
VCAFusion: A Framework for Infrared and Low Light Visible Image Fusion Based on Visual Characteristics Adjustment

Abstract
1. Introduction
- An infrared-visible fusion method enhancing detail preservation and visual quality in low-light conditions.
- A lighting correction and contrast enhancement approach to strengthen weak details while maintaining edge clarity.
- A hybrid multi-scale decomposition (MSD) for better structure handling and a saliency-preserving strategy for improved detail integration.
- Our method adapts to lighting variations and outperforms state-of-the-art methods in object highlighting and detail preservation (Figure 1e).
2. Related Works
2.1. Infrared and Visible Image Fusion
2.1.1. Traditional Image Fusion
2.1.2. Deep Learning-Based Fusion Methods
2.2. Low-Light Image Enhancement Methods
3. Materials and Methods
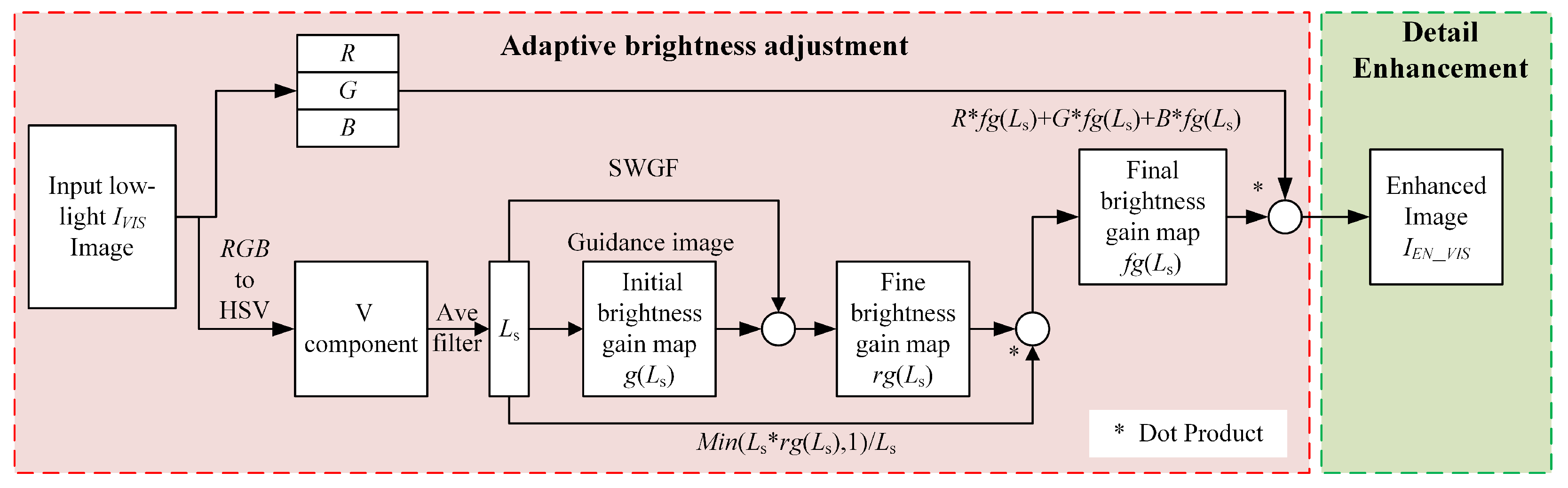
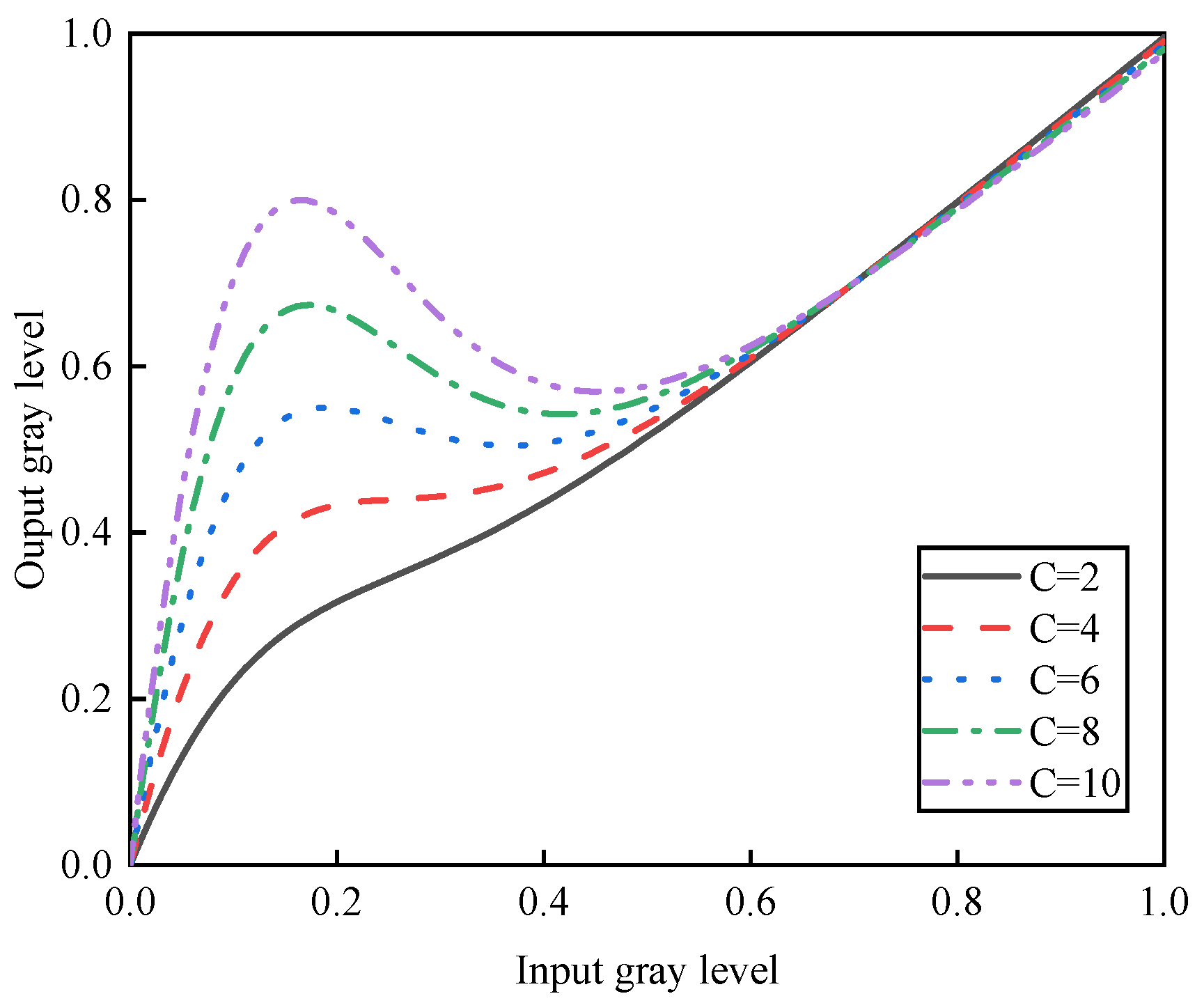
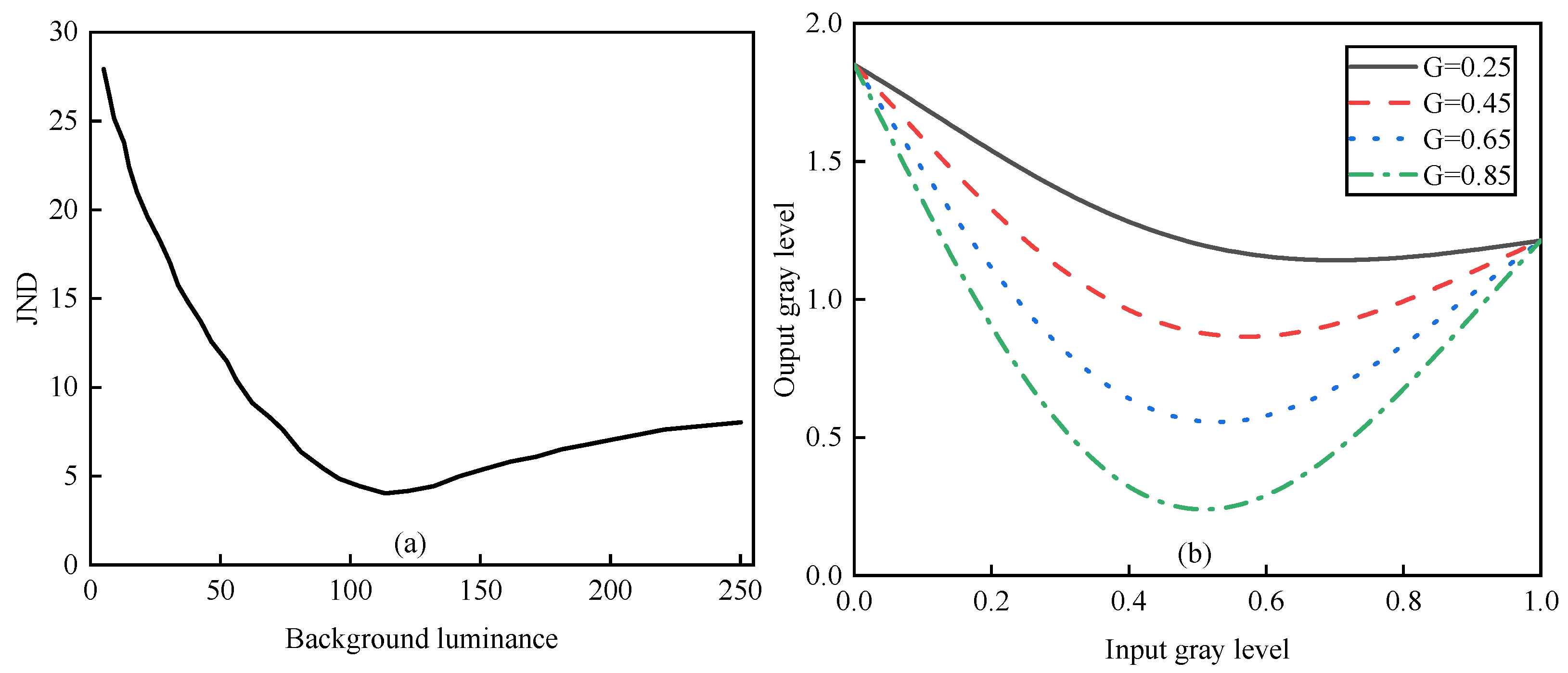
3.1. Adaptive Low-Light Enhancement
3.2. Infrared and Visible Image Fusion Based on SWGF
3.2.1. Image Decomposition
3.2.2. Weight Mapping-Based Detail Layer Fusion
3.2.3. Nonlinear Function-Based Saliency Layer Fusion
3.2.4. Visual Saliency-Based Base Layer Fusion
3.2.5. Image Reconstruction
4. Discussion
4.1. Datasets and Parameters Selection
4.2. Low-Light Enhancement Algorithm
4.3. Effect Analysis of Free Parameters
4.4. Comparisons of Fusion Results with Different Methods
4.4.1. Qualitative Comparisons
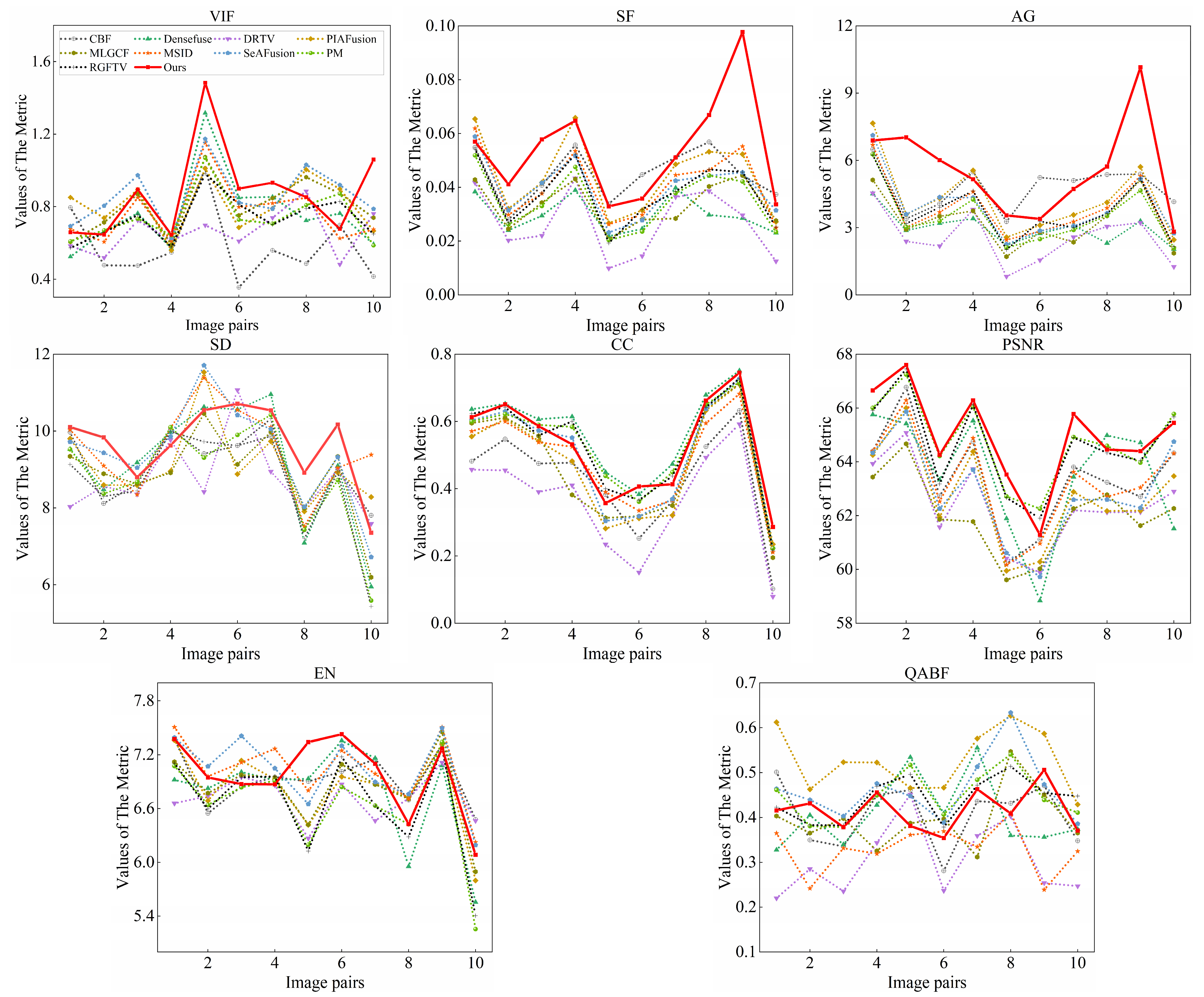
4.4.2. Quantitative Comparisons
4.5. Ablation Study
4.5.1. Analysis on Adaptive Brightness
4.5.2. Analysis of Saliency-Preserving Strategy
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, H.; Ma, M.; Wang, M.; Chen, Z.; Zhao, Y. SCFusion: Infrared and Visible Fusion Based on Salient Compensation. Entropy 2023, 25, 985. [Google Scholar] [CrossRef] [PubMed]
- Tang, L.; Xiang, X.; Zhang, H.; Gong, M.; Ma, J. DIVFusion: Darkness-free infrared and visible image fusion. Inf. Fusion 2023, 91, 477–493. [Google Scholar] [CrossRef]
- Zhou, Z.; Fei, E.; Miao, L.; Yang, R. A perceptual framework for infrared visible image fusion based on multiscale structure decomposition and biological vision. Inf. Fusion 2023, 93, 174–191. [Google Scholar] [CrossRef]
