1. Introduction
Accurate perception of outdoor environments is essential for a wide range of computer vision applications, including autonomous driving, video surveillance, and drone navigation. However, atmospheric phenomena such as haze can severely impair image visibility, degrading the performance of downstream tasks such as object detection and tracking. Consequently, image dehazing techniques have become critical to ensuring reliable performance under such adverse conditions. Among them, single-image dehazing—which aims to restore clear scenes without relying on auxiliary depth information—remains especially difficult due to the ill-posed nature of the task.
Early dehazing methods are primarily based on the atmospheric scattering model proposed by Narasimhan et al. [
1]. As shown in Equation (
1), this model restores a clear image by estimating the transmission map and global atmospheric light from a hazy input.
where
denotes the observed hazy image,
is the haze-free scene radiance,
A is the global atmospheric light, and
is the transmission map, which describes the portion of light that is not scattered and reaches the camera sensor. This process involves estimating the global atmospheric light and the transmission map to recover a clear image from a hazy observation. Based on this model, early studies [
2,
3,
4,
5] attempted to perform image dehazing by leveraging prior knowledge derived from statistical observations to estimate the global atmospheric light and the transmission map. However, these approaches heavily rely on statistical assumptions that often do not hold in real-world scenarios. In particular, when the atmospheric light is spatially non-uniform or object colors closely resemble the atmospheric light, these priors may become unreliable, leading to suboptimal restoration performance.
To address these limitations, recent approaches based on deep learning have been developed, focusing on learning a direct mapping from hazy to clear images via supervised learning. In particular, Vision Transformer (ViT)-based methods [
6,
7,
8] utilize multi-head attention mechanisms and large effective receptive fields to produce high-quality dehazed outputs. Nonetheless, these methods typically involve substantial parameter counts and computational overhead, which limits their feasibility for real-time applications or deployment on devices with limited resources. To mitigate the computational burden of ViT-based approaches, recent studies have adopted Convolutional Neural Network (CNN) architectures to develop lightweight models that preserve large effective receptive fields [
9,
10]. For instance, LKD-Net [
11] incorporates the Large Kernel Attention (LKA) mechanism [
12], achieving competitive performance with significantly fewer parameters—underscoring the computational efficiency of CNN-based frameworks. However, due to their reliance on fixed convolutional filters, CNN-based methods often struggle to capture diverse spatial relationships, particularly in complex visual scenes.
To overcome these limitations, we propose the Multi-Head Large Kernel Block (MLKD), which combines the lightweight structure of CNNs with the rich spatial modeling power of ViT-based methods. The proposed MLKD is a lightweight CNN-based module that integrates Multi-Head Large Kernel Attention (MLKA), enabling effective spatial feature learning while preserving large effective receptive fields and maintaining a low parameter count. In the MLKA module, input channels are partitioned into multiple heads, with each independently processed using the Large Kernel Attention (LKA) mechanism. This configuration enhances spatial feature learning while sustaining large effective receptive fields with minimal computational overhead. The primary contributions of this study are twofold: (1) the introduction of the Multi-Head Large Kernel Attention (MLKA) module, which effectively incorporates multi-head attention into a CNN framework; and (2) the development of MLKD-Net, a lightweight model optimized for efficient inference and suitable for deployment in resource-constrained environments.
2. Related Work
2.1. Prior-Based Image Dehazing Methods
Prior-based dehazing approaches generally depend on the atmospheric scattering model [
1]. Zhang et al. [
2] proposed the Dark Channel Prior (DCP), which assumes that in haze-free images, at least one color channel in a local region exhibits low intensity. Using this assumption, the dark channel is employed to estimate the haze density, from which the transmission map and atmospheric light are computed to reconstruct a clear image. Singh et al. [
3] introduced the Gradient Profile Prior (GPP) to estimate the depth of a scene from a hazy image. They further refined the transmission map using an edge-preserving filtering method and a learning-based image filter applied in several steps. Their final reconstruction model helps reduce common problems like overly bright pixels and unnatural colors in the output image. Similarly, Dai et al. [
4] proposed a method based on physical principles that separates a hazy image into two parts: reflectance and incoming light. They added regularization terms to help stabilize the solution and used an optimization technique called ADMM to estimate both parts together. To avoid overly bright or unnatural results in areas with heavy haze, they also included a transmission map and a correction term. Likewise, the Saturation Line Prior (SLP) [
5] estimates transmission by leveraging a linear correlation between color saturation and the inverse of brightness. While such methods perform well under ideal conditions, their effectiveness diminishes in real-world scenarios where these priors often break down.
2.2. CNN-Based Image Dehazing Methods
Initial CNN-based methods approached dehazing by estimating the transmission map as an intermediary and then applying the atmospheric scattering model to reconstruct the haze-free image. For example, DehazeNet [
13] extracts features from local image patches using multiple convolutional filters to estimate the transmission map, which is then used for image reconstruction. MSCNN [
14] employs a multi-scale, two-stage architecture that first captures coarse global structures and then refines finer details, enabling effective handling of haze with varying density and spatial distribution.
