1. Introduction
Sentence boundary disambiguation (SBD) is a fundamental task in natural language processing (NLP), which is crucial for understanding the structure and semantics of sentences [
1]. Humans are good at their languages and can quickly determine the location of sentence boundaries when reading a passage based on linguistic conventions or grammar. Humans cannot only determine sentence boundaries through punctuation but also rely on information about sentence meaning to assist in sentence boundary disambiguation. However, very often, when our task requires a large amount of data, sentence segmentation by manual methods is labor intensive. It can lead to inconsistent segmenting results due to differences in each person’s understanding of sentences [
2].
From a more macroscopic point of view, studying Tibetan clauses is of great significance in promoting the overall development of the Tibetan NLP field. Through the research and improvement of clause technology, we can promote the progress of other NLP tasks in the Tibetan language field and improve the automation level of Tibetan information processing. This helps promote the dissemination and communication of Tibetan culture and supports the informatization and modernization of Tibetan areas. Tibetan clause-splitting technology also shows many application prospects in practical application scenarios. Whether in news reporting, social media, or literature, Tibetan clause-splitting technology can help people process and analyze Tibetan texts more efficiently and improve work efficiency and accuracy. With the continuous development and improvement of the technology, it is believed that Tibetan clause-splitting technology will play a more significant role in more fields in the future. The Tibetan clause task has essential applications and significance in Tibetan NLP. It supports subsequent NLP tasks and is crucial in several practical application scenarios. With the deepening of research and the advancement of technology, the Tibetan clause task will play an even more critical role in the future [
3].
Tibetan is an ancient language belonging to the Tibetan–Burmese branch of the Sino-Tibetan language family, in which the SBD task is even more challenging because sentence boundaries are often unclear. Most existing Tibetan sentences are labeled by rules and statistical learning methods and then proofread by hand. Still, the efficiency could be better in the case of large amounts of data or high data demand. Therefore, batch data processing using deep learning techniques is essential. By training the model on a large amount of Tibetan text data, the model learns the syntactic structure and patterns of Tibetan text to determine sentence boundaries accurately [
4]. At this stage, NLP-based research includes basic tasks such as sentence segmentation, word segmentation, linguistic annotation, and syntactic analysis, as well as downstream tasks such as machine translation, dialog generation, information extraction, and summary generation. Most of these tasks require sentences as input units, so the merits of SBD tasks directly affect the efficiency of downstream tasks [
5]. Tibetan has its unique script, phonetics, grammatical features, and grammatical rules, and is a phonetic script. These foundations are still in use in the modern Tibetan script. The Tibetan language is a phonetic script spelled by phonetics. The modern Tibetan language consists of 30 consonant letters and four vowel letters [
6].
Units separated by a tsheg (“་”) in Tibetan are called syllables, and a Tibetan syllable corresponds to a word in English. A Tibetan syllable may have at least one consonant and up to seven phonemes. The seven parts are root, prefix, superfix, subfix, vowel, suffix, and postfix. Each letter in the syllable is called a component, and components are the constituent parts of a syllable and equal to characters in English. In Tibetan encoding, the character is the basic unit of the computer display, printing, and counting. Tibetan has both horizontal and vertical spelling, and this two-way spelling is a significant feature of Tibetan [
7].
In traditional Tibetan grammar, a sentence is a linguistic unit consisting of two or more syllabic words that can express the name of a transaction connected with a grammatical auxiliary or an ordinary dummy word to express the distinction of the transaction. Tibetan sentences contain various dummy words, among which gerunds mainly express semantic relations between noun components and verbs. Tibetan sentences can be divided into long sentences (compound sentences) and short sentences (single sentences). Nouns with grammatical auxiliaries form short sentences, while long sentences can express a complete meaning and usually have a dummy word at the end of the sentence to indicate the end of the sentence.
A complete sentence in Chinese or English has a distinct end punctuation mark, usually a period, question mark, exclamation point, semicolon, or ellipsis to indicate the end of a sentence. In Tibetan, due to the problem of the partitive class of end-of-sentence dots and intra-sentence dots, the end-of-sentence dots cannot be used as sentence clauses or syncopation markers [
8]. For example, “བཀྲ་ཤིས་རྟགས་བརྒྱད་ནི་དཔལ་བེའུ་དང་། ① པད་མ། ② གདུགས། ③ དུང། ④ འཁོར་ལོ། ⑤ རྒྱལ་མཚན། ⑥ བུམ་པ། ⑦ གསེར་ཉ་བཅས་སོ། ⑧” (the Eight Auspicious Treasures are the auspicious knot, the incredible lotus, the precious umbrella, the conch, the gold-lipped block, the precious vase, and the golden fish.) In the “Auspicious Eight Treasures”, the shad at ①~⑦ is an intra-sentence shad, and only the shad at ⑧ is an end-of-sentence shad. When divided into shad, the sentence will be divided into several non-sentence units such as “བཀྲ་ཤིས་རྟགས་བརྒྱད་ནི་དཔལ་བེའུ་དང།” and “པད་མ་”. The problem of concatenating end-of-sentence and intra-sentence shad in Tibetan has caused significant difficulties in automatic clause splitting [
9].
