1. Introduction
With the rapid development of photovoltaic power generation technology [
1], the defect detection of photovoltaic panels has become an important link to ensure the efficient operation of photovoltaic systems and extend the service life of equipment [
2]. Photovoltaic panels are exposed to complex natural conditions in outdoor environments for a long time, including high temperatures, ultraviolet rays, humidity, sandstorms, etc. These factors can cause different types of defects on the surface and inside of photovoltaic panels, such as cracks, fractures, dust, bird droppings, hot spots, etc. The timely and accurate detection of these defects can effectively ensure the stability of photovoltaic systems, improve their power generation efficiency, and extend the service life of equipment.
However, the defect detection of photovoltaic panels faces multiple challenges [
3]. Firstly, photovoltaic panels have diverse types of defects, and the shapes, sizes, and colors of various defects vary greatly, which makes it difficult for traditional detection methods to achieve precise identification. Secondly, the surface of photovoltaic panels is often covered with substances such as dust and bird droppings, and these environmental interference factors can lead to errors in the detection results. Moreover, traditional image processing methods and deep learning methods often fail to achieve satisfactory results when detecting small-sized defects. Finally, photovoltaic systems are mostly deployed in remote areas with limited resources, which requires the detection model not only to have high accuracy but also to be lightweight to adapt to the resource limitations of on-site equipment [
4].
The current methods for detecting defects on photovoltaic panels can be classified into two main categories: traditional image processing methods and those based on deep learning.
Traditional methods, such as the K-Means clustering algorithm, the algorithm combining HOG (Histogram of Oriented Gradients) and SVM (Support Vector Machine) [
