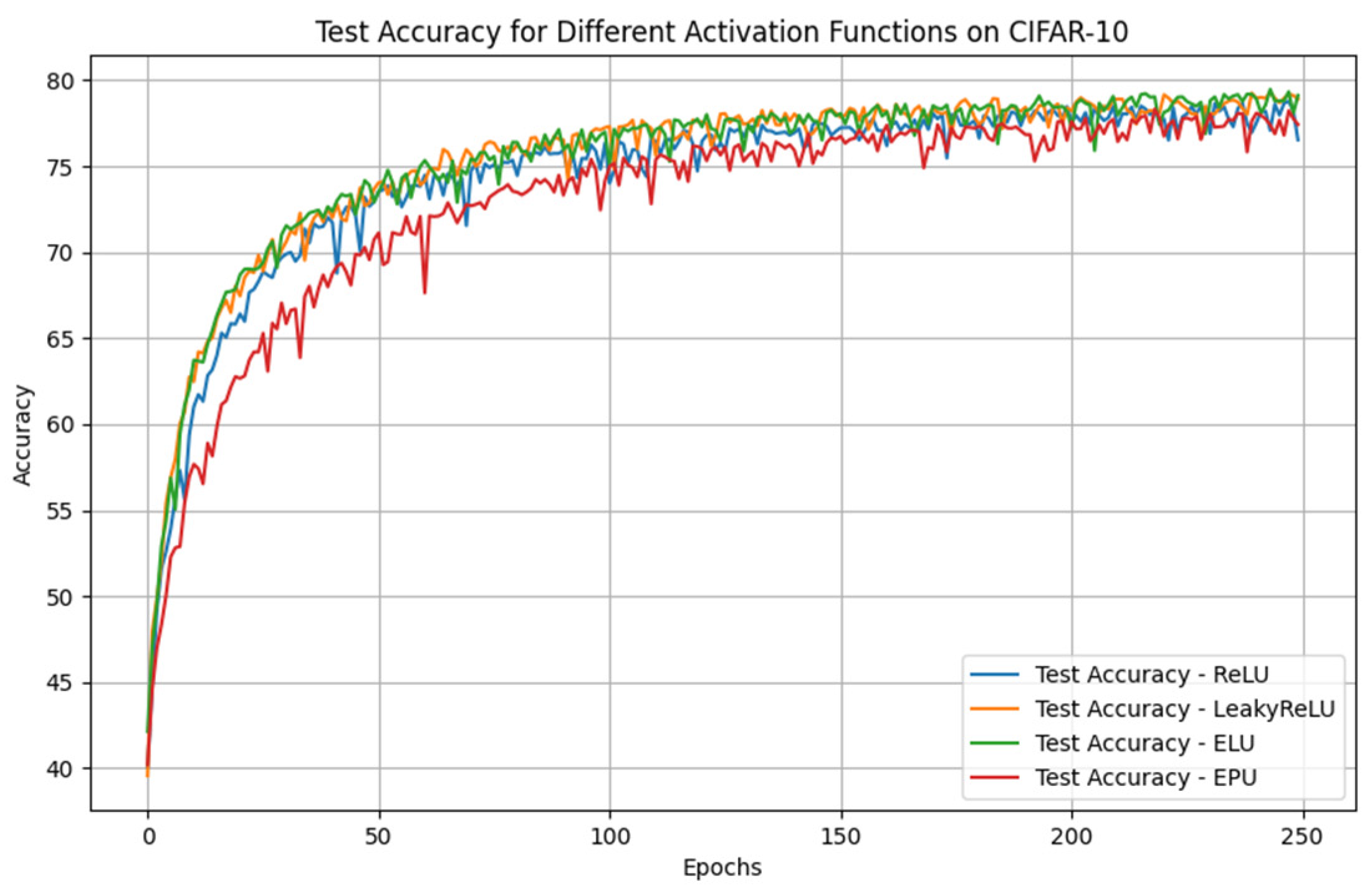
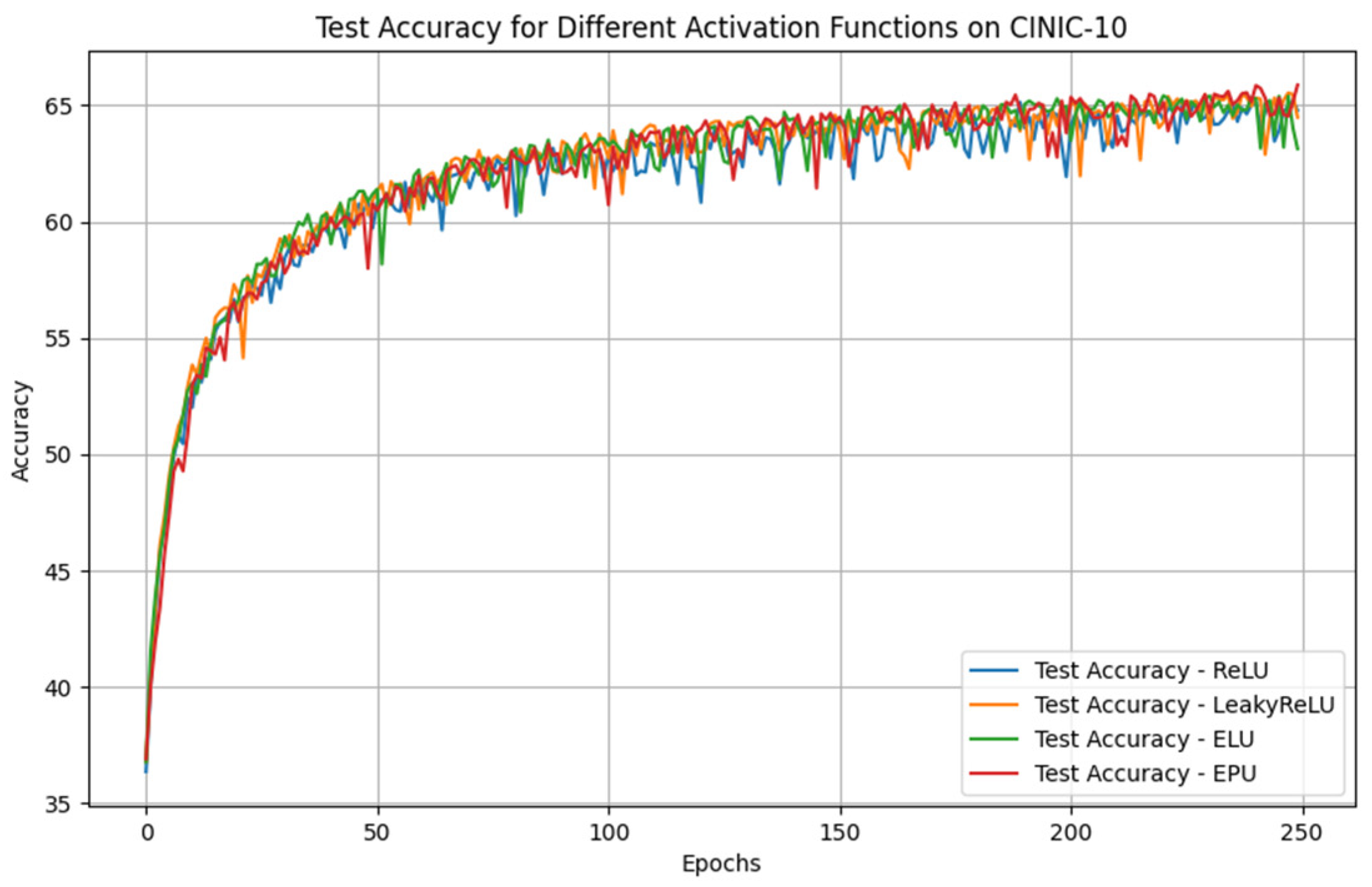
3.1. Exponential Partial Unit (EPU)
During the development of neural networks, it was found that their efficient training requires the use of nonlinear activation functions. The most popular of these is ReLU (Rectified Linear Unit) [
16]. Its popularity is attributed to its simplicity and efficiency, which are reflected in high accuracy and easy computation.
However, this simplicity can lead to problems. One of them is the so-called exploding gradient, when the error gradients become extremely large, leading to excessively large changes in the model weights. This can make the model unstable—in extreme cases the weights reach huge values or even cause numerical errors that interrupt training. The solution to this problem lies in limiting the activation values to a certain maximum.
where
a is the coefficient of clipping. But this solution does not solve the other existing problem known in the community as the “Dying ReLU” problem. This means that the weighted sum of the inputs to these neurons consistently results in a negative value, causing the ReLU activation to output zero. Once a neuron becomes inactive, it effectively stops learning since the gradient during backpropagation is zero for negative inputs, due to the zero-derivative generated by the ReLU philosophy. There are also solutions to this, such as Leaky ReLU [
17], which adds a small gradient for negative numbers so that the slope is not 0.
α is a constant in this equation, usually a small number. Other related solutions include ELU (Exponential Linear Unit) [
18] and SeLU (Scaled Exponential Linear Unit) [
19]. However, there are activation functions that are trained during training offering additional benefits by allowing the network to optimize the activation parameters depending on the specific characteristics of the data and the training process, resulting in better performance and stability of the models. Examples of such features are PReLU (Parametric ReLU) [
20] and LeLeLU (Learnable Leaky ReLU) [
21].
This paper presents a new activation function called Exponential Partial Unit (EPU), which is based on the exponential function. Although it does not belong to the ReLU family, it combines low computational complexity and greater flexibility with respect to real data. The formula that describes the EPU is as follows:
where
represents the exponential function with base
e raised to the power of the scaling factor
k times the input variable.
represent the minimum and maximum bounds, respectively. The clip function is defined as
In the proposed function, the parameters k,
are defined as learnable parameters, allowing them to be dynamically optimized during the training process, all initialized following uniform distribution. The boundary of initialization of these parameters differs from each other. The parameter min is initialized within a negative range, ensuring that it acts as a lower bound when clamping input values, between −5 and −1.
Symmetrically,
is initialized within a positive range from 1 to 5. By enforcing
<
at initialization, the function ensures a well-defined input transformation.