- Zhang, X.; Demiris, Y. Visible and infrared image fusion using deep learning. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 10535–10554. [Google Scholar] [CrossRef]
- Cai, H.; Zhuo, L.; Chen, X.; Zhang, W. Infrared and visible image fusion based on BEMSD and improved fuzzy set. Infrared Phys. Technol. 2019, 98, 201–211. [Google Scholar] [CrossRef]
- Ma, J.; Tang, L.; Xu, M.; Zhang, H.; Xiao, G. STDFusionNet: An infrared and visible image fusion network based on salient target detection. IEEE Trans. Instrum. Meas. 2021, 70, 5009513. [Google Scholar] [CrossRef]
- Luo, X.; Fu, G.; Yang, J.; Cao, Y.; Cao, Y. Multi-modal Image Fusion via Deep Laplacian Pyramid Hybrid Network. IEEE Trans. Circ. Syst. Video. Technol. 2023, 33, 7354–7369. [Google Scholar] [CrossRef]
- Sharma, A.M.; Dogra, A.; Goyal, B.; Vig, R.; Agrawal, S. From pyramids to state-ofthe-art: A study and comprehensive comparison of visible–infrared image fusion techniques. IET Image Process. 2020, 14, 1671–1689. [Google Scholar] [CrossRef]
- Guo, L.; Cao, X.; Liu, L. Dual-tree biquaternion wavelet transform and its application to color image fusion. Signal Process. 2020, 171, 107513. [Google Scholar] [CrossRef]
- Chen, J.; Li, X.; Luo, L.; Ma, J. Multi-focus image fusion based on multi-scale gradients and image matting. IEEE Trans. Multim. 2021, 24, 655–667. [Google Scholar] [CrossRef]
- Li, H.; Qi, X.; Xie, W. Fast Infrared and visible image fusion with structural decomposition. Knowl.-Based Syst. 2020, 204, 106182. [Google Scholar] [CrossRef]
- Zhang, S.; Huang, F.; Liu, B.; Li, G.; Chen, Y.; Chen, Y.; Zhou, B.; Wu, D. A multi-modal image fusion framework based on guided filter and sparse representation. Opt. Lasers Eng. 2021, 137, 106354. [Google Scholar] [CrossRef]
- Yang, Y.; Zhang, Y.; Huang, S.; Zuo, Y.; Sun, J. Infrared and visible image fusion using visual saliency sparse representation and detail injection model. IEEE Trans. Instrum. Meas. 2020, 70, 5001715. [Google Scholar] [CrossRef]
- Chen, J.; Wu, K.; Cheng, Z.; Luo, L. A saliency based multiscale approach for infrared and visible image fusion. Signal Process 2021, 182, 107936. [Google Scholar] [CrossRef]
