1. Introduction
Low-light imaging remains a fundamental challenge in computer vision, as adverse lighting conditions degrade the visual quality of captured images, introducing severe noise, poor contrast, color distortions, and the loss of structural detail. These degradations significantly impact both the perceptual quality for human observers and the performance of downstream automated vision systems. Applications such as surveillance, autonomous driving, mobile photography, and medical diagnostics frequently suffer from poor performance due to visibility issues under low illumination [
1,
2]. This challenge is further compounded in underwater environments, where severe light absorption and scattering distort both color and contrast. As a result, a growing body of work has explored underwater low-light image enhancement using discriminative learning [
3], reinforcement learning guided by perceptual cues [
4], and large foundation models [
5].
Traditional image enhancement techniques, including histogram equalization, gamma correction, and Retinex-based methods, are widely used due to their computational efficiency and simplicity. However, these algorithms often fail to generalize across diverse lighting scenarios and tend to produce over-enhanced or artifact-laden outputs when applied to complex real-world scenes [
6,
7]. These limitations have prompted the research community to adopt data-driven solutions based on deep learning, particularly convolutional neural networks (CNNs), to learn robust mappings from low-light to well-lit image domains [
8,
9,
10].
Among these, several supervised learning approaches have achieved remarkable visual quality by leveraging large-scale datasets of paired low-/normal-light images [
11,
12]. However, collecting and aligning such pairs is labor-intensive and impractical in many real-world contexts. To address this, recent advances have proposed unsupervised, self-supervised, and zero-reference frameworks, such as Zero-DCE [
9] and RetinexDIP [
10], which alleviate the need for labeled data while still achieving compelling results.
Despite this progress, most high-performing models are computationally demanding and not suitable for deployment in resource-constrained environments like mobile phones, embedded systems, or real-time platforms. Recent works have attempted to bridge this gap by developing lightweight architectures [
13,
14,
15] or designing cascaded and progressively refined pipelines [
16,
17], but a clear trade-off between image quality and model efficiency remains.
In this work, we propose a lightweight (i.e., low-parameter and low-FLOP) deep learning architecture for low-light image enhancement that is suitable for real-time inference on edge devices. Our model builds upon a UNet-inspired encoder–decoder backbone and integrates attention modules to dynamically suppress noise and highlight meaningful features. The network is trained using a composite loss function combining pixel-wise reconstruction, structural similarity (SSIM), and perceptual quality metrics.
To further support data efficiency and generalization, we construct a hybrid dataset comprising both real low-light images from established benchmarks and synthetic image pairs generated through physically inspired exposure manipulation and noise modeling applied to clean images. This enables more flexible training and better simulation of varied lighting conditions.
The main contributions of this paper are as follows:
We propose a lightweight, attention-augmented deep neural network architecture tailored for real-time low-light image enhancement.
We introduce a flexible pipeline for synthetic low-light data generation based on exposure manipulation and noise modeling.
We demonstrate the effectiveness of our model through extensive experiments on benchmark datasets (LOL, SID), achieving competitive performance in PSNR and SSIM while significantly reducing computational cost.
We highlight potential applications in industrial scenarios such as mobile photography, autonomous driving, and smart surveillance.
The remainder of this paper is organized as follows.
Section 2 presents a review of related work in low-light enhancement.
Section 3 details our proposed methodology and network architecture.
Section 4 describes the datasets, data generation methods, and experimental settings.
Section 5 discusses the results, and
Section 6 concludes the paper and outlines potential future work.
2. Related Work
Low-light image enhancement has evolved from classical pixel-wise transformations to complex deep learning frameworks that aim to recover perceptual and structural fidelity under severe illumination deficits. In this section, we group the related work into three major categories: traditional enhancement techniques, deep learning-based methods, and lightweight architectures for real-time deployment.
2.1. Traditional Methods
Historically, low-light image enhancement has been approached through techniques such as histogram equalization, gamma correction, and Retinex theory. Histogram equalization improves global contrast but tends to produce unnatural-looking results under non-uniform lighting conditions [
18]. Retinex-based methods, inspired by the human visual system, decompose an image into reflectance and illumination components [
6]. While such models, including Single-Scale and Multi-Scale Retinex [
19], can enhance local contrast effectively, they often suffer from artifacts, noise amplification, and limited adaptability to different environments.
