1. Introduction
With the rapid advancement of Industry 4.0, the demand for the health monitoring and operational stability of intelligent industrial equipment has significantly increased [
1,
2]. As core components of rotating machinery, the condition of rolling bearings directly impacts the safety and stability of industrial systems. Due to their operation under variable speed and load conditions, bearings are susceptible to a variety of faults. Furthermore, when localized faults occur, transient pulses often contain interference noise and harmonic components that are challenging to detect through vibration signal analysis, posing substantial risks to industrial machinery [
3,
4,
5]. Therefore, the monitoring and fault diagnosis of rolling bearings is critical for ensuring the safe and reliable operation of industrial equipment [
6,
7].
Traditional fault diagnosis methods typically rely on the analysis of 1D vibration signals from sensors, requiring professionals to manually extract and assess signal features before designing classifiers [
8,
9,
10]. These approaches have achieved high accuracy by utilizing entropy features, autocorrelation analysis, or specialized classifiers like U-SVM. However, they are often time-consuming and labor-intensive, limiting their adaptability to large-scale or real-time industrial applications.
The success of convolutional neural networks (CNNs) has spurred the development of data-driven fault diagnosis frameworks. For example, Wang et al. [
11] integrated CNNs with Hidden Markov Models to enhance the classification of multi-fault signals. Gan et al. [
12] introduced a hierarchical diagnosis network (HDN) using deep belief networks for layered fault recognition. Shao et al. [
13] combined compressed sensing with convolutional deep belief networks for efficient feature learning. Wang et al. [
14] proposed a multi-sensor fusion CNN that improves diagnostic precision by incorporating diverse signal sources. These methods automate feature extraction and achieve state-of-the-art performance under sufficient training data. Moreover, recent works have proposed more specialized architectures for interpretable or compound fault diagnosis. Li et al. [
15] proposed an interpretable composite fault diagnosis method of WavCapsNet, which is capable of intelligently diagnosing composite faults in vibration signals. Wen et al. [
16] introduced a novel hierarchical convolutional neural network (HCNN) capable of simultaneously identifying both the type and severity of faults. Ma et al. [
17] proposed a hybrid feature transformation approach, which optimizes the fault diagnosis performance by combining random forests and auto-coding. However, most of these methods are sample data-driven, focusing on model selection, network architecture, and hyperparameter tuning. When sample data are limited, these models often struggle to achieve the desired detection accuracy due to insufficient training data, failing to meet practical requirements.
Despite the challenges posed by limited or imbalanced data, the data generation capabilities of GANs offer promising solutions for fault diagnosis [
18]. The underlying principle of GANs involves a generator and discriminator optimizing each other through a zero-sum game, ultimately converging to a Nash equilibrium [
19,
20]. For instance, Yang et al. [
21] proposed a feature fusion GAN with embedded category constraints to improve small-sample generation fidelity. Guo et al. [
22] utilized an ACGAN variant for multi-label fault generation, enhancing classifier performance. Shao et al. [
23] designed a 1D CNN-based ACGAN for realistic signal synthesis. Qin et al. [
24] incorporated attention modules into GANs to handle multisensor and compound fault scenarios effectively. Further, several targeted GAN-based frameworks have been proposed for specific applications. Gao et al. [
25] introduced ICoT-GAN for bearing fault diagnosis under limited data, using global–local feature fusion. Yang et al. [
26] proposed CGAN-2-D-CNN, coupling data augmentation with a 2D CNN classifier. Liu et al. [
27] presented a hybrid GAN-capsule network to balance sample distribution and enhance feature discrimination.
These developments demonstrate the increasing integration of generative modeling with traditional and deep learning-based diagnostics, offering a promising pathway for overcoming data scarcity and imbalance in real-world fault diagnosis scenarios.
While existing studies have addressed the issues of data scarcity and imbalance to some extent through variants of GANs, several limitations remain:
(1) Most current approaches primarily rely on simple statistical features derived from time-domain signals, overlooking the critical role that frequency and time-frequency domain features play in characterizing fault modes. This single-feature dependence hinders generative networks from effectively capturing both global features and the fine-grained feature distributions associated with complex fault modes, resulting in generated samples that inadequately represent the diversity and complexity of fault signals.
(2) Many existing generative networks employ traditional convolutional structures that are capable of capturing local features but are limited in modeling the cross-domain dependencies and intricate features of high-dimensional vibration signals. This limitation becomes particularly pronounced in the case of multimodal faults, where the generated samples fail to reflect the complex interdependencies of real-world signals.
(3) Most GANs rely on conventional loss functions (e.g., Jensen–Shannon divergence), which are susceptible to issues such as gradient vanishing and mode collapse during adversarial training, leading to inconsistencies in the quality of generated samples. Moreover, the inherent conflict between the discriminator’s classification task and its adversarial discrimination role further compromises both the quality and diversity of the generated samples.
To address the aforementioned challenges, we propose a Multi-Domain Feature Transformer Generative Adversarial Network (MDFT-GAN). This framework leverages multi-domain feature fusion, an enhanced network structure, and an improved training mechanism to significantly enhance the quality and diversity of generated samples, overcoming the limitations of existing methods. The main contributions of this paper are as follows:
(1) We introduce a multi-domain information fusion strategy that effectively combines time-domain, frequency-domain, and time-frequency domain features, capitalizing on their complementarity. This approach provides comprehensive feature support for generating complex fault modes, thereby improving the completeness and diversity of the generated samples.
(2) To enhance the generative network’s ability to model both global dependencies and local features, we design a network structure that combines convolutional layers with a Transformer encoder. A multi-head self-attention mechanism and channel attention are incorporated to refine the quality and feature representation of the generated samples. Additionally, we introduce an adversarial loss based on Wasserstein distance, supplemented with a gradient penalty mechanism, to significantly improve training stability while maintaining an auxiliary classification loss.
(3) We conduct a comprehensive comparative analysis using two publicly available bearing fault datasets. The results demonstrate the superiority of MDFT-GAN in terms of both the quality and diversity of the generated samples. Experimental findings further confirm that the proposed method outperforms mainstream generative adversarial networks, exhibiting higher accuracy and robustness in fault diagnosis tasks.
(4) To enhance the transparency and interpretability of the diagnostic process, we further incorporate a Grad-CAM-based visual interpretability framework. This enables visualization of hierarchical feature activations in the discriminator and classifier, offering insight into the learned fault representations and supporting the explainability of decision boundaries across different fault types.
The remainder of this paper is organized as follows:
Section 2 outlines the theoretical foundations relevant to the research;
Section 3 provides a detailed description of the proposed method;
Section 4 presents experimental validation of the method’s effectiveness; and
Section 5 concludes the paper, discussing potential directions for future research.
3. The Proposed Method
3.1. Motivation
To address the data imbalance and complex feature extraction problems in bearing fault diagnosis, this paper proposes a diagnosis method based on MDFT-GAN. First, to alleviate the problems of limited and imbalanced data, this paper designs a novel generative adversarial network model, MDFT-GAN. Second, to further improve the fault classification accuracy, this paper proposes an improved classifier model based on residual blocks and a hybrid vision transformer.
3.2. Proposed Fault Diagnosis Method Based on MDFT-GAN
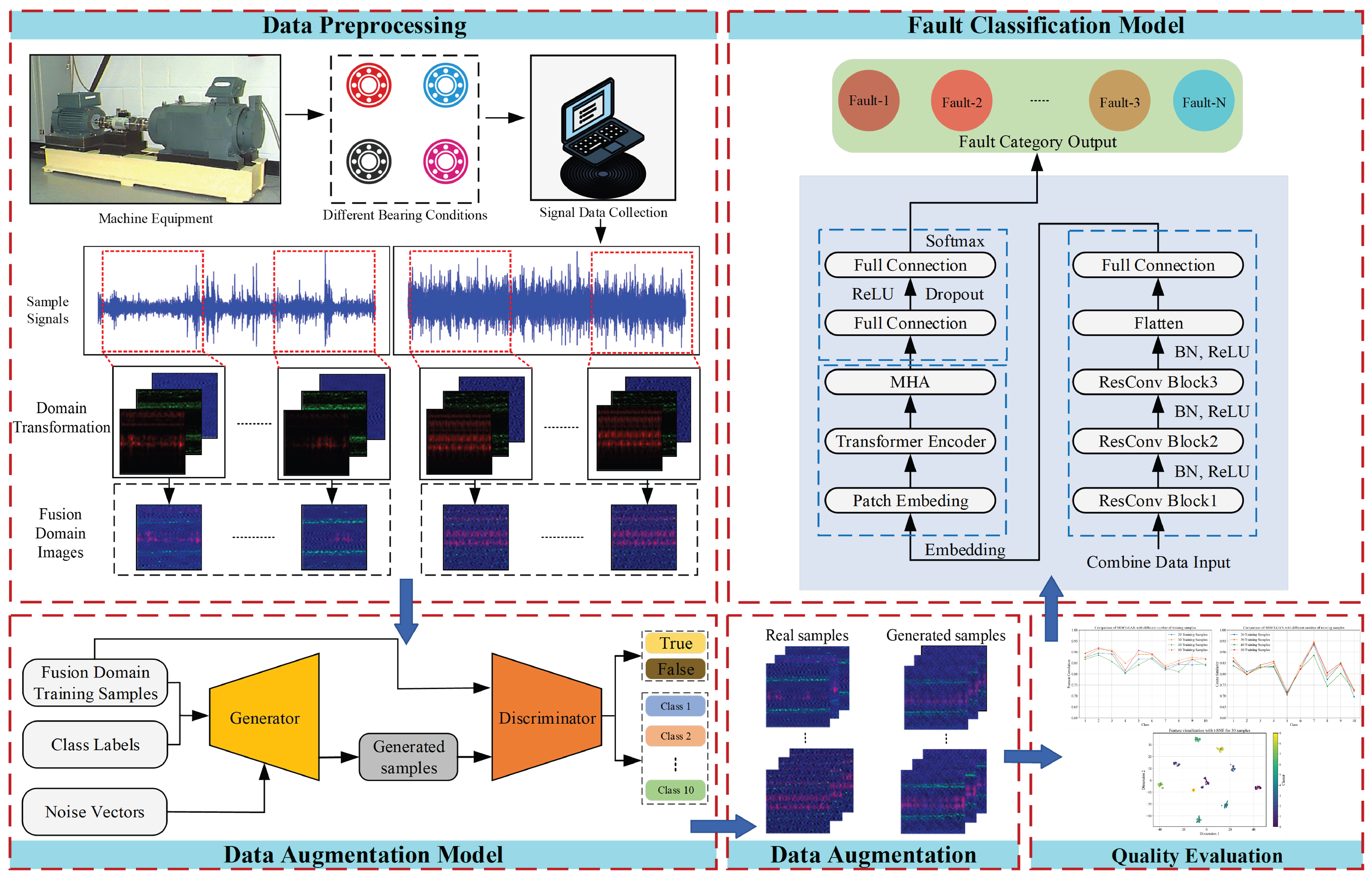
Figure 3 illustrates the overall framework of the fault diagnosis method based on MDFT-GAN. The method consists of three components: multi-domain data fusion, the data augmentation model, and the fault classification model. These components work together to achieve multi-domain feature representation, high-quality sample generation, and accurate fault classification.
The multi-domain feature representation process converts a one-dimensional vibration signal into a two-dimensional RGB image by extracting time-domain signals, frequency-domain features using the FFT, and time-frequency domain features via the STFT. This fusion retains the signal’s local details while capturing its global distribution characteristics, providing high-quality input for downstream tasks.
The data augmentation model employs the MDFT-GAN structure, comprising a generator (G) and a discriminator (D). The generator produces high-quality samples by modeling multi-domain features, while the discriminator enhances the quality of sample generation through adversarial training. The model utilizes multi-level MDFT modules to extract both global and local features, accurately capturing the data distribution and alleviating the impact of sample imbalance on classification performance.
The fault classification model is structured as a hybrid feature extraction framework, incorporating a front-end convolutional module, a Transformer encoder, and an improved classification layer. Local features are extracted through the front-end convolutional module, while the Transformer encoder models global dependencies using a self-attention mechanism. Finally, the enhanced classification head ensures high-precision predictions across multiple fault categories.
In summary, this method enables efficient modeling and diagnosis of vibration signals by leveraging multi-domain information fusion, data augmentation, and classification framework optimization.
