1. Introduction: The Significance and Aims of Forensic Facial Soft Tissue Reconstruction
Facial soft tissue reconstruction (FSTR) is a method of reconstructing the face of an unknown deceased person directly on the skull or on a replica of the skull [
1,
2,
3]. Reconstructions are carried out for both forensic and archaeological purposes. However, in the forensic context, the aim of an FSTR is to reconstruct the image of the unknown individual as accurately as possible and to use the resulting evidence to identify the person, whereas, in the archaeological context, the focus is more on the symbolic representation of the person during their lifetime. Forensic FSTR can be used in cases where typical identification methods such as DNA, dental, and X-ray data are not available to identify the deceased [
4]. This is the case when there is no antemortem comparative data of a potentially suitable person, and thus, the attribution of human remains to a specific person is severely limited [
5]. The lack of comparison material often results in the failure of investigations into the identification of unknown deceased individuals. Given the significant methodological effort and associated costs incurred years ago, the concept of high-throughput identification through facial soft tissue reconstruction was unthinkable. A digital approach combined with software-specific developments and medical insights enables a time-effective and flexible implementation of facial soft tissue reconstruction. Once the image of an unknown deceased individual has been reconstructed, the next step is identification. By presenting a reconstructed face to the public, investigators hope to obtain valuable information about the individual’s identity from witnesses or photographs of potentially relevant persons. Once such comparison material is available, a quantitative comparison can be made using basic facial landmarks and measurements or employing computer vision techniques.
The creation of a biological (bio-anthropological) profile of an unknown individual, as well as well-established reconstruction methods, form the basis of any forensic facial soft tissue reconstruction. Useful information about the biological profile can be obtained by applying classical and modern methods of forensic anthropology when examining the remains of unknown individuals. In detail, the biological profile includes information on sex, age, and ethnic origin [
4,
6,
7]. Standard procedures include morphognostic (visual assessment of form-based anatomical features) and osteometric (based on bone measurement techniques) examinations of the bones, particularly the skull, pelvis, and individual long bones, which allow sex to be determined by assessing and measuring sex-specific characteristics such as the shape of the eye sockets. In addition, age-specific features such as the racemization of aspartic acid in the root dentin of teeth (a biochemical technique for age estimation based on amino acid conversion in teeth), adhesions of bone joints, and analyses of the histological structure of bones can provide an estimate of age at death [
8]. Morphognostic sex determination on the skeleton is carried out by analyzing sexually dimorphic skeletal characters, e.g., on the skull or pelvis, which are particular carriers of these sexual dimorphisms [
4]. For the morphognostic evaluation, the characteristics are categorized according to their degree of expression on a scale from hyperfeminine to feminine, indifferent, masculine, and hypermasculine. The overall view of all assessed traits leads to a diagnosis of feminine, masculine, or indifferent [
4]. Osteometric methods have been developed to counter the accusation of the subjectivity of morphognostic methods [
9]. Discriminant analysis, in particular, has become established in sex determination [
10]. This involves taking sex-specific length and distance measurements on bone material and developing so-called discriminant functions. These, in turn, make it possible to assign a possible sex to the unknown individual. In addition to the classical methods, modern techniques such as DNA analysis or the radiocarbon method are used to determine the age at death or the lifespan of the individual.
In addition to the creation of the biological profile mentioned at the beginning, the reconstruction methods that have been established over the years form an essential basis for any facial soft tissue reconstruction. The three most prominent methods that initially relied on manual 3D modeling of soft tissues directly onto the skull are the Russian, American, and Manchester methods. The first is the Russian method, also known as the Gerasimov method, which is based on a purely muscular reconstruction of the face, taking into account the individual facial muscles and muscle attachments to the bone structures [
11,
12]. The second method is the American method of Betty Pat Gatliff and Clyde Snow, which is based on the knowledge and application of craniometric reference markers, so-called anatomical soft tissue markers, which are characteristic of the age, sex, and ethnic group of the person whose face is to be reconstructed [
13]. Anatomical soft tissue markings are applied to specific areas of the skull, and the spaces between them are filled in to accentuate the facial features [
12,
14,
15]. The final method is the British or Manchester method of Richard Neave, which combines the Russian and American techniques to create a successful method of facial reconstruction [
2,
16,
17].
In recent years, digital methods have become increasingly important compared to manual FSTR [
18,
19,
20,
21]. This is not only due to time-saving and high flexibility but also to the possibility of optimizing individual steps of the reconstruction process through automation.
Digital facial reconstruction methods can fundamentally be divided into two categories: 2D and 3D techniques. In 2D reconstruction, one common approach is digital drawing, in which a forensic artist, often in collaboration with an anthropologist, sketches the facial features directly onto an image of the skull [
22]. This technique follows similar principles to traditional manual methods, such as the application of average soft tissue thicknesses and anatomical guidelines for feature placement [
22]. Another 2D technique is superimposition, where an algorithm reconstructs the face by overlaying skull images with portrait photo databases to find the best visual match [
23]. In contrast, 3D digital reconstructions include both the virtual implementation of traditional methods, such as the American, Russian, or Manchester approaches, using computer-aided design (CAD) software [
24] and more advanced techniques involving the approximation of facial soft tissues through 3D morphing based on large anatomical databases [
25,
26]. A detailed comparison of both classical and digital methods of forensic facial soft tissue reconstruction, including their methodological foundations, advantages, and limitations, is provided in
Table 1.
However, in order to be able to carry out a computer-aided reconstruction in a virtual environment, and for ethical reasons also for manual reconstructions, the remains, in particular the skull, must first be digitized or replicated. Various methods, such as photogrammetry, laser scanning, imaging techniques, and 3D printing techniques, can be used for this purpose [
26,
27,
28,
29,
30,
31]. Photogrammetric methods, in particular, are becoming increasingly important for the production of digitized data alongside imaging techniques such as CT scans [
32,
33,
34,
35]. A large number of commercial and open-source software applications are available for processing the captured data in the form of image and video recordings or sectional images for CT scans [
34,
36,
37,
38]. Another digitization option is laser scanners, which are also widely used depending on the objects to be digitized [
39,
40,
41,
42].
Depending on the evidence and the underlying technology, different methods can be used to create high-quality digital copies of remains, which form the basis for computer-aided reconstructions. These are carried out using open-source software such as Blender, a 3D suite that covers the entire 3D pipeline from modeling, rigging, animation, simulation, rendering, compositing, and motion tracking [
27,
43,
44]. A particular advantage of such applications is that already integrated functions can be constantly extended by means of specially developed scripts and modules, so-called add-ons (an add-on is a small piece of software or a feature that enhances or extends the functionality of a main program or application like Blender), such as those used in this publication. As with the manual approach, the virtual face is created using one of the reconstruction methods presented. Established methods for positioning the eyeballs and generating facial features such as the nose, mouth, and ear [
2,
45,
46,
47,
48,
49,
50] help.
However, in order to improve the accuracy and plausibility of facial soft tissue reconstructions, it is important to analyze the technical possibilities for producing digitized data, the extent to which manual approaches can be further digitized, and how existing digital procedures can be improved.
Therefore, using two real cases, this paper presents an optimized procedure for forensic facial soft tissue reconstruction based on [
51]. Furthermore, a comparison is made between a manual reconstruction and the results of a digital reconstruction based on the optimized reconstruction process. Additionally, using computer vision, a facial comparison was performed between photographs of the missing and identified person and the digital reconstruction of another case.
3. Procedure for Forensic Facial Soft Tissue Reconstruction in Detail
The process of computer-aided forensic facial soft tissue reconstruction is divided into the areas of information acquisition, digitization of the underlying skeletal material, modeling process, and plausibility checks. The database used in FSTR typically includes photographs and video recordings, as well as data from imaging techniques such as CT or MRI scans. These imaging modalities can be used, for example, to generate 3D models of the skull or to extract anatomical landmarks (e.g., the anterior nasal spine) that guide the reconstruction of specific facial features. Anthropological and molecular biological methods provide useful information on the biological profile of the unknown individual. Evidence, such as clothing, can also provide additional information. Once the information has been obtained and the remains have been digitized, the actual reconstruction steps are carried out within the appropriate software applications.
We chose the Manchester method for facial reconstruction due to its recognized accuracy in forensic identification. Developed by Neave in 1977, it combines the objectivity of depth markers with individual muscle structure, making it a reliable and widely accepted method [
52]. This approach is frequently used in forensic cases and provides a solid foundation for detailed facial reconstruction [
52], making it a suitable choice for our study.
The positioning of anatomical soft tissue markers, the modeling of individual facial features, and the modeling of age-specific features are the key process steps. To optimize the reconstruction process, these steps have been partially automated based on the preliminary work of [
51]. Once the facial and age characteristics have been reconstructed, each model is individualized by integrating further details such as accessories and hairstyles; then, the model is subjected to a final plausibility check. A detailed overview of the individual process steps, including optimizations, can be found in the following
Figure 2. The shown process is computer-aided.
The reconstructions were originally carried out using Blender version 2.7 (2021). For the generation of the final visualizations included in this publication, Blender version 3.4 was used.
In the following sections, we will provide a detailed procedure for digital forensic facial soft tissue reconstruction. This will include the methodologies used, the step-by-step process of reconstructing facial features, and the tools and technologies employed in the reconstruction.
