4. Discussion
Dementia patients are at a greater risk of harming themselves and others during episodes of aggression. The risk factors involved in these behaviors have been widely studied. One vital goal is to reduce caregiver stress by informing them of the risks involved in these behaviors. Additional investigation of the interaction among different cases of behaviors has been accomplished through examination of vocally and physically aggressive and non-aggressive behaviors in order to better understand the factors related to agitation and aggressive behaviors among dementia patients. Findings showed that verbal aggression was most disruptive [
44,
45].
In this project, a machine learning model was designed, trained, and evaluated, capable of detecting and classifying aggressive and non-aggressive human behavior based on visual and audio data. To complete this proof-of-concept study, two meta-classifier fusion methods were proposed: the Early and Late Fusion models. This multimodal combination of previous works will further contribute to the competencies of this proof of concept and predict episodes of aggressive behavior in dementia patients more accurately and with improved reliability. As in the prior work, limitations in acquiring clinical datasets of real dementia patients are a drawback due to ethical concerns as well as patient consent. Partnerships with psychiatric hospitals are necessary to acquire such data and verify the applicability of the model in real-life scenarios. A proof of concept established the basis for the model to be created to simulate real-life scenarios, increase model reliability, and prepare it for clinical use, and enable future model validation with clinical data [
46,
47].
Dimensionality of Data
In multimodal datasets, a dataset with high dimensionality plays a crucial role when it comes to providing a rich and analytical representation of aggressive behavior prediction. The incorporation of visual and audio cues in this multimodal analysis benefits both models by providing enriched and complementary data sources. This allows a more analytical, comprehensive view of the classification and prediction of aggressive behaviors. Multimodal fusion also enhances the potential abilities of the model to learn from new data, since variability in modalities provides unique insights.
