A Real-Time Semi-Supervised Log Anomaly Detection Framework for ALICE O2 Facilities

 , ,
, ,
Abstract
1. Introduction
- We present a complete framework for automatic log anomaly detection with a focus on explaining semantics inside each topic and automatically labeling the incoming log messages.
- We developed a semi-supervised real-time log anomaly detection model designed to provide actionable insights for shifters as new log messages arrive.
- We provide a monitoring dashboard to analyze distribution of topics in log messages, which helps identify anomalies effectively.
2. Literature Review
2.1. Latent Dirichlet Allocation (LDA)
2.2. Latent Semantic Analysis (LSA)
2.3. Non-Negative Matrix Factorization (NMF)
2.4. Word Embeddings
2.4.1. Bag of Words (BoW)
2.4.2. Term Frequency-Inverse Document Frequency (TF-IDF)
2.4.3. Sentence Transformer (SBERT)
3. Methodology
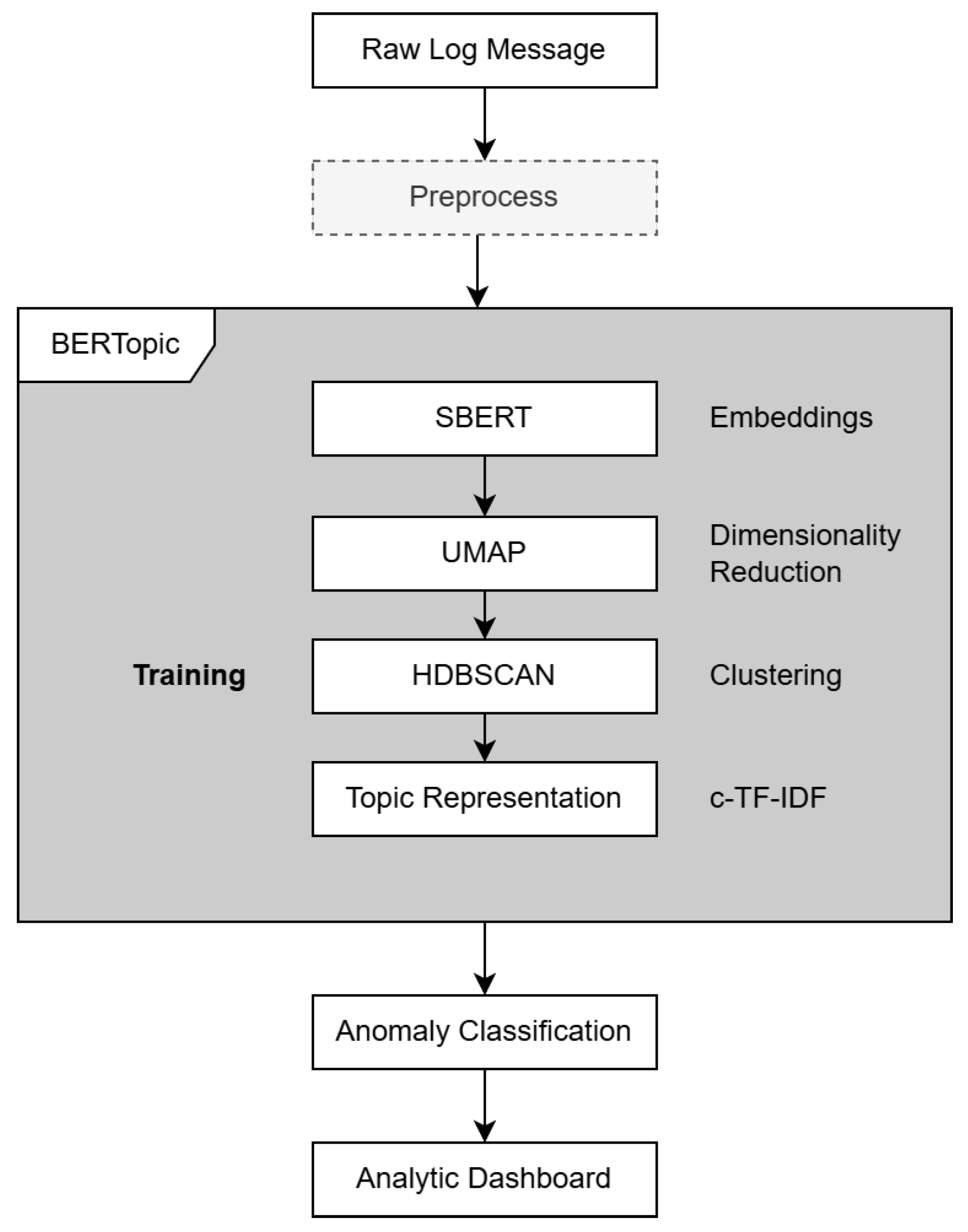
3.1. Proposed Framework
3.1.1. Data Preprocessing
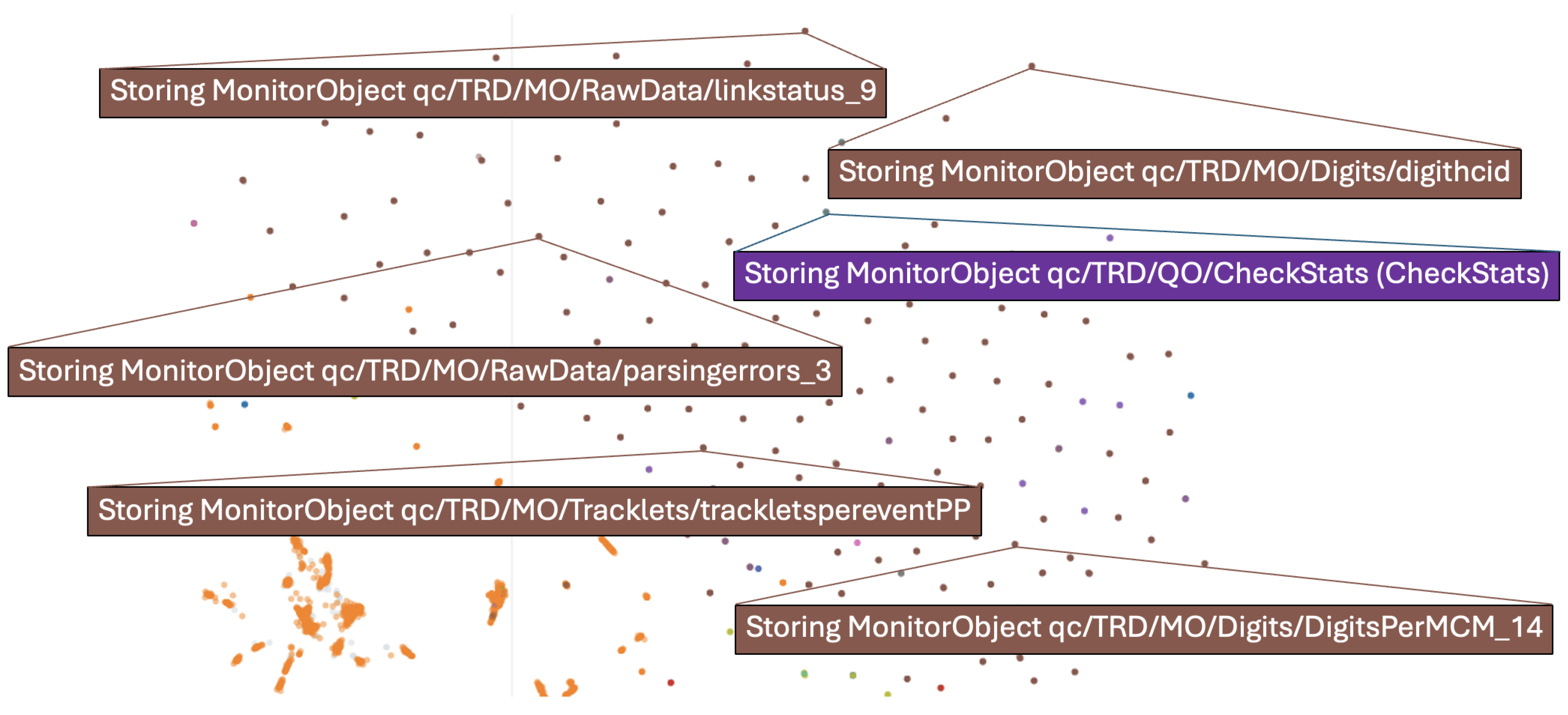
3.1.2. BERTopic
- Text embedding: BERTopic utilizes pre-trained transformer models, sentence transformer embeddings (SBERTs), to convert textual data into dense vector representations, capturing the contextual relationships between words and sentences.
