



LLM-Based Cyberattack Detection Using Network Flow Statistics

 , ,
, ,  and
and 
Abstract
1. Introduction
2. Materials and Methods
2.1. Cyberattack Datasets
- KDD Cup 1999 [31] was published by the University of California, Irvine, CA, USA, in 1999. This dataset is an updated version of DARPA98. It has been widely used in academic settings for research on IDS.
- NSL-KDD [32] was published in 2009 by the University of New Brunswick (UNB), Fredericton, NB, Canada, being the improved and updated version of the KDD Cup 1999 dataset. It essentially solves different problems that were detected in the previous version.
- UNSW-NB15 [33] was published by the University of New South Wales (UNSW), Sydney, NSW, Australia, for academic purposes. The training set was generated over a period of time of 16 h and the test set over a period of 15 h. This dataset contains 9 types of attacks and 49 features.
- CIC-IDS-2017 [34,35] was created to respond to the lack of adequate datasets to properly evaluate the new cyberattack detection models developed by researchers. It was published by the Canadian Institute for Cybersecurity (CIC), UNB, Fredericton, NB, Canada. They concluded that all the public datasets published before were unreliable, outdated, and had little data volume. To fill this gap, a dataset was published with a wealth of information, including benign traffic and 14 types of attacks, grouped into 7 main types, which are the most popular so far. Moreover, this dataset was designed in an environment that is as realistic as possible. It is still widely used because it contains the most popular and up-to-date types of attacks. It was built using the CICFlowMeter [36] tool, which generates 84 features of network flow statistics.
- CSE-CIC-IDS2018 [35,37] was published after a collaboration between CIC, UNB, Fredericton, NB, Canada, and the Communications Security Establishment (CSE), Ottawa, ON, Canada. It follows the same structure as the previous dataset, CIC-IDS-2017. Although the main difference between them is that the latter version was configured over an Amazon Web Service (AWS) environment, both datasets are considered the most modern and up-to-date ones for IDS and continue to be widely used. It was also built using the CICFlowMeter tool. Therefore, the number of features and their nature is the same. However, their creators selected almost the same types of attacks.
- AWID2 [40] and AWID3 [41] are datasets focused on 802.11 networks. They were published in 2016 and 2021, respectively, by the University of the Aegean, Mytilene, Greece. AWID2 contains the most popular attacks on 802.11 and is focused on their signatures. This dataset contains normal and attack traffic against 802.11 networks [42]. AWID3 is a newer version that includes some modern attacks, focused on WPA2 Enterprise, 802.11w, and Wi-Fi 5. It also contains multilayer attacks, such as Krack and Kr00k [43].
- BCCC-CIC-IDS-2017 [44,45], launched in 2024, is an augmented dataset, published by the Behavior-Centric Cybersecurity Center (BCCC), York University, Toronto, ON, Canada. This dataset was created by processing the original PCAP files from the CIC-IDS-2017 dataset with NTLFlowLyzer [44,46], which is a data analyzer specifically developed to solve the weaknesses of CICFlowMeter. Unlike CIC-IDS-2017 and CSE-CIC-IDS2018, this dataset contains 122 features.
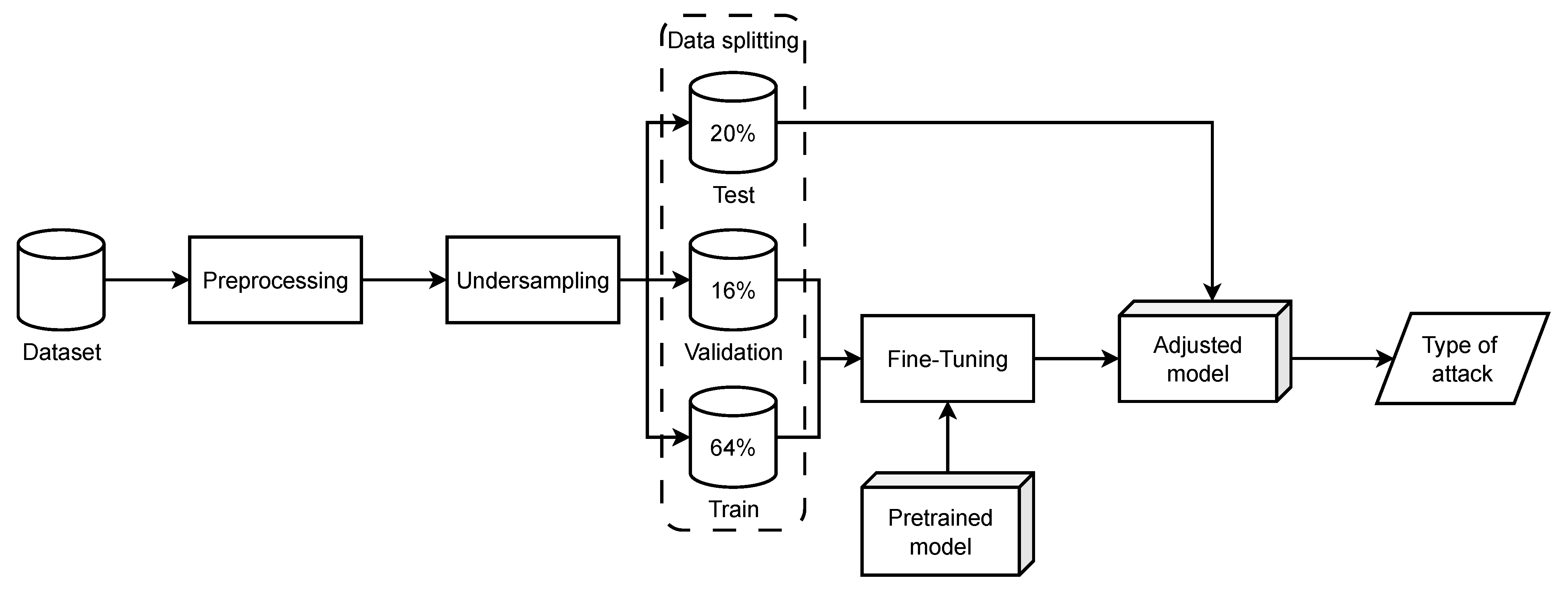
2.2. Designing the Cyberattack Detection System
- As the LLM (in our case, the T5 model) is inherently designed for text-based input, the next stage converts the numerical features to strings.
- Finally, it sequentially concatenates these strings, building an input string that represents an abstract artificial language.

2.3. Training the Cyberattack Detection System
2.3.1. Data Preprocessing
- 1.
- Data cleaning
- Homogenization of column names: The selected dataset contains column names with all lowercase letters, words with the first letter capitalized, words with all letters capitalized, words separated by blanks or with the underscore character, and most names start with a blank space. We decided to remove initial blanks and to homogenize column names. To achieve this, all leading and trailing blanks were removed, all blanks were replaced by an underscore, and all letters were changed to upper case.
- Removal of useless columns: The selected dataset contains a number of useless columns, since they are available for just a few rows of data, and are located in a single file. This involves missing values for most records. These columns are: (a) FLOW_ID identifies the flow, (b) SRC_IP identifies the source machine by its IP address, (c) SRC_PORT identifies the port in the source machine, and (d) DST_IP identifies the destination machine by its IP address. With the exception of the columns mentioned above, which were removed, the rest of the columns were maintained.