In addition, Tibetan is rich in the phenomenon of linguistic partitions; for example, in the dictionary samples listed in the above literature, there are several noun-verb partitions such as “རྒྱུ་”, “སྲིད་”, and “སྐོར” [
10]. The text does not propose any corresponding disambiguation strategy or method, which leads to the fact that when splitting a sentence; the noun-verb partitions will be taken for the verb of the sentence end, resulting in the splitting of many incorrect sentences [
11].
We now provide an example of a sentence ending in “g-” without “shad” and discuss other uses of “shad”. In Tibetan, sentences ending in “g-” usually denote statements or commands and often do not need “shad” to mark the end of the sentence. Note the following example: “དེབ་འདི་ཡག་པོ་འདུག” (This is a great book). In this example, the sentence ends with “ཡག་” indicating a complete declarative sentence without the need for “shad”. As for other uses of “shad”, in addition to marking sentence structure, it can also be used to enumerate elements in a list. In this case, “shad” may appear after each enumerated item to help the listener or reader distinguish between different items. For example, note the following: “གཅིག། གཉིས། གསུམ།” (one, two, three.) In this enumeration example, “shad” appears after each number, indicating that three elements are enumerated.
To summarize, shad in Tibetan is a multi-functional auxiliary that plays various roles in a sentence, such as marking structure, linking clauses, and enumerating elements. By understanding these uses, we can better analyze and understand the complex sentence structure of Tibetan. The functions of standard punctuation in modern Tibetan are shown in
Table 1; this study focuses on Tibetan SBD based on the shad (“།”).
With the development of the global Tibetan language community and the popularization of digitization technology, the data resources of Tibetan text are gradually enriched, providing favorable conditions for developing Tibetan pre-training technology [
12]. In recent years, some research has been attempted to pre-train Tibetan, and some results have been achieved. The core idea of the pre-trained language model is to use unlabeled text data to pre-train the model so that the model learns the intro, mosaic structure, and language pattern. Currently, models such as ELMo [
13], GPT [
14], and BERT [
15] have become benchmark models in NLP. However, the development and application of pre-training techniques still face many challenges for low-resource languages like Tibetan [
16].
In the pre-trained language model, the training unit is fundamental, and many tasks use the word as the minimum processing unit, and a word is a token. In Chinese text encoding, we can use “character” as the encoding unit, and in English processing, we can use “letter” or “word” as the primary encoding unit. The use of “letters” as the coding unit is prone to the problem of long coding length, which leads to a high computational cost of the model. When using “word” as the basic unit, the number of “words” is fixed, and words beyond the dictionary’s scope cannot be processed, resulting in the instability of the word list. In deep learning model training, the word list is too extensive, which leads to computational overload; most models discard low-frequency words during training or fix the word list size [
17]. Although such a setup reduces the computational load, it also encounters the Out of Vocabulary (OOV) problem. The simplest solution to the OOV problem is to label these words as Unknown (UNK) uniformly. However, too many words labeled “UNK” during training will affect the model’s generalization ability. Based on this, people began to study different methods to solve this problem, namely, the subword cut algorithm. Subword refers to the subunit in a word, which is a method of dividing words or phrases into smaller units [
18], with a granularity between words and letters. For example, “subword” can be divided into two subwords: “sub” and “word” [
19]. Commonly used encoding methods are Byte Pair Encoding (BPE) [
20], byte-level BPE(BBPE) [
21], Wordpiece [
22], and Sentencepiece [
23].
