1. Introduction
The evolution of surgery has been remarkable, stretching from rudimentary practices to the advanced techniques we see today [
1]. The development of Future Operating Rooms (FORs) increasingly relies on Context-Aware Systems (CASs), which streamline surgical workflows and enhance patient outcomes through real-time data analysis [
2]. CAS integration in FORs will enhance knowledge-based systems with data-driven surgical treatments. These data-driven treatments necessitate collaborative interactions for multi-perspective knowledge sharing among medical teams, such as surgical and anesthetic teams [
3,
4]. In this context, CASs must be capable of envisioning workflows within the OR and understanding the current situation by fusing data from various perspectives, including both procedural and patient-related data [
5].
The emerging field of Surgical Data Science (SDS) leverages big data analysis to model surgical processes and develop CASs, representing a significant leap forward in the advancement of surgical procedures [
6]. The automatic identification of surgical tools is a crucial component for modelling the surgical processes. Thus, the recognition of surgical tools is addressed in this work. However, Minimally Invasive Surgery (MIS) presents unique challenges, particularly due to the narrow operative space and limited field of view [
7,
8]. These constraints make precise navigation of surgical tools critical. Moreover, this problem involves other challenging aspects such as rapid camera movements, variable tissues, and obstructive elements like smoke and blood, as illustrated in
Figure 1. These challenges hinder the performance of existing methodologies. Combining spatial and temporal features can overcome the limitations of previous approaches and provide more accurate and robust tool classification in MIS environments.
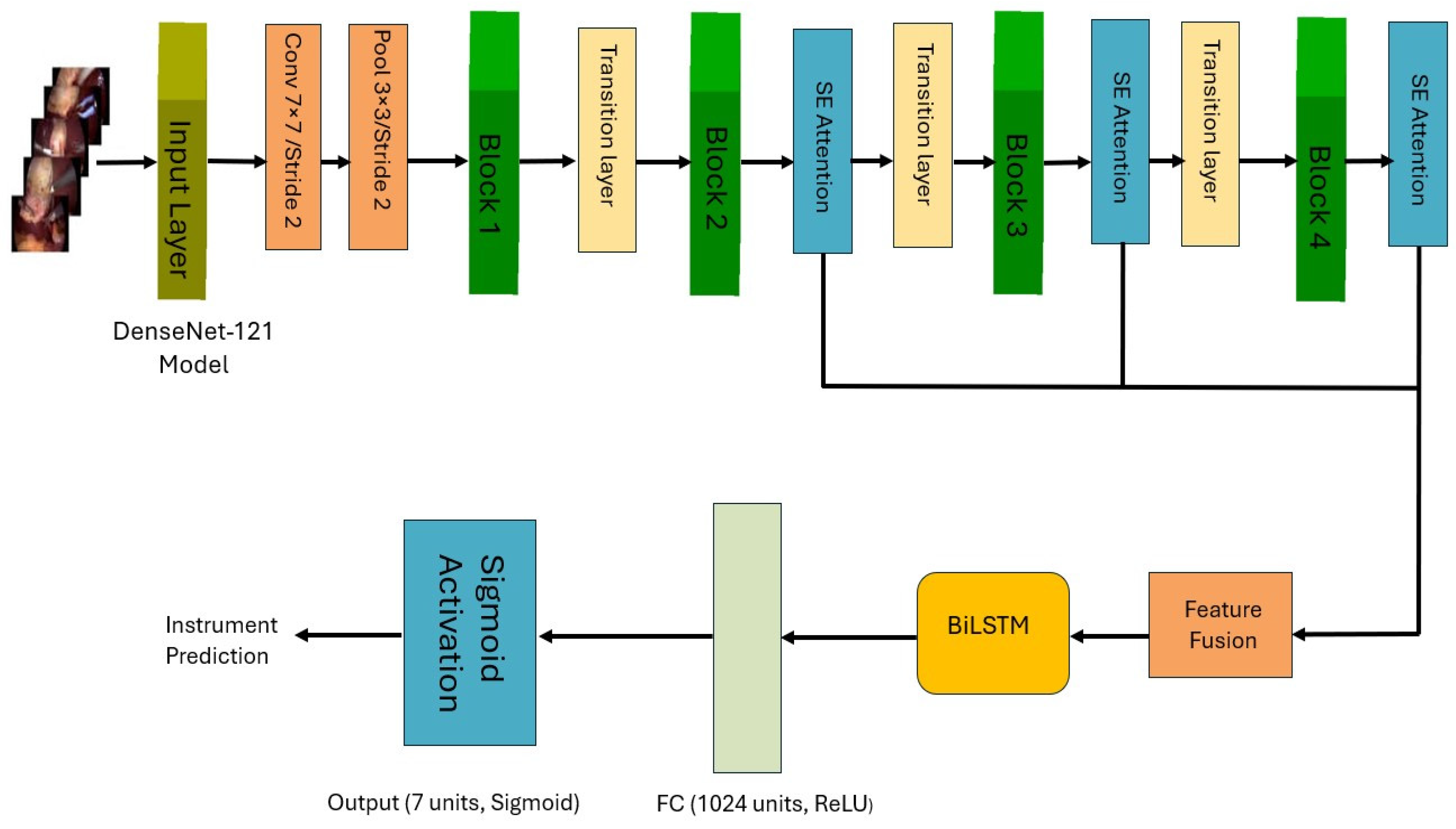
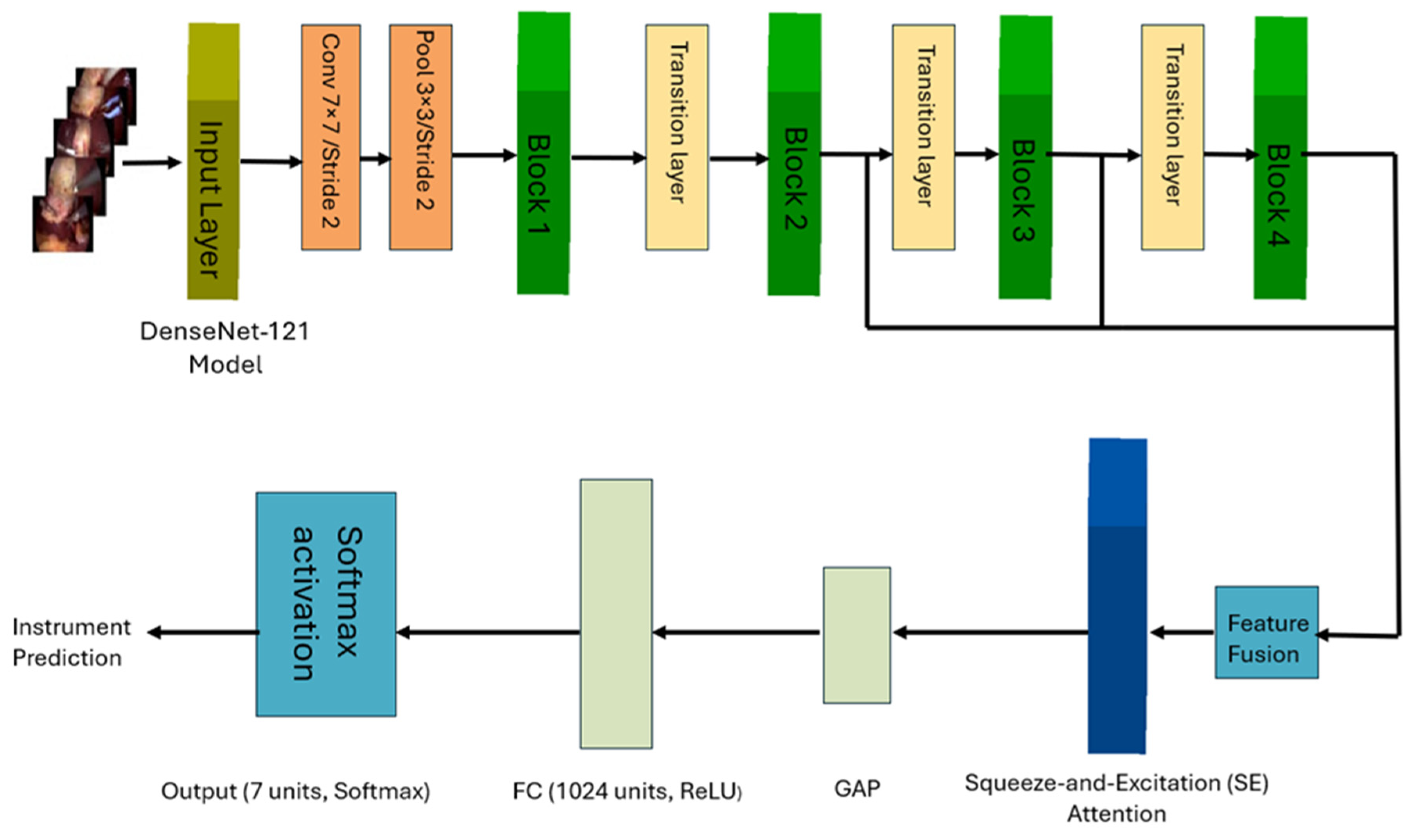
In this work, we propose a novel architecture to identify surgical tools in laparoscopic images. Our approach employs a modified DenseNet121 architecture [
