Abstract
Re-identification in automated surveillance systems is a challenging deep learning problem. Learning part-based features augmented with one or more global features is an efficient approach for enhancing the performance of re-identification networks. However, the latter may increase the number of trainable parameters, leading to unacceptable complexity. We propose a novel part-based model that unifies a global component by taking the distances of the parts from the global feature vector and using them as loss weights during the training of the individual parts, without increasing complexity. We conduct extensive experiments on two large-scale standard vehicle re-identification datasets to test, validate, and perform a comparative performance analysis of the proposed approach, which we named the global–local similarity-induced part-based network (GLSIPNet). The results show that our method outperforms the baseline by 2.5% (mAP) in the case of the VeRi dataset and by 2.4%, 3.3%, and 2.8% (mAP) for small, medium, and large variants of the VehicleId dataset, respectively. It also performs on par with state-of-the-art methods in the literature used for comparison.
1. Introduction
CCTV cameras are an effective and pervasive component of most modern surveillance systems that have numerous applications, including law enforcement, event monitoring, process monitoring, crime analysis, and other smart city processes [1]. They generate vast amounts of image and video data for these systems. The tasks performed by surveillance systems that deal with such data can be narrowed down to activities like recognition, identification, re-identification, tracking, or the retrieval of objects, persons, or vehicles [2]. Various tasks, like object detection [3] and classification [4], can be performed on the data to generate important insights. In this paper, we focus specifically on vehicle re-identification (VReID), which involves retrieving an image of a particular vehicle from a database of vehicle images, given a particular vehicle image as a query. In surveillance applications, VReID is used in traffic- and fleet-management-based industrial processes. The VReID problem is closely related to person re-identification, which has been more thoroughly studied and researched than VReID. Successful results in person re-identification, usually achieved through deep learning, have inspired parallel research on VReID, and in some aspects, the latter often poses more challenges to the problem of re-identification matching.
In any re-identification problem, discriminating features are extracted from the ‘query’ image to find matches from a collection of ‘gallery’ images. Methods used in person re-identification have been found to work well in the case of vehicle re-identification. Initially, some handcrafted image-processing-based features were used along with deep learning features [5,6]. However, due to the low performance of these features, subsequent works have utilized deep learning-based methods only for feature extraction. Most methods use backbone models pre-trained on ImageNet [7], like AlexNet [5,7], VGG [8,9], GoogLeNet [6,10], ResNet [11,12], and MobileNet [13], for feature extraction. The features can be attribute-based, local component-based, part-based, or global deep features. Attribute-based features include global features like vehicle color, make, model, and viewpoint. The attributes are first learned using a separate dedicated module/network, and then the learned attributes are mapped to labels. This causes an inherent disadvantage in such methods with respect to increased complexity, as a separate module is required for attribute identification. Local features can be one of two types: (i) salient features directly extracted from vehicle images like headlights, mirrors, number plates, back lights, etc., or (ii) features extracted from a deeply learned feature vector. The latter are termed part-based local features. In this approach, the convolutional tensor obtained after the backbone model is partitioned into different parts to obtain local representations [14]. Attention layers have also been employed in some works to generate localized discriminative features [15,16]. The global deep features are generally features generated by the backbone model. Conventionally, approaches used in VReID use a combination of part-based layers along with a global layer. The layers obtained from the deeply learned global features proceed in parallel in different branches, which are all trained by fully connected layers. These local features can be used independently or together with a global network to generate a feature map. We propose a different approach in which we unify global and part-based features without actually training any global branches.
In this paper, we set out to increase the accumulated body of knowledge on part-based re-identification methods by proposing a novel approach to unifying global and part-based features. In this method, we initially perform a generalized uniform partition on the convolutional tensor generated after passing the image through the backbone network. Then, at a later stage, we introduce a global component into the model during training by applying a weighted classification loss function to the parts. The weights are calculated according to the distance of the part features from the global feature, rewarding those parts that are closer to the global feature. Our focus and contribution in this paper are on learning better discriminative features from localized parts during training by incorporating a global component without training a separate global branch. The major significance of this method is that it introduces a global component during training without explicitly training a global tensor, as the scores generated by the similarity generator reflect agreement between global and local features. This results in finer feature learning. In this work, we compare the performance of the proposed model with a model comprising only part-based features without the global component, which is considered the baseline in this paper. Our approach is found to generate better results than training part-based features alone.
The major contribution of this work is the proposed GLSIPNet model, which effectively utilizes cues from the global feature to train the part-based features via the distance between the global and part-based features, without explicitly training the global features. This makes the process less complex than training global features directly. To the best of our knowledge, this method of incorporating global features without explicit training of the global features has not been reported in the literature, which is the novelty of the proposed method. Experiments are conducted on two large-scale datasets—VeRi and VehicleId—using the proposed method to show the extent of improvement in matching performance over the baseline and other related results in the recent literature.
The rest of this paper is organized as follows. Section 2 presents a literature review and the motivation for this work. Section 3 describes the methodology used. The results of the experiments and the comparative performance analysis with the state of the art are discussed in Section 4, and the overall conclusions are summarized in Section 5.
2. Motivation and Related Works
In this section, we discuss the standard datasets for vehicle re-identification and the state-of-the-art methods for solving the vehicle re-identification problem.
