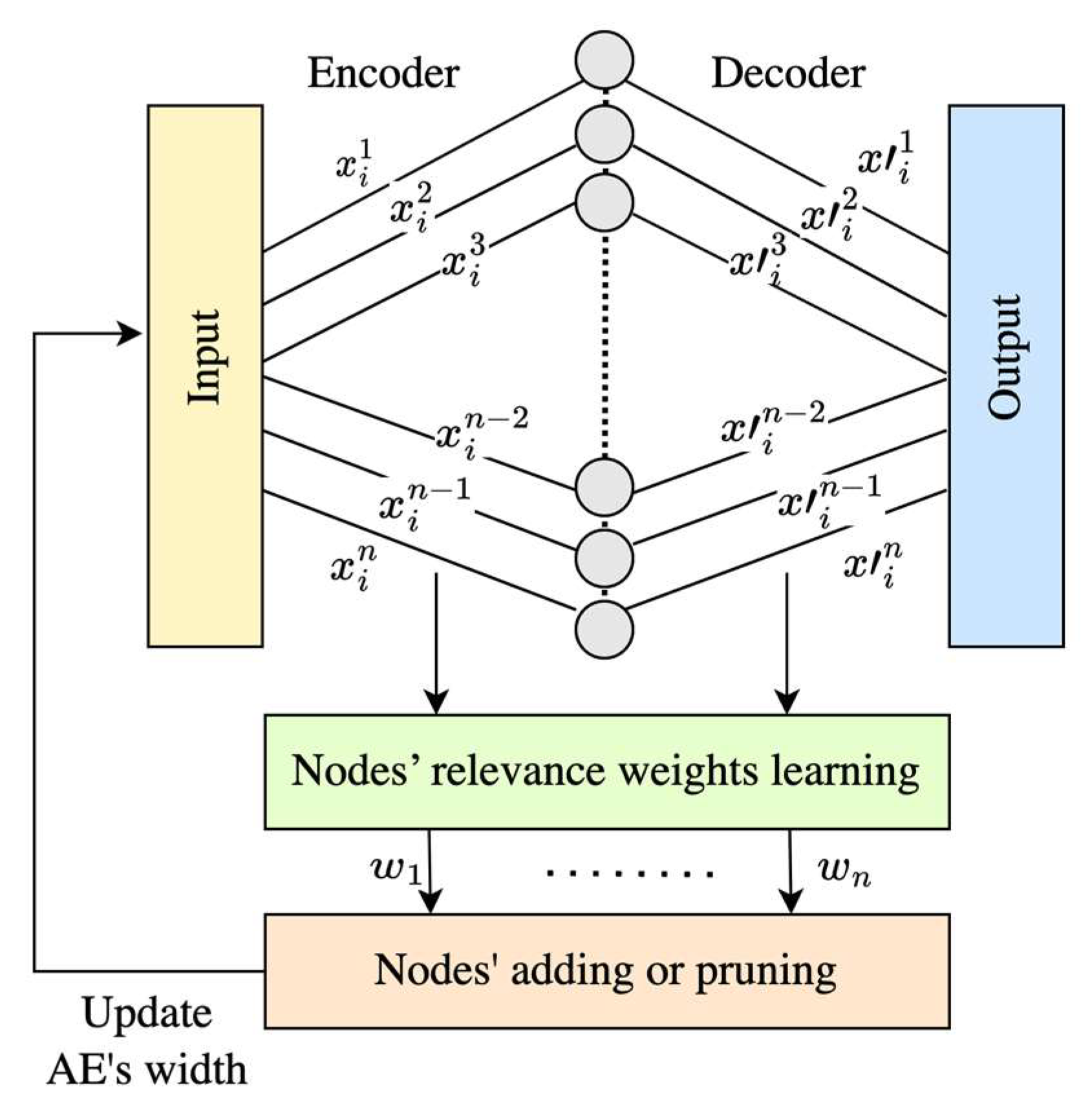
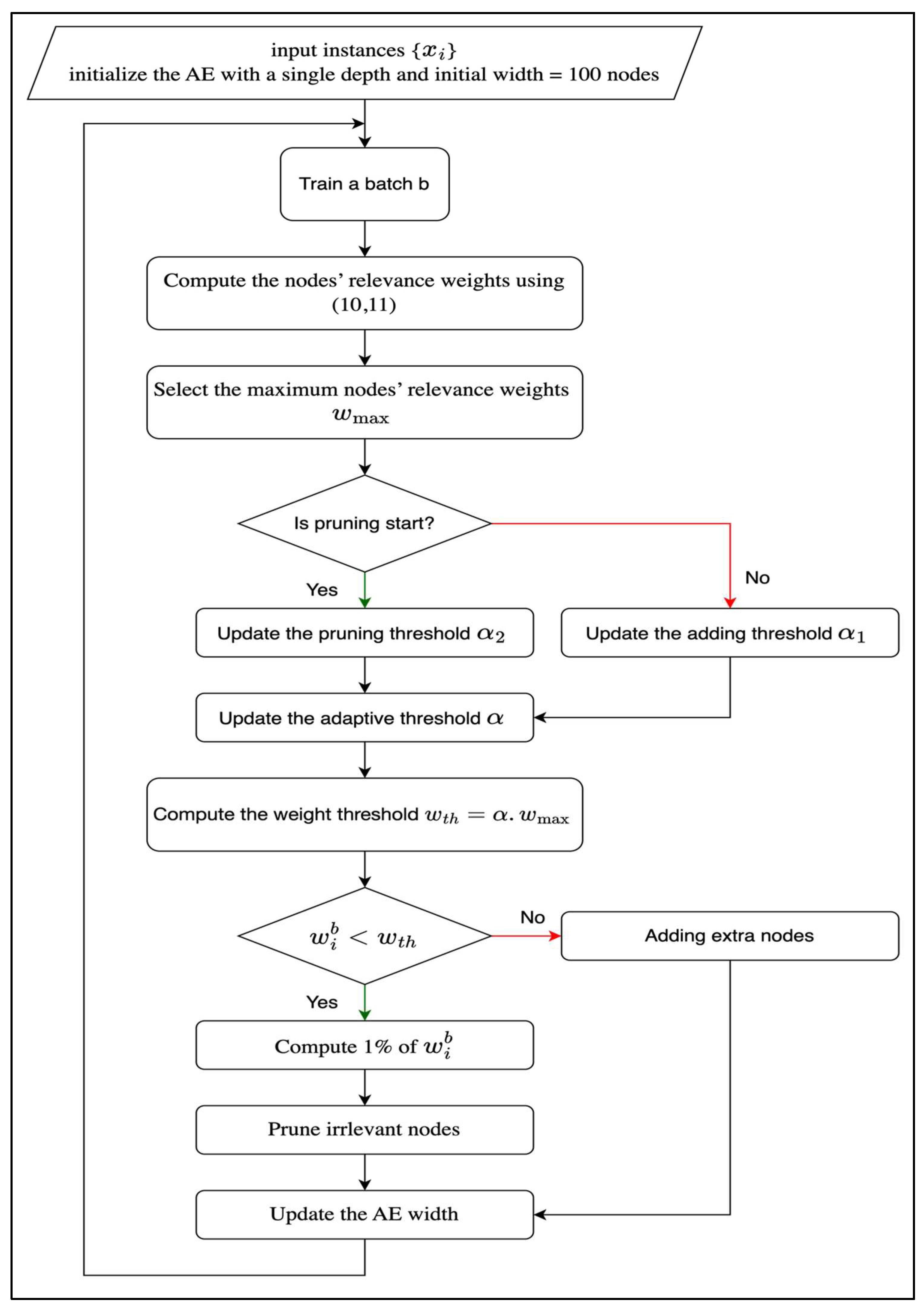
During the training phase, the encoder’s width was initially set to 100 nodes. It was incrementally increased by 10 nodes per batch until the first pruning occurred. The initial number of 100 hidden nodes and the incremental addition of 10 nodes per batch were selected as practical and computationally efficient defaults, consistent with common practice in adaptive architecture methods. These values allow the network to grow gradually while maintaining manageable training times. Importantly, due to the built-in relevance-weighting and pruning mechanisms, the final architecture is not highly sensitive to these choices. The model adaptively converges to a suitable width regardless of the initial or incremental size. Thus, these settings primarily affect convergence speed rather than the final performance. Following this, pruning was progressively applied until the model converged and the optimal width was achieved. The autoencoder (AE) hyperparameters, including learning rate, batch size, optimizer, and loss function, were configured as detailed in
