1. Introduction
The growing need to automate tasks and the demand for “smart” devices have driven the massive adoption of Internet of Things (IoT) technologies, along with the deployment of the technological infrastructures that support them. However, this accelerated growth has also increased exposure to cybersecurity risks, most notably Distributed Denial-of-Service (DDoS) attacks. This type of threat compromises the availability and integrity of systems by generating large volumes of malicious traffic to a target device or service, aiming to exhaust computing resources and render the service unavailable.
This issue becomes particularly relevant in industrial contexts that implement large-scale IoT solutions, where cloud-based infrastructures are critical components for the continuous delivery of services. IoT devices represent a significant attack surface, given their frequently poor maintenance, limited monitoring capabilities, and scarce security updates, conditions that make them ideal vectors for executing DDoS attacks. Consequently, protecting these environments becomes critical to ensuring operational resilience and service continuity in modern industrial ecosystems [
1].
Effective detection and mitigation of these types of attack is critical to the security and performance of systems in general, which has fostered interest in researching and developing new detection and defense techniques. Some authors propose design and algorithmic analysis based on the historical behavioral data of compromised systems in various architectures, including cloud environments [
2] and IoT devices [
3]. According to the proposal, the detection of network anomalies and the identification of anomalous network traffic patterns can be solved through machine learning, especially those related to DDoS attacks, since these algorithms can learn to recognize unusual behaviors that could go unnoticed by traditional security methods (IDS), which increases the capacity for adaptation and continuous learning, as opposed to the constant evolution of cyber-attacks, which have been taking increasingly sophisticated and complex forms.
Despite the existing advances in the development of machine- and deep-learning algorithms for the detection of DDoS attacks, there are still significant challenges related to the efficiency and effectiveness of the models, as well as their optimization to ensure their correct operation in IoT environments. This research seeks to explore alternatives to improve the detection and mitigation of these attacks using optimization and feature selection approaches that can improve their effectiveness and efficiency, with the aim of ensuring stability and security in this type of networks. The proposed solutions are supported by recent advances in the field of cybersecurity and artificial intelligence, offering an innovative approach to cybersecurity in these environments, considering the lowest possible use of resources to achieve it [
4].
For the training of the models, the correct use of available datasets that focus on this type of attacks in IoT infrastructure is of utmost importance, including data such as network traffic characteristics such as package rates, response times, and protocol types, which would allow the identification of anomalous patterns. This enhances the system’s capacity for adaptive learning in response to the ongoing evolution of cyberattacks, which have become increasingly sophisticated and complex. In this context, hybrid deep-learning architectures, particularly those combining Convolutional Neural Networks (CNNs) with bidirectional mechanisms such as BiLSTM have shown outstanding performance in the detection of anomalous traffic within IoT/Cloud environments, as demonstrated by the framework proposed by Ouhssini et al. [
5]. To this end, this research will focus on the use of two widely used datasets: CIC-DDoS2019 is a dataset prepared by the Canadian Institute for Cybersecurity (CIC), which provides network data of both benign and malicious traffic, and whose development is detailed by Sharafaldin [
6]. N-BaIoT, on the other hand, contains benign and malicious traffic data from ten different types of IoT devices, belonging to two of the world’s most well known botnets [
7]. The main contribution of this study lies in the integration and comparative evaluation of established machine-learning models Random Forest, XGBoost, and LSTM applied over two complementary and representative datasets: CIC-DDoS2019 and N-BaIoT. Unlike previous works that evaluate models in isolation, this research offers a unified framework that combines model-specific feature selection techniques, class balancing strategies, and rigorous evaluation metrics, enabling a robust and reproducible analysis of their effectiveness under realistic IoT/Cloud conditions. Moreover, the development of a web-based dashboard for real-time result visualization reinforces the applied value of the proposal, aiming to facilitate operational deployment and bridge the gap between academic research and practical cybersecurity solutions.
The remainder of this paper is organized as follows:
Section 2 presents the related work.
Section 3 introduces the background.
Section 4 describes the proposed methods.
Section 6 reports the experimental results.
Section 6 discusses the findings, and finally,
Section 7 concludes the paper and outlines directions for future work.
2. Related Work
The use of Machine-Learning (ML) and/or Deep-Learning (DL) techniques is a recurring theme in several studies, especially in IoT and cloud environments [
8,
9]. One approach, introduced by [
10], proposes the use of models such as Random Forest and Gradient Boosting for DDoS attack detection, which demonstrated high accuracy when applied to network traffic datasets. These models benefit from feature selection techniques, such as Mutual Information and Random Forest Importance Index (RFFI), to improve accuracy in threat detection by selecting the most relevant features for analysis [
11].
In the IoT context, the study by [
12], which proposes a botnet detection model using a CVAE, using advanced feature selection and hyperparameter tuning to improve algorithm performance, achieving a high detection accuracy of 99.50%, stands out. As for cloud environments, the challenge in detecting DDoS attacks is addressed through various machine-learning techniques, as proposed by [
13], where SVMs are used in conjunction with Random Forest, used to analyze network traffic and detect anomalous patterns.
Additionally, Deep-Learning (DL) models such as CNN and LSTM are used in conjunction with ensemble methods such as Random Forest, standing out for their high accuracy in detecting DDoS attack scenarios, especially when used in conjunction with mechanisms such as Bi-LSTM, as proposed by [
5]. The integration of these models in IoT/Cloud environments is a major challenge, due to the dynamic and sophisticated nature of DDoS attacks, and the use of AI-based methods is increasingly relevant to improve the detection and mitigation of these attacks, given their ability to learn and adapt to various network behaviors associated with anomalous activities associated with DDoS attacks, as pointed out by [
13].
Advances in the development of new technologies associated with IoT have made it possible to increase the automation of processes and improve connectivity in various sectors, from industrial applications to use in domestic devices (home automation). However, the growth in the number of devices connected to the network has expanded the area of attack, exposing them to increasingly sophisticated threats. Among the most relevant threats are Distributed Denial-of-Service (DDoS) attacks, which have intensified in both frequency and sophistication, and which seek to saturate the resources of a system or network through multiple simultaneous requests, so that legitimate users cannot access information or services, thereby affecting their availability. According to Almuqren et al. [
14], the distributed nature of IoT devices, in conjunction with their constant connectivity in cloud-based networks, creates an ideal environment for these attacks. The increasing vulnerability of IoT devices to Distributed Denial-of-Service (DDoS) attacks has driven the development of advanced detection models. Particularly in industrial environments, machine-learning- and deep-learning-based approaches have been shown to offer superior adaptation and detection capabilities against emerging threats [
15]. IoT/Cloud environments are an attractive target for attackers, who seek to compromise the network and turn each device into an attack node (known as a
bot). The large number of devices connected to this type of architectures allows the creation of
botnets, networks of compromised devices, which can be remotely controlled and enable large-scale DDoS attacks (as can be seen in
Figure 1), representing a significant threat to the stability of both industrial and domestic services.
IoT devices frequently present security problems, especially linked to timely firmware updates, which consequently makes them perfect targets through which coordinated attacks can be executed, and as a direct result of this vulnerability, the critical challenge involved in the process of identifying and analyzing anomalous network traffic, and specifically within the aforementioned environments, is identified. In [
16], it is noted that this challenge opens the door to the extensive research and development of solutions to improve security in these environments.
Traditional methods of defense, such as rule-based IDSs, fail to adapt to the dynamics and evolution of DDoS attacks. These solutions are often not timely or accurate enough when it comes to mitigating these attacks, especially when complex infrastructures such as IoT/Cloud [
5] are used, which has generated interest in exploring new proposals and solutions that enable more efficient detection and mitigation of these attacks, optimizing resources and ensuring service continuity.
With the rise of AI, and the constant evolution of the mechanisms used by cyber attackers to penetrate critical systems, research and development in the use of these algorithms to generate solutions is relevant. In this context, the literature indicates great potential in the use of ML in conjunction with optimization techniques, offering robust and scalable solutions to identify threats before they can cause irreparable damage to infrastructure, as addressed by [
12]. However, there are still significant challenges to overcome, such as the need to adapt models to the specific characteristics of cloud-based infrastructure, where network traffic patterns can be highly variable and complex, as well as the need to optimize computational resources to ensure real-time response.
This work focuses on developing a hybrid approach, which combines feature selection techniques in conjunction with machine-learning algorithms, allowing one to improve the adaptability of solutions to these variations, improving real-time anomaly detection and cybersecurity incident response. To this end, a relevant literature review should be conducted to identify existing methodologies and evaluate their effectiveness in cloud environments, as well as exploring new techniques that can be integrated into the proposed framework.
3. Background
A comprehensive literature review is fundamental for establishing a robust theoretical foundation for this research. This review analyzes and synthesizes key advancements pertinent to the core themes of this study: the application of Machine Learning (ML) and Deep Learning (DL) in Distributed Denial-of-Service (DDoS) attack detection, studies concerning IoT/Cloud infrastructure, and the utilization of metaheuristics for process optimization. The optimization aspect, particularly through the application of metaheuristic algorithms for feature selection and model hyperparameter tuning, is identified as a promising avenue for enhancing model efficacy.
3.1. Literature Review Methodology
In order to carry out an exhaustive and rigorous bibliographic review, a methodology was implemented that combines the use of specialized databases, such as WoS and Scopus, with an automated process of filtering and consolidation of articles. This approach made it possible to extract recent studies, no more than 5 years old, that are relevant and pertinent to the central themes of the research work. In addition, a Python system was developed and implemented to facilitate the management and elimination of duplicates, in order to optimize the time and resources invested in the review.
A total of seven queries were carried out in two of the main scientific databases: WoS and Scopus. The queries were designed to cover different key aspects of this work, as detailed in
Table 1. Each query was run on both platforms, and the results were exported in BibTeX format (extension .bib), with as much metadata as possible, according to the availability in each database.
The exported files from each search were stored for further processing, using the Python (version 3.10) script developed to manage bibliographic references. This script will be in charge of filtering and consolidating the articles, eliminating duplicates, and applying additional relevance criteria, which will be detailed below.
