
A Strawberry Ripeness Detection Method Based on Improved YOLOv8


Abstract
1. Introduction
2. Materials and Methods
2.1. Image Collection
2.2. Dataset Construction
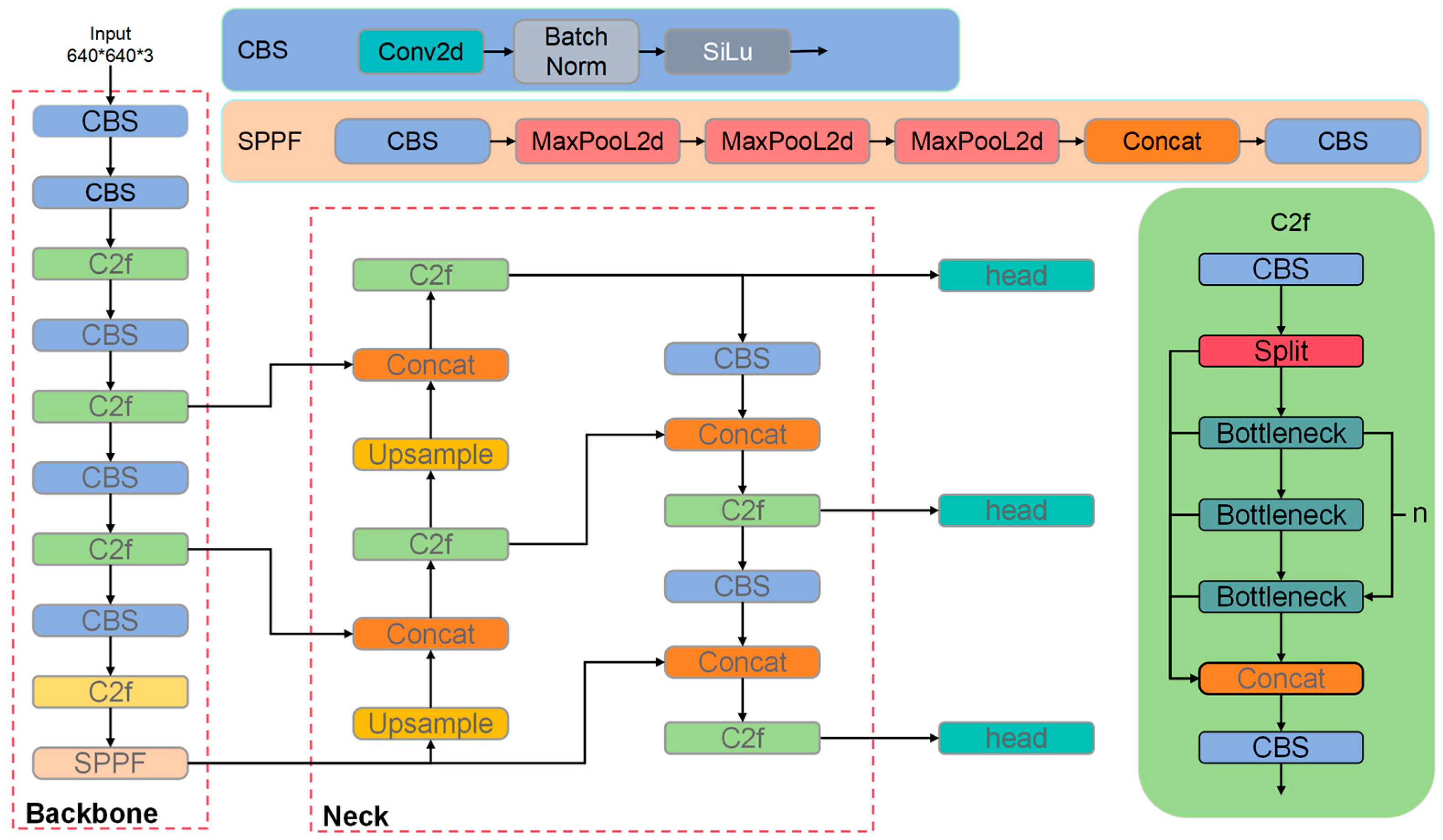
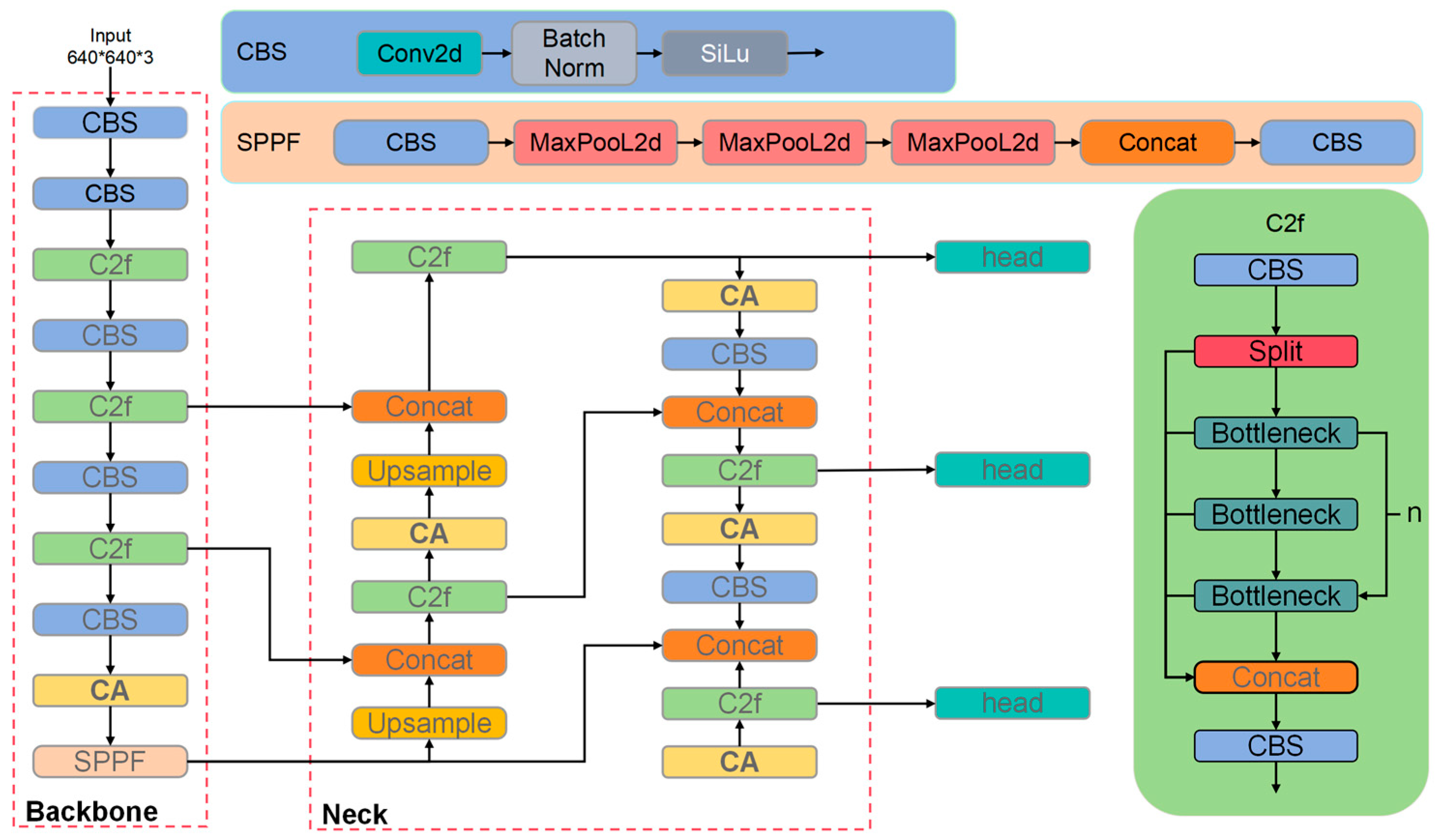
2.3. Network Model Architecture for Strawberry Ripeness Detection
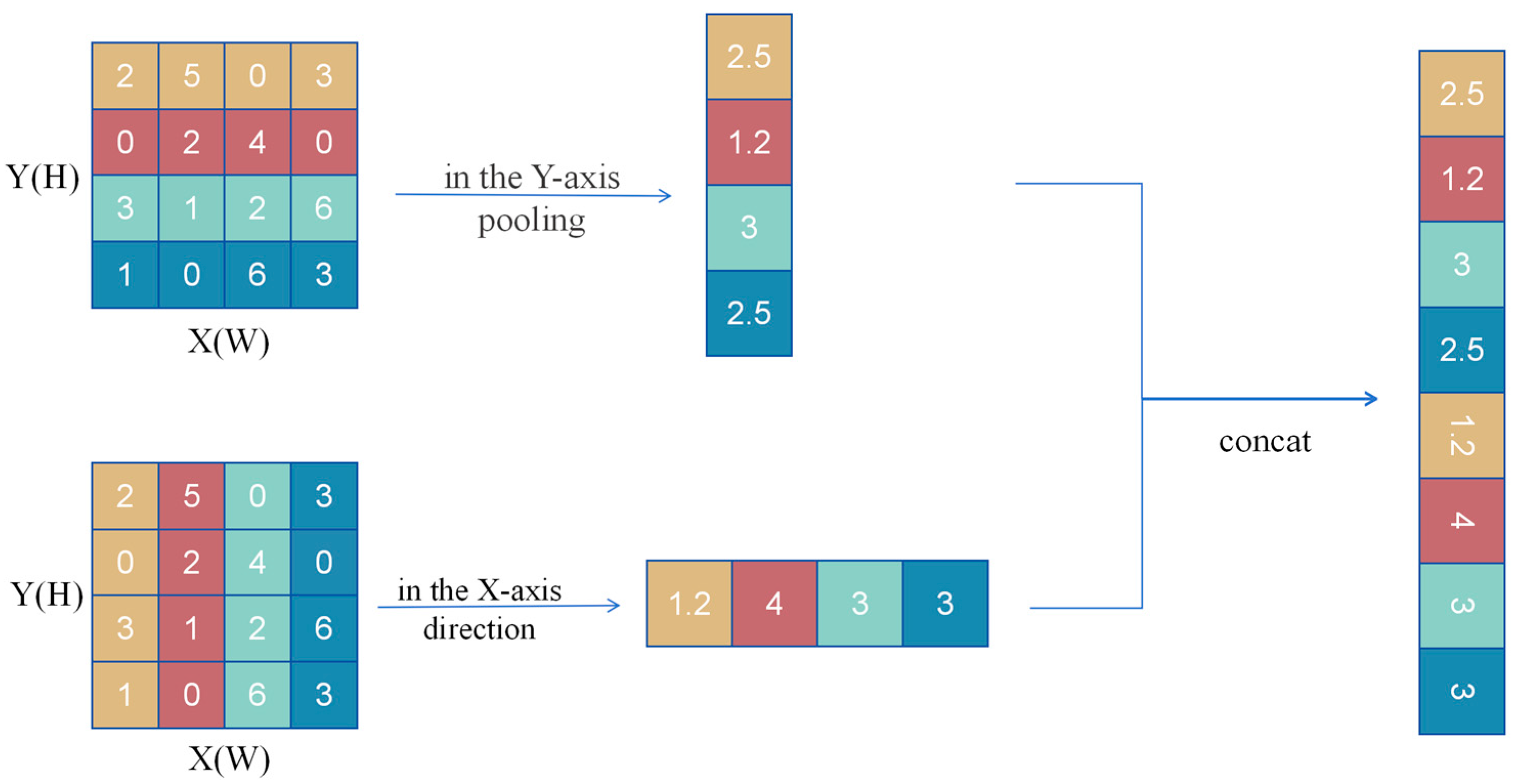
2.3.1. Channel Attention
2.3.2. DySample
2.3.3. Wise-IoU Loss Function
2.4. Evaluation Indicators
2.5. Experimental Environment
3. Analysis of Experimental Results
3.1. Comparative Experiment
3.2. Ablation Experiment
3.3. Heatmap Visualization
4. Discussion
5. Conclusions
- The integration of a CA mechanism into the backbone network of the original YOLOv8 significantly enhances the model’s capacity to capture fine-grained features by reinforcing inter-channel dependencies within feature maps. This modification allows the model to better represent the subtle visual cues associated with different ripeness stages, such as variations in surface texture and color gradients, thereby improving its discriminative power in challenging scenarios.