3.1. Preceding Preparation and Information Gathering
Prior to the actual reconstruction, extensive research and fact-finding are required to obtain as much information as possible about the subject. In most cases, the investigating authorities and forensic experts provide information in the form of photographs of the crime scene and post-mortem reports. The latter primarily contain information on the biological profile of the individual as well as possible clues as to the circumstances of death or, if applicable, the use of force [
54].
In addition to the information provided, databases of photographs of people of different genders and ages are searched to provide reconstructors an overview of, for example, signs of aging and age-related changes [
55]. It is also important to take the spirit of the times into account. This means, for example, a typical hairstyle at a certain time (e.g., the 1990s). This is particularly important for cold cases, such as Case 1. The most important prerequisite for facial soft tissue reconstruction is the presence of a largely intact skull and mandible. Although facial reconstruction without the mandible is possible, the results are not satisfactory. However, procedures are now available to reconstruct the lower jaw, which in turn allows the soft parts of the face to be reconstructed. Examples include [
8,
56,
57]. Injuries or fractures of the skull must also be reconstructed beforehand [
58]. In addition to these methods of obtaining information, the methods mentioned above for predicting facial features, such as the shape of the nose and mouth, are indispensable.
Once a biological profile has been established and the anatomical soft tissue markers and corresponding facial reconstruction methods have been researched, the actual practical process steps of computer-aided forensic soft tissue facial reconstruction of the unknown individuals in both cases are followed.
3.2. Digitization of the Mortal Remains
As a basis for further steps in the facial soft tissue reconstruction process, available remains, more specifically the skull, are digitized using photogrammetric and imaging techniques. The latter was particularly important in Case 1. This was because the facial soft tissue reconstruction carried out by Prof. Helmer in 1994 was based on the original skull, not a replica. As this reconstruction had to be preserved, the only option was to use imaging techniques, in this case, CT scans, to visualize the bone structure of the skull under the plaster and then to calculate a model of the skull. The same procedure was followed for the skull of the victim in Case 2, with the addition of photogrammetric images. A detailed description of the procedures can be found in the following sections.
3.2.1. Modeling on the Basis of CT Data for the Victim in Case 1
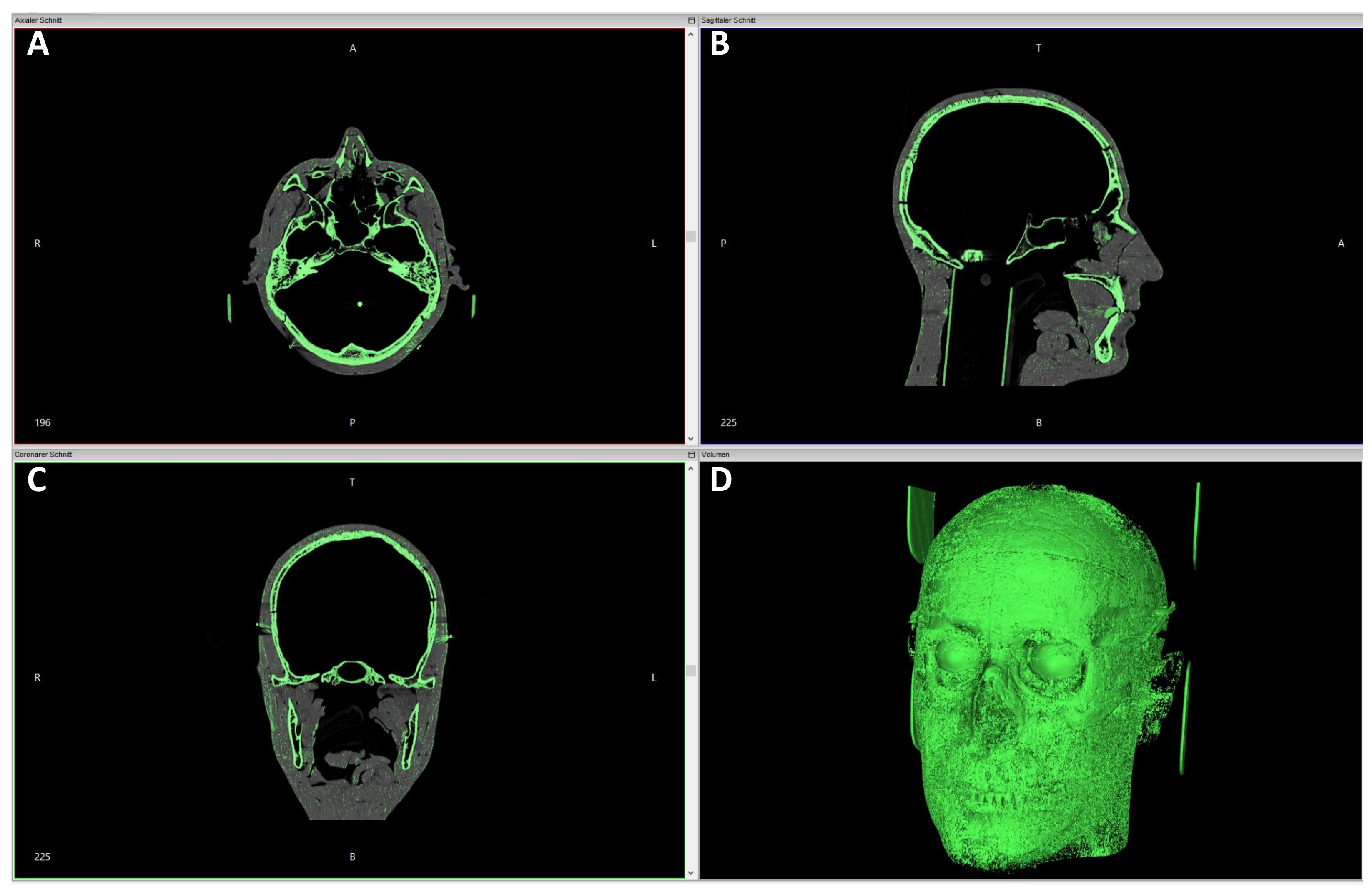
In Case 1, due to the situation described above, it was only possible to collect data using imaging techniques, more specifically, CT scans. The CT dataset comprised a total of 2082 individual images in the DICOM format. The open-source software application InVesalius version 3.1.1 on Windows 7 and 10 (both 64-bit) [
37] was used for data processing. With the help of the application, a volume model was calculated from the axial, sagittal, and coronal sectional images. As both the modeling material and the ocular prostheses were available in the CT data from the 3D model previously acquired by computed tomography, the bony structure of the skull in the CT dataset had to be determined first using software-specific parameters. InVesalius provides the ability to select different tissue planes for 3D visualization based on a minimum and maximum threshold value. A minimum threshold of 850 and a maximum threshold of 3071 were used to visualize the bony structures.
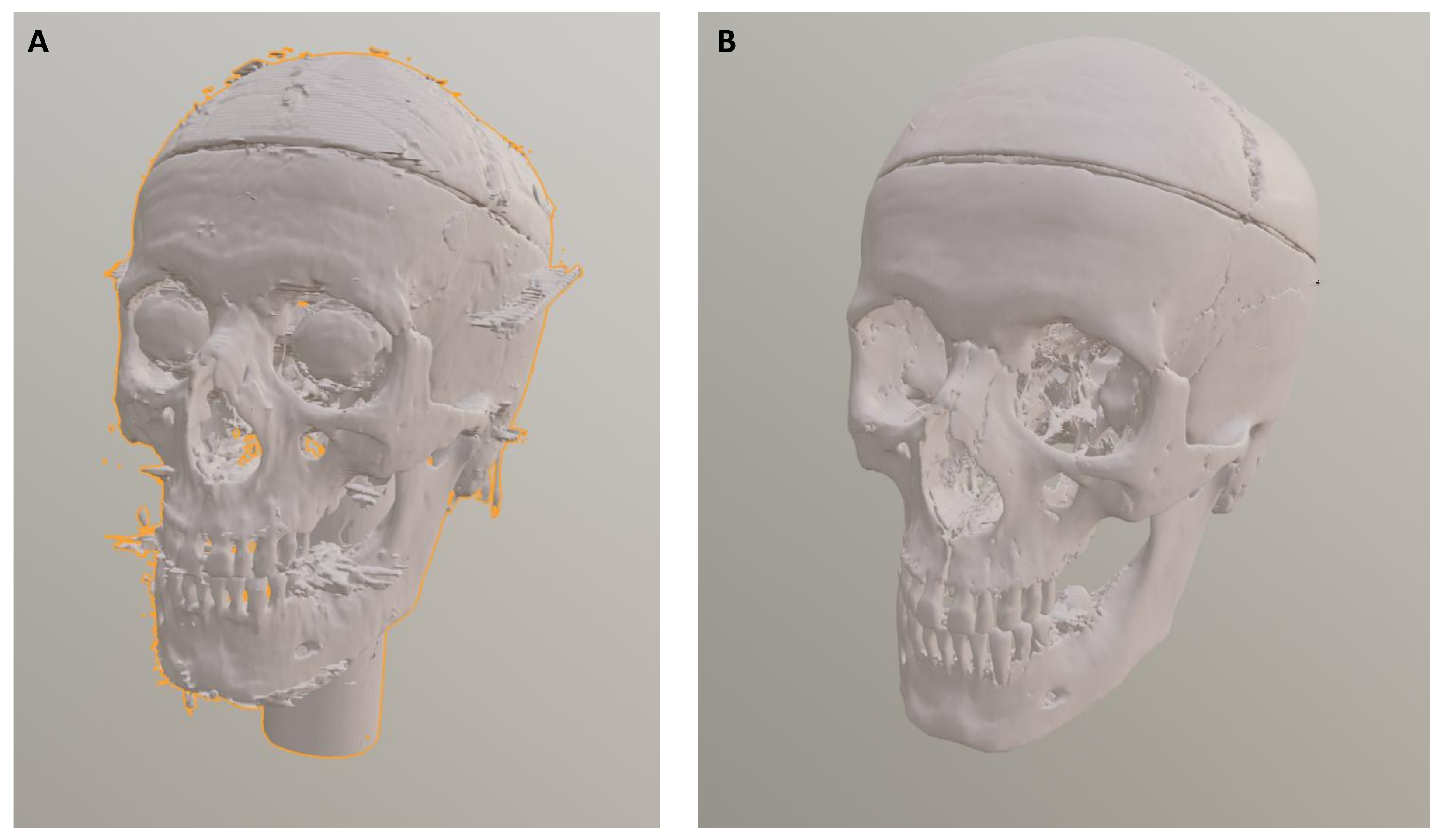
Artifacts that occurred during the volume calculation of the 3D skull model (e.g., small surface irregularities or unnatural protrusions caused by the interpolation and meshing of CT data) were manually removed in Blender using the edit mode. This post-processing step ensures that facial reconstruction is based on anatomically plausible bony structures and not distorted by technical artifacts introduced during model generation.