3.3. The Design of the Data Augmentation Model
Although ACGAN offers certain advantages in ensuring sample category consistency, it has significant limitations when dealing with complex working condition data: (1) it struggles to effectively capture both the global and local characteristics of the data; (2) under conditions of severe sample category imbalance, the generated samples fail to fully represent the characteristics of the real data. These limitations are particularly pronounced in complex multi-category fault scenarios, where the inability to accurately model the distribution of different categories in the generated samples reduces the robustness of the classification model.
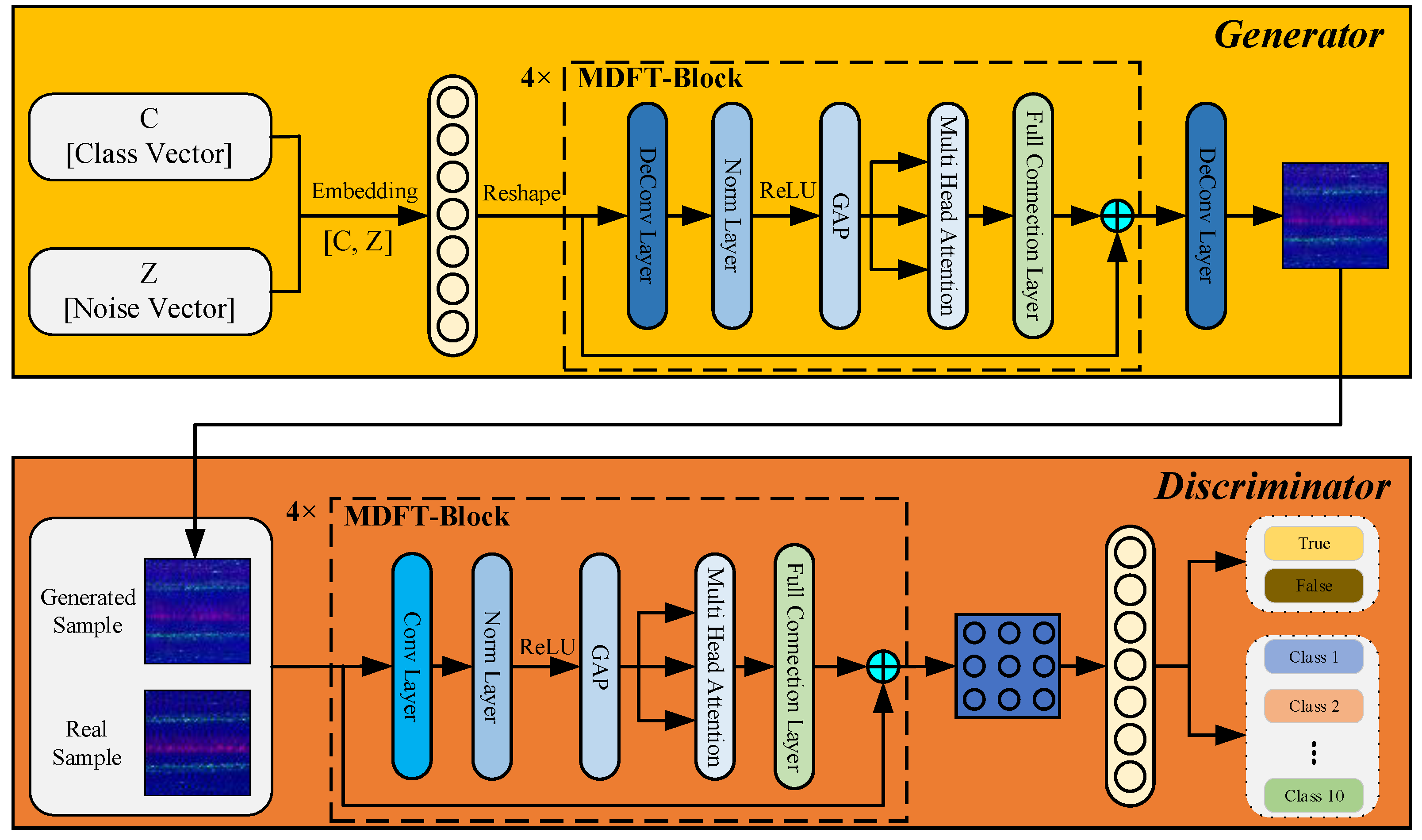
To address these shortcomings, this paper introduces MDFT-GAN, designed to generate high-resolution, high-fidelity samples that meet the generation requirements of multi-class complex fault data. The structure of MDFT-GAN is illustrated in
Figure 4.
The generator input consists of two components: (a) a noise vector, which is a randomly sampled latent vector used to introduce diversity in the generated samples, and (b) a category label vector, which is mapped to a high-dimensional feature vector through an embedding layer. The parameter matrix of the embedding layer is defined as follows:
where
is the number of categories and
is the embedding dimension. The noise vector
Z and category vector
C are element-wise multiplied to form joint features, which are then converted into a four-dimensional tensor. This tensor serves as the initial input to the MDFT module in the generator.
The MDFT module aims to construct an efficient and generalizable generative feature representation framework. By synergizing convolutional operations with a Transformer encoder, the module introduces a multi-domain feature modeling strategy, achieving a deep integration of local details and global information, rather than merely stacking modules. The MDFT module first extracts local features and retains spatial information using 2D convolution. Simultaneously, it innovatively integrates an attention mechanism with dynamic feature reallocation to address the challenge of high-dimensional feature interaction in complex data distributions.
Specifically, after convolutional feature extraction, the MDFT module introduces MHA, which dynamically adjusts feature weights between different channels according to the uneven distribution of global features. This approach not only captures the global dependencies of the generated features but also enhances the expressiveness of sparse features by optimizing attention distribution. This addresses the limitations of traditional attention mechanisms in processing high-dimensional data. Furthermore, the module incorporates ECA to refine feature interactions between channels. This not only improves the consistency of the generated samples under different category conditions but also significantly enhances feature representation in multi-class imbalance scenarios.
In addition, the MDFT module employs a unique normalization and feature mapping strategy to address the issue of modal mismatch in multi-domain feature fusion. The module utilizes multi-level feature modeling to efficiently capture both the global and local distributions of complex signals, providing a strong conditional constraint for the category relevance of generated samples. This design transcends traditional module stacking by seamlessly integrating feature extraction, enhancement, and redistribution, ensuring the stability and adaptability of MDFT-GAN in generating high-quality samples.
For an input feature
, each channel feature is first compressed along the spatial dimension using Global Average Pooling (GAP) to obtain a channel feature vector
Y. The process is as follows:
where c is the number of channels and
H and
W are the height and width of the feature map, respectively. Next, the channel features
are reshaped into a sequence format suitable for MHA calculations, serving as the input for subsequent dynamic modeling. To enable dynamic modeling of channel dependencies, MHA constructs the
Q,
K and
V through linear mappings, as follows:
where
represents the dimension of each attention head,
h is the number of attention heads, and
is the linear projection matrix. MHA captures long-distance dependencies between channels while incorporating multi-scale information representation capabilities. To further optimize the feature distribution, a normalization layer (NL) is applied before MHA to enhance training efficiency and mitigate overfitting. The process is as follows:
where
Y and
represent the embedding sequence and the MHA output, respectively, and
denotes the normalization operation. To improve feature selection accuracy, the ECA module optimizes feature weighting using an adaptive weight allocation mechanism, expressed as follows:
where
denotes the Sigmoid activation function and
is the output feature after channel attention weighting.
By combining MHA’s modeling of global channel dependencies with ECA’s dynamic weighting of channel features, the MDFT module effectively captures comprehensive feature information from the wide-area fused image.
In summary, the generator and discriminator of MDFT-GAN are constructed using multiple MDFT modules, enabling the comprehensive representation of both global and local signal information. This design significantly improves generation quality and discrimination accuracy, providing robust support for high-quality sample generation and precise fault classification.
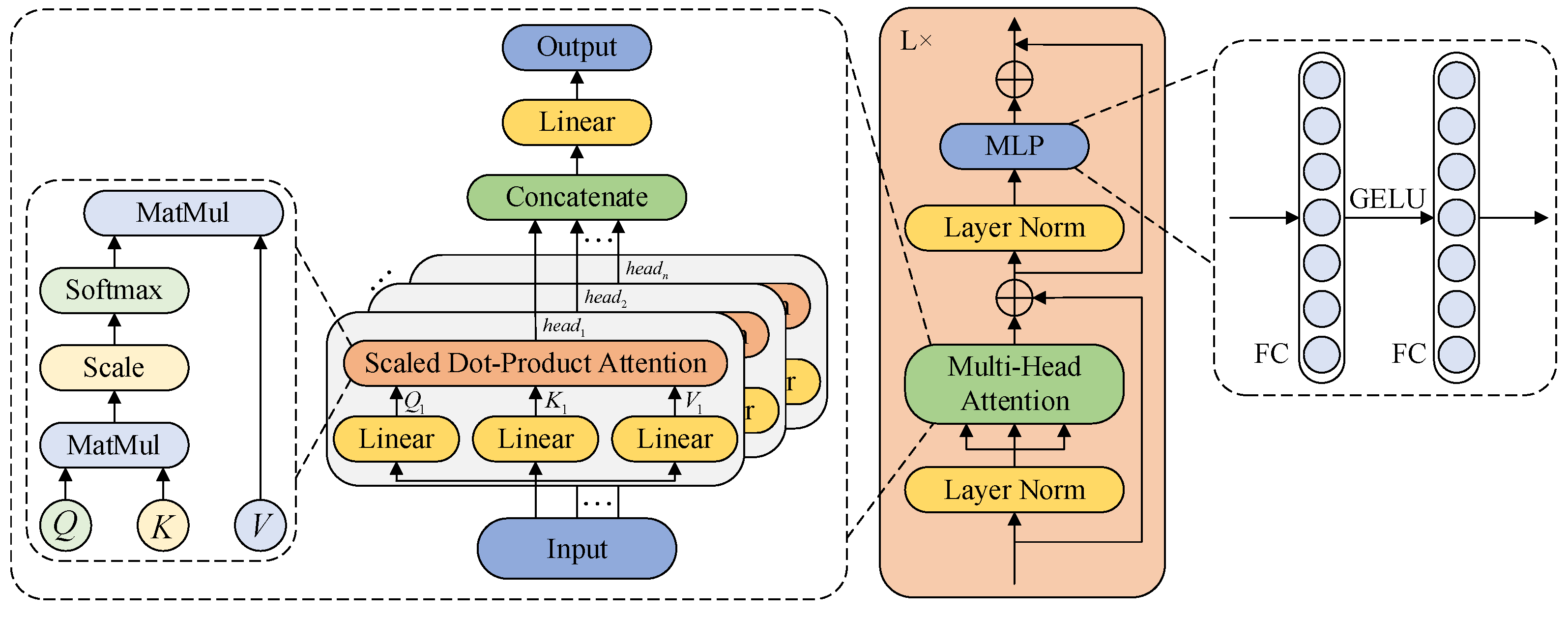
3.4. The Design of Classification Model
The main problem of current bearing fault classification models is that they cannot effectively capture multi-scale features. Traditional CNNs are able to extract local features, but it is difficult to model global information, while Transformer is good at capturing global features but underperforms in detail feature extraction. To solve this problem, we improved the ViT model [
30], and in this paper, we propose an enhanced hybrid visual transformer (EH-ViT) model, which combines the local feature extraction capability of CNN and the global modeling advantage of the transformer. The model extracts local features through a convolutional front-end, utilizes multi-head self-attention and feed-forward networks for global feature modeling, and introduces a two-stage feature selection mechanism in the classification layer, which effectively improves the representation and classification performance of global features. The EH-ViT demonstrates excellent multi-category classification performance in bearing fault diagnosis tasks and is able to accurately capture the complex relationship between local and global features while at the same time demonstrating excellent classification performance in the face of unbalanced data and diverse fault modes. EH-ViT demonstrates strong adaptability and robustness in the face of unbalanced data and diverse failure modes.
