
Bibliometric Insights into Time Series Forecasting and AI Research: Growth, Impact, and Future Directions



Abstract
1. Introduction
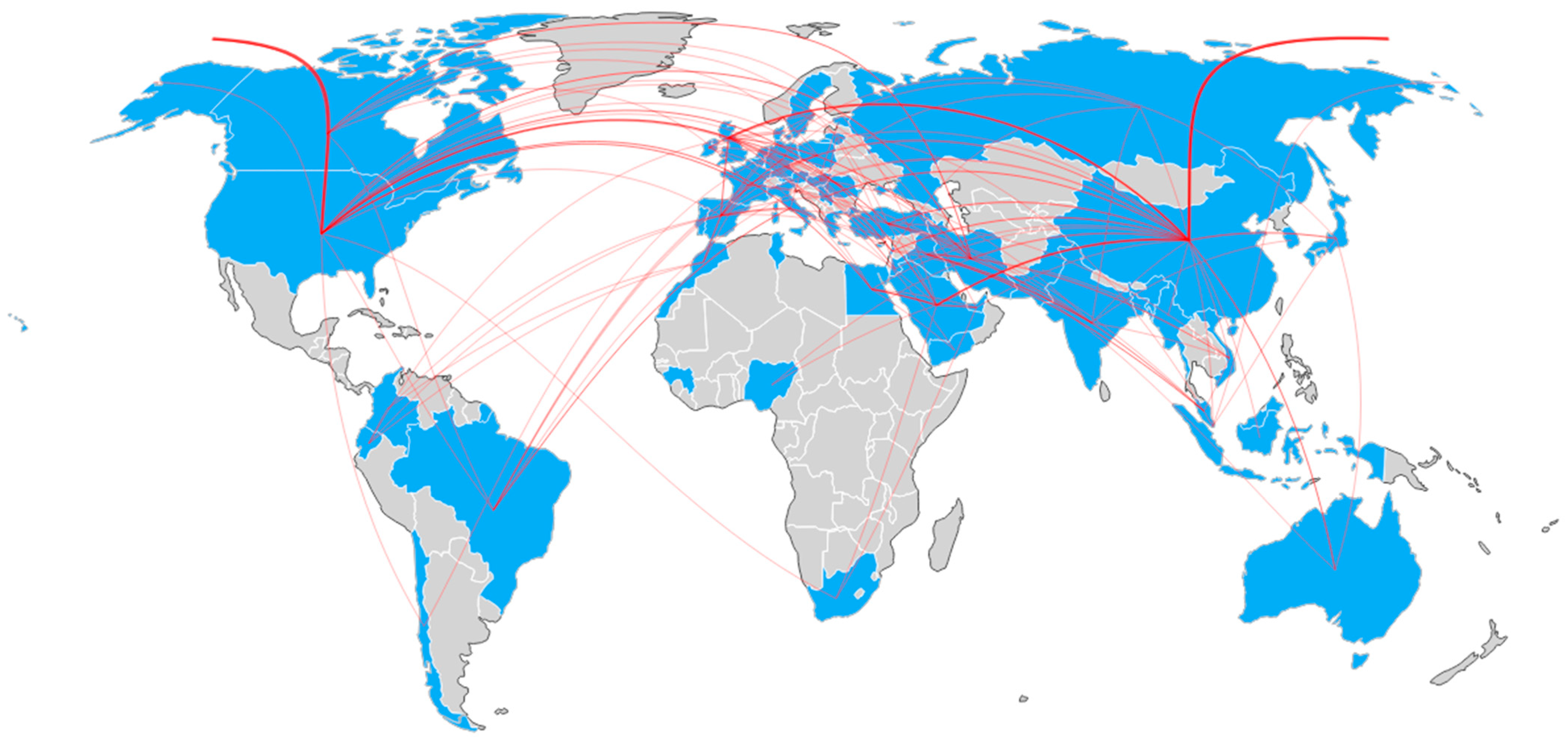
- SQ1: Are the authors contributing to this field likely to collaborate? If yes, what does the collaboration map look like?
- SQ2: What are the most relevant themes discussed in the time series and artificial intelligence topics?
- SQ3: Which countries are the most representative, taking into account the number of publications and citations?
- SQ4: What are the outcomes of the 10 most cited articles?
- SQ5: What are the sources with the highest impact based on the number of articles published?
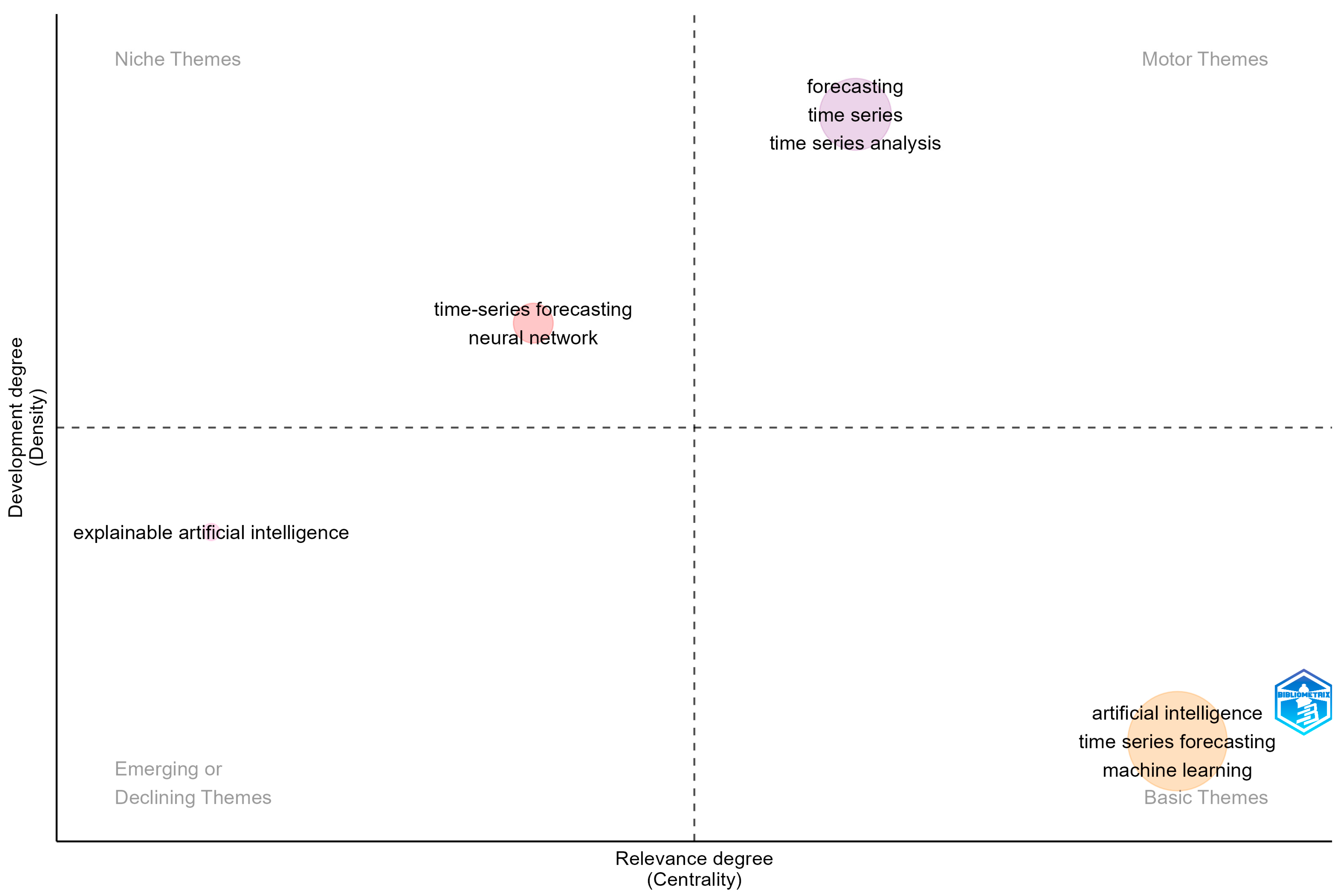
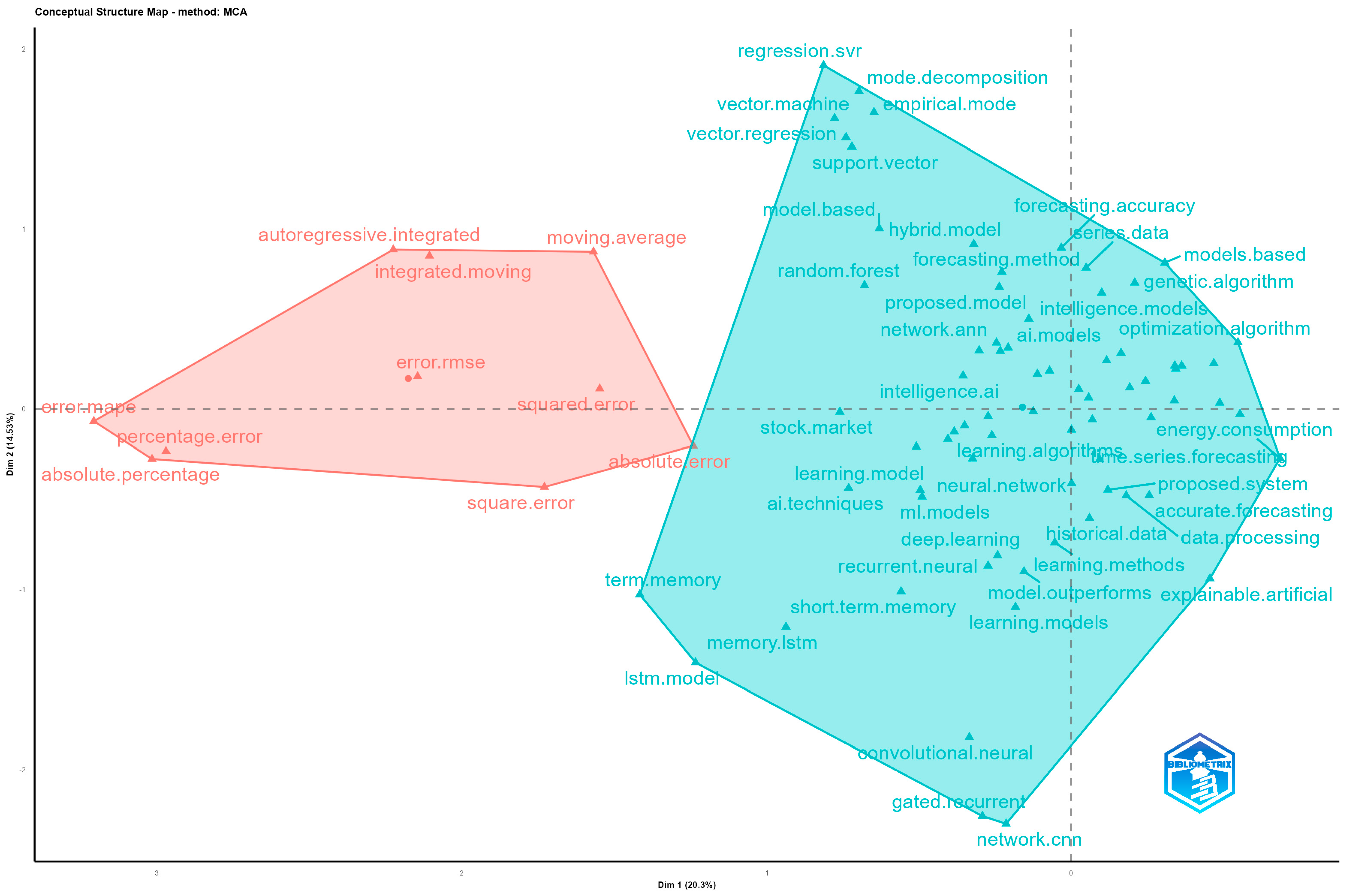
- SQ6: What are the main keywords included in the thematic graphical representation?