- The incorporation of the Wise-IoU loss function during training enables the model to dynamically adjust the weights assigned to bounding boxes based on their quality. This adaptive weighting mechanism increases the influence of high-quality bounding boxes while effectively reducing the impact of noisy or low-quality samples. As a result, the model better handles the imbalance between easy and hard samples—a common challenge in object detection tasks involving variable natural conditions.
- Experimental results on a self-collected strawberry dataset demonstrate the superior performance of the proposed YOLOv8_CDW model. It achieved an accuracy of 96.9%, a recall of 93.6%, a mAP@50 of 0.973, and an F1 score of 95.5%, outperforming baseline models including FAST R-CNN, YOLOv5, YOLOv7, and the original YOLOv8 in both accuracy and inference speed. Notably, in visually complex environments where unripe strawberries closely resemble the surrounding foliage in color and texture, YOLOv8_CDW maintained high detection robustness. These results validate the model’s ability to support efficient, precise, and real-time fruit detection, which is essential for intelligent agricultural applications such as automated harvesting and field monitoring.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ma, Z.; Guo, J. Current Status of Machine Vision Technology for Fruit Positioning. South. Agric. Mach. 2024, 55, 6–9. [Google Scholar]
- Food and Agriculture Organization of the United Nations (FAO). FAOSTAT Database. Available online: https://www.fao.org/faostat/zh/#data/QCL (accessed on 24 March 2023).
- Qian, J.P.; Yang, X.T.; Wu, X.M.; Chen, M.X.; Wu, B.G. A method for recognizing ripe apples in natural scenes based on hybrid color space. J. Agric. Eng. 2012, 28, 137–142. [Google Scholar]
- Khojastehnazhand, M.; Mohammadi, V.; Minael, S. Maturity detection and volume estimation of apricot using image processing technique. Sci. Hortic. 2019, 251, 247–251. [Google Scholar] [CrossRef]
- Fu, L.; Duan, J.; Zou, X.; Lin, G.; Song, S.; Ji, B.; Yang, Z. Banana detection based on color and texture features in the natural envronment. Comput. Electron. Agric. 2019, 167, 105057. [Google Scholar] [CrossRef]
- Zhou, W.J.; Zha, Z.H.; Wu, J. Improved circular Hough transform for in-field red globe grape cluster ripeness discrimination. J. Agric. Eng. 2020, 36, 205–213. [Google Scholar]
- Khisanudin, I.S. Dragon fruit maturity detection based-HSV space color using naive bayes classifier method. In IOP Conference Series: Materials Science and Engineering; IOP Publishing: Bristol, UK; Yogyakarta, Indonesia, 2020; Volume 771, p. 12022. [Google Scholar]
- Sinanoglou, V.J.; Tsiaka, T.; Aouant, K.; Mouka, E.; Ladika, G.; Kritsi, E.; Konteles, S.J.; Ioannou, A.-G.; Zoumpoulakis, P.; Strati, I.F.; et al. Quality assessment of banana ripening stages by combining analytical methods and image analysis. Appl. Sci. 2023, 13, 3533. [Google Scholar] [CrossRef]
- Jiang, W.; Xu, H.; Chen, G.; Zhao, W.; Xu, W. An improved edge-adaptive image scaling algorithm. In Proceedings of the IEEE 8th International Conference on ASIC, Changsha, China, 20–23 October 2009; pp. 895–897. [Google Scholar]
- Malik, M.H.; Zhang, T.; Li, H.; Zhang, M.; Shabbir, S.; Saeed, A. Mature tomato fruit detection algorithm based on improved HSV and watershed algorithm. IFAC PapersOnLine 2018, 51, 431–436. [Google Scholar] [CrossRef]