Recent CNN-based approaches favor end-to-end learning pipelines that directly map hazy inputs to clear outputs, eliminating the need to estimate intermediate variables. GCANet [
15] incorporates smoothed dilated convolutions and gated feature fusion to enhance local structure and texture recovery. FFA-Net [
16] introduces a Feature Fusion Attention mechanism that combines channel and pixel attention to model both spatial and contextual dependencies, leading to improved dehazing performance. Yu et al. [
17] proposed a novel dehazing method that jointly leverages spatial and frequency information through a dual-guided framework that learns detailed representations in both domains. This joint learning strategy enables more natural restoration of textures and structures, particularly in complex scenes, thereby minimizing detail loss.
DEA-Net [
18] introduces a Detail-Enhanced Attention Block (DEAB) composed of a Detail-Enhanced Convolution (DEConv) and a Content-Guided Attention (CGA) module. DEConv leverages difference convolution to enhance the representational capacity of standard convolution by capturing subtle variations. CGA assigns a Spatial Importance Map (SIM) to each channel, allowing the network to focus more effectively on informative regions during feature encoding. Despite these advancements, the inherently limited receptive fields of standard CNNs hinder their ability to capture long-range dependencies, particularly in visually complex environments.
2.3. Vision Transformer-Based Image Dehazing Methods
To address the receptive field limitations of CNNs, Vision Transformer-based [
19] methods have recently emerged as a powerful alternative in image dehazing, owing to their ability to model long-range dependencies through multi-head attention and large effective receptive fields. Dehamer [
6] incorporates the Dark Channel Prior (DCP) with 3D positional embeddings and Transformer layers, effectively incorporating prior knowledge into the Transformer framework.
Similarly, DehazeFormer [
7] leverages the Swin Transformer [
20] for hierarchical feature extraction using shifted window-based self-attention. GTM-Net [
21] proposes a Guided Transmission Map (GTM) that combines DCP-based guidance with Transformer modeling and enhances local details through an SOS boost module. MB-TaylorFormer [
8] introduces a novel architecture that combines multi-scale patch embedding with Taylor Self-Attention, which approximates Softmax Attention via Taylor series expansion to reduce computational complexity. Additionally, Gating Attention is incorporated to improve the modeling of local information. Although Transformer-based approaches achieve state-of-the-art performance, their high parameter counts and computational requirements often limit their practicality in real-time or resource-constrained environments.
2.4. Attention Mechanisms in Efficient Neural Architectures
Attention mechanisms have been widely adopted in both Transformer-based and CNN-based architectures to enhance feature representation. In CNNs, channel and spatial attention modules such as SE [
22], CBAM [
23], and ECA [
24] recalibrate feature maps to emphasize informative regions. Meanwhile, Transformer-based models rely on multi-head self-attention (MHSA) to model long-range dependencies. However, MHSA introduces quadratic complexity with respect to sequence length and multiple heads, motivating the development of lightweight variants such as grouped or factorized multi-head attention [
25,
26] and Sparse Attention [
27,
28].
Unlike these methods, which are primarily designed to reduce the cost of handling many attention heads in Transformer-based architectures, our proposed Multi-Head Large Kernel Attention (MLKA) focuses on incorporating multi-head attention into a CNN-based framework. MLKA extends the Large Kernel Attention (LKA) mechanism [
12] by embedding multiple attention heads and introducing a Channel Shuffle operation to promote interaction between them, enhancing spatial representation rather than compressing existing attention structures.
2.5. Expanding Receptive Fields in CNNs
Building on the success of ViT, which demonstrated robust performance via large effective receptive fields, researchers have explored lightweight CNN-based architectures capable of capturing similarly broad spatial contexts. RepLKNet [
9] attained competitive semantic segmentation results using 31 × 31 kernels, whereas OKNet [
10] extended this by utilizing 63 × 63 kernels for enhanced image restoration performance. While large kernels facilitate broader receptive fields, they often incur substantial computational overhead. To alleviate this issue, Large Kernel Attention (LKA) [
12] decomposes large kernels into a combination of depth-wise convolution (DWConv) and depth-wise dilated convolution (DWDConv), enabling efficient receptive field expansion with reduced parameter complexity. This study adopts LKA to build multiple attention heads, allowing the model to effectively capture diverse spatial features while sustaining expansive large effective fields.