Table 2. To evaluate the performance of the AE, features were extracted from the encoder and subsequently classified using two classifiers: a Support Vector Machine (SVM) and a SoftMax layer. While the training of the WAAE is entirely unsupervised, we use a SoftMax classifier only for post-hoc evaluation purposes. Specifically, once the autoencoder has learned the latent representations, a separate SoftMax layer is trained using the encoded features to assess their discriminative power. This approach does not influence the learning of the autoencoder itself. Furthermore, the structure of the latent space can also be evaluated without labels using metrics such as clustering quality, but labeled data is used here solely to quantify classification accuracy as a means of comparison with other models.
4.2.1. Performance Evaluation of the Proposed Approach on Benchmark Datasets
The proposed WAAE is trained using two benchmark datasets, MNIST [
36] and CIFAR-10 [
37], to assess its ability to dynamically learn the width of an AE in an unsupervised manner.
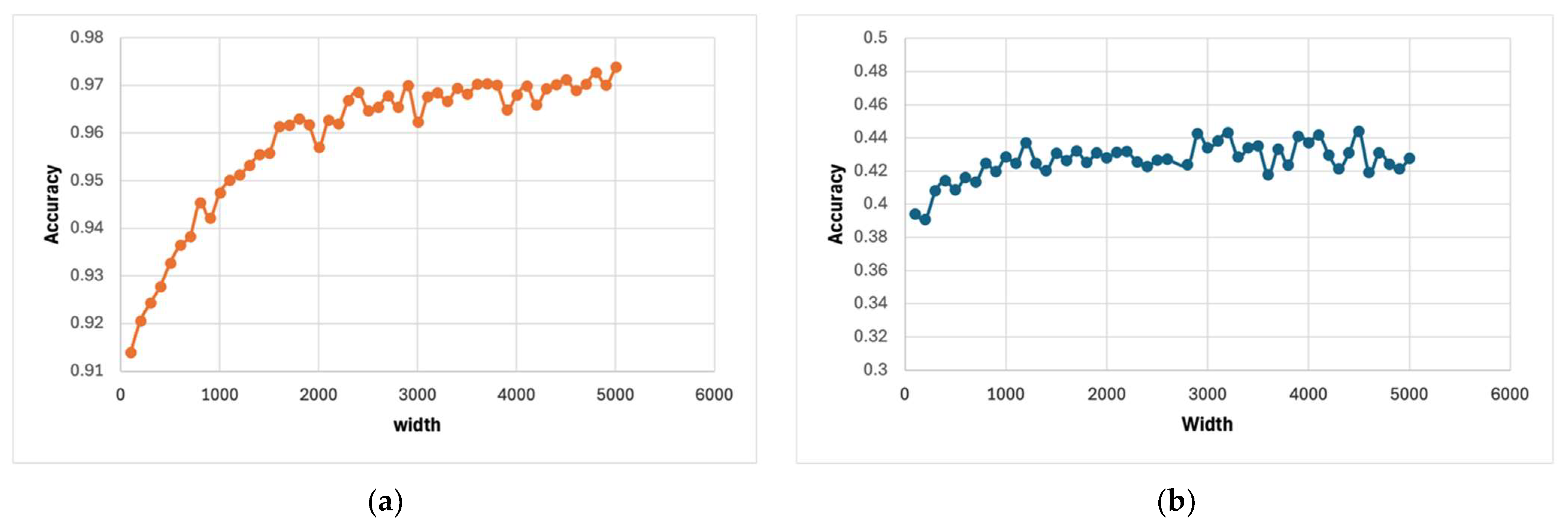
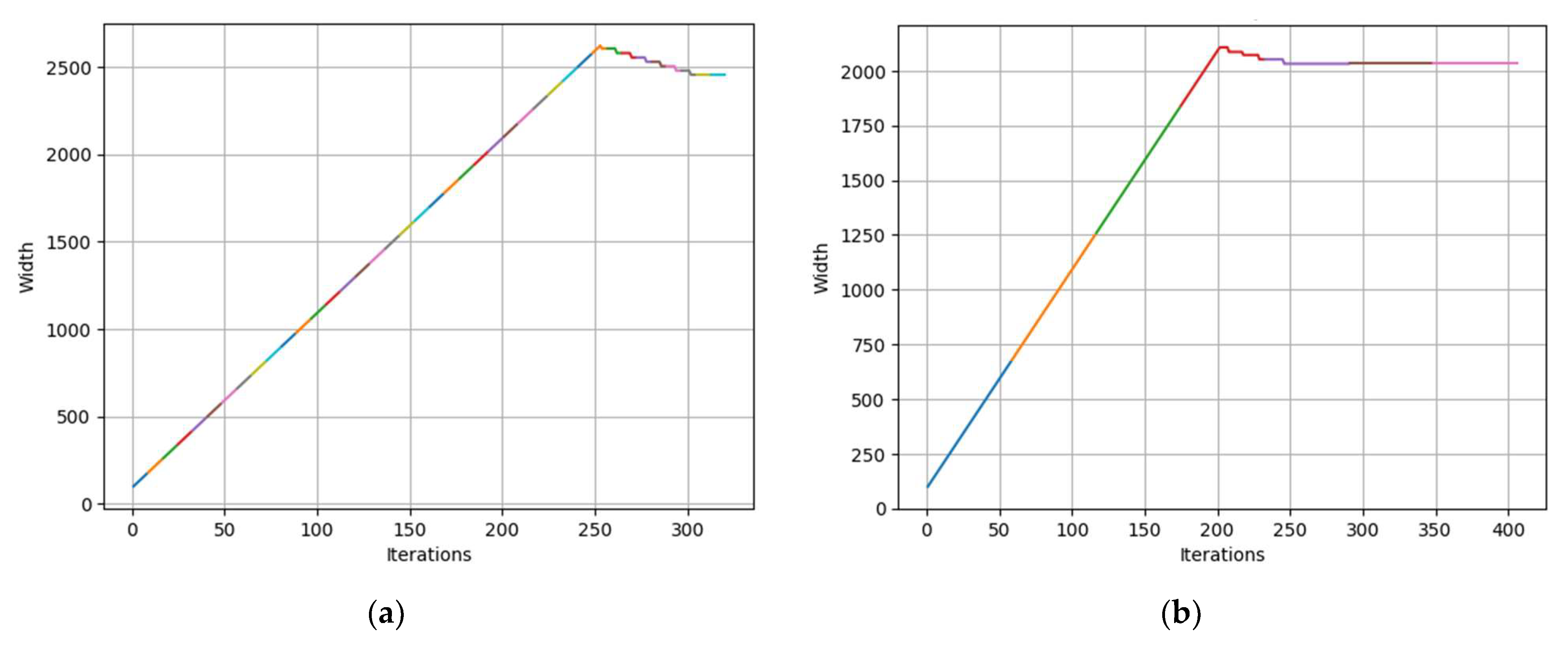
Figure 6 illustrates the evolution of the number of active nodes (i.e., the learned width) across training iterations for both the MNIST [
36] and CIFAR-10 [
37] datasets. In the early iterations, the number of nodes increases rapidly, reflecting the model’s adaptive expansion to capture complex patterns in the input data. For MNIST, the node count peaks at around iteration 250, whereas for CIFAR-10, the maximum is reached near iteration 300. Beyond these peaks, the model begins pruning less informative or redundant nodes, thereby reducing the architecture’s size. This pruning behavior helps prevent saturation and encourages model efficiency. Ultimately, the number of nodes stabilizes, converging to 1593 for MNIST and 1896 for CIFAR-10. These final widths reflect the respective complexities of the datasets and confirm the model’s ability to dynamically adapt its architecture.
