1. Introduction
Swelling pressure (p
s) is a critical parameter in various fields, including geotechnical engineering [
1]. It refers to the pressure exerted by a material when it expands upon absorbing a fluid, usually water. This phenomenon is particularly significant in the context of expansive soils, which can undergo substantial volume changes due to variations in moisture content. Expansive soils can pose significant economic costs due to their swelling and shrinking behaviours. These changes can lead to structural damage in buildings and infrastructure, resulting in a remarkably high cost, with the annual global expenditure on repairs estimated to reach several billion dollars [
2,
3]. Sabtan [
4] indicated that the swelling behaviour is primarily influenced by the combined effect of several interacting factors, which can be categorized as: (a) local geology; (b) engineering properties; and (c) local environment of deposition. Geological factors encompass the rock type and age, which are related to the type and quantity of clay minerals, the type and amount of cementing material, and the arrangement of soil particles. Engineering factors include moisture content, Atterberg limits, and dry density. Environmental factors involve confining pressure, weathering type and degree, clay fraction content, initial water content, and water chemistry. While the swelling potential is influenced by geological and engineering factors, the amount and rate of swelling are governed by environmental conditions.
Expansive soils are widely distributed throughout the world, although they are especially abundant in arid zones, where conditions are suitable for the formation of clayey minerals of the smectite group such as montmorillonite or some types of illites [
5]. In geotechnical practice, the determination of p
s is crucial for designing foundations and retaining structures, tunnels, and other geotechnical structures. Accurate predictions can facilitate the implementation of appropriate engineering measures to mitigate its effects and reduce costs in engineering projects [
6,
7]. There are different techniques applicable in this type of soil to mitigate its potential volume changes, essentially involving the addition of a stabilizing material (e.g., refs. [
8,
9,
10,
11]). Various laboratory tests, such as the oedometer test and the triaxial test, are commonly employed to directly measure p
s [
12]. However, there are numerous correlations available that relate p
s to other easily obtainable geotechnical parameters [
13]. Many researchers have extensively investigated the factors influencing soil swelling and have attempted to establish relationships between soil properties, including clay content, dry unit weight, water content, liquid limit, and plasticity index (e.g., refs. [
4,
14,
15,
16,
17,
18,
19]). In the face of these challenges, the application of machine learning (ML) techniques can offer promising opportunities for advancing the understanding of clay swelling [
20]. ML models can handle the complexity of the swelling process, making them powerful tools for predicting p
s based on a range of input parameters (e.g., refs. [
21,
22,
23]). Gahlot et al. [
24] provided a comprehensive review of the ML methods applied to obtain p
s. However, it is important to note that most traditional statistical correlations and existing ML algorithms are based on datasets of remoulded clay samples, where the soil structure is altered during both the extraction process and the compaction for testing. This reliance on remoulded samples may not accurately represent the behaviour of undisturbed soils, potentially limiting the applicability of these models to in situ soil conditions. Numerous studies (e.g., ref. [
25]) have shown that correlations derived from remoulded samples can differ significantly from those based on undisturbed samples, highlighting the need for caution when applying such models to natural soil conditions.
Although effective, ML models often lack transparency (black boxes), posing challenges for specific applications or when dealing with new data categories. As a result, efficient analytical formulas and algorithms could be preferred [
26]. Symbolic regression (SR), a machine learning approach, aims to automatically discover formulas that capture correlations within a given dataset [
27], offering models in the form of easily understandable mathematical equations. While it has traditionally been implemented using Genetic Programming [
28], alternative approaches also exist. These include deterministic methods that systematically explore the space of mathematical expressions, deep learning-based techniques, transformer-based methods, and hybrid algorithms that combine multiple strategies to enhance the efficiency and accuracy of SR, among others. SR has been used in geological and geotechnical engineering [
29,
30,
31,
32] and, specifically, to obtain p
s [
33] with satisfactory results.
Despite the increasing number of studies addressing the prediction of ps using empirical or machine learning approaches, several critical gaps remain. Firstly, most existing correlations are based on remoulded samples, which fail to reflect in situ conditions and may lead to misleading predictions. Secondly, widely used ML models often operate as black-box systems, lacking interpretability and offering limited insight into the influence of input parameters. Lastly, few studies have explored the use of SR algorithms that produce simple, physically meaningful equations while maintaining high predictive accuracy.
In response to these limitations, this study aims to explore the capabilities of SR as a tool to discover patterns in complex datasets in order to synthesize simple equations that allow engineers to estimate the ps value in clayey soils with the same characteristics as those studied here, with a high degree of reliability. To achieve this, it is only necessary to know some easily obtainable index properties, such as: liquid limit (LL), plasticity index (PI), dry density (γd), percentages passing through a 0.075 mm sieve, and natural water content (w). Additionally, the most influential input variables on the final value of ps were evaluated.
