1. Introduction
The dynamic response calculation of a foundation beam under moving loads represents a highly complex mechanical issue that integrates knowledge and techniques from multiple disciplines. Addressing this problem not only deepens our understanding of dynamic responses in practical engineering scenarios but also offers theoretical and technical support to ensure structural safety and reliability [
1,
2]. The solutions to this problem typically involve analytical and numerical methods. Analytical methods necessitate the formulation of mathematical models, followed by the application of integral transforms (e.g., Laplace, Fourier) to solve the governing equations. This process yields closed-form solutions that offer clear insights into how different parameters influence dynamic responses [
3,
4]. However, these methods are generally restricted to idealized models and specific loading conditions. In contrast, numerical methods, which often utilize the finite element method (FEM), are capable of tackling complex real-world engineering problems. They can manage irregular geometries, complex boundary conditions, and multiphysics couplings but demand significant computational resources [
5]. Furthermore, a single finite element simulation can only provide the solution for a particular case. When variables such as material properties, structural models, or loading patterns change, remodeling and remeshing become necessary. This lack of adaptability renders finite element simulation inefficient for certain problems [
6].
In recent years, deep learning (DL) techniques, celebrated for their remarkable fitting capabilities, have garnered significant attention in the analysis and prediction of dynamic responses induced by moving loads [
7,
8,
9]. The effectiveness of these DL methods largely hinges on supervised training, where the model adjusts its parameters by calculating the error between predicted and true labels (loss function) and then uses backpropagation and optimizers (e.g., gradient descent) to minimize this error. Repeated iterations of this process enable the model to improve and achieve high accuracy on test data [
10,
11]. However, in practical applications, obtaining high-quality monitoring data is often fraught with difficulties [
12]. As a result, accurately predicting the dynamic response of structures becomes extremely challenging when data are scarce or unavailable. Recently, physics-informed neural networks (PINNs), which combine scientific computing and machine learning, have shown considerable potential for solving partial differential equations (PDEs) in data-scarce scenarios [
13,
14,
15]. Research on the application of PINNs to beam bending problems, particularly dynamic responses under moving loads, is still in its early stages. Kapoor et al. [
16] explored single—and double—beam structures using PINNs based on Euler–Bernoulli (E–B) and Timoshenko theories. Their work proved PINNs’ effectiveness in solving forward and inverse problems in complex beam systems. In follow-up studies, by modeling moving loads with Gaussian functions, PINNs were used to calculate beam deflection and predict moving loads [
17]. However, this method treated the moving load as a static load progressing across different positions, neglecting dynamic effects. Fallah and Aghdam [
18] applied PINNs to study the bending, natural frequencies, and free vibrations of 3D functionally graded porous beams, analyzing how material distribution, elastic foundation, porosity factor, and porosity distribution type affect bending response and natural frequencies. However, their research focused only on the spatial conditions under external loads, ignoring complex spatiotemporal effects. Li et al. [
19] approximated the Dirac function with a Gaussian function, introduced a Fourier embedding layer into PINNs’ deep neural network, and incorporated causal weights into the loss function to obtain beam dynamic responses under moving loads. When beam parameters are unknown, a physics- and data-driven PINN can determine the beam response with minimal monitored data. When the training data are incomplete, the performance of PINNs often surpasses that of existing data-driven DL networks [
13].
Although PINN has demonstrated significant potential in addressing computational physics problems involving sparse, noisy, unstructured, and multi-fidelity data, they still encounter numerous challenges when it comes to structural vibration problems under moving loads. PINN can only serve as a solver for specific parameter domains. When it comes to predicting dynamic responses over a broad range of parameter domains, the stability of PINN is not satisfactory. Each minor adjustment to the model means that retraining is necessary, a limitation that undoubtedly increases computational costs and makes it inconvenient to apply to practical engineering [
20]. Constructing PINN-based surrogate models is seen as a way to enhance prediction generalization across broad parameter spaces [
21,
22,
23]. Traditional PINN-based surrogate models can make wide-ranging predictions across parameter spaces by dynamically combining input parameters. However, these models face three key practical limitations: First, they struggle with computational efficiency as more parameters are added. This “dimensionality problem” becomes especially serious in complex cases like tuning multiple hyperparameters together, modeling interacting physical systems, or simulating time-dependent processes. The computational load grows much faster than for simpler PINN models. Second, the models need large amounts of training data to work accurately. Their prediction quality depends heavily on having enough data points covering the parameter space. With too little data, errors become much larger at the edges of the parameter range. The problem gets worse for systems with multiple scales or sudden physical changes. Most importantly, to work across all possible parameter values, the models must simplify the underlying physics. They use less complex versions of the governing equations and are less strict about satisfying physical laws exactly. While this helps the models fit data overall, it leads to bigger mistakes when dealing with special cases like sharp boundaries or critical parameter values where the physics changes suddenly. These limitations reduce how much we can trust the models in realistic, complex situations.
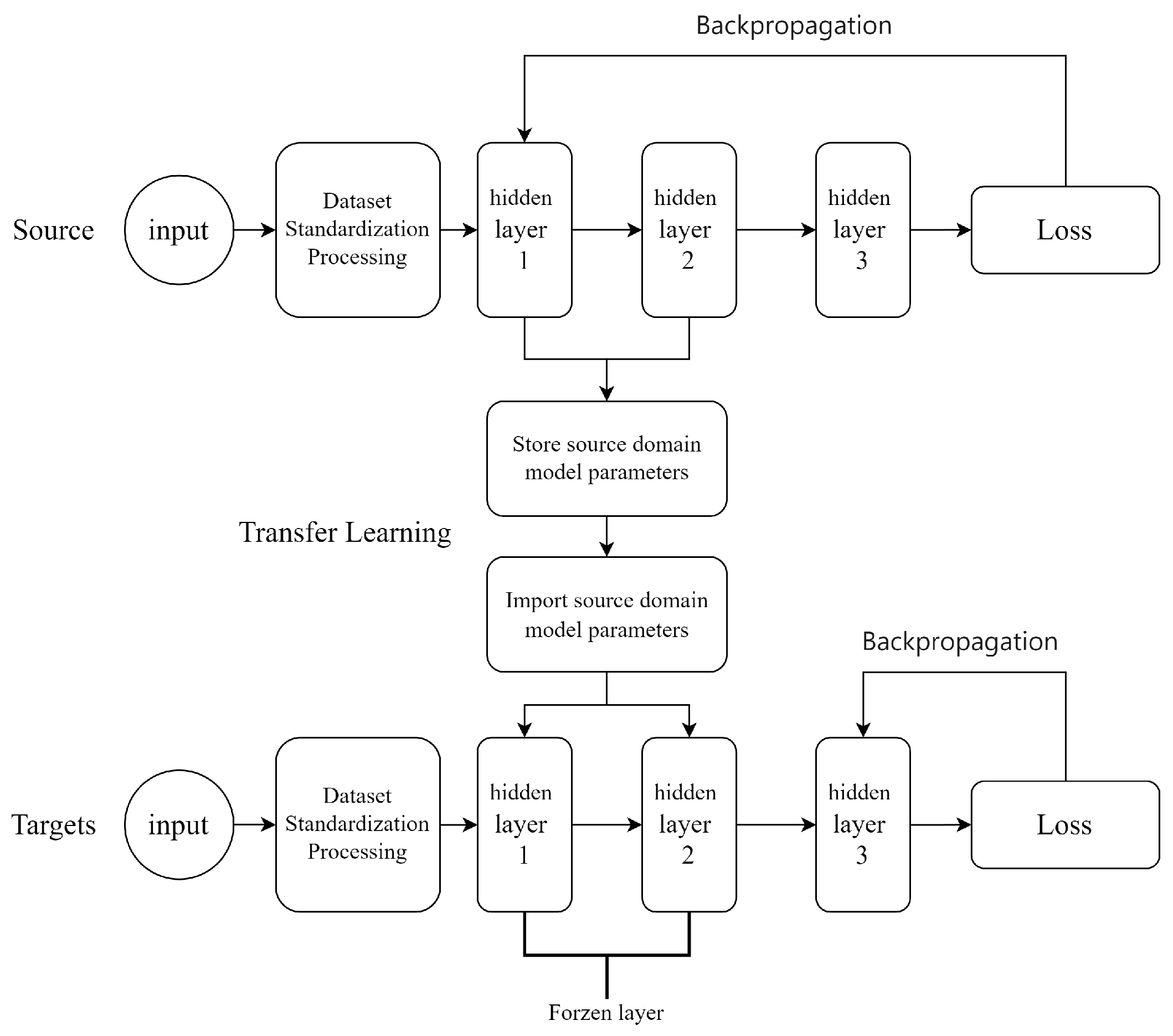
Based on the above considerations, our study addresses these challenges by developing a novel transfer learning [
24,
25]-enhanced PINN framework that strategically combines localized physical modeling with data-driven generalization. This hybrid approach enables accurate prediction of steady-state beam responses under moving loads across broad parameter ranges while significantly reducing the experimental or computational data needed for model training—a crucial advancement for practical engineering applications where comprehensive parameter testing is often infeasible. The proposed methodology begins by establishing local PINN models trained on displacement data obtained at strategically distributed points throughout the parameter space. These sampled points form the source domain, with their immediate adjacent regions designated as target domains. Leveraging transfer learning techniques, the initially trained source domain models undergo systematic refinement to achieve proper adaptation to each corresponding target domain. Ultimately, predictions generated by all localized PINN models across both source and target domains are integrated to construct a comprehensive PINN-based surrogate model capable of representing the system’s behavior across the full parameter spectrum. Transfer learning can significantly reduce the required input data volume for target domain tasks [
26,
27]. However, the transfer strategies employed in transfer learning can substantially impact the predictive performance of the resulting target domain models [
28,
29,
30]. Current transfer strategies often rely heavily on experimental experience while lacking universal guiding principles. This paper provides relevant recommendations by examining how migration paths influence final prediction accuracy.