- Removal of columns with unique values: Columns with unique values are not useful for model building as they provide no extra information. To carry out this process, the standard deviation of all columns is calculated, and if the deviation is 0, it means that all values are equal. If the deviation is close to 0, it means that almost all values are equal, and, in fact, it would also contribute nothing to the future model. In the experiments, we compared the number of columns with a standard deviation of 0 and with a very low standard deviation, for example, 0.01, and applying both filters, we obtained the same columns to be removed. Hence, we decided to eliminate all columns with a standard deviation equal to 0, since for both filters, we would have to remove the same columns.
- Removal of columns with high correlation: Columns with high correlation were removed because they are not useful for the future model. The steps are as follows: (a) calculate the correlation matrix, (b) obtain the upper triangular matrix, (c) list the columns whose correlation is greater than 0.95, and (d) remove the columns with high correlation.
- Removal of infinite, empty, and null values: Infinite, empty, and null values are useless, since they provide no additional information to the model. Therefore, rows containing such values were deleted.
- Removal of duplicate rows: Finally, duplicated rows have to be removed, since they contribute nothing to our dataset, a common step in a data cleaning process.
- 2.
- Data transformation
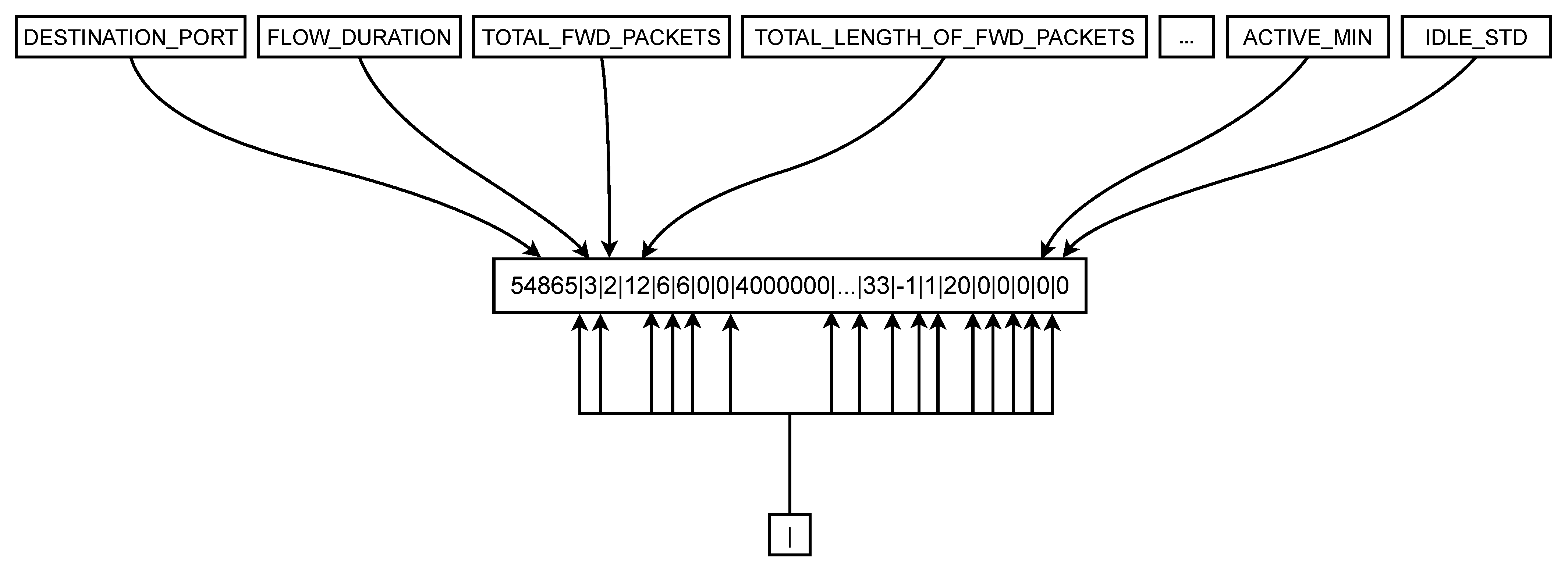
- Preparation of input strings: The T5 model, having been pre-trained on diverse NLP tasks, inherently requires string-based input for its “source_text” field. Our dataset, however, comprises 44 numerical features representing network flow statistics. To bridge this modality gap and enable the T5 model to process network flow data, we developed an abstract artificial language.This innovative design involves a two-step transformation process for each row of numerical data:
- -
- Feature-to-text conversion: Each numerical feature is individually converted into its string representation.
- -
- Sequential concatenation: These string representations of the features are then sequentially concatenated to form a single continuous input string. Inspired by the data representation strategy that we designed in a previous work [49], where adapted T5 for translation tasks involving multiple input features (such as jokes and puns) against a single model input, we used the vertical bar character (|) as a separator between each feature’s string value, following a predefined, consistent order.This process results in a unique character string for each network flow, effectively translating the numerical statistics of a network flow into a structured textual sequence. This abstract language allows the T5 model to process network flow data as if it were a specialized form of text, enabling the fine-tuning process to adapt the model’s powerful pattern recognition capabilities from linguistic structures to the complex patterns present in network flow statistics for cyberattack detection. Figure 3 shows an example of the construction of these input strings, given statistics of network flows. The top section displays the characteristics, while the bottom section shows the separator character. The central box presents a preprocessed input entry. Arrows indicate where each feature value is placed, alongside the vertical bar separating them.
- -
- Labeling: The labels with the types of attacks contained in the dataset are strings with alphanumeric characters, and, in this way, they are useful if the intention is to identify the type of attack at first sight. However, labels must be encoded to avoid issues in classification. We decided to encode the labels using sequential numbers, starting from 0.
2.3.2. Data Cleaning Results for CSE-CIC-IDS2018
2.3.3. Undersampling
2.3.4. Data Splitting
2.3.5. Fine-Tuning Process
- max_epochs is the maximum number of epochs for the training step. It is set to 10, since LLMs have a high level of maturity and require relatively few epochs to achieve a good model. Therefore, after performing the preliminary experiments, we observed that the best-performing model of an experiment was never selected beyond the tenth epoch. Depending on the experiment, an overfitting could appear in one of the first epochs, even in the second one. Hence, 10 is a sufficiently large value.
- target_max_token_len contains the maximum number of output tokens. Since the selected model performs a classification task, it is unnecessary to set an excessively large value. It should be pointed out that the output of the model is a numerical value between 0 and 14. The maximum number of tokens is 512, which substantially exceeds the number typically required. Preliminary experiments concluded that the minimum number of tokens was 3 and we observed that the values for the selected metrics maintained the same trend for any value between 3 and 512. In addition, this parameter has the same behavior as the variable source_max_token_len parameter in terms of the relationship between the number of tokens and training time. Therefore, setting 3 as its value significantly reduces training times.
- batch_size is the parameter that contains the batch size to be used to train this model. The default value is 8 and values that are a power of 2 are typically used, such that values like 8, 16, or 32 are commonly used. The value 16 is set, which is a medium value, since it is neither the minimum nor is it too large.