3. Method
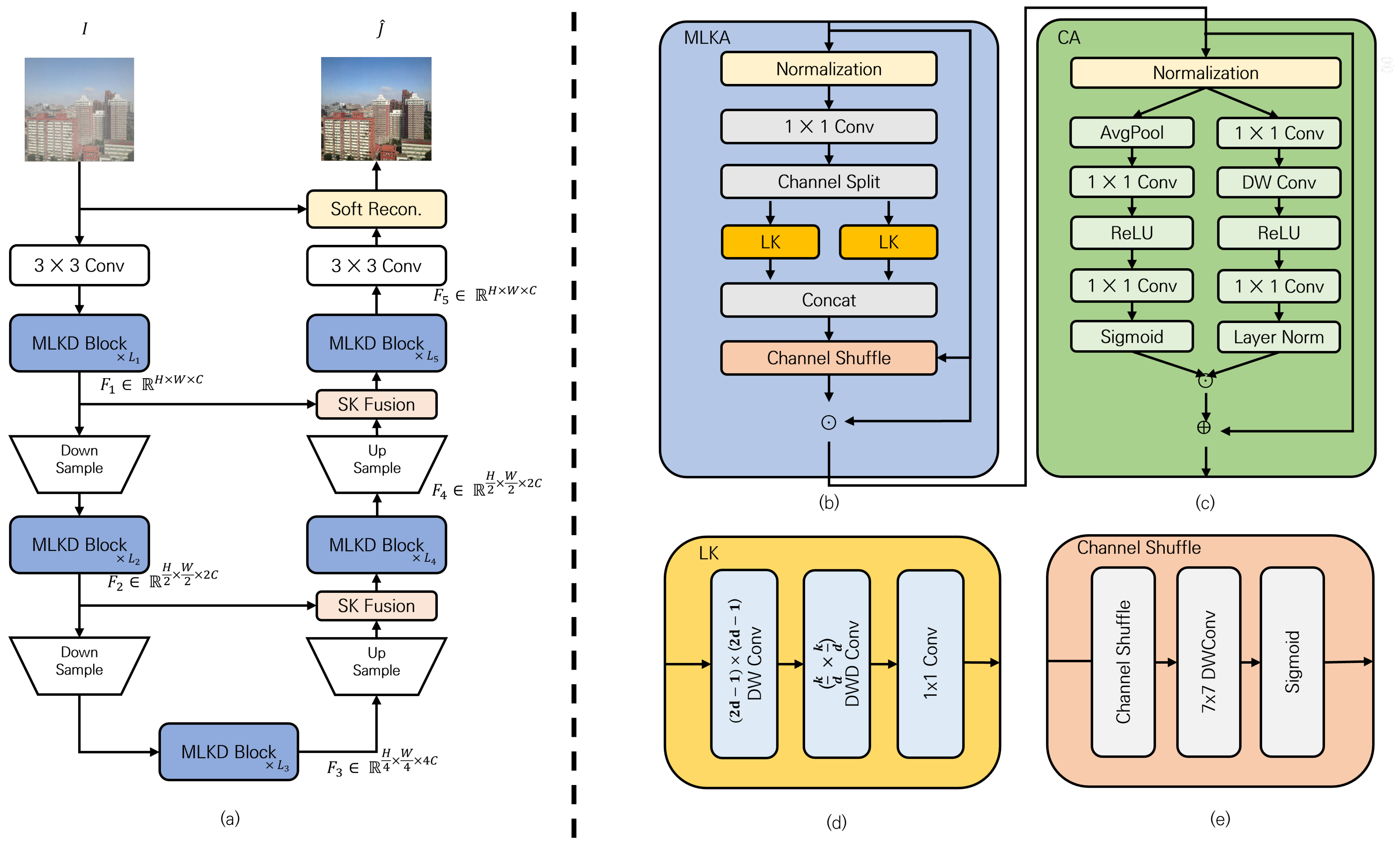
This section outlines the architecture of MLKD-Net, a lightweight U-Net–based model tailored for single image dehazing. As illustrated in
Figure 1a, MLKD-Net incorporates multiple Multi-Head Large Kernel Dehaze (MLKD) blocks to extract and refine features efficiently. The network synergizes the expressive capacity of Vision Transformers with the computational efficiency of CNNs by employing a Multi-Head Large Kernel Attention (MLKA) mechanism for spatial modeling coupled with a Channel Attention (CA) module [
11] for selective feature enhancement.
The CA module adaptively emphasizes feature channels that are more relevant to haze characteristics (e.g., color distortion or low contrast) while suppressing less informative ones. In feature maps produced by convolutional layers, not all channels contribute equally to the task of haze removal. Some channels may capture haze-relevant visual cues, while others may represent redundant or irrelevant information. The CA module addresses this by applying learnable weights to each channel, allowing the model to focus its attention on meaningful features. This improves both the discriminative power and overall representation quality of the network. The effectiveness of CA has also been proven in previous studies [
11,
18], showing measurable improvements over baseline models without CA.
3.1. Network Architecture
MLKD-Net receives a hazy image as input and initially extracts low-level features through a 3 × 3 convolutional layer, followed by an MLKD block. The encoder–decoder architecture comprises down-sampling layers, a series of MLKD blocks, and up-sampling layers. To facilitate effective fusion between encoder and decoder features, the network employs SK Fusion [
7], which improves inter-channel feature interaction. Following the final MLKD block, the output is refined through a 3 × 3 convolution and a Soft Reconstruction Layer [
7], replacing the conventional global skip connection to enable more adaptive learning and restoration. MLKD-Net was trained independently on the ITS and OTS subsets and evaluated using the SOTS dataset. A comprehensive description of the training settings and implementation details is provided in
Section 4.1 and
Section 4.2.
