
Comparative Analysis of Local Differential Privacy Schemes in Healthcare Datasets



Abstract
1. Introduction

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Perturbation | Estimation | Evaluation | |
|---|---|---|---|---|
| Sung [16] | Synthetic eICU | Normalize Bounded Laplacian Discretization | NA | (ML Models) misclassification rates mean squared error |
| Arcolezi [2] | Adults ACSCoverage LSAC | GRR BLH OLH RAPPOR OUE SS THE | NA | (ML Models) f1-score AUC DI SPD EOD OAD |
| LOPUB [6] | Nursery Lung Cancer Stroke | Bloom Filter Randomize Respose | LASSO with EM | |
| LOCOP [10] | NHANES Bank National Massachusets Texas | LASSO with Gaussian Copula | Joint probability distribution | |
| Ours | MS FIMU Adults Hypertension Skin Cancer Diabetes US CENSUS Cirrhosis | BRR [17] | AVD |
- We propose a new LDP schema using BRR for joint probability estimation and the baseline algorithm LOPUB [6].
- We propose two metrics, R-squared and AAR, for evaluation of the performance.
- We show in this document the experimental results using six open datasets that demonstrates the superiority of estimation accuracy and the robustness across diverse characteristics including numbers of users, attributes, and AARs.
2. Preliminaries
2.1. LDP Overview and the Curse of High Dimensionality
2.2. Correlation between Variables in Healthcare Datasets
- Age and Disease Risk:
- −
- The risk of developing many diseases increases with age.
- −
- Certain diseases are more likely to occur in specific age groups.
- Body Mass Index (BMI) and Diabetes:
- −
- People with a higher BMI are more likely to develop type 2 diabetes.
- −
- Excess body weight can lead to insulin resistance, increasing the risk of diabetes.
- Blood Pressure and Cardiovascular Diseases:
- −
- High blood pressure is a major risk factor for cardiovascular diseases.
- −
- The risk of developing cardiovascular diseases increases with blood pressure.
- Cholesterol Levels and Atherosclerosis:
- −