9], to learn spatial features, integrated with a Bidirectional LSTM (BiLSTM) network to capture temporal dependencies in laparoscopic videos. We developed two deep learning multi-label models for surgical tools. The first model incorporates multiple Squeeze-and-Excitation (SE) attention modules, a Feature Fusion Module (FFM) and a BiLSTM layer. The second model employs a single SE block after the FFM, followed by a BiLSTM layer. Additionally, we explored a simpler and computationally less-expensive single-label surgical tool classification model for classifying surgical tools in cholecystectomy images, where only one tool is present at a time.
The primary objectives of this study are the following:
To develop a novel architecture that effectively combines spatial and temporal feature extraction for surgical tool classification.
To investigate the effect of integrating a single SE block, multiple SE attention modules and combining features at different levels on classification performance.
To explore the classification performance of the proposed approaches on multi-label and single-label data.
To compare our method’s performance against state-of-the-art approaches in surgical tool classification.
2. State of the Art
Recent approaches have primarily employed deep learning techniques, with convolutional neural networks (CNNs) serving as a foundation, often combined with other methods to enhance performance and address specific challenges in the field. Alshirbaji et al. introduced a hierarchical neural network architecture that incorporates both spatial and temporal information. Their method combines a CNN with two long short-term memory (LSTM) models to capture temporal relationships across subsequent laparoscopic images. Evaluation on the Cholec80 dataset using Monte Carlo six-fold cross-validation showed a 3.00% improvement in mean average precision (mAP) compared to baseline methods [
10]. However, the authors noted that integrating the three models into an end-to-end framework could potentially offer additional discriminative spatiotemporal properties.
To address the challenge of imbalanced datasets, Alshirbaji et al. [
