
A Novel Hybrid Approach for Concrete Crack Segmentation Based on Deformable Oriented-YOLOv4 and Image Processing Techniques


Abstract
1. Introduction
2. Related Work
2.1. CNN-Based Object Detection
2.2. IPTs-Based Segmentation
3. Methodology
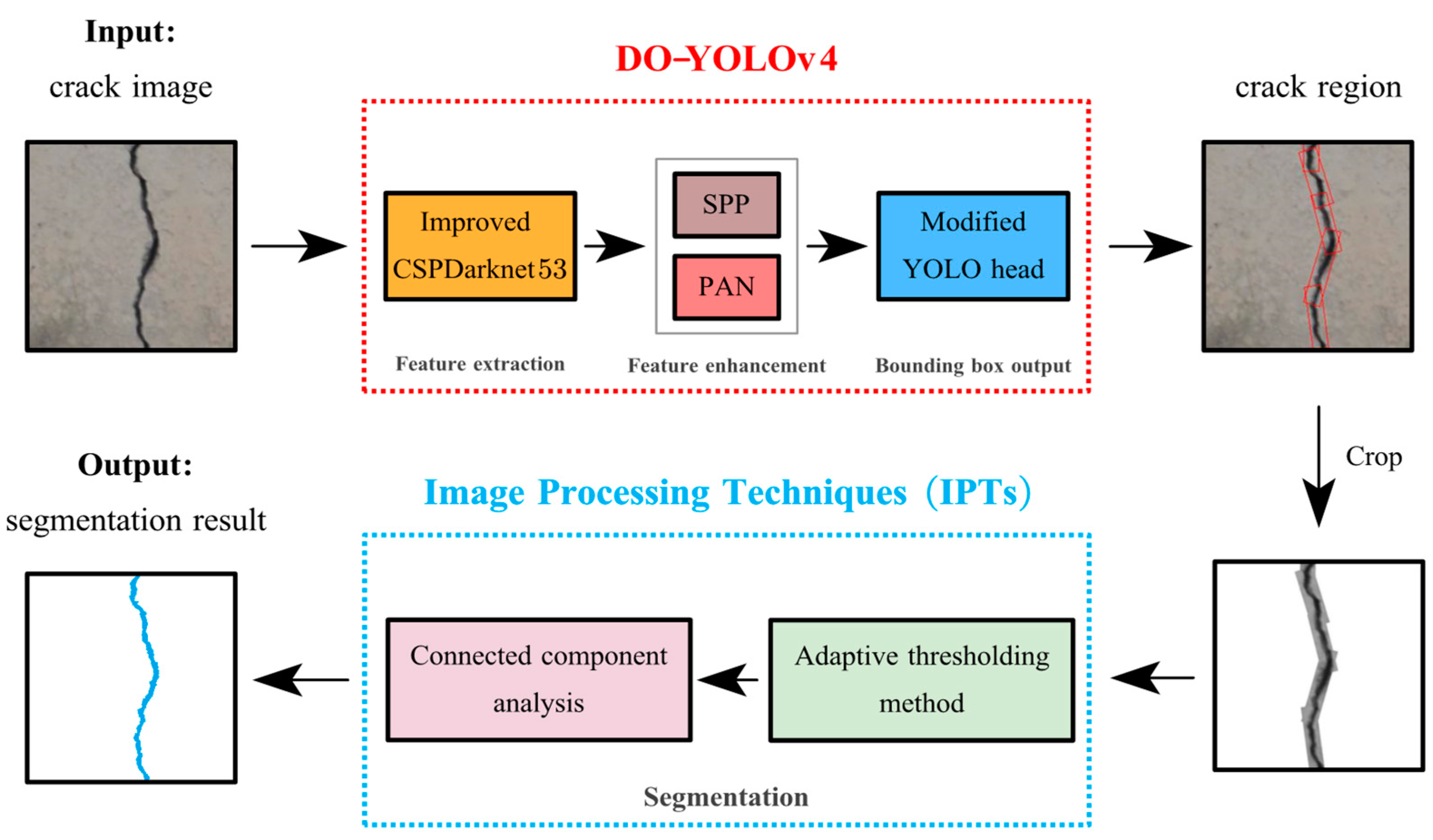
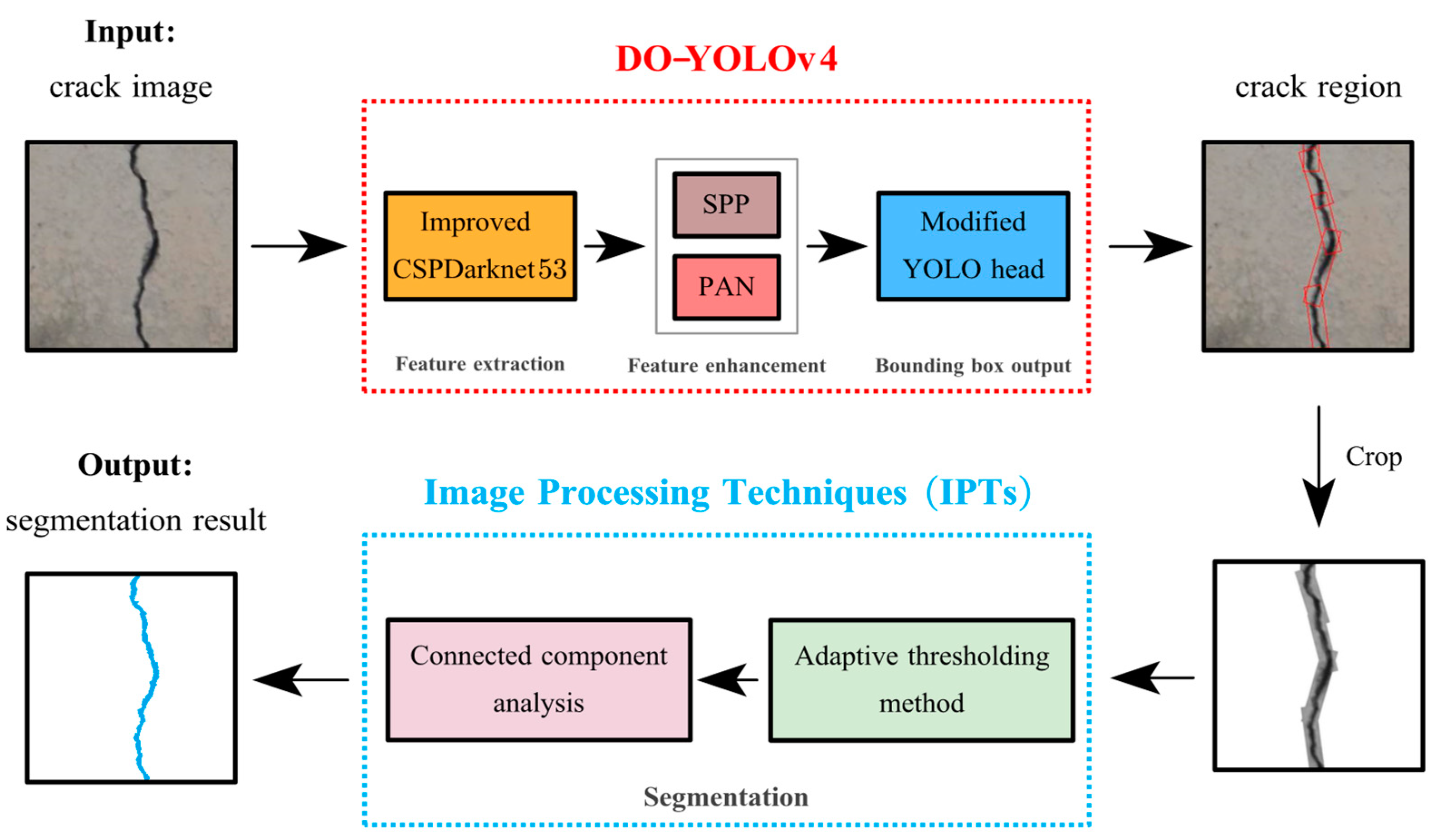
3.1. Overview of DO-YOLOv4-IPTs
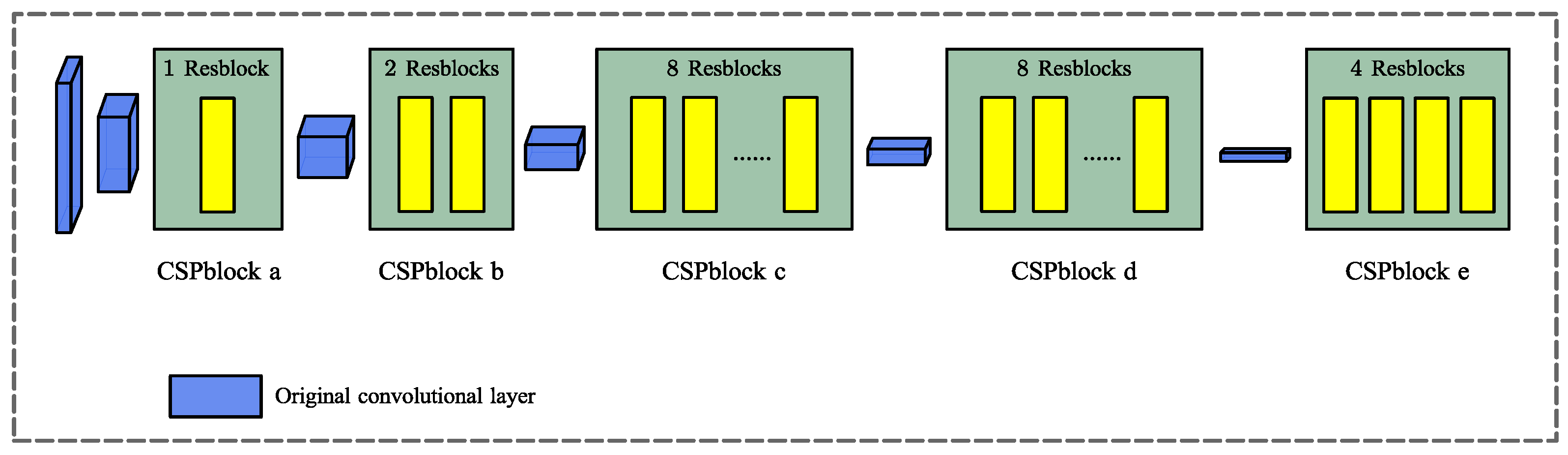
3.2. DO-YOLOv4 for Crack Detection
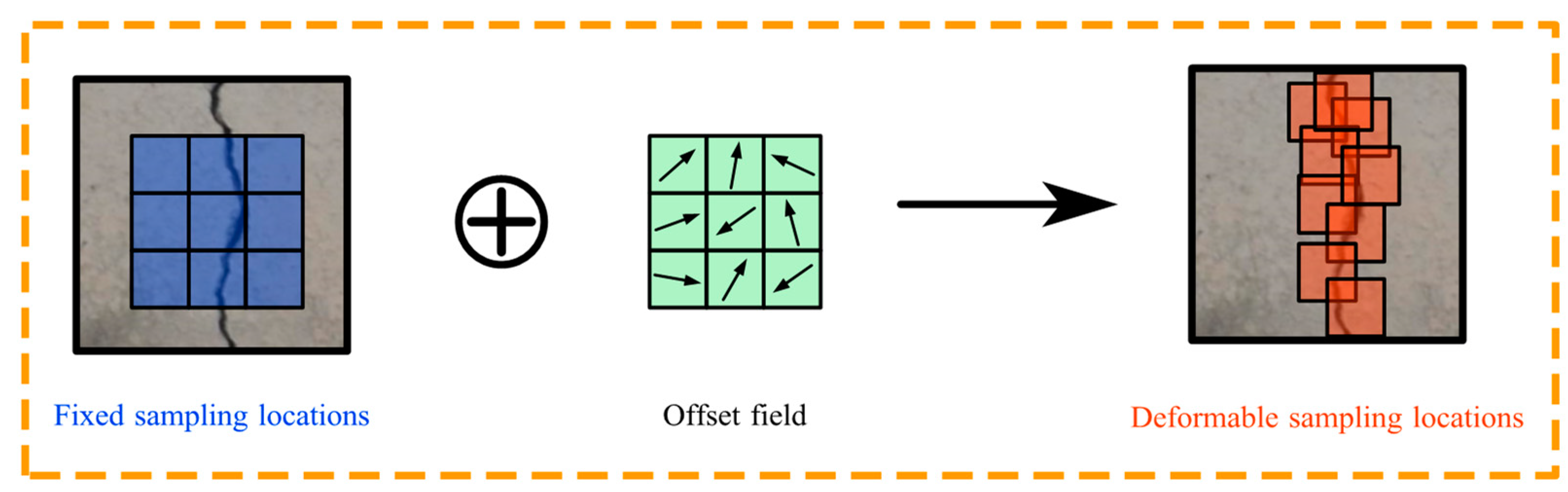
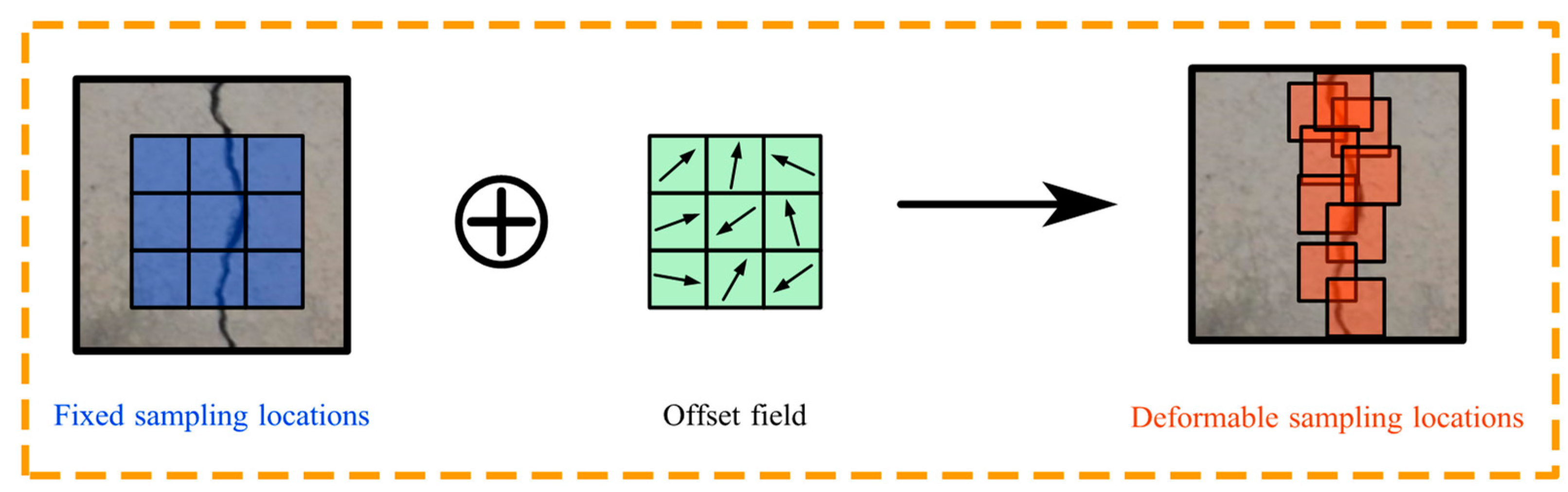
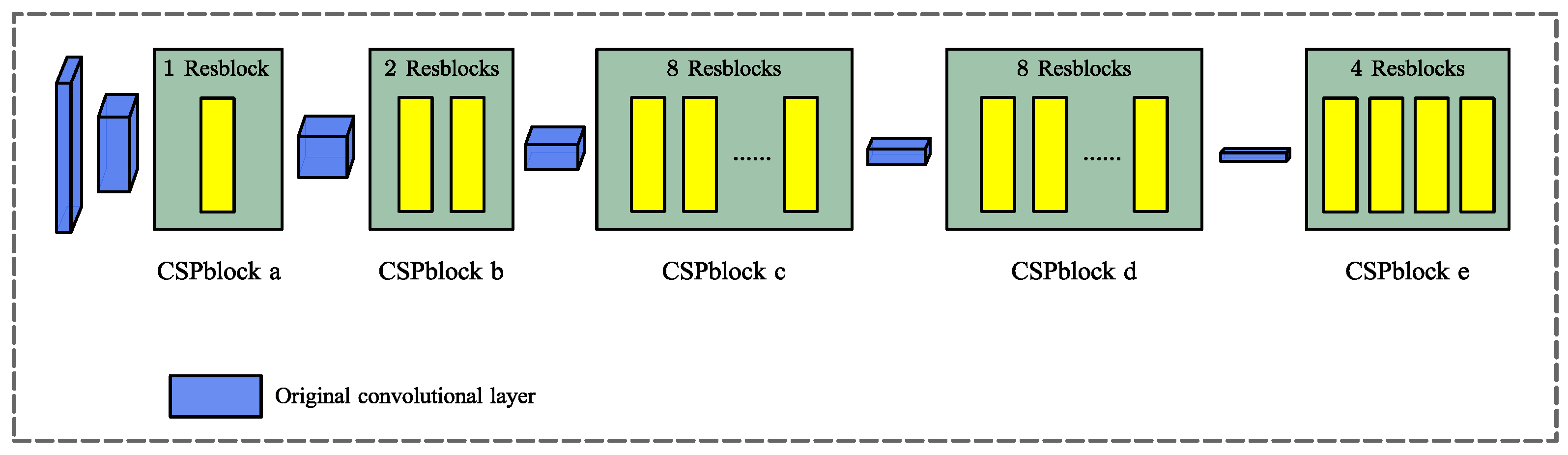
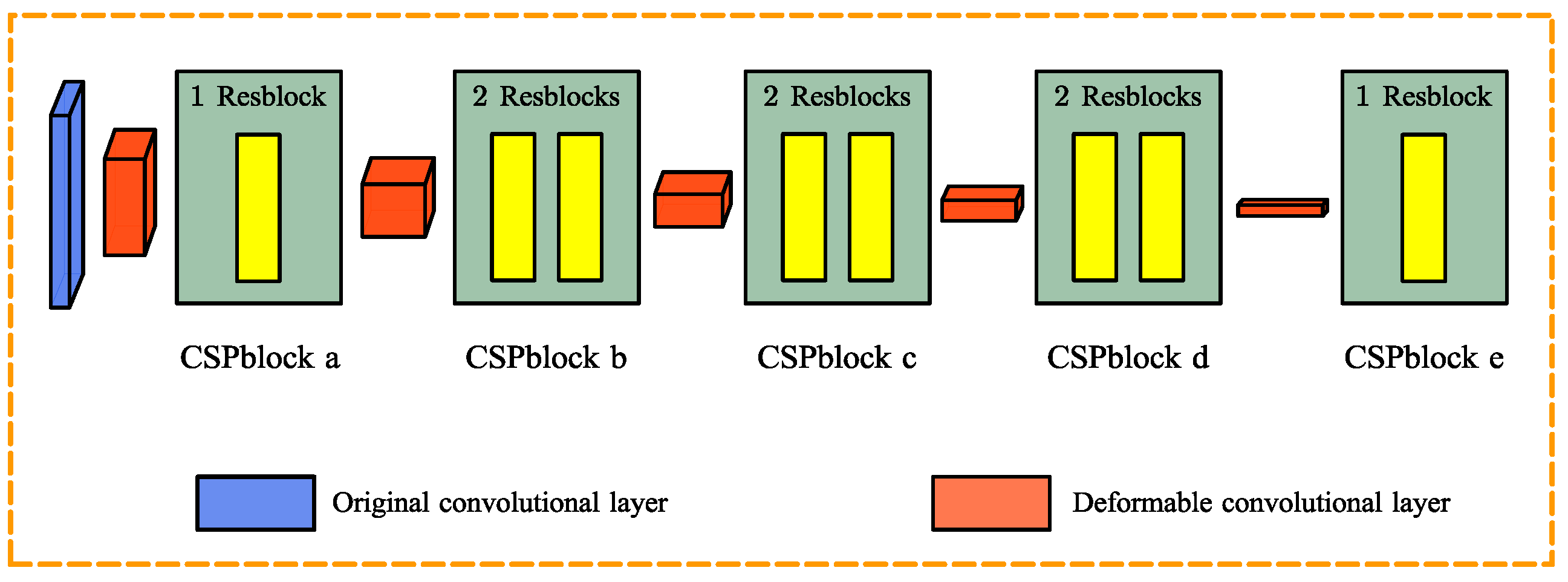
3.2.1. Deformable Convolutional Layers for Feature Extraction
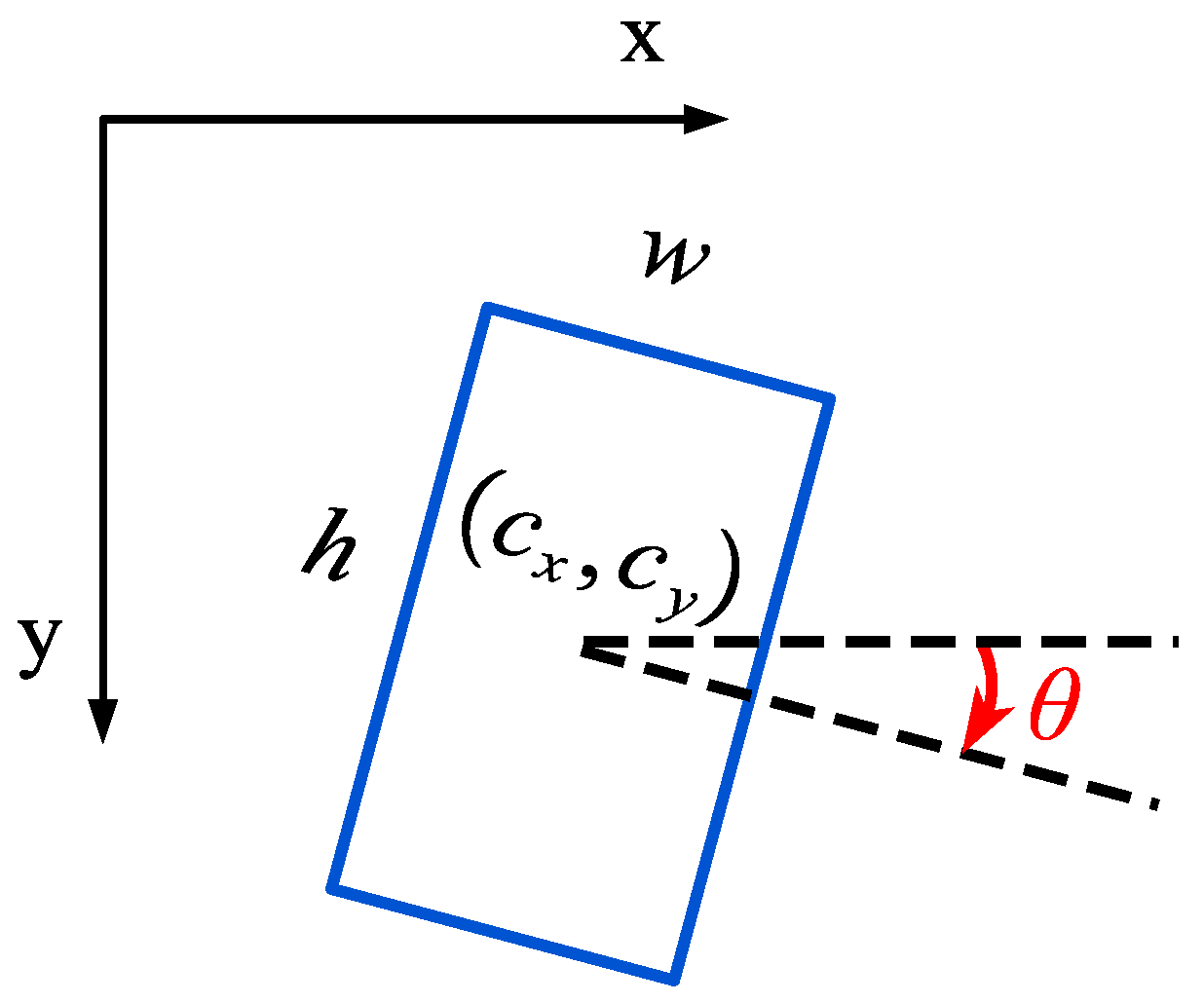
3.2.2. Multiple Oriented Bounding Boxes for Training
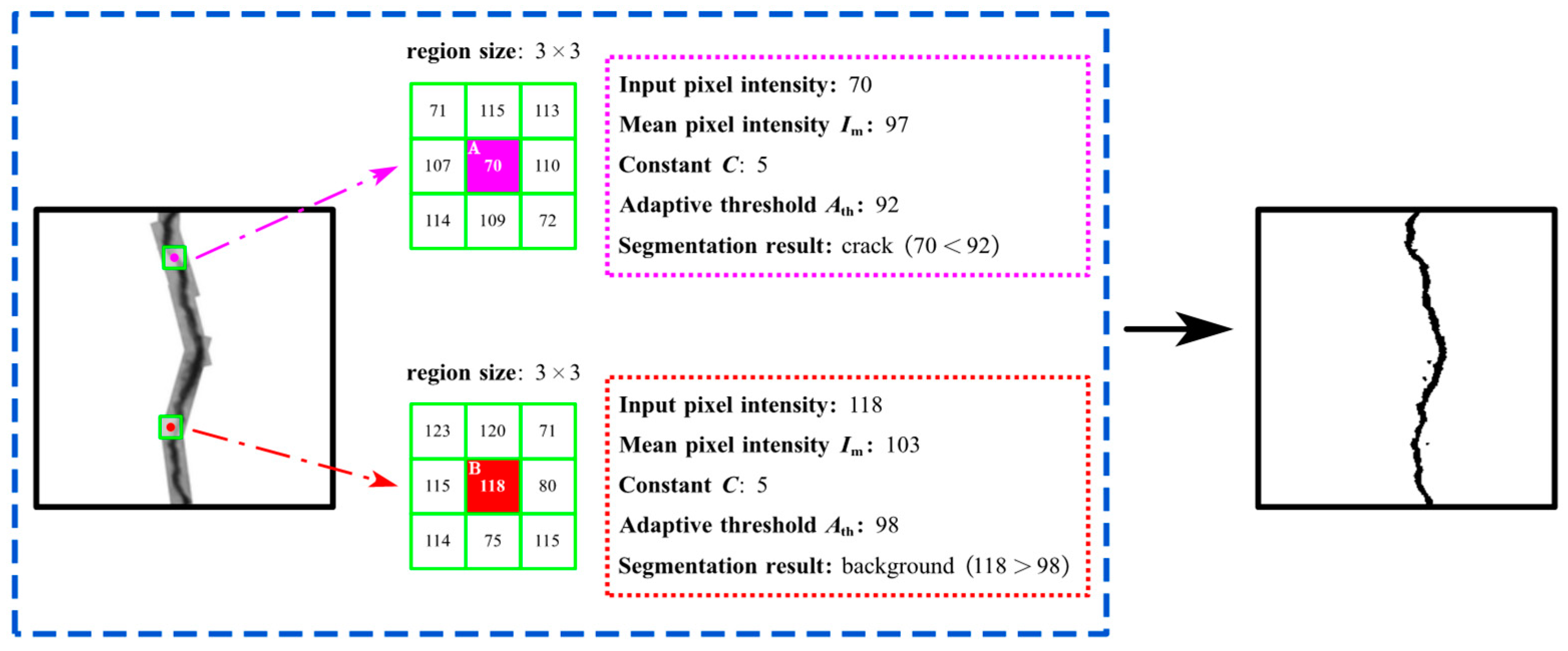
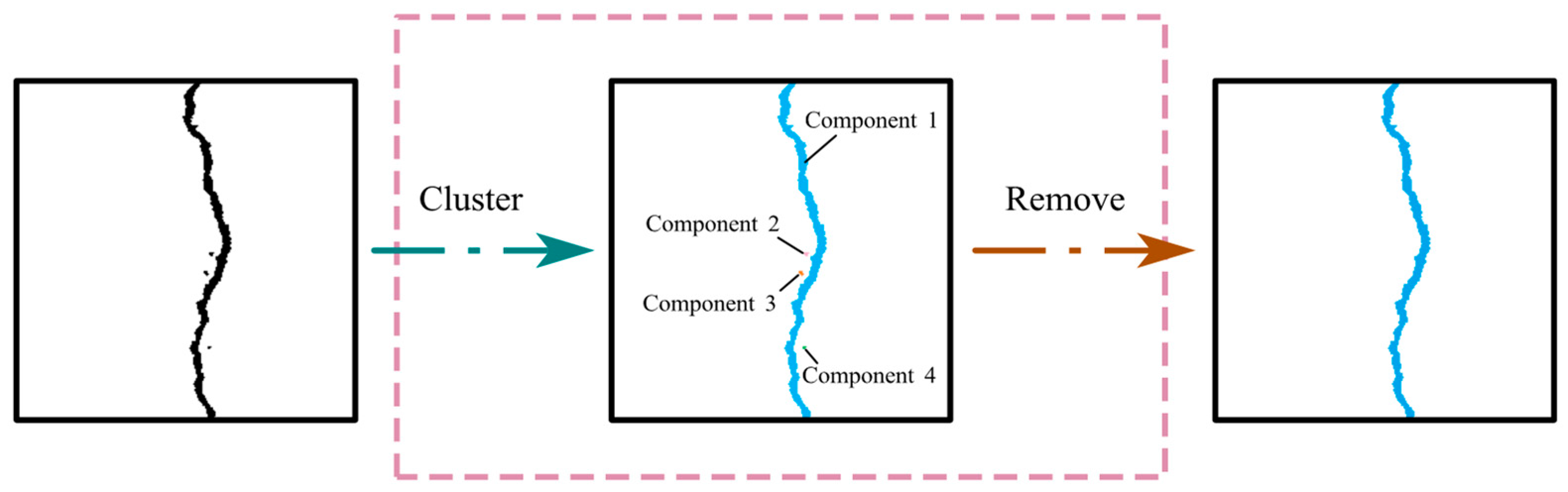
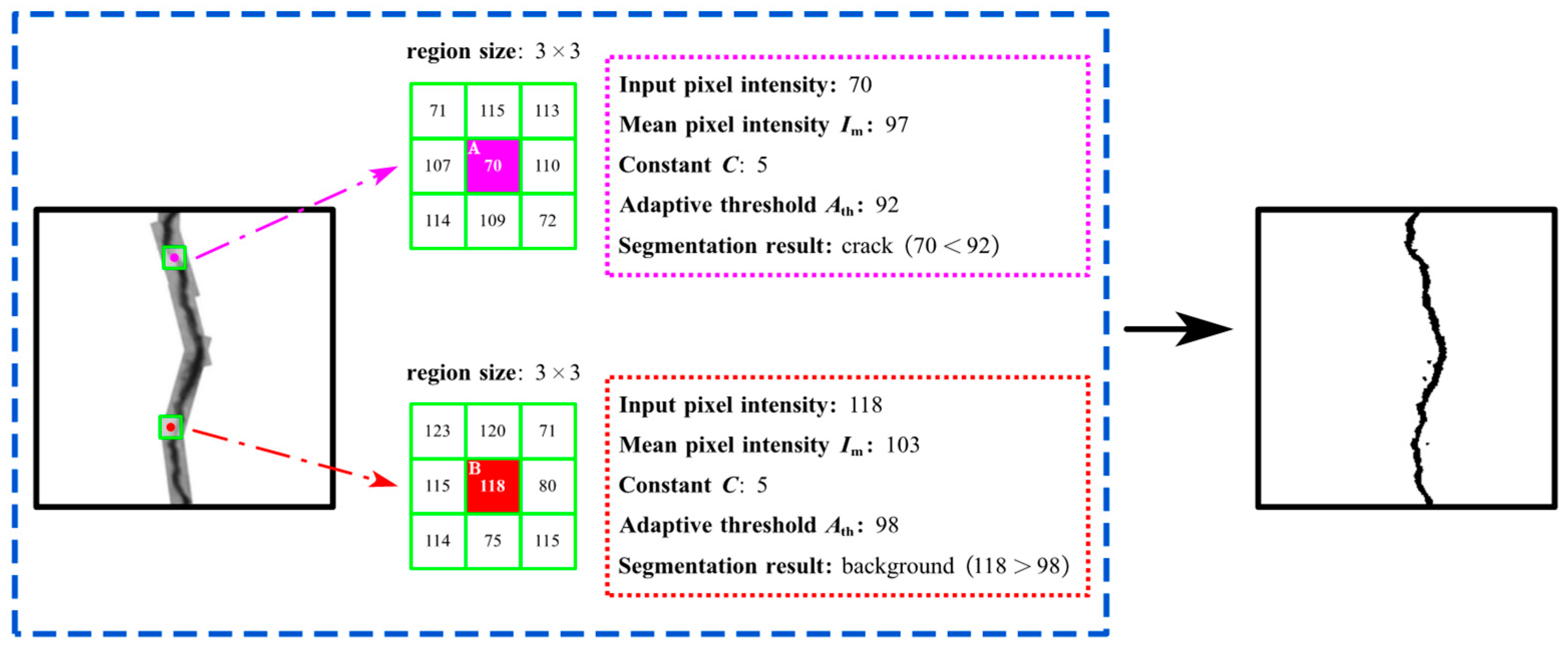
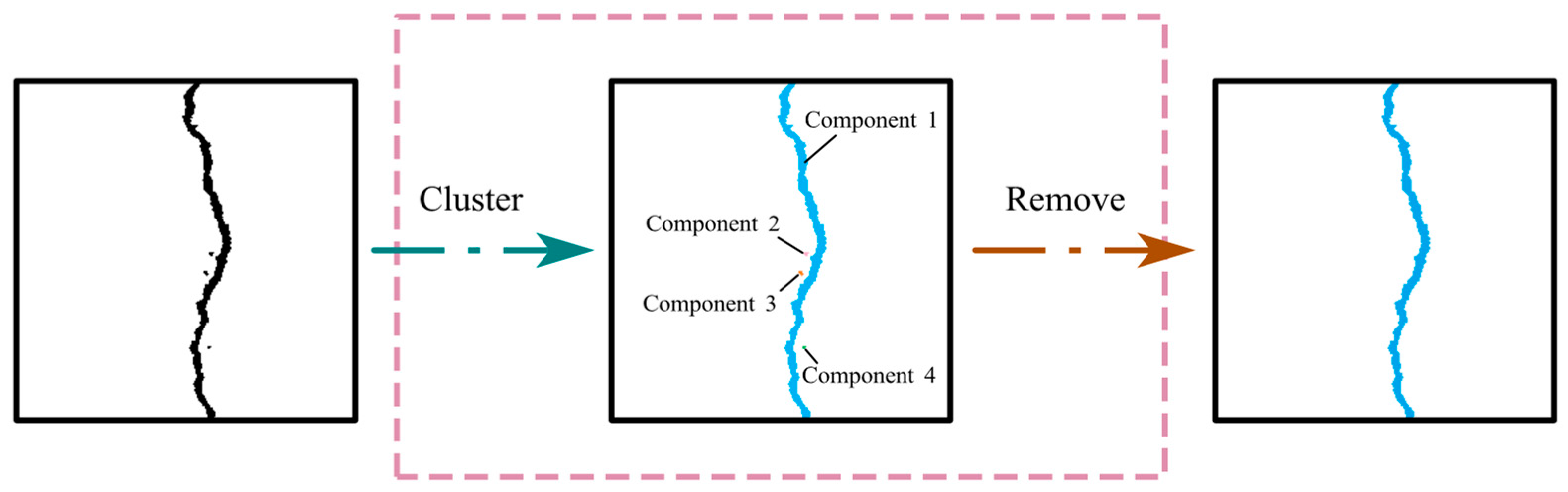
3.3. IPTs for Crack Segmentation
4. Experiments
4.1. Dataset Construction and Implementation Details
4.2. Evaluation of DO-YOLOv4 for Crack Detection
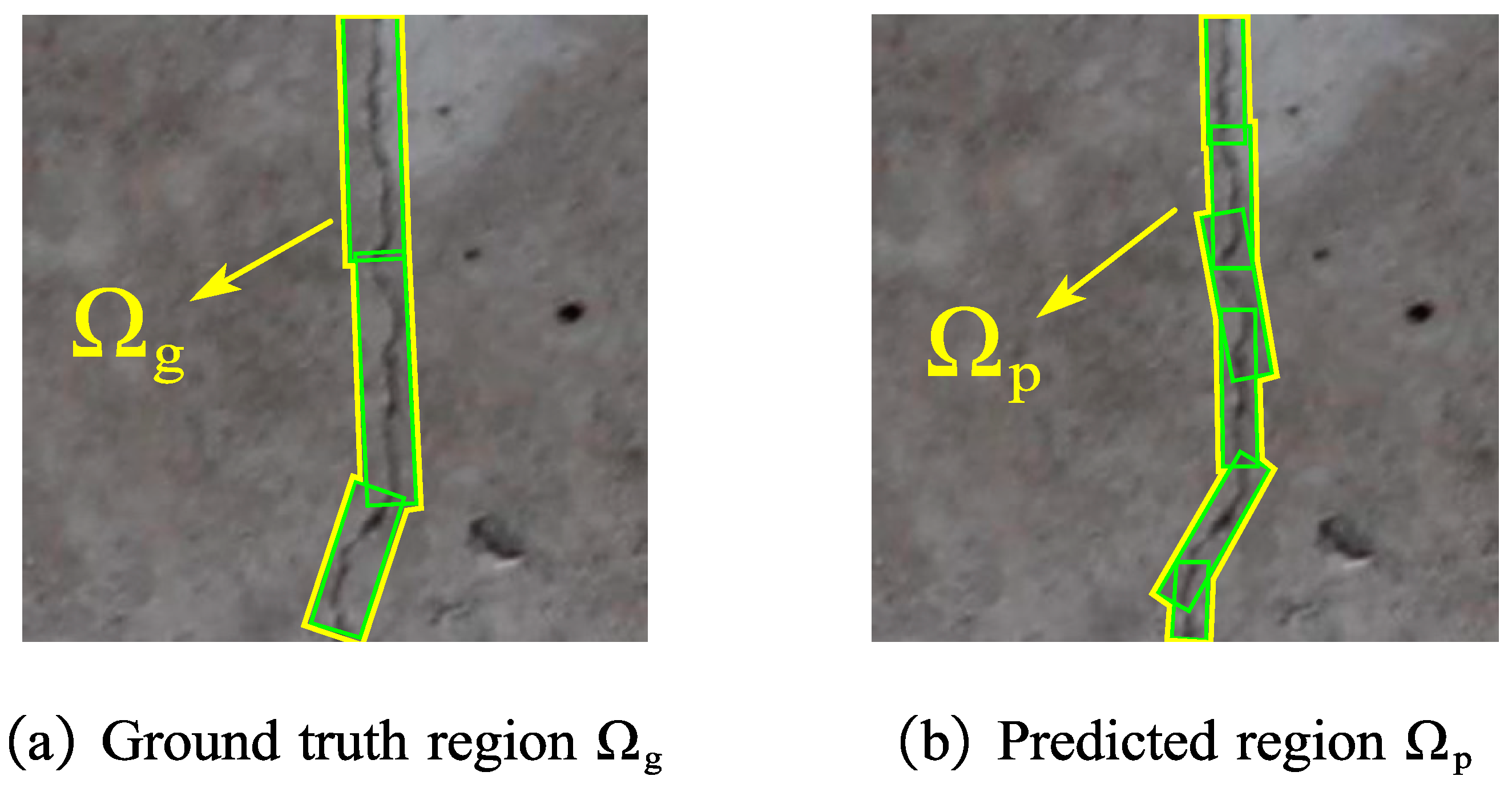
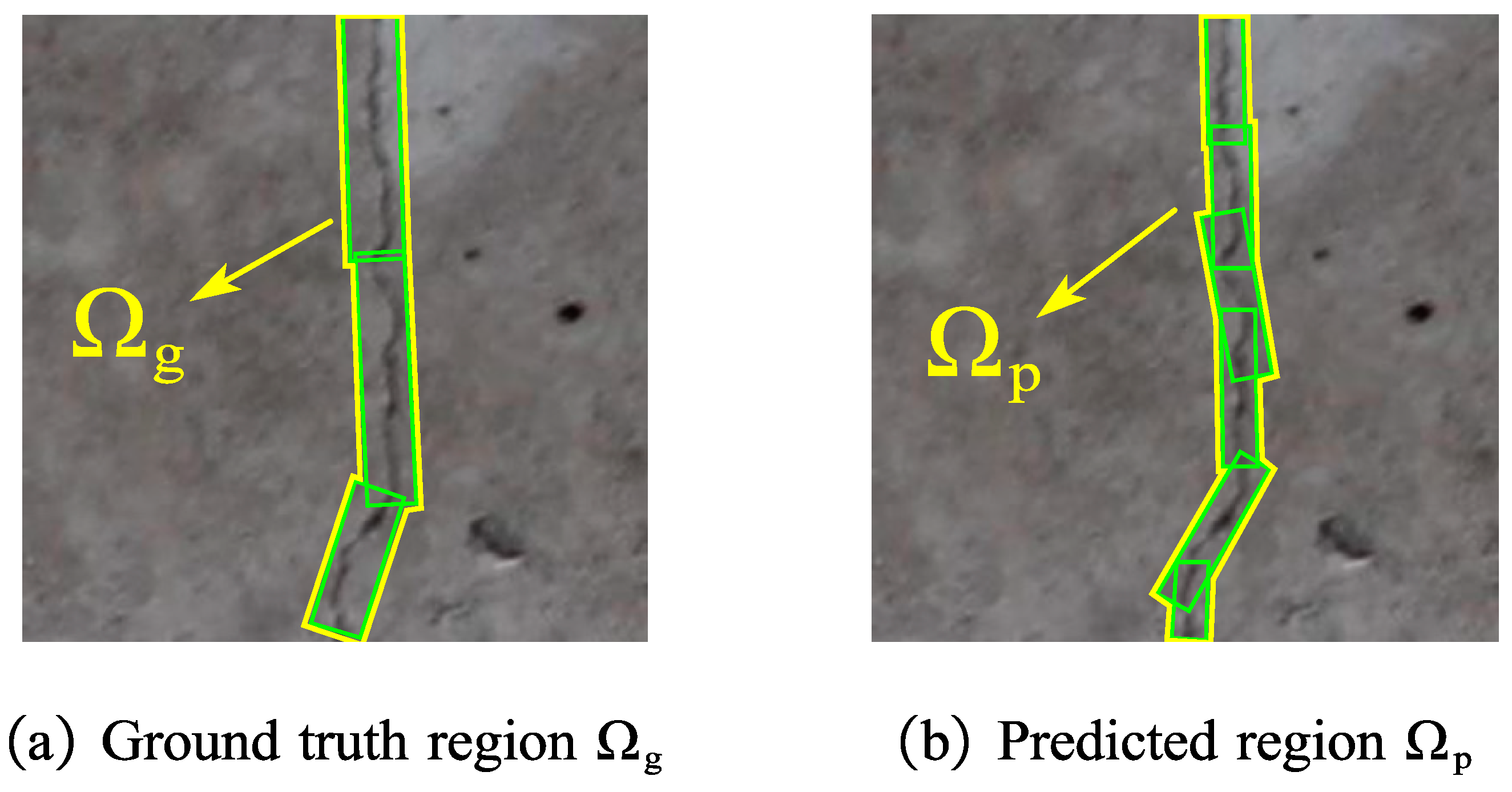
4.2.1. Evaluation Metrics
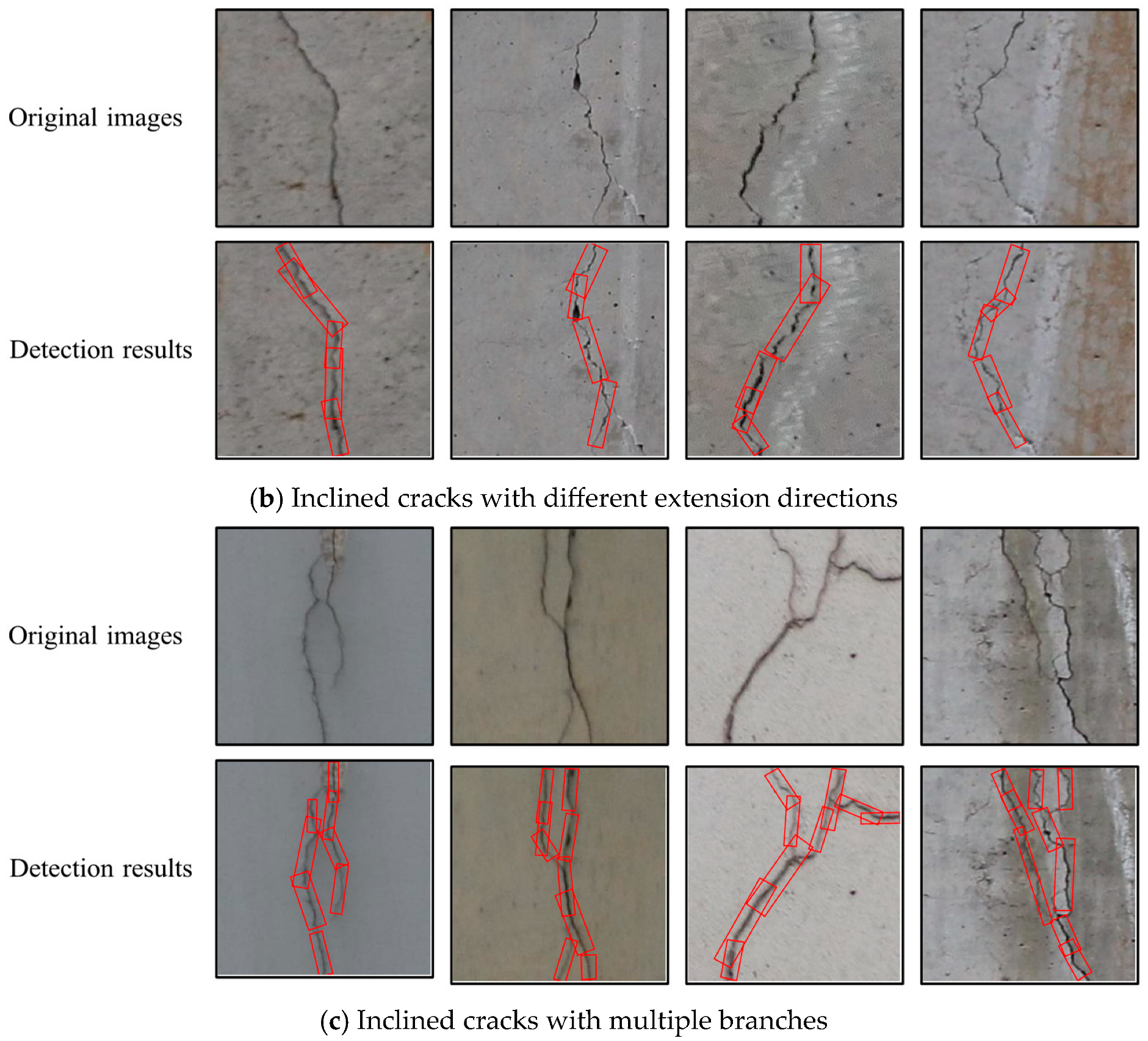
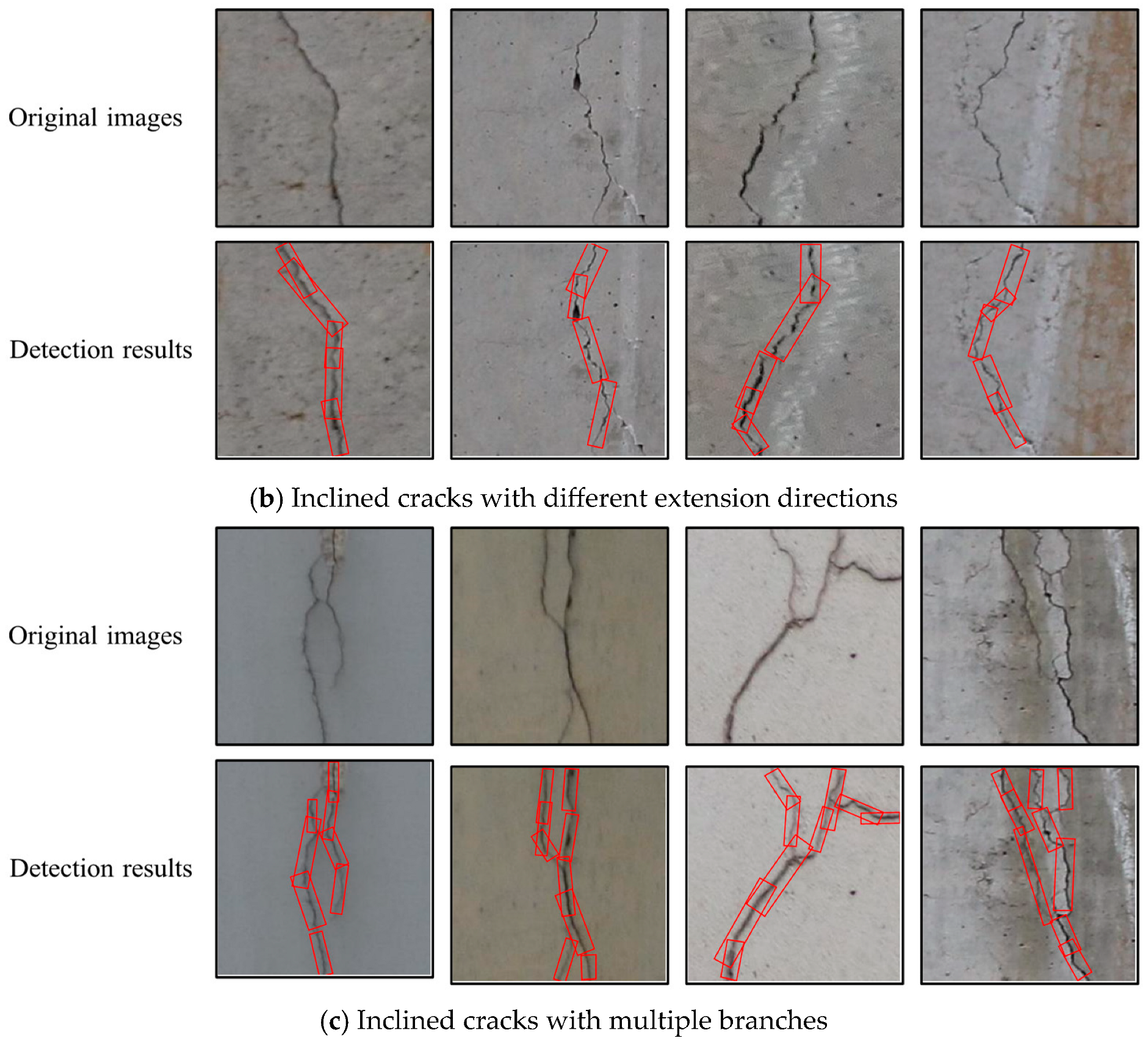
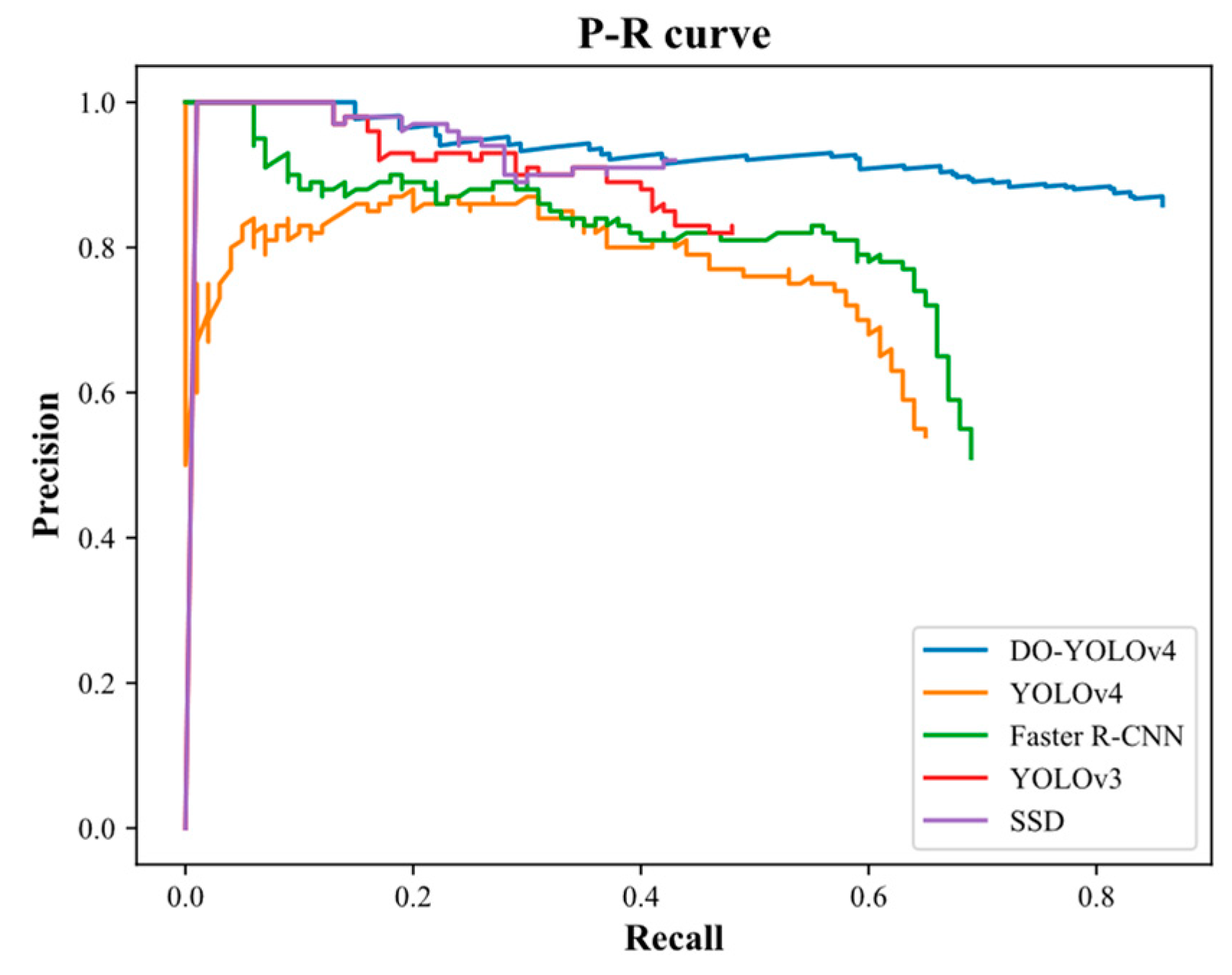
4.2.2. Testing Results and Analysis
4.3. Evaluation of DO-YOLOv4-IPTs for Crack Segmentation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hu, W.B.; Wang, W.D.; Ai, C.B.; Wang, J.; Wang, W.J.; Meng, X.F.; Liu, J.; Tao, H.W.; Qiu, S. Machine vision-based surface crack analysis for transportation infrastructure. Autom. Constr. 2021, 132, 103973. [Google Scholar] [CrossRef]
- Ali, R.; Chuah, J.H.; Talip, M.S.A.; Mokhtar, N.; Shoaib, M.A. Structural crack detection using deep convolutional neural networks. Autom. Constr. 2022, 133, 103989. [Google Scholar] [CrossRef]