3.2. Multi-Head Large Kernel Attention (MKLA) Module
To improve spatial modeling within CNN-based architectures, this study introduces the Multi-Head Large Kernel Attention (MLKA) module, which extends the original LKA [
12] by employing multiple attention heads.
Specifically, the MLKA module introduces multiple attention heads to expand the diversity of receptive fields and enhance the model’s representational capacity. By dividing different channel subsets into separate large kernel attention paths, the model can capture richer and more diverse spatial dependencies. In addition, a Channel Shuffle block is integrated to facilitate inter-head communication and improve the module’s representational efficiency.
This design maintains a balance between computational efficiency and expressive power, resulting in improved quantitative performance, as validated through the ablation studies shown in
Section 5.1.
As illustrated in
Figure 1b, the MLKA module comprises three key stages: (1) channel-wise splitting, (2) spatial feature extraction, and (3) feature refinement. Initially, MLKA applies Batch Normalization (BN) followed by a 1 × 1 convolution to the input feature map, after which the output is split into multiple attention heads (Equation (
2)). Each head is independently processed using a Large Kernel (LK) block to capture wide spatial context, and the resulting outputs are concatenated (Equation (
3)). The LK block, shown in
Figure 1d, comprises two components: a standard depth-wise convolution (DWConv) and a dilated depth-wise convolution (DWDConv). Instead of relying on a single large kernel, this design approximates a wide receptive field by combining these two operations, following the decomposition scheme proposed in [
12]. Specifically, the effective kernel sizes of the two branches are defined as
where
K is the original kernel size, and
d denotes the dilation rate. By combining these two operations, the LK block effectively approximates the receptive field of a much larger convolution (e.g.,
) while significantly reducing computational complexity.
The concatenated features are subsequently refined using a Channel Shuffle block, as described in Equation (
4). Within this block, the Channel Shuffle (CS) operation refers specifically to the process of reshaping and transposing the feature map to interleave the output channels from multiple attention heads. In the MLKA module, each head processes a distinct subset of channels independently to capture diverse spatial patterns. However, this independence may lead to isolated feature learning and hinder effective integration across heads. The CS operation addresses this by mixing channel information across heads, enabling the subsequent
depth-wise convolution to access a more diverse and unified representation. This enhances inter-head communication and contributes to improved spatial modeling performance.
Through this process, spatial features learned by different heads are effectively fused, allowing their outputs to influence one another. This inter-head communication not only mitigates the potential fragmentation of learned features but also enhances the overall expressiveness and spatial modeling capability of the MLKA module.
4. Experimental Results
4.1. Model and Implementation Details
This section presents an evaluation of the proposed MLKD-Net, a lightweight U-Net-based architecture developed for single-image dehazing. Model efficiency was assessed through comparative analysis of its performance metrics and parameter count. The Large Kernel (LK) block was constructed by combining a
depth-wise convolution and a
dilated depth-wise convolution with a dilation rate of 3, as recommended in the optimal configuration presented in [
12]. This design approximates the effective receptive field of a
kernel. A dilation rate of 3 was selected based on the receptive field approximation shown in Equations (
5) and (
6), which achieves the desired kernel size efficiently. Although a larger dilation rate such as 7 could also approximate the same receptive field, it would require excessively large convolution kernels, which are inefficient and unsuitable for lightweight network design. Therefore, a dilation rate of 3 was adopted as a practical and effective choice.
Two model variants were evaluated to examine scalability: MLKD-Net-Tiny and MLKD-Net-Small. As summarized in
Table 1, the Tiny variant adopts a block configuration of [1, 1, 2, 1, 1] across five levels (
L1 to
L5), totaling six MLKD blocks. These levels correspond to the sequential stages in the encoder–decoder structure, with
L1 and
L2 in the encoder,
L3 at the bottleneck, and
L4 and
L5 in the decoder. The Small variant uses a deeper configuration of [2, 2, 4, 2, 2], totaling twelve blocks. Both models share identical embedding dimensions: [24, 48, 96, 48, 24]. Both variants use two attention heads per MLKD block, which was empirically determined to be the optimal configuration based on an ablation study with one, two, and four heads. Among the tested configurations, using two heads yielded the best dehazing performance. A detailed analysis is provided in
Section 5.1.
All models were optimized using the AdamW optimizer [
29], with exponential decay rates of
and
. An initial learning rate of 0.0002 was used and subsequently adjusted via a cosine annealing schedule. Training was conducted with a batch size of 16, and
input patches were generated through random cropping. Prior to training, all images were linearly scaled from the
range to
. During training, random horizontal flipping was applied as an additional augmentation technique. The model was supervised using a pixel-wise L1 loss, which encourages accurate restoration by minimizing the absolute difference between predicted and ground truth images. Following the evaluation protocol proposed in [
7,
16], MLKD-Net was trained separately on the ITS and OTS subsets for 300 and 30 epochs, respectively. The final evaluation was conducted on the SOTS test set. All experiments were performed using PyTorch 1.10.1 on NVIDIA A100 GPUs (Algorithm 1).