Aiming at the current research status of Tibetan SBD, the need for downstream task dataset establishment, and Tibetan grammar semantic analysis, this study explores the automatic recognition of Tibetan sentence boundaries based on the BERT pre-trained language model combined with the classical deep learning model through which the computer learns the meaning of the sequence composed of each shad (“།”) and the text preceding it, which transforms the SBD problem into a binary classification problem to determine whether the current shad (“།”) is an actual sentence end marker. Since the current publicly available pre-trained language models for Tibetan are generally effective on the SBD task we first train a BERT pre-trained language model for Tibetan in this study based on BPE and Sentencepiece and verify the performance of the model by combining CNN [
24], RNN [
25], RCNN [
26], and DPCNN [
27] on the two pre-trained language models. Meanwhile, to verify the effectiveness of the data in this study, experiments are also conducted on the publicly available TiBERT [
28] model and Multilingual BERT(Multi-BERT) [
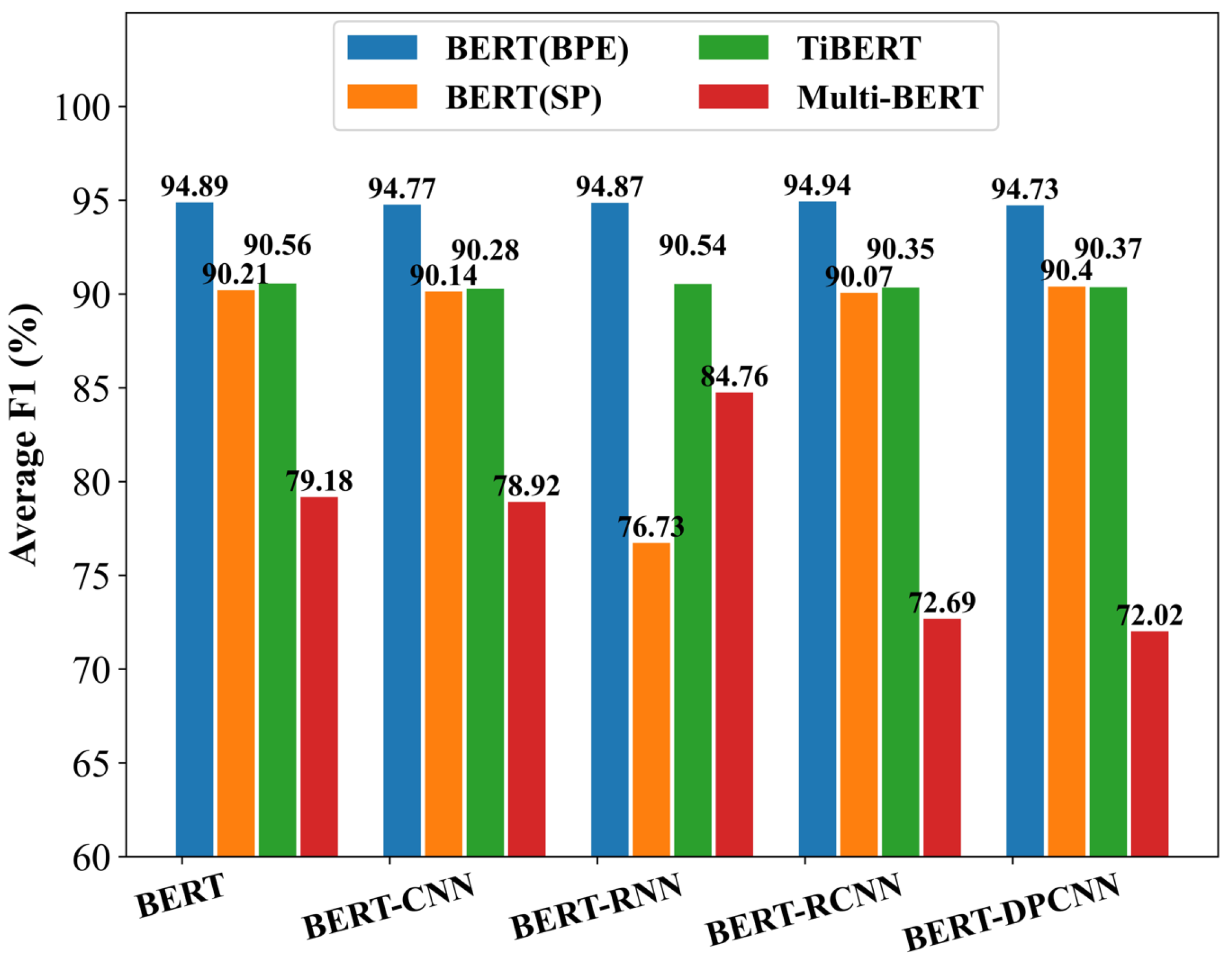
29], which proves the effectiveness of the SBD data in this study on multiple pre-trained language models, as well as the suitability of Tibetan SBD tasks for the BERT pre-trained language model based on the BPE word cutting approach. Meanwhile, to reduce the model’s computational complexity and training cost, the experiment selects the number of token sequences in the window before the punctuation mark to participate in the training and testing. Finally, it proves the high efficiency of the BERT(BPE) deep learning-based model in the Tibetan SBD task.
2. Related Work
Most NLP technologies develop first with English, then German, French, Chinese, and then low-resource languages such as Tibetan. The research for SBD tasks lies in new features and models that effectively distinguish between bounded and unbounded. For languages such as English, where NLP research has been conducted earlier, most SBD is based on machine learning methods such as Decision Tree (DT) [
30], Multilayer Perceptron (MLP) [
31], Hidden Markov Model (HMM) [
32], maximum entropy (ME) [
33], Conditional Random Field (CRF) [
34], and other models [
35].
