
View-Aware Contrastive Learning for Incomplete Tabular Data with Low-Label Regimes

Abstract
1. Introduction
- A multi-view consistency constraint mechanism is designed to encode data through multiple views, enabling the model to learn stable and discriminative latent representations from distinct feature subspaces. Consistency-based contrastive learning is employed to enhance the ability to capture relationships across views, improving both robustness and generalization.
- A view-disentangled encoder is developed in order to effectively address the heterogeneity of tabular data. Data features are partitioned into multiple subspaces, each corresponding to a distinct view, with independently designed encoding paths for each view. This design allows the model to capture localized structure and improves its representational capacity.
- A cross-view consistency loss is introduced during training to ensure alignment of latent representations across different views. Such a constraint guides the model to learn semantically meaningful features, thereby enhancing its performance on diverse datasets.
- A self-supervised learning framework is adopted, allowing the proposed model to leverage the latent information in unlabeled data. This approach addresses the challenges of label sparsity and missing values, enabling effective training even under incomplete data conditions.
2. Related Work
2.1. Modeling Methods for Sparse Tabular Data
2.2. Self-Supervised Learning in Structured Data
2.3. Multi-View Learning and Consistency Modeling
3. Materials and Method
3.1. Data Collection
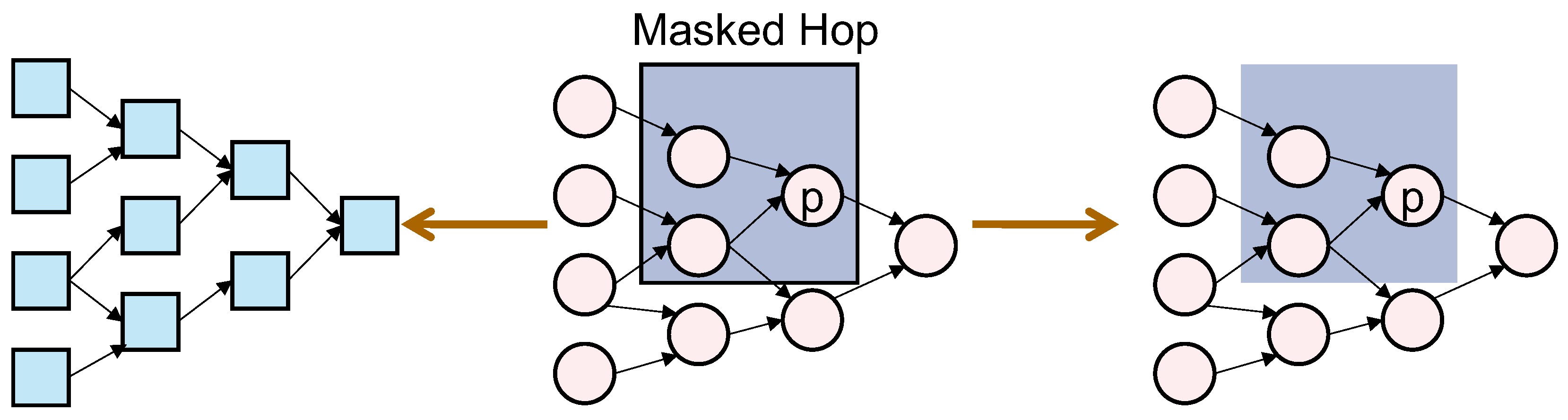
3.2. Data Augmentation
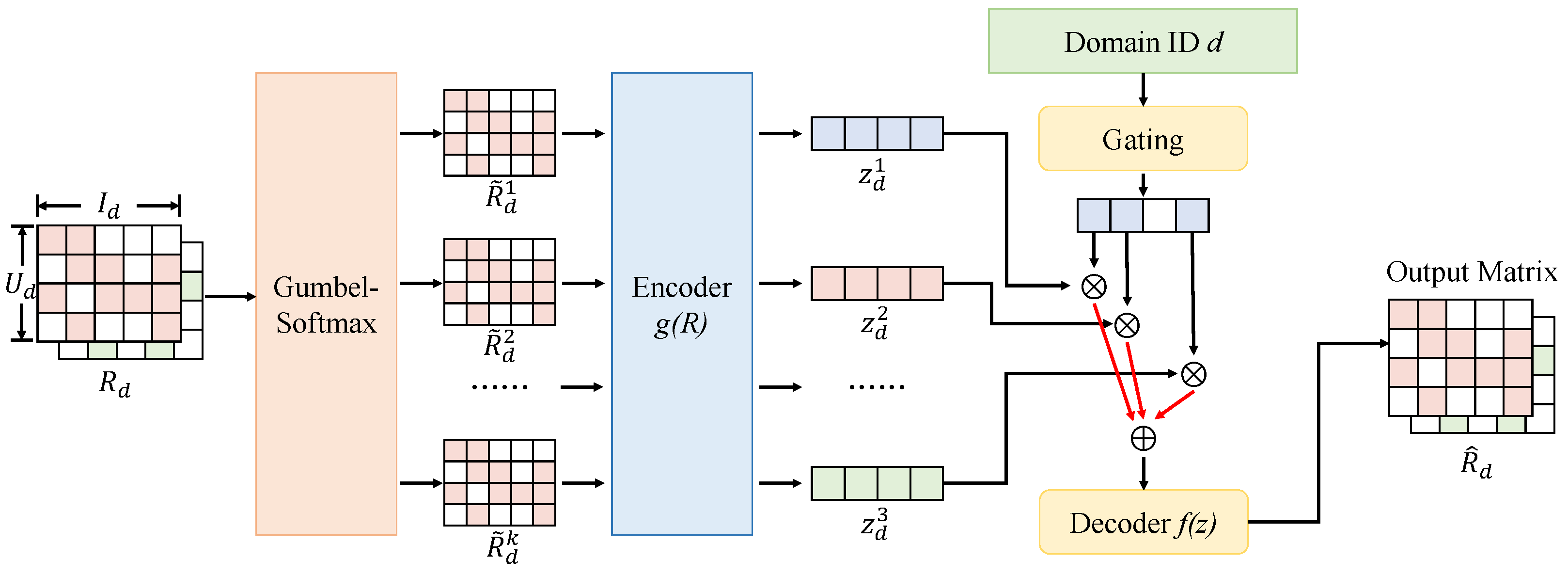
3.3. Proposed Method
3.3.1. Multi-View Encoder
3.3.2. View Consistency Contrastor
3.3.3. Consistency Fusion and Loss Function Design
3.4. Hardware and Software Environment
3.5. Dataset Description and Experimental Protocol
3.6. Evaluation Metrics
3.7. Baseline
4. Results and Discussion
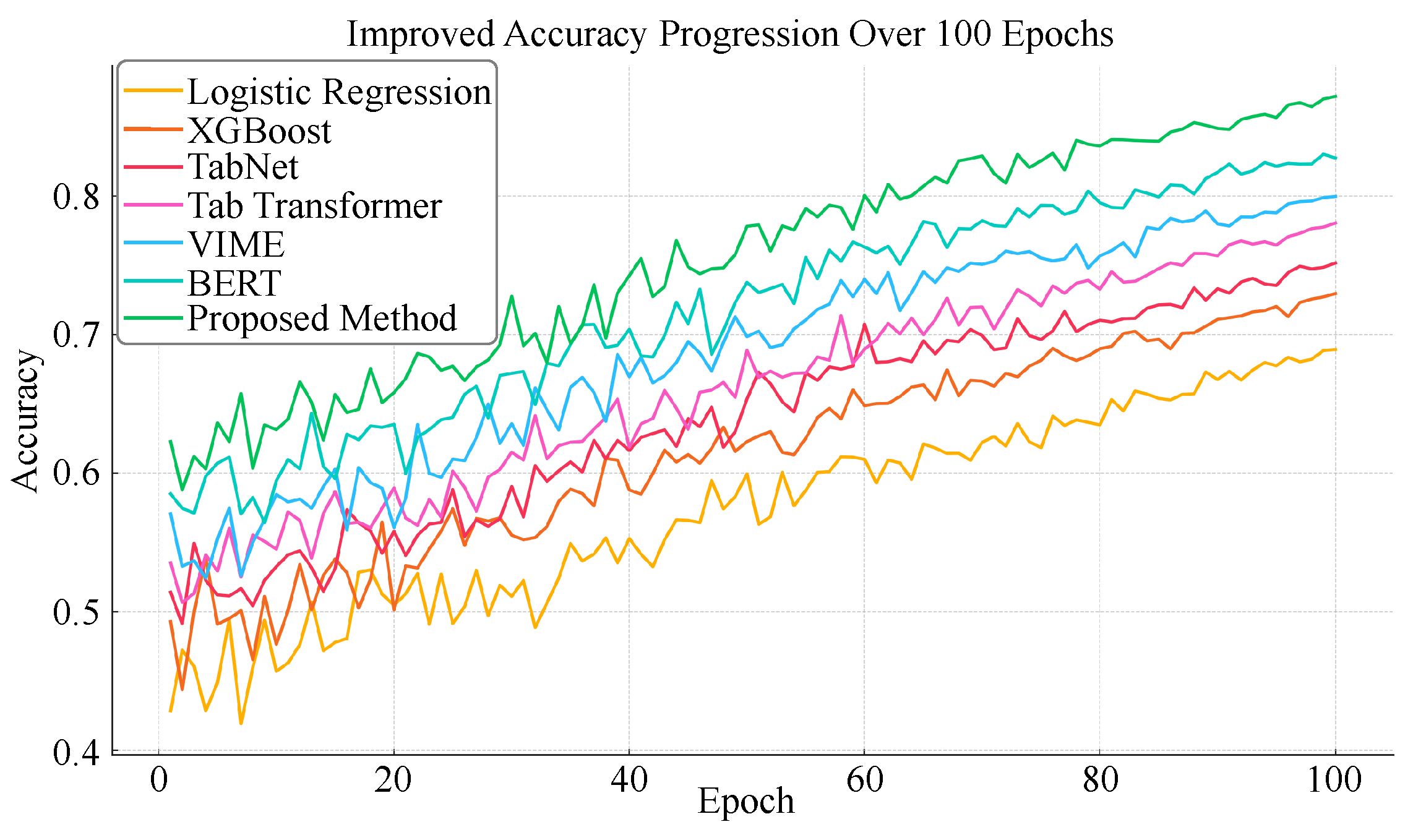
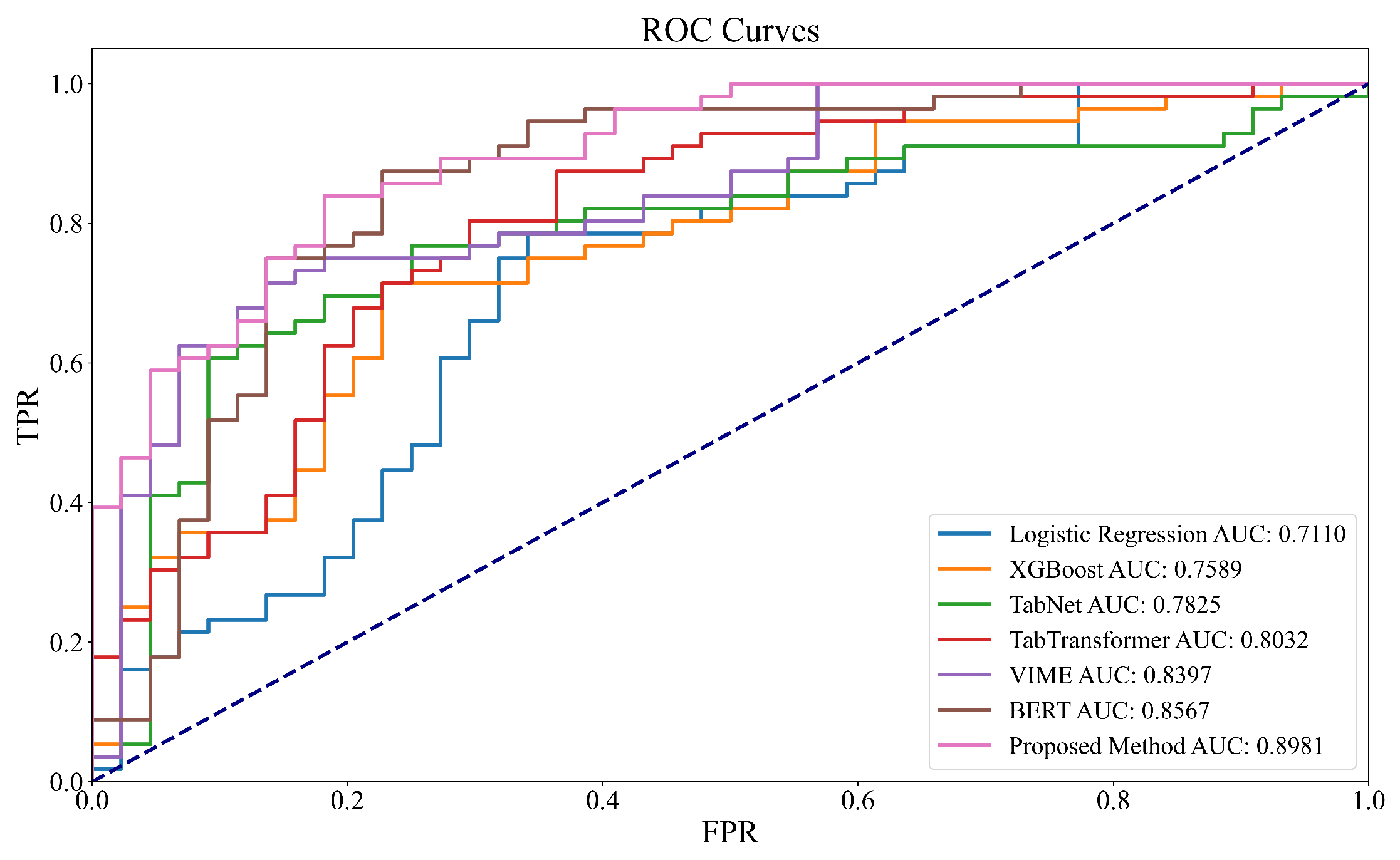
4.1. Experimental Results of Different Models Under Missing Labels and Incomplete Features
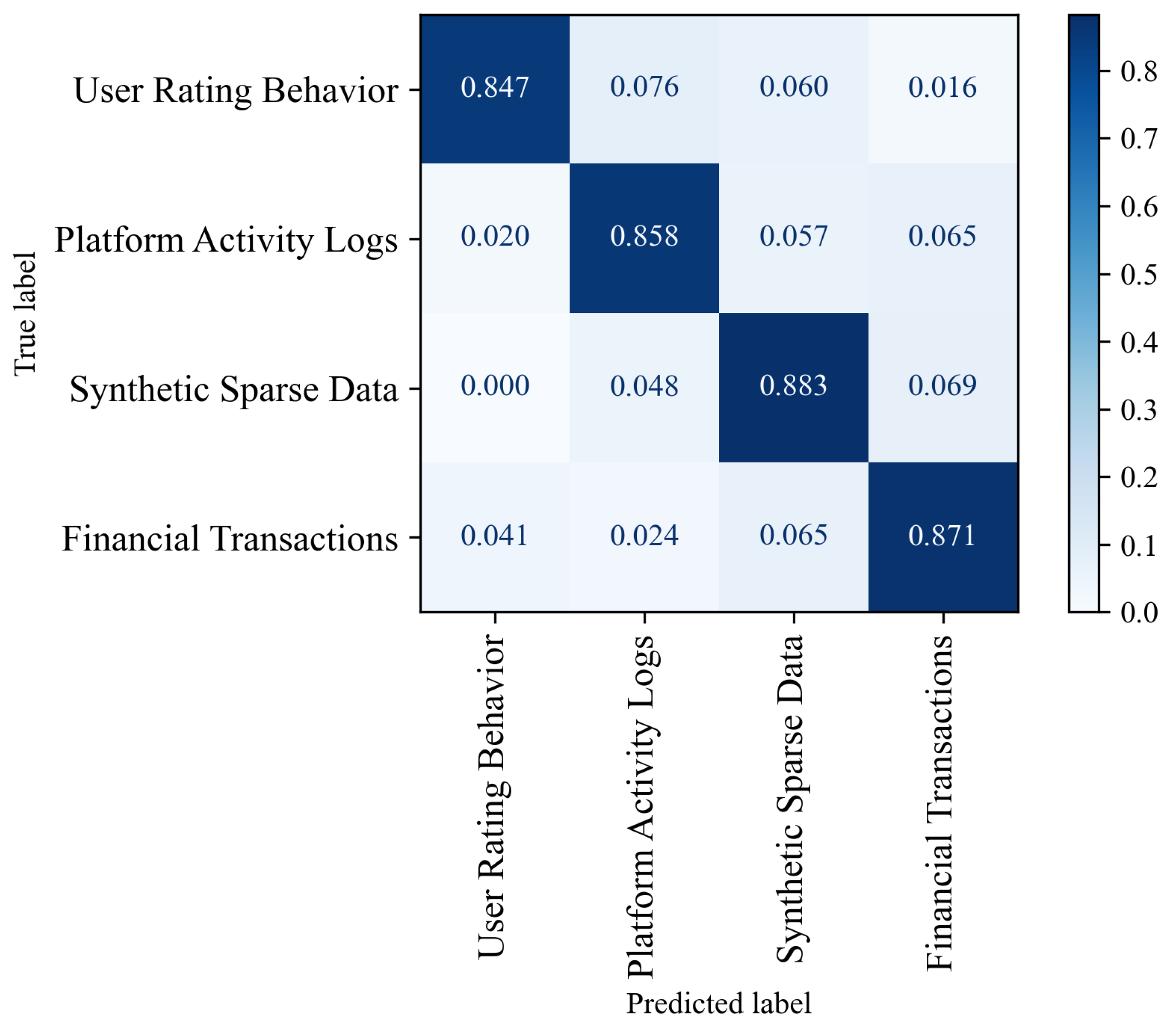
4.2. Performance Evaluation on Diverse Structured Datasets
4.3. Monte Carlo Analysis and Significance Testing
4.4. Computational Complexity Analysis