3.5. Model Training Procedure
The training process of the data augmentation model is shown in Algorithm 1.
| Algorithm 1 Training Process of the MDFT-GAN |
- Require:
Training epochs E, batch size B, noise dimension Z, number of classes C, Generator G, Discriminator D, Learning rates and , Gradient penalty coefficient , data loader - Ensure:
Trained Generator G and Discriminator D - 1:
Initialize Generator G and Discriminator D networks with random weights - 2:
Initialize Adam optimizers for G and D with learning rates and - 3:
for each epoch do - 4:
for each batch do - 5:
Sample real data: - 6:
Sample noise and labels: - 7:
Generate fake data: - 8:
(a) Train Discriminator: - 9:
Discriminator outputs , - 10:
Adversarial and auxiliary loss: - 11:
- 12:
- 13:
Apply gradient penalty: - 14:
Total loss of discriminator: - 15:
Update Discriminator parameters: - 16:
(b) Train Generator (every steps): - 17:
Generate fake data: - 18:
Generator output: - 19:
Total loss of generator: - 20:
Update Generator parameters: - 21:
end for - 22:
end for - 23:
Save the trained models: Generator G, Discriminator D
|
To ensure the effectiveness and robustness of both the data augmentation model and the fault classification model, this paper implements two independent training mechanisms.
The loss function of the discriminator consists of two components: classification loss and category classification loss. For real samples
, the real sample loss
is defined as:
where
represents the true label. For generated samples
, the generated loss
is defined as:
where
denotes the generated label. To improve training stability, a Gradient Penalty (GP) term is introduced:
where
is a regularization parameter. Consequently, the total loss of the discriminator is expressed as:
The objective of the generator is to deceive the discriminator while ensuring that the generated samples are assigned the correct class labels. The generator’s loss function is defined as:
The fault classification model achieves accurate recognition of different fault modes through supervised learning and is optimized using a cross-entropy-based loss function. To further enhance model performance, real and generated data are combined for training. The loss function of the fault classification model is defined as:
3.6. Mdft-Gan Based Fault Diagnosis Steps
To summarize, the fault diagnosis process based on MDFT-GAN includes the following five steps.
Step 1: Collection of the original bearing vibration signals and construction of a dataset. The dataset includes signals from various operating conditions, encompassing normal signals and multiple fault modes. A multi-domain fusion method is applied to preprocess the one-dimensional signals into multi-domain two-dimensional images. The preprocessed dataset is then divided into training and test sets.
Step 2: Establishment of an MDFT-GAN-based data augmentation framework and initialization of the model parameters. The generator and discriminator are trained using an adversarial learning mechanism. The generator employs the MDFT module to produce high-quality data, while the discriminator applies multi-domain feature distribution learning to differentiate between real and synthetic signals and perform supervised classification.
Step 3: Use of the trained MDFT-GAN generator to create high-quality synthetic data. The generated data are automatically labeled with fault categories based on the input category labels.
Step 4: Quantitative evaluation of the quality of the generated data using metrics such as SSIM and PSNR. The high-quality synthetic data are combined with real data to construct an augmented dataset, thereby expanding the training set and improving the model’s generalization ability.
Step 5: Training of the fault classification model using the augmented dataset. The classifier learns pattern features from both real and synthetic data. Finally, the classification model on the test dataset is validated to assess its fault diagnosis performance and ensure high accuracy, even with limited training data.
In summary, MDFT-GAN not only generates high-quality synthetic data but also significantly enhances the accuracy and robustness of fault classification. By expanding the training dataset and improving its feature distribution, it provides an effective solution for small-sample fault diagnosis tasks.
4. Experiments and Analysis of Results
4.1. Mdft-Gan Based Fault Diagnosis Steps
To validate the effectiveness of the rolling bearing fault diagnosis method based on MDFT-GAN proposed in this paper, extensive experiments and data analysis were conducted on two case datasets: the CWRU dataset [
31,
32] and the Jiangnan University dataset [
33]. The experimental process was divided into three stages. First, MDFT-GAN was trained using preprocessed data to generate high-quality synthetic samples. Second, the quality of the generated samples was evaluated using sample quality assessment metrics. Third, the generated samples were combined with the original samples to expand the training dataset for fault diagnosis model training. The effectiveness and superiority of the MDFT-GAN-based method were demonstrated by comparing its performance with several state-of-the-art fault diagnosis methods.
The method was implemented using the PyTorch deep learning framework in Python 3.11. The development environment was Pycharm 2023, and the experimental hardware configuration included an Intel Xeon Platinum 8362 CPU and an NVIDIA GeForce RTX 3090 GPU. The hyper-parameter settings for the modeling process are detailed in
Table 1. The network structure of the proposed methodology is shown in
Table 2.
4.2. Sample Quality Evaluation Indicator
To evaluate the data generation capability of MDFT-GAN, this paper adopts a joint evaluation method based on sample quality metrics. This method includes Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index Measure (SSIM), cosine similarity, and Pearson correlation coefficient, all of which are widely used in computer vision [
34,
35,
36,
37]. These four metrics comprehensively assess pixel error, perceptual error, and feature distribution, providing a holistic evaluation of the quality of the generated images. The generative models used for comparison in this paper are GAN [
18], ACGAN [
28], DCGAN [
38], WCGAN-GP [
20], and the MDFT-GAN proposed in this paper.
PSNR quantifies the overall pixel error between the generated image and the original image. The formula for PSNR is as follows:
where MSE denotes the mean square error;
M and
N denote the width and height of the image respectively;
and
are the pixel values of the original and generated images, respectively; and
represents the maximum possible pixel value.
SSIM evaluates the perceptual similarity between the generated image and the original image. Its formula is as follows:
where
and
are the means of the two images;
and
are their variances;
denote the covariance of the two images, respectively;
and
are constants to ensure computational stability.
Cosine similarity (CS) measures the angular similarity between the original and generated images and is calculated as:
where
x and
y represent the vectorized forms of the two images.
Pearson correlation (PC) coefficient assesses the linear correlation between the original and generated images. It is defined as:
where
and
are the
ith pixel values of the two images;
and
are their mean pixel values; and
N is the total number of pixels.
4.3. Data Preprocessing
The vibration signals of rolling bearings are inherently nonlinear and nonsmooth, and the signals collected by sensors often include random noise and shock interference. As a result, direct feature extraction and sample generation from one-dimensional vibration signals tend to be less effective. However, when these signals are transformed into images, the extracted patterns and features more intuitively reflect the dynamic changes in the signals. To fully leverage the limited vibration signal data, RGB images are generated by fusing time-domain, frequency-domain, and time-frequency domain information.
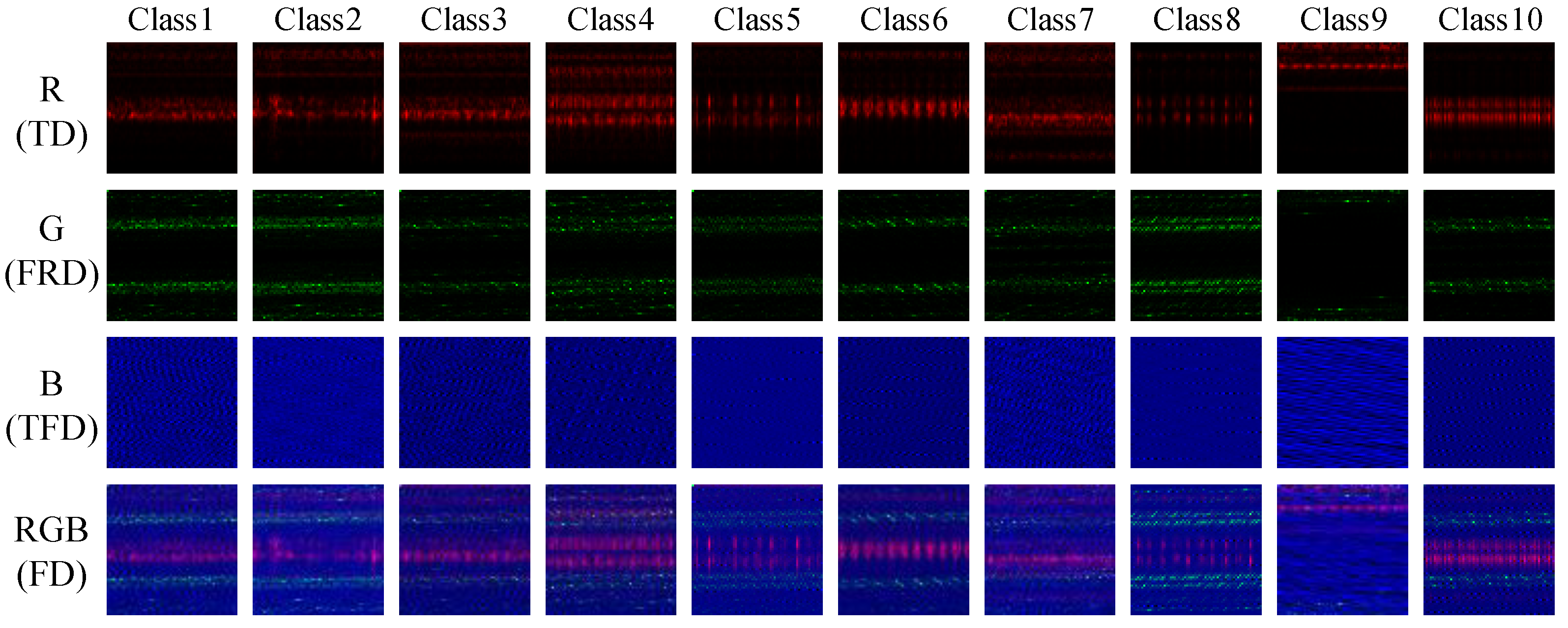
Figure 5 illustrates the corresponding images for the ten categories of CWRU bearing states across the time domain (TD), frequency domain (FRD), time-frequency domain (TFD), and fusion domain (FD).
The time-domain transformation retains the temporal characteristics of the original signal, while the time-frequency domain transformation captures the dynamic variations within the signals. By employing multi-domain feature fusion, the model effectively captures the nonlinear and nonsmooth characteristics associated with complex mechanical failures, enabling improved feature extraction and fault analysis.
To ensure consistent visual representation, all generated RGB images were constructed by normalizing each of the time-domain, frequency-domain, and time-frequency domain channels to the [0, 255] range. These normalized values were rendered using the standard RGB colormap without additional contrast enhancement or nonlinear remapping in order to faithfully preserve the structural properties of the signal transformations. All subfigures use consistent image dimensions and interpolation settings to support fair cross-model visual comparison.
