
Semi-Supervised Learning for Intrusion Detection in Large Computer Networks


Abstract
1. Introduction
2. Related Works
3. Methodology
3.1. Data Collection and Preprocessing
3.1.1. Description of the Dataset
- Size and Scope: The CIC-DDoS2019 dataset is substantial in size, containing a 30 gigabyte collection of network traffic records. It spans a wide range of network activities, making it suitable for both research and real-world application.
- Variety of Network Traffic: It comprises diverse network traffic data, encompassing legitimate network transactions and various forms of network attacks. The dataset includes BENIGN, DNS, LDAP, MSSQL, NetBIOS, NTP, SNMP, SSDP, UDP, Portmap, Syn, TFTP, and UDPLag data labels. This diversity reflects the complexity of real-world network environments.
- Real-World Relevance: The dataset is curated to mirror real-world scenarios, capturing network behaviors observed in operational networks. This real-world relevance ensures that the research findings are applicable to practical network security situations.
- Network Protocols: It covers a wide range of network protocols, including HTTP, TCP, UDP, ICMP, and others. This protocol diversity reflects the complexity of modern network communications.
- Traffic Features: Each network traffic record is associated with a set of features, which include flow characteristics, packet attributes, and temporal information. In total, the standard dataset before preprocessing contains 85 features. These features are essential for building effective intrusion detection models.
- Imbalanced Data: To mirror common real-world intrusion detection scenarios, the dataset exhibits class imbalance in which normal traffic significantly outweighs malicious traffic. Addressing class imbalance is a crucial aspect of our research.
- Size and Scope: The UNSW-NB15 dataset contains over 2.5 million network traffic records. The dataset’s large size ensures that it encompasses a broad spectrum of network behaviors, providing ample data for training and testing intrusion detection models.
- Variety of Network Traffic: The dataset includes a mix of legitimate (normal) network traffic and a wide range of attack vectors. In addition to normal traffic, it contains nine categories of attack labels: Fuzzers, Analysis, Backdoor, DoS, Exploits, Generic, Reconnaissance, Shellcode, and Worms. This variety offers a diverse set of data to evaluate the effectiveness of different detection techniques.
- Real-World Relevance: UNSW-NB15 was designed to replicate realistic network environments and modern-day cyber threats. It reflects the behavior of real-world traffic, making it highly relevant for evaluating security models aimed at practical deployment in current network security systems.
- Network Protocols: The dataset captures network flows that involve various protocols such as TCP, UDP, ICMP, and HTTP. The inclusion of multiple protocols makes it possible to explore a wide range of attack surfaces and defense mechanisms.
- Traffic Features: Each record in the UNSW-NB15 dataset includes 49 features, which cover both network flow characteristics and packet-level details. These features are critical for building robust machine learning models for intrusion detection. Key features include flow duration, service type, packet size, and content-based attributes.
- Imbalanced Data: As with many real-world intrusion detection datasets, UNSW-NB15 exhibits class imbalance, where the number of normal records is significantly larger than the attack records. This imbalance presents a challenge for machine learning models and underscores the need for specialized techniques to handle skewed data distributions.
3.1.2. Data Preprocessing
- Data cleaning and Transforming
- (i)
- Redundant data removal
- (ii)
- Imputation of missing values
- (iii)
- Imputation of infinite values
- (iv)
- Data type conversion
- (v)
- Managing inconsistencies in the data
- Feature Selection and Engineering
- (i)
- Label encoding
- (ii)
- Feature hashing
- (iii)
- Feature extraction
- (iv)
- Adding/removing features
3.2. Design and Implementation
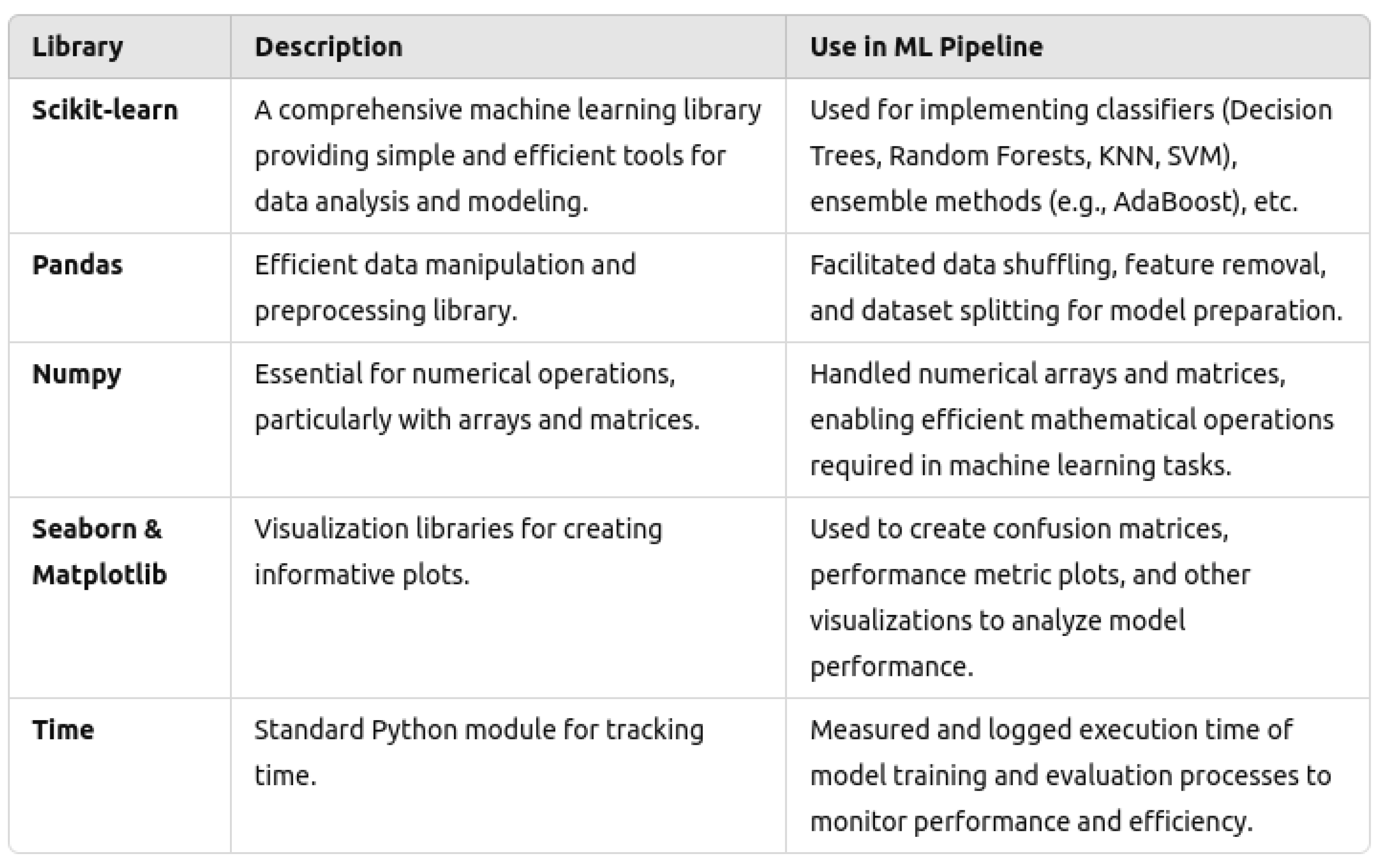
3.2.1. Libraries and Frameworks
3.2.2. Hyperparameter Tuning Strategies
3.3. Proposed Semi-Supervised Learning Models
3.3.1. Decision Trees
- Root Node: The top node, representing the entire dataset.