- Liu, X.; Huo, H.; Yang, X.; Li, J. A three-dimensional feature- based fusion strategy for infrared and visible image fusion. Pattern Recognit. 2025, 157, 110885. [Google Scholar] [CrossRef]
- Xu, C.; Liu, L.; Kong, X. The fusion of Infrared and visible images via decomposition-based structure transfer and local saliency detection. Opt. Lasers Technol. 2022, 149, 107787. [Google Scholar]
- Tang, W.; He, F.; Liu, Y. ITFuse: An interactive transformer for infrared and visible image fusion. Pattern Recognit. 2024, 156, 110822. [Google Scholar] [CrossRef]
- Tang, L.; Yuan, J.; Ma, J. Image fusion in the loop of high-level vision tasks: A semantic-aware real-time Infrared and visible image fusion network. Inf. Fusion 2022, 82, 28–42. [Google Scholar] [CrossRef]
- Liu, J.; Fan, X.; Huang, Z.; Wu, G.; Liu, R.; Zhang, W.; Luo, Z. Target-aware dual adversarial learning and a multi-scenario multi-modality benchmark to fuse Infrared and visible for object detection. In Proceedings of the IEEE International Conference on Computer Vision, New Orleans, LA, USA, 18–24 June 2022; pp. 5802–5811. [Google Scholar]
- Tang, L.; Zhang, H.; Xu, H.; Ma, J. Rethinking the necessity of image fusion in high-level vision tasks: A practical infrared and visible image fusion network based on progressive semantic injection and scene fidelity. Inf. Fusion 2023, 99, 101870. [Google Scholar] [CrossRef]
- Yin, H.; Gong, Y.; Qiu, G. Side window filtering. In Proceedings of the IEEE International Conference on Computer Vision, Long Beach, CA, USA, 15–20 June 2019; pp. 8758–8766. [Google Scholar]
- Liu, Y. Region level based multi-focus image fusion using quaternion wavelet and normalized cut. Signal Process. 2014, 97, 9–30. [Google Scholar] [CrossRef]
- Liu, W.; Mei, W.; Du, H. Structure tensor and nonsubsampled shearlet transform based algorithm for CT and MRI image fusion. Neurocomputing 2017, 235, 131–139. [Google Scholar] [CrossRef]
- Choi, M.; Kim, R.Y.; Nam, M.R.; Kim, H.O. Fusion of multispectral and panchromatic satellite images using the curvelet transform. IEEE Geosci. Remote Sens. Lett. 2005, 2, 136–140. [Google Scholar] [CrossRef]