- Dimensionality reduction: BERTopic applies dimensionality reduction techniques (i.e., uniform manifold approximation and projection (UMAP) [41]). This reduces the complexity of the embedding space while preserving the essential structure of the data, facilitating efficient and meaningful clustering in subsequent steps.
- Clustering: The embedded vectors are clustered using Hierarchical Density-Based Spatial Clustering of Applications with Noise (HDBSCAN) [42] as a default algorithm in BERTopic. HDBSCAN excels at identifying clusters of varying densities, handling noise, and automatically determining the optimal number of clusters, making it ideal for complex data. Alternatively, other algorithms can be applied. DBSCAN [43], another density-based method, performs well for uniform-density clusters but requires manual parameter tuning and struggles with varying densities. K-means [44,45], a centroid-based algorithm, is computationally efficient but assumes spherical clusters and requires the number of clusters to be predefined.
- Topic representation: Class-based Term Frequency-Inverse Document Frequency (c-TF-IDF) has been introduced in BERTopic for topic representation. It is an adaptation of the traditional TF-IDF technique designed for topic modeling. Unlike TF-IDF, c-TF-IDF calculates term significance within specific clusters or classes (e.g., topics). It aggregates term frequencies within a class and adjusts for their rarity across other classes, highlighting terms that define each topic. This approach is particularly effective in methods such as BERTopic, as it emphasizes the key terms that characterize each topic. This approach provides a meaningful representation of the underlying clusters by highlighting the terms that are used to define the cluster. The c-TF-IDF score for a term x within topic c is computed as follows:where tfx,c is the frequency of word x in class c, fx is the frequency of word x across all classes, and A is the average number of words per class.
3.1.3. Anomaly Classification
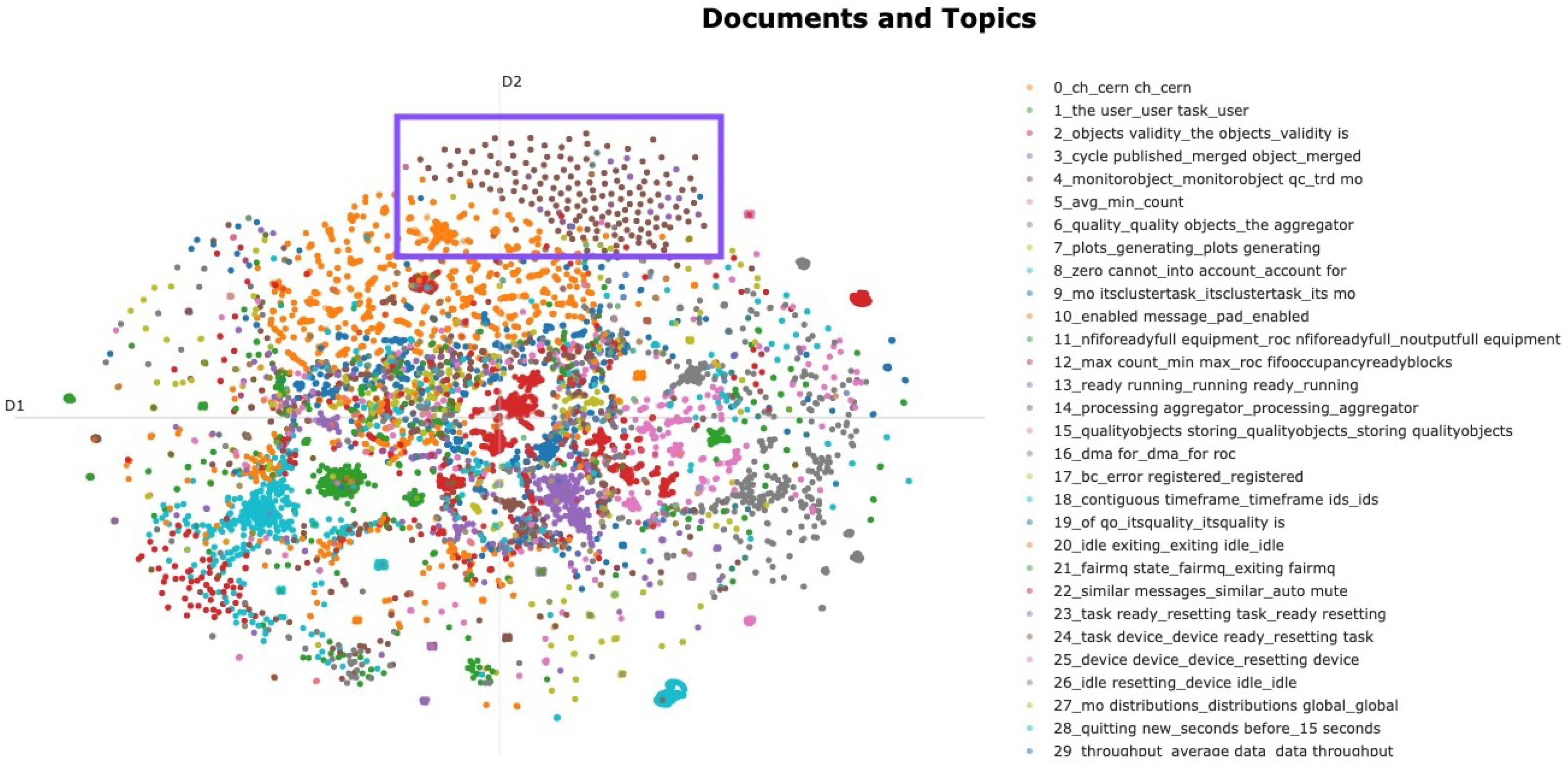
3.1.4. Analytic Dashboard
- Anomaly status: This section prominently displays whether the analyzed log message is classified as an anomaly or normal. It enables operators to immediately assess the urgency of the issue.
- Log message content: This part presents the original content of the log message, allowing users to understand the raw system output. It provides a whole context for interpreting the detected anomaly.
- Classified topic: This shows the topic number assigned to the log message by BERTopic, indicating the cluster it belongs to. This helps group similar incidents and track recurring issues.
- Log message information: This section contains key metadata fields extracted from the log, including severity, system, detector, and facility. These metadata elements are crucial for routing alerts to the correct subsystem experts and understanding the operational scope of the issue.
- Topic terms: This panel lists the top keywords and multi-word expressions that define the assigned topic, along with their corresponding c-TF-IDF scores. These terms offer insight into the semantic themes captured via the model and aid in identifying anomaly terms.
- Topic distribution: This pie chart illustrates the probabilistic topic distribution for the log message, showing how strongly the message aligns with other topics beyond the primary one. This probabilistic view supports uncertainty estimation and highlights potential overlaps or ambiguities in the message’s classification.