- Internal Nodes: Nodes representing tests on features.
- Branches: Outcomes of the tests.
- Leaf Nodes: Terminal nodes that represent class labels or regression values.
3.3.2. Entropy
3.3.3. Semi-Supervised Learning
3.3.4. Combining These Concepts
- Initial Training: Start with a small labeled dataset and train a decision tree.
- Uncertainty Estimation: Use the trained decision tree to predict class probabilities for the unlabeled instances and calculate their entropy.
- Instance Selection: Select the unlabeled instances with the highest entropy for labeling.
- Labeling: Query an oracle (e.g., a human annotator) to obtain the true labels for these selected instances.
- Model Update: Retrain the decision tree with the expanded labeled dataset, now including the newly labeled instances.
- Iteration: Repeat the process of uncertainty estimation, instance selection, labeling, and model updating until a stopping criterion is met (e.g., a certain number of iterations, achieving a performance threshold, or exhausting the labeling budget).
| Algorithm 1 Semi-Supervised Learning Workflow Using Decision Tree |
|
3.3.5. Logistic Regression
3.3.6. Self-Training
- Train the model on the initial labeled dataset.
- Use the trained model to predict labels for the unlabeled data.
- Select the most confident predictions and add them to the labeled dataset.
- Retrain the model on the updated labeled dataset.
- Repeat the process until a stopping criterion is met.
3.3.7. Combining These Concepts
- Initial Training: Train the logistic regression model on a small labeled dataset.
- Prediction: Use the trained model to predict probabilities for the unlabeled instances.
- Confidence Selection: Select the instances with the highest confidence (i.e., the highest predicted probabilities) for which the model is most certain.
- Labeling: Assign the predicted labels to these selected instances.
- Model Update: Add the newly labeled instances to the labeled dataset.
- Retraining: Retrain the logistic regression model with the expanded labeled dataset.
- Iteration: Repeat the process of prediction, selection, labeling, and retraining until a stopping criterion is met (e.g., a certain number of iterations, achieving a performance threshold, or exhausting the labeling budget).
| Algorithm 2 Semi-Supervised Learning Workflow Using Logistic Regression |
|
3.3.8. Random Forest
- Ensemble Method: Combines the predictions of several decision trees to improve generalization and robustness.
- Bagging: Uses bootstrap aggregation to create diverse subsets of the training data for each tree.
- Feature Randomness: Introduces additional randomness by selecting a random subset of features for each split in the trees.
3.3.9. Co-Training
- Multiple Views: It is assumed that the features can be split into two disjoint sets (views) that are sufficient to make predictions independently.
- Initial Training: Two classifiers (one for each view) are trained using the initial labeled dataset.
- Labeling: Each classifier labels the unlabeled instances that it is most confident about.
- Teaching: The labeled instances from one classifier are added to the training set of the other classifier.
- Iteration: The process is repeated iteratively to improve both classifiers.
3.3.10. Combining These Concepts
- Initial Training: Train two random forest classifiers on different views of a small labeled dataset.
- Prediction: Use each random forest classifier to predict labels for the unlabeled instances.
- Confidence Selection: Select the instances with the highest confidence from each classifier’s predictions.
- Teaching: Add the confidently labeled instances from one classifier to the training set of the other classifier.
- Model Update: Retrain each random forest classifier with its expanded training set.
- Iteration: Repeat the process of prediction, selection, teaching, and retraining until a stopping criterion is met (e.g., a certain number of iterations, achieving a performance threshold, or exhausting the labeling budget).
| Algorithm 3 Co-Training Workflow Using Random Forests on Split Feature Views |
|
4. Experimental Results and Discussion
4.1. Experimental Setup
4.2. Hardware
- CPU Cores: 32
- CPU Speed: 4.22 GHz
- Memory: 1 TB (1024 GB)
4.3. Software
- Python 3.7.6
- PyCharm (python version 3.8.10)
- RStudio 2023.03.0+386
- BigQuery
4.4. Parameter Settings
4.5. Dataset Preparation and Coding
- Data shuffling: The dataset was shuffled for every model.
- Data splitting: For each model and its variants, 80% of the data was used for training and 20% was used for testing.
- Data stratification: The dataset was stratified for every model, which ensures that all labels are present in both training and testing.
- Second data splitting: All data were divided into scenarios in which 1%, 5%, 10%, 50%, or 100% of the training data were unlabeled.
- Data Reports: Classification reports and a confusion matrix were documented for each model.
4.6. Hyperparameters
4.6.1. Decision Tree with Entropy-Based Uncertainty Sampling
- Data shuffling and splitting were performed with random_state = 42 to ensure reproducibility.
- For semi-supervised learning, entropy-based sampling was performed to select the most uncertain samples from the unlabeled data. n_samples = 20 were selected in each iteration.
- The semi-supervised learning process was iterated n_iterations = 10 times.
4.6.2. Logistic Regression with Self-Training
- Data shuffling and splitting were performed with random_state = 42 to ensure reproducibility.
- A confidence threshold of 0.8 was used to add pseudo-labeled data to the labeled set.
- The self-training process was iterated max_iterations = 10 times.
- Class weights were assigned based on the presence of labels in the initially labeled data. Labels present in y_labeled were assigned a weight of 1.0, while others were assigned a weight of 0.5.
4.6.3. Co-Training with Random Forest
- Data shuffling and splitting were performed with random_state = 42 to ensure reproducibility.
- The dataset was split into num_views = 2 different views, each using a subset of the features.
- Features were evenly split between the views, with
features_per_view = len(X_train_labeled.columns) // num_views.
4.7. Results and Analysis
4.7.1. Evaluation Metrics
4.7.2. Confusion Matrix
| Predicted Positive | Predicted Negative | |
| Actual Positive | True Positive (TP) | False Negative (FN) |
| Actual Negative | False Positive (FP) | True Negative (TN) |
4.7.3. Classification Report
- Accuracy: The proportion of correctly classified instances (both true positives and true negatives) among the total instances:
- Precision: The proportion of true positive instances among those instances predicted as positive:
- Recall (Sensitivity or True Positive Rate): The proportion of true positive instances among the actual positive instances:
- Specificity (True Negative Rate): The proportion of true negative instances among the actual negative instances:
- F1-Score: The harmonic mean of precision and recall, which provides a balance between the two metrics:
- Macro Average: Unweighted mean of the metrics for each class.