Vehicle Re-Identification Datasets
A few vehicle re-identification datasets, like VeRi [5], VehicleId [8], VRIC [17], VeRi-Wild [18], CityFlow [19], PKU-VD [20], and ToyCars [21], have been developed for use in vehicle re-identification tasks. Most existing works report results on the VeRi and VehicleId datasets. Hence, we use these datasets in our experiments, which are described as follows:
(a) VeRi Dataset: This dataset contains 49,357 images of 776 vehicles captured by 20 cameras over a 1 sq km area. The images were captured in a real-world, unconstrained surveillance scene. Each vehicle was captured by 20 cameras from different viewpoints, under varying illuminations, and with different resolutions and occlusions. The training set comprises 575 vehicle identities, and the remaining images are used for testing. The test set comprises a query set and a gallery set. The query set includes only one image per vehicle identity, which is used to find matches in the gallery set. The vehicle identities of the training and test sets are different. Hence, no cross-validation is used during testing.
(b) VehicleId Dataset: This dataset contains 221,763 images of 26,267 vehicles. Each vehicle image was captured from either the front or the back, i.e., from two different viewpoints. The training set contains 110,178 images of 13,134 vehicles. The test data are split into three subsets containing 800, 1600, and 2400 vehicles, with 7332, 12,995, and 20,038 images, respectively. The query set for each of the three test subsets contains one vehicle image for each vehicle identity, and the gallery set contains the rest of the vehicle images used to determine the match. In this dataset, the vehicle identities of the training and test sets are different; hence, cross-validation is not used during evaluation to ensure a proper comparison with the state of the art.
Re-identification methods based on global and local feature learning are broadly divided into two categories:
- Attribute-based models, which generally use a separate dedicated network for the identification of attributes or local parts.
- Part-based models, which use single or multiple branches to extract local features with different schemes of partitioning. These methods may or may not include a global branch that learns the global features. Single-branch models are inherently less complex than multi-branch models due to their smaller number of convolutional layers.
In this section, we first review the existing works on VReID in the literature that use either global, local, or a combination of the two feature learning methods. Methods for learning attributes utilize a wide variety of techniques for feature extraction. A joint approach for learning deep features along with attributes such as camera view, vehicle color, and vehicle type was proposed by Wang et al. [22]. In another work, a single-stage, single-shot detector is used to detect regions of interest in vehicle images, and the deep features of the regions are used as local features [23]. VDG, a method for viewpoint-aware learning in an unsupervised context, where novel views are generated and then a contrastive loss is used to learn viewpoint-invariant features, was proposed in [24]. He et al. introduced a two-pronged approach which involved first generating the local regions of interest and then projecting them onto the global feature map, thereby ensuring a mix of local attribute-based and global re-identification features [25]. This approach followed a scheme similar to that used in object detection and segmentation models [26]. Qian et al. used a two-branch model in which local features are extracted by applying horizontal stripes to the output of a backbone layer, and these are combined with a global layer. The global layer comprises two fully connected layers, one with ID predictions and the other with attribute information, that generate a combined feature [27]. Wang et al. extracted region feature vectors for multiple region segmentation results using a convolutional neural network and obtained appearance feature vectors of the target vehicle by fusing them with global feature vectors [28]. Other works used short and densely connected convolutional units without a backbone network to develop an architecture from scratch for feature learning. This is then utilized with a Siamese network-type architecture for improving feature detection and with a modified quadrature pooling layer for feature generation [29,30,31]. Peng proposed a feature learning approach that employs a spatial transformer network-based localization model for integrating global and local features into a representation for VReID [32]. The major disadvantage of models that learn attributes or local features is that a separate module is required to extract attributes, which increases complexity.
Methods for learning part-wise features follow a strategy that involves dividing either the raw image or the convolutional tensor into different parts or directing attention to specific regions within them. Convolutional features are then learned from these targeted areas. This approach addresses a major limitation of the methods described above, i.e., it does not require any additional networks or training to identify the local features and can be used in a straightforward manner [33]. The part-based convolutional baseline, or PCB [14], which uses horizontal part-based features as local features, has been widely used in person re-identification. Refined part pooling has also been used to address partial inconsistencies by training the learned parts. Another work [34] introduced a two-branch, part-based network with horizontal and vertical partitioning, as well as an external identity memory to store the features from the two branches separately. The network also includes a triplet center loss and softmax loss for metric learning. The DGPM (Distance-Based Global and Partial Multi-Regional Feature) [35] model consists of three branches—one global and two local branches, one with horizontal parts and the other with vertical parts. The local branches incorporate a self-attention module prior to partitioning in order to suppress background information inside the parts. The authors of [36] utilized three branches, namely a global, local, and complementary branch, for feature extraction. Their method uses partition-based as well as local attribute extraction for robust feature learning. A two-branch model, with one global branch and another part-based local branch using horizontal parts and an attention block prior to partitioning, was described in [37]. In [38], the authors proposed the Multi-Granularity Network (MGN), a three-branch network with one global branch and two part-based branches with a varying number of parts. Each part-based branch includes its own global branch. In unsupervised re-identification methods, complementary part-based and global features are used to generate labels. The complementary association of these features is achieved by exploiting the k-nearest neighbors in the part and global feature spaces [33]. A global–local supervision scheme with channel partitions was proposed in [15]; however, it involves a complex attention layer applied to the channel parts and training of the global layer, which increases complexity. URRNet addresses the problem of viewpoint variation while preserving vehicle details in the re-identification problem by integrating global and local features. The global features are enhanced using a graph convolutional network, and then the keypoints, viewpoint, and multiscale characteristics of the vehicle are extracted [39]. DRReid was trained on multiple source domains and evaluated on unseen target domains for person re-identification [40]. An identity-guided spatial attention mechanism was used to mask discriminative areas, without the need for manual annotation, to address vehicle re-identification in [41]. MDFE-Net addresses re-identification by incorporating a non-local attention block that enhances long-range dependence in discriminative features [42]. A method that integrates convolutional and vision transformer features was proposed in [43] by applying channel-by-channel convolution within the feed-forward layer. To address the VReID problem, a three-branch structure with one global and two local branches was proposed in [16]. The local branches include channel attention modules to generate subtle discriminative features. The authors of [44] utilized a transformer architecture to model the relationship between global and local features for VReID applications. A multilayer fusion approach was designed to achieve this. A two-stage feature generation method was proposed in [45], where the pixel-level feature map is first transformed into a patch-level map within a global context; then, the patches are further refined in a local context using self-attention.