- Zhang, Q.; Xavier, M. An adaptive fusion method for infrared and visible images based on NSCT and compressed sensing. Infrared Phys. Technol. 2016, 74, 11–20. [Google Scholar] [CrossRef]
- Li, S.; Kang, X.; Hu, J. Image fusion with guided filtering. IEEE Trans. Image Process. 2013, 22, 2864–2875. [Google Scholar]
- Hu, J.; Li, S. The multiscale directional bilateral filter and its application to multisensor image fusion. Inf. Fusion 2012, 13, 196–206. [Google Scholar] [CrossRef]
- Tan, W.; Zhou, H.; Song, J.; Li, H.; Yu, Y.; Du, J. Infrared and visible image perceptive fusion through multi-level Gaussian curvature filtering image decomposition. Appl. Opt. 2019, 58, 3064–3073. [Google Scholar] [CrossRef]
- Zou, D.; Bin, Y. Infrared and low-light visible image fusion based on hybrid multiscale decomposition and adaptive light adjustment. Opt. Lasers Eng. 2023, 160, 107268. [Google Scholar] [CrossRef]
- Cvejic, N.; Bull, D.; Canagarajah, N. Region-based multi-modal image fusion using ICA bases. IEEE Sens. J. 2007, 7, 743–751. [Google Scholar] [CrossRef]
- Fu, Z.; Wang, X.; Xu, J.; Zhou, N.; Zhao, Y. Infrared and visible images fusion based on RPCA and NSCT. Infrared Phys. Technol. 2016, 77, 114–123. [Google Scholar] [CrossRef]
- Kong, W.; Lei, Y.; Zhao, H. Adaptive fusion method of visible light and infrared images based on non-subsampled shearlet transform and fast non-negative matrix factorization. Infrared Phys. Technol. 2014, 67, 161–172. [Google Scholar] [CrossRef]
- Li, H.; Wu, X. DenseFuse: A fusion method to infrared and visible images. IEEE Trans. Image Process. 2018, 28, 2614–2623. [Google Scholar] [CrossRef] [PubMed]
- Xu, H.; Ma, J.; Le, Z.; Jiang, J.; Guo, X. FusionDN: A unified densely connected network for image fusion. Proc. AAAI Conf. Artif. Intell. 2020, 34, 12484–12491. [Google Scholar] [CrossRef]
- Ma, J.; Yu, W.; Liang, P.; Li, C.; Jiang, J. FusionGAN: A generative adversarial network for infrared and visible image fusion. Inf. Fusion 2019, 48, 11–26. [Google Scholar] [CrossRef]
- Prabhakar, K.R.; Srikar, V.S.; Babu, R.V. Deepfuse: A deep unsupervised method for exposure fusion with extreme exposure image pairs. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Huang, S.; Cheng, F.; Chiu, Y. Efficient contrast enhancement using adaptive gamma correction with weighting distribution. IEEE Trans. Image Process. 2012, 22, 1032–1041. [Google Scholar] [CrossRef]
