. arXiv 2023, arXiv:2304.10592. [Google Scholar]
- ISO 25178-2:2021; Geometrical Product Specifications (GPS)—Surface Texture: Areal—Part 2: Terms, Definitions and Surface Texture Parameters. ISO: Geneva, Switzerland, 2021.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).