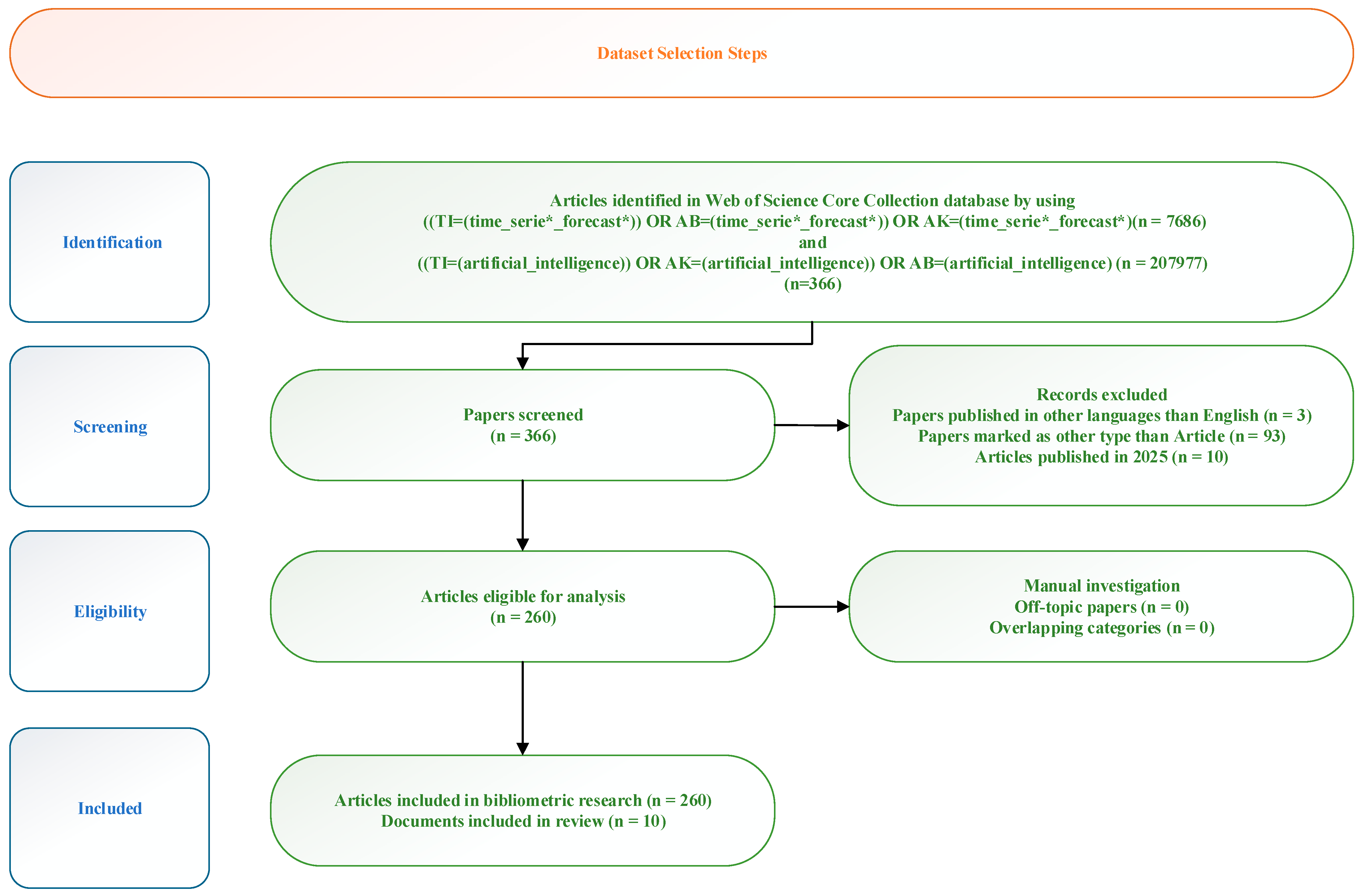
2. Materials and Methods
- Social Sciences Citation Index (SSCI)—1975–present;
- Book Citation Index—Science (BKCI-S)—2010–present;
- Emerging Sources Citations Index (ESCI)—2005–present;
- Science Citation Index Expanded (SCIE)—1900–present;
- Index Chemicus (IC)—2010–present;
- Book Citation Index—Social Sciences and Humanities (BKCI-SSH)—2010–present;
- Arts and Humanities Citation Index (A&HCI)—1975–present;
- Conference Proceedings Citation Index—Science (CPCI-S)—1990–present;
- Conference Proceedings Citation Index—Social Sciences and Humanities (CPCI-SSH)—1990–present;
- Current Chemical Reactions (CCR-Expanded)—2010–present;
3. Overview of Results
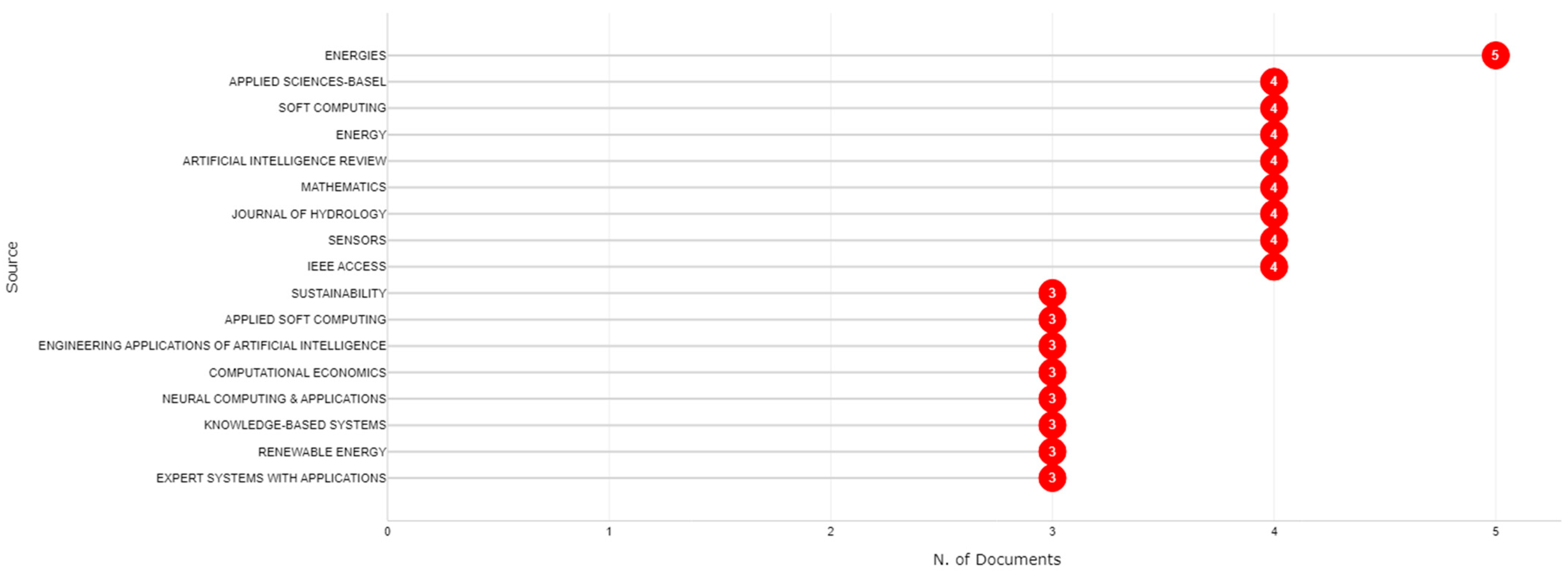
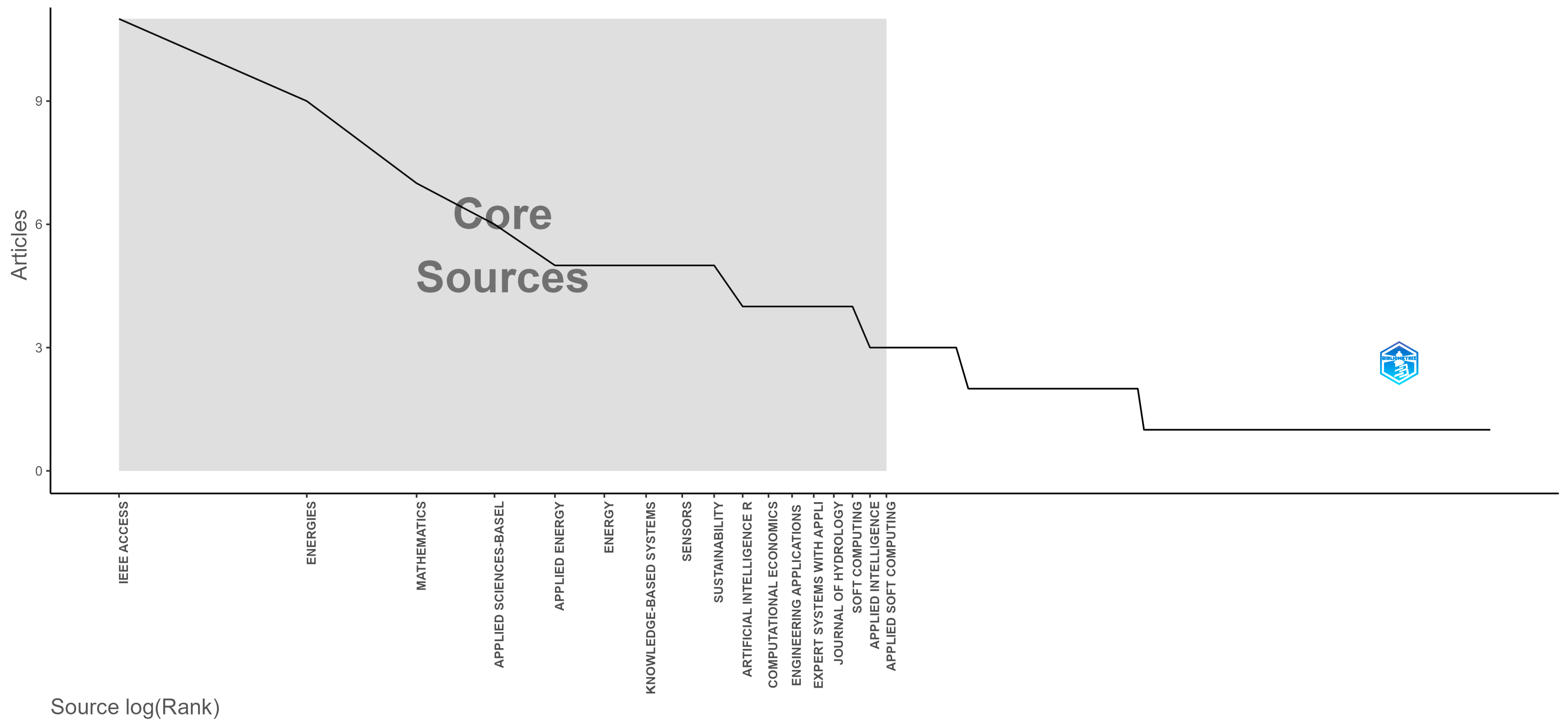
3.1. Journal Analysis
- Initial Year Production refers to the initial year for the latest period of the timespan in which all years have at least one publication
- Final Year Production refers to the final year for the latest period of the timespan in which all years have at least one publication
- Timespan refers to the period between the initial and the final year of the latest period of the timespan in which all years have at least one publication
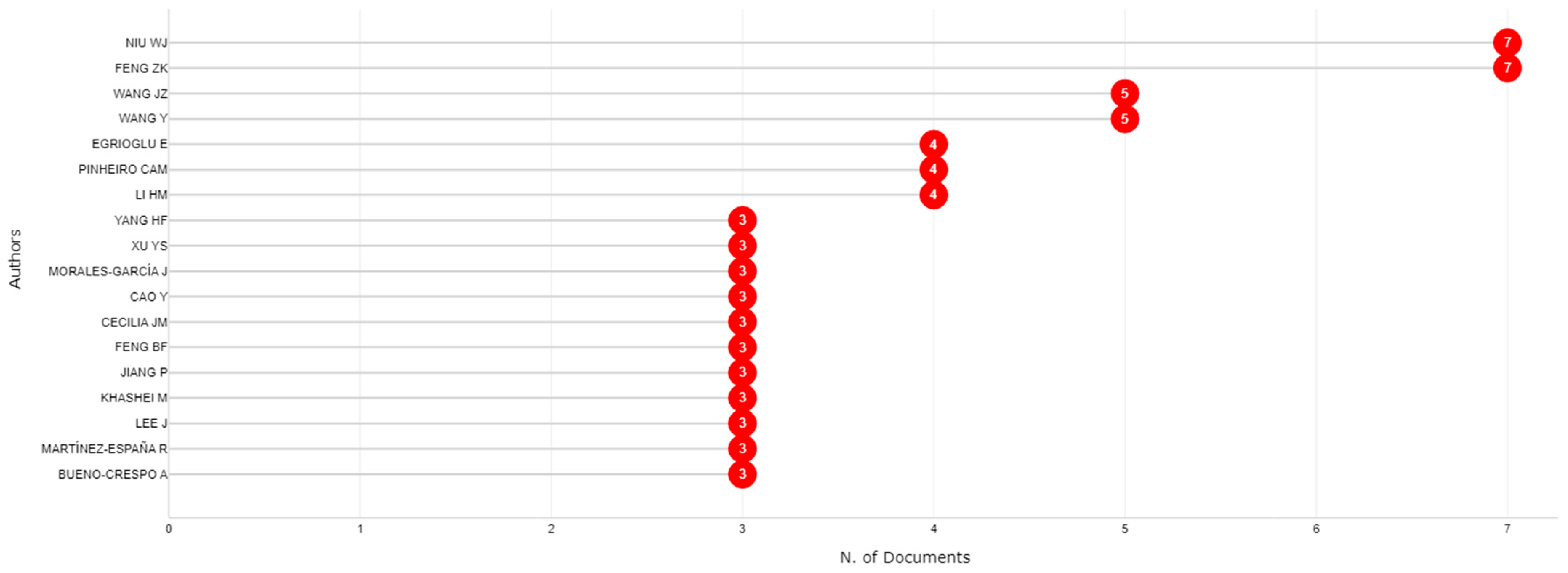
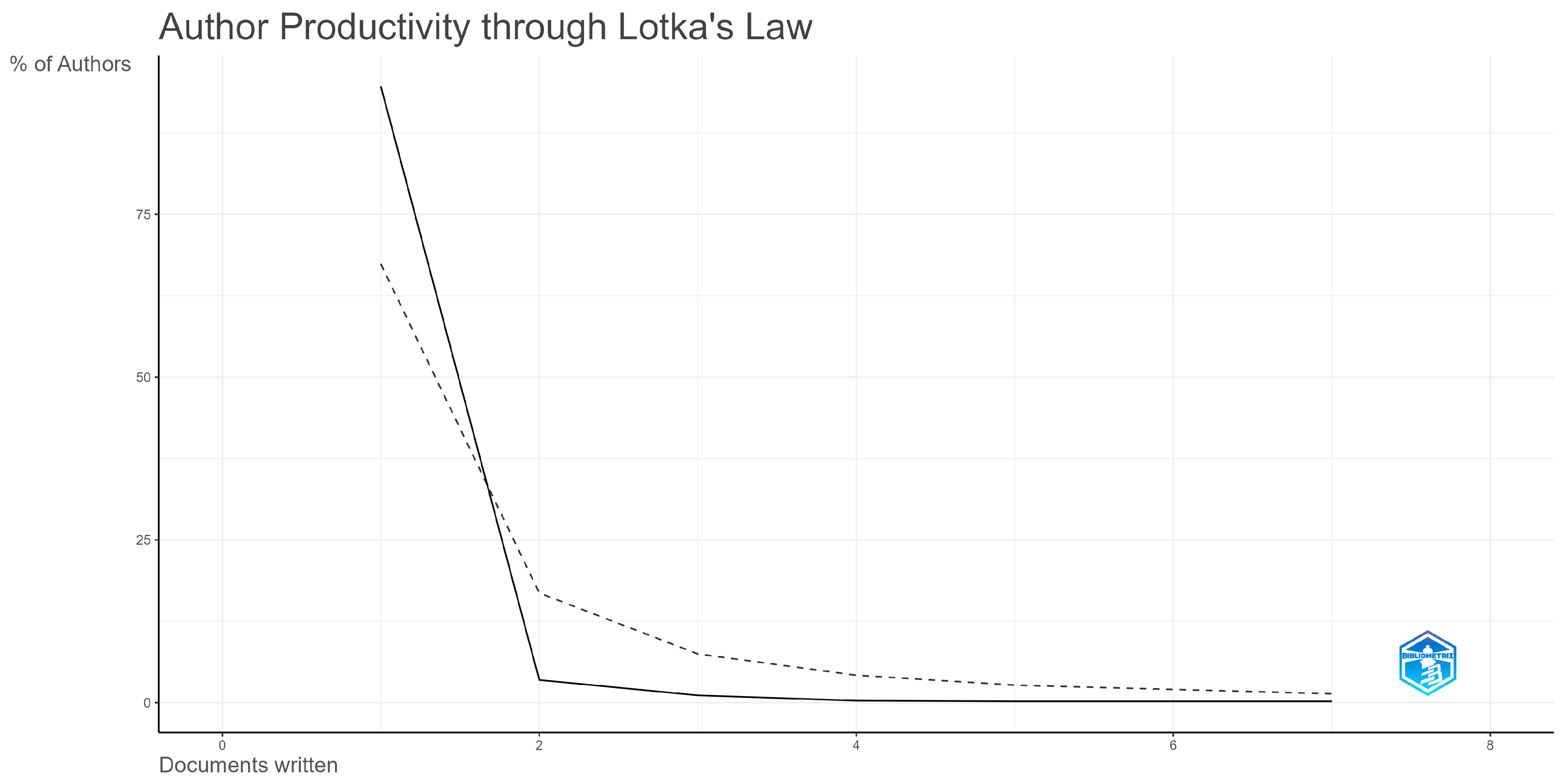
3.2. Authors and Affiliations Analysis
3.3. Most Cited Documents

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Paper (First Author, Year, Journal, Reference) | Number of Authors | Total Citations (TC) | Total Citations per Year (TCY) | Normalized TC (NTC) |
|---|---|---|---|---|---|
| 1 | Wang WC., 2009, Journal of Hydrology [44] | 4 | 614 | 36.12 | 1.00 |
| 2 | Song XY., 2020, Journal of Petroleum Science and Engineering [55] | 8 | 241 | 40.17 | 5.70 |
| 3 | Sharadga H., 2020, Renewable Energy [56] | 3 | 225 | 37.50 | 5.32 |
| 4 | Cho V., 2003, Tourism Management [61] | 1 | 193 | 8.39 | 1.00 |
| 5 | Sahoo BB., 2019, Acta Geophysica [62] | 4 | 171 | 24.43 | 4.73 |
| 6 | Qu JQ., 2021, Energy [63] | 3 | 154 | 30.80 | 7.13 |
| 7 | Chou JS, 2018, Energy [57] | 2 | 146 | 18.25 | 2.40 |
| 8 | Nourani V., 2017, Journal of Hydrology [58] | 1 | 137 | 15.22 | 1.96 |
| 9 | Ledoux C., 1997, Transportation Research Part C: Emerging Technologies [59] | 1 | 108 | 3.72 | 1.00 |
| 10 | Ismail S., 2011, Expert Systems with Applications [60] | 3 | 100 | 6.67 | 2.29 |
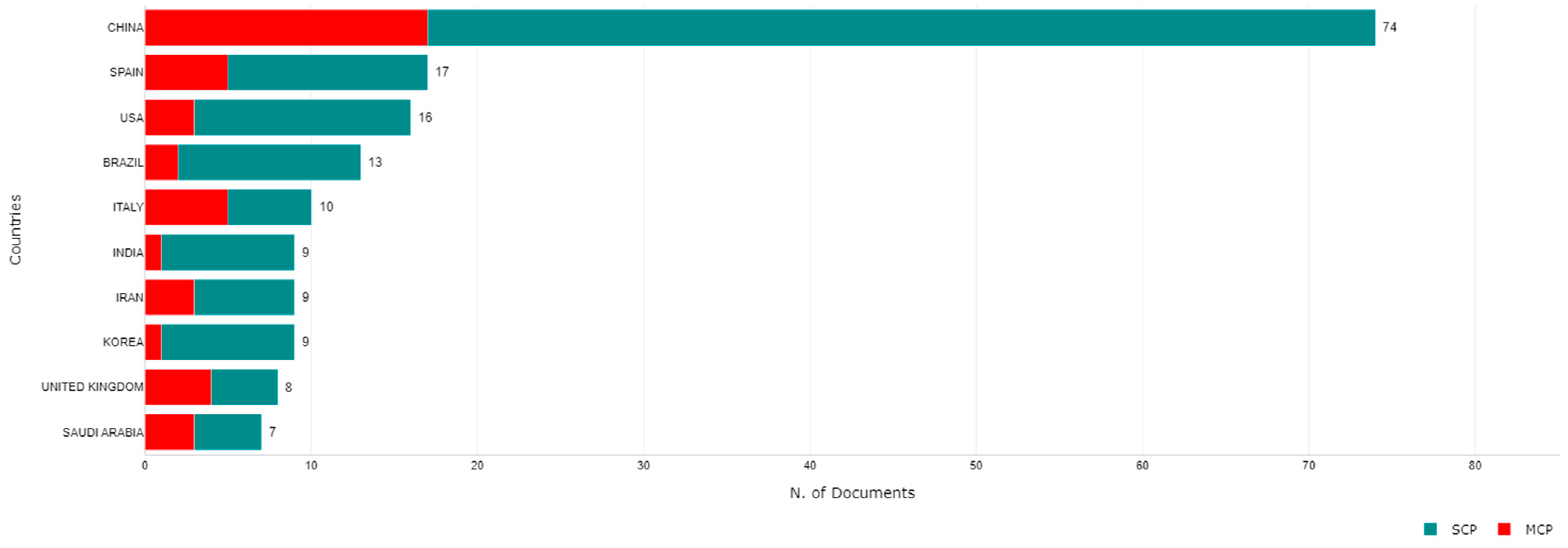
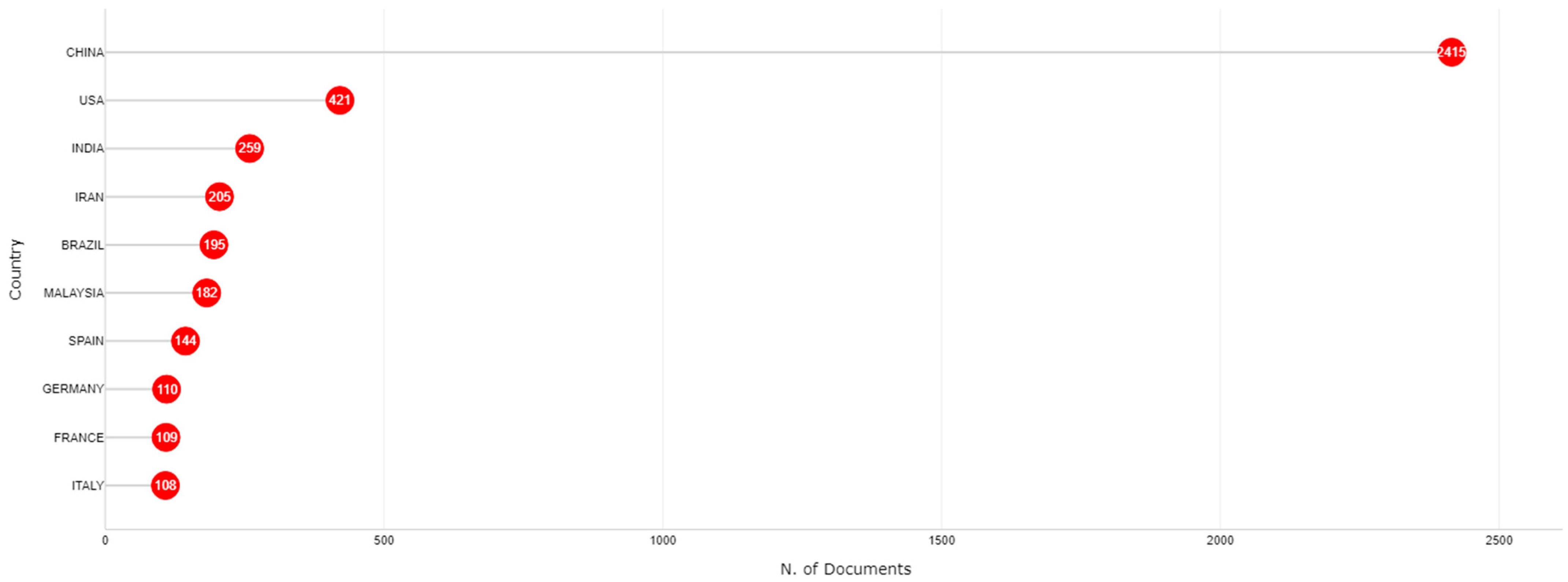
3.4. Country Analysis
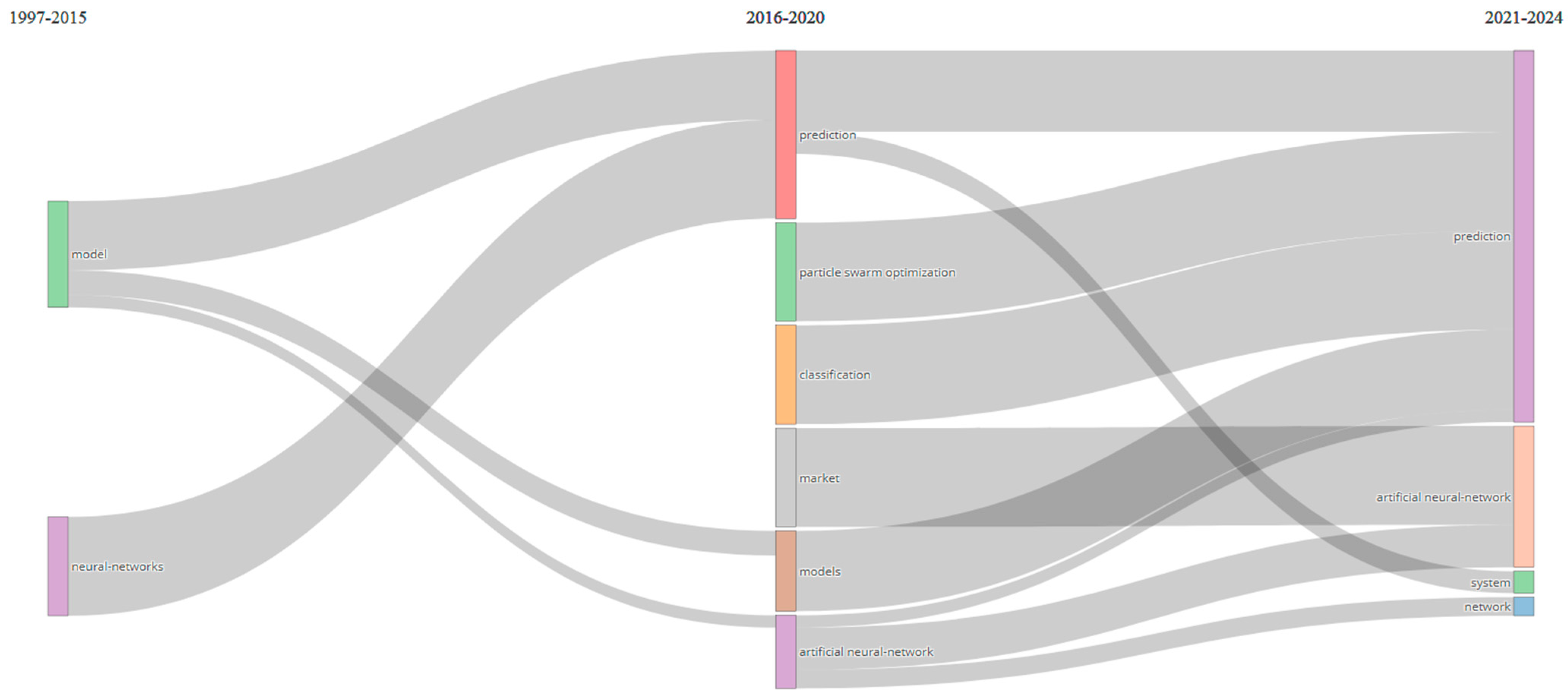
3.5. Mixed Analysis
4. Discussion and Limitations
4.1. Bibliometric Research Summary
4.2. Discussion of Specific Topics
4.2.1. Implications of Time Series Forecasting and Artificial Intelligence in the Energy and Electricity Sector
4.2.2. Implications of Time Series Forecasting and Artificial Intelligence for Tourism and Economic Activities
4.2.3. Implications of Time Series Forecasting and Artificial Intelligence for Hydrologic Predictions
4.3. Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AB | abstract |
| ACF | autocorrelation function |
| AI | Artificial Intelligence |
| AK | authors’ keywords |
| ANN | artificial neural network |
| AR | autoregressive models |
| ARIMA | autoregressive integrated moving average |
| A&HCI | Arts and Humanities Citation Index |
| BKCI-S | Book Citation Index-Science |
| CCR | Current Chemical Reactions |
| CNN | Convolutional Neural Networks |
| CPCI-S | Conference Proceedings Citation Index—Science |
| DBN | Dynamic Bayesian Networks |
| DIFORMER | dynamic self-differential transformer method |
| EANN | emotional artificial neural network |
| ELM | extreme learning machine |
| ESCI | Emerging Sources Citations Index |