3.2. Datasets
3.2.1. Infologger
3.2.2. BGL
3.3. Data Labeling
3.4. Baseline Methods
3.5. Hyperparameter Tuning on HDBSCAN
3.5.1. Min_Samples
3.5.2. Min_Cluster_Size
3.5.3. Cluster_Selection_Epsilon
3.6. Evaluation
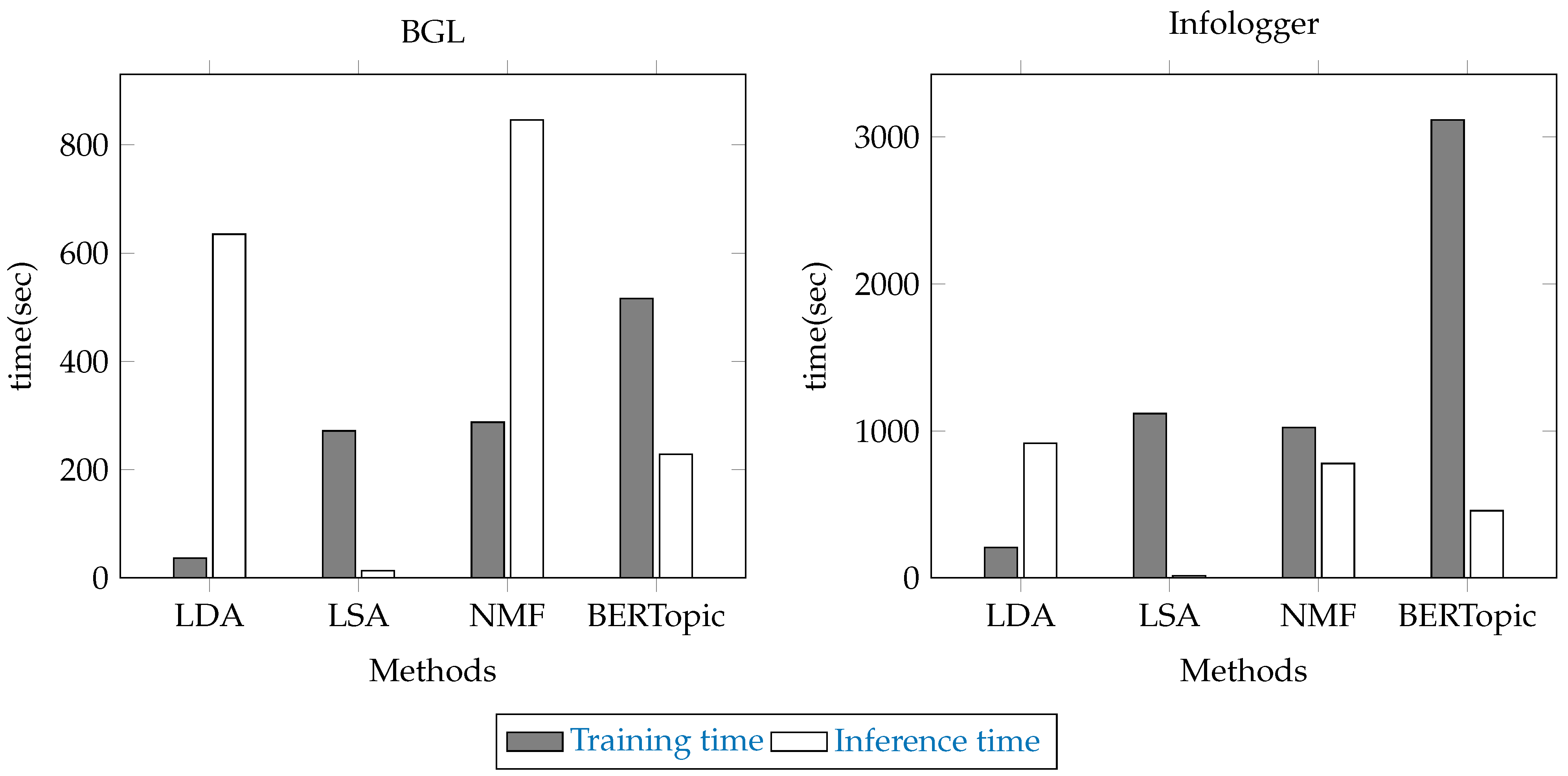
3.7. Experimental Setup
4. Results and Discussion
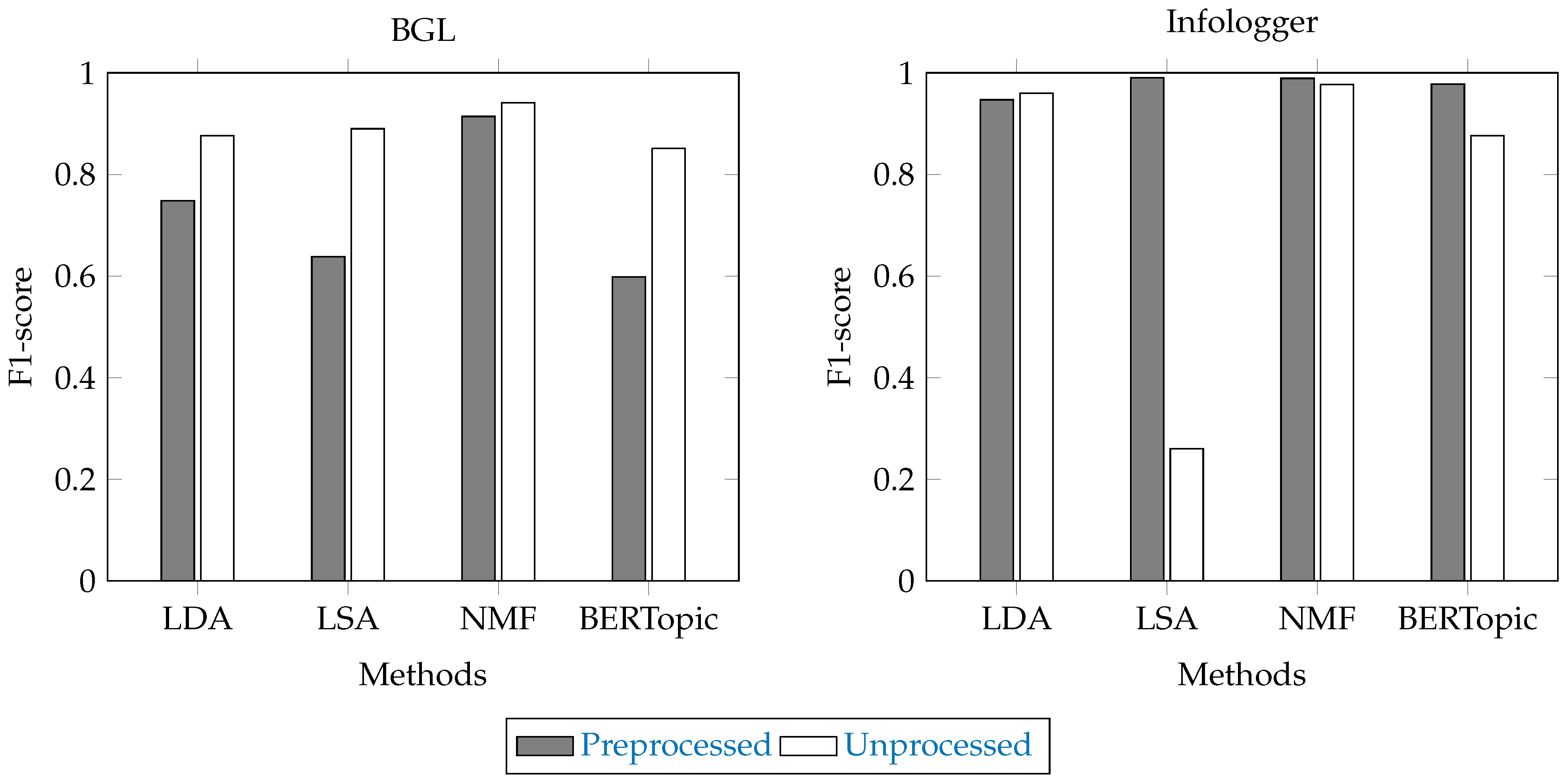
4.1. Comparison with Traditional Topic Models
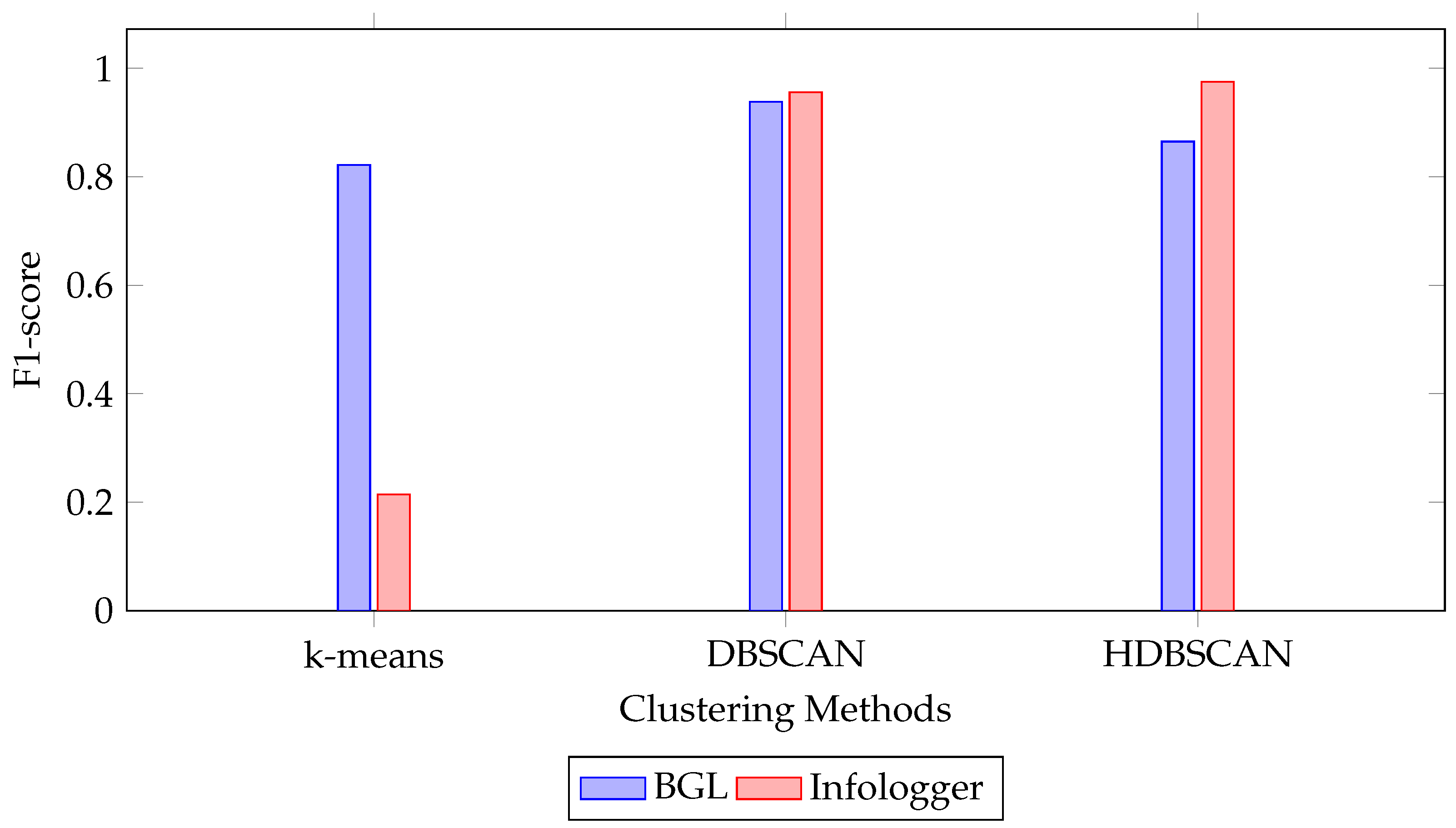
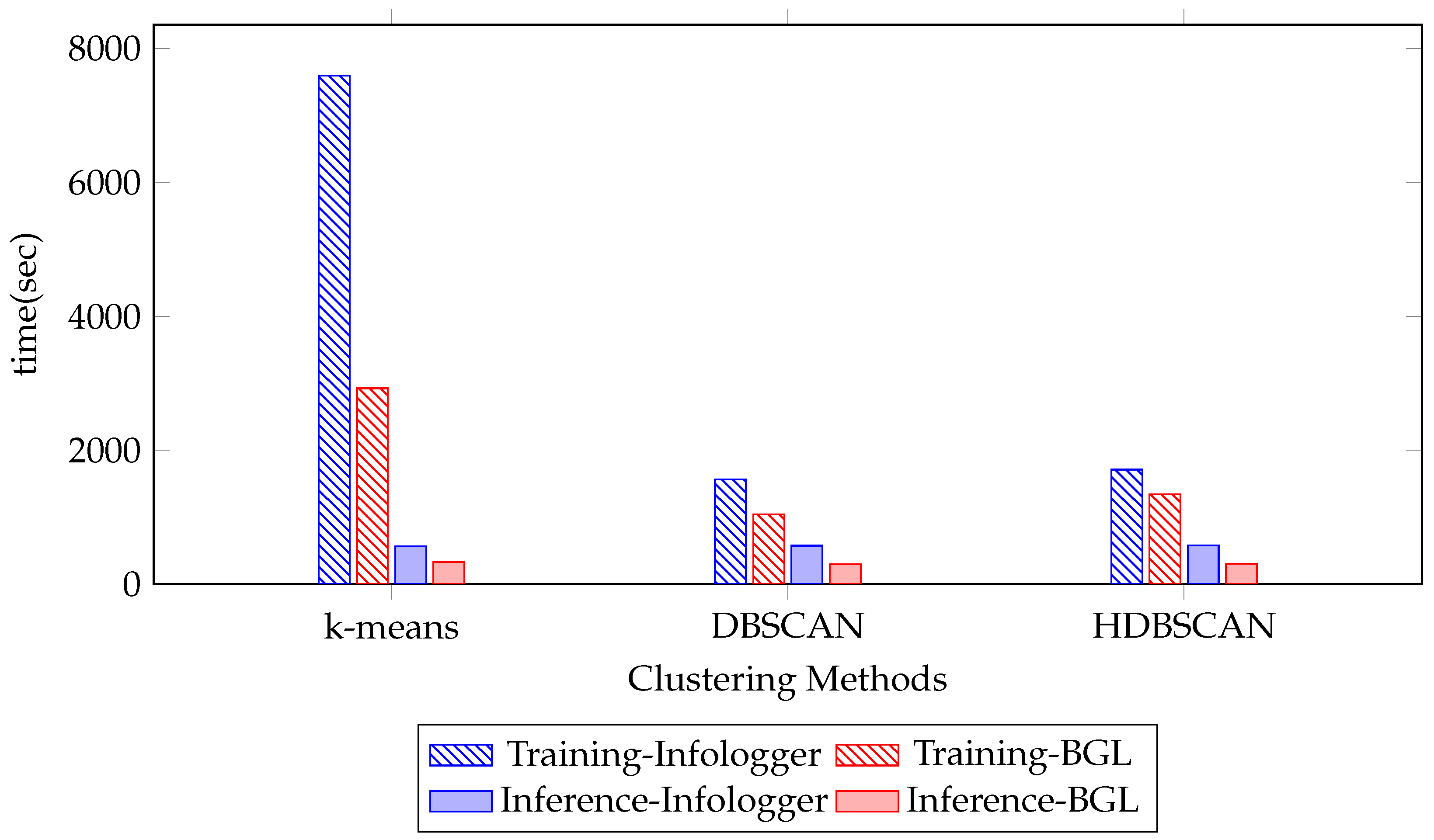
4.2. The Effect of Clustering Algorithm
4.3. The Effect of Hyperparameter in the HDBSCAN
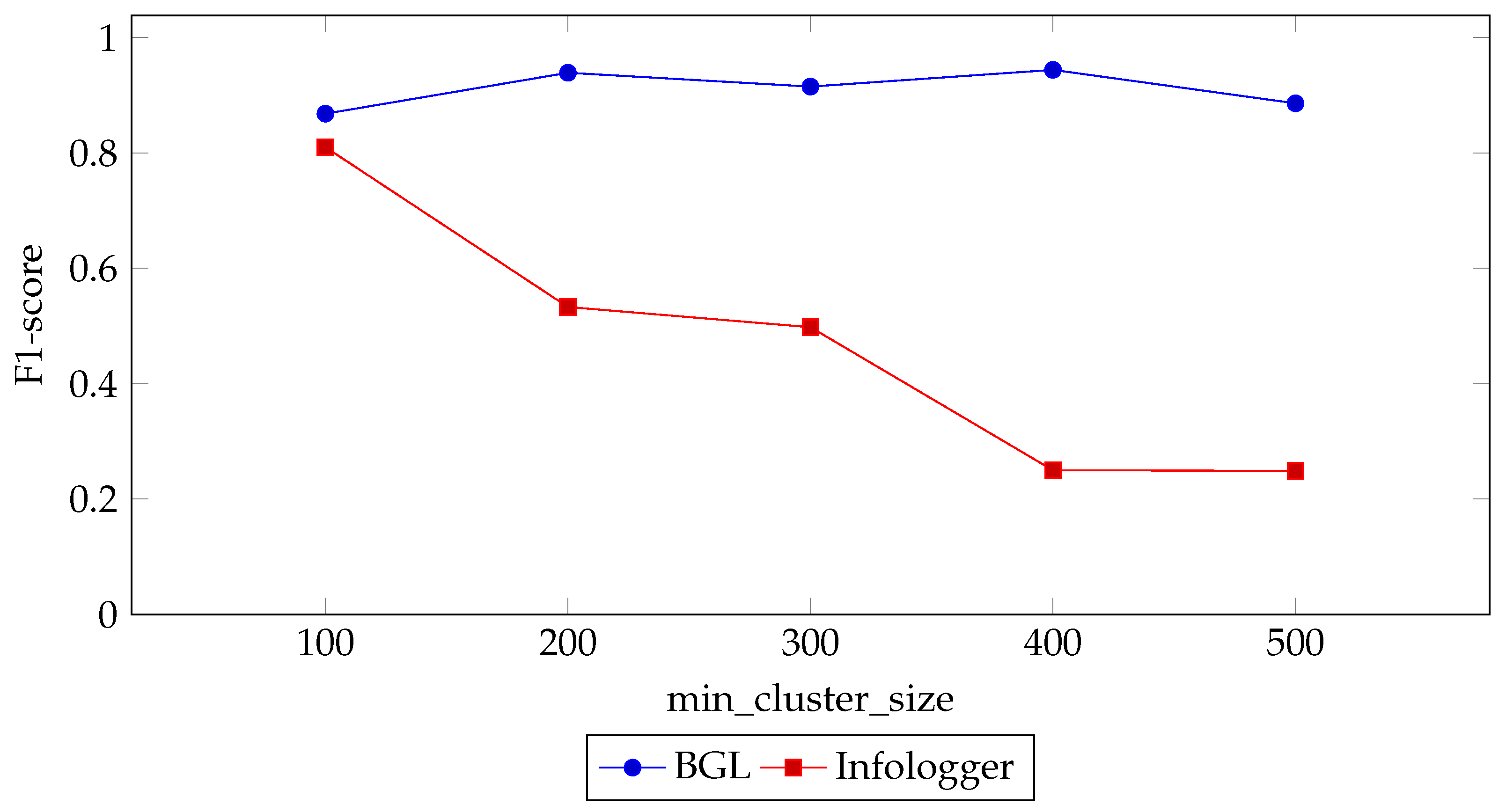
4.3.1. Min_Cluster_Size
4.3.2. Cluster_Selection_Epsilon (ε)
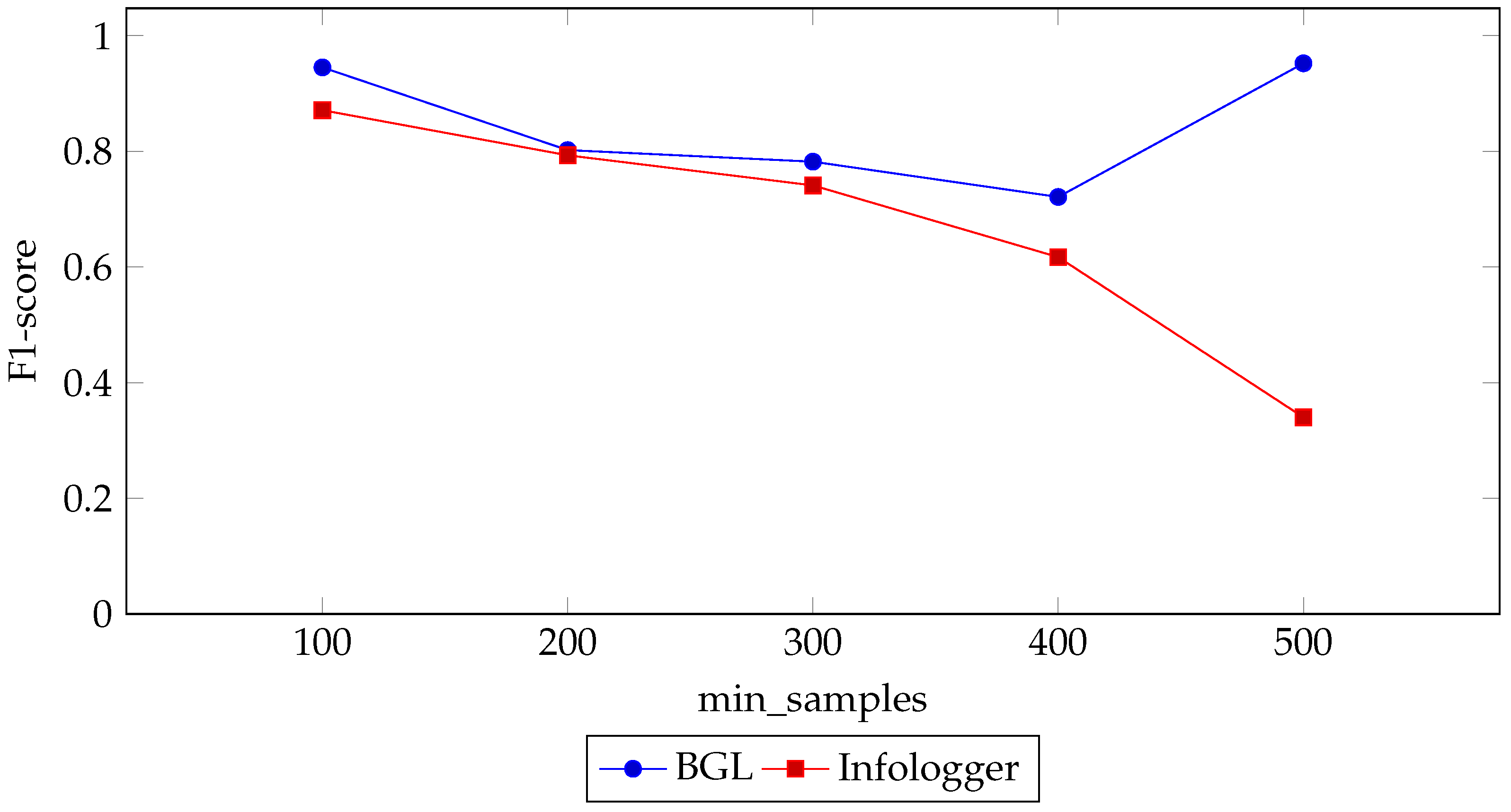
4.3.3. Min_Samples
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ALICE | A Large Ion Collider Experiment |
| BERT | Bidirectional Encoder Representations from Transformers |
| BGL | BlueGene/L Supercomputer System |
| Bi-LSTM | Bidirectional Long Short-Term Memory |
| BoW | Bag-of-Words |
| CERN | The European Organization for Nuclear Research |
| CNN | Convolutional Neural Network |
| c-TF-IDF | Class-based Term Frequency-Inverse Document Frequency |
| DBSCAN | Density-Based Spatial Clustering of Applications with Noise |
| FLP | First-Level Processing |
| FN | False Negative |
| FNR | False Negative Rate |
| FP | False Positive |
| FPR | False Positive Rate |
| HDBSCAN | Hierarchical Density-Based Spatial Clustering of Applications with Noise |
| LDA | Latent Dirichlet Allocation |
| LHC | Large Hadron Collider |
| LSA | Latent Semantic Analysis |
| LSTM | Long Short-Term Memory |
| MDPI | Multidisciplinary Digital Publishing Institute |
| MLP | Multi-Layer Perceptron |
| NMF | Non-Negative Matrix Factorization |
| O2 | Online–Offline |
| PCA | Principal Component Analysis |
| QC | Quality Control |
| SBERT | Sentence Transformer Embeddings |
| TF-IDF | Term Frequency–Inverse Document Frequency |
| TN | True Negative |
| TP | True Positive |
| TPR | True Positive Rate |
| UMAP | Uniform Manifold Approximation and Projection |
References
- The ALICE Collaboration; Aamodt, K.; Abrahantes, A.; Achenbach, R.; Acounis, S.; Adamova, D.; Adler, C.; Aggarwal, M.; Agnese, F.; Aglieri Rinella, G.; et al. The ALICE experiment at the CERN LHC. J. Instrum. 2008, 3, S08002. [Google Scholar] [CrossRef]
- Buncic, P.; Krzewicki, M.; Vande Vyvre, P. Technical Design Report for the Upgrade of the Online-Offline Computing System; Technical Report CERN-LHCC-2015-006; CERN: Geneva, Switzerland, 2015. [Google Scholar]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation Forest. In Proceedings of the 2008 8th IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 413–422. [Google Scholar] [CrossRef]
- Du, M.; Li, F.; Zheng, G.; Srikumar, V. DeepLog: Anomaly Detection and Diagnosis from System Logs Through Deep Learning. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security (CCS ’17), Dallas, TX, USA, 30 October–3 November 2017; pp. 1285–1298. [Google Scholar] [CrossRef]