- Weighted Average: Mean of the metrics weighted by the support of each class.
4.7.4. Key Metrics
4.7.5. Decision Tree with Entropy-Based Uncertainty Sampling
4.7.6. Key Metrics
- Accuracy: Near-perfect across all levels of labeled data
- Misclassifications:
- –
- 1% labeled data: 4225 samples
- –
- 5% labeled data: 1408 samples
- –
- 10% labeled data: 1408 samples
- –
- 50% labeled data: 197 samples
- –
- 100% labeled data: 98 samples
4.7.7. Performance by Class
4.7.8. Highlights
4.7.9. Logistic Regression with Self-Training
4.7.10. Key Metrics
- Accuracy: Suboptimal across all levels of labeled data
- Misclassifications:
- –
- 1% labeled data: 9,654,220 samples
- –
- 5% labeled data: 9,844,375 samples
- –
- 10% labeled data: 9,809,161 samples
- –
- 50% labeled data: 9,559,847 samples
- –
- 100% labeled data: 8,875,291 samples
4.7.11. Performance by Class
4.7.12. Highlights
4.7.13. Co-Training with Random Forest Base Estimator
4.7.14. Key Metrics
- Accuracy: Very high across all levels of labeled data
- Misclassifications:
- –
- 1% labeled data: 140,869 samples
- –
- 5% labeled data: 140,855 samples
- –
- 10% labeled data: 140,855 samples
- –
- 50% labeled data: 140,855 samples
- –
- 100% labeled data: 140,855 samples
4.7.15. Performance by Class
4.7.16. Highlights
4.7.17. Comparative Results
4.8. Discussion
5. Conclusions
6. Future Work
- Enhancing model robustness: Investigate methods to further improve the robustness of semi-supervised learning models, especially in real-world noisy environments where unlabeled data may contain significant noise or outliers.
- Incorporating domain knowledge: Explore techniques to incorporate domain knowledge or priors into the semi-supervised learning framework, potentially through Bayesian approaches or reinforcement learning paradigms.
- Scalability and efficiency: Address scalability challenges by developing scalable algorithms that can efficiently handle large-scale datasets without sacrificing accuracy.
- Multimodal and multi-task learning: Extend the multi-view learning paradigm to more complex scenarios involving multimodal data sources or multi-task learning objectives, aiming for more comprehensive understanding and utilization of available information.
- Theoretical foundations: Advance the theoretical understanding of semi-supervised learning methods, particularly in terms of convergence guarantees, optimization landscapes, and generalization bounds.
- Applications in emerging domains: Apply semi-supervised learning techniques to emerging domains where labeled data are scarce but high-quality predictions are crucial, e.g., healthcare, cybersecurity, and autonomous systems.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Usman, F.M.; Pavan, S.; Suhas, M.R.; Yogesh, B.; Surendra Babu, K.N.; Thirumala, A.K.; Riyaz, A.M. Intrusion Detection Landscape: Exploring Progress and Confronting Challenges in Security Advances. In Proceedings of the 2024 International Conference on Integrated Circuits and Communication Systems (ICICACS), Bangalore, India, 21–23 February 2024; pp. 1–8. [Google Scholar] [CrossRef]
- Taghavinejad, S.M.; Taghavinejad, M.; Shahmiri, L.; Zavvar, M.; Zavvar, M.H. Intrusion Detection in IoT-Based Smart Grid Using Hybrid Decision Tree. In Proceedings of the 2020 6th International Conference on Web Research (ICWR), Tehran, Iran, 21–22 April 2020; pp. 152–156. [Google Scholar] [CrossRef]
- Reddy, A.V.S.; Reddy, B.P.; Sujihelen, L.; Mary, A.V.A.; Jesudoss, A.; Jeyanthi, P. Intrusion Detection System in Network using Decision Tree. In Proceedings of the 2022 International Conference on Sustainable Computing and Data Communication Systems (ICSCDS), Erode, India, 7–8 April 2022; pp. 1186–1190. [Google Scholar] [CrossRef]
- Zou, L.; Luo, X.; Zhang, Y.; Yang, X.; Wang, X. HC-DTTSVM: A Network Intrusion Detection Method Based on Decision Tree Twin Support Vector Machine and Hierarchical Clustering. IEEE Access 2023, 11, 21404–21416. [Google Scholar] [CrossRef]
- Atefi, K.; Hashim, H.; Kassim, M. Anomaly Analysis for the Classification Purpose of Intrusion Detection System with K-Nearest Neighbors and Deep Neural Network. In Proceedings of the 2019 IEEE 7th Conference on Systems, Process, and Control (ICSPC), Malacca, Malaysia, 13–14 December 2019; pp. 269–274. [Google Scholar] [CrossRef]
- Abdaljabar, Z.H.; Ucan, O.N.; Alheeti, K.M.A. An Intrusion Detection System for IoT Using KNN and Decision-Tree Based Classification. In Proceedings of the 2021 International Conference of Modern Trends in Information and Communication Technology Industry (MTICTI), Baghdad, Iraq, 24–25 October 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Gao, X.; Shan, C.; Hu, C.; Niu, Z.; Liu, Z. An Adaptive Ensemble Machine Learning Model for Intrusion Detection. IEEE Access 2019, 7, 82512–82521. [Google Scholar] [CrossRef]
- Chen, Y.; Yuan, F. Dynamic detection of malicious intrusion in wireless network based on improved random forest algorithm. In Proceedings of the 2022 IEEE Asia-Pacific Conference on Image Processing, Electronics and Computers (IPEC), Dalian, China, 14–16 April 2022; pp. 27–32. [Google Scholar] [CrossRef]
- Lu, T.; Huang, Y.; Zhao, W.; Zhang, J. The Metering Automation System based Intrusion Detection Using Random Forest Classifier with SMOTE+ENN. In Proceedings of the 2019 IEEE 7th International Conference on Computer Science and Network Technology (ICCSNT), Dalian, China, 19–20 October 2019; pp. 370–374. [Google Scholar] [CrossRef]