The remainder of this paper is organized as follows: In
Section 2, an analytical solution is presented for the vibration problem of an infinite beam on a foundation subjected to a moving load. The analytical approach yields a limited dataset of displacement responses for the beam under prescribed parameter conditions. These displacement data are subsequently perturbed with noise to emulate sensor measurements. Additionally, the analytical solution is employed to generate response data across a broader range of arbitrary parameters, which serve as benchmark values for validating the surrogate model results in subsequent sections. In
Section 3, three PINN models are developed to learn displacement data across various parameter conditions, aiming to identify the relationship between coordinates and beam displacement under specific parameters with limited measured data. In
Section 4, transfer learning is utilized to adjust the weights of the initial PINN models for specific parameters. By leveraging the mapping capabilities of these PINN models, a large dataset of beam displacement responses is generated across several targeted regions within the parameter space. This dataset is then utilized in
Section 5 to train a PINN-based surrogate model. Numerical examples show that the surrogate model accurately predicts beam displacement over a wide parameter range. A comparison between the prediction results of this study and those from traditional PINN-based surrogate models is presented in
Section 6.
Section 7 examines the impact of sensor measurement noise and transfer quantity and paths in transfer learning on the prediction accuracy of the surrogate model. The conclusions are presented in
Section 8. For easy understanding, a list of symbols used in this paper along with their definitions is placed at the end of the text.
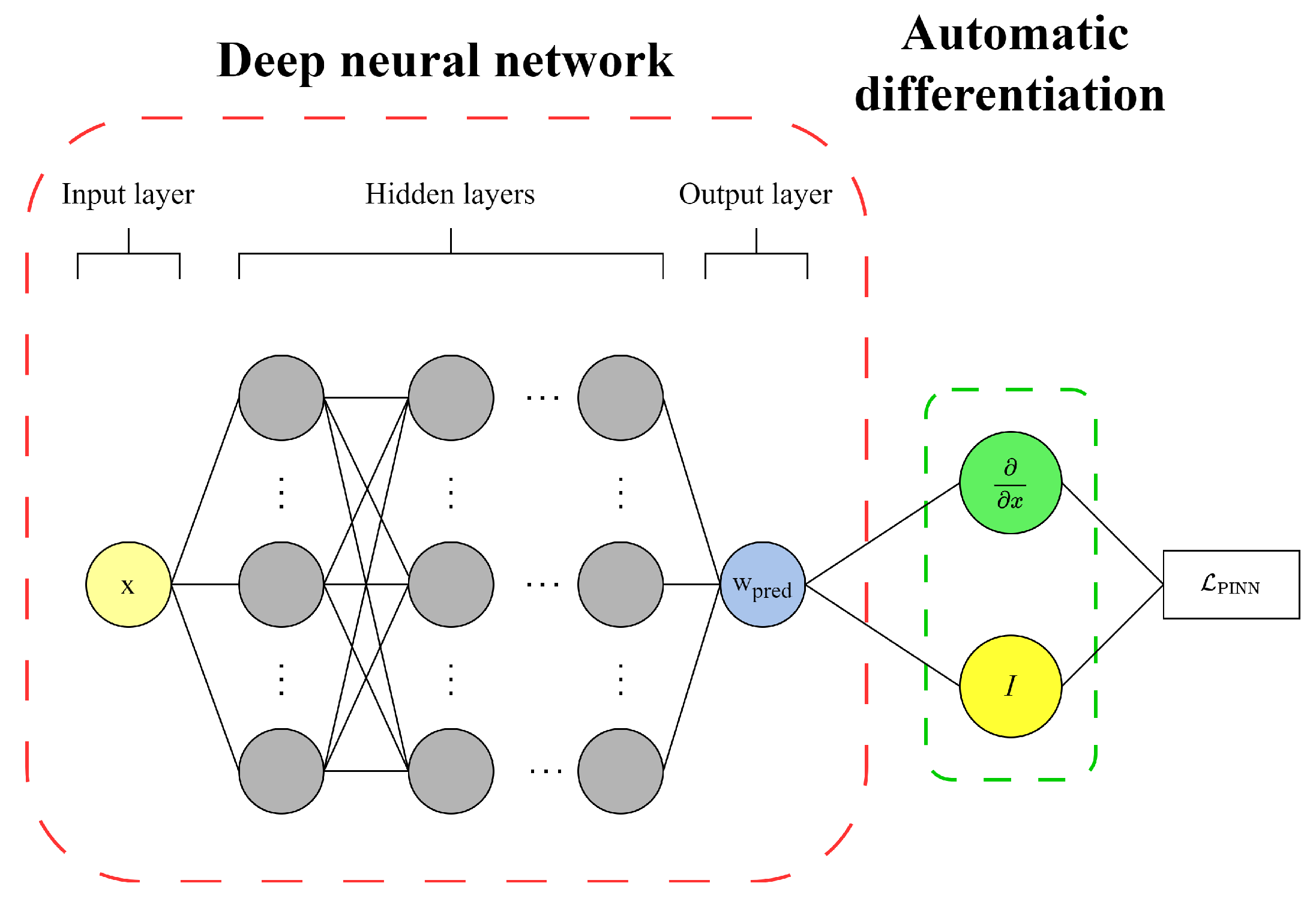
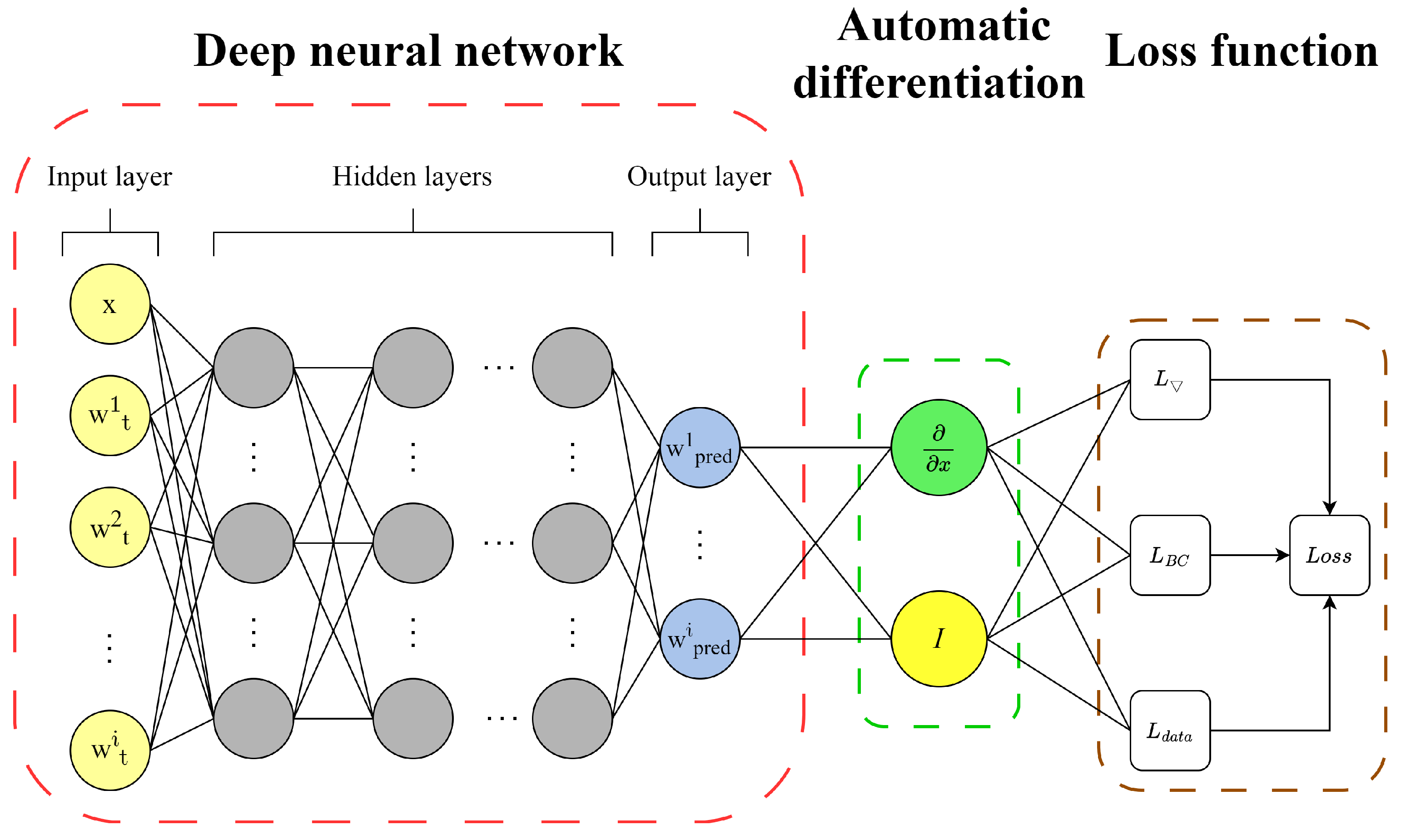
5. The PINN-Based Surrogate Model
To achieve precise predictions of the beam’s displacement across an extensive parameter plane, a PINN-based surrogate model is constructed, as depicted in
Figure 8. The outputs from the 15 PINN models presented in the previous section serve as the comprehensive training dataset for this surrogate model. The methodology and essential steps are outlined as follows:
The input data comprise 50 evenly spaced coordinate points selected within the range
, along with the corresponding beam displacement predictions generated by the 15 pre-established target-domain PINN models. These inputs are denoted as
(coordinate values) and
(displacement predictions), where
and
. The output layer of the surrogate model represents the beam displacement predictions, matching the dimensionality of the input displacement values and denoted as
, with
and
. To construct the feedforward neural network architecture, a structured weight constraint approach is employed to define the mapping relationship between the output layer
and the input layers
and
. Sparsity constraints are imposed on the network’s weight matrix
M and bias vector