11] proposed in another study a CNN-based approach utilizing resampling methods and a loss-sensitive learning strategy. This work highlighted the bias in CNN training caused by imbalanced distribution of the training data. As a result, CNNs struggle with minority classes such as scissors and irrigator in the Chlolec80 data set. The proposed approaches by Alshirbaji et al. showed improved performance in categorizing rarely used surgical instruments.
In another study, data augmentation methods were explored to improve model generalization [
12]. Uniform, random, or distinctive backdrop patterns and artificially produced images were used as training patterns. Their experiments showed that classification accuracy increased by 10% when trained with augmented data. Interestingly, training on datasets with identical backgrounds rather than random backgrounds allowed the CNN model to focus more effectively on areas containing target items such as surgical tools. However, the low performance on original background datasets indicated a significant dependence on background patterns and weak generalization capacity, highlighting the ongoing challenges in developing robust models for surgical tool classification.
Attention mechanisms have also been explored to improve surgical tool detection. Jalal et al. [
13] proposed a deep learning technique for surgical tool localization in laparoscopic images, which was trained on binary tool presence data. The model uses an attention-based CNN, from which gradient class activation maps (Grad-CAMs) were extracted. The Grad-CAMs were then processed to generate bounding boxes around the surgical instruments. The performance of this method was evaluated using the Dice similarity coefficient. Results showed that the proposed attention–CNN achieved a mean tool localization precision of 72.4%, significantly outperforming the base CNN model, which had a precision of 28.3%. However, the method lacked high accuracy for certain instruments such as irrigators, clippers, and scissors.
Recent work has also focused on multi-task learning and feature fusion. Jin et al. [
14] developed a Multi-Task Recurrent Convolutional Network with Correlation Loss (MTRCNet-CL) to simultaneously improve phase recognition and surgical instrument identification. This approach demonstrated superior performance on the Cholec80 dataset, achieving a mAP of 89.1% for tool presence identification.