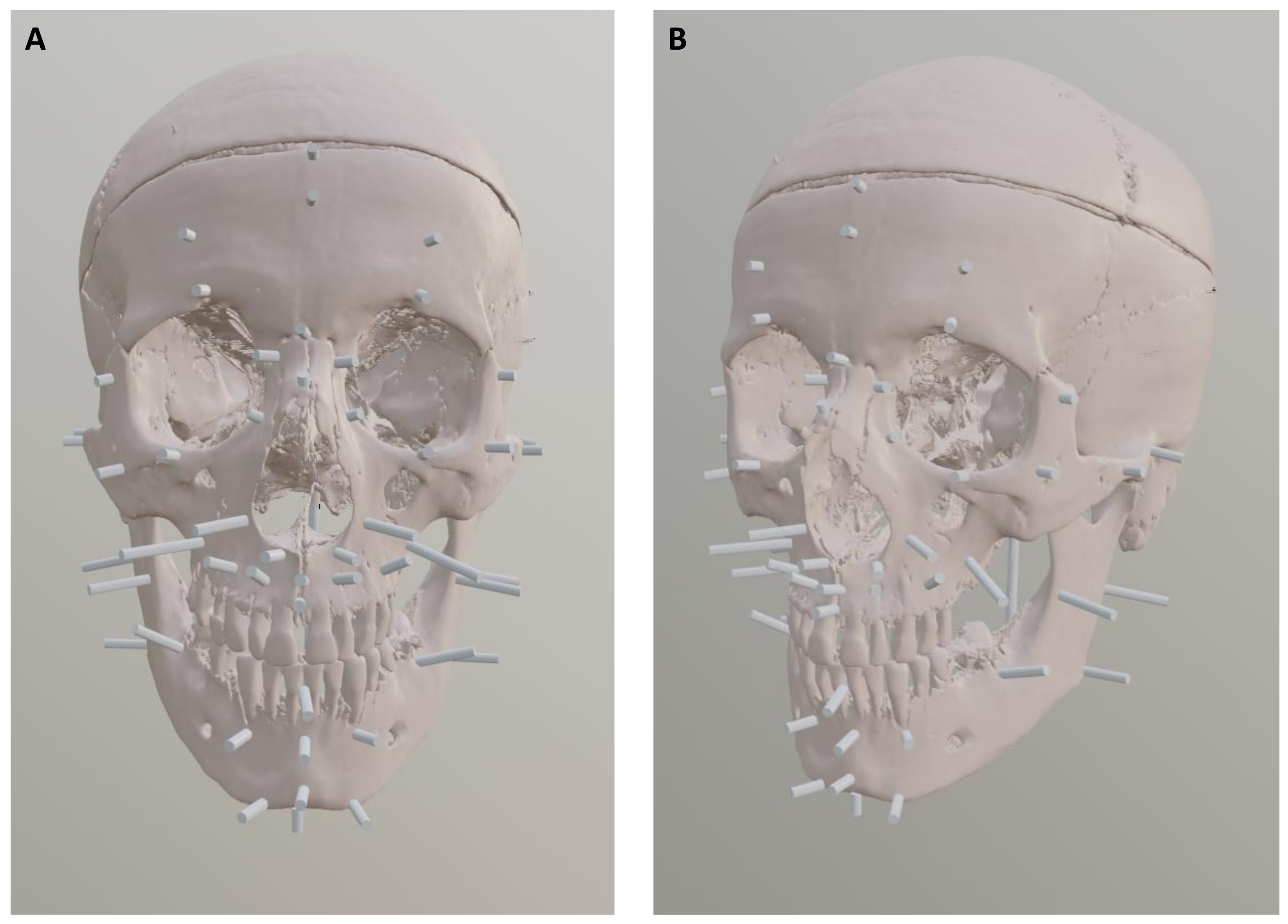
Figure 3 and
Figure 4 show the volume calculation in InVesalius and the final result after artifact removal.
3.2.2. Photogrammetric Images and Modeling of the Victim in Case 2
Photogrammetric images and photogrammetry itself are based on non-contact measurement methods and evaluation procedures that indirectly determine the position and shape of an object from photographs by measuring the image. This procedure is known in the literature as the “photogrammetric method” [
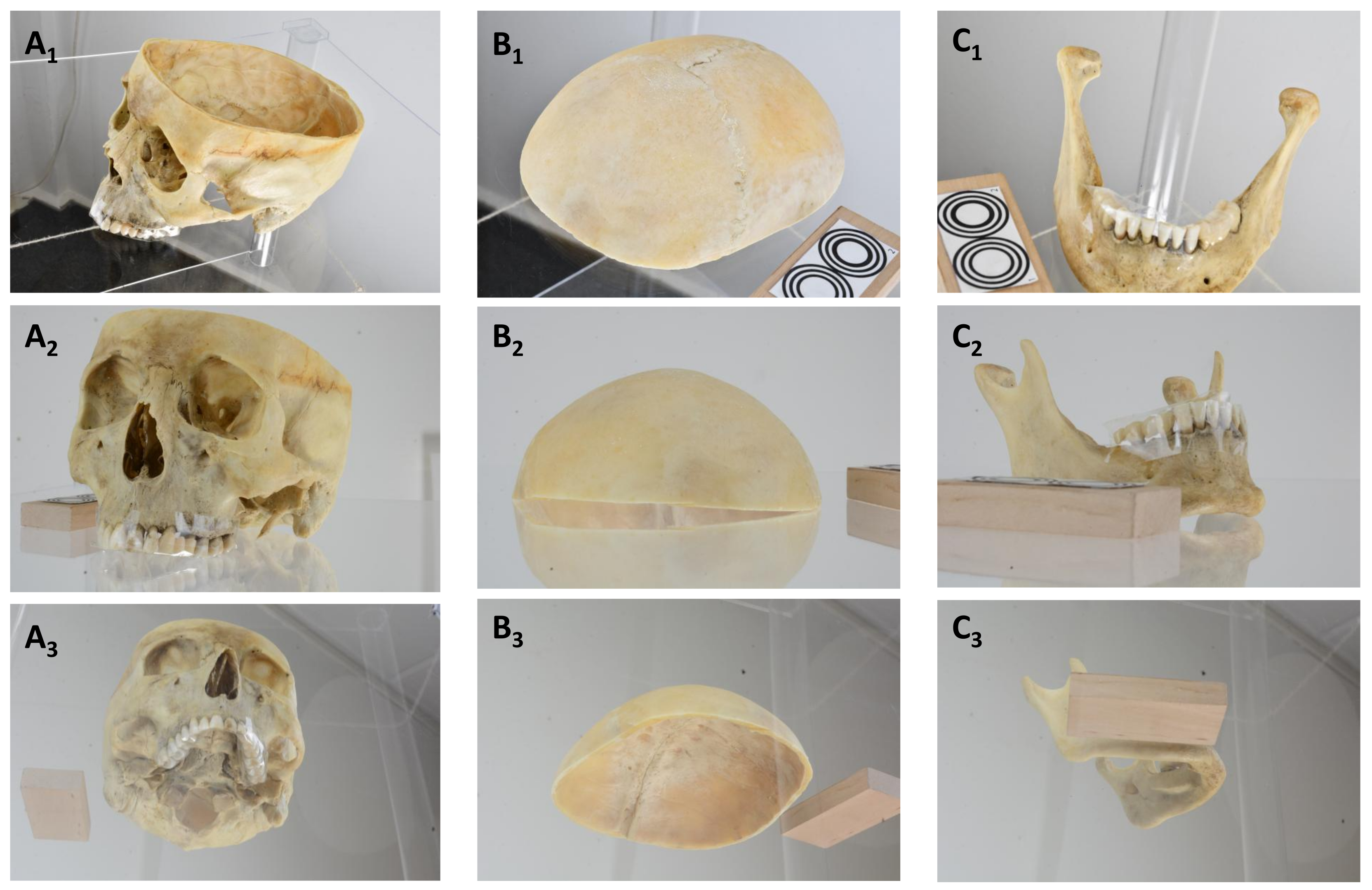
59]. The use of specially developed algorithms, such as the SIFT algorithm (SIFT stands for scale-invariant feature transform), enables the calculation of 3D models of the depicted objects from overlapping photogrammetric images. In Case 2, the skull, or more precisely, the cranium, skullcap, and lower jaw, were positioned on a turntable (company: stageonair, Penzing, Germany; [
60]) and photographed 90 times, i.e., every 4°, with reference marks from three different perspectives using three Nikon D7100 and D7500 SLR cameras with simultaneous shutter release (Nikon Corporation, Tokyo, Japan; a total of 270 images per run, i.e., 90 images per SLR camera). Three NG-220A continuous light studio lights from NANGUANG (Guangdong Nanguang Photo&Video Systems Co., Ltd., Dongguan, China) were used as a light source, some of which were fitted with softboxes to ensure homogeneous illumination. The principle of photogrammetry and the test setup are shown in
Figure 5. The photogrammetric images of the skull, more precisely the cranium, skullcap, and mandible, are shown in
Figure 6.