b to enforce selective connectivity during training. This ensures that each neuron’s output is influenced exclusively by its corresponding input channel, while non-essential connections are pruned by constraining their weights to zero. This optimization strategy can be formally represented as
where tanh is the activation function, and
denotes the diagonal elements of the weight matrix.
The loss function for the PINN surrogate model is formulated as an ensemble of loss functions derived from multiple local PINN models. This formulation is expressed as
The PINN surrogate model differs from local PINN models in that it must handle a significantly larger dataset, leading to considerably higher computational costs during training. To address this, the surrogate model constructed in this study adopts a three-layer fully connected architecture (20 neurons per layer) with the “tanh” activation function. For data partitioning, a 4:1 ratio is implemented to divide the training set and validation set. The model training employs an adaptive learning rate scheduling strategy, where the initial learning rate is set to
and halved every 200 training epochs. A dual early-stopping mechanism is triggered when the learning rate decays below the
threshold or when the validation loss shows no downward trend for 30 consecutive epochs. Additionally, the surrogate model’s training employs the Adam optimizer. Training iterations are increased to 20,000. Notably, to prevent interference from sparsity constraints (e.g., L1/L2 regularization) with the physical governing equation loss terms, these regularization components have been intentionally excluded from the model design. In terms of prediction mechanism design, the surrogate model adopts a dynamic network activation strategy based on the domain features of the parameter space. More specifically, for a given prediction point
, the closest target-domain reference model within the parameter plane is first identified using the minimum Euclidean distance criterion, as follows:
The surrogate model activates the sub-network module corresponding to the nearest neighbor model. The target parameter coordinates and the beam coordinate are then fed into this sub-network module simultaneously for deflection prediction. This mechanism significantly enhances the model’s ability to represent local features by preserving the domain-specific characteristics inherent to the parameter space.
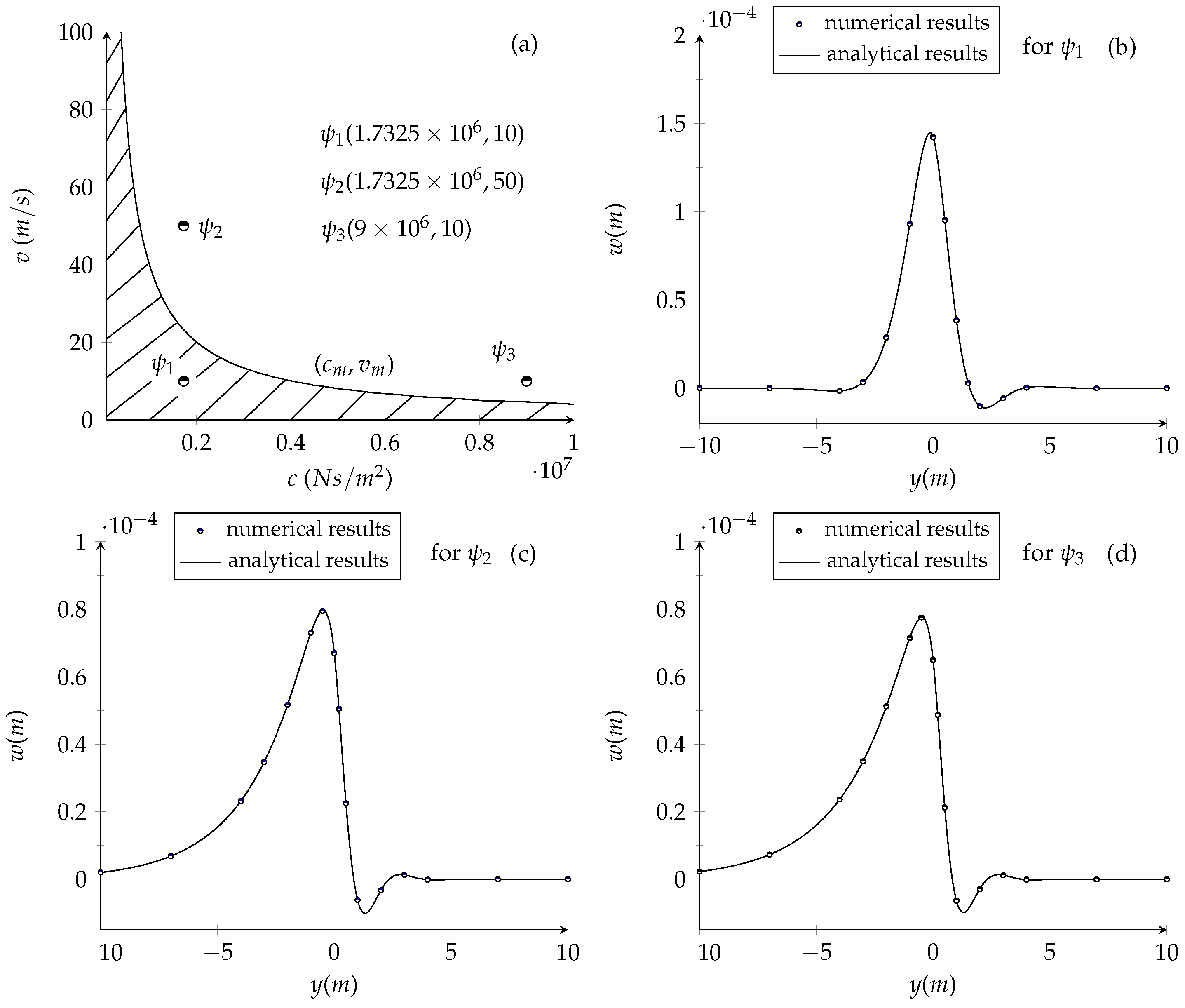
To assess the model’s generalization capability, this study creates a 15 × 10 grid of test points in the parameter space, defined by
and
, totaling 150 test points. For each test point, 400 equidistant points are positioned within a 5 m span both ahead of and behind the moving load on the beam to predict deflection. We use the metrics MAE (mean absolute error), RMSE (root mean square error), and coefficient of determination
to evaluate the accuracy of model predictions. The formulations for MAE and RMSE are expressed as
where n is the number of sample data points, and
and
represent the predicted and actual displacement values, respectively.
