1. Introduction
Although the internet facilitates global communication, it cannot always be regarded as a fully secure channel, especially when handling sensitive information. Therefore, appropriate security protocols must be employed to ensure that confidential information is exchanged safely. A common approach to defending internet communications is to encrypt messages during transmission. However, because encrypted messages are often easy to recognize, they may themselves become targets of attack. An alternative method known as data hiding (DH) [
1,
2,
3,
4] involves embedding information within digital media. Because this process can appear the same as ordinary data transmission, it tends to draw less attention from potential attackers. Leveraging this characteristic can further strengthen the security of data exchanges.
DH can be broadly classified into reversible (RDH) and non-reversible (N-RDH) methods. RDH techniques have the characteristic that the original cover image can be fully restored after extracting the hidden data from the stego image. Several representative RDH algorithms have been proposed to date, including difference expansion (DE)-based methods [
5,
6,
7], histogram shifting (HS) techniques [
8,
9,
10], and prediction error expansion (PEE) [
11].
First introduced by Tian in [
5], the DE approach has demonstrated excellent performance in terms of embedding capacity. The histogram shifting (HS) method [
8], first introduced in 2006, is regarded as an improvement over previous techniques due to the relatively lower distortion it causes to the cover medium. However, RDH schemes require a location map to embed data and recover the original cover image. While this method achieves good visual quality and reasonable embedding capacity, it has the drawback of requiring the transmission of two peak points and a zero-point pair to the receiver. PEE [
11] involves obtaining prediction errors from the neighborhood of each pixel and embedding information bits into the expanded errors. If the difference between the original and predicted pixels is large, the embedding process can cause significant distortion to the cover image. DH methods based on ordered prediction can reduce distortion at low embedding rates.
On the other hand, secret sharing [
12] has the feature that while
n participants create
n shadows using the same cover image to share data, the data can only be reconstructed when there are shadows of
participants. If the number of participants is less than
k, then data reconstruction will fail. In terms of data confidentiality, secret sharing is very powerful and can be used in various applications.
Dual image-based RDH [
13,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23,
24,
25,
26] adopts some features of secret sharing, utilizing
cover images. Thus, two shadow images are required to recover the original image. Chang et al. (2007) [
13] introduced a dual-image RDH method using the exploitation modification direction (EMD). In their approach, two quinary secret data points are used to form a pair of stego pixels, with cover pixel pairs referenced according to the main and secondary diagonals of the EMD matrix. Later, Chang et al. (2013) [
14] proposed an improved method for enhancing the visual quality of the stego images.
Lee and Huang (2013) [
15] enhanced the visual quality of stego images by limiting modifications during the data hiding process to at most plus or minus one. Qin et al. [
16] proposed an asymmetric dual-image RDH method in which the first stego image is generated using the EMD technique and the second is created based on three rule analyses applied to the first image. As a result, the first stego image experiences greater distortion compared to the second.
Lu et al. (2015) [
17] discovered that the LSB-matching technique, originally used in N-RDH, could be adapted for dual-image schemes. However, because direct application was not feasible, they devised seven new rules for pixel recovery and applied them to the dual-image restoration process. They then demonstrated the effectiveness of their proposed method through experiments. In a separate work, Lu et al. (2015) [
18] introduced a dual-image-based data hiding strategy utilizing a center folding technique. In this approach, secret data values are first compressed using the folding strategy, allowing more data to be embedded. The folded secret data are then hidden across two stego image pixels. Building on this, Yao et al. (2017) [
19] focused on improving the visual quality of stego images by identifying and enhancing areas where Lu’s [
18] method could be further optimized.
Jana et al. (2018) [
21] proposed a method that extracts seven-pixel blocks from the original image and duplicates them into two arrays. The least significant bits (LSBs) of each array are adjusted using odd parity, increasing error resilience during transmission. Secret message bits are embedded into specific positions within these arrays while deliberately excluding certain predesignated positions reserved for integrity checks. During the embedding phase, bit modifications may introduce errors, which are subsequently detected and corrected by the receiver using Hamming (7,4) error correction codes. While this method demonstrates innovative integration of error-correcting codes, its low embedding capacity (0.21 bpp) limits its suitability for applications requiring high payloads.
Chen and Hong (2021) [
23] introduced a dual-image RDH scheme utilizing the exploiting modification direction (EMD) method, achieving reversibility without additional overhead. While their method represents an improvement in eliminating auxiliary data, it falls short of surpassing earlier EMD-based methods such as that of Chang et al. (2013) [
14]. In addition, it involves complex orientation combinations, which increase implementation complexity and make optimization difficult.
Lee and Chan (2024) [
26] proposed a novel dual-image RDH method based on vector coordinates with triangular order coding (TOC), achieving superior embedding capacity and image quality without requiring additional side information. Their method focuses on position-based embedding, allowing for flexible adjustment of capacity via the
k parameter. Wan et al.(2025) [
27] proposed a multi-party RDH framework for medical information that utilizes texture-guided hierarchical quantization coding (TGHQC) to enhance embedding capacity and security. Additionally, both image owners and data providers perform data embedding through a dual embedding mechanism, allowing for role-specific data access. This method maintains data reversibility and security, thereby improving the efficiency of medical information management. Zhan et al. (2024) [
28] proposed a reversible fragile watermarking scheme based on the insect matrix reversible embedding algorithm to enable full recovery of untampered cover images. Upon tampering, adaptive dual recovery schemes are employed to restore corrupted data while maintaining high image quality. Moreover, image-rendering techniques are introduced to enhance the accuracy of tampering detection, particularly in cases of tampering coincidence.
