
Causal Reinforcement Learning for Knowledge Graph Reasoning

Abstract
1. Introduction
- We propose a prior knowledge generation method based on causal inference. Specifically, it is implemented through the relationship importance identification module. The generated prior knowledge is mainly used to measure the contribution of the relationship in the triple to be completed.
- We introduce a new method combining causal inference and reinforcement learning that applies to knowledge graph reasoning. Specifically, the prior knowledge is integrated into the control strategy of the reinforcement model, allowing the agent to select the relation more accurately in each step. Our model also applies to large-scale knowledge graphs.
- The experiments demonstrate that our method’s performance outperforms the current baseline methods in most cases. Additionally, we conduct ablation experiments to highlight that our method is more effective than solely employing reinforcement learning.
2. Related Work
2.1. Knowledge Graph Reasoning
2.2. Casual Inference
2.3. Reinforcement Learning
2.4. Causal Reinforcement Learning
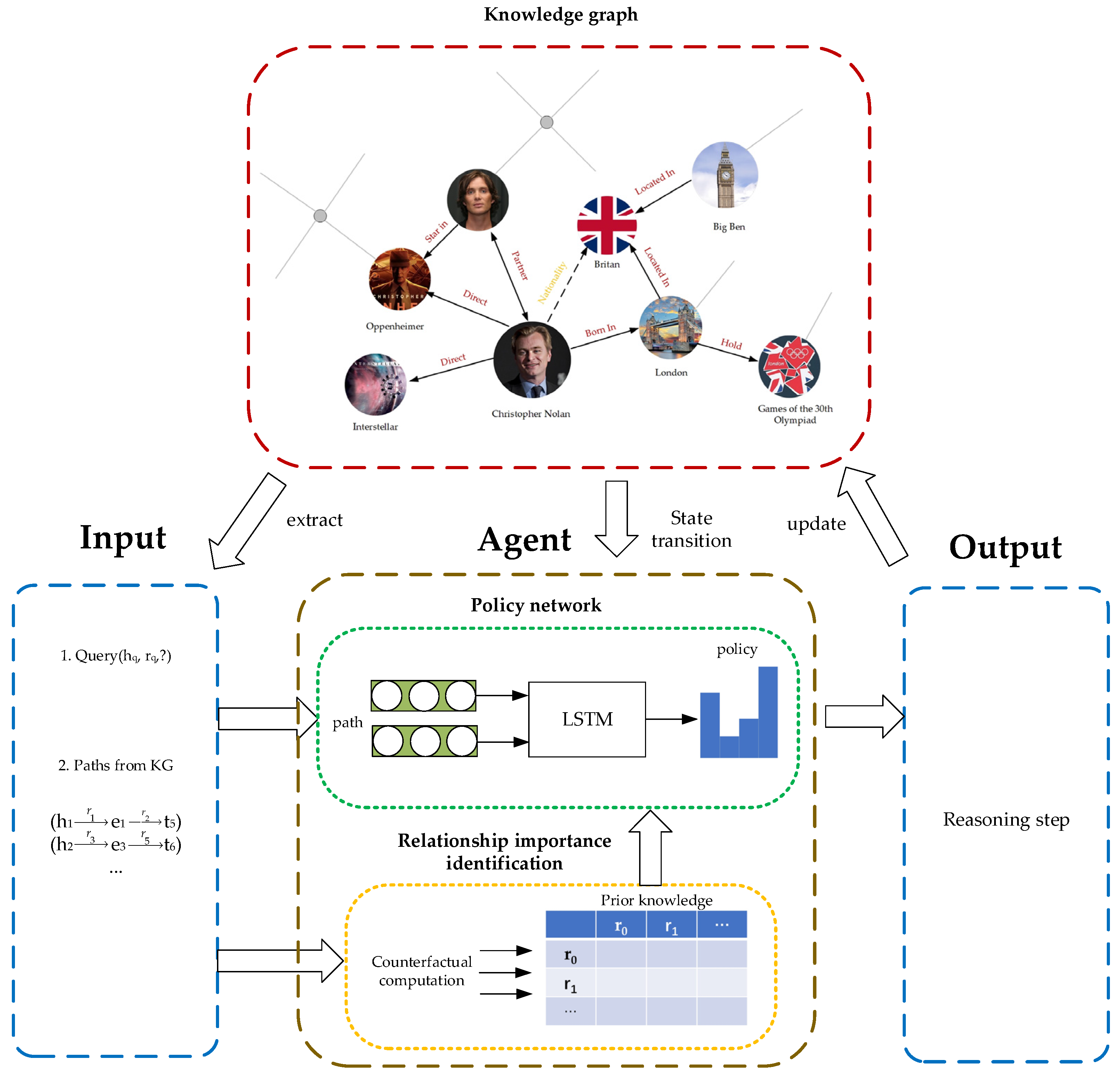
3. Proposed Method
3.1. Problem Definition
3.2. Overall Architecture
3.3. Relationship Importance Identification
3.4. Reinforcement Learning Framework
3.4.1. Environment
3.4.2. Policy Network
3.4.3. Training
| Algorithm 1. Training Procedure | |
| 01 | Initialize |
| 02 | for episode1 to N do |
| 03 | Initialize path p |
| 04 | Initialize entity representation |
| 05 | for do |
| 06 | Calculate history embedding |
| 07 | Obtain reward R(p) |
| 08 | |
| 09 | Update |
| 10 | end for |
| 11 | end for |
4. Experiments
4.1. Datasets
4.2. Baseline Methods
4.3. Evaluation Protocol
