1. Introduction
With the emergence of image-generative AI such as Stable Diffusion and Midjourney, research on the integration of generative AI across various fields has been actively conducted. Examples of such fields range from entertainment and media [
1] to gaming and virtual worlds [
2]. These AIs are provided in a highly user-friendly manner for both personal and commercial use, allowing even non-experts to use them without understanding the internal structure of the model. They are capable of generating high-quality images, significantly contributing to the efficiency of various tasks.
However, most existing generative AI systems focus on producing a single final image. The intermediate stages of creation—the process of drawing—are often neglected, despite their value in educational and creative contexts. The drawing process contains essential information for understanding structure, style, and technique, especially for learners and creators. A system that can generate and visualize these stages can greatly enhance user understanding and engagement.
In our research, we focus on creating a drawing support system using generative AI. The system under development is designed to implement the following two features:
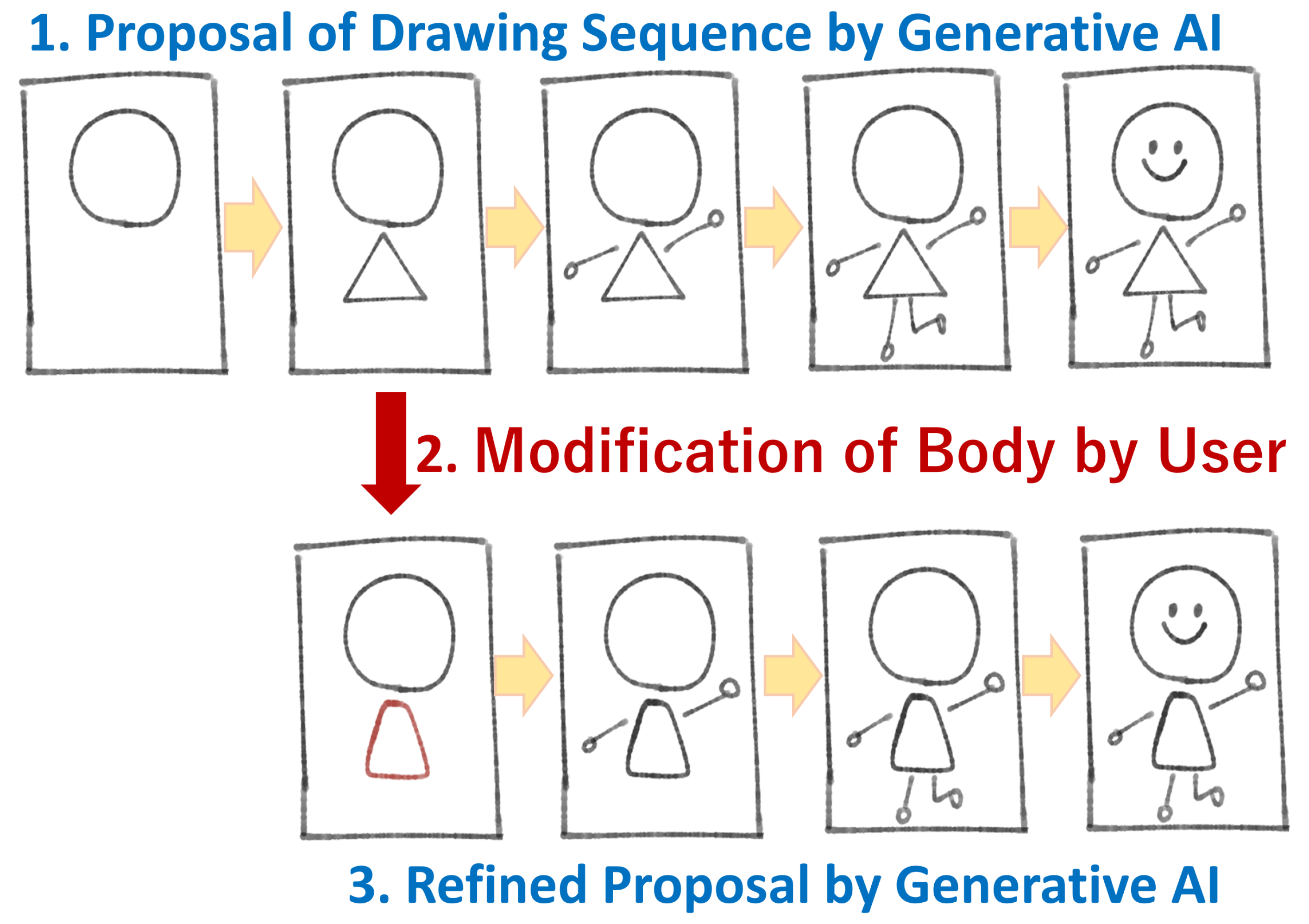
The generative AI creates a drawing sequence, including the drawing process, allowing users to modify any stage of the process to refine the final image.
The user inputs images of the drawing process into the generative AI, which then generates a balanced image based on the provided input.
In this paper, we specifically deal with creating a basic model of the first feature. A schematic diagram of the model is shown in
Figure 1.
To build such a system, it is necessary to develop a generative AI capable of sequentially generating a series of drawing images. While there are prior studies that use RNNs or vector-based models to simulate stroke-by-stroke sketching [
3,
4], they are often limited to symbolic or vector inputs and do not directly operate on pixel-based sketch images.
Our approach focuses on raster images of the drawing process, which are more commonly used in practice and do not require specialized annotation. To sequentially generate time-series images of the drawing process, it is necessary to train the model using images of the drawing process. However, while current generative AI models are trained on a vast amount of completed images available on the web, images of the drawing process are generally not publicly shared. Therefore, collecting training data becomes a major challenge for training this system.
In order to address this challenge, we built our own training database. Specifically, we focused on images of human figures, creating various character images and continuously adding images of their drawing processes to the database. By using the constructed database, we built and trained a generative AI model to verify the effectiveness of our approach.
This drawing support system has potential applications in a wide range of fields, such as interactive learning platforms for art education, AI-assisted illustration tools, and creative assistance for users with limited drawing skills or motor impairments. Rather than simply generating final outputs, our model aims to assist users through each stage of the creative process.
The main contributions of this study are summarized as follows:
We propose a novel drawing sequence-generation system based on a convolutional encoder–decoder architecture, which enables step-by-step image synthesis from a single sketch input.
We introduce a noise-augmented training strategy that significantly improves sequence stability by reducing accumulated prediction error, a critical challenge in recursive image generation.
We conduct comprehensive comparisons with a state-of-the-art recurrent baseline (PredRNN), providing both qualitative and quantitative evaluations using the PSNR, SSIM, LPIPS, FID, inference time, and parameter count.
Our approach emphasizes architectural simplicity and efficiency, making it well suited for real-time or resource-constrained applications, such as educational tools and creative assistance systems.
In this paper, we present the composition of the generative AI model and report the experimental results using a small number of character images. The remainder of this paper is organized as follows.
Section 2 introduces related research on the system.
Section 3 describes the training model used to build the system.
Section 4 explains the experimental setup.
Section 5 presents the experimental results and discussion. A summary and future work are provided in
Section 6.
2. Related Works
Generative AI is currently a rapidly developing tool in the field of character image generation. In this section, we first introduce some works related to character image generation using generative AI and then present some works focusing on drawing support using generative AI.
2.1. Research on Generative AI for Character Image Generation
Generative AI has been instrumental in enhancing character design, particularly in interdisciplinary fields like game development. The tool “Sketchar” exemplifies this by allowing designers to prototype game characters and generate images based on conceptual input. This tool facilitates better communication between designers and illustrators, especially when designers lack artistic skills, by providing immediate visual feedback and refining design details [
3].
Generative Adversarial Networks (GANs) have also been widely used to generate character images, particularly in the realm of anime and comic characters. Research comparing different GAN variants, such as DCGAN and CycleGAN, highlights their effectiveness in creating authentic and diverse anime character images. These models are evaluated using metrics like the Fréchet Inception Distance (FID) and Inception Score (IS), which assess the quality and diversity of the generated images [
5].
Deep learning methods, including GANs and Variational Autoencoders, have also been applied to generate images of handwritten characters. These models aim to produce images that not only replicate the input but also introduce variations to mimic human-like creativity. In [
6], the authors explored the transferability of these models across different datasets, demonstrating their ability to generate novel images beyond the training set.
Generative AI has also been explored for creating 2D character animations in platformer games. The application described in [
7] focuses on controlling randomness in AI-generated animations, using tools like ChatGPT and Stable Diffusion to streamline the production process. The research underscores the potential of generative AI to enhance the production of 2D game animations, showcasing its feasibility and potential.
While these works have demonstrated their effectiveness in generating character images, most of them use methods that generate a complete image from text input or generate a completed character image from random latent variables. The novelty of our approach lies in generating not only the final character image but also the drawing process.