| GARCH | generalized autoregressive conditional heteroscedasticity |
| GEP | gene expression programming |
| GRU | Gated Recurrent Unit |
| IC | Index Chemicus |
| LSSVM | least square support vector machine |
| LSTM | Long Short-Term Memory |
| LSTM-RNN | Long-Short Term Memory Recurrent Neural Network |
| MA | moving average |
| MAE | mean absolute error |
| MAPE | mean absolute percentage error |
| MARS | multivariate adaptive regression splines |
| MCP | Multiple-Country Publications |
| ML | machine learning |
| MLP | multilayer perception |
| MLR | multiple linear regression |
| NRMSE | normalized root mean square error |
| NTC | normalized total citations |
| PCSA | Parallel cooperation search algorithm |
| PGM | probabilistic graphical models |
| PRISMA | Preferred Reporting Items for Systematic Reviews and Meta-Analysis |
| RF | random forests |
| RMSE | root mean squared error |
| SARIMA | seasonal autoregressive integrated moving average |
| SCIE | Science Citation Index Expanded |
| SCP | Single-Country Publications |
| SETAR | self-exciting threshold autoregressive |
| SOM | Self-organizing Maps |
| SSCI | Social Sciences Citations Index |
| SVM | support vector machine |
| TC | total citations |
| TCY | total citations per year |
| TI | titles |
| UK | United Kingdom |
| USA | United States of America |
| WI | Willmott Index |
| WoS | Clarivate Analytics’ Web of Science Core Collection database |
References
- Abbass, H. Editorial: What Is Artificial Intelligence? IEEE Trans. Artif. Intell. 2021, 2, 94–95. [Google Scholar] [CrossRef]
- Lim, B.; Zohren, S. Time-Series Forecasting with Deep Learning: A Survey. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2021, 379, 20200209. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Gong, P.; Fu, R.; Zhang, M.; Chen, J.; Liang, S.; Xu, B.; Shi, J.; Dickinson, R. Erratum: The Role of Satellite Remote Sensing in Climate Change Studies. Nat. Clim. Change 2013, 3, 1001. [Google Scholar] [CrossRef]
- Naciri, H.; Ben Achhab, N.; Ezzaher, F.E.; Raissouni, N. AIRS: A QGIS Plugin for Time Series Forecasting Using Deep Learning Models. Environ. Model. Softw. 2024, 177, 106045. [Google Scholar] [CrossRef]
- Fathian, F.; Mehdizadeh, S.; Kozekalani Sales, A.; Safari, M.J.S. Hybrid Models to Improve the Monthly River Flow Prediction: Integrating Artificial Intelligence and Non-Linear Time Series Models. J. Hydrol. 2019, 575, 1200–1213. [Google Scholar] [CrossRef]
- Aghelpour, P.; Varshavian, V. Evaluation of Stochastic and Artificial Intelligence Models in Modeling and Predicting of River Daily Flow Time Series. Stoch. Environ. Res. Risk Assess. 2020, 34, 33–50. [Google Scholar] [CrossRef]
- Mehdizadeh, S.; Fathian, F.; Safari, M.J.S.; Adamowski, J.F. Comparative Assessment of Time Series and Artificial Intelligence Models to Estimate Monthly Streamflow: A Local and External Data Analysis Approach. J. Hydrol. 2019, 579, 124225. [Google Scholar] [CrossRef]
- Wang, M.; Qin, F. A TCN-Linear Hybrid Model for Chaotic Time Series Forecasting. Entropy 2024, 26, 467. [Google Scholar] [CrossRef]
- Faustino, C.P.; Pinheiro, C.A.M.; Carpinteiro, O.A.; Lima, I. Time Series Forecasting through Rule-Based Models Obtained via Rough Sets. Artif. Intell. Rev. 2011, 36, 299–310. [Google Scholar] [CrossRef]
- Bas, E.; Egrioglu, E.; Cansu, T. Robust Training of Median Dendritic Artificial Neural Networks for Time Series Forecasting. Expert Syst. Appl. 2024, 238, 122080. [Google Scholar] [CrossRef]
- Edalatpanah, S.A.; Hassani, F.S.; Smarandache, F.; Sorourkhah, A.; Pamucar, D.; Cui, B. A Hybrid Time Series Forecasting Method Based on Neutrosophic Logic with Applications in Financial Issues. Eng. Appl. Artif. Intell. 2024, 129, 107531. [Google Scholar] [CrossRef]