- High levels of LDL (bad) cholesterol can lead to atherosclerosis.
- −
- The risk of developing atherosclerosis increases with LDL cholesterol levels.
- Exercise Habits and Overall Health:
- −
- Regular exercise has many health benefits, including a reduced risk of various conditions.
- −
- Exercise also helps to improve mental health and overall mood.
- Smoking and Respiratory Diseases:
- −
- Smoking is a leading cause of preventable death.
- −
- Smoking is a major risk factor for respiratory diseases.
R-Squared,
- : With linear regression with no constraints, is non-negative.
- : The fitted line (or hyperplane) is horizontal. With two numerical variables, this is the case if the variables are independent, that is, are uncorrelated.
- : This case is only possible with linear regression when either the intercept or the slope are constrained so that the “best-fit” line (given the constraint) fits worse than a horizontal line, for instance, if the regression line (hyperplane) does not follow the data.
2.3. Generalizing the Problem
2.4. Local Differential Privacy
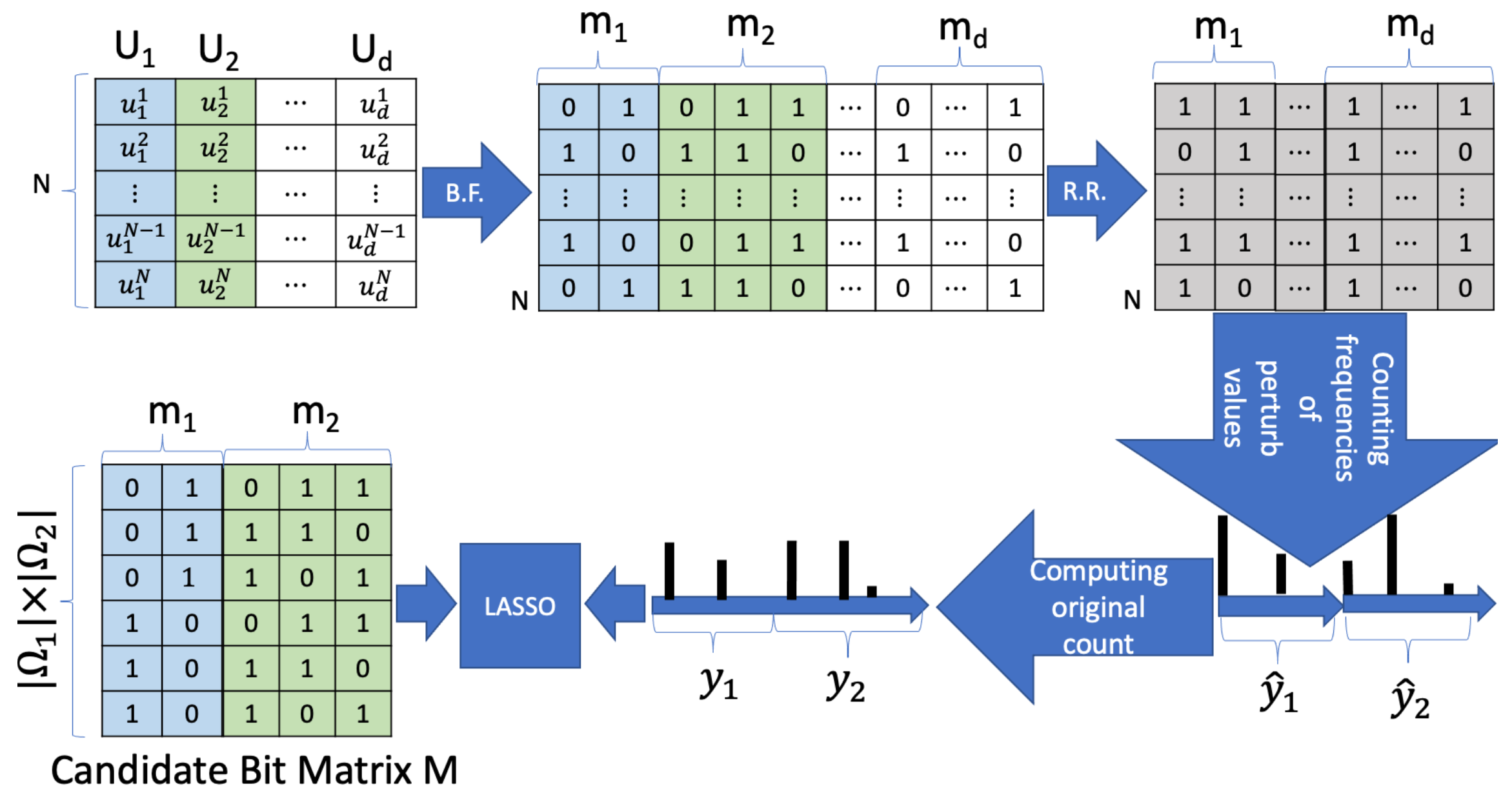
2.5. LOPUB Scheme
2.5.1. Bloom Filters
2.5.2. Randomized Response
2.5.3. Estimation, LASSO
2.6. LOCOP Scheme
Estimation, LASSO with Gaussian Copula
| Algorithm 1 Copula-based Multiple Variable Sampling and Synthesizing |
| : attribute |
| for do |
| Generating marginal distribution function |
| Computing the inverse cumulative distribution function |
| end for |
| Computing R |
| Generating d-dimensional random vector following |
| Computing , where is the standard normal distribution |
| Computing |
| return |
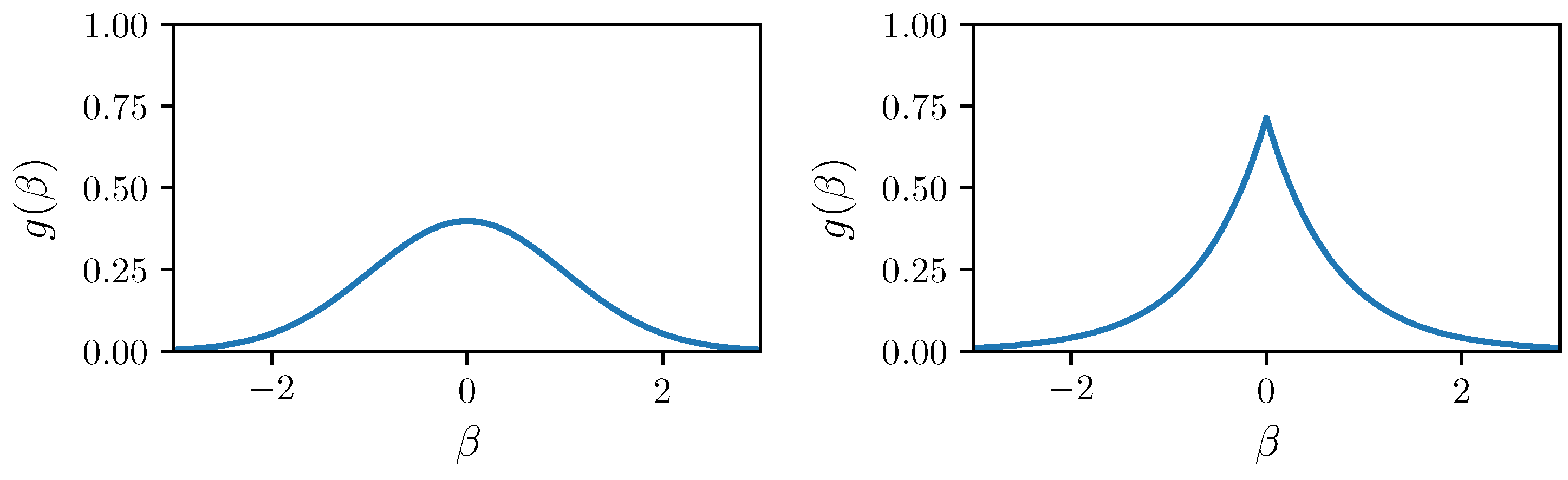
2.7. Bayesian Ridge Regression
- Effective Handling of Multicollinearity: BRR incorporates a regularization term, which is essentially a penalty for large coefficients. This helps to shrink the coefficients of correlated features, making them more stable and less sensitive to small changes in the data [17].