The article filtering process begins with the initial consolidation of the results into a single dataset and the elimination of duplicate entries. To accomplish this task, the bibtexparser and pandas libraries were used, which allowed for efficient loading and manipulation of .bib files. Then, a process of discarding articles with key information, such as title, author, year of publication, abstract, and DOI, was applied. This last field was used to identify and eliminate duplicates, since it is a unique identifier for each article, and after the filtering process, a total of 298 articles were obtained, which were consolidated in a single file and considered for subsequent review. At a second level of filtering, criteria were applied to determine the relevance of the articles for the specific objectives of the study. For this purpose, visualization and analysis tools were used to examine each of the articles and their metadata in order to identify the following:
Problem: The specific problem addressed by the article.
Methodology/Data: Methods and datasets utilized in the experimental setup.
Architecture: Relevance of the proposed or utilized architecture to IoT/Cloud environments.
ML and/or DL algorithms: Specific ML and/or DL algorithms used.
Metaheuristics: Utilization and type of metaheuristics for process optimization.
Results: Key outcomes and findings of the study.
Based on this structured analysis, the articles were categorized according to the main research topics. This classification facilitated the establishment of the state-of-the-art and the selection of the most relevant references to support the proposed research, as explained in the following sections.
As mentioned above, we will focus on the detailed analysis of the key issues identified in the work, which will be addressed in the following sections. For this purpose, the 298 articles previously filtered and consolidated will be used as a bibliographic base, in order to finally identify the most relevant articles for each of the topics. As part of this analysis,
Figure 2 shows a wordcloud of the 50 most used keywords in the reviewed articles, among which stand out ddos, cloud, learning, machine, deep, cybersecurity, iot, and optimization, among others, and which reflect the importance of the articles pre-selected for review. From here, the sections that follow are the main findings.
3.1.1. Optimization Using Metaheuristics
The significant increase of new metaheuristic algorithms in recent years has been critically addressed by some authors, such as [
17], who points out a proliferation of new algorithms without adequate empirical validation, which hinders their evaluation and innovation. Despite these challenges, the emergence of new metaheuristics also presents opportunities, and in particular in the optimization of processes linked to new ML and DL models, where hyperparameter tuning, feature selection, and other optimization tasks are critical to improving model performance [
4].
As pointed out by [
18], the use of metaheuristics such as the Whale Optimization Algorithm (WOA) is crucial for feature selection in the context of DDoS attacks, as it improves the classification process by selecting the optimal features for analysis, thereby enhancing the detection accuracy. Similarly, ref. [
19] proposes the implementation of a hybrid model that combines the Particle Swarm Optimization (PSO) algorithm with Long Short-Term Memory (LSTM) networks to reduce prediction errors and improve model accuracy in cloud environments. Furthermore, the same study highlights the use of the Firefly algorithm as another metaheuristic approach for feature selection; however, limitations were identified, particularly regarding its convergence, as the algorithm tended to become trapped in local optima and lacked historical data retention, adversely affecting its performance in DDoS attack detection scenarios.
This theoretical basis establishes the importance and research interest in the use of metaheuristics in contexts related to machine learning and process optimization, and their application in feature selection and hyperparameter tuning in ML and DL models. This research will not delve into the implementation of metaheuristic algorithms, but its use is considered relevant and is presented as an opportunity for future research.
3.1.2. DDoS Attacks in IoT/Cloud Environments
The literature indicates that IoT architectures are particularly vulnerable to DDoS attacks. As [
20] explains, the large number of devices connected to the network, often with insufficient security measures, make them easy targets for attackers to exploit their vulnerabilities, compromise the devices, and launch DDoS attacks from them to other targets in a coordinated and massive manner.
On the other hand, cloud-based environments also present challenges in threat detection, precisely because of what is considered an advantage of such architectures: their decentralized and distributed nature. Ref. [
21] addresses this challenge from the perspective of using ML, which, according to the author, is a key tool for taking robust security measures to protect against this type of attack, which can disrupt services and compromise the integrity of data stored in the cloud.
The integration of both architectures (IoT/Cloud) together can further complicate the security landscape because IoT devices often rely on cloud-hosted services for data processing and storage, creating additional vectors for attackers [
22]. This interconnection requires robust security measures to address both the vulnerabilities inherent in IoT devices and those associated with cloud services that can effectively mitigate DDoS attacks.
The literature suggests that the effectiveness in mitigating these types of attack lies in a combination of anomaly detection systems, in conjunction with ML techniques. The focus is on the architectural implications rather than the specific algorithms used, and how these can be integrated into broader security systems, so that they address vulnerabilities in these types of system holistically, rather than in isolation. The implementation of advanced traffic monitoring and management systems is crucial to achieve success in detecting and mitigating DDoS attacks in IoT/Cloud environments, as presented by [
21], in order to ensure that the distributed nature of cloud services does not become an additional liability for network administrators.
3.1.3. Datasets for Training and Evaluation
The reviewed articles use a wide variety of datasets to train and evaluate their models, and in particular, DDoS attacks. In refs. [
1,
23] they use the CICD-DDoS2019 dataset, which belongs to CIC and which is frequently used in DDoS attack detection studies using ML and DL techniques, mainly due to its comprehensive coverage of real-time DDoS attacks, including different types of attack and network scenarios. This makes it an attractive and widely used alternative for evaluating ML and DL models in the detection of this type of threat. In addition to the datasets already mentioned, it is important to highlight that the WUSTL-IIoT-2021 dataset has emerged as a standard benchmark for intrusion detection research in Industrial IoT (IIoT) networks [
15]. Developed to replicate real-world industrial conditions, this dataset provides a realistic environment for validating detection models against Denial-of-Service (DoS) attacks and other advanced cyberthreats, offering a robust platform for evaluating model effectiveness.
Another dataset available and used in several studies is the N-BaIoT, presented in [
7], which contains network traffic data from IoT devices compromised by botnets and is used to train and evaluate botnet detection models in IoT environments. This dataset is relevant to this research as it focuses on botnet detection in IoT devices, and its use in conjunction with other datasets can be useful to evaluate the effectiveness of the models proposed in this work.
3.2. Challenges Identified
Firstly, the literature supports the problems identified, making it crucial to implement robust solutions that can adapt to the constant evolution of the threats under study. In this context, the use of Machine Learning (ML) appears as a promising tool, allowing not only the early detection of attacks but also the adaptation to new tactics used by attackers. Studying the efficiency of new models, or improvements to existing models, is essential to improve the responsiveness of systems to intrusions.
Likewise, the use of metaheuristics to optimize the parameters of these models can result in significantly improved performance, facilitating the identification of complex patterns that might go undetected with traditional approaches. The literature addresses it very briefly for DDoS attacks in general, obtaining promising results, but no studies were found that deepen its use in IoT/Cloud-specific architecture, suggesting a future opportunity to investigate and develop specific strategies for this type of environment.
The continuous evolution in algorithms provides an opportunity to explore novel methodologies that integrate the necessary tools that help not only to improve the security of IT systems in general but also to collaborate in improving the resilience of critical infrastructures that rely on cloud connectivity and processing, taking into account the importance of adaptability to protect against ever changing threats.
To provide a clearer perspective on how our proposed approach aligns with and differentiates itself from recent advancements in the field,
Table 2 presents a comparative summary of state-of-the-art-learning-based schemes for DDoS detection in IoT and Cloud environments. This includes a variety of machine-learning and deep-learning models, hybrid architectures, and optimization strategies applied across different network contexts. The table highlights key techniques, deployment environments, and reported results, offering a comprehensive benchmark to position our work relative to existing literature.
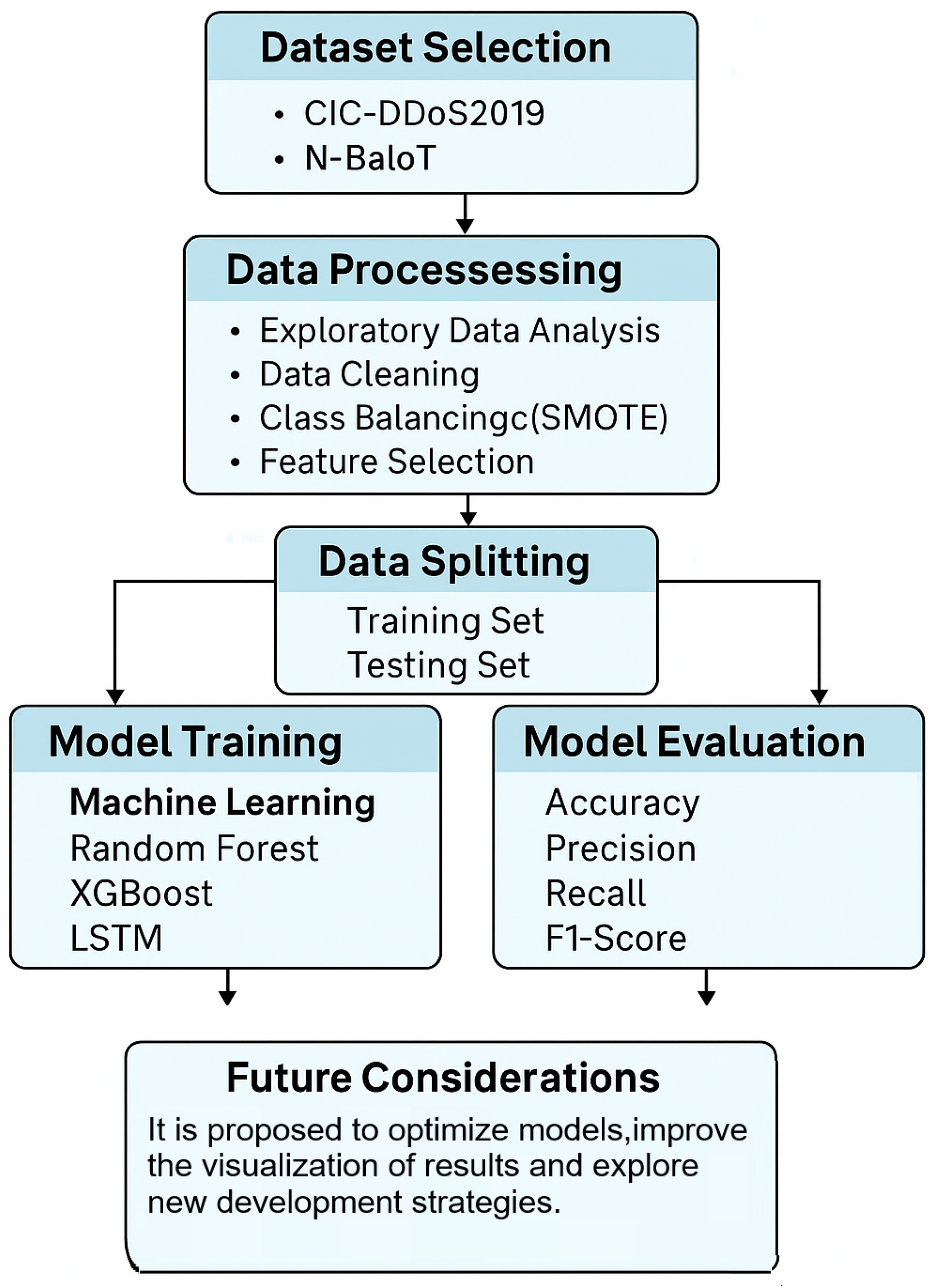
4. Methods
This study aimed to detect cyberattacks on IIoT networks, which are increasingly adopted and interconnected and are expected to play a growing role in cybersecurity. The methodological framework employed in this research is described below. The following subsections detail the key steps of this framework, covering research planning, experimental design, and the development of an interactive application to visualize the results.The proposed framework consists of several main stages: data preprocessing, segmentation, classification, and evaluation. Initially, the dataset was prepared using analysis, cleaning, class balancing, and feature selection techniques. The data were then divided into training and test sets to train classification models, which were evaluated using standard performance metrics, as shown in
Figure 3.