- Mohammadi, V.; Kheiralipour, K.; Ghasemi-Varnamkhastl, M. Detecting maturity of persimmon fruit based on image processing technique. Sci. Hortic. 2015, 184, 123–128. [Google Scholar] [CrossRef]
- Jiang, H.; Hu, Y.; Jiang, X.; Zhou, H. Maturity stage discrimination of Camellia oleifera fruit using visible and nearinfrared hyperspectral imaging. Molecules 2022, 27, 6318. [Google Scholar] [CrossRef]
- Sun, M.; Jiang, H.; Yuan, W.; Jin, S.; Zhou, H.; Zhou, Y.; Zhang, C. Discriminaion of maturity of Camellia oleifera fruit on-site based on generaive adversarial network and hyperspectral imaging technique. J. Food Meas. Charact. 2023, 18, 10–25. [Google Scholar] [CrossRef]
- Septiarini, A.; Sunyoto, A.; Hamdani, H.; Kasim, A.A.; Utaminingrum, F.; Hatta, H.R. Machine vision for the maturity classification of oil palm fresh fruit bunches based on color and texture features. Sci. Hortic. 2021, 286, 110245. [Google Scholar] [CrossRef]
- Wang, L.S.; Qin, M.X.; Lei, J.Y.; Wang, X.F.; Tan, K.Z. A method for blueberry ripeness recognition based on the improved YOLOv4-Tiny model. J. Agric. Eng. 2021, 37, 170–178. [Google Scholar]
- MacEachern, C.B.; Esau, T.J.; Schumann, A.W.; Hennessy, P.J.; Zaman, Q.U. Detection of fruit maturity stage and yield estimation in wid blueberry using deep learing convolutional neural networks. Smart Agric. Technol. 2023, 3, 100099. [Google Scholar] [CrossRef]
- Xiao, B.; Nguyen, M.; Yan, W.Q. Apple ripeness identification from digital images using transformers. Multimed. Tools Appl. 2024, 83, 7811–7825. [Google Scholar] [CrossRef]
- Zhao, H.; Qiao, Y.J.; Wang, H.J.; Yue, Y.J. Apple fruit recognition in complex orchard environments based on the improved YOLOv3 model. J. Agric. Eng. 2021, 37, 127–135. [Google Scholar]
- Zhang, L.; Hao, Q.; Cao, J. Attention-based fine-grained lightweight architecture for fuji apple maturity classification in an open-world orchard environment. Agriculture 2023, 13, 228. [Google Scholar] [CrossRef]
- Ignacio, J.S.; Eisma, K.N.A.; Caya, M.V.C. A YOLOv5-based deep leaning model for in-situ detection and matunity grading of mango. In Proceedings of the 6th Intenational Conference on Communication and Information Systems (ICCIS), Chongqing, China, 14–16 October 2022; pp. 141–147. [Google Scholar]
- Wang, Z.; Ling, Y.; Wang, X.; Meng, D.; Nie, L.; An, G.; Wang, X. An improved Faster R-CNN model for multi-object tomato maturity detection in complex scenarios. Ecol. Inform. 2022, 72, 101886. [Google Scholar] [CrossRef]
- Yan, B.; Fan, P.; Lei, X.; Liu, Z.; Yang, F. A real-time apple targets detection method for picking robot based on improved YOLOv5. Remote Sens. 2021, 13, 1619. [Google Scholar] [CrossRef]
- Zhang, J.N.; Bi, Z.Y.; Yan, Y.; Wang, P.C.; Hou, C.; Lv, S.S. Rapid recognition of greenhouse tomatoes based on attention mechanism and improved YOLO. J. Agric. Mach. 2023, 54, 236–243. [Google Scholar]
- Gao, X.Y.; Wei, S.; Wen, Z.Q.; Yu, T. Improved YOLOv5 lightweight network for citrus detection. Comput. Eng. Appl. 2023, 59, 212–221. [Google Scholar] [CrossRef]
- Zhang, H.; Zhang, K.; Zhang, J.; Tao, D. SCNet: Spatial and Channel-wise Attention for Semantic Segmentation. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence (AAAI), Palo Alto, CA, USA, 2–9 February 2021; Volume 35, pp. 10765–10773. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Volume 11211, pp. 3–19. [Google Scholar]