- Lu, S.; Wei, X.; Li, Y.; Wang, L. Detecting Anomaly in Big Data System Logs Using Convolutional Neural Network. In Proceedings of the 2018 IEEE 16th International Conference on Dependable, Autonomic and Secure Computing, 16th International Conference on Pervasive Intelligence and Computing, 4th International Conference on Big Data Intelligence and Computing and Cyber Science and Technology Congress (DASC/PiCom/DataCom/CyberSciTech), Athens, Greece, 12–15 August 2018; pp. 151–158. [Google Scholar] [CrossRef]
- Le, V.H.; Zhang, H. Log-Based Anomaly Detection Without Log Parsing. In Proceedings of the 2021 36th IEEE/ACM International Conference on Automated Software Engineering (ASE 2021), Melbourne, Australia, 15–19 November 2021; pp. 492–504. [Google Scholar] [CrossRef]
- Alsini, R.; Alsaedi, N.; Alarifi, A.; Alsulaiman, M. Topic Modeling for Anomaly Detection on Twitter. Appl. Sci. 2022, 12, 11059. [Google Scholar] [CrossRef]
- Song, Y.J.; Nam, K.H.; Yun, I.D. Anomaly Detection through Grouping of SMD Machine Sounds Using Hierarchical Clustering. Appl. Sci. 2023, 13, 7569. [Google Scholar] [CrossRef]
- Mazarbhuiya, F.A.; Shenify, M. A mixed clustering approach for real-time anomaly detection. Appl. Sci. 2023, 13, 4151. [Google Scholar] [CrossRef]
- Grootendorst, M. BERTopic: Neural topic modeling with a class-based TF-IDF procedure. arXiv 2022, arXiv:2203.05794. [Google Scholar]
- Farzad, A.; Gulliver, T.A. Unsupervised log message anomaly detection. ICT Express 2020, 6, 229–237. [Google Scholar] [CrossRef]
- Bank, D.; Koenigstein, N.; Giryes, R. Autoencoders. In Machine Learning for Data Science Handbook: Data Mining and Knowledge Discovery Handbook; Rokach, L., Maimon, O., Shmueli, E., Eds.; Springer International Publishing: Cham, Switzerland, 2023; pp. 353–374. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- He, P.; Zhu, J.; He, S.; Li, J.; Lyu, M.R. An Evaluation Study on Log Parsing and Its Use in Log Mining. In Proceedings of the 2016 46th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN 2016), Toulouse, France, 28 June–1 July 2016; pp. 654–661. [Google Scholar] [CrossRef]
- Fukushima, K. Visual Feature Extraction by a Multilayered Network of Analog Threshold Elements. IEEE Trans. Syst. Sci. Cybern. 1969, 5, 322–333. [Google Scholar] [CrossRef]
- Rosenblatt, F. The perceptron: A probabilistic model for information storage and organization in the brain. Psychol. Rev. 1958, 65, 386–408. [Google Scholar] [CrossRef]
- Zhang, X.; Xu, Y.; Lin, Q.; Qiao, B.; Zhang, H.; Dang, Y.; Xie, C.; Yang, X.; Cheng, Q.; Li, Z.; et al. Robust Log-Based Anomaly Detection on Unstable Log Data. In Proceedings of the 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE 2019), Tallinn, Estonia, 26–30 August 2019; pp. 807–817. [Google Scholar] [CrossRef]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Netw. 2005, 18, 602–610. [Google Scholar] [CrossRef]
- Meng, W.; Liu, Y.; Zhu, Y.; Zhang, S.; Pei, D.; Liu, Y.; Chen, Y.; Zhang, R.; Tao, S.; Sun, P.; et al. Loganomaly: Unsupervised Detection of Sequential and Quantitative Anomalies in Unstructured Logs. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Lee, D.D.; Seung, H.S. Learning the parts of objects by non-negative matrix factorization. Nature 1999, 401, 788–791. [Google Scholar] [CrossRef]
- Kasliwal, B.; Bhatia, S.; Saini, S.; Thaseen, I.S.; Kumar, C.A. A Hybrid Anomaly Detection Model Using G-LDA. In Proceedings of the 2014 IEEE International Advance Computing Conference (IACC), Gurgaon, India, 21–22 February 2014; pp. 288–293. [Google Scholar] [CrossRef]