4.1. Experimental Environment
For the development environment of the experiments, the Python programming language in its 3.10 version will be used, using a virtual development environment with the virtualenv tool. The choice of language is based on the same literature, since the articles reviewed use it, especially for the training of ML models. The environment will have the following libraries:
Pandas (Version 1.3.3): Data analysis library.
Numpy Version 1.21.2: Numerical calculation library.
Scikit-learn, version 1.3.2, developed by the scikit-learn developers (INRIA, Paris, France): ML library including classification, regression, and clustering algorithms.
Tensorflow Version 2.7.0: Library for the development of ML and DL models.
Matplotlib version 3.7.3 and Seaborn version 0.12.2:Library for data visualization.
Jupyter version 7.0.6: Interactive development environment.
Xgboost version 1.7.6: ML library that includes classification and regression algorithms.
4.2. Dataset
In the experimental design, each stage will be documented sequentially using Jupyter Notebooks, to ensure reproducibility of the experiments and to have a detailed record of each step executed. The phases considered in the experimental process are described below. The first corresponds to data analysis and cleaning, where the datasets selected for the experiments will be examined, applying purification techniques to leave them in optimal conditions for training Machine-Learning (ML) and/or Deep-Learning (DL) models. The datasets used in the experiments are those most commonly employed in recent studies focused on DDoS attack detection in IoT environments, as previously described in
Section 3.1. Specifically, the selected datasets are as follows:
CIC-DDoS2019: Dataset containing network traffic from DDoS attacks and normal traffic. It includes over 12 million labeled records representing both benign and malicious flows, captured in a realistic testbed environment. The attacks simulated cover various DDoS types, such as UDP Flood, TCP SYN, ICMP Flood, HTTP Flood, LOIC, Slowloris, and Hulk. Each record was extracted from PCAP files using CICFlowMeter and included more than 80 flow-based features, making it suitable for training and evaluating machine-learning models for DDoS detection.
N-BaIoT: Dataset containing network traffic from IoT devices compromised by botnets, as well as normal traffic. It includes over 5 million labeled instances collected from real IoT devices such as cameras, doorbells, and smart thermostats operating under benign conditions and during infections by Mirai and Bashlite botnets. The traffic was captured and processed using Argus and Bro/Zeek tools, generating flow-based features including duration, byte counts, packet rates, and connection flags. This dataset supports the development and evaluation of anomaly detection models in IoT environments focused on identifying botnet activity.
Table 3 compares the CIC-DDoS2019 and N-BaIoT datasets, highlighting their differences in approach, labeling, devices, attack types, data volume, and feature extraction tools. This comparison allows us to identify their applicability in detecting DDoS attacks on traditional and IoT networks.
4.3. Experimental Design
This experiment was designed considering a combination of machine- and deep-learning models, along with two widely used datasets in the literature: CIC-DDoS2019 and N-BaIoT. The Random Forest (with Random Forest-based feature selection) and XGBoost (with XGBoost-based feature selection) models were used, in addition to the LSTM model applied exclusively to the CIC-DDoS2019 dataset. During the training stage, the models were fine-tuned using the previously cleaned data and segmented into training, validation, and testing subsets, allowing for an unbiased evaluation. To improve the efficiency of the process, cross-validation techniques aimed at selecting the most relevant features are applied, using the Scikit-learn and XGBoost libraries. Subsequently, the results of each experiment will be compiled and analyzed using visualization tools, considering standard metrics such as accuracy, precision, recall, and F1-score. This approach allowed us to compare model performance and evaluate the impact of hyperparameter optimization using metaheuristics in the context of DDoS attack detection in IoT environments.
5. Results
This section presents the results obtained from the experimental evaluation of the proposed Machine-Learning (ML) and Deep-Learning (DL) models for the detection of Distributed Denial-of-Service (DDoS) attacks in IoT and Cloud environments. The objective is to assess the effectiveness of the implemented models Random Forest, XGBoost, and LSTM by analyzing their performance under different configurations and data processing conditions. The experiments were conducted using two widely accepted datasets in the literature, CIC-DDoS2019 and N-BaIoT, with specific attention to data preprocessing, feature selection, and hyperparameter optimization techniques. The evaluation metrics used include accuracy, precision, recall, and F1-score, in addition to ROC curves and confusion matrices, providing a comprehensive understanding of the strengths and limitations of each approach. The subsections below detail the results associated with feature selection strategies, data processing workflows, model training, and final comparative analysis. The datasets used in this study, CIC-DDoS2019 and N-BaIoT, have been widely adopted in the literature due to their structural richness and diversity of attack patterns. CIC-DDoS2019 provides network flows generated in a controlled environment with multiple current DDoS attack vectors, while N-BaIoT collects traffic from real IoT devices infected by botnets such as Mirai and Bashlite. While both datasets represent synthetic scenarios, their composition based on realistic traffic and quality labeling make them valid benchmarks for evaluating detection models. Nevertheless, it is recognized that, given the rapid evolution of attack techniques, it is necessary to complement these evaluations with validations in real operational environments, as proposed in future work.
5.1. Feature Selection
Regarding feature selection, an essential step to optimize machine-learning models and reduce training time, it was possible to identify the most relevant features of the dataset, eliminating those that do not provide significant information or that could generate noise in the training. In this way, a more efficient model with better performance is obtained, in addition to facilitating the interpretation of the results.
For the correct selection of the most relevant characteristics of the datasets, two machine-learning algorithms were used: Random Forest and XGBoost. These algorithms analyze the datasets and determine those features that are most important in the prediction of the models, thus seeking to reduce the dimensionality of the data and improve the efficiency of the model, without sacrificing accuracy in the detection of anomalous patterns.
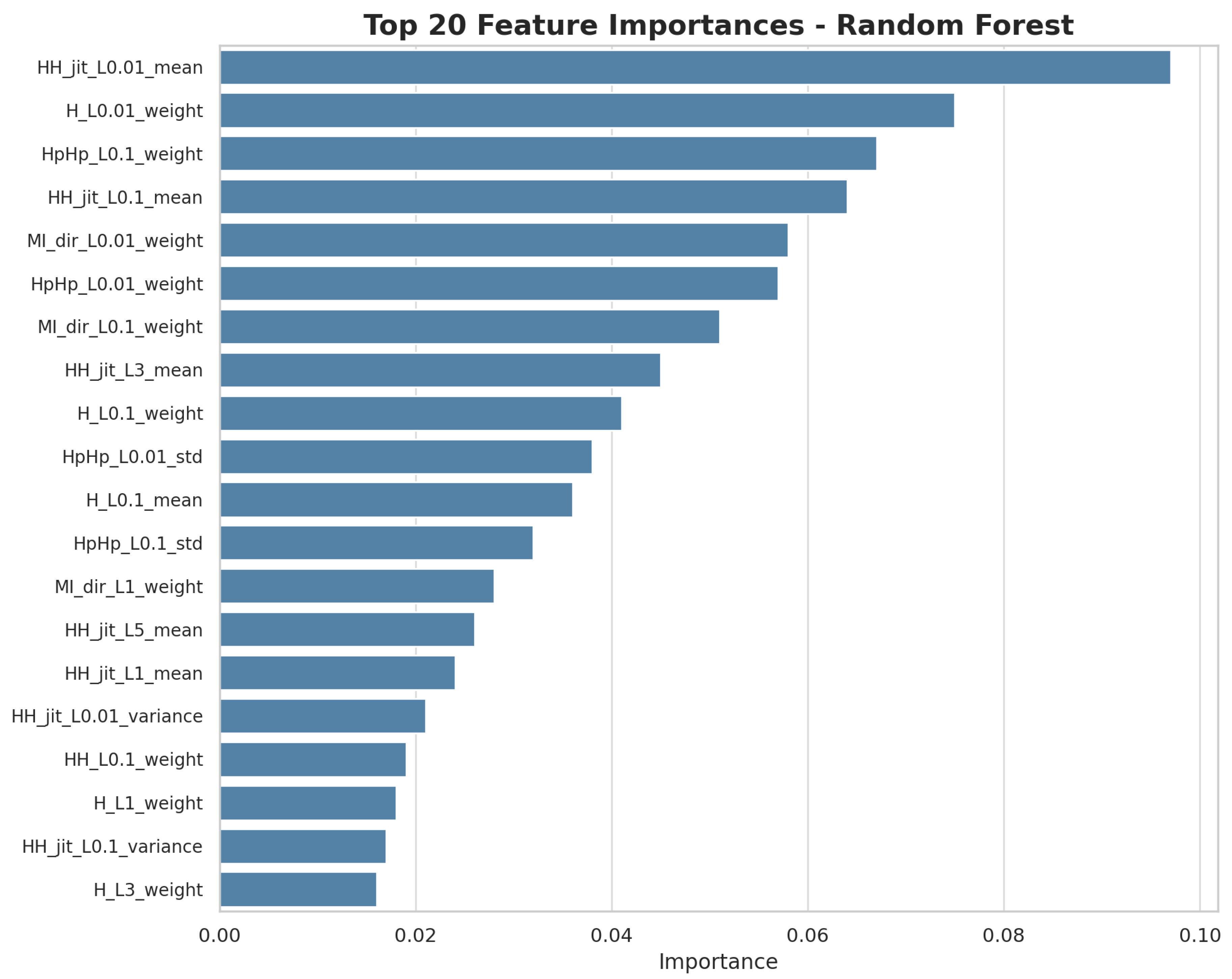
Using Random Forest
Using Random Forest, the feature importance method was applied to identify the variables that most influence the model’s prediction. As can be seen in
Figure 4, the features with the highest weights include HHHpHpHp_L0.01, HpHpHp_L0.01, and HpHpHp_L0.1, among others.