4.5. Impact of Multi-View Partitioning Strategies on Model Performance
4.6. Ablation Study on Contrastive Loss Mechanisms Under Label and Feature Incompleteness
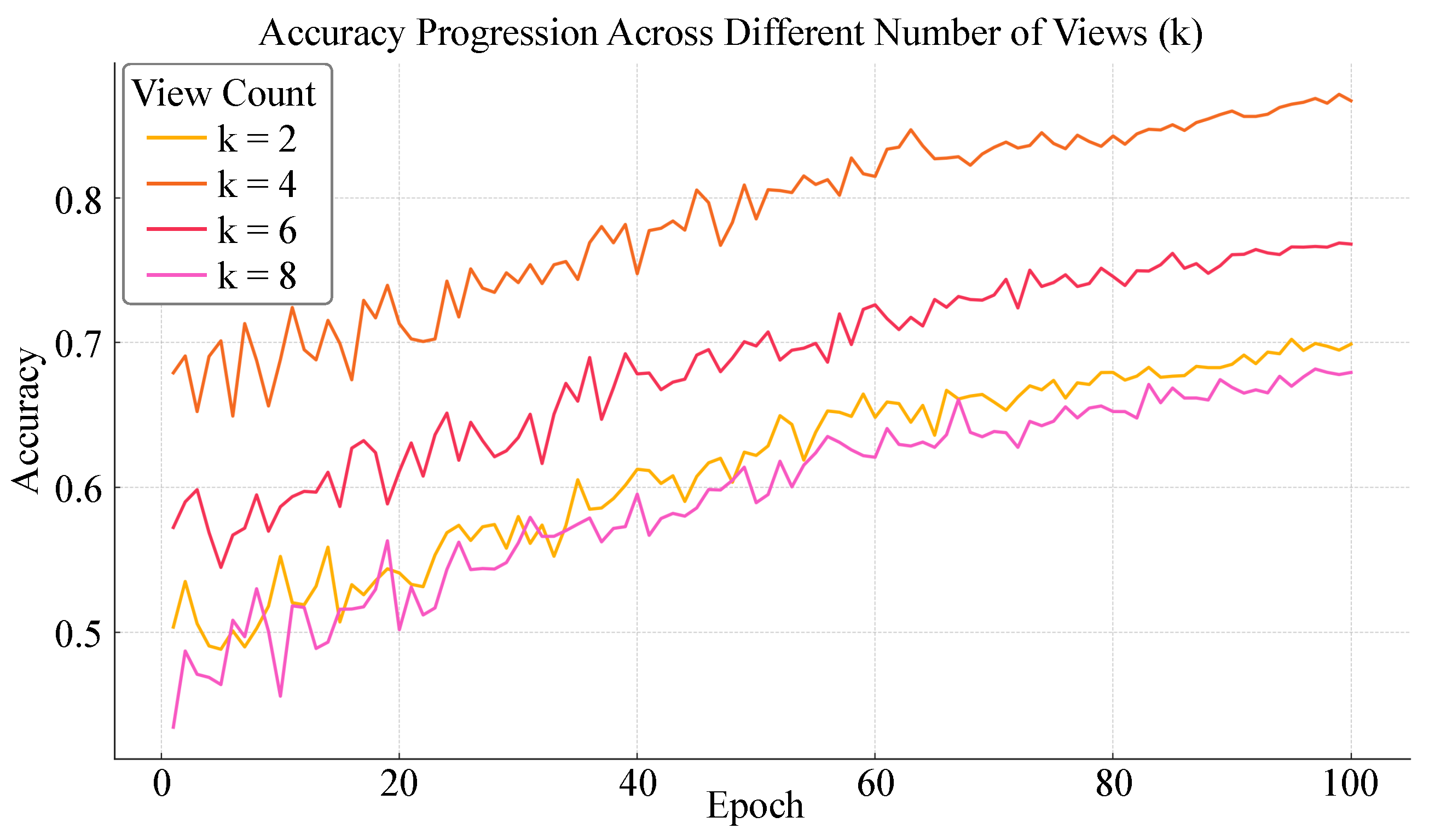
4.7. Impact of View Quantity on Model Performance Under Incomplete Supervision
4.8. Discussion
4.9. Limitation and Future Work
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ruan, Y.; Lan, X.; Ma, J.; Dong, Y.; He, K.; Feng, M. Language modeling on tabular data: A survey of foundations, techniques and evolution. arXiv 2024, arXiv:2408.10548. [Google Scholar]
- Sarker, I.H. Data science and analytics: An overview from data-driven smart computing, decision-making and applications perspective. SN Comput. Sci. 2021, 2, 377. [Google Scholar] [CrossRef] [PubMed]
- Goldstein, I.; Spatt, C.S.; Ye, M. Big data in finance. Rev. Financ. Stud. 2021, 34, 3213–3225. [Google Scholar] [CrossRef]
- Lei, X.; Mohamad, U.H.; Sarlan, A.; Shutaywi, M.; Daradkeh, Y.I.; Mohammed, H.O. Development of an intelligent information system for financial analysis depend on supervised machine learning algorithms. Inf. Process. Manag. 2022, 59, 103036. [Google Scholar] [CrossRef]
- Sharma, N.; Soni, M.; Kumar, S.; Kumar, R.; Deb, N.; Shrivastava, A. Supervised machine learning method for ontology-based financial decisions in the stock market. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2023, 22, 1–24. [Google Scholar] [CrossRef]
- Qu, L.; Liu, S.; Liu, X.; Wang, M.; Song, Z. Towards label-efficient automatic diagnosis and analysis: A comprehensive survey of advanced deep learning-based weakly-supervised, semi-supervised and self-supervised techniques in histopathological image analysis. Phys. Med. Biol. 2022, 67, 20TR01. [Google Scholar] [CrossRef]
- Petrini, L.; Cagnetta, F.; Vanden-Eijnden, E.; Wyart, M. Learning sparse features can lead to overfitting in neural networks. Adv. Neural Inf. Process. Syst. 2022, 35, 9403–9416. [Google Scholar] [CrossRef]
- Zhao, H.; Lou, Y.; Xu, Q.; Feng, Z.; Wu, Y.; Huang, T.; Tan, L.; Li, Z. Optimization strategies for self-supervised learning in the use of unlabeled data. J. Theory Pract. Eng. Sci. 2024, 4, 30–39. [Google Scholar] [CrossRef]
- Ndifon, V.B. The Reliability and Efficiency of Replacing Missing Data in Sparse Data Sets. Ph.D. Thesis, Northcentral University, Scottsdale, AZ, USA, 2023. [Google Scholar]