Edge-preserving filters and image fusion techniques have also been explored [
20]. However, most traditional approaches rely on handcrafted priors and lack the capacity to generalize to diverse and complex real-world lighting scenarios.
2.2. Deep Learning-Based Methods
Deep learning methods have significantly advanced the field by learning data-driven mappings between low-light and well-lit image domains. One of the earliest influential works, Learning to See in the Dark (SID), introduced a dataset of raw low-light images and trained a fully supervised model directly in the raw domain [
11]. Another seminal work, Retinex-Net, combined Retinex theory with a neural network for decomposing and enhancing images [
8].
Unsupervised and zero-reference methods have gained popularity due to the challenge of obtaining paired datasets. Zero-DCE [
9] proposed a zero-reference curve estimation network to enhance images without ground truth, using a set of non-reference quality metrics as loss functions. RetinexDIP [
10] extended this concept by integrating the Retinex decomposition into an unsupervised deep image prior framework. More recent efforts also leverage self-attention mechanisms, transformer-based backbones, and foundation models for improved perceptual consistency, particularly in challenging conditions like haze or underwater scenarios [
3,
4,
5,
13].
Recent studies also explored the use of multi-exposure fusion [
1], semi-supervised learning [
21], and wavelet-domain learning [
16] to improve both the visual quality and robustness of enhancement methods. Despite the high performance of these models, most remain too computationally heavy for deployment in time-sensitive or power-constrained environments.
2.3. Lightweight and Real-Time Models
In response to growing demand for deployable solutions, researchers have introduced several lightweight architectures for low-light image enhancement. EnlightenGAN [
12] proposed an unpaired learning framework with a relatively shallow architecture. Zhang et al. [
13] presented a fast and lightweight network that balances inference time and image quality for real-time applications.
Several models employ encoder–decoder frameworks optimized with depthwise separable convolutions, channel attention mechanisms, or mobile-friendly backbones such as MobileNet and GhostNet [