- Kim, T.; Paik, J.; Kang, B. Contrast enhancement system using spatially adaptive histogram equalization with temporal filtering. IEEE Trans. Consum. Electron. 1998, 44, 82–87. [Google Scholar]
- Jobson, D.J.; Rahman, Z.; Woodell, G.A. Properties and performance of a center/surround retinex. IEEE Trans. Image Process. 1997, 6, 451–462. [Google Scholar] [CrossRef]
- Rahman, Z.; Jobson, D.J.; Woodell, G.A. Retinex processing for automatic image enhancement. J. Electron. Imaging 2004, 13, 100–110. [Google Scholar]
- Lore, K.G.; Akintayo, A.; Sarkar, S. Llnet: A deep autoencoder method to natural low-light image enhancement. Pattern Recognit. 2017, 61, 650–662. [Google Scholar] [CrossRef]
- Chen, W.; Wang, W.; Yang, W.; Liu, J. Deep retinex decomposition for low-light enhancement. arXiv 2018, arXiv:1808.04560. [Google Scholar]
- Wang, W.; Chen, Z.; Yuan, X.; Wu, X. Adaptive image enhancement method for correcting low-illumination images. Inform. Scien. 2019, 496, 25–41. [Google Scholar] [CrossRef]
- Toet, A.; Franken, E. Perceptual evaluation of different image fusion schemes. Displays 2003, 24, 25–37. [Google Scholar] [CrossRef]
- Zhou, Z.; Dong, M.; Xie, X.; Gao, Z. Fusion of infrared and visible images for night-vision context enhancement. Appl. Opt. 2016, 55, 6480–6490. [Google Scholar] [CrossRef] [PubMed]
- Fu, X.; Zeng, D.; Huang, Y.; Zhang, X.; Ding, X. A weighted variational model for simultaneous reflectance and illumination estimation. In Proceedings of the IEEE International Conference on Computer Vision, Las Vegas, NV, USA, 27–30 June 2016; pp. 2782–2790. [Google Scholar]
- Fu, X.; Zeng, D.; Huang, Y.; Liao, Y.; Ding, X.; Paisley, J. A fusion-based enhancing method for weakly illuminated images. Signal Process. 2016, 129, 82–96. [Google Scholar] [CrossRef]
- Zhang, B.; Gao, M.; Chen, P.; Shang, Y.; Li, S.; Bai, Y.; Liao, H.; Liu, Z.; Li, Z. Infrared and visible image fusion based on contrast enhancement guided filter and Infrared feature decomposition. Infrared Phys. Technol. 2022, 127, 104404. [Google Scholar] [CrossRef]