2. Study Area
In Spain, expansive soils cover approximately 30% of the territory and primarily belong to the montmorillonite group [
34]. Additionally, 67% of the country is located in climates where significant moisture changes can occur in the soil, with dry periods ranging from two to eight months [
35]. The study area is located in the southeastern region of Spain, specifically in the provinces of Murcia and Almería.
Figure 1 presents the potential swelling risk map of Spain [
35] along with the locations of the two primary sample sources used in this study. The samples were obtained in the context of different engineering projects, including road infrastructures, slope stability works, building structures, and foundation reinforcements for existing structures. As such, they are disseminated. In this way, the study areas were defined based on whether the samples belong to geotechnical units exhibiting similar swelling behaviours, according to the potential ranges established in
Figure 1. As can be observed, the studied areas fall into the category of expansive clays with a moderate to high swelling potential (expected p
s between 125–300 kPa) and high to very high potential (expected p
s upper than 300 kPa). They consist of clayey–marly soils with medium-to-high plasticity and contain clays from the montmorillonite group, belonging to Neogene materials. According to the authors’ experience, they can achieve relatively high p
s values (above 400 kPa).
In the study area, there are numerous cities, as well as associated structures, roads, railway lines, and slopes. If adequate measures are not taken, all of these may experience pathologies due to cyclic swelling and shrinkage. Specifically, buildings can suffer differential settlement, triggering diagonal or stair-step cracks in walls and foundation displacement, particularly in lightweight structures with shallow footings. Slopes develop vertical or subvertical desiccation cracks during droughts, followed by superficial landslides upon wetting due to a reduction in shear strength. Roadways develop longitudinal cracks parallel to the direction of traffic due to differential heave between the centreline and shoulders. Concurrently, edge uplift occurs along rigid boundaries (e.g., medians, curbs) caused by moisture-induced swelling pressure gradients. In concrete pavements, differential heave or settlement causes edges or corners of the concrete slabs to lift or sink, creating uneven surfaces. This process induces cracks at slab edges or joints, as well as mid-slab longitudinal cracking, along with minor associated transverse cracks.
Figure 2 shows damage in recently constructed structures on expansive clays, where the authors were involved in structural rehabilitation and underpinning work. In
Figure 2a, typical cracks associated with soil expansion and shrinkage phenomena are observed, in this case at a 45° angle, with a crack monitor to track movement.
Figure 2b presents a similar case, but with more severe damage due to the combined effect of highly expansive clays and construction defects. In
Figure 2c,d, it can be seen how swelling affects the lighter parts of the structure such as rigid concrete floor slabs and garage slabs in direct contact with expansive clays.
This is, therefore, a very common problem that needs to be anticipated, with ps being the most important parameter for its assessment. Likewise, when implementing the necessary reinforcement measures (e.g., underpinning), ps remains the key soil-related factor for their design.
4. Collected Database and Statistical Analysis
A comprehensive and detailed dataset consisting of 181 data points was created for the development of predictive models. The independent variables were selected according to two key criteria: (1) they represent standard geotechnical index properties routinely measured in site investigations, and (2) they have been established as significant factors influencing swelling pressure, as discussed in the
Section 1 based on the existing literature. Prior to modelling, a statistical analysis was conducted to understand the behaviour and relationships of the input variables in the dataset. The goal was to evaluate their distribution, variability, and possible interdependencies and to identify any multicollinearity or redundancies that might affect model interpretation.
Table 1 provides descriptive statistics for all the input parameters analysed in this study. It includes measures of central tendency, dispersion, and distribution characteristics. In
Figure 3, the distribution histograms of the parameters considered are depicted.
Table 1 and
Figure 3 provide a detailed understanding of the characteristics of the clayey soils included in the dataset, making it easier to interpret their properties.
The soil fraction below #0.075 mm has an average of 81.2% with a standard deviation of 20.2%, indicating a notable level of variability. Additionally, its mode is 100%, indicating that a considerable number of samples were composed almost entirely of fine-grained material. Regarding the LL, a nearly symmetric distribution with a mean of 51.3% is observed, accompanied by a moderate level of variability (standard deviation of 16.3%). PI shows a slight right skew with a mean of 27.3% and moderate variability. Natural water content (w) exhibits relatively low variability with a mean of 23.9%. The variable γd demonstrates a symmetric distribution and relatively low variability. Lastly, the ps shows a right-skewed distribution with a mean of 163.0 kPa and a median of 149.2 kPa. The high variability in the data is indicated by a standard deviation of 105.7 kPa.