- Shafiei, A.; Tatar, A.; Rayhani, M.; Kairat, M.; Askarova, I. Artificial neural network, support vector machine, decision tree, random forest, and committee machine intelligent system help to improve performance prediction of low salinity water injection in carbonate oil reservoirs. J. Pet. Sci. Eng. 2022, 219, 111046. [Google Scholar] [CrossRef]
- Abdulhafedh, A. Comparison between common statistical modeling techniques used in research, including: Discriminant analysis vs logistic regression, ridge regression vs LASSO, and decision tree vs. random forest. Open Access Libr. J. 2022, 9, e8414. [Google Scholar] [CrossRef]
- Teegavarapu, R.S. Imputation Methods: An Overview. Imputation Methods for Missing Hydrometeorological Data Estimation; Springer: Cham, Switzerland, 2024; pp. 27–41. [Google Scholar]
- Brini, A.; van den Heuvel, E.R. Missing data imputation with high-dimensional data. Am. Stat. 2024, 78, 240–252. [Google Scholar] [CrossRef]
- Zhang, Y.; Wa, S.; Liu, Y.; Zhou, X.; Sun, P.; Ma, Q. High-accuracy detection of maize leaf diseases CNN based on multi-pathway activation function module. Remote Sens. 2021, 13, 4218. [Google Scholar] [CrossRef]
- Lee, T.; Shi, D. A comparison of full information maximum likelihood and multiple imputation in structural equation modeling with missing data. Psychol. Methods 2021, 26, 466. [Google Scholar] [CrossRef] [PubMed]
- Borisov, V.; Leemann, T.; Seßler, K.; Haug, J.; Pawelczyk, M.; Kasneci, G. Deep neural networks and tabular data: A survey. IEEE Trans. Neural Netw. Learn. Syst. 2022, 35, 7499–7519. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, Y.; Ma, X. A New Strategy for Tuning ReLUs: Self-Adaptive Linear Units (SALUs). In Proceedings of the ICMLCA 2021 2nd International Conference on Machine Learning and Computer Application, Shenyang, China, 17–19 December 2021; VDE: Offenbach, Germany, 2021; pp. 1–8. [Google Scholar]
- Shakir, W.A. Benchmarking TabLM: Evaluating the Performance of Language Models Against Traditional Machine Learning in Structured Data Tasks. In Proceedings of the 2024 1st International Conference on Emerging Technologies for Dependable Internet of Things (ICETI), Sana’a, Yemen, 25–26 November 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–10. [Google Scholar]
- McDonnell, K.; Murphy, F.; Sheehan, B.; Masello, L.; Castignani, G. Deep learning in insurance: Accuracy and model interpretability using TabNet. Expert Syst. Appl. 2023, 217, 119543. [Google Scholar] [CrossRef]
