2.2. Methods
Model development begins with transforming data from numerical form to categorical form using discretization, consisting of crisp discretization and fuzzy discretization. Each is built based on the notion of crisp and fuzzy set membership. In the notion of crisp set, an entry of universal
is denoted as
if it is a member of set
. On the contrary, if
is not an entry of
, it is denoted as
. Consequently, the membership degree of
in set
is limited to either 1 or 0, which is written as
or
[
22]. In the notion of fuzzy set, the membership degree
in set
is contained in the range [0, 1]. This value is formulated in a function called the fuzzy membership function. This function shows the value of the membership of each value in a given fuzzy set
. If
possesses the highest membership value, it is considered a member of set
[
22,
35].
The number of categories in each predictor variable is determined by antecedent information or expert justification in crisp discretization, and the interval boundaries between categories are distinct [
22,
29]. Determining the category interval limits for each numeric variable with a ratio scale using (1),
and
are the
-th continuous and the
-th discretized predictor variable values, respectively [
22]:
The number of categories in fuzzy discretization is determined by the categories that are established through crisp discretization, but it also accommodates overlapping class intervals [
22]. Each variable is discretized through three categories, and each category is represented by a single fuzzy membership function. Suppose
is the universal set of the fuzzy set,
with element
and membership function
, then the fuzzy set
is the ordered pairs of each
and
[
35]:
The fuzzy membership function
is defined as
, and every element
of
is assigned a value within the interval [0, 1].
Naïve Bayes is a high-performance method for making predictions based on digital images [
36,
37], especially those that handle the vagueness that results from discretization [
22]. However, sometimes this method also does not provide satisfactory performance [
38]. The ensemble method is a machine learning-based algorithm that integrates multiple single prediction methods to enhance performance [
30]. This technique is one of the solutions available when the prediction performance of a single prediction method is not satisfactory [