- Prevention of Overfitting: BRR’s shrinkage mechanism effectively reduces overfitting by preventing the model from overemphasizing specific features [25].
- Automatic Shrinkage: BRR automatically determines the optimal degree of shrinkage based on the data, reducing the need for manual tuning of the ridge parameter.
2.8. Privacy Analysis
3. Proposed Scheme
3.1. Model Definition of Bayesian Ridge Regression (M,y)
3.2. Bayesian Ridge Distribution Estimation
| Algorithm 2 Bayesian Ridge Regression k-way Joint Probability Distributions |
| : jth attribute () |
| : domain of () |
| : perturbed bloom filter () () |
| f: flipping probability |
| : set of hash functions for |
| D: a subset of attributes |
| : joint probability distribution of k attributes specified by D |
| for do |
| for do |
| compute |
| compute |
| end for |
| Bloom filters are constructed by the server using |
| end for |
| Candidate bit matrix is created |
| return |
4. Experiments
4.1. Experimental Method
- The US Census (1990) dataset [29] is a raw dataset extracted from the Public Use Microdata Samples person records. Recognized for its widespread usage, this dataset holds significance for evaluating the efficacy of both CDP and LDP approaches. In our experiments, we opt to utilize 10% of the available users within the dataset, considering the substantial scale of available users. The continuous attributes within the dataset have been discretized into five distinct categories.
- The Bank dataset [30] has the information for marketing campaigns. Through a discretization process, the dataset has been transformed, converting its continuous attributes into five distinct categories.
- The Adult dataset [31] stands out as one of the most widely utilized datasets for assessing the efficacy of CDP and LDP approaches. The continuous attributes within the dataset have been discretized into ten distinct categories.
- The Ms Fimu dataset [32] concerns multiple tourism statistics of the frequency of visitors by days and by the union of consecutive days. The continuous attributes within the dataset have been discretized into five distinct categories.
- The Nursery dataset [33] is derived from a decision model originally developed to rank applications for nursery schools in the 1980s. The dataset has discretized its continuous attributes into ten distinct categories.
- The Diabetes, Stroke, and Hypertension datasets belong to the Behavioral Risk Factor Surveillance System (BRFSS) 2015 [34]. The dataset has undergone a discretization process, resulting in the transformation of its continuous attributes into ten distinct categories.
- The Cirrhosis dataset [37] compiles information gathered during a Mayo Clinic trial of primary biliary cirrhosis of the liver. The continuous attributes within the dataset have been discretized into ten distinct categories.
- The Lung Cancer dataset [38] comprises information on individuals diagnosed with lung cancer, encompassing various factors such as age, gender, exposure to air pollution, and alcohol consumption. The continuous attributes within the dataset have been discretized into ten distinct categories.
- The Skin Cancer dataset [39] encompasses a summary of dermatoscopic images. Organized in a tabular format, the dataset includes a comprehensive collection of crucial diagnostic categories for pigmented lesions. The dataset has undergone a discretization process, resulting in the transformation of its continuous attributes into ten distinct categories.
- The NIST [40] Privacy Engineering Program introduced National, Texas, and Massachusetts datasets, initiating the Collaborative Research Cycle (CRC) to stimulate research, innovation, and comprehension of data deidentification techniques. These datasets have undergone a discretization process, resulting in the transformation of its continuous attributes into ten distinct categories.