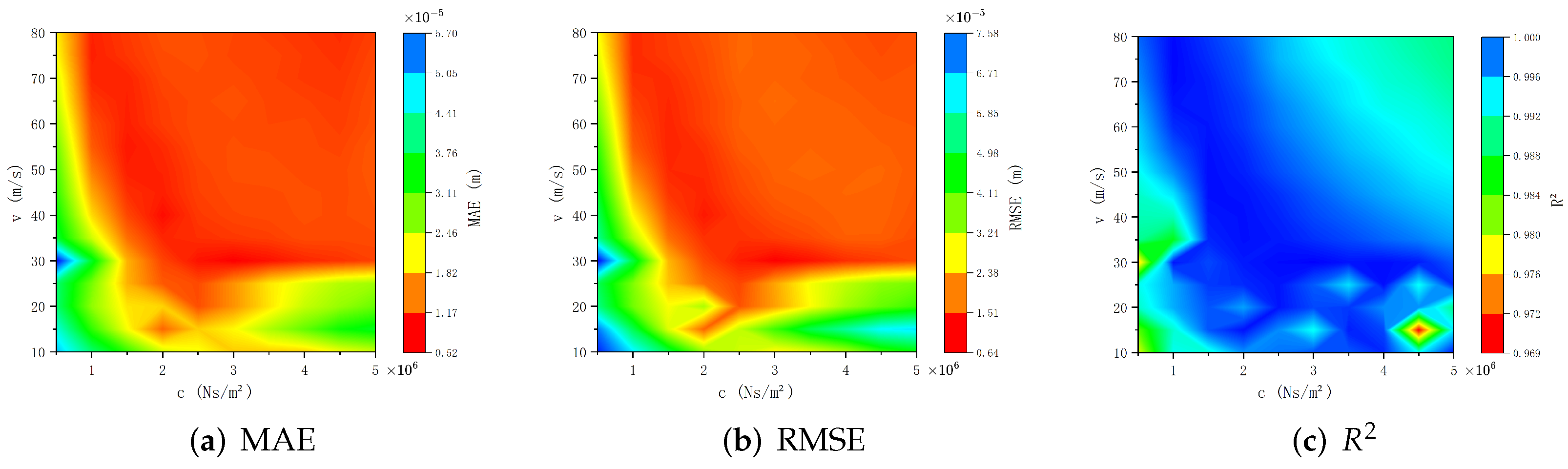
The evaluation values for each parameter point are mapped onto the
parameter plane, resulting in the contour plot shown in
Figure 9.
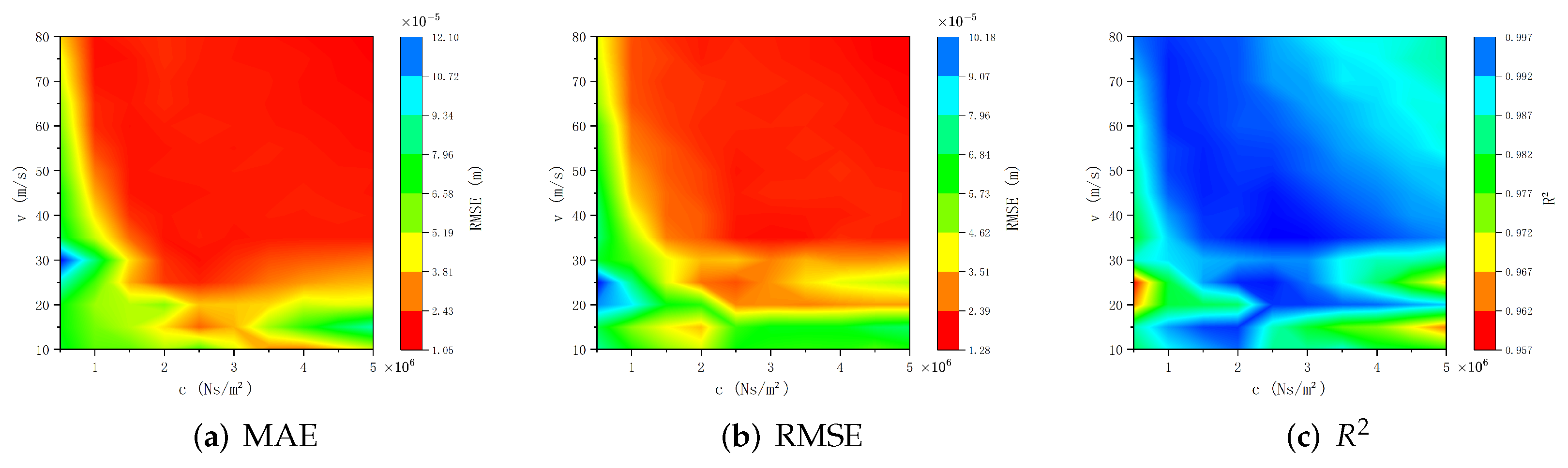
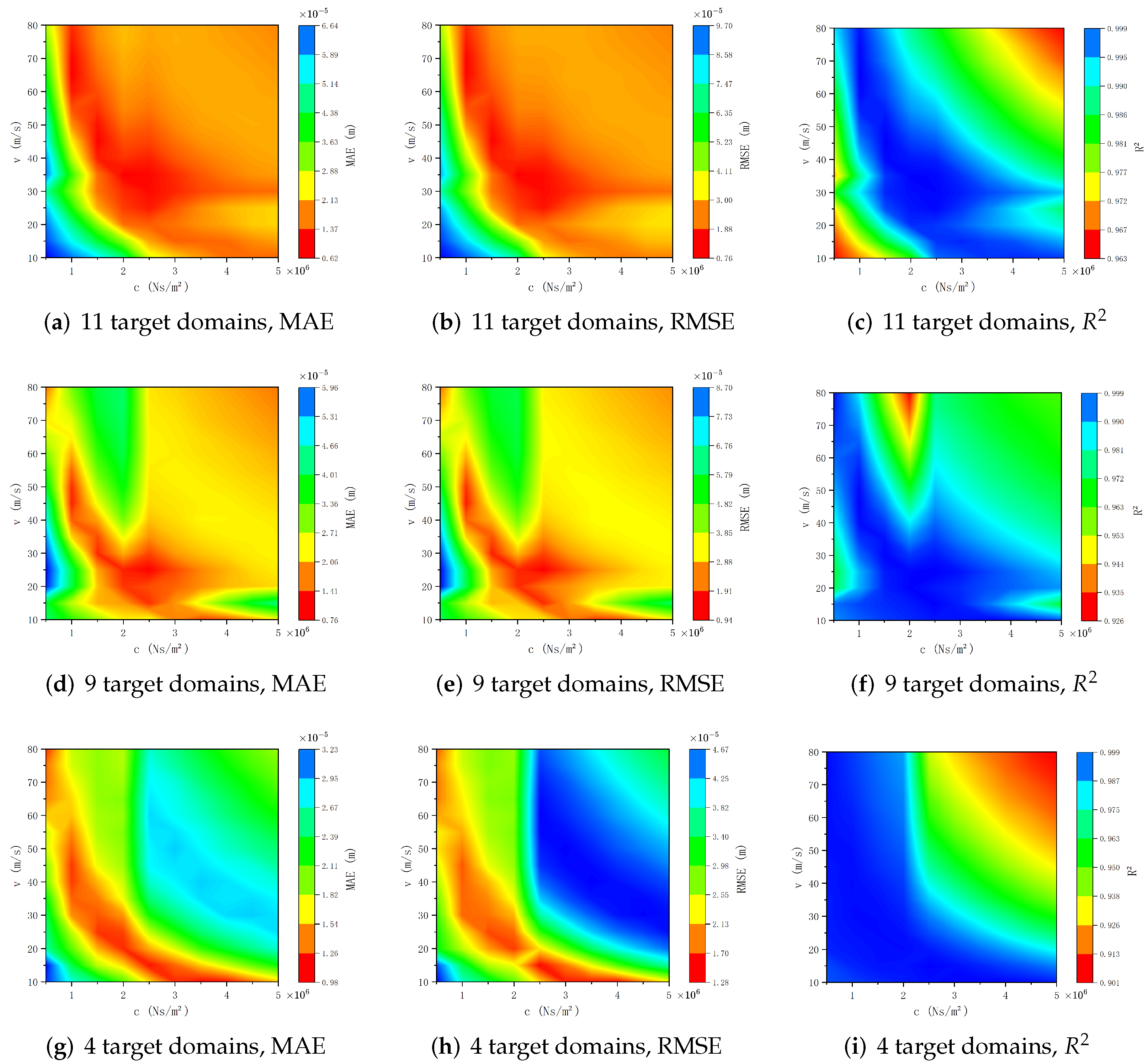
Figure 9 demonstrates the prediction accuracy of the surrogate models through three evaluation metrics (MAE, RMSE, and
). Numerical experiments reveal that, in most parameter regions, the MAE and RMSE values are approximately
, with
values approaching 1. Next, we incrementally increase the noise intensity by introducing controlled noise levels equivalent to 2% and 3% of the maximum amplitude of the analytical solutions.