4.4. Case Study 1: CWRU Dataset
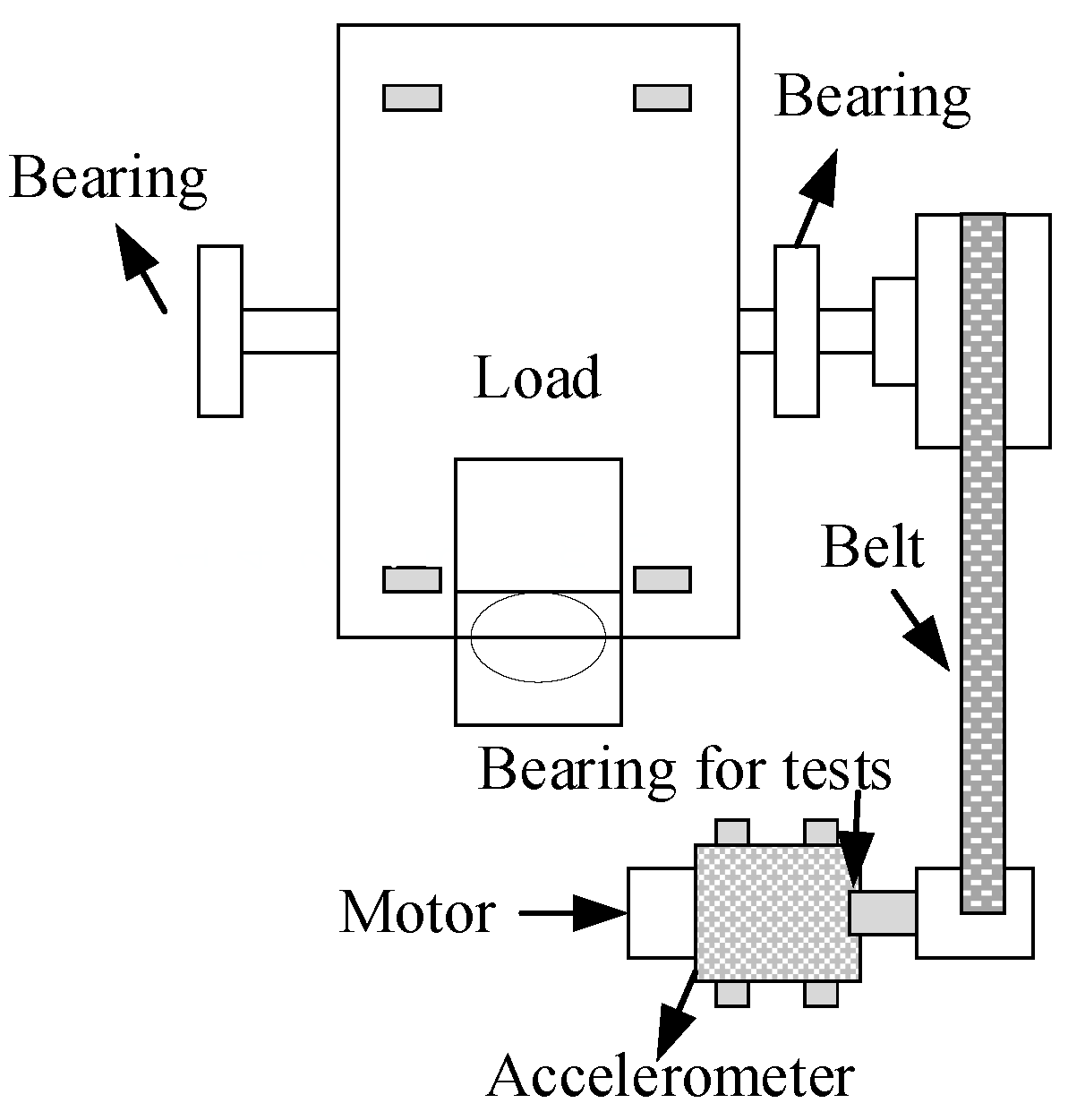
This case utilizes a bearing dataset published by Case Western Reserve University (CWRU), which is widely used to evaluate bearing fault diagnosis performance and is publicly accessible through the Bearing Data Center website. The data were collected using the equipment depicted in
Figure 6, which includes motors, torque sensors/encoders, and control electronics. The dataset comprises vibration signals for four bearing states: ball fault (BF), inner ring fault (IRF), outer ring fault (ORF), and normal (N). Each condition includes various damage diameters (e.g., 0.007, 0.014, 0.021 inches), and the sampling frequencies available are 12 kHz and 48 kHz.
In this paper, vibration signal data for four bearing states sampled at 12 kHz were selected. This selection resulted in a total of 10 bearing state categories. Each signal was divided into sample blocks of length 4096, and overlapping sampling (with an overlap size of 2048) was applied to mitigate boundary effects during preprocessing. A detailed description of the data is provided in
Table 3.
4.4.1. Data Augmentation Model Evaluation
To assess the data generation capability of the MDFT-GAN model under varying conditions, performance tests are conducted with limited training data, with sample sizes of 50, 40, 30, and 20 per category. A detailed analysis is presented for the case with 50 samples per category.
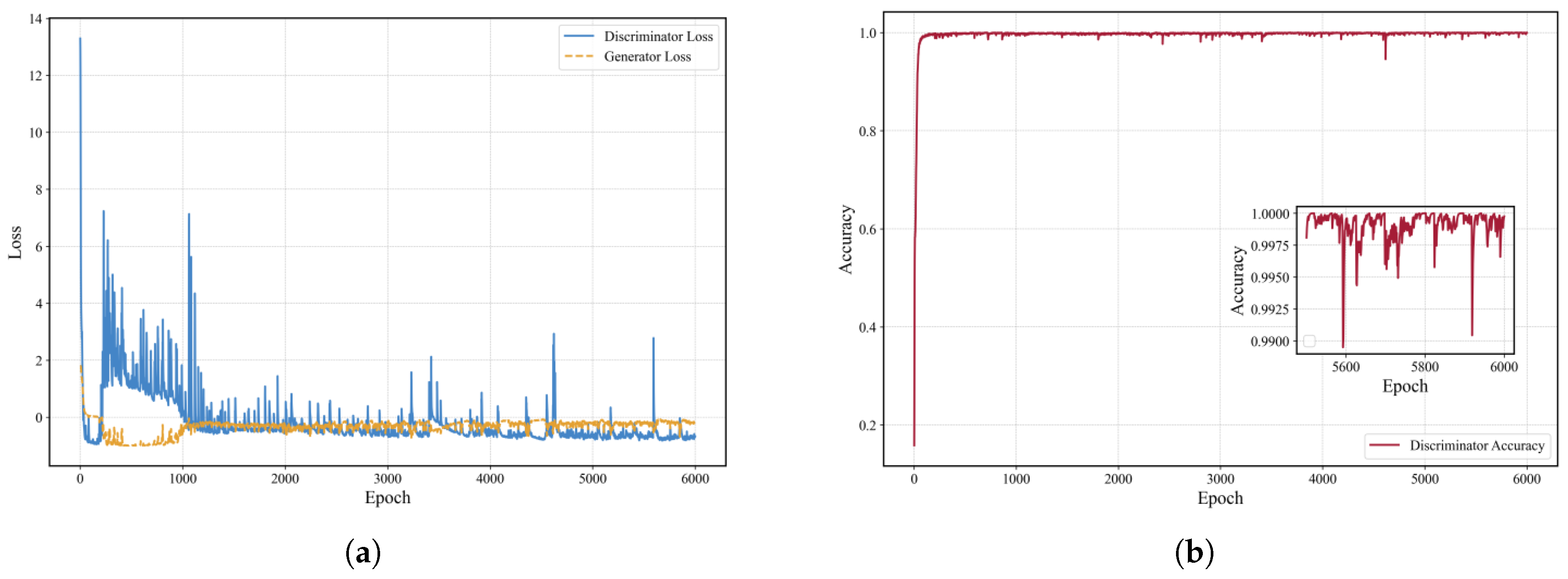
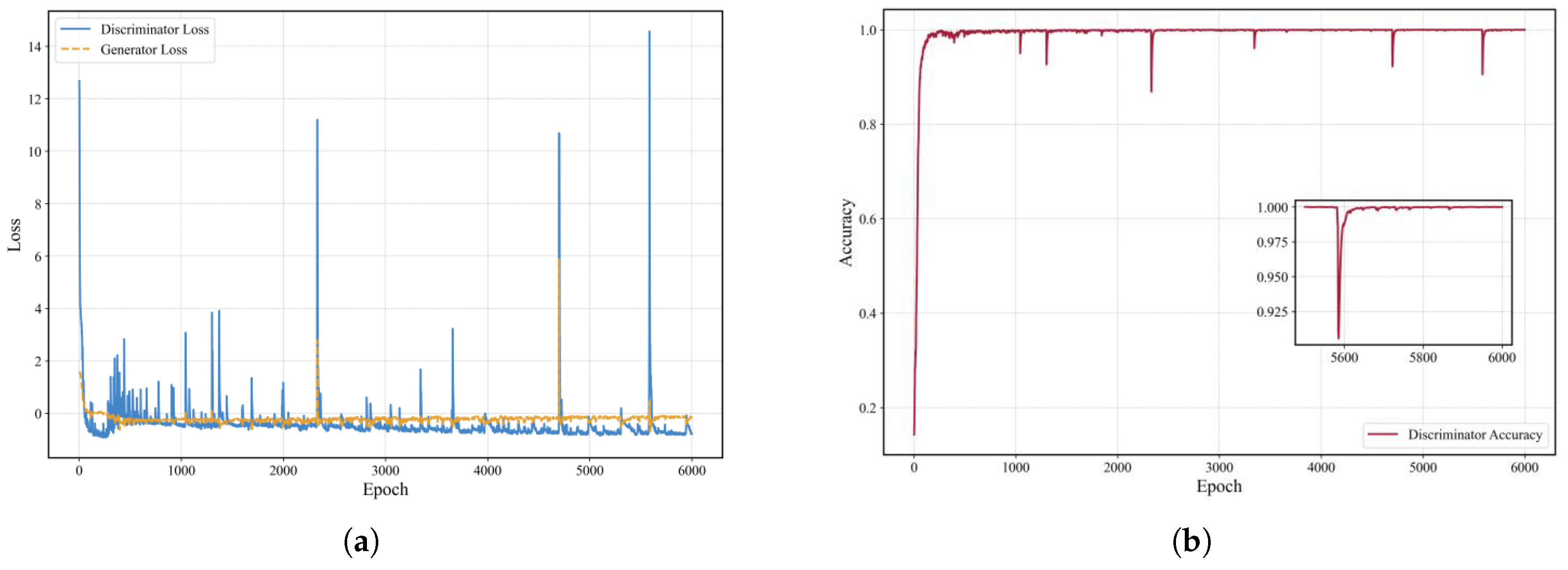
Figure 7 shows the model training progression under this condition. The loss curve reveals that during the first 2000 epochs, the generator and discriminator engage in intense adversarial training, causing significant fluctuations in loss. Between 2000 and 4000 epochs, the generator persistently attempts to deceive the discriminator, while the discriminator adapts to more effectively distinguish generated data. By 4000 to 6000 epochs, the system reaches a relatively stable state, indicating convergence. As illustrated in
Figure 7, the discriminator’s accuracy steadily improves throughout the training, approaching 1 by the end, demonstrating successful adaptation to the generated data and achievement of a steady state.
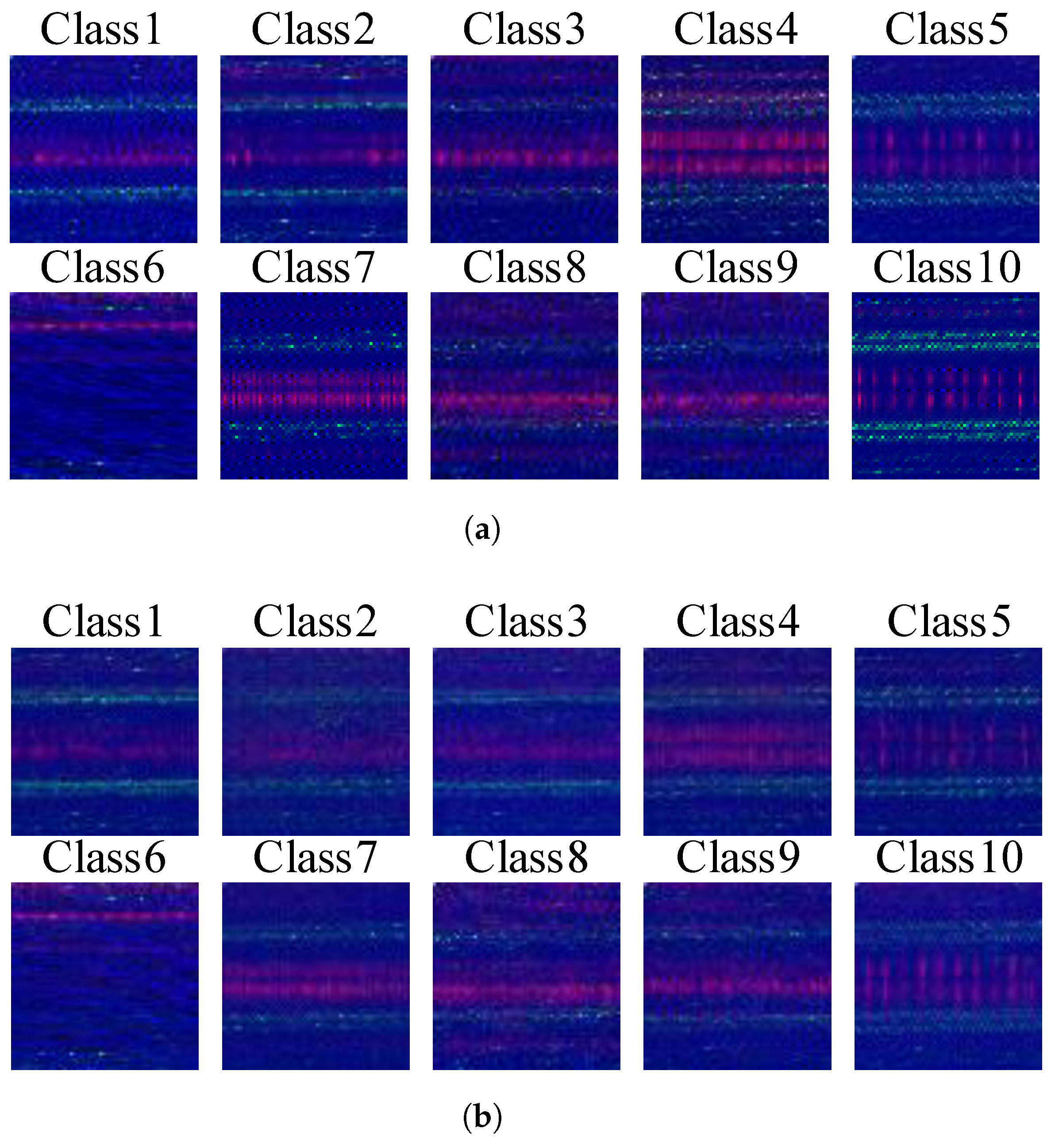
Figure 8 presents the 10 classes of signal samples generated by the MDFT-GAN model after training under the 50-sample condition, alongside their corresponding original training samples. It is evident that the images generated by MDFT-GAN closely resemble the original samples in terms of texture, state, and feature distribution. The absence of noticeable artifacts or significant noise further demonstrates the model’s exceptional signal generation capability and stability.