- precision is the parameter that contains the training precision. The available values are double precision (64), full precision (32), or half precision (16). By default, this wrapper uses the value 32, which is the value used for the experiments. Here, 32 was selected because it is the central value, for instance, being neither the smallest nor the largest value.
- source_max_token_len contains the maximum number of input tokens, which, in this case, is 512 tokens. The larger the number of input tokens, the longer the training time, while the lower the value, the shorter the training time. Logically, a shorter training time is desired, so it is of interest to set this variable to the lowest possible value. However, given that the character strings used as input have an average of 189 characters, a minimum of 109, and a maximum of 345, it is important to consider that if too few tokens are selected, then the model will not take into account much of the input information needed for satisfactory task performance. Therefore, we must seek a balance, taking this parameter into account in the search for an optimal value that allows the model to be trained in the shortest possible time while keeping the selected metrics as high as possible. We planned to perform the optimization with 50, 100, 150, 200, 250, 350, and 500 tokens. The evaluation of the hyperparameter optimization process was carried out using the following evaluation metrics: accuracy, precision, recall, and F-score.
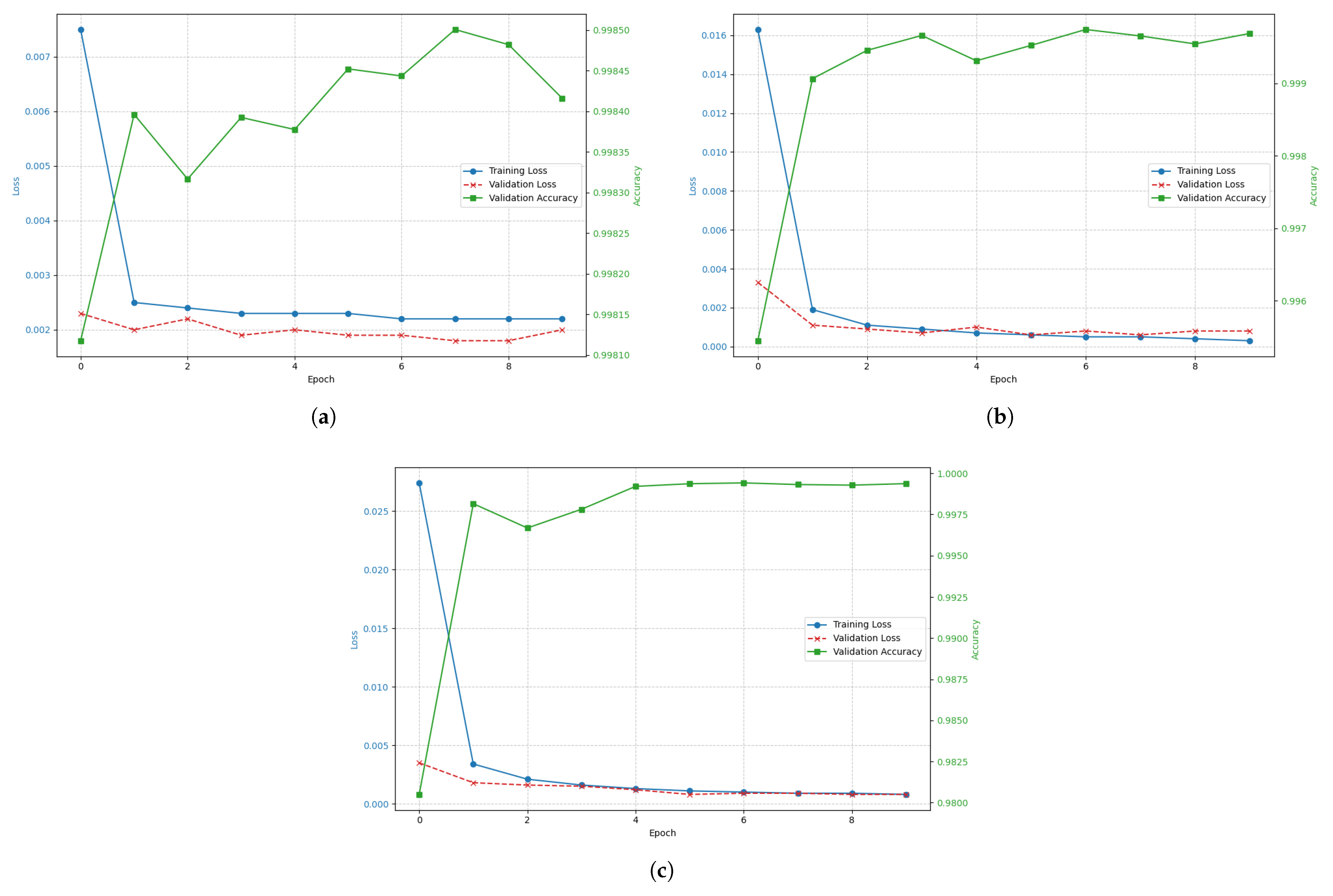
3. Experimental Results
4. Related Work
4.1. Strategies Based on LLM
4.2. Other Strategies Non-LLM Based on ML
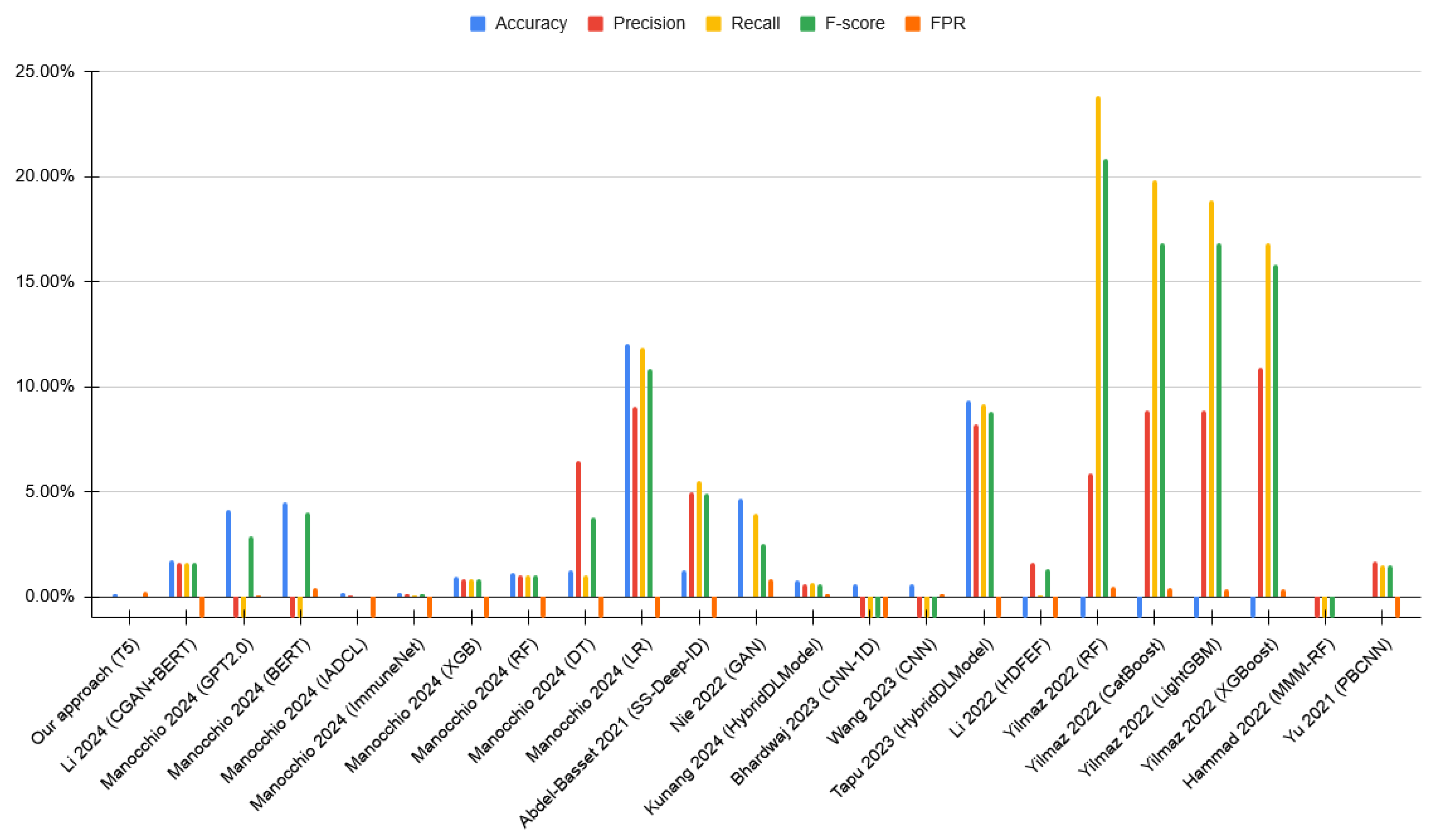
4.3. Comparative Analysis
4.3.1. Using the CSE-CIC-IDS2018 Dataset
4.3.2. Using the CIC-IDS-2017 Dataset
4.3.3. Using the BCCC-CIC-IDS-2017 Dataset
5. Conclusions and Future Work
Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Validation with Other Datasets

| Label | Benign | DoS Hulk | PortScan | DDoS | DoS GoldenEye | FTP-Patator | SSH-Patator | DoS Slowloris | DoS Slowhttptest | Bot | Web Attack—Brute Force | Web Attack—XSS | Infiltration | Web Attack—Sql Injection | Heartbleed | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Class | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | Misclassified |
| 0 | 89,933 | 0 | 0 | 1 | 0 | 0 | 0 | 2 | 0 | 2 | 2 | 4 | 0 | 0 | 0 | 0.01% |
| 1 | 8 | 35,628 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.02% |
| 2 | 8 | 0 | 23,976 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.03% |
| 3 | 5 | 0 | 0 | 25,600 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.02% |
| 4 | 1 | 0 | 0 | 0 | 2056 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.05% |
| 5 | 1 | 0 | 0 | 0 | 0 | 1375 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.07% |
| 6 | 2 | 0 | 0 | 0 | 0 | 0 | 1018 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.2% |
| 7 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 1135 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.26% |
| 8 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1051 | 0 | 0 | 0 | 0 | 0 | 0 | 0.19% |
| 9 | 6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 385 | 0 | 0 | 0 | 0 | 0 | 1.53% |
| 10 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 301 | 0 | 0 | 0 | 0 | 0% |
| 11 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 127 | 0 | 0 | 0 | 2.31% |
| 12 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 0 | 0 | 57.14% |
| 13 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 4 | 0 | 0% |
| 14 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 0 | 100% |
| Label | Benign | DoS_Hulk | Port_Scan | DDoS_LOIT | FTP-Patator | DoS_GoldenEye | DoS_Slowhttptest | SSH-Patator | Botnet_ARES | DoS_Slowloris | Web_Brute_Force | Web_XSS | Web_SQL_Injection | Heartbleed | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Class | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | Misclassified |
| 0 | 71,326 | 13 | 4 | 4 | 14 | 0 | 1 | 4 | 3 | 1 | 25 | 6 | 0 | 0 | 0.11% |
| 1 | 0 | 69,240 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0% |
| 2 | 6 | 0 | 32,259 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.02% |
| 3 | 1 | 0 | 0 | 19,145 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.01% |