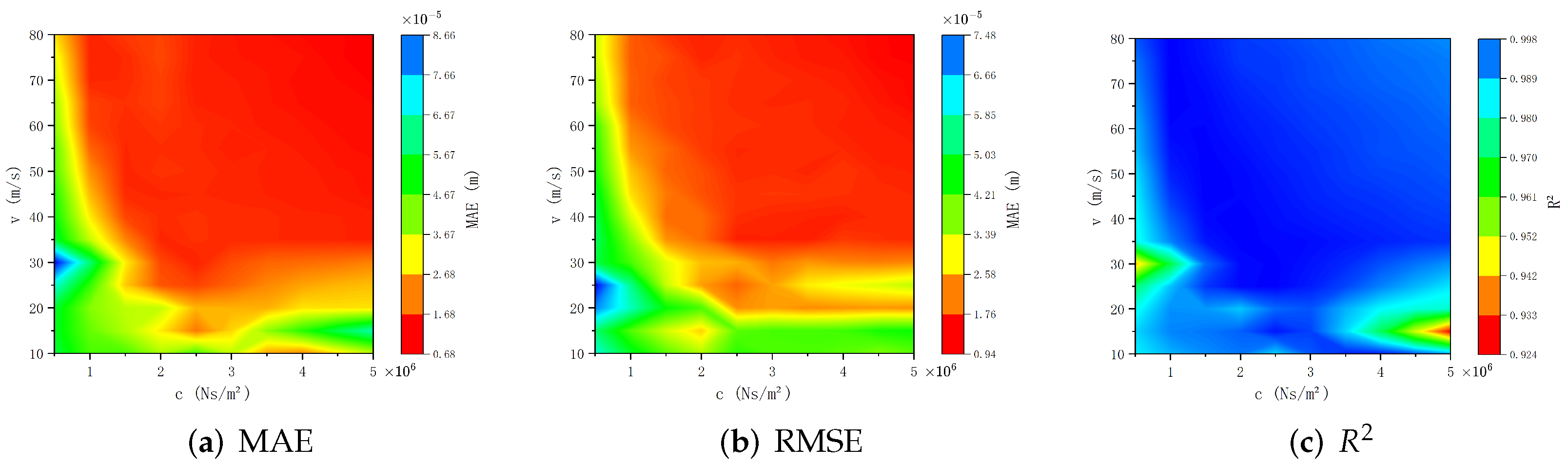
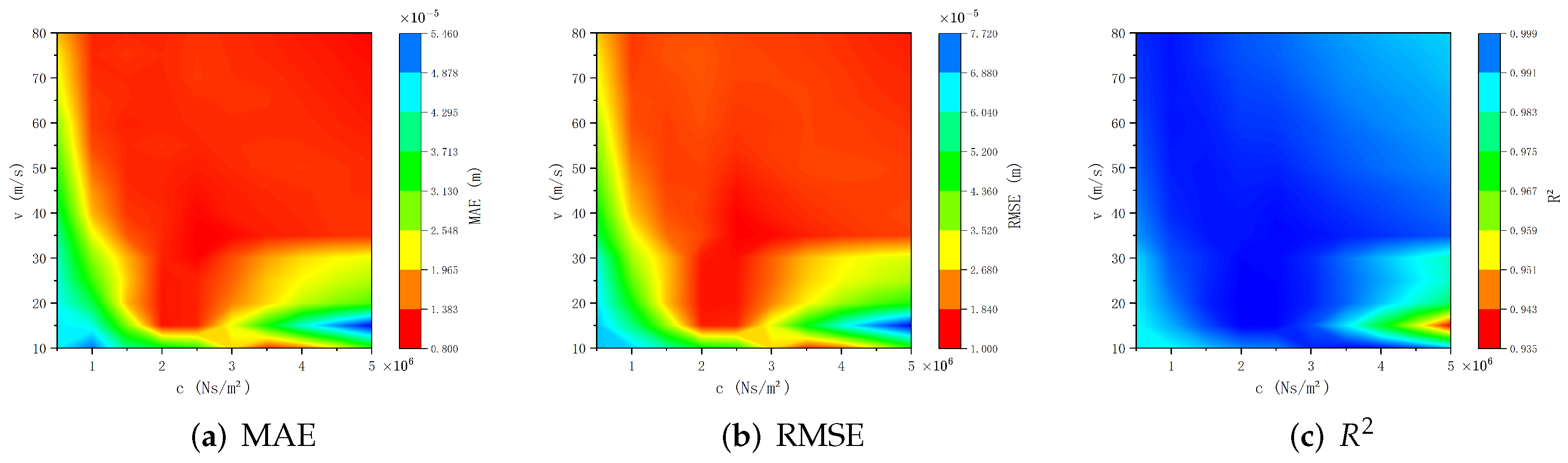
Figure 10 and
Figure 11 visually present the prediction results of the PINN surrogate model under higher noise standard deviation through MAE, RMSE, and
. The figures show that as the noise standard deviation increase, MAE and RMSE values for extreme outliers rise; however, in most parameter regions of the model, MAE and RMSE only slightly increase to approximately
, with
remaining close to 1. This indicates that the surrogate model possesses good robustness against noise.