This approach comes with a key advantage, which is the model’s ability to handle missing data, therefore providing a more robust approach. In case of missing data, such as verbal audio data or missing or distorted images, the model can still provide meaningful predictions from available data. This highlights the robustness of this approach and ensures a more stable and reliable classification process. Moreover, the integration of deep-level interactions in features between audio and visual data helps the model to develop a better understanding of aggression patterns.
Interpretation of Results
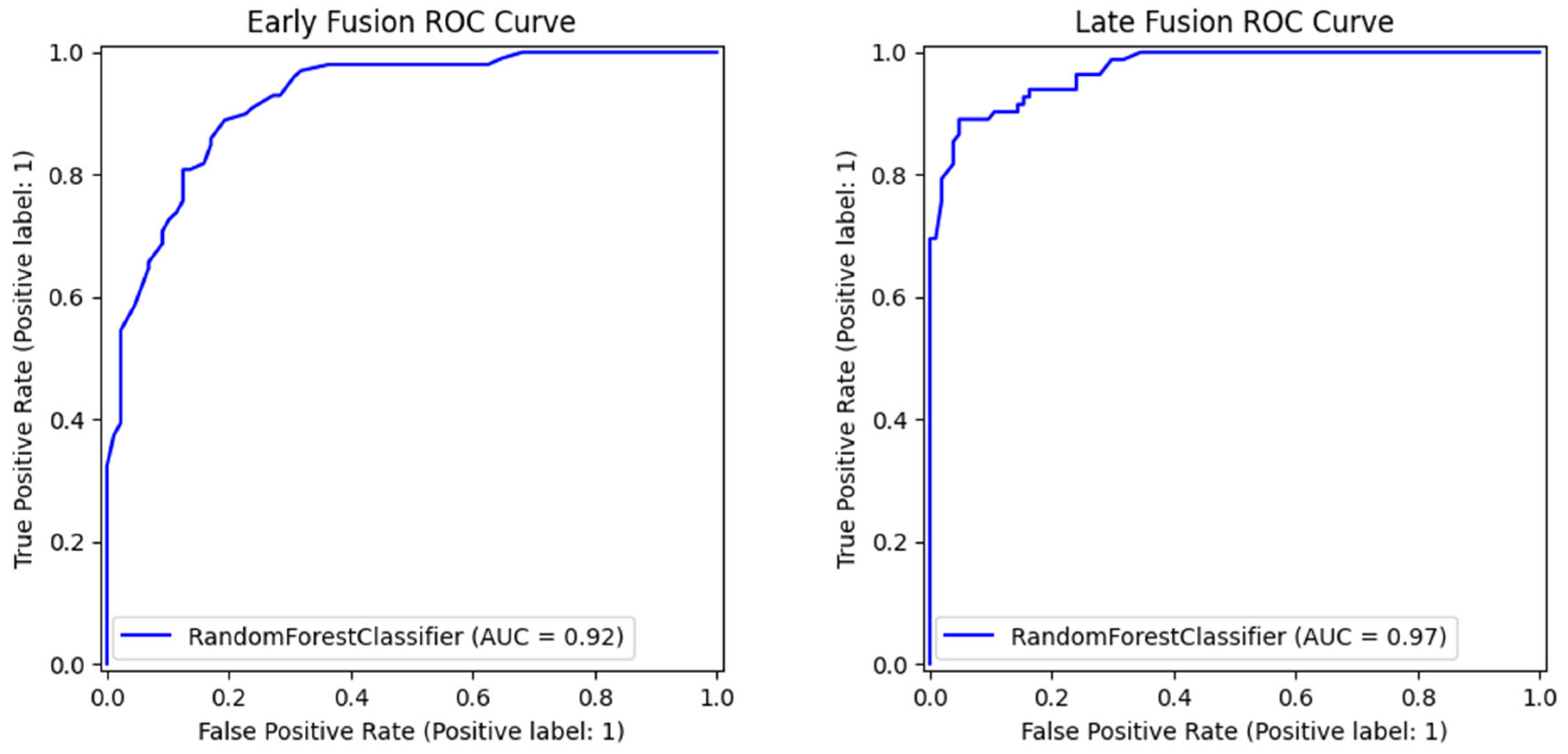
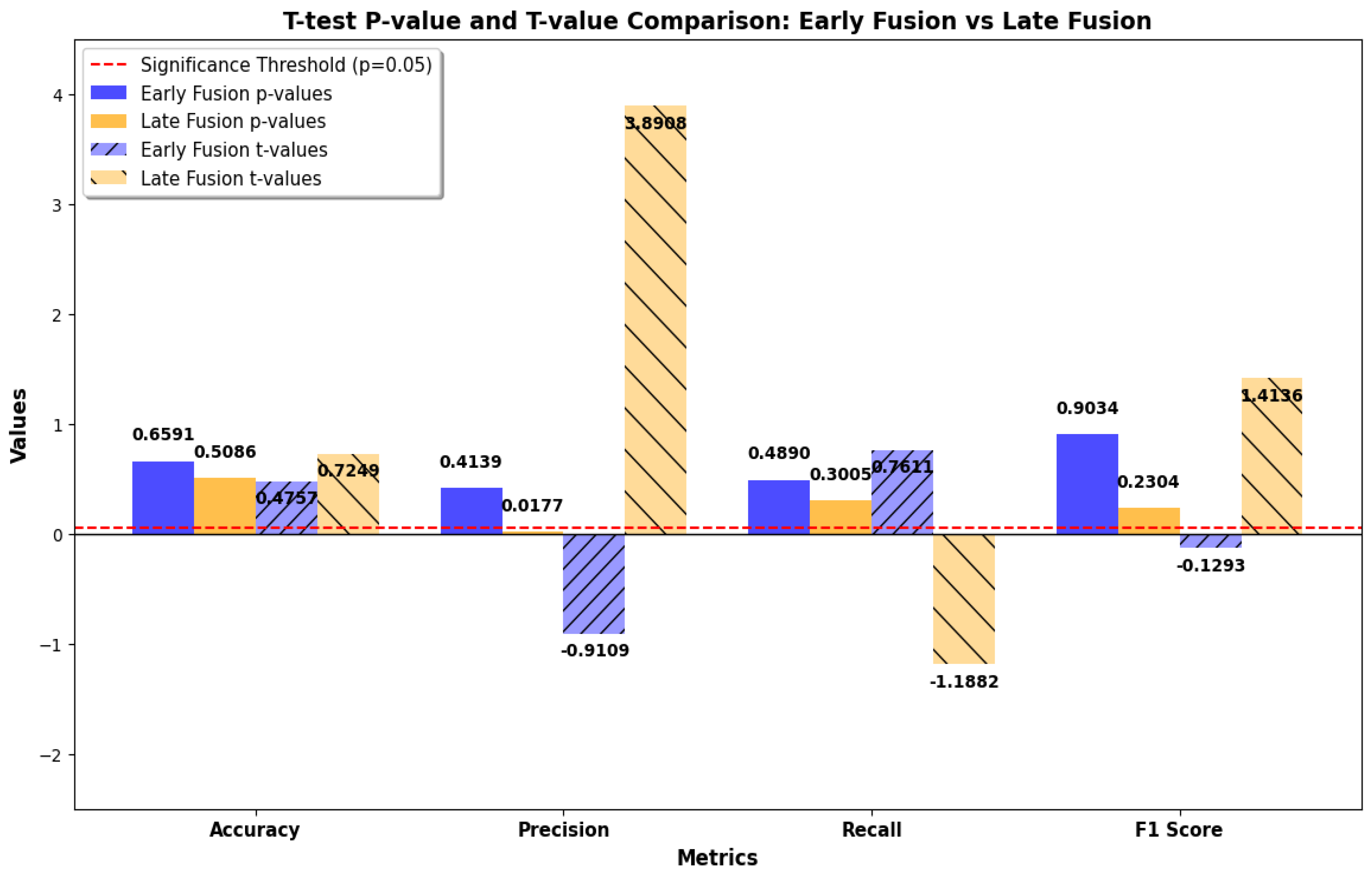
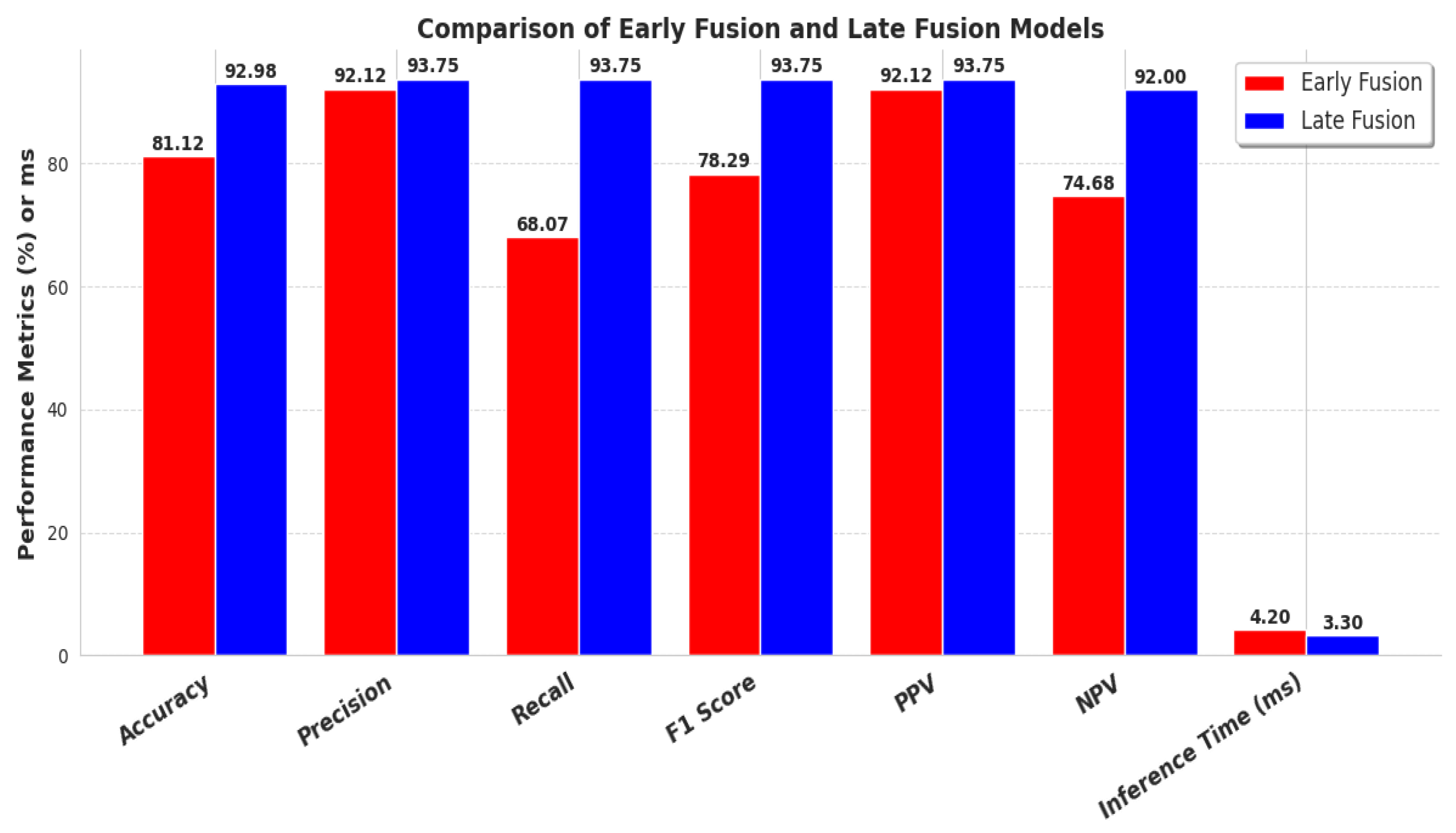
Comparative analysis in this research between Early and Late Fusion approaches highlights the strengths and trade-offs of each method. The Late Fusion model outperformed Early Fusion in the majority of the evaluation metrics, including recall, accuracy, F1-score, ROC-AUC score, and inference time, while at the same time, no significant statistical differences were present between the comparison of the two models. This suggests that the aggregation of data of different natures in decision-level predictions provides a more robust process for real-world clinical applications.
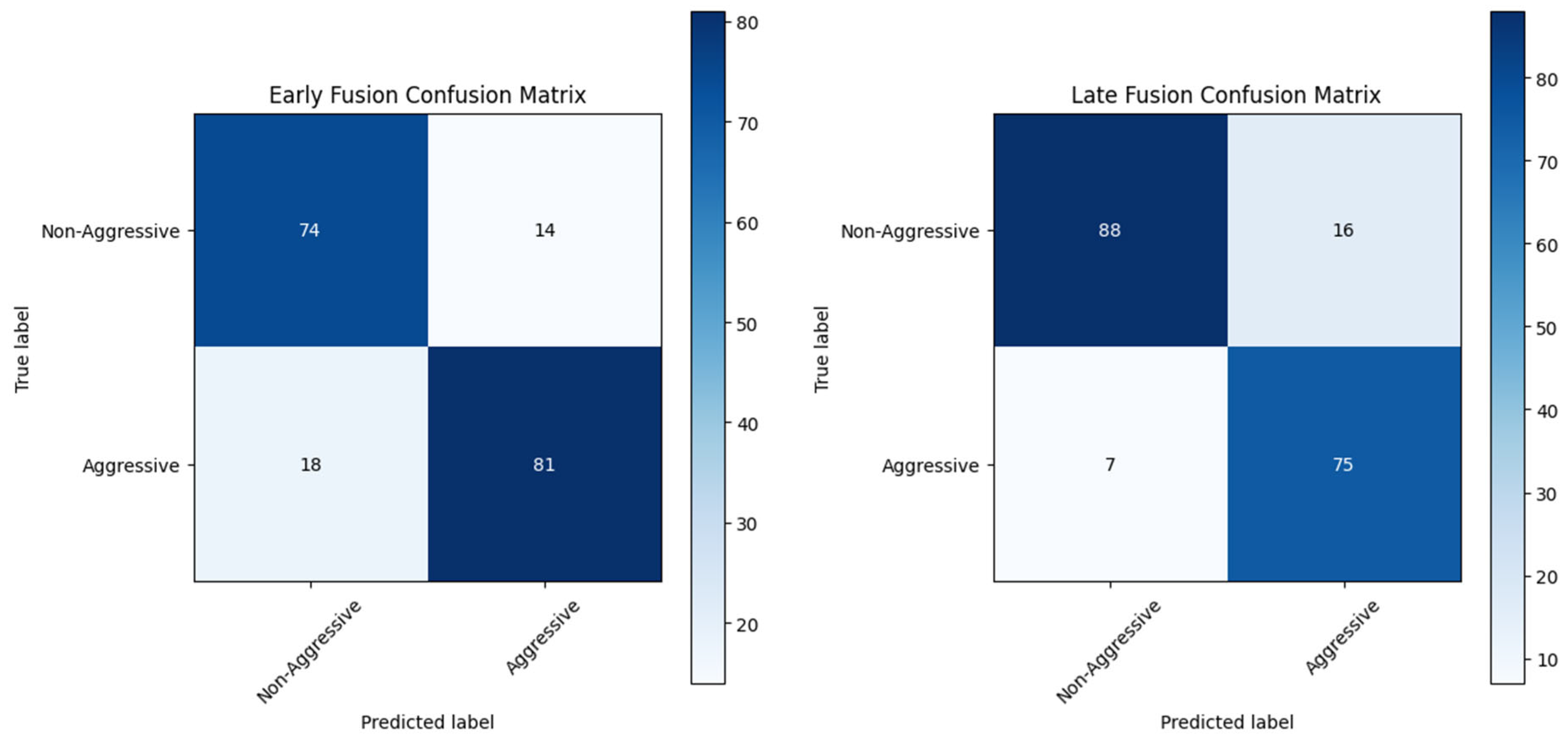
Despite being outperformed by Late Fusion, Early Fusion exhibits better precision metrics with a low rate of false positive values, suggesting that it is better at avoiding false detections. This improvement comes with the trade-off of a higher risk of missing aggressive occurrences due to its low recall score. This showcases the importance of selecting a fusion strategy that is best suited for the requirements of the environment in which it is needed to perform. Healthcare application settings with human supervision may need to prioritize recall so that aggressive instances will not be overlooked, whereas in automated surveillance systems, it might be more crucial to emphasize precision in order to minimize unnecessary calls for interventions.
