5.2. Ablation Study
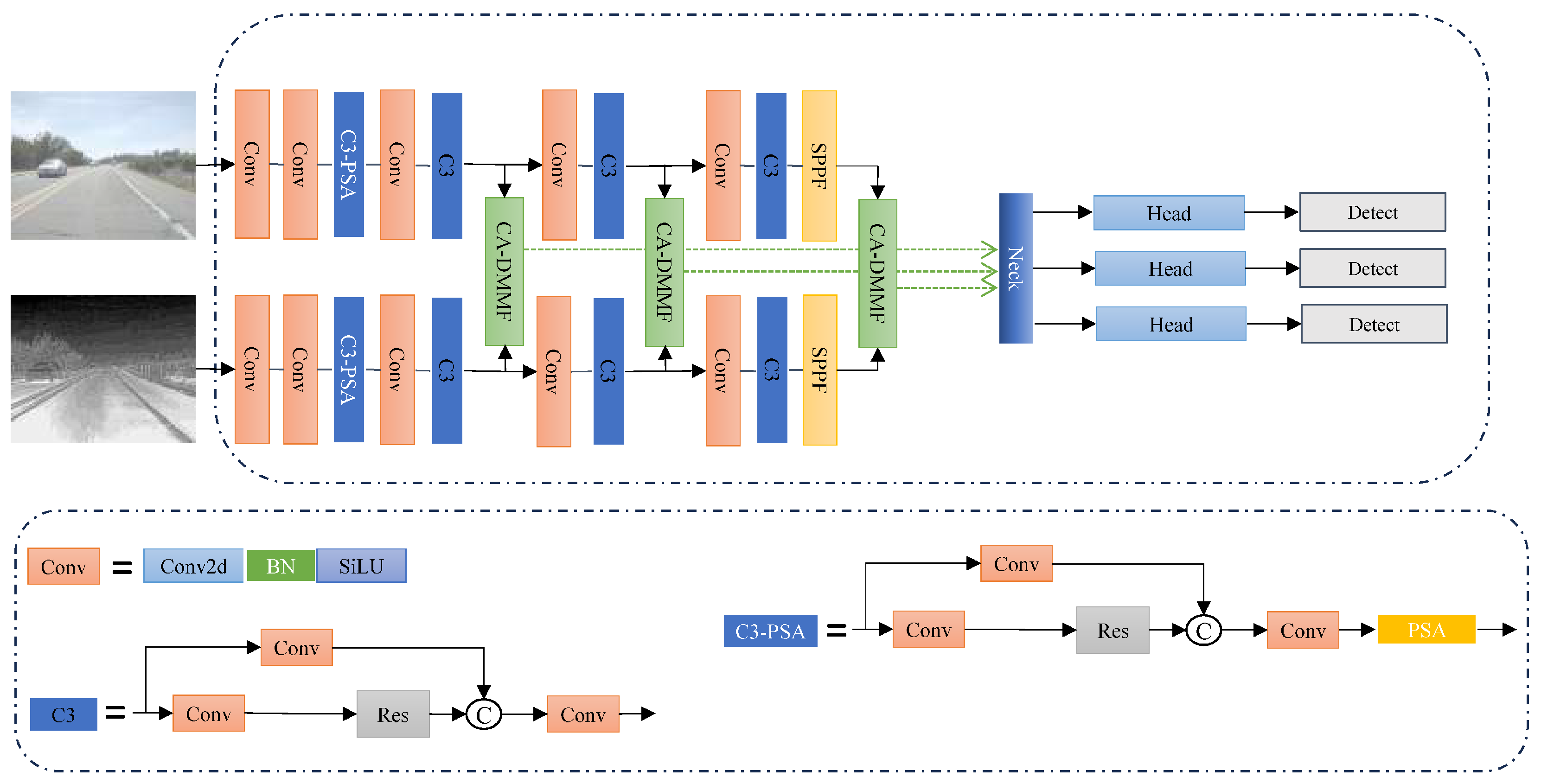
In this section, we conducted a series of ablation experiments to thoroughly evaluate the performance of the proposed network. For comparison, we constructed two parallel CSPDarknet53 networks using element-wise summation as the fusion operation to build the baseline backbone network, as shown in
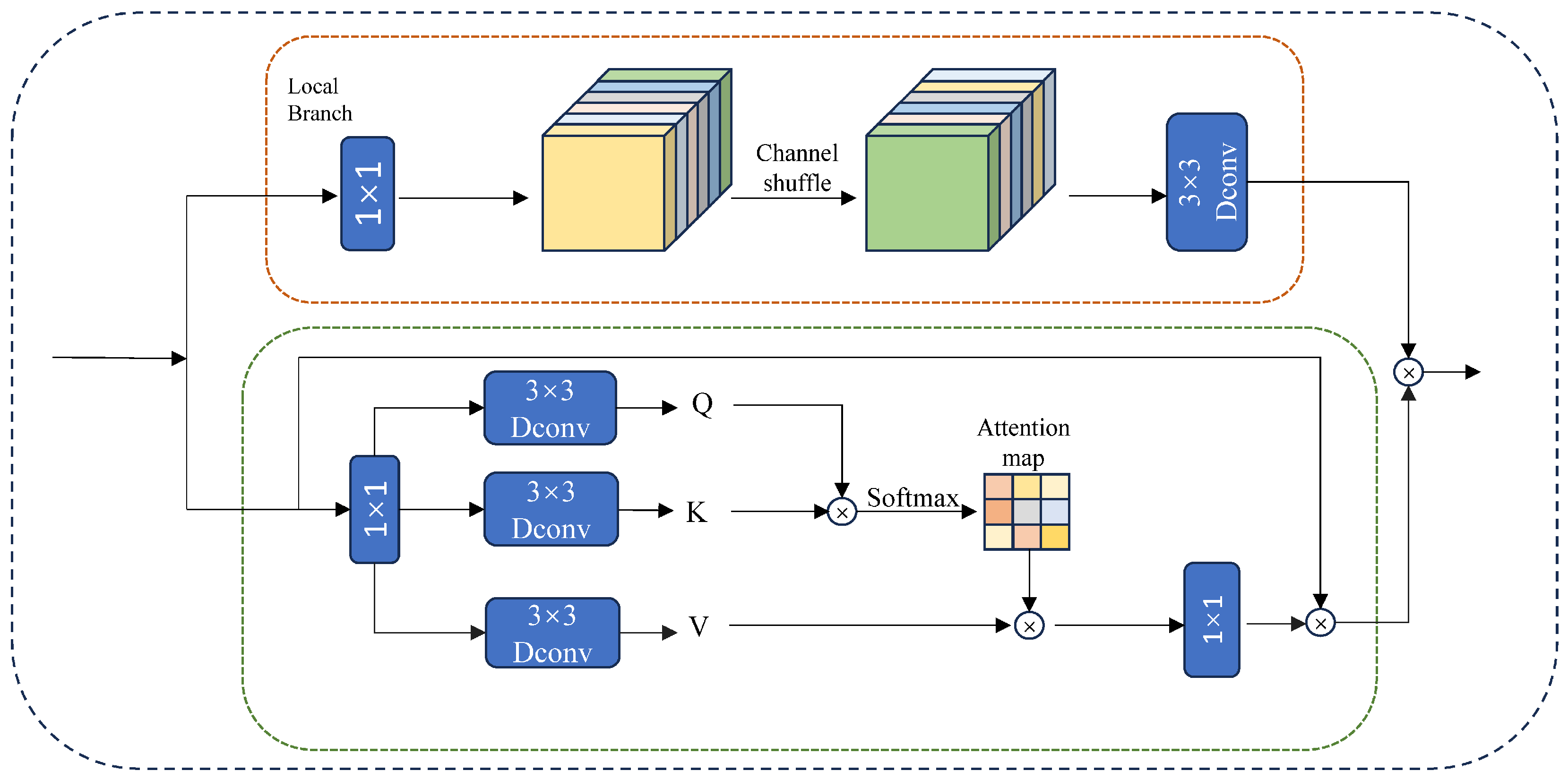
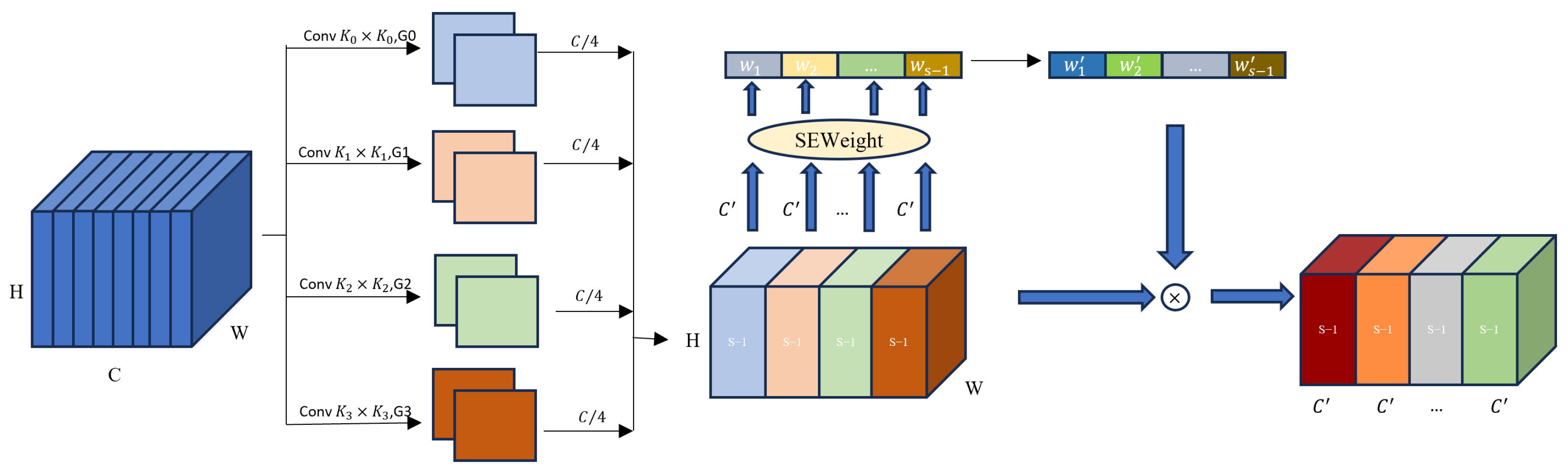
Figure 6. Subsequently, we introduced various improvements for experimentation, primarily including the AEFF and the C3-PSA module. In this study, we compared the performance of different model configurations based on the key evaluation metric, mean Average Precision (mAP), which covers all categories in the dataset. Specifically, M1, M2, and M3 represent the following: a YOLOv5 trained exclusively for visible light image detection, a YOLOv5 trained exclusively for infrared image detection, and a dual-stream YOLOv5 