4. Results
4.1. Model Performance
The performance of the two main architectures, CNN-SE-FFM-BiLSTM and CNN-FFM-SE-BiLSTM, was evaluated on the tool presence classification task. The models were trained and validated on the Cholec80 dataset, and their performance was assessed using average precision metrics for each tool.
Figure 4 shows the performance of both models. As demonstrated in
Figure 4, the CNN-SE-FFM-BiLSTM demonstrated better overall performance compared to the CNN-FFM-SE-BiLSTM model. The boost in performance is clearly pronounced in tools with more complex patterns of usage, especially the scissors and irrigator which are less represented in the data set compared to other tools and are held near the grasper, which led to them being confused with it in some instances or even occluded by it in some other cases.
Table 2 presents accuracy, precision, recall and F1 score calculated at a threshold of 0.5 for the CNN-SE-FFM-BiLSTM model.
The single-label model achieved an outstanding performance with only one SE block placed after the feature fusion module and without the need for additional temporal features extracted by the BiLSTM network in the multi-label setting.
Figure 4 demonstrates the performance for the CNN-FFM-SE single-label model evaluated on single tool images of the Cholec80 data set.
Figure 4 also presents the performance of the CNN-SE-FFM-BiLSTM model to allow comparison of the performance of single-label and multi-label classification approaches.
4.2. Ablation Study
An ablation study was conducted to analyze the contribution of various components of the proposed multi-label model and the single-label architecture for the overall classification performance in both problems. The results of the study are summarized in
Table 3 and
Table 4, respectively, validating the proposed design and network block selections in both settings.
For the multi-label classification problem, our experiments showed that the BCE loss coupled with the cosine-annealing learning-rate (LR) scheduler achieved slightly higher mAP performance (mAP =94.63) compared to focal loss (FL) with the same learning-rate scheduler (mAP= 94.49). As for Focal Loss with ReduceLROnPlateau scheduler, the mAP was a bit lower, at mAP of 94.27. So, while no major difference is noticed, the cosine-annealing LR scheduler with BCE loss function remains optimal for the multi-label setting.
In contrast, the single-label task suffers from more pronounced class imbalance and less overall training data samples (the single-label model operates only on single tool images). As a result, the best performance for the single-label task was achieved with Focal Loss and ReduceLROnPlateau scheduler (mAP = 95.32). Ablation runs on the single-label model show significant increases in the average precision of minority tools such as Scissors and Clipper by 13–21% compared to the standard BCE loss, and an overall increase in mAP by 10%.
4.3. Computation Time and Efficiency
The total computation time for the experiments was 5.7 h with training performed on an NVIDIA RTX 4090 GPU (see
Table 5). The models were trained for up to 25 epochs, with early stopping applied based on validation loss to prevent overfitting. The models demonstrated efficient convergence, particularly when employing the optimized hyperparameters identified through the Optuna framework.
The inclusion of multiple SE blocks before the fusing of the mid to high level features led to a slightly improved performance compared to one SE block after the fused features. Nonetheless, both scenarios needed the same training time of 1.60 h as well as the same inference time of 1.33 ms per image in both multi-label settings based on a 32-frame batch size.
To assess feasibility for real-time deployment, the proposed CNN-SE-FFM-BiLSTM model was also evaluated using a 1-frame batch size, simulating single-frame inference typical in surgical assistance systems. Under this setting, the proposed CNN-SE-FFM-BiLSTM model required only 2.90 GFLOPs per image, had 8.27 million parameters, and consumed 0.27 GB of GPU memory. It achieved an average inference latency of 11.58 ms, corresponding to 86.3 FPS, compared to 25 FPS for the original video recording in the Cholec80 dataset.
4.4. Hyperparameter Optimization
The hyperparameters optimized via Optuna were critical in achieving the best performance. The final values for the learning rate, batch size, focal loss parameters, and mixup alpha are as follows:
These hyperparameters resulted in the best combination of accuracy, precision, recall, and F1 score across all evaluated models.
5. Discussion
This work introduces CNN-based architectures for classifying surgical tools in laparoscopic images. Two training strategies were explored which are training with images containing one tool (single-label training) and training with images sampled from complete procedure videos at a rate of 1 Hz. Furthermore, the study demonstrates the benefits of attention modules, feature fusion and temporal modeling for classifying the type of surgical tool in laparoscopic images.