The main reason Late Fusion is better at recall is in its ability to decouple and process each modality separately before making a final decision. This decoupling allows the model to establish modality-specific decision boundaries that are less susceptible to cross-modal interference. For instance, even when the visual cues include motion blur, occlusion, or uneven lighting, the audio classifier can still provide a strong and assured input to the final prediction. The redundancy naturally resolves the modality-specific noise risk. Further, Late Fusion circumvents temporal asynchrony by disconnecting the learning processes. As compared to relying on ideal temporal coincidence, each modality is free to detect patterns of aggression from within its native temporal context, and the fusion system is tasked with combining these asynchronous predictions. Unlike Early Fusion, this technique does not suffer from the necessity of temporally aligned and cleaned features for best performance and thus is less sensitive to performance degradation when confronting real-world aberrations. Thus, the power of Late Fusion not only involves its decision-level structure but also its noise insensitivity, modality imbalance insensitivity, and temporal lag insensitivity. These characteristics are the most critical in the context of identifying aggressive behavior in erratic clinical environments.
Key Points of Comparison
Fusion Strategy Implications
As mentioned above, the choice between Early and Late Fusion is challenging. Each model has its own strengths and weaknesses, which must be taken into consideration when choosing the preferred strategy for a specific application. The Late Fusion approach is preferable in applications where high recall is crucial for real-world clinical scenarios, with human supervision, where an imminent episode of aggressive behavior must be identified in time to reduce risk. Early Fusion is preferable for applications where priority is given to precision, such as in automated systems without human supervision, where there is a need to minimize false cases.