- Subbiah, S.; Anbananthen, K.S.M.; Thangaraj, S.; Kannan, S.; Chelliah, D. Intrusion detection technique in wireless sensor network using grid search random forest with Boruta feature selection algorithm. J. Commun. Netw. 2022, 24, 264–273. [Google Scholar] [CrossRef]
- Xu, G.; Zhou, J.; He, Y. Network Malicious Traffic Detection Model Based on Combined Neural Network. In Proceedings of the 2022 6th Asian Conference on Artificial Intelligence Technology (ACAIT), Chongqing, China, 25–28 August 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Zhang, T.; Bao, S. A Novel Deep Neural Network Model for Computer Network Intrusion Detection Considering Connection Efficiency of Network Systems. In Proceedings of the 2022 4th International Conference on Smart Systems and Inventive Technology (ICSSIT), Tirunelveli, India, 20–22 January 2022; pp. 962–965. [Google Scholar] [CrossRef]
- Yang, H.; Wang, F. Wireless Network Intrusion Detection Based on Improved Convolutional Neural Network. IEEE Access 2019, 7, 64366–64374. [Google Scholar] [CrossRef]
- Alhidaifi, S.M.; Asghar, M.R.; Ansari, I.S. A Survey on Cyber Resilience: Key Strategies, Research Challenges, and Future Directions. ACM Comput. Surv. 2024, 56, 196. [Google Scholar] [CrossRef]
- Yao, H.; Fu, D.; Zhang, P.; Li, M.; Liu, Y. MSML: A Novel Multilevel Semi-Supervised Machine Learning Framework for Intrusion Detection System. IEEE Internet Things J. 2019, 6, 1949–1959. [Google Scholar] [CrossRef]
- Camacho, J.; Maciá-Fernández, G.; Fuentes-García, N.M.; Saccenti, E. Semi-Supervised Multivariate Statistical Network Monitoring for Learning Security Threats. IEEE Trans. Inf. Forensics Secur. 2019, 14, 2179–2189. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; Hawash, H.; Chakrabortty, R.K.; Ryan, M.J. Semi-Supervised Spatiotemporal Deep Learning for Intrusion Detection in IoT Networks. IEEE Internet Things J. 2021, 8, 12251–12265. [Google Scholar] [CrossRef]
- Dong, S.; Xia, Y.; Peng, T. Network Abnormal Traffic Detection Model Based on Semi-Supervised Deep Reinforcement Learning. IEEE Trans. Netw. Serv. Manag. 2021, 18, 4197–4212. [Google Scholar] [CrossRef]
- Xu, R.; Zhang, Q.; Zhang, Y. TSSAN: Time-Space Separable Attention Network for Intrusion Detection. IEEE Access 2024, 12, 98734–98749. [Google Scholar] [CrossRef]
- Cai, S.; Han, D.; Li, D. A Feedback Semi-Supervised Learning With Meta-Gradient for Intrusion Detection. IEEE Syst. J. 2023, 17, 1158–1169. [Google Scholar] [CrossRef]
- Duan, G.; Lv, H.; Wang, H.; Feng, G. Application of a Dynamic Line Graph Neural Network for Intrusion Detection with Semisupervised Learning. IEEE Trans. Inf. Forensics Secur. 2023, 18, 699–714. [Google Scholar] [CrossRef]
- Lin, Z. Network Intrusion Detection based on Semi-Supervised Ensemble Learning Algorithm for Imbalanced Data. In Proceedings of the 2021 International Conference on Networking and Network Applications (NaNA), Dalian, China, 24–26 October 2021; pp. 338–344. [Google Scholar] [CrossRef]
- Niu, Z.; Guo, W.; Xue, J.; Wang, Y.; Kong, Z.; Huang, L. A Novel Anomaly Detection Approach Based on Ensemble Semi-Supervised Active Learning (ADESSA). Comput. Secur. 2023, 129, 103190. [Google Scholar] [CrossRef]
- Ye, F.; Zhao, W. A Semi-Self-Supervised Intrusion Detection System for Multilevel Industrial Cyber Protection. Comput. Intell. Neurosci. 2022, 2022, 4043309. [Google Scholar] [CrossRef]
- Fan, Z.; Sohail, S.; Sabrina, F.; Gu, X. Sampling-Based Machine Learning Models for Intrusion Detection in Imbalanced Dataset. Electronics 2024, 13, 1878. [Google Scholar] [CrossRef]
- Canadian Institute for Cybersecurity. DDoS 2019 | Datasets | Canadian Institute for Cybersecurity | UNB. 2019. Available online: https://www.unb.ca/cic/datasets/ddos-2019.html (accessed on 14 March 2023).
- Moustafa, N.; Slay, J. UNSW-NB15: A Comprehensive Data Set for Network Intrusion Detection Systems (UNSW-NB15 Network Data Set). In Proceedings of the 2015 Military Communications and Information Systems Conference (MilCIS), Canberra, ACT, Australia, 10–12 November 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Settles, B. Active Learning Literature Survey; University of Wisconsin-Madison: Madison, WI, USA, 2009. [Google Scholar]
- Krawczyk, B. Learning from imbalanced data: Open challenges and future directions. Prog. Artif. Intell. 2016, 5, 221–232. [Google Scholar] [CrossRef]
- Packwood, D.; Nguyen, L.T.H.; Cesana, P.; Zhang, G.; Staykov, A.; Fukumoto, Y.; Nguyen, D.H. Machine Learning in Materials Chemistry: An Invitation. Mach. Learn. Appl. 2022, 8, 100265. [Google Scholar] [CrossRef]
- Yarowsky, D. Unsupervised word sense disambiguation rivaling supervised methods. In Proceedings of the 33rd Annual Meeting on Association for Computational Linguistics, Stroudsburg, PA, USA, 26–30 June 1995; pp. 189–196. [Google Scholar]
- Van Engelen, J.E.; Hoos, H.H. A survey on semi-supervised learning. Mach. Learn. 2020, 109, 373–440. [Google Scholar] [CrossRef]
- Saidi, A.; Ben Othman, S.; Dhouibi, M.; Ben Saoud, S. FPGA-based implementation of classification techniques: A survey. Integration 2021, 81, 280–299. [Google Scholar] [CrossRef]
- Zhou, Z.H.; Li, M. Tri-training: Exploiting unlabeled data using three classifiers. IEEE Trans. Knowl. Data Eng. 2005, 17, 1529–1541. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Mohanty, A.; Gao, G. A Survey of Machine Learning Techniques for Improving Global Navigation Satellite Systems. arXiv 2024, arXiv:2406.16873. [Google Scholar] [CrossRef]
- GeeksforGeeks. Metrics for Machine Learning Model. 2024. Available online: https://www.geeksforgeeks.org/metrics-for-machine-learning-model/ (accessed on 10 December 2024).