- Du, Q.; Xu, H.; Ma, Y.; Huang, J.; Fan, F. Fusing Infrared and visible images of different resolutions via total variation model. Sensors 2018, 18, 3827. [Google Scholar] [CrossRef]
- Kumar, B.K. Image fusion based on pixel significance using cross bilateral filter. Signal Image Video Process. 2015, 9, 1193–1204. [Google Scholar] [CrossRef]
- Chen, Y.; Chen, L.; Wu, H.; Mo, F.; Chen, Z. Infrared and visible image fusion based on iterative differential thermal information filter. Opt. Lasers Eng. 2022, 148, 106776. [Google Scholar] [CrossRef]
- Han, Y.; Cai, Y.; Cao, Y.; Xu, X. A new image fusion performance metric based on visual information fidelity. Inf. Fusion 2013, 14, 127–135. [Google Scholar] [CrossRef]
- Eskicioglu, A.; Fisher, P. Image quality measures and their performance. IEEE Trans. Commun. 1995, 43, 2959–2965. [Google Scholar] [CrossRef]
- Cui, G.; Feng, H.; Xu, Z.; Li, Q.; Chen, Y. Detail preserved fusion of visible and Infrared images using regional saliency extraction and multi-scale image decomposition. Opt. Commun. 2015, 341, 199–209. [Google Scholar] [CrossRef]
- Rao, Y.; Wu, D.; Han, M.; Wang, T.; Yang, Y.; Lei, T.; Zhou, C.; Bai, H.; Xing, C.L. AT-GAN: A generative adversarial network with attention and transition for infrared and visible image fusion. Inf. Fusion 2023, 92, 336–349. [Google Scholar] [CrossRef]
- Benesty, J.; Chen, J.; Huang, Y.; Cohen, I. Pearson correlation coefficient. In Noise Reduction in Speech Processing; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1–4. [Google Scholar]
- Jagalingam, P.; Hegde, A. A review of quality metrics for fused image. Aquat. Procedia 2015, 4, 133–142. [Google Scholar] [CrossRef]
- Roberts, J.; Aardt, J.; Ahmed, F. Assessment of image fusion procedures using entropy, image quality, and multispectral classification. J. App. Remote Sens. 2008, 2, 023522. [Google Scholar]
- Xydeas, C.; Petrovic, V. Objective image fusion performance measure. Electron. Lett. 2000, 36, 308–309. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Disadvantages | VCAFusion’s Novel Contributions |
|---|---|---|
| Traditional MSD | Sensitive to illumination variations. | Adaptive MSD with side window filtering. |
| Sparse Representation | Lose weak details in dark regions. | Retinex-based brightness adjustment. |