Additionally, the Late Fusion method provides flexibility considering the update of the model since audio and visual features are trained separately. This can improve the maintenance and scalability of the model, since it is not dependent on all modalities at a given time; therefore, retraining is not required to make additional improvements to one modality. This provides modularity to the Late Fusion approach, which is beneficial for frequently updated systems that need to adapt to new data.
Model Robustness
Model robustness is another critical factor during the evaluation of the model fusion approach, especially in cases of missing modalities or handling variations in data, fast and efficiently in real-world deployment challenges. Based on the results discussed earlier, Late Fusion demonstrates superior performance thanks to its independent decision-making process, which allows for compensation in missing and corrupted data in modalities. This highlights its resilience in real-world conditions where data are often inconsistent or come with high noise.
Early Fusion implementation, on the other hand, can effectively integrate multimodal features from different cues and is more sensitive to data inconsistencies between audio and visual data. Feature concatenation at an early stage compensates for data discrepancies, as well as noise in the data, and can propagate through the model. This reduces overall classification performance and also reduces real-world adaptability due to its dependence on balanced and synchronized multimodal data.
Performance Behavior Across Data Conditions
The observed difference in performance between Early and Late Fusion models is explained through an examination of how each of the fusion approaches responds to sample-specific modality information under varying conditions of samples. Early Fusion combines audio and vision features at the input level in the form of a concatenated single feature vector. This approach enables the model to learn representations together. It also introduces the risk of modality imbalance, whereby dominant or noisy features from a single modality (like irregular audio information or poor-quality visual frames) can obscure informative patterns from the competitor model. This phenomenon is especially significant in borderline or uncertain samples, adding to Early Fusion’s decreased recall, due to the fact that it struggles to respond to minimal cues of aggression.
