

Vision AI System Development for Improved Productivity in Challenging Industrial Environments: A Sustainable and Efficient Approach


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
1.1. Image Acquisition Device
1.2. Vision Inspection Algorithm Development
2. Related Works
3. Proposal Method
4. Detailed Proposed Technology and Test Results
4.1. Acquisition of High-Quality Deep Learning and Inspection Data
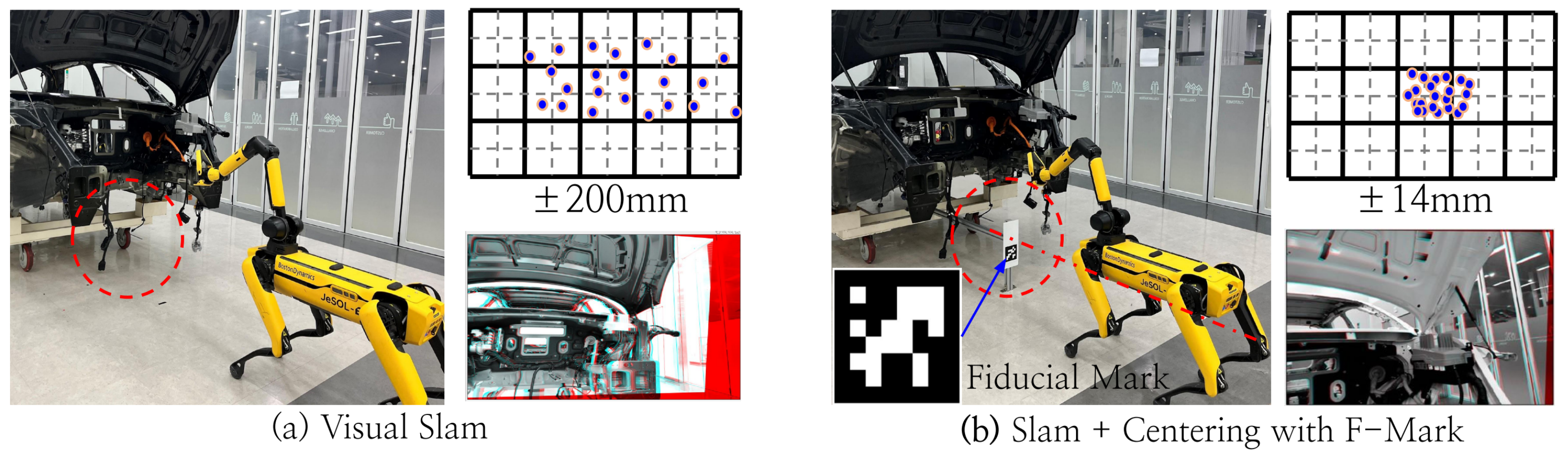
4.1.1. Landmark (Fiducial Mark) Centering Technique for Improving the Repeat Positioning Accuracy of SPOT
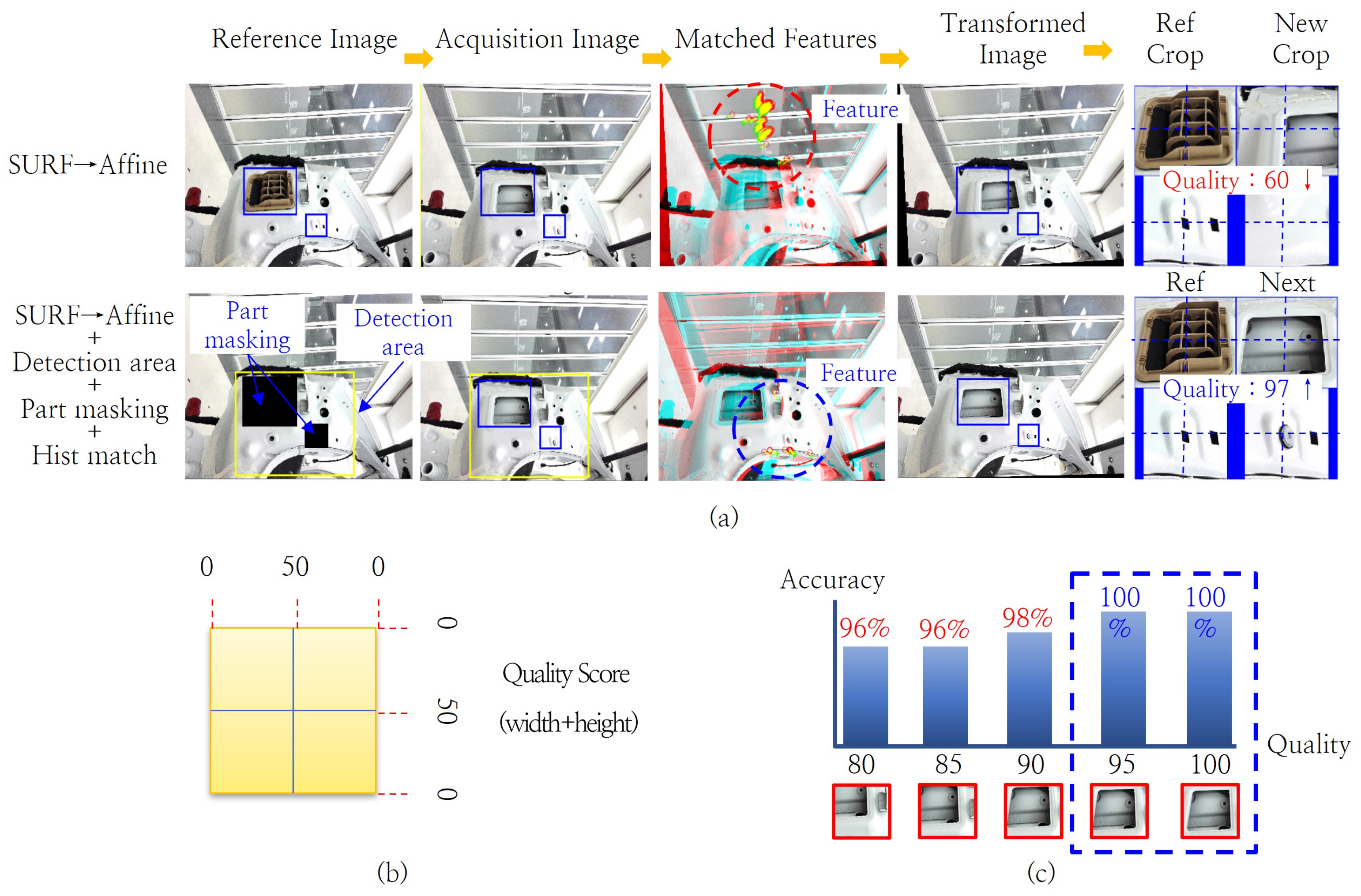