- Bergstra, J.; Bengio, Y. Random Search for Hyper-Parameter Optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Oliver, A.; Odena, A.; Raffel, C.; Cubuk, E.D.; Goodfellow, I.J. Realistic Evaluation of Deep Semi-Supervised Learning Algorithms. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; Curran Associates Inc.: Red Hook, NY, USA, 2018; pp. 3239–3250. [Google Scholar]
- Ferrag, M.A.; Maglaras, L.; Moschoyiannis, S.; Janicke, H. Deep Learning for Cyber Security Intrusion Detection: Approaches, Datasets, and Comparative Study. J. Inf. Secur. Appl. 2020, 50, 102419. [Google Scholar] [CrossRef]

{kind=link}
| Parameter | Setting |
|---|---|
| Software | PyCharm (Python version 3.8.10) |
| Packages | pandas (1.5.3), numpy (1.24.2), sklearn (1.2.2), scipy (1.10.1), matplotlib.pyplot (3.7.1), seaborn (0.12.2) |
| Functions/Modules | shuffle, train_test_split, classification_report, confusion_matrix, entropy |
| Classifiers | DecisionTreeClassifier, LogisticRegression, RandomForestClassifier |
| Data Tools | BigQuery |
| Class | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| 0.0 | 0.9787 | 0.9687 | 0.9737 | 22,766 |
| 1.0 | 0.9996 | 0.9995 | 0.9995 | 1,014,202 |
| 2.0 | 0.9997 | 0.9998 | 0.9998 | 819,011 |
| 3.0 | 0.9998 | 0.9998 | 0.9998 | 2,061,989 |
| 4.0 | 0.9995 | 0.9997 | 0.9996 | 1,550,155 |
| 5.0 | 0.9995 | 0.9994 | 0.9994 | 240,528 |
| 6.0 | 0.9996 | 0.9998 | 0.9997 | 1,031,974 |
| 7.0 | 0.9998 | 0.9996 | 0.9997 | 522,122 |
| 8.0 | 0.9998 | 0.9997 | 0.9997 | 1,400,360 |
| 9.0 | 0.9954 | 0.9984 | 0.9969 | 37,392 |
| 10.0 | 0.9997 | 0.9996 | 0.9996 | 1,294,758 |
| 11.0 | 1.0000 | 0.9999 | 1.0000 | 4,016,516 |
| 12.0 | 0.9954 | 0.9992 | 0.9973 | 73,667 |
| 13.0 | 0.7778 | 0.4773 | 0.5915 | 88 |
| Accuracy | 0.9997 (14,085,528) | |||
| Macro Avg | 0.9817 | 0.9600 | 0.9683 | 14,085,528 |
| Weighted Avg | 0.9997 | 0.9997 | 0.9997 | 14,085,528 |
| Class | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| 0.0 | 0.9931 | 0.9881 | 0.9906 | 22,766 |
| 1.0 | 0.9999 | 0.9999 | 0.9999 | 1,014,202 |
| 2.0 | 0.9999 | 0.9999 | 0.9999 | 819,011 |
| 3.0 | 1.0000 | 1.0000 | 1.0000 | 2,061,989 |
| 4.0 | 0.9999 | 0.9999 | 0.9999 | 1,550,155 |
| 5.0 | 0.9998 | 0.9998 | 0.9998 | 240,528 |
| 6.0 | 0.9999 | 1.0000 | 0.9999 | 1,031,974 |
| 7.0 | 0.9999 | 0.9998 | 0.9999 | 522,122 |
| 8.0 | 0.9999 | 0.9999 | 0.9999 | 1,400,360 |
| 9.0 | 0.9981 | 0.9996 | 0.9988 | 37,392 |
| 10.0 | 0.9999 | 1.0000 | 1.0000 | 1,294,758 |
| 11.0 | 1.0000 | 1.0000 | 1.0000 | 4,016,516 |
| 12.0 | 0.9996 | 0.9996 | 0.9996 | 73,667 |
| 13.0 | 0.9667 | 0.9886 | 0.9775 | 88 |
| Accuracy | 0.9999 (14,085,528) | |||
| Macro Avg | 0.9969 | 0.9982 | 0.9975 | 14,085,528 |
| Weighted Avg | 0.9999 | 0.9999 | 0.9999 | 14,085,528 |
| Class | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| 0.0 | 0.9957 | 0.9939 | 0.9948 | 22,766 |
| 1.0 | 0.9999 | 1.0000 | 1.0000 | 1,014,202 |
| 2.0 | 1.0000 | 1.0000 | 1.0000 | 819,011 |
| 3.0 | 1.0000 | 1.0000 | 1.0000 | 2,061,989 |
| 4.0 | 0.9999 | 1.0000 | 1.0000 | 1,550,155 |
| 5.0 | 0.9999 | 1.0000 | 1.0000 | 240,528 |
| 6.0 | 0.9999 | 1.0000 | 1.0000 | 1,031,974 |
| 7.0 | 1.0000 | 0.9999 | 1.0000 | 522,122 |
| 8.0 | 1.0000 | 1.0000 | 1.0000 | 1,400,360 |
| 9.0 | 0.9992 | 0.9994 | 0.9993 | 37,392 |
| 10.0 | 1.0000 | 1.0000 | 1.0000 | 1,294,758 |
| 11.0 | 1.0000 | 1.0000 | 1.0000 | 4,016,516 |
| 12.0 | 0.9994 | 0.9995 | 0.9994 | 73,667 |
| 13.0 | 0.9322 | 0.9659 | 0.9487 | 88 |
| Accuracy | 0.9999 (14,085,528) | |||
| Macro Avg | 0.9975 | 0.9983 | 0.9979 | 14,085,528 |
| Weighted Avg | 0.9999 | 0.9999 | 0.9999 | 14,085,528 |
| Class | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| 0.0 | 0.9987 | 0.9987 | 0.9987 | 22,766 |
| 1.0 | 1.0000 | 1.0000 | 1.0000 | 1,014,202 |
| 2.0 | 1.0000 | 1.0000 | 1.0000 | 819,011 |
| 3.0 | 1.0000 | 1.0000 | 1.0000 | 2,061,989 |
| 4.0 | 1.0000 | 1.0000 | 1.0000 | 1,550,155 |
| 5.0 | 1.0000 | 1.0000 | 1.0000 | 240,528 |
| 6.0 | 1.0000 | 1.0000 | 1.0000 | 1,031,974 |
| 7.0 | 1.0000 | 1.0000 | 1.0000 | 522,122 |
| 8.0 | 1.0000 | 1.0000 | 1.0000 | 14,00,360 |
| 9.0 | 0.9999 | 0.9999 | 0.9999 | 37,392 |
| 10.0 | 1.0000 | 1.0000 | 1.0000 | 1,294,758 |
| 11.0 | 1.0000 | 1.0000 | 1.0000 | 4,016,516 |
| 12.0 | 0.9999 | 0.9999 | 0.9999 | 73,667 |
| 13.0 | 0.9647 | 0.9886 | 0.9765 | 88 |