Meanwhile, k is initialized within a small positive range, controlling the scaling factor in the exponential function.
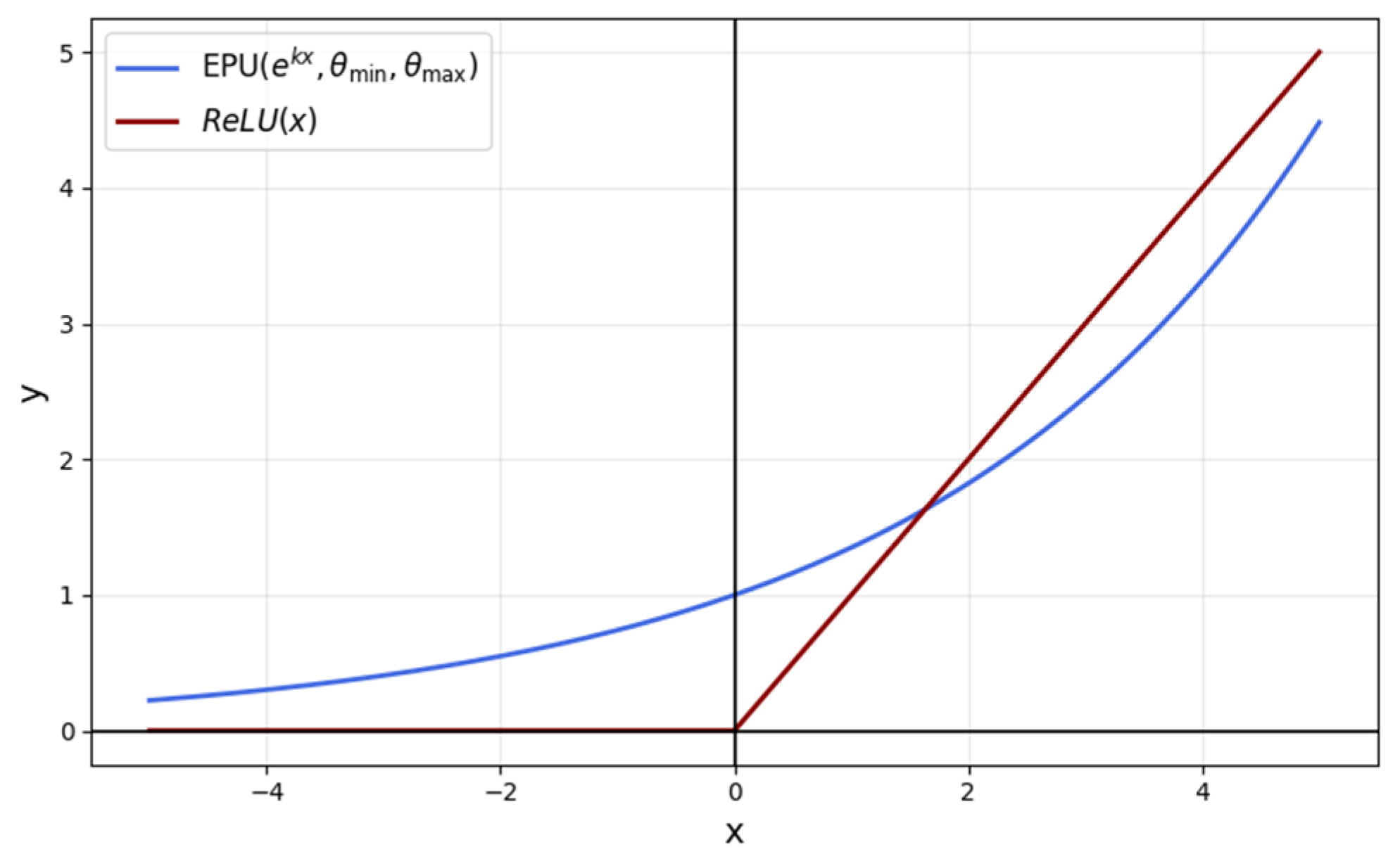
Figure 1 illustrates the comparison between the ReLU and EPU functions, highlighting their respective behaviors across the specified range.
