Underground pipe networks play a crucial role in the daily operation of cities. As part of the urban municipal system, they cannot be ignored in the process of urban intelligent digitization. With the continuous development of smart cities and the continuous enrichment of urban functions, the process of municipal public facilities construction is gradually accelerating. This means that municipal, power, communications, and other departments need more practical measures to manage a large number of municipal equipment and assets.
At present, many old urban areas have a lack of information on underground pipelines, which makes it impossible to carry out intelligent management of pipelines. In turn, the precise lack of access to underground pipelines is a challenge for urban infrastructure management. Although a variety of techniques, such as ground penetrating radar (GPR), acoustic detection, stratigraphic detection, geomagnetic detection, and holographic interferometry, exist for the detection of underground pipe networks [
1,
2,
3]. These methods usually require a large investment of labor and resources, which limits their efficiency and usefulness. These traditional methods are labor intensive and often lead to excessive consumption of time and cost. Manhole covers, serving as critical connectors between the underground pipeline network and the surface, play an essential role; thus, mapping the layout of the underground network can be achieved by acquiring information on the type and location of manhole covers.
As artificial intelligence technology progresses and the use of unmanned aerial vehicles (UAVs) becomes more widespread in engineering applications, more and more deep learning techniques are being leveraged to solve engineering-related problems [
4,
5,
6]. For example, many researchers have applied object detection algorithms to the task of locating manhole covers. Ying [
7] and colleagues had introduced a method termed MA-FPN, which integrated the core concepts of attention mechanisms with feature pyramid networks, aiming to improve the accuracy of object detection in remote sensing. Liu et al. [
8] designed a diversity feature extractor based on a VGG feature extractor to improve the performance of manhole cover localization by increasing the size of the receptive field. These methods obtained the city image by using UAV aerial photography, and then used the object detection technology to detect the aerial image to obtain the localization of the manhole cover. It greatly reduced the consumption of manpower and material resources, and also improved the survey efficiency. However, these methods had not solved the problem of obtaining the category information of manhole covers, and could only obtain the location information of manhole covers. However, in the process of urban digitization, the category information of manhole cover is indispensable. Only by correctly obtaining the category information of manhole cover can we build a complete municipal pipe network system. Other scholars have proposed using vehicles equipped with cameras and lidars to collect ground images and combine target detection methods to obtain manhole cover information [
9,
10]. For example, Wei et al. [
11] used a combination of multiple symmetrically arranged cameras and lidars to classify manhole covers through descriptors and support vector machine algorithms. Pang et al. [
12] proposed a real-time road manhole cover detection method based on deep learning model. By optimizing the network structure and reducing the size of the model and the number of parameters, the effect of deployment on vehicle-mounted embedded devices is achieved. Mattheuwsen et al. [
13] developed a fully automatic method for manhole cover detection using mobile mapping point cloud data. Although the above method can solve the problem of manhole cover classification, due to the limitation of vehicle-mounted tools, a large number of manhole covers are located in places where cars cannot reach. It is also labor-intensive and time-consuming to collect ground images through radar- and camera-equipped vehicles, which are still inefficient methods. However, it is a feasible way to classify manhole covers after obtaining ground images by UAV. How to realize the classification of manhole covers is the main problem to be solved in this paper. Classification of manhole covers is mainly realized by recognizing the text on the cover; however, the manhole covers acquired from aerial images often lose the detail information of the text on the cover, so directly classifying manhole covers by target detection is not a feasible method. Image super-resolution reconstruction methods were designed to enhance the detail performance of low-resolution images. By recovering high-frequency detail information from low-resolution images, the image becomes clearer and has a higher detail resolution. These methods are widely used in the fields of aeronautics, medicine, and engineering [
14,
15]. In the field of aviation, a variety of image super-resolution reconstruction algorithms had been proposed [
16,
17,
18,
19,
20]. Zhou et al. [
18] proposed a super-resolution reconstruction strategy based on self-attention generative adversarial networks, which improves the details of remote sensing images by adding self-attention modules. Yue et al. [
21] proposed an improved enhanced super-resolution generative adversarial network (IESRGAN) based on enhanced U-Net structure, which is used to perform a four-fold scale detail reconstruction of LR images using NaSC-TG2 remote sensing images. The above method can improve the detail of aerial images well. Therefore, it becomes possible to recover the details of manhole cover text by reconstructing the manhole cover from aerial photographs through super-resolution reconstruction network.