- Li, Q.; Zhang, Y. Confidential Federated Learning for Heterogeneous Platforms against Client-Side Privacy Leakages. In Proceedings of the ACM Turing Award Celebration Conference-China 2024, Changsha China, 5–7 July 2024; pp. 239–241. [Google Scholar]
- Vyas, T.K. Deep learning with tabular data: A self-supervised approach. arXiv 2024, arXiv:2401.15238. [Google Scholar]
- Li, Q.; Zhang, Y.; Ren, J.; Li, Q.; Zhang, Y. You Can Use But Cannot Recognize: Preserving Visual Privacy in Deep Neural Networks. arXiv 2024, arXiv:2404.04098. [Google Scholar]
- Sun, Y.; Li, J.; Xu, Y.; Zhang, T.; Wang, X. Deep learning versus conventional methods for missing data imputation: A review and comparative study. Expert Syst. Appl. 2023, 227, 120201. [Google Scholar] [CrossRef]
- Li, Q.; Ren, J.; Zhang, Y.; Song, C.; Liao, Y.; Zhang, Y. Privacy-Preserving DNN Training with Prefetched Meta-Keys on Heterogeneous Neural Network Accelerators. In Proceedings of the 2023 60th ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 9–13 July 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–6. [Google Scholar]
- Wei, Y.; Zhao, L.; Zheng, W.; Zhu, Z.; Rao, Y.; Huang, G.; Lu, J.; Zhou, J. Surrounddepth: Entangling surrounding views for self-supervised multi-camera depth estimation. In Proceedings of the Conference on Robot Learning, PMLR, Atlanta, GA, USA, 6–9 November 2023; pp. 539–549. [Google Scholar]
- Wandt, B.; Rudolph, M.; Zell, P.; Rhodin, H.; Rosenhahn, B. Canonpose: Self-supervised monocular 3d human pose estimation in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 13294–13304. [Google Scholar]
- Sun, L.; Bian, J.W.; Zhan, H.; Yin, W.; Reid, I.; Shen, C. Sc-depthv3: Robust self-supervised monocular depth estimation for dynamic scenes. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 46, 497–508. [Google Scholar] [CrossRef]
- Chen, K.; Hong, L.; Xu, H.; Li, Z.; Yeung, D.Y. Multisiam: Self-supervised multi-instance siamese representation learning for autonomous driving. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 7546–7554. [Google Scholar]
- Koo, H.; Kim, T.E. A comprehensive survey on generative diffusion models for structured data. arXiv 2023, arXiv:2306.04139. [Google Scholar]