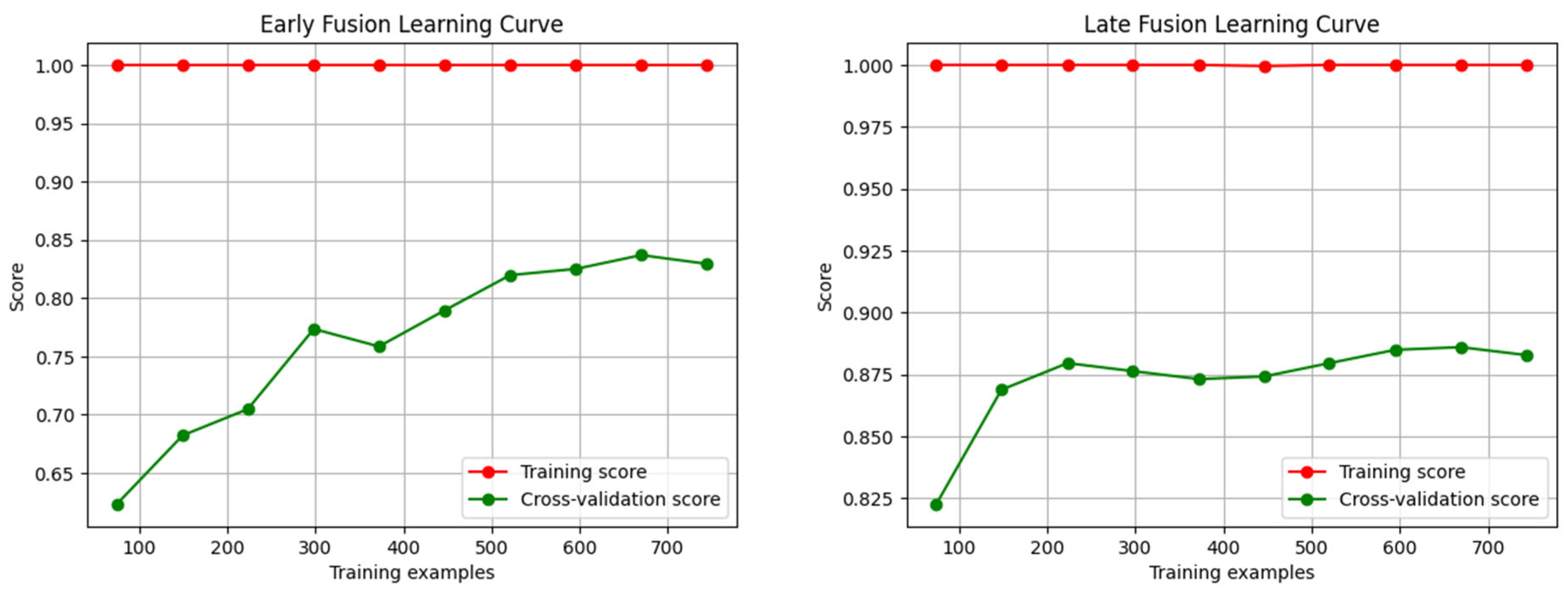
Late Fusion, in contrast, has modality-specific decision boundaries with different classifiers and fuses their decisions at the decision level. The design of Late Fusion allows for the exploitation of asynchronous modality salience. When there is only a single modality that provides a strong signal (e.g., clear speech tone changes even when visually occluded), the classifier can nevertheless trigger a correct aggressive classification. This results in better recall and improved ROC-AUC, particularly in edge cases. The steeper slope of its learning curve up to 210 samples also suggests that modality-specific classifiers are more data-efficient at initial stages, and therefore have more discriminatory within-modality structures, and are quicker to converge with fewer samples.
Moreover, Early Fusion’s increased accuracy is the result of higher decision thresholds that are a byproduct of early integration. As predictions are based on a combined feature space, only samples with clear, consistent signals across both modalities are labeled as aggressive. This reduces false positives but increases false negatives, as seen from the confusion matrix. This is especially critical where minimizing false alarms is of primary concern (e.g., autonomous surveillance), but not ideal in high-stakes contexts where missing an aggressive incident can undermine safety.
Lastly, the performance gap is non-uniform but data-based, with Early Fusion performing relatively better in clean and well-aligned input situations and Late Fusion dominating noisy, heterogeneous, or modality-damaged situations, bearing testament to its resilience and adaptability.
Choice of Methodology
Based on earlier research, the pipeline was chosen for this study and stayed the same in order to adhere to the model’s hierarchy and produce reliable results. Consequently, the Random Forest classifier’s ensemble classification feature was repurposed since it is the best method for the application due to its versatility in operating conditions and consistent performance across a range of decision thresholds [
48]. Alternative classification model options could be used in this study, but doing so would render the improvement’s purpose moot because a different classifier would not offer consistency or dependability for a later comprehensive application of the model in real-world situations.
Real-World Clinical Settings Challenges
The use of controlled and/or simulated datasets and their effects on actual clinical settings must be discussed. As was previously mentioned, the datasets used in the audio and visual models came from open-source, free online datasets. These helped create the models and produce a proof-of-concept model that could be subsequently tested in actual clinical settings.
In future research, these models can be further enhanced using clinical audio and visual data. Clinical datasets may reveal issues that could affect the type of results, like background noise and other environmental noise present in clinical settings. Further, since every patient has different behaviors, individual variability may impede predictions.
Real World Application Strategies
Quality control is another crucial consideration when looking at actual clinical data. The quality of real-world data is impacted by missing values and incorrect labeling and usability. In order to achieve this, mitigation strategies have already been applied in every model under study. Robust data augmentation techniques that mimic clinical data noise in training and domain adaptation methods that use fine-tuning to transfer learning from a controlled dataset to a clinical dataset are examples of adaptation strategies that can be put into practice in response to the challenges discussed. Lastly, cooperation with healthcare organizations is required to obtain clinical data from mental health facilities and to engage in active learning within an active feedback loop where human specialists can oversee and determine the reliability of the results.