2.2. Research on Generative AI for Drawing Support
A deep generative model, namely AI Sketcher, has been designed to produce high-quality sketches by addressing the limitations of previous models like Sketch-RNN. It employs a CNN-based autoencoder to capture positional information at the pixel level and introduces an influence layer to guide stroke generation more precisely. This model supports multi-class sketch generation through a conditional vector, demonstrating its effectiveness on large-scale sketch datasets [
8].
Similarly, Sketch-pix2seq has been proposed to extend the traditional sequence-to-sequence framework by incorporating convolutional and recurrent neural networks for generating diverse sketches across multiple categories [
9]. It learns both structural features and temporal stroke dependencies, contributing to more coherent and realistic sketch generation.
Generative machine learning models, including large language models, play a significant role in supporting design ideation, early prototyping, and sketching. These models assist in generating diverse design concepts and facilitate co-creative processes between humans and AI. The interaction with these models shapes user expectations and highlights the potential and limitations of AI in creative design processes [
10].
Generative AI is also making strides in architectural design through the Sketch-to-Architecture workflow. This approach uses AI models to transform simple sketches into conceptual floorplans and 3D models, enabling rapid ideation and controlled generation of architectural renderings. This innovation represents a new direction in computer-aided architectural design, showcasing the potential of generative AI in this field [
11].
A generative AI tool called DesignAID has also been developed to support the exploration of large design spaces by generating diverse ideas and images. It combines large language models with image-generation software to create a wide range of visual concepts quickly. This tool has been found to be more inspirational and useful than traditional image search methods, although the value of generating highly diverse ideas varies [
12].
Recent research has also proposed drawing support systems tailored to specific creative workflows. For example, a four-frame manga drawing support system offers frame and layout suggestions based on user content and storyline, supporting manga creators in their visual storytelling process [
13]. Another study introduced an illustration drawing interface incorporating image retrieval and adjustable grid guidance, enabling amateur users to enhance their digital illustrations through structured visual prompts [
14].
Other notable works include systems that provide process-based feedback, such as recording and replaying the drawing process via digital pens for remote tutoring [
15]. Remote support systems using robotic pointing and gesture overlays have also been explored to enhance drawing instruction in collaborative settings [
16].
While the focus of these studies varies, most aim to generate or support completed images or enhance instruction. In contrast, the novelty of our system lies in its ability to generate images of the drawing process itself, enabling users to view or modify intermediate stages during creation. This contributes to both the creative flexibility and educational value of drawing support systems.
2.3. Comparisons with Sequential Generation Models
While our proposed model is based on a convolutional encoder–decoder architecture, various existing methods have been developed for spatiotemporal image prediction. Convolutional LSTM (ConvLSTM) networks [
17] were among the earliest approaches to introduce temporal memory into convolutional architectures for sequential prediction. PredRNN [
18] further enhanced temporal modeling with dual memory states and spatiotemporal alignment mechanisms and has become a standard benchmark in video prediction. Variants such as Dual ConvLSTM have also been explored in vision-language tasks, demonstrating the adaptability of recurrent structures beyond pure video forecasting [
19].
In contrast to recurrent models, diffusion-based models have shown promising results in high-quality image-generation tasks. Denoising Diffusion Probabilistic Models (DDPMs) [
20] and latent diffusion models (LDMs) [
21] have achieved state-of-the-art results in both natural image synthesis and editing. Some works have also explored blended diffusion approaches [
22] and domain-specific enhancements, such as low-light imaging [
23] or 3D neuron segmentation using ConvLSTM [
24].
Recent evaluations [
25] have demonstrated that diffusion models can outperform GANs in fidelity and diversity. Score-based generation strategies using stochastic differential equations [
26] have further expanded the capabilities of diffusion frameworks.
Our proposed approach, while simpler and more lightweight, can be viewed as a first step toward integrating such advanced temporal or diffusion-based architectures into sketch-based drawing support systems. Future extensions may explore hybrid models or direct comparisons with recurrent architectures such as PredRNN and ConvLSTM.
3. Proposed System
The proposed encoder–decoder model is shown in the upper section of
Figure 1: “Proposal of Drawing Sequence by Generative AI.” The system is designed as a convolutional encoder–decoder network that predicts the next step in the drawing sequence based on the current frame.
Figure 2 shows the architecture of the proposed model. It consists of a convolutional encoder that extracts hierarchical features from the input image, followed by a convolutional decoder that reconstructs the image of the next step. Each convolutional layer in the encoder uses a
kernel with ReLU activation and batch normalization, progressively downsampling the spatial resolution. The decoder mirrors this structure, using transposed convolution layers to upsample the feature maps and restore spatial resolution.
During training, Gaussian noise is optionally added to the input images to improve robustness against perturbations and enhance generalization. The model is trained to map the input image at time step t to the image at time step , and this mapping is recursively applied across the sequence. In the final step, the model is trained to reproduce the same image, ensuring consistency. This recursive prediction mechanism enables the model to generate multi-step drawing sequences from a single initial sketch.
The model is structurally similar to a convolutional autoencoder, except for differences in the training data. While convolutional autoencoders are typically used for self-organizing image features [
27], our model is designed as a generator for time-series images. While recurrent neural networks (RNNs) [
28] and Transformer-based models are commonly used for sequential learning due to their ability to retain contextual information through hidden states or attention mechanisms, our model does not incorporate any such contextual layers. Instead, it relies on the structure of the training data to learn temporal progression implicitly. Although this limits its capacity to model long-term dependencies, it simplifies implementation and reduces the number of trainable parameters. As a result, the current model is not capable of handling time-series data that requires rich contextual understanding.
Other commonly used models for image learning and generation include Variational Autoencoders (VAEs) [
4] and diffusion models [
29]. A Variational Autoencoder (VAE) introduces a mechanism to estimate the mean and variance in an autoencoder, generating images by sampling vectors from the learned distribution. Meanwhile, diffusion models achieve high-performance image generation through iterative noise addition and removal. These models typically require large amounts of image data for training. However, since our study involves constructing and training a custom database, we use a standard convolutional autoencoder-based model, which allows for some degree of image generation even with a limited amount of training data. As our structured database expands, we plan to further investigate the effectiveness of these models. In future work, we also plan to explore hybrid architectures, such as combining convolutional encoders with Transformer-based decoders, to better handle long-range dependencies and spatial–temporal interactions that are difficult to model using convolutional structures alone.
4. Experimental Setup
In this section, we describe the experimental setup, including the database construction, model implementation, and training methodology.
4.1. Database Construction
To verify the effectiveness of the proposed model, we created a dataset consisting of image sequences from the drawing process of ten character illustrations. The character designs were created manually by a single illustrator using a digital drawing application with layer-based editing. Each character was drawn in six stages by incrementally adding details across layers, simulating realistic drawing progression.
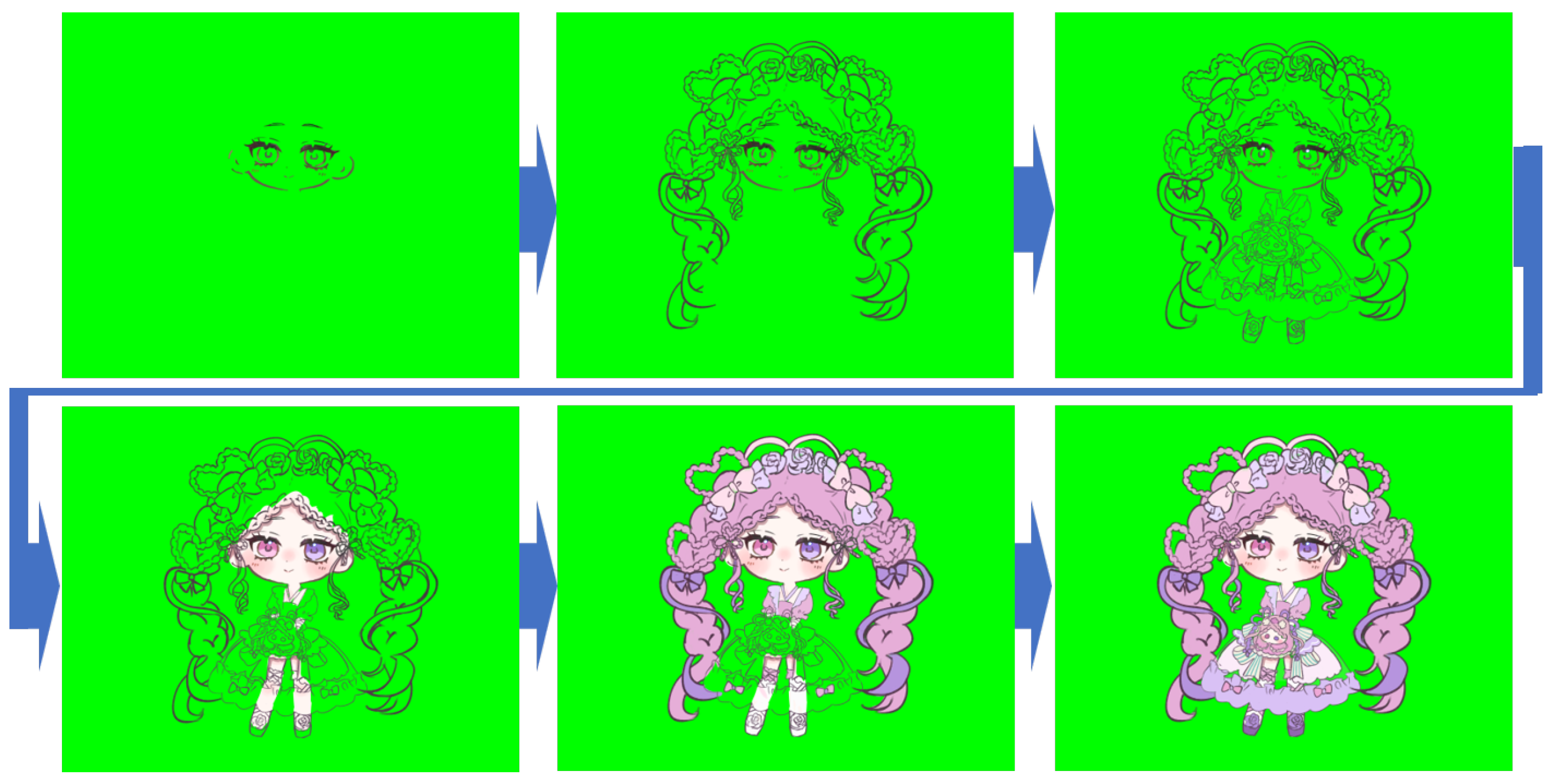
Figure 3 shows all ten characters, and
Figure 4 and
Figure 5 present detailed drawing sequences for two representative characters. Because light colors were frequently used, we selected green as the background color to improve the contrast and reduce ambiguity during training.