22,
23]. These designs reduce FLOPs and parameter count without drastically compromising visual quality.
There is also growing interest in hardware-aware neural architecture search (NAS) techniques to automatically discover efficient models tailored to specific deployment platforms [
24].
To better contextualize our approach,
Table 1 provides a comparative overview of recent low-light image enhancement methods, highlighting their supervision strategies, computational characteristics, and applicability to real-time and edge scenarios. This comparison also outlines how our model addresses key limitations in prior work.
3. Methodology
In this section, we describe the design of our proposed low-light enhancement model, including its lightweight architecture, training objectives, data preparation strategy, and overall optimization procedure.
3.1. Network Architecture
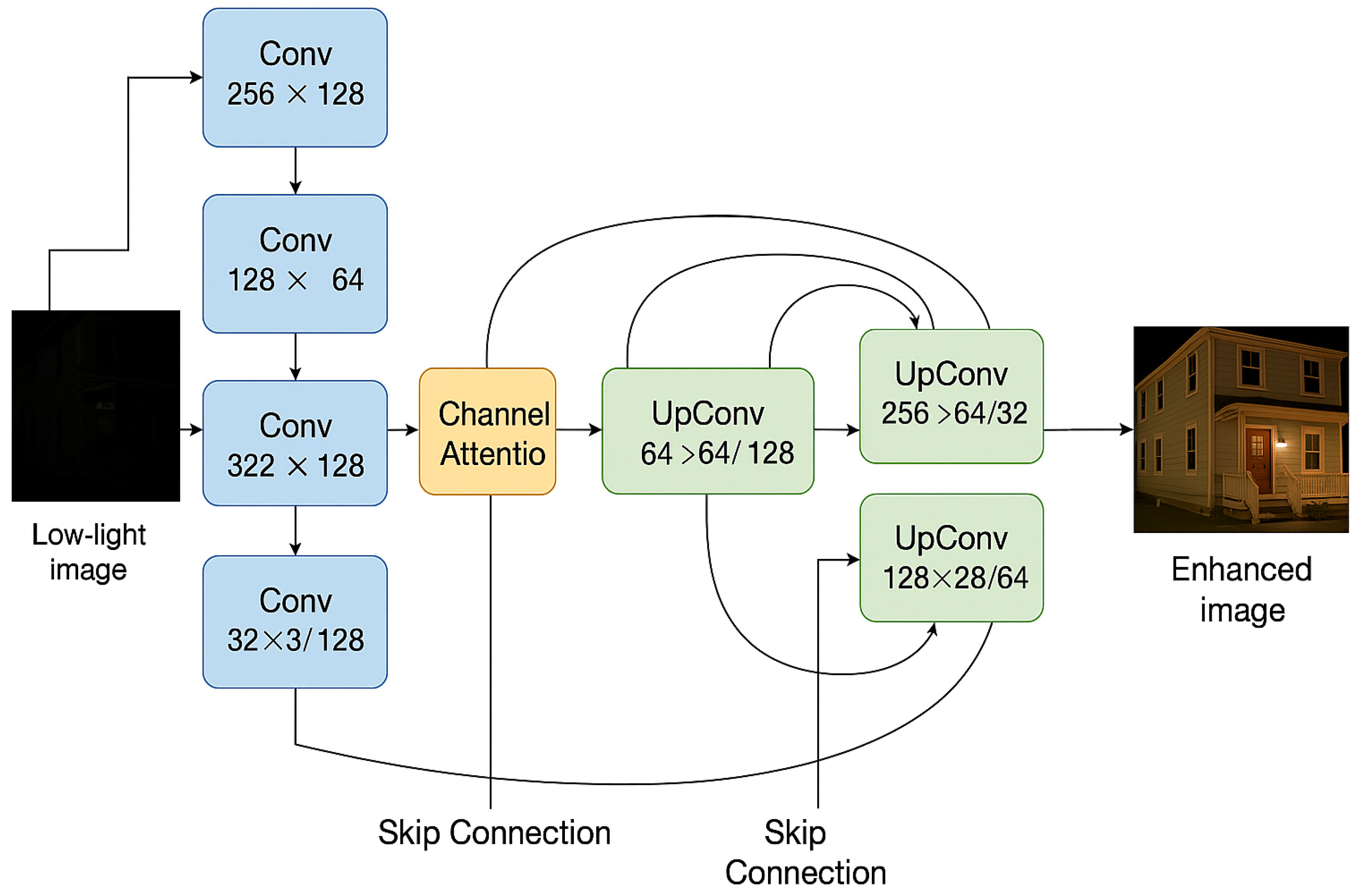
Our proposed network follows a UNet-inspired encoder–decoder design, optimized for lightweight deployment and real-time performance. The architecture includes the following:
Encoder: A series of convolutional blocks with downsampling, designed to extract hierarchical low-level to mid-level features. Each encoder block contains two convolutional layers with kernel size 3 × 3, batch normalization, and ReLU activation. We use depthwise separable convolutions to reduce the number of parameters and computational cost, inspired by MobileNet [
22]. The feature map sizes progressively reduce from 256 × 256 to 64 × 64.
Attention Modules: Integrated between encoder and decoder stages, we adopt channel attention mechanisms (similar to SE-Blocks [
25]) to emphasize informative feature maps and suppress noise.
Decoder: Uses transposed convolutions (or bilinear upsampling + convolution) to reconstruct the image. Skip connections from the encoder ensure high-frequency detail is preserved.
Final Output Layer: A 1 × 1 convolution with a sigmoid activation outputs a 3-channel RGB image normalized between 0 and 1.
The overall architecture of the proposed low-light enhancement network is illustrated in
Figure 1, highlighting the encoder–decoder backbone, attention modules, and skip connections that facilitate feature preservation and noise suppression.