This study proposes an enhanced dual-image RDH method based on the HC(7,4) Hamming code to overcome limitations in prior methods. By applying this Hamming code to pixel groups across two cover images, our method significantly increases embedding capacity, reaching 1.5 bpp, which is over seven times greater than in Jana et al. (2018) [
21]. In addition, our method ensures high visual quality with PSNR values between 48 and 49 dB, outperforming methods such as that of Chang et al. (2013) [
14]. Compared to complex EMD-based design of Chen and Hong (2021) [
23], our scheme offers a simpler and more efficient solution. Unlike halftone-based methods [
25], it supports general grayscale images while guaranteeing full reconstructability, making it suitable for secure high-capacity RDH applications.
The key contributions of this paper are summarized as follows: (1) The proposed scheme achieves a high embedding capacity of up to 1.5 bpp by applying enhanced Hamming codes to virtual pixels constructed from two cover images, offering a significant improvement over prior dual-image RDH methods. (2) Despite the high embedding rate, our method maintains excellent stego image quality with PSNR values of 48–49 dB, demonstrating a balanced tradeoff between capacity and imperceptibility. (3) The proposed method’s robustness against statistical steganalysis is validated through RS analysis, confirming its resistance to detection and ensuring security in data hiding applications. (4) The reversibility of both cover images is guaranteed without additional side information, making the proposed scheme applicable to sensitive fields such as medical imaging and secure communications. (5) The proposed method is computationally efficient, relying on simple bitwise operations and lookup tables, enabling practical implementation in real-time systems.
The rest of this paper is organized as follows:
Section 2 reviews the Hamming code used as a single error-correcting code along with the RDH method;
Section 3 presents the proposed partial RDH method based on dual images;
Section 4 presents the experimental results; and
Section 5 presents the conclusions.
3. Proposed Scheme
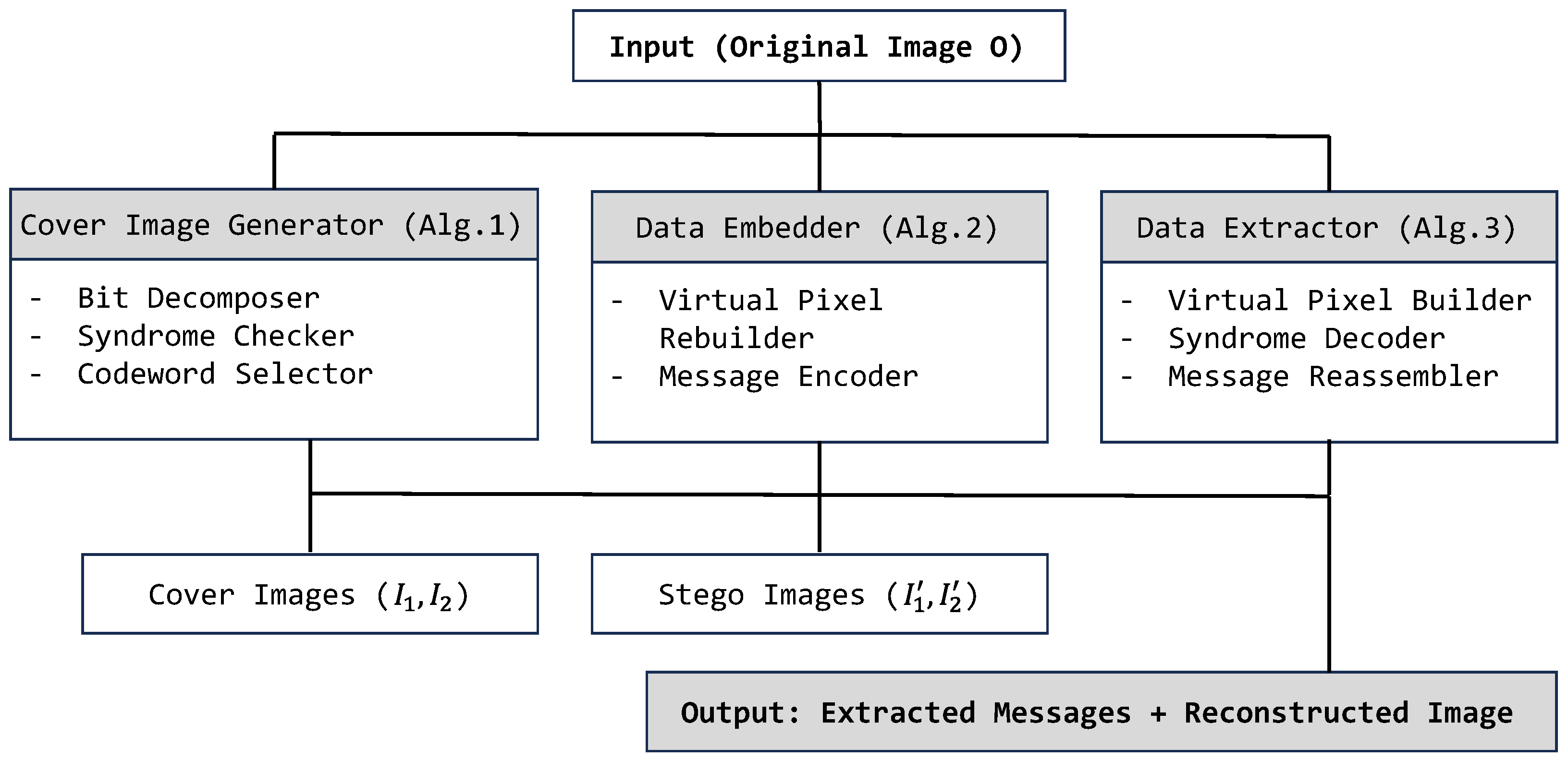
In this section, we propose an improved HC(7,4)-based dual-image reversible data hiding (RDH) technique. The overall conceptual workflow is illustrated in
Figure 1, which briefly outlines the transition from the original image through the structurally correlated cover image generation to the subsequent embedding process.
Figure 1 provides a high-level overview; in turn,
Figure 2 shows the internal architecture, clearly detailing the module interactions, data flow, and role of each component.