All images were saved at a resolution of pixels. This size was chosen to accommodate five stages of downsampling by convolutional layers, as the encoder–decoder architecture described later halves the resolution at each stage (i.e., divisible by ). The final dataset consisted of six image steps per character, aligned by drawing order.
4.2. Model Setup
The model used in this experiment is an encoder–decoder convolutional neural network implemented using PyTorch (ver. 2.7.0). The encoder consists of five convolutional layers with ReLU activations, while the decoder mirrors this structure with five transposed convolutional layers.
Table 1 and
Table 2 show the detailed configuration of each layer. In the encoder, each layer reduces the spatial resolution by half while doubling the number of feature channels. Conversely, in the decoder, each layer upsamples the spatial resolution by a factor of two, halving the number of channels. The final decoder layer has three output channels to reconstruct a color image in RGB format.
We used the Mean Squared Error (MSE) loss as the training objective, comparing the predicted image with the ground-truth image at the next step in the drawing sequence.
4.3. Model Training
To evaluate the effectiveness of our proposed method, we trained the model using two different strategies:
Standard Training: The model was trained on the original 60 images (10 characters × six stages per character).
Training with Noise-Augmented Images: Each of the 60 images was augmented with 99 noisy variants using Gaussian noise, resulting in a total of 6000 training images.
The same model architecture and hyperparameters were used for both training methods to ensure a fair comparison. We trained the model for 400,000 epochs with a batch size of 8 for standard training and 512 for noise-augmented training, using the SGD optimizer (learning rate = 0.8). Training was conducted on a machine equipped with an NVIDIA RTX 4080 GPU and 32 GB of RAM. A learning rate of 0.01 was adopted based on common practice in similar encoder–decoder models, and it provided stable training in our preliminary tests.
This dual-training setup allowed us to evaluate the impact of noise augmentation on the model’s stability and generalization performance.
4.4. Comparison with PredRNN Baseline
To provide a comparative baseline, we also trained PredRNN [