Reported results show that incorporating both global and local features usually gives rise to higher accuracy due to completeness in learning [38]. However, a major drawback of training the global and local branches is the large number of trainable parameters, which leads to higher complexity. Also, the attention layers used to generate local features, along with the multi-branch architecture, result in increased complexity. This drawback can be addressed by our proposed single-branch method, which is discussed in the next section.
3. Proposed Unified Framework for Global and Part-Based Local Features
The structure of the part-based network is shown in Figure 1. Here, the images are pre-processed and passed through a backbone network to obtain a convolutional tensor T, which is then partitioned into a number of uniform parts by a pooling layer. The parts are then trained independently using an equal number of fully connected (FC) layers. During evaluation, the obtained parts before the FC layer are concatenated to form the feature vector, which is used for re-identification.
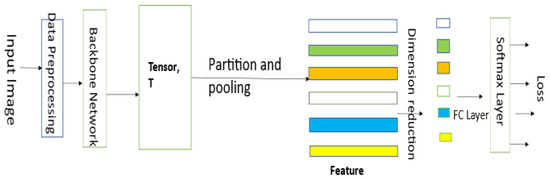
Figure 1.
Structure of the part-based network.
In the images from the VeRi dataset shown in Figure 2, we can see that there are certain parts of the image, such as background information and occlusion, which do not contain meaningful information and which can give rise to unnecessary, irrelevant information in the parts obtained from the image. To address this and improve image retrieval accuracy, we need contextual global information with respect to the entire image. However, this comes with added complexity. We illustrate this below.

Figure 2.
Vehicle images from the VeRi Dataset. Patches of irrelevance are visible around the edges of the images, as indicated by the orange borders.
A convolutional or a fully connected layer contains trainable parameters. Let the number of trainable parameters in the backbone network be denoted as x. For a part-based network with p parts, each part is accompanied by a pooling layer and a fully connected layer. Let the number of parameters for a fully connected layer be denoted as c.
So, for a part-based network, say W with p parts, the number of trainable parameters would be
For a global branch, an additional pooling layer and a fully connected layer are added. Let the branched network containing a part-based branch and a global branch be denoted as G.
If the number of global branches is g, then the number of parameters of network F becomes
So, we can see that just by adding a single global branch, the number of trainable parameters increases. In order to overcome these shortcomings, we propose a framework in which the global features are accounted for without adding any trainable parameters to the network. In our present work, we propose a model where the learning of uniform horizontal parts is augmented by taking into account their relative importance with respect to the global feature without introducing any new trainable layer. The learning is induced and influenced by the similarity between the global feature and the partitioned features. In this light, we call our approach the global–local similarity-induced part-based network (GLSIPNet). This approach does not add any extra trainable parameters other than those from the part-based network, and the number of parameters is static.
3.1. Data Pre-Processing
This is a normalization step for the images in the datasets. Raw images are subject to the following transformations in this step:
- The images are first resized to a fixed size (384,192). The resizing is performed to match the input size expected by the pretrained backbone model.
- Random Horizontal Flip—This is an image data augmentation technique in which an input image is flipped horizontally with a given probability.
- Random Erasing—Using this technique, a region in an image is randomly selected, and the pixels are erased. This is useful for the robust training of the given data.
- Finally, the images are tensorized and then normalized to the same mean (0.485, 0.456, 0.406) and standard deviation (0.229, 0.224, 0.225) as standard ImageNet [7] images. This is done to ensure the best results due to the use of a backbone architecture pretrained on ImageNet.
3.2. Backbone Network
Any image classification model can be selected as the backbone model. In this case, we use ResNet50 [11], pre-trained on the ImageNet dataset [7]. ResNets (residual networks) are used in many computer vision applications. They use interconnections from higher to lower layers to mitigate the problem of vanishing gradients, particularly in very deep networks. The building block of a ResNet is defined as
Here, x and y are the input and output vectors of the layers. The function represents the layers in between, where represents the weights. The output is obtained by adding the result of the intermediate layers to the original input, which helps preserve information from the input layer, which in effect is the essence of ResNet. ResNet has been used in similar part-based networks [12,14,26], which inspired us to use it as one of the base models.
3.3. Proposed GLSIPNet Model
The framework of the proposed GLSIPNet model is shown in Figure 3. The method includes two consecutive cycles of training with an equal number of epochs. The first cycle involves partitioning the convolutional tensor generated by the backbone network into uniform horizontal partitions, following a strategy similar to PCB [14]. The convolutional tensor is partitioned uniformly, and the parts are then pooled using average pooling to form the partitioned convolutional tensor set . The parts or vectors are then trained separately, and the weights are updated using the cross-entropy loss, which is calculated separately for each part and then combined.