with element-wise summation for modality fusion. M4 and M5 correspond to the dual-stream YOLOv5 with AEFF and C3-PSA improvements, respectively, while M6 represents the fully enhanced dual-stream YOLOv5 with both AEFF and C3-PSA improvements. Through ablation experiments, we performed a quantitative analysis of the mean values for the three fusion metrics: mAP@0.5, mAP@0.75, and mAP@0.5:0.95. For simplicity in this section, the experiments focus on the FLIR aligned dataset, the KAIST dataset, and the M3FD dataset, with the relevant results presented in
Table 7,
Table 8 and
Table 9.
The results of the ablation experiments performed on the FLIR dataset show that the dual-stream YOLOv5 architecture (M3) demonstrated significant improvements across several performance metrics compared to the unimodal models (M1 and M2). In terms of the mAP@0.5 metric, M3 achieved a performance of 78.4, surpassing M1’s 67.8 and M2’s 73.9. This highlights the dual-stream architecture’s ability to effectively fuse visible and infrared image data, thereby enhancing overall detection performance. Upon the introduction of the AEFF module, the mAP@0.5 value of M4 improved to 80.8, further validating the effectiveness of the AEFF in facilitating information interaction between different modalities. The inclusion of the AEFF enhances the network’s ability to fuse cross-modal features, thus improving the model’s robustness. In contrast, while the introduction of the C3-PSA in M5 led to a slight reduction in the mAP@0.5 metric (79.8), it significantly enhanced feature representation by improving detail. Finally, when both the AEFF and C3-PSA were applied to M6, the model’s performance for mAP@0.5 stabilized at 79.9 and maintained high values for the mAP@0.75 and mAP@0.5:0.95 metrics. This demonstrates that the synergy of the two modules is essential for optimizing the model’s performance in multimodal target detection.