- Zhou, X.; Liu, Y.; Yin, J.; Yang, J. Strawberry Ripeness Detection Using Improved YOLOv5 Model under Complex Backgrounds. Appl. Sci. 2023, 13, 1861. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 13708–13717. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Tong, Z.J.; Chen, Y.H.; Xu, Z.W.; Yu, R. Wise-IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the Computer vision–ECCV 2014: 13th European Conference (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Wang, X.; Wang, J.; Yu, H.; Liu, Z. Design and Experiment of a Strawberry Picking Robot with Visual Identification and Deep Learning. Appl. Sci. 2021, 11, 2327. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| FAST R-CNN | Backbone | Params | AP | AP50 | AP75 | APS | APM | APL |
|---|---|---|---|---|---|---|---|---|
| Nearest | R50 | 46.8 M | 37.5 | 58.2 | 40.8 | 21.9 | 41.1 | 48.9 |
| Deconv | R50 | +2.4 M | 37.3 | 57.8 | 40.3 | 21.3 | 41.1 | 48.0 |
| PiexlShuffle | R50 | +9.4 M | 37.5 | 58.5 | 40.4 | 21.5 | 41.5 | 48.3 |
| CARAFE | R50 | +0.3 M | 38.6 | 59.9 | 42.2 | 23.3 | 42.2 | 49.7 |
| IndexNet | R50 | +8.4 M | 37.6 | 58.4 | 40.9 | 21.5 | 41.3 | 49.2 |
| A2U | R50 | +38.9 K | 37.3 | 58.7 | 40.0 | 21.7 | 41.1 | 48.5 |
| FADE | R50 | +0.2 M | 38.5 | 59.6 | 41.8 | 23.1 | 42.2 | 49.3 |
| SAPA-B | R50 | +0.1 M | 37.8 | 59.2 | 40.6 | 22.4 | 41.4 | 49.1 |
| DySample-S | R50 | +4.1 K | 38.5 | 59.5 | 42.1 | 22.5 | 42.1 | 50.2 |
| DySample-S+ | R50 | +8.2 K | 38.6 | 59.8 | 42.1 | 22.5 | 42.1 | 50.0 |
| DySample | R50 | +32.7 K | 38.6 | 59.9 | 42.0 | 22.9 | 42.1 | 50.2 |
| DySample+ | R50 | +65.5 K | 38.7 | 60.0 | 42.2 | 22.5 | 42.4 | 50.2 |
| Nearest | R101 | 65.8 M | 39.4 | 60.1 | 43.1 | 22.4 | 43.7 | 51.1 |
| DySample+ | R101 | +65.5 K | 40.5 | 61.6 | 43.8 | 24.2 | 44.5 | 52.3 |
| Model | Precision | Recall | mAP@0.5 | mAP@0.5:0.95 | F1 Score |
|---|---|---|---|---|---|
| FAST R-CNN | 0.713 | 0.611 | 0.837 | 0.630 | 0.660 |
| YOLOv5 | 0.889 | 0.793 | 0.885 | 0.559 | 0.856 |
| YOLOv7 | 0.892 | 0.808 | 0.897 | 0.763 | 0.847 |
| YOLOv8 | 0.894 | 0.789 | 0.862 | 0.649 | 0.860 |
| YOLOv8_CDW | 0.969 | 0.936 | 0.973 | 0.823 | 0.972 |
| Model | Precision | Recall | mAP@0.5 | mAP@0.5:0.95 | F1 Score |
|---|---|---|---|---|---|
| YOLOv8 | 0.873 | 0.789 | 0.863 | 0.649 | 0.860 |
| YOLOv8_WioU | 0.951 | 0.926 | 0.957 | 0.793 | 0.924 |
| YOLOv8_CA | 0.951 | 0.926 | 0.958 | 0.793 | 0.938 |
| YOLOv8_DySample | 0.951 | 0.926 | 0.958 | 0.793 | 0.943 |
| YOLOv8_CA_DySample | 0.947 | 0.931 | 0.965 | 0.815 | 0.944 |
| YOLOv8_CDW | 0.969 | 0.936 | 0.973 | 0.823 | 0.972 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yue, Y.; Xu, S.; Wu, H. A Strawberry Ripeness Detection Method Based on Improved YOLOv8. Appl. Sci. 2025, 15, 6324. https://doi.org/10.3390/app15116324
Yue Y, Xu S, Wu H. A Strawberry Ripeness Detection Method Based on Improved YOLOv8. Applied Sciences. 2025; 15(11):6324. https://doi.org/10.3390/app15116324
Chicago/Turabian StyleYue, Yawei, Shengbo Xu, and Huanhuan Wu. 2025. "A Strawberry Ripeness Detection Method Based on Improved YOLOv8" Applied Sciences 15, no. 11: 6324. https://doi.org/10.3390/app15116324
APA StyleYue, Y., Xu, S., & Wu, H. (2025). A Strawberry Ripeness Detection Method Based on Improved YOLOv8. Applied Sciences, 15(11), 6324. https://doi.org/10.3390/app15116324