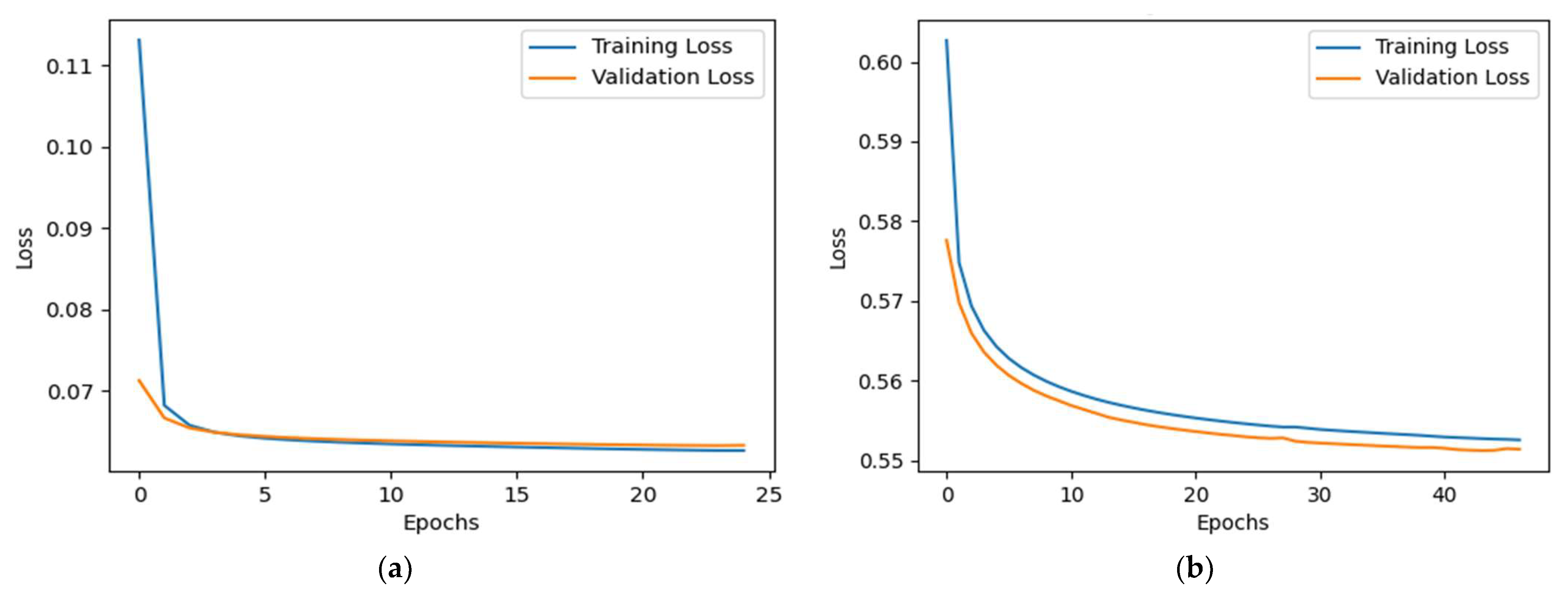
Figure 7 shows the training and validation loss curves over epochs. For MNIST, both losses decrease rapidly and converge closely within the first few epochs, with minimal discrepancy between the curves, indicating efficient learning and low overfitting. In contrast, CIFAR-10 shows a slower, steady decline in both losses, consistent with the dataset’s greater complexity. Notably, the validation loss remains slightly below the training loss throughout training on CIFAR-10, suggesting that the model generalizes well. Overall, both datasets demonstrate smooth and stable convergence, with MNIST exhibiting faster learning dynamics and CIFAR-10 requiring more training epochs to achieve similar performance stability.
Table 3 presents the final learned widths and classification accuracies for both the MNIST and CIFAR-10 datasets using two classifiers: SoftMax and SVM. The learned width of the encoder stabilizes at 1593 nodes for MNIST and 1896 for CIFAR-10, indicating that the model adapts to the complexity of each dataset by allocating more representational capacity for the more challenging CIFAR-10. In terms of classification performance, both classifiers achieve high accuracies on MNIST, with SVM slightly outperforming SoftMax (96.79% vs. 95.97%), suggesting that the extracted features are highly discriminative for this relatively simple digit recognition task. However, for CIFAR-10, the accuracies are considerably lower, 44.66% with SoftMax and 41.13% with SVM, reflecting the increased difficulty of the dataset.
Table 4 highlights the contrast between the manual tuning and dynamic learning approaches in terms of learned parameters, training time, and testing time for both MNIST and CIFAR-10 datasets. The dynamic approach demonstrates a significant reduction in computational complexity and resource usage while maintaining effective model training. For the MNIST dataset, manual tuning results in over 201 million parameters, whereas the dynamic method learns only around 2.5 million parameters. It exhibits a reduction by nearly 99%. Similarly, for CIFAR-10, the parameter’s count drops from over 1.1 billion to approximately 11.6 million, reflecting a similar magnitude of improvement. This reduction in model size translates directly into drastic savings in training and testing time. Training time is reduced from roughly 48,963 s to 701 s for MNIST and from 874,853 s to just 413 s for CIFAR-10. Testing time also benefits from this efficiency, decreasing from 186.11 s to 0.55 s on MNIST, and from 1025.81 s to 0.70 s on CIFAR-10. These improvements underscore the effectiveness of the dynamic approach in achieving high computational efficiency and scalability, particularly important when dealing with large-scale data or resource-constrained environments. Thus, the proposed dynamic learning approach not only significantly reduces model complexity and runtime but also maintains competitive accuracy, making it a highly attractive alternative to traditional manual tuning methods.
In fact, the dynamic approach provides substantial advantages over manual tuning when determining a model’s width. Specifically, manual addition necessitates an exhaustive search process to determine the optimal width, which requires significant time and computational resources. This is because the model must be retrained with various widths. Furthermore, the features’ efficacy frequently depends upon the dataset, rendering manual methods less efficient and adaptable. In contrast, dynamic strategies enable the model to derive the optimal width from the data by self-adjusting its architecture during training. This adaptive process guarantees the model captures significant patterns without saturation or underfitting.
4.2.2. Performance Evaluation of the Proposed Approach on Real Datasets
The performance of the proposed approach in dynamically learning the width of AE is assessed using two real datasets: Parkinson’s [
38] and Epilepsy [
39]. Since the two datasets are unbalanced, the F1 measure is used to assess the model’s performance.
Figure 8 shows the learned width for the two real datasets. As can be seen, the number of nodes for Parkinson’s reaches its maximum at iteration 250, when the model converges to 2454 nodes. On the other hand, the Epilepsy dataset reaches its maximum at iteration 200 and converges to 2032 nodes.
Similarly,
Figure 9 shows the training and validation loss for the two datasets. For the Parkinson’s dataset, which contains only 756 instances, the validation loss converges to a lower value (~0.6) than the training loss (~0.8). This unusual pattern may suggest that the model generalizes better on the validation set.
Table 5 reports the learned widths with respect to the two datasets. For the Parkinson dataset, the width is 2454, indicating a relatively high-dimensional feature space. This suggests that the dataset may contain a significant amount of detailed or complex information, potentially offering more nuanced patterns for the classifiers to capture. In contrast, the Epilepsy dataset has a width of 2032, which is slightly lower, suggesting fewer features or possibly a less complex data structure compared to the Parkinson dataset. Despite having fewer features, the Epilepsy dataset presents a greater challenge to both classifiers, as seen in the relatively lower accuracy and F1-scores.