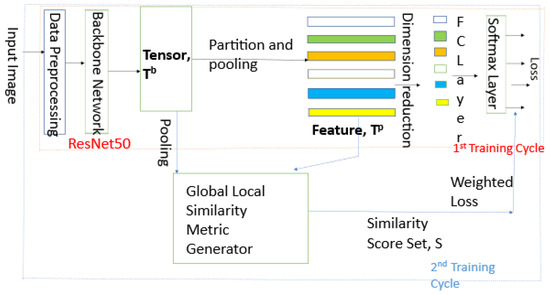
Figure 3.
Framework of the proposed method.
The second cycle is similar to the first one in terms of structure but involves a global component in addition to the local part-based features. A global–local similarity score is generated for each local part using the Euclidean distance of each part from the whole tensor. For every batch of input images, the respective scores are generated by the network. The score serves as the combination of weights for the individual losses. The cross-entropy losses for the individual trainable parts are combined in the ratio of their respective similarity scores.
3.4. Global–Local Similarity Score Generator
A copy of the convolutional tensor is fed into the score generator network. Similar to the first cycle, the partitioned convolutional tensor set is generated. Subsequently, the scores are generated as described below.
Let be the convolutional backbone tensor of size , which is then passed through an average pooling layer to obtain the tensor of size (global feature vector). Let denote the partitioned convolutional tensor set comprising n parts, each of size (part-based local feature vector).
Then, we have
where is the distance between each and . The distance may be any type of vector distance.
The similarity score between global and local features is then defined as
where f is any function such that the score is the inverse of the distance.
The above score set is returned by the network. We then modify our training scheme during the calculation of the total loss in order to incorporate the effect of the weighted scores S.
During the training of a convolutional neural network, the weights are updated according to a loss function. For classification problems, the cross-entropy loss is the widely used loss function. For an N-category classification problem, with the probabilities of each class denoted by the cross-entropy loss is given by
where is the probability of each class and is the ground-truth label for that class. Let the cross-entropy loss for each part i be . The total cross-entropy loss becomes
where S is the similarity score for a part. Here, the set S can be considered the unifying factor.
From Equation (9), we find that the loss function is the negative logarithm of the probabilities of the classes; the loss value will be lower for higher-ranked classes. Also, from (4), we find that the total loss is updated in such a way that parts with higher similarity with the global feature will have a lower absolute value of the loss. The framework penalizes parts that are farther from the global feature and reinforces parts that are more similar to it. This creates a scenario in which fine-grained local features are learned by training the network to focus more on parts that are relevant to the global context.
The rest of the training process, including weight updates after backpropagation, follows the standard process for training CNNs.
4. Experimental Results and Analysis
We conducted a series of experiments on the VeRi and VehicleId datasets using the proposed method. The input images were resized to 384 × 192 during the training and evaluation stages. The training batch size was set to 32. We performed uniform partitioning in the horizontal dimension with six parts. Training was conducted for 60 epochs in the first cycle and another 10 epochs in the second cycle using the VeRi dataset, and for 60 epochs using the VehicleId dataset. This was due to the larger size of the VehicleId dataset. The plots of the loss values on the training set and the mAP values on the testing set for the VeRi dataset are given in Figure 4 and Figure 5, respectively. It can be seen from the plots that the model was trained to convergence. For our experiments, we used the inverse function f in the second cycle such that .
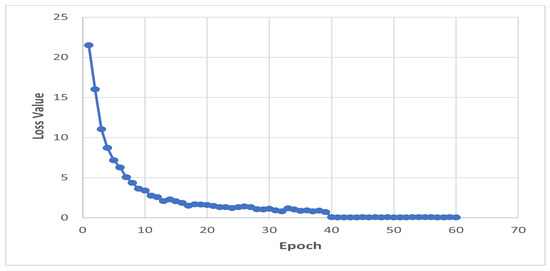
Figure 4.
Loss values of the training set on the VeRi dataset.
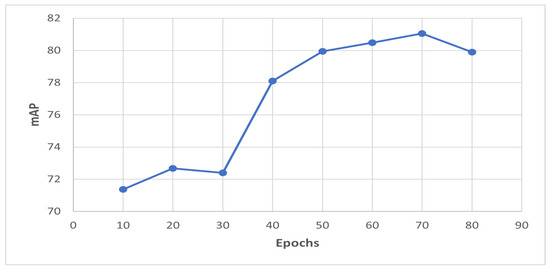
Figure 5.
mAP values on the testing set of the VeRi dataset.
We also conducted experiments using only the first cycle for 120 epochs on both datasets as a baseline and compared the results with those of the proposed method. We also used re-ranking with k-reciprocal nearest neighbors as a post-processing step during evaluation. This step generated a ranked list of gallery output images for each query image using a mixture of Euclidean and Jaccard distances, following the process described in [46]. This method has been shown to improve accuracy in the existing literature. In line with conventional re-identification works in the literature, we used mean average precision and Rank-1, Rank-5, and Rank-10 accuracies for both datasets.
Table 1 compares the results of our proposed method with those of the baseline on the VeRi and VehicleId datasets. Table 2 and Table 3 compare the results of our proposed method with those of other works on the VeRi and VehicleId datasets, respectively.