- Elkhadir, Z.; Chougdali, K.; Benattou, M. Combination of R1-PCA and Median LDA for Anomaly Network Detection. In Proceedings of the 2017 Intelligent Systems and Computer Vision (ISCV 2017), Fez, Morocco, 17–19 April 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Mahapatra, A.; Srivastava, N.; Srivastava, J. Contextual Anomaly Detection in Text Data. Algorithms 2012, 5, 469–489. [Google Scholar] [CrossRef]
- Wu, X.; Li, C. Short Text Topic Modeling with Flexible Word Patterns. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN 2019), Budapest, Hungary, 14–19 July 2019; pp. 1–7. [Google Scholar] [CrossRef]
- Furnas, G.W.; Deerwester, S.; Dumais, S.T.; Landauer, T.K.; Harshman, R.A.; Streeter, L.A.; Lochbaum, K.E. Information Retrieval Using a Singular Value Decomposition Model of Latent Semantic Structure. In Proceedings of the 11th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’88), Grenoble, France, 13–15 June 1988; pp. 465–480. [Google Scholar] [CrossRef]
- Lefoane, M.; Ghafir, I.; Kabir, S.; Awan, I.U. Latent Semantic Analysis for Feature Selection: A Proposed Approach for Anomaly Detection in Network Traffic. In Proceedings of the 2024 14th International Conference on Advanced Computer Information Technologies (ACIT 2024), Ceske Budejovice, Czech Republic, 19–21 September 2024; pp. 517–522. [Google Scholar] [CrossRef]
- Fawaz, A.M.; Sanders, W.H. Learning Process Behavioral Baselines for Anomaly Detection. In Proceedings of the 2017 IEEE 22nd Pacific Rim International Symposium on Dependable Computing (PRDC 2017), Christchurch, New Zealand, 22–25 January 2017; pp. 145–154. [Google Scholar] [CrossRef]
- McCulloh, I.; Daimler, E.; Carley, K.M. Using Latent Semantic Analysis of Email to Detect Change in Social Groups. In Proceedings of the 2008 International Conference on Data Mining (DMIN 2008), Las Vegas, NV, USA, 14–17 July 2008; pp. 613–618. [Google Scholar]
- Hofmann, T. Probabilistic Latent Semantic Analysis. arXiv 2013, arXiv:1301.6705. [Google Scholar]
- Wang, W.; Guan, X.; Zhang, X. Profiling Program and User Behaviors for Anomaly Intrusion Detection Based on Non-Negative Matrix Factorization. In Proceedings of the 2004 43rd IEEE Conference on Decision and Control (CDC 2004), Nassau, Bahamas, 14–17 December 2004; Volume 1, pp. 99–104. [Google Scholar]
- Alshammari, H.; Ghorbel, O.; Aseeri, M.; Abid, M. Non-Negative Matrix Factorization (NMF) for Outlier Detection in Wireless Sensor Networks. In Proceedings of the 2018 14th International Wireless Communications & Mobile Computing Conference (IWCMC 2018), Limassol, Cyprus, 25–29 June 2018; pp. 506–511. [Google Scholar] [CrossRef]
- Li, X.; Guan, Y.; Fu, B.; Luo, Z. Anomaly-aware symmetric non-negative matrix factorization for short text clustering. Knowl. Inf. Syst. 2024, 67, 1481–1506. [Google Scholar] [CrossRef]
- Esposito, F. A Review on Initialization Methods for Nonnegative Matrix Factorization: Towards Omics Data Experiments. Mathematics 2021, 9, 1006. [Google Scholar] [CrossRef]
- Wang, Y.X.; Zhang, Y.J. Nonnegative Matrix Factorization: A Comprehensive Review. IEEE Trans. Knowl. Data Eng. 2013, 25, 1336–1353. [Google Scholar] [CrossRef]