- Alharthi, A.M.; Lee, M.H.; Algamal, Z.Y. Improving Penalized Logistic Regression Model with Missing Values in High-Dimensional Data. Int. J. Online Biomed. Eng. 2022, 18, 113–129. [Google Scholar] [CrossRef]
- Konstantinov, A.V.; Utkin, L.V. Interpretable machine learning with an ensemble of gradient boosting machines. Knowl.-Based Syst. 2021, 222, 106993. [Google Scholar] [CrossRef]
- Pedro, F. A review of data mining, big data analytics, and machine learning approaches. J. Comput. Nat. Sci. 2023, 3, 169–181. [Google Scholar] [CrossRef]
- Ahmed, S.F.; Alam, M.S.B.; Hassan, M.; Rozbu, M.R.; Ishtiak, T.; Rafa, N.; Mofijur, M.; Shawkat Ali, A.; Gandomi, A.H. Deep learning modelling techniques: Current progress, applications, advantages, and challenges. Artif. Intell. Rev. 2023, 56, 13521–13617. [Google Scholar] [CrossRef]
- Somvanshi, S.; Das, S.; Javed, S.A.; Antariksa, G.; Hossain, A. A survey on deep tabular learning. arXiv 2024, arXiv:2410.12034. [Google Scholar]
- Song, H.; Kim, M.; Park, D.; Shin, Y.; Lee, J.G. Learning from noisy labels with deep neural networks: A survey. IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 8135–8153. [Google Scholar] [CrossRef] [PubMed]
- Jia, S.; Jiang, S.; Lin, Z.; Li, N.; Xu, M.; Yu, S. A survey: Deep learning for hyperspectral image classification with few labeled samples. Neurocomputing 2021, 448, 179–204. [Google Scholar] [CrossRef]
- Gui, J.; Chen, T.; Zhang, J.; Cao, Q.; Sun, Z.; Luo, H.; Tao, D. A survey on self-supervised learning: Algorithms, applications, and future trends. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 9052–9071. [Google Scholar] [CrossRef]
- Lin, S.Y.; Kung, Y.C.; Leu, F.Y. Predictive intelligence in harmful news identification by BERT-based ensemble learning model with text sentiment analysis. Inf. Process. Manag. 2022, 59, 102872. [Google Scholar] [CrossRef]
- Subakti, A.; Murfi, H.; Hariadi, N. The performance of BERT as data representation of text clustering. J. Big Data 2022, 9, 15. [Google Scholar] [CrossRef]
- Rani, V.; Nabi, S.T.; Kumar, M.; Mittal, A.; Kumar, K. Self-supervised learning: A succinct review. Arch. Comput. Methods Eng. 2023, 30, 2761–2775. [Google Scholar] [CrossRef]
- Liu, X.; Zhang, F.; Hou, Z.; Mian, L.; Wang, Z.; Zhang, J.; Tang, J. Self-supervised learning: Generative or contrastive. IEEE Trans. Knowl. Data Eng. 2021, 35, 857–876. [Google Scholar] [CrossRef]