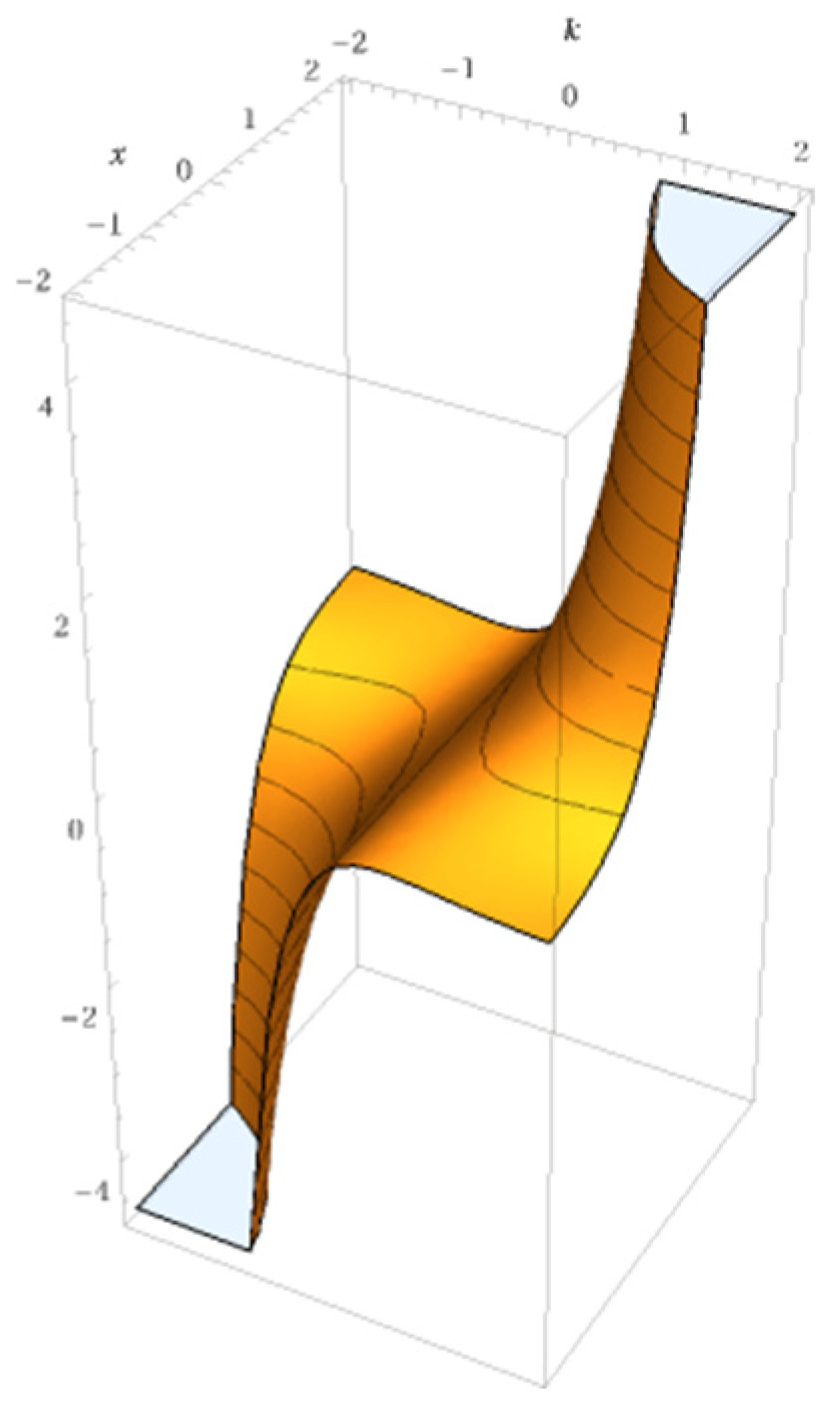
One of the major advantages of the EPU is its ability to introduce non-linearity while maintaining smooth gradient flow, which enhances optimization and helps prevent “vanishing gradients”. Another advantage is that its first derivative can be easily calculated during training. This property simplifies the backpropagation process, as the gradient of the activation function can be efficiently computed, ensuring smooth and stable updates to the learnable parameters. The derivative of the exponential function is straightforward, making it computationally efficient for optimization tasks, and it helps maintain the stability of the training process. The 3D plot is shown in
Figure 2, providing a visual representation of the function's behavior.
We acknowledge the extensive development of ReLU variants, each designed to address specific limitations of the original ReLU function. While these variants generally introduce only minor modifications to the core ReLU concept, they nonetheless offer measurable improvements in aspects like mitigating the vanishing gradient problem, accelerating convergence, or enhancing the performance of certain tasks.
In contrast, our proposed activation function presents a novel approach that distinguishes itself from the traditional ReLU family. By uniquely integrating the exponential function in a way that fundamentally redefines activation behavior, our method offers an innovative alternative that not only addresses existing limitations, but also introduces distinct performance benefits and enhanced stability. This new concept goes beyond incremental modifications, representing a significant and original contribution to the design of activation functions.
In modern deep learning frameworks, neural networks rely heavily on automatic differentiation to efficiently compute gradients during training. This capability is particularly important when employing novel activation functions like our Exponential Partial Unit (EPU). Thanks to the straightforward derivative of the exponential function our EPU enables faster, and more efficient gradient computation compared to more complex activation functions. This computational efficiency not only accelerates the automatic differentiation process, but also contributes to faster overall training and enhanced stability during backpropagation.
Furthermore, as noted in [
22,
23], the existing literature does not provide a detailed analysis of activation functions that employ such an exponential integration approach. This highlights the novelty of our method, which extends beyond traditional modifications of ReLU and offers a unique contribution to activation function design.
3.2. Batch Normalization
Generally, in neural networks, the output of the first layer is used as input to the second layer, the output of the second layer is fed to the third layer, and this process continues on. When the parameters of a layer are changed during training, this results in a change in the distribution of input values for subsequent layers. These input distribution changes can lead to serious complications, especially if the network has more layers. This problem is described in detail in [
24], as follows: “We define Internal Covariate Shift as the change in the distribution of network activations due to the change in network parameters during training”. This problem is solved precisely by Batch Normalization. Other normalization approaches have appeared as well, such as Group Normalization [
25] and Switchable Normalization [
26], but for the experiments in this study, we have decided to use Batch Normalization due to its popularity and good benchmark results.