- Zhang, J.M.; Lu, C.Q.; Wang, J.; Wang, L.; Yue, X.G. Concrete Cracks Detection Based on FCN with Dilated Convolution. Appl. Sci. 2019, 9, 2686. [Google Scholar] [CrossRef]
- Kang, D.H.; Cha, Y.J. Efficient attention-based deep encoder and decoder for automatic crack segmentation. Struct. Health Monit. 2022, 21, 2190–2205. [Google Scholar] [CrossRef]
- Chen, J.; He, Y. A novel U-shaped encoder-decoder network with attention mechanism for detection and evaluation of road cracks at pixel level. Comput. Aided Civ. Infrastruct. Eng. 2022, 37, 1721–1736. [Google Scholar] [CrossRef]
- Tong, Z.; Yuan, D.D.; Gao, J.; Wang, Z.J. Pavement defect detection with fully convolutional network and an uncertainty framework. Comput.-Aided Civ. Infrastruct. Eng. 2020, 35, 832–849. [Google Scholar] [CrossRef]
- Wang, W.J.; Su, C.; Han, G.H.; Zhang, H. A lightweight crack segmentation network based on knowledge distillation. J. Build. Eng. 2023, 76, 107200. [Google Scholar] [CrossRef]
- Zhu, Y.; Tang, H. Automatic Damage Detection and Diagnosis for Hydraulic Structures Using Drones and Artificial Intelligence Techniques. Remote Sens. 2023, 15, 615. [Google Scholar] [CrossRef]
- Yang, X.C.; Li, H.; Yu, Y.T.; Luo, X.C.; Huang, T. Automatic Pixel-Level Crack Detection and Measurement Using Fully Convolutional Network. Comput. Aided Civ. Infrastruct. Eng. 2018, 33, 1090–1109. [Google Scholar] [CrossRef]
- Liu, Z.Q.; Cao, Y.W.; Wang, Y.; Wang, W. Computer vision-based concrete crack detection using U-net fully convolutional networks. Autom. Constr. 2019, 104, 129–139. [Google Scholar] [CrossRef]
- Lee, S.J.; Hwang, S.H.; Choi, I.Y.; Choi, Y. Estimation of crack width based on shape-sensitive kernels and semantic segmentation. Struct. Control. Health Monit. 2020, 27, e2504. [Google Scholar] [CrossRef]