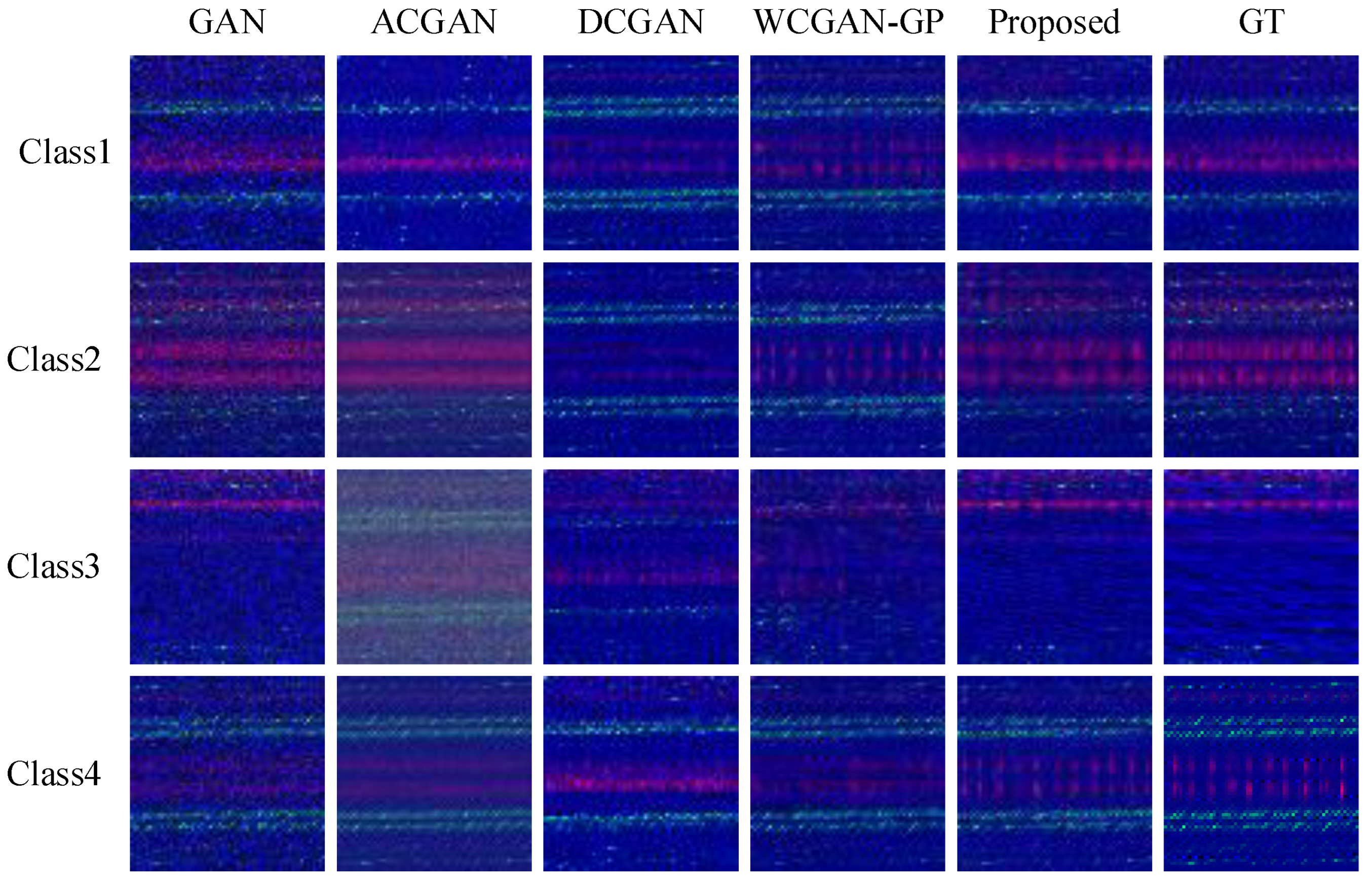
Figure 9 presents a qualitative comparison of generated samples across ten fault classes using four baseline generative models: GAN, ACGAN, DCGAN, and WCGAN-GP. Although these models can approximate coarse signal structures, clear discrepancies emerge in their ability to recover fault-discriminative features and maintain inter-class separability. GAN exhibits class-invariant high-frequency noise and texture collapse, especially in Classes 3 and 6, indicative of poor convergence and mode collapse. ACGAN alleviates some instability through label conditioning, yet suffers from oversmoothed representations in Classes 1 and 7, diluting crucial fault-specific frequency modulations. DCGAN introduces better periodicity, but its limited receptive field results in local inconsistency and spatial fragmentation—particularly visible in Classes 4 and 9—compromising semantic coherence. WCGAN-GP demonstrates improved noise suppression and global smoothness but lacks fine-grained detail restoration in Classes 2 and 8 due to the absence of cross-channel or contextual attention. These artifacts are not merely perceptual flaws; they reduce the fidelity of synthetic samples as training data and weaken their contribution to diagnostic learning. In contrast, the proposed MDFT-GAN effectively preserves both intra-class textural consistency and inter-class discriminative patterns as a result of its dual design: (i) multi-domain input encoding captures complementary signal characteristics across time, frequency, and time-frequency domains, and (ii) Transformer-based channel attention enhances global structural modeling while retaining fine detail. These design choices collectively enable the generation of diagnostically meaningful and visually faithful samples.
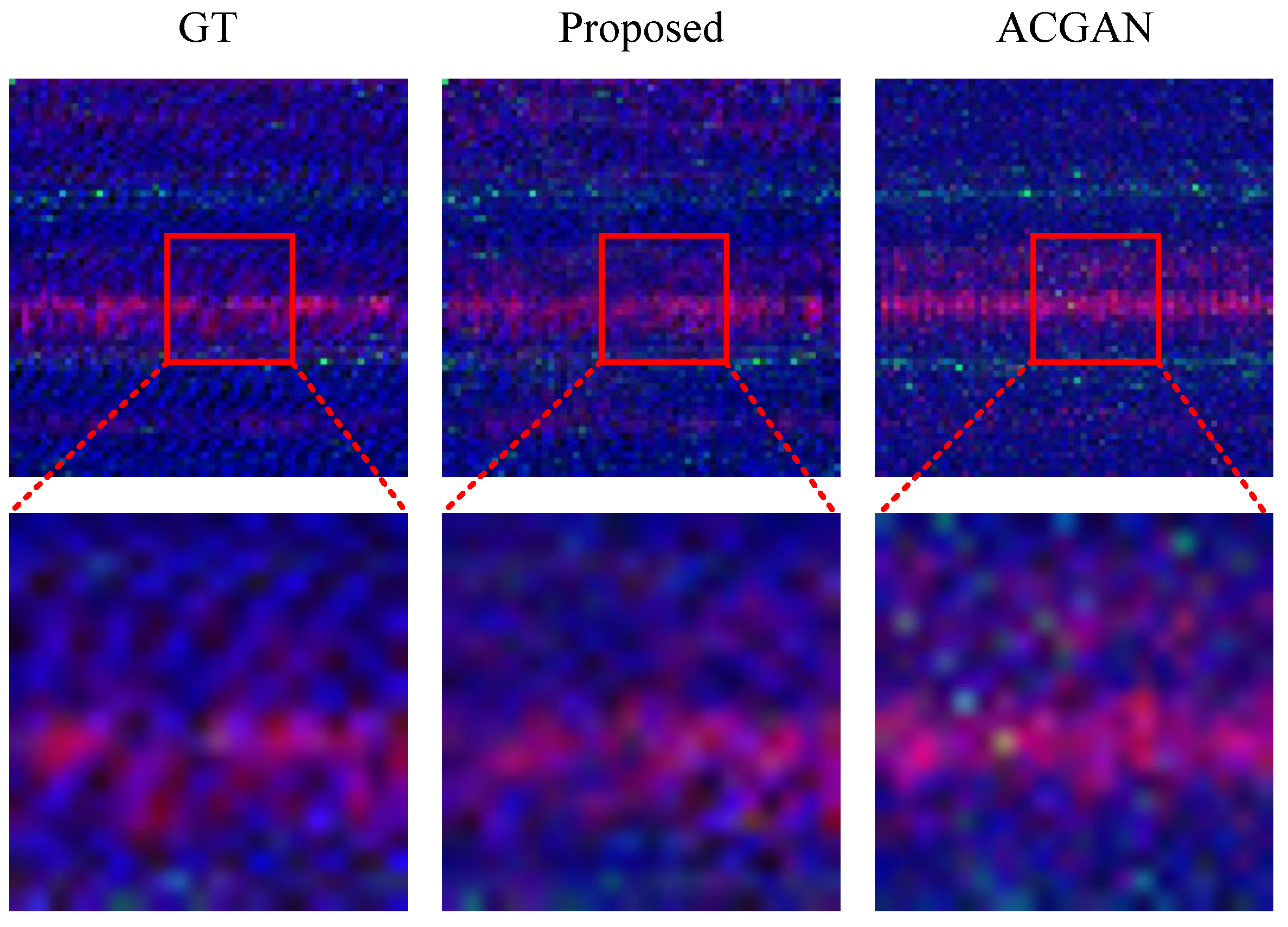
Figure 10 further compares the generation results of ACGAN and MDFT-GAN through localized zooming. In the zoomed-in areas, while the overall style of the ACGAN-generated images resembles the original samples, the restoration of texture details and feature distribution is clearly inadequate. In contrast, the signal samples generated by MDFT-GAN not only closely match the original images in terms of detail but also demonstrate greater stability during the generation process, significantly reducing artifacts and noise interference. This highlights MDFT-GAN’s ability to more accurately capture complex signal features, further validating its superiority in generation quality.
To rigorously evaluate the sample generation capability of MDFT-GAN, this study employs multiple quantitative metrics to assess image quality and similarity to real images. As shown in
Table 4 and
Figure 11, MDFT-GAN achieves the highest SSIM in most categories, with an average value of 0.91, demonstrating superior structural consistency and texture restoration. In terms of PSNR, MDFT-GAN slightly trails WGAN-GP but outperforms other models. Notably, for complex categories such as Class 7 and Class 9, it achieves the highest PSNR, highlighting its strong generative capacity for intricate visual structures.