| 4 | 3 | 0 | 0 | 0 | 1903 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.16% |
| 5 | 5 | 0 | 0 | 0 | 0 | 1667 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0.36% |
| 6 | 11 | 0 | 0 | 0 | 0 | 0 | 1359 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0.88% |
| 7 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1190 | 0 | 0 | 0 | 0 | 0 | 0 | 0% |
| 8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1102 | 0 | 0 | 0 | 0 | 0 | 0% |
| 9 | 7 | 0 | 0 | 0 | 0 | 0 | 3 | 0 | 0 | 1015 | 0 | 0 | 0 | 0 | 0.98% |
| 10 | 10 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 537 | 0 | 0 | 0 | 1.83% |
| 11 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 270 | 0 | 0 | 0.37% |
| 12 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100% |
| 13 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 0% |
References
- Admass, W.S.; Munaye, Y.Y.; Diro, A.A. Cyber security: State of the art, challenges and future directions. Cyber Secur. Appl. 2024, 2, 100031. [Google Scholar] [CrossRef]
- Vielberth, M.; Pernul, G. A Security Information and Event Management Pattern. In Proceedings of the 12th Latin American Conference on Pattern Languages of Programs (SLPLoP), Valparaíso, Chile, 20–23 November 2018. [Google Scholar] [CrossRef]
- Ashoor, A.S.; Gore, S. Difference between intrusion detection system (IDS) and intrusion prevention system (IPS). In Proceedings of the Advances in Network Security and Applications: 4th International Conference, CNSA 2011, Chennai, India, 15–17 July 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 497–501. [Google Scholar] [CrossRef]
- Ashoor, A.S.; Gore, S. Importance of intrusion detection system (IDS). Int. J. Sci. Eng. Res. 2011, 2, 1–4. [Google Scholar]
- Macas, M.; Wu, C.; Fuertes, W. A survey on deep learning for cybersecurity: Progress, challenges, and opportunities. Comput. Netw. 2022, 212, 109032. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Burkov, A. The Hundred-Page Machine Learning Book; Andriy Burkov: Quebec City, QC, Canada, 2019. [Google Scholar]
- Church, K.W.; Chen, Z.; Ma, Y. Emerging trends: A gentle introduction to fine-tuning. Nat. Lang. Eng. 2021, 27, 763–778. [Google Scholar] [CrossRef]
- Too, E.C.; Yujian, L.; Njuki, S.; Yingchun, L. A comparative study of fine-tuning deep learning models for plant disease identification. Comput. Electron. Agric. 2019, 161, 272–279. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Bai, J.; Al-Sabaawi, A.; Santamaría, J.; Albahri, A.; Al-dabbagh, B.S.N.; Fadhel, M.A.; Manoufali, M.; Zhang, J.; Al-Timemy, A.H.; et al. A survey on deep learning tools dealing with data scarcity: Definitions, challenges, solutions, tips, and applications. J. Big Data 2023, 10, 46. [Google Scholar] [CrossRef]
- Maruthupandi, J.; Sivakumar, S.; Dhevi, B.L.; Prasanna, S.; Priya, R.K.; Selvarajan, S. An intelligent attention based deep convoluted learning (IADCL) model for smart healthcare security. Sci. Rep. 2025, 15, 1363. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; Hawash, H.; Chakrabortty, R.K.; Ryan, M.J. Semi-Supervised Spatiotemporal Deep Learning for Intrusions Detection in IoT Networks. IEEE Internet Things J. 2021, 8, 12251–12265. [Google Scholar] [CrossRef]
- Nie, L.; Wu, Y.; Wang, X.; Guo, L.; Wang, G.; Gao, X.; Li, S. Intrusion Detection for Secure Social Internet of Things Based on Collaborative Edge Computing: A Generative Adversarial Network-Based Approach. IEEE Trans. Comput. Soc. Syst. 2022, 9, 134–145. [Google Scholar] [CrossRef]
- Kunang, Y.; Nurmaini, S.; Stiawan, D.; Suprapto, B. An end-to-end intrusion detection system with IoT dataset using deep learning with unsupervised feature extraction. Int. J. Inf. Secur. 2024, 23, 1619–1648. [Google Scholar] [CrossRef]
- Bhardwaj, S.; Dave, M. Enhanced neural network-based attack investigation framework for network forensics: Identification, detection, and analysis of the attack. Comput. Secur. 2023, 135, 103521. [Google Scholar] [CrossRef]
- Wang, Z.; Ghaleb, F. An Attention-Based Convolutional Neural Network for Intrusion Detection Model. IEEE Access 2023, 11, 43116–43127. [Google Scholar] [CrossRef]
- Tapu, S.; Shopnil, S.; Tamanna, R.; Dewan, M.; Alam, M. Malicious Data Classification in Packet Data Network Through Hybrid Meta Deep Learning. IEEE Access 2023, 11, 140609–140625. [Google Scholar] [CrossRef]