- Ni, F.T.; He, Z.L.; Jiang, S.; Wang, W.G.; Zhang, J. A Generative adversarial learning strategy for enhanced lightweight crack delineation networks. Adv. Eng. Inform. 2022, 52, 101575. [Google Scholar] [CrossRef]
- Tabernik, D.; Suc, M.; Skocaj, D. Automated detection and segmentation of cracks in concrete surfaces using joined segmentation and classification deep neural network. Constr. Build. Mater. 2023, 408, 133582. [Google Scholar] [CrossRef]
- Miao, P.Y.; Srimahachota, T. Cost-effective system for detection and quantification of concrete surface cracks by combination of convolutional neural network and image processing techniques. Constr. Build. Mater. 2021, 293, 123549. [Google Scholar] [CrossRef]
- Kang, D.H.; Benipal, S.S.; Gopal, D.L.; Cha, Y.J. Hybrid pixel-level concrete crack segmentation and quantification across complex backgrounds using deep learning. Autom. Constr. 2020, 118, 103291. [Google Scholar] [CrossRef]
- Li, S.Y.; Zhao, X.F. Pixel-level detection and measurement of concrete crack using faster region-based convolutional neural network and morphological feature extraction. Meas. Sci. Technol. 2021, 32, 065010. [Google Scholar] [CrossRef]
- Li, C.; Xu, P.J.; Niu, L.J.L.; Chen, Y.; Sheng, L.S.; Liu, M.C. Tunnel crack detection using coarse-to-fine region localization and edge detection. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2019, 9, e1308. [Google Scholar] [CrossRef]
- Dai, J.; He, K.; Sun, J. BoxSup: Exploiting Bounding Boxes to Supervise Convolutional Networks for Semantic Segmentation. In Proceedings of the International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1635–1643. [Google Scholar]