The results in
Table 6 show the comparison between manual tuning and dynamic learning approaches, particularly highlighting the impact of different model widths. In the manual tuning approach, the model’s width is varied, and experiments are repeated with different widths to identify the optimal configuration for the dataset. For the Parkinson dataset, the manual approach leads to a substantial number of learned parameters (457,948,938), as the width is likely set to large values in an attempt to capture more complex patterns. Similarly, for the Epilepsy dataset, manual tuning results in 74,522,760 learned parameters. This approach requires significant experimentation with different widths, resulting in longer training times, 10,866.75 s for Parkinson and 6192.44 s for Epilepsy. These extended times reflect the repeated trials to find the best width configuration. On the other hand, the dynamic learning approach, which doesn’t involve manual width adjustments but adapts automatically to the data, uses far fewer parameters (3,703,840 for Parkinson and 725,602 for Epilepsy), leading to a much more efficient model. As a result, dynamic learning drastically reduces both training time, 175.01 s for Parkinson and 176.62 s for Epilepsy, and testing time (0.11 s for Parkinson and 0.38 s for Epilepsy). Therefore, while manual tuning requires experimentation with different widths to find the optimal configuration, dynamic learning provides a more efficient alternative by automatically determining the best parameters, resulting in faster training and testing times while reducing model complexity.
4.2.3. Performance Comparison of the Proposed Approach with State-of-the-Art Models on Benchmark Datasets
In this experiment, the performance of the proposed method is evaluated against several state-of-the-art approaches specifically designed to adaptively determine the optimal width of autoencoders (AEs). The three most relevant and advanced methods considered for comparison are DEVDAN [
18], SAQN [
21], and NDL [
17]. Moreover, two configurations for the SAQN model are considered with and without epochs since the original version considers only one epoch. As previously discussed, DEVDAN (Deep Evolving Denoising Autoencoder Network) is a self-adaptive model that dynamically adjusts the width of its AE by adding or pruning neurons based on the Network Significance (NS) metric. The NS value is computed using the bias and variance of the encoder–decoder model. Before updating network parameters through a combination of generative and discriminative training, a SoftMax layer is appended to facilitate discriminative testing. This process follows a prequential “test-then-train” approach. Similarly, SAQN (Self-Adaptive Quasi-Autoencoder Network) adopts the same structural framework as DEVDAN but updates its network parameters using generative training exclusively. Neurons are added or removed based on the estimated NS value, allowing the model to adaptively reshape its architecture without engaging in discriminative learning phases. In contrast, NDL (Neurogenesis Deep Learning) is a dynamic deep learning approach that adds neurons only when the model fails to adequately reconstruct the input, as indicated by reconstruction error. While effective, NDL is memory-intensive due to its reliance on storing past samples for retraining and its progressively expanding architecture. Moreover, it requires frequent retraining and multiple forward passes to stabilize the updated network, making it computationally expensive. To assess the effectiveness of the proposed approach, experiments are conducted on the MNIST [
36] and CIFAR-10 [
37] benchmark datasets. A SoftMax classifier is used in all cases to evaluate classification performance after the final AE model is learned. DEVDAN [
18], SAQN [
21], and SAQN with epochs adopt the MSE loss function as specified by their approaches, while NDL [
17] and Width-Adaptive AE adopt Binary Cross-Entropy.
Table 7 presents a comprehensive comparison of performance metrics across several models on the MNIST dataset. The proposed WAAE achieves the highest accuracy at 95.97%, outperforming all baselines, including NDL (95.03%), DEVDAN (90.60%), SAQN with epochs (89.61%), and standard SAQN (86.37%). In terms of training and testing loss, the WAAE also records the lowest values (0.0627 and 0.0629, respectively), indicating effective optimization. This contrasts with the higher loss values observed in DEVDAN and SAQN, which correlates with their lower classification performance. A key distinction lies in the learned network width: the WAAE dynamically expands to 1593 neurons, significantly wider than NDL (560), SAQN (258), and DEVDAN (14). This flexibility enables the proposed model to better capture the underlying complexity of the data, contributing to its superior accuracy and lower loss. These results highlight the effectiveness of the WAAE. The superior performance of the WAAE can be attributed not only to its ability to dynamically learn an optimal network width but also to its robustness against the limitations inherent in competing models. For instance, while NDL achieves high accuracy, its architecture heavily depends on user-defined parameters such as the reconstruction threshold and MaxOutlier. These parameters require manual tuning through a trial-and-error process, as there is no standardized approach for their selection. As a result, NDL’s performance is sensitive to configuration choices, which can lead to inconsistent convergence and suboptimal generalization if not thoroughly optimized. The model’s behavior demonstrates that varying the MaxOutlier percentage affects node expansion in unintuitive ways, further complicating its tuning. In contrast, the WAAE eliminates this dependency by autonomously adjusting its width based on learning dynamics, achieving better convergence as evidenced by its significantly lower training and testing losses. Additionally, models like DEVDAN and SAQN suffer from structural limitations. DEVDAN’s use of only 14 neurons leads to high reconstruction errors and poor generalization due to its constrained representational capacity. This is confirmed by the DEVDAN model’s training loss displayed in
Figure 10. It is nearly constant, with minimal changes observed across batches. This implies that the model may not be learning effectively. Although SAQN utilizes more neurons, its static allocation (258 nodes) and lack of dynamic width adaptation result in inefficiencies, as reflected by its relatively high test loss. Moreover, as shown in
Table 7, by increasing the number of epochs, the SAQN model exhibits minimal improvements in both train and test losses with a little change in accuracy. There is no improvement to the model’s width, which implies that it has reached its learning capacity. This may be the result of over-regularization or restricted node adaption. The WAAE, by contrast, adaptively scales its architecture to 1593 neurons, enabling it to learn complex feature representations more effectively. This dynamic capacity, free from manual hyperparameter constraints and structural rigidity, allows it to consistently outperform the baseline models in both accuracy and reconstruction loss.