31].
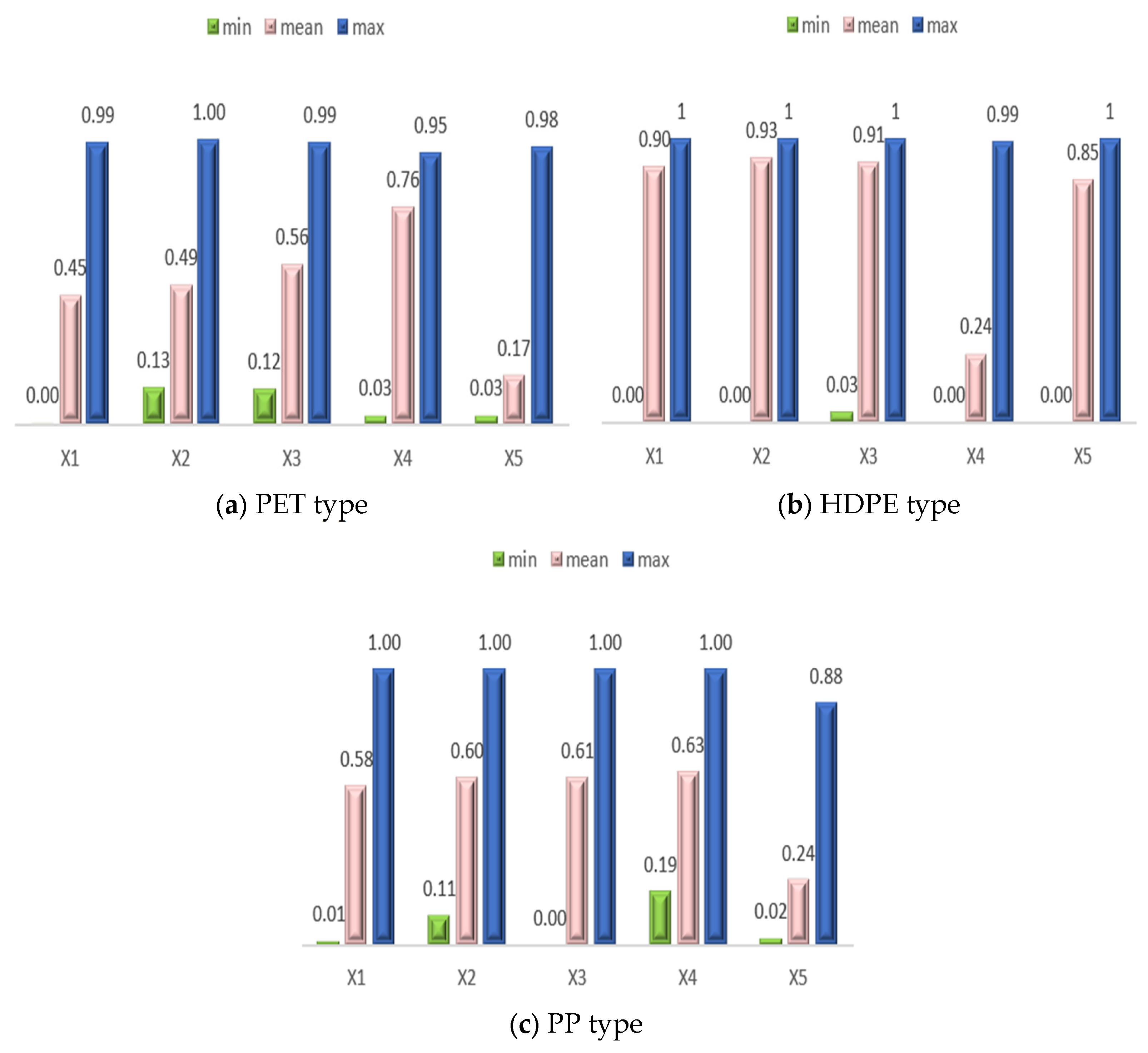
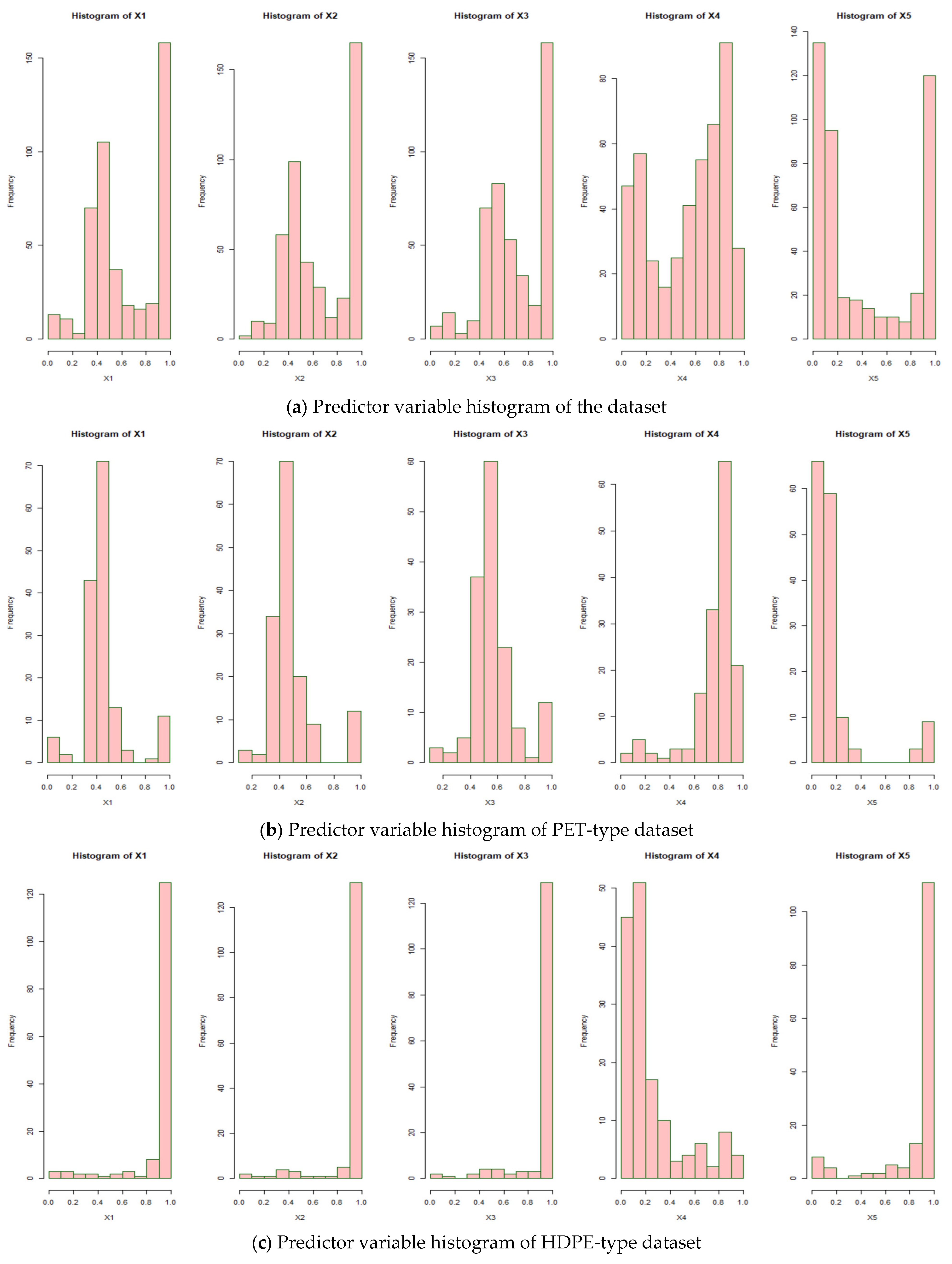
In this work, we suggest an ensemble method constructed from three basic naive Bayes models to predict plastic types. We form one naive Bayes model based on the results of the crisp discretization and two naive Bayes models based on the fuzzy discretization. Each discretization is formed based on antecedent information that the predictor variables obtained from digital image processing are categorized into dark, moderate, and light for each red, green, and blue color channel. The higher the color pixel value in each channel, the lighter the color displayed. The variance and entropy variables are also classified into three categories: low, moderate, and high. A higher value is indicated by a higher number in these two variables.
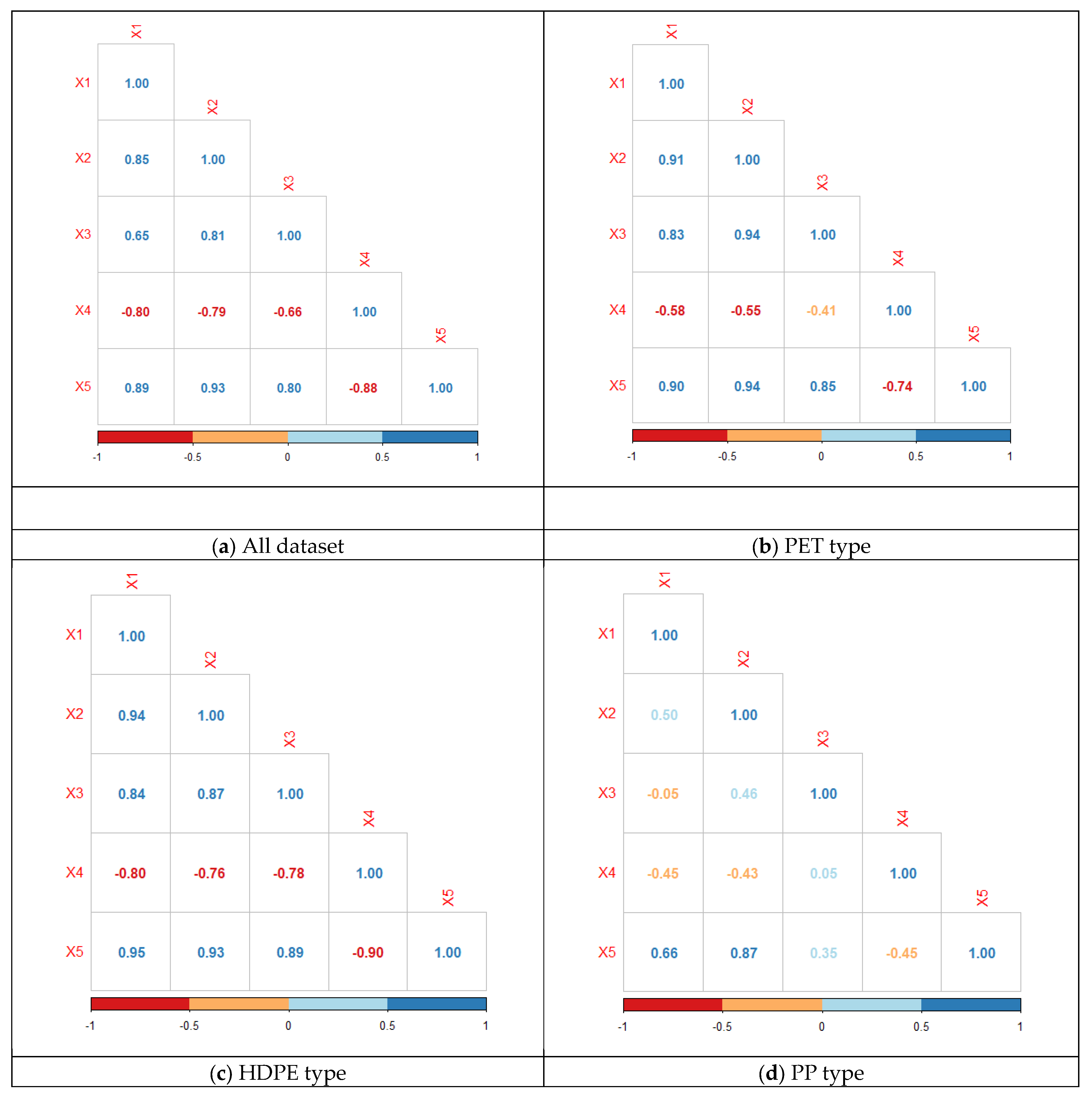
In the naïve Bayes method, an object or observation is predicted into a specific class based on the maximum posterior probability. The posterior probability is determined according to the Bayes theorem, which is based on the assumption that the predictor variables are independent in a naive (strong) manner.