4.2. Datasets
To assess the performance of single-image dehazing models, the RESIDE dataset [
30]—a widely adopted benchmark containing both indoor and outdoor scenes—was utilized. The dataset was partitioned into three subsets: the Indoor Training Set (ITS), the Outdoor Training Set (OTS), and the Synthetic Objective Testing Set (SOTS). ITS includes 13,990 image pairs, whereas OTS provides 313,950 synthetic image pairs tailored for outdoor training. SOTS comprises 500 test images each for indoor and outdoor conditions. MLKD-Net was trained on both ITS and OTS subsets and evaluated using the complete SOTS test set.
| Algorithm 1 MLKD-Net training procedure. |
- 1:
Input: Training set D, pretrained model - 2:
Initialize optimizer (AdamW), learning rate - 3:
for each epoch (300 for ITS / 30 for OTS) do - 4:
for each batch in D do - 5:
Random crop 256 × 256 patches from input images - 6:
Apply random horizontal flip - 7:
Normalize image range to [−1, 1] - 8:
Forward pass: - 9:
Compute L1 loss: - 10:
Backpropagation and update using AdamW - 11:
end for - 12:
Update learning rate via cosine annealing - 13:
end for - 14:
Return: Trained model
|
4.3. Evaluation Metrics
Model performance was evaluated using the Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index Measure (SSIM), both of which are widely used in image restoration tasks. The PSNR is a quantitative metric that measures the pixel-level difference between the restored image and the ground truth. It is defined as
where MAX denotes the maximum possible pixel value (typically 255), and MSE is the mean squared error between the restored and ground truth images. Higher PSNR values indicate better restoration quality.
The SSIM measures the structural similarity between two images based on the Human Visual System (HVS). Unlike the PSNR, which focuses on absolute error, the SSIM considers luminance, contrast, and structural information. It is defined as
In Equation (
8),
and
represent the mean intensities of the images
x and
y, respectively.
and
denote the variances of
x and
y, and
indicates the covariance between the two images. The constants
and
are included to stabilize the division and prevent numerical instability when the denominators are close to zero. SSIM values range from 0 to 1, where values closer to 1 indicate higher structural similarity and, consequently, better image restoration quality.
4.4. Quantitative and Qualitative Evaluation
The proposed MLKD-Net was quantitatively evaluated against state-of-the-art single-image dehazing methods on the SOTS dataset using the Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index Measure (SSIM) as performance metrics. The evaluation encompasses prior-based models (DCP [
2], DehazeNet [
13]), CNN-based models (FFA-Net [
16], LKD-Net [
11], DEA-Net [
18], OKNet [
10], ConvIR [
31]), and Transformer-based models (Dehamer [
6], DehazeFormer [
7], MB-TaylorFormer [
8]). As shown in
Table 2, both MLKD-Net-Tiny and MLKD-Net-Small delivered competitive performance on the SOTS-Indoor and SOTS-Outdoor datasets.
Specifically, MLKD-Net-Small achieved a PSNR of 37.58 dB on SOTS-Indoor and 37.26 dB on SOTS-Outdoor. According to
Table 2, when compared to the state-of-the-art MB-TaylorFormer [
8], MLKD-Net-Small achieved highly competitive results, with 90.9% fewer parameters and only a 1.9% reduction in the PSNR on the SOTS-Outdoor dataset. Moreover, it surpassed LKD-Net [
11], a similarly scaled CNN-based model, by 0.54 dB on SOTS-Indoor and 0.38 dB on SOTS-Outdoor. These findings demonstrate that the proposed Multi-Head Large Kernel Attention (MLKA) module effectively captures spatial features while keeping the model lightweight and efficient.
We also conducted a qualitative evaluation, with the results presented in
Figure 2 and
Figure 3, which compares dehazed outputs from MLKD-Net and the baseline methods on the SOTS dataset. The proposed model restores clearer structures and stronger contrast, particularly under dense haze conditions. Especially, as shown in
Figure 3, MLKD-Net demonstrated noticeably sharper restoration in several scenes than other models, particularly in fine details such as the outlines of buildings.
4.5. Evaluation on Embedded Systems
To assess the practical deployability of MLKD-Net-S, we evaluated its performance on an NVIDIA Jetson Orin Nano board. The model, trained on the RESIDE-Outdoor dataset, was converted to TensorRT format and tested under three precision modes: FP32, FP16, and INT8. Inference was conducted on
resolution images from the SOTS-Outdoor test set (
Figure 4). As shown in
Table 3, MLKD-Net-S achieved inference times of 74.97 ms (13.34 FPS) in FP32 and 55.24 ms (18.2 FPS) in INT8 mode. These results indicate that the model can perform real-time inference on embedded platforms, underscoring its suitability for deployment in resource-constrained systems such as drones and autonomous vehicles.