5], etc., were widely applied in the early detection of photovoltaic panel defects. These methods achieved the analysis of photovoltaic panel images through manually designed feature extractors. Although these methods were simple and easy to use, they had significant limitations when dealing with complex backgrounds, different scales, and different types of defects [
6]. For instance, in the defect detection of photovoltaic panels, since the defect targets are relatively small, after downsampling, the information is further compressed, resulting in significant loss of small target information on the low-resolution feature map, and the phenomena of false detection and missed detection are very serious.
CNN-based methods: With the development of deep learning technology [
7], CNN (the convolutional neural network) has gradually become the mainstream for detecting defects in photovoltaic panels. Deep learning models such as the YOLO series and Faster R-CNN have performed well in image classification and object detection tasks, especially in the detection of large-sized and obvious defects with high accuracy. Although the YOLO series models are fast [
8], they have poor robustness for small-sized defects and complex backgrounds.
DETR model: The DETR model achieves end-to-end object detection by integrating the Transformer network [
9]. Although the DETR model has certain advantages in handling global context information, its computational complexity is extremely high, making it difficult to deploy on devices with limited computing resources. Moreover, the training process of DETR is relatively complex, requiring a large amount of computing resources, and its real-time detection performance is poor.
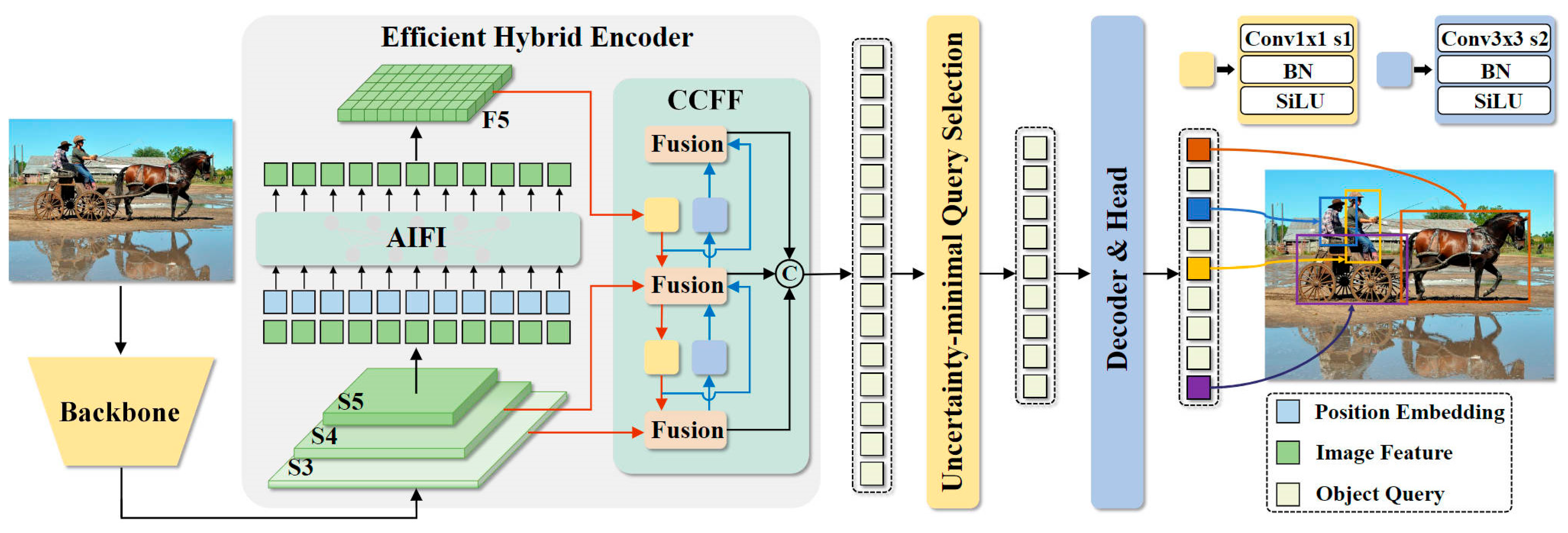
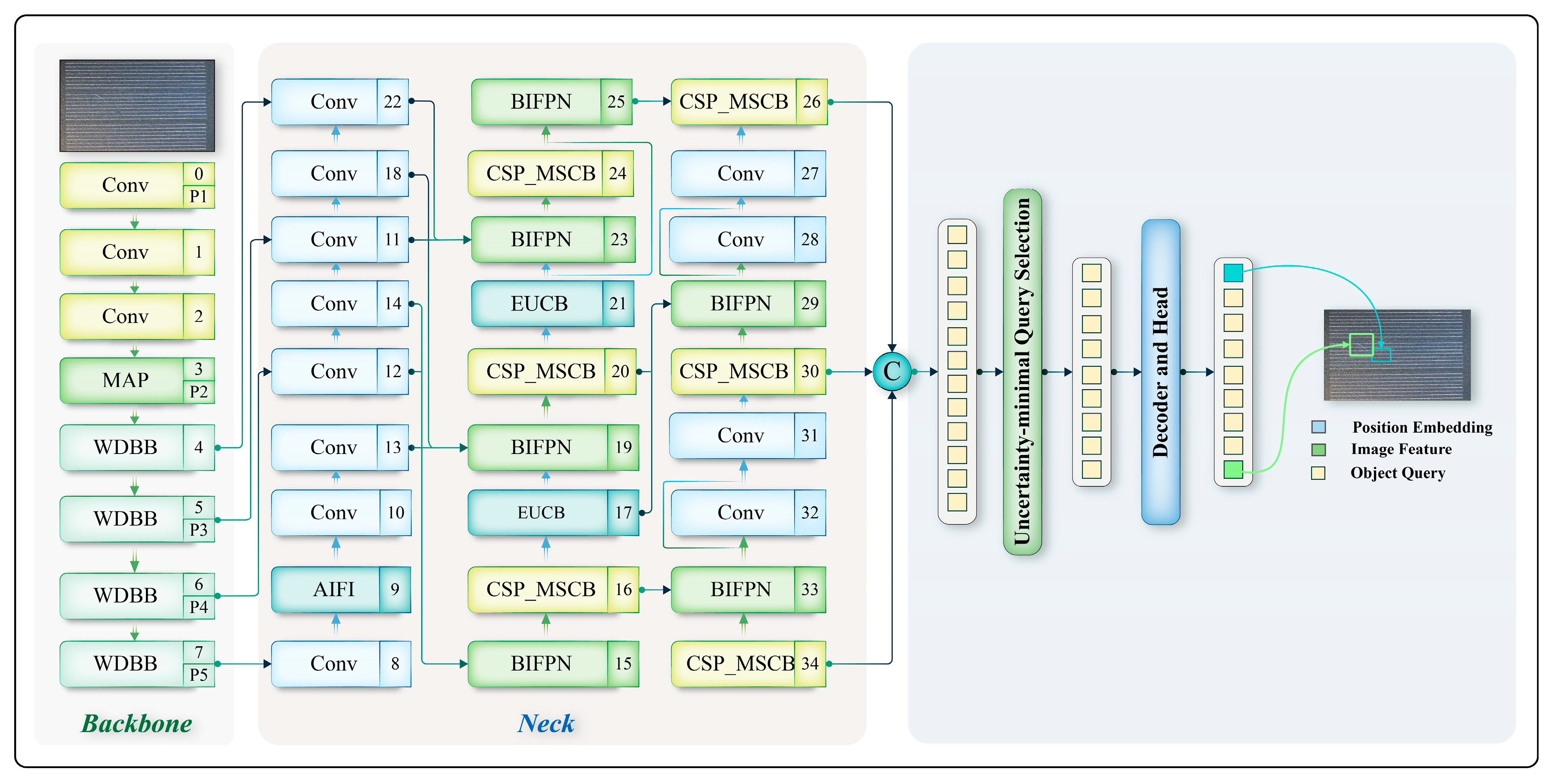
Regarding the aforementioned issues, this study proposes an improved photovoltaic panel defect detection method, EER-DETR, based on RT-DETR. To enhance the performance of RT-DETR in photovoltaic panel defect detection, we integrated and improved the following key modules: By adding the WDBB reparameterization module, we obtained the RepaNet feature extraction network, which is more conducive to the convergence of the network and enables it to learn more information during the training of small targets. It learns richer feature representations and, to some extent, solves the problem that traditional methods