Next, all soils were classified according to the USCS. The results of this classification are presented in
Table 2. In addition,
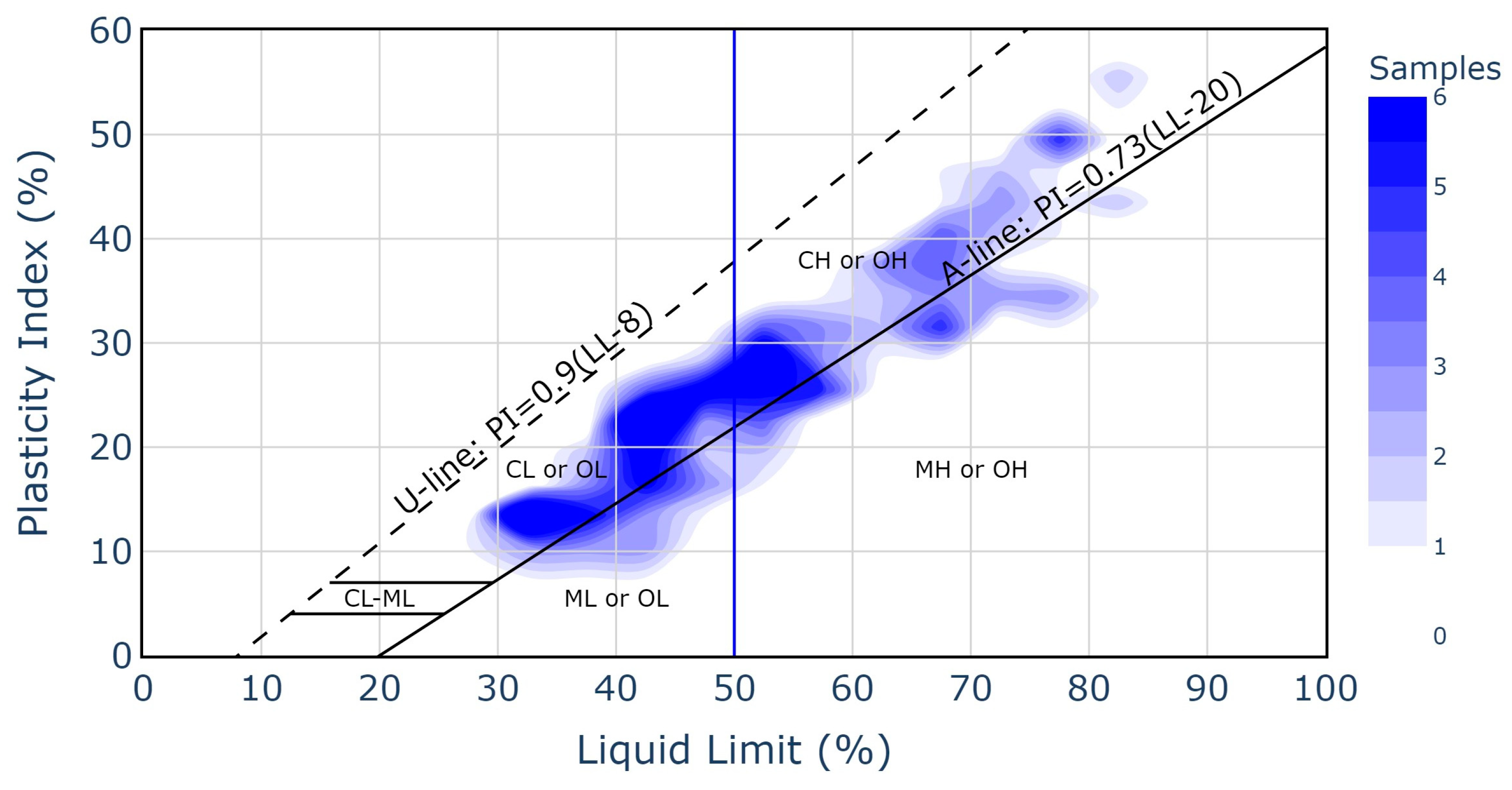
Figure 4 presents the distribution of the 181 undisturbed soil samples on the Casagrande plasticity chart, with colour intensity representing sample density. Most samples are concentrated above the A-line, corresponding predominantly to clays of medium to high plasticity (CL and CH, according to the USCS). A dense cluster can be observed between LL values of 30 and 60% and PI values of 12–32%, indicating a dominance of plastic clayey soils. Only a few samples (approximately 20%) fall below the A-line, within the silt categories (ML or MH). Specifically, the results of this classification indicate that 143 samples correspond to clays (C), 48 to silts (M), 93 to high-plasticity soils (H) (LL ≥ 50), and 50 to low-plasticity soils (L) (LL < 50). Moreover, according to Chen’s [
45] criteria, 102 of these samples would be classified as moderately expansive and 51 as highly expansive.