- Li, Y.; Qin, T.; Huang, Y.; Lan, J.; Liang, Z.; Geng, T. HDFEF: A hierarchical and dynamic feature extraction framework for intrusion detection systems. Comput. Secur. 2022, 121, 102842. [Google Scholar] [CrossRef]
- Yilmaz, M.; Bardak, B. An Explainable Anomaly Detection Benchmark of Gradient Boosting Algorithms for Network Intrusion Detection Systems. In Proceedings of the 2022 Innovations in Intelligent Systems and Applications Conference (ASYU 2022), Antalya, Turkey, 7–9 September 2022. [Google Scholar] [CrossRef]
- Hammad, M.; Hewahi, N.; Elmedany, W. MMM-RF: A novel high accuracy multinomial mixture model for network intrusion detection systems. Comput. Secur. 2022, 120, 102777. [Google Scholar] [CrossRef]
- Yu, L.; Dong, J.; Chen, L.; Li, M.; Xu, B.; Li, Z.; Qiao, L.; Liu, L.; Zhao, B.; Zhang, C. PBCNN: Packet Bytes-based Convolutional Neural Network for Network Intrusion Detection. Comput. Netw. 2021, 194, 108117. [Google Scholar] [CrossRef]
- Wang, J.; Wang, X. An optimization model of computer network security based on GABP neural network algorithm. EURASIP J. Inf. Secur. 2025, 2025, 14. [Google Scholar] [CrossRef]
- Guo, D.; Xie, Y. Research on Network Intrusion Detection Model Based on Hybrid Sampling and Deep Learning. Sensors 2025, 25, 1578. [Google Scholar] [CrossRef]
- Hariharan, S.; Annie Jerusha, Y.; Suganeshwari, G.; Syed Ibrahim, S.P.; Tupakula, U.; Varadharajan, V. A Hybrid Deep Learning Model for Network Intrusion Detection System Using Seq2Seq and ConvLSTM-Subnets. IEEE Access 2025, 13, 30705–30721. [Google Scholar] [CrossRef]
- Liu, Y.; He, H.; Han, T.; Zhang, X.; Liu, M.; Tian, J.; Zhang, Y.; Wang, J.; Gao, X.; Zhong, T.; et al. Understanding LLMs: A comprehensive overview from training to inference. Neurocomputing 2025, 620, 129190. [Google Scholar] [CrossRef]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. arXiv 2020, arXiv:1910.10683. [Google Scholar]
- Li, F.; Shen, H.; Mai, J.; Wang, T.; Dai, Y.; Miao, X. Pre-trained language model-enhanced conditional generative adversarial networks for intrusion detection. Peer-to-Peer Netw. Appl. 2024, 17, 227–245. [Google Scholar] [CrossRef]
- Manocchio, L.D.; Layeghy, S.; Lo, W.W.; Kulatilleke, G.K.; Sarhan, M.; Portmann, M. FlowTransformer: A transformer framework for flow-based network intrusion detection systems. Expert Syst. Appl. 2024, 241, 122564. [Google Scholar] [CrossRef]
- Ferrag, M.A.; Ndhlovu, M.; Tihanyi, N.; Cordeiro, L.C.; Debbah, M.; Lestable, T.; Thandi, N.S. Revolutionizing Cyber Threat Detection with Large Language Models: A Privacy-Preserving BERT-Based Lightweight Model for IoT/IIoT Devices. IEEE Access 2024, 12, 23733–23750. [Google Scholar] [CrossRef]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- University of California. KDD Cup 1999 Data; University of California: Irvine, CA, USA, 1999. [Google Scholar]
- UNB. NSL-KDD Dataset; UNB: Fredericton, NB, Canada, 2009. [Google Scholar]
- UNSW. The UNSW-NB15 Dataset; UNSW: Sydney, NSW, Australia, 2015. [Google Scholar]
- UNB. Intrusion Detection Evaluation Dataset (CIC-IDS2017); UNB: Fredericton, NB, Canada, 2017. [Google Scholar]
- Sharafaldin, I.; Habibi Lashkari, A.; Ghorbani, A.A. Toward Generating a New Intrusion Detection Dataset and Intrusion Traffic Characterization. In Proceedings of the 4th International Conference on Information Systems Security and Privacy (ICISSP), Funchal, Portugal, 22–24 January 2018; SciTePress: Setúbal, Portugal, 2018; pp. 108–116. [Google Scholar] [CrossRef]
- UNB. CICFlowMeter; UNB: Fredericton, NB, Canada, 2016. [Google Scholar]
- UNB. IPS/IDS Dataset on AWS (CSE-CIC-IDS2018); UNB: Fredericton, NB, Canada, 2018. [Google Scholar]
- UNB. DDoS Evaluation Dataset (CIC-DDoS2019); UNB: Fredericton, NB, Canada, 2019. [Google Scholar]
- Sharafaldin, I.; Lashkari, A.H.; Hakak, S.; Ghorbani, A.A. Developing Realistic Distributed Denial of Service (DDoS) Attack Dataset and Taxonomy. In Proceedings of the 2019 International Carnahan Conference on Security Technology (ICCST), Chennai, India, 1–3 October 2019; pp. 1–8. [Google Scholar] [CrossRef]
- University of the Aegean. The AWID2 Dataset; University of the Aegean: Mytilene, Greece, 2016. [Google Scholar]