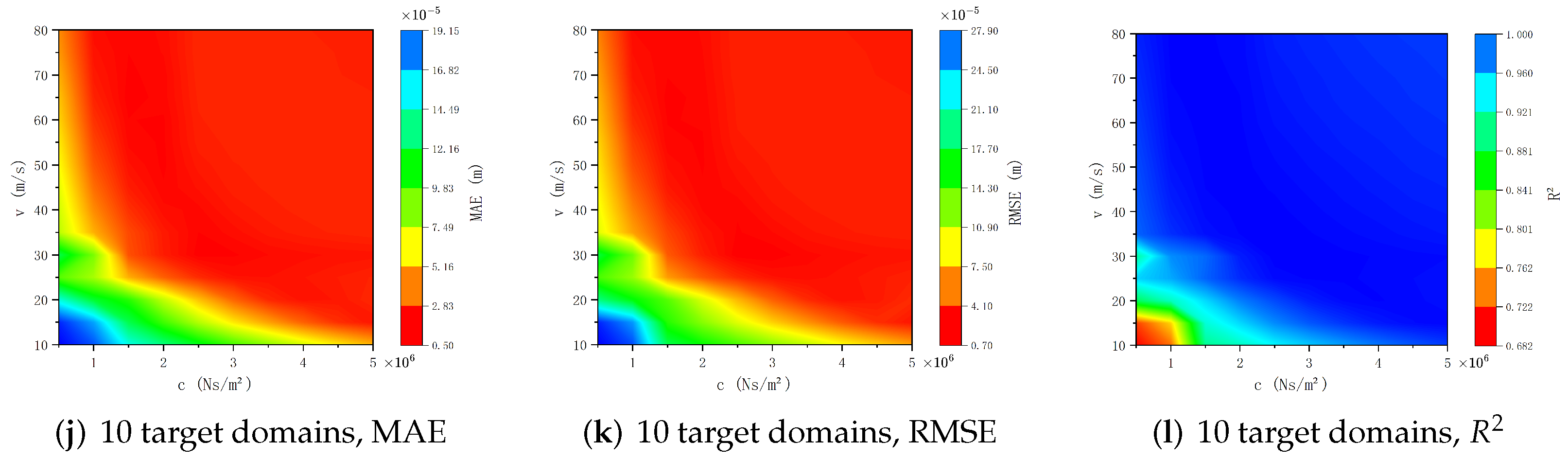
6. Comparison of Result Accuracy with Existing PINN-Based Surrogate Model
In contrast with existing PINN-based surrogate modeling techniques, our novel approach achieves a substantial reduction in data sampling requirements. Within a single source domain of the parameter space, merely 50 data points are sampled, spread over a 5 m span both ahead of and behind the moving load. Through the application of local PINN models, these 50 data points are augmented to 400. In
Figure 12,
Figure 13 and
Figure 14, we present the prediction accuracy demonstration of the surrogate model trained with the existing method based on more data [
21,
22,
23,
32].
Compare
Figure 12,
Figure 13 and
Figure 14 with
Figure 9,
Figure 10 and
Figure 11. Although this augmentation process in our new approach may introduce a certain degree of inaccuracy when contrasted with measured values, it nonetheless maintains a satisfactory level of precision.
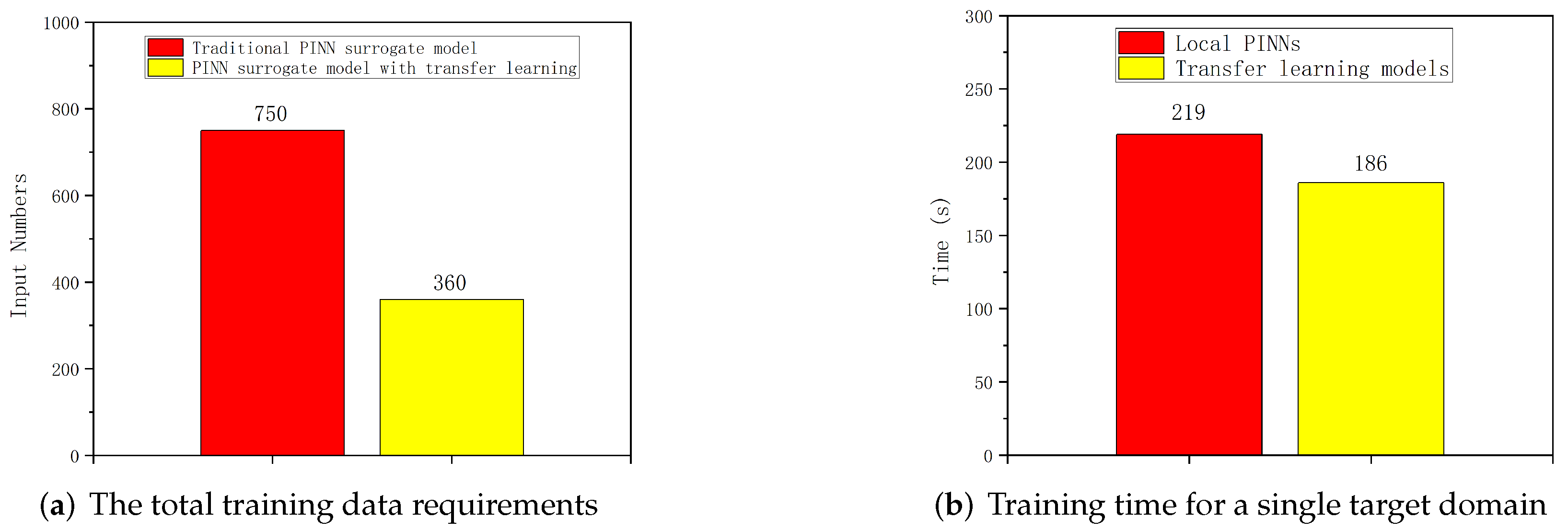
Figure 15 illustrates a comparison of total data requirements and training time for a single target domain in the parameter space between our proposed method and the existing approach. The computer configuration utilized in our experiments is as follows: CPU AMD Ryzen 7 8845H with 8 cores, GPU NVIDIA GeForce RTX 4060 laptop, physical memory RAM 24 GB, and no GPU usage.
In the transfer learning phase, when transferring the local PINN model from the source domain to the target domain, a portion of the network layers of the local PINN model are frozen. Consequently, the target domain marks a substantial reduction from the source domain. Overall, in comparison with existing methods, our approach diminishes measured data sampling by a minimum of 50%. Furthermore, when transferring the local PINN model from the source to the target domain, only a minor fine-tuning of weights is necessary to attain commendable accuracy. In our numerical experiments, the training efficiency improves by 15% in comparison with conventional methods for a single target domain in the parameter space. The extent of efficiency enhancement is contingent upon the number of target domains, which subsequently determines the final accuracy of the surrogate model. By moderately relaxing the local precision requirements, our method attains significant improvements in computational efficiency and a marked reduction in data demand. This strategic trade-off allows for a more efficient computational process while still maintaining a satisfactory level of accuracy.