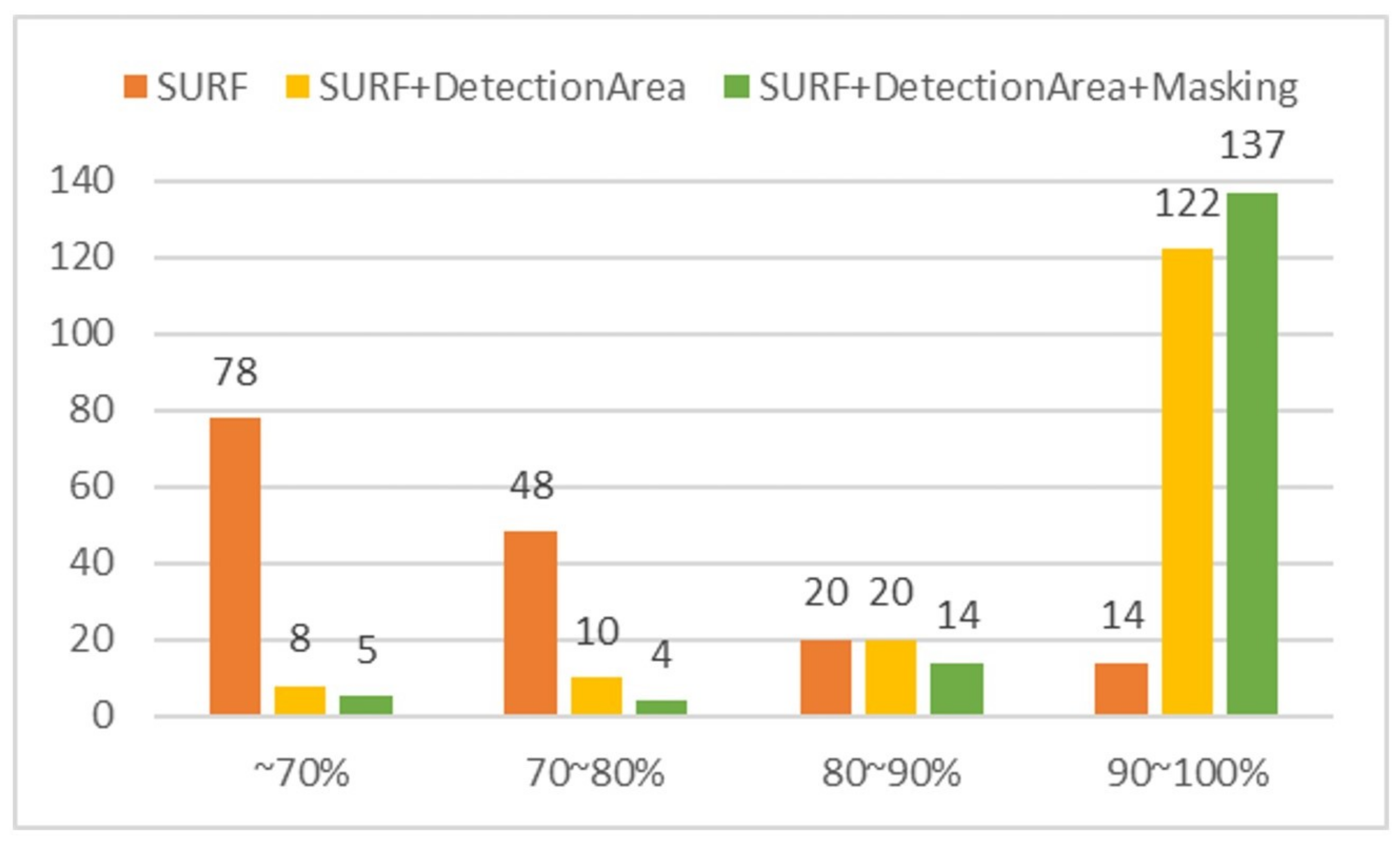
4.1.2. Automatic Correction Algorithm for Image Matching Deviation Caused by Positional Precision Error
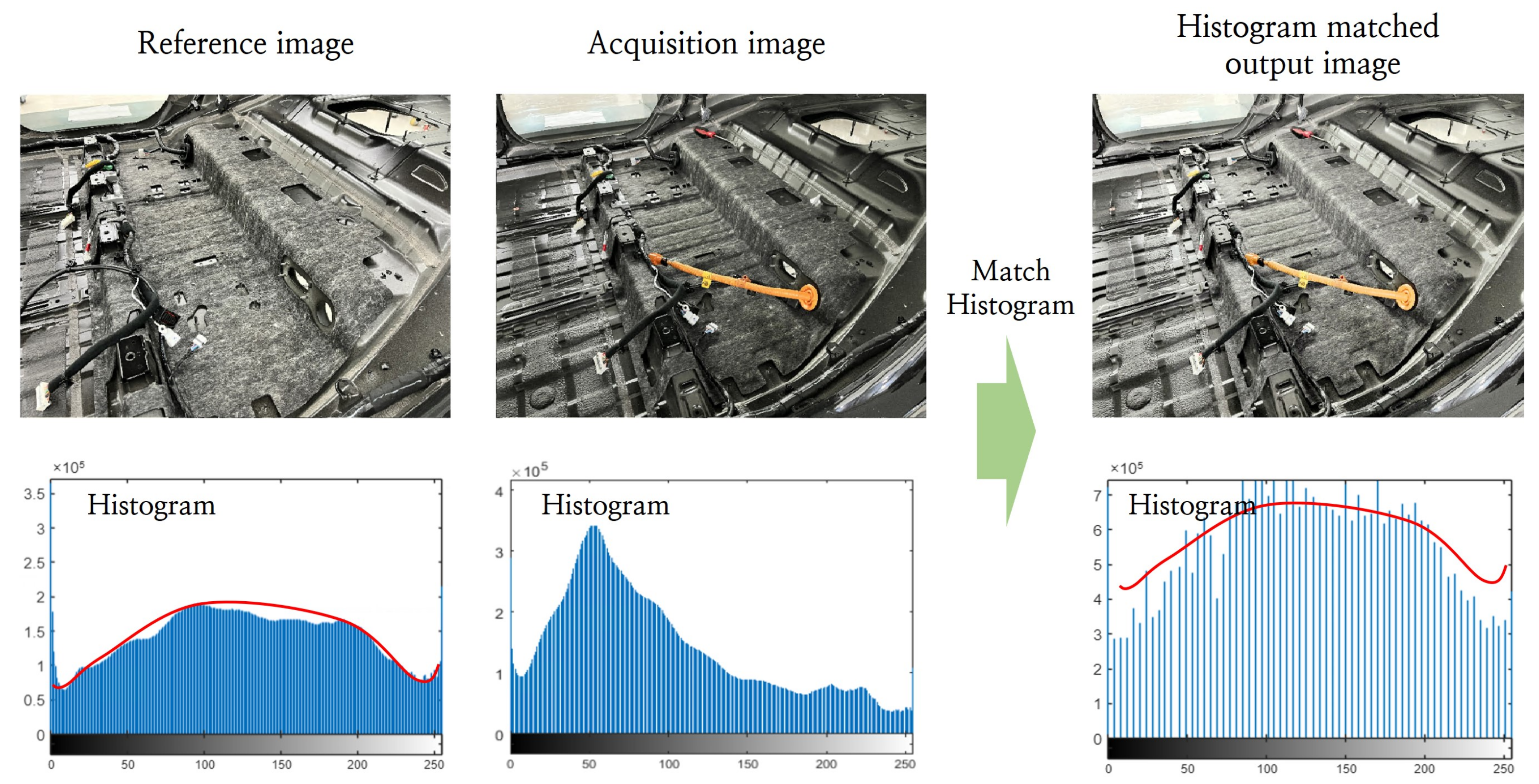
4.2. Image Pre-Processing Strategy for Minimizing Lighting Changes Caused by Environmental Variations
4.3. Development Plan for Vision-Based AI Algorithms Enabling Maintenance and Continuous Management
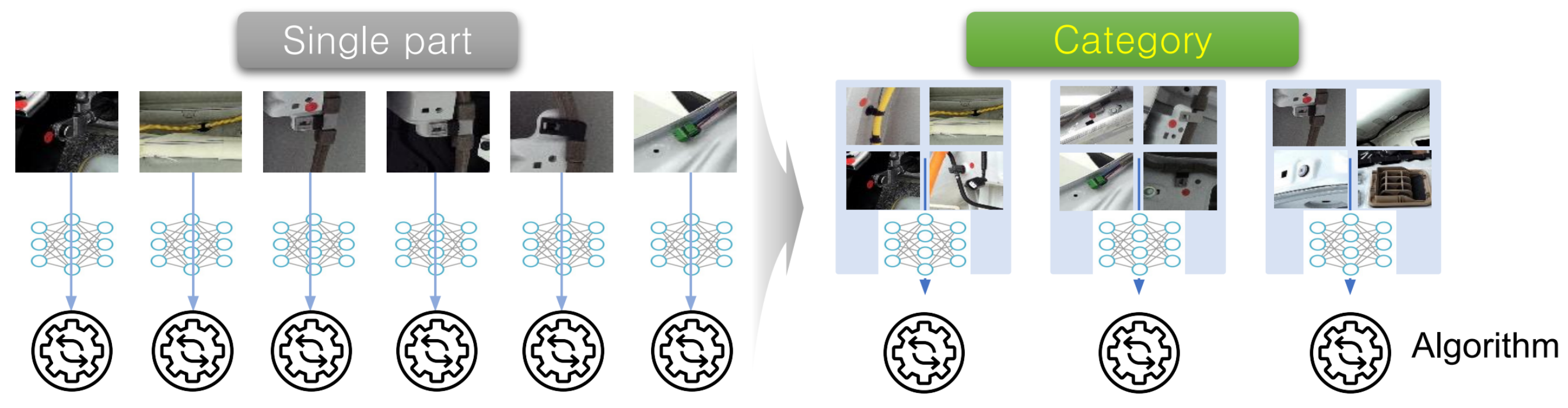
4.3.1. Cropping Technique to Reduce Learning Data Acquisition Time
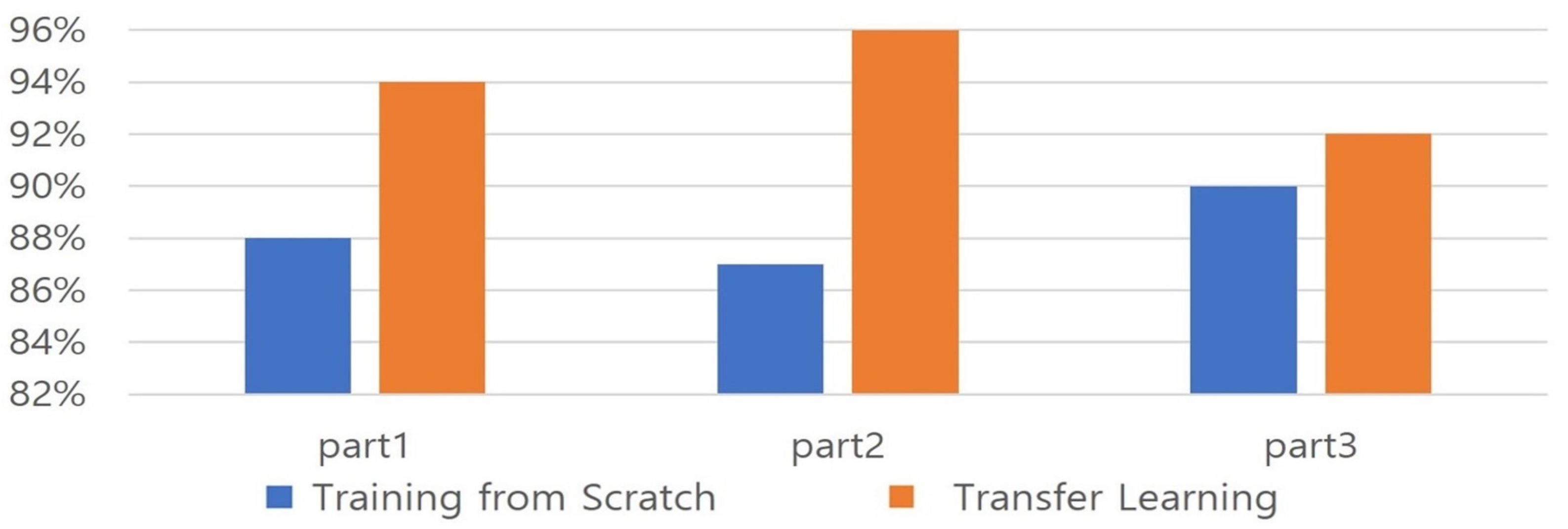