| Accuracy | 0.999999 (14,085,528) | |||
| Macro Avg | 0.9987 | 0.9990 | 0.9988 | 14,085,528 |
| Weighted Avg | 1.0000 | 1.0000 | 1.0000 | 14,085,528 |
| Class | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| 0.0 | 0.9993 | 0.9994 | 0.9993 | 22,766 |
| 1.0 | 1.0000 | 1.0000 | 1.0000 | 1,014,202 |
| 2.0 | 1.0000 | 1.0000 | 1.0000 | 819,011 |
| 3.0 | 1.0000 | 1.0000 | 1.0000 | 2,061,989 |
| 4.0 | 1.0000 | 1.0000 | 1.0000 | 1,550,155 |
| 5.0 | 1.0000 | 1.0000 | 1.0000 | 240,528 |
| 6.0 | 1.0000 | 1.0000 | 1.0000 | 1,031,974 |
| 7.0 | 1.0000 | 1.0000 | 1.0000 | 522,122 |
| 8.0 | 1.0000 | 1.0000 | 1.0000 | 1,400,360 |
| 9.0 | 0.9999 | 1.0000 | 0.9999 | 37,392 |
| 10.0 | 1.0000 | 1.0000 | 1.0000 | 1,294,758 |
| 11.0 | 1.0000 | 1.0000 | 1.0000 | 4,016,516 |
| 12.0 | 1.0000 | 1.0000 | 1.0000 | 73,667 |
| 13.0 | 0.9667 | 0.9886 | 0.9775 | 88 |
| Accuracy | 0.999999 (14,085,528) | |||
| Macro Avg | 0.9987 | 0.9990 | 0.9988 | 14,085,528 |
| Weighted Avg | 1.0000 | 1.0000 | 1.0000 | 14,085,528 |
| Class | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| 0.0 | 0.0000 | 0.0000 | 0.0000 | 22,766 |
| 1.0 | 0.2090 | 0.2500 | 0.2277 | 1,014,202 |
| 2.0 | 0.0000 | 0.0000 | 0.0000 | 819,011 |
| 3.0 | 0.2850 | 0.8989 | 0.4327 | 2,061,989 |
| 4.0 | 0.2012 | 0.4039 | 0.2686 | 1,550,155 |
| 5.0 | 0.0000 | 0.0000 | 0.0000 | 240,528 |
| 6.0 | 0.0000 | 0.0000 | 0.0000 | 1,031,974 |
| 7.0 | 0.0000 | 0.0000 | 0.0000 | 522,122 |
| 8.0 | 0.0000 | 0.0000 | 0.0000 | 1,400,360 |
| 9.0 | 0.0000 | 0.0000 | 0.0000 | 37,392 |
| 10.0 | 0.9326 | 0.2691 | 0.4177 | 1,294,758 |
| 11.0 | 0.4681 | 0.3360 | 0.3912 | 4,016,516 |
| 12.0 | 0.0000 | 0.0000 | 0.0000 | 73,667 |
| 13.0 | 0.0000 | 0.0000 | 0.0000 | 88 |
| Accuracy | 0.3146 (14,085,528) | |||
| Macro Avg | 0.1497 | 0.1541 | 0.1241 | 14,085,528 |
| Weighted Avg | 0.2981 | 0.3146 | 0.2593 | 14,085,528 |
| Class | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| 0.0 | 0.0000 | 0.0000 | 0.0000 | 22,766 |
| 1.0 | 0.2005 | 0.1208 | 0.1508 | 1,014,202 |
| 2.0 | 0.0000 | 0.0000 | 0.0000 | 819,011 |
| 3.0 | 0.2784 | 0.8963 | 0.4248 | 2,061,989 |
| 4.0 | 0.1716 | 0.4095 | 0.2419 | 1,550,155 |
| 5.0 | 0.0000 | 0.0000 | 0.0000 | 240,528 |
| 6.0 | 0.0000 | 0.0000 | 0.0000 | 1,031,974 |
| 7.0 | 0.0000 | 0.0000 | 0.0000 | 522,122 |
| 8.0 | 0.0000 | 0.0000 | 0.0000 | 1,400,360 |
| 9.0 | 0.0000 | 0.0000 | 0.0000 | 37,392 |
| 10.0 | 0.9349 | 0.2806 | 0.4317 | 1,294,758 |
| 11.0 | 0.4631 | 0.3167 | 0.3762 | 4,016,516 |
| 12.0 | 0.0000 | 0.0000 | 0.0000 | 73,667 |
| 13.0 | 0.0000 | 0.0000 | 0.0000 | 88 |
| Accuracy | 0.3011 (14,085,528) | |||
| Macro Avg | 0.1463 | 0.1446 | 0.1161 | 14,085,528 |
| Weighted Avg | 0.2921 | 0.3011 | 0.2466 | 14,085,528 |
| Class | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| 0.0 | 0.0000 | 0.0000 | 0.0000 | 22,766 |
| 1.0 | 0.2660 | 0.1160 | 0.1615 | 1,014,202 |
| 2.0 | 0.0000 | 0.0000 | 0.0000 | 819,011 |
| 3.0 | 0.2879 | 0.9578 | 0.4427 | 2,061,989 |
| 4.0 | 0.1327 | 0.2492 | 0.1732 | 1,550,155 |
| 5.0 | 0.0000 | 0.0000 | 0.0000 | 240,528 |
| 6.0 | 0.0000 | 0.0000 | 0.0000 | 1,031,974 |
| 7.0 | 0.0000 | 0.0000 | 0.0000 | 522,122 |
| 8.0 | 0.0000 | 0.0000 | 0.0000 | 1,400,360 |
| 9.0 | 0.0000 | 0.0000 | 0.0000 | 37,392 |
| 10.0 | 0.9291 | 0.2780 | 0.4231 | 1,294,758 |
| 11.0 | 0.4820 | 0.3184 | 0.3848 | 4,016,516 |
| 12.0 | 0.0000 | 0.0000 | 0.0000 | 73,667 |
| 13.0 | 0.0000 | 0.0000 | 0.0000 | 88 |
| Accuracy | 0.3082 (14,085,528) | |||
| Macro Avg | 0.1507 | 0.1501 | 0.1205 | 14,085,528 |
| Weighted Avg | 0.2957 | 0.3082 | 0.2551 | 14,085,528 |
| Class | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| 0.0 | 0.0000 | 0.0000 | 0.0000 | 22,766 |
| 1.0 | 0.2457 | 0.1364 | 0.1760 | 1,014,202 |
| 2.0 | 0.0000 | 0.0000 | 0.0000 | 819,011 |
| 3.0 | 0.2892 | 0.9569 | 0.4432 | 2,061,989 |
| 4.0 | 0.1698 | 0.3521 | 0.2305 | 1,550,155 |
| 5.0 | 0.0000 | 0.0000 | 0.0000 | 240,528 |
| 6.0 | 0.0000 | 0.0000 | 0.0000 | 1,031,974 |
| 7.0 | 0.0000 | 0.0000 | 0.0000 | 522,122 |
| 8.0 | 0.0000 | 0.0000 | 0.0000 | 1,400,360 |
| 9.0 | 0.0000 | 0.0000 | 0.0000 | 37,392 |
| 10.0 | 0.9324 | 0.2822 | 0.4324 | 1,294,758 |
| 11.0 | 0.4653 | 0.3072 | 0.3680 | 4,016,516 |
| 12.0 | 0.0000 | 0.0000 | 0.0000 | 73,667 |
| 13.0 | 0.0000 | 0.0000 | 0.0000 | 88 |