The photogrammetric images of the bony structures of the skull were processed into 3D models using the open-source software Meshroom (Version 2021.1.0) [
38]. The basis for the 3D modeling was 270 photographs (90 images per SLR camera) for the cranium, skullcap, and mandible, respectively. The primary processing steps involved the extraction of image features, the alignment of the overlapping images, the calculation of the point cloud, the meshing of the point clouds, and the subsequent texturing of the calculated 3D models. Following data processing, a 3D model was generated for each of the images of the cranium, the skull, and the mandible. These were then combined into an overall model in the Blender software application. An overview of the calculated individual models and the combined model is presented in
Figure 7.
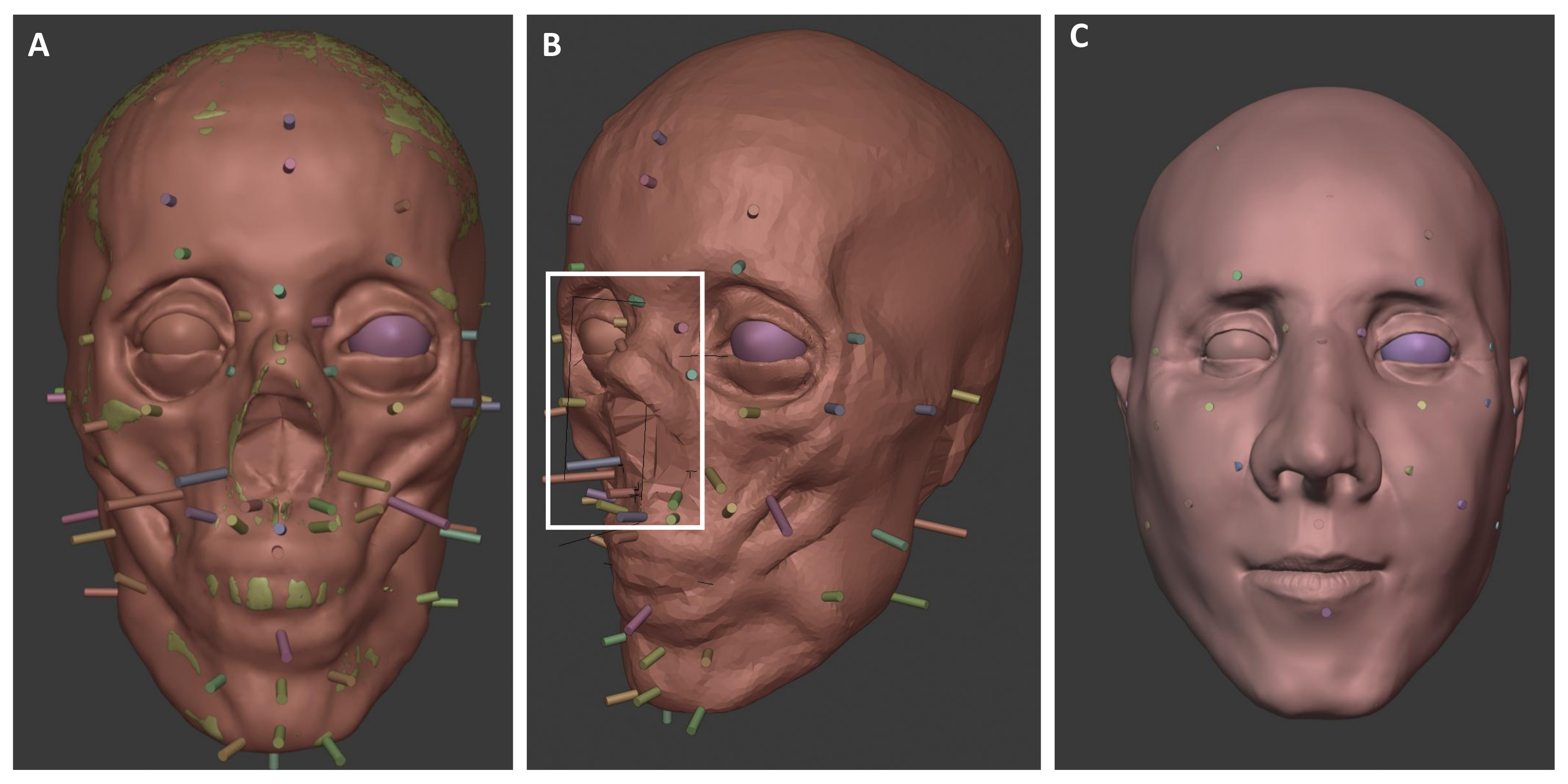
3.3. Placement of Anatomical Soft Tissue Markers
Anatomical soft tissue markers, known as landmarks, represent average soft tissue thicknesses at defined anatomical points on the face or skull [
26]. The mean millimeter values have been determined using scientific measurement methods and differ between men and women and between leptosome and obese individuals. Of particular importance to the reconstruction process is the extent to which the actual values required for optimal reconstruction of the face of an unknown deceased person deviate from the average soft tissue thicknesses at the respective anatomical points. Deviations result from, among other things, the aging process, nutritional status, and lifestyle of the person to be identified. Data on these soft tissue thicknesses used to be obtained from cadavers [
61]. Today, more modern methods such as ultrasound, MRI, and CT are available. Another advantage of imaging techniques is that they allow measurements to be made on living people, eliminating post-mortem changes and artifacts [
62]. In addition, differences in soft tissue thickness between sitting and lying positions can be studied [
63]. There are many publications that provide information on soft tissue thickness in different ethnicities, sexes, and age groups [
13,
64].
The data for soft tissue markers are based on the 2006 study by S. De Greef et al. [
13]. In this study, the soft tissue thicknesses of 967 adult Caucasians were measured, taking into account the age and BMI of the subjects. The datasets were then categorized into age groups, e.g., 18 to 29 years and 30 to 39 years. The positions of the anatomical soft tissue markers on the human skull were also taken from [
13] for subsequent facial reconstruction. For the reconstruction, the anatomical soft tissue markers were applied in the Blender software application to the 3D models of the skulls with the corresponding dimensions from Table 3b in [
13] for the victim in Case 1 and Table 3c in [
13] for the victim in Case 2. In both cases, a normal BMI was assumed, which was taken into account in the anatomical soft tissue thickness data collected by [
13] for the unknown individuals. In the cold case, the body was described as a “medium body type”; in the case of 2021, no information was available. An overview of the positions of the anatomical soft tissue markers on the skulls of the present cases is shown in the following
Figure 8 and
Figure 9.
The add-on, called the enchanted soft tissue marker (ESTM), optimizes the creation and placement of anatomical soft tissue markers. In previous facial soft tissue reconstructions, it was necessary to search the literature outside of Blender to find the optimal soft tissue thicknesses for each individual. Depending on age and gender, as well as other factors such as leptosomal or obese physique, data sheets with average soft tissue thicknesses have been collected by numerous research groups. In addition to these preparations, process steps such as the manual creation of each individual soft tissue marker in terms of its length and its application to the skull itself were very time-consuming. Subsequent changes also required several additional software-specific steps. This ESTM add-on provides the ability to import preferred marker lists into the software. This allows the user to select the most appropriate anatomical soft tissue markers based on the information available about the biological profile of the individual. The selection includes data from De Greef et al. and Rhine and Moore. The data are available in .csv format, which is read by the add-on, and are divided into depth, name, and description. The soft tissue markers can be selected and imported from a drop-down menu. If necessary, the name and length can then be adjusted using numeric input or other functions. This includes the percentage adjustment of each soft tissue marker depending on the changes that may result from an increased or decreased BMI [
13,
65,
66]. The adjustments ±5% and ±10% have been chosen here.
3.4. Reconstruction of Selected Facial Features and Modeling of the Soft Tissue and Skin
3.4.1. Reconstruction and Modeling of the Victim in Case 1
The musculature of the face was built up step by step in relation to the anatomical soft tissue markers up to the skin tissue. The muscle markers on the bones provided indications of the strength of the musculature attached to these areas.