Unlike conventional dual-image RDH techniques that simply replicate the original image into two identical cover images and , our method performs a controlled bit-level transformation using an enhanced HC(7,4) Hamming code. This transformation introduces fine-grained structural modifications in the bit-plane, enabling error correction while preserving visual fidelity. Initially, and are generated by duplicating the original image. Then, for each pair of corresponding pixels from and , a virtual 7-bit vector y is constructed by selecting specific bits from both pixels.
If the virtual vector y fails to satisfy the Hamming code condition , a precomputed lookup table (LUT) is used to identify the closest codeword in the zero-syndrome coset. The selected codeword is then split and reassigned to the two pixels in such a way that structural similarity with the original is maintained. This process is applied iteratively across all pixels, resulting in two modified cover images that remain visually close to the original while ensuring compatibility with reversible data embedding in the following stage.
Figure 2 presents a more comprehensive block-level system architecture comprising three functional modules: the
cover image generator, the
data embedder, and the
data extractor. These modules respectively correspond to Algorithms 1–3, and are designed for modular independence and engineering clarity.
| Algorithm 1 Generation of Cover Images |
| Require: Original image O (grayscale, 8-bit) |
| Ensure: Cover images and satisfying HC(7,4) constraints |
- 1:
; - 2:
for to do - 3:
Read pixel from O ▹ Original pixel - 4:
Extract and from ▹ Bit vectors from pixel - 5:
Construct virtual pixel y ▹ Selected bits from and - 6:
▹ Decimal from - 7:
▹ Decimal from - 8:
if then ▹ Coset condition check - 9:
Initialize , - 10:
for each codeword h in LUT do ▹ Candidate codeword - 11:
▹ Decimal upper bits - 12:
▹ Decimal lower bits - 13:
▹ Similarity measure - 14:
if then - 15:
- 16:
▹ Update best codeword - 17:
end if - 18:
end for - 19:
Update and with - 20:
end if - 21:
Save to , to - 22:
end for
|
| Algorithm 2 Embedding Procedure |
| Require: Two cover images , ; secret bits |
| Ensure: Two stego images , |
- 1:
; - 2:
▹ Secrect bit index - 3:
for to do - 4:
Access pixel from and - 5:
Construct virtual pixel y according to Equation ( 4) - 6:
- 7:
- 8:
Extract secret bits (3 bits) - 9:
if coset(y) ≠ target coset leader derived from then - 10:
Initialize , - 11:
for each codeword h in LUT do - 12:
- 13:
- 14:
- 15:
if then - 16:
- 17:
- 18:
end if - 19:
end for - 20:
Update and according to Equation ( 6) - 21:
end if - 22:
Save updated to ; to - 23:
▹ Move to next 3 secret bits - 24:
end for
|
| Algorithm 3 Extraction and Recovery Procedure |
| Require: Two stego images , |
| Ensure: Recovered cover images , , and extracted secret bits m |
- 1:
Initialize: - 2:
for to do - 3:
Access pixel data from and - 4:
Reconstruct virtual pixel y using selected bits - 5:
Calculate syndrome ▹ Extract hidden bits - 6:
Store S into ; - 7:
; - 8:
Initialize , - 9:
for each codeword h in LUT do - 10:
; - 11:
- 12:
if then - 13:
; - 14:
end if - 15:
end for - 16:
Update and based on ▹ Recover cover pixels - 17:
Save into ; into - 18:
end for
|
The process begins with the Cover Image Generator, which takes the original image O and produces two structurally optimized cover images and using HC(7,4)-based syndrome modulation. These images are generated to support reliable and low-distortion embedding.
Next, the Data Embedder receives the cover images and a payload bitstream, then embeds the payload through a syndrome-modulated mapping strategy using a preconstructed lookup table. This process results in two stego images and containing the hidden information while preserving high image fidelity.
Finally, the Data Extractor takes the stego images as input, reconstructs the original message by performing parity-check-based extraction, and reverses the embedding steps to accurately restore the original image. This module ensures lossless recovery of both the hidden data and the original content.
3.1. Generation of Cover Images
In this subsection, we present the process for generating two cover images using the improved HC(7,4) scheme. The detailed procedure is summarized in Algorithm 1.
Initially, two copies of the original image are created, denoted by
and
. For each pixel
in the original image
O, the same value is assigned to the corresponding pixels in
and
, denoted as
and
, respectively. Each of these pixel values is represented in 8-bit binary format as
where
and
represent individual bits of
and
.
A virtual 7-bit pixel
y is then constructed by concatenating selected bits from
and
:
where
denotes bit-wise concatenation. Here,
corresponds to the most significant bit (MSB) of
y and
to the least significant bit (LSB) of
y.
