

Perspective Transformation and Viewpoint Attention Enhancement for Generative Adversarial Networks in Endoscopic Image Augmentation

Abstract
1. Introduction
2. Related Work
2.1. Basic Transformation for Image Augmentation
2.2. GAN Augmentation
2.3. Endoscopic Image Augmentation
2.4. StarGAN
2.5. Deep Learning Models for Medical Image Classification
3. Materials and Methods
3.1. Dataset
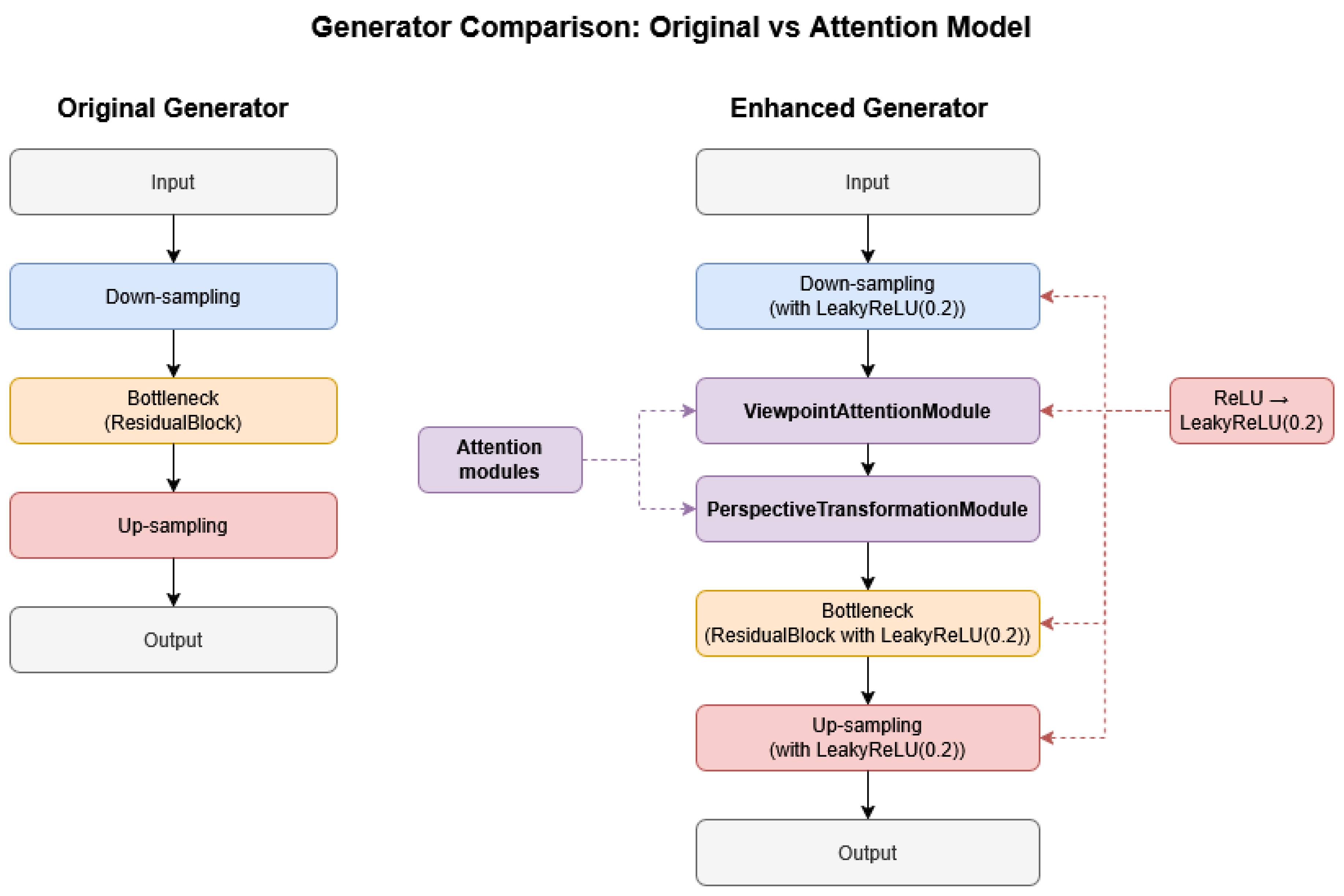
3.2. Architectural Enhancements over Original StarGAN
3.2.1. Attention Mechanisms
Perspective Transformation Module (PTM)
- Feature Extraction Component. This component processes the input data to extract relevant information about spatial relationships and visual structures within the image. It reduces the spatial dimensions while increasing the feature richness, effectively compressing the visual information into a representation that is suitable for predicting transformation parameters.