Notably, the accuracy degradation under INT8 quantization was minimal, with the PSNR and SSIM remaining nearly unchanged. We attribute this robustness to the model’s quantization-friendly architecture: depth-wise convolutions are inherently less sensitive to quantization noise due to their channel-wise independence, and channel attention mechanisms rely on relative feature scaling, making them stable under reduced precision.
5. Ablation Study
This section presents ablation studies to validate the effectiveness of the proposed MLKD-Net architecture. All experiments were performed by training the models on the RESIDE Outdoor Training Set for 30 epochs and evaluating them on the SOTS-Outdoor dataset.
5.1. Evaluation on the Number of Heads in MLKA
This study investigated the impact of the number of heads in the MLKA module by evaluating MLKD-Net in both its Tiny and Small configurations. The number of heads was determined by how the input channels are split or expanded before applying attention. We analyzed two aspects: the effect of different channel splitting strategies and the effect of expanding the number of channels per head.
5.1.1. Evaluation on Channel Splitting Strategy
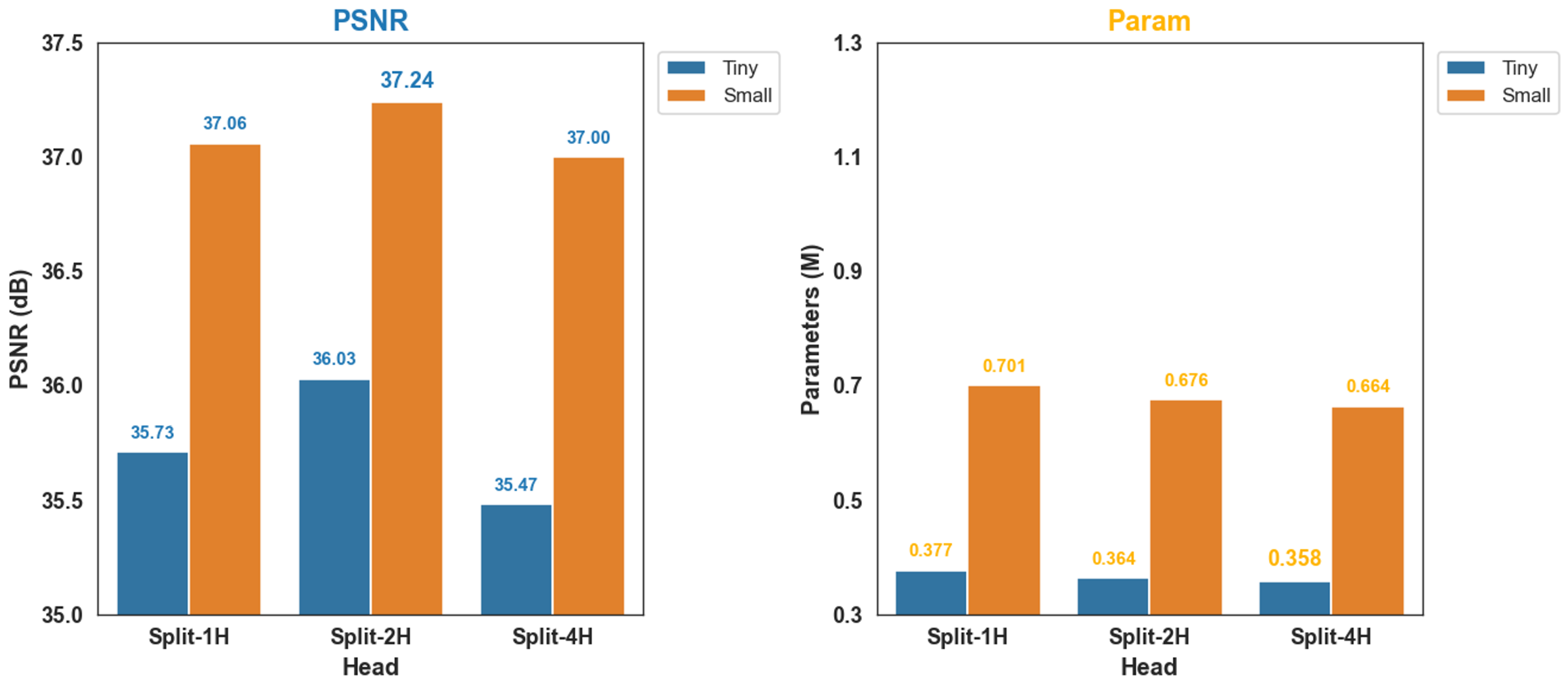
To assess the influence of the channel splitting strategy, we varied the number of heads in the MLKA module, which corresponds to how many groups the input channels are divided into during the channel split step (Equation (
2)). Specifically, the configurations Split-H1, Split-H2, and Split-H4 correspond to one, two, and four heads, respectively.