suffer from a severe loss of small target information in low-resolution feature maps. The advantage of structural reparameterization lies in the fact that the multi-branch structure during training can learn more comprehensive feature representations, while the single-branch structure during inference can maintain efficiency. During the training phase, the WDBB module can effectively capture the key information of small targets, even if this information is relatively weak in low resolution. During inference, through parameter merging without increasing the computational burden, the detection performance is improved. In the inference process, only one branch is used for inference, thereby reducing the memory usage and computational complexity during the inference process.
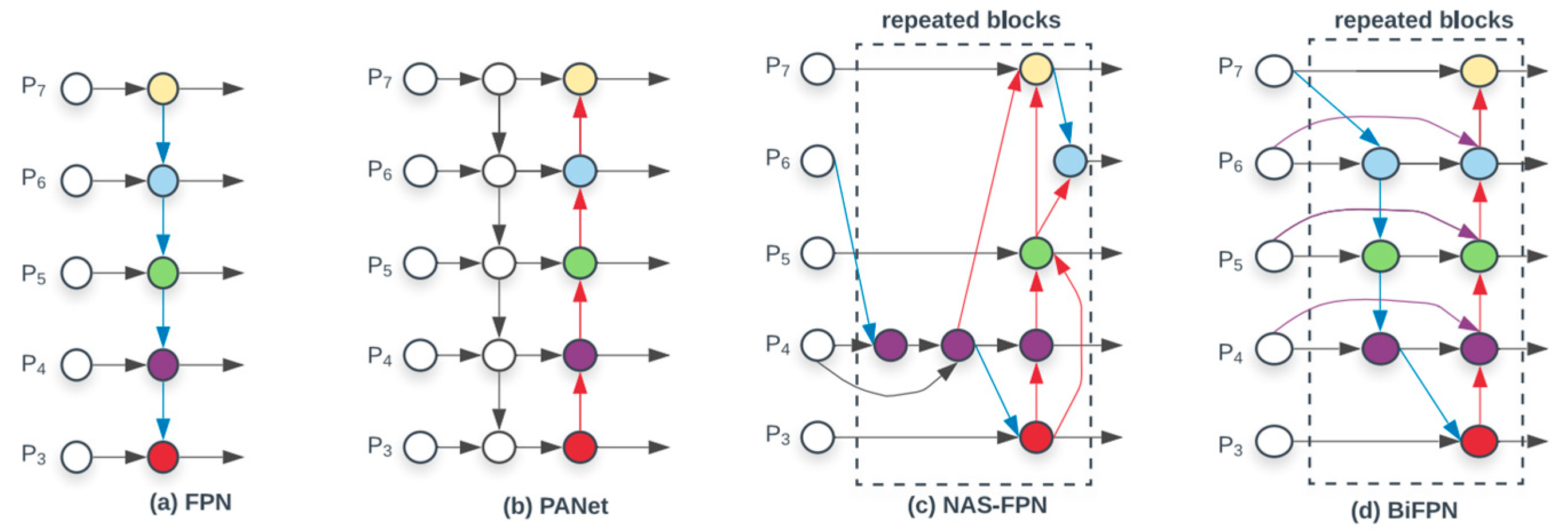
The enhanced multi-scale feature pyramid network (EHFPN) is designed, inspired by BIFPN and MAF-YOLO, aiming to enhance the feature expression ability of the model through multi-scale feature fusion and efficient convolution. Firstly, BiFPN can compensate for the important information that may be lost during the feature extraction process of the RT-DETR backbone network. And our designed EHFPN builds a multi-scale efficient convolution module and a global heterogeneous kernel selection mechanism on this basis. Research on the Trident network indicates that a network with a larger receptive field is more suitable for detecting larger objects, while smaller-scale targets benefit from a smaller receptive field. Therefore, in the FPN stage, we select different multi-scale convolution kernels for different scale feature layers to adapt and gradually obtain multi-scale perception field information. We draw on the multi-scale feature-weighted fusion in BIFPN and replace Concat with Add to reduce the number of parameters and computational cost. Moreover, it can perform self-adaptive weighted fusion based on the importance of different scale features. Thus, our model not only has efficient detection performance but also reduces redundant computations and, to a certain extent, solves the problem that DETR requires a large amount of computational resources and has poor real-time detection performance.