4.4. Implementation Details
4.5. Results
4.6. Analysis
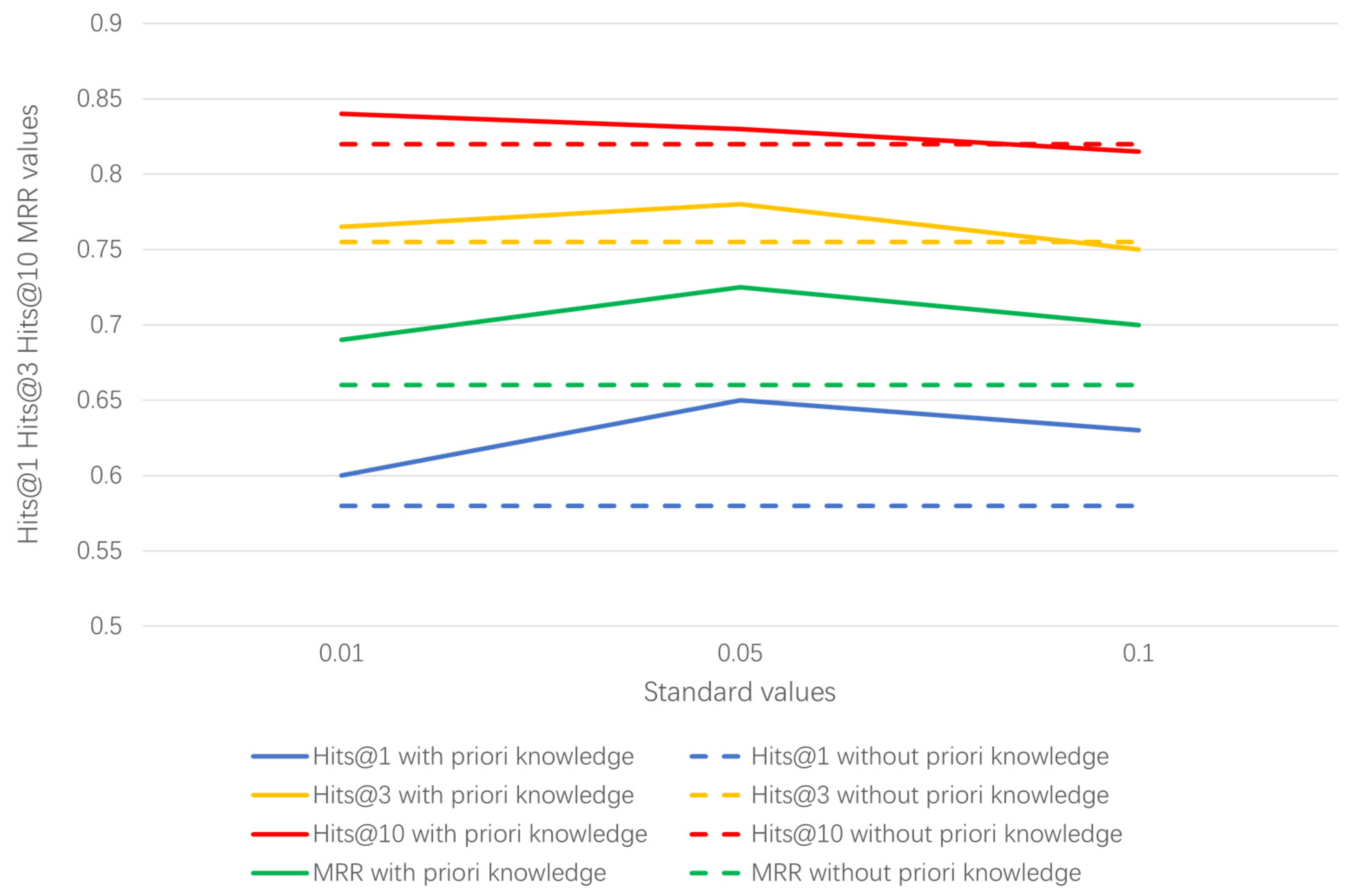
4.6.1. Setting of Standard Values and Ablation Study
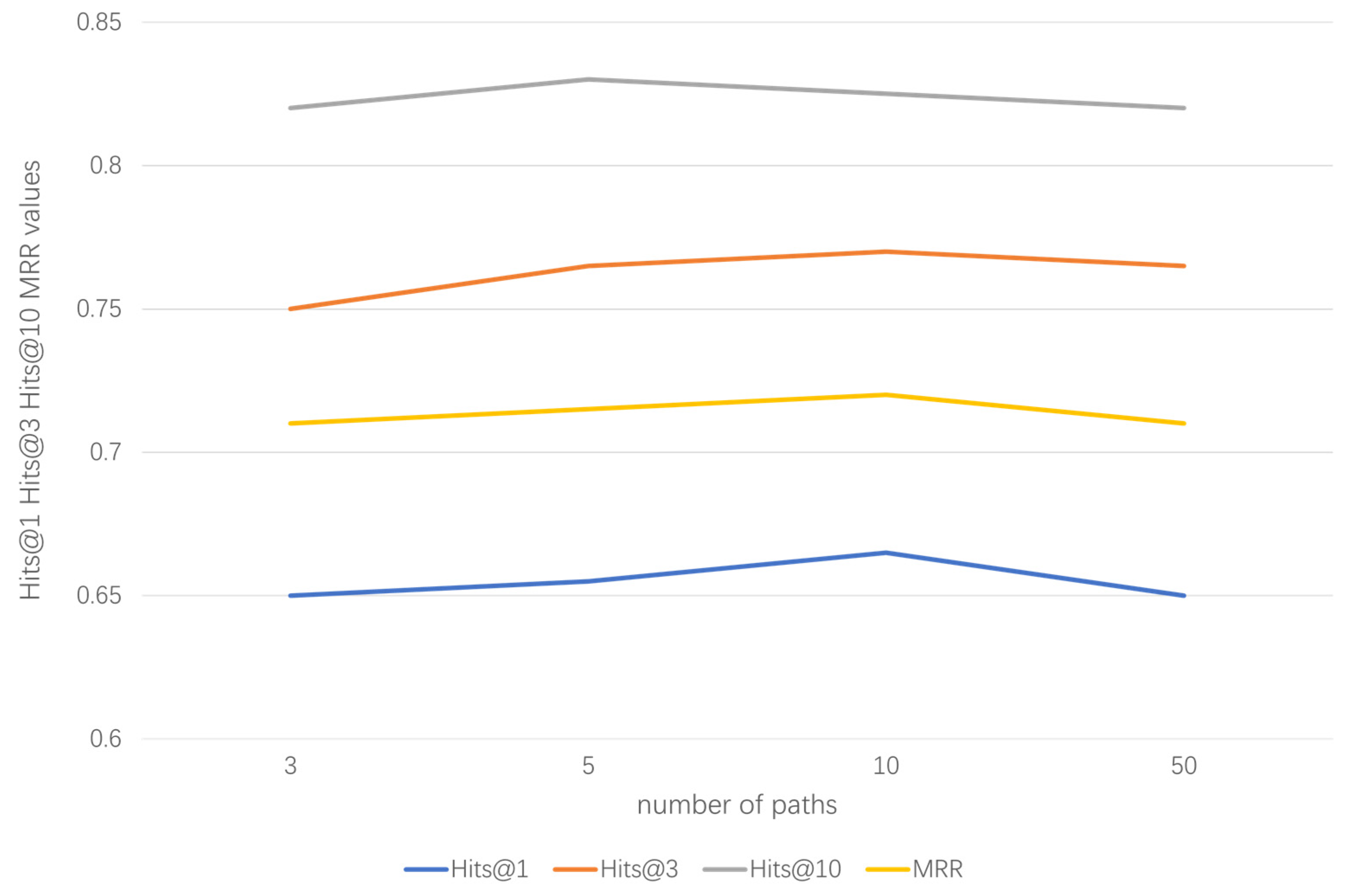
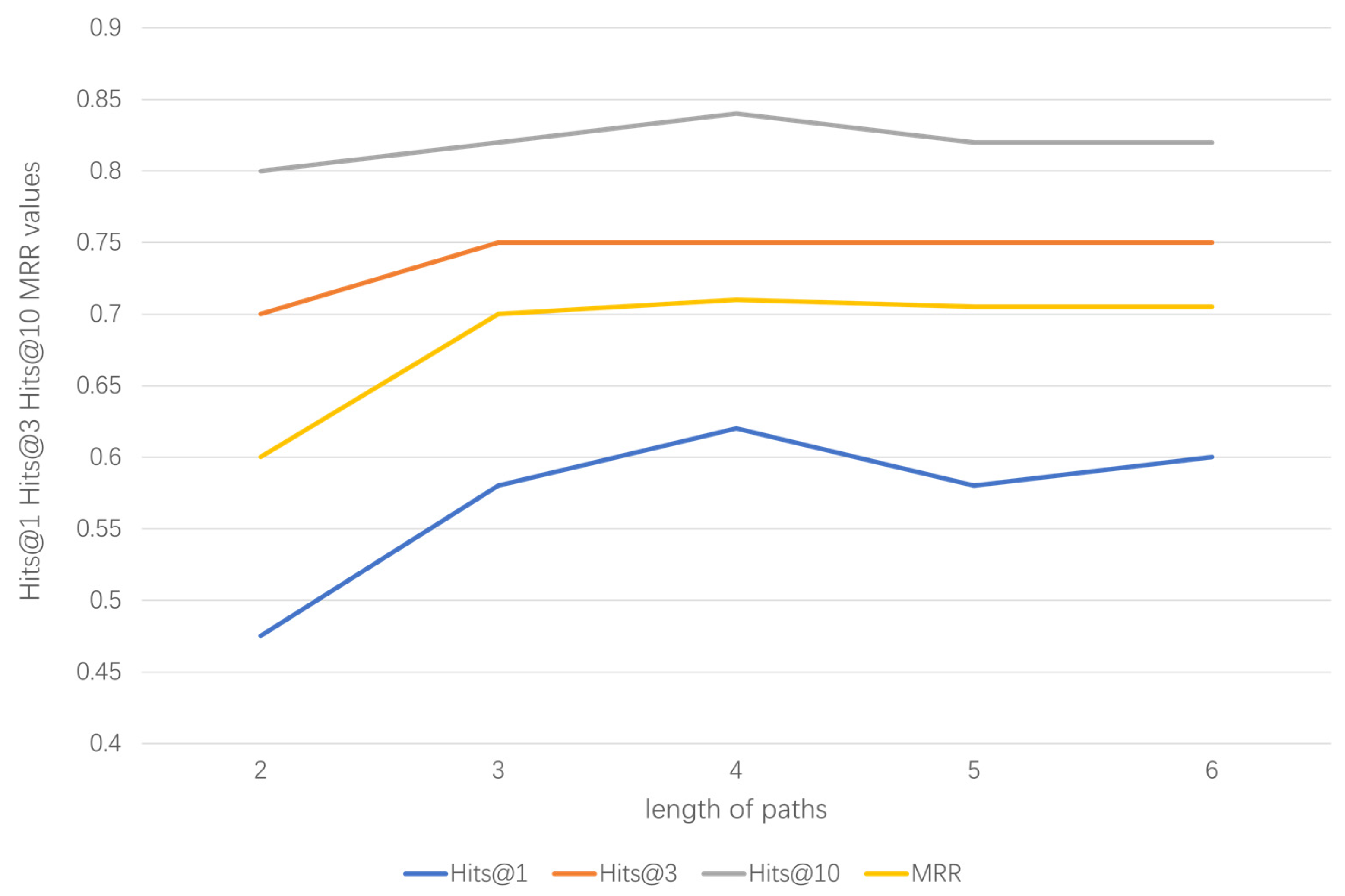
4.6.2. Impact Analysis of the Number and Length of Paths
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| KGC | Knowledge Graph Completion |
| SCM | Structural Causal Model |
| CF-GPS | CounterFactually Guided Policy Search |
| SARSA | State Action Reward State Action |
| LSTM | Long Short-Term Memory |
| MAP | Mean Average Precision |
| MRR | Mean Reciprocal Rank |
References
- Xiong, C.; Merity, S.; Schoer, R. Dynamic memory networks for visual and textual question answering. In Proceedings of the 33rd International Conference on Machine Learning, Honolulu, HI, USA, 23–26 July 2016; pp. 2397–2406. [Google Scholar]
- Logan, R.; Liu, N.F.; Peters, M.E. Using knowledge graphs for fact-aware language modeling. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 22–24 August 2019; pp. 5962–5971. [Google Scholar]
- Xiong, W.; Yu, S.; Guo, X. Improving question answering over incomplete KBs with knowledge-aware reader. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 22–24 August 2019; pp. 4258–4264. [Google Scholar]
- Linardatos, P.; Papastefanopoulos, V.; Kotsiantis, S. Explainable AI: A review of machine learning interpretability methods. Entropy 2020, 23, 180–192. [Google Scholar] [CrossRef] [PubMed]
- Bordes, A.; Usunier, N.; Garcia-Duran, A. Translating embeddings for modeling multi-relational data. Adv. Neural Inf. Process. Syst. 2013, 26, 2787–2795. [Google Scholar]