Each stage in the architecture is designed with computational efficiency and enhancement quality in mind:
Encoder Blocks: Each block contains depthwise separable convolutions followed by batch normalization and ReLU activation. These layers capture hierarchical features while keeping parameter count low. Downsampling is achieved via strided convolutions.
Attention Module: We integrate Squeeze-and-Excitation (SE) blocks [
25] between encoder and decoder stages to perform dynamic channel-wise feature recalibration. The SE module learns to suppress noisy or irrelevant channels by modeling interdependencies, which helps reduce amplification of low-light noise during upsampling.
Decoder Blocks: These use transposed convolutions or bilinear upsampling + convolution to restore spatial resolution. Skip connections from the encoder are fused to preserve texture and structural detail.
This modular design enables compactness while maintaining the visual fidelity of restored images. The SE module works by globally pooling feature maps, passing them through a bottleneck fully connected layer (squeeze), and reweighting the channels based on learned importance (excitation). This mechanism is particularly effective in low-light scenarios where some channels may represent structured noise or overamplified darkness. A detailed layer-by-layer breakdown of the network architecture, including output shapes and activation functions, is provided in
Appendix B.
3.2. Loss Functions
We train the model using a composite loss function that balances pixel-level fidelity, structural consistency, and perceptual realism:
This measures pixel-wise absolute differences.
This encourages structural alignment based on luminance, contrast, and texture.
This uses feature maps
from a pre-trained VGG-16 network [
26] to measure high-level perceptual similarity.
We use weights
,
, and
by default. These values were determined empirically through ablation experiments (see
Section 5.4) to achieve a balance between structural fidelity and perceptual sharpness.
3.3. Synthetic Data Generation
To supplement real datasets and improve generalization, we simulate low-light conditions on clean images using two main steps:
This synthetic pipeline is applied to images from public datasets such as DIV2K and BSD500. Specifically, we apply gamma correction with γ ∈ [2.0, 3.5] and add Gaussian noise (σ = 10–25) or Poisson noise to simulate sensor degradation. Each enhanced image is paired with its original clean version to form synthetic ground-truth pairs. This enables us to train with supervised losses while avoiding the need for manually captured low-light images.
3.4. Training Procedure
Datasets: We train on a hybrid dataset combining real (LOL, SID) and synthetic low-light images. For LOL, we use the standard split: 485 images for training and 15 for testing. For SID, we train only on the Sony subset and evaluate using its standard test set to avoid overlap.
Preprocessing: All images are resized to 256 × 256 or 512 × 512 and normalized to [0, 1].
Training Details:
- ○
Optimizer: Adam;
- ○
Learning Rate: 10−4, reduced on plateau;
- ○
Batch Size: 8–16 (GPU-dependent);
- ○
Epochs: 100–200.
Hardware: Training is conducted on an NVIDIA RTX-class GPU.
We implement the model using PyTorch (version 2.2.2), and training takes approximately 24–48 h depending on resolution and dataset size. Full training configurations, including optimizer settings, learning rate schedules, batch sizes, and data augmentation strategies, are summarized in
Appendix A.
4. Experimental Setup
This section details the datasets used to train and evaluate our model, the metrics adopted for performance assessment, and specific aspects of the experimental environment not previously described.
4.1. Datasets Sizes, Splits, and Image Dimensions
We evaluate our model using a combination of real-world and synthetic datasets to ensure robustness and generalization:
LOL Dataset [
8]: Contains 500 paired low-/normal-light images captured with dual-exposure setups in varied lighting conditions. We use the standard split of 485 images for training and 15 for testing, as specified in the dataset documentation. Each image has a resolution of 600 × 400 pixels, resized to 256 × 256 or 512 × 512 during preprocessing.
SID Dataset [
11]: Provides raw short- and long-exposure image pairs from Sony and Fuji sensors. Following common practice, we preprocess raw data into sRGB using the authors’ pipeline and use the Sony subset for training and testing. For SID, we follow common practice and use only the Sony subset, consisting of 509 training pairs and 41 testing pairs. Raw data is processed into sRGB format using the pipeline provided by the dataset authors. Images are cropped and resized to 512 × 512 during preprocessing.