To ensure that
y satisfies the Hamming code constraint
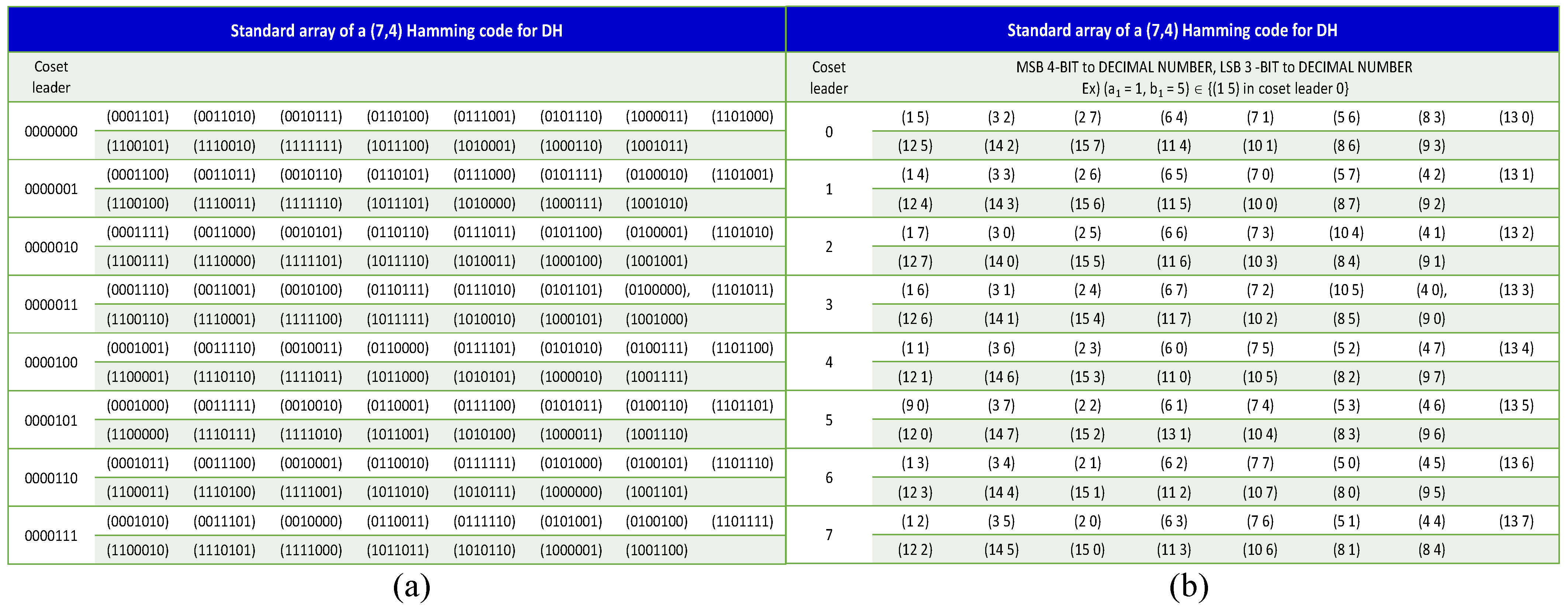
, a syndrome check is performed. If the condition is not satisfied, the closest valid codeword is selected from a preconstructed lookup table (LUT) derived from the standard array of HC(7,4) codewords, as shown in
Figure 3. This enables efficient correction by identifying the nearest codeword within the corresponding coset. The following algorithm corresponds to the Cover Image Generator module described in
Figure 2, and performs syndrome-based modifications to construct cover images
and
.
To formalize this process, the selection of the most suitable codeword
h is defined as a distortion minimization problem over the zero-syndrome coset
:
where
h is a candidate codeword from the LUT and
are derived from the original bits of
and
, respectively. This formulation explicitly expresses the objective of minimizing perceptual distortion while satisfying HC(7,4) compliance.
Here, quantifies the difference between the original and candidate virtual pixel representations. The codeword that minimizes is selected as the best match. Among these bits, the first four are written into the least significant bits of in and the last three are written into the least significant bits of in .
This process is repeated for every pixel in the original image. As a result, two structurally correlated cover images and are generated, both of which are optimized for low-distortion reversible data embedding.
3.2. Data Embedding
In this subsection, we describe the detailed procedure for embedding secret data into two cover images by applying the improved HC(7,4) scheme. The overall process is summarized in Algorithm 2.
In HC(7,4) codes, coset leaders correspond to eight distinct patterns, which can be naturally represented by 3-bit binary numbers ranging from 000 to 111. Thus, in the proposed embedding scheme, each group of three secret bits is directly mapped to a target coset leader. This mapping forms the basis for aligning the virtual pixel structure with the intended secret message. For each pixel location, the corresponding values from
and
are accessed to reconstruct the virtual pixel
y by selecting and concatenating specific bits, as defined in Equation (
4).
To embed secret data, a group of three consecutive secret bits is selected. The three bits are interpreted as the target coset leader corresponding to the intended secret message. Thus, the coset leader pattern is defined as a 3-bit sequence indicating the desired coset class for the constructed virtual pixel.
Although the same error minimization formula presented in Equation (
5) is employed, its purpose in this phase differs from that in cover image generation (
Section 3.1). While the previous minimization aimed solely at ensuring codeword validity, here it is driven by the secret bits to align the virtual pixel with the target coset leader while minimizing visual distortion.
If the current virtual pixel
y does not belong to the desired coset (i.e., the syndrome of
y does not match the target coset leader pattern), then the closest matching codeword
h is selected from the lookup table (LUT) by minimizing the error
as defined in Equation (
5).
After selecting the optimal codeword
h, the cover pixel bits are updated according to
Finally, the modified pixels are stored into the stego images and . The full embedding process is outlined in Algorithm 2.
3.3. Data Extraction And Recovery Procedure
In this subsection, we describe the procedure for extracting the hidden information and recovering the original cover images from the two stego images
and
generated during the embedding process (
Section 3.3). Based on the virtual pixel construction method described in
Section 3.1 and the syndrome computation process defined in
Section 3.3, the extraction and recovery are performed sequentially for each pixel pair in the stego images.
For data extraction, the virtual pixel y is reconstructed at each pixel position and the syndrome S is recalculated using the previously defined parity-check matrix H. Each extracted syndrome directly corresponds to a group of three secret bits, which are sequentially collected to form the hidden message vector m.
Following extraction, the recovery of the original cover images proceeds by leveraging the property that all virtual pixels belonged to the zero-syndrome coset prior to embedding. In this way, the codeword associated with the zero syndrome that minimizes the discrepancy from the current stego pixel is identified for each virtual pixel. The optimal codeword is determined by minimizing the Euclidean error between the extracted bits and the candidate codewords, following the error metric introduced in
Section 3.1.
After the nearest codeword is found, the cover pixel values are reconstructed accordingly, restoring the two original cover images and .
The overall extraction and recovery process is summarized in Algorithm 3.
3.4. Numerical Examples
3.4.1. Generating Two Cover Images
Suppose that a pixel in the original image is provided by
Following the generation procedure described in
Section 3.1, two cover pixels are derived as follows:
- (1)
Initialization: Copy the original pixel to create two initial cover pixels
- (2)
Virtual Pixel Construction: A virtual pixel
y is constructed by selecting four LSB bits from
and three LSB bits from
, as defined in Equation (
4):
This process compresses the essential information of two pixels into a compact 7-bit structure, facilitating efficient error management.