- Ren, S.Q.; He, K.M.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the 29th Annual Conference on Neural Information Processing Systems (NIPS), Montreal, Canada, 7–12 December 2015; pp. 1137–1149. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision; Springer: Berlin, Germany, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, LasVegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ma, D.; Fang, H.Y.; Xue, B.H.; Wang, F.M.; Msekn, M.A.; Chan, C.L. Intelligent detection model based on a fully convolutional neural network for pavement cracks. Comput. Model. Eng. Sci. 2020, 123, 1267–1291. [Google Scholar] [CrossRef]
- Pang, J.; Zhang, H.; Feng, C.C.; Li, L.J. Research on crack segmentation method of hydro-junction project based on target detection network. KSCE J. Civ. Eng. 2020, 24, 2731–2741. [Google Scholar] [CrossRef]
- Xu, G.Y.; Han, X.; Zhang, Y.W.; Wu, C.Y. Dam Crack Image Detection Model on Feature Enhancement and Attention Mechanism. Water 2023, 15, 64. [Google Scholar] [CrossRef]
- Yang, J.; Fu, Q.; Nie, M.X. Road Crack Detection Using Deep Neural Network with Receptive Field Block. IOP Conf. Ser. Mater. Sci. Eng. 2020, 782, 042033. [Google Scholar] [CrossRef]
- Zhang, J.; Qian, S.R.; Tan, C. Automated bridge surface crack detection and segmentation using computer vision-based deep learning model. Eng. Appl. Artif. Intell. 2022, 115, 105225. [Google Scholar] [CrossRef]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable Convolutional Networks. In Proceedings of the International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Cha, Y.J.; Choi, W.; Suh, G.; Mahmoudkhani, S.; Buyukozturk, O. Autonomous Structural Visual Inspection Using Region-Based Deep Learning for Detecting Multiple Damage Types. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 731–747. [Google Scholar] [CrossRef]
- Deng, J.H.; Lu, Y.; Lee, V.C.S. Concrete crack detection with handwriting script interferences using faster region-based convolutional neural network. Comput. Aided Civ. Infrastruct. Eng. 2019, 35, 373–388. [Google Scholar] [CrossRef]