- Kocian, A.; Massa, D.; Cannazzaro, S.; Incrocci, L.; Di Lonardo, S.; Milazzo, P.; Chessa, S. Dynamic Bayesian Network for Crop Growth Prediction in Greenhouses. Comput. Electron. Agric. 2020, 169, 105167. [Google Scholar] [CrossRef]
- Li, C.; Mahadevan, S.; Ling, Y.; Choze, S.; Wang, L. Dynamic Bayesian Network for Aircraft Wing Health Monitoring Digital Twin. AIAA J. 2017, 55, 930–941. [Google Scholar] [CrossRef]
- Fan, H.; Jia, H.; He, X.; Lyu, J. Navigating Uncertainty: A Dynamic Bayesian Network-Based Risk Assessment Framework for Maritime Trade Routes. Reliab. Eng. Syst. Saf. 2024, 250, 110311. [Google Scholar] [CrossRef]
- Guo, J.; Ma, K. Risk Analysis for Hazardous Chemical Vehicle-Bridge Transportation System: A Dynamic Bayesian Network Model Incorporating Vehicle Dynamics. Reliab. Eng. Syst. Saf. 2024, 242, 109732. [Google Scholar] [CrossRef]
- Delcea, C.; Oprea, S.-V.; Dima, A.M.; Domenteanu, A.; Bara, A.; Cotfas, L.-A. Energy Communities: Insights from Scientific Publications. Oecon. Copernic. 2024, 15, 1101–1155. [Google Scholar] [CrossRef]
- Block, J.H.; Fisch, C. Eight Tips and Questions for Your Bibliographic Study in Business and Management Research. Manag. Rev. Q. 2020, 70, 307–312. [Google Scholar] [CrossRef]
- Sandu, A.; Ioanăș, I.; Delcea, C.; Florescu, M.-S.; Cotfas, L.-A. Numbers Do Not Lie: A Bibliometric Examination of Machine Learning Techniques in Fake News Research. Algorithms 2024, 17, 70. [Google Scholar] [CrossRef]
- Sandu, A.; Cotfas, L.-A.; Stănescu, A.; Delcea, C. A Bibliometric Analysis of Text Mining: Exploring the Use of Natural Language Processing in Social Media Research. Appl. Sci. 2024, 14, 3144. [Google Scholar] [CrossRef]
- Sandu, A.; Cotfas, L.-A.; Delcea, C.; Crăciun, L.; Molănescu, A.G. Sentiment Analysis in the Age of COVID-19: A Bibliometric Perspective. Information 2023, 14, 659. [Google Scholar] [CrossRef]
- WoS Web of Science. Available online: http://webofknowledge.com (accessed on 10 October 2024).
- Ciuverca, A.-C.-D.; Oprea, S. The Influence of AI on Price Forecasting. The View of the Academic Community. JBEM 2025, 26, 231–254. [Google Scholar] [CrossRef]
- Întorsureanu, I.; Oprea, S.-V.; Bâra, A.; Vespan, D. Generative AI in Education: Perspectives Through an Academic Lens. Electronics 2025, 14, 1053. [Google Scholar] [CrossRef]
- Oprea, S.-V.; Bâra, A. Generative Literature Analysis on the Rise of Prosumers and Their Influence on the Sustainable Energy Transition. Util. Policy 2024, 90, 101799. [Google Scholar] [CrossRef]
- Cișmașu, I.-D.; Cibu, B.R.; Cotfas, L.-A.; Delcea, C. The Persistence Puzzle: Bibliometric Insights into Dropout in MOOCs. Sustainability 2025, 17, 2952. [Google Scholar] [CrossRef]
- Sandu, A.; Cotfas, L.-A.; Stănescu, A.; Delcea, C. Guiding Urban Decision-Making: A Study on Recommender Systems in Smart Cities. Electronics 2024, 13, 2151. [Google Scholar] [CrossRef]
- Bakır, M.; Özdemir, E.; Akan, Ş.; Atalık, Ö. A Bibliometric Analysis of Airport Service Quality. J. Air Transp. Manag. 2022, 104, 102273. [Google Scholar] [CrossRef]
- Koca, T.T. Bibliometric Analysis of “Sarcopenia” in Web of Science. Egypt. Rheumatol. Rehabil. 2023, 50, 26. [Google Scholar] [CrossRef]
- Singh, V.K.; Singh, P.; Karmakar, M.; Leta, J.; Mayr, P. The Journal Coverage of Web of Science, Scopus and Dimensions: A Comparative Analysis. Scientometrics 2021, 126, 5113–5142. [Google Scholar] [CrossRef]
- Clarivate. KeyWords Plus Generation, Creation, and Changes. Available online: https://support.clarivate.com/ScientificandAcademicResearch/s/article/KeyWords-Plus-generation-creation-and-changes?language=en_US (accessed on 2 March 2024).