- Xie, Z.; Zhang, Z.; Cao, Y.; Lin, Y.; Bao, J.; Yao, Z.; Dai, Q.; Hu, H. Simmim: A simple framework for masked image modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 9653–9663. [Google Scholar]
- Hua, T.; Wang, W.; Xue, Z.; Ren, S.; Wang, Y.; Zhao, H. On feature decorrelation in self-supervised learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 9598–9608. [Google Scholar]
- Yan, X.; Hu, S.; Mao, Y.; Ye, Y.; Yu, H. Deep multi-view learning methods: A review. Neurocomputing 2021, 448, 106–129. [Google Scholar] [CrossRef]
- Yu, Z.; Dong, Z.; Yu, C.; Yang, K.; Fan, Z.; Chen, C.P. A review on multi-view learning. Front. Comput. Sci. 2025, 19, 197334. [Google Scholar] [CrossRef]
- Kumar, A.; Yadav, J. A review of feature set partitioning methods for multi-view ensemble learning. Inf. Fusion 2023, 100, 101959. [Google Scholar] [CrossRef]
- Li, Z.; Tang, C.; Liu, X.; Zheng, X.; Zhang, W.; Zhu, E. Consensus graph learning for multi-view clustering. IEEE Trans. Multimed. 2021, 24, 2461–2472. [Google Scholar] [CrossRef]
- Zhao, P.; Zhao, S.; Zhao, X.; Liu, H.; Ji, X. Partial multi-label learning based on sparse asymmetric label correlations. Knowl.-Based Syst. 2022, 245, 108601. [Google Scholar] [CrossRef]
- Liu, D.; Tian, Y.; Zhang, Y.; Gelernter, J.; Wang, X. Heterogeneous data fusion and loss function design for tooth point cloud segmentation. Neural Comput. Appl. 2022, 34, 17371–17380. [Google Scholar] [CrossRef]
- Tan, Z.; Li, D.; Wang, S.; Beigi, A.; Jiang, B.; Bhattacharjee, A.; Karami, M.; Li, J.; Cheng, L.; Liu, H. Large language models for data annotation and synthesis: A survey. arXiv 2024, arXiv:2402.13446. [Google Scholar]
- Salazar, A.; Vergara, L.; Vidal, E. A proxy learning curve for the Bayes classifier. Pattern Recognit. 2023, 136, 109240. [Google Scholar] [CrossRef]
- Salazar, A.; Vergara, L.; Safont, G. Generative Adversarial Networks and Markov Random Fields for oversampling very small training sets. Expert Syst. Appl. 2021, 163, 113819. [Google Scholar] [CrossRef]
- Kleinbaum, D.G.; Dietz, K.; Gail, M.; Klein, M.; Klein, M. Logistic Regression; Springer: Berlin/Heidelberg, Germany, 2002. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Arik, S.Ö.; Pfister, T. Tabnet: Attentive interpretable tabular learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 6679–6687. [Google Scholar]