18], a well-established recurrent neural network for spatiotemporal predictive learning, on the same dataset. Training and evaluation were conducted under identical conditions using the same image sequences, training epochs, and image resolution. We used publicly available PyTorch implementations of PredRNN and adapted them to our data format.
Both our proposed model and PredRNN were evaluated using the same three metrics: Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), and Learned Perceptual Image-Patch Similarity (LPIPS). These metrics were computed for each generated frame in the sequence, allowing us to assess both image quality and temporal consistency throughout the drawing process.
5. Results of Experiments and Discussion
In this section, we present the results of the two experiments and discuss the outcomes in both qualitative and quantitative terms. In the image-generation experiment, the first image from the drawing sequences, such as those in
Figure 4 and
Figure 5, was used as the input to generate the next image. The generated images were then recursively fed back to the model to generate the entire drawing sequence.
5.1. Results from Standard Training
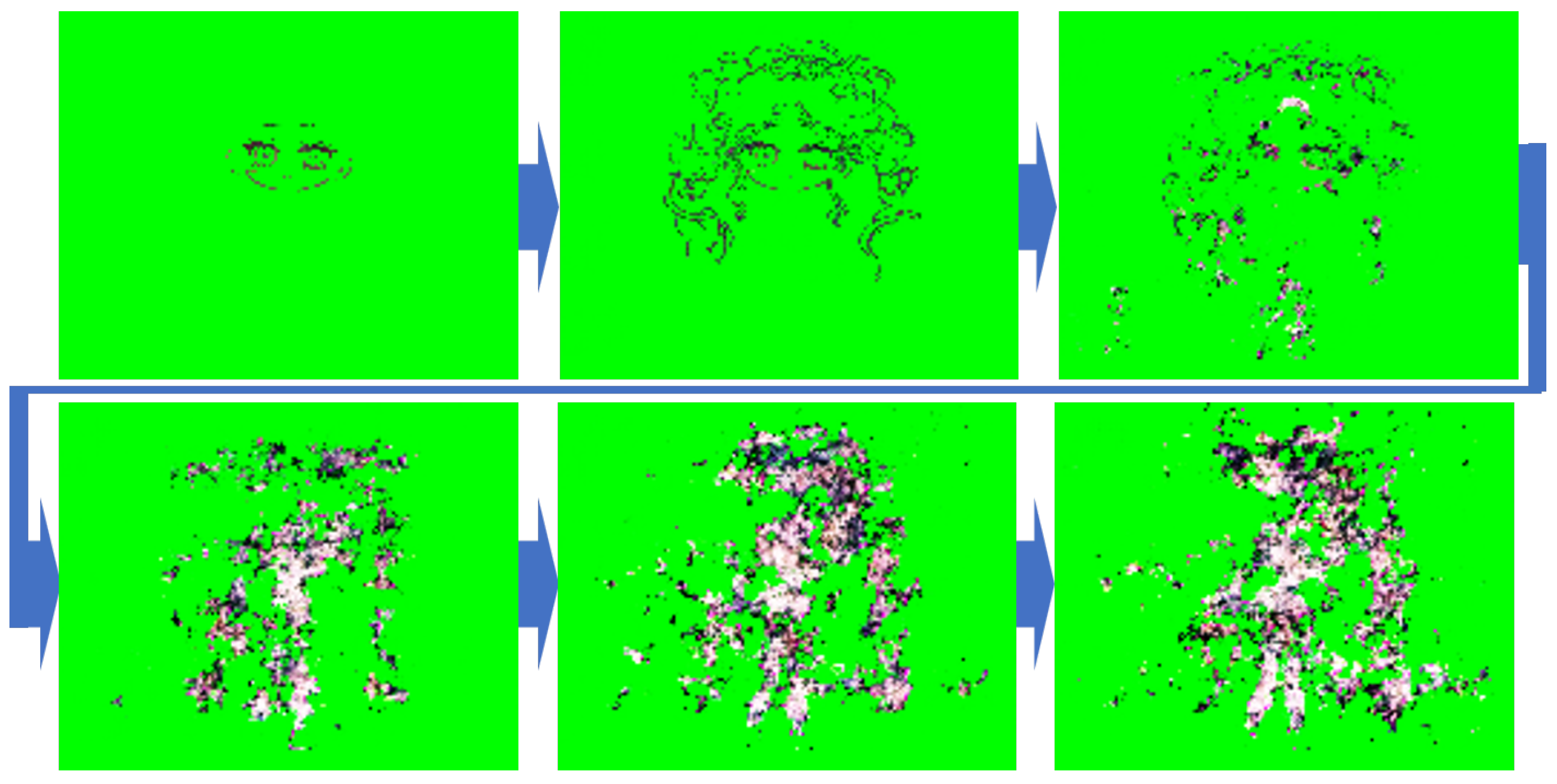
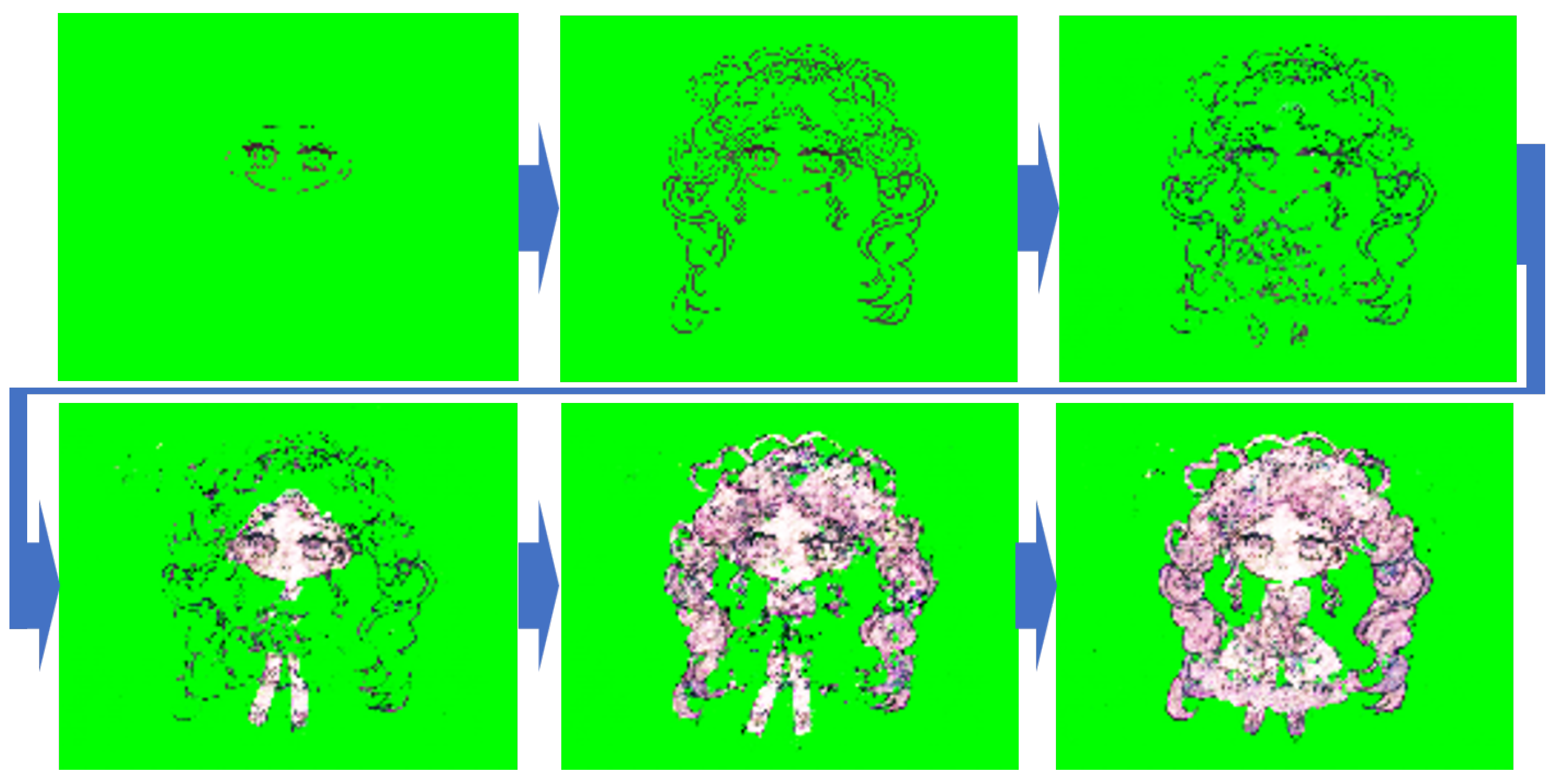
An example of the generated image sequence using standard training is shown in
Figure 6.
Figure 6 illustrates the drawing sequence generated by the model for the character in
Figure 4. In
Figure 6, as well as in the generation of other characters, it was observed that the second image in the sequence was relatively well-generated. However, as the model generated the third and fourth images, a significant amount of noise was introduced, leading to degradation in the generated images. This degradation is considered to result from error accumulation due to the recursive nature of the model.
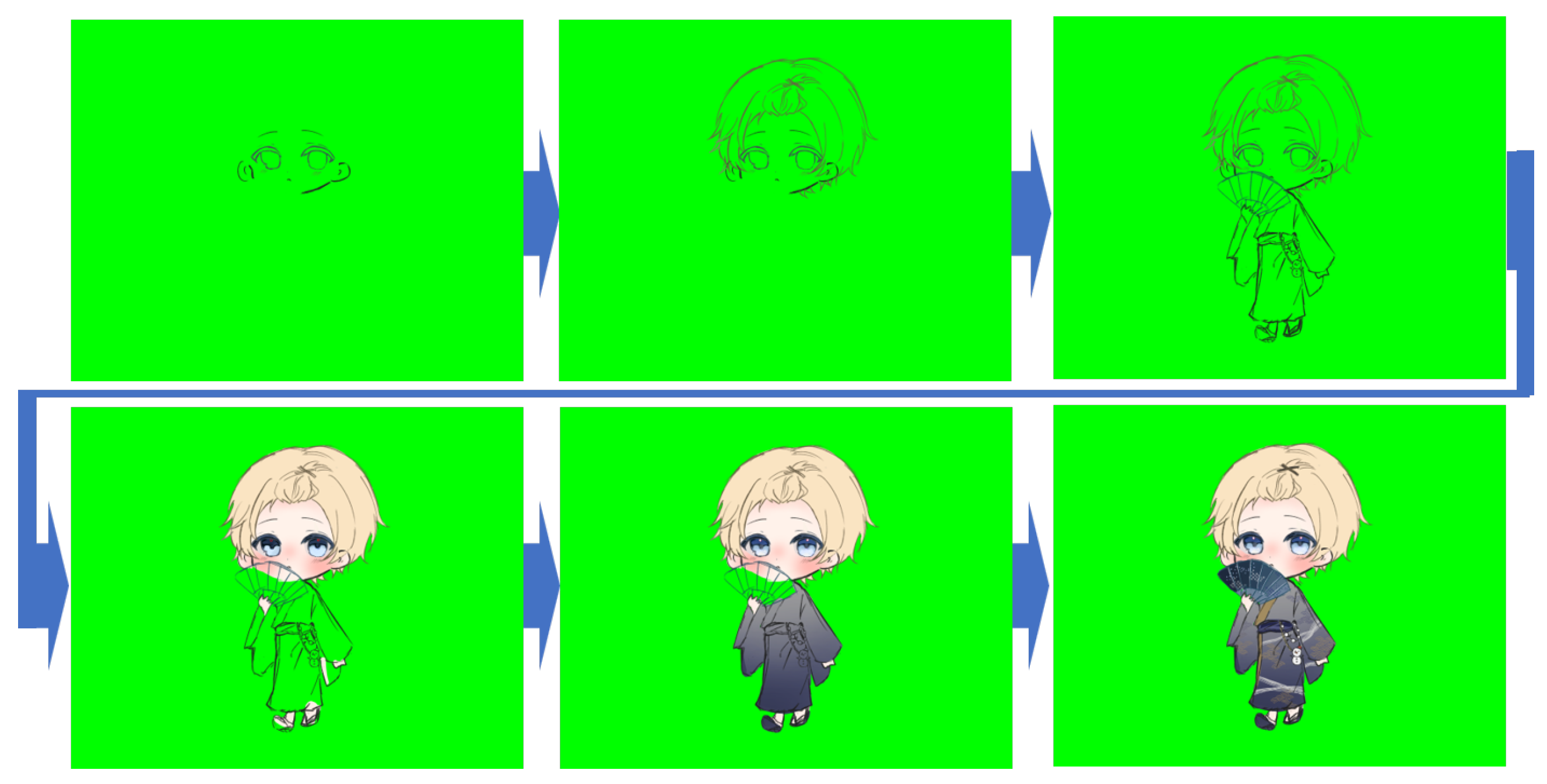
5.2. Results from Training with Noise-Augmented Images
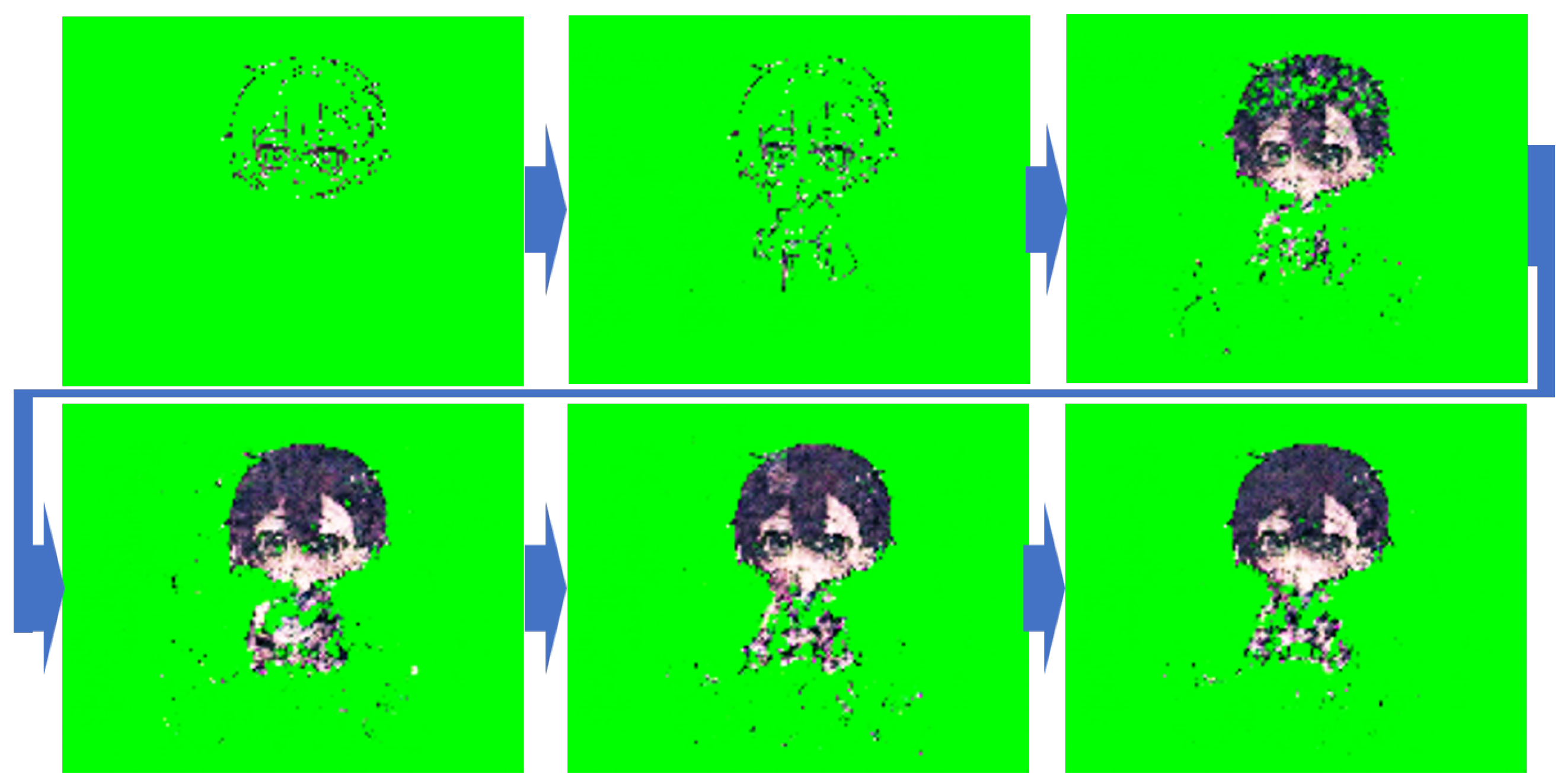
The generation results of the model trained using noise-augmented images for the same character are shown in
Figure 7. Unlike
Figure 6,
Figure 7 demonstrates that not only the second image but also the later steps were generated relatively well. Compared to