- Transformation Parameter Prediction. Based on the extracted features, this component generates a set of six parameters that define an affine transformation matrix. These parameters control various aspects of the transformation, including rotation, scaling, shearing, and translation effects. The component is initially configured to predict an identity transformation (no change) and learns to predict appropriate transformations during training.
- Randomization Mechanism. To introduce diversity in the transformations, this component adds controlled randomness to the predicted parameters. It applies random rotations, scaling factors, and small translations that vary from one input to another. This variability ensures that the module can produce diverse viewpoint changes rather than a single fixed transformation.
- Transformation Application. The final component constructs a transformation grid based on the combined predicted and randomized parameters. It then applies this transformation to the input data using interpolation techniques that ensure the resulting output maintains visual coherence. This process warps the input according to the specified perspective change while preserving the overall visual content.
Viewpoint Attention Module (VAM)
- Query, Key, and Value Projections. The module utilizes three parallel transformations of the input data:
- ○
- Query Projection transforms the input features to represent “what we’re looking for” at each position. This projection typically reduces the feature dimensionality to create a more compact representation.
- ○
- Key Projection creates a representation of “what information is available” at each position, with similar dimensionality reduction as the query projection.
- ○
- Value Projection represents the actual information content at each position that will be selectively emphasized or attenuated by the attention mechanism. This projection typically maintains the original feature dimensions.
- Attention Computation. The attention mechanism operates by:
- ○
- Computing similarity scores between query and key representations, measuring how relevant each position is to every other position.
- ○