- Huang, X.; Khetan, A.; Cvitkovic, M.; Karnin, Z. Tabtransformer: Tabular data modeling using contextual embeddings. arXiv 2020, arXiv:2012.06678. [Google Scholar]
- Yoon, J.; Zhang, Y.; Jordon, J.; Van der Schaar, M. Vime: Extending the success of self-and semi-supervised learning to tabular domain. Adv. Neural Inf. Process. Syst. 2020, 33, 11033–11043. [Google Scholar]
- Koroteev, M.V. BERT: A review of applications in natural language processing and understanding. arXiv 2021, arXiv:2103.11943. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Type | Source | Sample Size | Feature Dimension | Max Missing Rate |
|---|---|---|---|---|
| User Rating Behavior | MovieLens, Book-Crossing | 170,000 | 50 | 28% |
| Platform Activity Logs | Kaggle Web Logs | 200,000 | 60 | 33% |
| Synthetic Sparse Data | Scikit-learn (Synthetic) | 100,000 | 100–200 | 40% |
| Financial Transactions | IEEE-CIS, UCI Default | 180,000 | 120 | 35% |
| Data Type | Class Type (Label Categories) |
|---|---|
| User Rating Behavior | Binary: Liked (rating ), Not Liked (rating ) |
| Platform Activity Logs | Binary: High-Intent Action, Low-Intent Action |
| Synthetic Sparse Data | Multi-class: 5 synthetic categories |
| Financial Transactions | Binary: Fraudulent, Non-Fraudulent |
| Model | Accuracy | F1-Score | AUC | Normalized MSE |
|---|---|---|---|---|
| Logistic Regression | 0.69 | 0.65 | 0.71 | 0.164 |
| XGBoost | 0.73 | 0.69 | 0.76 | 0.147 |
| TabNet | 0.75 | 0.70 | 0.78 | 0.130 |
| TabTransformer | 0.78 | 0.73 | 0.80 | 0.122 |
| VIME | 0.80 | 0.76 | 0.84 | 0.108 |
| BERT | 0.83 | 0.79 | 0.86 | 0.089 |
| Proposed Method | 0.87 | 0.83 | 0.90 | 0.066 |
| Dataset Type | Accuracy | F1-Score | AUC | Normalized MSE |
|---|---|---|---|---|
| User Rating Behavior (MovieLens, Book-Crossing) | 0.85 | 0.81 | 0.88 | 0.070 |
| Platform Activity Logs (Kaggle Web Logs) | 0.86 | 0.82 | 0.89 | 0.068 |
| Synthetic Sparse Data (Scikit-learn) | 0.88 | 0.84 | 0.91 | 0.063 |
| Financial Transactions (IEEE-CIS, UCI) | 0.87 | 0.83 | 0.91 | 0.067 |
| Model | Accuracy | F1-Score | AUC | Normalized MSE |
|---|---|---|---|---|
| Logistic Regression | 0.690 ± 0.008 | 0.650 ± 0.011 | 0.710 ± 0.009 | 0.164 ± 0.012 |
| XGBoost | 0.730 ± 0.006 | 0.690 ± 0.007 | 0.760 ± 0.005 | 0.147 ± 0.008 |
| TabNet | 0.750 ± 0.006 | 0.700 ± 0.007 | 0.780 ± 0.006 | 0.130 ± 0.007 |
| TabTransformer | 0.780 ± 0.004 | 0.730 ± 0.005 | 0.800 ± 0.003 | 0.122 ± 0.006 |