Table 1.
Comparison of GLSIPNet with the baseline on the VeRi and VehicleId datasets.
Table 2.
Comparison of different methods on the VeRi dataset. NR: not reported.
Table 3.
Comparison of different methods on the VehicleId dataset. NR: not reported.
In Table 1, we can see that the proposed method consistently outperformed the baseline across all metrics. Re-ranking significantly improved accuracy on the VeRi dataset but resulted in only a slight improvement on the VehicleId dataset. This is due to the dataset structure of VehicleId, which contains only one image per vehicle identity in the gallery set, in contrast to VeRi, which contains many images per vehicle identity. Also, the VehicleId dataset includes only two camera viewpoints, whereas VeRi includes 20. The Euclidean distance is therefore sufficient for the VehicleId dataset, and nearest-neighbor extrapolation does not have any additional advantage. Also, it can be seen that the improvement due to re-ranking on the VeRi dataset was more pronounced for GLSIPNet than for the baseline
We present a comparison of the performance of our proposed method with that of several state-of-the-art methods for vehicle re-identification in Table 2 and Table 3.
The comparison includes different methods that focus on global and part/local feature-based learning, adopting various strategies. SLSR uses a DenseNet121 backbone for feature extraction. It also uses a generative network to generate fake images at different scales for better feature learning [48]. VANeT addresses the problem of different viewpoints [49]. The method learns the viewpoint of the image—front/rear—along with deep features using a GoogleNet backbone. The idea of sampling information data points was explored for vehicle re-identification in a batch sample through the introduction of a triplet sampling variant [50]. Part regularized near duplicate is a framework for combining local region-of-interest-based features and global features [25]. First, the different parts of the vehicle, like windows and lights, are extracted using a part extraction network. Then, a two-branch model is used, where the local branch learns deep features from the local parts generated by the earlier network, and a global branch learns the global features using the ResNet50 backbone. MRL divides the problem of re-identification into two groups on the basis of view—one of images with the same view and the other with different views. Further, on a ResNet 50 backbone, with global features, it uses two types of ranking loss to optimize the training process [50]. Local feature extraction is performed in detail in MRM, where a separate labeled dataset is created to train a model for local feature/attribute extraction [23]. The model is then used to extract the features from the re-identification dataset and then merge them with the global features generated using a ResNet backbone. A part-based network with horizontal partitions, along with a global branch, was introduced in SAN [27]. Here, the global branch has two fully connected layers—one for ID prediction and the other for attribute prediction (model/type)—with a DenseNet backbone. TCPM uses part-based horizontal and vertical partitioning in two branches, along with a triplet center loss and a softmax loss for optimization [35]. A three-branch network with a global branch and two part-based branches (one with horizontal parts and the other with vertical parts) is used in DGPM, along with an attention module to suppress background information interference in the part-based branches [36]. The method also uses spatio-temporal information (camera and time) to improve accuracy. However, our method generates results without spatio-temporal information for a better comparison. AttributeNet is a joint network that generates attribute-based and global re-identification features [51]. A constraint is used to encourage the joint feature. PGAN is a local feature/attribute aggregating method with a local feature branch and a global feature branch [52]. However, it uses an attention mechanism to assign weights to the local features prior to aggregation with the global feature. URRNet integrates global and local features. The global features are enhanced using a graph convolutional network, and then the keypoints, viewpoint, and multiscale characteristics of the vehicle are extracted as local features [39]. MDFE-Net includes a non-local attention block to enhance the long-range dependence of discriminative features [42]. A three-branch structure with one global and two local branches was proposed in [16]. The local branches include channel attention modules to generate subtle discriminative features. A two-stage feature generation method was proposed in [45], where the pixel-level feature map is first transformed into a patch-level map within a global context; then, the patches are further refined in a local context using self-attention.
Analysis on VeRi: In Table 2, it can be seen that our proposed approach outperformed the other methods in mean average precision. However, AttributeNet [51] and PGAN [52] outperformed our proposed approach in Rank-1 accuracy. AttributeNet uses separate networks to generate attributes, which adds to the complexity of the network. PGAN uses attribute-based features along with an attention model, which increases complexity. Our model outperformed SAN, which combines a global network with a horizontal part-based network [27]. This result is significant because it establishes the motivation for our proposed approach in that our unifying framework can effectively replace a global feature branch. Our approach also outperformed general transformer-based methods like TransReid and Swin Transformer, as well as recent state-of-the-art methods like URRNet, MIMANet, and CFSA.
Analysis on VehicleId: In Table 3 it can be seen that our proposed model outperformed the other models in Rank-5 accuracy. However, in Rank-1 accuracy, VANet [48] and DGPM [35] performed better due to their complex attention mechanism and partitioning in multiple dimensions. Again, our model outperformed SAN [27], thereby establishing the superiority of our induced global similarity learning over direct global feature learning. Our approach outperformed most recent state-of-the-art approaches on the VehicleId dataset.
Empirical analysis: The proposed GLSIPNet model rewards parts that are more similar to, or more representative of, the vehicle image while penalizing parts that are dissimilar. In Figure 6, the similarity scores are shown for three vehicle images. The scores are used as weights for the losses of the individual parts to arrive at the total loss over which the entire network is trained. This leads to higher attention on the more relevant parts. We can see in Figure 6 that the model accurately identified regions of more relevance in the vehicle images. This can help in cases of images with occlusion and other interference in patches.