Table 8 presents the results of ablation experiments conducted on the KAIST dataset, comparing the two-stream YOLOv5 baseline model (M3) with the models incorporating the AEFF (M4), the C3-PSA module (M5), and a combination of both the AEFF and C3-PSA (M6). The performance differences in terms of the mAP@0.5 and mAP@0.5:0.95 metrics across these models are analyzed.
The baseline model, M3, achieved mAP@0.5 and mAP@0.5:0.95 scores of 74.9 and 32.8, respectively. With the addition of the AEFF (M4), these metrics improved to 75.23 and 32.95, respectively, demonstrating AEFF’s effectiveness in enhancing the interaction between cross-modal features. The application of the C3-PSA (M5) further increased the mAP@0.5 and mAP@0.5:0.95 metrics to 75.73 and 32.8, respectively, emphasizing the C3-PSA module’s role in focusing on key information and refining feature representation. Finally, when both the AEFF and C3-PSA were integrated into the model (M6), the mAP@0.5 rose to 75.8, while the mAP@0.5:0.95 improved to 33.11, achieving the best performance in this experiment. These results highlight the significant synergistic effect of the AEFF and C3-PSA in improving cross-modal feature fusion and target detection tasks.
In the ablation experiments on the FD dataset, the dual-stream YOLOv5 architecture (M6) also demonstrated superior performance compared to the unimodal configurations (M1 and M2), particularly in the mAP@0.5 (84.2) and mAP@0.5:0.95 (52.4) metrics. Compared to the unimodal models, the dual-stream YOLOv5 architecture significantly enhanced the model’s detection capability in complex environments by effectively fusing visible and infrared image features. The dual-stream YOLOv5 (M4), with the introduction of the AEFF, reached 84.4 for the mAP@0.5 score and 51.6 for the mAP@0.5:0.95 score, showcasing the positive impact of the AEFF in improving the efficiency of inter-modal feature fusion. However, the dual-stream YOLOv5 (M5), which integrates the C3-PSA, showed a slight decrease in the Recall metric but maintained relatively stable performance in the mAP@0.5 and mAP@0.5:0.95 metrics, further highlighting the effectiveness of the C3-PSA in enhancing inter-modal feature processing. Finally, when both the AEFF and C3-PSA were applied to the dual-stream YOLOv5 (M6), the model maintained high performance across all metrics, with 84.2 for the mAP@0.5 score and 52.4 for the mAP@0.5:0.95 score. This underscores the important role of the combination of these two techniques in enhancing the model’s detection performance.
To further quantify the computational cost of our proposed improvements, we report the FLOPs and parameter counts for key model variants in
Table 10. Compared to ICAFusion, which incurs 192.6 GFLOPs and 120.3 million parameters, the model using only the AEFF increases to 216.8 GFLOPs and 120.8 M parameters, while the C3-PSA-only model reduces the parameters to 108.8 M with 203.7 GFLOPs. The full YOLO-MEDet model (M6), which integrates both the AEFF and C3-PSA, reaches 227.9 GFLOPs and 121.0 M parameters. These increases in complexity are justified by the observed performance gains in the Precision, Recall, and mAP metrics across multiple datasets. Although our model is not optimized for lightweight deployment, its computational scale remains comparable to state-of-the-art architectures commonly used in multispectral detection tasks.
In summary, these results demonstrate that through the synergistic effects of feature fusion and enhancement techniques, dual-stream YOLOv5 shows substantial performance improvements in complex multimodal scenarios and significantly enhances the accuracy and robustness of target detection.