NLP techniques for languages such as English provide ideas and references for the study of Tibetan, and the study of English SBD is mainly concerned with determining whether an abbreviated period (“.”) is an actual sentence boundary or just an abbreviation representing a particular position. Scholars have conducted studies based on rule-based and statistical learning methods to address this issue. Read et al. [
36] counted 75,000 English scientific abstracts in which 54.7–92.8% of the sentence dots appeared at the end, about 90% indicated the end of the sentence, 10% indicated abbreviation, and 0.5% both. Mikheev [
37], based on determining whether the words to the left of a potential sentence boundary or the right side of a word are an abbreviation or a proprietary name, uses a set of rules to implement SBD. Mikheev [
38] combines the approach in the literature [
37] with lexical tagging methods for supervised learning, including tagging for sentence endings, to reduce the error rate. Kiss and Strunk [
39] propose a completely unsupervised system called PUNKT. The system is rooted in recognizing acronyms by finding collocation keys between candidate words and sentence points. Riley [
40] proposed a DT classifier to determine whether acronyms mark sentence boundaries. It utilizes the probability of a word being the end or beginning of a sentence, word length, and word case as features to perform SBD. Reynar et al. [
41] used supervised ME learning to study SBD by considering sentence segmentation as a disambiguation task with good results. Gillick et al. [
42] used SVM to study SBD in English by using a large amount of training data through an SVM model to determine the function of abbreviated periods in English.
For Tibetan, rule-based research, machine learning, and a combination of both have been applied to the study of SBD. A rule-based approach based on auxiliary suffixes to detect sentence boundaries in Tibetan was proposed by Zhao et al. [
43], which provided a preliminary analysis and exploration of the syntactic features of Tibetan legal texts. Ren and An [
44] proposed an SBD method for constructing three lexicons (ending word lexicon, non-ending word lexicon, and unique word lexicon), which transforms the SBD problem into a query of to which lexicon the word to the left of a shad (“།”) belongs. Cai [
45] proposed a verb-centered binary SBD method based on maximum entropy. First, the maximum entropy model detects Tibetan sentences by grammar rules and thesaurus and then further identifies ambiguous sentences. Based on the literature [
45], Li et al. [
46] proposed a rule and maximum entropy-based approach. The ambiguous sentence boundaries are first identified using Tibetan boundary word lists. Then, the maximum entropy model is used to identify the ambiguous sentence boundaries that the rules cannot recognize. This is the first time that rules and machine learning methods have been combined for the Tibetan SBD task. Ma et al. [
47] proposed a Tibetan SBD based on linguistic tagging. Firstly, the text is segmented into words and lexically tagged; then, the text is scanned; when scanning a shad (“།”) or a double shad (“།།”), it determines whether the word to the left of the shad (“།”) or double shad (“།།”) is a conjunction or not and whether the position of the word is a noun, a numeral, or a state word, if yes, the model will continue scanning; otherwise, sentence segmentation is performed. Zhao et al. [
48] studied the SBD method for Modern Tibetan auxiliary verb endings, which first identifies the auxiliary verb to the left of the shad (“།”), then determines whether the auxiliary verb to the left is a verb by the auxiliary verb, and finally considers whether the syllable number of the sentence is more significant than seven and segments it from the location of the shad (“།”). Zha and Luo [
49] extracted Tibetan sentences by reverse search of function word position and suffix lexical properties. The method improved the efficiency of Tibetan sentence extraction and identified 11 lexemes that mark the end of a sentence. Que et al. [
50] investigated the problem of automatic recognition of tight cuneiforms (“།”) in Tibetan based on rules and SVM. The method first builds a feature vocabulary using terminal words and tight wedge characters and then uses SVM for classification. Wan [
51] investigated the rule-based SBD problem for Tibet by analyzing the concepts and properties of Tibetan sentences and statistically studying the forms of Tibetan sentence endings and sentence-final lexemes.
The above studies used rule-based, statistical learning, and a combination of the two to solve the SBD problem in modern Tibetan from different perspectives. However, the corpora used in the above studies are oriented to different research focuses and have not been publicized. Among them, the rule-based approach requires researchers to have a high level of linguistic and grammatical foundation, and they need to construct the corresponding word and lexical dictionaries that can identify the sentence boundaries in advance; at the same time, the rule-based study needs to perform the tasks of participle and linguistic annotation, and based on the principle of error amplification in the deep learning model, the performance of participle and lexical labeling performance has a certain degree of influence on SBD research.