4.3.2. Minimizing the Development Period and Investment Cost of Algorithm Development Plan
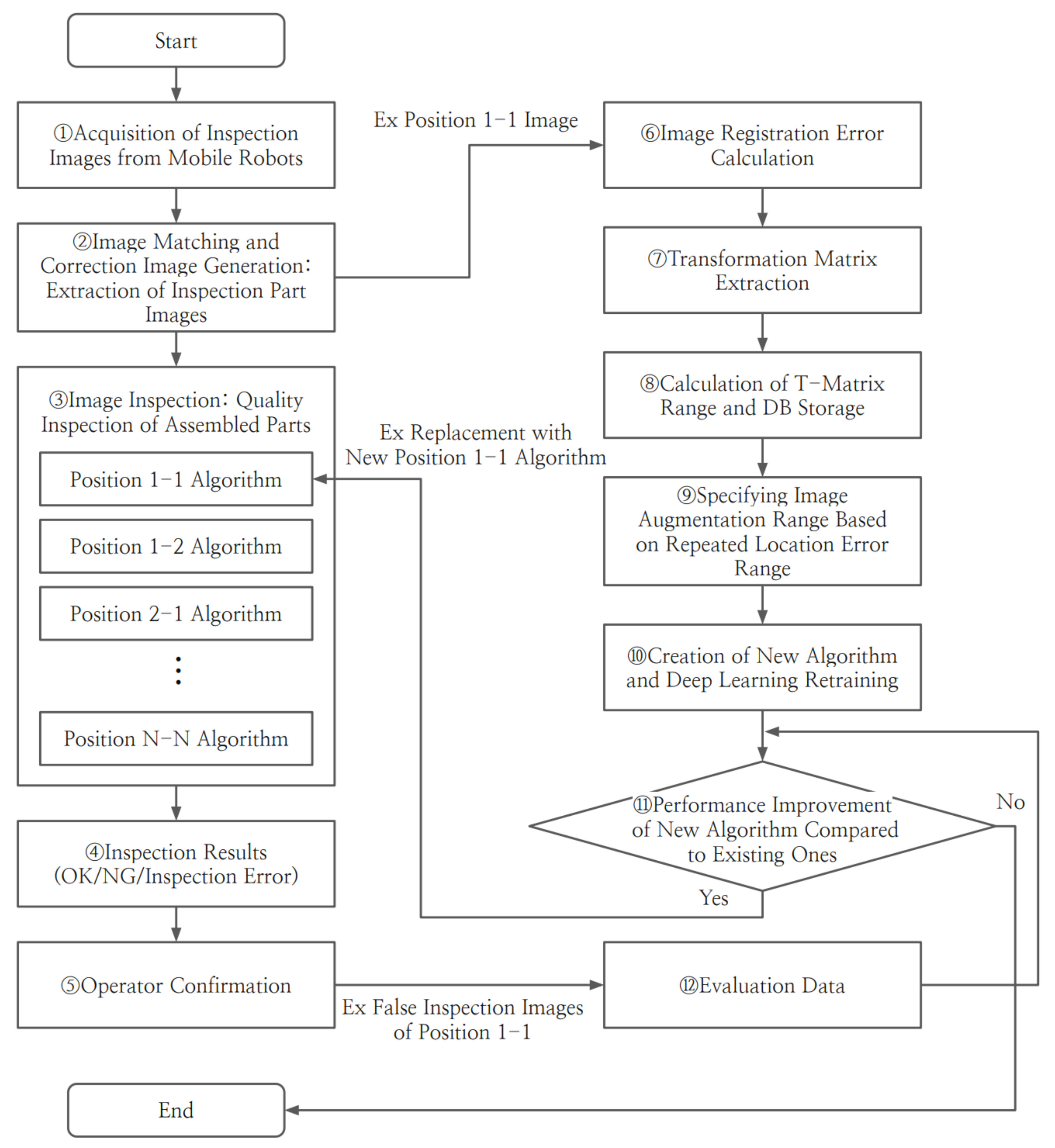
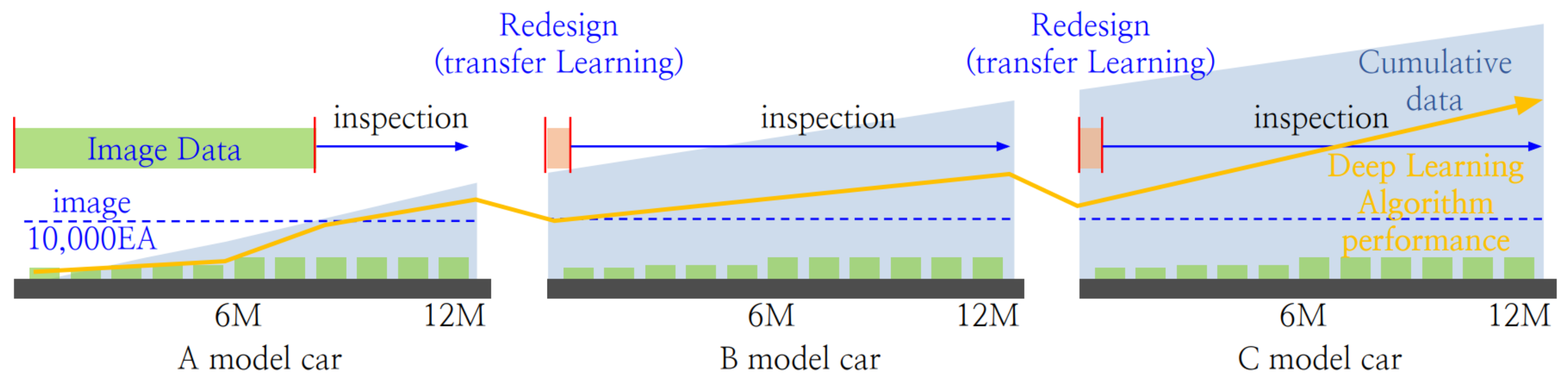
4.4. Automation Technology for Maintaining the Performance of AI Algorithms
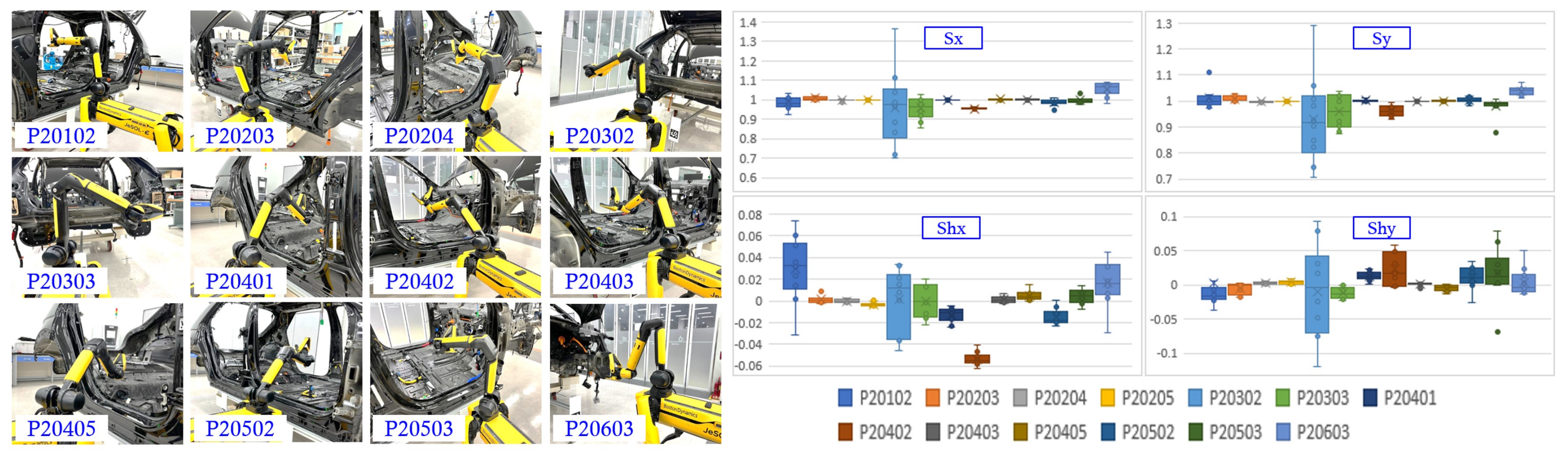
4.4.1. Automatic Image Augmentation Technology That Accounts for Deviation in Mobile Robot’s Shooting Position
4.4.2. Automatic Data Acquisition Method for Re-Learning AI Algorithms
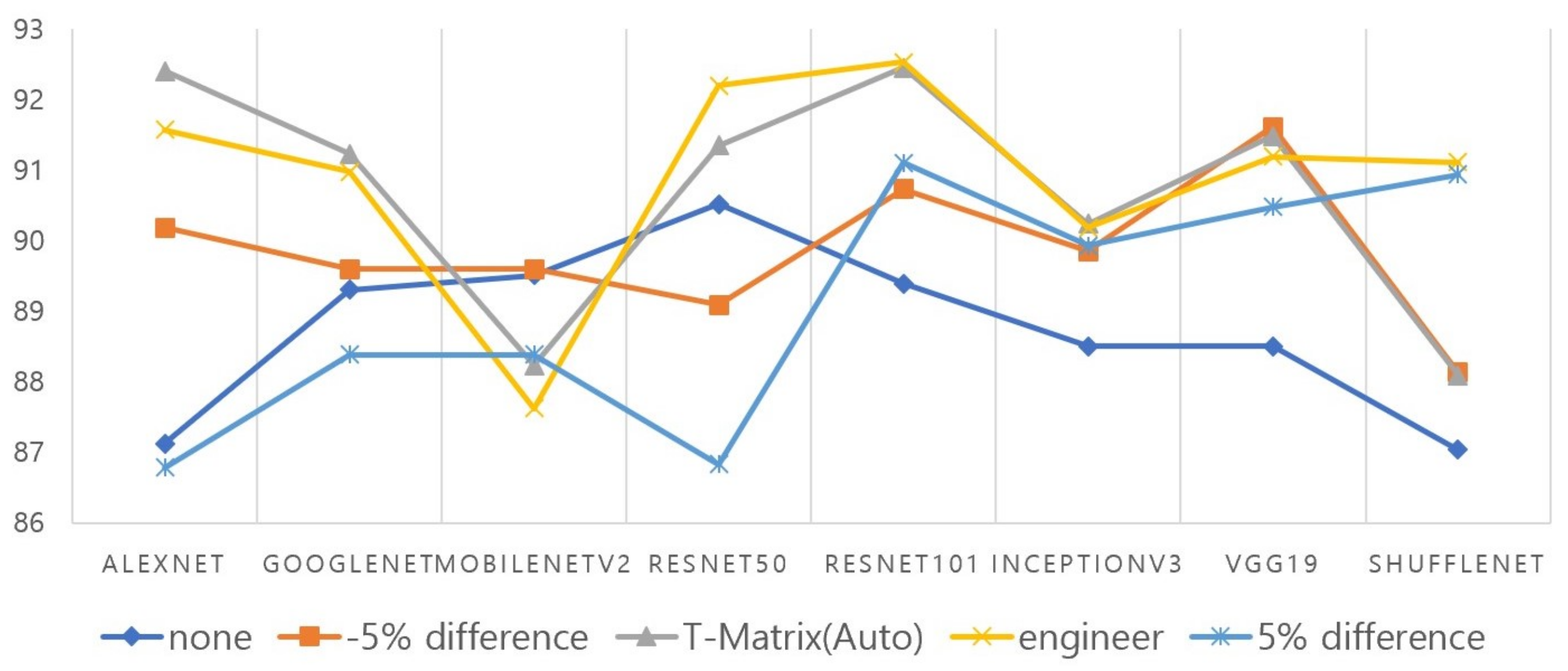
4.5. Industrial Field AI Algorithm Development Plan
| Algorithm 1 Finding optimal algorithm for car parts |
|