- Wang, Z.; Zhang, J.; Feng, J. Knowledge graph embedding by translating on hyperplanes. In Proceedings of the 28th Association for the Advancement of Artificial Intelligence, San Francisco, CA, USA, 3–6 June 2014; pp. 1112–1119. [Google Scholar]
- Lin, X.; Liang, Y.; Giunchiglia, F.; Feng, X.; Guan, R. Compositional learning of relation path embedding for knowledge base completion. arXiv 2015, arXiv:1611.07232. [Google Scholar]
- Ji, G.; He, S.; Xu, L. Knowledge graph embedding via dynamic mapping matrix. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; pp. 687–696. [Google Scholar]
- Pasquale, M.; Pontus, S.; Sebastian, R. Convolutional 2D Knowledge Graph Embeddings. arXiv 2018, arXiv:1707.01476. [Google Scholar]
- Trouillon, T.; Welbl, J.; Riedel, S. Complex Embeddings for Simple Link Prediction. arXiv 2016, arXiv:1606.06357. [Google Scholar]
- Lao, N.; Mitchell, T.; Cohen, W.W. Rotate: Random walk inference and learning in a large scale knowledge base. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, Scotland, UK, 8–11 July 2011; pp. 529–539. [Google Scholar]
- Xiong, W.; Hoang, T.; Wang, W.Y. Deeppath: A reinforcement learning method for knowledge graph reasoning. arXiv 2017, arXiv:1707.06690. [Google Scholar]
- Das, R.; Dhuliawala, S.; Zaheer, M. Go for a walk and arrive at the answer: Reasoning over paths in knowledge bases using reinforcement learning. In Proceedings of the ICLR, Vancouver, BC, Canada, 28–30 March 2018; pp. 688–696. [Google Scholar]
- Wan, G.; Pan, S.; Gong, C. Reasoning like human: Hierarchical reinforcement learning for knowledge graph reasoning. In Proceedings of the 29th International Joint Conference on Artificial Intelligence, Yokohama, Japan, 7–15 January 2021; pp. 1926–1932. [Google Scholar]