3. Tibetan SBD Based on BERT (BPE)
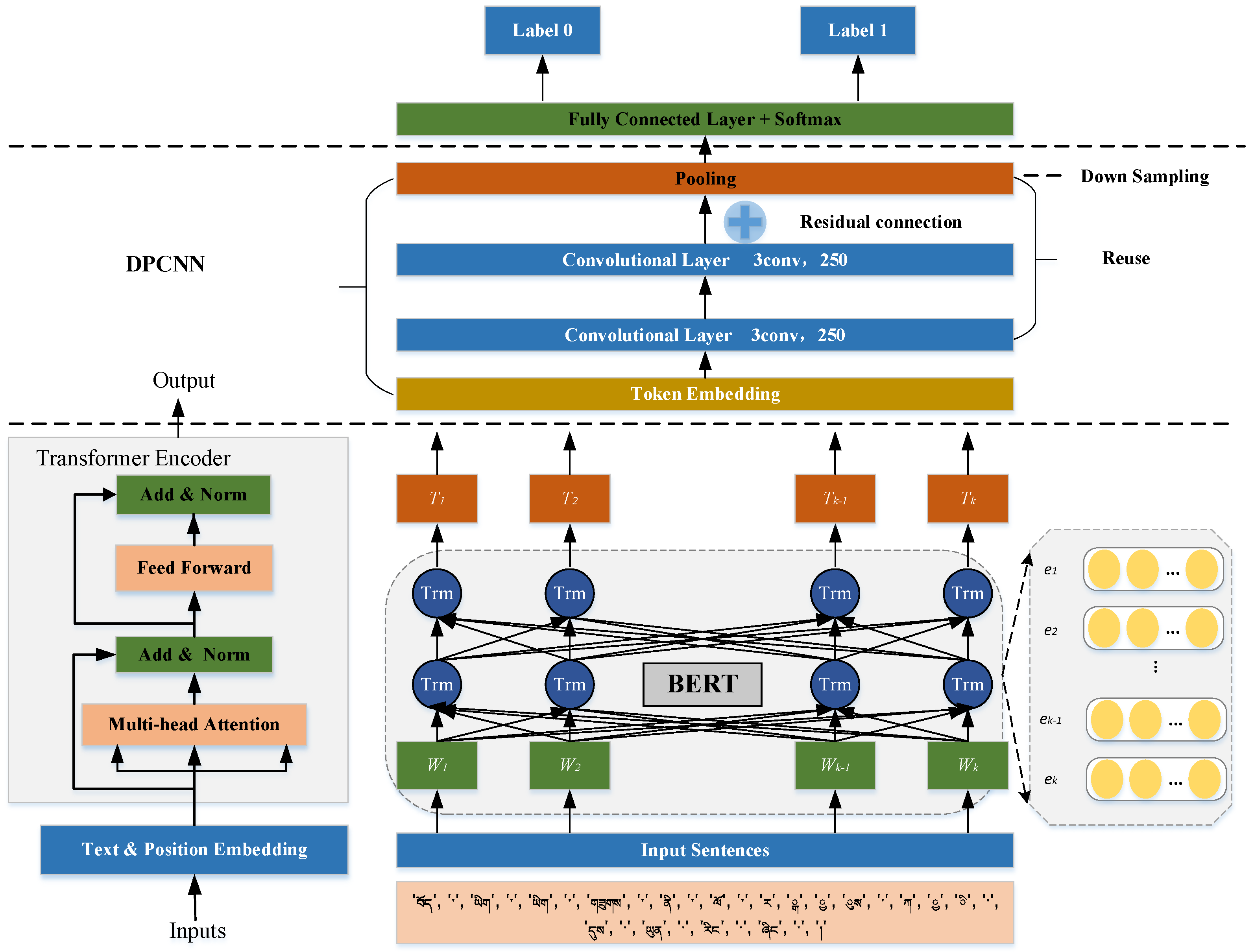
In this study, Tibetan sentence boundary disambiguation based on BERT (BPE) is investigated, which mainly includes the exploration of the BPE-based Tibetan subword method, the training of the BERT (BPE) pre-trained language model, and the disambiguation of Tibetan sentence boundaries based on BERT and its improved model, and this study chooses BERT-DPCNN as an example of the improved model to be introduced.
Figure 1 is the structure of the BERT-DPCNN model.
3.1. Subword Method of BPE
In the process of NLP training, the input unit of the training text is crucial, and there are differences in the impact of different input units on the results. The commonly used subword methods in the BERT pre-trained language model are BPE, Sentencepiece Wordpiece, etc., and the subword methods are closely related to linguistic features. In this study, we researched the Tibetan BERT pre-trained language model based on two subword methods, BPE and Sentencepiece. BPE is one of the essential coding methods in NLP, and its effectiveness has been proved by the most powerful language models such as GPT-2, RoBERTa, XLM, FlauBERT, and so on. Since it was found during the preliminary attempts that the Wordpiece subword method would have lost information such as vowels, resulting in incomplete information of Tibetan after word cutting, and the units generated by the Sentencepiece subword method are longer, this study uses the BPE subword method during the research of Tibetan pre-trained language model. BPE, designed by Gage in 1994, is a statistically based sequence compression algorithm designed to solve the string compression problem and is widely used in subword slicing in NLP.
The basic flow of the BPE subword slicing method is as follows:
Step 1: Slice each word into a sequence of characters and add a special ending symbol to each character.
Step 2: Calculate word frequency: count the number of occurrences of each character sequence.
Step 3: Merge characters: find a pair of neighboring character sequences with the highest word frequency and merge them into a new character sequence. At the same time, update the word frequency table and recalculate the number of times each character sequence occurs.
Step 4: Repeat step 3 until the specified number of subwords is reached or all the character sequences in the word frequency table can no longer be merged.
Step 5: Final slicing: the initial word is sliced according to the final vocabulary list to obtain the subword sequences.