The results in
Figure 4 show a significant variation in the AP of different tools across the tested architectures. The CNN-SE-FFM-BiLSTM model generally outperformed the other model, particularly for tools like Scissors, Clipper and Irrigator, achieving AP values of 90.73%, 97.62% and 91.70%, respectively. The model’s effectiveness can be attributed to its use of multiple SE blocks within the CNN layers, which enhance feature representation.
The CNN-FFM-SE-BiLSTM model, while slightly underperforming compared to CNN-SE-FFM-BiLSTM, still showed promising results, especially in detecting frequently used tools like Hook, with AP values of 99.57% (see
Figure 4). This model showed lower performance on tools like Scissors and Irrigator (89.12% and 90.46% AP, respectively). The classification performance was improved by introducing multiple SE blocks before fusing mid level to high level features which made the CNN-SE-FFM-BiLSTM model the best performer for the multi-label classification problem over all surgical instruments.
The proposed models demonstrate that the inclusion of SE blocks and temporal modeling can significantly enhance the classification accuracy of certain tools, though challenges remain in consistently detecting tools that are less frequently used or more likely to be obscured in the surgical field.
Compared to state-of-the-art methods, the proposed CNN-SE-FFM-BiLSTM architecture demonstrated competitive performance. The mean average precision (mAP) for the CNN-SE-FFM-BiLSTM model is 94.63%, which marks a significant improvement over earlier approaches like ToolMod [
11], MTRC [
14], and Nwoye [
25] (see
Table 6). These results demonstrate the efficacy of combining spatial and temporal features to classify surgical tools.
In comparison to the CNN-LSTM model in [
12], our approach shows a comparable performance in mAP, validating the benefit of integrating SE blocks with feature fusion modules. However, the performance on minority classes like Scissors and Irrigator still indicates an area where further improvements are necessary.
While the proposed models showed competitive performance, a slight but noticeable difference in performance was observed between the single-label and the multi-label approaches. The CNN-FFM-SE model, when applied in a single-label context, achieved excellent performance, with a mean average precision (mAP) of 95.32%. However, when the model was adapted for multi-label classification, as seen in the CNN-SE-FFM-BiLSTM and CNN-FFM-SE-BiLSTM architectures, the performance dropped, with mAP values of 94.63% and 94.26%, respectively. This drop in performance can be attributed to the increased complexity of multi-label classification. In multi-label scenarios, the model must simultaneously identify multiple tools that may be present in a single frame, often under challenging conditions such as tool overlap, occlusion, or varying scales. This is significantly more complex than single-label classification, where only one tool is present at a time. The presence of multiple tools introduces additional challenges, such as the need for more precise feature discrimination and the handling of inter-class dependencies, which the current architecture might not fully capture. The proposed approach helped to mitigate the increased complexities in multi-label classification compared to single-label classification through the inclusion of multiple SE blocks before fusing the mid to high level features followed by a BiLSTM network.
Despite the strong performance of deep neural networks, they remain vulnerable to adversarial attacks where imperceptible modifications to input data can lead to incorrect model predictions [
26]. This vulnerability presents a critical limitation in the deployment of AI models in clinical settings and highlights the need for further research into model robustness.
Finally, future work will explore how the proposed architecture generalizes across different surgical procedures and datasets, as the current study is limited to Cholec80. Also, investigating alternative temporal modules, such as temporal convolutions or Transformers, could further enhance temporal modeling and scalability, potentially improving both overall and per-tool classification performance.
6. Conclusions
This study introduced novel deep learning architectures for surgical tool classification, integrating DenseNet121 with SE blocks and BiLSTM layers to capture spatial and temporal features. Our results showed that the CNN-SE-FFM-BiLSTM model performed well in single-label and multi-label classification scenarios with a slight drop in overall performance in the multi-label setting compared to the single-label setting. This highlights the complexity of identifying multiple tools simultaneously and the continuous need for more refined approaches in multi-label settings.
The models were competitive with state-of-the-art methods, but further improvements are necessary, particularly in handling imbalanced classes and optimizing for real-time applications. Future work should focus on enhancing feature fusion techniques, broadening dataset evaluations, and refining models for practical use in surgical environments, aiming to improve both surgical workflows and patient outcomes.



 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}