- Jurafsky, D.; Martin, J.H. Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition; Prentice Hall: Hoboken, NJ, USA, 2000; p. 106. [Google Scholar]
- McTear, M.; Callejas, Z.; Griol, D. The Conversational Interface: Talking to Smart Devices; Springer: Cham, Switzerland, 2016; p. 167. [Google Scholar]
- Sparck Jones, K. A Statistical Interpretation of Term Specificity and Its Application in Retrieval. J. Doc. 1972, 28, 11–21. [Google Scholar] [CrossRef]
- He, P.; Zhu, J.; Zheng, Z.; Lyu, M.R. Drain: An Online Log Parsing Approach with Fixed Depth Tree. In Proceedings of the 2017 IEEE International Conference on Web Services (ICWS 2017), Honolulu, HI, USA, 25–30 June 2017; pp. 33–40. [Google Scholar] [CrossRef]
- McInnes, L.; Healy, J.; Melville, J. UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction. arXiv 2020, arXiv:1802.03426. [Google Scholar]
- Campello, R.J.G.B.; Moulavi, D.; Sander, J. Density-based clustering based on hierarchical density estimates. In Advances in Knowledge Discovery and Data Mining; Pei, J., Tseng, V.S., Cao, L., Motoda, H., Xu, G., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 160–172. [Google Scholar]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. In Proceedings of the 2nd International Conference on Knowledge Discovery and Data Mining (KDD’96), Portland, OR, USA, 2–4 August 1996; pp. 226–231. [Google Scholar]
- Lloyd, S. Least squares quantization in PCM. IEEE Trans. Inf. Theory 1982, 28, 129–137. [Google Scholar] [CrossRef]
- MacQueen, J. Some Methods for Classification and Analysis of Multivariate Observations. In Proceedings of the 5th Berkeley Symposium on Mathematical Statistics and Probability, Berkeley, CA, USA, 21 June–18 July 1965; University of California Press: Berkeley, CA, USA, 1967. [Google Scholar]
- Chapeland, S.; Carena, F.; Carena, W.; Barroso, V.C.; Costa, F.; Dénes, E.; Divià, R.; Fuchs, U.; Grigore, A.; Ionita, C.; et al. The ALICE DAQ infoLogger. J. Phys. Conf. Ser. 2014, 513, 012005. [Google Scholar] [CrossRef]
- Zhu, J.; He, S.; He, P.; Liu, J.; Lyu, M.R. Loghub: A Large Collection of System Log Datasets for AI-Driven Log Analytics. In Proceedings of the IEEE International Symposium on Software Reliability Engineering (ISSRE), Florence, Italy, 9–12 October 2023. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Infologger Dataset | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Line Id | severity | level | timestamp | hostname | rolename | pid | username | system | facility | detector | partition | run | content |
| 1 | E | 2 | 1716783000 | alio2-cr1-qc03 | alio2-cr1-qc03 | 1649194 | qc | QC | post/TOFQualityTask | TOF | 2nenhEPazQ4 | 552028 | Requested resource does not exist: |
| BGL Dataset | |||||||||||||
| Line Id | label | timestamp | date | node | time | noderepeat | type | component | level | content | |||
| 1 | KERNDTLB | 1118536327 | 2005.06.11 | R30-M0-N9-C:J16-U01 | 2005-06-11-17.32.07.581048 | R30-M0-N9-C:J16-U01 | RAS | KERNEL | FATAL | data TLB error interrupt | |||
| Dataset | Max # Logs/Sequence | Normal # Sessions | Anomaly # Sessions | Total # Sessions |
|---|---|---|---|---|