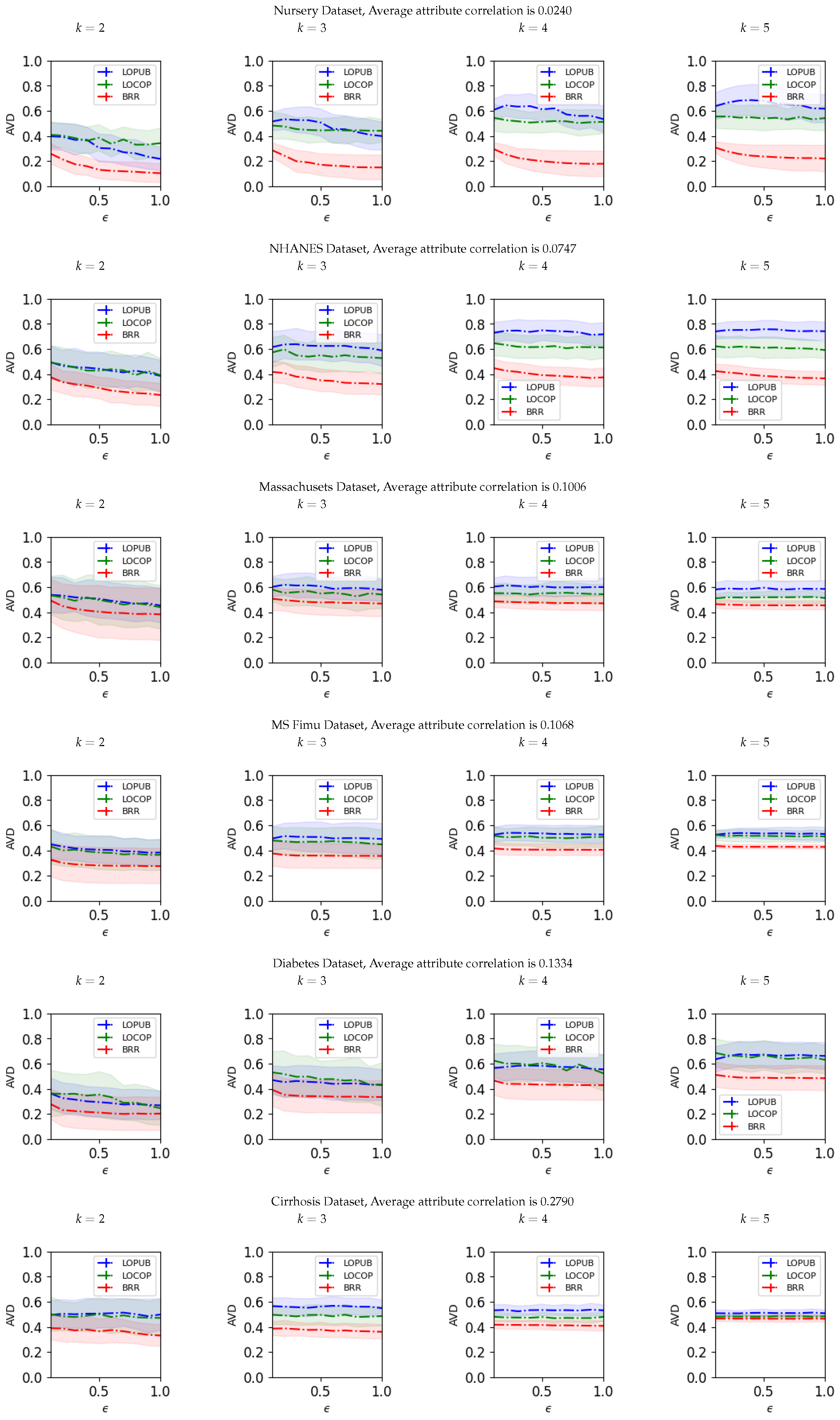
| Dataset | # Users | # Attributes | AAR |
|---|---|---|---|
| Nursery | 12,960 | 9 | 0.0240 |
| Lung Cancer | 53,427 | 5 | 0.0411 |
| Stroke | 40,910 | 11 | 0.0645 |
| NHANES | 4189 | 10 | 0.0747 |
| Bank | 45,211 | 17 | 0.0919 |
| National | 27,253 | 24 | 0.1002 |
| Massachusets | 7634 | 24 | 0.1006 |
| Texas | 9276 | 24 | 0.1035 |
| MS FIMU | 88,935 | 6 | 0.1068 |
| Adults | 45,222 | 10 | 0.1088 |
| Hypertension | 26,083 | 14 | 0.1237 |
| Skin Cancer | 10,015 | 5 | 0.1268 |
| Diabetes | 70,692 | 18 | 0.1334 |
| US CENSUS | 245,828 | 68 | 0.1607 |
| Cirrhosis | 418 | 17 | 0.2790 |
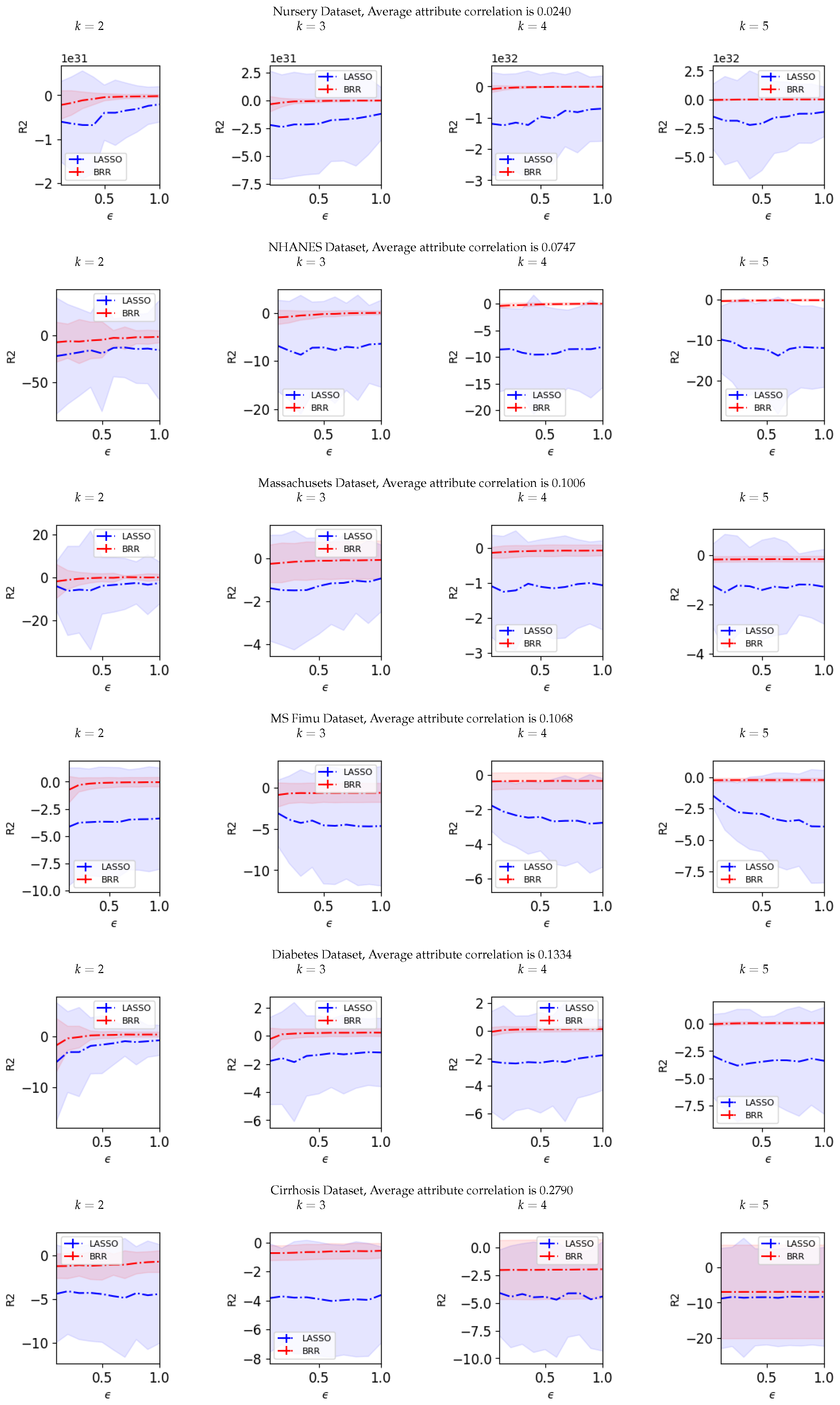
4.2. Results
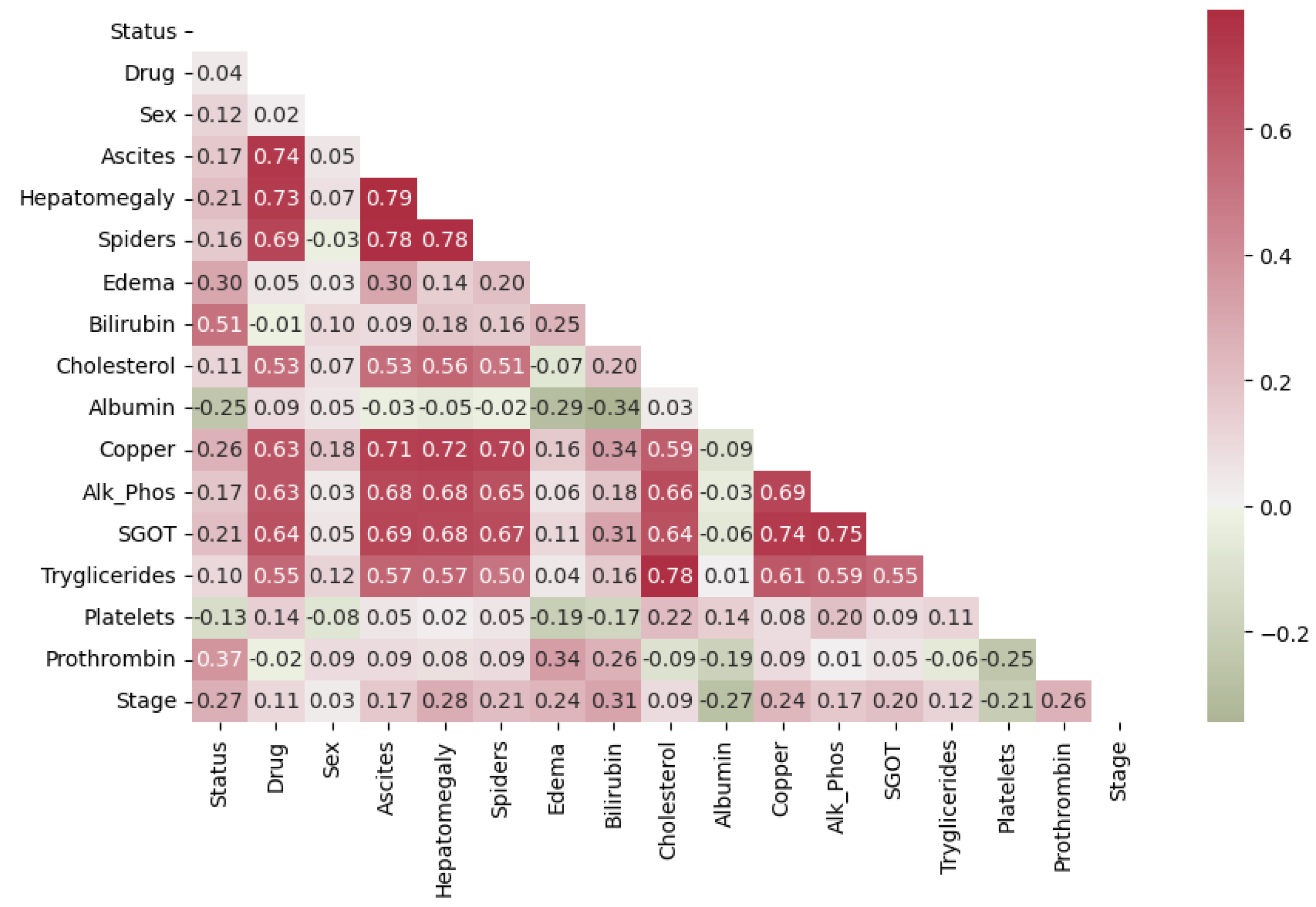
Joint Probability
- Sex, categorized as male or female, could be correlated with various health parameters and responses to treatment.