| Deep Learning | Require extensive night-image training. | Physics-inspired enhancement (no retraining needed). |
| Saliency Methods | Over-emphasize infrared thermal features. | Biologically-inspired saliency preservation. |
| Subspace Techniques | Poor edge preservation in low-light. | Hybrid MSD with edge-aware texture refinement. |
| Metrics | VIF | SF | AG | SD | CC | PSNR | EN | QABF |
|---|---|---|---|---|---|---|---|---|
| CBF | 0.581 | 0.044 | 4.794 | 8.992 | 0.423 | 63.403 | 6.926 | 0.406 |
| DenseFuse | 0.762 | 0.029 | 2.965 | 9.141 | 0.546 | 63.539 | 6.770 | 0.408 |
| DRTV | 0.661 | 0.026 | 2.535 | 8.773 | 0.358 | 62.394 | 6.709 | 0.303 |
| PIAFusion | 0.809 | 0.044 | 4.263 | 9.119 | 0.468 | 62.750 | 6.820 | 0.527 |
| MLGCF | 0.802 | 0.033 | 3.265 | 8.885 | 0.467 | 62.029 | 6.8245 | 0.395 |
| MSID | 0.765 | 0.041 | 3.781 | 9.553 | 0.481 | 63.291 | 7.031 | 0.329 |
| SeAFusion | 0.861 | 0.039 | 3.913 | 9.429 | 0.493 | 62.869 | 7.020 | 0.462 |
| PM | 0.742 | 0.035 | 3.463 | 8.804 | 0.523 | 64.773 | 6.614 | 0.446 |
| RGFTV | 0.732 | 0.037 | 3.720 | 8.709 | 0.521 | 64.615 | 6.649 | 0.442 |
| Ours | 0.874 | 0.053 | 5.542 | 9.659 | 0.525 | 64.968 | 6.970 | 0.416 |
| Metrics | VIF | SF | AG | SD | CC | PSNR | EN | QABF |
|---|---|---|---|---|---|---|---|---|
| CBF | 0.502 | 0.067 | 6.659 | 9.351 | 0.581 | 63.795 | 7.002 | 0.317 |
| DenseFuse | 0.663 | 0.049 | 4.591 | 9.355 | 0.729 | 64.776 | 6.934 | 0.371 |
| DRTV | 0.821 | 0.051 | 4.625 | 9.826 | 0.579 | 62.540 | 7.148 | 0.296 |
| PIAFusion | 0.820 | 0.081 | 7.442 | 9.506 | 0.658 | 63.038 | 7.072 | 0.536 |
| MLGCF | 0.754 | 0.055 | 5.283 | 9.133 | 0.632 | 62.031 | 7.013 | 0.333 |
| MSID | 0.748 | 0.066 | 6.060 | 9.553 | 0.644 | 63.547 | 7.282 | 0.316 |
| SeAFusion | 0.858 | 0.067 | 6.2766 | 9.969 | 0.686 | 62.510 | 7.205 | 0.464 |
| PM | 0.665 | 0.058 | 5.3950 | 9.283 | 0.688 | 64.879 | 6.976 | 0.346 |
| RGFTV | 0.671 | 0.056 | 5.3204 | 9.109 | 0.682 | 64.713 | 7.016 | 0.328 |
| Ours | 0.880 | 0.072 | 6.8076 | 9.885 | 0.704 | 65.025 | 7.007 | 0.447 |
| Methods | CBF | DenseFuse | DRTV | PIAFusion | MLGCF |
|---|---|---|---|---|---|
| Times | 20.24 | 0.06 | 1.09 | 0.09 | 104.99 |
| Methods | MSID | SeAFusion | PM | RGFTV | Ours |