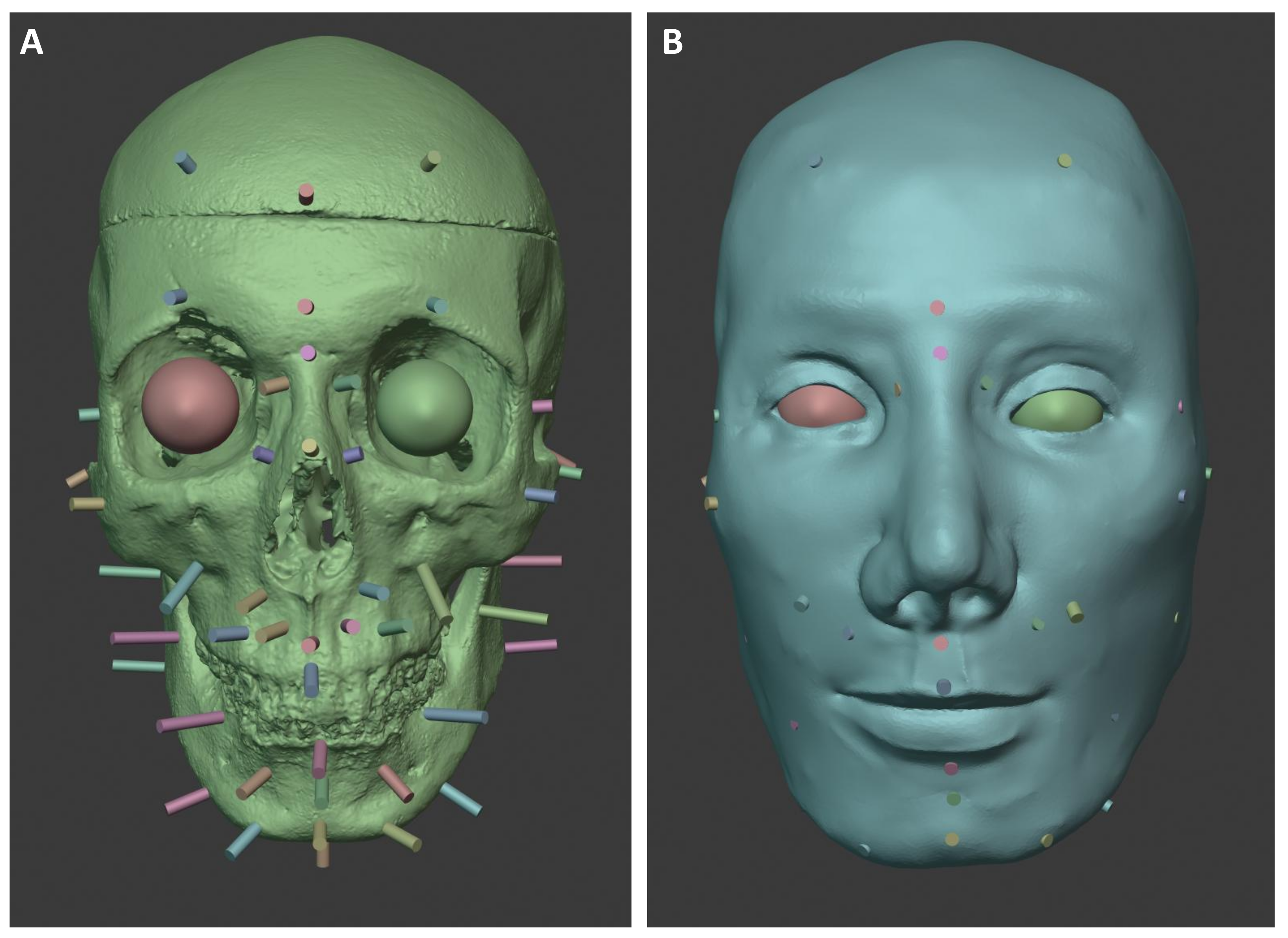
The eyeballs were positioned in the 3D model according to C. Wilkinson and K. Taylor [
2,
67]. For this purpose, an eye add-on can be utilized. The add-on can be used to create a model of the right eye at the position of the 3D cursor in the Blender software application, whose position, size, and rotation can then be changed using appropriate sliders. To create the second eye, the user simply places the 3D cursor in the appropriate position and then creates the eye using the function regarding it. This eye model is an exact copy of the other eyeball, which can be duplicated and mirrored. The orbicularis muscle (the circular muscle around the eyes) can then be added to both eyes, and the distance between the eyes can be adjusted.
The shape of the mouth was reconstructed according to the mathematical basis of C.N. Stephan [
68]. To support this process, a custom-developed Blender add-on (“Mouth Editor”) was used, which facilitates the application of Stephan’s method within the 3D modeling environment. It allows the user to import a mouth model and customize it to their needs. In addition, the predefined phenotypes Caucasian, Mongoloid, and Negroid can be applied to the mouth model. This is divided into sub-areas, such as the lower and upper lip and the mandible, which can be transformed independently.
The reconstruction of the nose was based on the mathematical principles developed by C. Rynn (European dataset) and Gerasimov [
45]. A nose construction add-on allows the user to make changes to an existing nose model or import and edit a completely new model. By selecting predefined areas, specifically columella (nasal base), side, tip, dorsum (bridge), rhinion (bony–cartilaginous junction on the nasal bridge), radix (nasal root between the eyes), and alae (nostril wings), the model can be adapted to the needs or underlying reconstruction method of the nose. Once the model is complete, it can be integrated into the existing reconstruction process.
All the measurements required for this, taken on the 3D model of the skull, and the values calculated from them for the reconstruction of the nose and mouth are shown in
Table 2,
Table 3 and
Table 4.
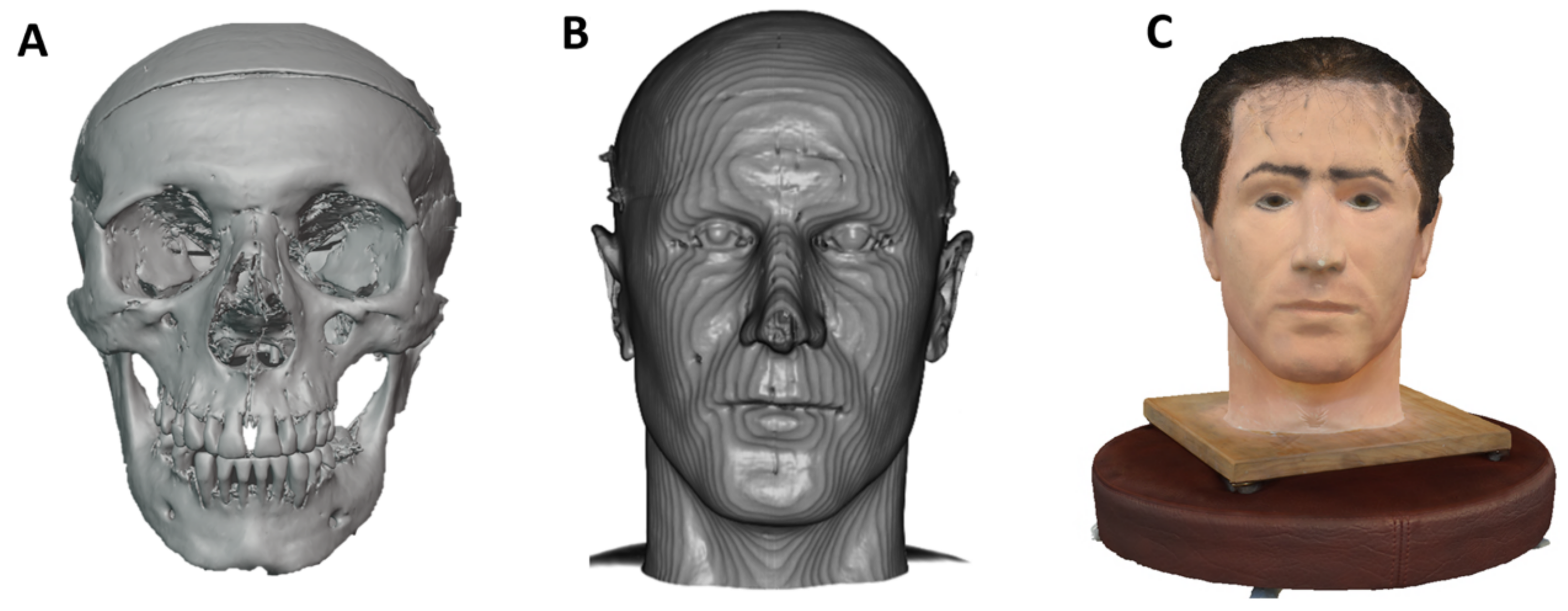
Figure 10 shows the reconstructed soft tissue and the facial features based on the measured values.
3.4.2. Reconstruction and Modeling for the Victim in Case 2
As in the previous case, the eyeballs were positioned in the 3D model according to C. Wilkinson and K. Taylor [
2,
67], the shape of the mouth was reconstructed according to the mathematical basis of C.N. Stephan [
68], and the shape of the nose according to the mathematical basis of C. Rynn (European dataset) and Gerasimov [
45]. Reconstruction of the eyes, nose, and mouth also utilized the previously described add-ons. All measured values for the reconstruction of the nose and mouth are shown in
Table 5,
Table 6 and
Table 7. The following
Figure 11 shows the reconstructed soft tissue and facial features based on the measurements taken.