- Ascites, hepatomegaly, and spiders are variables indicating the presence or absence of certain clinical features. Correlations with other health parameters, especially liver-related ones, may exist.
- Bilirubin, cholesterol, albumin, copper, alkaline phosphatase, SGOT, triglycerides, platelets, and prothrombin are laboratory measurements indicating different aspects of a patient’s health. Examining correlations among these variables may unveil concealed patterns associated with physiological processes, such as liver function and blood composition.
5. Discussion
5.1. Curse of Dimensionality
5.2. Real-World Applicability of the Proposed Method
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dwork, C.; Roth, A. The Algorithmic Foundations of Differential Privacy. Found. Trends Theor. Comput. Sci. 2014, 9, 211–407. [Google Scholar] [CrossRef]
- Arcolezi, H.H.; Makhlouf, K.; Palamidessi, C. (Local) Differential Privacy has NO Disparate Impact on Fairness. In Data and Applications Security and Privacy XXXVII; Atluri, V., Ferrara, A.L., Eds.; DBSec 2023. Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2023; Volume 13942. [Google Scholar] [CrossRef]
- Yang, M.; Guo, T.; Zhu, T.; Tjuawinata, I.; Zhao, J.; Lam, K.Y. Local differential privacy and its applications: A comprehensive survey. Comput. Stand. Interfaces 2023, 89, 103827. [Google Scholar] [CrossRef]
- Erlingsson, Ú.; Pihur, V.; Korolova, A. RAPPOR: Randomized Aggregatable Privacy-Preserving Ordinal Response. In Proceedings of the 2014 ACM SIGSAC Conference on Computer and Communications Security, Scottsdale, AZ, USA, 3–7 November 2014; Association for Computing Machinery: New York, NY, USA, 2014. ISBN 9781450329576. [Google Scholar]
- Mac Apple. Differential Privacy Technical Overview. Available online: https://www.apple.com/privacy/docs/Differential_Privacy_Overview.pdf (accessed on 26 November 2022).