For a given mini-batch of input data, the mean and variance are first computed.
Then, this “normalization” is applied to each input
x by subtracting the mean
and dividing by the square root of the variance
, with a small constant
ϵ added to the denominator to prevent division by zero and ensure numerical stability.
After normalization, the data are scaled and shifted using learnable parameters γ and β These parameters, which are optimized during training, allow the network to retain or adapt an optimal representation of the data after normalization.
3.3. Regularization
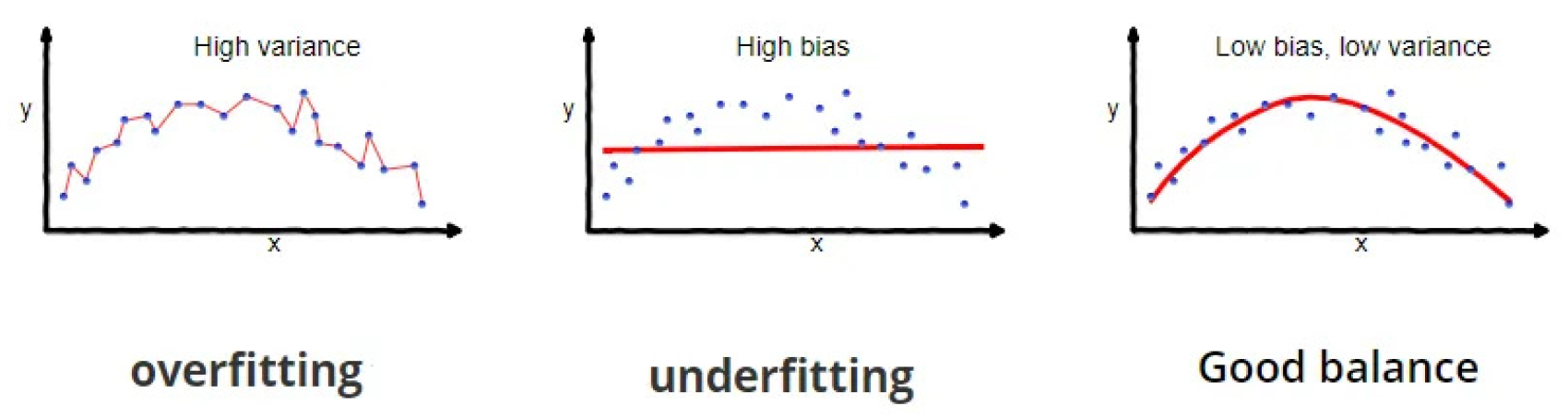
Oversaturation has always plagued neural network designers. Ordinary users would never realize how much time and effort is required for solving high-variance problems. High variance and high bias are two major components of prediction error. A high-variance model pays too much attention to the training data and fails to perform well on new, unseen data. This can lead to very high scores on the training data, but low scores on validation and tests. On the other hand, a high-bias model pays too little attention to the training data and makes overly simplistic inferences that do not reflect the complexity of the problem well. This leads to large errors in all data distributions. These two types of errors—variance and bias—create a tradeoff called the bias–variance tradeoff, shown in
Figure 3. When we try to reduce one error, it often leads to an increase in the other. To find the perfect balance, various regularization methods have emerged. Among the most well-known methods are L2 regularization [
27] and Dropout [
28]. As presented in [
29], L2 shows better results in some cases, while Dropout works better in others. To address the bias–variance tradeoff effectively, we use both methods in this study.
The idea behind Dropout is simple: During training some neurons are “turned off’’. At each training step, a random subset of neurons in a layer is selected and temporarily deactivated. These neurons do not contribute to either forward propagation or backpropagation during that step. By deactivating neurons at random, the network is forced to rely on a wider range of neurons rather than depending too much on specific ones. This encourages the model to learn more robust and diverse patterns from the data, making it better at handling new, unseen examples.
The dropout rate is a hyperparameter that determines the probability of a neuron being dropped. For instance, a dropout rate of 0.2 means that 20% of neurons will be deactivated at each training step. Sometimes, an improperly chosen dropout rate can significantly impact the effectiveness of training, potentially deteriorating the model’s performance. To compensate for the absence of the dropped neurons, the outputs of the remaining active neurons are scaled up. For instance, if 50% of neurons are deactivated, the outputs of the remaining active neurons are scaled up by a factor equal to the probability of keeping a neuron active. This helps maintain the network’s overall functionality and balance during training. During testing, dropout is turned off. All neurons are active, but their weights are adjusted to match the expected behavior during training. In our study, wherever dropout is used, the dropout rate is set to 0.2.