- University of the Aegean. The AWID3 Dataset; University of the Aegean: Mytilene, Greece, 2021. [Google Scholar]
- Kolias, C.; Kambourakis, G.; Stavrou, A.; Gritzalis, S. Intrusion detection in 802.11 networks: Empirical evaluation of threats and a public dataset. IEEE Commun. Surv. Tutor. 2016, 18, 184–208. [Google Scholar] [CrossRef]
- Chatzoglou, E.; Kambourakis, G.; Kolias, C. Empirical Evaluation of Attacks against IEEE 802.11 Enterprise Networks: The AWID3 Dataset. IEEE Access 2021, 9, 34188–34205. [Google Scholar] [CrossRef]
- Shafi, M.; Lashkari, A.H.; Roudsari, A.H. NTLFlowLyzer: Towards generating an intrusion detection dataset and intruders behavior profiling through network and transport layers traffic analysis and pattern extraction. Comput. Secur. 2025, 148, 104160. [Google Scholar] [CrossRef]
- York University. Behaviour-Centric Cybersecurity Center (BCCC): Cybersecurity Datasets; York University: Toronto, ON, Canada, 2025. [Google Scholar]
- York University. NTLFlowLyzer; York University: Toronto, ON, Canada, 2025. [Google Scholar]
- Ali, W.; Sandhya, P.; Roccotelli, M.; Fanti, M.P. A Comparative Study of Current Dataset Used to Evaluate Intrusion Detection System. Int. J. Eng. Appl. (IREA) 2022, 10, 336. [Google Scholar] [CrossRef]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. arXiv 2016, arXiv:1609.08144. [Google Scholar]
- Galeano, L.G. LJGG @ CLEF JOKER Task 3: An improved solution joining with dataset from task 1. In Proceedings of the CEUR Workshop Proceedings, Bologna, Italy, 5–8 September 2022; Volume 3180, pp. 1818–1827. [Google Scholar]
- scikit-learn developers. Cross-Validation: Evaluating Estimator Performance, 2007–2024. Available online: https://scikit-learn.org/stable/modules/cross_validation.html (accessed on 11 May 2025).
- Roy, S. simpleT5. 2022. Available online: https://github.com/Shivanandroy/simpleT5 (accessed on 11 May 2025).
- Torre, D.; Mesadieu, F.; Chennamaneni, A. Deep learning techniques to detect cybersecurity attacks: A systematic mapping study. Empir. Softw. Eng. 2023, 28, 76. [Google Scholar] [CrossRef]
- Lira, O.G.; Marroquin, A.; Antonio To, M. Harnessing the Advanced Capabilities of LLM for Adaptive Intrusion Detection Systems. In Proceedings of the Advanced Information Networking and Applications; Barolli, L., Ed.; Springer: Cham, Switzerland, 2024; pp. 453–464. [Google Scholar]
- Vo, H.; Du, H.; Nguyen, H. APELID: Enhancing real-time intrusion detection with augmented WGAN and parallel ensemble learning. Comput. Secur. 2024, 136, 103567. [Google Scholar] [CrossRef]
- Amin, R.; El-Taweel, G.; Ali, A.; Tahoun, M. Hybrid Chaotic Zebra Optimization Algorithm and Long Short-Term Memory for Cyber Threats Detection. IEEE Access 2024, 12, 93235–93260. [Google Scholar] [CrossRef]
- Harrell, F.E. Regression Modeling Strategies: With Applications to Linear Models, Logistic and Ordinal Regression, and Survival Analysis, 2nd ed.; Springer: Cham, Switzerland, 2015. [Google Scholar]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Year | Attack Types | Features | Records |
|---|---|---|---|---|
| KDD Cup 1999 | 1999 | 4 | 41 | 4,898,431 |
| NSL-KDD | 2009 | 22 | 41 | 125,973 |
| UNSW-NB15 | 2015 | 9 | 49 | 2,540,047 |
| CIC-IDS-2017 | 2017 | 14 | 84 | 2,830,743 |
| CSE-CIC-IDS2018 | 2018 | 14 | 84 | 16,232,943 |
| CIC-DDoS2019 | 2019 | 18 | 84 | 12,794,627 |
| AWID2 | 2016 | 3 | 155 | 42,388,298 |
| AWID3 | 2021 | 13 | 253 | 15,574,911 |
| BCCC-CIC-IDS-2017 | 2025 | 13 | 122 | 2,438,052 |
| Step | Rows | Removed Rows | Columns | Removed Columns |
|---|---|---|---|---|
| Initial status | 16,232,943 | 84 | ||
| Removal of useless columns | 16,232,943 | 80 | 4 | |
| Removal of columns with unique values | 16,232,943 | 72 | 8 | |
| Removal of columns with high correlation | 16,232,943 | 45 | 27 | |
| Removal of infinite, empty and null values | 16,137,183 | 95,760 | 45 | |
| Removal of duplicate rows | 15,705,343 | 431,840 | 45 |
| Types of Attacks | Initial Rows | After Cleaning | Removed Rows | Removed Proportion |
|---|---|---|---|---|
| Benign | 13,484,708 | 13,352,392 | 132,316 | 0.98% |
| DDoS attacks-LOIC-HTTP | 576,191 | 576,175 | 16 | 0.00% |
| DDOS attack-HOIC | 686,012 | 668,461 | 17,551 | 2.56% |
| DoS attacks-Hulk | 461,912 | 434,873 | 27,039 | 5.85% |
| Bot | 286,191 | 282,310 | 3881 | 1.36% |