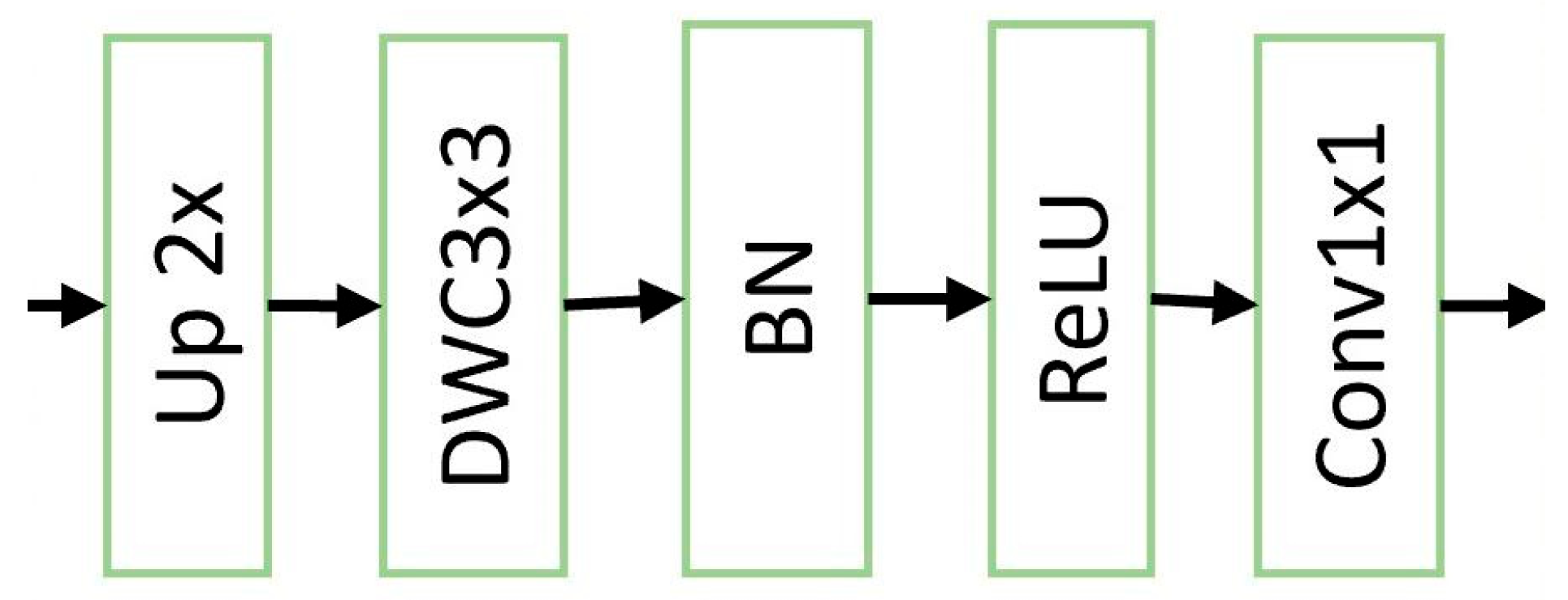
To further address the issue of large computational resources in RT-DETR, we added an efficient upsampling convolution block (EUCB) module. The EUCB employs an efficient upsampling strategy, using deep convolution instead of standard convolution to prevent the loss of important information during upsampling, especially for the details of small targets. At the same time, it reduces the number of channels through 1 × 1 convolution to maintain computational efficiency and reduce redundant features. This optimized the computational burden encountered by the model when performing upsampling on images while maintaining high accuracy.
Key improvements and innovations:
Significant improvement in detection accuracy: By combining the WDBB module and the EHFPN module, the detection accuracy of the model in handling multi-scale defects and fine-grained defects was significantly improved, particularly in complex scenarios where photovoltaic panel backgrounds and defects are intertwined.