Table 8 presents a comparative analysis of the computational complexity and processing time of the WAAE against several state-of-the-art models on the MNIST dataset. While the WAAE exhibits the longest training time (701.06 s), it achieves a competitive testing time (0.5542 s), outperforming models like NDL (0.8997 s) and SAQN (1.8377 s). Although DEVDAN remains the fastest in testing (0.1964 s), its limited architecture restricts performance. In terms of training GFLOPs, the WAAE requires 2789.45 GFLOPs, significantly less than NDL’s computationally intensive 34,162.17 GFLOPs, yet much higher than the lightweight DEVDAN and SAQN models. The testing GFLOPs of the WAAE (49.9) reflect its richer representational capacity, which supports its superior performance. Furthermore, the model’s total FLOPs (0.00499 GFLOPs) are the highest among the compared approaches, consistent with its broader network width and adaptive design. In contrast, models like DEVDAN and SAQN demonstrate minimal computational requirements but suffer from limited learning capabilities and lower accuracy. Despite its higher computational demand, the WAAE offers a more favorable trade-off between accuracy and complexity, demonstrating that its dynamic architecture and resource allocation lead to improved learning and generalization, justifying the increased training cost.
The results in
Table 8 further reinforce the effectiveness of the WAAE by contextualizing its computational cost in light of architectural and operational efficiencies. Unlike NDL, which adopts a class-by-class training strategy requiring repeated replay and adjustment after each new class, the WAAE is trained on all classes simultaneously. This enables it to generalize more effectively without excessive reliance on replay mechanisms that inflate FLOPs. In fact, NDL reaches over 34,000 training GFLOPs due to continual reprocessing of prior data. Furthermore, NDL’s sequential learning approach risks overfitting to early classes, undermining its generalization. Similarly, while DEVDAN is lightweight with only 14 nodes and incurs just 21 GFLOPs during training, its three-step batch processing framework adds overhead and limits convergence. DEVDAN struggles to stabilize, continuously pruning and adding nodes even in later training batches, which hinders consistent learning. In contrast, the WAAE achieves stable convergence within a few epochs by dynamically adjusting its width in response to learned patterns, resulting in superior reconstruction performance and the highest accuracy (95.97%) among all models. SAQN, despite requiring up to 467 GFLOPs during training, fails to achieve similar performance due to inadequate iterative learning and a static architecture that underutilizes its computational potential. The model’s inability to dynamically expand to meet data complexity results in poor feature extraction and elevated reconstruction loss. This results in inferior reconstructions, as demonstrated by the sample instances from the MNIST dataset in
Figure 11. Notably, the WAAE also excels in inference efficiency. It delivers a faster test time (0.5542 s) than both SAQN and NDL, despite utilizing significantly more nodes (1593). This suggests that the model’s architecture is not only scalable but also optimized for real-time deployment. Thus, although the WAAE entails higher training cost, its design allows it to balance complexity and performance more effectively than its peers, justifying the resource investment with its superior learning capacity and generalization.
Figure 11 provides a visual comparison of the reconstruction quality of 10 random MNIST digit instances using five different models: DEVDAN, SAQN, SAQN without epochs, NDL, and WAAE. The top row in each subfigure shows the original digit images, while the bottom row displays the corresponding reconstructions. Among the models, WAAE clearly produces the most accurate and visually faithful reconstructions, with digits that are crisp, well-formed, and closely match the original inputs in both shape and structure. The NDL model also performs well, producing generally recognizable digits with minor blurring, indicating a solid capacity to capture data representations. In contrast, the DEVDAN model yields reconstructions that are blurred and less distinct, though some digit structures remain identifiable. Both SAQN and SAQN without epochs perform poorly, with reconstructions that resemble random noise rather than digit shapes, reflecting a failure to learn meaningful latent representations. These visual results align with earlier quantitative findings and underscore the effectiveness of WAAE’s adaptive architecture and appropriate loss function in achieving superior reconstruction and representational quality.
Table 9 presents a performance comparison of several models on the CIFAR-10 dataset using various evaluation metrics, including accuracy, train and test loss, and model width. Among the models, the WAAE achieves the highest accuracy at 44.66%, which can be attributed to its large width (1896). DEVDAN also shows reasonable performance with 41% accuracy and balanced train and test losses, indicating good generalization despite its relatively small width of 262. In contrast, the SAQN models, both with and without epoch-based training, report the lowest accuracies (33.89% and 32.99%, respectively) even though they achieve very low loss values. This suggests a misalignment between the MSE loss function used and the classification nature of the task, leading to poor predictive performance. The NDL model, with a wider architecture (width of 798) achieves moderate accuracy (37.47%) but does not outperform DEVDAN, underscoring that higher width alone does not guarantee better performance.
The superior performance of the WAAE in
Table 9 can be further understood in light of how model width is determined in comparison to other models such as NDL. Notably, NDL relies on user-defined thresholds. Specifically, the MaxOutlier percentage is used to determine its width. This approach introduces variability and a degree of uncertainty into the model configuration, as the width is highly sensitive to this parameter. For example, when the MaxOutlier threshold is decreased to 10% of the data, the NDL model reaches its maximum width, with a corresponding loss of 0.63. Conversely, increasing the threshold to 30% reduces the width significantly to 308, yet the loss remains nearly unchanged. This demonstrates that the NDL model’s performance does not scale linearly with its width, and that finding an optimal configuration requires trial and error that may not generalize well across datasets.
In contrast, the WAAE employs a more systematic and data-driven method for determining width, enabling it to dynamically adjust its architecture in response to the data characteristics without requiring manual threshold tuning. This adaptability likely contributes to its ability to achieve the highest accuracy (44.66%) among all models in the comparison. The model’s large width of 1896 further enhances its capacity to learn complex patterns in the CIFAR-10 dataset. The consistency between its low train and test losses (0.5526 and 0.5538, respectively) also reflects strong generalization. Therefore, the WAAE demonstrates the advantages of automated architecture tuning and the use of suitable loss functions, which together result in more reliable and higher classification performance than models like NDL that depend on manually selected, dataset-specific parameters.