Besides Dropout, as mentioned earlier, another method of regularization is used—L2 Regularization also known as Weight Decay. In our case, we limit the complexity of the model with this method by limiting the update of the weights. This function takes away from the complexity of the model by adding the element called the regularization term. The regularization term is added to the underlying cost function, thus affecting the optimization process. The standard cost function J(W), which measures the difference between predicted and actual output values, can be extended by adding the L2 regularization. Thus, the cost function becomes
This addition to the cost function results in smaller weights, which in turn reduces the ability of the model to overfit to specific examples in the training data. λ is a regularization hyperparameter that controls the balance between the model’s accuracy on the training data and its complexity. m is the number of training examples used to train the model, and L is the loss function that computes the difference between the predicted value
and the actual value y for each training example i.
represents the L2-norm of the weights of layer l, that is, the sum of the squares of all the elements of the weights.
Once we compute the gradients of the cost function with an added regularization term, the weight update is
3.4. He Initialization
Initialization in neural networks is the process of setting the initial values of the weights before training. This step is the key in creating models with fast convergence. Poorly initialized weights can slow down training or even make it impossible. Typically, these weights are initialized by following some distribution (most commonly a normal or uniform distribution) [
30]. However, there are other methods that are based on activation functions. For example, Xavier Initialization [
31] is designed for functions such as sigmoid and tanh, guaranteeing similarity of variance of inputs and outputs.
This paper considers another initialization approach, He Initialization [
20], which we empirically found to be the most appropriate in our case. After all, this method was designed to improve the performance of image recognition architectures. The main idea behind He Initialization is to ensure that the variance of the outputs from each layer of the network remains almost unchanged when passing through a layer. This helps prevent excessive increase or decrease in gradients during training, which can lead to faster convergence and better model performance.
This formula describes the He initialization of the weights in the neural network, where the weights are initialized with a normal distribution with zero mean and variance proportional to two, divided by the number of inputs to the layer nin. This method ensures the stability of the gradients and prevents the problems of decay or explosion of the gradients when using activation functions such as ReLU and, in our case, EPU.
3.5. The Neural Network
Deep neural networks are a foundational approach in artificial intelligence (AI) to solve different types of problems in a robust manner. They are the basis of popular architectures such as transformer [
32], which in turn underlie modern chatbots and solutions for natural language processing (NLP) tasks. In computer vision, architectures such as Vision Transformer (ViT) [
33], built on the principles of the previously mentioned transformers, find applications in tasks such as image classification, object detection, and segmentation. Other models, such as U-Net [
34], specialize in semantic and medical segmentation tasks, making them widely used in medical diagnostics. These neural networks can be of different types—feed-forward neural networks (FFNNs), convolutional neural networks (CNNs), recurrent neural networks (RNNs), as well as specialized architectures such as graph neural networks (GNNs) and autoencoders for specific tasks.
One of the first approaches to solving the image classification problem considered in this paper is using a FFNN. Ever since the distant past [
35] until now [
36], people have been trying to develop models that can efficiently process and classify visual data using FFNNs. Although FFNNs can be used for tasks such as image classification, it has its limitations, especially when it comes to processing high-resolution images or large amounts of data. This is due to the fact that FFNN does not take into account the scale structure of the images. One of the main problems in using this type of networks for image classification is related to the size of the input data. Images are usually represented as matrices of pixels, and in order to be processed by FFNNs, these matrices need to be transformed into long vectors. For high-resolution images, this leads to increased computational complexity, memory requirements, and the risk of overtraining. Other serious issues are spatial locality and translational invariance. Spatial locality means that the pixels that form an object are located close to each other, but FFNNs treat each pixel as independent, ignoring these dependencies and losing important information about the structure of the object. Translational invariance assumes that objects remain identical even if they are shifted in the image, but FFNNs do not recognize such shifts, requiring retraining for each new position. These limitations lead to an extremely large number of parameters and inefficiency in classifying more complex images. This is when CNNs (convolutional neural networks) came along and revolutionized image processing. The first successful model of this kind was LeNet [
37], which laid the foundation for all modern image recognition models. Convolution in CNNs refers to processing the input image with a series of filters. Using these filters, instead of treating pixels as isolated points, CNNs use connection layers (convolutional layers) that analyze small regions of the image (called receptive fields). This allows the extraction of local features such as edges, textures, and shapes. CNNs also use pooling operations that aggregate information into small areas and allow the network to recognize objects regardless of their exact location in the image. Another important aspect, which is also a major theme of this paper, is that, thanks to these filters, the parameters in such networks are significantly smaller compared to traditional FFNNs.