- Wang, H.; Li, S.; Pan, R. Incorporating graph attention mechanism into knowledge graph reasoning based on deep reinforcement learning. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 2623–2631. [Google Scholar]
- Peter, J.; Micheal, D.; Nachiketa, C. A framework for causal discovery in non-intervenable systems. Chaos 2021, 31, 123–142. [Google Scholar]
- Eric, J.; Isabel, F.; Ilya, S. Auto-G-Computation of Causal Effects on a Network. arXiv 2019, arXiv:1709.01577. [Google Scholar]
- Nicola, G.; Jonas, P.; Sebastian, E. Causal discovery in heavy-tailed models. arXiv 2020, arXiv:1908.05097. [Google Scholar]
- Bi, X.T.; Wu, D.; Xie, D. Large-scale chemical process causal discovery from big data with transformer-based deep learning. Process Saf. Environ. Prot. 2023, 173, 163–177. [Google Scholar] [CrossRef]
- Cui, Y.; Pu, H.; Shi, X. Semiparametric Proximal Causal Inference. J. Am. Stat. Assoc. 2023, 11, 211–224. [Google Scholar] [CrossRef]
- Wang, Z.; Li, L.; Zeng, D. Incorporating prior knowledge from counterfactuals into knowledge graph reasoning. Knowl.-Based Syst. 2021, 223, 1307–1323. [Google Scholar] [CrossRef]
- Pearl, J.; Creager, E.; Garg, A. Causal Inference in Statistics: A Primer, 1st ed.; John Wiley & Sons: Chichester, NY, USA, 2016; pp. 254–256. [Google Scholar]
- Pitis, S.; Pan, S.; Gong, C. Counterfactual data augmentation using locally factored dynamics. In Proceedings of the 34th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020; pp. 2906–2922. [Google Scholar]
- Madumal, P.; Miller, T.; Sonenberg, L. Explainable reinforcement learning through a causal lens. In Proceedings of the 34th AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 2493–2500. [Google Scholar]