In summary, the dataset covers a wide range of geotechnical conditions representative of expansive soils in southeastern Spain. According to their index properties, the soils span low- to high-plasticity ranges and include both clays and silts, as confirmed by the subsequent USCS classification. This variety of properties supports the generalizability and robustness of the proposed models.
Next,
p-values and Variance Inflation Factor (VIF) for the predictive variables were calculated (
Table 3). The
p-value represents the probability that the observed relationships between the independent variables and the dependent variable occurred by chance. A lower
p-value indicates a statistically significant effect, typically below a threshold of 0.05. VIF measures multicollinearity among independent variables, with values above 10 suggesting a high degree of correlation. In the analysis, the
p-values for the percentage of soil passing #0.075 mm, LL, PI, and γ
d were well below 0.05, indicating that these variables had a statistically significant impact on the dependent variable. Conversely, w presented a high
p-value (0.852), suggesting it is not significantly contributing to the model. The VIF values indicated strong multicollinearity, particularly for LL and the percentage of soil passing #0.075 mm, as these properties are related to most of the others.
Additionally, the correlation matrix between the variables of the dataset is presented in
Figure 5, using the Pearson correlation coefficient (r) and the Spearman coefficient. These correlation matrices revealed critical insights about the relationships between soil properties and p
s. Pearson correlations indicate linear dependencies, while Spearman correlations capture monotonic relationships, providing a comprehensive view of variable interactions.
For the target variable (ps), both matrices showed consistently strong associations, though with notable differences in magnitude. PI exhibited the highest correlation with ps in both methods, suggesting PI is the most reliable predictor. LL also showed strong positive correlations, reinforcing its importance in swelling prediction models. Water content demonstrated moderate correlations, indicating a secondary role in swelling behaviour, as well as showing a moderate to high correlation with the percentage of soil passing #0.075 mm and a very high p-value. γd showed a weak negative correlation with ps, which may justify its inclusion as a secondary predictor, especially considering its low correlation with the other variables. The percentage of soil passing #0.075 mm presented moderate positive correlations, though the Spearman coefficient is notably lower, suggesting the relationship may involve nonlinear components.
6. Results and Discussion
A consistent random seed was applied to divide the dataset into 70% for training and 30% for testing, ensuring reproducibility in the model evaluation. In engineering applications, it is often essential to maximize predictive accuracy while keeping the resulting expressions simple; however, these objectives can be at odds. To derive the final equations, each symbolic regression algorithm was trained through multiple iterations, progressively increasing the allowed complexity. In each case, a pool of candidate formulas was generated and assessed based on a trade-off between predictive performance and simplicity. To avoid overfitting and ensure model interpretability, complex or higher-order terms were penalized or excluded. The final expressions were chosen by comprehensively evaluating each candidate for both predictive performance and structural simplicity. The results of this process were the formulas included in
Table 4.
To ensure reproducibility, the main hyperparameters adopted for each model were included in
Table A1,
Table A2,
Table A3 and
Table A4. Hyperparameters not listed were those set by default in each model and therefore not modified. As much as possible, all algorithms were restricted to the use of basic operators: addition, subtraction, multiplication, division, exponentiation, square root, and logarithm, excluding more complex ones.
For the application of these equations, it is important to consider the input units, which are LL, PI, w, and #0.075 mm in % and γd in kN/m3, yielding ps in kPa. Additionally, the ranges in which the algorithms were trained must be taken into account, as predictions outside these ranges may be unrealistic. The following are the ranges:
Pass #0.075 mm (%): ≥28.2 and ≤100.0.
LL (%): ≥27.7 and ≤85.1.
PI (%): ≥7.9 and ≤57.8.
w (%): ≥8.9 and ≤49.1.
γd (kN/m3): ≥13.0 and ≤19.2.
ps (kPa): ≥17.2 and ≤514.2.
The parameters selected by each SR algorithm were different, except for PySR and MOSR, which selected the same parameters (all except w). This provides an advantage, as it enables the use of the equations depending on the available parameters. Natural water content was included in only one of the four equations (PGSR), in line with the findings of the statistical analysis conducted previously. It is normal not to observe a clear impact due to the undisturbed nature of the samples, as each sample has varying levels of water content and saturation.