- (3)
Decimal Conversion: The selected bits are separated into two groups and converted into decimal:
- (4)
Codeword Selection: To ensure that the virtual pixel belongs to a valid codeword set, the closest matching codeword is identified by minimizing the error defined in Equation (
5):
Thus, the optimal codeword
h is determined as:
- (5)
Cover Pixel Reconstruction: Using the selected codeword
h, the two cover pixels are reconstructed according to Equation (
6):
- (6)
Assignment: The updated pixels and are assigned to their respective positions within the cover images and .
- (7)
Iteration: The above process is repeated for each pixel of the original image to complete the construction of the two cover images.
3.4.2. Data Embedding Phase
Assume that the secret bits to be embedded are
The two cover pixels prepared for embedding are
The embedding process proceeds as follows:
- (1)
Virtual Pixel Reconstruction: A virtual pixel is formed:
- (2)
Target Coset Leader Mapping: The secret bits correspond to a coset leader index of 5.
- (3)
Optimal Codeword Identification: Among the codewords associated with coset leader 5, the optimal codeword minimizing the error is selected:
- (4)
Stego Pixel Reconstruction: The cover pixels are updated as follows:
These updated pixels are stored in the stego images and respectively.
3.4.3. Data Extraction and Recover Phase
Given two stego pixels
extraction and recovery are performed as follows:
- (1)
Virtual Pixel Reconstruction: Reconstruct the virtual pixel
- (2)
Syndrome Computation: Compute the syndrome to extract the embedded bits:
recovering the secret bits
.
- (3)
Cover Pixel Recovery: To restore the original cover images, the closest codeword associated with zero syndrome is selected:
The recovered cover pixels are
Thus, both the hidden secret data and the cover images are perfectly restored.
4. Experimental Results and Discussions
In this section, we present the experimental evaluation of the proposed partial reversible data hiding (PRHB) method based on the enhanced HC(7,4) Hamming code. The primary objective of the experiments is to demonstrate the feasibility and advantages of the proposed technique through comprehensive simulations. All experiments were conducted on a system equipped with a Core i5-8250U processor (1.60 GHz) and 8 GB of RAM, utilizing Matlab R2019b as the simulation platform. This study aims to improve both embedding capacity and image quality through a dual-image RDH scheme. The proposed approach addresses prior limitations by incorporating structured virtual pixel construction and optimized codeword selection.
Unlike conventional RDH, our design avoids side-information overhead and achieves near-constant embedding performance across all tested images. The improvements introduced in the data embedding process can be summarized as follows:
Optimized Virtual Pixel Construction: Virtual pixels are generated from two cover images to enhance error correction performance.
Complete Data Recovery Without Auxiliary Information: The embedded data can be perfectly extracted without the need for any additional side information.
Adaptive Tradeoff Between Embedding Capacity and Visual Distortion: The method employs an adaptive adjustment strategy to maintain a balance between data embedding rate and image quality.
High Stego Image Quality: The visual quality of the stego images is preserved, as quantitatively measured by the peak signal-to-noise ratio (PSNR) [
2].
To objectively evaluate the performance of the proposed method, extensive experiments were carried out using nine standard 512 × 512 grayscale images from the USC-SIPI dataset [
30] (
Figure 4). The evaluation metrics included embedding capacity (EC), embedding rate (ER, measured in bits per pixel, bpp, Equation (
7)), and PSNR.
By comparing these metrics with those achieved by conventional dual-image-based RDH methods, the superiority of the proposed scheme in terms of both capacity and visual quality is clearly demonstrated. The embedding rate (ER) is defined by Equation (
7):
The PSNR [
2] is widely employed as an objective metric to evaluate the quality of marked images. It quantifies the difference between the reference image and the distorted (or marked) image in a logarithmic scale. The PSNR is defined by Equation (
8):
where
represents the square of the maximum possible pixel value in an 8-bit image. The mean squared error (MSE), provided by Equation (
9), measures the average squared intensity difference between corresponding pixels of the original and marked images:
In this expression, and denote the pixel values of the original and marked images at position i, respectively. The error term reflects the squared deviation at each pixel. A lower MSE value indicates smaller distortion, leading to a higher PSNR value, which implies better perceived image quality. Typically, for 8-bit images, PSNR values for acceptable lossy compression range from 30 dB to 50 dB. A higher PSNR generally correlates with improved visual fidelity.
Table 1 presents a comparative analysis of PSNR values for cover images (#1 and #2) and stego images (#1 and #2) when embedding 10,000 bits using the enhanced HC(7,4) PRDH method. The evaluation focuses on three key PSNR measurements:
PSNR(CI−OI): The PSNR between the original image (OI) and the cover image (CI), indicating the degree of modification introduced by the cover image generation process.
PSNR(SI−CI): The PSNR between the cover image and the stego image (SI), measuring the level of distortion caused by data embedding.
PSNR(SI−OI): The PSNR between the stego image and the original image, providing an overall assessment of image quality after data embedding.
Across all test images, PSNR(CI−OI) exhibits stable values around 47 dB for cover image #1 and 48 dB for cover image #2, indicating that the initial cover image generation introduces minimal distortion. Notably, PSNR(SI−CI) reaches approximately 67 dB for stego image #1 and 68 dB for stego image #2, demonstrating that the data embedding process maintains high image quality with minimal impact on the cover image. The final PSNR(SI−OI) values, which range between 47 dB and 48.7 dB, further confirm that the proposed method effectively preserves the original image quality. Given these results, PSNR(SI−CI) was selected as the primary metric for evaluating stego image quality in this study, as it directly reflects the influence of the embedding process while isolating any distortions introduced during cover image generation. These findings validate the efficiency of our enhanced HC(7,4) PRDH method in achieving high embedding capacity while maintaining superior image fidelity.