Synthetic Dataset: To enhance training diversity, we generate synthetic low-light images by applying gamma correction (γ ∈ [2.0, 5.0]) and additive Gaussian noise (σ ∈ [0.01, 0.05]) to clean images sourced from the DIV2K and BSD500 datasets. This process yields a synthetic dataset comprising 2000 training pairs and 500 validation pairs, with all images uniformly resized to 256 × 256 pixels.
As described in
Section 3.4, all images are resized to 256 × 256 or 512 × 512 and normalized to the [0, 1] range during preprocessing.
4.2. Evaluation Metrics
To assess the quality of enhanced images, we use both full-reference and no-reference metrics:
This measures pixel-wise fidelity between output and ground truth.
SSIM (Structural Similarity Index): This captures perceptual similarity in terms of luminance, contrast, and structure.
NIQE (Natural Image Quality Evaluator): A no-reference metric assessing image naturalness.
LPIPS (Learned Perceptual Image Patch Similarity) [
27]: This computes perceptual distance in deep feature space (lower is better).
These complementary metrics allow us to evaluate the method across both quantitative and perceptual dimensions.
4.3. Experimental Environment
The implementation details—including optimizer, learning rate, batch size, epochs, and hardware—are described in
Section 3.4. To support reproducibility, we publicly release the source code and configuration files (link to be added upon publication acceptance).
5. Results and Discussion
In this section, we present the quantitative and qualitative results of our proposed method, evaluate its efficiency, and compare it against state-of-the-art (SOTA) techniques. Where applicable, we also perform ablation studies to analyze the impact of architectural and training choices.
5.1. Quantitative Evaluation
We assess performance using PSNR, SSIM, and LPIPS (for perceptual quality), as well as FLOPs and parameter count (for efficiency).
Table 2 summarizes the results on the LOL test set.
Our model achieves the best trade-off between visual quality and computational cost. While SID achieves slightly higher PSNR, it is significantly larger and slower. The full set of raw quantitative metrics for individual test images from the LOL dataset is available in
Appendix C to support reproducibility and detailed analysis.
5.2. Qualitative Evaluation
Figure 2 presents qualitative comparisons of enhanced outputs from several methods. Our model successfully brightens dark regions while preserving natural textures and minimizing color distortion. Unlike GAN-based models (e.g., EnlightenGAN), it avoids over-saturation or hallucination of details.
5.3. Efficiency Analysis
To validate suitability for edge deployment, we benchmarked runtime on an NVIDIA Jetson Nano (4 GB RAM, ARM Cortex-A57 CPU, Maxwell GPU, Nvidia, Santa Clara, CA, USA) and a desktop GPU (NVIDIA RTX 3090). These devices represent constrained and high-performance inference environments, respectively.
Our model maintains inference speeds of approximately 40 FPS on an NVIDIA RTX 3090 (24 GB VRAM) and 6 FPS on a Jetson Nano (4 GB RAM, ARM Cortex-A57 CPU, 128-core Maxwell GPU) when processing 256 × 256 resolution inputs. The model has ~1.3 million parameters and requires ~12.7 GFLOPs per forward pass. In comparison, SID contains ~6.7 million parameters and consumes over 120 GFLOPs, making our model nearly 10× more efficient in terms of computation. We also monitored memory usage during inference: our model requires ~180 MB on the Jetson Nano and ~240 MB on the RTX 3090.
While our model is compact and well-suited for deployment on embedded platforms such as the Jetson Nano, real-time performance (e.g., ≥30 FPS at 512 × 512) may require further optimization or lower input resolutions depending on the use case.
5.4. Ablation Study
To understand the contribution of each design choice, we conducted ablation experiments on the following:
Loss functions: Removing perceptual loss () increases LPIPS by +0.021, indicating lower perceptual fidelity. Removing SSIM results in structural degradation and amplification of local artifacts.
Attention modules: Disabling channel-wise attention (SE blocks) reduces SSIM by approximately 0.02 and leads to visibly over-smoothed textures.