Figure 6.
Similarity scores corresponding to images passed through the network, given on the right axis.
The following conclusions can be drawn from the above experimental results:
- Our proposed model clearly outperforms the baseline, thereby establishing the significance of global–local similarity-induced part learning in addressing the VReID problem using local part-based features. Our method achieves improvements of 2.5% (mAP) on the VeRi dataset and 2.4%, 3.3%, and 2.8% (mAP) on the small, medium, and large variants of the VehicleId dataset, respectively.
- Our proposed model also performs better than the other comparison models in terms of mAP on the VeRi dataset and Rank-5 accuracy on the VehicleId dataset.
- The models proposed in [51,52], which outperform our model in Rank-1 and Rank-5 accuracies on the VeRi dataset, fail to do so on the VehicleId dataset. Similarly, the models proposed in [35,48] perform better in Rank-1 accuracy, but in Rank-5 accuracy on the VeRi dataset, our method performs better. Thus, considering its low complexity and consistent performance, our approach offers a better trade-off than attention-based models with higher complexity.
- Our proposed model successfully achieves better results in part-based vehicle re-identification by incorporating a global aspect without adding any additional complexity. This approach is found to be more effective than directly incorporating a global feature branch, as demonstrated by the comparison with SAN [27] in Table 2 and Table 3.
5. Conclusions
The current work proposes an improved part-feature extraction and aggregation strategy, named GLSIPNet, as a novel contribution to the deep learning CNN framework. Without increasing model complexity or adding trainable parameters, the effect of learning part-based features using global cues is incorporated through a similarity score computed between the global and partitioned features. We have thoroughly evaluated the proposed approach through extensive experimentation on two standard datasets, VehicleId and VeRi, demonstrating its superior accuracy compared to both the baseline and other related works in the literature. Our method outperforms the baseline by 2.5% (mAP) on the VeRi dataset and by 2.4%, 3.3%, and 2.8% (mAP) on the small, medium, and large variants of the VehicleId dataset, respectively. These results show potential for further extension using other distance metrics and other similarity scores and their combinations. Also, the framework may be extended to address other retrieval problems like person re-identification. The accuracy of the model needs to be increased further, which is a limitation of the current work, and it could be improved by incorporating attention modules and state-of-the-art vision transformers. Also, the effect of parameters, like the number of parts and the mode of partitioning, may be analysed as part of future work.
Author Contributions
Conceptualization and methodology, R.K.N. and D.M.; software R.K.N.; validation, R.K.N. and D.M.; formal analysis, R.K.N. and D.M.; investigation, R.K.N. and D.M.; data curation, R.K.N. and D.M.; writing—original draft preparation, R.K.N.; writing—review and editing, R.K.N. and D.M.; supervision D.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
In this paper, we used the publicly available VeRi and VehicleId datasets.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Babu, R.; Rajitha, B. Accident Detection through CCTV Surveillance. In Proceedings of the 2022 IEEE Students Conference on Engineering and Systems (SCES), Prayagraj, India, 1–3 July 2022; pp. 01–06. [Google Scholar] [CrossRef]
- Wang, H.; Hou, J.; Chen, N. A Survey of Vehicle Re-Identification Based on Deep Learning. IEEE Access 2019, 7, 172443–172469. [Google Scholar] [CrossRef]
- Yan, L.; Li, K.; Gao, R.; Wang, C.; Xiong, N. An Intelligent Weighted Object Detector for Feature Extraction to Enrich Global Image Information. Appl. Sci. 2022, 12, 7825. [Google Scholar] [CrossRef]
- Huan, W.; Shcherbakova, G.; Sachenko, A.; Yan, L.; Volkova, N.; Rusyn, B.; Molga, A. Haar Wavelet-Based Classification Method for Visual Information Processing Systems. Appl. Sci. 2023, 13, 5515. [Google Scholar] [CrossRef]
- Liu, X.; Liu, W.; Ma, H.; Fu, H. Large-scale vehicle re-identification in urban surveillance videos. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME), Seattle, WA, USA, 11–15 July 2016. [Google Scholar]
- Liu, X.; Liu, W.; Mei, T.; Ma, H. PROVID: Progressive and Multimodal Vehicle Reidentification for Large-Scale Urban Surveillance. IEEE Trans. Multimed. 2018, 20, 645–658. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems; Pereira, F., Burges, C., Bottou, L., Weinberger, K., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2012; Volume 25. [Google Scholar]
- Liu, H.; Tian, Y.; Wang, Y.; Pang, L.; Huang, T. Deep Relative Distance Learning: Tell the Difference between Similar Vehicles. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2167–2175. [Google Scholar] [CrossRef]