Figure 4, the generated images contain some noise, but overall, the model achieved higher generation performance. However, as shown in
Figure 8, there were cases where the model failed to generate specific body parts, such as the feet. This issue likely arises because the model lacks a contextual mechanism, which prevents it from maintaining spatial consistency across time steps.
5.3. Quantitative Evaluation
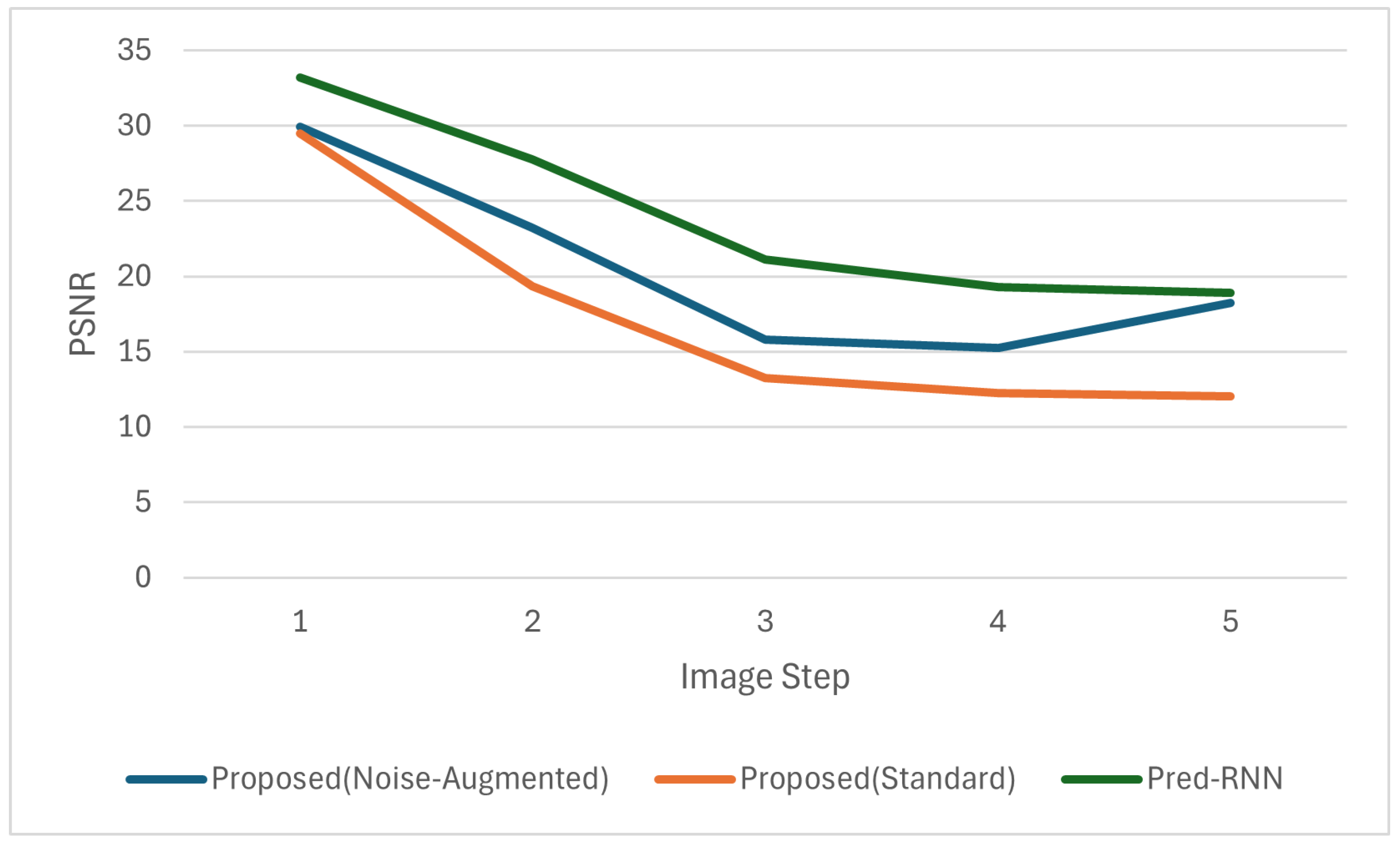
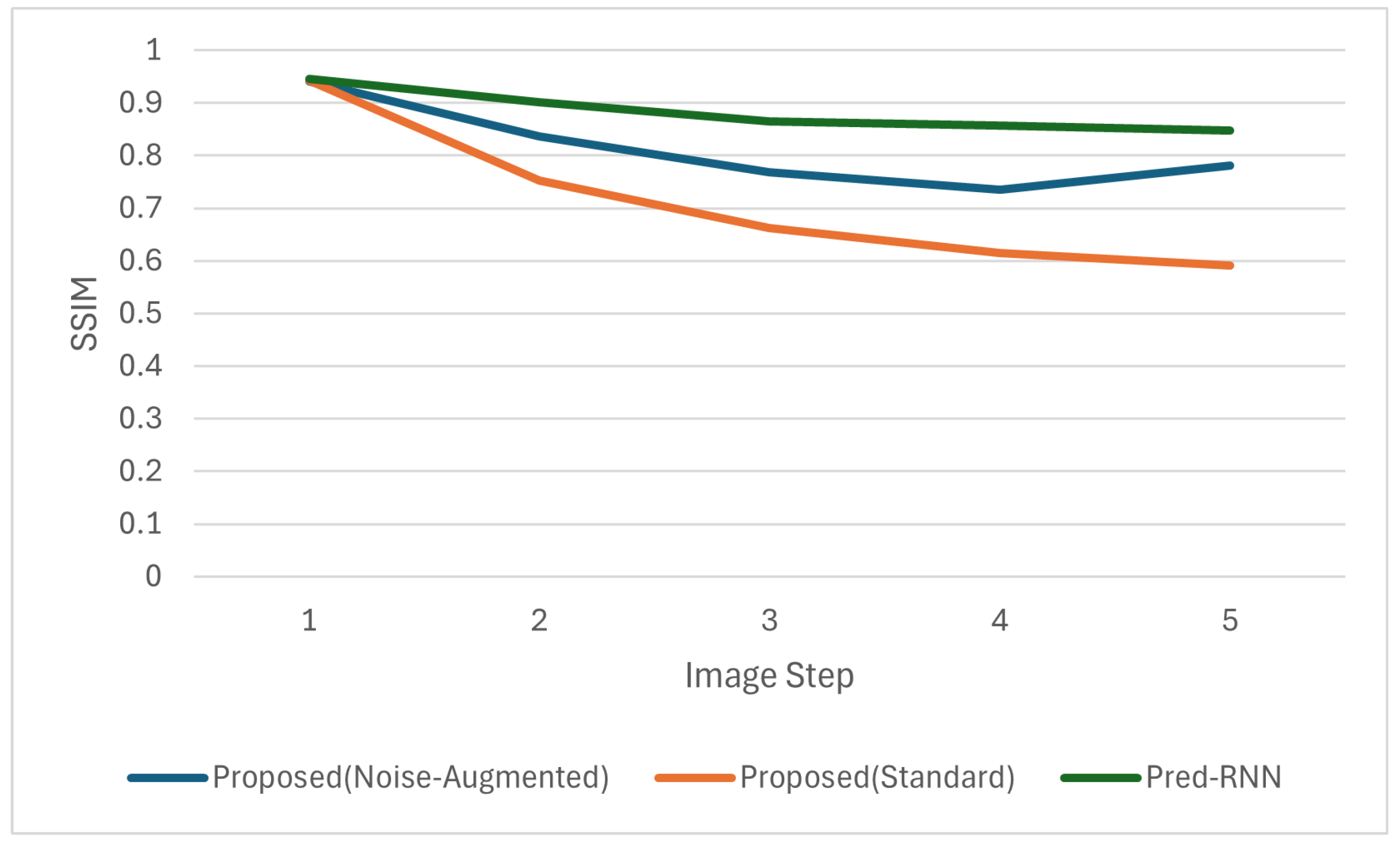
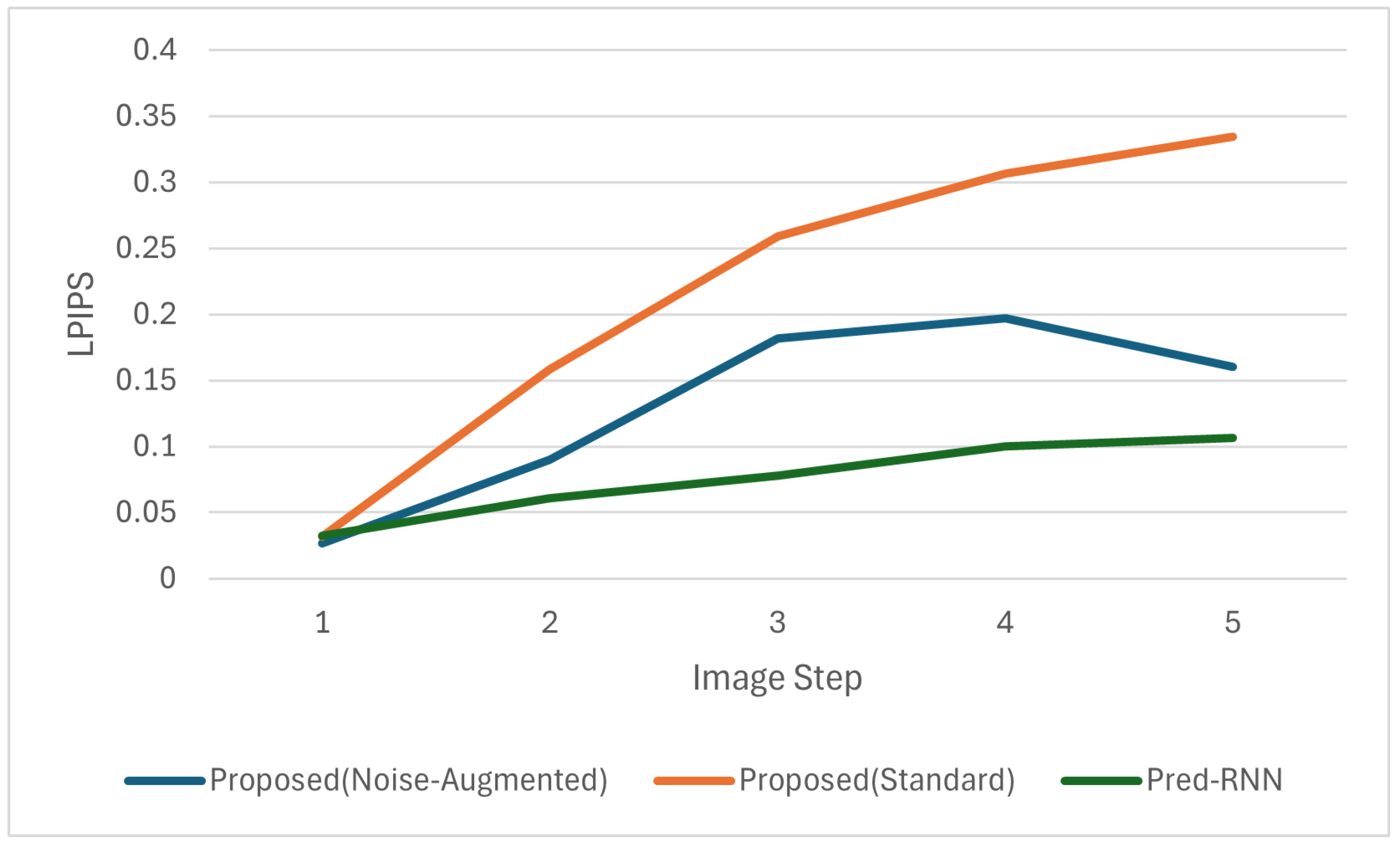
To evaluate the image quality of the generated drawing sequences, we conducted quantitative comparisons using three widely adopted metrics: Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), and Learned Perceptual Image-Patch Similarity (LPIPS). These metrics were computed frame by frame over the entire predicted sequences, and the average scores across all test samples are plotted in
Figure 9,
Figure 10 and
Figure 11.
As shown in the figures, our proposed model with noise-augmented training consistently outperformed standard training across all metrics, confirming that adding noise during training improves the stability and visual quality of sequential generation.
In comparison to PredRNN, a strong recurrent baseline, our model performed competitively in early frames but exhibited greater degradation in later frames. PredRNN achieved the highest overall performance, particularly in preserving spatial and perceptual consistency, as indicated by its superior SSIM and LPIPS scores across the sequence. For example, PredRNN achieved an average PSNR of 24.05, SSIM of 0.88, and LPIPS of 0.08, while our noise-augmented model achieved 20.48, 0.81, and 0.13, respectively.
Additionally, we conducted a case-level analysis comparing the final frames of the generated sequences for 10 samples. The results, shown in
Table 3, indicate that the noise-augmented model outperformed PredRNN in 3 out of 10 cases across all metrics (PSNR, SSIM, and LPIPS). This highlights that although PredRNN performed better on average, the proposed method can achieve superior results in specific sequences, suggesting its robustness and potential advantage in certain drawing styles or structures.