- Lu, C.C.; Huang, B.W.; Schölkopf, B. Sample-efficient reinforcement learning via counterfactual-based data augmentation. arXiv 2020, arXiv:2012.09092. [Google Scholar]
- Buesing, L.; Weber, T.; Zwols, Y. Woulda, coulda, shoulda: Counterfactually-guided policy search. In Proceedings of the 7th International Conference on Learning Representations, New Orleans, LA, USA, 1–5 May 2019; pp. 1693–1710. [Google Scholar]
- Moerland, T.M.; Broekens, J.; Plaat, A. Model-based reinforcement learning: A survey. Found. Trends Mach. Learn. 2023, 16, 101–118. [Google Scholar] [CrossRef]
- Yi, F.; Fu, W.; Liang, H. Model-based reinforcement learning: A survey. In Proceedings of the 18th International Conference on Electronic Business, Guilin, China, 2–6 December 2018; pp. 421–429. [Google Scholar]
- Singh, S.; Jaakkola, T.; Littman, M. Convergence results for single-step on-policy reinforcement-learning algorithms. Mach. Learn. 2000, 38, 287–308. [Google Scholar] [CrossRef]
- Watkins, C.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Mnih, V.; Silver, D.; Graves, A. Playing Atari with deep reinforcement learning. arXiv 2013, arXiv:1312.09092. [Google Scholar]
- Mnih, V.; Silver, D.; Graves, A. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Fortunato, M.; Azar, M.; Piot, B. Noisy networks for exploration. In Proceedings of the 6th International Conference on Learning Representations, Vancouver, BC, Canada, 12-16 August 2018; pp. 1321–1330. [Google Scholar]
- Kaelbling, L.P.; Littman, M.; Moore, A. Reinforcement learning: A survey. J. Artif. Intell. Res. 1996, 4, 237–255. [Google Scholar] [CrossRef]
- Wang, H.; Huang, T.; Wang, W. Deep reinforcement learning: A survey. Front. Inf. Technol. Electron. Eng. 2020, 21, 1726–1744. [Google Scholar] [CrossRef]