- Liu, S.; Deng, W. Very deep convolutional neural network based image classification using small training sample size. In Proceedings of the 2015 3rd IAPR Asian Conference on Pattern Recognition (ACPR), Kuala Lumpur, Malaysia, 3–6 November 2015; pp. 730–734. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Los Alamitos, CA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Chen, H.; Lagadec, B.; Bremond, F. Partition and Reunion: A Two-Branch Neural Network for Vehicle Re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sun, Y.; Zheng, L.; Li, Y.; Yang, Y.; Tian, Q.; Wang, S. Learning Part-based Convolutional Features for Person Re-Identification. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 902–917. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Yu, H.; Hu, C.; Wang, H. Multi-Branch Feature Learning Network via Global-Local Self-Distillation for Vehicle Re-Identification. IEEE Trans. Veh. Technol. 2024, 73, 12415–12425. [Google Scholar] [CrossRef]
- Pang, X.; Zheng, Y.; Nie, X.; Yin, Y.; Li, X. Multi-axis interactive multidimensional attention network for vehicle re-identification. Image Vis. Comput. 2024, 144, 104972. [Google Scholar] [CrossRef]
- Kanacı, A.; Zhu, X.; Gong, S. Vehicle Re-identification in Context. In Proceedings of the Pattern Recognition: 40th German Conference, GCPR 2018, Stuttgart, Germany, 9–12 October 2018; Brox, T., Bruhn, A., Fritz, M., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 377–390. [Google Scholar]
- Lou, Y.; Bai, Y.; Liu, J.; Wang, S.; Duan, L. VERI-Wild: A Large Dataset and a New Method for Vehicle Re-Identification in the Wild. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3230–3238. [Google Scholar] [CrossRef]
- Tang, Z.; Naphade, M.; Liu, M.; Yang, X.; Birchfield, S.; Wang, S.; Kumar, R.; Anastasiu, D.; Hwang, J. CityFlow: A City-Scale Benchmark for Multi-Target Multi-Camera Vehicle Tracking and Re-Identification. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Los Alamitos, CA, USA, 15–20 June 2019; pp. 8789–8798. [Google Scholar] [CrossRef]
- Yan, K.; Tian, Y.; Wang, Y.; Zeng, W.; Huang, T. Exploiting Multi-grain Ranking Constraints for Precisely Searching Visually-similar Vehicles. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 562–570. [Google Scholar] [CrossRef]
- Zhou, Y.; Liu, L.; Shao, L. Vehicle Re-Identification by Deep Hidden Multi-View Inference. IEEE Trans. Image Process. 2018, 27, 3275–3287. [Google Scholar] [CrossRef]
- Wang, H.; Peng, J.; Chen, D.; Jiang, G.; Zhao, T.; Fu, X. Attribute-Guided Feature Learning Network for Vehicle Reidentification. IEEE Multimed. 2020, 27, 112–121. [Google Scholar] [CrossRef]
- Zhao, Y.; Shen, C.; Wang, H.; Chen, S. Structural Analysis of Attributes for Vehicle Re-Identification and Retrieval. IEEE Trans. Intell. Transp. Syst. 2020, 21, 723–734. [Google Scholar] [CrossRef]
- Li, Z.; Shi, Y.; Ling, H.; Chen, J.; Liu, B.; Wang, R.; Zhao, C. Viewpoint Disentangling and Generation for Unsupervised Object Re-ID. Acm Trans. Multimed. Comput. Commun. Appl. 2024, 20. [Google Scholar] [CrossRef]
- He, B.; Li, J.; Zhao, Y.; Tian, Y. Part-Regularized Near-Duplicate Vehicle Re-Identification. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3992–4000. [Google Scholar] [CrossRef]
- Yan, B.; Liu, Y.; Yan, W. A Novel Fusion Perception Algorithm of Tree Branch/Trunk and Apple for Harvesting Robot Based on Improved YOLOv8s. Agronomy 2024, 14, 1895. [Google Scholar] [CrossRef]
- Qian, J.; Jiang, W.; Luo, H.; Yu, H. Stripe-based and attribute-aware network: A two-branch deep model for vehicle re-identification. Meas. Sci. Technol. 2020, 31, 095401. [Google Scholar] [CrossRef]
- Wang, Z.; Tang, L.; Liu, X.; Yao, Z.; Yi, S.; Shao, J.; Yan, J.; Wang, S.; Li, H.; Wang, X. Orientation Invariant Feature Embedding and Spatial Temporal Regularization for Vehicle Re-identification. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 379–387. [Google Scholar] [CrossRef]
- Zhu, J.; Zeng, H.; Lei, Z.; Liao, S.; Zheng, L.; Cai, C. A Shortly and Densely Connected Convolutional Neural Network for Vehicle Re-identification. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 3285–3290. [Google Scholar] [CrossRef]
- Zhu, J.; Du, Y.; Hu, Y.; Zheng, L.; Cai, C. VRSDNet: Vehicle re-identification with a shortly and densely connected convolutional neural network. Multimed. Tools Appl. 2019, 78, 29043–29057. [Google Scholar] [CrossRef]
- Zhu, J.; Huang, J.; Zeng, H.; Ye, X.; Li, B.; Lei, Z.; Zheng, L. Object Reidentification via Joint Quadruple Decorrelation Directional Deep Networks in Smart Transportation. IEEE Internet Things J. 2020, 7, 2944–2954. [Google Scholar] [CrossRef]
- Peng, J.; Wang, H.; Zhao, T.; Fu, X. Learning multi-region features for vehicle re-identification with context-based ranking method. Neurocomputing 2019, 359, 427–437. [Google Scholar] [CrossRef]