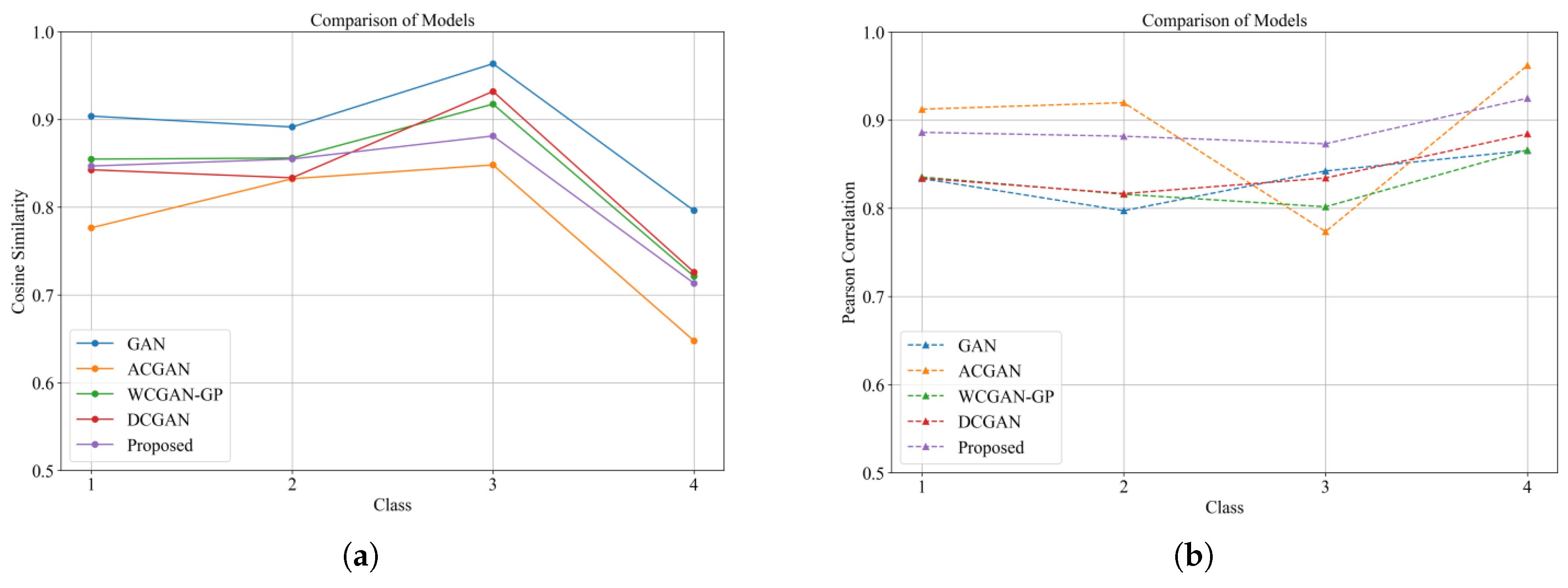
Figure 12a,b illustrate the cosine similarity and Pearson correlation coefficients of different models, respectively. MDFT-GAN consistently achieves high cosine similarity across categories, significantly outperforming other models, particularly in Categories 4, 5, and 10. Regarding Pearson correlation coefficients, MDFT-GAN shows a strong correlation close to 1.0 in most categories, indicating a superior fit to the real data distribution. In contrast, GAN exhibits significant fluctuations in correlation values across multiple categories. Although ACGAN and DCGAN show improvement over GAN, they still fall short of MDFT-GAN, particularly in complex categories.
To further evaluate the robustness of MDFT-GAN under limited sample conditions, experiments were conducted using different numbers of training samples, with results shown in
Table 5. The experimental settings included 20, 30, and 40 training samples, and the SSIM and PSNR performance of MDFT-GAN was compared across these sample sizes. The results indicate that as the number of training samples decreases, the performance of MDFT-GAN slightly declines, but the overall change remains minimal, demonstrating strong stability.
4.4.2. Fault Classification Model Evaluation
To validate the effectiveness of the data generated by MDFT-GAN in classification tasks, t-SNE was employed to visually analyze the feature distributions generated by different models. The comparison results are presented in
Figure 13 and
Table 6, along with the calculated accuracy and F1 scores of the classification task. The calculation formulas are as follows:
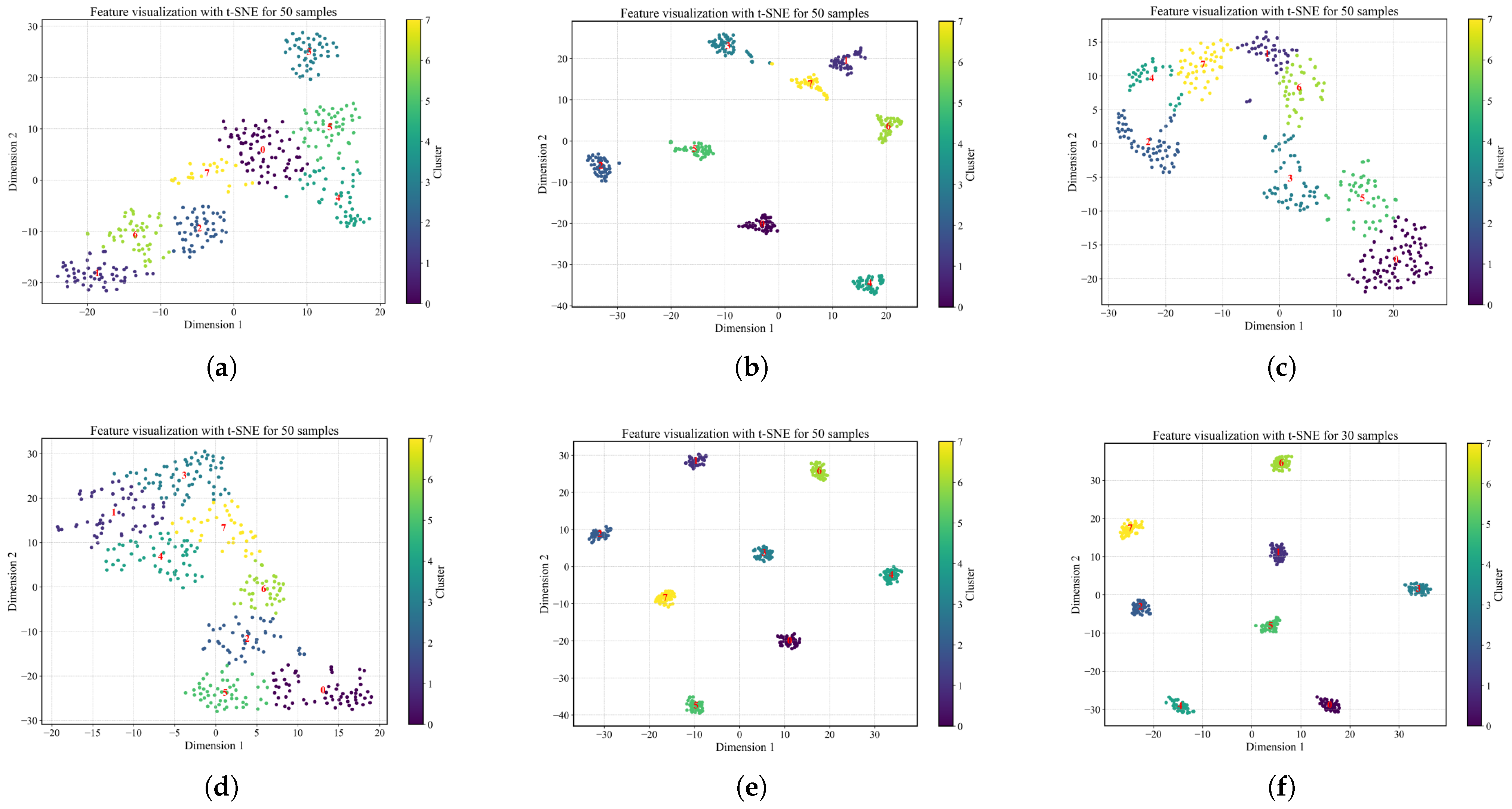
Figure 13a–f show the t-SNE feature distributions of the data generated by each model. From the clustering patterns of the feature distributions, it is evident that the data generated by MDFT-GAN exhibit compact clusters, with clear separation between classes and high consistency within classes. In contrast, the feature distributions generated by GAN and ACGAN show significant overlap, suggesting that the generated data lack distinguishability and are less representative of the real data. This indicates that the data generated by MDFT-GAN more accurately represent the true feature distribution and align closely with the real data.
Table 6 describes the effect of data generated by different models on the fault classification performance. With 50 samples per category, the proposed MDFT-GAN model achieves a classification accuracy of 99.41, which is significantly better than the compared models. In addition, MDFT-GAN has the highest F1 score of 99.53, showing its excellent classification performance and cross-category equalization results. Even when the number of samples in each category is reduced to 30, MDFT-GAN still maintains a classification accuracy of 98.69 and an F1 score of 98.74, which further validates its robustness under limited samples.
To validate the effectiveness of the proposed EH-ViT in generating data for classification tasks, this study compares its performance with several classical machine learning methods and deep learning models. The comparison methods include random forest (RaF), support vector machine (SVM), hierarchical CNN (HCNN), 2D-CNN, and 2D-ResNet. The experiments are evaluated using four metrics: accuracy, precision, recall, and F1 score, calculated as follows:
Table 7 shows that Random Forest and SVM have comparable performance in traditional machine learning methods. Among deep learning methods, hierarchical CNN performs better in F1. However, the classification performance of 2D-CNN and 2D-ResNet is low, especially 2D-ResNet, with an accuracy of 92.54 and an F1 score of 93.06. In contrast, the proposed method in this paper has significant advantages in all evaluation metrics and outperforms other models in all four metrics.
These results indicate that a classification model utilizing data generated by MDFT-GAN can more effectively capture data characteristics, delivering superior performance in both classification accuracy and stability.
4.5. Case Study 2: JNU Dataset
In this section, the experiments utilize the bearing fault diagnosis dataset provided by Jiangnan University. The data acquisition setup is illustrated in
Figure 14. The dataset encompasses four bearing operating states: normal (N), inner ring fault (IRF), outer ring fault (ORF), and rolling element fault (REF). Vibration signals were collected under various typical operating conditions at three motor speeds: 600 r/min, 800 r/min, and 1000 r/min. The signal data were recorded using a high-precision data acquisition device with a sampling frequency of 50 kHz, while a torque sensor was employed to measure power and speed during the experiments.
As shown in
Table 8, the experiment selected data from four operating states at rotational speeds of 600 r/min and 800 r/min. Given the relatively low rotational speed (600 r/min = 10 Hz), we ensured that each 4096-point sample (corresponding to 81.9 ms at 50 kHz) covers nearly a full rotation cycle. This temporal span allows the preservation of key low-frequency components associated with fault periodicity. Moreover, the use of FFT and STFT over the full window helps maintain adequate spectral resolution at lower frequencies.
4.5.1. Data Augmentation Model Evaluation
Figure 15 illustrates the loss function curve of the MDFT-GAN during training. In the initial stages, the generator’s loss gradually decreases, while the discriminator’s loss stabilizes, indicating that the MDFT-GAN has reached a dynamic equilibrium. Further demonstration of the model’s discriminative ability is shown in
Figure 15b by the discriminative accuracy curve. The figure shows that the discriminator’s accuracy increases rapidly during the early stages of training and approaches 1.0, signifying its ability to effectively distinguish between generated and real data. This validates the effectiveness of the training process for the MDFT-GAN.