5.3. Per-IoU AP Analysis
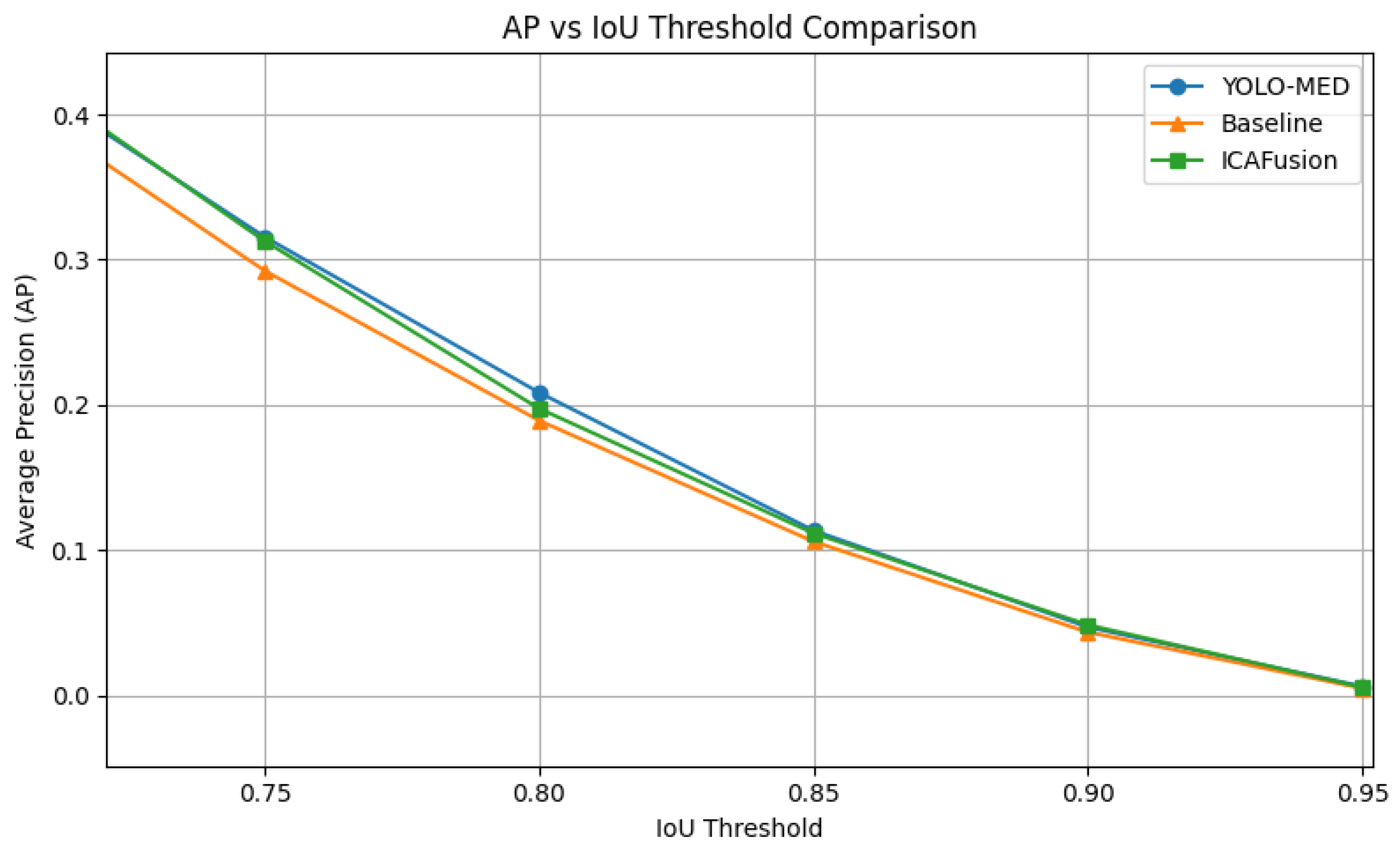
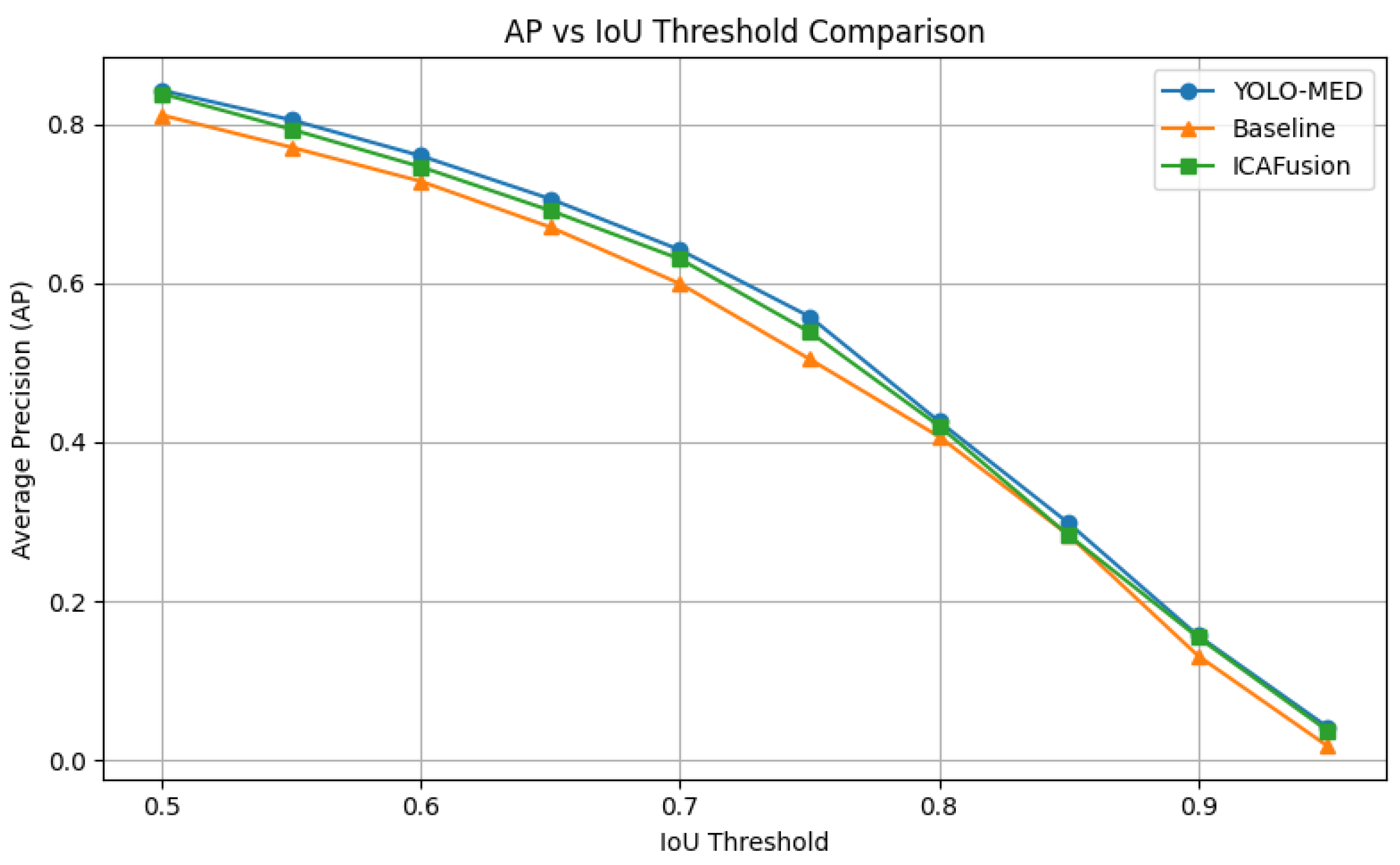
To gain deeper insight into the localization capability of different fusion strategies under varying spatial precision requirements, we conducted a per-IoU AP evaluation on both the FLIR and FD datasets. Following the COCO-style evaluation protocol, we report the Average Precision (AP) scores at discrete IoU thresholds ranging from 0.50 to 0.95.
As shown in
Figure 7, YOLO-MEDet consistently outperformed the baseline fusion method across intermediate IoU thresholds (0.75–0.85), highlighting its enhanced localization precision under moderately strict conditions. Although ICAFusion slightly exceeded YOLO-MEDet at the highest threshold levels (IoU ≥ 0.90), the overall trend indicates that YOLO-MEDet maintains more stable and robust localization across the entire IoU range. This helps explain the observed 2.9% decrease in the overall mAP@0.5:0.95, which is largely attributable to performance at stricter thresholds rather than a uniform decline.