| Infologger | 2,194,073 | 79,528 (99.52%) | 387 (0.48%) | 79,915 (100%) |
| BGL | 152,329 | 37,875 (54.69%) | 31,374 (45.31%) | 69,249 (100%) |
| No. | Parameter | Value |
|---|---|---|
| 1. | min_cluster_size | 5 |
| 2. | min_samples | 5 |
| 3. | cluster_selection_epsilon | 0.0 |
| Dataset | Model | No. of Topics | P | R | F1 | FPR | FNR |
|---|---|---|---|---|---|---|---|
| Infologger | LDA | 100 | 0.933 | 0.994 | 0.960 | 0.0002 | 0.0064 |
| (CERN) | 200 | 0.757 | 0.993 | 0.811 | 0.0030 | 0.0065 | |
| 300 | 0.141 | 0.994 | 0.247 | 0.0149 | 0.0058 | ||
| LSA | 100 | 0.148 | 0.993 | 0.258 | 0.0141 | 0.0070 | |
| 200 | 0.144 | 0.996 | 0.252 | 0.0146 | 0.0041 | ||
| 300 | 0.150 | 0.996 | 0.260 | 0.0140 | 0.0041 | ||
| NMF | 100 | 0.948 | 0.976 | 0.962 | 0.0001 | 0.0239 | |
| 200 | 0.147 | 0.987 | 0.257 | 0.0141 | 0.0130 | ||
| 300 | 0.962 | 0.994 | 0.977 | 0.0001 | 0.0064 | ||
| BERTopic | 100 | 0.775 | 0.988 | 0.868 | 0.0007 | 0.0123 | |
| 200 | 0.782 | 0.996 | 0.876 | 0.0007 | 0.0043 | ||
| 300 | 0.783 | 0.995 | 0.876 | 0.0007 | 0.0048 | ||
| BGL | LDA | 100 | 0.826 | 0.932 | 0.876 | 0.0138 | 0.0678 |
| 200 | 0.438 | 1.000 | 0.609 | 0.0903 | 0.0000 | ||
| 300 | 0.415 | 1.000 | 0.587 | 0.0987 | 0.0000 | ||
| LSA | 100 | 0.747 | 0.706 | 0.726 | 0.0168 | 0.2942 | |
| 200 | 0.778 | 0.991 | 0.872 | 0.0198 | 0.0089 | ||
| 300 | 0.808 | 0.990 | 0.890 | 0.0165 | 0.0098 | ||
| NMF | 100 | 0.618 | 0.706 | 0.659 | 0.0306 | 0.2944 | |
| 200 | 0.895 | 0.991 | 0.941 | 0.0081 | 0.0090 | ||
| 300 | 0.869 | 0.988 | 0.925 | 0.0105 | 0.0115 | ||
| BERTopic | 100 | 0.679 | 0.970 | 0.790 | 0.0365 | 0.0305 | |
| 200 | 0.766 | 0.970 | 0.851 | 0.0223 | 0.0303 | ||
| 300 | 0.703 | 0.972 | 0.811 | 0.0309 | 0.0285 |
| Dataset | Model | No. of Topics | P | R | F1 | FPR | FNR |
|---|---|---|---|---|---|---|---|
| Infologger | LDA | 100 | 0.906 | 0.996 | 0.946 | 0.0003 | 0.0040 |
| (CERN) | 200 | 0.903 | 0.996 | 0.947 | 0.0003 | 0.0039 | |
| 300 | 0.906 | 0.996 | 0.946 | 0.0003 | 0.0040 | ||
| LSA | 100 | 0.149 | 0.996 | 0.259 | 0.0141 | 0.0039 | |
| 200 | 0.149 | 0.996 | 0.259 | 0.0141 | 0.0039 | ||
| 300 | 0.984 | 0.996 | 0.990 | 0.0000 | 0.0039 | ||
| NMF | 100 | 0.149 | 0.992 | 0.259 | 0.0140 | 0.0084 | |
| 200 | 0.148 | 0.992 | 0.258 | 0.0141 | 0.0080 | ||
| 300 | 0.985 | 0.992 | 0.989 | 0.0000 | 0.0080 | ||
| BERTopic | 100 | 0.149 | 0.996 | 0.259 | 0.0141 | 0.0039 | |
| 200 | 0.959 | 0.995 | 0.976 | 0.0001 | 0.0050 | ||
| 300 | 0.960 | 0.996 | 0.978 | 0.0001 | 0.0045 | ||
| BGL | LDA | 100 | 0.831 | 0.680 | 0.748 | 0.0097 | 0.3196 |
| 200 | 0.415 | 1.000 | 0.587 | 0.0987 | 0.0000 | ||
| 300 | 0.415 | 1.000 | 0.587 | 0.0988 | 0.0000 | ||
| LSA | 100 | 0.486 | 0.923 | 0.636 | 0.0686 | 0.0770 | |
| 200 | 0.487 | 0.922 | 0.638 | 0.0680 | 0.0779 | ||
| 300 | 0.487 | 0.922 | 0.638 | 0.0680 | 0.0779 | ||
| NMF | 100 | 0.899 | 0.925 | 0.912 | 0.0073 | 0.0752 | |
| 200 | 0.907 | 0.922 | 0.914 | 0.0067 | 0.0778 | ||
| 300 | 0.907 | 0.922 | 0.914 | 0.0067 | 0.0778 | ||
| BERTopic | 100 | 0.430 | 0.947 | 0.592 | 0.0878 | 0.0533 | |
| 200 | 0.441 | 0.931 | 0.598 | 0.0833 | 0.0688 | ||
| 300 | 0.428 | 0.933 | 0.587 | 0.0875 | 0.0668 |
| Dataset | Clustering Method | P | R | F1 | FPR | FNR |
|---|---|---|---|---|---|---|