Let
be the target variable that denotes the
-th class of plastic type,
be the
-th class or type prior probability,
be the likelihood function of the
predictor variables, and
be the joint distribution function of the plastic type. The posterior probability of the plastic type is written as follows [
18,
22]:
To involve discretization in the naive Bayes method, either crisp or fuzzy discretization, the predictor variables need to be of categorical type, so Equation (3) is adjusted to become Equation (4) [
22,
36]:
where
is the amount of plastic images associated to the
-th class in all variables
,
is the amount of plastic images in the
-th class,
is the amount of plastic images associated to the
-th class in a variable
with category
, and
is the number of categories in the variable
.
The
-th likelihood function and the
-th class or type prior probability, respectively, can be expressed as follows [
18,
22,
36]:
The following assumptions are needed to integrate fuzzy discretization into naive Bayes. Suppose
is the fuzzy sample information space of the red, green, and blue as predictor variables of
,
is the independent event, and
is the fuzzy membership function of
, then the fuzzy sample conditional probability function is formulated as
, and the prior probability of the predictor variable is
. Since the evidence is not fixed in the fuzzy set and the Laplace smoothing effect, the posterior probability is as follows [
22,
39]:
The development of the naive Bayes model using fuzzy discretization includes two different combinations of fuzzy membership functions. First, a combination of triangular functions and linear functions (decreasing, increasing). Second, a combination of trapezoidal functions and linear functions (also decreasing and increasing). In both combinations, decreasing and increasing linear functions are used to discretize the first and third categories for each predictor variable, while triangular and trapezoidal functions are used to discretize the second category in each combination. The fuzzy membership functions are presented in Equations (8)–(11).
Assume that
is the least conspicuous domain entry with a membership value of 1, and
b is the most conspicuous domain entry with a membership value of 0. The decreasing linear function is expressed as follows [
22,
40]:
Let
be the least conspicuous domain entry with a membership value of 0, and
b be the most conspicuous domain entry with a membership value of 1. The increasing linear function can be written as follows [
22,
40]:
For the triangular membership function, assume that
is the least conspicuous domain entry with a membership value of 0,
is a domain entry with a membership value of 1, and
is the most conspicuous domain element with a membership value of 0. The function can be formulated as follows [
22,
29,
41]:
Let
be the least conspicuous domain entry with a membership value of 0,
be a domain entry with a membership value of 1,
be a domain entry with a membership value of 1, and
be the most conspicuous domain entry with a membership value of 0. The trapezoidal membership function is represented as follows [
22,
41]:
In the machine learning concept, the prediction model performance is validated for unseen data, so the data must be split into training or modeling and test data. This research applied the k-fold cross-validation with k = 5 in the split dataset. The dataset was randomly separated into five folds of similar size, with one fold allocated as testing data and the remaining four assigned as modeling data. Each of the five iterations contained distinct data compositions for modeling and testing with a ratio of 80:20. The final model performance was the average of the five iterations [
42,
43]. The 5 fold was less biased compared to other numbers of folds [
44] and capable of evaluating the quality and the stability of the model as well as preventing overfitting without reducing the quantity of learning data used [
42].