- Williams, R. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Mach. Learn. 1992, 8, 229–246. [Google Scholar] [CrossRef]
- Deng, Z.; Jiang, J.; Long, G.; Zhang, C. Causal Reinforcement Learning: A Survey. arXiv 2023, arXiv:2307.01452. [Google Scholar]
- Maximilian, S.; Bernhard, S.; Georg, M. Causal Reinforcement Learning: A Survey. arXiv 2016, arXiv:2106.03443. [Google Scholar]
- Guo, J.; Gong, M.; Tao, D. A Relational Intervention Approach for Unsupervised Dynamics Generalization in Model-Based Reinforcement Learning. In Proceedings of the 10th International Conference on Learning Representations (Virtual), Toulon, France, 25–29 April 2022; pp. 3453–3470. [Google Scholar]
- Pim, D.H.; Dinesh, J.; Sergey, L. Causal Confusion in Imitation Learning. Statistics 2022, 11, 1467–1480. [Google Scholar]
- Deng, Z.; Fu, Z.; Wang, L.; Yang, Z.; Bai, C.; Zhou, T.; Wang, Z.; Jiang, J. False Correlation Reduction for Offline Reinforcement Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 46, 1199–1211. [Google Scholar] [CrossRef] [PubMed]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Carlson, A.; Betteridge, B.; Kisiel, B. Toward an architecture for never-ending language learning. In Proceedings of the 25th AAAI Conference on Artificial Intelligence, Atlanta, GA, USA, 10–15 June 2010; pp. 1306–1313. [Google Scholar]
- Bollacker, K.; Evans, P.; Paritosh, T. Freebase: A collaboratively created graph database for structuring human knowledge. In Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, New York, NY, USA, 6–10 May 2008; pp. 1586–1604. [Google Scholar]
- Bordes, A.; Weston, R.; Collobert, Y. Learning structured embeddings of knowledge bases. In Proceedings of the 25th AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 16–22 August 2011; pp. 301–306. [Google Scholar]