Nevertheless, our model maintains advantages in terms of computational simplicity and training efficiency. These trade-offs are valuable for lightweight or real-time applications where latency and model size are critical factors. This comparison suggests that while temporal architectures such as PredRNN are more effective in long-term consistency, the proposed encoder–decoder framework still provides reasonable accuracy under constrained conditions. To further compare the computational efficiency, we measured the number of trainable parameters and inference time for generating one sequence (five images per character). PredRNN had approximately 6.41 million trainable parameters and an average inference time of 0.188 s per sequence, whereas our proposed model had 5.20 million parameters and achieved a significantly faster inference time of 0.005 s. This supports the suitability of our model for lightweight or real-time applications where responsiveness is critical.
To complement frame-level metrics such as PSNR, SSIM, and LPIPS, we also calculated the Fréchet Inception Distance (FID) using the set of final generated images. FID evaluates the overall distributional similarity between the generated and ground-truth images.
The results showed that PredRNN achieved a lower FID score (242.8) than the noise-augmented training model (311.5), indicating that PredRNN’s generated images were closer in distribution to the target images. This aligns with the LPIPS results, reinforcing that PredRNN better preserves high-level perceptual and semantic coherence across frames.
Note that the FID scores were computed on a limited set of 10 final-frame images per model, which may introduce some variability and should be interpreted as indicative rather than definitive.
5.4. Discussion
The results of this experiment confirmed that including noise-augmented images in the training data enabled the model to generate image sequences more stably. In this section, we discuss the possible reasons for this outcome and consider potential improvements to the model, including a comparison with baseline temporal architectures.
5.4.1. Effects of Noise-Augmented Images
It has been shown that adding noise during the training of RNNs helps stabilize learning [
30], particularly in improving robustness to small perturbations in input. In this experiment, although our model is not recurrent, it recursively generated outputs based on its previous predictions, making it similarly sensitive to accumulated error.