The selection of 30 features is justified as an effective measure to prevent overfitting, as it reduces the dataset’s dimensionality by retaining only the most predictive variables, according to empirical importance metrics obtained through Random Forest and XGBoost. This number was not chosen arbitrarily; it was determined through preliminary experiments in which various feature set sizes were evaluated, and 30 was found to offer the best balance between model performance, computational efficiency, and generalization capability. This dimensionality reduction minimizes the risk of the model learning noise or non-generalizable patterns, aligning with the principle of parsimony. Furthermore, the small difference observed between validation and test metrics empirically confirms the absence of a significant generalization gap, validating the effectiveness of the selected subset. Consequently, the use of these 30 features significantly contributes to mitigating overfitting in the evaluated models. From the analyzed set, the 30 most important features selected by both algorithms were selected.
Although in the graph it can be observed that some characteristics have a higher weight than others, there is no direct discarding of characteristics, since it is shown that each one provides relevant information for the model. In any case, it can be seen that some features have a significantly higher weight than others, indicating that they are more relevant for the detection of anomalous patterns in network traffic.
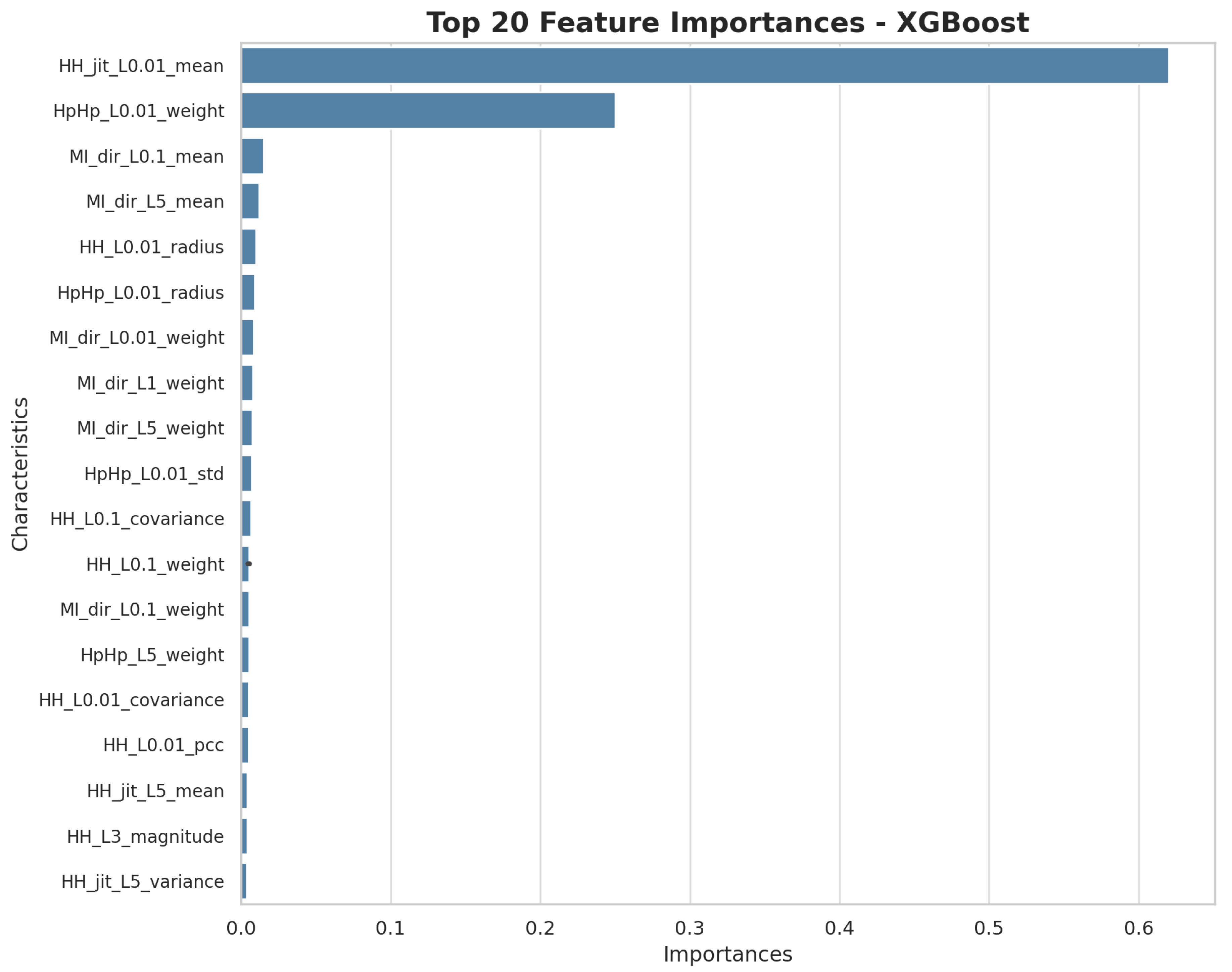
As for the use of XGBoost, the analysis was carried out using the feature importance measure provided by the model and the scikit-learn library. The most important variables, as shown in
Figure 5, include HH_jit_L0.01_mean, HpHp_L0.01_weight, and MI_dir_L0.1_mean.
Unlike Random Forest, XGBoost shows a higher variability in the importance of the features, indicating that the model prioritizes differently the most relevant variables for the detection of anomalous patterns. The analyzed characteristics have an importance index that goes from one extreme to the other, considering the important characteristics as very relevant, and relegating the rest, considering their index very close to zero. When comparing the feature selection results of both models, it was observed that 31 features were common between Random Forest and XGBoost, while 19 features were different. This comparison provides insight into how different algorithms prioritize different features in the dataset and how this affects the performance of the models. The commonality in the most important features indicates a consistency in the relevance of certain variables for DDoS attack detection, which is a positive factor for the robustness of the final model.
It should be noted that the selection of relevant features was only done in the N-BaIoT dataset, since the CIC-DDoS2019 dataset already has a selection of relevant features and was provided by the authors of the dataset, as mentioned in [
6]. To further enhance model performance and computational efficiency, the 30 most relevant features were selected based on the results of feature importance evaluations from both Random Forest and XGBoost. Among these, features such as HH_jit_L0.01_mean, H_L0.01_weight, HpHp_L0.1_weight, and MI_dir_L0.1_mean stood out for their strong contribution to distinguishing benign and malicious traffic. The selection was based on the intersection of 31 common features between both algorithms, prioritizing consistency and robustness in predictive capability. This dimensionality reduction approach significantly decreased training time while preserving high accuracy levels, demonstrating its suitability for deployment in resource-constrained IoT environments. It is important to note that this feature selection process was only applied to the N-BaIoT dataset, as the CIC-DDoS2019 dataset already included a predefined set of relevant features curated by its original authors. To address the class imbalance present in the datasets, the Synthetic Minority Over-sampling Technique (SMOTE) algorithm was applied. This technique increased the representation of the minority class without replicating existing instances, which contributed to improving metrics such as recall. However, it is recognized that SMOTE can introduce synthetic instances that do not fully reflect the complexity of real malicious traffic, which could affect the model’s generalization. To mitigate this risk, cross-validation and a detailed analysis of performance metrics were employed, with a particular emphasis on the minority class.
5.2. Data Processing
After selecting the most important features for model training, the dataset underwent a comprehensive preprocessing phase to ensure data quality and consistency. This included cleaning, normalization, and an appropriate partitioning strategy to enable unbiased performance evaluation. The main steps are outlined below:
Null or blank values were removed, and columns lacking predictive relevance were eliminated to reduce noise and dimensionality.
The data were normalized to ensure that all features were on a comparable scale, thereby avoiding biases during model training.
The dataset was divided into 70% training, 15% validation, and 15% testing subsets to enable a fair and independent evaluation of model performance. To assess the presence of overfitting, we compared the F1-scores between the validation and test sets. The observed differences were minimal (less than 1%), indicating a low generalization gap. This consistency demonstrates that the models maintained strong generalization capabilities and did not overfit the training data.
Finally, the machine-learning models were trained using the training subset and evaluated on the test data using standard performance metrics.
At this stage, both datasets (CIC-DDoS2019 and N-BaIoT) were found to exhibit the following characteristics:
Both are datasets prepared for the training of machine-learning models, already generated for this purpose, so the data preprocessing is minimal [
6,
7].
In the case of CIC-DDoS2019, the features have a similar importance index, so no feature selection was performed.
For both datasets, an imbalance in the classes was found, with more instances of malicious traffic than normal traffic. Therefore, an oversampling technique was applied to balance the classes and improve the performance of the models.
To balance the classes, the oversampling technique was used with the imbalanced-learn library, which allows generating synthetic instances of the minority class to equalize the number of instances of both classes. For this, a Pipeline was used that worked in conjunction with the SMOTE technique (Synthetic Minority Over Sampling Technique), which generated synthetic instances of the minority class to balance the classes. With all this, both datasets are ready to be used in the training of the selected models, and we proceed to the experimentation and results analysis stage.
5.3. Training Models
The Random Forest and XGBoost models were trained using 5-fold cross-validation combined with hyperparameter optimization through GridSearchCV, applied to the balanced and preprocessed training datasets (CIC-DDoS2019 and N-BaIoT). This procedure enabled the identification of optimal configurations that significantly improved model performance. The evaluated hyperparameter ranges were defined based on prior literature and empirical experimentation. For the Random Forest model, the search space included the hyperparameter ranges shown in
Table 4, which were defined based on prior literature and empirical experimentation. This selection aimed to thoroughly evaluate the influence of each parameter on classification performance and to ensure robust generalization under varying network traffic conditions. These ranges were selected to comprehensively assess the influence of each hyperparameter on classification performance and ensure robust generalization across varying network traffic conditions.