- Sun, Z.; Deng, Z.H.; Nie, J.Y. Rotate: Knowledge graph embedding by relational rotation in complex space. In Proceedings of the 7th International Conference on Learning Representations, New Orleans, LA, USA, 9–12 May 2019; pp. 1–18. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | E | R | Training Triples | Test Triples |
|---|---|---|---|---|
| FB15K-237 | 14,541 | 237 | 272,115 | 20,466 |
| WN18RR | 40,943 | 11 | 86,835 | 3134 |
| NELL-995 | 75,492 | 200 | 154,213 | 3992 |
| YAGO3-10 | 123,182 | 37 | 1,079,040 | 5000 |
| Dataset | Tasks | TransE | PRA | DeepPath | MINERVA | Our Model |
|---|---|---|---|---|---|---|
| NELL-995 | AthletePlaysInLeague | 77.3 | 84.1 | 92.7 | 95.2 | 95.4 |
| AthletePlaysForTeam | 62.7 | 54.7 | 75.0 | 82.4 | 86.9 | |
| AthleteHomeStadium | 71.8 | 85.9 | 89.0 | 89.5 | 90.7 | |
| TeamPlaySports | 76.1 | 79.1 | 73.8 | 84.6 | 85.5 | |
| OrgHeadquaterCity | 62.0 | 81.1 | 79.0 | 94.5 | 93.6 | |
| BornLocation | 71.2 | 66.8 | 75.7 | 79.3 | 82.2 | |
| OrgHiredPerson | 71.9 | 59.9 | 74.2 | 85.1 | 86.4 | |
| PersonLeadsOrg | 75.1 | 68.1 | 75.5 | 83.0 | 81.4 | |
| … | ||||||
| Overall | 71.0 | 72.5 | 79.4 | 86.7 | 87.8 | |
| FB15k-237 | adjoins | 68.4 | 41.8 | 69.1 | 71.8 | 60.1 |
| contains | 56.7 | 32.5 | 39.8 | 41.5 | 40.8 | |
| personNationality | 44.2 | 42.1 | 52.8 | 62.1 | 42.9 | |
| filmDirector | 41.5 | 32.8 | 45.6 | 38.9 | 46.3 | |
| filmLanguag | 61.5 | 45.1 | 52.5 | 58.9 | 46.1 | |
| filmWritten | 56.1 | 32.1 | 36.5 | 59.1 | 36.2 | |
| capitalOf | 42.5 | 25.8 | 43.8 | 48.9 | 50.6 | |
| musicianOrigin | 38.2 | 18.5 | 23.7 | 23.8 | 38.7 | |
| … | ||||||
| Overall | 45.3 | 31.5 | 39.8 | 42.3 | 45.2 |