3.5. Modeling of Hair and Age Characteristics, as Well as Individualization of Faces by Incorporating Special Features and Accessories
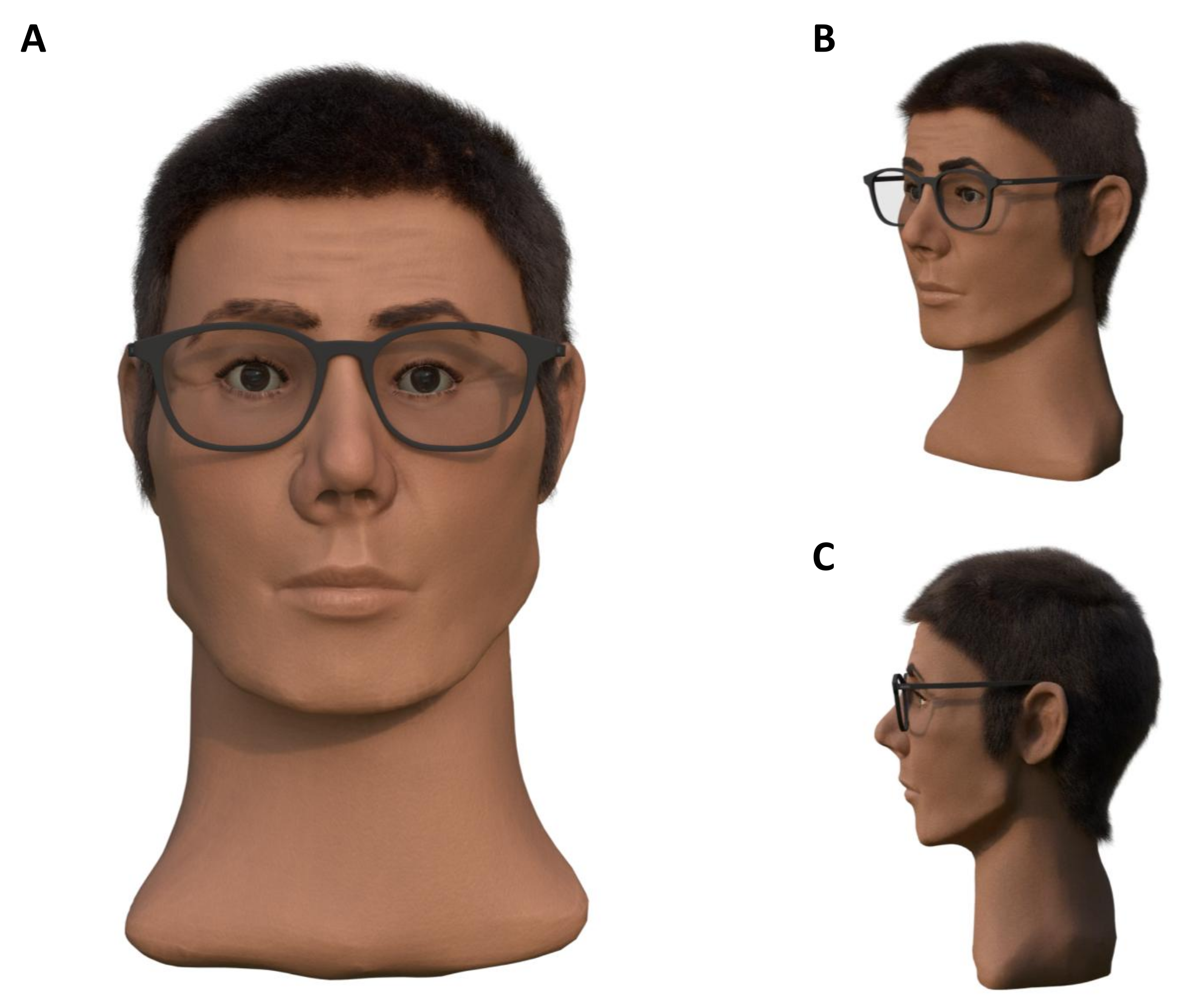
3.5.1. Modeling of of Individual Characteristics in Case 1
The following procedures were used for the victim in Case 1. By including the described face databases [
55], corresponding wrinkles, which can occur in the age range of 30–40 years, were transferred to the 3D model. For the realization of hairstyles, extensive Internet research was carried out on typical hairstyles in Europe from 1993. Hair combed backwards, slicked back, and worn loose was widespread. In the Blender software application, it is possible to transfer hair of different lengths, colors, and textures to models and create different hairstyles for them. In the present case, the most frequently represented hairstyles were modeled on the basis of the hair length interval of 10 to 15 cm specified in the files in accordance with the research carried out. A dark hair color was chosen for the file entries. Based on Prof. Helmer’s statements, one model was modeled with a scar. As no information about eye color was available, the final results were presented with different eye colors. The results of the reconstruction are shown in
Figure 12.
3.5.2. Modeling of of Individual Characteristics in Case 2
The following procedures were used for the victim in Case 2. By including the described face databases [
55], corresponding wrinkles, which can occur in the age range of 40–50 years, were transferred to the 3D model. Based on the information about the hair attachments to the skull, different facial features were modeled. The results of the reconstruction are shown in
Figure 13.
3.6. Integration of the Model into Everyday Life (Rotation, Presentation, and Visualization)
The primary goal of forensic facial soft tissue reconstruction is to identify the unknown individual. Once the face is finally modeled and individualized, the identification process can start using a variety of techniques. Firstly, searches and comparisons with missing person databases are carried out, followed by media coverage of the discovery of an unknown deceased person in the hope of obtaining information relevant to the investigation from the civilian population. Nowadays, social networks are also available to disseminate such information to the general public.
A common prerequisite for all procedures is the availability of high-resolution photographs of the facial soft tissue reconstruction in order to provide the best possible conditions for the identification process. A few years ago, it was common practice to take photographs of the final facial models in photo studios, but digital reconstructions and virtual space offer many advantages in generating and providing such information.
Thanks to the ability to parameterize virtual cameras according to all the technical parameters of their analogue counterparts, high-resolution images of computer-aided facial soft tissue reconstructions from Full HD, QHD, to UHD and beyond can be produced in a very short time. Perspective is irrelevant, i.e., models can be presented and new images calculated as required by simple rotation operations. Thanks to modern and simple software and web applications (such as Paint3D or Sketchfab) that allow the visualization of 3D models by dragging and dropping, the models themselves can be used for presentations without the need to photograph them.
The presentation of three-dimensional data is now widely used in other fields, such as archaeology, demonstrating the clear added value of such presentation [
69,
70]. The ongoing development of visualization software, which optimizes the effects of light, shadow, and texture, means that the models and scenes created are becoming ever more realistic, which can only benefit third parties. Finally, it should be noted that while traditional photography is perfectly adequate for the purpose, the use of computer-aided visualization techniques provides valuable additional assistance in the identification process.
An overview of the methodological workflow, including the software applications, applied techniques, and corresponding literature, is provided in
Table 8.
3.7. Discussion of Methodological Foundations
While the process of facial reconstruction inherently involves some degree of estimation, the core components of our method are grounded in established anatomical and statistical principles. The placement of the eyes, the reconstruction of the nose, the width of the mouth, and the positioning and average thickness of soft tissue markers are all derived from well-documented anthropological studies and follow reproducible mathematical procedures. The anatomical landmarks used for soft tissue marker placement are clearly defined and leave minimal room for subjective interpretation. It should be noted, however, that the objectivity of these elements also depends on the quality, sample size, and demographic representativeness of the underlying anthropological datasets.
Nevertheless, certain facial features remain less constrained by skeletal morphology. For instance, while mouth width and vertical positioning can be estimated based on dentition, the shape and fullness of the lips cannot be reliably inferred from bone structures due to the lack of direct anatomical correlates. Similarly, features such as the hairline and eyebrow shape exhibit significant individual variation and are only partially informed by underlying craniofacial structures. As such, these elements are reconstructed with greater artistic freedom, although we aim to minimize arbitrariness by adhering to population-level norms and anatomical plausibility.
4. Comparison of Classical and Computer-Aided Reconstruction Results in Case 1
When considering the reconstruction results of a forensic facial soft tissue reconstruction, it should not be assumed that the individual appearance of an unknown deceased person can be reconstructed in every detail. However, according to experience and scientific publications on facial soft tissue reconstructions carried out to date, a considerable approximation to the overall appearance of an unknown individual is achieved. Even if there are strong influences on the external appearance of a reconstructed face, such as the reproduction of the correct hairstyle, the overall impression of the face and the facial proportions remain very decisive for a reconstruction. This means that there is at least the certainty that the basic character of a face will be reproduced exactly.
It is not uncommon for the reconstructed face to achieve a very high degree of similarity with the actual appearance of the deceased. In other cases, however, the unavoidable margin of judgment in the interpretation of the empirical reconstruction rules leads to a deviation in the reconstruction from the individual appearance. It is irrelevant whether the reconstruction is carried out classically or computer-aided. A comparison of the reconstruction results is usually made on a quantitative basis. However, as the identity of the unknown man in Case 1 remains unconfirmed, no reference images or identity-validating data are currently available. Consequently, no formal validation can be conducted at this stage. Therefore, any further discussion regarding this case will be based solely on qualitative criteria.