| Accuracy | 0.3042 (14,085,528) | |||
| Macro Avg | 0.1502 | 0.1467 | 0.1165 | 14,085,528 |
| Weighted Avg | 0.2944 | 0.3042 | 0.2506 | 14,085,528 |
| Class | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| 0.0 | 0.0000 | 0.0000 | 0.0000 | 22,766 |
| 1.0 | 0.2597 | 0.1431 | 0.1856 | 1,014,202 |
| 2.0 | 0.0000 | 0.0000 | 0.0000 | 819,011 |
| 3.0 | 0.2900 | 0.9554 | 0.4441 | 2,061,989 |
| 4.0 | 0.1664 | 0.3217 | 0.2206 | 1,550,155 |
| 5.0 | 0.0000 | 0.0000 | 0.0000 | 240,528 |
| 6.0 | 0.0000 | 0.0000 | 0.0000 | 1,031,974 |
| 7.0 | 0.0000 | 0.0000 | 0.0000 | 522,122 |
| 8.0 | 0.0000 | 0.0000 | 0.0000 | 1,400,360 |
| 9.0 | 0.0000 | 0.0000 | 0.0000 | 37,392 |
| 10.0 | 0.9346 | 0.2801 | 0.4312 | 1,294,758 |
| 11.0 | 0.4601 | 0.3011 | 0.3627 | 4,016,516 |
| 12.0 | 0.0000 | 0.0000 | 0.0000 | 73,667 |
| 13.0 | 0.0000 | 0.0000 | 0.0000 | 88 |
| Accuracy | 0.3007 (14,085,528) | |||
| Macro Avg | 0.1500 | 0.1442 | 0.1158 | 14,085,528 |
| Weighted Avg | 0.2928 | 0.3007 | 0.2463 | 14,085,528 |
| Class | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| 0.0 | 0.99 | 1.00 | 1.00 | 22,766 |
| 1.0 | 0.99 | 1.00 | 0.99 | 1,014,202 |
| 2.0 | 0.99 | 1.00 | 0.99 | 819,011 |
| 3.0 | 0.99 | 1.00 | 1.00 | 2,061,989 |
| 4.0 | 0.96 | 0.99 | 0.97 | 1,550,155 |
| 5.0 | 1.00 | 1.00 | 1.00 | 240,528 |
| 6.0 | 0.99 | 0.95 | 0.97 | 1,031,974 |
| 7.0 | 0.91 | 0.99 | 0.95 | 522,122 |
| 8.0 | 0.99 | 0.96 | 0.98 | 1,400,360 |
| 9.0 | 1.00 | 0.07 | 0.14 | 37,392 |
| 10.0 | 1.00 | 1.00 | 1.00 | 1,294,758 |
| 11.0 | 1.00 | 1.00 | 1.00 | 4,016,516 |
| 12.0 | 1.00 | 0.89 | 0.94 | 73,667 |
| 13.0 | 1.00 | 0.83 | 0.91 | 88 |
| Accuracy | 0.9899 (14,085,528) | |||
| Macro Avg | 0.99 | 0.91 | 0.92 | 14,085,528 |
| Weighted Avg | 0.99 | 0.99 | 0.99 | 14,085,528 |
| Class | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| 0.0 | 0.99 | 1.00 | 1.00 | 22,766 |
| 1.0 | 0.99 | 1.00 | 0.99 | 1,014,202 |
| 2.0 | 0.99 | 1.00 | 0.99 | 819,011 |
| 3.0 | 0.99 | 1.00 | 1.00 | 2,061,989 |
| 4.0 | 0.96 | 0.99 | 0.97 | 1,550,155 |
| 5.0 | 1.00 | 1.00 | 1.00 | 240,528 |
| 6.0 | 0.99 | 0.95 | 0.97 | 1,031,974 |
| 7.0 | 0.91 | 0.99 | 0.95 | 522,122 |
| 8.0 | 0.99 | 0.96 | 0.98 | 1,400,360 |
| 9.0 | 1.00 | 0.07 | 0.14 | 37,392 |
| 10.0 | 1.00 | 1.00 | 1.00 | 1,294,758 |
| 11.0 | 1.00 | 1.00 | 1.00 | 4,016,516 |
| 12.0 | 1.00 | 0.89 | 0.94 | 73,667 |
| 0.0 | 0.99 | 1.00 | 1.00 | 22,766 |
| 1.0 | 0.99 | 1.00 | 0.99 | 1,014,202 |
| 2.0 | 0.99 | 1.00 | 0.99 | 819,011 |
| 3.0 | 0.99 | 1.00 | 1.00 | 2,061,989 |
| 4.0 | 0.96 | 0.99 | 0.97 | 1,550,155 |
| 5.0 | 1.00 | 1.00 | 1.00 | 240,528 |
| 6.0 | 0.99 | 0.95 | 0.97 | 1,031,974 |
| 7.0 | 0.91 | 0.99 | 0.95 | 522,122 |
| 8.0 | 0.99 | 0.96 | 0.98 | 1,400,360 |
| 9.0 | 1.00 | 0.07 | 0.14 | 37,392 |
| 10.0 | 1.00 | 1.00 | 1.00 | 1,294,758 |
| 11.0 | 1.00 | 1.00 | 1.00 | 4,016,516 |
| 12.0 | 1.00 | 0.89 | 0.94 | 73,667 |
| 13.0 | 1.00 | 0.92 | 0.96 | 88 |
| Accuracy | 0.9900 (14,085,528) | |||
| Macro Avg | 0.99 | 0.91 | 0.92 | 14,085,528 |
| Weighted Avg | 0.99 | 0.99 | 0.99 | 14,085,528 |
| Class | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| 0.0 | 0.99 | 1.00 | 1.00 | 22,766 |
| 1.0 | 0.99 | 1.00 | 0.99 | 1,014,202 |
| 2.0 | 0.99 | 1.00 | 0.99 | 819,011 |
| 3.0 | 0.99 | 1.00 | 1.00 | 2,061,989 |
| 4.0 | 0.96 | 0.99 | 0.97 | 1,550,155 |
| 5.0 | 1.00 | 1.00 | 1.00 | 240,528 |
| 6.0 | 0.99 | 0.95 | 0.97 | 1,031,974 |
| 7.0 | 0.91 | 0.99 | 0.95 | 522,122 |
| 8.0 | 0.99 | 0.96 | 0.98 | 1,400,360 |
| 9.0 | 1.00 | 0.07 | 0.14 | 37,392 |
| 10.0 | 1.00 | 1.00 | 1.00 | 1,294,758 |
| 11.0 | 1.00 | 1.00 | 1.00 | 4,016,516 |
| 12.0 | 1.00 | 0.89 | 0.94 | 73,667 |
| 13.0 | 1.00 | 0.92 | 0.96 | 88 |
| Accuracy | 0.9900 (14,085,528) | |||
| Macro Avg | 0.99 | 0.91 | 0.92 | 14,085,528 |
| Weighted Avg | 0.99 | 0.99 | 0.99 | 14,085,528 |
| Class | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| 0.0 | 0.99 | 1.00 | 1.00 | 22,766 |
| 1.0 | 0.99 | 1.00 | 0.99 | 1,014,202 |
| 2.0 | 0.99 | 1.00 | 0.99 | 819,011 |
| 3.0 | 0.99 | 1.00 | 1.00 | 2,061,989 |
| 4.0 | 0.96 | 0.99 | 0.97 | 1,550,155 |
| 5.0 | 1.00 | 1.00 | 1.00 | 240,528 |
| 6.0 | 0.99 | 0.95 | 0.97 | 1,031,974 |
| 7.0 | 0.91 | 0.99 | 0.95 | 522,122 |
| 8.0 | 0.99 | 0.96 | 0.98 | 1,400,360 |
| 9.0 | 1.00 | 0.07 | 0.14 | 37,392 |
| 10.0 | 1.00 | 1.00 | 1.00 | 1,294,758 |