| Dataset | Metric | TransE | ComplEX | ConvE | MINERVA | Our Model |
|---|---|---|---|---|---|---|
| NELL-995 | Hit@1 | 0.514 | 0.612 | 0.672 | 0.663 | 0.684 |
| Hit@3 | 0.678 | 0.761 | 0.808 | 0.773 | 0.797 | |
| Hit@10 | 0.751 | 0.827 | 0.864 | 0.831 | 0.871 | |
| MRR | 0.456 | 0.694 | 0.747 | 0.725 | 0.740 | |
| FB15K-237 | Hit@1 | 0.248 | 0.303 | 0.313 | 0.217 | 0.228 |
| Hit@3 | 0.401 | 0.434 | 0.457 | 0.329 | 0.464 | |
| Hit@10 | 0.450 | 0.572 | 0.600 | 0.456 | 0.491 | |
| MRR | 0.361 | 0.394 | 0.410 | 0.293 | 0.422 | |
| WN18RR | Hit@1 | 0.289 | 0.382 | 0.403 | 0.413 | 0.440 |
| Hit@3 | 0.475 | 0.433 | 0.452 | 0.456 | 0.485 | |
| Hit@10 | 0.560 | 0.480 | 0.519 | 0.513 | 0.542 | |
| MRR | 0.359 | 0.415 | 0.438 | 0.448 | 0.474 | |
| YAGO3-10 | Hit@1 | 0.248 | 0.260 | 0.350 | 0.355 | 0.380 |
| Hit@3 | 0.412 | 0.405 | 0.490 | 0.498 | 0.510 | |
| Hit@10 | 0.315 | 0.550 | 0.620 | 0.650 | 0.678 | |
| MRR | 0.308 | 0.360 | 0.440 | 0.470 | 0.492 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, D.; Lu, Y.; Wu, J.; Zhou, W.; Zeng, G. Causal Reinforcement Learning for Knowledge Graph Reasoning. Appl. Sci. 2024, 14, 2498. https://doi.org/10.3390/app14062498
Li D, Lu Y, Wu J, Zhou W, Zeng G. Causal Reinforcement Learning for Knowledge Graph Reasoning. Applied Sciences. 2024; 14(6):2498. https://doi.org/10.3390/app14062498
Chicago/Turabian StyleLi, Dezhi, Yunjun Lu, Jianping Wu, Wenlu Zhou, and Guangjun Zeng. 2024. "Causal Reinforcement Learning for Knowledge Graph Reasoning" Applied Sciences 14, no. 6: 2498. https://doi.org/10.3390/app14062498
APA StyleLi, D., Lu, Y., Wu, J., Zhou, W., & Zeng, G. (2024). Causal Reinforcement Learning for Knowledge Graph Reasoning. Applied Sciences, 14(6), 2498. https://doi.org/10.3390/app14062498