- Normalizing these similarity scores using SoftMax to create attention weights that sum to 1.
- ○
- These weights effectively create a probability distribution indicating which regions should receive greater focus.
- Feature Aggregation. After computing attention weights, the module:
- ○
- Uses these weights to create a weighted combination of value features.
- ○
- This aggregation process allows information to flow between different positions based on their computed relevance.
- ○
- Positions with higher attention scores contribute more strongly to the final representation.
- Functional Significance. The Viewpoint Attention Module enhances neural networks by:
- ○
- Enabling long-range dependencies between distant spatial positions.
- ○
- Creating a dynamic, content-dependent focus mechanism.
- ○
- Selectively emphasizing relevant features while suppressing irrelevant ones.
- ○
- Providing a flexible way to incorporate global context into local feature processing.
- ○
- Maintaining training stability through gradual introduction of the attention mechanism.
3.2.2. Integration of LeakyReLU Activation
3.2.3. Module Integration into StarGAN
3.3. Experiment Setup
4. Experiments and Results
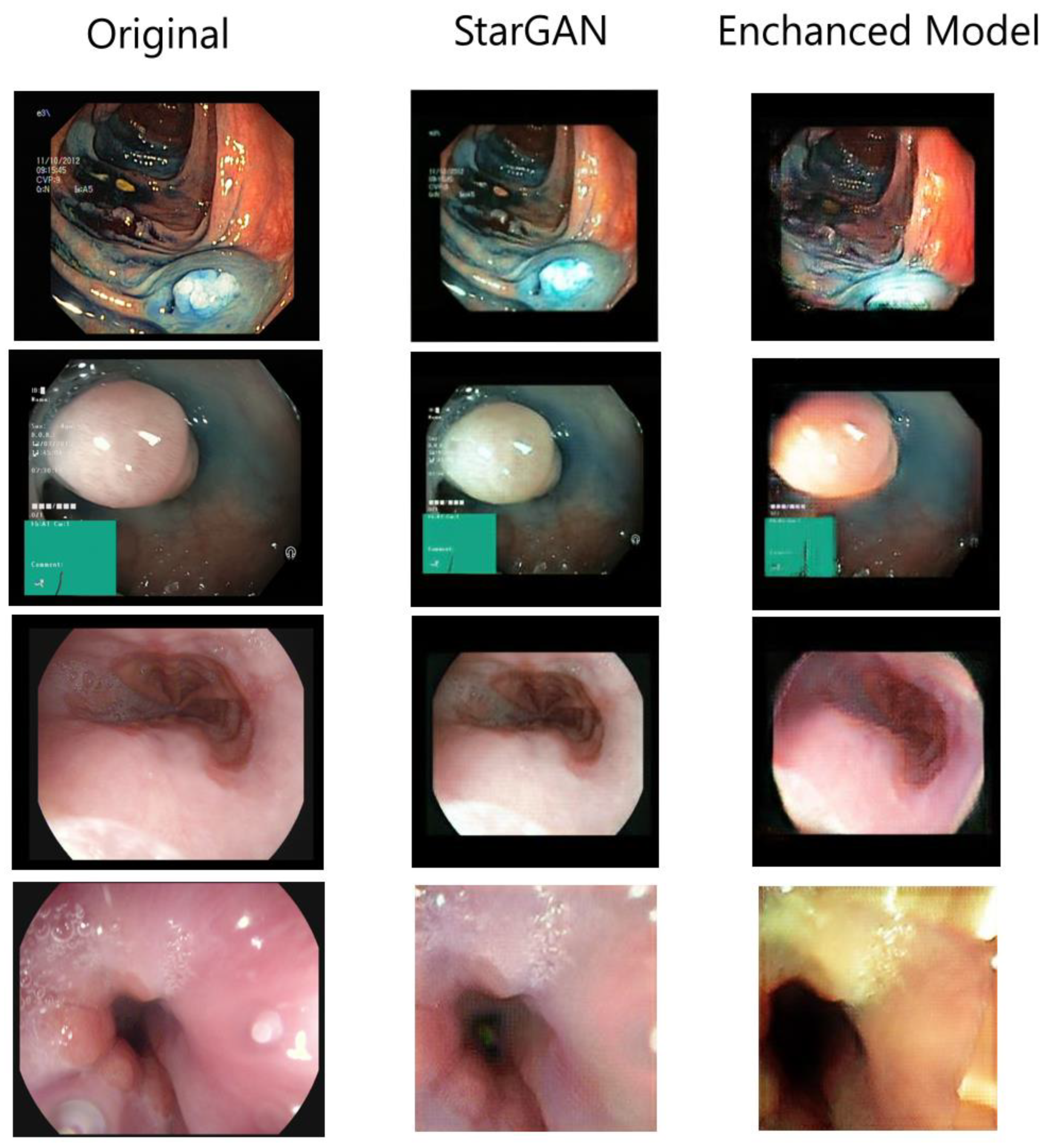
4.1. Augmented Images
4.2. Experiment Results
- All five models (VGG-16, ResNet-50, DenseNet-121, InceptionNet-V3, and EfficientNet-B7) showed improvements in accuracy after augmenting the training dataset with additional GAN-generated images.
- VGG-16 showed the largest relative improvement, increasing from 93.43% to 94.13%, resulting in a gain of 0.704 percentage points with a confidence interval of ±0.118.
- ResNet-50 improved from 94.18% to 94.68%, with a gain of 0.504 percentage points (±0.106).
- DenseNet-121 improved from 94.50% to 94.81%, with a gain of 0.318 percentage points (±0.131).
- InceptionNet-V3 had the highest baseline accuracy and achieved 95.22% after augmentation, a gain of 0.298 percentage points (±0.082). This model had the narrowest confidence interval, suggesting more consistent improvement.
- EfficientNet-B7 showed the second-largest improvement and achieved the highest overall accuracy after augmentation (95.25%), with a gain of 0.636 percentage points (±0.097).