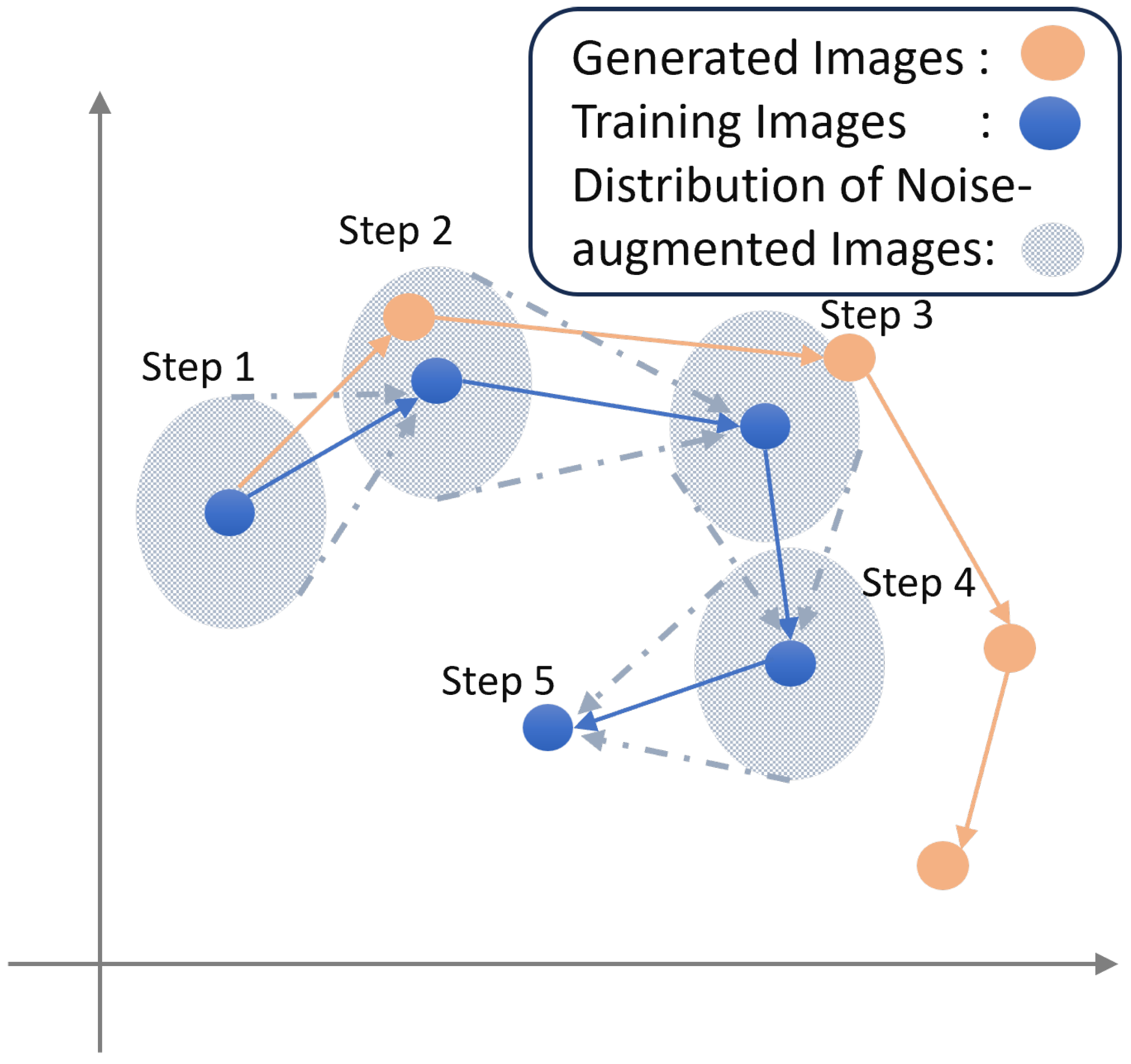
A schematic diagram comparing the image-generation process of standard training and training with noise-augmented images is shown in
Figure 12. Note that
Figure 12 is a conceptual illustration. The horizontal and vertical axes do not represent physical coordinates; instead, they serve as an abstract visualization of the transition between ground-truth and predicted image states during the generation process.
In
Figure 12, the blue dots represent the ground-truth image steps, and the blue arrows represent ideal transitions. Standard training may cause deviations (orange arrows) that accumulate across steps. In contrast, noise-augmented training helps the model generalize across a wider range (gray zone), making it more robust to imperfect input and reducing error propagation.
This stabilization effect was also reflected in the perceptual metrics: the noise-augmented model achieved consistently better LPIPS scores than standard training across steps, indicating improved preservation of structural similarity and visual features.
5.4.2. Potential Model Improvements
In this study, we utilized a convolutional encoder–decoder network. While simple and efficient, this structure lacks temporal modeling capabilities. More advanced image-generation models, such as Variational Autoencoders (VAEs) and diffusion models, can produce high-quality outputs but often require large datasets and computational resources.
As our dataset expands, we plan to evaluate the application of such models to our drawing sequence task. In addition, integrating sequential models such as Long Short-Term Memory (LSTM) or Gated Recurrent Unit (GRU) networks into our architecture could allow the model to better preserve spatial continuity and semantic progression across drawing steps.
Moreover, we compared our approach with PredRNN, a recurrent baseline model, and observed its superiority in long-term consistency and perceptual quality (lower LPIPS, higher SSIM). This suggests that incorporating explicit temporal memory can be critical for maintaining detail in deeper stages of sequential generation. However, this comes at the cost of greater model complexity.
5.4.3. Applicability and Future Directions
This system has potential applications in educational tools for learning drawing techniques, intelligent assistance for illustration workflows, and accessibility tools for users with motor impairments. Future development will focus on deploying the model in interactive applications where users can guide or adjust intermediate steps of the drawing, thereby enhancing creative control.
For practical use, the trade-off between generation quality and model simplicity must be carefully considered. Lightweight models such as ours may be advantageous in resource-constrained settings such as real-time drawing tools or mobile applications.
6. Conclusions and Future Work
In this study, we proposed a drawing support system using generative AI that generates not only the final image but also the entire drawing sequence. To achieve this, we developed a CNN-based encoder–decoder model trained on a custom-built dataset of time-series drawing images. Our experimental results confirmed that introducing noise-augmented images in the training process significantly improves image sequence generation by reducing accumulated errors.
To further validate our approach, we compared our model with PredRNN, a state-of-the-art recurrent model for spatiotemporal prediction. While PredRNN outperformed our method in terms of average PSNR, SSIM, and LPIPS across the generated sequence, our noise-augmented encoder–decoder showed competitive performance, particularly in early frames. This suggests that, even without temporal memory mechanisms, simple convolutional architectures can still perform reasonably well under certain conditions.
Moreover, a case-based evaluation of the final generated frames revealed that our proposed model outperformed PredRNN in 3 out of 10 samples. Despite its lower average scores, this result suggests that the proposed method can be more effective for certain types of drawing sequences or structural patterns. Such cases highlight the potential of noise-augmented training to offer robustness and localized performance gains, even in comparison with more complex temporal models.
In addition, our model offers advantages in training efficiency and architectural simplicity, making it suitable for applications where computational cost and model size are critical factors. These trade-offs highlight potential use cases in lightweight or interactive systems, especially where real-time responsiveness is prioritized over long-term consistency. The quantitative comparison confirmed this advantage: our model had fewer parameters (5.20 M vs. 6.41 M in PredRNN) and generated a sequence 37 times faster (0.005 s vs. 0.188 s), making it more viable for deployment on resource-limited devices or time-sensitive applications.
In future work, we plan to investigate the following directions:
Expand the training dataset by incorporating a larger variety of character drawings and refining the annotation process.
Integrate advanced generative models, such as Variational Autoencoders (VAEs) and diffusion models, to improve image quality and long-term consistency.
Improve the current encoder–decoder architecture by incorporating skip connections (e.g., U-Net structure) to enable more effective learning on higher-resolution images, and evaluate the model’s applicability to finer-detail drawing tasks.
Explore the use of temporal architectures, such as ConvLSTM or hybrid CNN–RNN models, to capture contextual dependencies across frames.
Evaluate inference speed and parameter efficiency in detail to quantify the trade-offs between model simplicity and performance.
Develop a user-interactive interface that allows real-time modifications to the generated drawing process, making the system more practical for creative applications.
By addressing these challenges, we aim to further improve the capabilities of AI-assisted drawing tools, bridging the gap between generative AI and human creativity.
Author Contributions
Conceptualization, H.M. and S.N.; methodology, H.M.; software, H.M.; validation, H.M., A.N. and S.N.; formal analysis, S.N.; investigation, H.M.; data curation, H.M.; writing—original draft preparation, H.M.; writing—review and editing, S.N. and A.N.; visualization, H.M.; supervision, S.N.; project administration, S.N. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by JSPS KAKENHI under grant number JP23K11277.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The dataset used in this study consists of hand-created drawing process images and is not publicly available due to privacy and copyright considerations, as the hand-drawn data constitutes the personal intellectual property of the creators. However, the data may be made available from the corresponding author upon reasonable request.