- Li, D.W.; Xie, Q.; Gong, X.X.; Yu, Z.H.; Xu, J.X.; Sun, Y.X.; Jun, W. Automatic defect detection of metro tunnel surfaces using a vision-based inspection system. Adv. Eng. Inform. 2021, 47, 101206. [Google Scholar] [CrossRef]
- Teng, S.; Liu, Z.C.; Chen, G.F.; Cheng, L. Concrete Crack Detection Based on Well-Known Feature Extractor Model and the YOLO_v2 Network. Appl. Sci. 2021, 11, 813. [Google Scholar] [CrossRef]
- Du, Y.C.; Pan, N.; Xu, Z.H.; Deng, F.W.; Shen, Y.; Kang, H. Pavement distress detection and classification based on YOLO network. Int. J. Pavement Eng. 2021, 22, 1659–1672. [Google Scholar] [CrossRef]
- Cao, M.T.; Tran, Q.V.; Nguyen, N.M.; Chang, K.T. Survey on performance of deep learning models for detecting road damages using multiple dashcam image resources. Adv. Eng. Inform. 2020, 46, 101182. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.M.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Zhang, C.B.; Chang, C.C.; Jamshidi, M. Concrete bridge surface damage detection using a single-stage detector. Comput. -Aided Civ. Infrastruct. Eng. 2020, 35, 389–409. [Google Scholar] [CrossRef]
- Yu, Z.W.; Shen, Y.G.; Shen, C.K. A real-time detection approach for bridge cracks based on YOLOv4-FPM. Autom. Constr. 2021, 122, 103514. [Google Scholar] [CrossRef]
- Zhou, Z.; Zhang, J.J.; Gong, C.J. Automatic detection method of tunnel lining multi-defects via an enhanced You Only Look Once network. Comput. Aided Civ. Infrastruct. Eng. 2022, 37, 762–780. [Google Scholar] [CrossRef]
- Koch, C.; Georgieva, K.; Kasireddy, V.; Akinci, B.; Fieguth, P. A review on computer vision based defect detection and condition assessment of concrete and asphalt civil infrastructure. Adv. Eng. Inform. 2015, 29, 196–210. [Google Scholar] [CrossRef]
- Ayenu-Prah, A.; Attoh-Okine, N. Evaluating Pavement Cracks with Bidimensional Empirical Mode Decomposition. EURASIP J. Adv. Signal Process. 2008, 2008, 861701. [Google Scholar] [CrossRef]