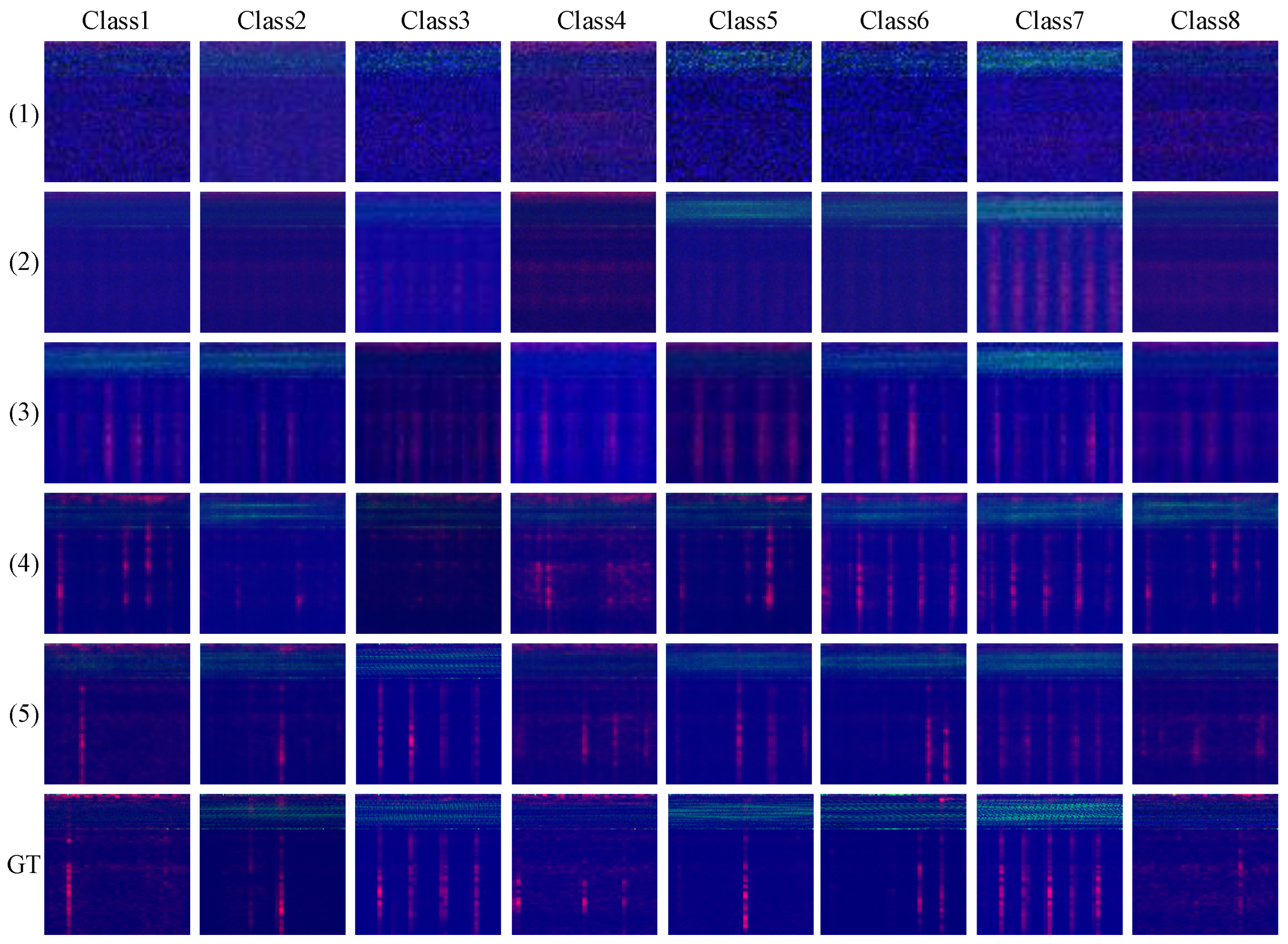
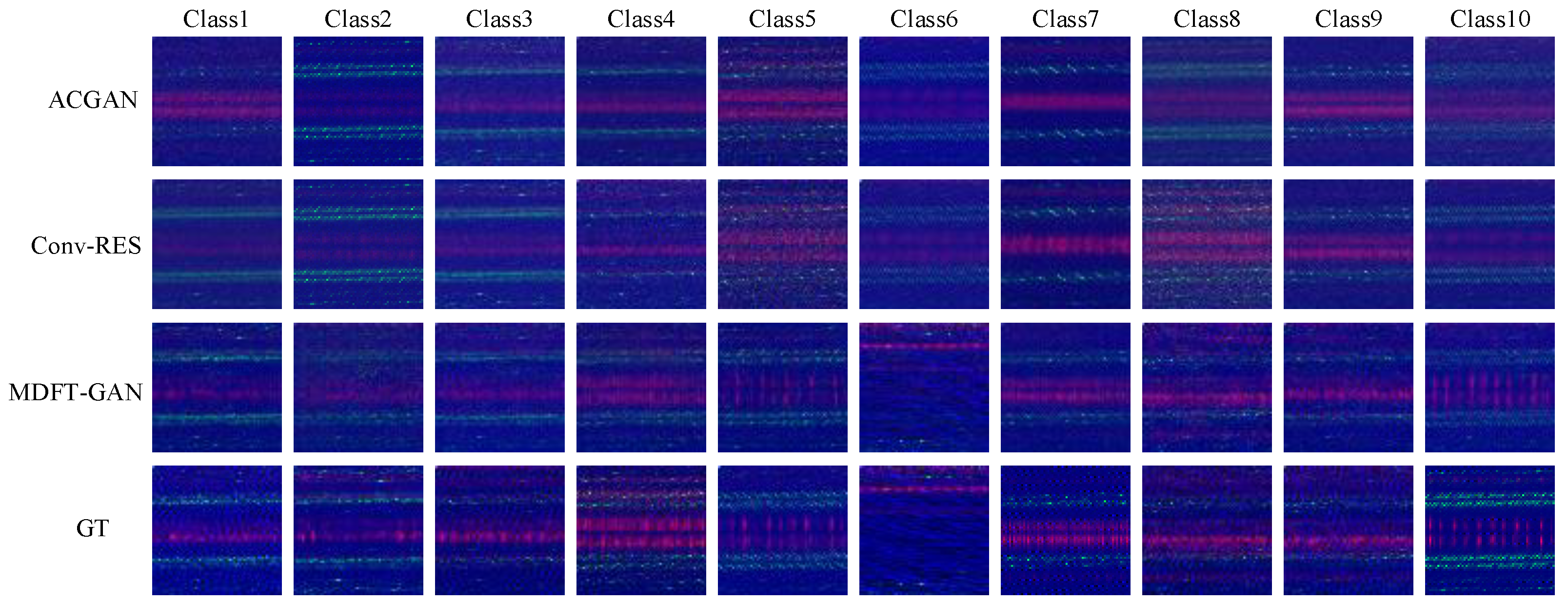
Figure 16 presents images of vibration signals generated by (1) GAN, (2) ACGAN, (3) DCGAN, (4) WCGAN-GP, and (5) MDFT-GAN across eight categories, compared with the ground truth (GT). The visual comparison indicates that MDFT-GAN demonstrates significant advantages in image detail preservation, texture distribution accuracy, and noise suppression, outperforming the other models. To be specific, images generated by GAN exhibit significant random noise and lower overall quality. ACGAN and WCGAN-GP improve the image quality partly, but still suffer from missing details and feature distortion. Compared to them, the images generated by MDFT-GAN are highly similar to real images in all categories. The generated signals have clear texture distribution and accurate feature details, showing excellent generation capabilities.
Figure 17a,b show the cosine similarity and Pearson correlation coefficient results for each model, respectively. Compared with other models, MDFT-GAN performs relatively well in terms of performance. It means that the images generated by MDFT-GAN can accurately capture the feature distribution of different categories.
To visualize the feature distribution of the generated data, t-SNE was used in
Figure 18 to reduce the dimensionality of the generated data features.
Figure 18a–f show that the MDFT-GAN generated data features have a compact distribution, with clear separation between classes, and effectively retain the structure of the real data features. The feature distributions generated by other models have intra-class mixing or inter-class overlap, and it is difficult to accurately distinguish them, especially at the category boundaries.
4.5.2. Fault Classification Model Evaluation
To evaluate the impact of generated data from different generative models on classification performance, this study compares GAN, ACGAN, WGAN-GP, DCGAN, and the proposed MDFT-GAN. The experimental results are presented in
Table 9. Although ACGAN and DCGAN are the better performers among the compared models, regarding MDFT-GAN, it outperforms all the other models with an accuracy of 99.91 and an F1 score of 99.90. Therefore, this suggests that superior data quality facilitates subsequent fault diagnosis.
To further validate the effectiveness of the classification model proposed in this paper, it was compared with several mainstream classification models. The results are detailed in
Table 10.
In machine learning models, due to the limitations of traditional feature extraction methods in capturing high-dimensional representations, the ability of random forests and support vector machines to classify complex fault signals remains limited. The performance of deep learning models varies, with 2D-ResNet performing relatively well, but with an accuracy of 98.12.
However, the proposed method performs the best on all evaluation metrics, achieving 99.25 on all metrics. These results highlight the superiority of MDFT-GAN in generating high-quality synthetic data and efficiently capturing the features of complex fault signals.
4.6. Imbalanced Training Sample Evaluation
To evaluate the generative ability of the MDFT-GAN model under data imbalance conditions, two imbalanced training sample settings were designed: (a) 4-classification: Under identical damage size conditions, the data volumes for different fault types are imbalanced. (b) 7-classification: Under varying combinations of damage sizes and fault types, the data volumes are imbalanced. The specific training data settings for these scenarios are detailed in
Table 11.
In the 4-class experiment, the dataset consists of four types: ballistic fault (BF), internal race fault (IRF), outer race fault (ORF), and normal (N). The damage size for each fault type is 0.007, and the sample sizes are 40, 30, 20, and 50, respectively. This reflects a significant imbalance in sample sizes between the different categories.
In the 7-class experiment, the dataset is expanded to include combinations of two different damage sizes (0.007 and 0.021), covering the same three fault types (BF, IRF, ORF) and the normal state (N). In this setting, the data imbalance is more pronounced, with differences in the number of samples not only across fault types but also within the same fault type under different damage sizes. For example, the sample size for Ball Fault is 40 for a damage size of 0.007 but drops to 20 for a damage size of 0.021. This experimental design more closely resembles the uneven data distribution typically encountered in real-world industrial scenarios.
Figure 19 and
Figure 20 show the images generated by the GAN family of models trained under four and seven classes of imbalance conditions. The results show that the proposed method significantly outperforms the other models in terms of detail restoration and global consistency. The images generated by GAN and ACGAN exhibit significant blurring and loss of detail, whereas WCGAN-GP, although it improves the contrast, still falls short of restoring complex textures. In contrast, the images generated by MDFT-GAN not only closely resemble the ground truth in terms of texture details, but also maintain a high degree of consistency in terms of global structure. This shows that the method is able to take into account both detailed and global features when generating high-quality images.
Figure 21 and
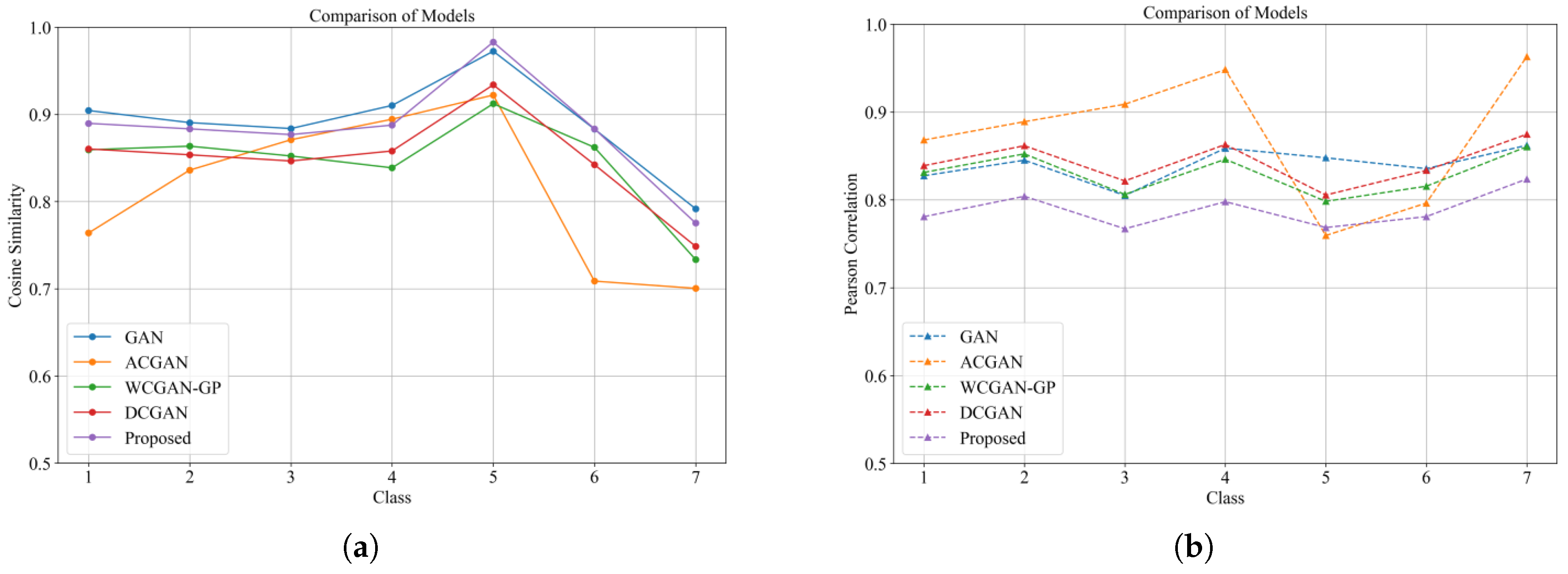
Figure 22 show the cosine similarity and Pearson correlation coefficient curves of the compared models, respectively. The results show that MDFT-GAN achieves high levels of cosine similarity and correlation in all categories, which emphasizes the excellent agreement between its generated image distributions and the real image distributions. Compared to other models, MDFT-GAN generates more stable samples with higher consistency with real image distributions.