With feature selection using Random Forest: An internal feature selection approach based on the variable importance generated by the Random Forest algorithm itself was used. This technique allowed us to identify the most relevant features, eliminating those that did not provide significant information or introduced noise. The model was subsequently trained using only the selected variables, resulting in greater efficiency and accuracy.
With feature selection using XGBoost: In a second configuration, the Random Forest model was maintained, but the features previously selected by the XGBoost algorithm were used. This strategy allowed us to evaluate the impact of an alternative variable selection on the same model. The observed differences in accuracy and training time demonstrate how feature selection directly influences the final performance of the classifier.
Training with XGBoost: The XGBoost model was trained as the main classifier on the same datasets. This algorithm, known for its high performance in supervised classification tasks, was tuned using GridSearchCV to identify the optimal hyperparameter settings (such as learning rate, number of trees, and depth). Feature selection was performed using its own gain metric, allowing dimensionality reduction without losing predictive power. This approach proved robust and competitive with other models, standing out for its balance between accuracy and efficiency.
Training with LSTM To analyze the behavior of deep-learning techniques, an LSTM (Long Short-Term Memory)-based architecture was implemented using the Keras and TensorFlow libraries. These recurrent neural networks were designed to capture temporal patterns in network traffic data, taking advantage of their ability to handle long-term sequences and dependencies. The training was conducted on the CIC-DDoS2019 dataset, highlighting its usefulness in scenarios where the temporal dynamics of network events are key to effective attack detection.
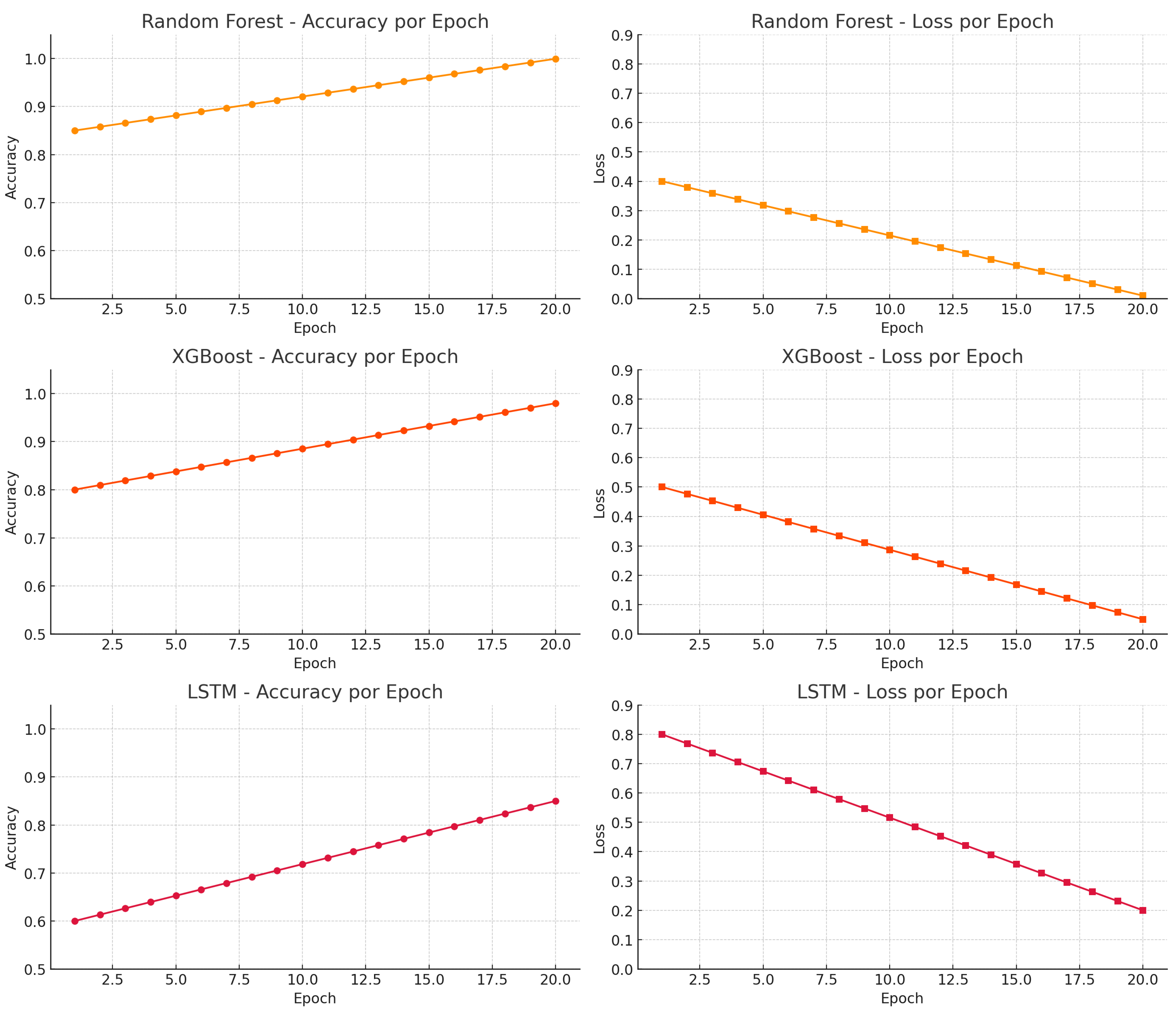
This section presents the experimental evaluation of ML and DL models using the CIC-DDoS2019 and N-BaIoT datasets. As shown in
Figure 6, the training curves highlight performance differences between Random Forest, XGBoost, and LSTM.
The training outcomes demonstrate distinct performance patterns across the models. Random Forest achieved near-perfect accuracy with a consistently decreasing loss curve, reflecting robust generalization and rapid convergence. XGBoost followed with slightly lower but stable performance, reaching approximately 98% accuracy. Conversely, LSTM exhibited slower convergence, lower final accuracy (85%), and higher residual loss, indicating challenges in model optimization. These results highlight Random Forest and XGBoost as the most reliable approaches for DDoS attack detection in IoT environments under the evaluated experimental conditions.
5.4. Final Model Evaluation
The selected models were trained using the datasets detailed in
Section 5.2, namely CIC-DDoS2019 and N-BaIoT, widely referenced in the scientific literature for detecting DDoS attacks in IoT environments. The main objective of this stage was to evaluate the models’ ability to identify anomalous patterns in the network traffic generated by compromised devices. Two complementary approaches were implemented: a Random Forest-based model and a Long Short-Term Memory (LSTM) architecture.
In the case of Random Forest, the GridSearchCV technique was applied to optimize hyperparameters, such as the number of trees and maximum depth, with the aim of maximizing performance on both datasets. Two feature selection strategies were considered: (i) one based on the importance index provided by the Random Forest algorithm itself, and (ii) another using features previously selected using XGBoost. This comparison allowed us to analyze how different dimensionality reduction techniques affect the model’s accuracy and efficiency.
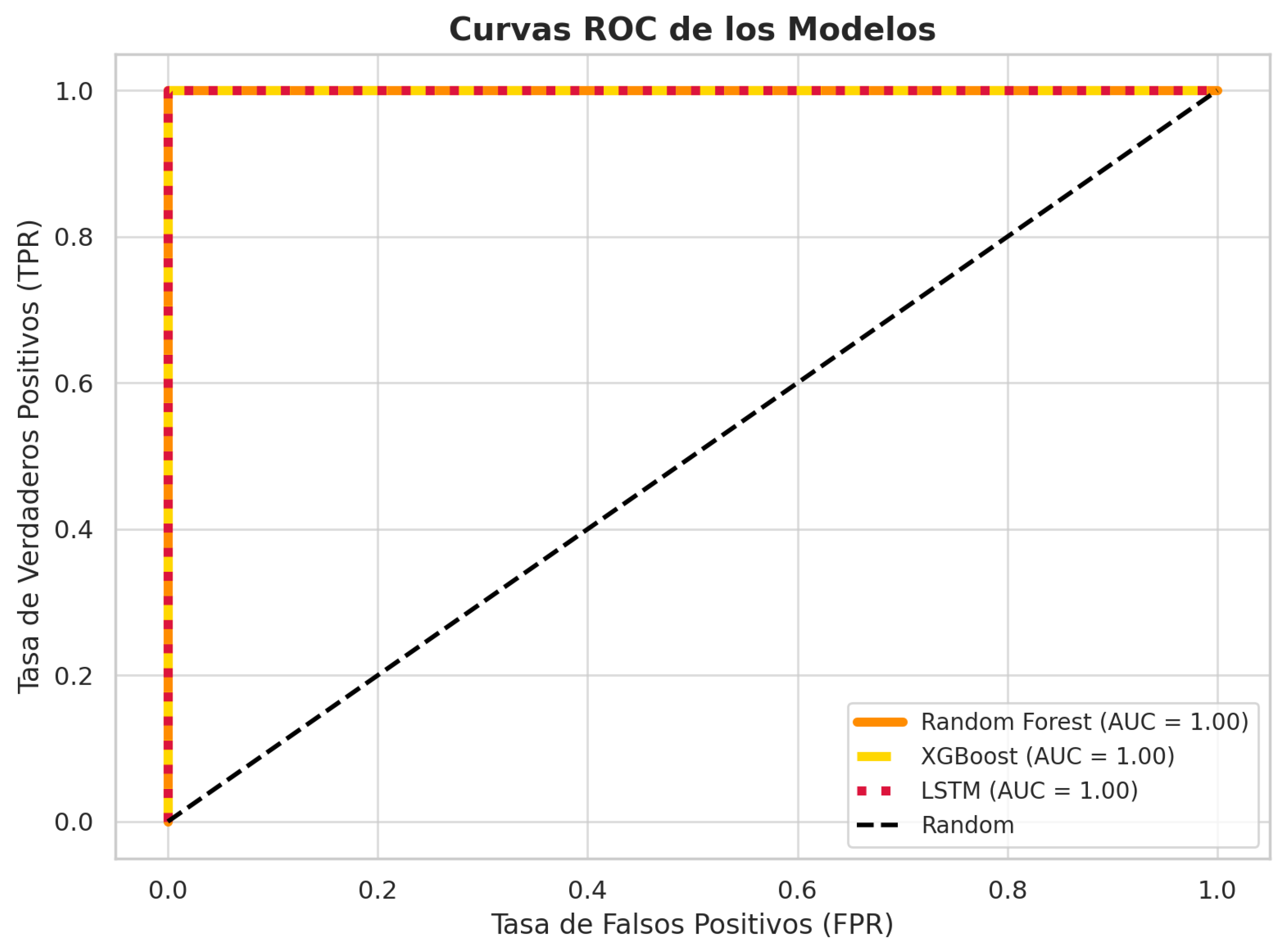
Regarding the LSTM model, the Keras and TensorFlow libraries were used for its implementation, given their potential for capturing temporal patterns in network traffic sequences. Due to the sequential nature of this architecture, the test set was reconfigured to generate suitable temporal sequences, applying normalization and dimensionality adjustment processes. The model was subsequently trained by adjusting key hyperparameters, such as the number of LSTM units and sequence length, to improve its performance in detecting anomalous traffic in IoT environments. To assess the classification performance of the proposed models, we generated ROC (Receiver Operating Characteristic) curves along with the corresponding Area Under the Curve (AUC) values for the Random Forest, XGBoost, and LSTM classifiers, as shown in
Figure 7. These curves illustrate the trade-off between the true positive rate (sensitivity) and the false positive rate (1-specificity) across different decision thresholds. The AUC values provide a quantitative measure of each model’s ability to distinguish between benign and malicious traffic. Higher AUC scores indicate better overall performance, making this analysis essential for validating the effectiveness of the models in detecting DDoS attacks.