3.6. The Proposed Architecture
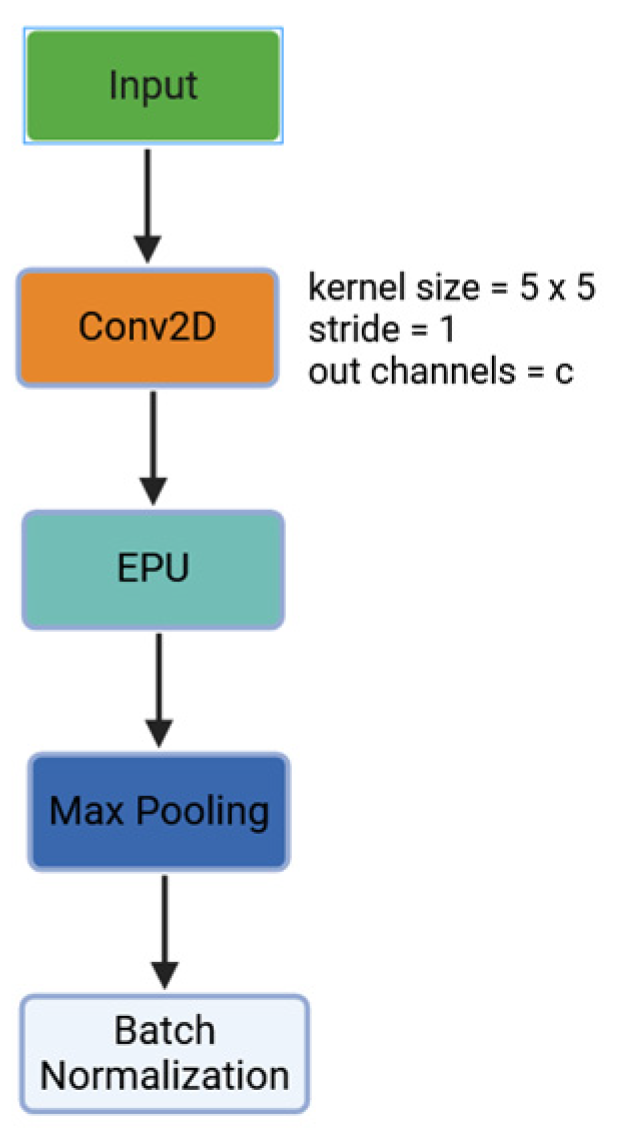
In this subsection, we present our CNN structure, which contains only three convolutional layers, one fully connected layer, and the output layer. Each convolutional layer follows the same structure, which we refer to as a ConvBlock, visualized in
Figure 4.
As already mentioned, the input image is presented in a two-dimensional format with a size of 32 × 32 pixels. Each pixel contains information for three color channels (R, G, and B), with 8 bits allocated for each channel, for a total of 24 bits per pixel. We will write the input information to the first ConvBlock for processing as a tensor with dimensions 32 × 32 × 3.
The information is first processed through a convolutional layer (filter) that is configured with a kernel size of 5, a stride equal to 1, and padding set to “same”. This configuration preserves the spatial dimensions of the image. The output of this layer consists of a c number of (color) channels, which determines the number of features that will be extracted from the input image. After performing the convolution, the output, organized into a tensor with dimensions (h, w, and c)–with h and w representing the spatial dimensions–is fed directly to the proposed activation function EPU for further processing. After convolution, the data are subjected to pooling, specifically max pooling, which is applied with kernel size 2 and stride 2. This reduces the spatial dimensions significantly, which helps to lower the computational complexity and eliminate redundant information while preserving the most important features for the subsequent processing steps. After the convolution and merging operations are completed, the data undergo Batch Normalization. This process normalizes the values in the tensor with respect to the mean and standard deviation, as previously described by Formulas (1)–(3).
The whole network has a total of three such ConvBlocks. After being processed, the input information (image) of size (32 × 32 × 3) is resized to (4 × 4 × 64), where 64 is the value of c, for the last ConvBlock. This final tensor is considered a feature vector which contains (4 × 4 × 64), 1024 elements in total. Each element of this vector represents a numerical feature extracted from the input image that summarizes its essence and is ready for further processing by the fully connected layer and the output layer of the network. This feature vector is the input to the fully connected layer containing 128 hidden units, this time followed by ReLU activation function instead of EPU. The output from the fully connected layer then goes to the output layer of the network, which is again FF, but this time with only 10 hidden units because that is the number of classes in the dataset. In order to make a prediction, the output from the output layer goes through a softmax activation function that looks like this:
It provides the probability for each class. The class with the highest probability is set as the final answer.
3.7. Parameters
As presented in
Section 2, the number of parameters required to achieve similar levels of accuracy has been significantly reduced. By optimizing the number of learnable parameters, this architecture can achieve a performance that is comparable to the most advanced models in the field, while being much more efficient. The number of learnable parameters in the three convolutional layers within each ConvBlock has been reduced to a minimal value. The number of a convolutional layer is calculated using the following formula:
In this formula Fh and Fw are the height and width of the kernel, while Cin, Cout correspond to the input and output channels, respectively. The term Cout is added to account for the bias parameters, with one bias per output channel.
This formula helps in determining the number of parameters needed for each convolutional layer, considering factors like the size of the filter, the number of filters, and the input and output dimensions.