| Times | 0.47 | 0.04 | 11.534 | 23.08 | 1.88 |
| Image | VIF | SF | AG | CC | EN | |
|---|---|---|---|---|---|---|
| “Queens Road” | Without ADB | 0.758 | 0.033 | 2.294 | 0.628 | 6.103 |
| With ADB | 0.82 | 0.045 | 3.683 | 0.675 | 6.998 | |
| “Kaptein_1123” | Without ADB | 0.837 | 0.03 | 2.281 | 0.522 | 6.868 |
| With ADB | 0.874 | 0.057 | 5.01 | 0.585 | 6.882 | |
| “01432” | Without ADB | 0.791 | 0.094 | 9.682 | 0.512 | 7.5 |
| With ADB | 0.724 | 0.136 | 11.10 | 0.619 | 7.546 | |
| “01454” | Without ADB | 0.836 | 0.028 | 2.156 | 0.647 | 7.064 |
| With ADB | 0.993 | 0.063 | 4.621 | 0.697 | 7.133 |
| Image | VIF | SF | AG | CC | EN | |
|---|---|---|---|---|---|---|
| “Queens Road” | Without SAP | 0.761 | 0.031 | 3.217 | 0.436 | 6.325 |
| With SAP | 0.82 | 0.045 | 3.683 | 0.675 | 6.998 | |
| “Kaptein_1123” | Without SAP | 0.838 | 0.029 | 3.467 | 0.34 | 6.76 |
| With SAP | 0.874 | 0.047 | 5.01 | 0.585 | 6.882 | |
| “01432” | Without SAP | 0.714 | 0.055 | 6.664 | 0.488 | 7.43 |
| With SAP | 0.724 | 0.136 | 11.10 | 0.619 | 7.546 | |
| “01454” | Without SAP | 0.987 | 0.046 | 4.217 | 0.631 | 7.327 |
| With SAP | 0.993 | 0.063 | 4.621 | 0.697 | 7.433 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Huang, Z.; Peng, J.; Zhang, X.; Zhang, R. VCAFusion: A Framework for Infrared and Low Light Visible Image Fusion Based on Visual Characteristics Adjustment. Appl. Sci. 2025, 15, 6295. https://doi.org/10.3390/app15116295
Li J, Huang Z, Peng J, Zhang X, Zhang R. VCAFusion: A Framework for Infrared and Low Light Visible Image Fusion Based on Visual Characteristics Adjustment. Applied Sciences. 2025; 15(11):6295. https://doi.org/10.3390/app15116295
Chicago/Turabian StyleLi, Jiawen, Zhengzhong Huang, Jiapin Peng, Xiaochuan Zhang, and Rongzhu Zhang. 2025. "VCAFusion: A Framework for Infrared and Low Light Visible Image Fusion Based on Visual Characteristics Adjustment" Applied Sciences 15, no. 11: 6295. https://doi.org/10.3390/app15116295
APA StyleLi, J., Huang, Z., Peng, J., Zhang, X., & Zhang, R. (2025). VCAFusion: A Framework for Infrared and Low Light Visible Image Fusion Based on Visual Characteristics Adjustment. Applied Sciences, 15(11), 6295. https://doi.org/10.3390/app15116295