The ensemble prediction model performance was then tested to obtain prediction results, as are all basic models. Let
be the true positive prediction at
-th class,
be the true negative prediction at
-th class,
be the false positive prediction at
-th class, and
be the false negative prediction at
-th class. For the first class, all of the true and the false predictions are given in
Table 1, and the other classes can be found similarly.
The evaluation metrics of model performance for
classes of plastic type are given in (12)–(14) [
20,
45].
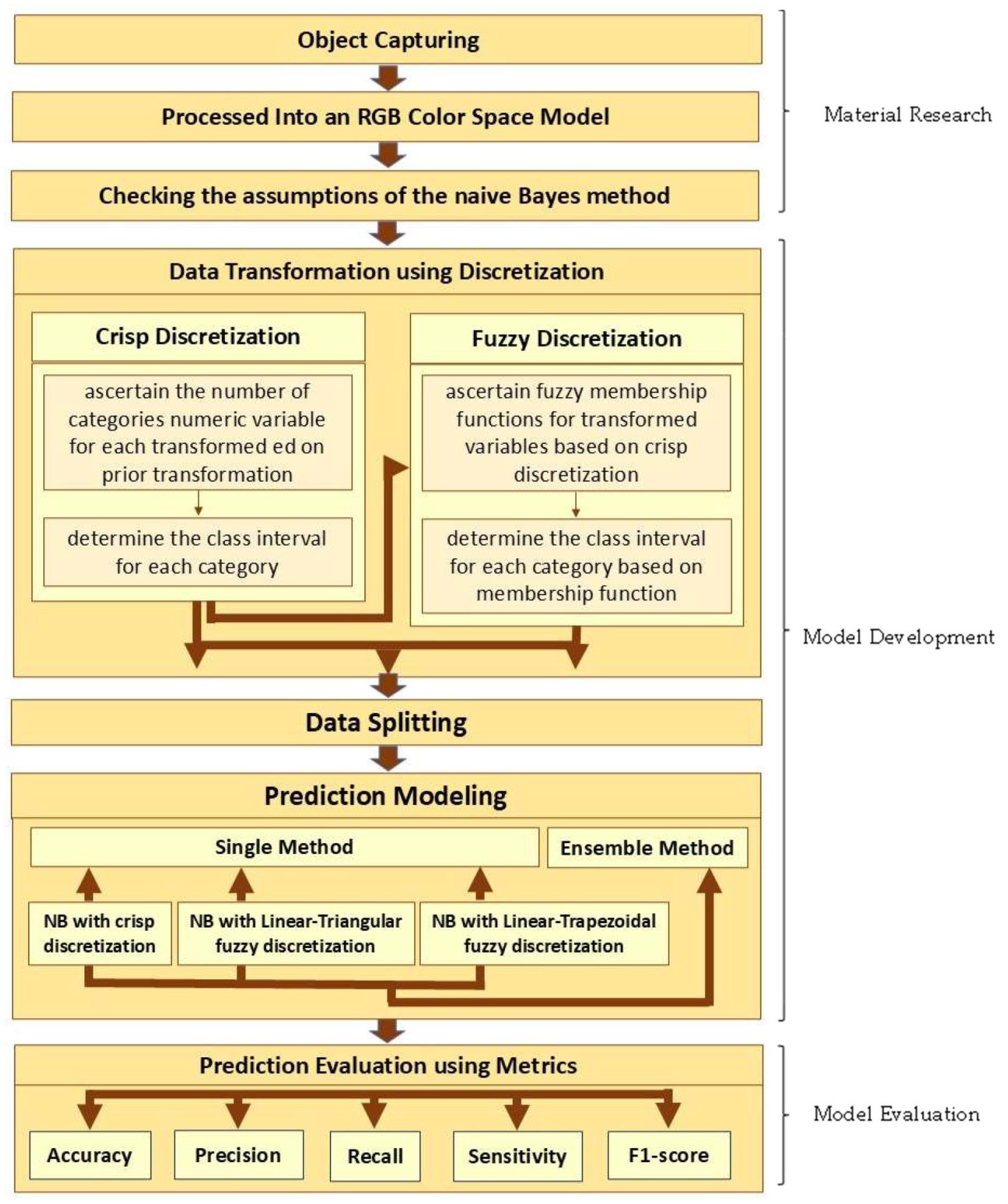
A satisfactory prediction performance is indicated by the highest metric size. In general, the research steps are described in
Figure 2.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}