In addition to the convolutional layers, the Batch Normalization layers and the proposed activation function EPU are also parameter-dependent in ConvBlock. The Batch Normalization layer adds two learnable parameters per channel (mean and standard deviation), while EPU includes three additional learnable parameters. This is the result of the way they are configured. Therefore, the total number of parameters in a ConvBlock is the sum of the parameters of all convolutional layers, the parameters from Batch Normalization and the parameters from the activation function:
In turn, in a fully connected neural network (FFNN), the number of parameters depends on the number of neurons in each layer and the connections between them. Each layer contains two types of learnable parameters: weights and biases. The weights define the strength of the connections between neurons in different layers, while the biases adjust the output of each neuron to improve the model’s ability to fit the data. The number of weight parameters for a certain layer in an FFNN is calculated as follows:
where
and
are the number of neurons in the past and previous layer, respectively. The number of bias parameters for a layer is equal to the number of neurons in that layer, as each neuron has one associated bias parameter. Therefore, the number of bias parameters for a layer is
The total number of parameters, for a layer is
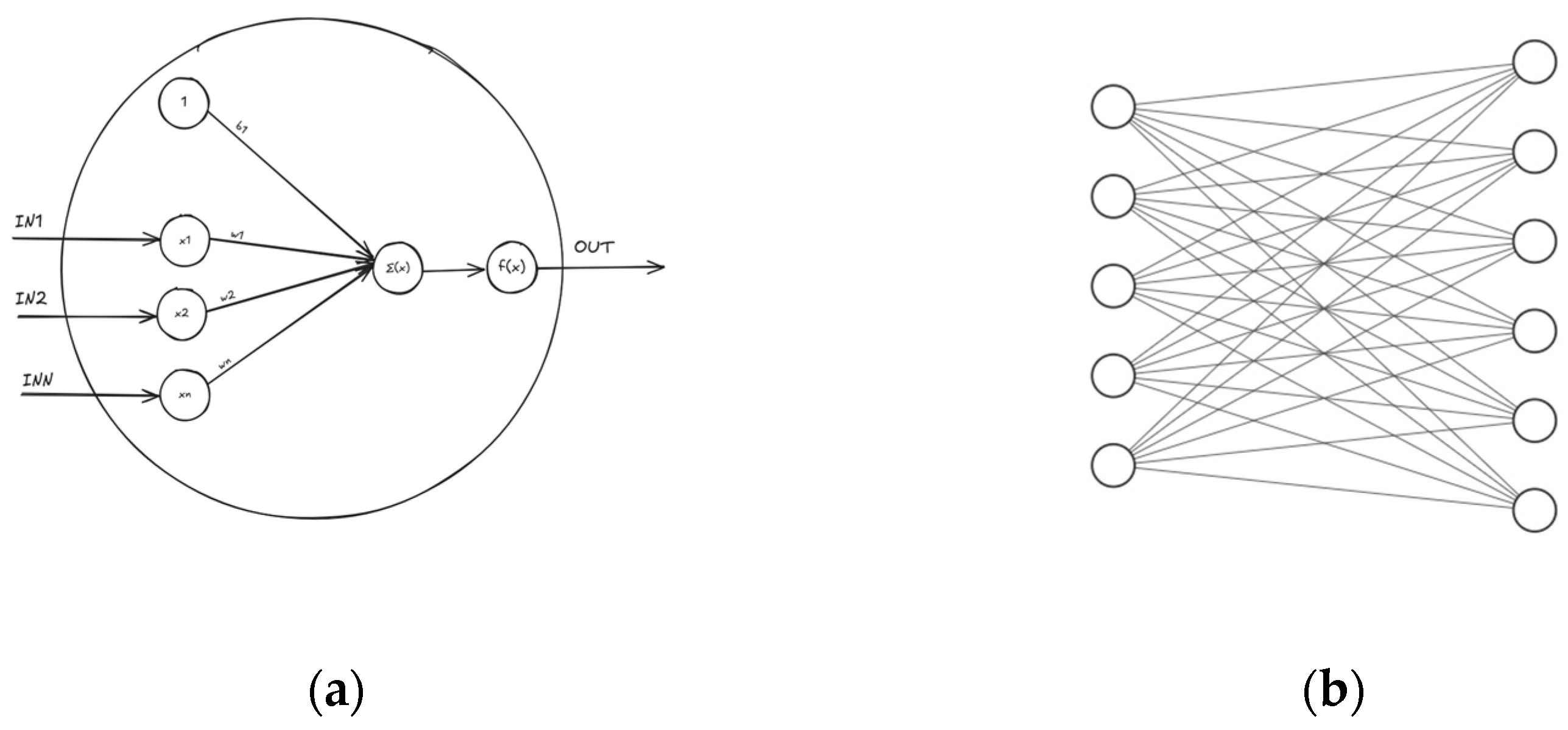
Figure 5a illustrates the architecture of a classical perceptron or one (hidden) unit, where IN1 to INn represent the input nodes, w1 to wn correspond to the associated weights, and b1 denotes the bias term. Σ(x) represents the summation function, while f(x) is the activation function that introduces non-linearity.
For example,
Figure 5b considers a connection between two layers where the first layer contains five hidden units and the second layer contains six. The total number of parameters would be calculated as 5 × 6 + 6 = 36, accounting for both the weights and biases. In our particular case, the system has two of these connections, as previously mentioned.
The first connection in our network has an input dimensionality (Nin) of 1024 and an output dimensionality (Nout) of 128. The second connection then takes this 128-dimensional feature representation as its input (Nin = 128) and maps it to an output of size 10 (Nout = 10), corresponding to the number of distinct classes in our dataset.
As shown in
Table 1, the number of parameters in our proposed architecture’s network blocks is as follows:






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}