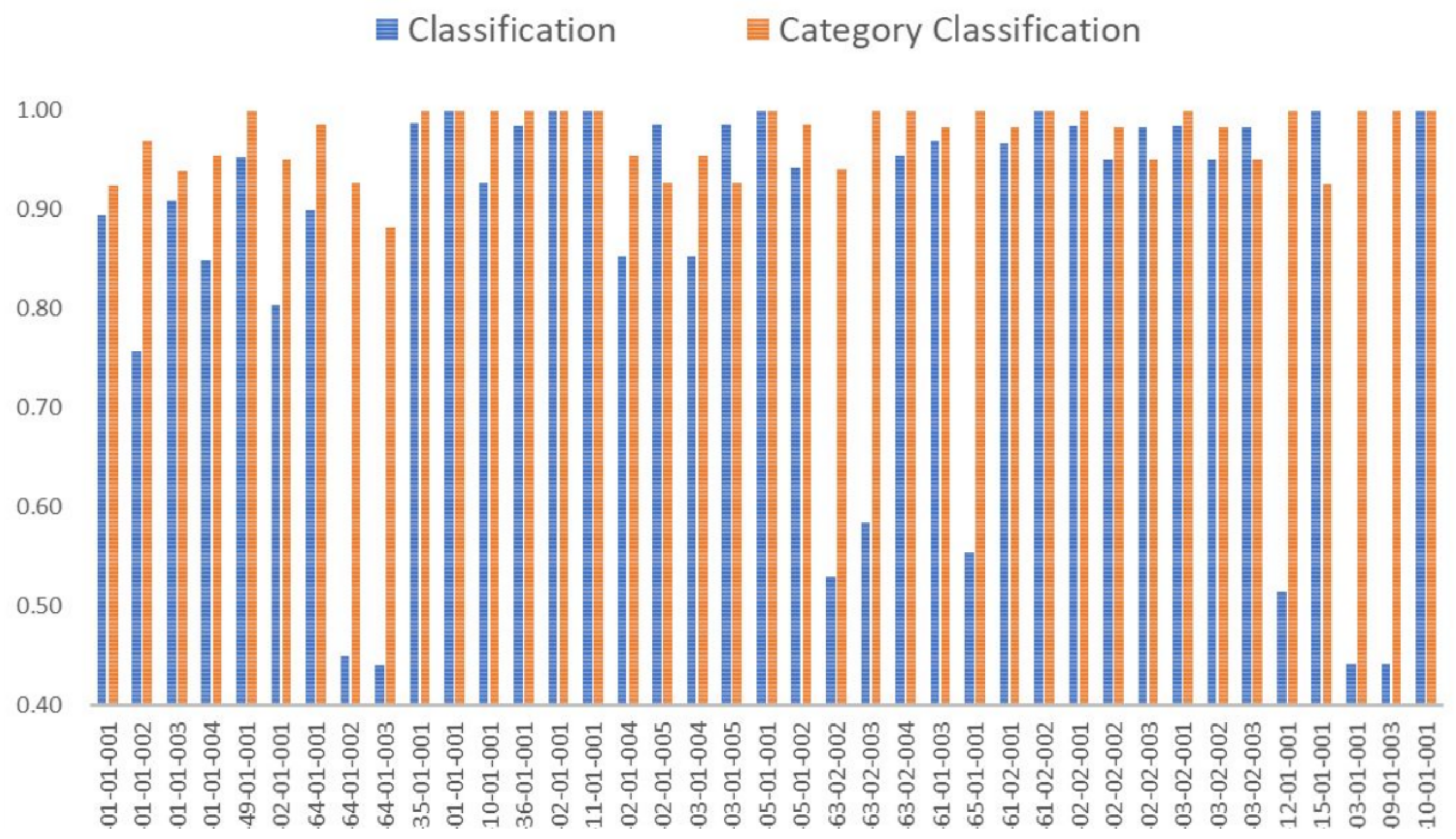
5. AI System Empirical Evaluation
6. Future Work
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| SLAM | Simultaneous Localization and Mapping |
| SW | Software |
| ToF | Time-of-Flight |
| UWB | Ultra-Wideband |
| SURF | Speeded-Up Robust Features |
| ROI | Region of Interest |
| CNN | Convolutional Neural Network |
| OK | Acceptable or Correct |
| NG | Not Good or Incorrect |
| NA | Not Applicable or Not Available |
| AGV | Automated Guided Vehicle |
| T-Matrix | Transformation Matrix |
| F-Mark | Fiducial Mark |
References