Synthetic data: Excluding synthetically generated low-light samples from training results in a PSNR drop of approximately 1.1 dB on test cases with challenging illumination conditions.
These findings confirm that each component meaningfully contributes to the model’s ability to generalize and recover image quality under low-light conditions.
To further validate this, we present a visual ablation study in
Figure 3, comparing the outputs of the full model against three ablated variants: (i) without perceptual loss, (ii) without attention modules, and (iii) without synthetic training data. The visual results demonstrate the practical effects of each modification, highlighting texture degradation, structural blur, or reduced illumination robustness in the respective variants.
We further expand the study to include three additional low-light scenarios: (1) an indoor scene with sensor noise, (2) an outdoor scene with uneven lighting, and (3) a highly textured natural scene.
Figure 4 illustrates these cases, and quantitative metrics are reported in
Table 3.
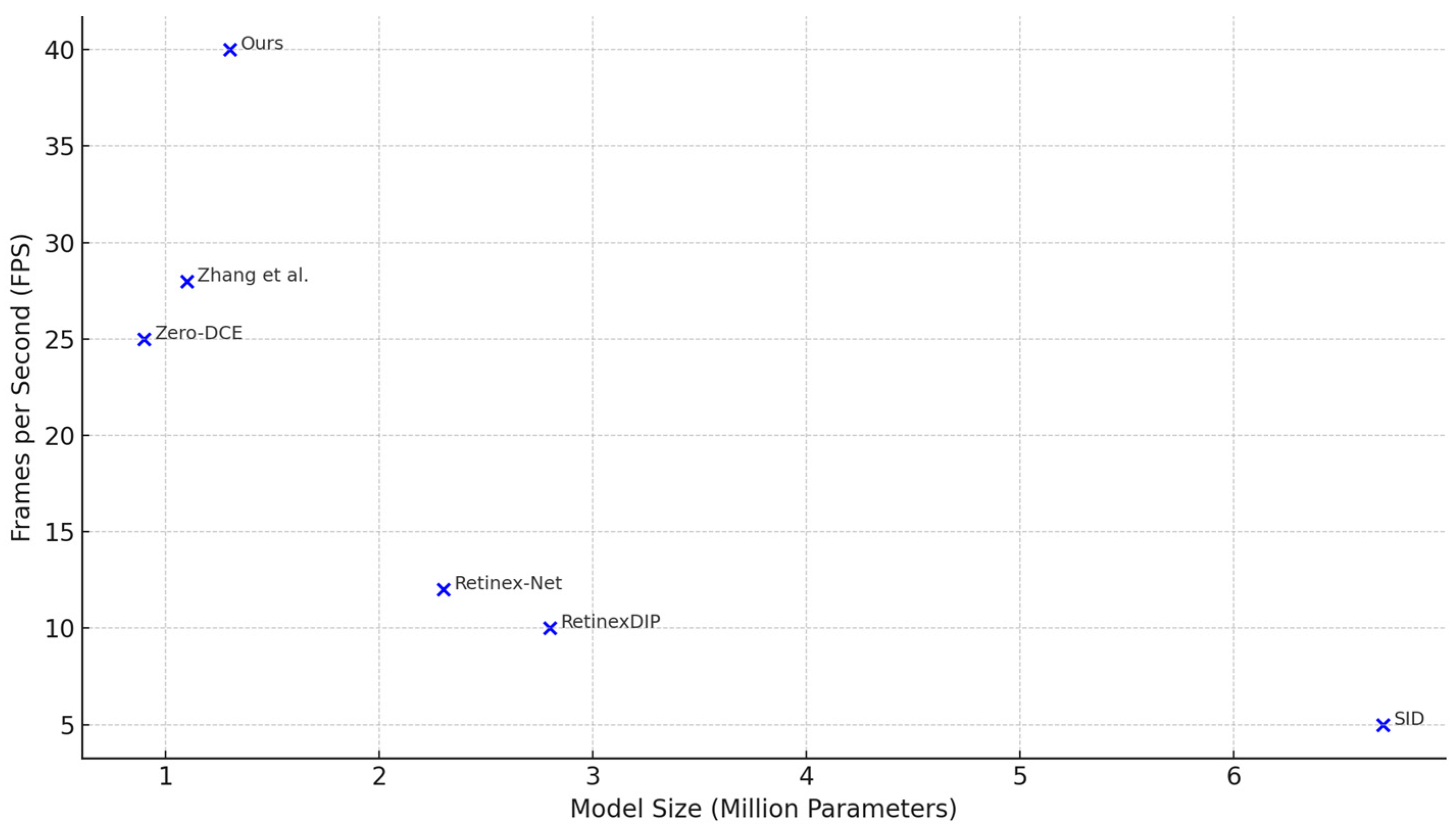
5.5. Comparison with State-of-the-Art Methods
Our model outperforms other lightweight and unsupervised methods (e.g., Zero-DCE, EnlightenGAN) and approaches the quality of fully supervised large-scale networks (e.g., SID) with a fraction of the complexity. It is among the few models achieving
To further assess the practicality of our approach for real-time applications,
Figure 5 presents a comparative analysis of runtime performance versus model complexity across several state-of-the-art low-light enhancement methods.