Model Robustness and Clinical Application Challenges
It is important to explore potential challenges to the implementation of the model in real clinical environments. Specifically, background noise issues, patient diversity, and missing sensor data are all difficulties that would likely have significant impacts on the model’s performance. To further enhance our model’s robustness, future work will entail testing the model in noisy environments, with artificially injected noise during training. This will challenge the model’s ability to perform in less-than-perfect conditions, common in clinical practice.
In addition, behavioral and patient heterogeneity must be examined. The model’s effectiveness would rely on some patient characteristics, like age, cognitive status, and history of behavior. This issue could be addressed through the implementation of solutions such as transfer learning, whereby the model will learn to generalize to new settings and datasets without the need for lengthy fine-tuning.
Early Fusion’s high precision advantage, as demonstrated in this study, also needs to be considered in the context of specific clinical circumstances. While Early Fusion is better at avoiding false alarms, this needs to be balanced against the clinical need to detect aggressive behaviors in a timely manner. The cost of reducing false positives in the clinical setting must be weighed carefully against the cost of missing an aggressive incident. Future research would have to address the clinical usefulness of such a trade-off, concerning real-world contexts in which false positives and false negatives both have direct implications for patient safety and care.
Ethical Considerations
Given the broader ethical implications of using machine learning algorithms to forecast violent tendencies in susceptible groups, we have to discuss associated moral concerns like the risk of misclassification and privacy.
Privacy: Sensitive information, such as audio biometric data, images, video recordings, and behavioral logs, is commonly used in predictive models. To stop misuse or illegal use, we must adhere to strict privacy laws and moral principles. Participants must give their consent after being fully informed about how their data will be used, and all datasets and participants must remain anonymous. Another essential duty of researchers is strict data privacy, especially for vulnerable populations [
49,
50];
Risk of False Positives and False Negatives: False positives may result in unnecessary medical treatment or stigmatization due to inaccurate forecasts of aggressive behavior. These might result in poor decisions or negatively affect the health of those who are already at risk. Predictive models are used to support clinical decision-making. Combining machine learning with the expertise of knowledgeable staff members can lessen these risks [
51,
52];
Fairness and Bias: Algorithms may apply biases in training data, producing inaccurate results. This is especially problematic when working with vulnerable populations or communities. Mitigation techniques are used when developing such models. To ensure equity, openness, and the reduction of prejudice in such systems, regular measures must be implemented. Taking bias and misclassification into account, the two datasets were not balanced at the time of their creation. Cross-validation methods with 5 × 5 folds were employed to eliminate randomness and lower the risk of misclassification in order to mitigate bias and fairness [
49,
50];
Ethical Implementation and Monitoring: When implementing such models in public settings such as schools, prisons, or mental hospitals, it is crucial to include expert teams in mental health and interdisciplinary fields. The morality of these models must be guaranteed in order to avoid putting people who are already in danger at needless risk [
49,
50];
Accountability and Human Agency: Machine learning models are meant to support human decision-making. Experts who can comprehend the model’s behavior and predictions in a larger context should be the ones to use it on a case-by-case basis. To guarantee such functionality when working with vulnerable groups, formal accountability structures ought to be put in place;
Patient Consent and Privacy: The data utilized for this research came from free, open-source datasets with audio and visual files suitable for academic purposes. Because of the nature of the dataset, there was no need for a consent form. This study did not require or involve the utilization of an institutional review board (IRB) or ethics board. Both the video and audio information were anonymized right from the source, thus no harm or risk was caused to the targeted application. The dataset was public and did not have any personally identifiable information (PII) or direct interaction with the patients. Both the existing and new models utilized 5 × 5 fold cross-validation in order to eliminate random prediction and unethical data bias.
In real-world clinical applications, patient privacy and consent are of major importance, and any system developed on top of the model outlined here would have to be completely compliant with legal and ethical standards for data protection. Specifically, the following would have to be in place to preserve patient privacy and regulatory compliance, such as the General Data Protection Regulation (GDPR) and Health Insurance Portability and Accountability Act (HIPAA):
Data Encryption: Any sensitive patient data (audio, video, and behavioral logs) in real clinical settings needs to be encrypted both in transit and in storage. This would ensure that unauthorized access to data is prevented, upholding patient confidentiality in storage as well as in communication between systems;
Access Permissions: There must be strict access control mechanisms such that sensitive information is viewable or analyzable only by authorized personnel. Role-based access control (RBAC) must be followed such that health care providers, researchers, and clinicians view information related to their roles only. Auditing trails must also be conducted to track access to sensitive information and assign accountability;
Data Minimization: According to the GDPR and HIPAA regulations, patient data should be maintained to the minimum required for clinical or research use. This can be achieved by adopting approaches such as anonymization or pseudonymization in a way that non-personally identifiable information is used unless explicit consent is provided;
Regulatory Compliance: Any data collected and processed in real clinical practice has to be compliant with relevant privacy legislation, i.e., GDPR for European patients and HIPAA for United States patients. This includes providing the patient with sufficient and comprehensible information on how their data will be processed, informed consent prior to collection of the information, and providing patients with the option to revoke consent at any time. Moreover, compliance with those laws would guarantee that activities of data storing, processing, and sharing are compatible with the legal framework of data protection;
Anonymization and Pseudonymization: Where personal identifiers have to be held for clinical reasons, anonymization or pseudonymization techniques must be used. Anonymization wipes out identifying information from the data set in a way that cannot be reversed, so that it is no longer feasible to link data with an individual. Pseudonymization, by comparison, entails substituting identifying information with pseudonyms such that the data may be linked to a person under certain conditions with approved access only.