The pseudo-code for BPE word cutting is as Algorithm 1:
| Algorithm 1 Byte-pair encoding |
| 1: Input: a set of string , target vocab size |
| 2: procedure BPE |
| 3: ←all unique characters in |
| 4: while do Merge tokens |
| 5: , ←Most frequent bigram in |
| 6: ← + Make a new token |
| 7: ← + [] |
| 8: Replace each occurrence of , in with |
| 9: end while |
| 10: return |
| 11: end procedure |
This study has tried three subword methods: BPE, Sentencepiece, and Wordpiece.
Table 2 is an example of three different subword methods. From
Table 2, we can see that the average length of the sequence after Sentencepiece cutting is the longest, the length of Wordpiece cutting is the shortest, and many of them are single characters, while the length of the BPE is between Wordpiece and Sentencepiece. Meanwhile, we found that the result of the WordPiece cut word has the problem of losing some of the building blocks, so, in this study, we trained the BERT model for both the Sentencepiece and BPE word cutting methods.
3.2. BERT Model Training
Devlin et al. [
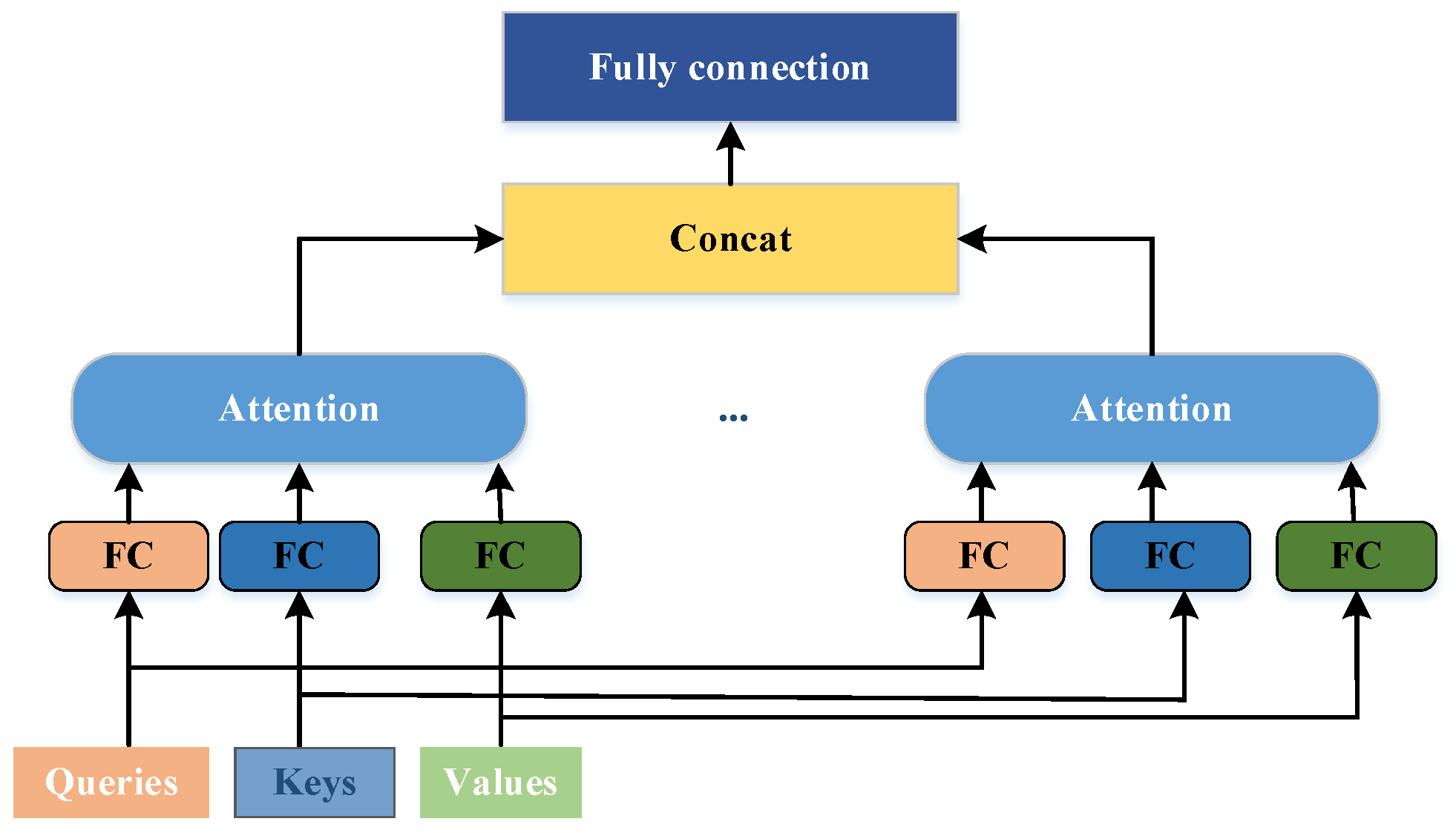
15] proposed a Transformer-based Bidirectional Encoder Model (BERT) in 2019, masking several words with unique tokens before predicting them and preprocessing the bidirectional representation of unlabeled text by jointly