| Infiltration | 161,934 | 160,604 | 1330 | 0.82% |
| SSH-Bruteforce | 187,589 | 117,322 | 70,267 | 37.46% |
| DoS attacks-GoldenEye | 41,508 | 41,455 | 53 | 0.13% |
| DoS attacks-Slowloris | 10,990 | 10,285 | 705 | 6.41% |
| DDOS attack-LOIC-UDP | 1730 | 1730 | 0 | 0% |
| Brute Force -Web | 611 | 611 | 0 | 0% |
| Brute Force -XSS | 230 | 230 | 0 | 0% |
| SQL Injection | 87 | 87 | 0 | 0% |
| DoS attacks-SlowHTTPTest | 139,890 | 19,462 | 120,428 | 86.09% |
| FTP-BruteForce | 193,360 | 39,346 | 154,014 | 79.65% |
| 16,232,943 | 15,705,343 | 527,600 | 3.25% |
| Types of Attacks | Initial Rows | After Cleaning | Removed Rows | Removed Proportion |
|---|---|---|---|---|
| Benign | 13,484,708 | 13,352,392 | 132,316 | 0.98% |
| Malignant | 2,748,235 | 2,352,951 | 395,284 | 14.38% |
| 16,232,943 | 15,705,343 | 527,600 | 3.25% |
| Types of Attacks | After Cleaning | Undersampling 20% Benign | ||
|---|---|---|---|---|
| Rows | Prop. | Rows | Prop. | |
| Benign | 13,352,392 | 85.02% | 2,670,478 | 53.16% |
| DDoS attacks-LOIC-HTTP | 576,175 | 3.67% | 576,175 | 11.47% |
| DDOS attack-HOIC | 668,461 | 4.26% | 668,461 | 13.31% |
| DoS attacks-Hulk | 434,873 | 2.77% | 434,873 | 8.66% |
| Bot | 282,310 | 1.80% | 282,310 | 5.62% |
| Infiltration | 160,604 | 1.02% | 160,604 | 3.20% |
| SSH-Bruteforce | 117,322 | 0.75% | 117,322 | 2.34% |
| DoS attacks-GoldenEye | 41,455 | 0.26% | 41,455 | 0.83% |
| DoS attacks-Slowloris | 10,285 | 0.07% | 10,285 | 0.20% |
| DDOS attack-LOIC-UDP | 1730 | 0.01% | 1730 | 0.03% |
| Brute Force -Web | 611 | 0.004% | 611 | 0.01% |
| Brute Force -XSS | 230 | 0.001% | 230 | 0.005% |
| SQL Injection | 87 | 0.001% | 87 | 0.002% |
| DoS attacks-SlowHTTPTest | 19,462 | 0.12% | 19,462 | 0.39% |
| FTP-BruteForce | 39,346 | 0.25% | 39,346 | 0.78% |
| 15,705,343 | 5,023,429 | |||
| Types of Attacks | After Cleaning | Undersampling 20% Benign | ||
|---|---|---|---|---|
| Rows | Prop. | Rows | Prop. | |
| Benign | 13,352,392 | 85.02% | 2,670,478 | 53.16% |
| Malignant | 2,352,951 | 14.98% | 2,352,951 | 46.84% |
| 15,705,343 | 5,023,429 | |||
| Max. Input Tokens | Accuracy | Precision | Recall | F-score | Training Time |
|---|---|---|---|---|---|
| 50 | 99.75% | 99.75% | 99.75% | 99.75% | 2:22:33 |
| 100 | 99.84% | 99.84% | 99.84% | 99.84% | 2:45:20 |
| 150 | 99.84% | 99.85% | 99.84% | 99.84% | 3:15:47 |
| 200 | 99.84% | 99.85% | 99.84% | 99.84% | 3:43:27 |
| 250 | 99.84% | 99.85% | 99.84% | 99.84% | 4:20:27 |
| 350 | 99.84% | 99.85% | 99.84% | 99.84% | 5:28:13 |
| 500 | 99.84% | 99.85% | 99.84% | 99.84% | 7:42:27 |
| Label | Benign | DDoS Attacks-LOIC-HTTP | DDOS Attack-HOIC | DoS Attacks-Hulk | Bot | Infiltration | SSH-Bruteforce | DoS Attacks-GoldenEye | DoS Attacks-Slowloris | DDOS Attack-LOIC-UDP | Brute Force -Web | Brute Force -XSS | SQL Injection | DoS Attacks-SlowHTTPTest | FTP-BruteForce | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Class | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | Misclassified |
| 0 | 532,635 | 19 | 0 | 0 | 14 | 1,420 | 5 | 0 | 0 | 0 | 3 | 0 | 0 | 0 | 0 | 0.27% |
| 1 | 4 | 115,231 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0% |
| 2 | 0 | 0 | 133,692 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0% |
| 3 | 0 | 0 | 0 | 86,975 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0% |
| 4 | 5 | 0 | 0 | 0 | 56,457 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.01% |
| 5 | 72 | 0 | 0 | 0 | 0 | 32,049 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.22% |
| 6 | 0 | 0 | 0 | 0 | 0 | 0 | 23,464 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0% |
| 7 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 8290 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.01% |
| 8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2057 | 0 | 0 | 0 | 0 | 0 | 0 | 0% |
| 9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 346 | 0 | 0 | 0 | 0 | 0 | 0% |
| 10 | 7 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 106 | 7 | 2 | 0 | 0 | 13.11% |
| 11 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 42 | 1 | 0 | 0 | 8.7% |
| 12 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 7 | 4 | 0 | 0 | 76.47% |
| 13 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3892 | 0 | 0% |
| 14 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 7869 | 0% |