Although the data sets used in this work were pre-collected and anonymized, clinical use of this model will have to adhere to stringent data protection and privacy laws. Future work will be necessary to incorporate robust encryption methods, secure access controls, and clear patient consent procedures to ensure that actual clinical settings using such models align with legal and ethical requirements, both safeguarding patient confidentiality and model integrity.
Limitations and Future Validation in Clinical Contexts
While this study achieves a sufficient demonstration of a robust and generalizable proof of concept with open-source datasets, we need to acknowledge that open-source datasets never completely reflect the real-world clinical setting complexity and variability. Therefore, the reported performance metrics and outcomes here should be viewed as foundational but not necessarily absolute. Confirmation in the future will depend on demonstrating the proposed fusion strategies within actual clinical workflows, that is, within dementia units, where the behavioral events are subtle, context-dependent, and affected by hundreds of confounding factors such as medication, cognitive impairment, and social relationships. The objective will be to validate the performance of the model on real clinical video and audio data with proper ethical approvals and data governance frameworks. Furthermore, longitudinal data collection will be accorded priority to account for intra-individual behavioral variation over time. These are necessary steps to progress from a simulated evaluation environment to a clinically validated assistive technology that can facilitate frontline caregivers in high-stakes decision-making reliably.
In this research, the findings indicate that in this proof of concept of a novel model for predicting episodes of aggressive behavior in dementia patients, Late Fusion is the best choice due to its robustness and effective approach with a superior recall, accuracy, and overall performance. Its advantages make it the best choice for applications where clinical caregivers and institutions must accurately and timely intervene to prevent such scenarios. However, the Early Fusion technique remains a solid alternative for scenarios where the avoidance of false positive alarms is the main concern in unsupervised applications. Future research should focus on implementing and testing real clinical data (
S1.3) from partnerships with clinical institutions and shed further light on the results or the need for optimized fusion strategies by exploring hybrid approaches that combine the strengths of each methodology.
Comparative Analysis with Recent Research in Violence and Pose Detection
In this section, a contrast of the current work with recent advancements in the field of violence and pose detection is presented and highlighting the similarities, the differentiating aspects, strengths, and weaknesses with respect to current techniques. The papers of Rodrigues et al. [
33], Kumar et al. [
34], Ding and Li [
35], Xu et al. [
36], Abundez et al. [
37], and Negre et al. [
38] that we considered provide valuable information on the state-of-the-art methods in violence detection and pose estimation. We compare and summarize below significant information from these studies with our approach.
Similarities and Common Approaches
Deep Models for Object and Action Detection: Like Kumar et al. [
34], our methodology also utilizes sophisticated deep models (YOLOv7 and LSTM) for object detection and action detection. Both methods seek to boost real-time detection accuracy for the recognition of violent behavior. Our emphasis, however, on recognizing a wider variety of violent postures, including defensive and aggressive movements, sets our work apart by enhancing the applications beyond violent objects only;
Real-Time Edge Deployment: As is the case with Rodrigues et al. [
33] and Kumar et al. [
34], our solution gives emphasis to real-time edge deployment. The approach takes embedded system deployment complexities into account and uses low-latency-optimized YOLO and MediaPipe that ensures quick detection with instantaneous alerting within real setups. This priority entails that the developed system finds usability in safety-critical operations, as presented by both Rodrigues et al. [
33] and Kumar et al. [
34];
Action Recognition and Pose Estimation: Ding and Li [
35] designed a real-time 3D pose recognition system from a deep convolutional neural network, with some resemblance to our pose estimation technique. Though Ding and Li are concerned with character animation, we utilize a holistic model to estimate body poses, using MediaPipe to detect physical postures signaling violence. This intersection signifies a shared interest in applying pose analysis to action recognition systems, although our application is to real-world violence detection.
Differentiation and Unique Contributions
Focus on Violence Detection Based on Holistic Postures of the Body: While most of the works reviewed, e.g., Kumar et al. [
34] and Xu et al. [
36], focus on detecting violent objects (e.g., weapons), our work is novel in its focus on detecting violent actions through body postures and movement. Both offensive and defensive moves are covered under this work, which can provide insights into violence and aggression based on the motion of the human body rather than based on objects utilized;
Enhanced Dataset and Action Classification: In contrast to Abundez et al. [
37], who utilize an active learning approach with a threshold that is used for continuously enhancing the classifier across environments, our approach includes a multimodal action classification system. While Abundez et al. [
37] rely on recalibrating the model on new ambiguous images to produce higher accuracy, our solution improves on that idea by focusing on the physical postures of violence and classifying them as defensive and aggressive. This enables more subtle violent behaviors beyond simple object detection;
Multi-Class Pose Recognition: Our system identifies poses and actions in a real setting, as opposed to Ding and Li [
35], who work on identifying animated character poses. Our system is specifically designed to identify violent and aggressive postures from video streams, which is an important practical distinction in deployment.
Strengths
Inter-Model Comprehensive Integration: Our approach combines object detection (via YOLOv7) and pose estimation (via MediaPipe) into a single solution, providing an end-to-end solution for both the object and the action context of violence. Kumar et al. [
34] and Xu et al. [
36] concentrate on violence detection based on object identification only, but our multi-faceted system detects violent actions, improving classification accuracy for diverse violent behavior;
Real-Time Performance and Robustness: Similar to Rodrigues et al. [
33] and Kumar et al. [
34], we emphasize real-time performance and deploy our model on embedded systems for rapid inference. The combination of YOLO for object detection and MediaPipe for pose estimation ensures that our system functions optimally under real-world scenarios, such as surveillance in complex environments. Our optimized model provides high performance with low latency; thus, it is usable in urgent response scenarios, such as security monitoring;
Generalization Across Multiple Environments: Our approach is able to handle a wide variety of video environments and hostile postures, addressing a common issue reported in Abundez et al. [
37]. Using pretrained models and carefully curating the dataset, we ensure that our model generalizes well across multiple environments, hence being insensitive to a range of scenarios even when it encounters novel environments during training.