- Cho, Y.; Kim, W.J.; Hong, S.; Yoon, S.E. Part-based Pseudo Label Refinement for Unsupervised Person Re-identification. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 7298–7308. [Google Scholar] [CrossRef]
- Wang, H.; Peng, J.; Jiang, G.; Xu, F.; Fu, X. Discriminative feature and dictionary learning with part-aware model for vehicle re-identification. Neurocomputing 2021, 438, 55–62. [Google Scholar] [CrossRef]
- Chen, X.; Sui, H.; Fang, J.; Feng, W.; Zhou, M. Vehicle Re-Identification Using Distance-Based Global and Partial Multi-Regional Feature Learning. IEEE Trans. Intell. Transp. Syst. 2021, 22, 1276–1286. [Google Scholar] [CrossRef]
- Sun, W.; Dai, G.; Zhang, X.; He, X.; Chen, X. TBE-Net: A Three-Branch Embedding Network with Part-Aware Ability and Feature Complementary Learning for Vehicle Re-Identification. IEEE Trans. Intell. Transp. Syst. 2022, 23, 14557–14569. [Google Scholar] [CrossRef]
- Xu, Y.; Jiang, Z.; Men, A.; Pei, J.; Ju, G.; Yang, B. Attentional Part-based Network for Person Re-identification. In Proceedings of the 2019 IEEE Visual Communications and Image Processing (VCIP), Sydney, NSW, Australia, 1–4 December 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Wang, G.; Yuan, Y.; Chen, X.; Li, J.; Zhou, X. Learning Discriminative Features with Multiple Granularities for Person Re-Identification. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 274–282. [Google Scholar] [CrossRef]
- Qian, J.; Pan, M.; Tong, W.; Law, R.; Wu, E.Q. URRNet: A Unified Relational Reasoning Network for Vehicle Re-Identification. IEEE Trans. Veh. Technol. 2023, 72, 11156–11168. [Google Scholar] [CrossRef]
- Li, J.; Gong, X. Unleashing the Potential of Pre-Trained Diffusion Models for Generalizable Person Re-Identification. Sensors 2025, 25, 552. [Google Scholar] [CrossRef]
- Lv, K.; Han, S.; Lin, Y. Identity-Guided Spatial Attention for Vehicle Re-Identification. Sensors 2023, 23, 5152. [Google Scholar] [CrossRef]
- Bai, L.; Rong, L. Vehicle re-identification with multiple discriminative features based on non-local-attention block. Sci. Rep. 2024, 14, 31386. [Google Scholar] [CrossRef] [PubMed]
- Gong, R.; Zhang, X.; Pan, J.; Guo, J.; Nie, X. Vehicle Reidentification Based on Convolution and Vision Transformer Feature Fusion. IEEE Multimed. 2024, 31, 61–68. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, P.; Wang, D.; Lu, H. Other tokens matter: Exploring global and local features of Vision Transformers for Object Re-Identification. Comput. Vis. Image Underst. 2024, 244, 104030. [Google Scholar] [CrossRef]
- Huang, F.; Lv, X.; Zhang, L. Coarse-to-fine sparse self-attention for vehicle re-identification. Knowl.-Based Syst. 2023, 270, 110526. [Google Scholar] [CrossRef]
- Zhong, Z.; Zheng, L.; Cao, D.; Li, S. Re-ranking Person Re-identification with k-Reciprocal Encoding. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3652–3661. [Google Scholar] [CrossRef]
- Xu, Y.; Jiang, N.; Zhang, L.; Zhou, Z.; Wu, W. Multi-scale Vehicle Re-identification Using Self-adapting Label Smoothing Regularization. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 2117–2121. [Google Scholar] [CrossRef]
- Chu, R.; Sun, Y.; Li, Y.; Liu, Z.; Zhang, C.; Wei, Y. Vehicle Re-Identification with Viewpoint-Aware Metric Learning. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8281–8290. [Google Scholar] [CrossRef]
- Kuma, R.; Weill, E.; Aghdasi, F.; Sriram, P. Vehicle Re-identification: An Efficient Baseline Using Triplet Embedding. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–9. [Google Scholar] [CrossRef]
- Lin, W.; Li, Y.; Yang, X.; Peng, P.; Xing, J. Multi-View Learning for Vehicle Re-Identification. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019; pp. 832–837. [Google Scholar] [CrossRef]
- Quispe, R.; Lan, C.; Zeng, W.; Pedrini, H. AttributeNet: Attribute enhanced vehicle re-identification. Neurocomputing 2021, 465, 84–92. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, R.; Cao, J.; Gong, D.; You, M.; Shen, C. Part-Guided Attention Learning for Vehicle Instance Retrieval. IEEE Trans. Intell. Transp. Syst. 2022, 23, 3048–3060. [Google Scholar] [CrossRef]
- Li, J.; Yu, C.; Shi, J.; Zhang, C.; Ke, T. Vehicle Re-identification method based on Swin-Transformer network. Array 2022, 16, 100255. [Google Scholar] [CrossRef]
- He, S.; Luo, H.; Wang, P.; Wang, F.; Li, H.; Jiang, W. TransReID: Transformer-Based Object Re-Identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 15013–15022. [Google Scholar]
- Li, B.; Liu, P.; Fu, L.; Li, J.; Fang, J.; Xu, Z.; Yu, H. VehicleGAN: Pair-flexible Pose Guided Image Synthesis for Vehicle Re-identification. In Proceedings of the 2024 IEEE Intelligent Vehicles Symposium (IV), Jeju Island, Republic of Korea, 2–5 June 2024; pp. 447–453. [Google Scholar] [CrossRef]
- Sun, K.; Pang, X.; Zheng, M.; Nie, X.; Li, X.; Zhou, H.; Yin, Y. Heterogeneous context interaction network for vehicle re-identification. Neural Netw. 2024, 169, 293–306. [Google Scholar] [CrossRef] [PubMed]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).