| VIME | 0.800 ± 0.007 | 0.760 ± 0.008 | 0.840 ± 0.005 | 0.108 ± 0.009 |
| BERT | 0.830 ± 0.004 | 0.790 ± 0.006 | 0.860 ± 0.003 | 0.089 ± 0.005 |
| Proposed Method | 0.870 ± 0.003 * | 0.830 ± 0.004 * | 0.900 ± 0.003 * | 0.066 ± 0.004 * |
| p-value | 0.031 | 0.028 | 0.019 | 0.015 |
| Model | Training Time (s/Epoch) | Inference Time (ms/Sample) | Peak Memory (MB) |
|---|---|---|---|
| Logistic Regression | 0.2 | 0.03 | 50 |
| XGBoost | 1.5 | 0.05 | 130 |
| TabNet | 3.2 | 0.08 | 280 |
| TabTransformer | 7.8 | 0.19 | 820 |
| BERT | 16.4 | 0.29 | 1024 |
| VIME | 4.2 | 0.09 | 310 |
| Proposed Method | 12.7 | 0.25 | 940 |
| Partition Strategy | Accuracy | F1-Score | AUC | Normalized MSE |
|---|---|---|---|---|
| Random Partition | 0.74 | 0.70 | 0.78 | 0.120 |
| Information Gain-Based | 0.81 | 0.75 | 0.84 | 0.101 |
| Cluster-Based Partition | 0.87 | 0.83 | 0.90 | 0.072 |
| Contrastive Setting | Accuracy | F1-Score | AUC | Normalized MSE |
|---|---|---|---|---|
| Intra-View Only | 0.73 | 0.70 | 0.76 | 0.157 |
| Cross-View Only | 0.79 | 0.75 | 0.82 | 0.113 |
| Intra + Cross View | 0.87 | 0.83 | 0.90 | 0.072 |
| Number of Views (k) | Accuracy | F1-Score | AUC | Normalized MSE |
|---|---|---|---|---|
| 8 | 0.68 | 0.63 | 0.70 | 0.185 |
| 2 | 0.70 | 0.66 | 0.72 | 0.172 |
| 6 | 0.77 | 0.72 | 0.80 | 0.120 |
| 4 | 0.87 | 0.83 | 0.90 | 0.072 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Y.; Lin, Q.; Li, Z.; Wang, Y.; Liang, S.; Zhang, S.; Wang, Y.; Lv, C. View-Aware Contrastive Learning for Incomplete Tabular Data with Low-Label Regimes. Appl. Sci. 2025, 15, 6001. https://doi.org/10.3390/app15116001
Yang Y, Lin Q, Li Z, Wang Y, Liang S, Zhang S, Wang Y, Lv C. View-Aware Contrastive Learning for Incomplete Tabular Data with Low-Label Regimes. Applied Sciences. 2025; 15(11):6001. https://doi.org/10.3390/app15116001
Chicago/Turabian StyleYang, Yingqiu, Qianye Lin, Zeyue Li, Yakui Wang, Siyu Liang, Siyuan Zhang, Yiyan Wang, and Chunli Lv. 2025. "View-Aware Contrastive Learning for Incomplete Tabular Data with Low-Label Regimes" Applied Sciences 15, no. 11: 6001. https://doi.org/10.3390/app15116001
APA StyleYang, Y., Lin, Q., Li, Z., Wang, Y., Liang, S., Zhang, S., Wang, Y., & Lv, C. (2025). View-Aware Contrastive Learning for Incomplete Tabular Data with Low-Label Regimes. Applied Sciences, 15(11), 6001. https://doi.org/10.3390/app15116001