| 11.0 | 1.00 | 1.00 | 1.00 | 4,016,516 |
| 12.0 | 1.00 | 0.89 | 0.94 | 73,667 |
| 13.0 | 1.00 | 0.92 | 0.96 | 88 |
| Accuracy | 0.9900 (14,085,528) | |||
| Macro Avg | 0.99 | 0.91 | 0.92 | 14,085,528 |
| Weighted Avg | 0.99 | 0.99 | 0.99 | 14,085,528 |
| Metrics | Base Model | Proposed Model |
|---|---|---|
| Precision (Macro Avg) | 0.47243 | 0.62157 |
| Recall (Macro Avg) | 0.47695 | 0.45497 |
| F1-Score (Macro Avg) | 0.47177 | 0.46753 |
| Precision (Weighted Avg) | 0.79098 | 0.82486 |
| Recall (Weighted Avg) | 0.78901 | 0.82722 |
| F1-Score (Weighted Avg) | 0.78955 | 0.81179 |
| Accuracy | 0.78901 | 0.82722 |
| Metrics | Base Model | Proposed Model |
|---|---|---|
| Precision (Macro Avg) | 0.54269 | 0.61963 |
| Recall (Macro Avg) | 0.55215 | 0.54234 |
| F1-Score (Macro Avg) | 0.54682 | 0.55647 |
| Precision (Weighted Avg) | 0.83050 | 0.85081 |
| Recall (Weighted Avg) | 0.83122 | 0.85297 |
| F1-Score (Weighted Avg) | 0.83079 | 0.84714 |
| Accuracy | 0.83122 | 0.85297 |
| Metrics | Base Model | Proposed Model |
|---|---|---|
| Precision (Macro Avg) | 0.58713 | 0.77094 |
| Recall (Macro Avg) | 0.60104 | 0.57212 |
| F1-Score (Macro Avg) | 0.59308 | 0.59138 |
| Precision (Weighted Avg) | 0.84939 | 0.86714 |
| Recall (Weighted Avg) | 0.84928 | 0.86401 |
| F1-Score (Weighted Avg) | 0.84932 | 0.85975 |
| Accuracy | 0.84928 | 0.86401 |
| Metrics | Base Model | Proposed Model |
|---|---|---|
| Precision (Macro Avg) | 0.29998 | 0.26 |
| Recall (Macro Avg) | 0.21074 | 0.19 |
| F1-Score (Macro Avg) | 0.18447 | 0.14 |
| Precision (Weighted Avg) | 0.51886 | 0.51 |
| Recall (Weighted Avg) | 0.56098 | 0.55 |
| F1-Score (Weighted Avg) | 0.47851 | 0.41 |
| Accuracy | 0.56098 | 0.55 |
| Metrics | Base Model | Proposed Model |
|---|---|---|
| Precision (Macro Avg) | 0.16 | 0.23478 |
| Recall (Macro Avg) | 0.18 | 0.19994 |
| F1-Score (Macro Avg) | 0.13 | 0.16741 |
| Precision (Weighted Avg) | 0.41 | 0.46723 |
| Recall (Weighted Avg) | 0.54 | 0.55308 |
| F1-Score (Weighted Avg) | 0.40 | 0.44911 |
| Accuracy | 0.54 | 0.55308 |
| Metrics | Base Model | Proposed Model |
|---|---|---|
| Precision (Macro Avg) | 0.20 | 0.19405 |
| Recall (Macro Avg) | 0.20 | 0.19831 |
| F1-Score (Macro Avg) | 0.17 | 0.16435 |
| Precision (Weighted Avg) | 0.42 | 0.43987 |
| Recall (Weighted Avg) | 0.54 | 0.55135 |
| F1-Score (Weighted Avg) | 0.43 | 0.44469 |
| Accuracy | 0.54 | 0.55135 |
| Metrics | Base Model | Proposed Model |
|---|---|---|
| Precision (Macro Avg) | 0.49496 | 0.61501 |
| Recall (Macro Avg) | 0.44648 | 0.48520 |
| F1-Score (Macro Avg) | 0.45134 | 0.51273 |
| Precision (Weighted Avg) | 0.79908 | 0.82203 |
| Recall (Weighted Avg) | 0.81743 | 0.83795 |
| F1-Score (Weighted Avg) | 0.80544 | 0.81859 |
| Accuracy | 0.81743 | 0.83795 |
| Metrics | Base Model | Proposed Model |
|---|---|---|
| Precision (Macro Avg) | 0.63372 | 0.54920 |
| Recall (Macro Avg) | 0.48442 | 0.51740 |
| F1-Score (Macro Avg) | 0.51185 | 0.52878 |
| Precision (Weighted Avg) | 0.82432 | 0.83616 |
| Recall (Weighted Avg) | 0.84017 | 0.84141 |
| F1-Score (Weighted Avg) | 0.81829 | 0.83783 |
| Accuracy | 0.84017 | 0.84141 |
| Metrics | Base Model | Proposed Model |
|---|---|---|
| Precision (Macro Avg) | 0.61529 | 0.61760 |
| Recall (Macro Avg) | 0.47534 | 0.58065 |
| F1-Score (Macro Avg) | 0.50116 | 0.58895 |
| Precision (Weighted Avg) | 0.81912 | 0.85338 |
| Recall (Weighted Avg) | 0.83543 | 0.85460 |
| F1-Score (Weighted Avg) | 0.81190 | 0.85353 |
| Accuracy | 0.83543 | 0.85460 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Williams, B.; Qian, L. Semi-Supervised Learning for Intrusion Detection in Large Computer Networks. Appl. Sci. 2025, 15, 5930. https://doi.org/10.3390/app15115930
Williams B, Qian L. Semi-Supervised Learning for Intrusion Detection in Large Computer Networks. Applied Sciences. 2025; 15(11):5930. https://doi.org/10.3390/app15115930
Chicago/Turabian StyleWilliams, Brandon, and Lijun Qian. 2025. "Semi-Supervised Learning for Intrusion Detection in Large Computer Networks" Applied Sciences 15, no. 11: 5930. https://doi.org/10.3390/app15115930
APA StyleWilliams, B., & Qian, L. (2025). Semi-Supervised Learning for Intrusion Detection in Large Computer Networks. Applied Sciences, 15(11), 5930. https://doi.org/10.3390/app15115930