A similar pattern is observed on the
FD dataset, as presented in
Figure 8. YOLO-MEDet consistently surpassed the baseline across all IoU thresholds, with particularly strong advantages in the 0.60–0.85 range. While the performance outcomes of YOLO-MEDet and ICAFusion converged at higher thresholds, the proposed model demonstrates a more balanced and resilient performance under varying spatial overlap constraints.
These findings confirm that YOLO-MEDet achieves reliable localization across a spectrum of IoU conditions, with notable strengths in medium to strict overlap scenarios. This contributes to its practical applicability, even in cases where the overall mAP@0.5:0.95 appears marginally reduced.
5.4. Qualitative Analysis
To comprehensively evaluate the performance of each model, we visualize the detection results of the baseline model, ICAFusion, and our proposed method on the FLIR and
FD datasets and compare them with the ground truth annotations.
Figure 9 illustrates the detection results under various lighting and environmental conditions, covering daytime and nighttime scenes with high target density, long target distances, and strong light interference.
As one can observe, the baseline model and ICAFusion frequently failed to detect certain cars and pedestrians in daytime scenes, and their performance degraded significantly at night. In contrast, our method performed consistently under all lighting conditions, successfully detecting nearly all targets during both day and night. In target-intensive scenes (e.g., daytime scene a and nighttime scene c), our method accurately detected all pedestrians and vehicles within the field of view, whereas the baseline model and ICAFusion were particularly prone to missing small targets at night. Furthermore, when targets were at greater distances, the baseline model also struggled with misdetections under strong illumination in nighttime scene d, while our method continued to recognize all targets successfully.
Additionally,
Figure 10 presents the detection results of the three methods in different scenarios, including regular scenes, small-target scenes, and crowded scenes. In regular scenes, both the baseline model and ICAFusion failed to detect certain targets compared to our model. In small-target scenes, our method consistently classified and localized all targets, regardless of daytime or nighttime, whereas the baseline model and ICAFusion missed more distant and smaller targets, such as pedestrians and vehicles. In crowded scenes, our model effectively captured all targets, while the baseline model and ICAFusion continued to suffer from missed detections.
These experimental results further validate the advantages of our method in multispectral information fusion and cross-modal feature interaction, as well as its superior detection capability in complex scenes.
To complement the qualitative detection comparisons, we further visualized the training dynamics of each model to objectively validate performance differences.
Figure 11 presents the evolution of the mAP@0.5 and mAP@0.5:0.95 scores on the FLIR dataset, while
Figure 12 shows the training loss trajectories for box, objectness, and classification components.
As seen in
Figure 11, it is evident that YOLO-MEDet achieved faster convergence and higher accuracy across all IoU thresholds compared to the baseline and ICAFusion. Meanwhile,
Figure 12 illustrates that our model maintained consistently lower training losses throughout training. These results confirm that the improvements introduced by the AEFF and C3-PSA not only enhance detection quality but also facilitate more stable and efficient optimization during training.
To verify the generality of this behavior, we conducted the same training visualization on the
FD dataset. As shown in
Figure 13 and
Figure 14, similar trends are observed. YOLO-MEDet not only outperformed the baseline and ICAFusion models in terms of its mAP@0.5 and mAP@0.5:0.95 scores across epochs, but it also demonstrated superior convergence and lower training losses in all components. The consistent advantage on both datasets further validates the robustness and scalability of our proposed architecture under varying environmental and spectral conditions.
These qualitative results demonstrate that the proposed method offers stronger feature discrimination, more complete object contours, and higher robustness against environmental interference. The improvements are primarily attributed to two architectural enhancements: the Attention-Enhanced Feature Fusion (AEFF) module, which enables effective cross-modal interaction between visible and thermal features, and the C3-PSA module, which enriches multiscale spatial awareness while preserving key structural details. Functionally, these modules improve detection precision under challenging conditions and enhance model reliability in both sparse and crowded scenes. Although they introduce moderate computational overhead, the model remains deployable on modern GPU-equipped platforms, and further optimization is possible for edge-oriented applications.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}