- Yang, J.; Li, S.; Wang, Z.; Dong, H.; Wang, J.; Tang, S. Using deep learning to detect defects in manufacturing: A comprehensive survey and current challenges. Materials 2020, 13, 5755. [Google Scholar] [CrossRef] [PubMed]
- Block, S.B.; da Silva, R.D.; Dorini, L.B.; Minetto, R. Inspection of imprint defects in stamped metal surfaces using deep learning and tracking. IEEE Trans. Ind. Electron. 2020, 68, 4498–4507. [Google Scholar] [CrossRef]
- Mazzetto, M.; Teixeira, M.; Rodrigues, É.O.; Casanova, D. Deep learning models for visual inspection on automotive assembling line. arXiv 2020, arXiv:2007.01857. [Google Scholar] [CrossRef]
- Hemamalini, V.; Rajarajeswari, S.; Nachiyappan, S.; Sambath, M.; Devi, T.; Singh, B.K.; Raghuvanshi, A. Food quality inspection and grading using efficient image segmentation and machine learning-based system. J. Food Qual. 2022, 2022, 5262294. [Google Scholar] [CrossRef]
- Lang, W.; Hu, Y.; Gong, C.; Zhang, X.; Xu, H.; Deng, J. Artificial intelligence-based technique for fault detection and diagnosis of EV motors: A review. IEEE Trans. Transp. Electrif. 2021, 8, 384–406. [Google Scholar] [CrossRef]
- Zhou, Q.; Chen, R.; Huang, B.; Liu, C.; Yu, J.; Yu, X. An automatic surface defect inspection system for automobiles using machine vision methods. Sensors 2019, 19, 644. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Fu, P.; Gao, R.X. Machine vision intelligence for product defect inspection based on deep learning and Hough transform. J. Manuf. Syst. 2019, 51, 52–60. [Google Scholar] [CrossRef]
- Chalapathy, R.; Menon, A.K.; Chawla, S. Anomaly detection using one-class neural networks. arXiv 2018, arXiv:1802.06360. [Google Scholar]
- Boston Dynamics. SPOT. Available online: https://dev.bostondynamics.com/ (accessed on 21 March 2024).