| Dataset | Accuracy | Precision | Recall | F-score | FPR | FNR | Detection Latency |
|---|---|---|---|---|---|---|---|
| CIC-IDS-2017 | 99.94% | 99.94% | 99.94% | 99.94% | 0.01% | 0.05% | 0.035 s |
| CSE-CIC-IDS2018 | 99.84% | 99.84% | 99.84% | 99.84% | 0.27% | 0.02% | 0.032 s |
| BCCC-CIC-IDS-2017 | 99.90% | 99.90% | 99.90% | 99.90% | 0.11% | 0.04% | 0.037 s |
| Reference | Technique | Accuracy | Precision | Recall | F-score | FPR | FNR |
|---|---|---|---|---|---|---|---|
| Our approach | T5 | 99.84% | 99.84% | 99.84% | 99.84% | 0.27% | 0.02% |
| Li et al. [27] | CGAN + BERT | 98.22% | 98.25% | 98.22% | 98.23% | – | – |
| Manocchio et al. [28] | GPT 2.0 | 95.86% | – | – | 96.93% | 0.11% | – |
| BERT | 95.48% | – | – | 95.80% | 0.47% | – | |
| Maruthupandi et al. [11] | IADCL | 99.82% | 99.80% | 99.81% | 99.80% | – | – |
| Immune Net | 99.78% | 99.77% | 99.78% | 99.70% | – | – | |
| XGBoost | 99.00% | 99.03% | 99.00% | 99.01% | – | – | |
| RF | 98.81% | 98.82% | 98.81% | 98.81% | – | – | |
| DT | 98.69% | 93.41% | 98.79% | 96.03% | – | – | |
| LR | 87.96% | 90.80% | 87.96% | 88.99% | – | – | |
| Abdel-Basset et al. [12] | SS-Deep-ID | 98.71% | 94.91% | 94.30% | 94.92% | – | – |
| Nie et al. [13] | GAN | 95.32% | 99.88% | 95.85% | 97.30% | 0.89% | – |
| Kunang et al. [14] | Hybrid DL Model | 99.17% | 99.26% | 99.17% | 99.20% | 0.18% | – |
| Bhardwaj et al. [15] | CNN-1D | 99.40% | – | – | – | – | – |
| Wang et al. [16] | CNN | 99.36% | – | – | – | 0.16% | 0.79% |
| Tapu et al. [17] | Hybrid DL Model | 90.64% | 91.66% | 90.64% | 91.00% | – | – |
| Li et al. [18] | HDFEF | – | 98.22% | 99.77% | 98.49% | – | – |
| Yilmaz et al. [19] | RF | – | 94.00% | 76.00% | 79.00% | 0.53% | – |
| CatBoost | – | 91.00% | 80.00% | 83.00% | 0.43% | – | |
| LightGBM | – | 91.00% | 81.00% | 83.00% | 0.42% | – | |
| XGBoost | – | 89.00% | 83.00% | 84.00% | 0.42% | – | |
| Hammad et al. [20] | MMM-RF | 99.98% | – | – | – | 0.02% | – |
| Yu et al. [21] | PBCNN | 99.99% | 98.20% | 98.30% | 98.30% | – | – |
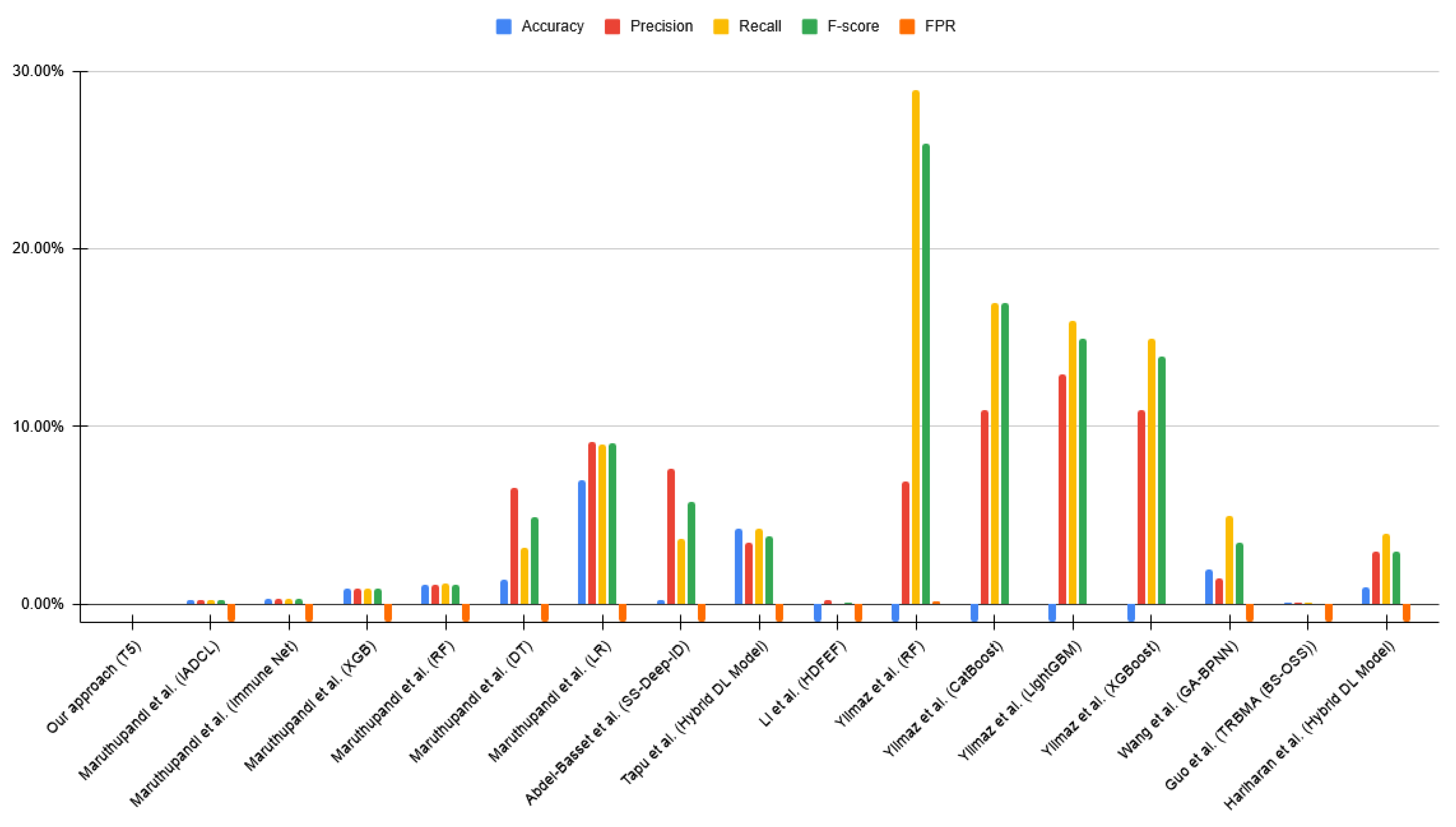
| Reference | Technique | Accuracy | Precision | Recall | F-Score | FPR | FNR |
|---|---|---|---|---|---|---|---|
| Our approach | T5 | 99.94% | 99.94% | 99.94% | 99.94% | 0.01% | 0.05% |
| Maruthupandi et al. [11] | IADCL | 99.70% | 99.72% | 99.70% | 99.71% | – | – |
| Immune Net | 99.63% | 99.64% | 99.63% | 99.63% | – | – | |
| XGBoost | 99.09% | 99.03% | 99.07% | 99.07% | – | – | |
| RF | 98.81% | 98.82% | 98.81% | 98.81% | – | – | |
| DT | 98.54% | 93.41% | 96.76% | 95.06% | – | – | |
| LR | 92.96% | 90.80% | 90.96% | 90.87% | – | – | |
| Abdel-Basset et al. [12] | SS-Deep-ID | 99.69% | 92.31% | 96.29% | 94.18% | – | – |
| Tapu et al. [17] | Hybrid DL Model | 95.68% | 96.50% | 95.68% | 96.10% | – | – |
| Li et al. [18] | HDFEF | – | 99.73% | 99.96% | 99.84% | – | – |
| Yilmaz et al. [19] | RF | – | 93.00% | 71.00% | 74.00% | 0.14% | – |
| CatBoost | – | 89.00% | 83.00% | 83.00% | 0.02% | – | |
| LightGBM | – | 87.00% | 84.00% | 85.00% | 0.01% | – | |
| XGBoost | – | 89.00% | 85.00% | 86.00% | 0.02% | – | |
| Wang et al. [22] | GA-BPNN | 98.00% | 98.50% | 95.00% | 96.50% | – | – |
| Guo et al. [23] | TRBMA (BS-OSS) | 99.88% | 99.86% | 99.88% | 99.89% | – | – |
| Hariharan et al. [24] | Hybrid DL Model | 99.00% | 97.00% | 96.00% | 97.00% | – | – |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gutiérrez-Galeano, L.; Domínguez-Jiménez, J.-J.; Schäfer, J.; Medina-Bulo, I. LLM-Based Cyberattack Detection Using Network Flow Statistics. Appl. Sci. 2025, 15, 6529. https://doi.org/10.3390/app15126529
Gutiérrez-Galeano L, Domínguez-Jiménez J-J, Schäfer J, Medina-Bulo I. LLM-Based Cyberattack Detection Using Network Flow Statistics. Applied Sciences. 2025; 15(12):6529. https://doi.org/10.3390/app15126529
Chicago/Turabian StyleGutiérrez-Galeano, Leopoldo, Juan-José Domínguez-Jiménez, Jörg Schäfer, and Inmaculada Medina-Bulo. 2025. "LLM-Based Cyberattack Detection Using Network Flow Statistics" Applied Sciences 15, no. 12: 6529. https://doi.org/10.3390/app15126529
APA StyleGutiérrez-Galeano, L., Domínguez-Jiménez, J.-J., Schäfer, J., & Medina-Bulo, I. (2025). LLM-Based Cyberattack Detection Using Network Flow Statistics. Applied Sciences, 15(12), 6529. https://doi.org/10.3390/app15126529