Figure 7 presents scatterplots illustrating the relationship between the actual values of p
s (
x-axis) and the predicted values of p
s (
y-axis) for the four SR algorithms considered. The analysis demonstrated that a significant portion of the data points lay in close proximity to the identity line and were mostly located within the error range of ±15%, indicating a strong agreement between the predicted and actual values. This suggests that the models performed well in accurately predicting p
s, with minimal deviation from the true values. The residuals (defined as the difference between the real and predicted values) are also shown in
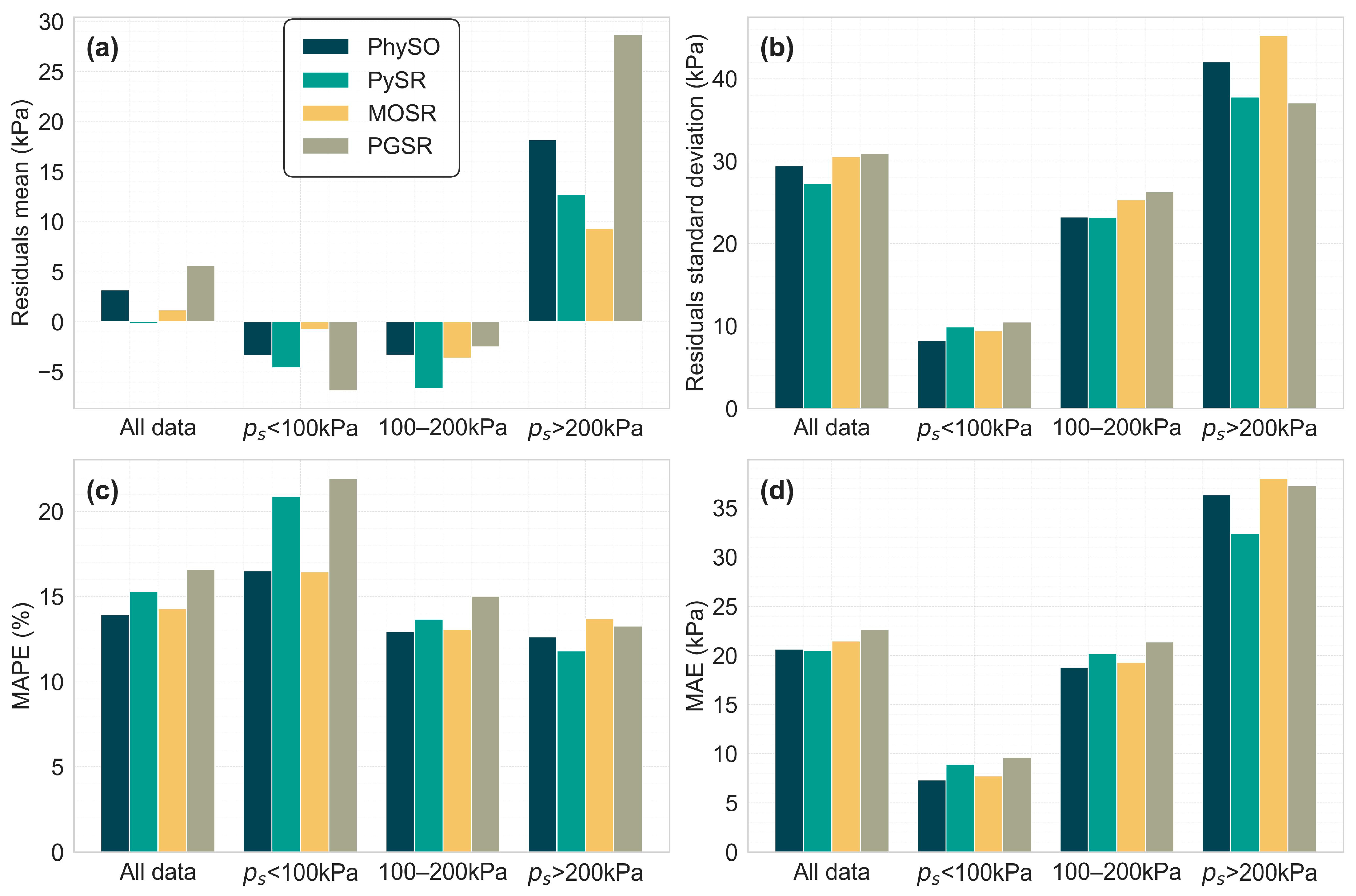
Figure 6, revealing that PhySO, MOSR, and PGSR slightly underestimated the predictions (mean residuals +3.20, +1.2, and +5.64 kPa, respectively), while PySR demonstrated near-zero bias (−0.16 kPa). PySR also exhibited the lowest standard deviation (STD) among the models (27.34 kPa), whereas PGSR showed the highest dispersion (STD = 30.94 kPa). Considering this global analysis, PySR emerged as the most robust model, exhibiting minimal bias and the lowest variability in residuals.