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fedoruk, O.; Klimaszewski, K.; Ogonowski, A.; Kruk, M. Additional Look into GAN-Based Augmentation for Deep Learning COVID-19 Image Classification. Mach. Graph. Vis. 2023, 32, 107–124. [Google Scholar] [CrossRef]
- Dash, A.; Swarnkar, T. CoVaD-GAN:An Efficient Data Augmentation Technique for COVID CXR Image Classification. In Proceedings of the 2023 2nd International Conference on Ambient Intelligence in Health Care (ICAIHC), Bhubaneswar, India, 17–18 November 2023; pp. 1–7. [Google Scholar] [CrossRef]
- Al-Adwan, A. Evaluating the Effectiveness of Brain Tumor Image Generation Using Generative Adversarial Network with Adam Optimizer. Int. J. Adv. Comput. Sci. Appl. 2024, 15. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Pogorelov, K.; Randel, K.R.; Griwodz, C.; Eskeland, S.L.; de Lange, T.; Johansen, D.; Spampinato, C.; Dang-Nguyen, D.-T.; Lux, M.; Schmidt, P.T.; et al. KVASIR: A Multi-Class Image Dataset for Computer Aided Gastrointestinal Disease Detection. In Proceedings of the 8th ACM on Multimedia Systems Conference; MMSys’17, Taipei, Taiwan, 20–23 June 2017; Association for Computing Machinery: Taipei, Taiwan, 2017; pp. 164–169. [Google Scholar] [CrossRef]
- Kancharagunta, K.B.; Nayakoti, R.; Nukarapu, S. Generative Adversarial Networks in Medical Image Analysis: A Comprehensive Survey. In Proceedings of the International Conference On Innovative Computing And Communication, Zhengzhou, China, 18–20 October 2024; Springer: Singapore, 2024; pp. 367–398. [Google Scholar] [CrossRef]
- Shaukat, A.; Kahi, C.J.; Burke, C.A.; Rabeneck, L.; Sauer, B.G.; Rex, D.K. ACG Clinical Guidelines: Colorectal Cancer Screening 2021. Am. J. Gastroenterol. 2021, 116, 458–479. [Google Scholar] [CrossRef]
- Chen, X.; Wang, X.; Zhang, K.; Fung, K.-M.; Thai, T.C.; Moore, K.; Mannel, R.S.; Liu, H.; Zheng, B.; Qiu, Y. Recent advances and clinical applications of deep learning in medical image analysis. Med. Image Anal. 2022, 79, 102444. [Google Scholar] [CrossRef] [PubMed]
- Goceri, E. Medical image data augmentation: Techniques, comparisons and interpretations. Artif. Intell. Rev. 2023, 56, 12561–12605. [Google Scholar] [CrossRef]
- Guo, K.; Chen, J.; Qiu, T.; Guo, S.; Luo, T.; Chen, T.; Ren, S. MedGAN: An Adaptive GAN Approach for Medical Image Generation. Comput. Biol. Med. 2023, 163, 107119. [Google Scholar] [CrossRef]
- Islam, T.; Hafiz, S.; Jim, J.R.; Kabir, M.; Mridha, M. A Systematic Review of Deep Learning Data Augmentation in Medical Imaging: Recent Advances and Future Research Directions. Healthc. Anal. 2024, 5, 100340. [Google Scholar] [CrossRef]
- Park, H.-C.; Hong, I.-P.; Poudel, S.; Choi, C. Data Augmentation Based on Generative Adversarial Networks for Endoscopic Image Classification. IEEE Access 2023, 11, 49216–49225. [Google Scholar] [CrossRef]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.-W.; Kim, S.; Choo, J. StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8789–8797. [Google Scholar] [CrossRef]
- Üreten, K.; Maraş, H.H. Automated Classification of Rheumatoid Arthritis, Osteoarthritis, and Normal Hand Radiographs with Deep Learning Methods. J. Digit. Imaging 2022, 35, 193–199. [Google Scholar] [CrossRef]
- Zhang, G.; Dang, H.; Xu, Y. Epistemic and aleatoric uncertainties reduction with rotation variation for medical image segmentation with ConvNets. SN Appl. Sci. 2022, 4, 56. [Google Scholar] [CrossRef]
- Li, X.; Hu, X.; Qi, X.; Yu, L.; Zhao, W.; Heng, P.-A.; Xing, L. Rotation-Oriented Collaborative Self-Supervised Learning for Retinal Disease Diagnosis. IEEE Trans. Med. Imaging 2021, 40, 2284–2294. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, Q.; Hu, B. Minimalgan: Diverse medical image synthesis for data augmentation using minimal training data. Appl. Intell. 2023, 53, 3899–3916. [Google Scholar] [CrossRef]