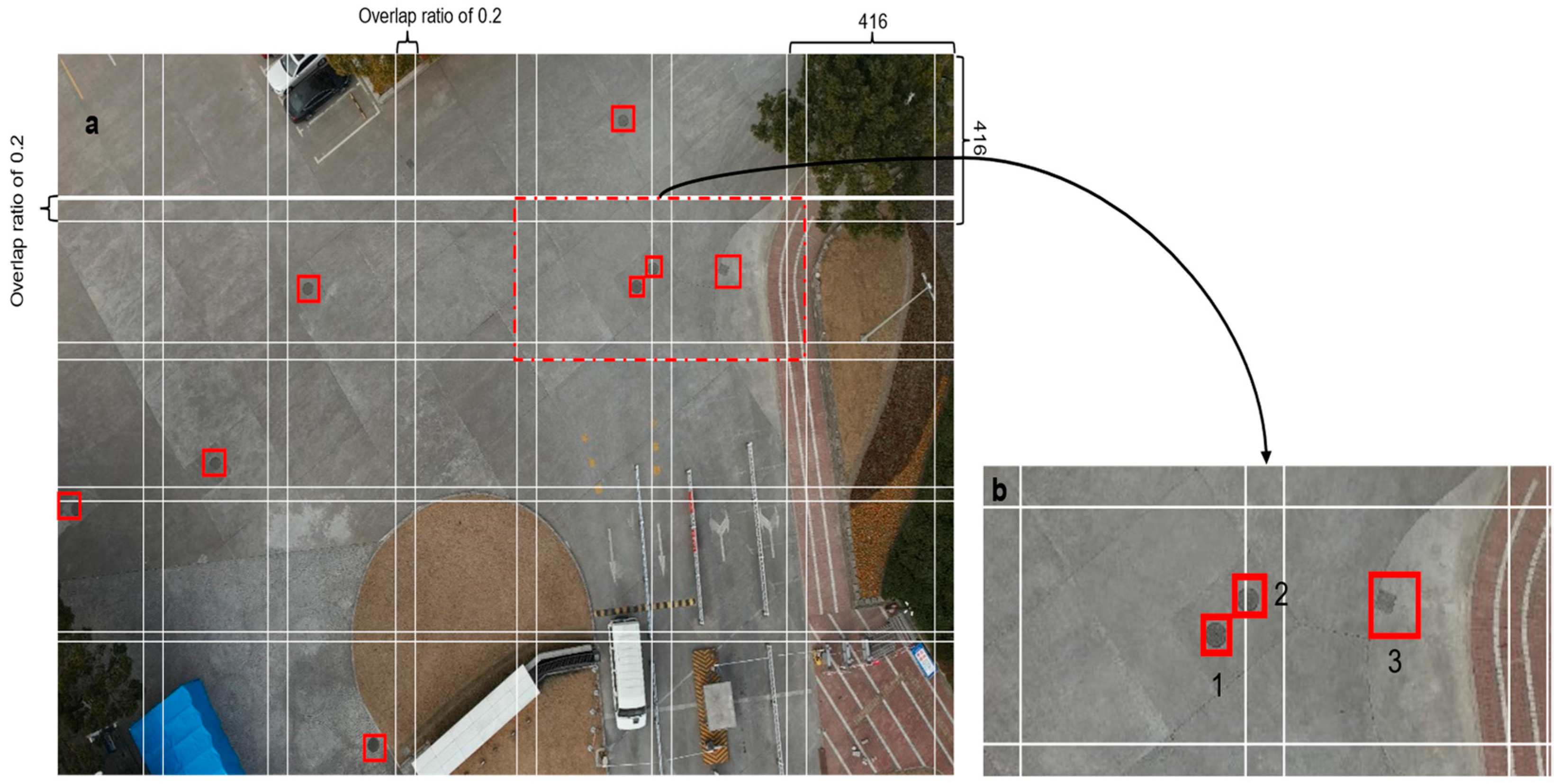
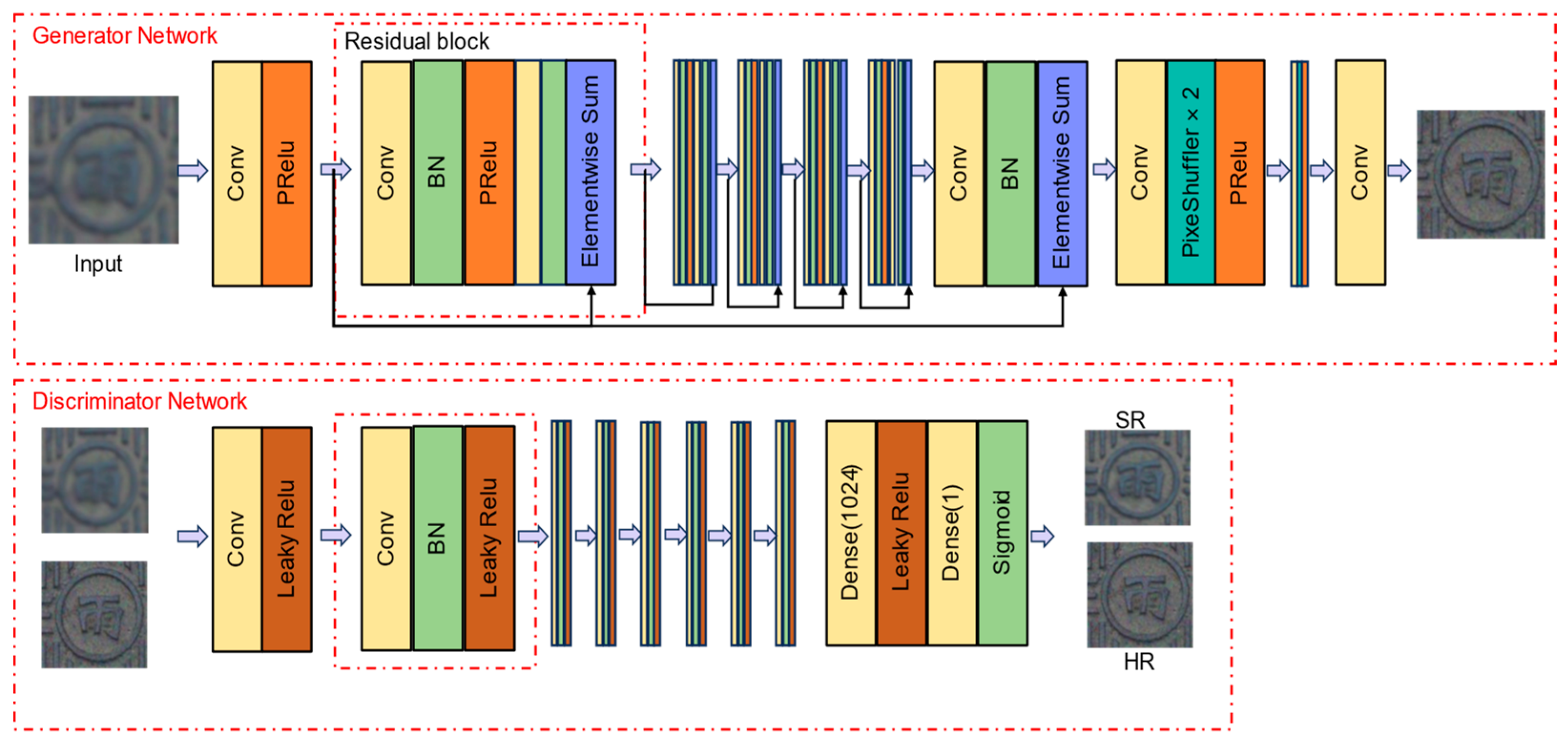
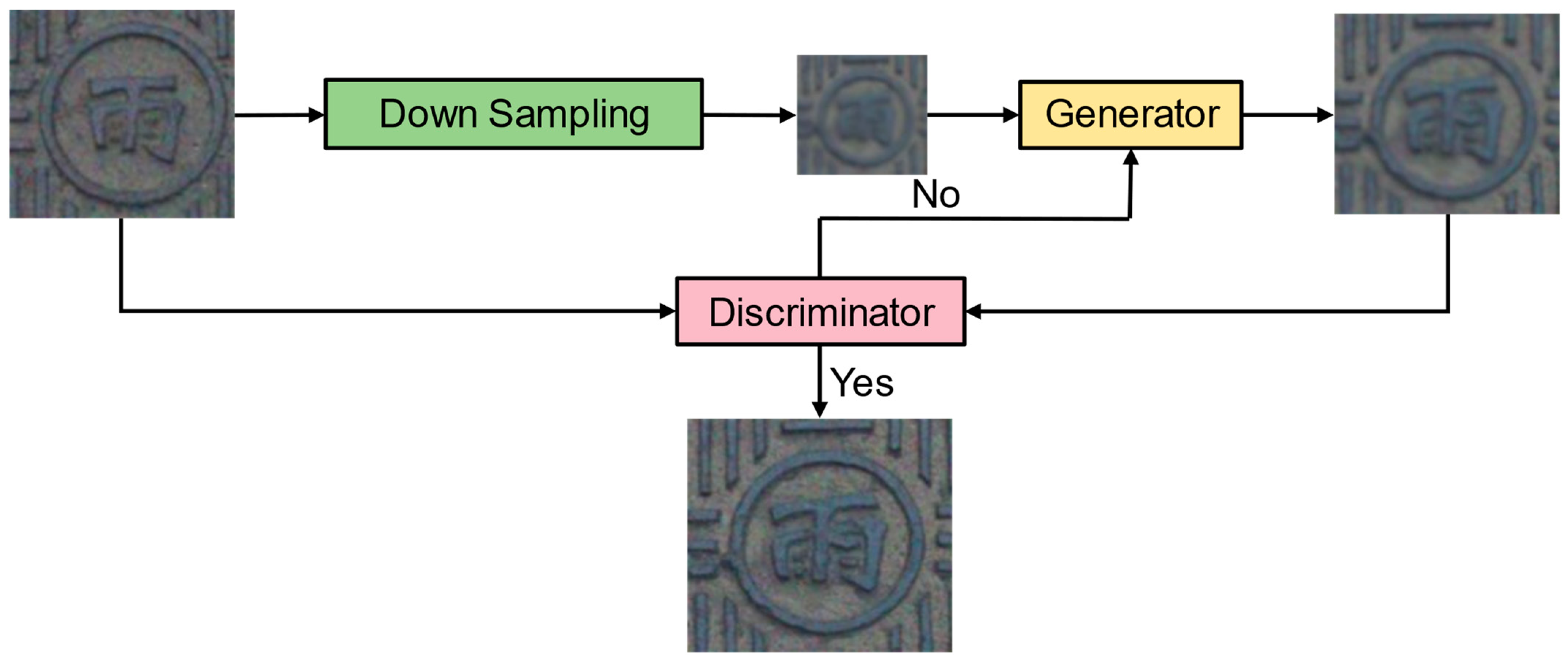
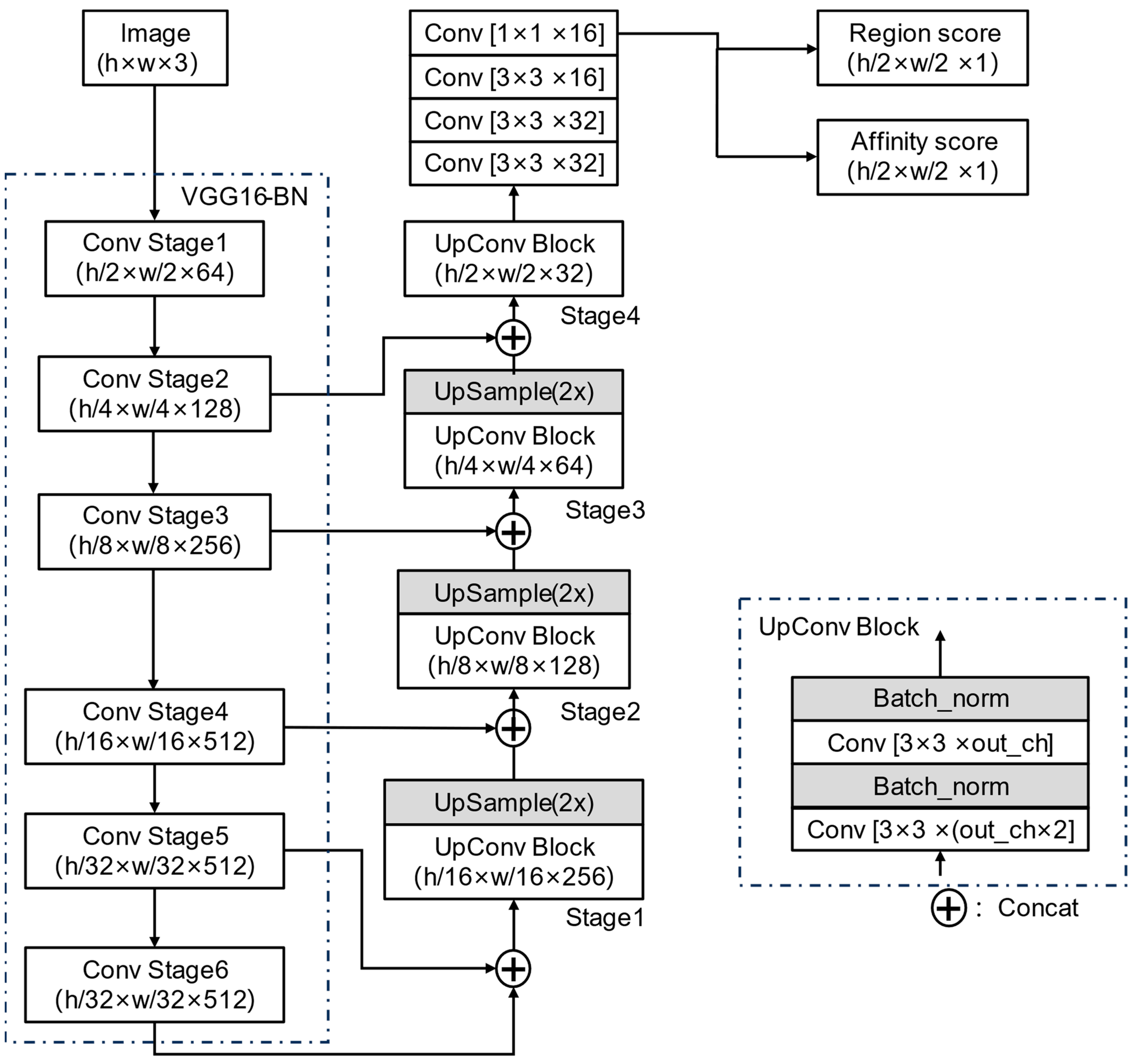
Based on the above analysis, this paper proposed a method to localize and classify manhole covers based on super-resolution generative adversarial network reconstruction of UAV aerial images. Initially, the YOLOv8 object detection network was employed to localize manhole covers. Post-localization, these covers were segmented from the captured images. Further text localization was conducted on the segmented images using YOLOv8. This was followed by the application of the SRGAN super-resolution network to enhance the image quality of the manhole covers. The final step involved classifying the manhole covers using the VGG16_BN image classification network. The method used in this paper can greatly improve the efficiency of manhole cover survey and reduce the loss of manpower and material resources.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}