Acknowledgments
We would like to thank the members of the Nishide Laboratory at Kyoto Tachibana University for their support in preparing the dataset and the experimental setup. During the preparation of this manuscript, the authors used ChatGPT (OpenAI, GPT-4.0, May 2025) to verify ideas and improve clarity. All authors reviewed and edited the output and take full responsibility for the content.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| AI | Artificial Intelligence |
| CNN | Convolutional Neural Network |
| DDPM | Denoising Diffusion Probabilistic Model |
| FID | Fréchet Inception Distance |
| GRU | Gated Recurrent Unit |
| GAN | Generative Adversarial Network |
| LDM | Latent Diffusion Model |
| LPIPS | Learned Perceptual Image-Patch Similarity |
| LSTM | Long Short-Term Memory |
| PSNR | Peak Signal-to-Noise Ratio |
| RNN | Recurrent Neural Network |
| SSIM | Structural Similarity Index |
| VAE | Variational Autoencoder |
References
- Prasad, R.K.; Makesh, D. Impact of AI on Media & Entertainment Industry. In Media & Journalism Transformations—Emerging Trends and Paradigm Shifts; Emerald Publications: Bingley, UK, 2024; pp. 41–71. [Google Scholar]
- Menapace, W.; Siarohin, A.; Lathuilière, S.; Achlioptas, P.; Golyanik, V.; Tulyakov, S.; Ricci, E. Promptable Game Models: Text-Guided Game Simulation via Masked Diffusion Models. ACM Trans. Graph. 2023, 43, 1–16. [Google Scholar] [CrossRef]
- Ling, L.; Chen, X.; Wen, R.; Li, T.; LC, R. Sketchar: Supporting Character Design and Illustration Prototyping Using Generative AI. Proc. ACM Hum.-Comput. Interact. 2024, 8, 337. [Google Scholar] [CrossRef]
- Pu, Y.; Gan, Z.; Henao, R.; Yuan, X.; Li, C.; Stevens, A.; Carin, L. Variational Autoencoder for Deep Learning of Image, Labels and Captions. In Proceedings of the 30th Annual Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 2360–2368. [Google Scholar]
- Noor, N.Q.M.; Zabidi, A.; Jaya, M.I.B.M.; Ler, T.J. Performance Comparison between Generative Adversarial Networks (GAN) Variants in Generating Anime/Comic Character Images—A Preliminary Result. In Proceedings of the 2024 IEEE Symposium on Industrial Electronics & Applications (ISIEA), Kuala Lumpur, Malaysia, 6–7 July 2024; pp. 248–252. [Google Scholar]
- Kırbıyık, Ö.; Simsar, E.; Cemgil, A.T. Comparison of Deep Generative Models for the Generation of Handwritten Character Images. In Proceedings of the 2019 27th Signal Processing and Communications Applications Conference (SIU), Sivas, Turkey, 24–26 April 2019; pp. 1–4. [Google Scholar]
- Qiu, S. Generative AI Processes for 2D Platformer Game Character Design and Animation. Lect. Notes Educ. Psychol. Public Media 2023, 29, 146–160. [Google Scholar] [CrossRef]
- Cao, N.; Yan, X.; Shi, Y.; Chen, C. AI-Sketcher: A Deep Generative Model for Producing High-Quality Sketches. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 2564–2571. [Google Scholar]
- Chen, Y.; Tu, S.; Yi, Y.; Xu, L. Sketch-pix2seq: A Model to Generate Sketches of Multiple Categories. arXiv 2017, arXiv:1709.04121. [Google Scholar]
- Tholander, J.; Jonsson, M. Design Ideation with AI—Sketching, Thinking and Talking with Generative Machine Learning Models. In Proceedings of the 2023 ACM Designing Interactive Systems Conference, Pittsburgh, PA, USA, 10–14 July 2023; pp. 1930–1940. [Google Scholar]
- Li, P.; Li, B.; Li, Z. Sketch-to-Architecture: Generative AI-Aided Architectural Design. In Proceedings of the 31th Pacific Conference on Computer Graphics and Applications, Deajeon, Republic of Korea, 10–13 October 2023; pp. 99–102. [Google Scholar]
- Cai, A.; Rick, S.R.; Heyman, J.; Zhang, Y.; Filipowicz, A.; Hong, M.K.; Klenk, M.; Malone, T. DesignAID: Using Generative AI and Semantic Diversity for Design Inspiration. In Proceedings of the ACM Collective Intelligence Conference, Delft, The Netherlands, 6–9 November 2023; pp. 1–11. [Google Scholar]
- Nagao, Y.; Fukuda, S. 4-Frame Manga Drawing Support System. In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, San Francisco, CA, USA, 29 October–1 November 2023; pp. 1–3. [Google Scholar]
- Kanayama, H.; Xie, H.; Miyata, K. Illustration Drawing Interface with Image Retrieval and Adjustable Grid Guidance. In Proceedings of the 2023 Nicograph International (NicoInt), Sapporo, Japan, 9–10 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 54–61. [Google Scholar]
- Nagai, T.; Kayama, M.; Itoh, K. A Drawing Learning Support System Based on the Drawing Process Model. Interact. Technol. Smart Educ. 2014, 11, 146–164. [Google Scholar] [CrossRef]
- Hiroi, Y.; Ito, A. A Robotic System for Remote Teaching of Technical Drawing. Educ. Sci. 2023, 13, 347. [Google Scholar] [CrossRef]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.-Y.; Wong, W.-K.; Woo, W.-C. Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting. In Advances in Neural Information Processing Systems; NeurIPS: La Jolla, CA, USA, 2015; Volume 28. [Google Scholar]
- Wang, Y.; Gao, Z.; Long, M.; Wang, J.; Yu, P.S. PredRNN: A Recurrent Neural Network for Spatiotemporal Predictive Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 2208–2225. [Google Scholar] [CrossRef] [PubMed]
- Zuo, Y.; Li, L.; Wang, Y.; Qiao, Y. Dual Convolutional LSTM Network for Referring Image Segmentation. IEEE Trans. Multimed. 2022, 25, 2501–2513. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising Diffusion Probabilistic Models. In Advances in Neural Information Processing Systems; NeurIPS: La Jolla, CA, USA, 2020; Volume 33, pp. 6840–6851. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-Resolution Image Synthesis With Latent Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 10684–10695. [Google Scholar]
- Avrahami, O.; Bahat, Y.; Dekel, T. Blended Diffusion for Text-driven Editing of Natural Images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18208–18218. [Google Scholar]
- Chan, K.C.K.; Xie, J.; Lu, W.; Loy, C.C. GLEAN: Generative Latent Bank for Large-Factor Image Super-Resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14257–14266. [Google Scholar]
- Zhou, J.; Liu, Y.; Zhu, Y.; Zhang, Z.; Li, R. Accurately 3D Neuron Localization Using 2D Conv-LSTM Super-Resolution Segmentation. IET Image Process. 2023, 18, 535–547. [Google Scholar] [CrossRef]
- Dhariwal, P.; Nichol, A.Q. Diffusion Models Beat GANs on Image Synthesis. In Advances in Neural Information Processing Systems; NeurIPS: La Jolla, CA, USA, 2021; Volume 34, pp. 8780–8794. [Google Scholar]
- Song, Y.; Sohl-Dickstein, J.; Kingma, D.P.; Kumar, A.; Ermon, S.; Poole, B. Score-Based Generative Modeling through Stochastic Differential Equations. In Proceedings of the International Conference on Learning Representations, Virtual Event, 3–7 May 2021. [Google Scholar]
- Siradjuddin, I.A.; Wardana, W.A.; Sophan, M.K. Feature Extraction Using Self-Supervised Convolutional Autoencoder for Content Based Image Retrieval. In Proceedings of the 2019 3rd International Conference on Informatics and Computational Sciences (ICICoS), Semarang, Indonesia, 29–30 October 2019; pp. 1–5. [Google Scholar]
- Yu, W.; Kim, I.Y.; Mechefske, C. Analysis of Different RNN Autoencoder Variants for Time Series Classification and Machine Prognostics. Mech. Syst. Signal Process. 2021, 149, 107322. [Google Scholar] [CrossRef]
- Ho, J.; Saharia, C.; Chan, W.; Fleet, D.J.; Norouzi, M.; Salimans, T. Cascaded Diffusion Models for High Fidelity Image Generation. J. Mach. Learn. Res. 2022, 23, 2249–2281. [Google Scholar]
- Lim, S.H.; Erichson, N.B.; Hodgkinson, L.; Mahoney, M.W. Noisy Recurrent Neural Networks. In Proceedings of the 35th Annual Conference on Neural Information Processing Systems, Online, 6–14 December 2021; pp. 5124–5137. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}