Above all, the choice of the basic method for reconstructing the face and the individual facial features, as well as the underlying data on the anatomical soft tissue markings, can influence the result. In the present case, computer-aided reconstruction was carried out using the Manchester method. It was not clear from the documents provided which method was used for the classic reconstruction. However, according to the descriptions of the procedure in the protocols from 1994 and in conjunction with the statements in [
12], it can be assumed that the American method was used for the classic facial soft tissue reconstruction.
Another difference could lie in the data used for the anatomical soft tissue markings. In computer-aided reconstruction, data on anatomical soft tissue thicknesses from de Greef et al. [
13] were available. In comparison, the documents do not contain any information on the underlying tissue thicknesses but only indicate that the data were collected from living individuals. For this reason, only a limited statement can be made at this point about possible influences on the reconstruction results based on the anatomical soft tissue markers. The following statements can be made regarding the reconstruction methods used for the individual facial features. In the computer-aided reconstruction, the nose was modeled according to the established method of Rynn et al. [
45], and in the classic method, according to A. Macho [
71].
5. Comparison of Computer-Aided Reconstruction Results with Photographs of the Deceased Person in Case 2
In Case 2, the identity of the body found could be clarified in the course of the investigation. This means that photographs of the deceased were available for comparison, which allowed for a quantitative evaluation of how similar the reconstructed face appears to the original. This approach should help to assess the accuracy of the reconstruction in a more objective manner. It is important to note that the focus of this work was less on evaluating face recognition models themselves and more on quantitatively assessing the similarity between the reconstructed face and the actual appearance of the individual.
A quantitative comparison can be made using basic facial landmarks and measurement distances. However, these methods are generally limited to images captured under strictly controlled conditions. These conditions include, for example, a homogeneous background and a neutral expression but primarily focus on well-defined frontal upright captures of faces [
72,
73].
A quantitative comparison using computer vision, especially through machine learning, is often not constrained by specific conditions and can yield robust results, even with faces of varying perspectives [
74]. Facial recognition can be used in many applications, including surveillance, security, crime prevention, and access control.
One possibility for performing face recognition is the use of the Dlib software library (Dlib version 19.3.0 was used in this work) [
75]. Dlib is an open-source toolkit written in C++ that provides machine learning and computer vision algorithms. It enables automatic face detection, comparison, and identification using artificial intelligence techniques. The facial features are not explicitly defined but are learned from large datasets such that the resulting numerical representations (embeddings) are nearly identical for different images of the same individual.
In this work, Dlib serves as one of the core systems for face recognition. To compare two faces, the framework requires an input image of the target person and an image of the 3D model’s face. The comparison process involves multiple preprocessing steps, including face detection and localization, facial landmark detection for alignment, and feature vector extraction using Dlib’s CNN-based pipeline [
75]. The implementation is based on the open-source project by [
76].
In addition to Dlib, two modern deep learning-based face recognition models, VGG-Face [
77] and GhostFaceNet [
78], were also employed. These models offer high recognition accuracy and robust feature extraction capabilities. They are integrated via the DeepFace framework and utilize YOLOv8 (Version 8.0.0) [
79] for initial face detection. Unlike Dlib, they do not rely on explicit facial landmark detection for alignment but instead process the cropped and scaled face images directly. The individual preprocessing steps and model differences are explained in more detail in the following sections.
5.1. Procedure of the Comparison Using Dlib-Based Face Recognition
5.1.1. Step 1: Face Detection and Localization
To detect the presence of faces in complex scenes and accurately delineate their positions and areas, face detection must be performed as a preliminary step. Once a face is identified, the region containing the face is globally analyzed, and the positions of all faces are marked based on the input image data. The coordinates of the bounding boxes for the faces are then output [
75].
There are multiple selectable alternatives for face detection, each with its own disadvantages and advantages. One of the methods used in this study is a convolutional neural network (CNN)-based face detector, specifically the CNN Face Detection Model V1 provided by the Dlib library [
80], along with the corresponding pre-trained model file (mmod_human_face_detector.dat). The advantage of this method is its ability to work well, even from odd angles [
81,
82]. Convolutional neural networks (CNNs) are a prime example of classical neural networks and are increasingly being utilized across various fields. Their primary application lies in pattern recognition within images [
83], making them well-suited for detecting objects in images.
In addition to the Dlib pipeline, an alternative approach was implemented using YOLOv8 [
79] as the detection module. YOLOv8 is a state-of-the-art object detection model known for its high speed and accuracy in identifying objects, including human faces [
79]. From experience, YOLOv8 proves to be very reliable in detecting faces across various lighting and background conditions. However, in contrast to Dlib, YOLOv8 does not output facial landmarks, it only provides bounding boxes. This limitation directly affects the alignment step described below.
5.1.2. Step 2: Feature Point Location for Face Alignment
To acquire comprehensive information about the detected face image, it is crucial to pinpoint facial feature points. This process enables the identification of facial contour boundaries, including the eyebrows, eyes, nose tip, and mouth corners, among other significant features. By accurately locating these points, we can precisely determine the face’s position and structure [
75].
For feature point localization in the Dlib-based pipeline, the CNN-based five-point shape predictor (shape_predictor_5_face_landmarks.dat) provided by Dlib was employed, which detects five key facial landmarks: the inner and outer corners of both eyes and the tip of the nose [
84]. Based on these landmarks, facial alignment is performed using Dlib’s get_face_chip function [
84], which rotates, scales, and crops the face region to produce a standardized, centered, and frontal view, thereby reducing pose-related variance. Research indicates that face alignment enhances face recognition accuracy [
85]. To normalize the faces, basic image transformations such as rotation and scale, which preserve parallel lines (referred to as affine transformations), are applied [
75] until the key points are centered as accurately as possible.
In contrast, the YOLOv8-based setup [
79] does not support explicit landmark-based alignment since YOLOv8 does not return facial landmarks. As a result, step 2 is omitted in this pipeline. Nevertheless, the preprocessing ensures that the faces are cropped based on the bounding box and rescaled to a fixed input size, which introduces a basic level of normalization.
The test images used in this study are controlled to a high degree. Image 1 is a passport-style frontal photograph, which does not require alignment. Image 2, however, exhibits a slightly lateral view, which may introduce minor pose-related differences. While this could be mitigated by applying facial alignment, it was not considered substantial enough to necessitate an additional alignment procedure in this context. Prior studies suggest that such alignment becomes especially important when dealing with larger pose variations or uncontrolled input conditions [
75,
85].
5.1.3. Step 3: Face Feature Vector Extraction
To facilitate the mathematical comparison of faces, a numerical representation known as face encoding is necessary. These encodings are matrix representations of faces, where similar faces yield similar matrix representations, as previously mentioned [
75]. Conversely, dissimilar faces produce distinct matrix representations.
In the Dlib-based approach, the aligned face images are converted into 128D feature vectors representing each face, using the pretrained ResNet model for face recognition (dlib_face_recognition_resnet_model_v1.dat) [
84]. This model achieved a verification accuracy of 0.9938 [
84] on the Labeled Faces in the Wild (LFW) dataset [
86], making it a very effective and lightweight solution for practical use cases.
In addition, two modern deep learning models were also used for feature extraction in the YOLOv8-based pipeline:
VGG-Face [
77]: A deep convolutional neural network trained on a large-scale dataset of celebrity faces. It is known for its robust performance and has achieved a verification accuracy of 0.9895 [
77] on the LFW dataset [
86], classifying it as a highly accurate model for face recognition.
GhostFaceNet [
78]: A lightweight yet powerful model that incorporates ArcFace loss to generate highly discriminative facial embeddings. GhostFaceNet achieved a verification accuracy of 0.9971 [
78] on the LFW dataset [
86], thereby outperforming both Dlib and VGG-Face.
The models were used via the DeepFace framework, which internally handles preprocessing and supports multiple backends [
87].
The use of multiple recognition models enables a broader evaluation and allows the comparison of classical and modern face representation techniques under the same preprocessing conditions.
5.1.4. Step 4: Face Comparison
As a final step, a mathematical comparison between two faces is conducted using the extracted feature vectors. Typically, the Euclidean distance or cosine similarity is employed to calculate the distance between these vectors. The result is a distance measure, where higher values indicate greater differences and thus lower similarity, while lower values suggest higher similarity.
It is important to note that each face recognition model defines its own optimal threshold for deciding whether two faces belong to the same person. These thresholds are typically determined empirically, based on the model’s performance during training and validation on a specific dataset, aiming to balance the rates of false positives (incorrectly matching different individuals) and false negatives (failing to match the same individual). For instance, using the Euclidean metric, Dlib uses a recommended threshold of 0.60 [
84], and VGG-Face typically applies a threshold of around 1.17 [
87]. To ensure comparability of results across different models, all distance scores were normalized by dividing by the respective model-specific threshold, resulting in a uniform decision boundary of 1.0 for all models. In this normalized setting a value below 1.0 indicates a match (same identity), a value above 1.0 indicates a non-match (different identities).
It is important to remember, however, that this normalization is a heuristic for comparison purposes only. The resulting values are not linearly related to the semantic similarity between faces and must not be interpreted as probabilities. They merely indicate the relative position of a score with respect to the model’s acceptance threshold.
This approach allows consistent evaluation across models with different embedding characteristics and scales while preserving their individual performance behavior.