Table 2 presents a comparative analysis of the maximum embedding ratio (ER) across various reversible data hiding methods, including those proposed by Lee et al. (2013) [
15], Liu et al. (2018) [
20], Lin et al. (2019) [
24], Chen et al. (2020) [
22], Chen et al. (2021) [
23], and Jana et al. (2018) [
21], alongside our proposed method.
Among the evaluated techniques, the highest embedding ratio is achieved by the method of Chen et al. (2021) [
23], which reaches a maximum ER of 1.56, demonstrating its superior capacity for data embedding. Our proposed method achieves an ER of 1.50, which is the second-highest among the compared methods and only 0.06 lower than Chen et al. (2021) [
23]. Despite this slight reduction in embedding capacity, our approach maintains a balance between embedding efficiency and computational complexity, offering a simpler and more efficient process for data hiding, extraction, and restoration.
Other methods, such as those presented by Lee et al. (2013) [
15], Liu et al. (2018) [
20], and Lin et al. (2019) [
24], which exhibit embedding ratios ranging from 1.00 to 1.14. In comparison, our proposed method offers a significant improvement in data hiding capacity. Notably, the method presented by Jana et al. (2018) [
21] has the lowest embedding ratio of 0.21, indicating a strong tradeoff between image quality preservation and data embedding capacity. Overall, our proposed method provides a near-optimal embedding ratio while maintaining computational efficiency, making it a strong candidate for practical reversible data hiding applications where both high capacity and low complexity are required.
Note: The embedding ratio (ER) is constant at 1.50 across all tested images. This is a deterministic result of the proposed scheme, with a standard deviation of 0.00. This consistency reflects the deterministic nature of the proposed embedding mechanism and demonstrates its robustness across diverse image contents.
Table 3 presents a comparative analysis of the embedding capacity (bpp) and peak signal-to-noise ratio (PSNR) across existing reversible data hiding methods, including those proposed by Chang et al. (2007) [
13], Chang et al. (2013) [
14], Lee & Huang (2013) [
15], Qin et al. (2015) [
16], Lu et al. (2015) [
17], and Jana et al. (2018) [
21], alongside our proposed approach.
Among the evaluated methods, the highest embedding rate is achieved by Chang et al. (2013) [
14] with 1.53 bpp, followed closely by our proposed method, which attains 1.50 bpp. In contrast, the method by Jana et al. (2018) [
21] exhibits the lowest embedding rate, limited to 0.21 bpp. Notably, Qin et al. (2015) [
16] and Jana et al. (2018) [
21] achieve the highest PSNR values, exceeding 52 dB, albeit at the cost of significantly lower embedding rates. This trend suggests an inherent tradeoff between embedding capacity and image quality, where methods optimizing for PSNR often exhibit lower data-hiding capability.