- Ren, X.; Yu, C.M.; Yu, W.; Yang, S.; Yang, X.; McCann, J.A.; Philip, S.Y. LoPub: High-Dimensional Crowdsourced Data Publication with Local Differential Privacy. IEEE Trans. Inf. Forensics Secur. 2018, 13, 2151–2166. [Google Scholar] [CrossRef]
- Warner, S.L. Randomized Response: A Survey Technique for Eliminating Evasive Answer Bias. J. Am. Stat. Assoc. 1965, 60, 63–69. [Google Scholar] [CrossRef]
- Zou, H.; Hastie, T.; Tibshirani, R. On the “degrees of freedom” of the LASSO. In The Annals of Statistics; Institute of Mathematical Statistics: Hayward, CA, USA, 2007; Volume 35. [Google Scholar]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. 1977, 39, 1–22. [Google Scholar] [CrossRef]
- Wang, T.; Yang, X.; Ren, X.; Yu, W.; Yang, S. Locally Private High-Dimensional Crowdsourced Data Release Based on Copula Functions. IEEE Trans. Serv. Comput. 2022, 15, 778–792. [Google Scholar] [CrossRef]
- Jiang, X.; Zhou, X.; Grossklags, J. Privacy-Preserving High-dimensional Data Collection with Federated Generative Autoencoder. Proc. Priv. Enhancing Technol. 2022, 2022, 481–500. [Google Scholar] [CrossRef]
- Van Wieringen, W.N. Lecture notes on ridge regression. arXiv 2021, arXiv:1509.09169. Available online: https://arxiv.org/pdf/1509.09169 (accessed on 26 November 2022).
- Sambasivan, R.; Das, S.; Sahu, S.K. A Bayesian perspective of statistical machine learning for big data. Comput. Stat. 2020, 35, 893–930. [Google Scholar] [CrossRef]
- Assaf, A.G.; Tsionas, M.; Tasiopoulos, A. Diagnosing and correcting the effects of multicollinearity: Bayesian implications of ridge regression. Tour. Manag. 2019, 71, 1–8. [Google Scholar] [CrossRef]
- Hernandez-Matamoros, A.; Kikuchi, H. An Efficient Local Differential Privacy Scheme Using Bayesian Ridge Regression. In Proceedings of the 20th Annual International Conference on Privacy, Security and Trust (PST), Copenhagen, Denmark, 21–23 August 2023; pp. 1–7. [Google Scholar] [CrossRef]
- Sung, M.; Cha, D.; Park, Y. Local Differential Privacy in the Medical Domain to Protect Sensitive Information: Algorithm Development and Real-World Validation. JMIR Med. Inform. 2021, 9, e26914. [Google Scholar] [CrossRef]
- Michimae, H.; Emura, T. Bayesian ridge estimators based on copula-based joint prior distributions for regression coefficients. Comput. Stat. 2022, 37, 2741–2769. [Google Scholar] [CrossRef]
- Wang, T.; Zhang, X.; Feng, J.; Yang, X. A Comprehensive Survey on Local Differential Privacy toward Data Statistics and Analysis. Sensors 2020, 20, 7030. [Google Scholar] [CrossRef]
- Chicco, D.; Warrens, M.J.; Jurman, G. The coefficient of determination R-squared is more informative than SMAPE, MAE, MAPE, MSE and RMSE in regression analysis evaluation. PeerJ Comput. Sci. 2021, 7, e623. [Google Scholar] [CrossRef]
- Kasiviswanathan, S.P.; Lee, H.K.; Nissim, K.; Raskhodnikova, S.; Smith, A. What Can We Learn Privately? In Proceedings of the 49th Annual IEEE Symposium on Foundations of Computer Science, Philadelphia, PA, USA, 25–28 October 2008. [Google Scholar]
- Bloom, B.H. Space/Time Trade-Offs in Hash Coding with Allowable Errors. Assoc. Comput. Mach. 1970, 13, 422–426. [Google Scholar] [CrossRef]
- Broder, A.Z.; Mitzenmacher, M. Survey: Network Applications of Bloom Filters: A Survey. Internet Math. 2003, 1, 485–509. [Google Scholar] [CrossRef]
- Santosa, F.; Symes, W.W. Linear inversion of band-limited reflection seismograms. SIAM J. Sci. Stat. Comput. 1986, 7, 1307–1330. [Google Scholar] [CrossRef]
- Tipping, M.E. Sparse bayesian learning and the relevance vector machine. J. Mach. Learn. Res. 2001, 1, 211–244. [Google Scholar] [CrossRef]
- Posch, K.; Arbeiter, M.; Pilz, J. A novel Bayesian approach for variable selection in linear regression models. Comput. Stat. Data Anal. 2020, 144, 106881. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer Science Business Media: New York, NY, USA, 2009. [Google Scholar]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B Methodol. 1996, 58, 267–288. [Google Scholar] [CrossRef]
- McSherry, F.D. Privacy integrated queries: An extensible platform for privacy-preserving data analysis. In Proceedings of the 2009 ACM SIGMOD International Conference on Management of Data, Providence, RI, USA, 29 June–2 July 2009; pp. 19–30. [Google Scholar]
- Meek Thiesson and Heckerman; US Census Data. UCI Machine Learning Repository. 1990. Available online: https://archive.ics.uci.edu/dataset/116/us+census+data+1990 (accessed on 15 November 2023).