Table 10 presents a comparison of computational complexity and runtime performance for several models on the CIFAR-10 dataset, highlighting the trade-offs between training cost, inference efficiency, and model complexity. The WAAE, while more computationally intensive than some alternatives, demonstrates a balanced trade-off between performance and resource usage. It achieves a training time of 413.14 s, which is significantly faster than models like NDL (965.32 s) and SAQN with epochs (1258.41 s), despite having higher training FLOPs at 8246.78 gigaflops. This suggests that the WAAE is computationally heavier but more optimized. At test time, it maintains a competitive speed (0.698 s), similar to DEVDAN (0.6918 s) and SAQN (0.6849 s), although it incurs the highest testing FLOPs at 233.03 gigaflops, reflecting its increased model complexity. The model’s FLOPs per inference (0.0233 G) are also the highest among all compared approaches, corresponding to its larger width and adaptive architecture. In contrast, models like SAQN and DEVDAN are computationally lighter but offer lower accuracy, while NDL exhibits extremely high training FLOPs (131,579.84 G) without delivering superior predictive performance. Consequently, the WAAE achieves the best balance between training efficiency, inference speed, and classification accuracy, making it a robust choice when moderate computational resources are available.
It is important to note that the compared models, DEVDAN [
18], SAQN [
21], and NDL [
17], employ simpler node selection or importance heuristics such as activation frequency and threshold-based pruning. These models therefore serve as effective baselines to isolate the impact of the inner-product-based relevance weighting used in our approach. The consistently superior performance of the WAAE across both accuracy and computational cost demonstrates the effectiveness of our more principled node relevance strategy.
4.2.4. Performance Comparison of the Proposed Approach with State-of-the-Art Models on Real Datasets
A comprehensive performance comparison was performed between the proposed WAAE and several state-of-the-art models across the two considered real-world datasets. The evaluation focuses on key performance metrics such as accuracy, F1-score, loss values, computational complexity, and model width.
Table 11 presents a performance comparison of several models on the Parkinson’s dataset, evaluating key metrics such as accuracy, F1-score, training loss, testing loss, and model width. Among all models, the WAAE demonstrates the strongest performance across all metrics, achieving the highest accuracy (87.04%) and F1-score (86.45%), along with the lowest training (0.7551) and testing loss (0.6925). This indicates that the model is not only highly accurate but also generalizes well, maintaining low error rates across both seen and unseen data.
In contrast, while DEVDAN shows moderate results with an accuracy of 81.58% and F1-score of 81%, it still falls short of the WAAE. Its training and test losses are considerably higher (1.2428 and 1.1740), suggesting less efficient learning and potential overfitting or underfitting. SAQN, although having a wider architecture (width = 256), delivers slightly lower performance (76.31% accuracy, 77.86% F1-score), with marginally better losses compared to DEVDAN. Interestingly, SAQN with epochs performs even worse, indicating that simply increasing training epochs does not lead to better performance, possibly due to overfitting or a misaligned training strategy.
The NDL model performs the worst across the board, with only 50.66% accuracy and 53.62% F1-score, despite having a wider architecture than DEVDAN. Its relatively low training and test losses do not translate into meaningful classification performance, suggesting that the model may struggle with learning discriminative features for this dataset.
The WAAE’s high width (2454), paired with low loss values and superior classification metrics, demonstrates the advantage of its dynamic architecture. By adaptively adjusting model width to the complexity of the data, it successfully captures informative representations, outperforming static-width models that rely on trial-and-error or fixed parameters. This reinforces the importance of architectural flexibility and data-driven design in achieving optimal performance on medical datasets like Parkinson’s.
Table 12 highlights the computational complexity and runtime performance of the models on the Parkinson’s dataset, emphasizing the trade-offs associated with the WAAE. While the WAAE records the highest training time (175.01 s) and training FLOPs (281.31 G), it maintains a relatively efficient test time (0.109 s), outperforming DEVDAN and closely matching SAQN variants. Its higher testing FLOPs (1.1248 G) and model FLOPs (0.0074 G) are a direct result of its significantly larger width, as also shown in
Table 11. This relationship underscores the fact that the model’s time and computational complexity scale with its width. However, this increase in complexity translates into substantial performance gains, confirming that the adaptive width mechanism enables the model to learn richer representations and achieve superior results on the Parkinson’s dataset.
Table 13 presents a comparative performance analysis of different models on the Epilepsy dataset, clearly highlighting the effectiveness of the WAAE. Among all the models, WAAE achieves the highest accuracy (65.32%) and F1-score (65.21%), outperforming all competing approaches by a substantial margin. This demonstrates its strong classification ability, especially on complex and imbalanced datasets like Epilepsy. Furthermore, it achieves the lowest training and testing loss values (0.7044 and 0.7899, respectively), indicating better learning stability and generalization. In contrast, other models such as DEVDAN, SAQN, and NDL perform significantly worse, with accuracies ranging between 25–31% and notably lower F1-scores, suggesting they struggle to capture meaningful patterns in the data. Although the WAAE has the largest model width (2032), this increased capacity enables it to represent complex temporal patterns more effectively, reinforcing the idea that adaptive width contributes significantly to its superior performance.
Table 14 presents a comparative analysis of the computational complexity and runtime performance of the WAAE against several state-of-the-art models using the Epilepsy dataset. Although the WAAE exhibits the highest test FLOPs (3.335 G) and model FLOPs (0.00145 G), it maintains competitive training time (176.62 s) and moderate training FLOPs (174.02 G). In contrast, DEVDAN, while having the lowest model FLOPs (0.00048 G), shows an exceptionally high training FLOPs (837742.70 G), suggesting inefficiency. SAQN variants achieve low model and test FLOPs but vary significantly in training time depending on epochs. NDL stands out with the shortest training and testing time and the lowest model FLOPs, but at the cost of slightly higher test FLOPs than SAQN. Overall, the WAAE strikes a balance between adaptability and computational efficiency, offering a favorable trade-off for real-time epilepsy data processing.