| Infologger | HDBSCAN | 0.955 | 0.995 | 0.975 | 0.000 | 0.005 |
| (CERN) | DBSCAN | 0.923 | 0.995 | 0.956 | 0.000 | 0.005 |
| K-means | 0.123 | 0.821 | 0.214 | 0.014 | 0.179 | |
| BGL | HDBSCAN | 0.814 | 0.930 | 0.865 | 0.016 | 0.070 |
| DBSCAN | 0.953 | 0.924 | 0.938 | 0.003 | 0.076 | |
| K-means | 0.789 | 0.903 | 0.822 | 0.023 | 0.097 |
| Dataset | min_cluster_size | P | R | F1 | FPR | FNR |
|---|---|---|---|---|---|---|
| Infologger | 100 | 0.786 | 0.881 | 0.810 | 0.0009 | 0.1186 |
| (CERN) | 200 | 0.373 | 0.963 | 0.533 | 0.0043 | 0.0367 |
| 300 | 0.333 | 0.992 | 0.498 | 0.0049 | 0.0085 | |
| 400 | 0.143 | 0.992 | 0.250 | 0.0147 | 0.0078 | |
| 500 | 0.142 | 0.993 | 0.249 | 0.0148 | 0.0067 | |
| BGL | 100 | 0.796 | 0.972 | 0.868 | 0.0200 | 0.0284 |
| 200 | 0.909 | 0.974 | 0.939 | 0.0074 | 0.0259 | |
| 300 | 0.859 | 0.986 | 0.915 | 0.0126 | 0.0143 | |
| 400 | 0.910 | 0.987 | 0.944 | 0.0079 | 0.0129 | |
| 500 | 0.862 | 0.932 | 0.886 | 0.0122 | 0.0676 |
| Dataset | Cluster_Selection_Epsilon | P | R | F1 | FPR | FNR |
|---|---|---|---|---|---|---|
| Infologger | 0.01 | 0.957 | 0.995 | 0.976 | 0.0001 | 0.0046 |
| (CERN) | 0.03 | 0.761 | 0.996 | 0.840 | 0.0012 | 0.0043 |
| 0.05 | 0.797 | 0.995 | 0.864 | 0.0010 | 0.0048 | |
| 0.07 | 0.468 | 0.996 | 0.637 | 0.0028 | 0.0039 | |
| 0.09 | 0.203 | 0.996 | 0.338 | 0.0096 | 0.0039 | |
| BGL | 0.01 | 0.792 | 0.941 | 0.853 | 0.0200 | 0.0588 |
| 0.03 | 0.765 | 0.983 | 0.858 | 0.0222 | 0.0172 | |
| 0.05 | 0.683 | 0.973 | 0.801 | 0.0325 | 0.0270 | |
| 0.07 | 0.765 | 0.849 | 0.796 | 0.0142 | 0.1514 | |
| 0.09 | 0.839 | 0.997 | 0.908 | 0.0144 | 0.0033 |
| Dataset | min_samples | P | R | F1 | FPR | FNR |
|---|---|---|---|---|---|---|
| Infologger | 100 | 0.810 | 0.946 | 0.871 | 0.0006 | 0.0539 |
| (CERN) | 200 | 0.903 | 0.751 | 0.793 | 0.0003 | 0.2487 |
| 300 | 0.831 | 0.716 | 0.741 | 0.0004 | 0.2843 | |
| 400 | 0.686 | 0.562 | 0.617 | 0.0006 | 0.4380 | |
| 500 | 0.211 | 0.963 | 0.340 | 0.0102 | 0.0366 | |
| BGL | 100 | 0.920 | 0.972 | 0.945 | 0.0296 | 0.0279 |
| 200 | 0.883 | 0.746 | 0.802 | 0.0069 | 0.2540 | |
| 300 | 0.918 | 0.695 | 0.782 | 0.0050 | 0.3048 | |
| 400 | 0.937 | 0.586 | 0.721 | 0.0137 | 0.4144 | |
| 500 | 0.958 | 0.947 | 0.952 | 0.0029 | 0.0534 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Techaviseschai, A.; Tarnpradab, S.; Barroso, V.C.; Phunchongharn, P. A Real-Time Semi-Supervised Log Anomaly Detection Framework for ALICE O2 Facilities. Appl. Sci. 2025, 15, 5901. https://doi.org/10.3390/app15115901
Techaviseschai A, Tarnpradab S, Barroso VC, Phunchongharn P. A Real-Time Semi-Supervised Log Anomaly Detection Framework for ALICE O2 Facilities. Applied Sciences. 2025; 15(11):5901. https://doi.org/10.3390/app15115901
Chicago/Turabian StyleTechaviseschai, Arnatchai, Sansiri Tarnpradab, Vasco Chibante Barroso, and Phond Phunchongharn. 2025. "A Real-Time Semi-Supervised Log Anomaly Detection Framework for ALICE O2 Facilities" Applied Sciences 15, no. 11: 5901. https://doi.org/10.3390/app15115901
APA StyleTechaviseschai, A., Tarnpradab, S., Barroso, V. C., & Phunchongharn, P. (2025). A Real-Time Semi-Supervised Log Anomaly Detection Framework for ALICE O2 Facilities. Applied Sciences, 15(11), 5901. https://doi.org/10.3390/app15115901