Lightweight and efficient architecture: EHFPN reduces the number of model parameters through efficient feature fusion, making it lightweight and suitable for real-time deployment and large-scale photovoltaic panel automated detection tasks.
Efficient computational performance: The EUCB module ensures that the model maintains high performance while reducing the computational burden, making it particularly suitable for large-scale applications in actual industrial environments.
4. Experiments and Analysis
4.1. Experimental Environment
In the experimental setup of the RT-DETR model, the hardware configuration adopted an NVIDIA RTX 4090 GPU (NVIDIA Corporation, Santa Clara, CA, USA) equipped with 24 GB memory, and an Intel(R) Xeon(R) CPU with a base frequency of 2.10 GHz. In terms of software, the system runs in the environment of Python 3.7, PyTorch 1.7.0, and CUDA 11.3. To optimize the experimental results, the experimental parameters were carefully adjusted. The initial learning rate was set to 0.01, the batch size was 32, the training cycle was 100, and the input image size processed was 640 × 640.
Optimizer: The AdamW optimizer is adopted, with weight decay set to 0.0001, momentum parameters β1 = 0.9 and β2 = 0.999, to balance training stability and convergence speed.
Loss function: The model combines Focal Loss and GIoU Loss. In Focal Loss, the class imbalance parameter α is set to 0.25, and the focusing parameter γ is set to 2.0, to alleviate the problem of unbalanced positive and negative samples; GIoU Loss is used for bounding box regression, enhancing localization accuracy and training stability.
Learning rate scheduler: The Cosine Annealing Scheduler is used, dynamically adjusting the learning rate based on the training cycle, gradually decreasing from the initial 0.01, to avoid the model getting stuck in local optimum.
Data shuffling strategy: At the beginning of each training cycle (epoch), the training data are randomly shuffled through the shuffle = True parameter of the PyTorch DataLoader to ensure the randomness of data input and improve the model’s generalization ability.
4.2. Dataset
This experiment utilized two datasets. The first one is the public dataset panel, which contains 2400 defect images of solar panels provided by enterprises. These images were split into a training set of 1920 images and a test set of 480 images in a ratio of 4:1. The dataset includes three types of defects: scratches, broken grids, and dirtiness. This study addressed the issue of insufficient initial data samples by employing various data augmentation strategies, such as random cropping, scale transformation, and illumination adjustment. Through geometric and intensity domain transformations on the original training data, the sample size was effectively expanded, thereby enhancing the model’s understanding of the feature space [
33]. The experimental results demonstrated that by generating derivative samples with rich variations, the heterogeneity of the dataset was significantly improved. This not only inhibited the model’s excessive reliance on specific sample patterns but also significantly enhanced its adaptability to new scenarios. The augmented dataset includes 7528 training images, 892 validation images, and 866 test images. The second dataset is the PVEL-AD dataset, jointly released by Hebei University of Technology and Beihang University [
34], which contains 36,543 near-infrared images with various internal defects and heterogeneous backgrounds. It includes 1 type of normal image and 12 different types of abnormal defect images, such as cracks (linear and star-shaped), broken grids, black cores, misalignment, thick lines, scratches, fragments, broken corners, and material defects. We selected 9842 images from this dataset for testing our model.
Before using these datasets, we carefully examined the data overlap and leakage risks between the Panel and PVEL-AD datasets. By cross-checking the image identifiers, collection times, and scene information, we confirmed that the two datasets were completely independent and had no intersection. Additionally, to evaluate the domain transfer ability and overfitting potential of the model, we trained the model on the Panel dataset and then tested its generalization performance in different defect types and complex backgrounds on the PVEL-AD dataset. At the same time, by monitoring the changes in the loss function during the training process and the performance of the validation set, we evaluated whether the model had an overfitting tendency, thereby ensuring the reliability and generalization ability of the model across different datasets.
4.3. Experiment Metrics
Precision (P), Recall (R), and average precision (AP) are commonly used evaluation metrics in the fields of machine learning and computer vision, especially in tasks such as object detection and information retrieval.
Precision measures the proportion of samples predicted as positive by the model that are actually positive. It is calculated using Equation (17), where TP represents the correctly predicted objects and FP represents the incorrectly predicted objects.
Recall (R), also known as Recall rate, represents the proportion of actual positive samples that are correctly predicted as positive by the model. It is calculated using Equation (18), where FN represents the objects that exist but are not correctly detected.