Figure 23a,b show the confusion matrix results of the proposed model for four- and seven-category experiments, respectively; in the four-category experiments, the classification results show 100 accuracy for all categories, despite the imbalanced sample distribution. In the more complex seven-category experiment, the data variance is more pronounced, but the proposed model still exhibits excellent classification performance. Although slight classification errors were observed in the first and fourth categories, the overall classification performance was better.
These results confirm that MDFT-GAN can generate high-quality samples and exhibit excellent adaptability and robustness in the presence of multi-category and unbalanced data, making it a reliable solution for complex industrial diagnostic tasks.
4.7. Ablation Experiments
To verify the effectiveness of each module in the MDFT-GAN model and its contribution to overall performance, a series of ablation experiments were conducted, as summarized in
Table 12.
Figure 24 and
Figure 25 visually illustrate the results of the comparison. The comparison includes three model variants: ACGAN, ACGAN with Conv-RES, and MDFT-GAN. The visual quality and quantitative classification performance of the generated images highlights the contribution of each module to the overall improvement.
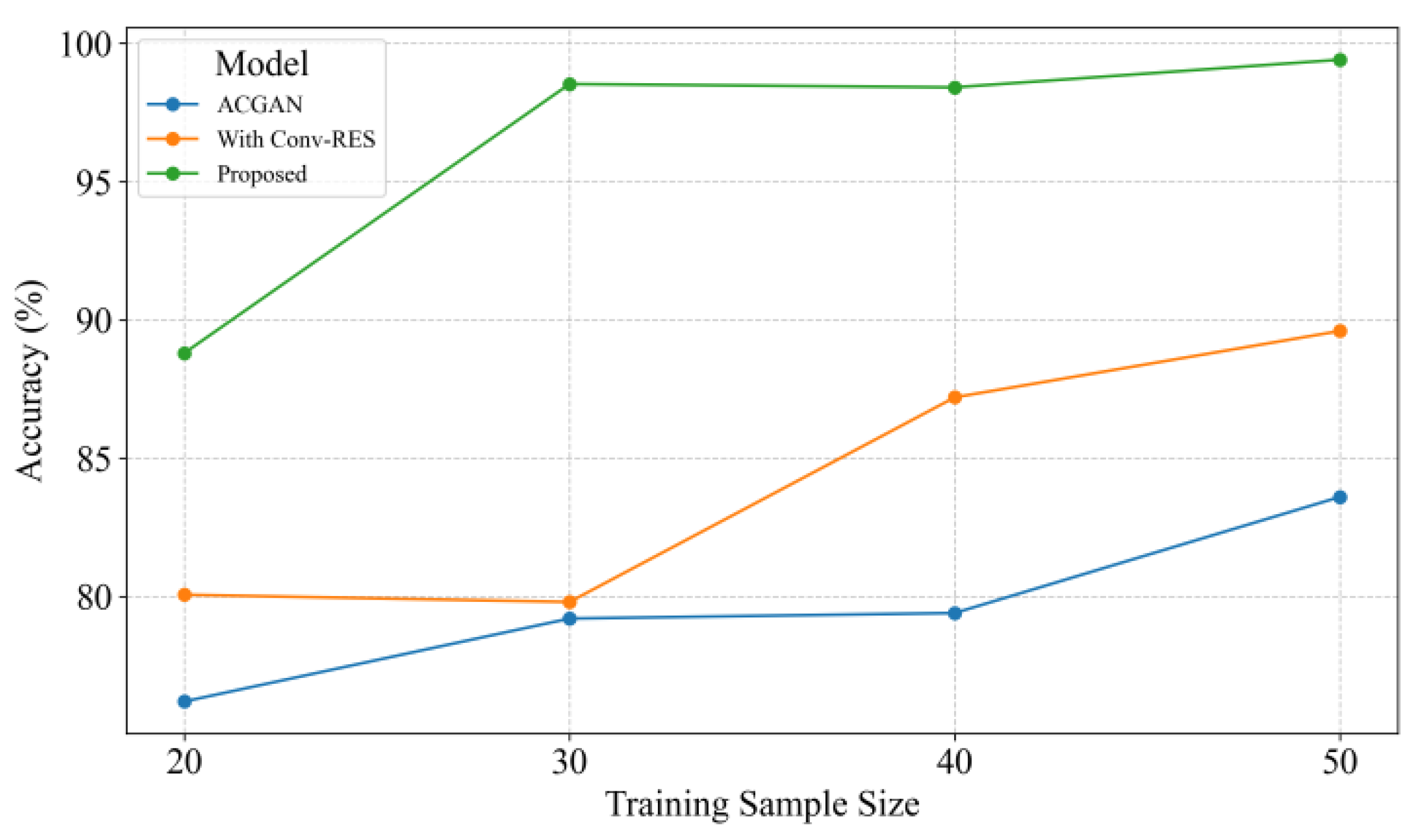
Obviously, the MDFT-GAN with Conv-RES and Transformer is highly consistent with the ground truth in terms of both local details and global distribution, thus greatly improving the quality of the generated samples. The classification accuracy results further validate the above conclusions: among 50 samples, the classification accuracy of ACGAN is 83.60, which is improved to 89.60 after the introduction of the Conv-RES module, which indicates that Conv-RES can effectively enhance the local feature extraction, and the classification accuracy reaches 99.41 after the Transformer is introduced.
4.8. Interpretability Analysis
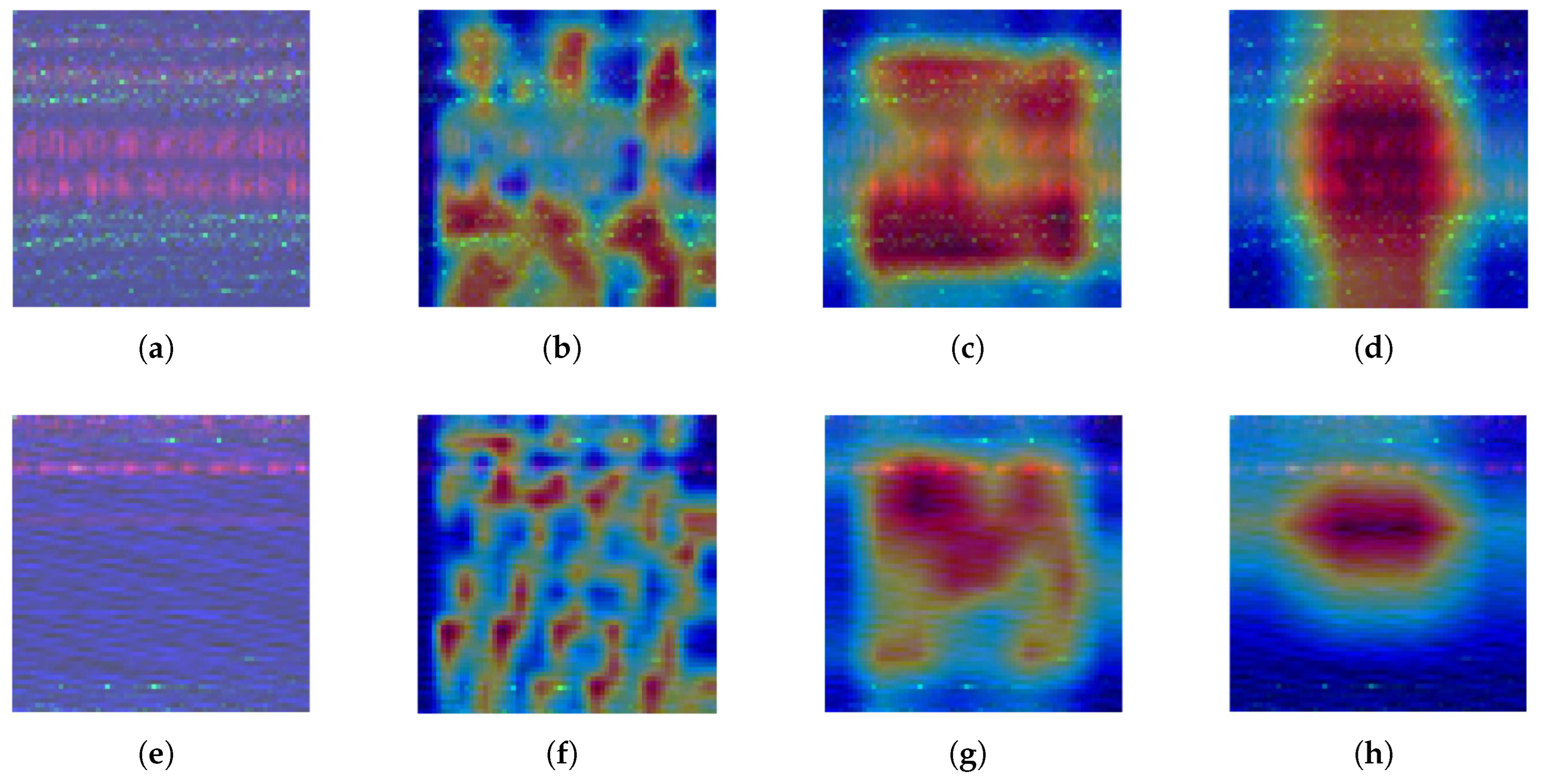
In order to further elucidate the hierarchical characterization mechanism of the MDFT-GAN discriminator in fault pattern recognition, the feature responses of Class 4 and Class 7 samples in the CWRU dataset at each discriminative layer are visualized based on the Grad-CAM method in this paper, as shown in
Figure 26.
The results show that in the shallow stage (
Figure 26a,e), the model mainly responds to the low-frequency periodic structure, which reflects its effective suppression of background noise and the modeling ability of spectral prior; the activation of the intermediate layer (
Figure 26b,f) is significantly enhanced, and the model begins to perceive the local non-stationary features, in which the activation of Class 4 samples concentrates in the amplitude mutation points, while Class 7 shows a multi-region sparse distribution, revealing the differential sensitivity mechanism of the model to local degradation features under different fault patterns.
In the high-level semantic space (
Figure 26c,d,g,h), the feature responses of the two classes of samples are further focused and show the trend of increasing intra-class consistency, with the activation of Class 4 expanding to the edge region to integrate extensive fault information, while Class 7 forms the discriminative core of center contraction, indicating that the model realizes the local nonsmooth features at the deeper level, with the activation of Class 4 concentrated at the amplitude mutation point, while Class 7 shows multi-region sparse distribution, which reveals the model’s differential sensitivity mechanism to local degradation features under different fault patterns.
This indicates that the model realizes class-specific semantic embedding and spatial aggregation at a deep level. The above activation evolution process systematically reveals the structural path of MDFT-GAN from low-level perception to high-level discrimination and demonstrates its discriminative robustness and semantic interpretability for complex fault types.
Overall, these results demonstrate the effectiveness and robustness of MDFT-GAN in modeling complex vibration signals and performing fault diagnosis. The model excels in both generation and classification tasks, providing a reliable solution for challenging diagnostic applications.
5. Conclusions
This study addresses the persistent challenge of bearing fault diagnosis in industrial applications, particularly under conditions of limited and imbalanced datasets. We introduced a novel Multi-Domain Feature Transformer Generative Adversarial Network (MDFT-GAN) that effectively augments data by transforming bearing signals into two-dimensional RGB images across time, frequency, and time-frequency domains. The integration of a Transformer encoder with an efficient channel attention mechanism within the MDFT submodule allows the MDFT-GAN to capture intricate global feature interactions and local dependencies, thereby generating high-quality synthetic samples. Additionally, the proposed enhanced hybrid vision transformer classification model, which combines front-end convolutional layers with residual connections, significantly improves the robustness and accuracy of fault classification.
Experimental evaluations conducted on the CWRU and Jiangnan University fault datasets demonstrate that the MDFT-GAN method substantially outperforms existing state-of-the-art approaches in terms of both robustness and diagnostic accuracy. These results underscore the efficacy of our approach in mitigating the limitations posed by scarce and unbalanced data, thereby advancing the reliability of bearing fault diagnosis in industrial settings.
Furthermore, a Grad-CAM-based interpretability framework is incorporated to visualize hierarchical feature activations within the discriminator and classifier, offering intuitive and quantitative insight into the model’s decision process and enhancing its transparency in real-world industrial deployment.
Future work will explore the application of MDFT-GAN to other types of industrial fault diagnosis and investigate how to integrate other domain-specific functions to further improve performance. In addition, more lightweight generative models will continue to be explored without compromising model performance.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}