These results further highlight the advantage of using the proposed inner-product-based relevance weighting mechanism compared to the simpler heuristics used in DEVDAN, SAQN, and NDL. Although these baseline models incorporate basic node evaluation methods, they fall short in adapting to data complexity as efficiently as our approach. This provides indirect but strong evidence of the contribution and necessity of our more structured weighting criterion.
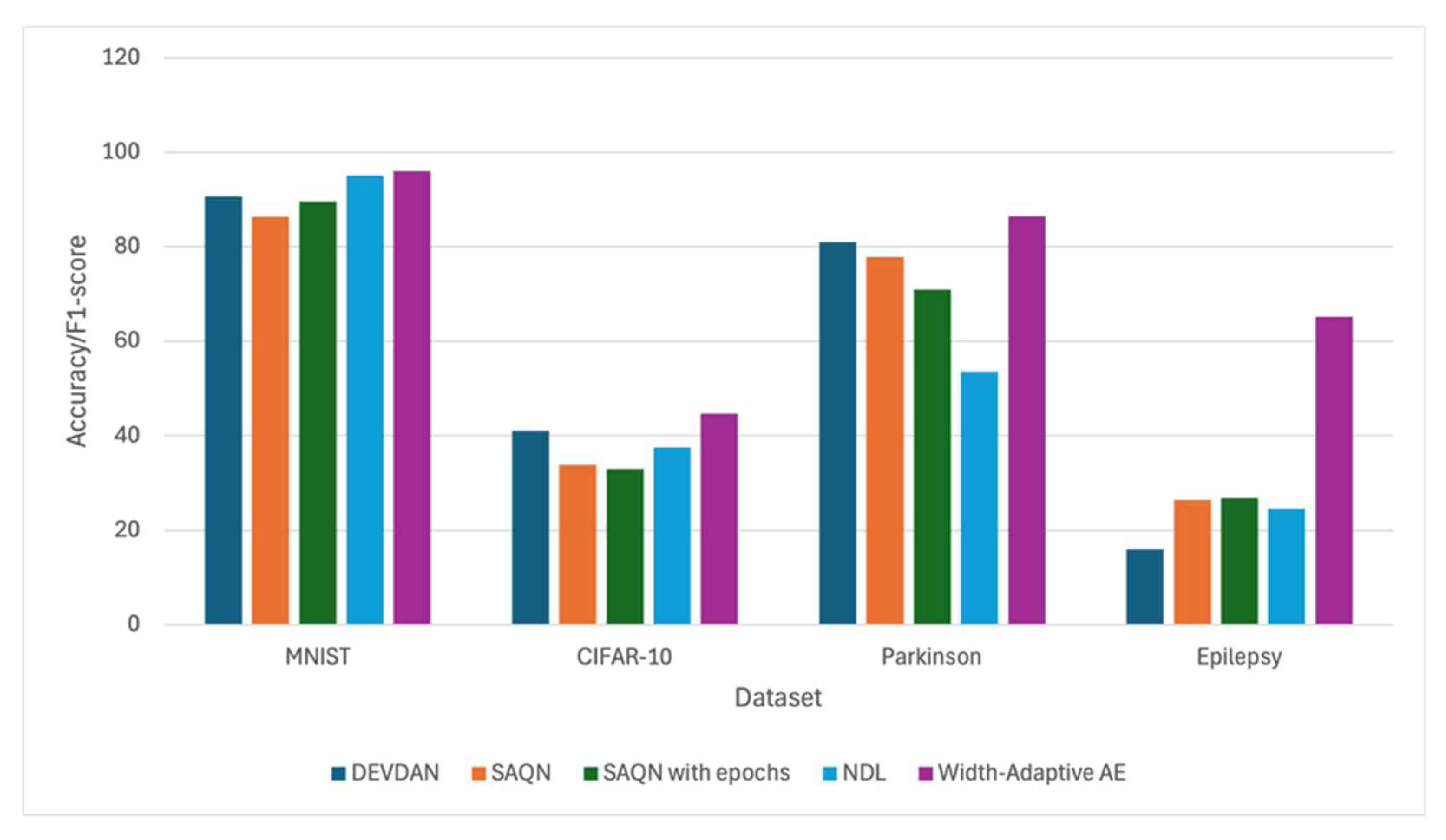
Figure 12 displays a bar chart comparing the accuracy or F1-score of five models, DEVDAN, SAQN, SAQN with epochs, NDL, and WAAE, across four datasets: MNIST, CIFAR-10, Parkinson, and Epilepsy. Since the real datasets are unbalanced, the F1-score is used for comparison rather than accuracy. WAAE consistently outperforms or matches other models in terms of accuracy or F1-score across all datasets. For MNIST, all models perform similarly with high accuracy (~90–100%), with WAAE slightly leading. In CIFAR-10, accuracies drop overall, but WAAE achieves the highest performance again. On the Parkinson dataset, WAAE shows a notable lead over others, achieving the highest F1-score among all models. Notably, on the challenging Epilepsy dataset, where other models hover around 20–30% F1-score, WAAE significantly outperforms them, achieving over 60%. This highlights its robustness and adaptability across varying data complexities and domains.
The experimental results across both benchmark (MNIST, CIFAR-10) and real-world (Parkinson, Epilepsy) datasets demonstrate that the proposed WAAE consistently achieves high classification accuracy while maintaining computational efficiency. The model dynamically adjusted its width by adding and pruning nodes, resulting in architectures that are both compact and effective. Compared to manually tuned and state-of-the-art models, the proposed method showed competitive or superior performance in terms of accuracy, training time, and resource utilization. These findings confirm the model’s ability to adapt to varying dataset complexities and support its effectiveness in both simple and challenging learning scenarios.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}