5.6. Cross-Dataset Generalization
To assess the generalization capability of our model, we conducted a cross-dataset evaluation using images from the DICM dataset (
https://paperswithcode.com/dataset/dicm (accessed on 27 May 2025) and
https://github.com/baidut/BIMEF (accessed on 27 May 2025)), which was not included in training. This dataset features challenging low-light scenarios distinct from those found in LOL or SID, including real-world urban scenes, varied lighting conditions, and high noise levels.
We compare our model against several state-of-the-art approaches, including Zero-DCE, Retinex-Net, and SID. Since ground-truth references are not available for this dataset, we use no-reference image quality metrics, specifically NIQE and BRISQUE, along with qualitative visual comparisons.
Table 4 presents the results in terms of NIQE and BRISQUE scores, where lower values indicate higher perceptual quality and more natural image statistics, while
Figure 6 presents a comparison on an unseen low-light image from a DICM-style dataset. Note that PSNR and SSIM could not be computed on DICM images due to the lack of reference images. We therefore rely on widely used no-reference metrics (NIQE and BRISQUE) to evaluate perceptual quality.
5.7. Subjective Human Evaluation
In addition to objective metrics, we conducted a structured user study involving 15 participants (aged 21–45, with normal or corrected vision), selected from a university population. Each participant reviewed 10 randomly selected low-light scenes, enhanced by five different models (SID, Retinex-Net, Zero-DCE, LLFormer, and Ours). Images were randomized and rated using a 5-point Likert scale across three dimensions: brightness, naturalness, and sharpness. All evaluations were conducted under consistent ambient lighting on calibrated displays.
Participants rated each image on a scale from 1 to 5 for the following aspects:
Brightness: Is the image sufficiently illuminated?
Naturalness: Does the image look visually plausible?
Sharpness: Are textures and edges clearly preserved?
Mean scores across all scenes are reported in
Table 5. Our model received the highest scores in all categories, indicating a favorable perception among human viewers.
In addition to numeric scores, we collected optional free-text feedback from participants to better understand their qualitative impressions. Selected representative comments are summarized below to illustrate common perceptions associated with each method:
“This one feels most like a real photo” (Ours).
“Too bright, slightly artificial” (SID).
“Details are a bit fuzzy” (Retinex-Net).
“Nice balance of contrast and color” (LLFormer).
5.8. Failure Case Analysis
While the proposed method performs robustly across a variety of low-light scenes, we observed several failure cases where enhancement results were suboptimal. These failures fall into three common categories:
Extreme Darkness with Minimal Structure: In some near-black inputs with severely low exposure and little structural information, the model tends to over-amplify noise or produce unnatural brightness gradients. This is likely due to the lack of such extreme examples in the training distribution and the limited ability of the attention mechanism to differentiate noise from faint structure.
Strong Color Casts or Sensor Artifacts: Images captured with low-end sensors or under unbalanced lighting conditions (e.g., yellow streetlights) occasionally result in amplified color distortions. The model attempts to “normalize” the color but may hallucinate incorrect tones due to the absence of ground-truth cues.