7. Discussion
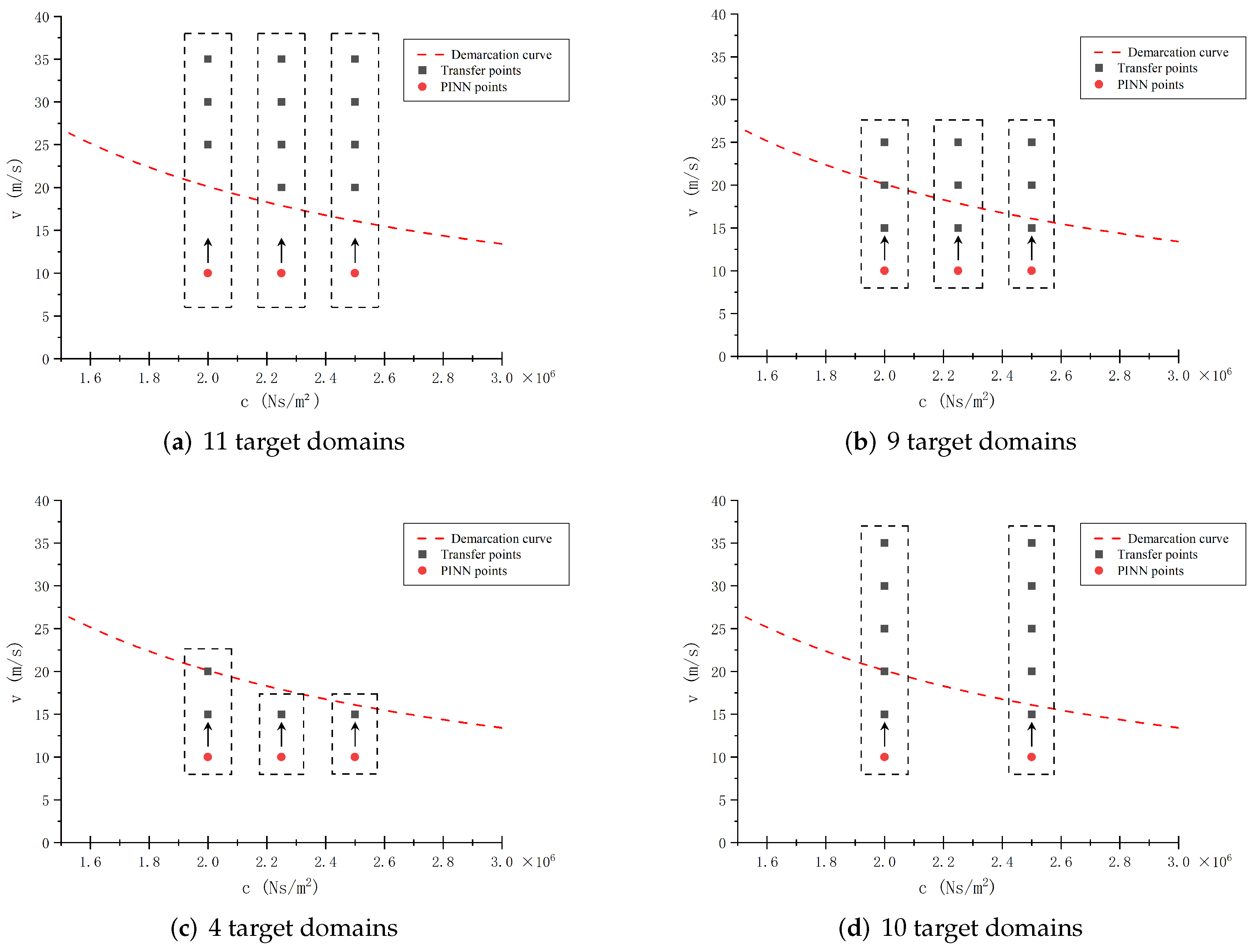
In this section, we conduct a systematic analysis of how migration path configurations impact the predictive accuracy of proposed PINN-based surrogate models. By examining the interactive effects of varying migration paths and noise levels on model performance, this evaluation provides critical insights into the reliability and robustness of the proposed surrogate models across diverse operational scenarios. Our findings deepen the understanding of how these factors collectively influence predictive capabilities and establish a foundation for optimizing transfer learning strategies in practical applications. We consider the following four distinct migration paths depicted in
Figure 16:
Figure 16a: Derived from the configuration in
Figure 7, this path reduces the number of target domains from 15 to 11, with all target domains positioned above the demarcation curve in the parameter plane.
Figure 16b: Building on
Figure 7, the number of target domains is reduced from 15 to 9, and the target domains are distributed across both sides of the demarcation curve.
Figure 16c: Extending from
Figure 16b, the number of target domains is further reduced from 9 to 4, with both the source and target domains positioned below the demarcation curve.
Figure 16d: Derived from
Figure 7, this path reduces the number of source domains from 3 to 2 while decreasing the number of target domains from 15 to 10.
These configurations collectively allow for a thorough assessment of how transfer learning strategies perform across different levels of data sparsity and domain positioning. This evaluation provides critical insights into enhancing model reliability and robustness in practical applications.
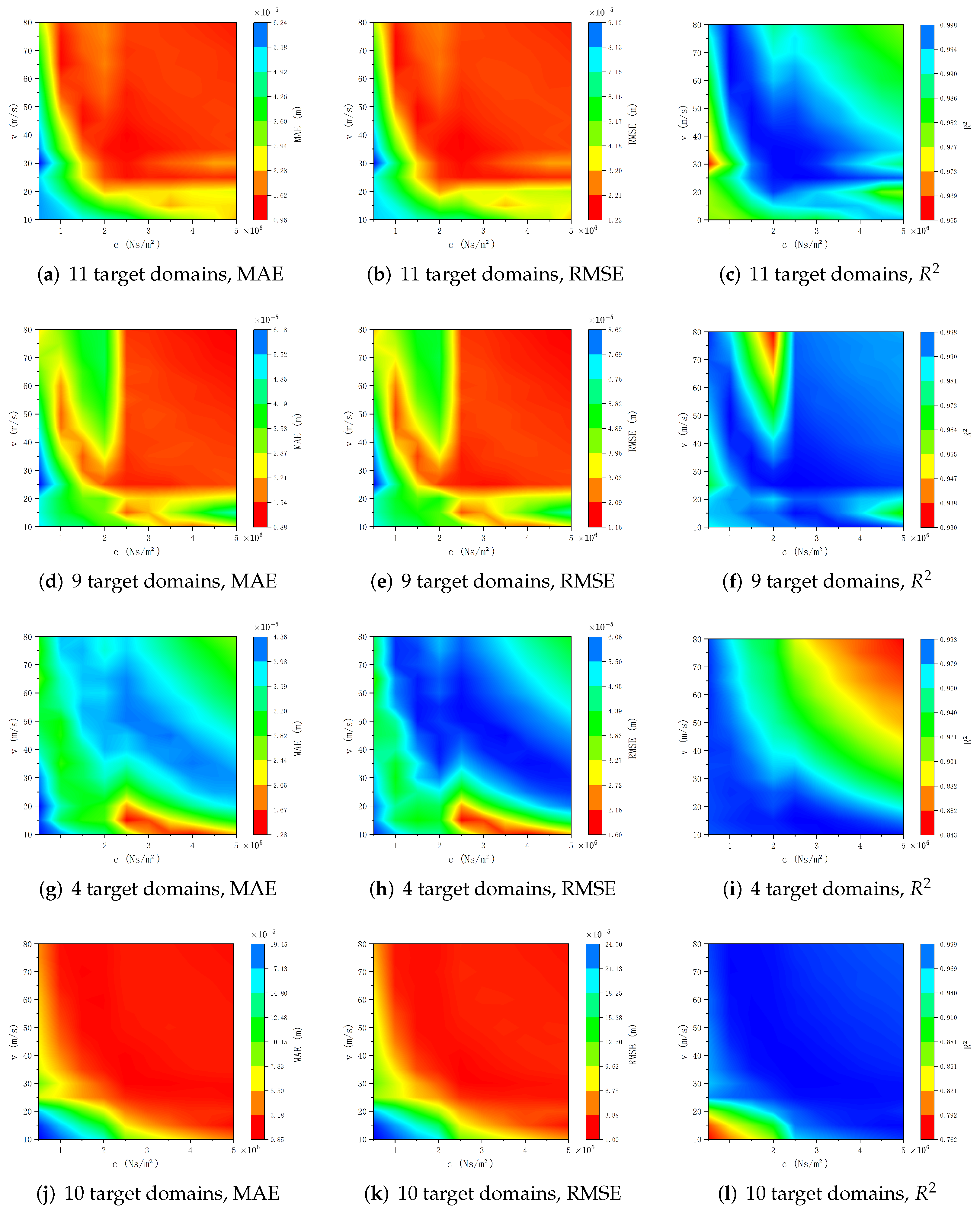
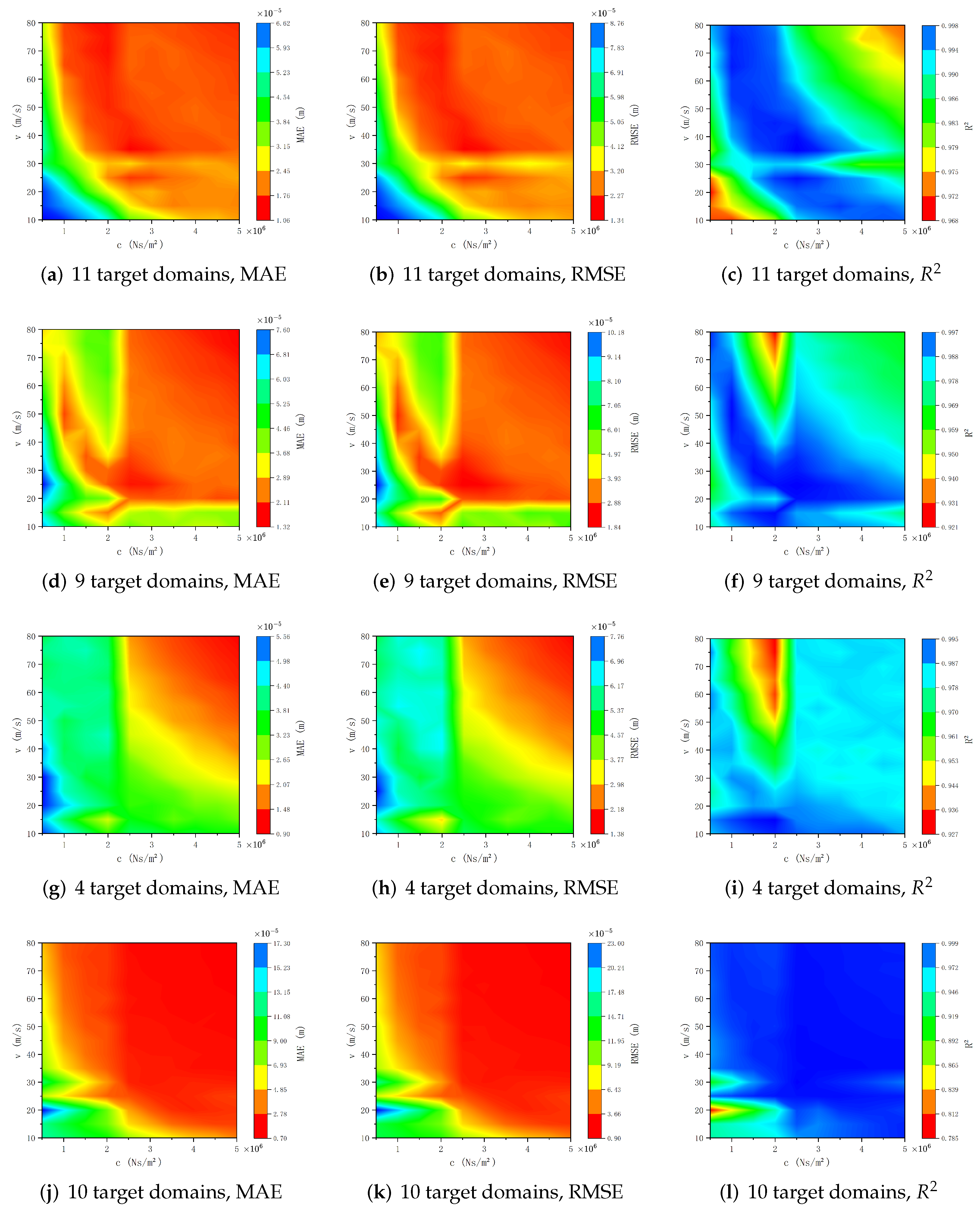
Figure 17,
Figure 18 and
Figure 19 depict how the four distinct migration paths illustrated in
Figure 16 affect the surrogate model’s prediction accuracy under varying noise intensities, with noise standard deviations set at 1%, 2%, and 3% of the true value’s amplitude.
Figure 17,
Figure 18 and
Figure 19 show that the transfer learning strategy on the
parameter plane significantly impacts the surrogate model’s prediction accuracy. Under the same noise conditions, reducing the number of target domains leads to a corresponding drop in prediction accuracy. Moreover, when the number of target domains is progressively reduced while their distribution density in the occupied space remains largely unchanged, the surrogate model’s prediction accuracy consistently declines across the entire parameter plane. Conversely, when the distribution density of target domains in the occupied space is significantly reduced, the decline in prediction accuracy becomes notably non-uniform across the parameter plane, with some regions experiencing greater accuracy reductions than others (
Figure 17j–l,
Figure 18j–l, and
Figure 19j–l). This spatially heterogeneous accuracy reduction underscores the importance of both the number and spatial organization of target domains in determining the surrogate model’s performance. To enhance the surrogate model’s reliability and robustness, particularly in complex modeling scenarios where data sparsity may be a concern, it is crucial to maintain adequate distribution density of target domains and strategically optimize their spatial arrangement.
Analysis of
Figure 17,
Figure 18 and
Figure 19 shows that noise intensity significantly affects the surrogate model’s prediction accuracy, with a clear decline as the noise standard deviation increases. Notably, even when the noise standard deviation reaches 3% of the true amplitude and the number of target domains is reduced to just four, the surrogate model developed in this study maintains high prediction accuracy. The prediction MAE and RMSE are both maintained at
across the whole parameter space, while