- Liu, F. Retrieval Strategy and Possible Explanations for the Abnormal Growth of Research Publications: Re-Evaluating a Bibliometric Analysis of Climate Change. Scientometrics 2023, 128, 853–859. [Google Scholar] [CrossRef]
- Liu, W. The Data Source of This Study Is Web of Science Core Collection? Not Enough. Scientometrics 2019, 121, 1815–1824. [Google Scholar] [CrossRef]
- Sarkis-Onofre, R.; Catalá-López, F.; Aromataris, E.; Lockwood, C. How to Properly Use the PRISMA Statement. Syst. Rev. 2021, 10, 117. [Google Scholar] [CrossRef] [PubMed]
- Khin Khin Oo, N.C.; Rakthin, S. Integrative Review of Absorptive Capacity’s Role in Fostering Organizational Resilience and Research Agenda. Sustainability 2022, 14, 12570. [Google Scholar] [CrossRef]
- Pham, X.-L.; Le, T. Bibliometric Analysis and Systematic Review of Research on Expert Finding: A PRISMA-Guided Approach. Int. Arab J. Inf. Technol. 2024, 21, 661–674. [Google Scholar] [CrossRef]
- Peixoto, B.; Pinto, R.; Melo, M.; Cabral, L.; Bessa, M. Immersive Virtual Reality for Foreign Language Education: A PRISMA Systematic Review. IEEE Access 2021, 9, 48952–48962. [Google Scholar] [CrossRef]
- Frioui, S.; Graa, A. Bibliometric Analysis of Artificial Intelligence in the Scope of E-Commerce: Trends and Progress over the Last Decade. Manag. Econ. Rev. 2024, 9, 5–24. [Google Scholar] [CrossRef]
- Bawack, R.E.; Wamba, S.F.; Carillo, K.D.A.; Akter, S. Artificial Intelligence in E-Commerce: A Bibliometric Study and Literature Review. Electron. Mark. 2022, 32, 297–338. [Google Scholar] [CrossRef] [PubMed]
- Ofer, D.; Kaufman, H.; Linial, M. What’s next? Forecasting Scientific Research Trends. Heliyon 2024, 10, e23781. [Google Scholar] [CrossRef]
- Vincent-Lancrin, S. What Is Changing in Academic Research? Trends and Futures Scenarios. Eur. J. Educ. 2006, 41, 169–202. [Google Scholar] [CrossRef]
- Aria, M.; Cuccurullo, C. Bibliometrix: An R-Tool for Comprehensive Science Mapping Analysis. J. Informetr. 2017, 11, 959–975. [Google Scholar] [CrossRef]
- Monroy, S.E.; Diaz, H. Time Series-Based Bibliometric Analysis of the Dynamics of Scientific Production. Scientometrics 2018, 115, 1139–1159. [Google Scholar] [CrossRef]
- Palomero, L.; García, V.; Sánchez, J.S. Fuzzy-Based Time Series Forecasting and Modelling: A Bibliometric Analysis. Appl. Sci. 2022, 12, 6894. [Google Scholar] [CrossRef]
- Wang, W.-C.; Chau, K.-W.; Cheng, C.-T.; Qiu, L. A Comparison of Performance of Several Artificial Intelligence Methods for Forecasting Monthly Discharge Time Series. J. Hydrol. 2009, 374, 294–306. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, W.; Chen, X.M. Bibliometric Methods in Traffic Flow Prediction Based on Artificial Intelligence. Expert Syst. Appl. 2023, 228, 120421. [Google Scholar] [CrossRef]
- Shabani, M.; Ghousi, R.; Mohammadi, E. Exploring the Evolution of Scientific Publication on Portfolio Optimization in the Light of Artificial Intelligence: A Bibliometric Study. Accounting 2025, 11, 71–90. [Google Scholar] [CrossRef]
- Hirsch, J.E. An Index to Quantify an Individual’s Scientific Research Output. Proc. Natl. Acad. Sci. USA 2005, 102, 16569–16572. [Google Scholar] [CrossRef]
- Egghe, L. Theory and Practise of the G-Index. Scientometrics 2006, 69, 131–152. [Google Scholar] [CrossRef]
- Yang, J.-M.; Tseng, S.-F.; Won, Y.-L. A Bibliometric Analysis on Data Mining Using Bradford’s Law. In Proceedings of the 3rd International Conference on Intelligent Technologies and Engineering Systems (ICITES2014) 2016, Kaohsiung, Taiwan, 19–21 December 2014; pp. 613–620. [Google Scholar] [CrossRef]
- Bibliometrix—Home. Available online: https://www.bibliometrix.org/home/ (accessed on 3 July 2024).