Over-saturation in Highly Reflective Regions: When enhancing scenes that contain bright highlights (e.g., signs, metallic surfaces), the decoder may produce overexposed regions with loss of detail. This can be attributed to limited dynamic range handling in the current architecture.
To visually illustrate some of the limitations discussed above,
Figure 7 presents representative failure cases where the model struggles under particularly challenging low-light conditions.
To address these limitations, future research could explore
Raw image enhancement pipelines to preserve low-level detail and dynamic range.
Scene-aware attention modules that condition enhancement on contextual priors (e.g., geometry or semantic features).
Noise-aware learning objectives that penalize hallucinated structures in ambiguous regions.
Augmenting training data with synthetically generated extreme darkness scenarios and sensor artifacts.
While our model achieves substantial gains in efficiency over large-scale networks, it exhibits slightly higher FLOPs compared to some ultra-compact architectures (e.g., Zero-DCE, Zhang et al. [
13]). This trade-off is primarily due to the inclusion of perceptual and attention mechanisms that improve structural fidelity and texture preservation. We argue that this marginal increase in FLOPs is justified by the notable gains in LPIPS and subjective human evaluation scores, which reflect enhanced perceptual quality—a key requirement in many vision-critical applications.
6. Conclusions and Future Work
In this paper, we proposed a lightweight, attention-augmented deep learning model for low-light image enhancement, designed for real-time performance and resource-constrained deployment. Our model integrates a UNet-inspired architecture with channel attention modules and is trained using a composite loss function that balances pixel-level accuracy, structural similarity, and perceptual quality.
To improve generalization and reduce reliance on manually collected paired data, we constructed a hybrid training dataset that combines real-world low-light images with synthetically generated samples based on gamma correction and noise modeling. Through comprehensive experiments on public benchmarks such as LOL and SID, we demonstrated that our approach achieves competitive or superior performance compared to several state-of-the-art methods—while maintaining low computational complexity.
In addition to strong PSNR, SSIM, and LPIPS scores, our model demonstrates real-time inference capabilities on both desktop GPUs and edge devices such as the Jetson Nano. These characteristics support deployment in a variety of real-world applications, including low-light video enhancement on smartphones, nighttime pedestrian detection in automotive systems, and intelligent surveillance platforms requiring real-time visibility improvements under low-light or infrared conditions. Additionally, our approach may serve as a foundation for domain-specific extensions, such as underwater visual perception, where low illumination and color distortion pose compounding challenges [
3,
4,
5].
Future work will explore several directions:
Video enhancement: Extending the model to handle temporal consistency and frame-level stability in low-light video sequences.
Raw image input: Adapting the network to process raw sensor data directly for better low-light fidelity.
Hardware-specific optimization: Applying neural architecture search and pruning techniques to further reduce latency on edge accelerators (e.g., ARM, Jetson, mobile NPUs).
Task-aware enhancement: Integrating enhancement with downstream tasks like object detection and semantic segmentation in dark scenes.
This work represents a practical step forward in bridging high-quality enhancement with efficient deployment.
While our model demonstrates strong generalization and visual quality across diverse low-light conditions, certain limitations remain. Specifically, enhancement may inadvertently amplify artifacts (e.g., compression noise or motion blur) in extremely degraded inputs. Moreover, in high-stakes applications such as surveillance, security, or forensic analysis, enhanced images may alter perceived object boundaries, facial features, or scene lighting in ways that could mislead human interpretation or downstream vision models. We emphasize that enhanced images should not be treated as original evidence in such contexts. Future work could explore uncertainty-aware enhancement and trust calibration techniques to mitigate these risks. Furthermore, although our model enhances perceptual quality, the added complexity from perceptual and attention modules introduces a small computational overhead compared to some minimalist baselines—a design trade-off chosen deliberately to optimize perceptual realism. Finally, in forensic or high-stakes domains, users should be aware that enhancement can alter pixel-level properties and should not substitute raw data for evidentiary purposes.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}