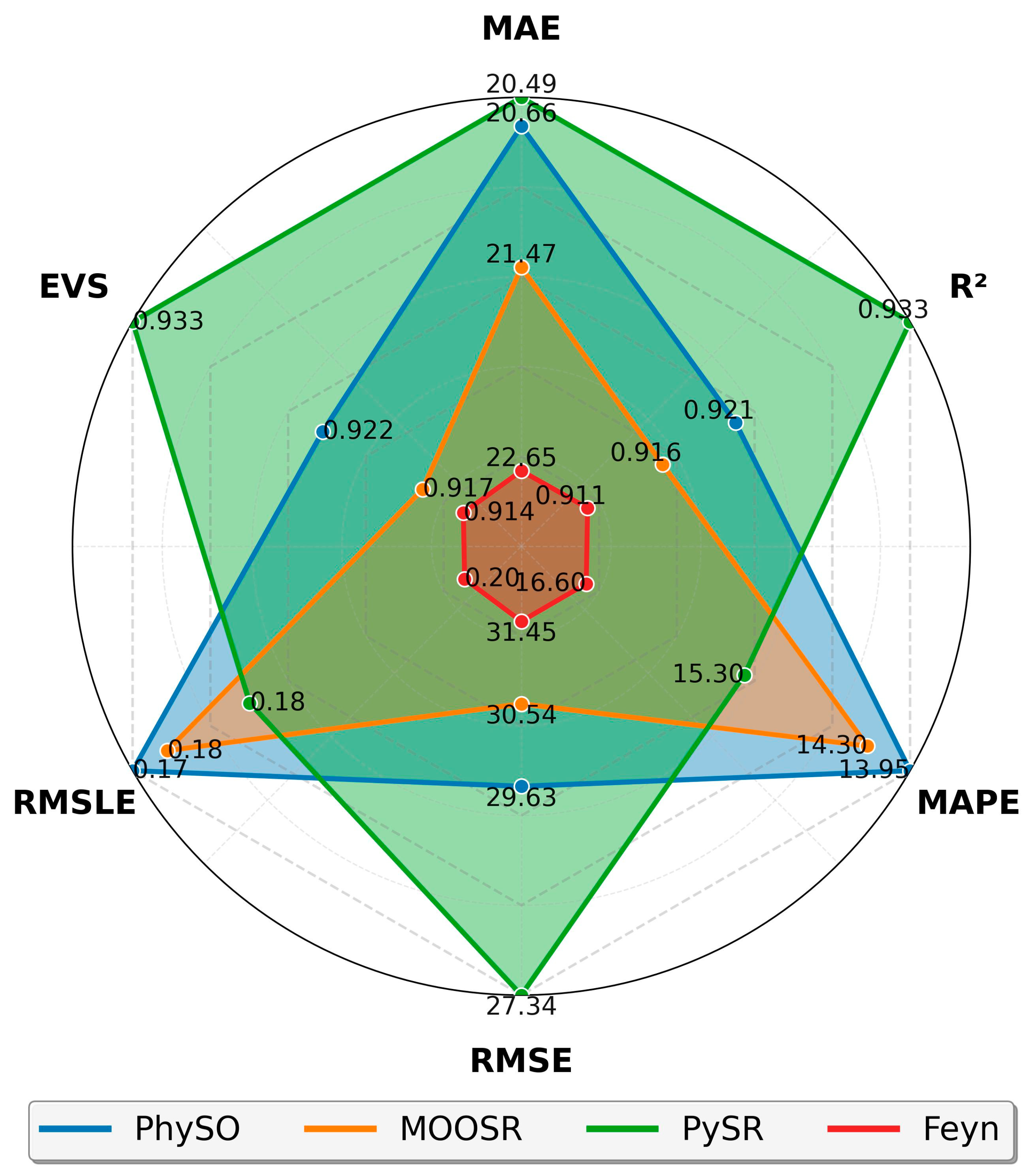
Based on the same residual and prediction data shown in
Figure 7, a comparative summary of model performance was constructed using standard evaluation metrics, as shown in
Figure 8. The evaluated metrics included Mean Absolute Error (MAE), Coefficient of Determination (R
2), Mean Absolute Percentage Error (MAPE), Root Mean Square Error (RMSE), Root Mean Square Logarithmic Error (RMSLE), and Explained Variance (EVS). The results of this analysis are included in
Figure 8 as a radar chart. The performance analysis of the four models revealed differences across the considered metrics. PySR exhibited superior accuracy, with the lowest MAE (20.49 kPa) and RMSE (27.34 kPa), alongside the highest R
2 (0.933) and EVS (0.933), indicating a strong ability to capture data variability. PhySO, with an MAE of 20.66 kPa and RMSE of 29.63 kPa, performed competitively and achieved the lowest MAPE (13.95%) and a low RMSLE (0.174), making it particularly reliable in terms of relative errors. PhySO prioritized relative accuracy and performance across different data scales, while PySR optimized overall accuracy more effectively and demonstrated greater robustness against outliers. MOOSR displayed intermediate results, with an MAE of 21.47 kPa and RMSE of 30.54 kPa, and lower R
2 (0.916) and EVS (0.917), indicating that it explained less variance compared to PySR and PhySO. The PGSR model registered the highest error levels, MAE (22.65 kPa), RMSE (31.45 kPa), MAPE (16.60%), and RMSLE (0.205), along with the lowest R
2 (0.911) and EVS (0.914), suggesting it was less effective in capturing data variability. In summary, while all models demonstrated reasonable predictive capabilities, PySR and PhySO led in accuracy and consistency, with MOOSR being moderately effective and PGSR performing in a less robust manner.
After completing the global analysis, a comparative analysis of the four SR regression models was conducted across different ranges of p
s. The dataset was then divided into several ranges of p
s: below 100 kPa, between 100 and 200 kPa, and above 200 kPa. For this analysis, MAPE, MAE, the mean, and the STD of the residuals were calculated. The results of this analysis are presented in
Figure 9.
This analysis revealed distinct strengths for each model depending on the p
s interval. PhySO showed the best overall performance in relative terms, achieving the lowest MAPE on the full dataset and in the 100–200 kPa range (12.96%), and nearly the best in the <100 kPa segment. It also recorded the lowest residual STD in the <100 kPa range (8.27 kPa) and was close to the best in the 100–200 kPa range, indicating high precision at low to mid p