- He, W.; Liu, M.; Tang, Y.; Liu, Q.; Wang, Y. Differentiable Automatic Data Augmentation by Proximal Update for Medical Image Segmentation. IEEE/CAA J. Autom. Sin. 2022, 9, 1315–1318. [Google Scholar] [CrossRef]
- Wang, W.; Yu, X.; Fang, B.; Zhao, Y.; Chen, Y.; Wei, W.; Chen, J. Cross-Modality LGE-CMR Segmentation Using Image-to-Image Translation Based Data Augmentation. IEEE/ACM Trans. Comput. Biol. Bioinform. 2022, 20, 2367–2375. [Google Scholar] [CrossRef] [PubMed]
- Showrov, A.; Aziz, M.; Nabil, H.R.; Jim, J.; Kabir, M.; Mridha, M.F.; Asai, N.; Shin, J. Generative Adversarial Networks (GANs) in Medical Imaging: Advancements, Applications and Challenges. IEEE Access 2024, 12, 35728–35753. [Google Scholar] [CrossRef]
- Liu, J.; Li, K.; Dong, H.; Han, Y.; Li, R. Medical Image Processing based on Generative Adversarial Networks: A Systematic Review. Curr. Med. Imaging Former. Curr. Med. Imaging Rev. 2023, 20, 31. [Google Scholar] [CrossRef]
- Adhikari, R.; Pokharel, S. Performance Evaluation of Convolutional Neural Network Using Synthetic Medical Data Augmentation Generated by GAN. Int. J. Image Graph. 2021, 23, 2350002. [Google Scholar] [CrossRef]
- Deng, B.; Zheng, X.; Chen, X.; Zhang, M. A Swin Transformer Encoder-Based StyleGAN for Unbalanced Endoscopic Image Enhancement. Comput. Biol. Med. 2024, 175, 108472. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE Computer Society: Los Alamitos, CA, USA, 2016; pp. 2818–2826. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. arXiv 2019, arXiv:1905.11946. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Component | Parameter | Value |
|---|---|---|
| Enhanced GAN | Generator Learning Rate | 0.00007 |
| Discriminator Learning Rate | 0.00005 | |
| Image Size | 224 × 224 | |
| Classification Models | Batch Size (VGG-16, ResNet-50, DenseNet-121, InceptionNet-V3) | 64 |
| Batch Size (EfficientNet-B7) | 32 | |
| Initial Learning Rate | 0.0001 | |
| Image Size (VGG-16, ResNet-50, DenseNet-121, EfficientNet-B7) | 224 × 224 × 3 | |
| Image Size (InceptionNet-V3) | 299 × 299 × 3 | |
| Optimizer (VGG-16, DenseNet-121) | Adam | |
| Optimizer (ResNet-50, InceptionNet-V3, EfficientNet-B7) | RMSprop | |
| Scheduler | CosineAnnealingLR | |
| Scheduler Max Iterations | 50 | |
| Scheduler Min Learning Rate | 0 | |
| Loss Function | CrossEntropyLoss | |
| Training Epochs | 300 | |
| Data Augmentation | Rotation Range | −90° to 90° |
| Flipping | Random Horizontal and Vertical | |
| Cropping | Random |
| Model | Reported Accuracy | Achieved Accuracy | Improvement | Confidence Interval |
|---|---|---|---|---|
| VGG-16 | 0.9343 | 0.9413 | +0.704 | ±0.118 |
| ResNet-50 | 0.9418 | 0.9468 | +0.504 | ±0.106 |
| DenseNet-121 | 0.9450 | 0.9481 | +0.318 | ±0.131 |
| InceptionNet-V3 | 0.9493 | 0.9522 | +0.298 | ±0.082 |
| EfficientNet-B7 | 0.9462 | 0.9525 | +0.636 | ±0.097 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Janutėnas, L.; Šešok, D. Perspective Transformation and Viewpoint Attention Enhancement for Generative Adversarial Networks in Endoscopic Image Augmentation. Appl. Sci. 2025, 15, 5655. https://doi.org/10.3390/app15105655
Janutėnas L, Šešok D. Perspective Transformation and Viewpoint Attention Enhancement for Generative Adversarial Networks in Endoscopic Image Augmentation. Applied Sciences. 2025; 15(10):5655. https://doi.org/10.3390/app15105655
Chicago/Turabian StyleJanutėnas, Laimonas, and Dmitrij Šešok. 2025. "Perspective Transformation and Viewpoint Attention Enhancement for Generative Adversarial Networks in Endoscopic Image Augmentation" Applied Sciences 15, no. 10: 5655. https://doi.org/10.3390/app15105655
APA StyleJanutėnas, L., & Šešok, D. (2025). Perspective Transformation and Viewpoint Attention Enhancement for Generative Adversarial Networks in Endoscopic Image Augmentation. Applied Sciences, 15(10), 5655. https://doi.org/10.3390/app15105655