As illustrated in
Figure 5, both variants achieved optimal performance on the SOTS-Outdoor dataset when the number of heads was set to two. In particular, the Split-H2 configuration achieved the highest PSNR in both model sizes, recording 36.03 in the Tiny version and 37.24 in the Small version. The performance improvement from Split-H1 to Split-H2 highlights the advantage of adopting a multi-head structure within the MLKA module. By employing multiple heads, MLKA enables each head to focus on distinct spatial patterns or receptive field regions. This allows the model to extract diverse and complementary features in parallel, enriching the overall representation without increasing the parameter count significantly. The resulting feature diversity enhances the model’s ability to capture fine-grained haze distributions and structural details, thereby improving the perceptual quality of the restored image.
Conversely, the four-head configuration (Split-H4) yielded lower performance, which we attribute to the reduced number of channels assigned to each head. In our model, where the embedding dimensions are relatively compact ([24, 48, 96, 48, 24]), this constraint limits each head’s ability to learn expressive spatial features. As a result, excessive fragmentation weakens the overall effectiveness of the attention mechanism and ultimately leads to the observed performance degradation.
To further investigate whether this degradation was primarily caused by reduced channel capacity per head, we conducted a channel expansion experiment in which the feature map was first expanded before splitting, allowing each head to receive the same number of channels as in the original input.
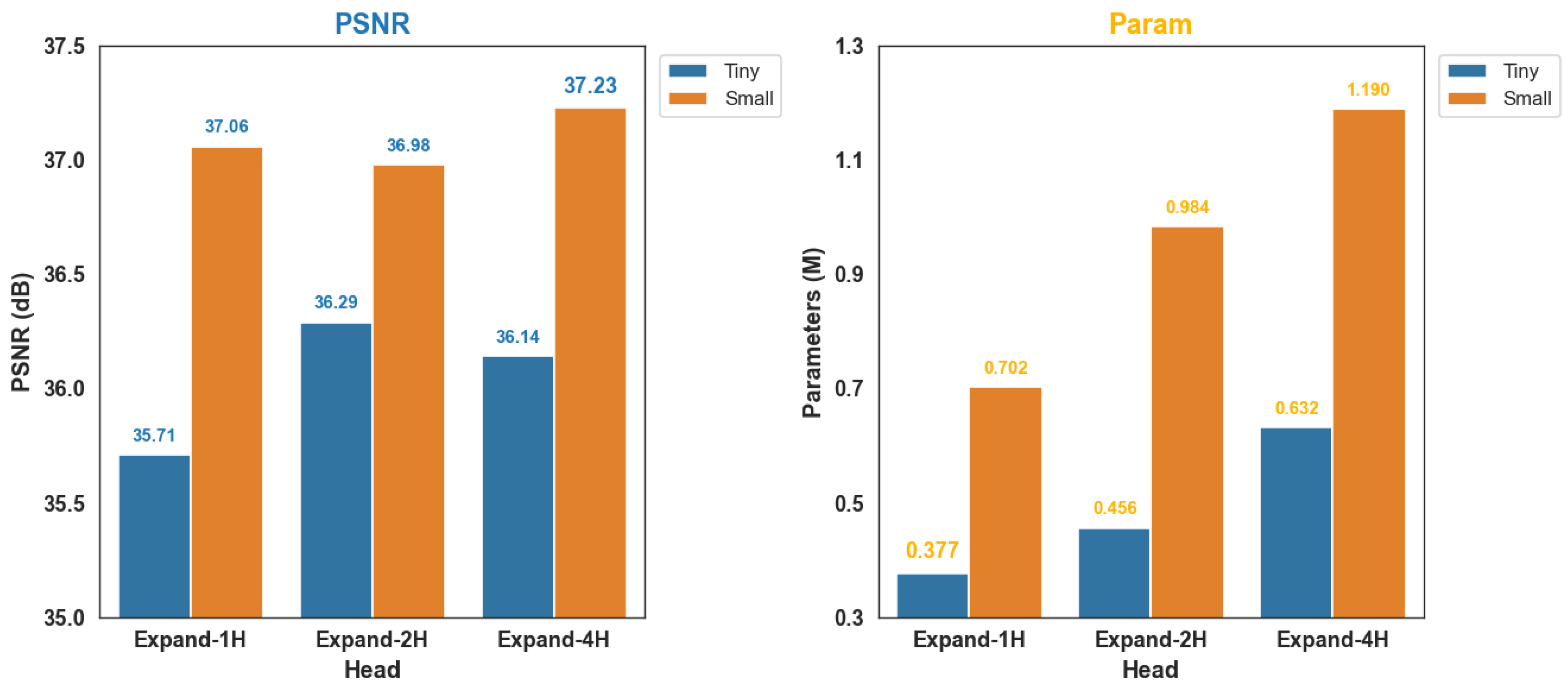
5.1.2. Evaluation on Channel Expansion Strategy
To compare with the channel splitting strategy, we conducted a channel expansion experiment. In this setup, the input feature map was expanded along the channel dimension using a
convolution, as defined in Equation (
2), so that each head received a feature map with the same channel size as the original input. The Expand-H1 configuration represents the baseline in this strategy and is structurally equivalent to Split-H1, as both use a single head without any channel splitting or expansion. Expand-H2 and Expand-H4 indicate models with two and four expanded heads, respectively.