- Abdel-Qader, I.; Abudayyeh, O.; Kelly, M.E. Analysis of Edge-Detection Techniques for Crack Identification in Bridges. J. Comput. Civil Eng. 2003, 17, 255–263. [Google Scholar] [CrossRef]
- Li, Q.Q.; Zou, Q.; Zhang, D.Q.; Mao, Q.Z. FoSA: F* Seed-growing Approach for crack-line detection from pavement images. Image Vis. Comput. 2011, 29, 861–872. [Google Scholar] [CrossRef]
- Zhou, Y.X.; Wang, F.; Meghanathan, N. Seed-Based Approach for Automated Crack Detection from Pavement Images. Transp. Res. Recode 2016, 2589, 162–171. [Google Scholar] [CrossRef]
- Gavilan, M.; Balcones, D.; Marcos, O.; LIorca, D.F. Adaptive Road Crack Detection System by Pavement Classification. Sensors 2011, 11, 9628–9657. [Google Scholar] [CrossRef] [PubMed]
- Zou, Q.; Cao, Y.; Li, Q.Q.; Mao, Q.Z.; Wang, S. CrackTree: Automatic crack detection from pavement images. Pattern Recognit. Lett. 2012, 33, 227–238. [Google Scholar] [CrossRef]
- Tang, J.S.; Gu, Y.L. Automatic Crack Detection and Segmetnation Using A Hybrid Algorithm for Road Distress Analysis. In Proceedings of the 2013 IEEE International Conference on Systems, Man, and Cybernetics, Manchester, UK, 13–16 October 2013; pp. 3026–3030. [Google Scholar]
- Li, Q.Q.; Liu, X.L. Novel approach to pavement image segmentation based on neighboring difference histogram method. In Proceedings of the 1st International Congress on Image and Signal Processing, Sanya, China, 27–30 May 2008; pp. 792–796. [Google Scholar]
- Oliveira, H.; Correia, P. Automatic road crack segmentation using entropy and image dynamic thresholding. In Proceedings of the 17th European IEEE Signal Processing Conference, Glasgow, Scotland, 24–28 August 2009; pp. 622–626. [Google Scholar]
- Jin, Q.G.; Meng, Z.P.; Pham, T.D.; Chen, Q.; Wei, L.Y.; Su, R. DUNet: A deformable network for retinal vessel segmentation. Knowl. Based Syst. 2019, 178, 149–162. [Google Scholar] [CrossRef]