regulating left and right up and down in all layers. In this study, the Tibetan BERT pre-trained language model based on two subword methods, Sentencepiece and BPE, is applied in the SBD model. The Tibetan SBD task is investigated based on the BERT + deep learning model. The BERT uses the encoder part of the Transformer, which consists of multiple layers of bi-directional Transformer [
52] encoder stacked together. Each layer of the Transformer’s encoder consists of a multi-head attention mechanism and a feed-forward network with layer normalization. The feed-forward network consists of two fully connected layers and a nonlinear activation function RELU;
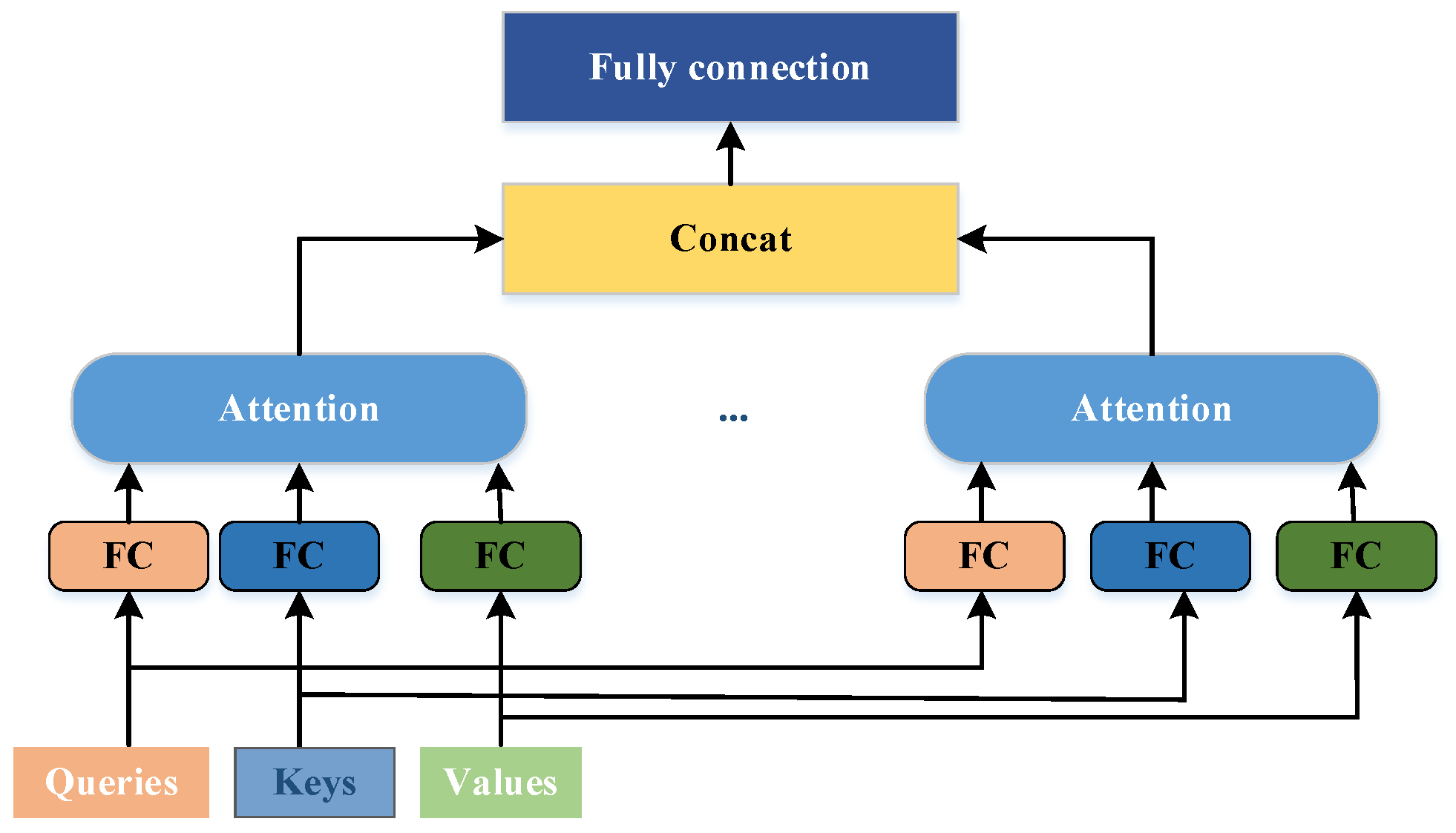
Figure 2 shows the structure of the multi-head attention mechanism.
The multi-head attention mechanism is an extension of the attention mechanism, which independently calculates attention weights in multiple representation subspaces, allowing the model to learn different attention patterns in different subspaces, thereby improving the model’s representation ability. The attention mechanism creates three vectors before input: Query vector , Key vector , and Value vector . Attention is computed in three general steps:
(1) Calculate the weights; firstly,
and all
calculate the weights using the similarity method.