As illustrated in
Figure 6, in the Tiny model, the two-head configuration (Expand-H2) achieved a 1.6% improvement in the PSNR over the baseline (Expand-H1), increasing from 35.71 to 36.29. However, when the number of heads was increased to four (Expand-H4), the performance dropped slightly to 36.14. In contrast to the Tiny model, the Small model showed a decrease in performance at the two-head setting (Expand-H2), with the PSNR dropping from 37.06 to 36.98, but the performance increased again at the four-head setting (Expand-H4), reaching 37.23. These results suggest that channel expansion does not consistently lead to performance gains despite the increase in parameters.
However, the channel splitting strategy achieves performance improvement by dividing the input channels among heads while introducing almost no change in the number of parameters. Notably, the two-head configuration in the splitting strategy (Split-H2) not only outperformed the expanded four-head setting (Expand-H4) but also did so with approximately 43% fewer parameters, demonstrating superior parameter efficiency. This indicates that, compared to the expansion strategy, the splitting strategy provides a more lightweight and effective solution. Therefore, the two-head configuration in the channel splitting strategy (Split-H2) offers the best balance between model expressiveness and computational efficiency.
5.2. Experiment on the Channel Shuffle Block
The Channel Shuffle block within MLKA is designed to establish indirect interactions between attention heads, thereby enhancing the model’s ability to learn spatial representations. To evaluate its contribution, we conducted an ablation study by removing the Channel Shuffle block from MLKD-Net-T under various head configurations: Split-H1 (single head), Split-H2 (two heads), and Split-H4 (four heads). The results, summarized in
Table 4, demonstrate that the absence of the Channel Shuffle block led to consistent performance degradation across all configurations.
Specifically, in the Split-H1-T setting, the PSNR dropped slightly from 35.71 dB to 35.67 dB, indicating only a marginal impact when using a single head. In contrast, Split-H2-T showed a more noticeable drop from 36.03 dB to 35.54 dB, and Split-H4-T exhibited the most significant decline—from 35.49 dB to 35.07 dB. These results indicate that in multi-head mechanisms, the indirect connections between attention heads enabled by the Channel Shuffle block play a critical role in effectively learning spatial representations.
6. Discussion
The proposed MLKA adopts a channel splitting strategy, whereas conventional multi-head approaches typically allow all heads to process the full input feature map. However, the results of Experiment 5.1.2 demonstrate that designing a scalable architecture—where the performance consistently improves with increased parameters—remains a challenging problem, particularly in convolution-based structures. In many cases, an increase in parameters does not lead to proportional improvements in performance. From this perspective, the splitting-based MLKA mechanism emerges as a competitive and efficient alternative, especially in scenarios where lightweight design is critical.
Thanks to its lightweight architecture and fast inference capability, MLKD-Net is highly suitable for real-time applications on resource-constrained platforms such as mobile devices, drones, and embedded systems like the NVIDIA Jetson series. In addition, the proposed MLKA mechanism is expected to provide performance gains when applied to a variety of low-level vision tasks, including deraining, denoising, and image enhancement.
7. Conclusions and Future Work
This study presented MLKD-Net, which is a lightweight and efficient deep learning model tailored for single image dehazing. Central to the proposed architecture is the Multi-Head Large Kernel Attention (MLKA) module, which successfully combines the multi-head attention mechanism and large effective receptive fields—inspired by Vision Transformers—within a CNN-based framework. This hybrid design enables robust spatial feature modeling while preserving computational efficiency.
Extensive experiments demonstrate that MLKD-Net-S achieved competitive performance across both quantitative and qualitative evaluations, incurring only a 1.9% PSNR drop compared to state-of-the-art Transformer-based models, while reducing the number of parameters by over 90%. Furthermore, MLKD-Net-S achieved real-time inference at 55.24 ms per image (18.2 FPS) on the NVIDIA Jetson Orin Nano using TensorRT-INT8, highlighting its strong potential for deployment in embedded and resource-constrained environments. These results suggest that the proposed model can be effectively integrated into real-world systems such as autonomous vehicles, robotic platforms, and mobile devices, where both efficiency and low latency are essential.
While MLKD-Net effectively removes haze in diverse outdoor conditions, it does not explicitly model haze thickness, which may affect object visibility, color consistency, and edge sharpness. This limitation indicates a key avenue for future research: integrating dynamic haze modeling, such as scene-adaptive thickness estimation and uncertainty-aware learning, could further enhance dehazing accuracy in complex real-world scenarios. In summary, MLKD-Net offers a practical, scalable, and high-performing solution for single-image dehazing and lays a solid foundation for next-generation dehazing networks optimized for both performance and efficiency.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}