- Soliman, M.; Fatnassi, T.; Elgammal, I.; Figueiredo, R. Exploring the Major Trends and Emerging Themes of Artificial Intelligence in the Scientific Leading Journals amidst the COVID-19 Era. Big Data Cogn. Comput. 2023, 7, 12. [Google Scholar] [CrossRef]
- Newby, G.B.; Greenberg, J.; Jones, P. Open Source Software Development and Lotka’s Law: Bibliometric Patterns in Programming. J. Am. Soc. Inf. Sci. Technol. 2003, 54, 169–178. [Google Scholar] [CrossRef]
- Cibu, B.; Delcea, C.; Domenteanu, A.; Dumitrescu, G. Mapping the Evolution of Cybernetics: A Bibliometric Perspective. Computers 2023, 12, 237. [Google Scholar] [CrossRef]
- Jigani, A.-I.; Delcea, C.; Florescu, M.-S.; Cotfas, L.-A. Tracking Happiness in Times of COVID-19: A Bibliometric Exploration. Sustainability 2024, 16, 4918. [Google Scholar] [CrossRef]
- Song, X.; Liu, Y.; Xue, L.; Wang, J.; Zhang, J.; Wang, J.; Jiang, L.; Cheng, Z. Time-Series Well Performance Prediction Based on Long Short-Term Memory (LSTM) Neural Network Model. J. Pet. Sci. Eng. 2020, 186, 106682. [Google Scholar] [CrossRef]
- Sharadga, H.; Hajimirza, S.; Balog, R.S. Time Series Forecasting of Solar Power Generation for Large-Scale Photovoltaic Plants. Renew. Energy 2020, 150, 797–807. [Google Scholar] [CrossRef]
- Chou, J.-S.; Tran, D.-S. Forecasting Energy Consumption Time Series Using Machine Learning Techniques Based on Usage Patterns of Residential Householders. Energy 2018, 165, 709–726. [Google Scholar] [CrossRef]
- Nourani, V. An Emotional ANN (EANN) Approach to Modeling Rainfall-Runoff Process. J. Hydrol. 2017, 544, 267–277. [Google Scholar] [CrossRef]
- Ledoux, C. An Urban Traffic Flow Model Integrating Neural Networks. Transp. Res. Part C Emerg. Technol. 1997, 5, 287–300. [Google Scholar] [CrossRef]
- Ismail, S.; Shabri, A.; Samsudin, R. A Hybrid Model of Self-Organizing Maps (SOM) and Least Square Support Vector Machine (LSSVM) for Time-Series Forecasting. Expert Syst. Appl. 2011, 38, 10574–10578. [Google Scholar] [CrossRef]
- Cho, V. A Comparison of Three Different Approaches to Tourist Arrival Forecasting. Tour. Manag. 2003, 24, 323–330. [Google Scholar] [CrossRef]
- Sahoo, B.B.; Jha, R.; Singh, A.; Kumar, D. Long Short-Term Memory (LSTM) Recurrent Neural Network for Low-Flow Hydrological Time Series Forecasting. Acta Geophys. 2019, 67, 1471–1481. [Google Scholar] [CrossRef]
- Qu, J.; Qian, Z.; Pei, Y. Day-Ahead Hourly Photovoltaic Power Forecasting Using Attention-Based CNN-LSTM Neural Network Embedded with Multiple Relevant and Target Variables Prediction Pattern. Energy 2021, 232, 120996. [Google Scholar] [CrossRef]
- Wilczewski, M.; Alon, I. Language and Communication in International Students’ Adaptation: A Bibliometric and Content Analysis Review. High Educ. 2023, 85, 1235–1256. [Google Scholar] [CrossRef]
- Romero-Riaño, E.; Rico-Bautista, D.; Martinez-Toro, M.; Medina-Cárdenas, Y.; Rico-Bautista, N. Artificial Intelligence Theory: A Bibliometric Analysis. J. Phys. Conf. Ser. 2021, 2046, 012078. [Google Scholar] [CrossRef]
- Özdoğan Sarıkoç, G. Artificial Intelligence Applications in the Field of Streamflow: A Bibliometric Analysis of Recent Trends. Hydrol. Sci. J. 2024, 69, 1141–1157. [Google Scholar] [CrossRef]
- Loan, F.A.; Bashir, B.; Nasreen, N. Applied Artificial Intelligence: A Bibliometric Study of an International Journal. COLLNET J. Scientometr. Inf. Manag. 2021, 15, 27–45. [Google Scholar] [CrossRef]
- Feng, Z.; Niu, W. Hybrid Artificial Neural Network and Cooperation Search Algorithm for Nonlinear River Flow Time Series Forecasting in Humid and Semi-Humid Regions. Knowl. Based Syst. 2021, 211, 106580. [Google Scholar] [CrossRef]
- Fu, X.; Feng, Z.; Cao, H.; Feng, B.; Tan, Z.; Xu, Y.; Niu, W. Enhanced Machine Learning Model via Twin Support Vector Regression for Streamflow Time Series Forecasting of Hydropower Reservoir. Energy Rep. 2023, 10, 2623–2639. [Google Scholar] [CrossRef]
- Feng, Z.; Niu, W.; Wan, X.; Xu, B.; Zhu, F.; Chen, J. Hydrological Time Series Forecasting via Signal Decomposition and Twin Support Vector Machine Using Cooperation Search Algorithm for Parameter Identification. J. Hydrol. 2022, 612, 128213. [Google Scholar] [CrossRef]
- Niu, W.; Feng, Z.; Feng, B.; Xu, Y.; Min, Y. Parallel Computing and Swarm Intelligence Based Artificial Intelligence Model for Multi-Step-Ahead Hydrological Time Series Prediction. Sustain. Cities Soc. 2021, 66, 102686. [Google Scholar] [CrossRef]
- Carpinteiro, O.A.S.; Leite, J.P.R.R.; Pinheiro, C.A.M.; Lima, I. Forecasting Models for Prediction in Time Series. Artif. Intell. Rev. 2012, 38, 163–171. [Google Scholar] [CrossRef]
- Faustino, C.P.; Novaes, C.P.; Pinheiro, C.A.M.; Carpinteiro, O.A. Improving the Performance of Fuzzy Rules-Based Forecasters through Application of FCM Algorithm. Artif. Intell. Rev. 2014, 41, 287–300. [Google Scholar] [CrossRef]
- Vilela, L.F.S.; Leme, R.C.; Pinheiro, C.A.M.; Carpinteiro, O.A.S. Forecasting Financial Series Using Clustering Methods and Support Vector Regression. Artif. Intell. Rev. 2019, 52, 743–773. [Google Scholar] [CrossRef]
- Li, H.; Wang, J.; Yang, H.; Wang, Y. Air Quality Deterministic and Probabilistic Forecasting System Based on Hesitant Fuzzy Sets and Nonlinear Robust Outlier Correction. Knowl. Based Syst. 2022, 237, 107789. [Google Scholar] [CrossRef]
- Wang, J.; Li, H.; Wang, Y.; Lu, H. A Hesitant Fuzzy Wind Speed Forecasting System with Novel Defuzzification Method and Multi-Objective Optimization Algorithm. Expert Syst. Appl. 2021, 168, 114364. [Google Scholar] [CrossRef]
- Jiang, P.; Yang, H.; Li, H.; Wang, Y. A Developed Hybrid Forecasting System for Energy Consumption Structure Forecasting Based on Fuzzy Time Series and Information Granularity. Energy 2021, 219, 119599. [Google Scholar] [CrossRef]