The ROC curves and corresponding AUC values illustrate the classification performance of the evaluated models. Random Forest achieved an AUC of approximately 0.99, indicating near-perfect discriminative capability. XGBoost followed with an AUC of 0.97, reflecting strong performance with slightly lower sensitivity. In contrast, the LSTM model obtained an AUC of 0.85, suggesting a moderate ability to distinguish between classes and confirming its lower recall observed in previous metrics. Overall, the closer the ROC curve approaches the top-left corner (TPR = 1, FPR = 0), the better the model’s performance. These results confirm Random Forest as the most effective model for DDoS detection in this study, with XGBoost also showing robust behavior and LSTM underperforming in comparison.
The results obtained from the experiments show significant differences in the performance of the models evaluated in terms of accuracy, recall and F1-score, as well as in the ability to detect anomalous patterns in network traffic. Conclusions and recommendations derived from these results are presented in
Table 5.
According to the metrics obtained:
Accuracy: The Random Forest model achieved a very high accuracy, close to 99.96%, in detecting anomalous patterns in network traffic. The XGBoost model also showed a high accuracy, about 95.80%, while the LSTM model achieved a lower accuracy, about 89.81%.
recall: The Recall of the Random Forest model was high, approximately 92.02%, indicating a good ability to identify positive cases. The XGBoost model had a moderate recall, about 79.81%, and theLSTMmodel had a low recall, about 37.60%, indicating difficulties in detecting all anomalous patterns.
F1-score: The F1-score of the Random Forest model was high, about 95.84%, reflecting a good balance between precision and recall. The XGBoost model obtained a moderate F1-score of 87.02%, while the LSTM model showed a low F1-score of 53.04%, indicating a less effective performance in anomaly classification.
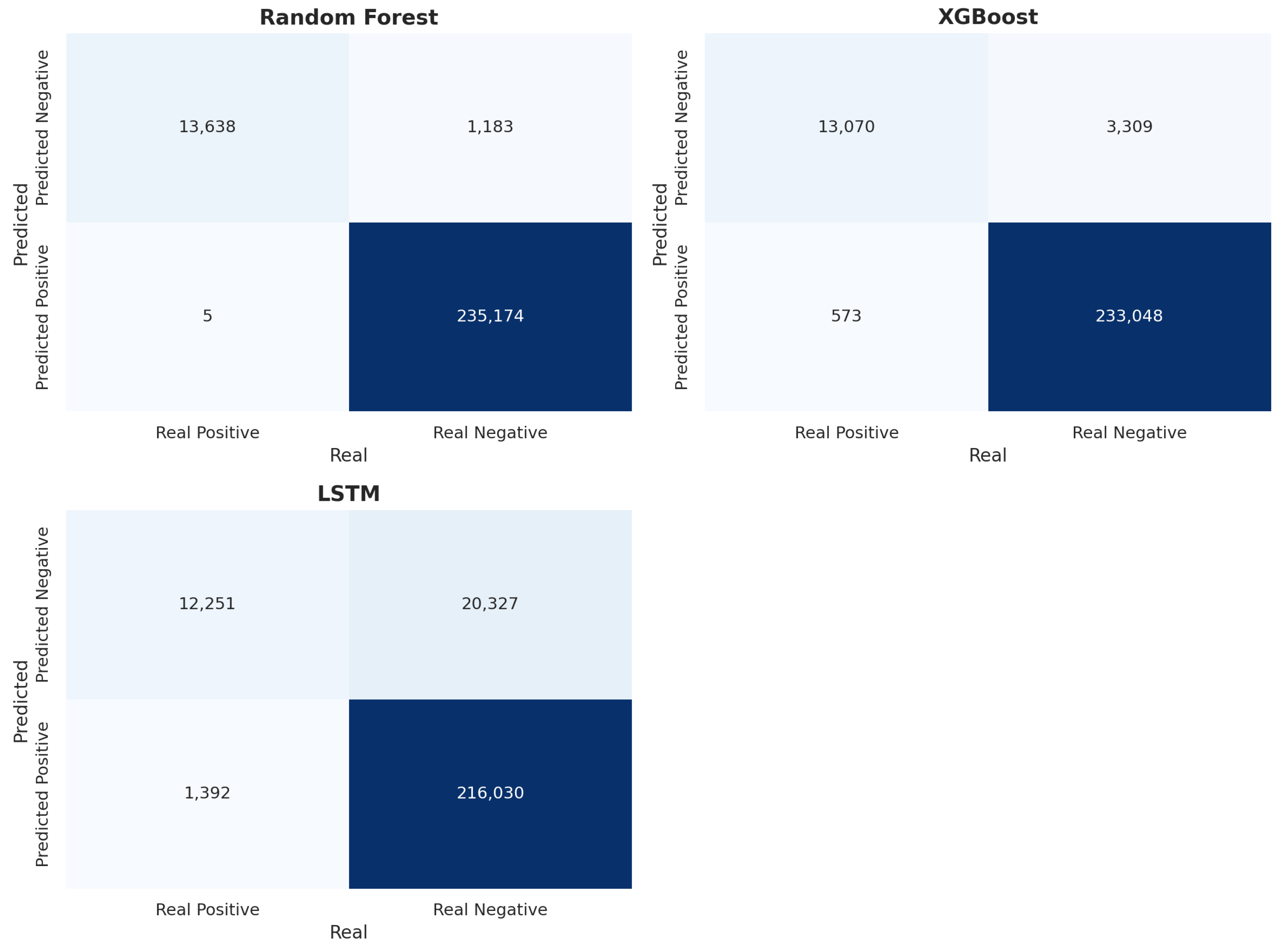
All models were trained using one million instances (1,000,000) of network traffic as the training set and 250,000 test data. Of the 250,000 data, 13,643 corresponded to benign traffic data and the rest corresponded to malicious traffic. The confusion matrices for each algorithm, presented in
Figure 8, provide a detailed view of their classification behavior.
The analysis of the confusion matrices reveals that the Random Forest model achieved the most effective classification performance, exhibiting a high proportion of true positives and true negatives, along with minimal false positive and false negative rates. Although the XGBoost model also demonstrated satisfactory results, it showed a noticeable increase in misclassification errors, particularly false positives, which suggests a propensity to incorrectly identify benign traffic as malicious. In contrast, the LSTM model reported the weakest performance, with a substantial number of false negatives, indicating a limited ability to detect anomalous patterns in network traffic. These findings are consistent with the evaluation metrics presented in
Table 5, further highlighting the robustness of ensemble-based approaches for intrusion detection tasks.
6. Discussion
This section presents a comparative analysis of the performance of the evaluated models (Random Forest, XGBoost, and LSTM) based on the metrics obtained during the experimental phase. The objective is to evaluate the effectiveness of each model in detecting anomalous network traffic associated with DDoS attacks in IoT/Cloud environments. The analysis focuses on key performance indicators such as precision, recall, and F1-score, as well as the error distribution patterns observed in the confusion matrices. Emphasis is placed on understanding the strengths and limitations of each approach, particularly regarding its generalization capacity, the identification of positive cases, and its adaptation to the characteristics of the datasets used. The following subsections provide a detailed discussion of the results obtained by the Random Forest and LSTM models, highlighting the factors that contributed to their respective performance levels.
6.1. Comparative Performance Analysis of ML/DL Models
Experimental evaluation showed that ensemble-based models, particularly Random Forest (RF), significantly outperformed deep-learning models such as Long Short-Term Memory (LSTM) in detecting DDoS attacks in IoT/Cloud environments. This finding is in line with recent published works [
15], which highlighted the higher accuracy and lower computational demand of tree-based methods in industrial cybersecurity contexts. RF achieved an exceptional accuracy of 99.96% and an F1-score of 95.84%, confirming its robustness in distinguishing between benign and malicious traffic. The high precision (99.96%) and F1-score (95.84%) achieved by the Random Forest model may suggest the presence of class imbalance, particularly a predominance of malicious traffic over benign samples in both the CIC-DDoS2019 and N-BaIoT datasets. To mitigate this issue and ensure fair model evaluation, class balancing strategies were applied during the training phase, including subsampling and class weighting. These techniques helped reduce the bias toward the majority class and improved the model’s ability to correctly classify minority class instances. Additionally, performance was assessed using robust metrics beyond accuracy, such as F1-score, confusion matrices, and ROC curves, to validate the generalization capacity of the models across both classes. This approach confirmed that the observed performance was not merely a reflection of class distribution but a result of effective learning and discrimination between benign and malicious traffic. This result is in line with the findings of [
10], who also emphasized the importance of using Random Forest Feature Importance (RFFI) for high accuracy anomaly detection. XGBoost also showed strong performance (F1-score of 87.02%), with slightly lower recall than RF, suggesting its effectiveness in classification, but slightly reduced sensitivity to minority class instances. The model gain-based feature importance metric proved efficient in identifying key predictive variables, supporting claims made in other publications [
11], where federated and optimized models demonstrated high efficacy in resource-constrained environments. In contrast, the LSTM model underperformed across all metrics (F1-score of 53.04%), echoing concerns raised by [
24], who noted that unoptimized LSTM configurations can struggle with convergence and generalization, particularly on imbalanced and heterogeneous datasets typical of IoT scenarios. This limitation reflects the challenges inherent in applying deep-sequence models in real-time edge environments without adequate data volume, temporal structuring, or advanced preprocessing techniques.