- Rita, P.; Cortez, P.; Moro, S.; Bank Marketing. UCI Machine Learning Repository. Available online: https://archive.ics.uci.edu/dataset/222/bank+marketing (accessed on 15 November 2023).
- Adult. UCI Machine Learning Repository. 1996. Available online: https://archive.ics.uci.edu/dataset/2/adult (accessed on 15 November 2023).
- Arcolezi, H.H.; Couchot, J.-F.; Baala, O.; Contet, J.-M.; Al Bouna, B.; Xiao, X. Mobility modeling through mobile data: Generating an optimized and open dataset respecting privacy. In Proceedings of the 2020 International Wireless Communications and Mobile Computing (IWCMC), Limassol, Cyprus, 15–19 June 2020; pp. 1689–1694. [Google Scholar]
- Rajkovic, V. Nursery. UCI Machine Learning Repository. 1997. Available online: https://archive.ics.uci.edu/dataset/76/nursery (accessed on 15 November 2023).
- CDC. CDC—2015 BRFSS Survey Data and Documentation. 2015. Available online: https://www.cdc.gov/brfss/annual_data/annual_2015.html (accessed on 15 November 2023).
- Kikuchi, H. PWS Cup 2021. Data Anonymization Competition ‘Diabetes’. Available online: https://github.com/kikn88/pwscup2021 (accessed on 26 November 2022).
- PWS. PWS 2021. Available online: https://www.iwsec.org/pws/2021/cup21.html (accessed on 26 November 2022).
- Fleming, T.R.; Harrington, D.P. Counting Processes and Survival Analysis. In Wiley Series in Probability and Mathematical Statistics: Applied Probability and Statistics; John Wiley and Sons Inc.: New York, NY, USA, 1991. [Google Scholar]
- Hong, Z.Q.; Yang, J.Y. Optimal Discriminant Plane for a Small Number of Samples and Design Method of Classifier on the Plane. Pattern Recognit. 1991, 24, 317–324. [Google Scholar] [CrossRef]
- Tschandl, P.; Rosendahl, C.; Kittler, H. The HAM10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions. Sci. Data 2018, 5, 180161. [Google Scholar] [CrossRef] [PubMed]
- Collaborative Research Cycle—NIST Pages—National Institute of Standards and Technology, Howarth, Gary, National Institute of Standards and Technology USA. 2023. Available online: https://github.com/usnistgov/privacy_collaborative_research_cycle (accessed on 26 September 2023).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- GBD 2017 Cirrhosis Collaborators. The global, regional, and national burden of cirrhosis by cause in 195 countries and territories, 1990–2017: A systematic analysis for the Global Burden of Disease Study 2017. Lancet Gastroenterol. Hepatol. 2020, 5, 245–266. [Google Scholar] [CrossRef] [PubMed]

| Notation | Description |
|---|---|
| k | dimensionality of joint probability distribution estimation |
| U | dataset |
| N | number of users |
| ith user | |
| d | number of attributes in U |
| jth attribute in U | |
| value of ith user with attribute jth in U | |
| domain of | |
| set of hash functions | |
| p | false-positive probability used to calculate |
| length of | |
| bloom filter of , | |
| bth bit of | |
| randomized bloom filter of | |
| bth bit of | |
| counts the number of 1’s in | |
| bth bit of | |
| y | original count |
| bth bit of y | |
| M | candidate bit matrix |
| Pearson correlation coefficient matrix | |
| marginal distribution function of | |
| inverse cumulative distribution function of |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hernandez-Matamoros, A.; Kikuchi, H. Comparative Analysis of Local Differential Privacy Schemes in Healthcare Datasets. Appl. Sci. 2024, 14, 2864. https://doi.org/10.3390/app14072864
Hernandez-Matamoros A, Kikuchi H. Comparative Analysis of Local Differential Privacy Schemes in Healthcare Datasets. Applied Sciences. 2024; 14(7):2864. https://doi.org/10.3390/app14072864
Chicago/Turabian StyleHernandez-Matamoros, Andres, and Hiroaki Kikuchi. 2024. "Comparative Analysis of Local Differential Privacy Schemes in Healthcare Datasets" Applied Sciences 14, no. 7: 2864. https://doi.org/10.3390/app14072864
APA StyleHernandez-Matamoros, A., & Kikuchi, H. (2024). Comparative Analysis of Local Differential Privacy Schemes in Healthcare Datasets. Applied Sciences, 14(7), 2864. https://doi.org/10.3390/app14072864