Our proposed scheme effectively balances embedding capacity and image quality, achieving a competitive 48–49 dB PSNR while maintaining a high embedding rate. Compared to other methods with similar embedding rates, such as that of Chang et al. (2013) [
14], our approach demonstrates superior PSNR performance, indicating reduced distortion in the stego images. This suggests that the proposed method offers an optimal tradeoff between embedding rate and visual fidelity, making it a strong candidate for practical reversible data hiding applications.
The proposed method shows a fixed embedding rate of 1.50 bpp across all images, resulting in a standard deviation of 0.00. In addition, the PSNR values exhibit only minor variations (standard deviation ≤ 0.06 dB), confirming our method’s consistent visual quality across different images.
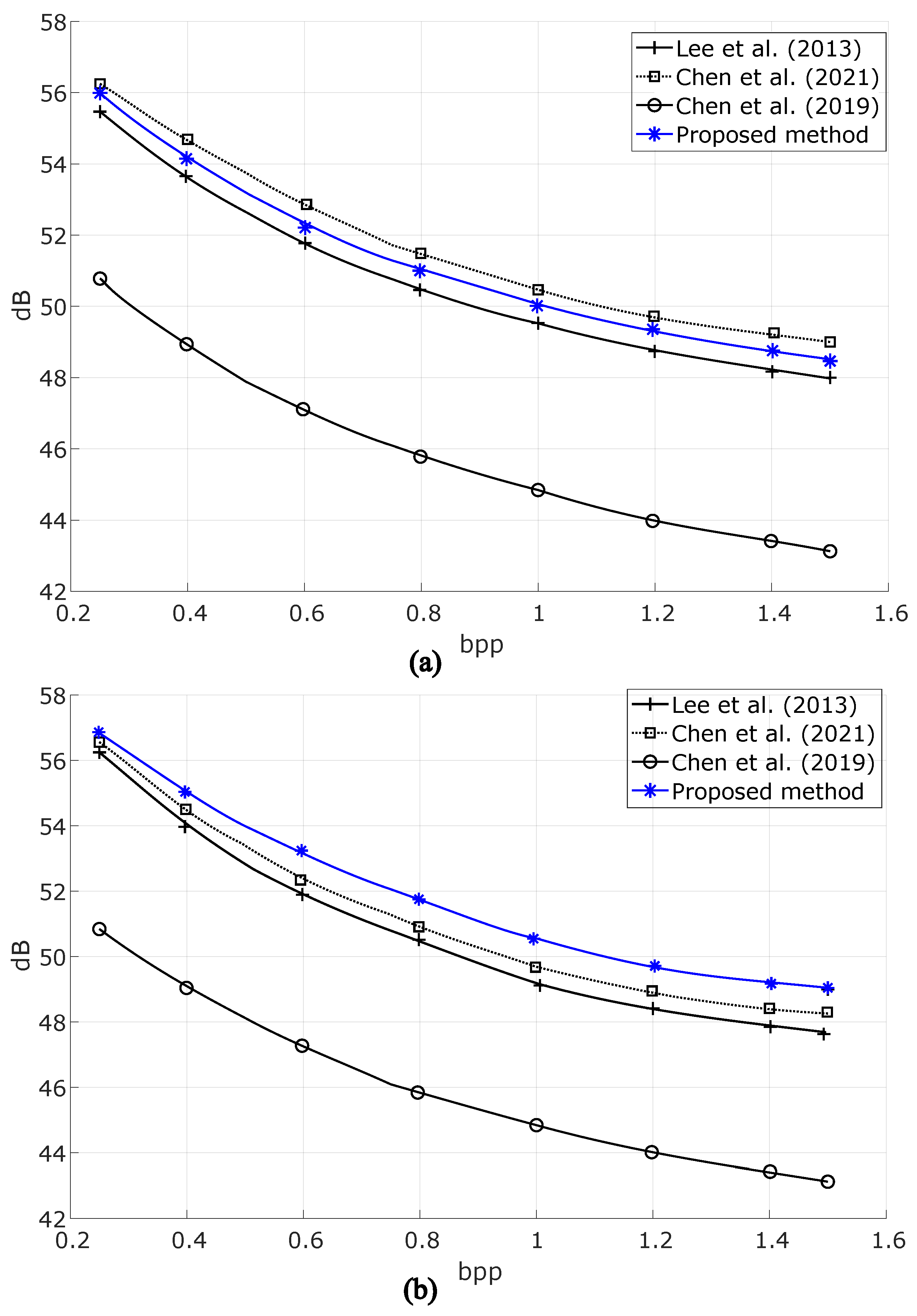
Figure 5a presents a comparative analysis of the average PSNR of stego image #1 across different reversible data hiding methods. The embedding rate (ER) of the proposed method is measured at 1.5 bpp. Among the evaluated techniques, the method proposed by Chen et al. (2021) [
23] is also capable of embedding up to 1.5 bpp, although achieving a PSNR approximately 1–2 dB higher than the proposed method. Overall, except for the method of Chen et al. (2019) [
22], all evaluated techniques maintain a marked image quality above 48 dB even at embedding rates exceeding 1.5 bpp, demonstrating a balance between high embedding capacity and imperceptibility.
In
Figure 5b, the relationship between PSNR and bpp for stego image #2 is illustrated. At an embedding rate of 0.2 bpp, the proposed method achieves a PSNR of 56.83 dB, marking the highest recorded value among all evaluated approaches. Furthermore, the proposed method consistently maintains the highest PSNR across the entire embedding range up to 1.5 bpp, ensuring superior image quality preservation. On the other hand, the method of Chen et al. (2021) [
23] achieves the second-highest PSNR performance among the evaluated techniques, further demonstrating its effectiveness in maintaining image quality.
Overall, our proposed method effectively balances high embedding capacity and PSNR, making it a competitive solution for reversible data hiding. The ability to sustain high PSNR values across a broad embedding range highlights its robustness in preserving image quality while embedding a substantial amount of data.
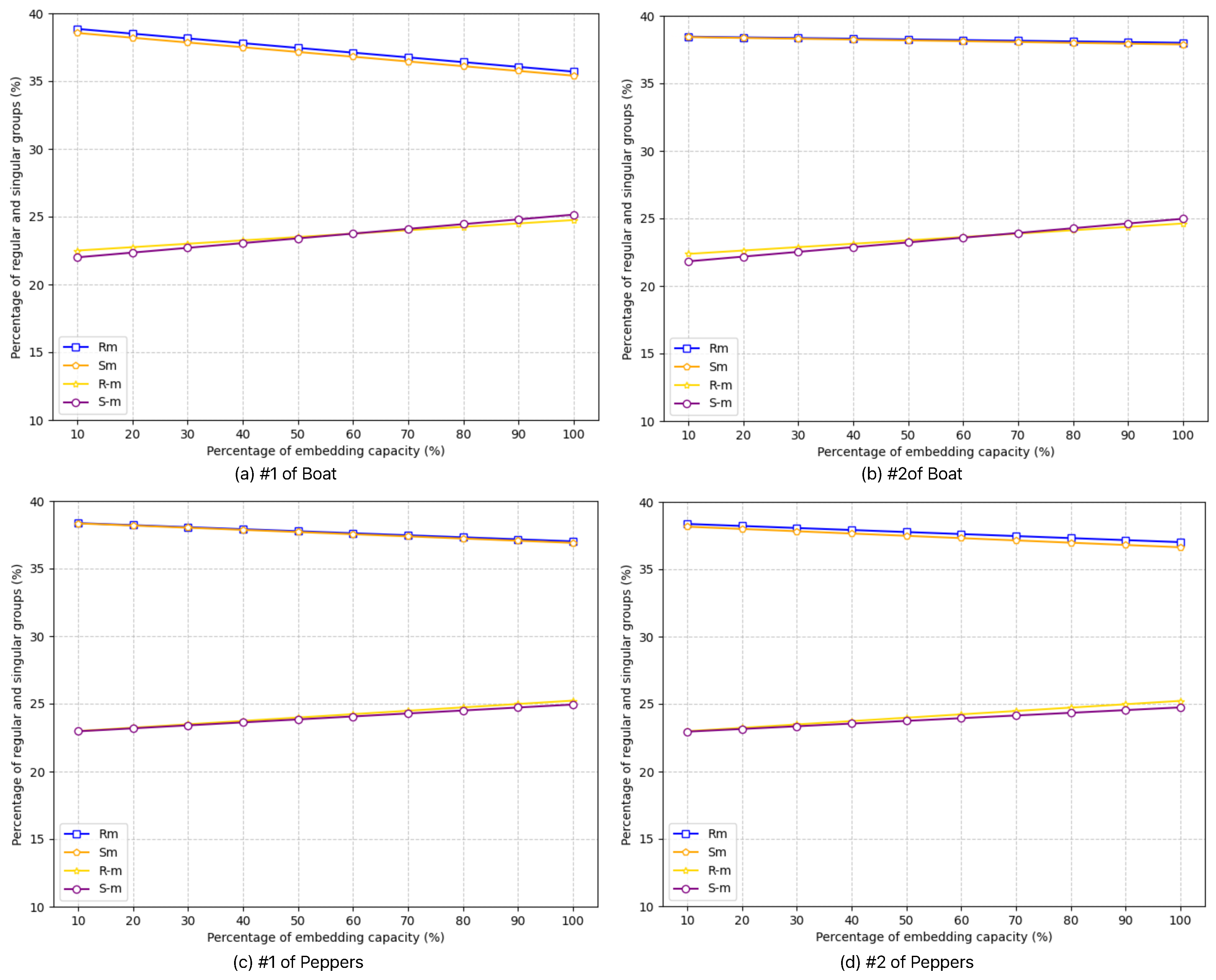
The RS analysis results in
Figure 6 illustrate the resistance of the proposed method against regular–singular (RS) analysis attacks. RS analysis is a commonly used statistical attack technique that helps detect the presence of hidden information in an image by analyzing local pixel patterns. In this method, each shadow image is divided into three distinct categories:
Regular Group (RM or R-M)—Represents smooth pixel regions that follow predictable patterns.