Average precision (AP) evaluates the performance of the model by combining the performance of Precision and Recall, especially for the predictions under different thresholds in object detection tasks. AP is evaluated by calculating the area under the Precision–Recall Curve (PR Curve), calculated using Equation (19), providing an overall assessment of the model’s performance. For multi-class problems, AP calculates the AP of each class and takes the average of all class APs to obtain mAP (mean average precision), which is derived via Equation (20). mAP@50 and mAP@95 are two common indicators of mAP, where mAP@50 indicates that when calculating mAP, the standard using the IoU (Intersection over Union) threshold of 0.5 is adopted; that is, a predicted box is considered correct when its intersection over union ratio with the real box is greater than 50%. mAP@95 calculates the IoU thresholds from 0.5 to 0.95 and takes the average to evaluate the standard more strictly.
4.4. Comparative Experimental Results and Analysis
4.4.1. Analysis of Training Process
Our EER-DETR model has demonstrated excellent performance in detecting three types of defects, and the verification result is shown in
Figure 6. Among them, the Precision rate for the spot is as high as 0.943, while the rates for crack and grid reach 0.891 and 0.882, respectively, indicating that the detection results are highly reliable, with an extremely low false detection rate. At the same time, the model also has strong Recall capabilities. The Recall rates for the three types of defects all exceed 0.85, proving that the model can effectively capture the vast majority of defects and significantly reduce the risk of missed detections. Under the conventional IoU threshold (0.5), the mAP50 for the grid and spot both exceed 0.9, and cracks are close to this level. This demonstrates the model’s balanced advantages in detection accuracy and coverage. The model maintains stable performance for different types of defects, verifying its practicality and generalization ability in complex industrial quality inspection scenarios. In summary, the EER-DETR model shows high accuracy, strong robustness, and comprehensiveness in detecting defects on photovoltaic panels, providing efficient and reliable technical support for industrial automated quality inspection.
Table 1 presents the detection results for three different types of defects.
4.4.2. Comparative Experiments
From
Table 2, we can observe that EER-DETR outperforms the original model RT-DETR in multiple key indicators. In terms of Precision, EER-DETR achieved 0.916, while RT-DETR only reached 0.893, indicating that EER-DETR is more accurate in identifying targets and can more effectively reduce false alarms. In terms of Recall, EER-DETR also demonstrated an advantage, reaching 0.872, while RT-DETR was 0.841. This suggests that EER-DETR is more comprehensive in detecting targets and can more effectively reduce missed detections. In terms of mAP50 (mean average precision at 50%) and mAP50-90 (mean average precision at different IoU thresholds), EER-DETR also performed well, reaching 0.905 and 0.458, respectively, while RT-DETR was 0.886 and 0.456, respectively. Compared to the original model, this indicates an improvement of 1.9%. This shows that EER-DETR has superior comprehensive performance across different detection difficulties. Additionally, EER-DETR also demonstrated advantages in terms of parameter quantity and computational complexity. The parameter quantity of EER-DETR is 17,941,933, while that of RT-DETR is 19,875,612. The computational complexity (GFLOPs) of EER-DETR is 48.6, while that of RT-DETR is 56.9. This indicates that EER-DETR maintains high performance while having better computational efficiency and model lightweight characteristics.
Figure 7 shows a comparison chart of the detection performance between EER-DETR and RT-DETR. It can be seen that the performance of our model has improved significantly.
To verify the stability of the model performance and the reliability of the improvements, five independent experiments were conducted on RT-DETR and EER-DETR, with the same data division and training configuration used in each experiment. The stability of the evaluation metrics was assessed by calculating the mean and standard deviation, and the paired t-test was used to verify whether the performance difference between the improved model and the original model was statistically significant (significance level α = 0.05).
The data in the table represent the mean values of five independent experiments, with standard deviations as follows: Precision (RT-DETR: ±0.008, EER-DETR: ±0.006); Recall (RT-DETR: ±0.009, EER-DETR: ±0.007); mAP50 (RT-DETR: ±0.007, EER-DETR: ±0.005). Paired t-test shows that EER-DETR is significantly superior to RT-DETR in Precision (t = 4.21, p < 0.05), Recall (t = 3.12, p < 0.05), and mAP50 (t = 5.12, p < 0.01).