5.2. Results of the Comparison Using Dlib-Based Face Recognition
The comparison of the results from facial soft tissue reconstruction of the victim in Case 2 with two seized photographs of the deceased person (not shown to protect the individual’s right to privacy) was carried out using computer vision, employing three different face recognition models: Dlib [
75], VGG-Face [
77], and GhostFaceNet [
78]. The precise results of the computer-vision-aided comparison between the face of the person in question and the reconstructed 3D face in Case 2, normalized and rounded to the fourth decimal place, are shown in
Table 9.
The comparison of the reconstructed face in Case 2 with two reference photographs (Image 1: frontal passport-style; Image 2: slightly lateral view) yielded normalized similarity scores above the model-specific thresholds, indicating no similarity between the faces. All scores were normalized such that a value of 1.0 corresponds to the respective model’s verification threshold.
For Image 1, the models produced normalized distances above 1.0, suggesting that the face in this frontal image does not match the reconstructed face closely. The closest match was achieved by VGG-Face (Euclidean: 1.1396) and GhostFaceNet (Euclidean: 1.1664), with Dlib showing a slightly higher value (Euclidean: 1.2827).
For Image 2, GhostFaceNet displayed a much higher distance (Cosine: 1.4823), indicating a clear mismatch. VGG-Face and Dlib both returned similar values (Euclidean: 1.1382 for VGG-Face and 1.2950 for Dlib), still above the threshold and suggesting no significant similarity.
In conclusion, all models returned distances that exceeded the normalized threshold of 1.0, implying that the reconstructed face does not exhibit a strong resemblance to the reference images of the deceased person, according to the evaluated face recognition models.
To provide context and improve the interpretability of the similarity scores, we additionally compared the passport photograph of the identified individual with a photo of a subject who is subjectively perceived as clearly dissimilar (e.g., female, more angular facial features, different hair color, mouth, and nose shape). Interestingly, the resulting Euclidean distances (VGG-Face: 1.1883; GhostFaceNet: 1.1732) were only slightly higher than those observed in the comparisons with the reconstructed face. Cosine distances were more distinct (VGG-Face: 1.4213; GhostFaceNet: 1.556), indicating greater dissimilarity. However, this comparison shows that absolute distance values do not differ as strongly as one might expect based on human perception. It also highlights that these similarity metrics, especially when close to model thresholds, must be interpreted cautiously, as they are not linearly scaled or normally distributed and do not directly correspond to perceptual similarity.
5.3. Discussion of the Comparison Using Computer Vision
As mentioned above, when considering the reconstruction results of a forensic facial soft tissue reconstruction, it should not be assumed that the individual appearance of an unknown deceased person can be reconstructed in every detail. It is more of an approximation to the individual’s appearance.
The minimal differences in the normalized similarity scores between Image 1 (frontal passport photo) and Image 2 (slightly lateral view) suggest that the pose angle had little impact on the face recognition results. Despite the slight lateral angle in Image 2, the face remains largely frontal, meaning the models did not encounter significant pose variation. Both VGG-Face and GhostFaceNet are known for their robustness to small pose changes, which is reflected in the consistent results across both images.
It is important to note that all the face recognition models used here were trained on large benchmark datasets that include a wide variety of individuals in diverse environments. These datasets typically feature significant variations in lighting, exposure, angles, facial expressions, and even occlusions [
86], which makes the models highly robust to such factors. Consequently, these models perform well even when the images deviate slightly from the ideal frontal view, as seen in the comparison of Image 1 and Image 2.
These findings indicate that the slight pose change did not significantly affect the results, though larger pose variations might yield different outcomes.
Human perception seems capable of recognizing similarities even when deviations in facial features are noticeable upon closer examination. This ability was reflected in Case 2, where the police officers involved noted that the similarity to the reconstructed face was “astonishing” (translated from German), with one remarking, “As a layperson, I see a significant match” (translated from German). Additionally, the press reported, “Indeed, based on comparison photos of the missing person […], a resemblance to the reconstructed face was noticeable, the investigators reported” (translated from German) [
88]. However, facial recognition software is particularly sensitive to minor facial features and will reject matches if there are discrepancies. The ultimate goal is to enable the automatic and rapid search of large databases using facial recognition software based on soft tissue reconstructions. To achieve this, further research is needed to generate more accurate reconstructions.
An additional approach for facial recognition could involve training models to compare a 3D-generated or reconstructed face with a photograph of the person. However, this approach is quite challenging due to the need for a large dataset containing both 3D models of individuals and corresponding photographs. A possible method would resemble the approach taken in the work of Moreno et al., which tackles the recognition of composite sketches and photographs using deep learning techniques [
89].
6. Summary and Prospects
6.1. Summary
This section summarizes the advantages of the computerized approach. Essentially, using modern digitization methods such as photogrammetry, digital images of a skull can be produced in the form of three-dimensional models in a matter of minutes. These are then used as the basis for further modeling steps. For ethical reasons, the costly reproduction of the original is not necessary, as the modeling is always carried out on the digital image and not on the original skull.
Particularly in the case of people who have been lying down for a long time or victims of severe violence in the facial area, skull finds often show fragmentation and destruction, which must be reconstructed before the actual work can begin. Traditionally, this is carried out by hand, using plaster, clay, or other materials. Computer-aided approaches work in a similar way but are much more flexible. Where it is not possible to reconstruct missing parts of the face using traditional methods, methods such as computer-aided morphing open up new possibilities for reconstructing missing areas of the skull.
One of the most important factors in facial soft tissue reconstruction is the use of anatomical soft tissue markers. An exception is the Russian method, developed by Gerasimov in 1971, in which only the anatomy of the skull forms the basis of the reconstruction. The reference to these markers is essential for the individualization of a face, as some of them are deliberately over- or under-represented at any given time, depending on the information available about the individual in question. Thanks to the many visualization features of facial soft tissue reconstruction software, such problems can be solved literally at the touch of a button. In contrast, reference to anatomical soft tissue markers is possible with conventional methods, but only to a limited extent.
A problem that tends to arise with historical findings is the subsequent adaptation of the models, especially when the information base is sparse. Classical methods are clearly limited in their flexibility, as individual facial features of hardened plaster models cannot be easily exchanged and optimized or hairstyles quickly colored. The use of digital model libraries makes it possible to adapt computer-generated models quickly and easily, for example, to color hair or reduce the size of a nose. In addition, the computer-aided reconstruction process can be partially automated using developed scripts and modules in the form of so-called add-ons, in particular for the selection and positioning of anatomical soft tissue markers and the generation of individual facial features.
In summary, classical methods are not obsolete or ineffective. However, computer-aided approaches offer advantages that make it possible to deal with the known problems in this field more flexibly and, in some cases, more effectively and efficiently.
The advantages of digital reconstruction are particularly evident in so-called cold cases, where conventional investigations often fail due to a lack of comparative material. In the past, the high methodological requirements and costs made widespread use of such techniques almost impossible. Digital approaches, combined with specialized software development and medical expertise, now allow for time-efficient and flexible implementation. A practical example of the application of this method was illustrated using a case from 1993 (Case 1) and from 2021 (Case 2). Digital reconstruction techniques were used to illustrate the benefits of this modern technique. Digital facial soft tissue reconstruction not only offers greater accuracy but also significantly speeds up the entire identification process. This is particularly valuable in cases where traditional methods fail, and rapid identification can be critical. In summary, by integrating advanced software and medical expertise, digital facial soft tissue reconstruction offers an effective solution for the identification of unknown persons, especially in complex cold cases.
6.2. Prospects
However, these processes can be further improved and optimized. This is where approaches from the field of machine vision or AI in general offer opportunities. The gradual integration of these approaches in various disciplines has enabled significant progress to be made in dealing with complex problems. In this context, the application of AI technologies to forensic anthropology opens up new dimensions in facial soft tissue reconstruction. Not only does it promise to increase the accuracy of reconstruction and speed up the entire identification process, but it also offers the possibility of increased objectivity and standardization.
In particular, the objectivity of AI compared to studies such as those by Vanezis et al. [
1] or Stephan et al. [
15] is crucial. Both research groups investigated and critically examined the dependence of reconstruction accuracy on the skill, experience, and subjective bias of the reconstructor. The results of these studies showed significant differences in the resulting reconstructions due to the personal influence of the reconstructor.
AI approaches offer advantages in this context due to their objectivity, as they operate based on predefined algorithms and are not influenced by human bias [
90]. A key strength lies in their internal consistency: the same model will produce identical results when given the same input, regardless of the user or the time of execution [
90]. However, it is important to note that consistency cannot be expected across different models, especially if they are trained on varying datasets or follow different architectures. Nevertheless, the reproducibility of individual AI models remains a valuable property, particularly in applications that demand standardized and transparent procedures. The integration of more advanced machine learning algorithms and 3D modeling techniques is expected to build upon this foundation and further improve reliability and performance in this field.
Yet, the effective application of such AI-driven methods relies on a solid foundation of extensive and high-quality data. To generate reconstructions that reflect individual-specific features with high accuracy, a large and diverse dataset of cranial and facial information is essential. This need highlights the importance of developing a dedicated dataset that includes both 3D cranial models and corresponding facial data. Such a dataset would enable systematic evaluation and benchmarking of facial reconstruction techniques, particularly in the context of digital and automated workflows. However, assembling such data poses significant ethical, legal, and logistical challenges, especially regarding data availability and consent.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}