Singular Group (SM or S-M)—Represents highly textured or noisy pixel regions.
Unchanged Group (U)—Represents pixels that remain stable and are not affected by the embedding process.
The RM and SM (or R-M and S-M) values indicate the proportion of regular and singular pixels, respectively, under different masks (M or -M). In our experiments, four consecutive pixels were grouped together, with the applied mask M is defined as [0,1,1,0].
The statistical relationship between the regular and singular groups must satisfy the following conditions:
From
Figure 6, it can be observed that both shadow images (number 1 and number 2) conform to the constraints defined in Equations (
10) and (
11), ensuring that the statistical integrity of the stego images is preserved. This indicates that the proposed method effectively maintains a balanced distribution of regular and singular groups, making it resilient against RS analysis attacks.
Furthermore, the similarity between RM and R-M as well as SM and S-M, across different shadow images suggests that the embedding operation does not introduce significant statistical anomalies that could be exploited by steganalysis techniques. This highlights the robustness of the proposed scheme in preserving the natural statistical properties of the host image while embedding data.
In conclusion, the RS analysis results confirm that the proposed method maintains imperceptibility and structural consistency, reducing the likelihood of detection by statistical steganalysis techniques. The ability to resist RS analysis ensures that the hidden information remains undetectable, making the method a strong candidate for secure reversible data hiding applications.
Furthermore, a deeper analysis of the comparative results reveals the underlying reasons for the differences in performance among existing methods. For instance, the scheme proposed by Chang et al. (2013) [
14] achieves a relatively high embedding capacity of 1.53 bpp; however, this comes at the cost of significantly reduced image quality, with PSNR values falling below 40 dB. This degradation can be attributed to their approach of embedding two bits per pixel pair, which introduces substantial pixel distortion and consequently lowers visual fidelity.
In contrast, the EMD-based method by Chen and Hong (2021) [
23] demonstrates more balanced performance, offering reversibility without overhead and maintaining stable PSNR values for the first stego image. Nonetheless, their results indicate that the second stego image tends to exhibit slightly inferior image quality. This disparity is likely due to the nature of EMD-based embedding, where error adjustments are not evenly distributed and one image inevitably bears a greater share of modification, leading to perceptible quality differences.
The proposed method effectively addresses these issues by employing enhanced HC(7,4) codes in combination with virtual pixel grouping and error pattern optimization, resulting in a more uniform distribution of distortion across both stego images. Consequently, the experimental results demonstrate that the proposed method achieves a balance between embedding capacity and perceptual quality, maintaining PSNR values between 48 and 49 dB and outperforming several existing techniques.
The proposed method is also computationally efficient. Unlike matrix embedding or EMD-based techniques, which often require complex orientation checks and iterative optimization, the proposed scheme relies on simple bitwise operations, Hamming code lookups, and XOR computations. This design not only reduces computational overhead but also enables straightforward hardware or software implementation. Thus, the proposed method is well suited for real-time applications and resource-constrained environments. For example, it can be applied in medical imaging systems or secure communication platforms that require high performance and low computational overhead.
In addition to these performance advantages, the computational efficiency of the proposed method is noteworthy. Unlike matrix embedding or EMD-based techniques, which often require complex orientation checks and iterative optimization, the proposed scheme relies on simple bitwise operations, Hamming code lookups, and XOR computations. This design not only reduces computational overhead but also enables straightforward hardware or software implementation. Thus, the proposed method is well suited for real-time applications or resource-constrained environments where both high performance and low computational complexity are critical, such as medical imaging systems and secure communication platforms.
To further support this claim, we analyzed the algorithm’s complexity and conducted runtime evaluations. The core procedures in both the embedding and extraction phases involve selecting an optimal codeword from a fixed-size lookup table containing sixteen valid HC(7,4) codewords. For each pixel, this search requires only basic integer operations and a minimal comparison loop. As such, the algorithm runs in constant time per pixel, resulting in an overall time complexity of for an image with N pixels.
To empirically validate this efficiency, we measured the execution time of the full embedding and extraction process on a grayscale image using Matlab R2019b on a system equipped with an Intel Core i5-8250U processor (1.60 GHz) and 8 GB RAM. The total runtime including all encoding, decoding, and pixel reconstruction steps was approximately 0.97 s. These results demonstrate that the proposed method is computationally lightweight and suitable for low-latency applications. However, we acknowledge that strict real-time constraints in high-resolution or embedded systems may require additional platform-specific optimization, which is a topic for future research.
Although the proposed method provides excellent performance in terms of embedding capacity and image quality, it inherits the common limitation of LSB-based RDH schemes in that it is not robust against lossy image compression such as JPEG. Because the embedded data reside in the least significant bits, such transformations tend to remove or distort the hidden content. This tradeoff reflects a key difference between RDH and robust watermarking, and points toward a promising future research direction in transform-domain RDH.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}