- Wang, Y.H.; Ye, S.J.; Bai, Y.; Gao, G.M.; Gu, Y.F. Vehicle detection using deep learning with deformable convolution. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 2329–2332. [Google Scholar]
- Zhao, S.L.; Zhang, S.; Lu, J.M.; Wang, H.; Feng, Y.; Shi, C.; Li, D.L.; Zhao, R. A lightweight dead fish detection method based on deformable convolution and YOLOV4. Comput. Electron. Agric. 2022, 198, 107098. [Google Scholar] [CrossRef]
- Ye, X.W.; Jin, T.; Li, Z.X.; Ma, S.Y.; Ding, Y. Structural Crack Detection from Benchmark Data Sets Using Pruned Fully Convolutional Networks. J. Struct. Eng. 2021, 147, 04721008. [Google Scholar] [CrossRef]
- RoLabelImg. 2020. Available online: https://github.com/roLabelImg-master (accessed on 29 June 2020).
- PyTorch. Available online: https://pytorch.org (accessed on 1 January 2017).
- Kingma, D.P.; Ba, J.L. Adam: A method for stochastic optimization. arXiv 2015, arXiv:1412.6980. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. Proc. AAAI Conf. Artif. Intell. 2020, 34, 12993–13000. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef]
- OpenCV. Available online: https://opencv.org (accessed on 4 July 2011).
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The Pascal visual object classes (VOC) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Ren, Y.P.; Huang, J.S.; Hong, Z.Y.; Lu, W.; Yin, J.; Zou, L.J.; Shen, X.H. Image-based concrete crack detection in tunnels using deep fully convolutional networks. Constr. Build. Mater. 2020, 234, 117367. [Google Scholar] [CrossRef]
- Alipour, M.; Harris, D.K.; Miller, G.R. Robust Pixel-Level Crack Detection Using Deep Fully Convolutional Neural Networks. J. Comput. Civil Eng. 2019, 33, 04019040. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Feature Extraction Network (Size) | Bounding Box | AP (%) |