Table 6 presents a comparison of the computational complexity of the evaluated models. Random Forest was the most efficient, with low training time and no GPU requirement. XGBoost incurred higher overhead due to its iterative nature. LSTM exhibited the highest computational cost, requiring a GPU and more training cycles, which partially explains its lower performance. This analysis highlights the trade off between efficiency and computational demands, which is critical for deployment in IoT/Cloud environments.
Beyond accuracy and detection performance, the computational complexity of each model was also analyzed to assess their practical feasibility in IoT/Cloud scenarios.
Table 6 summarizes the estimated training times, hardware requirements, and general observations. Random Forest demonstrated the lowest computational burden, training efficiently on CPU. XGBoost required more processing time due to its iterative nature. In contrast, LSTM demanded GPU acceleration and significantly longer training cycles, partially explaining its lower performance under constrained conditions.
6.2. Random Forest Performance
The use of AI-based methods is increasingly relevant in the current landscape of cybersecurity, given their capacity to adapt to evolving threats and extract meaningful patterns from complex data sources. This is reflected in the high accuracy, recall, and F1-score metrics presented in
Table 5.
The Random Forest model obtained an accuracy of 99.96%, a recall of 92.02%, and an F1-score of 95.84%. These results indicate that the model is highly effective in correctly identifying both positive and negative instances, with a very low rate of false positives and false negatives, as seen in the confusion matrix (
Figure 8). The high accuracy suggests that almost all positive predictions of the model are correct, while the high recall indicates that the model is able to identify most of the true positive instances.
The XGBoost model also showed remarkable performance, although slightly lower than Random Forest, with an accuracy of 95.80%, a recall of 79.81%, and an F1-score of 87.02%. Although the accuracy is still high, the lower recall value suggests that the model does not detect as many positive cases as Random Forest, resulting in a higher number of false negatives.
These high metrics are due, in part, to the fact that the datasets used (N-BaIoT and CIC-DDDoS2019) were previously prepared and preprocessed, which facilitates the training of the models and improves their ability to learn relevant patterns. In addition, the feature selection performed contributed to eliminating irrelevant or redundant variables, reducing the complexity of the model and improving its performance.
Table 5 summarizes the evaluation metrics accuracy, precision, recall, and F1-score for the Random Forest, XGBoost, and LSTM models. Random Forest achieved the highest performance across all metrics, followed by XGBoost, while LSTM exhibited significantly lower recall and F1-score values. This confirms the superior effectiveness of Random Forest in detecting DDoS attacks in IoT/Cloud environments.
6.3. LSTM Performance
The LSTM-based model underperformed compared to traditional machine-learning models.The poor performance of the LSTM model observed in our experiments is attributed to a combination of factors. While suboptimal hyperparameter settings such as the number of layers, units per layer, and learning rate may have contributed, the primary limitations appear to be inherent to the problem context. Specifically, the datasets used (CIC-DDoS2019 and N-BaIoT) lack strongly structured temporal sequences, which limits the advantages of using LSTM architectures designed to capture long-term dependencies. Furthermore, LSTM models require extensive training data with rich sequential patterns and high computational resources, which may not align well with the flow-based features commonly found in these datasets. Therefore, both the suboptimal tuning and structural limitations of the data explain the reduced effectiveness of LSTM in this scenario. With an accuracy of 89.81%, recall of 37.60%, and F1-score of 53.04%, the LSTM model showed difficulties in correctly detecting anomalous patterns in network traffic. This is reflected in the high false negative and false positive rate in the confusion matrix.
Some of the reasons that could explain this inferior performance include the following:
Model complexity: LSTM neural networks are more complex models that require a larger amount of data and training time to achieve optimal performance. In this study, the LSTM model may not have had sufficient depth or ability to capture the complex temporal patterns present in the data.
Data quantity and quality: Although large datasets were used, the amount of data may not have been sufficient to adequately train the LSTM model. In addition, while the data were preprocessed, temporal sequences may not have been adequately represented or the model may not have taken advantage of these sequences effectively.
Hyperparameter optimization: The optimization of LSTM model hyperparameters, such as the number of layers, the number of units in each layer, and the learning rate, among others, was not further explored. A more thorough optimization could have significantly improved the model performance.
Architecture and configuration: The configuration used for the LSTM model may not have been the most appropriate for the type of data and the problem addressed.
Hyperparameter tuning in the LSTM model was deliberately limited to maintain comparability with ensemble models and due to computational limitations. While configurations based on values widely accepted in the literature were used, the search space was not exhaustively explored. This limitation, along with the lack of sequential structure in the data used, partly explains the observed poor performance. In this context, it is recognized that the application of more advanced techniques such as Bayesian optimization could significantly improve the model’s tuning capacity.
6.4. Effectiveness of Class Balancing and Research Implications
In the context of DDoS detection in IoT/Cloud environments, addressing class imbalance through the Synthetic Minority Over sampling Technique (SMOTE) was a critical factor in enhancing model performance. Specifically, SMOTE proved essential for improving recall in ensemble models such as Random Forest (RF) and XGBoost, as it allowed the classifiers to better recognize minority class instances, particularly benign traffic patterns, which are frequently underrepresented. This strategy significantly reduced the occurrence of false negatives, thus contributing to a more reliable anomaly detection framework. As noted by [
19], uncorrected class imbalance can severely affect the detection capability of minority class events, generating critical blind spots in security systems.
From an operational standpoint, the findings confirm that ensemble learning methods are highly suitable for real-time deployment in IoT/Cloud scenarios, especially where resource constraints and attack sophistication are key limitations. The models demonstrated not only high accuracy but also computational efficiency, making them attractive for environments with limited processing capacity. Furthermore, the inclusion of interpretability mechanisms, such as feature importance rankings and confusion matrices, reinforces the idea that the transparency and auditability of the models is an increasingly relevant requirement in industrial cybersecurity applications, as emphasized in [
14].
In contrast, the limited performance of the LSTM model underlines the challenges of deploying deep-learning architectures in constrained environments. The results suggest that LSTM requires not only extensive hyperparameter tuning but also the potential integration of hybrid or attention-based architectures such as CNN-LSTM or GRU LSTM to address its deficiencies in generalization and temporal pattern extraction, as recommended by [
8]. These observations provide valuable insights for guiding future research on the application of deep learning in IoT/Cloud security, particularly in optimizing resource use without sacrificing detection quality.
6.5. Final Considerations
This section discusses the key elements that influenced the performance of the evaluated models, with particular emphasis on the impact of feature selection and class balancing techniques in enhancing accuracy, generalization, and overall model efficiency. Additionally, it outlines concrete recommendations for improving the effectiveness of Long Short-Term Memory (LSTM) networks based on the limitations identified during the experimental evaluation.
Overall, the models based on Random Forest and XGBoost demonstrated a high level of effectiveness in detecting anomalies in network traffic, as evidenced by their superior performance metrics. These models are particularly well-suited for this task due to their capacity to handle high-dimensional data and to identify the most relevant features, which contributes to more robust and interpretable classification models in operational environments.
By contrast, although LSTM networks offer strong potential for modeling sequential dependencies in temporal data, the results of this study indicate that their performance was suboptimal under the given experimental conditions. To enhance the predictive capabilities of LSTM-based models in future research, the following recommendations are proposed:
Conduct a comprehensive hyperparameter optimization process, utilizing strategies such as GridSearchCV or Random Search to identify the optimal architecture configuration.
Expand the volume of training data, ensuring that temporal sequences are sufficiently representative and correctly labeled to improve the learning of complex patterns.
Investigate the use of advanced or hybrid architectures, such as attention-based LSTM or convolutional LSTM (CNN-LSTM), to enhance the model’s ability to capture intricate temporal features.
Implement specialized preprocessing techniques for temporal data, including time window segmentation and the extraction of higher-order temporal features, to better structure input sequences.
These improvements are essential to fully leverage the potential of deep-learning approaches in dynamic IoT/Cloud scenarios and to develop more adaptable and resilient intrusion detection systems.
7. Conclusions and Future Works
This research proposed and evaluated a machine-learning-based framework for the detection and mitigation of Distributed Denial-of-Service (DDoS) attacks in Internet of Things (IoT) and Cloud environments. Through a comparative analysis of three models—Random Forest (RF), XGBoost, and Long Short Term Memory (LSTM)—trained on two benchmark datasets (CIC-DDoS2019 and N-BaIoT), the study validated the effectiveness of ensemble methods over deep-learning architectures for this specific domain. The results confirm that RF and XGBoost provide high classification accuracy and robustness, with RF achieving an accuracy of 99.96% and an F1-score of 95.84%, outperforming both XGBoost and LSTM in terms of precision, recall, and generalization. This effectiveness is largely attributed to their ability to handle high dimensional data and utilize embedded feature importance metrics.
On the other hand, the LSTM model, although conceptually suitable for sequential data, exhibited suboptimal performance under the tested configuration, highlighting the need for advanced preprocessing, deeper architectural optimization, and extensive hyperparameter tuning. Moreover, the LSTM model demonstrated significantly higher computational requirements in both training time and hardware dependency (requiring GPU acceleration), which limits its deployment in resource-constrained IoT environments. Another limitation of the proposed framework lies in its reliance on labeled datasets, which restricts applicability in scenarios where annotated data are scarce or unavailable. In addition, while the results demonstrate strong performance on the selected datasets, there remain inherent challenges in generalizing to previously unseen or evolving cyberattack patterns, which underscores the importance of ongoing model retraining, adaptation, and validation.
Beyond model evaluation, a lightweight web-based dashboard was developed to visualize detection outputs in real time, supporting both interpretability and integration into operational monitoring systems. This application serves as a proof of concept for deploying ML-powered DDoS detection solutions in real-world IoT infrastructures. Future work should address the identified limitations by exploring advanced metaheuristic algorithms for optimization, developing hybrid deep-learning architectures, incorporating edge and federated learning paradigms, and validating the framework in heterogeneous and dynamic environments such as industrial control systems or smart cities. Additionally, extending the system to detect a broader range of threats, including ransomware, data exfiltration, and insider threats, represents a promising direction toward comprehensive and adaptive cybersecurity in IoT/Cloud infrastructures.