s. However, it exhibited notable bias in the extreme pressure ranges, particularly in >200 kPa (mean residuals = 18.20) and <100 kPa (−3.36 kPa), and its dispersion at high p
s (STD = 42.06 kPa) was among the highest. PySR minimized global bias most effectively (mean residuals = −0.16 kPa) and achieved the lowest MAPE (11.81%) and STD (37.79 kPa) in the ≥200 kPa range, making it particularly well-suited for high p
s applications. However, its performance in the <100 kPa range was not among the best, with the second highest MAPE (20.88%) and residual bias (−4.60 kPa). MOSR was the most robust in reducing residual bias at the extremes, with near-zero mean residuals in <100 kPa (−0.74 kPa) and the best bias in ≥200 kPa (9.36 kPa). Its MAPE in the low-pressure range (16.45%) was better than that of PhySO and PySR, although very close to PhySO. However, it exhibited high dispersion in the >200 kPa range (STD = 45.24 kPa) and demonstrated good performance in the 100–200 kPa range. PGSR demonstrated limited strengths compared to the other models. It showed moderate performance in the 100–200 kPa range but performed worst in terms of bias and MAPE in both the low (<100 kPa) and high (>200 kPa) ranges. Its lack of consistency made it the least competitive model overall, although its metrics remained good for the analysed case. In conclusion, PhySO was the most balanced model for general use, demonstrating strong performance particularly in low- to medium-pressure predictions. PySR excelled in high-pressure predictions while also maintaining good overall performance. MOSR minimized bias at the extremes and can be suitable for low to medium pressures, whereas PGSR did not exhibit a clear advantage in any specific pressure range. These strengths and weaknesses according to ranges should be considered along with the fact that each equation has parameters that others do not. Only PySR and MOSR share the same input variables (see
Table 4), so depending on the available parameters and the intended objective, the most suitable equation can be selected.
Next, a sensitivity analysis of the parameters involved in the four equations proposed was conducted. To this end, Sobol’s method [
57] was applied. It is commonly used to evaluate the significance of input parameters in computational models with respect to their impact on the output based on the contribution to the output variance.