Normalization, using the Softmax function to normalize :
(2) Sum the normalized weights with
weighting to obtain Attention:
where
,
, and
denote the query, index, and the value obtained from the query, respectively, all obtained from the input word vectors by linear transformation, and then the value of the Softmax function is solved by Equation (2), after calculating the attentional weights of each position to the other positions, the self-attention mechanism will generate a weighted vector for each position based on these weights, i.e., multiplying each position with the attentional weights of the other positions, and then summing up these products to obtain the weighted vector for that position, i.e., the attentional representation of that position [
53].
In the multi-head attention mechanism, i.e., for a given query
, essential
, and value
, each attention head
is computed as follows:
The multi-head attention mechanism is calculated as follows:
In this study, the specific process of sentence boundary disambiguation based on the Tibetan BERT pre-trained language model is as follows:
(1) Sentences are first segmented, and [CLS] markers are added to the beginning of each sentence, and [SEP] markers are added to the end of each sentence.
(2) The labeled sentences are input to the embedding layer: marker embedding, fragment embedding, and position embedding. Token embedding adds [CLS] tokens to the beginning of each sentence while separating each sentence fragment by [SEP]; fragment embedding is used to differentiate between multiple sentence fragments given, mapping the tokens to EA in odd-indexed sentences, and mapping the tokens to EB in even-indexed sentences. Positional embedding encodes the positional information of words in the input, as shown in Equations (5) and (6).
denotes the dimension of the embedding,
denotes the even dimension of the embedding dimension, and
is the odd dimension.
(3) The BERT model accepts these inputs, and after the model is trained, the context embedding representation of each token is the output. The [CLS] tokens in front of each sentence are entered into the output vector after modeling as the sentence vector representation of that sentence.
(4) Input the acquired sentence vector representation into the Softmax layer. Finally, for a simple binary classifier to determine whether the input text is to be disconnected from the current position or not, the judgment is shown in Equation (7).
In this study, in addition to studying the Tibetan SBD based on the BERT model, we also compare the SBD based on the BERT + deep learning model, which is presented as an example of DPCNN.
3.3. Introduction to the DPCNN Model
Early deep learning models mainly include Convolutional Neural Networks (CNNs) [
24] and Recurrent Neural Networks (RNN) [
25]. TextRNN and TextCNN are model architectures for multi-label text classification problems. The TextRNN model adopts a Bi-directional Long Short-Term Memory (Bi-LSTM), where the input of the latter time step depends on the output of the previous time step, which cannot be processed in parallel and affects the overall process speed. TextCNN mainly relies on sliding windows to extract the features, which are limited in their ability to model long distances and are insensitive to the order of speech. Based on TextCNN, researchers propose the text recurrent convolutional neural network (TextRCNN [
26]), in which the function of feature extraction in the convolutional layer is replaced by RNN, i.e., the feature extraction of TextCNN is replaced by an RNN. The advantage of RNNs is that it can better capture contextual information, which is conducive to capturing the semantics of long texts. Therefore, the overall structure becomes an RNN + pooling layer called RCNN. Based on TextCNN, Deep Pyramid Convolutional Neural Networks (DPCNN [
27]) have been proposed, which is strictly the first word-level widely effective deep text classification convolutional neural network, which can also be understood as a more effective deep CNN.
As shown in the upper part of
Figure 2, the DPCNN model mainly consists of region embedding, two equal-length convolutions, the Block region, and the residual connections represented by the plus sign. Among them, the Block region contains one-half pooling and two equal-length convolutional layers, which is why the model is called the deep pyramid model. The main advantage of DPCNN is its ability to extract long-distance textual dependencies by continually deepening the network. This study investigates BERT-DPCNN as an example of an improved BERT+ deep learning model.
3.4. Sentence Boundary Disambiguation
Figure 2 is the network structure diagram of this study based on the BERT-DPCNN model as an example of studying the Tibetan SBD based on the BERT + deep learning model. After training on the BERT model to obtain the representation of each token, it is inputted into the deep learning model for the second stage of training. Finally, the label of each clause is obtained by the softmax function. Training data may contain several clauses, assuming that each clause is represented by S. The clause where the shad (“།”) containing the end-of-sentence marker is labeled as a positive sample, and the other labels are negative samples. Suppose the clause S contains n tokens (where
is determined according to the length of
, then
is a sequence consisting of
,
, …,
. In this study, we use
to denote the probability that the shad (“།”) at the end of the current clause fragment is the true clause token
, where
is a parameter in the network.
After obtaining the vector representation
of the syllable
, a linear transformation will be performed with a
linear activation function to send the result to the next layer.
After all, the token is represented as a vector, and this study uses a maximum pooling layer to convert clauses of different lengths into fixed-length vectors that capture the information of the entire sentence.
The max function is the maximum function and the
element of
is the maximum of the
element of
. The pooling layer uses the output of the loop structure as input. The model ends with the output layer, which is defined as follows:
Finally, the output number
is converted into a probability using the softmax function, i.e., the probability that the current clause’s shad (“།”) is an accurate end-of-sentence marker.





{kind=link}
{kind=link}
{kind=link}
{kind=link}