Weaknesses and Areas for Development
Real-World Deployment Complexity: While our approach demonstrates real-time performance, it may still be constrained in highly cluttered or low-resolution video settings where object and pose detection may be impaired. Similar to the constraints defined by Rodrigues et al. [
33] and Kumar et al. [
34], our system must deal with realistic real-world scenarios where occlusions, low light, or high-speed motions may impact detection accuracy;
Limited Action Classification Granularity: While our system is strong in discriminating violent from non-violent action, further discrimination among violent behavior subclasses (i.e., physical assault, verbal aggression, or self-injury) would add more generality to the model. Fine-tuning in this way could lead to more specific intervention in real-world circumstances compared to a more general violent action classification;
Dependence on Pretrained Models: While pretrained models are convenient in terms of improving initial performance and training, they also carry limitations when it comes to processing very particular sets of data. Our reliance on such models could restrict the capacity of the system to learn novel behaviors or unexpected actions, much like the iterative learning model presented by Abundez et al. [
37].
In this work, a new contribution to the field of violence and pose detection is presented by integrating object detection and action recognition into an end-to-end system that can be applied in real-time on edge devices. Although adopting some of the features of recent progress, e.g., those of Kumar et al. [
34] and Xu et al. [
36], our system differs on the grounds of its focus on the recognition of violent acts through physical postures and gestures, offering a deeper contextual interpretation of aggression. Although there remain some problems with environment adaptability and action classification granularity, our system provides a scalable and robust solution for violence detection that can be used in many public safety scenarios.
5. Conclusions
This study presents a comparative analysis of Early and Late Fusion models for aggression detection in dementia patients using multimodal audio-visual data as a novel proof-of-concept methodology. According to the findings, Late Fusion outperforms Early Fusion in most key metrics, including accuracy (0.876 vs. 0.828), recall (0.914 vs. 0.818), F1-score (0.867 vs. 0.835), and ROC-AUC (0.970 vs. 0.922), making it more effective in detecting aggressive behaviors. Its higher recall suggests better detection of aggressive incidents, making it suitable for high-risk applications, while its faster inference times enhance its potential for real-time use. In contrast, Early Fusion achieved higher precision (0.852 vs. 0.824), indicating a lower false positive rate, which may be beneficial in scenarios where minimizing false alarms is crucial. Additionally, Late Fusion’s superiority is reinforced by its higher Balanced Accuracy (0.880 vs. 0.829) and Cross-Validated ROC-AUC (0.959 vs. 0.924), suggesting better generalizability.
Future Directions
This study provides results that open new opportunities for further advancements in human behavioral prediction models. It also paves the road for deep learning incorporation techniques for feature extraction that could improve the classification accuracy, such as CNNs and RNNs. The latest could be explored for a more complex approach in the visual and audio patterns.
Furthermore, hybrid fusion strategies that integrate certain aspects from both Early and Late Fusion techniques could provide an even more robust solution by integrating the strengths from each approach. This would provide increased accuracy and low false positive rates while maintaining the superior classification capabilities, providing a reliable detection system. Finally, attention mechanisms could be implemented during the fusion process to refine the decision-making ability of the model. This will allow for a more dynamic weight-critical feature mechanism and improve even more the classification performance.
While this research presents a strong way of identifying violence in terms of postures and gestures, there are still various directions for further development. One direction is the granularity of distinguishing between actions. Our system currently distinguishes violent from non-violent action but might, in future follow-up work, continue to distinguish action further to identify the more subtle domains of aggression involving physical aggression, verbal aggression, or self-injury. This would not merely enhance the ability of the model to react with greater accuracy against different types of violent conduct, but also provide more specific indications of actual-world intervention. On top of this, fine-grained action identification would help disambiguate between unlike intensities of aggressiveness, paving the way for more targeted action in public safety settings.
Deployability in the actual world is another key dimension for enhancement. Although the system has been tuned for real-time performance, precision is impacted by factors such as low-resolution video streams, occlusions, or adverse environmental conditions (e.g., low illumination, high-density environments, or high-speed motion). The aforementioned problems may be solved with data augmentation techniques, state-of-the-art pose detection algorithms, and multimodal fusion (e.g., combining audio or thermal data with visual data) that might boost the system’s resilience in uncontrolled and dynamic environments. Secondly, adaptive learning techniques could be employed to allow the model to continuously improve its detection abilities by adding new data in varied environments and conditions so that it becomes more suitable to generalize and adapt to variable conditions. All these advancements would significantly improve the system’s uses for real-time surveillance, and it would provide a more general solution for detecting violence in various real-world applications.
Real-Time Deployment
Implementation of these models in real-world clinical scenarios and settings is a crucial next step. Further research in this field should focus on an optimized model with efficiency high enough to ensure low-latency prediction times. Model compression and quantization strategies in the edge computing field should be considered to unlock further capabilities for resource-constrained devices that are commonly used in healthcare.
Validation of the model’s performance in clinical data and trials with real data from patients is essential to ensure the effectiveness and the reliability of the model. Collaboration with healthcare institutes and experts is mandatory to test and refine the usability of this method in real-time prediction of aggressive episodes, validating its usability in existing care protocols. The successful deployment of real-time aggression detection models could revolutionize patient monitoring, offering a proactive approach to managing aggression-related incidents in dementia care.

 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}