We also compared EER-DETR with the classic YOLO series models. From
Table 3, we can see that EER-DETR demonstrated significant advantages in multiple indicators such as Precision, Recall, mAP50, and mAP50-90. In terms of Precision, EER-DETR reached 0.909; this indicates that EER-DETR has higher accuracy in target recognition. In terms of Recall, EER-DETR reached 0.872, while the best-performing model in the YOLO series, YOLOv5, was 0.865. This shows that EER-DETR has better comprehensiveness in target detection. In terms of mAP50 and mAP50-90, EER-DETR reached 0.905 and 0.458, respectively, while the best-performing model in the YOLO series, YOLOv5, reached 0.888 and 0.446, respectively. This indicates that EER-DETR has superior comprehensive performance under different detection difficulties. In contrast, the YOLO series models have shortcomings in some aspects. For example, YOLOv7 performed poorly in Precision and Recall, with 0.862 and 0.743, respectively, indicating that its accuracy and comprehensiveness in target recognition need to be improved. YOLOv10 also performed poorly in Precision and Recall, with 0.851 and 0.795, respectively, indicating that its performance in target detection needs to be enhanced.
As shown in
Table 4 and
Table 5, we tested the performance of various models on the photovoltaic panel defect dataset. However, in general, none of them outperformed our designed EER-DETR model.
Firstly, regarding different backbone structures, after improving RT-DETR with SwinTransformer, although it has higher parameters and computational complexity, it still performs reasonably well in Precision, Recall, mAP50, and mAP50-90 indicators. This indicates that it has certain advantages in feature extraction and object detection. However, compared with EER-DETR, SwinTransformer is slightly inferior in these indicators, especially in Precision and mAP50. EER-DETR achieved 0.909 and 0.905, respectively, while SwinTransformer only reached 0.864 and 0.852. This shows that EER-DETR is more accurate and has better detection performance. Models such as VanillaNet, StarNet, and ConvNextV2, which are improved models, have relatively lower parameters and computational complexity, but they still have a gap compared to EER-DETR in Precision, Recall, mAP50, and mAP50-90 indicators. Although VanillaNet is slightly higher than SwinTransformer in Precision and mAP50, it does not show obvious advantages in other indicators. This indicates that VanillaNet may have certain potential from some aspects, but its overall performance still needs further optimization.
Improvements and comparisons on different structures of the neck part were also made. After improving RT-DETR with SlimNeck, its parameters were reduced and the computational complexity was lower. However, there is still a gap in terms of the Precision, Recall, mAP50 and mAP50-90 indicators compared with EER-DETR. Using mAP for comparison, EER-DETR increased by 4.2% compared with SlimNeck and by 3.4% and 2.3%, respectively, compared with MAFPN and BIFPN. Meanwhile, our model has the lowest parameter quantity. It can be clearly seen from
Figure 8 that EER-DETR has obvious advantages over the other models:
In conclusion, EER-DETR performs well in the Precision, Recall, mAP50, and mAP50-90 indicators and has relatively lower parameters and computational complexity. This indicates that EER-DETR has significant advantages in accuracy and detection performance and has high practicality and operability in actual applications. In contrast, other models have shortcomings in certain aspects. For instance, their recognition accuracy and detection comprehensiveness need to be improved, and their computational complexity and model lightweighting also require optimization. Therefore, the EER-DETR model has better performance and broader application prospects in practical applications.
4.4.3. Ablation Experiments
From
Table 6, it can be seen that, first, in the original RT-DETR model, mAP50 reached 0.886, with a parameter quantity of 19,875,612 and GFLOPs of 56.9. This indicates that the RT-DETR module itself already has a relatively high detection capability, but there is still room for improvement. When we improved RepaNet based on RT-DETR, the model’s mAP50 increased to 0.902, with the parameter quantity remaining unchanged and GFLOPs also remaining at 56.9. This shows that the RepaNet module significantly improves the detection performance of the model without increasing computational resources. Further, when the EHFPN module was added to RT-DETR, the model’s mAP50 slightly decreased to 0.871, but the parameter quantity was reduced to 17,821,836 and GFLOPs decreased to 47.5. This indicates that the EHFPN module reduces the computational resource requirements of the model to a certain extent, but the improvement in detection performance is limited. The EHFPN module reduces the parameter quantity and computational cost through a more efficient feature pyramid network design but may not be as good as RepaNet in feature extraction and fusion. When the EUCB module was added to RT-DETR, the model’s mAP50 increased to 0.901, the parameter quantity increased to 20,189,856, and GFLOPs increased to 57.7. This shows that the EUCB module further improves the detection performance of the model by increasing computational resources, enhancing the model’s ability to locate and classify targets. When RepaNet and EHFPN were added to RT-DETR simultaneously, the model’s mAP50 reached 0.899, the parameter quantity remained at 17,821,836, and GFLOPs remained at 47.5. This indicates that the combination of the RepaNet and EHFPN modules can still maintain high detection performance while reducing computational resources. The RepaNet module optimizes feature extraction and fusion, while the EHFPN module reduces the parameter quantity and computational cost through a more efficient feature pyramid network design. Finally, when the RepaNet, EHFPN, and EUCB modules are used simultaneously, our EER-DETR model is formed. The model’s mAP50 reached 0.905, the parameter quantity was reduced by 9.7% compared to the original RT-DETR model, and GFLOPs were significantly reduced. In conclusion, by gradually adding RepaNet, EHFPN, and EUCB modules, the detection performance of the model was significantly improved, and computational resource requirements were also optimized. This proves that our EER-DETR model achieved high accuracy and lightweight efficiency.