achieves values of 0.927 or higher across the parameter plane (
Figure 19g–i). These results emphasize the model’s robustness and reliability, demonstrating its ability to provide accurate predictions even with significant noise and limited target domain data. This performance demonstrates the model’s practical applicability in real-world scenarios where data quality and quantity may be limited.
In
Section 2, our theoretical analysis identifies a demarcation curve on the
parameter plane, where the beam’s vibration responses vary in form across this boundary. When all target domains lie below this curve (
Figure 16c), the surrogate model’s prediction accuracy exhibits marked differences above and below the boundary, particularly at low noise levels. This suggests that classifying the solutions to the governing equations can inform the selection of optimal migration paths, thereby boosting the surrogate model’s overall prediction accuracy.
8. Conclusions
This study presents a novel PINN-based surrogate modeling framework for predicting the steady-state dynamic response of infinite E–B beams on foundations under moving loads across broad parameter ranges. Our methodology involves (1) constructing localized PINN models trained on displacement data from specific points in the damping-velocity parameter space and (2) employing transfer learning techniques to generalize these models across different parameter regions. The key innovation of our approach lies in its ability to maintain high prediction accuracy while substantially reducing data requirements compared with conventional PINN-based surrogate modeling methods. Numerical experiments demonstrate that when selecting 15 target domains, our method achieves comparable accuracy to traditional PINN surrogate models while requiring less than half the training data. For applications where minor accuracy reduction is acceptable, the number of target domains can be further reduced to 4.
Empirical results confirm the proposed surrogate model’s reliability and robustness under various noise conditions and transfer learning pathways. Notably, we find that simply increasing the number of target domains does not necessarily improve prediction accuracy. Instead, enhancing the spatial distribution density of target domains proves more effective for maintaining performance. These findings enable large-scale parameter prediction in data-limited scenarios while preserving computational efficiency. The proposed framework represents a significant advancement in data-efficient surrogate modeling, demonstrating particular effectiveness in high-accuracy prediction with minimal training data, robust performance across diverse parameter conditions, and adaptability to noisy measurement environments. This work establishes a foundation for efficient dynamic response prediction in scenarios where experimental data collection is challenging or costly.
Existing PINN-based surrogate models often suffer from low training efficiency, primarily due to their dependence on extensive datasets. To address this limitation, we propose a novel method for predicting the steady-state response of infinite beams on foundations subjected to moving loads, particularly in scenarios where only sparse measurement data are available under constrained parameter conditions. A key practical challenge in our approach lies in balancing the trade-off between data requirements and predictive accuracy in surrogate modeling. Our numerical experiments demonstrate that partitioning the solution manifold into well-defined parameter regions enables the identification of optimal transfer learning pathways, thereby significantly improving model performance, especially in data-scarce regimes. Advancing this framework to optimize data efficiency and generalization capabilities will be the focus of our future research.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}