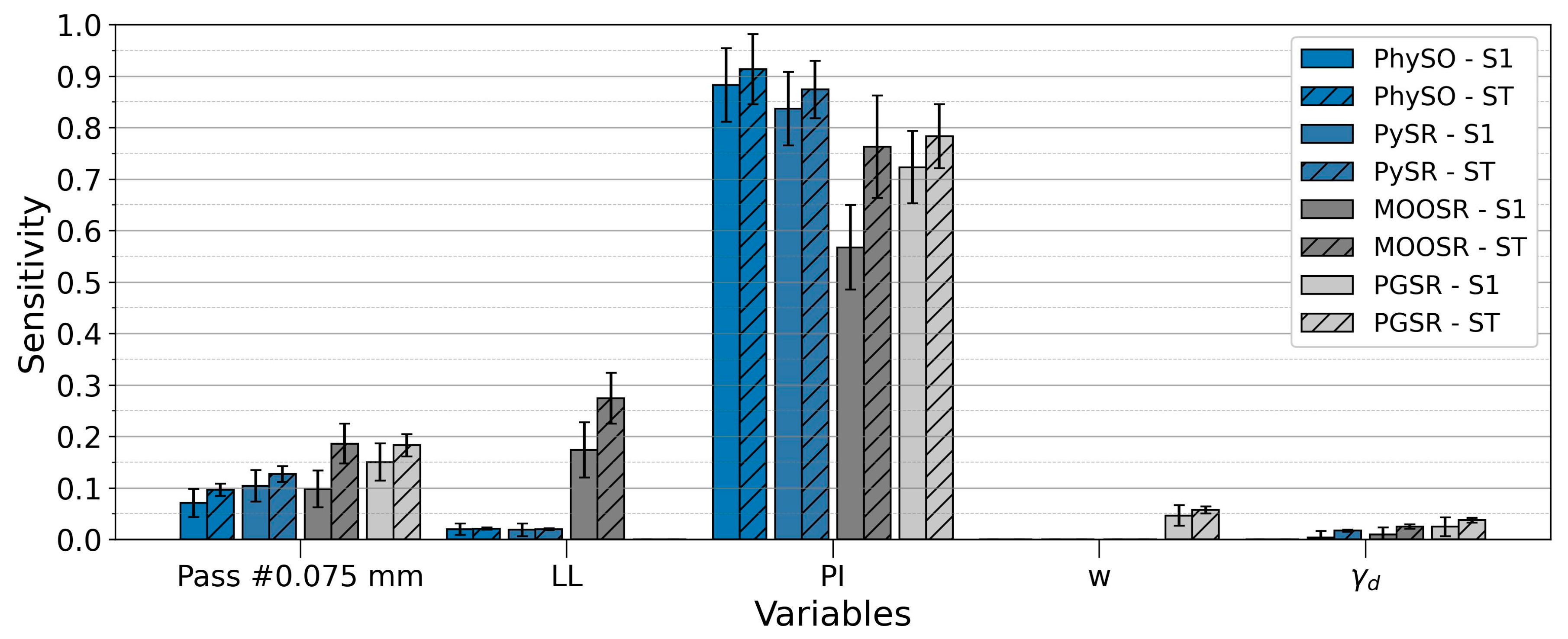
Figure 10 presents the results of this analysis, including the S1 and ST values.
In all four models, PI was the dominant factor, with high S1 and ST indices. In PhySO and PySR, PI accounted for almost all of the variability (ST ≈ 0.91 and 0.87; S1 ≈ 0.88 and 0.84, respectively), while the percentage of soil passing #0.075 mm showed moderate contributions, and both LL and γd contributed very little. In MOOSR, PI remains crucial (ST ≈ 0.76; S1 ≈ 0.57), but the influence of LL increases (ST ≈ 0.27; S1 ≈ 0.17), suggesting that interactions, deduced from the difference between ST and S1, begin to play a greater role. In PGSR, in addition to the predominance of PI (ST ≈ 0.78; S1 ≈ 0.72), stronger interaction effects are observed, with noticeable contributions from w and γd (ST ≈ 0.057 and 0.037). While the individual effects of PI dominate across all models, interaction effects become more relevant in MOOSR and, to a lesser extent, in PGSR.
These findings align with the established knowledge in geotechnical engineering regarding expansive soil behaviour. PI, LL, and the percentage of soil passing #0.075 mm are identified as the most significant parameters in predicting swelling pressure. Their importance stems from their direct correlation with the mineralogical composition and plasticity characteristics that govern water adsorption capacity and expansive potential. Conversely, w exhibits a relatively lower influence on the predictive model. This phenomenon can be attributed to the use of undisturbed samples exhibiting varying degrees of initial saturation. Since the natural water content does not represent a controlled or comparable condition across different samples, its contribution to ps prediction becomes less pronounced.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}