4.5. The Deployment on the NVIDIA Jetson Nano Platform
In practical applications, the real-time object detection capability of edge devices holds significant importance. This study deploys the improved EER-DETR model on the NVIDIA Jetson Nano platform, which is equipped with a quad-core Cortex-A57 CPU and a 128-core Volta architecture GPU and is suitable for edge computing scenarios. As shown in the
Table 7, compared with the original RT-DETR, EER-DETR has significant improvements in indicators such as FPS and memory usage. These data indicate that EER-DETR not only enhances detection accuracy but also reduces model complexity, making it more suitable for resource-constrained edge devices. Deploying EER-DETR on Jetson Nano provides a better solution for real-time object detection in edge scenarios, achieving a better balance between accuracy and efficiency through specific data support.
4.6. The Test Conducted on the EER-DETR Model on the PVEL-AD Dataset
As shown in
Table 8, We tested our model on 9842 image pairs extracted from the PVEL-AD dataset. The results showed that, compared with the original RT-DETR model, the mAP50 of our model increased by 1.6% and the number of parameters decreased by 9.6%. The results indicate that our model is universal across different datasets for photovoltaic panel defect detection and achieves the goal of integrating high accuracy and lightweight.
5. Discussion and Conclusions
To significantly enhance the accuracy and real-time performance of photovoltaic panel defect detection, thereby providing strong technical support for the intelligent operation and maintenance of photovoltaic systems, this study proposes an improved photovoltaic panel defect detection method, EER-DETR, based on RT-DETR. Through in-depth experimental verification of this algorithm, the results show that the designed EER-DETR model exhibits excellent performance in photovoltaic panel defect detection, achieving a significant improvement in detection accuracy, while significantly reducing the computational cost. The EER-DETR algorithm adds a structural re-parameterization module, WDBB, to form a new feature extraction network, RepaNet and designs an efficient multi-scale convolution module and global heterogeneous kernel selection mechanism, EHFPN, to reduce computational overhead; introducing EUCB to optimize the upsampling process not only retains more details when improving image resolution but also enables the network to effectively learn small target features at low resolutions, thereby reducing the problem of missed detections and improving the accuracy and robustness of photovoltaic panel defect detection. This optimization makes the algorithm more stable and efficient in practical applications, especially in the defect detection tasks of large-scale photovoltaic power stations, where it demonstrates stronger adaptability compared to traditional methods.
However, this study still has certain limitations. Although data augmentation strategies were employed, in extremely complex environmental conditions (such as extreme lighting), the model’s detection accuracy for some minor defects may decline, and there is a risk of overfitting. Through qualitative analysis of the detection results, it was found that in some cases, when the light is uneven or the edge defect features are blurry, the model may have false detections or missed detections. For example, when the scratch defect is too similar to the texture of the panel itself, the model has difficulty accurately distinguishing them, resulting in detection errors. There are also deficiencies in the detection of some internal issues. These situations indicate that the model’s robustness in handling complex visual information still needs to be improved.
EER-DETR as an innovative method for detecting defects in photovoltaic panels, not only providing a new solution for intelligent operation and maintenance from a theoretical perspective but also demonstrating strong application potential in practice, indicating its broad application prospects in the future photovoltaic industry. Looking to the future, it is recommended to conduct in-depth research in the following directions: firstly, expand the range of detectable defects to include more rare defect types, and enhance the model’s generalization ability; secondly, integrate multi-spectral data and utilize the feature information under different spectral conditions to improve the ability to identify complex defects; finally, further optimize the domain adaptation algorithm to ensure that the model maintains stable and efficient detection performance in different environments and scenarios, promoting the continuous progress of photovoltaic panel defect detection technology.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}