- Wang, J.; Li, H.; Wang, Y.; Yang, H. A Novel Assessment and Forecasting System for Traffic Accident Economic Loss Caused by Air Pollution. Environ. Sci. Pollut. Res. 2021, 28, 49042–49062. [Google Scholar] [CrossRef] [PubMed]
- Kocak, C.; Egrioglu, E.; Bas, E. A New Explainable Robust High-Order Intuitionistic Fuzzy Time-Series Method. Soft Comput. 2023, 27, 1783–1796. [Google Scholar] [CrossRef]
- Kocak, C.; Dalar, A.Z.; Cagcag Yolcu, O.; Bas, E.; Egrioglu, E. A New Fuzzy Time Series Method Based on an ARMA-Type Recurrent Pi-Sigma Artificial Neural Network. Soft Comput. 2020, 24, 8243–8252. [Google Scholar] [CrossRef]
- Yolcu, U.; Aladag, C.H.; Egrioglu, E.; Uslu, V.R. Time-Series Forecasting with a Novel Fuzzy Time-Series Approach: An Example for Istanbul Stock Market. J. Stat. Comput. Simul. 2013, 83, 599–612. [Google Scholar] [CrossRef]
- Morales-García, J.; Bueno-Crespo, A.; Martínez-España, R.; Cecilia, J.M. Data-Driven Evaluation of Machine Learning Models for Climate Control in Operational Smart Greenhouses. J. Ambient Intell. Smart Environ. 2023, 15, 3–17. [Google Scholar] [CrossRef]
- Morales-García, J.; Bueno-Crespo, A.; Martínez-España, R.; Posadas, J.-L.; Manzoni, P.; Cecilia, J.M. Evaluation of Low-Power Devices for Smart Greenhouse Development. J. Supercomput. 2023, 79, 10277–10299. [Google Scholar] [CrossRef]
- Morales-García, J.; Bueno-Crespo, A.; Terroso-Sáenz, F.; Arcas-Túnez, F.; Martínez-España, R.; Cecilia, J.M. Evaluation of Synthetic Data Generation for Intelligent Climate Control in Greenhouses. Appl. Intell. 2023, 53, 24765–24781. [Google Scholar] [CrossRef]
- Al-Ali, E.M.; Hajji, Y.; Said, Y.; Hleili, M.; Alanzi, A.M.; Laatar, A.H.; Atri, M. Solar Energy Production Forecasting Based on a Hybrid CNN-LSTM-Transformer Model. Mathematics 2023, 11, 676. [Google Scholar] [CrossRef]
- Niu, W.; Feng, Z.; Li, S.; Wu, H.; Wang, J. Short-Term Electricity Load Time Series Prediction by Machine Learning Model via Feature Selection and Parameter Optimization Using Hybrid Cooperation Search Algorithm. Environ. Res. Lett. 2021, 16, 055032. [Google Scholar] [CrossRef]
- Zhou, C.; Che, C.; Wang, P.; Zhang, Q. Diformer: A Dynamic Self-Differential Transformer for New Energy Power Autoregressive Prediction. Knowl. Based Syst. 2023, 281, 111061. [Google Scholar] [CrossRef]
- Hamdoun, H.; Sagheer, A.; Youness, H. Energy Time Series Forecasting-Analytical and Empirical Assessment of Conventional and Machine Learning Models. J. Intell. Fuzzy Syst. 2021, 40, 12477–12502. [Google Scholar] [CrossRef]
- Bareith, T.; Tatay, T.; Vancsura, L. Navigating Inflation Challenges: AI-Based Portfolio Management Insights. Risks 2024, 12, 46. [Google Scholar] [CrossRef]
- Louati, A.; Louati, H.; Alharbi, M.; Kariri, E.; Khawaji, T.; Almubaddil, Y.; Aldwsary, S. Machine Learning and Artificial Intelligence for a Sustainable Tourism: A Case Study on Saudi Arabia. Information 2024, 15, 516. [Google Scholar] [CrossRef]
- Zhang, B.; Li, N.; Shi, F.; Law, R. A Deep Learning Approach for Daily Tourist Flow Forecasting with Consumer Search Data. Asia Pac. J. Tour. Res. 2020, 25, 323–339. [Google Scholar] [CrossRef]
- Sohrabpour, V.; Oghazi, P.; Toorajipour, R.; Nazarpour, A. Export Sales Forecasting Using Artificial Intelligence. Technol. Forecast. Soc. Change 2021, 163, 120480. [Google Scholar] [CrossRef]
- Tang, Y.M.; Chau, K.-Y.; Li, W.; Wan, T.W. Forecasting Economic Recession through Share Price in the Logistics Industry with Artificial Intelligence (AI). Computation 2020, 8, 70. [Google Scholar] [CrossRef]
- Feng, Z.; Shi, P.; Yang, T.; Niu, W.; Zhou, J.; Cheng, C. Parallel Cooperation Search Algorithm and Artificial Intelligence Method for Streamflow Time Series Forecasting. J. Hydrol. 2022, 606, 127434. [Google Scholar] [CrossRef]
- Christian, K.; Roy, A.F.V.; Yudianto, D.; Zhang, D. Application of Optimized Support Vector Machine in Monthly Streamflow Forecasting: Using Autocorrelation Function for Input Variables Estimation. Sustain. Water Resour. Manag. 2021, 7, 29. [Google Scholar] [CrossRef]
- Yaseen, Z.M.; Allawi, M.F.; Yousif, A.A.; Jaafar, O.; Hamzah, F.M.; El-Shafie, A. Non-Tuned Machine Learning Approach for Hydrological Time Series Forecasting. Neural Comput. Appl. 2018, 30, 1479–1491. [Google Scholar] [CrossRef]
- Niu, W.; Feng, Z.; Xu, Y.; Feng, B.; Min, Y. Improving Prediction Accuracy of Hydrologic Time Series by Least-Squares Support Vector Machine Using Decomposition Reconstruction and Swarm Intelligence. J. Hydrol. Eng. 2021, 26, 04021030. [Google Scholar] [CrossRef]
- Sang, Y.-F.; Singh, V.P.; Sun, F.; Chen, Y.; Liu, Y.; Yang, M. Wavelet-Based Hydrological Time Series Forecasting. J. Hydrol. Eng. 2016, 21, 06016001. [Google Scholar] [CrossRef]
- Mishra, M.; Byomakesha Dash, P.; Nayak, J.; Naik, B.; Kumar Swain, S. Deep Learning and Wavelet Transform Integrated Approach for Short-Term Solar PV Power Prediction. Measurement 2020, 166, 108250. [Google Scholar] [CrossRef]
- Zhou, Y.; He, X.; Montillet, J.-P.; Wang, S.; Hu, S.; Sun, X.; Huang, J.; Ma, X. An Improved ICEEMDAN-MPA-GRU Model for GNSS Height Time Series Prediction with Weighted Quality Evaluation Index. GPS Solut. 2025, 29, 113. [Google Scholar] [CrossRef]
- Tay, A. Using VOSviewer as a Bibliometric Mapping or Analysis Tool in Business, Management & Accounting | Singapore Management University (SMU). Available online: https://library.smu.edu.sg/topics-insights/using-vosviewer-bibliometric-mapping-or-analysis-tool-business-management (accessed on 7 March 2025).