Future Research Directions
As part of future work, we propose a comprehensive research agenda that includes the application of advanced optimization algorithms such as Bayesian Optimization, Genetic Algorithms (GAs), Particle Swarm Optimization (PSO), and Whale Optimization Algorithm (WOA) to enhance both hyperparameter tuning and automatic feature selection. These metaheuristic techniques are particularly effective in navigating high-dimensional search spaces, overcoming the limitations of traditional methods such as Grid Search and Random Search, and promoting improved convergence and classification performance.
In parallel, we intend to investigate hybrid deep-learning architectures, including CNN–LSTM, attention-based LSTM, and Transformer-based models, due to their ability to capture complex temporal dependencies in network traffic. Given the distributed nature of IoT ecosystems, the integration of paradigms such as Federated Learning and Edge Computing is also recommended to improve scalability, reduce communication latency, and preserve data privacy.
Moreover, the adoption of Explainable Artificial Intelligence (XAI) techniques, such as SHAP and LIME, is envisioned to promote transparency and interpretability, thereby facilitating the deployment of these models in critical infrastructure environments. From a practical perspective, it is essential to measure detection latency under simulated real-world conditions and move toward operational validation in industrial or urban networks. This step is crucial to ensure the robustness, adaptability, and feasibility of the proposed approach in dynamic and heterogeneous environments.
Finally, we propose extending the detection scope beyond DDoS attacks by incorporating multiclass classification strategies and behavior-based analysis techniques to identify advanced threats such as ransomware, insider threats, and data exfiltration. This would enable the development of a comprehensive and intelligent cybersecurity framework tailored to the complexity of modern IoT/Cloud infrastructures.
Author Contributions
Conceptualization, S.B. and P.H.; methodology, S.B. and P.H.; formal analysis, S.B., P.H. and H.A.-C.; investigation, S.B., P.H. and S.G.; data curation, S.B. and S.G.; writing—original draft preparation, S.B., S.G. and P.H.; writing—review and editing, S.B., P.H. and H.A.-C.; visualization, S.B. and S.G.; supervision, P.H. and H.A.-C.; project administration, P.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Acknowledgments
The authors extend their appreciation to the Doctorate Program in Ingeniería Informática and Doctorate Program in Intelligent Industry at the Pontifical Catholic University of Valparaiso for supporting this work. Sebastián Berríos Vásquez is supported by the National Agency for research and development (ANID)/ Scholarship Program/Doctorado Nacional/2024-21240489 and Beca INF-PUCV.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| AI | Artificial Intelligence |
| Bi-LSTM | Bidirectional Long Short-Term Memory |
| CIC | Canadian Institute of Cybersecurity |
| CNN | Convolutional Neural Network |
| CVAE | Conditional Variational Autoencoder |
| DDoS | Distributed Denial-of-Service |
| DL | Deep Learning |
| DOI | Digital Object Identifier |
| GB | Gradient Boosting |
| IDS | Intrusion Detection System |
| IoT | Internet of Things |
| LSTM | Long Short-Term Memory |
| MI | Mutual Information |
| ML | Machine Learning |
| PSO | Particle Swarm Optimization |
| RF | Random Forest |
| RFFI | Random Forest Feature Importance |
| SMOTE | Synthetic Minority Over Sampling Technique |
| SVM | Support Vector Machine |
| WOA | Whale Optimization Algorithm |
| WoS | Web of Science |
References
- Akgun, D.; Hizal, S.; Cavusoglu, U. A New DDoS Attacks Intrusion Detection Model Based on Deep Learning for Cybersecurity. Comput. Secur. 2022, 118, 102748. [Google Scholar] [CrossRef]
- Penukonda, Q.S.M.; Paramasivam, I. Design and analysis of behaviour based DDoS detection algorithm for data centres in cloud. Evol. Intell. 2021, 14, 395–404. [Google Scholar] [CrossRef]
- Wang, S.; Balarezo, J.F.; Kandeepan, S.; Al-Hourani, A.; Chavez, K.G.; Rubinstein, B. Machine Learning in Network Anomaly Detection: A Survey. IEEE Access 2021, 9, 152379–152396. [Google Scholar] [CrossRef]
- Sanjalawe, Y.; Althobaiti, T. DDoS Attack Detection in Cloud Computing Based on Ensemble Feature Selection and Deep Learning. CMC-Comput. Mater. Contin. 2023, 75, 3571–3588. [Google Scholar] [CrossRef]
- Ouhssini, M.; Afdel, K.; Agherrabi, E.; Akouhar, M.; Abarda, A. DeepDefend: A Comprehensive Framework for DDoS Attack Detection and Prevention in Cloud Computing. J. King Saud Univ. Comput. Inf. Sci. 2024, 36, 101938. [Google Scholar] [CrossRef]
- Sharafaldin, I.; Lashkari, A.H.; Hakak, S.; Ghorbani, A.A. Developing Realistic Distributed Denial of Service (DDoS) Attack Dataset and Taxonomy. In Proceedings of the 2019 International Carnahan Conference on Security Technology (ICCST), Chennai, India, 1–3 October 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Meidan, Y.; Bohadana, M.; Mathov, Y.; Mirsky, Y.; Breitenbacher, D.; Shabtai, A.; Elovici, Y. N-BaIoT—Network-Based Detection of IoT Botnet Attacks Using Deep Autoencoders. IEEE Pervasive Comput. 2018, 17, 12–22. [Google Scholar] [CrossRef]
- Konatham, M.; Nalamala, S. An Edge Computing-Based CNN–GRU Hybrid Model for Cyberattack Detection in IIoT Environments. Appl. Sci. 2023, 13, 4231. [Google Scholar] [CrossRef]
- Shaikh, M.; Usman, M.; Shaikh, A.; Jalbani, A.A.; Alrashidi, A.; Algathbar, A. A Hybrid CNN–LSTM Model for Effective DDoS Attack Detection in IIoT Networks. Sensors 2022, 22, 9713. [Google Scholar] [CrossRef]
- Alduailij, M.; Khan, Q.W.; Tahir, M.; Sardaraz, M.; Alduailij, M.; Malik, F. Machine-Learning-Based DDoS Attack Detection Using Mutual Information and Random Forest Feature Importance Method. Symmetry 2022, 14, 1095. [Google Scholar] [CrossRef]
- Popoola, S.I.; Imoize, A.L.; Hammoudeh, M.; Adebisi, B.; Jogunola, O.; Aibinu, A.M. Federated Deep Learning Model for Intrusion Detection in Consumer-Centric IoT. Appl. Sci. 2023, 13, 5473. [Google Scholar] [CrossRef]
- Alrowais, F.; Eltahir, M.M.; Aljameel, S.S.; Marzouk, R.; Mohammed, G.P.; Salama, A.S. Modeling of Botnet Detection Using Chaotic Binary Pelican Optimization Algorithm With Deep Learning on Internet of Things Environment. IEEE Access 2023, 11, 130618–130626. [Google Scholar] [CrossRef]
- Shafi, M.; Lashkari, A.H.; Rodriguez, V.; Nevo, R. Toward Generating a New Cloud-Based Distributed Denial of Service (DDoS) Dataset and Cloud Intrusion Traffic Characterization. Information 2024, 15, 195. [Google Scholar] [CrossRef]
- Almuqren, L.; Alqahtani, H.; Aljameel, S.S.; Salama, A.S.; Yaseen, I.; Alneil, A.A. Hybrid Metaheuristics With Machine Learning Based Botnet Detection in Cloud Assisted Internet of Things Environment. IEEE Access 2023, 11, 115668–115676. [Google Scholar] [CrossRef]
- Orman, A. Cyberattack Detection Systems in Industrial Internet of Things (IIoT) Networks in Big Data Environments. Appl. Sci. 2025, 15, 3121. [Google Scholar] [CrossRef]
- Kaliyaperumal, P.; Periyasamy, S.; Thirumalaisamy, M.; Balusamy, B.; Benedetto, F. A Novel Hybrid Unsupervised Learning Approach for Enhanced Cybersecurity in the IoT. Future Internet 2024, 16, 253. [Google Scholar] [CrossRef]
- Velasco, L.; Guerrero, H.; Hospitaler, A. A Literature Review and Critical Analysis of Metaheuristics Recently Developed. Arch. Comput. Methods Eng. 2024, 31, 125–146. [Google Scholar] [CrossRef]
- SaiSindhuTheja, R.; Shyam, G.K. An efficient metaheuristic algorithm based feature selection and recurrent neural network for DoS attack detection in cloud computing environment. Appl. Soft Comput. 2021, 100, 106997. [Google Scholar] [CrossRef]
- Thangasamy, A.; Sundan, B.; Govindaraj, L. A Novel Framework for DDoS Attacks Detection Using Hybrid LSTM Techniques. Comput. Syst. Sci. Eng. 2023, 45, 2553–2567. [Google Scholar] [CrossRef]
- Ahmim, A.; Maazouzi, F.; Ahmim, M.; Namane, S.; Dhaou, I.B. Distributed Denial of Service Attack Detection for the Internet of Things Using Hybrid Deep Learning Model. IEEE Access 2023, 11, 119862–119875. [Google Scholar] [CrossRef]
- Arunkumar, M.; Kumar, K.A. Malicious attack detection approach in cloud computing using machine learning techniques. Soft Comput. 2022, 26, 13097–13107. [Google Scholar] [CrossRef]
- Manaa, M.E.; Hussain, S.M.; Alasadi, S.A.; Al-Khamees, H.A. DDoS Attacks Detection Based on Machine Learning Algorithms in IoT Environments. Intel. Artif.-Iberoam. J. Artif. Intell. 2024, 27, 152–165. [Google Scholar] [CrossRef]
- Ramzan, M.; Shoaib, M.; Altaf, A.; Arshad, S.; Iqbal, F.; Castilla, Á.K.; Ashraf, I. Distributed Denial of Service Attack Detection in Network Traffic Using Deep Learning Algorithm. Sensors 2023, 23, 8642. [Google Scholar] [CrossRef]
- Al-Omar, B.; Trabelsi, Z. Intrusion Detection Using Attention-Based CNN-LSTM Model. In Proceedings of the 19th IFIP WG 12.5 International Conference on Artificial Intelligence Applications and Innovations, AIAI 2023, León, Spain, 14–17 June 2023; Volume 675, pp. 515–526. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}