|---|---|---|---|
| Faster R-CNN | VGG16 (527.8 MB) | Single, horizontal | 58.89 |
| SSD | Resnet50 (89.67 MB) | Single, horizontal | 41.04 |
| YOLOv3 | Darknet53 (154.82 MB) | Single, horizontal | 45.16 |
| YOLOv4 | CSPDarknet53 (101.5 MB) | Single, horizontal | 53.10 |
| DO-YOLOv4 | Improved CSPDarknet53 (53.3 MB) | Multiple, oriented | 80.43 |
| Method | PIoU (%) | Mean PIoU (%) | Mean Time Cost of Labeling (min) | ||||
|---|---|---|---|---|---|---|---|
| Image (a) | Image (b) | Image (c) | Image (d) | Image (e) | |||
| FCN | 39.10 | 47.43 | 6.95 | 52.96 | 55.73 | 40.44 | 5 |
| Unet | 54.17 | 69.63 | 18.38 | 65.32 | 40.35 | 49.57 | 5 |
| CrackSegNet | 64.53 | 70.39 | 21.43 | 49.98 | 53.54 | 51.97 | 5 |
| CrackPix | 68.85 | 77.54 | 19.22 | 67.08 | 52.67 | 57.07 | 5 |
| DO-YOLOv4-IPTs | 72.49 | 75.14 | 61.42 | 78.24 | 70.93 | 71.64 | 0.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, Z.; Su, C.; Deng, Y. A Novel Hybrid Approach for Concrete Crack Segmentation Based on Deformable Oriented-YOLOv4 and Image Processing Techniques. Appl. Sci. 2024, 14, 1892. https://doi.org/10.3390/app14051892
He Z, Su C, Deng Y. A Novel Hybrid Approach for Concrete Crack Segmentation Based on Deformable Oriented-YOLOv4 and Image Processing Techniques. Applied Sciences. 2024; 14(5):1892. https://doi.org/10.3390/app14051892
Chicago/Turabian StyleHe, Zengsheng, Cheng Su, and Yichuan Deng. 2024. "A Novel Hybrid Approach for Concrete Crack Segmentation Based on Deformable Oriented-YOLOv4 and Image Processing Techniques" Applied Sciences 14, no. 5: 1892. https://doi.org/10.3390/app14051892
APA StyleHe, Z., Su, C., & Deng, Y. (2024). A Novel Hybrid Approach for Concrete Crack Segmentation Based on Deformable Oriented-YOLOv4 and Image Processing Techniques. Applied Sciences, 14(5), 1892. https://doi.org/10.3390/app14051892