- Cheng, T.; Venugopal, M.; Teizer, J.; Vela, P. Performance evaluation of ultra wideband technology for construction resource location tracking in harsh environments. Autom. Constr. 2011, 20, 1173–1184. [Google Scholar] [CrossRef]
- Karedal, J.; Wyne, S.; Almers, P.; Tufvesson, F.; Molisch, A.F. A measurement-based statistical model for industrial ultra-wideband channels. IEEE Trans. Wirel. Commun. 2007, 6, 3028–3037. [Google Scholar] [CrossRef]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-up robust features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Bansal, M.; Kumar, M.; Kumar, M. 2D object recognition: A comparative analysis of SIFT, SURF and ORB feature descriptors. Multimed. Tools Appl. 2021, 80, 18839–18857. [Google Scholar] [CrossRef]
- Wiki. 2D Affine Transformation Matrix. Available online: https://en.wikipedia.org/wiki/Affine_transformation (accessed on 21 March 2024).
- Rother, C.; Minka, T.; Blake, A.; Kolmogorov, V. Cosegmentation of image pairs by histogram matching-incorporating a global constraint into mrfs. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 1, pp. 993–1000. [Google Scholar]
- Chen, H.M.; Varshney, P.K. Mutual information-based CT-MR brain image registration using generalized partial volume joint histogram estimation. IEEE Trans. Med. Imaging 2003, 22, 1111–1119. [Google Scholar] [CrossRef]
- Pouyanfar, S.; Sadiq, S.; Yan, Y.; Tian, H.; Tao, Y.; Reyes, M.P.; Shyu, M.L.; Chen, S.C.; Iyengar, S.S. A survey on deep learning: Algorithms, techniques, and applications. ACM Comput. Surv. 2018, 51, 1–36. [Google Scholar] [CrossRef]
- Fischl, B.; Salat, D.H.; Busa, E.; Albert, M.; Dieterich, M.; Haselgrove, C.; Van Der Kouwe, A.; Killiany, R.; Kennedy, D.; Klaveness, S.; et al. Whole brain segmentation: Automated labeling of neuroanatomical structures in the human brain. Neuron 2002, 33, 341–355. [Google Scholar] [CrossRef] [PubMed]
- Gildea, D.; Jurafsky, D. Automatic labeling of semantic roles. Comput. Linguist. 2002, 28, 245–288. [Google Scholar] [CrossRef]
- Mei, Q.; Shen, X.; Zhai, C. Automatic labeling of multinomial topic models. In Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Jose, CA, USA, 12–15 August 2007; pp. 490–499. [Google Scholar]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images. 2009. Available online: https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf (accessed on 21 March 2024).
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; Van Der Laak, J.A.; Van Ginneken, B.; Sánchez, C.I. A survey on deep learning in medical image analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.; Xiong, Z.; Tian, X.; Zha, Z.J.; Wu, F. Real-world image denoising with deep boosting. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 3071–3087. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.; Xiong, Z.; Tian, X.; Wu, F. Deep boosting for image denoising. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–18. [Google Scholar]
- Dosovitskiy, A.; Springenberg, J.T.; Tatarchenko, M.; Brox, T. Learning to generate chairs, tables and cars with convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 692–705. [Google Scholar] [CrossRef] [PubMed]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep learning for computer vision: A brief review. Comput. Intell. Neurosci. 2018, 2018, 7068349. [Google Scholar] [PubMed]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, C.; Kim, J.; Kang, D.; Eom, D.-S. Vision AI System Development for Improved Productivity in Challenging Industrial Environments: A Sustainable and Efficient Approach. Appl. Sci. 2024, 14, 2750. https://doi.org/10.3390/app14072750
Yang C, Kim J, Kang D, Eom D-S. Vision AI System Development for Improved Productivity in Challenging Industrial Environments: A Sustainable and Efficient Approach. Applied Sciences. 2024; 14(7):2750. https://doi.org/10.3390/app14072750
Chicago/Turabian StyleYang, Changmo, JinSeok Kim, DongWeon Kang, and Doo-Seop Eom. 2024. "Vision AI System Development for Improved Productivity in Challenging Industrial Environments: A Sustainable and Efficient Approach" Applied Sciences 14, no. 7: 2750. https://doi.org/10.3390/app14072750
APA StyleYang, C., Kim, J., Kang, D., & Eom, D.-S. (2024). Vision AI System Development for Improved Productivity in Challenging Industrial Environments: A Sustainable and Efficient Approach. Applied Sciences, 14(7), 2750. https://doi.org/10.3390/app14072750