- WoS Document Types. Available online: https://webofscience.help.clarivate.com/en-us/Content/document-types.html (accessed on 3 December 2023).
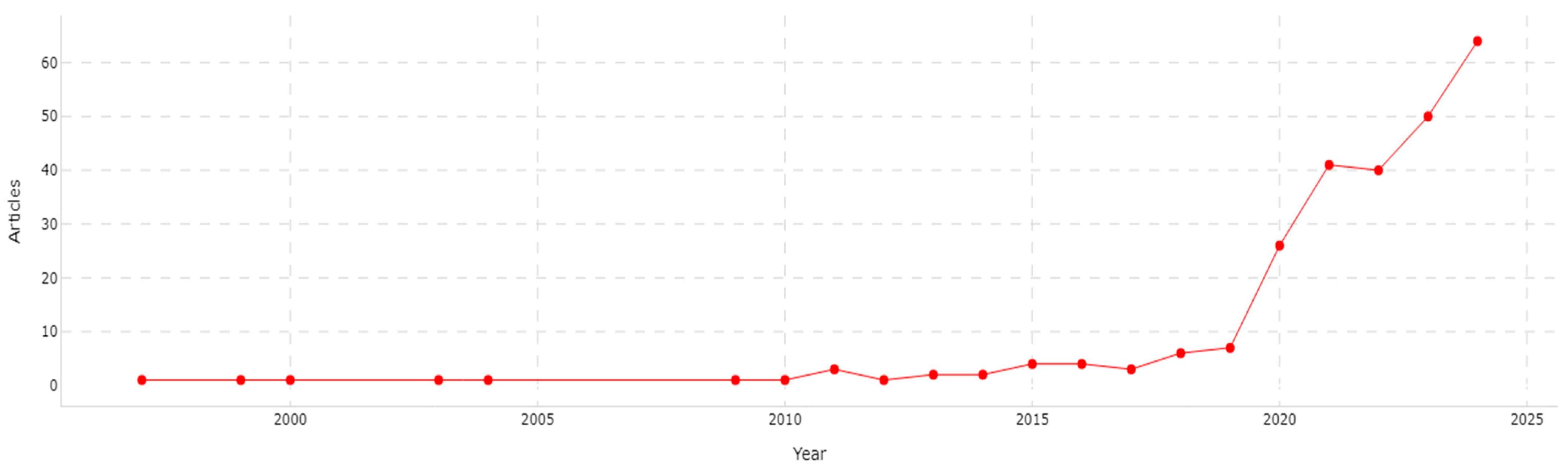
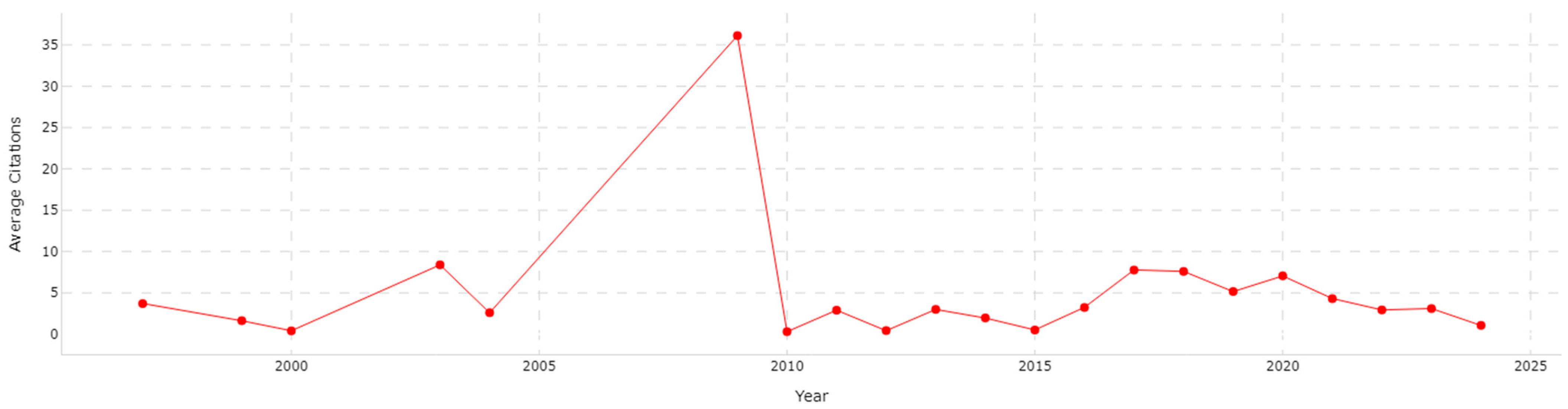

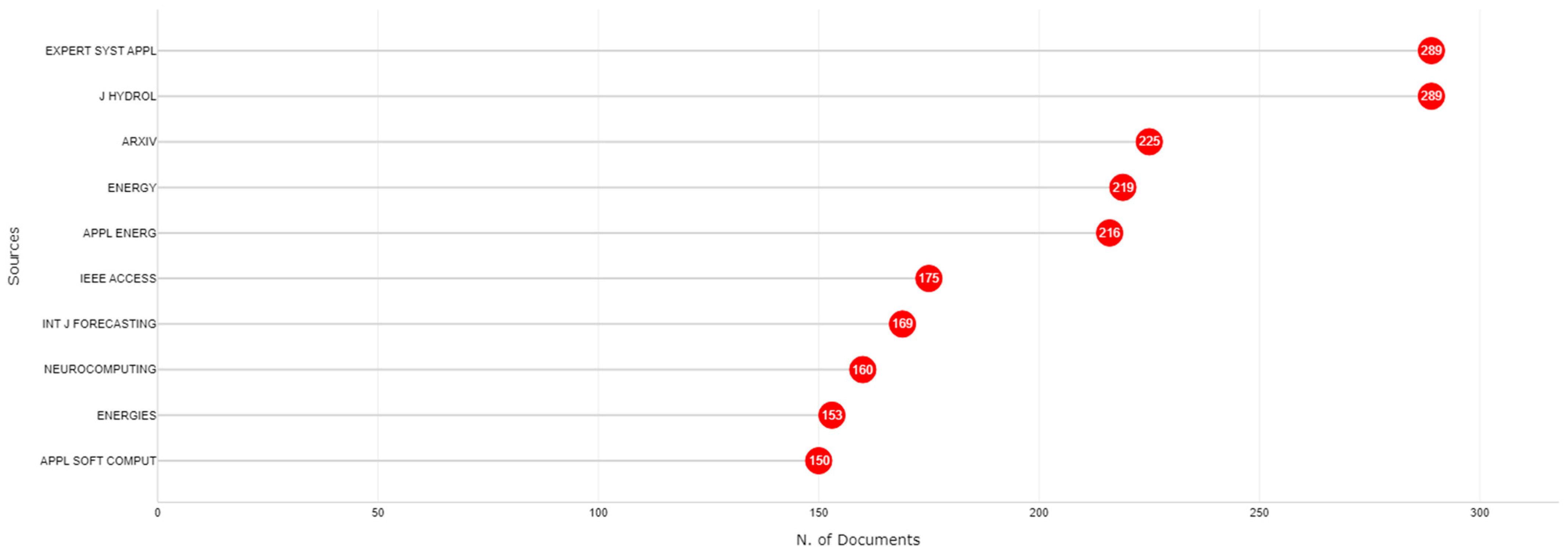

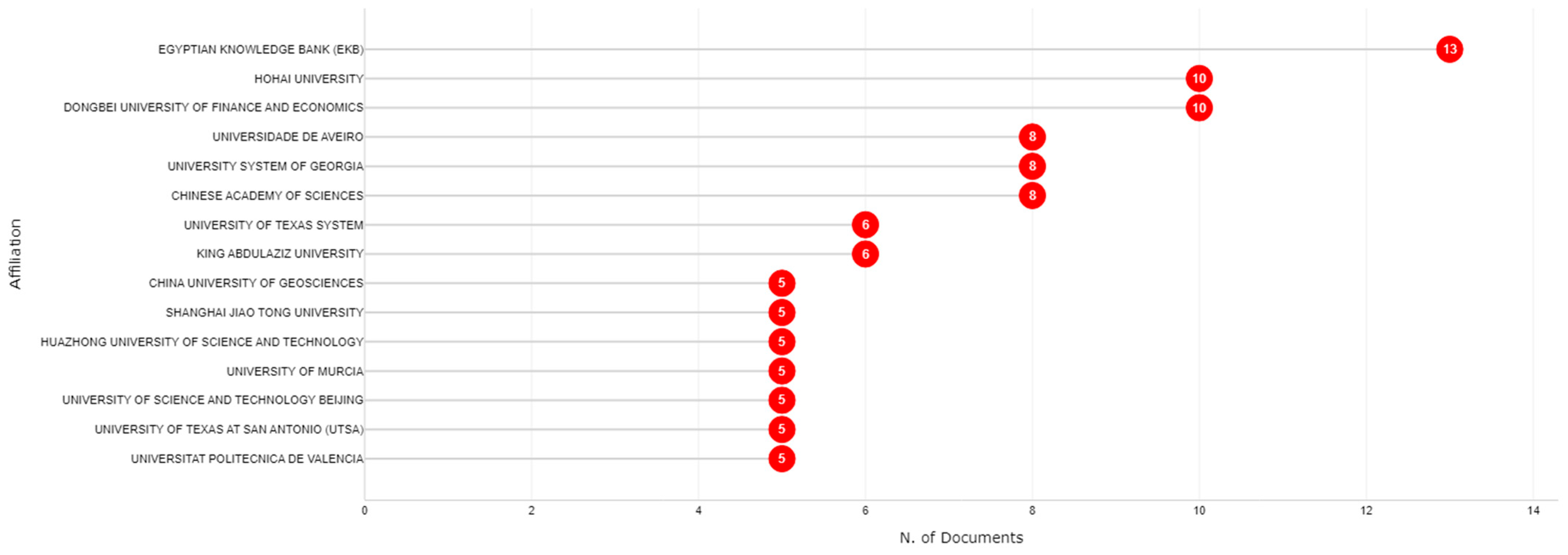



| Indicator | Value |
|---|---|
| Timespan | 1997–2024 |
| Sources | 158 |
| Documents | 260 |
| Average years from publication | 3.91 |
| Average citations per documents | 20.51 |
| Co-authors per document | 4.08 |
| References | 11,079 |
| No. | Paper (Primary Author, Year, Journal, Reference) | Title | Data | Purpose |
|---|---|---|---|---|
| 1 | Wang WC., 2009, Journal of Hydrology [44] | A comparison of performance of several artificial intelligence methods for forecasting monthly discharge time series | Hydrological data from January 1953 to December 2004 from Manwan Hydropower on Lancanjiang River | To develop a hydrological forecasting model based on historical values, in order to manage and schedule the hydropower reservoir in an optimal way, |
| 2 | Song XY., 2020, Journal of Petroleum Science and Engineering [55] | Time-series well performance based on long short-term memory (LSTM) neural network model | Two use cases from Xianjiang oilfield, China, with production rate over time | To predict the oil production by implementing a long short-term memory neural network algorithm, including the existing production limitations |
| 3 | Sharadga H., 2020, Renewable Energy [56] | Time series forecasting of solar power generation for large-scale photovoltaic plans | Time series data with historical production of solar power | To estimate the solar power for grid-connected photovoltaic systems |
| 4 | Cho V., 2003, Tourism Management [61] | A comparison of three different approaches to tourist arrival forecasting | Historical data from the USA, UK, Japan, Singapore, Korea regarding travel demand | To evaluate three time-series algorithms, ARIMA, Elman’s Model of Artificial Neural Networks, and exponential smoothing, to forecast travel demand such as the number of arrivals in various countries |
| 5 | Sahoo BB., 2019, Acta Geophysica [62] | Long short-term memory (LSTM) recurrent neural network for low-flow hydrological time series forecasting | Daily data from Basantapur, India gauging station which is situated in Mahanadi River basin | To explore the long short-term memory recurrent neural network (LSTM-RNN) algorithm and low-flow time series forecasting of Basantapur gauging station from India |
| 6 | Qu JQ., 2021, Energy [63] | Day-ahead hourly photovoltaic power forecasting using attention-based CNN-LSTM neural network embedded with multiple relevant and target variables prediction pattern | Historical data on photovoltaic systems extracted from DKASC website | To implement short-term and long-term temporal neural network algorithms that predict the photovoltaic power values based on historical data |
| 7 | Chou JS, 2018, Energy [57] | Forecasting energy consumption time series using machine learning techniques based on usage patterns of residential households | Real-time information extracted from a smart grid of an experimental building | To predict the energy consumption of buildings using machine learning algorithms and based on past data |
| 8 | Nourani V., 2017, Journal of Hydrology [58] | An emotional ANN (EANN) approach to modeling rainfall-runoff process | Data from two watersheds have been selected | To define an emotional artificial neural network approach for daily rainfall runoff |
| 9 | Ledoux C., 1997, Transportation Research Part C: Emerging Technologies [59] | An urban traffic flow model integrating neural networks | Simulated data | To explore the neural network technique in traffic management systems, in order to be integrated into a real-time adaptive urban traffic system if the results are in accordance with expectations |
| 10 | Ismail S., 2011, Expert Systems with Application [60] | A hybrid model of self-organizing maps (SOMs) and least square support vector machine (LSSVM) for time-series forecasting | Wolf yearly sunspot and monthly unemployed young women datasets have been taken into consideration | To develop self-organizing maps and least square support vector machine (SOM-LSSVM) algorithm and to test the accuracy of the model |
| Country | Number of Papers |
|---|---|
| China | 42 |
| USA | 26 |
| UK | 21 |
| Spain | 20 |
| Saudi Arabia | 20 |
| Iran | 15 |
| India | 12 |
| Turkey | 12 |
| France | 11 |
| Canada | 10 |
| Egypt | 10 |
| Serbia | 10 |
| Tunisia | 9 |
| Lebanon | 9 |
| Brazil | 8 |
| Iraq | 8 |
| Italy | 7 |
| United Arab Emirates | 7 |
| Malaysia | 6 |
| Ireland | 6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Domenteanu, A.; Diaconu, P.; Delcea, C. Bibliometric Insights into Time Series Forecasting and AI Research: Growth, Impact, and Future Directions. Appl. Sci. 2025, 15, 6221. https://doi.org/10.3390/app15116221
Domenteanu A, Diaconu P, Delcea C. Bibliometric Insights into Time Series Forecasting and AI Research: Growth, Impact, and Future Directions. Applied Sciences. 2025; 15(11):6221. https://doi.org/10.3390/app15116221
Chicago/Turabian StyleDomenteanu, Adrian, Paul Diaconu, and Camelia Delcea. 2025. "Bibliometric Insights into Time Series Forecasting and AI Research: Growth, Impact, and Future Directions" Applied Sciences 15, no. 11: 6221. https://doi.org/10.3390/app15116221
APA StyleDomenteanu, A., Diaconu, P., & Delcea, C. (2025). Bibliometric Insights into Time Series Forecasting and AI Research: Growth, Impact, and Future Directions. Applied Sciences, 15(11), 6221. https://doi.org/10.3390/app15116221